
Abstract
When rater-mediated assessments are conducted, human raters often appraise the performance of ratees. However, challenges arise regarding the validity of raters’ judgments in reflecting ratees’ competencies according to scoring rubrics. Research on rater cognition suggests that both impersonal judgments and personal preferences can influence raters’ judgmental processes. This study introduces a mixed IRTree-based model for rater judgments (MIM-R), which identifies professional and novice raters by sequentially applying the ideal-point and dominance item response theory (IRT) models to the cognitive process of raters. The simulation results demonstrate a satisfactory recovery of MIM-R parameters and highlight the importance of considering the mixed nature of raters in the rating process, as neglecting this leads to more biased estimations with an increasing proportion of novice raters. An empirical example of a creativity assessment is presented to illustrate the application and implications of MIM-R.
Introduction
When the performance of individuals is assessed based on external judgments that are made by human raters subject to certain criteria, such as in essay ratings, musical performance evaluations, and creativity assessments, concerns arise regarding the extent to which individuals’ actual proficiency can be inferred from the scores that the raters provide (Hung et al., 2012). Since human raters are not expected to function similarly to machines and produce purely objective judgments of ratees’ performance, distorted evaluations and biased ratings resulting from rater effects are inevitable. These biases can have significant consequences in rater-mediated assessments (Engelhard & Wind, 2018).
Several prominent types of rater effects have been documented in the literature seeking to identify sources of rater errors during the scoring process (Myford & Wolfe, 2003, 2004). For example, raters may assign scores that are higher or lower than ratees deserve (i.e., severity/leniency effects), overuse middle or extreme options on a rating scale (i.e., centrality/extremity effects), exhibit greater variability in their ratings than expected (i.e., inconsistency effects), show a preference for ratees who are similar to themselves (i.e., similarity effects), or overgeneralize ratees’ performance based on overall impressions. Within the framework of item response theory (IRT), the Rasch facets model (Linacre, 1989) and its extensions have been proposed to address these rater effects by separating the target traits of ratees from irrelevant variance introduced by rater behaviors (e.g., Huang, 2023; Jin & Chiu, 2022; Jin & Wang, 2018; Wang & Wilson, 2005). Alternatively, the hierarchical rater model framework provides a valuable approach to detecting potential rater effects by distinguishing between ratees’ true scores and the observed scores assigned by raters at different levels (DeCarlo et al., 2011).
Selecting an appropriate psychometric model to fit rater data is essential. Equally important is understanding the cognitive and decision-making processes that underpin raters’ scoring judgments. Increasing attention has been directed toward rater cognition to explore how raters form mental representations of ratee performance and apply scoring rubrics, and the factors that shape raters’ intrinsic cognitive processes (Bejar, 2012; Crisp, 2012; Suto, 2012). Consequently, developing a measurement model grounded in rater cognition is vital to providing a nuanced interpretation of raters’ scoring behavior and improving the accuracy of ratees’ proficiency estimates.
Study Purpose
In this study, we address rater severity and centrality effects by extending the Rasch facets model. We examine the possibility that raters may score ratees based on either personal preferences or objective judgments. Our goal is to develop a new class of mixed rater models that integrates ideal-point (unfolding) and dominance (cumulative) IRT models to capture the distinct mental representations underlying these two judgment processes.
The newly developed model not only quantifies raters’ severity and captures their tendency toward centrality, as outlined in traditional facets models for rater data, but also classifies raters based on preference-driven or rubric-based internal evaluations. The study includes simulation procedures to evaluate parameter recovery under various manipulation conditions and an empirical study to demonstrate the model’s applications and implications. Accordingly, we address the following research questions to guide the simulation and empirical studies: 1. What manipulation conditions affect parameter recovery for the newly developed model in the simulation design? What are the consequences of applying the traditional non-mixed facets model to simulated data generated from the proposed model? 2. Can the proposed novel measurement model be applied to creativity assessment data to differentiate between experienced and inexperienced raters during the rating process? If the new model provides a better fit to real-world data, what insights can be gained by analyzing raw score patterns and parameter estimations?
The next section provides a brief review of rater cognition, highlights critical concerns with current psychometric models, and offers a theoretically sound justification for developing a new model. Model formulation is then detailed in the Model Specification section. Next, simulation and empirical studies are presented sequentially to demonstrate the new model’s capabilities and applicability. The final section concludes by summarizing the findings, discussing the study’s limitations, and offering suggestions for future research.
Rater Cognition and Related Issues
When human raters evaluate the outcomes of ratees in a judgment task, the process of rater cognition can be explained using the traditional cognitive component theory. This approach can identify distinct steps in raters’ scoring using an information-processing framework. As the forerunners, Freedman & Calfee (1983) described an information-processing model for rater cognition and summarized three processes that are essential to the rating process. The information process starts by reading or analyzing a given response (e.g., an essay) or product (e.g., a created product) and forming the corresponding mental representation. Following the first step of mental image formation, the second step involves an evaluation of the mental image and an application of the scoring rubric by considering the similarity between two mental representations. An overall evaluation is subsequently obtained based on the previous step of mental representation comparison, in which the performance of ratees is evaluated according to the scores from the raters with respect to prespecified criteria. Although sequential methods used to construct rater cognition models differ from the original theory proposed by Freedman & Calfee (1983), they are based on the basic concepts of information-processing models extended to represent more complex decision-making processes in different rater-mediated assessment contexts (e.g., Bejar, 2012; Crisp, 2012).
The process of rater judgment can alternatively be described by the way light passes through a lens in an environment with a set of cues and conceptualized as a lens model that allows the intended construct and human judgments to be separate functions with different sets of cues in the decision-making process. Wang and Engelhard (2019) further proposed a general lens-based modeling framework of rater judgments in which the underlying construct indicated either the proficiency rate or the accuracy of the raters, and the response functions of the rating process could be established using either cumulative or unfolding IRT models. This approach was advantageous because both the cognitive and psychometric perspectives on rater-mediated assessments were considered, and model extensions were highly flexible.
Although the rating process of raters can be interpreted qualitatively and quantitatively by diverse substantive theories, rater judgment in making scoring decisions may not involve the linear mapping of cognitive processes assumed by existing models. When scoring a ratee based on a given essay, for example, raters are likely to briefly review or quickly scan all the text and generate an initial impression, and personal preferences may influence this assessment regardless of the scoring guidance given, which could result in a nonproficient evaluation result for the given ratee (Crisp, 2012; Suto, 2012). Factors that influence raters’ impression scores include but are not limited to the length of the essay, the quality of handwriting, the usage of formulaic templates, raters’ emotional responses (e.g., pleasure, dislike, or sympathy), and raters’ backgrounds (Bejar, 2012; Carey et al., 2011; Crisp, 2007, 2012).
