
Abstract
Fixed-precision between-item multidimensional computerized adaptive tests (MCATs) are becoming increasingly popular. The current generation of item-selection rules used in these types of MCATs typically optimize a single-valued objective criterion for multivariate precision (e.g., Fisher information volume). In contrast, when all dimensions are of interest, the stopping rule is typically defined in terms of a required fixed marginal precision per dimension. This asymmetry between multivariate precision for selection and marginal precision for stopping, which is not present in unidimensional computerized adaptive tests, has received little attention thus far. In this article, we will discuss this selection-stopping asymmetry and its consequences, and introduce and evaluate three alternative item-selection approaches. These alternatives are computationally inexpensive, easy to communicate and implement, and result in effective fixed-marginal-precision MCATs that are shorter in test length than with the current generation of item-selection approaches.
Keywords
Tailoring a test to a specific respondent has been a popular approach for many decades. The idea of adaptive item selection can be traced back to the first intelligence tests, where the test would be terminated once the correct “mental age” could be determined with sufficient certainty. In the last decades, adaptive testing has become much more sophisticated, owing in part to advancements in information technology (IT) and the development of item response theory (IRT). Computerized adaptive tests (CATs) 1 are becoming increasingly popular, and the continuing development in IT goes hand-in-hand with the further refinement of IRT and CAT methodology.
An important line of research focuses on multidimensional CAT (MCAT), which allows for “borrowing” of information across dimensions. Adams et al. (2016) described two types of multidimensional item response models: within-item and between-item multidimensional models, which correspond to the “complex” and “simple” structures in factor analysis, respectively (W.-C. Wang & Chen, 2004). In the current study, we focus on between-item multidimensionality, where each item relates to one subdimension only; multidimensionality is expressed through the correlations among the latent dimensions (for a thorough primer on multidimensional IRT, see Reckase, 2009). These types of MCATs are a popular choice across various fields, both in simulation studies and operational MCATs (e.g., Frey & Seitz, 2011; Lee et al., 2019; Makransky & Glas, 2013; C. Wang et al., 2019). By acknowledging the multidimensional dependence structure, MCAT typically results in more efficient tests as compared with using separate unidimensional CATs (UCATs) per dimension—a finding which has been shown to hold under a wide range of conditions (Paap et al., 2019).
Although MCATs hold a lot of promise, they are associated with a number of additional challenges as compared with UCATs. One of these challenges concerns the relation between the item-selection rule and stopping rule—two crucial components in every CAT. If the stopping rule is based on fixed precision (rather than fixed length), it is typically defined in similar terms as the selection rule in a UCAT: both criteria are a function of measurement precision. This direct link is advantageous in case of fixed-precision CAT, since it results in optimally short efficient tests. With the advancement of MCAT, a number of selection rules have been developed (see, for example, Mulder & van der Linden, 2009). In many cases, these are seemingly straightforward adaptations of the rules used for UCATs. Yet, when one intends to stop in terms of a fixed precision per dimension, the selection rules currently used in the context of fixed-precision MCAT are not directly linked to the stopping rules: Selection is based on multidimensional precision, whereas stopping is based on marginal precision. As a result, the MCAT administration will be suboptimal and result in longer test lengths than necessary. This discrepancy has hitherto received little attention in the literature. In this article, we will discuss this selection-stopping asymmetry, and introduce three solutions.
The remainder of the article is structured as follows. First, it is briefly described how measurement precision is defined in the multidimensional case, and several popular selection rules are discussed. Second, the asymmetry between selection and stopping rules used for MCATs is described, and it is argued how this asymmetry can negatively affect test length. Third, alternative item-selection rules are introduced that are more closely linked to fixed marginal precision stopping in MCATs. Fourth, the different selection rules are illustrated and evaluated using two types of simulation studies: one based on an “ideal” bank, and one based on an empirical bank. Finally, the implications of our findings are discussed and recommendations are given.
Measurement Precision in the Multidimensional Case
For didactical reasons, consider the two-dimensional case (
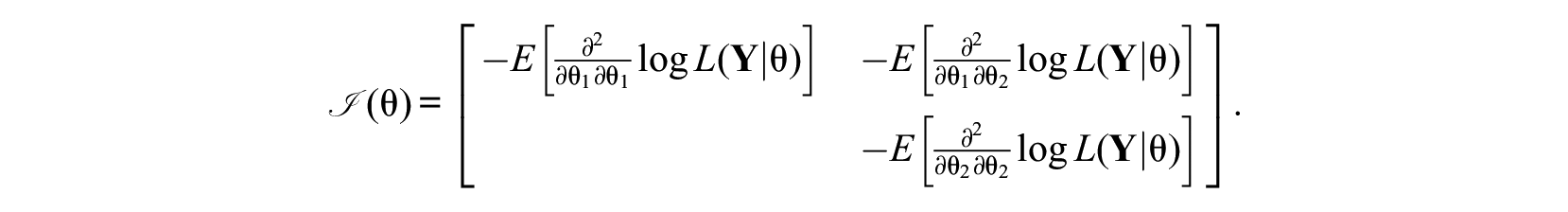
Under regularity conditions, the inverse of the information matrix results in the covariance matrix of the person parameter estimates
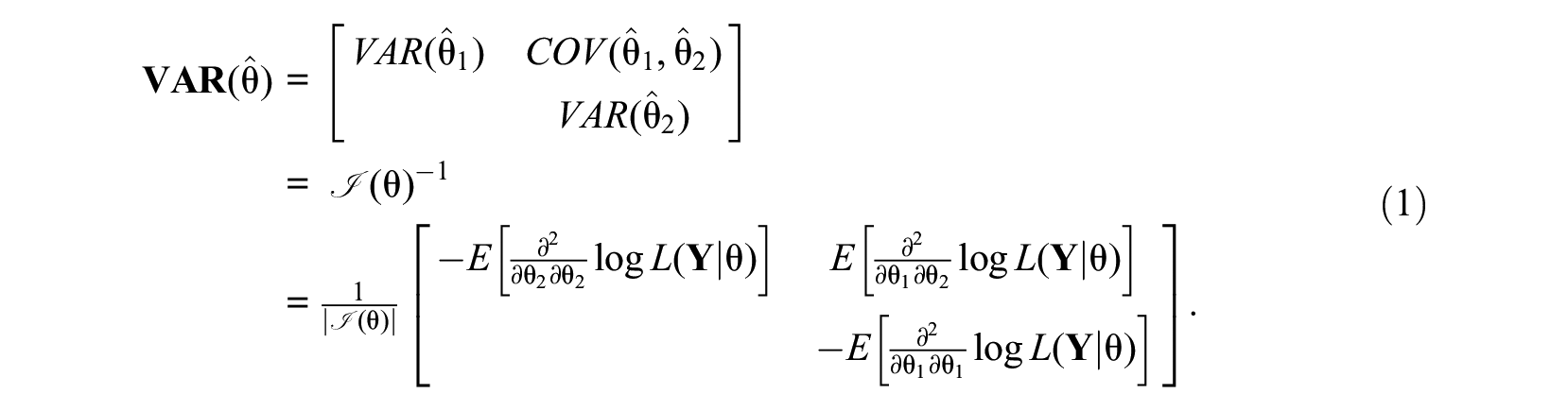
Equation 1 shows that the variance of one latent trait estimate depends on the information that is present on the latent trait estimate of the other dimension and the amount of interdependence in information on the latent traits as reflected by the determinant of the information matrix
In the unidimensional case, the information matrix reduces to a single cell and selecting the next item
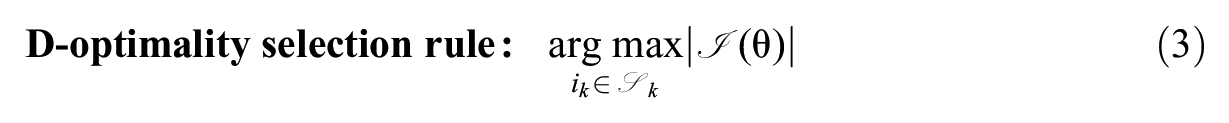
Hence, for fixed-precision UCAT, the objective criterion of the selection rule is exactly equivalent to that of the stopping rule; this symmetry ensures an optimal adaptive test administration.
