
Abstract
People are often advised to project confidence with their bodies and voices to convince others. Prior research has focused on the high and low thinking processes through which vocal confidence signals (e.g., fast speed, falling intonation, low pitch) can influence attitude change. In contrast, this research examines how the vocal confidence of speakers operates under more moderate elaboration levels, revealing that falling intonation only benefits persuasion under certain circumstances. In three experiments, we show that falling (vs. rising) vocal intonation at the ends of sentences can signal speaker confidence. Under moderate elaboration conditions, falling (vs. rising) vocal intonation increased message processing, bolstering the benefit of strong over weak messages, increasing the proportion of message-relevant thoughts, and increasing thought-attitude correspondence. In sum, the present work examined an unstudied role of vocal confidence in guiding persuasion, revealing new processes by which vocal signals increase or fail to increase persuasion.
People are often advised to convey confidence through their voices and bodies to enhance persuasion or social impact (Haas, 2019; Landrum, 2023). Indeed, scholars dating back at least to Aristotle’s rhetorical observations seem aware of the possible benefits of projecting confidence while communicating. Research on the downstream consequences of confident oral communication has grown (Brennan & Williams, 1995; Guyer, Briñol, et al., 2019; Guyer et al., 2018, 2021; Guyer, Fabrigar, et al., 2019; V. L. Smith & Clark, 1993; Van Zant & Berger, 2020; Vaughan-Johnston et al., 2021).
Past research has demonstrated a range of ways that vocal confidence can affect persuasion. For example, vocal confidence (sometimes manipulated via falling vs. rising intonation) can serve as a cue that directly prompts message agreement or may bias the thoughts that people have toward a message or its communicator (e.g., Guyer, Fabrigar, et al., 2019; Van Zant & Berger, 2020). Some vocal confidence indicators may also impair processing, such as a very fast rate of speech, making a message hard to understand (Briñol & Petty, 2003, Exp. 2; S. M. Smith & Shaffer, 1991, 1995).
However, the Elaboration Likelihood Model (ELM; Petty & Cacioppo, 1986, 1999) suggests that persuasion variables may work via other processes. We propose that vocal confidence, operationalized here as falling (vs. rising) pitch patterns at the end of a sentence (henceforth, “vocal intonation”), can boost the processing of persuasive messages by stimulating recipients’ motivation to process the messages. That is, in some cases vocal signals may signal that the speaker is a confident person, thus motivating the recipient to devote their limited cognitive resources to carefully processing the message, because a confident speaker is felt to be more worthy of a recipient’s limited cognitive resources. Consequently, this potentially motivation-driven process could result in several unique empirical patterns predicted by the ELM, including an enhanced persuasive benefit of strong over weak arguments. We use both moderation and mediation approaches to examine this phenomenon.
Speaker Confidence as a Source Variable
Persuasion involves influencing others to change their attitudes (i.e., internal evaluations of objects; Ajzen, 1991; Eagly & Chaiken, 1993; Maio & Haddock, 2009; Ostrom, 1989; Petty & Cacioppo, 1986). When people encounter persuasive messages, various factors determine their reactions. Classically, attitude scholars have sorted such influences into categories such as characteristics of the message (e.g., how logical and evidence-based a message is, termed argument quality, Petty & Cacioppo, 1979, 1986, 1999), the recipient (e.g., if the reader/listener likes to think; Cacioppo & Petty, 1982), the context (e.g., whether there are distracting elements in the environment; Harkins & Petty, 1981), and the source (e.g., whether the writer/speaker is credible; Burgoon et al., 1990).
Surprisingly, vocal properties have only occasionally been connected to formal persuasion theory (Guyer et al., 2018; Guyer, Fabrigar, et al., 2019; Van Kleef et al., 2015; Vaughan-Johnston et al., 2021), which most often focuses on written messages. This is a missed opportunity, considering that a speaker’s voice conveys emotion (Johnson et al., 1986; Vaughan-Johnston et al., 2021), personality and psychopathology (Helfrich & Wallbott, 1986), as well as confidence (Guyer et al., 2021)—all potentially important source variables. Furthermore, the voice is often an integral part of “real-world” persuasive appeals, from televised political speeches to telephone sales pitches to relationship negotiations. Moreover, a growing body of research has shown that various prosodic elements of speech do in fact influence how people respond to persuasive messages (e.g., Brennan & Williams, 1995; Guyer, Fabrigar et al., 2019, 2021; Van Zant & Berger, 2020). Taken together, ample data suggests that the complex inter-relationship between the human voice and persuasion holds great practical relevance across multiple domains, yet remains a relatively unstudied topic.
Many vocal signals suggest higher confidence, and/or predict persuasive effectiveness (for a review, see Guyer et al., 2021). These factors include increased vocal speed (Brown et al., 1985; Chebat et al., 2007; Guyer, Fabrigar, et al., 2019; Peterson et al., 1995; S. M. Smith & Shaffer, 1991), lower pitch (Guyer, Fabrigar, et al., 2019; Jiang & Pell, 2015, 2017; Monetta et al., 2008; Puts et al., 2006), and higher volume (Jiang & Pell, 2017; Kimble & Seidel, 1991; Scherer et al., 1973; Van Zant & Berger, 2020). Listeners often believe that speakers utilizing these characteristics are more confident. In the present work, we focus on a systematic pattern of fundamental frequency contour that signals high speaker confidence: intonation that falls versus rises at the ends of sentences, signaling more declarative (falling) versus interrogative (rising) communication intentions (Brooke & Ng, 1986; Erickson et al., 1978).