There is evidence that the tasks of raters should include providing their impressions of the text, the specific features of the text, and the meaning of the rating scale before a set of scores is produced (Lumley, 2002), where the former process is related to personal preferences and the latter two processes involve impersonal judgments. The evidence has also indicated that raters may have different understandings of what an ideal performance should be and interpret scoring rubrics differently (Bejar, 2012; Suto, 2012). An inexperienced or novice rater may struggle to select between cognitive strategies of controlled and automatic processing with limited memory resources when he or she makes judgments (Suto, 2012), implying that both impersonal judgments and personal preferences may simultaneously affect the judgment process of raters.
Wang and Engelhard’s (2019) general lens-based modeling framework can account for various judgment processes with respect to impersonal judgments and personal preferences; however, the two cognitive processes are considered separately so that a rater cannot be allowed to make judgments involving both distinct cognitive processes simultaneously. Inspired by the substantive theory and the evidence on rater cognition, we assume that when making scoring decisions, a less experienced rater is likely to perform an intuitive evaluation in accordance with personal preference, and then, based on the previous response, he or she begins to provide ratings regarding ratee proficiency with respect to scoring rubrics. The two distinct stages can be represented by an unfolding response process (i.e., an ideal-point IRT model) and a cumulative response process (i.e., a dominance IRT model). Specifically, we can apply an IRTree model (De Boeck & Partchev, 2012) to describe the sequential cognitive process of raters’ judgments and can utilize a mixed modeling approach (Huang, 2020) to separate various classes of raters. In the following, a new IRT model for rater-mediated assessments that combines an IRTree model and a mixed IRT model is provided to capture the heterogeneous internal processes of raters.
Model Specification
Because the scoring activity of raters may involve cognitive operations related to both personal preferences and impersonal judgments, raters’ final scores can be conceptualized as the results of sequential interconnected subprocesses in which a subjective preference evaluation precedes the consideration of scoring rubrics based on the substantive theory and abundant evidence regarding rater cognition (e.g., Bejar, 2012; Lumley, 2002; Suto, 2012). Specifically, some (i.e., experienced) raters are assumed to follow a traditional multifaceted IRT model (Linacre, 1989) to account for different severity levels, while others (i.e., inexperienced or new) are dominated by an ideal-point IRT model and a multifaceted IRT model in a sequential way. As a result, the mixed IRTree modeling approach (Huang, 2020) is applied to our new model.