When extending this stopping rule to the multidimensional case, the standard error of each of Q latent trait estimates
2
is required to be less than or equal to a fixed threshold value
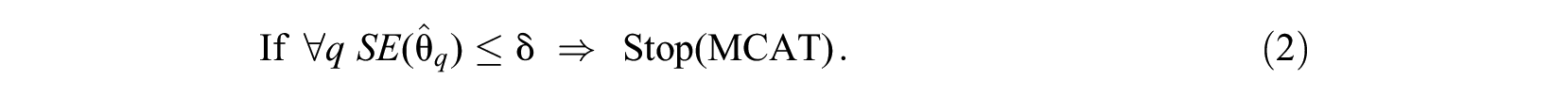
This is a straightforward extension of the stopping rule in fixed-precision UCAT, where only the precision of this one dimension is to be considered. The extension of the previously described UCAT item-selection rule to the multidimensional case is less straightforward, however, because items contribute information on more than one latent dimension at a time. For within-item multidimensionality this contribution is caused by items measuring multiple dimensions, whereas for between-item multidimensionality this is due to the dimensions being correlated. As a consequence of the multidimensionality, the objective criterion for item selection is formulated in terms of multivariate precision and inevitably an asymmetry between selection and stopping rule arises: Multivariate precision is used for selection, whereas marginal precision is used for stopping. This will be illustrated for two widely used objective criteria in the optimal design literature (Pukelsheim, 2006): the D- and A-optimality criteria.
Perhaps, the most popular choice of objective criterion for item selection in MCAT is the determinant of the information matrix, known as the D-optimality criterion:
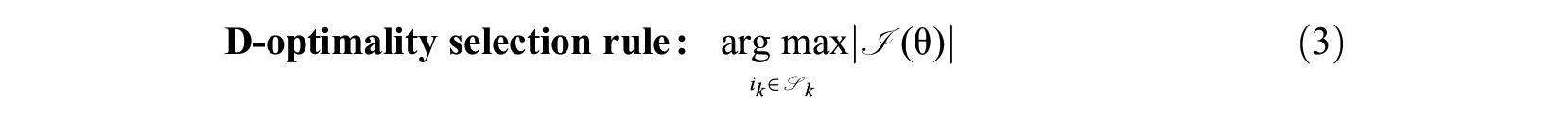
In multivariate statistics, the determinant is also known as a generalized variance measure, and maximizing the determinant of the information matrix is equivalent to minimizing the generalized multivariate variance of the latent trait estimates:
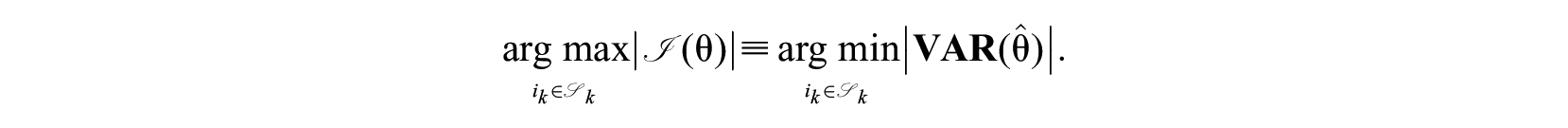
This rule will select the candidate item that leads to the largest decrease in volume of the confidence ellipsoid of the latent trait estimates (Segall, 1996). This is quite close to the situation we had in UCAT, but the determinant is not directly proportional to the measurement precisions for the marginal dimensions as given by the
An alternative MCAT selection rule selects the candidate item that leads to the largest reduction in the sum of expected marginal standard error around the latent trait estimates. The objective criterion is specified in terms of the trace of the covariance matrix of the estimates; in the optimal design literature referred to as A-optimality:
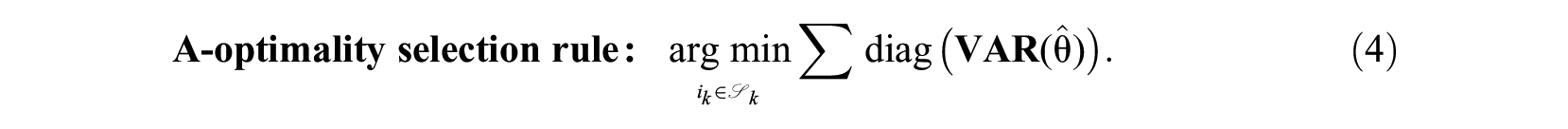
In multivariate statistics the trace is also known as a total variance measure. This selection rule is a direct function of the
Asymmetry Between Selection and Stopping Rule in Fixed-Precision MCAT
As mentioned earlier, in fixed-precision UCAT, there can be a one-to-one relation between the objective criterion used in the selection rule and in the stopping rule. This symmetry (see top half of Figure 1) ensures the optimality of the fixed-precision UCAT. In contrast, when the objective in a MCAT is to reach a fixed level of precision for each dimension, there is an asymmetry (see bottom half of Figure 1) between the objective criterion used in the selection rule and in the stopping rule. Decreasing the determinant or trace of the covariance matrix does not guarantee that each of the marginal standard errors would decrease (although the average standard error across dimensions is expected to decrease).
