Abstract
Ensuring that test scores are fair and comparable across different test forms and different test groups is a significant statistical challenge in educational testing. Methods to achieve score comparability, a process known as test score equating, often rely on including common test items or assuming that test taker groups are similar in key characteristics. This study explores a novel approach that combines propensity scores, based on test takers’ background covariates, with information from common items using kernel smoothing techniques for binary-scored test items. An empirical analysis using data from a high-stakes college admissions test evaluates the standard errors and differences in adjusted test scores. A simulation study examines the impact of factors such as the number of test takers, the number of common items, and the correlation between covariates and test scores on the method’s performance. The findings demonstrate that integrating propensity scores with common item information reduces standard errors and bias more effectively than using either source alone. This suggests that balancing the groups on the test-takers’ covariates enhance the fairness and accuracy of test score comparisons across different groups. The proposed method highlights the benefits of considering all the collected data to improve score comparability.
Keywords
Introduction
Assessment tests in education are important tools for measuring students’ knowledge, skills, and development. These tests also play a significant role in educational decision-making, influencing everything from teaching practices to college admissions. Given their impact, it is essential to ensure that test score interpretations are both valid and fair (see Chapter 3, American Educational Research Association et al., 2014). When test forms change or when different groups take different test forms, ensuring fair and comparable scores becomes a significant statistical challenge.
To address this challenge, traditional methods for adjusting scores often rely on including common items in the tests - known as anchor items - or assuming that the groups being compared are similar in their distributions of the latent ability the assessment test is designed to measure. These methods aim to adjust for variations in test difficulty and differences in group abilities. However, when no common items are available, these methods may not fully account for group differences, potentially having significant impacts on, for example, academic admission decisions. Complicating matters further, the latent trait levels of the test-takers are not directly observable, which makes it non-trivial to condition the analysis on their values.
In light of these challenges, test score equating has emerged as a routine statistical process for most large-scale testing programs around the world. Test equating methods, used to align scores from different test forms onto a common scale, account for variations in test difficulty and differences in the ability levels of test-taking groups (González & Wiberg, 2017). The choice of equating method depends on assumptions about the test-takers and the available data. When groups of test takers receiving different test forms can be assumed to be similar in their distributions of the ability the test is designed to measure, the Equivalent Groups (EG) design can be used. However, if these groups cannot be assumed equivalent but have completed a set of common items (an anchor test), the nonequivalent groups with anchor test (NEAT) design is suitable (von Davier et al., 2004). When test-taking groups are not similar and no anchor test is administered, but information about test takers’ covariates is available, the nonequivalent groups with covariates (NEC) design can be employed (Wiberg & Bränberg, 2015). Examples of tests with non-equivalent groups but without anchor items include the Invalsi test (INVALSI, 2013), the Armed Services Vocational Aptitude Battery (Quenette et al., 2006), and, until 2011, the Swedish Scholastic Aptitude Test (SweSAT; Stage & Ögren, 2004).
The importance of flexible equating methods became even more apparent during the global spread of Covid-19, which created unprecedented challenges for many large-scale assessments. For instance, the SweSAT faced restrictions on test-taker eligibility, resulting in new demographics taking the test (Wiberg et al., 2021). Despite these changes in the test-taking population, the need to compare scores with previous administrations remained crucial, given the role of SweSAT in college admissions. Historically, researchers addressing changing background distributions of test groups have employed either the NEAT design when an anchor test was available, or the NEC design. However, only a few attempts have been made to integrate information from both covariates and anchor tests, highlighting a gap in the current methodology. Notable exceptions include Wiberg and Bränberg (2015), who explored a case of merging NEAT and NEC designs using categorical covariates and anchor test scores, and Albano and Wiberg (2019), who examined traditional equating methods combining anchor scores with a single covariate. Further, Lu and Guo (2018) used simulations to include information from an anchor test with pseudo equivalent groups (PEG) in a NEAT design. They concluded that if the ability group difference were large, to use only NEAT design was to be preferred over PEG, but the NEAT linking could be improved by using PEG procedures based on background variables. If group ability differences were small, PEG linking produced comparable results to NEAT. Further, Lu and Kim (2021) used statistical matching for equating samples in a NEAT design, while Kim and Walker (2021) used PEG when examining nonequivalent groups caused by suboptimal randomization, a short anchor test of only five items, and minimal collateral information. Recently, Kim and Walker (2022) extended this study when building on the PEG approach and used resampling to evaluate the linking accuracy of group adjustment using sample weights via minimum discriminant information adjustment (MDIA) using test takers’ demographic information, a three-item anchor test, and a mixture of both. They concluded that using both sample weights via MDIA and a short anchor produced the most accurate equating results. More recently, Ozsoy and Kilmen (2023) compared NEAT and NEC designs in a modern equating framework, however they did not combine the two designs.
A promising approach to incorporating information about test takers from covariates is to use propensity scores. Define for each test taker the propensity score
Wallin and Wiberg (2019) proposed to use propensity scores with the NEAT design, framed within a modern equating framework building on kernel smoothing techniques. Their work demonstrated that stratifying on the propensity scores, an idea dating back to Rosenbaum and Rubin (1984), could achieve a similar level of precision and accuracy compared to the NEAT design, provided the propensity scores are known. Recognizing that propensity scores are never truly known in practice, Wallin and Wiberg (2023) conducted a sensitivity analysis of equated scores to various misspecifications in the propensity score model. Their findings revealed that omitting an important covariate leads to biased estimates of the equated scores, while misspecifying a nonlinear relationship between covariates and test scores increases the equating standard error in the tails of the score distributions. Encouragingly, they also found that the equating estimators are robust against omitting a second-order term and using an incorrect link function in the propensity score estimation model.
Building upon this rich body of research, our paper introduces a novel approach in test equating by combining propensity scores with anchor test scores within the generalized kernel equating framework (Wiberg et al., 2025). An important reason to use kernel equating here is that kernel equating methods are used in practice to equate the college admissions test which we use in the empirical study. While recent studies have utilized propensity scores in kernel equating, none have explored the integration of both propensity scores and anchor test scores in this context, as proposed here. Our overall aim is to examine kernel equating with binary scored items when using propensity scores together with anchor test scores and covariates, comparing this approach with using either only anchor scores in the NEAT design or only propensity scores with the NEC design. We conduct both an empirical study and a simulation study. This allows us to assess the practical implications of our method in a real-world context while also investigating the bias, root mean squared error, and standard errors under varying conditions.
The rest of this paper is structured as follows. In the next section, kernel equating in general is described, followed by a description of kernel equating with propensity scores. This is followed by an empirical study with some results and a simulation study. The last section contains a discussion with some concluding remarks and practical implications.
Kernel Equating
Kernel equating (von Davier et al., 2004; Wiberg et al., 2025; Wiberg & González, 2016) aims to equate test score X to test score Y on a target population T. For the NEAT and the NEC design, the target population T is not trivial to define since we are dealing with samples from two distinct population, P and Q. It is common to define a synthetic target population, defined symbolically as
Kernel equating comprises five steps: (1) Presmoothing, (2) Estimation of the score probabilities, (3) Continuization, (4) Equating, and (5) Evaluating the equating transformation. Denote the observations of X and Y by
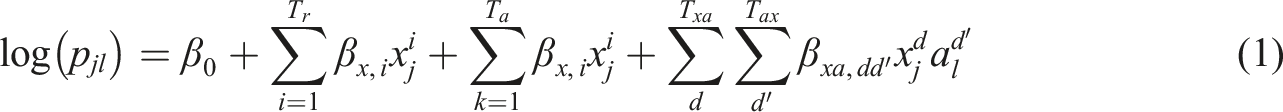
By estimating the parameters using maximum likelihood estimation, the sample moments are preserved in the distribution being modelled. Several models are typically fitted and the best fitting model according to some criteria is chosen. From the fitted model we obtain the estimated test score probabilities in step 2. If some other proxy of ability is available, such as a propensity score, these can also be modelled in the presmoothing model which will be demonstrated later in the paper.
To obtain the equating transformation, which maps the test scores onto a common scale, we define the cumulative distribution functions (CDFs) of X and Y in T as

The equipercentile transformation is the most commonly used method to equate test scores among large-scale testing organizations. As test scores are discrete, continuous approximations of the test score distributions are typically utilized. Kernel equating utilizes kernel functions for this purpose, most commonly a Gaussian kernel function. Let
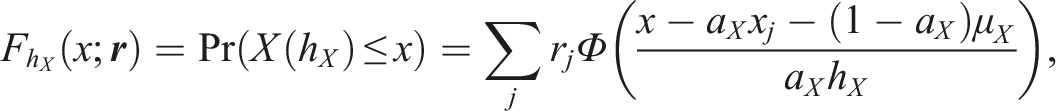

Finally, the equating transformation can be evaluated with different measures, including the asymptotic standard error of equating (SEE; von Davier et al., 2004), which, using the delta method, is defined as

The term
Kernel Equating with the NEAT Design and Categorized Covariates in the NEC Design
To perform kernel equating in the NEAT design we have two choices. First, we can utilize the mixture definition of the target population T to construct distributions of X and Y in T and obtain test score probabilities:
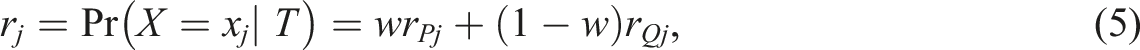
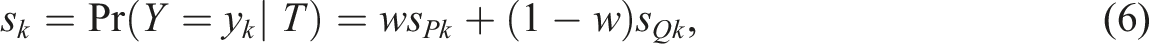

If we are using categorized covariates, as in Wiberg and Bränberg (2015), we just exchange the anchor test scores in equations (3) and (7) to the categorized covariate information. How to proceed if we instead of categorized covariates use propensity scores is described next.
Kernel Equating with Propensity Scores
Wallin and Wiberg (2019) proposed the use of propensity scores in the NEC design with both KPSE and KCE estimators and further expanded the theory in Wallin and Wiberg (2023). One advantage of using propensity scores in test equating is that they summarize multiple covariates into a single scalar, thereby reducing the dimensionality of the problem. This is particularly important when incorporating background variables in log-linear smoothing models, as modelling each covariate directly can lead to sparsity issues - many combinations of test scores and covariate values may have few or no observations, making parameter estimation unstable. By using propensity scores, we avoid sparsity issues while still adjusting for observed confounders.
A fundamental property of propensity scores is that if
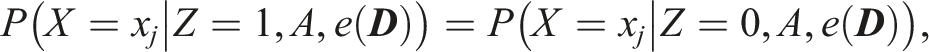
There are multiple ways to estimate propensity scores. In this paper, we use logistic regression, following the common approach of subdividing test takers into strata based on the percentiles of their estimated propensity scores (Rosenbaum & Rubin, 1984). Within each stratum, test takers are assumed to be comparable in ability. The number of strata is chosen based on the covariate distribution to ensure adequate balancing while maintaining a sufficient number of observations in each stratum.
Other methods for balancing covariates include weighting techniques, such as the minimum-variance balancing method proposed by Zubizarreta (2015), which adjusts the empirical distribution of covariates to achieve a prespecified level of balance. Additionally, a range of quantitative and qualitative diagnostics can be used to assess balance between test forms after weighting or stratification. For a comprehensive review of propensity score methods, we refer to Austin and Stuart (2015).