Figure 1 illustrates the mixed IRTree-based model for rater judgments (abbreviated as MIM-R hereafter), where each circle represents a decision node and the outcome at internal nodes can be determined by a specific IRT model. The observed rating categories represented by squares are established after information is passed through a set of branches, and the corresponding probability of each end node can be expressed as the product of multiple branch probabilities. For simplicity and easy interpretability, we first focus on a four-point rating scale and then extend the approach to rating scales with more than four rating categories (e.g., a five-point rating). Visual representation of MIM-R for rater-mediated assessments. (a) Tree structure of a four-point rating scale. (b) Tree structure of a five-point rating scale. Note. The subscripts of variables x and y are omitted for simplicity.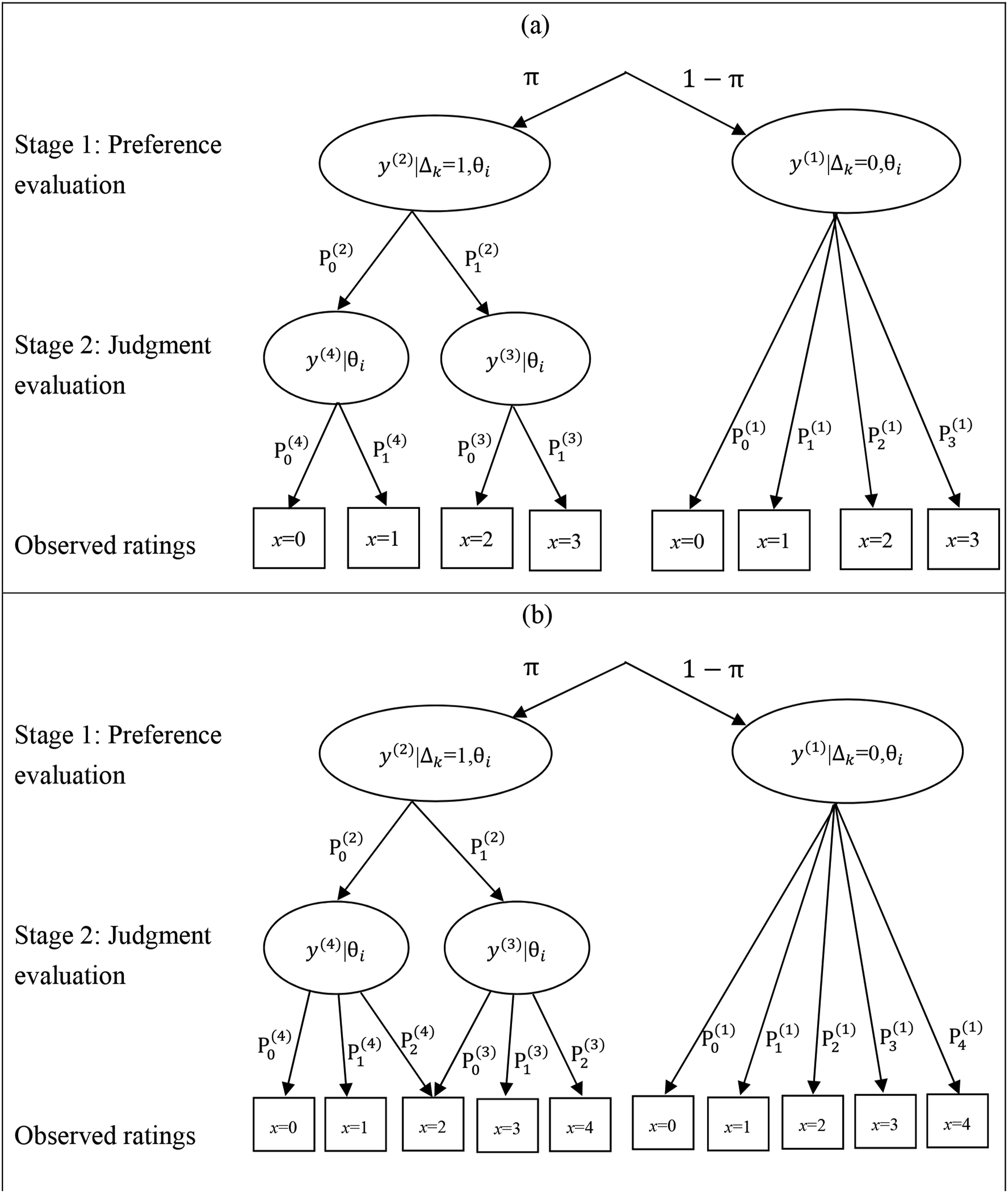
Within our notation in the mixed IRTree framework, k is the rater index, i is the ratee index, j is the rating-scale criterion index, x denotes the observed rating, and
When rater k scores ratee i with respect to an established scoring rubric and does not rely on subjective favorability, that is,
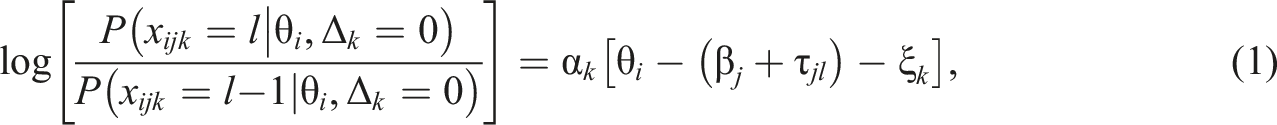
Note that the positive parameter
If
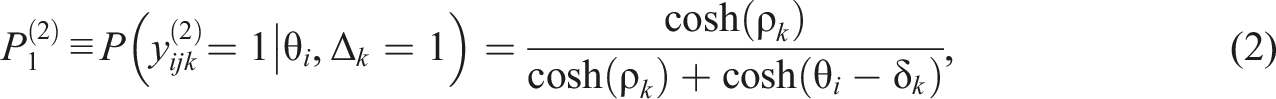

Accordingly, the probability of ratee i’s performance being scored as unfavorable by rater k based on criterion j can be denoted by
Suppose that there are three raters with
Following the first stage of preference evaluation, a given rater attempts to apply the provided assessment guidance, starts the judgment evaluation process, in which the obtained representation of a ratee’s product is compared with the mental representation built from the scoring rubric, and provides a final score with respect to the assessment criteria (Crisp, 2012; Lumley, 2002). The second stage of judgment evaluation involves two distinct decision nodes (
If the number of rating categories is four, the judgment is shifted in the positive or negative direction with probabilities
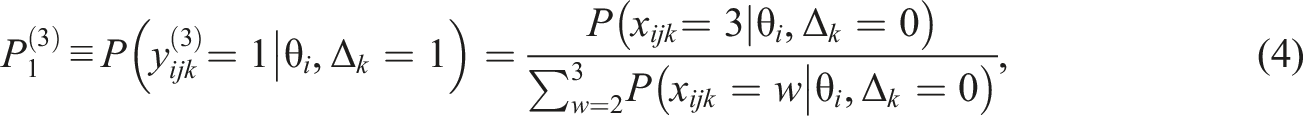
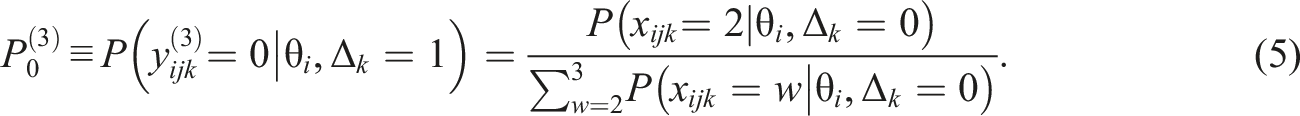
Similarly, when internal node
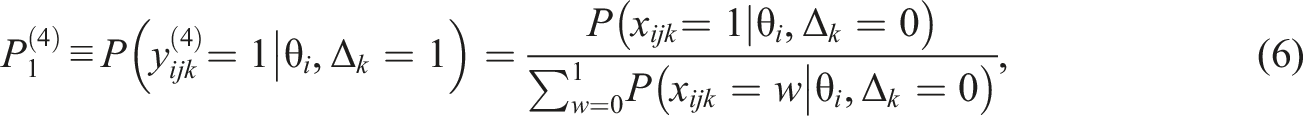
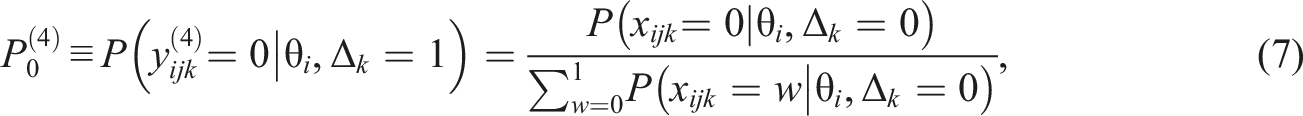
Recall that L indicates the maximum score on a rating scale and that L+1 is the number of rating categories. If even numbers of categories are used in the assessment criteria, the probabilities are
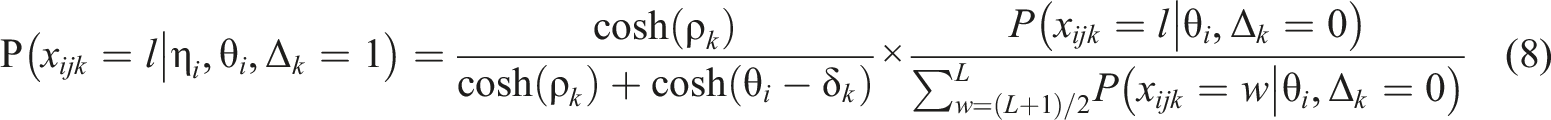
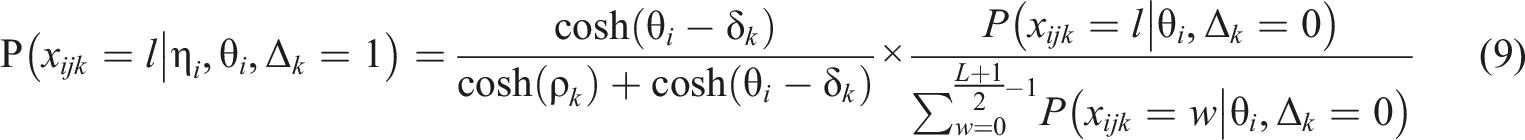
In the mixed modeling framework, the likelihood in the proposed model can be specified as
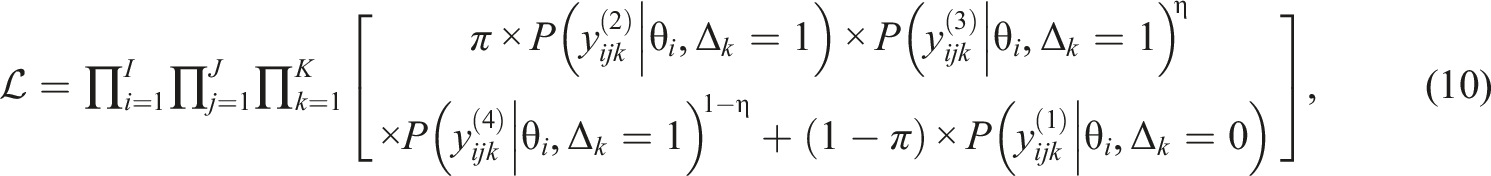
Method
Simulation Design
To evaluate the estimation efficiency of the newly proposed model in rater-mediated assessments, we generated simulated rating data using MIM-R and examined the model parameter recovery results in terms of manipulated conditions using Bayesian estimation. In our simulation design, 2500 ratees were scored by a subset of 25 raters with respect to three criteria and on a four-category rating scale, and each ratee was scored by either two or five raters. Specifically, all ratees were divided into 25 ratee groups, each with 100 ratees, and then two or five adjacent raters scored the ratee groups to establish connections among the raters and build a common scale for incomplete rating data (Wind & Ge, 2021). Accordingly, each rater provided ratings to 200 ratees in the two-rater case and 500 ratees in the five-rater case. The sample sizes of raters and the number of ratees that each rater was required to score were designed to reflect practical assessment settings (e.g., Wind & Engelhard, 2016) and align with previous simulation studies of rater measurement models (Huang, 2023; Jin & Wang, 2018; Wind & Sebok-Syer, 2019).