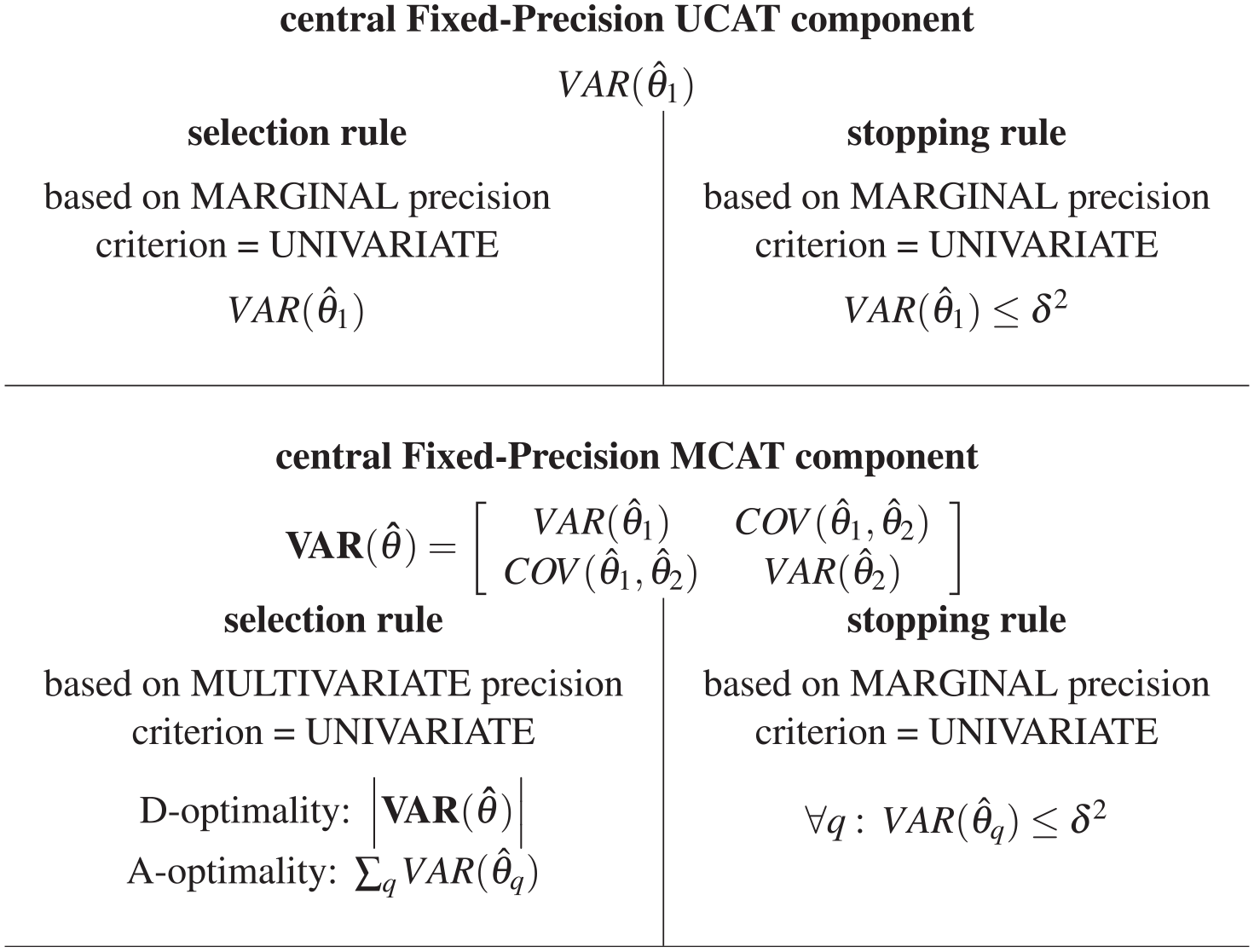
UCAT symmetry/MCAT asymmetry between selection and stopping rule.
Yet, Mulder and van der Linden (2009) point out that item-selection rules using the D- or A-optimality criterion have a built-in minimax mechanism: When the estimator of one of the abilities has a small sampling variance, they develop a preference for items highly informative about the other abilities. Hence, the next item will be most informative for dimensions that are lagging behind in measurement precision. As a result, the difference between the sampling variances of the estimators for the two abilities tend to be negligible toward the end of the test. This is precisely what we may want when both abilities are intended to be measured. (p. 280)
Their conclusion suggests that the asymmetry between selection and stopping rule might not have a big impact in practice. Yet, what is easily overlooked, and is implicitly touched upon in their discussion section, is that this minimax mechanism can only function properly when the CAT can draw items from a high-quality item bank, allowing for a wide choice among a large number of items for each dimension, with adequate targeting for the relevant trait range of the persons being tested. However, many empirical item banks suffer from information-range gaps and/or ceiling or floor effects; these issues may hamper the proper functioning of the minimax mechanism. Selecting items that are not well-matched to the examinee’s trait value could potentially result in an increase in measurement precision for a dimension whose measurement precision threshold
There is hardly any research that has focused on consequences of the asymmetry between the selection and stopping rule across wider trait ranges and less ideal item banks, although W.-C. Wang and Chen (2004) warned that current procedures might not necessarily stop at the potential minimum number of items and that further studies need to look into item-selection rules for fixed-precision MCATs.
We conjecture that the minimax tendency of the D-/A-optimality selection rules will function as expected for “ideal” item banks. However, for less-than-perfect item banks, we expect that the performance of the minimax tendency using current selection rules will be more erratic; which may result in artificially long test lengths. We argue that there is a need for smarter selection rules that incorporate knowledge regarding which of the dimensions already meet the fixed marginal precision threshold.
In sum, a solution to the multivariate selection—marginal stopping asymmetry in fixed-precision MCAT where all dimensions are intentional—is needed that is both practical and intuitive. We propose a solution where the marginal precision is directly reflected in the definition of the objective criterion used for item selection. In the following, we will present three approaches to modify the widely used D- and A-optimality criteria for item selection.
Refining Item-Selection Rules for Fixed-Precision MCAT
Each of the three approaches outlined below is formulated in terms of a selection rule that applies to the posterior covariance matrix of the latent trait estimates and minimizes an objective function using a D- or A-optimality summary statistic.
Approach 1. Dynamically Restrict the Available Item Pool
The first approach we propose leaves the traditional item-selection criterion intact, but dynamically restricts the remaining item pool from which items can be selected. This can be done in two ways, which we will label “hard restriction” and “soft restriction.” Hard restriction implies that, once the precision threshold
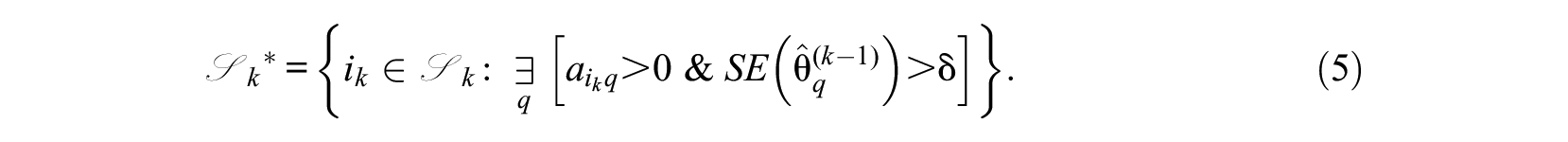
Using this approach leaves the D- or A-optimality selection criterion intact:
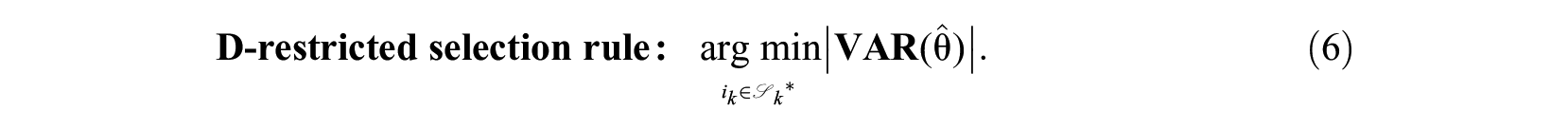
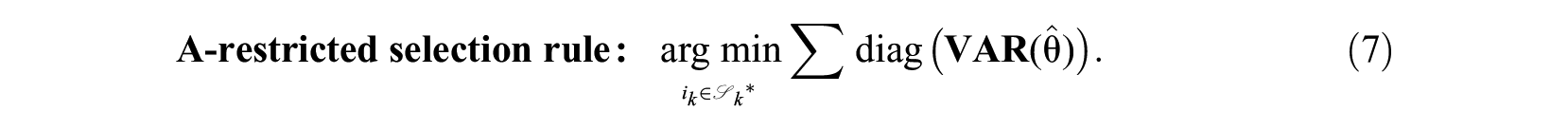
Both the hard- and soft-restriction variants prohibit selection of items pertaining to dimensions for which the desired marginal measurement precision has already been reached, even if administering those items could have increased multivariate precision even further. Under soft restriction, any item that loads on a dimension for which precision has not yet been met is eligible for selection. Hard restriction would then in contrast only allow items that do not load on a dimension for which precision has already been met. Hence, the difference between the two variants is whether items measuring specific dimensions can become available again after an unintended increase of the standard error for the relevant dimension. Under hard restriction, the item pool restriction is permanent and not reversible, because it assumes an implied monotonic decrease of the marginal SEs during the CAT administration that is mathematically not strictly guaranteed. Note that both variants have been applied in specific studies as ad hoc solutions (see, for example, Paap et al., 2018; Yao, 2013), but their performance has not been formally evaluated or compared with other approaches.