The KPSE Estimator with Propensity Scores
To obtain a KPSE estimator with propensity scores, i.e., the PS-KPSE estimator, denote the stratified propensity score for strata l,
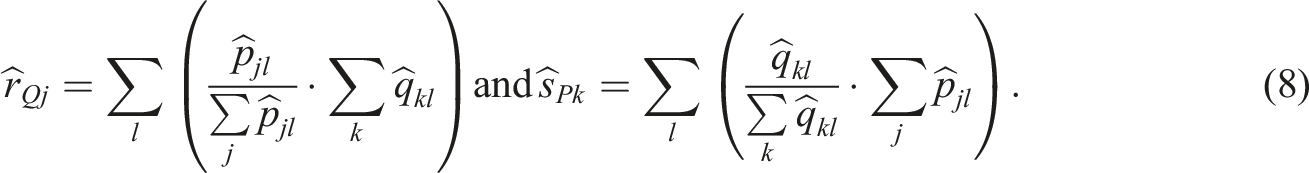
Equation (8) are then plugged into equations (3), (5), and (6) and we can obtain the PS-KPSE estimator as follows

The CE Estimator with Propensity Scores
To define an estimator when using CE with propensity scores, i.e. the PS-KCE estimator, define the continuized CDFs for X and Y in population Q as
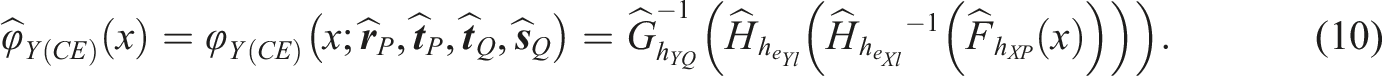
Combining Anchor Test and Covariate Information
Anchor test information can be incorporated in at least two different ways when using kernel equating with propensity scores. Either they can be incorporated directly in the propensity score model (labelled PSwA) or they can be a separate part of the presmoothing models (labelled PSwoA). If the anchor scores are incorporated directly into the propensity-score model, the resulting presmoothing log-linear models, which we call “inner models”, are obtained:
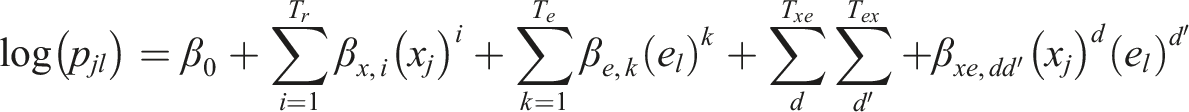
If the anchor scores instead are incorporated separately in the log-linear models, we obtain outer models:
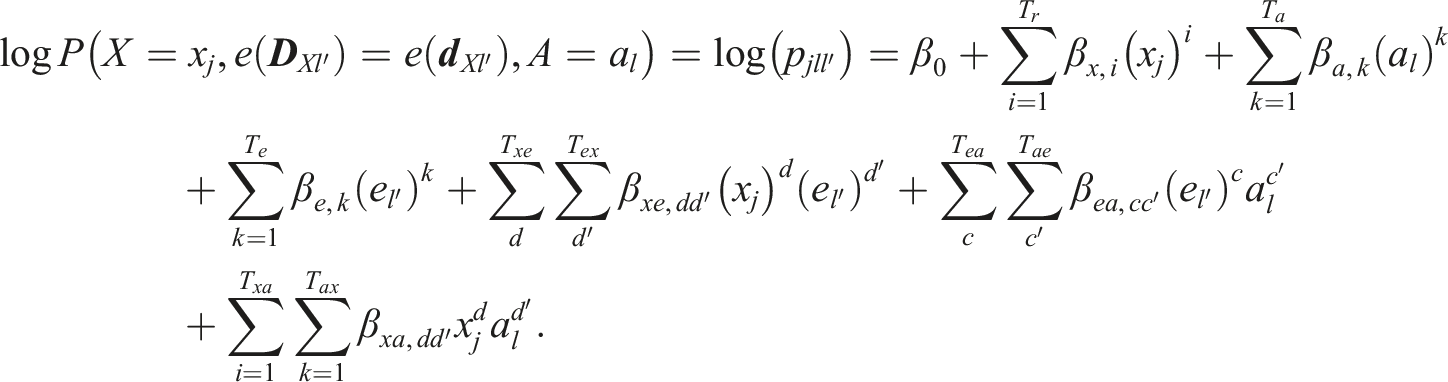
The obtained models are then used to estimate the score probabilities when performing kernel equating.
An alternative approach to presmoothing is the EM-based log-linear method proposed in Liou (1998), which integrates test scores, anchor items, and group membership into a unified model. This approach explicitly accounts for ignorable and nonignorable missing-data mechanisms. While our method shares a conceptual foundation with this framework, it differs in that we use the propensity score
Empirical Study
Data from the college admissions test SweSAT was used to illustrate the proposed extension of using propensity scores together with information from anchor tests within the kernel equating framework. SweSAT contains 160 multiple-choice, binary scored items, comprising a verbal section and a quantitative section of 80 items each. The two sections are equated separately. The test takers were also administered either an external 40 items (verbal or quantitative) anchor test or 40 (verbal or quantitative) try-out items. Typically, the SweSAT is given twice a year to between 28,000 and 60,000 test takers, and about 2,000 test takers receive the 40 items quantitative anchor test. Prior to introducing the anchor test in the SweSAT, the equating was done by using a set of covariates as described in Lyrén and Hambleton (2011). Although anchor tests are available nowadays, covariates are still of interest when equating the SweSAT as the empirical covariate distributions are not necessary the same at different administrations. Note that currently, when equating the SweSAT, several equating methods are used in practice including the KCE, KPSE and PS equating methods.
Descriptive statistics of the four administrations in total and for the anchor test groups
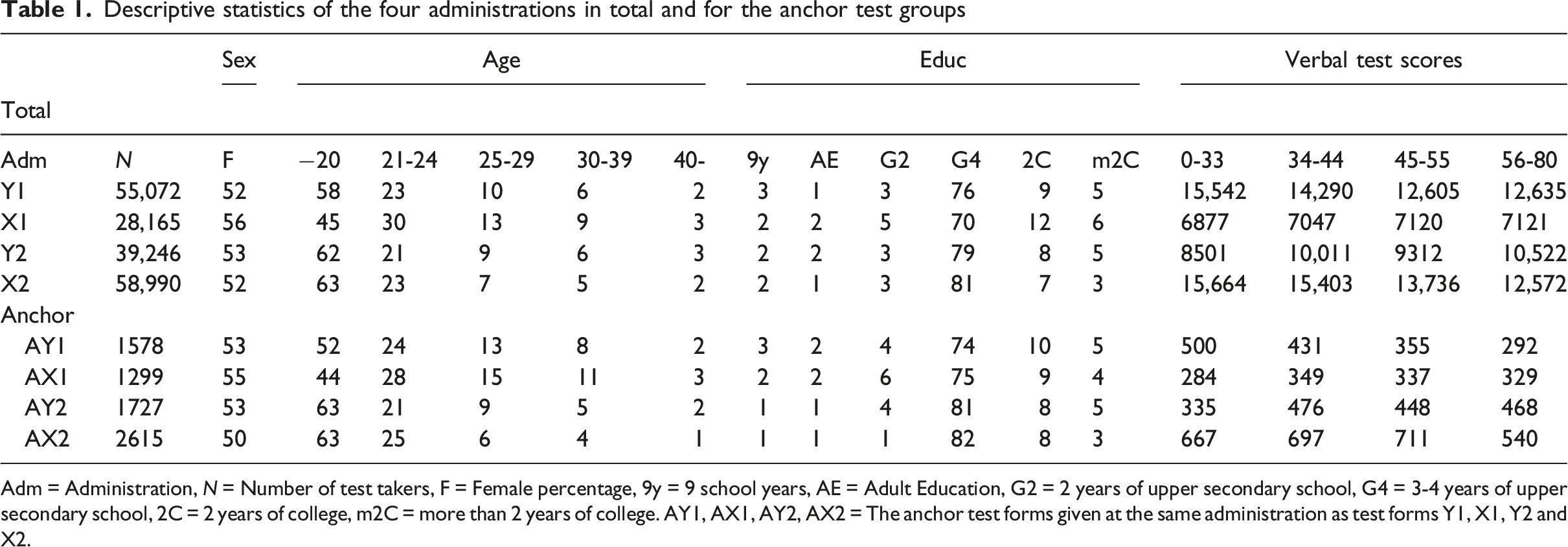
Adm = Administration, N = Number of test takers, F = Female percentage, 9y = 9 school years, AE = Adult Education, G2 = 2 years of upper secondary school, G4 = 3-4 years of upper secondary school, 2C = 2 years of college, m2C = more than 2 years of college. AY1, AX1, AY2, AX2 = The anchor test forms given at the same administration as test forms Y1, X1, Y2 and X2.
Mean, standard deviation (SD) and correlation of the four administrations used in the two scenarios in the empirical study
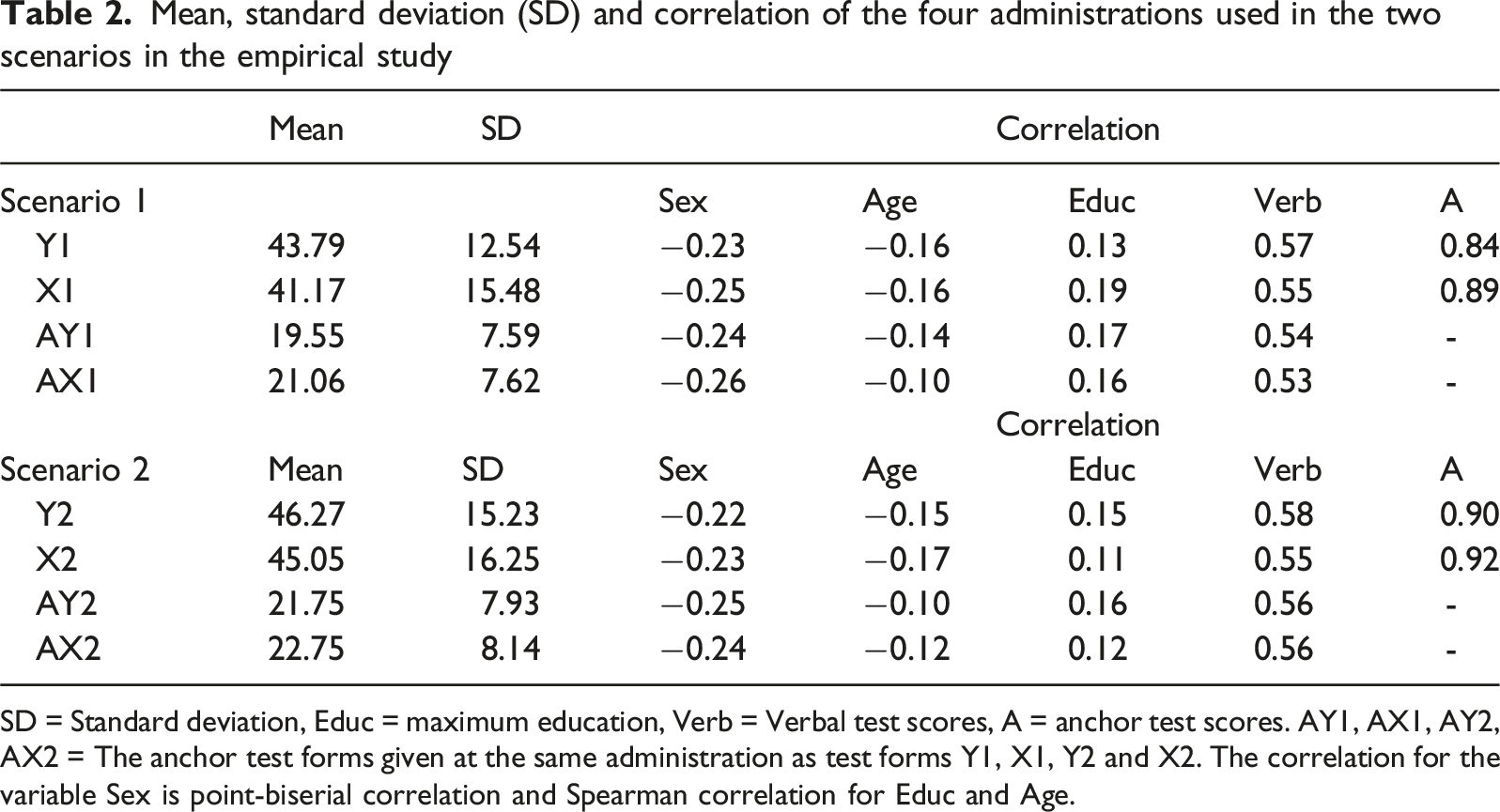
SD = Standard deviation, Educ = maximum education, Verb = Verbal test scores, A = anchor test scores. AY1, AX1, AY2, AX2 = The anchor test forms given at the same administration as test forms Y1, X1, Y2 and X2. The correlation for the variable Sex is point-biserial correlation and Spearman correlation for Educ and Age.
We assumed that we always equated a new test form X to an old test form Y. In scenario 1, we equated two test forms which had very different empirical distributions with respect to sex, age and education compared with all other administrations (see first two rows of Table 1). The reason was that test X1 was administered during a covid year, and it was equated to a test form given before Covid-19. The SweSAT is highly affected by the Swedish unemployment rate, as more test takers want to apply for university if they lose their jobs. The unemployment was higher during covid than the years before the pandemic. In the second scenario, we equated two administrations which had similar empirical distributions with respect to sex, age, and education (row 3 and 4 in Table 1) and the test forms were not administered during the pandemic. KPSE was used to equate the test forms when propensity scores were used.
In each scenario we compared the following method and designs: (1) NEC design with anchor test within the propensity score model (PSwA), (2) NEC design with propensity scores but anchor outside the propensity score model (PSwoA), (3) propensity scores with a NEC design without anchor information (PS), (4) NEAT design with KCE, (5) NEAT design with KPSE.
Propensity scores were obtained with logistic regression using all covariates including the anchor test in 1), and all covariates excluding the anchor test in (2) and 3). The estimated propensity scores from the fitted model were divided into several strata according to the percentiles. The propensity score models were assessed by checking the covariate balance in the strata using the absolute standardized mean difference (ASMD) in which a difference of less than 0.1 indicate good balance (Austin, 2008). The AMSD is defined as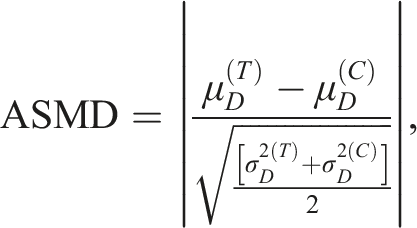
The Bayesian information criterion (BIC, Schwarz, 1978) was used to choose parametrization of the log-linear models in the presmoothing step as it has been shown to have a high selection accuracy for bivariate smoothing (Moses & Holland, 2010). The following log linear models were chosen for KCE and KPSE:
Summary statistics including correlation are given in Table 2. Note that some of the covariates are quite similar over the four administrations, however for education it differs substantially. The means differed considerably, and the standard deviations differed a lot in scenario 1.