The latent trait parameter (
Fifty replications were performed for each condition, and the simulated rating data were fit to the data-generating model to evaluate the quality of parameter estimation and to the traditional 2PLR model to investigate the consequences of ignoring the mixed rating patterns of raters in rater-mediated assessments.
Analysis
Version 4.3.0 of the JAGS program (Plummer, 2017) with Bayesian estimation was used to calibrate the model parameters by producing a joint posterior distribution of the unknown quantities and obtain estimates of the parameters of interest. The prior distributions of model parameters were specified before Bayesian estimation was performed, and the following priors were set to be less informative than those in the default case, in accordance with previous studies (e.g., Hung & Huang, 2022; Jin & Wang, 2018). A normal prior with a mean of 0 and a variance of 4 was set for the rater location, rater severity, criterion difficulty, and threshold parameters. A lognormal distribution with a mean of 0 and variance of 1 was used for the latitude and rater discrimination parameters. A Bernoulli distribution with a parameter of 0.5 was used for the indicators of latent classes, classifying the raters as either experienced (
All parameter estimates were calibrated by computing the means of univariate posterior distributions, a method referred to as the expected a posteriori (EAP) measure. For the classification indicator’s estimation, MIM-R flagged each rater during each Markov chain Monte-Carlo (MCMC) iteration as either following a single internal process (i.e., impersonal judgments,
The structural parameter recovery ability of the model was assessed by computing the bias and root mean square error (RMSE) across replications for each estimator. The quality of ratee parameter estimation was evaluated by calculating the absolute bias (i.e., the mean absolute difference between the true and estimated latent traits across ratees) and the root mean square difference (RMSD) (i.e., the square root of the mean squared difference between the true and estimated latent traits across ratees) for each replication. While RMSE is a commonly used metric for evaluating the effectiveness of recovering a model’s structural parameters, RMSD was specifically used in this study to assess the effectiveness of recovering individuals’ trait parameters. This choice aligns with our focus on measuring the precision of person parameter recovery, as RMSD directly quantifies the average squared difference between the true and estimated values, providing a more targeted evaluation in the context of ratee parameter estimation.
To assess the recovery of the mixing probability, the mean proportion of raters correctly identified as inexperienced was computed across replications. For all analyses, three random parallel chains were initialized to monitor convergence and determine the number of sampling iterations. The first 5000 iterations were discarded as the warm-up period, followed by 10,000 iterations with a thinning interval of 5, resulting in 2000 final sampling iterations used to estimate the means of the conditional posterior distributions for the parameter estimates.
Convergence was evaluated using Gelman–Rubin statistics, with all R-hat values for the posterior means of the parameters falling below 1.1 after the burn-in process, indicating acceptable convergence (Gelman & Rubin, 1992). Additionally, no label switching was observed during the sampling process, confirming the stability of the estimates.
Results
Considering space constraints and the clarity of interpretation, both the parameter recovery effectiveness of MIM-R and the consequences of ignoring raters’ preference scores by fitting the conventional 2PLR model were assessed using box plots of the bias and RMSE values for each structural parameter estimator. We first examine the recovery effectiveness by comparing MIM-R and the 2PLR model in terms of RMSE across the manipulation conditions and subsequently evaluate the bias specifically introduced by the misleading assumptions of the 2PLR model.