Approach 2. Dynamically Modify the Selection Criterion
In the second approach, dimensions for which the precision threshold
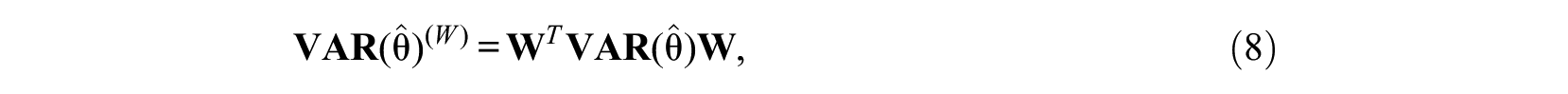
where
The filtered covariance matrix
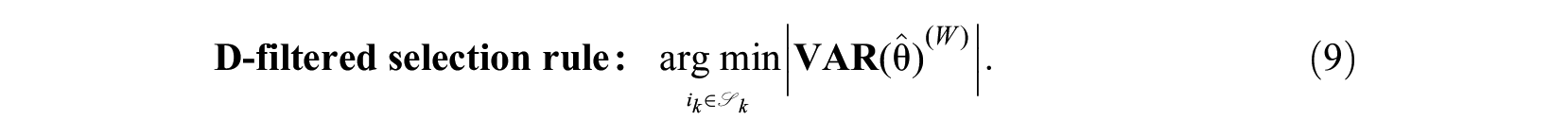
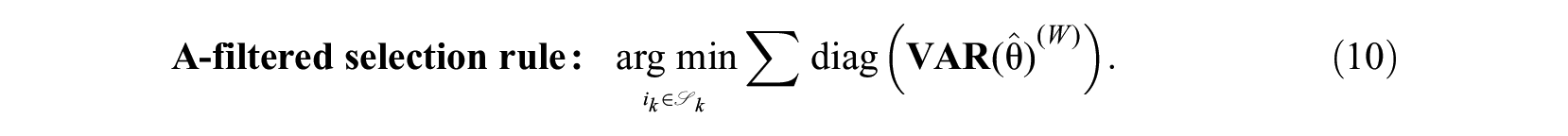
The “nuisance” filtering is performed on the covariance matrix and not directly on the information matrix; using the information matrix would result in the information contributed by the “nuisance” dimensions being ignored, whereas marginal precision is a direct function of all dimensions (cf., Equation 1).
Approach 3. Focus the Selection Criterion Along Least Precisely Measured Dimension(s)
In the third approach, the covariance matrix is summarized in terms of a maximal direction.
For the D-optimality variant, the item that minimizes the largest eigenvalue
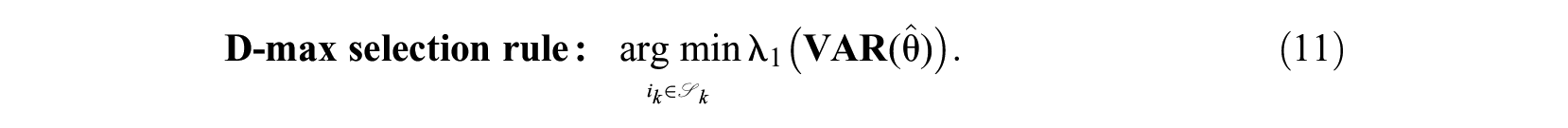
This selection rule is virtually identical to the E-rule used in the optimal design literature, where the minimum eigenvalue of the information matrix is maximized. The traditional D-optimality criterion uses the determinant of the matrix—which is equivalent to the product of all eigenvalues. The largest eigenvalue and corresponding eigenvector represent the multivariate direction along which the least measurement precision is present. By specifically focusing on this direction, an item-selection procedure leading to shorter test lengths could be achieved. In the ideal case where all dimensions reach equal precision, all eigenvalues will be identical.
The A-optimality variant selects the item that minimizes the largest variance element in the covariance matrix:
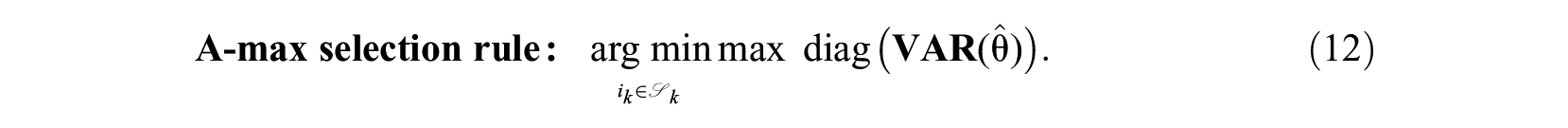
Using a similar principle, C. Wang et al. (2012, Equation 11) formulated a fixed-precision stopping rule: stopping when the maximum standard error across dimensions is below a fixed-precision threshold.
Evaluating the Item-Selection Rules
In this section, the alternative selection criteria will be compared with their “vanilla” (i.e., classic) counterparts (i.e., Equations 3 and 4) using two simulation studies. An overview of the 10 MCAT selection rules, introduced in the preceding sections, is given in Table 1. Two item banks were used for the evaluation: an “ideal” bank and an empirical bank. MCATs with item selection based on the vanilla implementation of the D- and A-rule functioned as baseline conditions. As an additional check, a condition running
Overview of the 10 Different MCAT Item-Selection Rules in Terms of the Objective Criterion Being Minimized.