Figure 1 displays the four test score distributions, and it is clear from both the mean and SD in Table 2 and Figure 1 that the test distributions are quite different, especially in the mid score range. Test Score Distributions for Both Scenario 1 and Scenario 2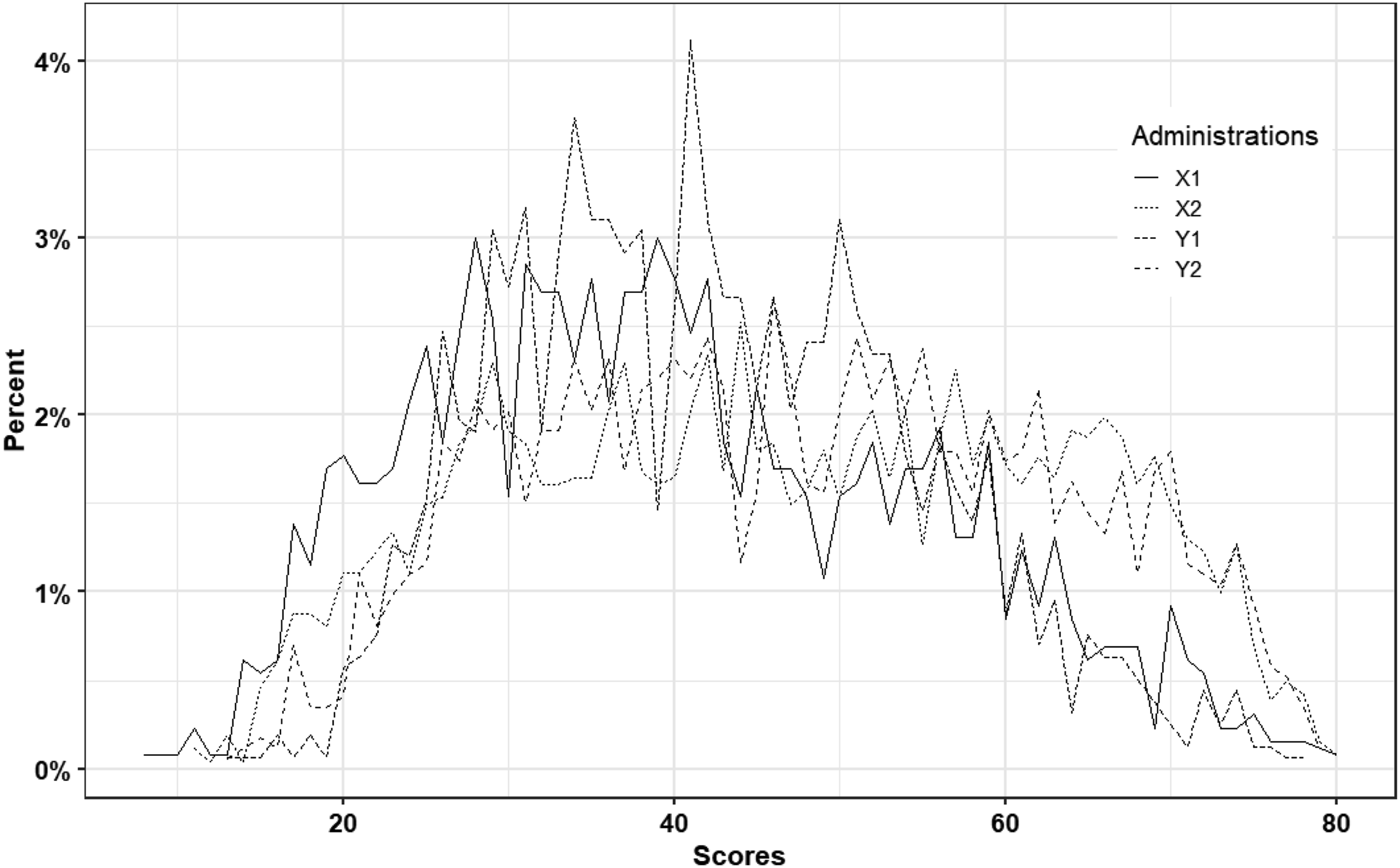
To evaluate the equating methods used in the empirical study we used the same measures as Wallin and Wiberg (2019, 2023) used in their empirical studies, i.e., difference between the equated score and the raw score, and the SEE. The empirical study was carried out in R with the package kequate (Andersson et al., 2013). To use propensity scores using kequate, one can simply replace the function call for the anchor with a call to the estimated and stratified propensity scores.
Results from the Empirical Study
The first row in Figure 2 illustrates the difference between equated scores and raw scores and the second row illustrates the equating transformations for the two scenarios when either NEAT design is used (KPSE and KCE) or NEC design with propensity scores is used (PS), or NEC design with anchor test within propensity scores (PSwA) or NEC design with propensity scores but anchor outside (PSwoA). The differences between equated scores and raw scores are much larger for lower test scores and are especially large in scenario 1. Clearly the equating transformations are quite similar, especially in scenario 2 regardless of the method used. In scenario 1, PS and PSwoA differed most from the other equating transformations. Difference Between Equated Scores and Raw Scores (First Row) and the Equating Transformations (second Row) for Scenario 1 (Left) and Scenario 2 (Right)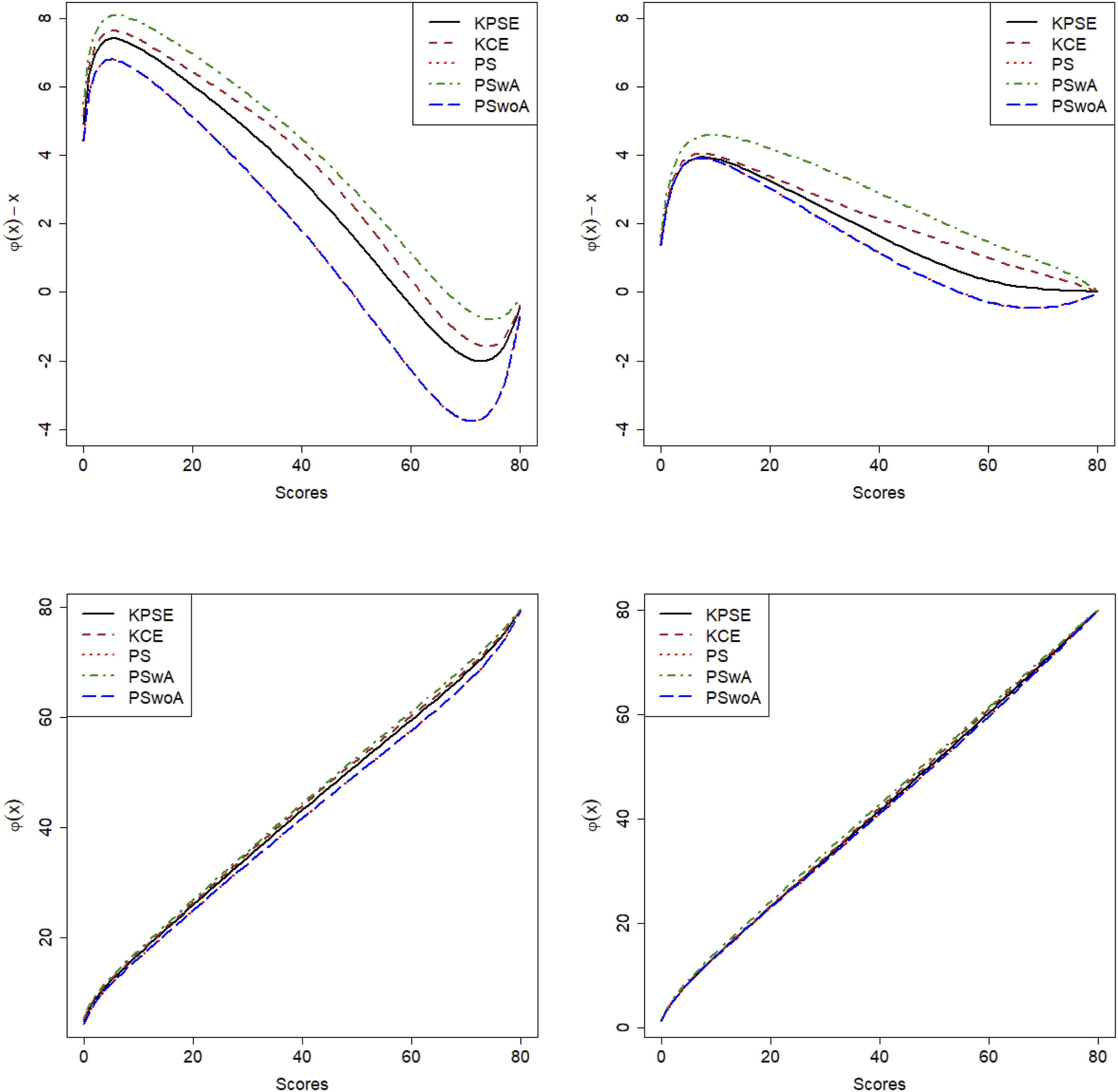
Figure 3 displays the SEE, and from this figure it is evident that when anchor test scores are included in the propensity scores the SEE is lower than if the anchor test scores are modelled as a separate term in the loglinear presmoothing models. The SEE is much higher in the low and high score range for both scenarios but as expected much lower in scenario 2. It is also interesting to note that SEE for KCE is higher in the mid score range than for the methods using covariate information in both scenarios. To demonstrate how loglinear presmoothing works, we added histograms comparing the distributions of non-smoothed and smoothed Form X scores, as well as comparisons between the methods, and they can be seen in Appendix A, figures A1 and A2. SEE for Scenario 1 to the Left and Scenario 2 to the Right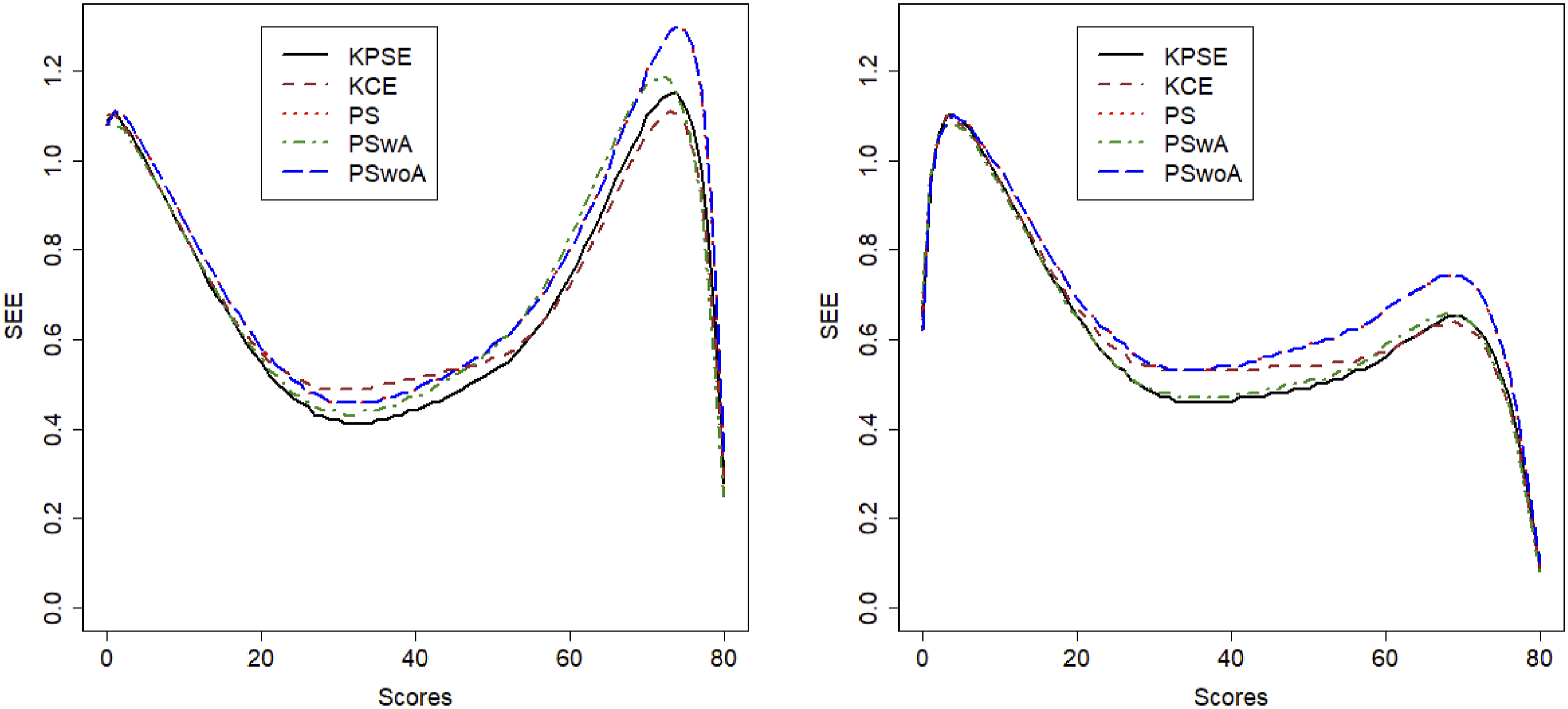
Summing up, when there are significant differences in the test distributions (Scenario 1), the SEE and the discrepancies between equated scores and raw scores were larger than when the score distributions were more similar (Scenario 2). Also, when anchor test scores are incorporated within the propensity score estimation, we obtained lower SEE compared to when they are treated as separate covariates.