Figure 2 shows the box plots of RMSEs for model parameter estimates across different mixing probabilities. Note that the two extreme cases where the mixing proportion is either 0 or 1 correspond to situations where all raters either strictly applied the scoring rubric or relied solely on personal preferences during the initial stage of the internal cognitive operation. If no raters were influenced by personal preferences, as shown in Figure 2(a) and (e), both models recovered the model parameters comparably well, suggesting that using the more complex MIM-R to fit the 2PLR data did little harm, albeit at the expense of parsimony. MIM-R provided satisfactory parameter recovery for the ideal-point and dominance IRT models, especially if more raters (i.e., five) were involved. Conversely, neglecting the differing judgmental processes by fitting the simpler 2PLR model resulted in notably biased parameter estimates, and the effectiveness of recovery worsened as mixing proportions increased. Box plots of RMSEs of model parameter estimates. (a) Mixing proportion = 0. (b) Mixing proportion = 0.4. (c) Mixing proportion = 0.6. (d) Mixing proportion = 1. (e) Mixing proportion = 0. (f) Mixing proportion = 0.4. (g) Mixing proportion = 0.6. (h) Mixing proportion = 1. Note. RMSE = root mean square error, 2PLR = two-parameter logistic rater, MIM-R = mixed IRTree-based model for rater judgments, Lat = latitude, Dif = difficulty, Dis = discrimination, Loc = location, Ser = severity, and Thr = threshold.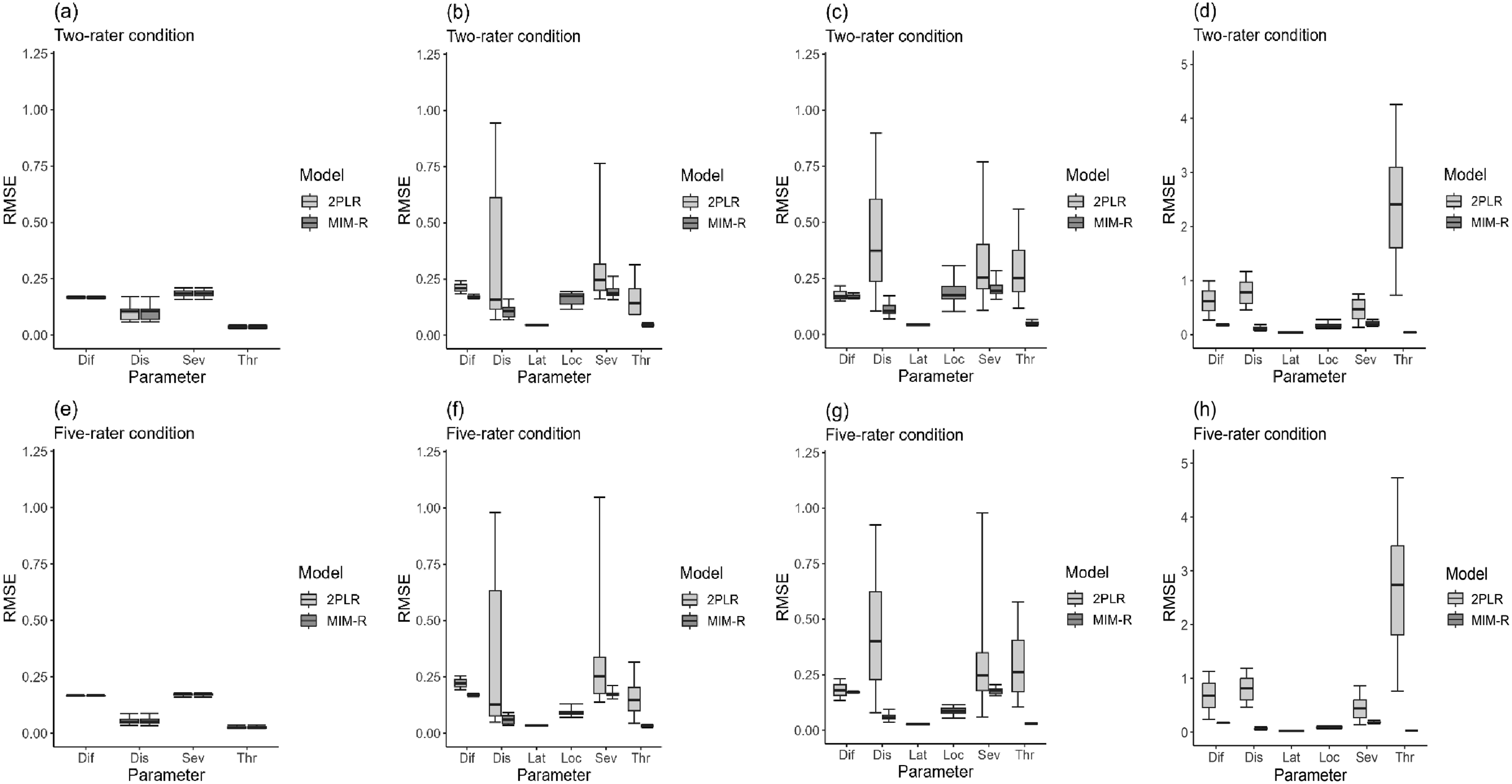
Box plots of biases are presented in Appendix C due to their similarity to patterns of RMSE of recovery effectiveness and space limitations. Examining the magnitude of bias across estimators offers insights into the mechanisms by which the conventional 2PLR model leads to inaccuracies if raters’ diverse rating strategies are neglected. As shown in Figure C1 of Appendix C, rater discrimination parameters were consistently underestimated, exhibiting a uniform negative bias across all conditions. Given the substantial deviation of rater discrimination parameter estimates from their true values, other parameters were also expected to suffer estimation inaccuracies to varying degrees.
Notably, criterion difficulty parameters displayed a positive bias, while most severity parameters exhibited a negative bias. For the threshold parameters, using the 2PLR model yielded a negative bias of generated threshold parameters with negative values and a positive bias of parameters with positive values. These results indicate that threshold parameter estimates were overexpanded on the scale; this phenomenon has been documented in the literature in the case of subjective judgments by individuals being made in response to rating scale items (Wang et al., 2006). However, interpreting the sources of positive or negative bias becomes challenging due to the interplay of mixed rater behaviors, as all model parameters are estimated simultaneously.
Regarding the person parameter recovery effectiveness, we first examined the distribution of RMSD values across replications using box plots and primarily compared MIM-R with the 2PLR model. As shown in Figure 3, MIM-R calibrated the latent trait parameters more accurately than the 2PLR model did, with the differences in estimation quality between the two models becoming significantly greater as the mixing proportion approached 1. The increased estimation errors associated with a larger proportion of raters engaging in subjective favorability evaluations were an inevitable consequence. This effect arose because the probabilities assigned in the second stage of judgment evaluation were contingent upon the initial scoring probabilities, determined by raters relying solely on impersonal judgment evaluations. Specifically, the quality of estimation information deteriorated if fewer raters were classified as experienced (i.e., Box plots of RMSDs of person parameter estimates. (a) Two-rater condition. (b) Five-rater condition. Note. RMSD = root mean square difference, 2PLR = two-parameter logistic rater, and MIM-R = mixed IRTree-based model for rater judgments.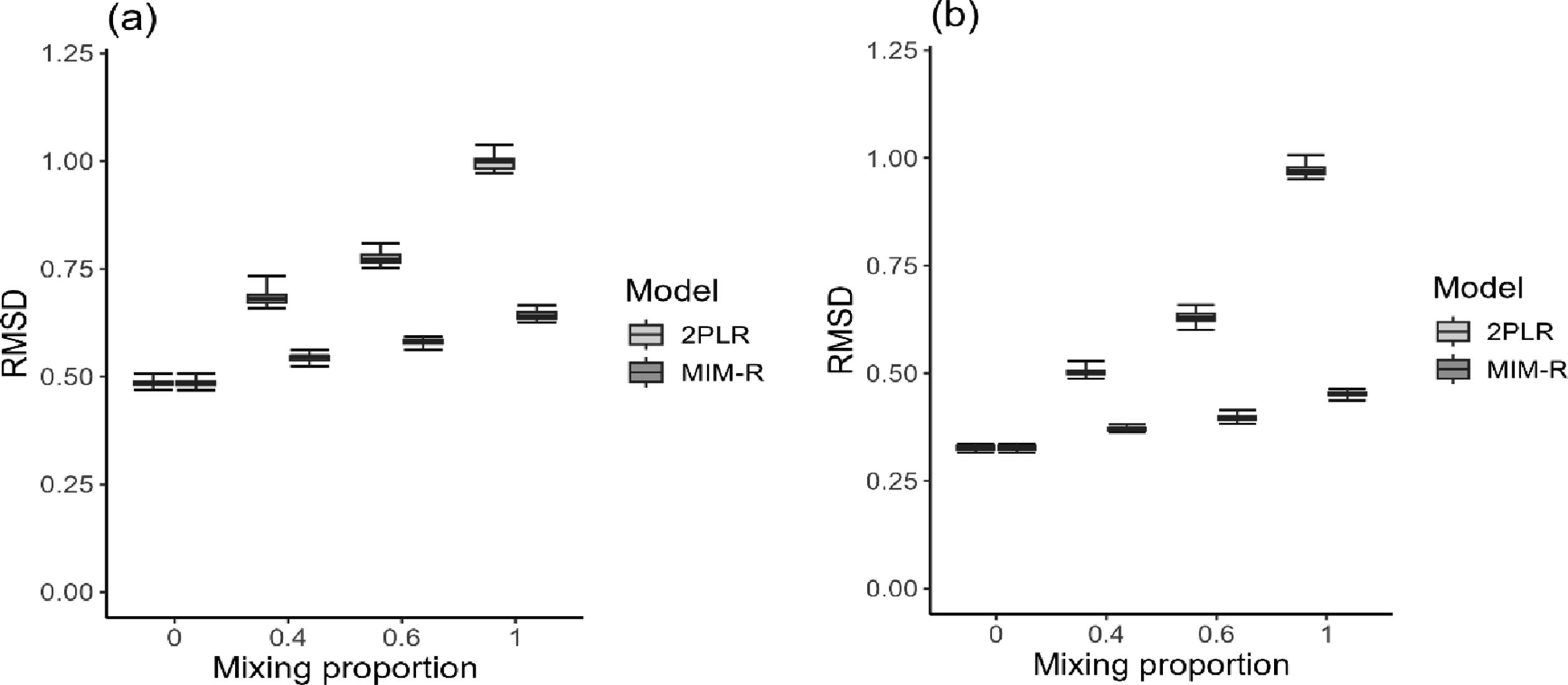
As expected from the literature, the precision of person parameter estimates improved significantly if a ratee’s performance was graded by sufficiently many raters (e.g., five in our design). Note that the improvement in person parameter estimation for the 2PLR model might not be significantly influenced by increasing the number of raters because the model did not account for the nature of the two-stage rating process. The absolute bias values for person parameter estimates followed a similar pattern, with their corresponding distributions provided in Appendix D for brevity. Lastly, the correct classification rate for identifying raters with different cognitive processes was 100%, demonstrating that MIM-R not only delivered reliable measurements but also effectively explored rater cognition.