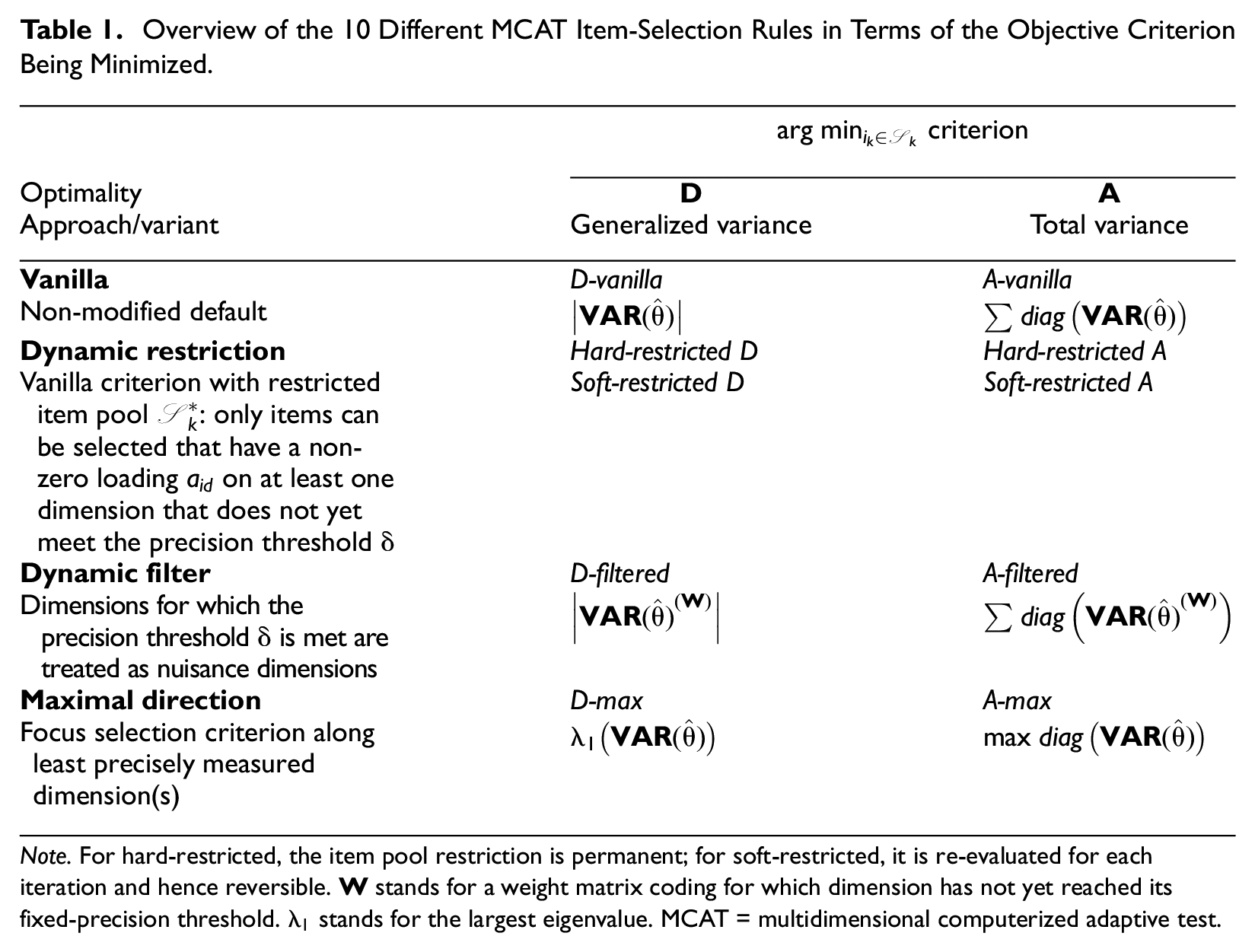
Note. For hard-restricted, the item pool restriction is permanent; for soft-restricted, it is re-evaluated for each iteration and hence reversible.
CAT Algorithmic Settings
For both item banks, 10 MCATs were run that were similar in all algorithmic settings except for the item-selection rule. The CAT simulations were run in R (R Core Team, 2017) version 3.4 with the package mirtCAT (Chalmers, 2016) version 1.5.2. We customized the available item-selection rules in mirtCAT to match the selection rules described in this article (see R-code for customized item-selection rules available at https://www.uv.uio.no/cemo/english/people/aca/johabrae/mirtcat-mcatitemselectionrules.r). For latent trait estimation, the maximum a posteriori (MAP) procedure was applied using a multivariate normal prior with 0-mean vector and correlation matrix
In the UCAT reference condition,
Evaluation: Performance Criteria
Feasibility of CAT administration was evaluated by examining whether the CATs under a given selection rule reached a proper stop (i.e., the required fixed precision
Quality of CAT-based trait recovery was evaluated using the estimation bias per dimension. Bias was computed as the difference between the CAT-based
Test length was evaluated using the total test length across the dimensions. Test length under each modified rule was contrasted to the test length under the D- and A-vanilla rule using a so-called landscaping technique (Navarro et al., 2004; Wagenmakers et al., 2004). Results were graphically inspected using scatterplots with each point representing a simulee’s test length for a CAT administered using a specified item-selection rule compared with this simulee’s test length for a CAT administration under the default vanilla selection rule; we will refer to these plots as landscape plots (see Supplemental Figure A1 for an illustration).
Evaluation: Item Sequence Characteristics
The selection rules were also evaluated in terms of characteristics of the resulting sequence of selected items. Similarity of item sequences was quantified for each simulee by computing the relative overlap in selected items
Study I: An Ideal Item Bank
A simulated item bank of
To cover a large area of the multidimensional latent space, a sample of
Results
For most item-selection rule conditions, the CAT algorithm reached a proper stop for 100% of the
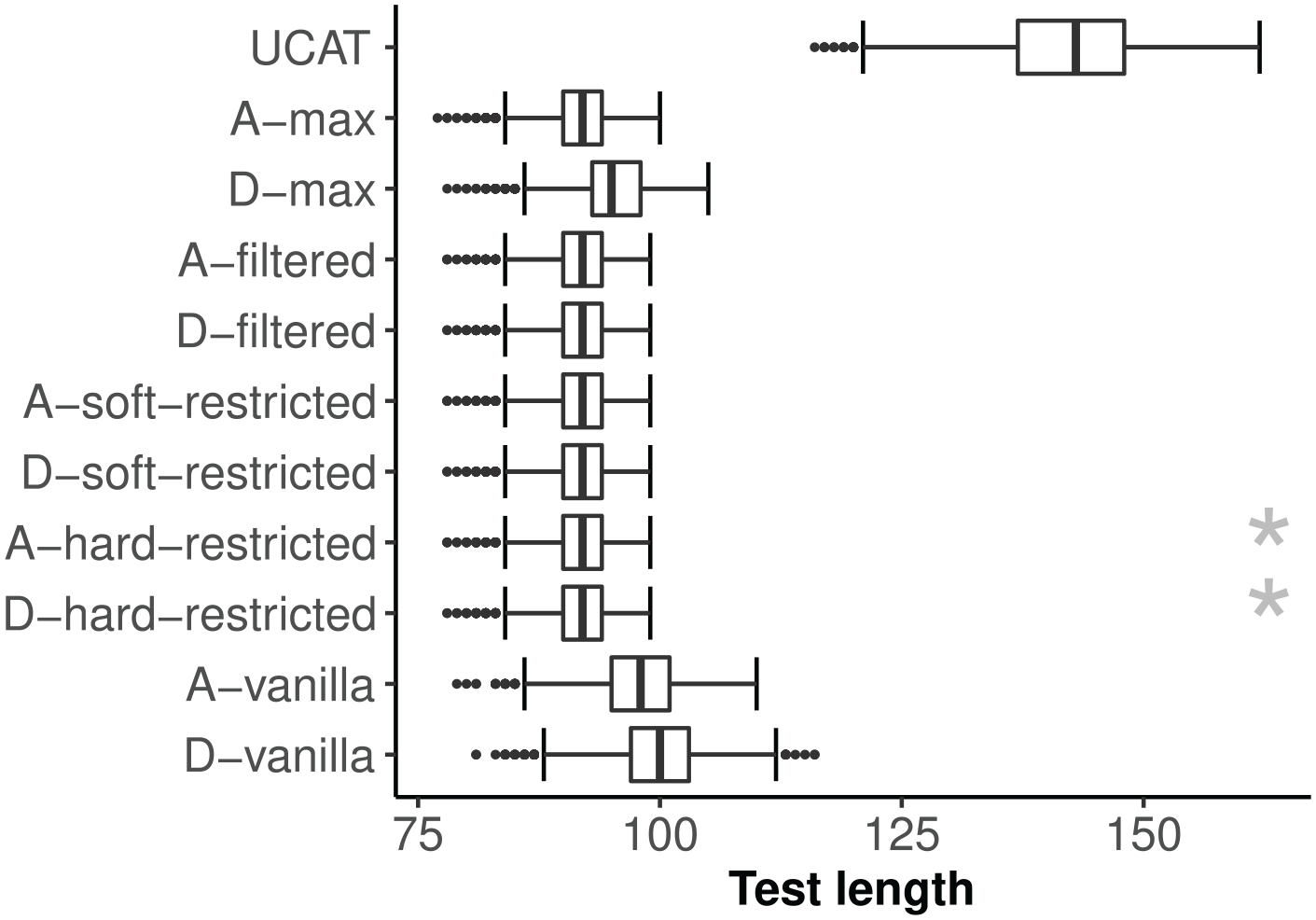
Ideal item bank: Distribution of CAT test length by item-selection rule.