Simulation Study
To be able to examine several different conditions we conducted a simulation study in which we varied number of test takers, anchor items, and the correlation level between the covariates and the test scores. In addition, the abilities of the test taker groups, and the difficulty of the anchor test were varied. In the following, the simulation design and the evaluation measures re described. For each simulation scenario, 500 replications were used. First, we summarize the scenarios considered, before describing how the simulated data was generated. • Two populations, • A subset of either 1,000 or 2,000 test takers was sampled for each replication. A regular test length of 80 and a varying anchor test length of either 20 or 40 were used. • Low and moderate correlations between the covariates and the test scores were considered.
Scenarios (S) in the simulation study
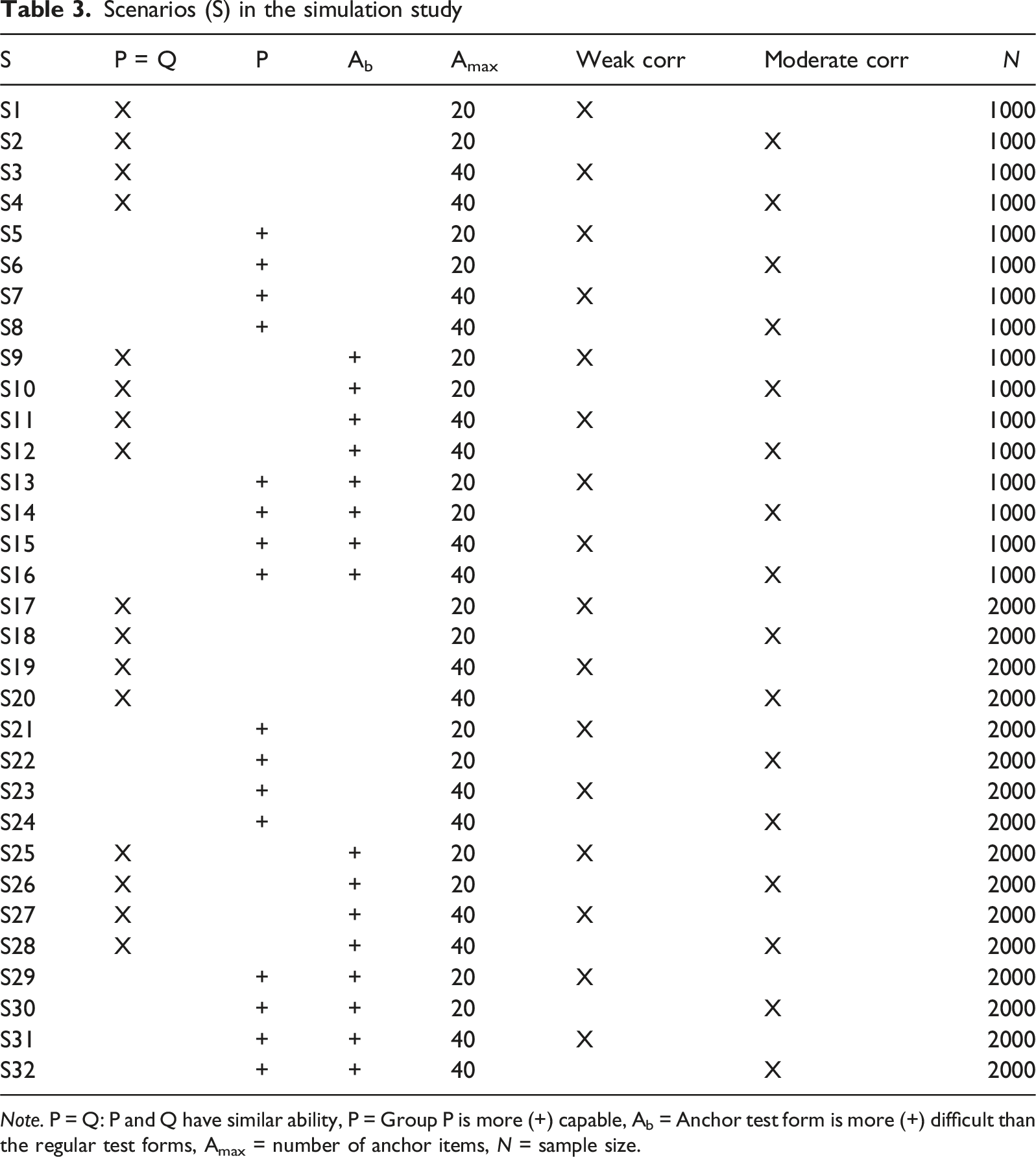
Note. P = Q: P and Q have similar ability, P = Group P is more (+) capable, Ab = Anchor test form is more (+) difficult than the regular test forms, Amax = number of anchor items, N = sample size.
Note that the simulation condition S23 (or S7 with a smaller sample) is the closest to the empirical study. From the anchor test results presented in Table 2, it is evident that X samples performed better than Y samples. Correlations between the scores and covariates were weak. In operational settings, anchor sample sizes ranged from 1000 to 2000, with the majority being closer to the upper end of that range.
Data-Generating Process
Two matrices,
For each test taker in the population, item responses were generated using the item response theory (e.g. van der Linden, 2018) logistic function: • Low correlation setting: • Moderate correlation setting: 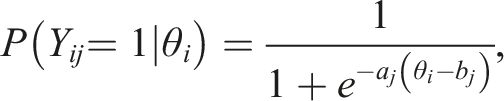
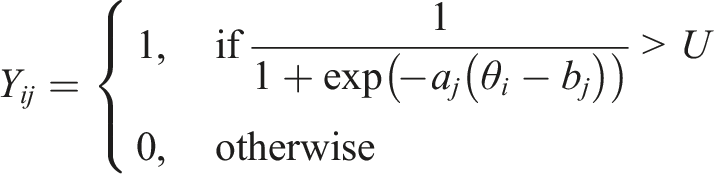
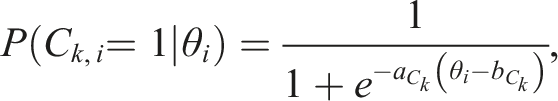
Lastly, we calculated the sum score of each covariate, thus creating three categorical covariates.
Population Model and Four Estimators
We examined a population model and four alternative estimators. For each scenario and estimator, the best-fitting log-linear models were selected separately using the Akaike information criterion (AIC; Akaike, 1974), BIC, and the likelihood ratio test (LRT; Haberman, 1974a; 1974b). This resulted in at most six unique models – one for (
Population model: Using the population-level data, propensity scores were estimated using a logistic regression model with the covariates as predictors. Test takers were stratified into 15 groups based on these propensity scores. Equating was thereafter performed using KPSE and KCE methods.
Common procedure for Estimators 1-3: For all propensity score estimators, test takers were stratified into 15 groups based on propensity scores, and the strata acted as predictors in the log-linear model together with the score variables. The estimators differ in their propensity score specification:
Estimator 1: Equating with propensity score that includes only covariates (PS) • Propensity scores were estimated using covariates only. • Equating was performed using KPSE and KCE methods.
Estimator 2: Equating with propensity scores that includes both covariates and anchor scores (PSwA) • Propensity scores were estimated including both covariates and anchor items. • Equating was performed using KPSE and KCE methods.
Estimator 3: Equating with anchor score outside of propensity score (PSwoA) • Propensity scores were estimated only with covariates. • A three-dimensional contingency table was created for the sum score, propensity score strata, and anchor score. • Equating was performed using the PSE method.
Estimator 4: NEAT Equating (KCE/KPSE) • Kernel equating with the NEAT design using both KCE and KPSE was conducted as a baseline comparison.
Evaluation Measures
To evaluate the equating transformations, we used four evaluation measures. We examined bias, over R replications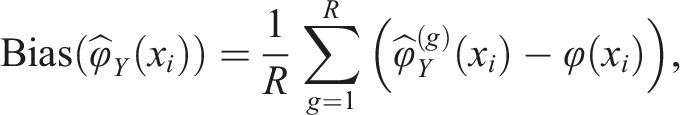
We examined the SEE from equation (4), and the root mean squared error (RMSE),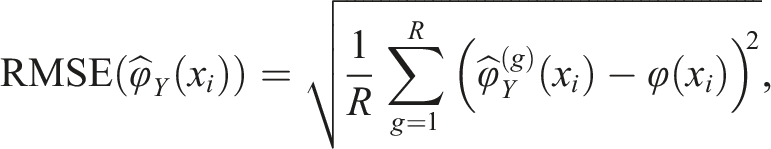
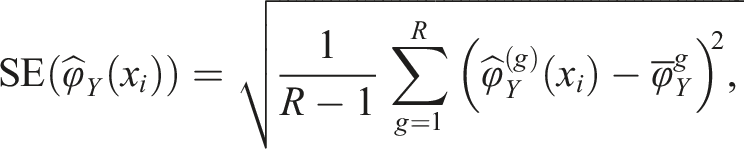
Results from the Simulation Study
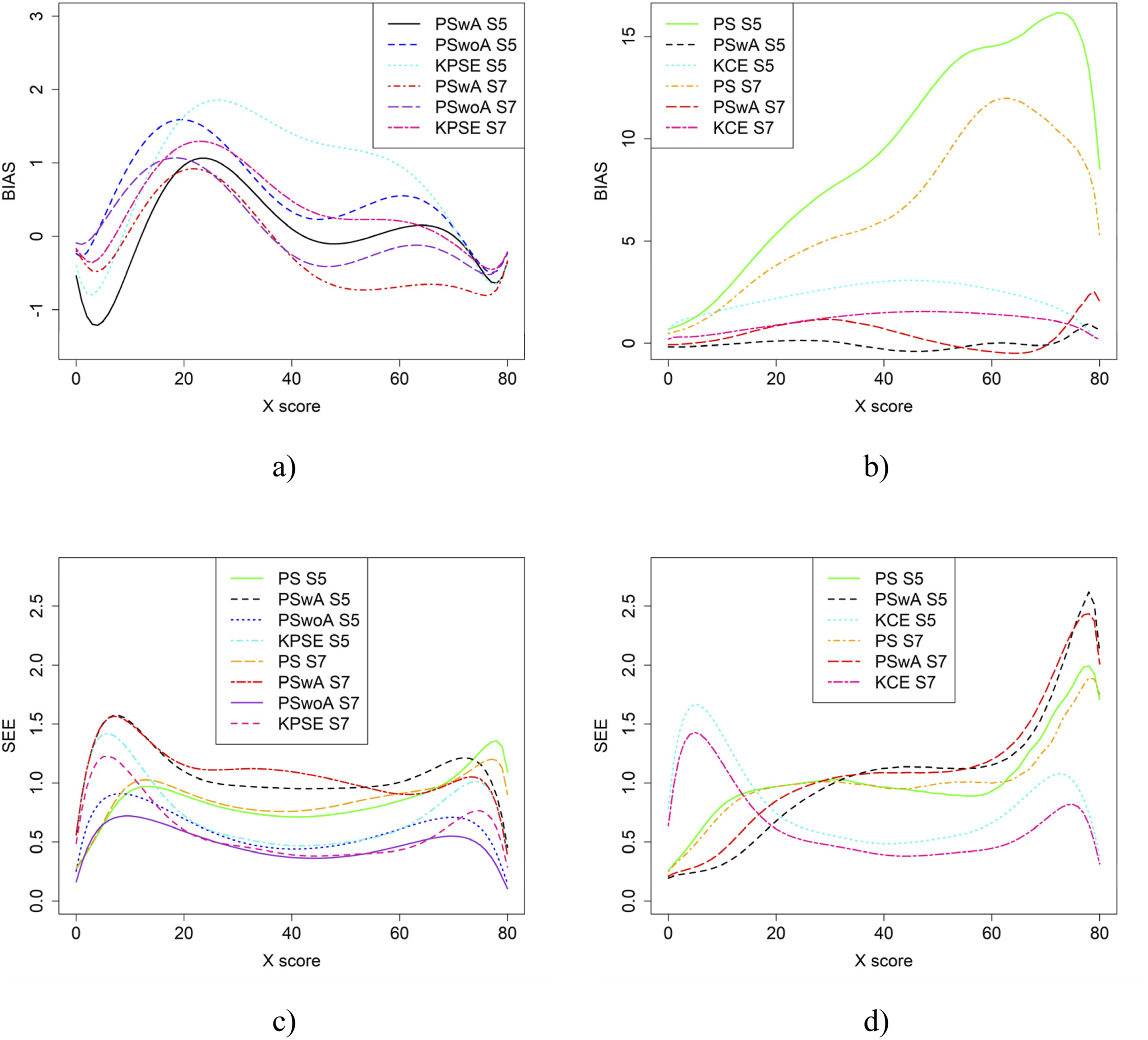