In a practical application of rater-mediated assessments, applicants may need to compete for certifications or grant funding, facing significant consequences if the quality of rater scores is compromised (Wang et al., 2014). To illustrate the impact of misapplying the 2PLR model to simulated data, ratees were ranked based on their proficiency estimates derived from both the MIM-R and 2PLR models, and these rankings were compared with the true proficiency values. Significant shifts in ranking indicate that the fitted model introduces severe bias in parameter estimates, potentially leading to substantial consequences.
The scenario of each ratee being evaluated by five raters, with the mixing probability set to 1, served as the basis for illustration. Statistics were computed by averaging across replications. The analysis revealed that the 2PLR model resulted in more substantial ranking changes, ranging from 0 to 2378 with a mean of 679, than did MIM-R, which showed changes from 0 to 1579 with a mean of 256. Specifically, the average ranking change under the 2PLR model was 165% greater than that under MIM-R (i.e., [679-256]/256). These findings highlight the potential drawbacks of using a nonmixed 2PLR model, which can compromise fairness and validity by failing to account for diverse cognitive processes of raters.
Empirical Example
To illustrate the application of the newly developed model to rater data, a creativity assessment dataset was utilized (Linares & Sellier, 2021). A total of 210 participants (76 males and 137 females, with a mean age of 21.89 years and a standard deviation of 3.08) were recruited from a European research laboratory and compensated 10 euros. Participants were tasked with designing a new toy for children aged from 5 to 11 as creatively as possible, using a fixed set of shapes provided by the researchers, and the task was to be completed within a 15-min time limit. Additionally, participants were asked to provide narratives listing five reasons their designed toys were creative and explaining how the toys functioned. In the original study, Linares and Sellier conducted an experiment to determine whether the presence of a smartphone impaired creative performance compared to the presence of a notebook. The scholars hypothesized that the use of a smartphone during a creativity-reliant task might negatively impact participants’ highest cognitive functions.
At the conclusion of the experiment, twelve college students, who were unfamiliar with the study’s hypotheses and conditions, were invited to independently evaluate the creative tasks in exchange for 25 euros. The raters were instructed to assess the outcomes on ten-point scales (ranging from “not at all” to “extremely so”) based on six criteria: overall creativity, originality, novelty, innovation, utility, and appropriateness. Each outcome was rated by all raters, which ensured that the rater data were complete and without any missing ratings. Since all raters were business school students who had only undergone a short training session, it was assumed that the rating process could be influenced by both impersonal judgments and personal preferences. Thus, the proposed MIM-R might provide a good fit for the data.
For simplicity and to reduce the computational burden, we converted the ten-point scale to a five-point one by collapsing the scores in two-point increments. We proposed and compared eight fitted models based on different assumptions: (a) whether sequential rating processes were compelling (i.e., nonmixed vs. mixed), (b) whether the raters’ discrimination parameters were necessary, and (c) whether the category thresholds were equidistant across criteria. Specifically, MIM-R was considered the most complex, while its reduced versions corresponded to MIM-R with a discrimination constraint (i.e.,
Comparison of Model Fit for the Creativity Assessment Dataset.
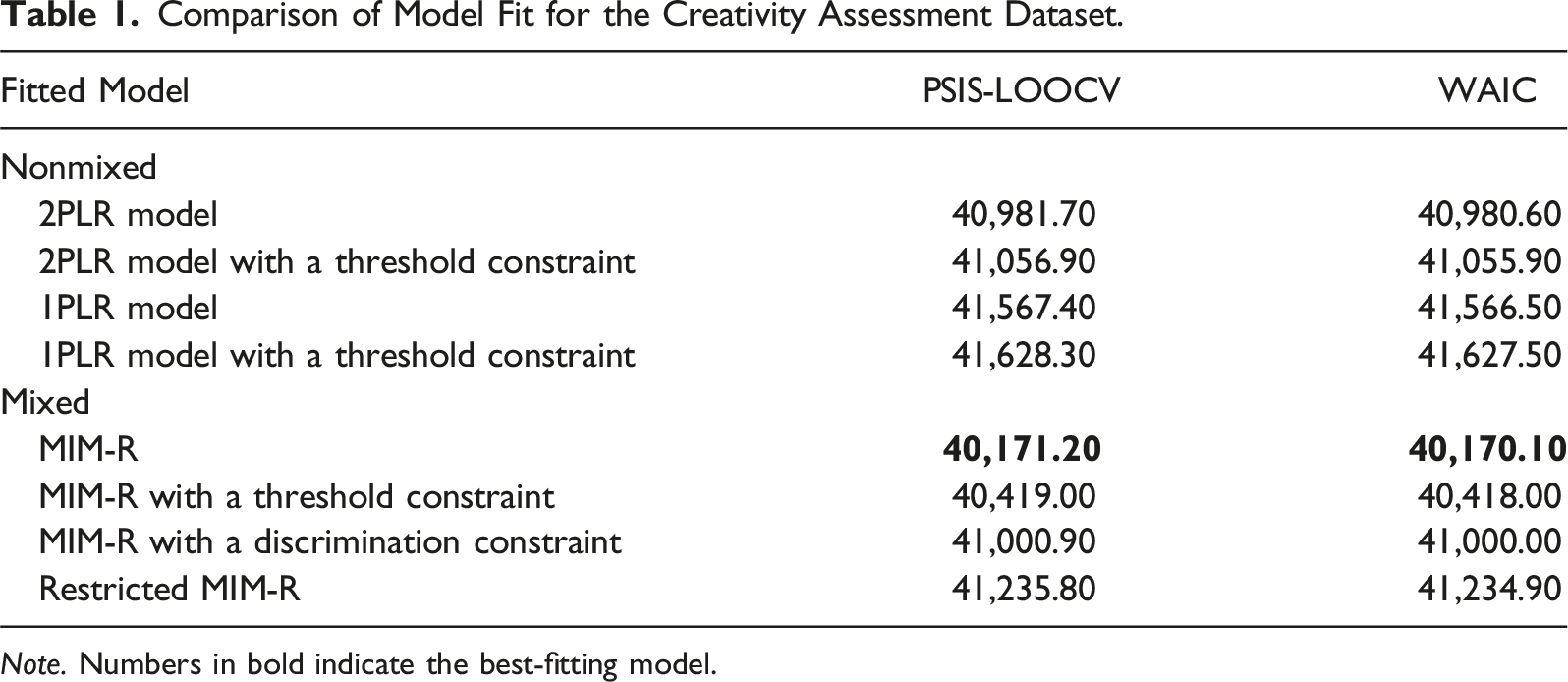
Note. Numbers in bold indicate the best-fitting model.