The landscape plots in Figure A2 (see Supplemental Appendix A) provide an overview of direct pairwise comparisons between the plain vanilla D-/A-rule and the suggested alternative selection rules. Test length was shorter for both vanilla rules as compared with the UCAT condition in 100% of the cases, with a minimum reduction of 14/16 items and a median reduction of 43/45 items, respectively. The A-vanilla rule resulted in shorter test length than the D-vanilla rule in 81% of the cases (median reduction of 2 items and maximum reduction of 14 items). The alternative selection rules resulted in shorter test length than the D-vanilla rule in 100% of the cases (median reduction of 8 items and maximum reduction of 24 items) and than the A-vanilla rule in 99% of the cases (median reduction of 6 items and maximum gain of 19 items), with the exception of the D-max rule for which the numbers equaled 97% and 91%, respectively. None of the alternative selection rules resulted in a longer test length than the D-/A-vanilla rules in any of the cases, with the exception for the D-max selection rule compared with the A-vanilla rule (1% of the cases).
The A-vanilla rule ended up selecting mostly the same items as the D-vanilla rule (M = 98%; see Figure 3A). Out of the alternative selection rules, the D-max rule showed the highest degree of relative overlap in selected items with the D-/A-vanilla rules (M = 95/97%). The relative overlap does not take into account the order of the items in the selection sequence during the MCAT. Hence, looking at the relative divergence point complements the picture (see Figure 3B). Although the D-vanilla rule showed high relative overlap in selected items with both D- and A-variants of the alternative selection rules, the relative divergence point confirmed the D-/A-family similarities, with the D-restricted and D-filtered variants’ item sequences running in parallel (on average) with the D-vanilla rule for up to 83% of its test length and the A-restricted and A-filtered variants running in parallel (on average) with the A-vanilla rule for up to 87% of its test length. Divergence from the opposite family variants generally occurred at an early stage, after only 6%–7% of the test length (i.e., approximately 6 items). The median number of times that an item was followed by an item of the same dimension equaled 16 for the selection rules belonging to the D-family, compared with 9 times for the A-family. The max variants were the odd ones out, with a median of only 4 and 1 time for D-max and A-max.
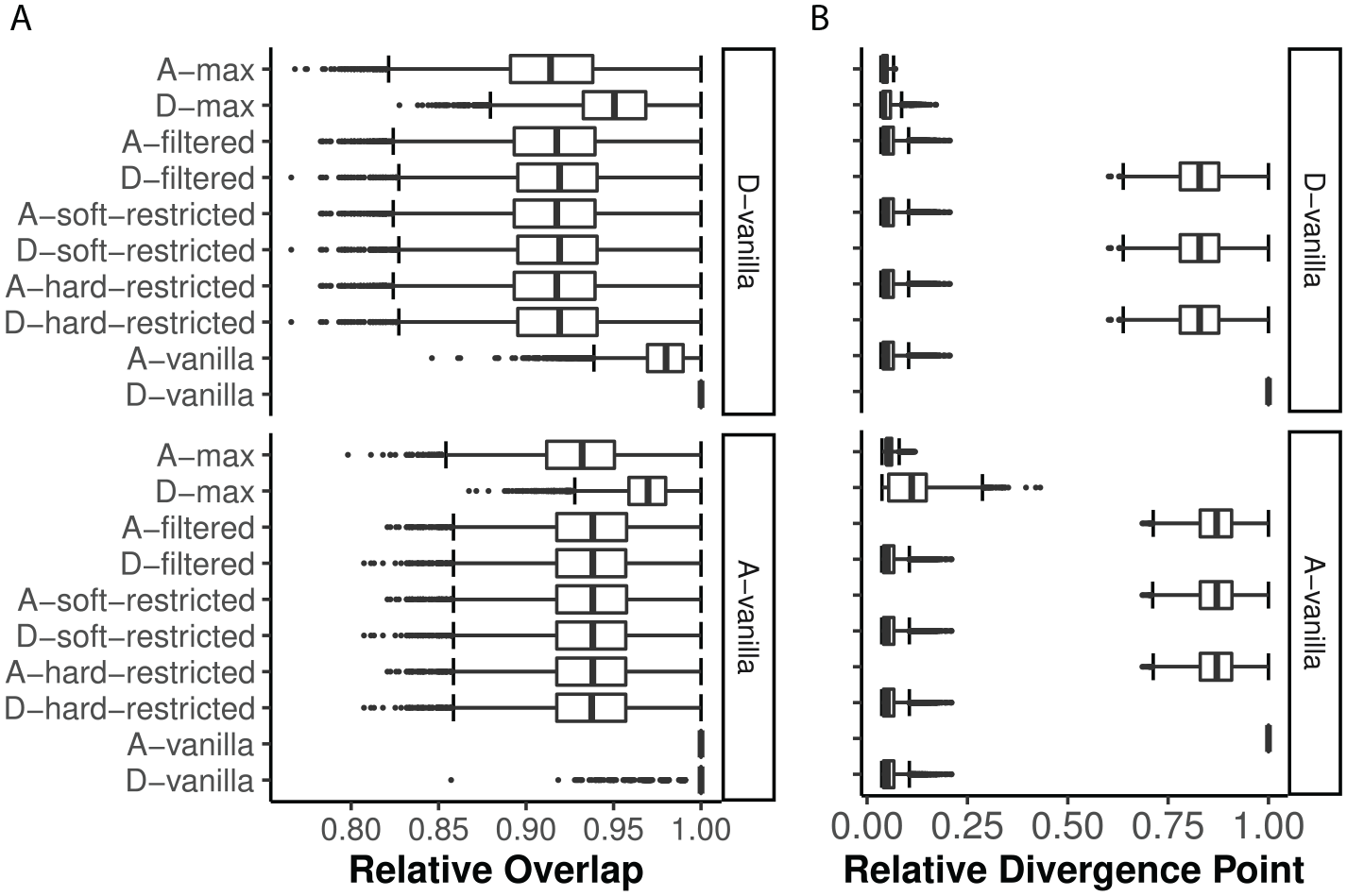
Ideal item bank: (A) Relative overlap and (B) relative divergence point of item sequences of alternative selection rules with the D-/A-vanilla rules.