In the simulation study, in addition to varying sample sizes, anchor test lengths, and correlation strength, we also varied the abilities of the test-taker groups and the difficulty of the anchor test. Note, in all figures in this section the left figures are based on the KPSE estimator, and the right figures are based on the KCE estimator. Figures 4 and 5 present the results for the baseline case where the groups had similar abilities, and the difficulty of the regular test forms and the anchor test form were comparable. The difference between the two figures is the strength of the correlation between the covariates. When the correlation between the covariates was moderately strong (see Figure 4(a) and (b)), the differences in bias between the studied equating methods were larger compared to when the correlation was weak (see Figure 8(a, b)), especially for KPSE. However, the differences in bias between the various anchor test lengths were more pronounced when the correlation was weak. For KCE, the differences in bias across different correlation strengths or anchor test lengths were small. Bias (a and b) and SEE (c and d) for the Baseline Case when Correlation Between Covariates was Moderate Strong and the Size of an Anchor Test Form was Either 20 Items (S2) or 40 items (S4). Bias (a and b) and SEE (c and d) for the Baseline Case when Correlation Between Covariates was Weak and the Size of an Anchor Test Form was Either 20 Items (S1) or 40 items (S3)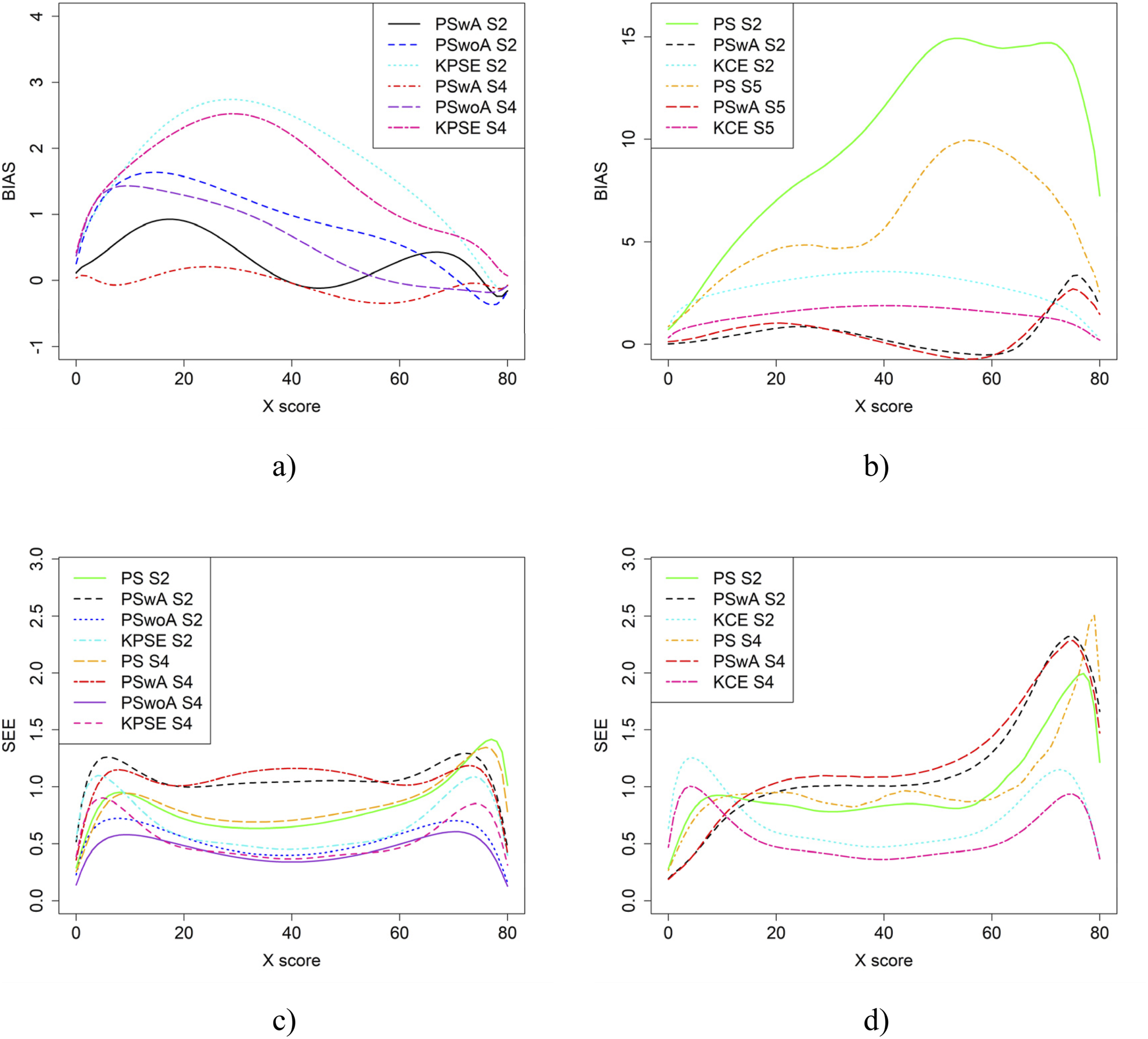
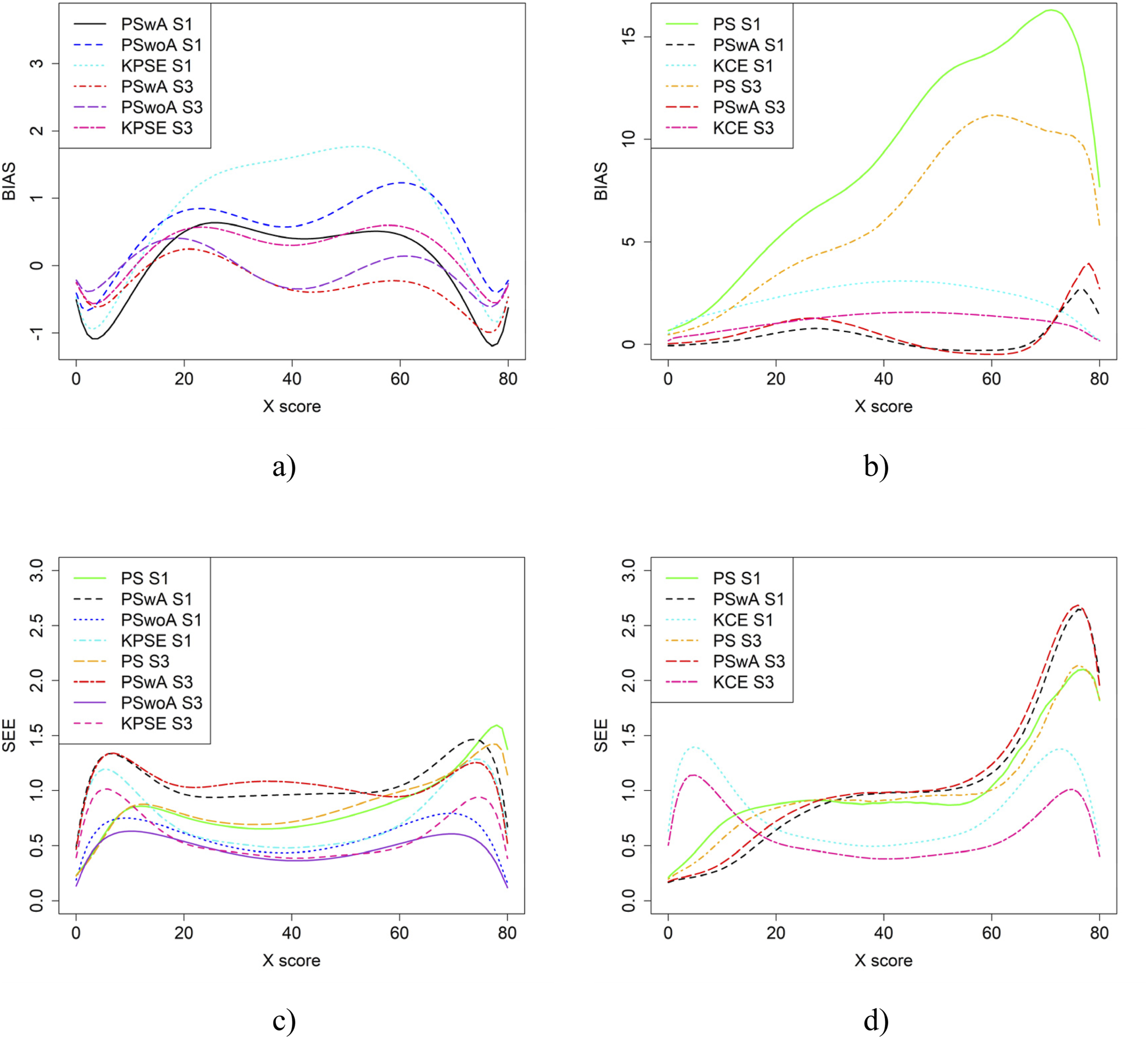
The main differences in SEE were observed between the different methods, with the smallest SEE occurring when the anchor score was outside of the propensity score (PSwoA) and the anchor test consisted of 40 items for KPSE (see Figures 4(c) and 5(c)), and for the NEAT design when using KCE (see Figures 4(d) and 5(d)).
Figure 6 displays the RMSE and SE for the baseline case in Figure 4. As their results are similar to the bias and SEE figures – we draw the same conclusions from them. For subsequent scenarios, we have therefore omitted RMSE and SE figures, but these can be obtained upon request from the corresponding author. RMSE (a and b) and SE (c and d) for the Baseline Case when Correlation Between Covariates was Moderate and the Size of an Anchor Test Form was Either 20 Items (S2) or 40 items (S4)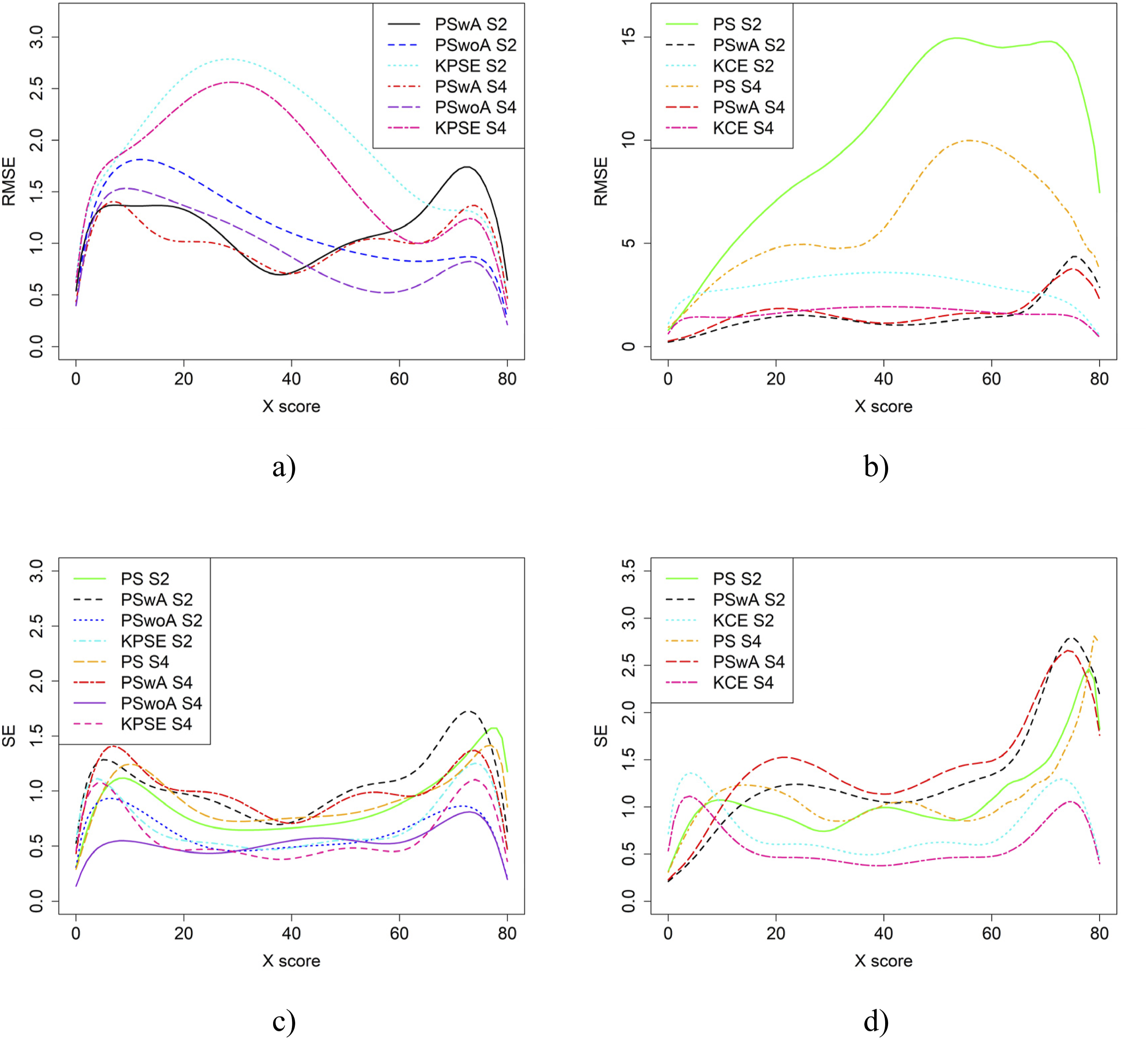
Figure 7 presents the results for bias and SEE for the baseline case for different sample sizes: 1000 (S2) and 2000 (S18). The bias only indicated minimal or no differences. The sample size, however, impacted the SEE results, with the largest differences occurring for equating with propensity scores (PS) and with propensity scores that included both covariates and anchor scores (PSwA). Bias (a and b) and SEE (c and d) for the Baseline Case when Correlation Between Covariates was Moderate and the Sample Size N was Either 1000 (S2) or 2000 (S18)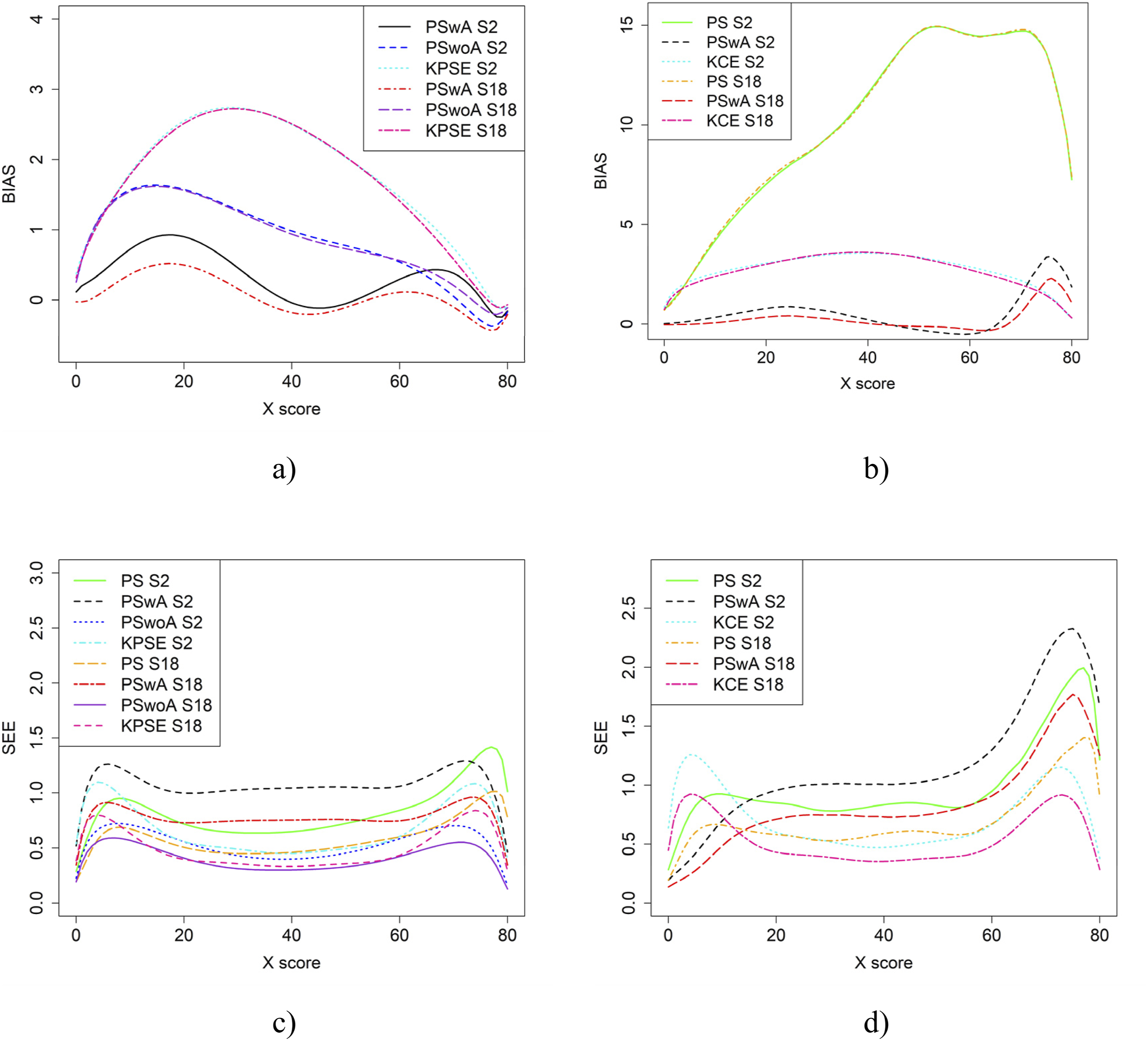
Figure 8 displays result similar to those shown in Figure 4. However, in this case, the scenarios involve one group with average ability and another with higher ability. SEE values for KPSE are nearly identical to those in the baseline case shown in Figure 4. For KCE, when the correlation between the covariates is moderate, SEE values are slightly lower at the high scores, especially for PswA and PS with longer anchor test (see Figure 10(b)) compared to the baseline case. In contrast, when correlation is weak, SEE values are higher at the high scores for these same methods (see Appendix Figure B3). The differences in group abilities had a slightly greater impact on bias values, particularly for KPSE compared to KCE. When the correlation between the covariates was weak, bias increased for the lower scores for KPSE equating, unlike in the baseline case. Bias (a and b) and SEE (c and d) for Groups Differing in Ability when Correlation Between Covariates was Moderate and the Size of an Anchor Test Form was Either 20 Items (S6) or 40 items (S8)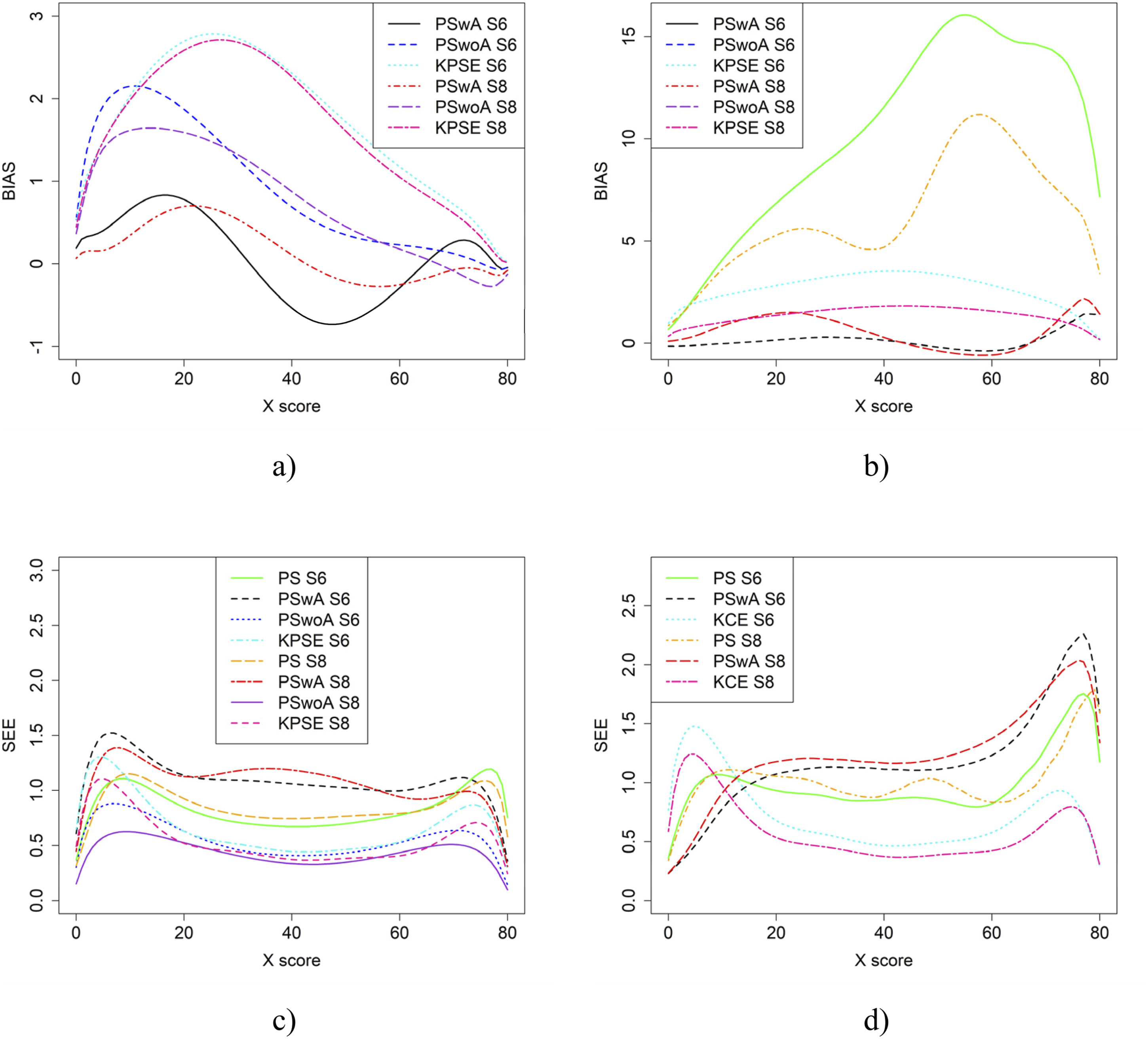
If the anchor test form is more difficult than the regular test forms, the bias results change significantly, especially when the correlation between the covariates is moderate (see Figure 9). The largest changes in bias are observed for equating methods using propensity scores. Interestingly, when the correlation between the covariates was weak, the bias results for KCE were similar to the baseline case (see Figure 4). The difficulty of the anchor test had only a minor effect on SEE values. Bias (a and b) and SEE (c and d) for Groups Similar in Ability when Anchor Test Form was More Difficult than the Regular Test Forms, Correlation Between Covariates was Moderate and the Size of an Anchor Test Form was Either 20 Items (S10) or 40 items (S12)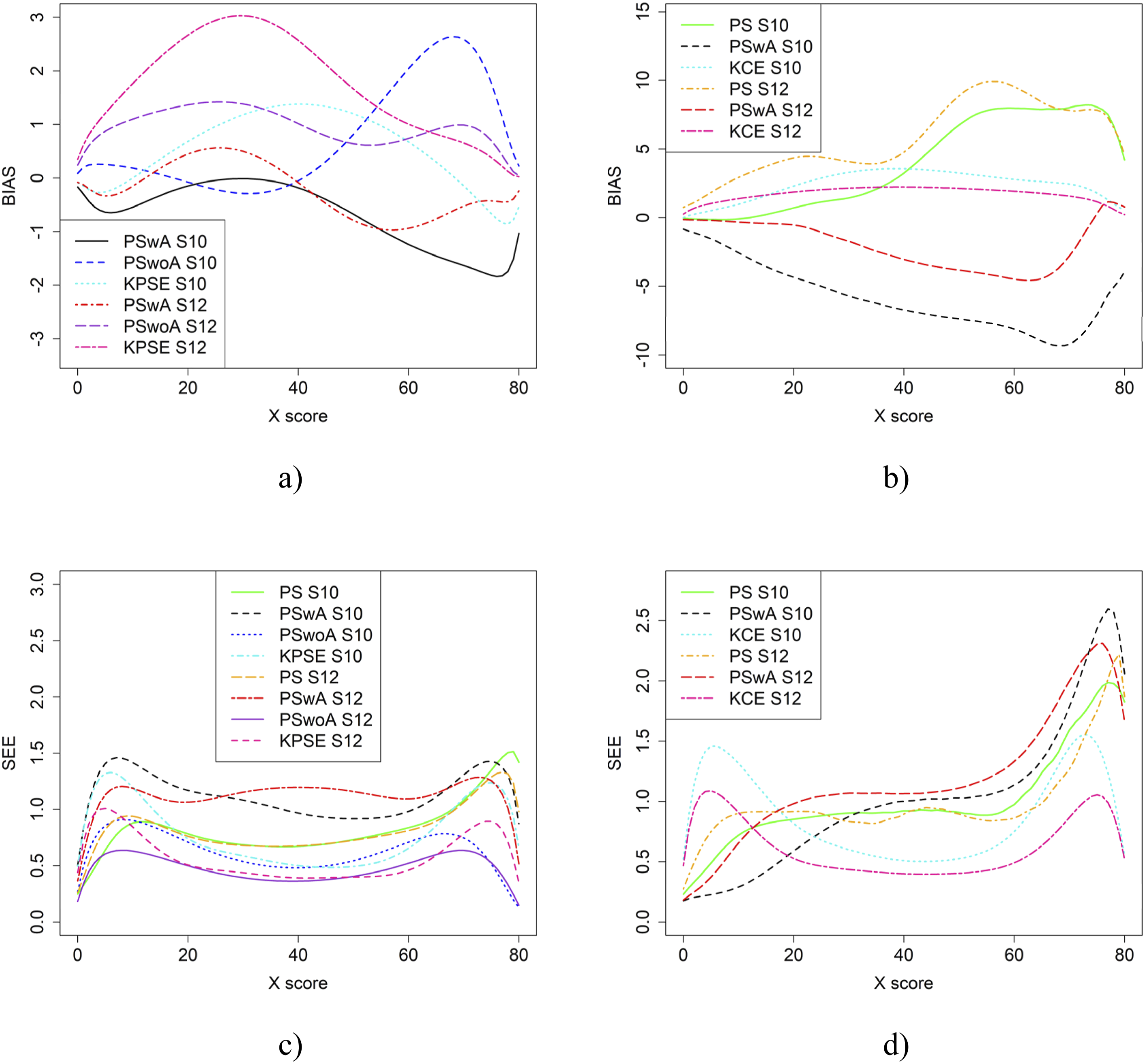