Rater Scoring Patterns and Parameter Estimates for Selected Samples.
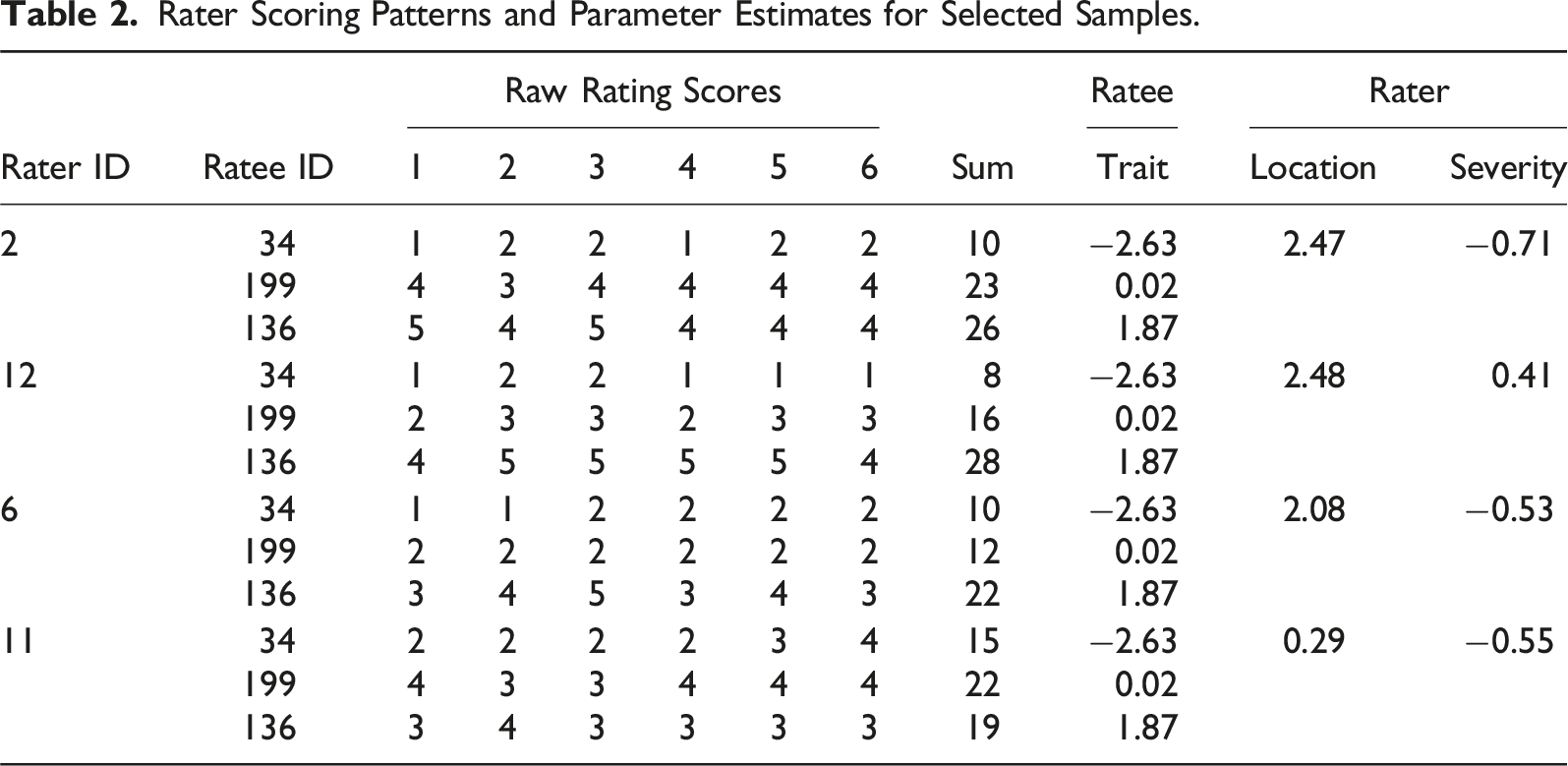
As shown in the top part of Table 2, trait parameter estimates for Ratees 34 and 199 were particularly distant from the location parameter estimates for Raters 2 and 12. As a result, these raters were more likely to judge ratees negatively during the initial personal preference process. Rater 2 gave higher scores to these ratees than Rater 12 did because Rater 2 was more lenient during the subsequent impersonal judgment process. Recall that an internal sequential rating process is assumed for raters influenced by personal preference evaluation. Raters 2 and 12 were identified as inexperienced, and their final scores for the ratees reflected the combined effects of the ideal-point and dominance rating processes in sequence.
As shown in the bottom part of Table 2, at a similar severity level, Rater 11 tended to give higher scores to Ratees 34 and 199 than Rater 6 did because Rater 11’s location estimate was closer to the ratee’s trait estimates. Conversely, Rater 11 gave lower scores to Ratee 136, despite this ratee being calibrated higher on the latent continuum under MIM-R. These exemplary cases clearly illustrate the internal mechanism of rater cognition under MIM-R, providing additional insights into the sequential cognitive processes influenced by personal preferences and impersonal judgments.
Regarding rater effects, in addition to two raters with severity parameter estimates close to 0, five raters had such parameter estimates ranging from 0.38 to 1.88 (Mean = 0.89), indicating a tendency toward stricter scoring during the evaluation process. Conversely, the remaining five raters were classified as lenient, with severity parameter estimates ranging from −1.54 to −0.53 (Mean = −0.89). Rater discrimination parameters were estimated to range from 0.17 to 1.22 (Mean = 0.62), with only one rater exceeding a value of 1. This suggests that most raters tended to use extreme ratings when evaluating ratees’ performance according to the scoring rubric.
Additional model parameter estimates are summarized as follows: criterion difficulty parameters ranged from −1.55 to 0.70 (Mean = 0.04), criterion threshold parameters ranged from −2.68 to 3.03 (Mean = 0.00), rater location parameters ranged from −0.13 to 2.48 (Mean = 0.98), and the threshold latitude parameter was estimated at 1.79. These results provide a comprehensive overview of the estimated parameters, highlighting the variability in both rater behavior and item characteristics.