Study II: A Real Item Bank Example
An empirical multidimensional item bank of
A sample of
Results
For all but two selection rules, the CAT algorithm reached a proper stop for 100% of the
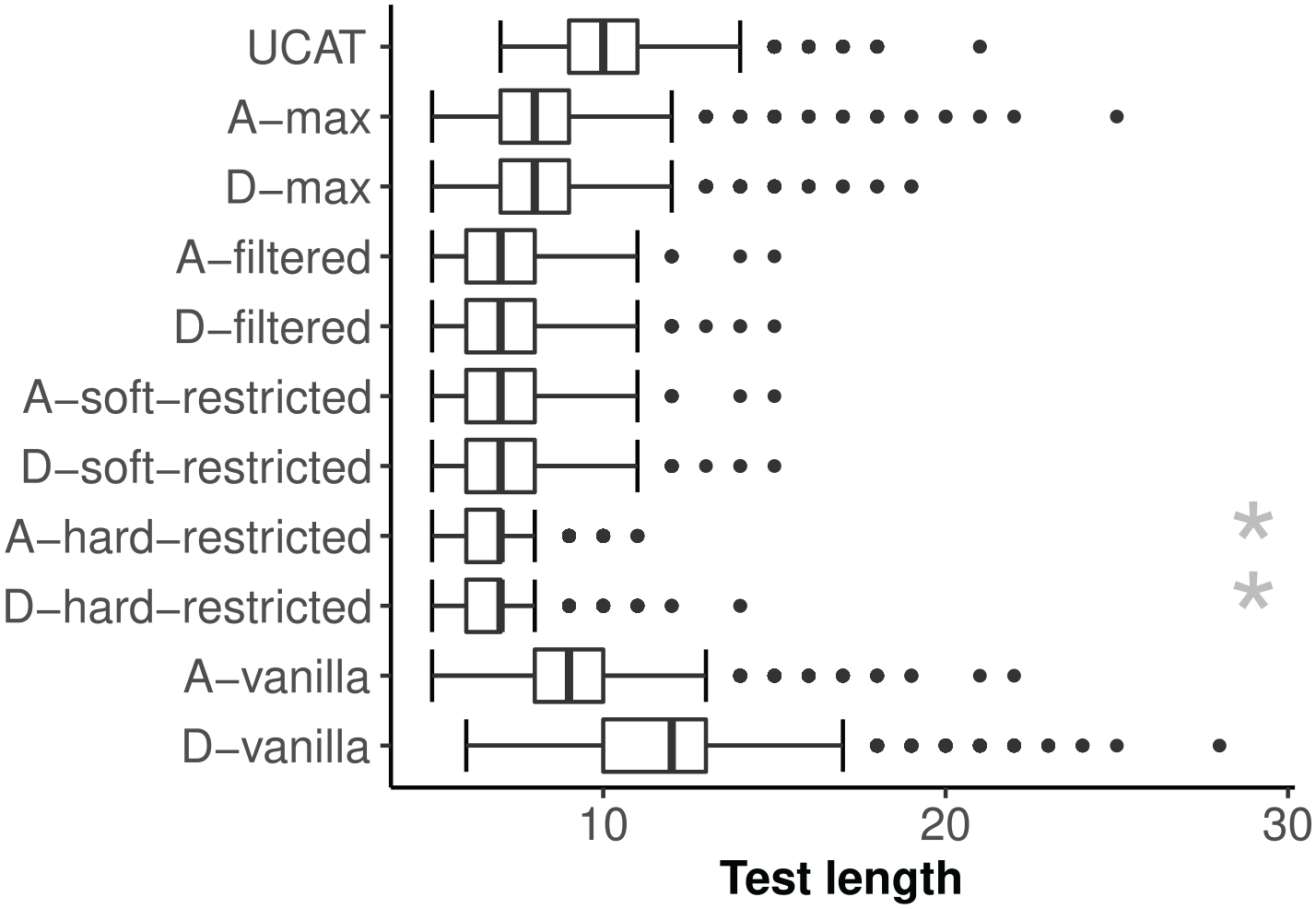
Empirical item bank: Distribution of CAT test length by item-selection rule.
The landscape plots in Supplemental Figure B1 provide an overview of direct pairwise comparisons between the plain vanilla D-/A-rule and the proposed alternative selection rules. The D-vanilla rule resulted in a shorter test length as compared with UCATs for 22% of the simulees, and in longer test length for 64% of the simulees. The latter observation is a realization of the worst-case consequence of the selection-stopping asymmetry, where a stream of selected items further reduces multivariate precision but not the marginal precision for the dimension that is not yet meeting the stopping criterion. For the A-vanilla rule, these figures were 62% and 17%, respectively. It being less affected by the asymmetry is consistent with the A-optimality selection criterion being somewhat closer to the stopping criterion than D-optimality. Furthermore, the alternative selection rules resulted in shorter test length than the D-vanilla rule for at least 97% of the simulees, and 81% for the A-vanilla rule, and never were longer than the combined UCATs test length. The exceptions were the D-max and A-max rules, where the numbers dropped to 92/91% and 60/65%, respectively, and that were also occasionally outperformed by the combined UCATs.
Although a moderate to high degree of relative overlap was found for all selection rules, regardless of A-/D-family, the relative divergence point results showed more differentiation (see Figure 5). The alternative rules were generally more similar (higher relative divergence point) to their respective vanilla rule than to the other rules. On average, the item sequences produced by the D-restricted and D-filtered rules were identical to those under the D-vanilla rule for up to 49% of its test length; this number increased to 70% for their A-variant counterparts. Divergence from opposite family variants generally occurred at an early stage: after only 20%–25% of the test length (i.e., approximately 2–3 items). The D-max rule was again an exception, diverging from its D-family at an early stage but from the A-family of selection rules only at a late stage. All selection rules had a median number of 1 time that an item was followed by an item of the same dimension, except for the vanilla and max variants where this was a median number of 0 times.