Figure 10 displays the equating results when the anchor test form is more difficult than the regular test forms and one group has higher ability than the other. For the KPSE based methods, PSwoA had the lowest SEE and PSwA had in general the lowest bias. The greatest impact on bias values was seen for the KPSE methods, compared with the KCE methods. Bias (a and b) and SEE (c and d) for Groups Differing in Ability when Anchor Test Form was More Difficult than the Regular Test Forms, Correlation Between Covariates was Moderate and the Size of an Anchor Test Form was Either 20 Items (S14) or 40 items (S16)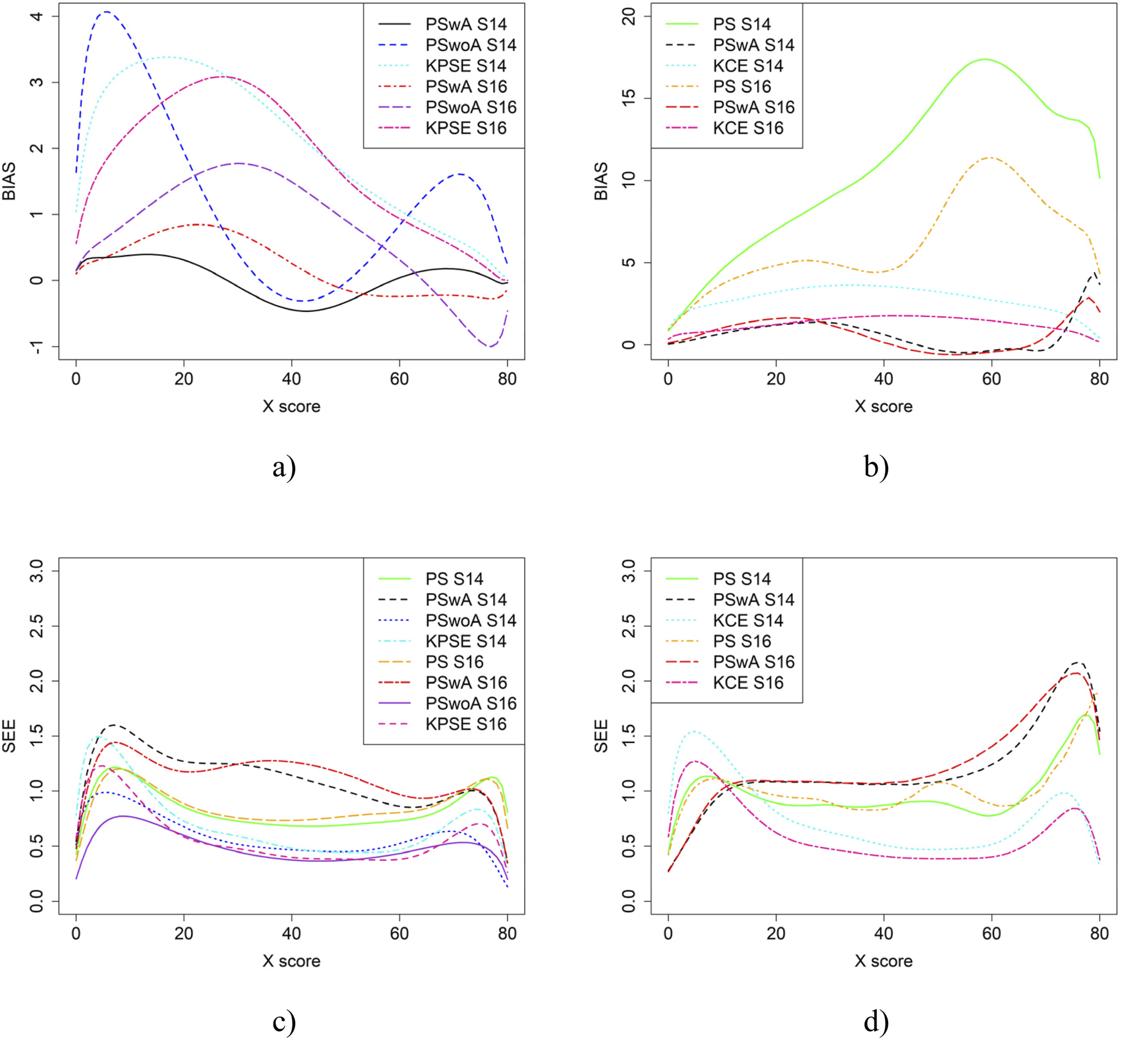
Discussion
The primary objective of this study was to propose and evaluate a novel approach that could be incorporated into generalized kernel equating. The proposed approach integrates propensity scores with anchor test scores. This approach was compared against two established methods: the NEAT design alone and the NEC design using propensity scores without anchor tlest scores. The empirical study showed that when test distributions exhibited significant differences (Scenario 1), the SEE and the discrepancies between equated scores and raw scores were more pronounced. This finding aligns with the results of Laukaityte and Wiberg (2024). Notably, the use of propensity scores led to a lower SEE, consistent with the conclusions of Wallin and Wiberg (2019), although their study did not examine the combined use of anchor test scores, and propensity scores derived from covariate information. As expected, incorporating anchor test scores within the propensity score estimation resulted in a lower SEE compared to treating them as separate covariates. This suggests that the integration of anchor test information into propensity scores may enhance the precision of equating. This is also in line with the results of Kim and Walker (2021; 2022) who concluded that using both sample weights via MDIA and a short anchor produced the most accurate equating results.
From the simulation study, we concluded that when the correlation between the covariates was moderately strong, the differences in bias and RMSE between the methods were larger compared to when the correlation was weak, especially when using KPSE. The difference was also more pronounced when a shorter anchor test was used in conjunction with weak correlation. This is not surprising, as a shorter anchor test and weaker correlation yield less overall information. For KCE, the differences in bias across different correlation strengths or anchor test lengths were small. For KPSE, the smallest SEE and SE occurred when the anchor score was outside of the propensity score (PSwoA) and the anchor test consisted of 40 items. For the NEAT design, the smallest SEE and SE occurred when using KCE. This is expected, as more information about the test takers should yield a smaller error, as seen, for example, in Bränberg and Wiberg (2011), who examined observed score linear equating with covariates.
Varying the sample sizes had little effect on bias but did impact the SEE results, with the largest differences occurring when equating with propensity scores (PS) and with propensity scores that included both covariates and anchor scores (PSwA). In general, SEE was lower when anchor test scores were used as a separate covariate (PSwoA) compared to when they were included within the propensity score (PSwA). This is probably because treating the anchor scores as a separate covariate provides more information about the test takers than when the anchor scores are combined with other covariates within the propensity score.
When the ability between the groups differed, the SEE values for KPSE were nearly identical to those in the baseline case. This is in line with Lu and Guo (2018) who concluded that if the ability group difference were large, to use NEAT is preferred in terms of RMSE and bias, instead of using only information in background variables through PEG. Also, our conclusion to use background information together with anchor test information is in line with their conclusion of using PEG procedures based on background variables together with the anchor test to improve the equating. When group ability differences were small (baseline case), the SEE were low when either PSwoA or NEAT (KCE/KPSE) were used. Although we used a different approach and used bias and SEE to evaluate, our result is in line with Lu and Guo (2018), who concluded that using only NEAT design compared with using PEG without an anchor test gave comparable results, in terms of bias and RMSE.