Conclusion
In this study, we propose a new measurement model called MIM-R that accounts for the distinct cognitive processes of raters by combining ideal-point and dominance IRT models. This model aligns with established theories that differentiate raters’ personal preferences from impersonal judgments based on rater cognition and rater judgment (Crisp, 2012; Suto, 2012). The simulation results demonstrate that MIM-R effectively identifies raters with differing cognitive processes and accurately recovers both the model’s structural parameters and individuals’ trait parameters. In contrast, as the proportion of inexperienced raters increases, the performance of the traditional 2PLR model in parameter calibration deteriorates.
Due to computational constraints, 50 replications were performed for each manipulation condition. Each calibration, depending on the complexity of conditions, required approximately 40 hours on a personal computer with an Intel Core i7 processor and 32 GB of DDR4 RAM. However, increasing the number of replications beyond 50 for certain conditions resulted in only a slight reduction in sampling variation, indicating stable estimates across replications. An alternative, more efficient program such as Stan (Carpenter et al., 2017) could replace JAGS and potentially offer faster and more efficient estimations, presenting a valuable direction for future research.
A creativity assessment was selected as an empirical example to demonstrate the application of MIM-R in real-world data analysis. As all operational raters were college students and might be considered inexperienced, it was expected that the quality of their scoring would inevitably be influenced by personal and subjective judgments. As anticipated, MIM-R provided a better fit to the data than other reduced-version rater models did. Examining the score patterns selected from the sample, we observed how the distance between a rater’s location parameter and a ratee’s trait level in the initial judgment process could influence the final scoring decision. This observation suggests that distinct internal mental processes are involved in raters’ scoring and that these effects cannot be neglected, especially if amateur raters receive only short-term intensive training. Although the complete rating design used in the empirical example differed from the incomplete rating design applied in the simulation, the main findings and conclusions were expected to remain unchanged. The reason is that a fully crossed design provides more precise parameter estimates and yields more efficient fit statistics (Guo & Wind, 2021; Wind & Guo, 2019).
Importantly, the hypothesis of the IRTree model used in constructing MIM-R for rater-mediated assessments was derived from substantive theories of raters’ cognitive processes. Accordingly, alternative hypothesized models based on diverse assumptions and theories should be developed, and these models should be compared using model-fit evaluation criteria. The empirical analysis demonstrated the application of PSIS-LOOCV and WAIC indices to identify the best-fitting model among several competing models. The above Bayesian information criteria offer practical utility for classifying latent responses within the framework of mixed IRT models (Kim & Bolt, 2024; Ulitzsch et al., 2024). However, it remains possible that raters’ scoring behavior may be influenced by different inherent cognitive processes. As such, the proposed IRTree model could be refined or modified based on additional evidence. Researchers are encouraged to generate alternative hypothesized models and compare them with our proposed model to gain a comprehensive understanding of rater cognition.
An additional critical consideration is whether other explanations or underlying cognitive processes for rater behavior can be captured by alternative mixed IRTree models. The answer is undoubtedly positive. As emphasized in the literature (e.g., Huang, 2020; Kim & Bolt, 2021), mixed cognitive sequential-process models not only are tools for predicting the probabilities of rating outcomes but also serve as frameworks for representing researchers’ conceptualizations of internal mechanisms driving rater cognition. The mixture-based structure of this modeling approach offers a versatile framework for exploring diverse rating behaviors and their implications across various contexts. For example, one possible scenario involves a completely inexperienced rater (i.e., someone with no prior training in rating), who might rely solely on personal preferences to evaluate ratees’ performance. In such cases, the cognitive sequential-processing model may fail to capture the rating process, as no systematic transition to rubric-based evaluation occurs. While this scenario is mathematically plausible, it is practically unlikely, as untrained raters are rarely employed in structured rating systems.
A more compelling extension of the model considers a dynamic modification of rater behavior. This approach posits that novice raters initially make judgments based on personal preferences but gradually shift to more impersonal evaluations grounded in specific scoring rubrics. Such a process reflects the effects of rating practices and assumes that raters exhibit dynamic behavioral changes over time rather than adhering to static patterns (e.g., Huang, 2023). While theoretically robust, this revised model introduces greater complexity, posing challenges for parameter estimation and necessitating larger sample sizes.
As a pilot study aimed at ease of interpretation, the developed MIM-R is currently limited to addressing only the rater severity and centrality effects when investigating the complexity of rater cognition. However, multiple rater effects often arise simultaneously in rater-mediated assessments, and MIM-R can be readily extended to accommodate diverse rater effects concurrently. By reparameterizing the 2PLR model within the framework of a multidimensional nominal response model and incorporating a scoring function (Falk & Cai, 2016), MIM-R can effectively capture hybrid rater effects and allow judgment-irrelevant tendencies in raters’ scoring to be governed by distinct latent dimensions. This approach enhances the interpretability and the generalizability of MIM-R by accounting for diverse rater effects simultaneously in rater-mediated assessment analyses.
Although the rater discrimination parameter in the 2PLR model can depict the centrality of raters by adjusting the distance between thresholds, it is inevitably and multiplicatively combined with other parameters, such as ratee proficiency and criterion difficulty, making parameter interpretation challenging (Jin & Wang, 2018). To address this dilemma between estimation and interpretation, this parameter could be restricted to interact only with the criterion threshold parameter, rather than with all model parameters, as originally assumed in the 2PLR model (Jin & Wang, 2018). Alternatively, modifying the tree structure within the dominant IRT model in MIM-R could allow the direction of judgment to precede the selection of central options. This modification allows the model to more effectively capture scenarios where raters first assess whether a ratee’s overall performance exceeds the standard for a given criterion before deciding to assign a neutral (central) score or an extreme score (Böckenholt, 2012; Thissen-Roe & Thissen, 2013). These extensions highlight the flexibility of MIM-R in addressing a wider range of rater effects.
Another potential extension involves relaxing the restrictions of MIM-R. For instance, to achieve stable estimation, the latitude parameters that determine positive judgments are assumed to be identical across raters in MIM-R, as is common in unfolding IRT models (Hung & Huang, 2022). This assumption could be relaxed to allow for rater-specific latitude parameters if sufficient rater responses are available. Moreover, MIM-R was developed based on the assumption of unidimensionality to ensure precise calibration and efficient parameter estimation. Future research could extend MIM-R to a multidimensional framework, enabling it to more accurately capture raters’ complex scoring behaviors and provide deeper insights into rater cognition.
Supplemental Material
Supplemental Material - Understanding Rater Cognition in Performance Assessment: A Mixed IRTree Approach
Supplemental Material for Understanding Rater Cognition in Performance Assessment: A Mixed IRTree Approach by Hung-Yu Huang in Applied Psychological Measurement.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the National Science and Technology Council (Nos. 113-2410-H-006-131-MY3 and 113-2918-I-845-002).
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.