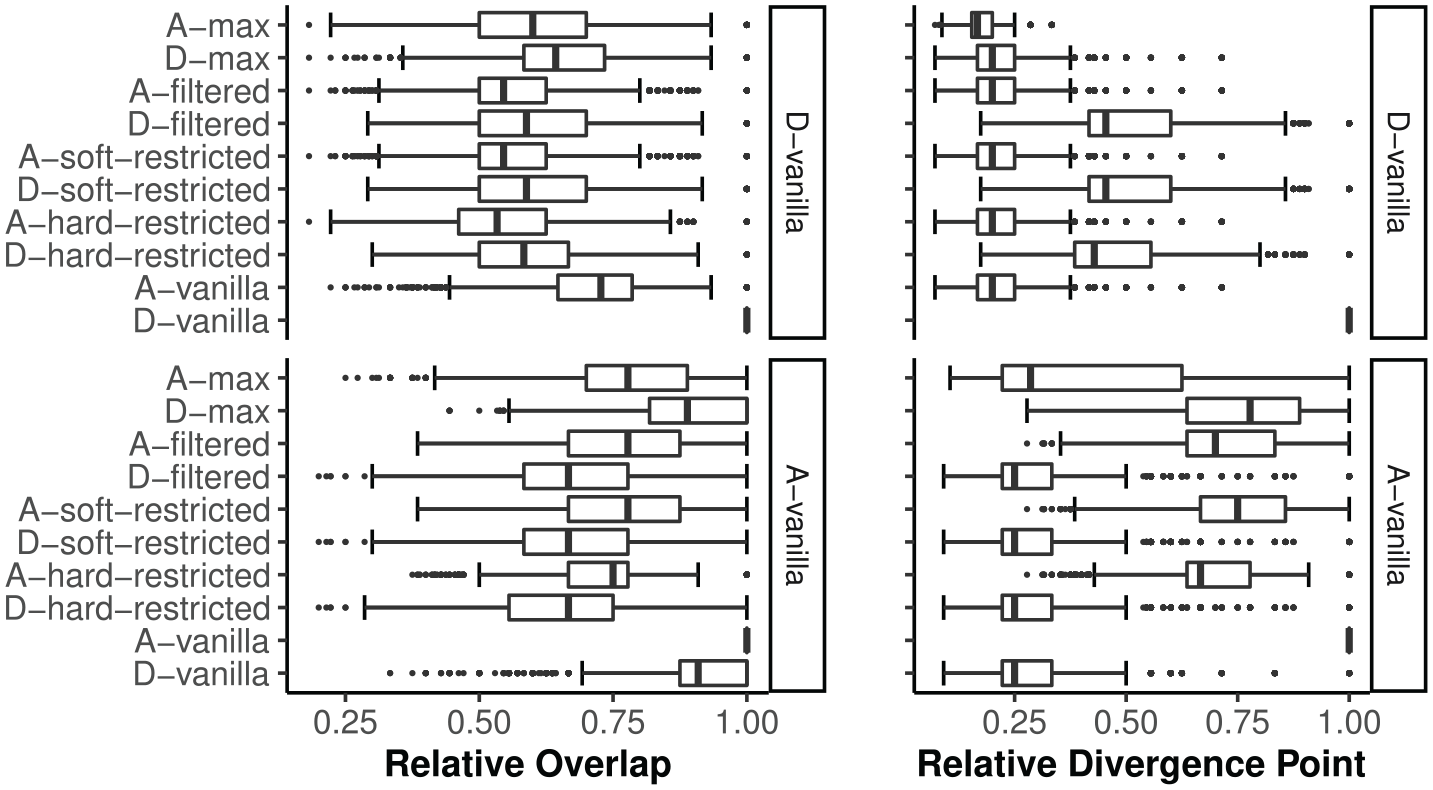
Empirical item bank: Relative overlap and divergence point of item sequences of alternative selection rules with the D-/A-vanilla rules.
Discussion
In the case that all dimensions are intentional, we showed that test length for between-item fixed-precision MCATs can be decreased through modification of the traditional D- and A-optimality criteria for MCAT item selection by incorporating knowledge on which of the dimensions already meet the required fixed marginal precision stopping threshold. Three approaches addressing the asymmetry between the inherently multivariate nature of the selection criterion and the marginal nature of the fixed-precision stopping criterion were introduced: (a) dynamically restricting the available item pool
We expected that under ideal circumstances (having a well-balanced, informative, and symmetric item bank), differences between the vanilla rules and the alternative rules would be small. Yet, the reduction in test length associated with using the modified selection rules was substantial for both the empirical bank and the ideal bank. Strikingly, the vanilla rules did not consistently outperform separate UCATs in terms of test length for the empirical bank. In fact, test length under the D-vanilla rule was longer than in the UCAT condition for a majority of the simulees. This finding underpins the importance of the need for an improved alignment of the item-selection rule with the stopping rule in fixed marginal precision between-item MCAT. Our findings imply that implementing one of the alternative selection rules rather than the vanilla selection rules can be expected to have a substantial impact on operational fixed marginal precision MCATs.
Not all proposed selection rules performed equally well. Although overall the hard-restricted selection rules resulted in shorter test length, CAT administration continued to bank depletion for a number of simulees. The hard-restricted rules virtually delete items pertaining to a specific dimension once the measurement precision on that dimension falls below the desired fixed-precision threshold. The latter is never re-evaluated throughout the remainder of the CAT administration: the SE is simply assumed to be monotonically non-increasing. However, this assumption is not mathematically supported; and especially at the start of a CAT, some variability in precision is expected across iterations in the multivariate setup (precision on one dimension also depends on the available information on the other dimensions, see Equation 1). Hence, when using a hard-restricted selection rule, there is a risk of items being removed from the active bank that might be needed later on in the CAT, which in turn may have substantial consequences for CAT feasibility. The number of CAT administrations for which this undesirable behavior occurred was rather low, but given that there are better options available, we would not recommend to pursue the hard-restricted selection variants any further nor implement these in operational CATs.
The D-max selection rule resulted in shorter CATs than the vanilla selection rules, but it did not perform as well as its competitors. Mulder and van der Linden (2009) also reported issues with this criterion (there listed as the E-rule) when used in fixed-length MCATs. They reported numerical instability and pointed out that the objective criterion did not map 1-to-1 on sampling variance for all dimensions (note that the latter feature was exactly why it was a reasonable candidate in our context). A similar conclusion as for the hard-restricted variants applies; given that there are better options available, it may not be advisable to implement the D-max selection rule in operational CATs.
Overall, the filtered and soft-restricted selection rules performed very favorably. Our findings suggest that these rules could be considered as the preferred choice for operational fixed-precision MCATs when all dimensions are intentional. Both filtered and soft-restricted rules are computationally inexpensive, easy to communicate, and easy to implement, with the filtered variants requiring a dynamically updated weighting matrix and the soft-restricted variants requiring a dynamically updated available item pool. Note that in the case of between-item multidimensionality, both approaches result in equivalent item-selection behavior.
If one would have to choose between the two vanilla rules, we suggest the A-vanilla rule should be favored since it consistently outperformed its D-rule counterpart in terms of test length; furthermore, it shows a higher degree of mathematical similarity with the fixed-precision stopping criterion.
The empirical example bank used in this study consisted of highly informative and discriminating polytomous items, which resulted in extremely short test lengths, especially for the MCAT selection rules. These “ultra-short” test lengths had an adverse side-effect: The variation in bias was somewhat larger for the MCAT selection rules due to the influence of the multivariate prior, especially affecting simulees with latent trait combinations that have low probability of occurring given the prior. In such instances, the prior will pull the
We recognize that item selection is just one aspect of the CAT machinery. As illustrated by the differences between the two item bank scenarios used in our study, it is important to keep in mind that efficiency and other qualities of measurement depend to a very large extent on the specific goals and item bank properties of the end user. This being said, our results have clearly illustrated that aligning the selection rules used in MCAT with the intended measurement purpose (measuring each dimension with a specific level of precision) can have a considerable impact in terms of performance by ameliorating the adverse effects of the asymmetry between the multivariate nature of the selection criterion and the marginal nature of the fixed-precision stopping criterion. Using the filtered or soft-restriction selection rules, which incorporate knowledge on which of the dimensions already meet the required fixed-precision threshold, can be expected to result in shorter test lengths for fixed marginal precision MCATs.
Supplemental Material
Appendix_assymetry_R2 – Supplemental material for Making Fixed-Precision Between-Item Multidimensional Computerized Adaptive Tests Even Shorter by Reducing the Asymmetry Between Selection and Stopping Rules
Supplemental material, Appendix_assymetry_R2 for Making Fixed-Precision Between-Item Multidimensional Computerized Adaptive Tests Even Shorter by Reducing the Asymmetry Between Selection and Stopping Rules by Johan Braeken and Muirne C. S. Paap in Applied Psychological Measurement
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by a FRIPRO Young Research Talent grant for the second author (Grant No. NFR 286893), awarded by the Research Council of Norway.
Supplemental Material
Supplementary material is available for this article online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.