When the correlation was moderate, SEE values were slightly lower at the higher scores, especially for PSwA and PS with a longer anchor test when KCE was used. This result is contrary to the findings of Ricker and von Davier (2007), who concluded that a shorter anchor yields a larger bias for KCE compared to KPSE; however, they did not examine the effect of correlation. Note that when the correlation was weak, the SEE values are higher at the higher scores for the same methods. The differences in group abilities had a slightly greater impact on the bias values, especially for KPSE compared to KCE. This is in line with, for example, Puhan (2010) and Powers and Kolen (2014), who concluded that CE is less affected by group differences. When the correlation between the covariates was weak, bias increased for the lower scores for KPSE equating, unlike in the baseline case. Lu and Guo (2018) conclusion that if the anchor test is weak (i.e. few items and low correlation), is like the conclusion here, i.e. that we can then improve the equating with background information. When the anchor test form is more difficult than the regular test form, the bias results change significantly, particularly when the correlation between the covariates is moderate. Notably, the bias is especially large when using propensity scores without anchor test information. A possible explanation is that the propensity scores diverge too much from the anchor test scores, though this requires further investigation.
In summary, when the anchor test form is more difficult than the regular test forms and one group has higher ability than the other, the bias was more affected when using KPSE methods compared to KCE methods. These results are consistent with those of Laukaityte and Wiberg (2024), who studied how differences in group abilities impact kernel equating methods. If one has access to covariates, it is advisable to include them in the presmoothing model, as this can reduce the SEE. When multiple covariates at different levels are available, using propensity scores is an effective way to incorporate a large amount of information. In our study, it was also evident that, in terms of bias and SEE, it is better to include the anchor scores as a standalone covariate rather than incorporating them into the propensity score model.
This study has some limitations. First, we included only binary-scored items; in the future, polytomously scored items and mixed-format tests incorporating information from covariates should be examined. For example, Wallmark et al. (2023) examined kernel equating in mixed-format tests. A second limitation is that we examined only a few presmoothing models. Wallin and Wiberg (2020; 2024) have shown that the presmoothing model has a significant impact on the equating transformation; therefore, several other models should be explored in future research. Another limitation concerns the choice of covariates and future studies should investigate other covariates and their usefulness when equating test scores. Note, there is a trade-off between test takers performance and precision of the test depending on the design of the test. On one hand, to include an anchor test prolongs the testing time and thus makes test takers more fatigue, on the other hand more information about the test takers is collected when including an anchor test and thus the precision of the equating can be increased.
While our primary focus was on horizontal equating scenarios where test-taker ability distributions differ but test content is similar, our approach may also be applicable to vertical equating. In vertical equating, test forms are tailored for different school grades, introducing additional complexities in modelling ability differences. As suggested in prior work (Liou, 1998), nonignorable missing-data models may be more appropriate in such contexts. Our method could potentially be adapted for vertical equating by extending the log-linear model to include additional covariates representing developmental differences across grades. Exploring this extension remains an interesting possibility for future research. Furthermore, continuous propensity scores can be used directly as conditioning variables in equating without requiring stratification, similar to how anchor scores function in traditional equating designs.
Another limitation is that the current standard error estimation approach does not explicitly account for the covariance between the empirical distributions F and G in the synthetic population. While we follow the framework of Wallin and Wiberg (2019) which provides estimates for the variances within each distribution, incorporating the covariance component would provide more accurate standard error estimates for the equated scores. Future methodological work should address how this covariance can be systematically incorporated into the standard error calculations for propensity score equating methods.
Finally, given that adjusting test score scales is a practical issue in many large-scale assessments, we included an empirical study to address this problem. Our results suggest that utilizing information from covariates, when they are available and informative, can be beneficial. However, we emphasize that an anchor test should also be used if available.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The Swedish Wallenberg MMW grant (2019.0129).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Appendix A
The comparison between the distributions of non-smoothed and smoothed with NEAT model Form X scores for scenarios 1 and 2 is presented in Figure A1. Smoothing results with other models are almost identical to the presented ones and thus are omitted. The Comparison Between the Distributions of Non-smoothed and Smoothed With NEAT Model Form X Scores for Scenarios 1 and 2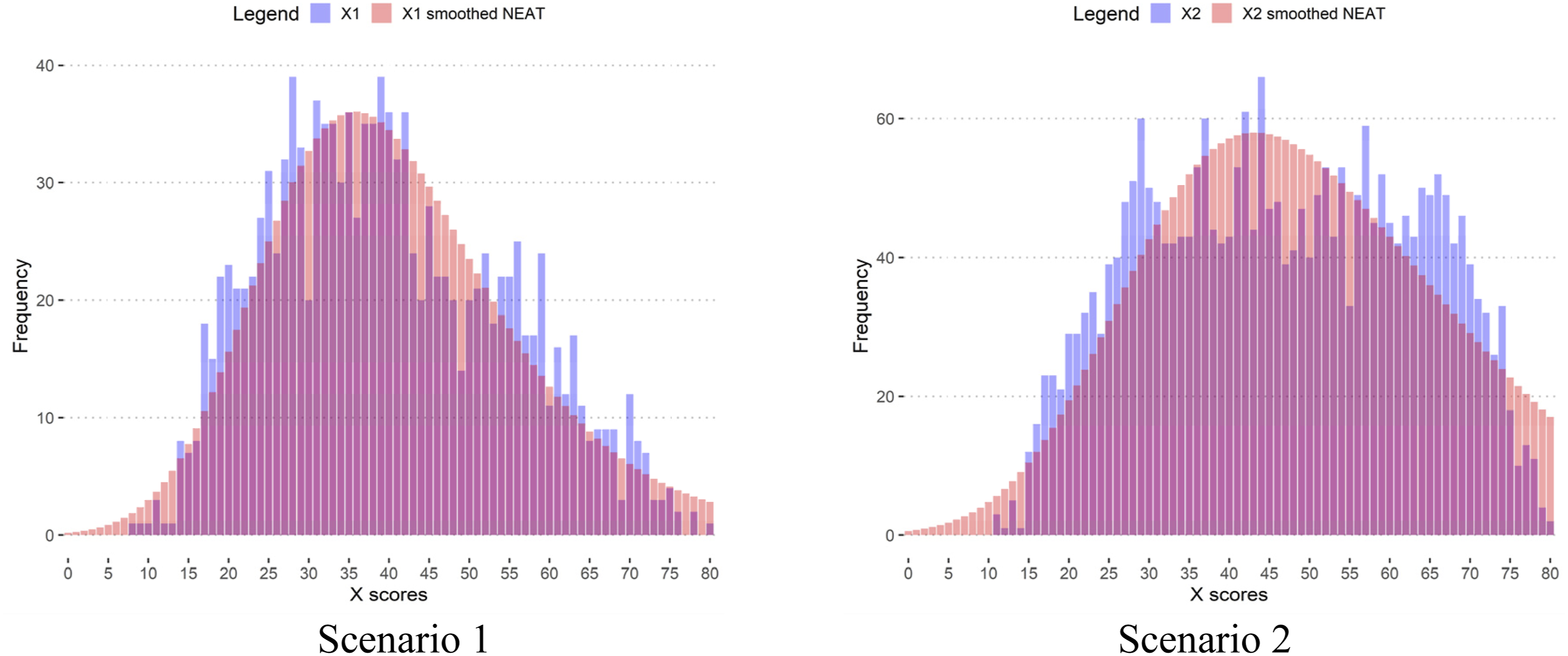
Figure A2 shows the comparison of smoothed distributions between different models used in the study. Only the results for Scenario 1 are presented here, as the results for Scenario 2 are almost identical. The Comparison Between the Methods for Scenario 1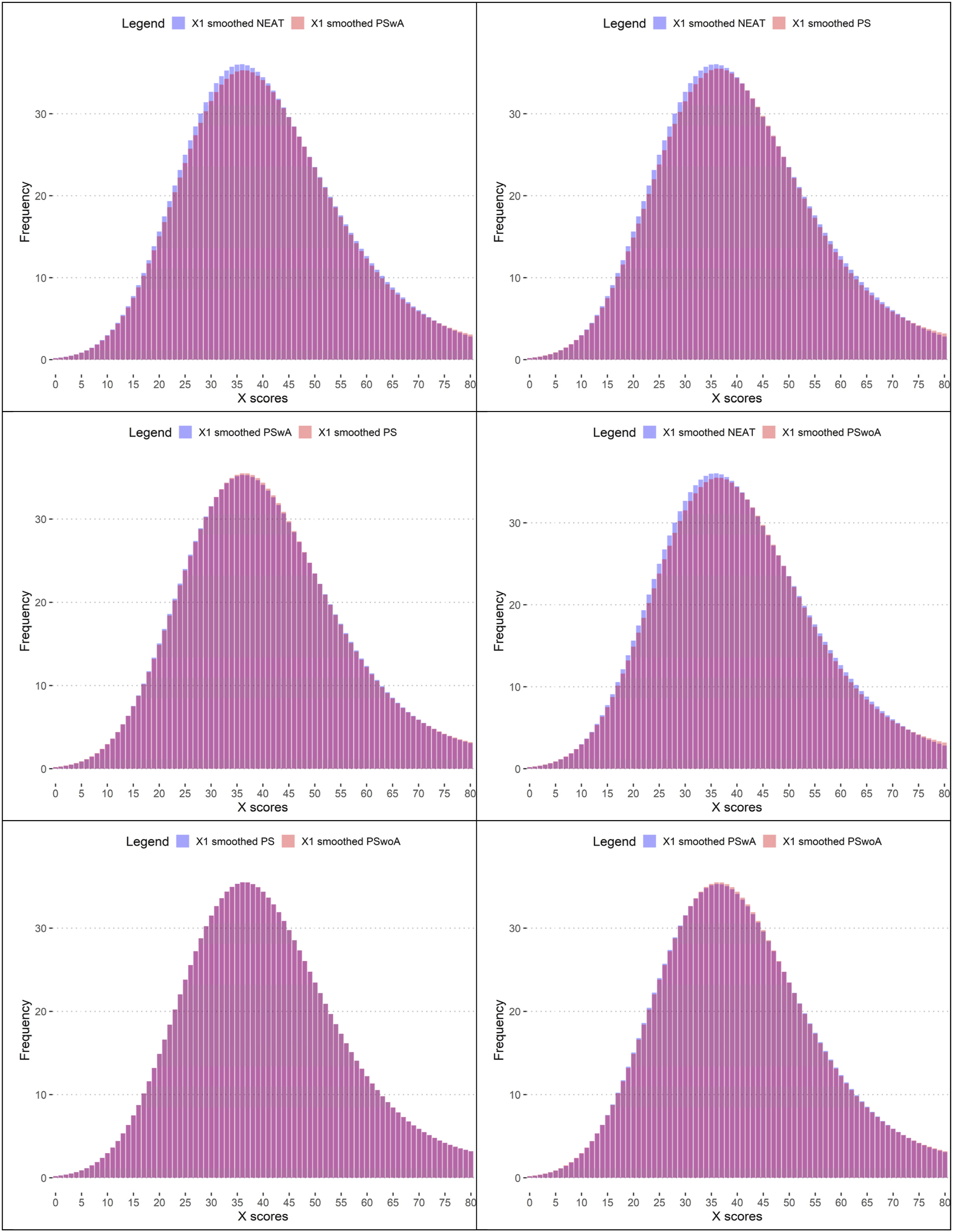
Appendix B
Bias for the Baseline Case when Correlation Between Covariates was Moderate and the Size of an Anchor Test Form was Either 20 Items (S2) or 40 Items (S4)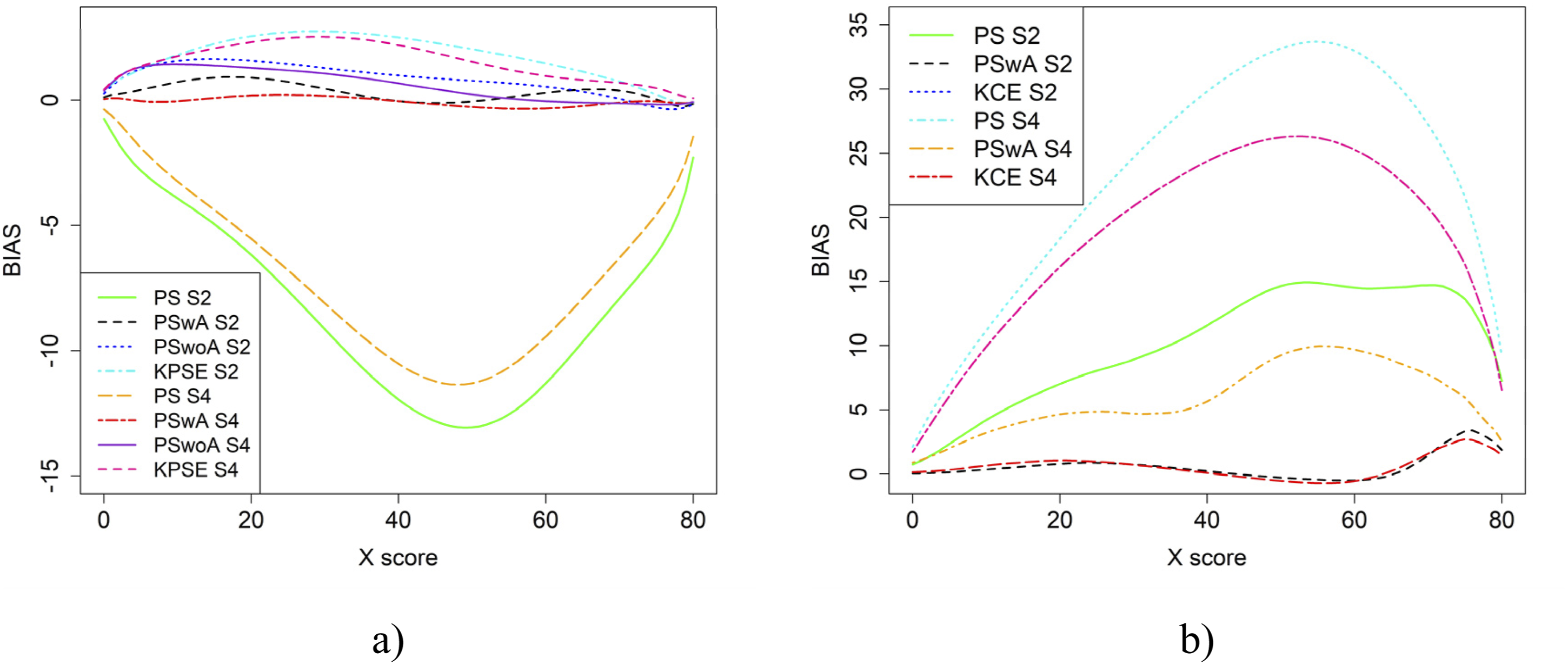
Bias for the Baseline Case when Correlation Between Covariates was Weak and the Size of an Anchor Test Form was Either 20 Items (S1) or 40 Items (S3)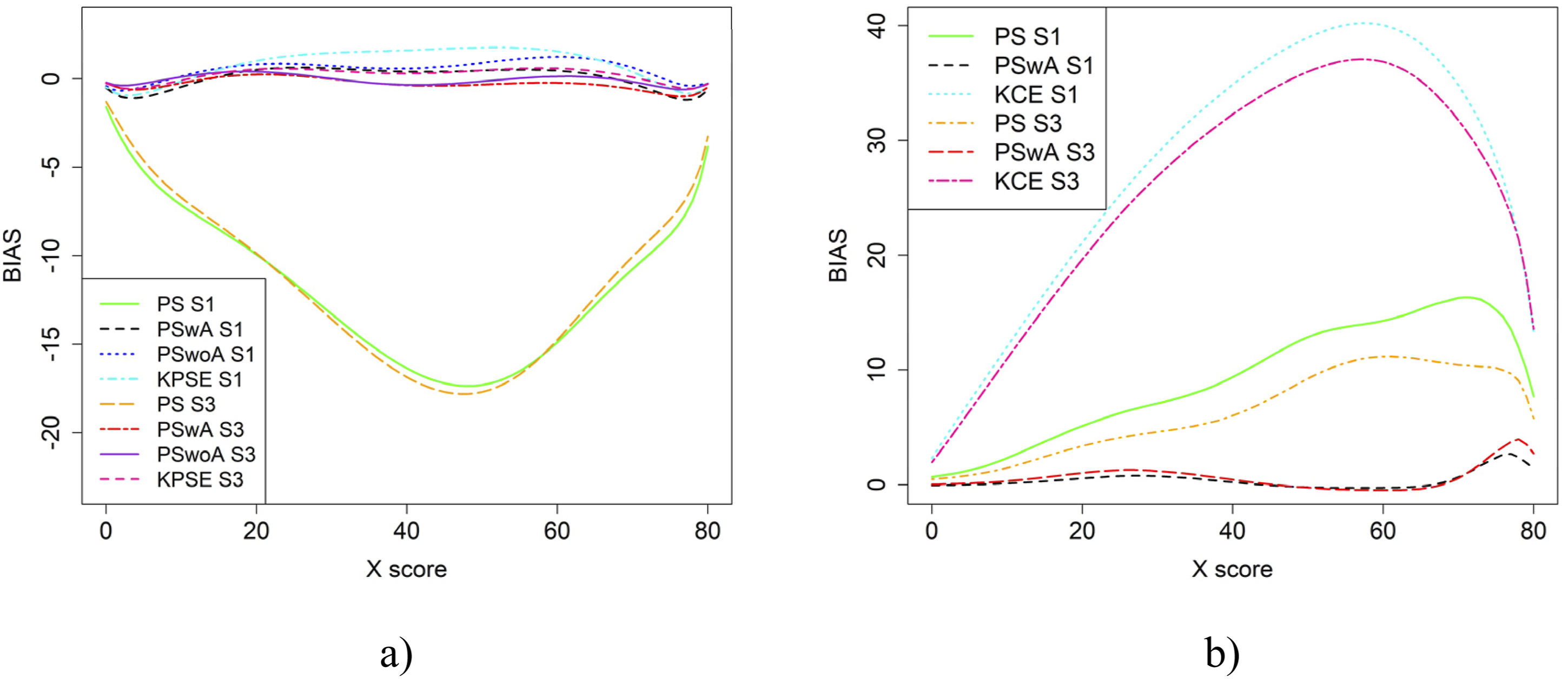
Bias (a and b) and SEE (c and d) for Groups Differing in Ability when Correlation Between Covariates was Weak and the Size of an Anchor Test Form was Either 20 Items (S5) or 40 Items (S7)