Vocal Confidence and the ELM
A principle of dual-system approaches to persuasion such as the ELM is that the degree to which recipients carefully think about persuasive messages can alter what psychological processes activate, affecting how and how much recipients change their attitudes (Chaiken, 1980; Petty & Cacioppo, 1986, 1999). In the ELM, the probability that participants will engage in deliberative, message-relevant thinking is termed elaboration likelihood. According to ELM’s multiple roles postulate, a single persuasion variable may potentially operate as a cue or heuristic when recipients are elaborating minimally, or it may bias thinking, serve as an argument, or alter recipients’ metacognitions when recipients elaborate greatly (Petty & Briñol, 2012). Alternatively, the same variable might affect the extent to which a recipient will cognitively elaborate on the message, given more moderate elaboration likelihood situations (e.g., if it is unclear whether the recipient should process more). Such situations include when the topic’s personal relevance to recipients is not explicitly specified, recipients are not specifically distracted or encouraged to pay very close attention to a message, and so on (see Petty & Cacioppo, 1986, for other moderators of elaboration likelihood).
Despite some early misunderstandings that source variables (e.g., how attractive or confident a source seems) are constrained to be heuristic influences (for a review, see Petty & Cacioppo, 1999), variables including source expertise (Clark et al., 2012; Heesacker et al., 1983) and even attractiveness (Puckett et al., 1983) can work via multiple ELM processes, such as increasing or decreasing elaboration likelihood (DeBono & Harnish, 1988; Tormala et al., 2007; also see Guyer, Briñol et al. (2019) for a review on the multiple processes of persuasive sources).
When we consider past work on vocal confidence (our conceptual variable), the ELM not only suggests how to interpret these results, but also suggests novel empirical directions for future research based on the ELM’s notion of multiple roles. For example, Guyer, Fabrigar et al. (2019) explicitly utilized the ELM in demonstrating distinct processes by which vocal confidence can affect persuasion. Participants were exposed to an audio passage discussing the benefits of phosphate-based laundry detergent, presented by a speaker with digitally altered falling intonation (high confidence) or rising intonation (low confidence) voice. Motivation and cognitive ability were manipulated by increasing or decreasing both factors, creating high- and low-elaboration conditions. As predicted, falling (vs. rising) intonation increased perceptions of speaker confidence and enhanced persuasion. Consistent with the ELM (Petty & Cacioppo, 1986), speaker confidence influenced persuasion through different processes depending on elaboration conditions. Under high elaboration, speaker confidence biased thought favorability, affecting attitudes. In contrast, under low elaboration, speaker confidence did not impact thought valence but influenced attitudes as a peripheral cue (see also Petty et al., 1993).
The ELM intriguingly suggests that vocal confidence might exert a different influence under conditions of moderate elaboration likelihood. Under such conditions, variables can affect recipients’ motivation and/or ability to process, influencing the degree to which they scrutinize message content. Higher elaboration tends to make recipients’ thoughts more influential in shaping their attitudes (Chaiken, 1980; Petty & Cacioppo, 1979, 1999). Moreover, increased elaboration can enhance the influence of argument quality—strengthening persuasion for strong arguments and reducing it for weak ones. Understanding variables that alter the level of elaboration is uniquely crucial in the ELM, as it suggests that the same variable (in this case, vocal intonation) may either enhance, fail to enhance, or even undermine persuasion. In conjunction with past work showing vocal confidence’s effects under low and high elaboration (e.g., Guyer, Fabrigar et al., 2019, 2025), establishing that vocal confidence can also stimulate more elaboration processing represents uniquely strong information supporting the ELM’s multiple roles postulate.
Past work connecting vocal properties to processing has focused exclusively on vocal speed (e.g., Moore et al., 1986; S. M. Smith & Shaffer, 1991, 1995), and has generally advanced our understanding of how very fast vocal speeds can undermine processing because it is difficult to think carefully about a message that is being delivered very quickly. Strictly, then, most of this work is not about confidence suggested by the voice so much as how such signals can make messages hard to understand. However, in the present work, we focus on how a vocal property (falling vs. rising intonation) may prompt increased processing by spurring perceptions that the speaker is confident, increasing recipients’ motivation to think about the message—assuming elaboration likelihood is not constrained to be very high or very low (i.e., is moderate).
Conditions of moderate elaboration likelihood are easy to envision because they are common (see Bless et al., 1990; Cacioppo & Petty, 1989 for empirical examples). Messages that only partially capture our interest are frequent, such as those found in television ads, political speeches, and educational lectures. Many listeners find these materials only somewhat interesting, and there is no powerful push to engage or disengage. Consequently, we often have the flexibility to choose whether to pay attention to messages. That is, the extent to which we devote our cognitive resources to processing a message is free to vary. Understanding variables that encourage or discourage attention in such environments is crucial.
Falling Intonation Increasing Processing
We test whether a speaker’s falling versus rising intonation impacts a listener’s motivation to elaborate on a message under conditions of moderate elaboration. We decided to focus on vocal intonation for several reasons. First, variations in falling versus rising intonation at the ends of sentences should not substantially interfere with listeners’ ability to process messages (we test this empirically in the present work), whereas many other vocal properties may interfere with listeners’ ability to process (e.g., low volume and fast speed).
Second, vocal intonation has been less studied in the persuasion literature than other vocal properties such as pitch (Guyer et al., 2025; Van Zant & Berger, 2020) and speed (Briñol & Petty, 2003, Experiment 2; Moore et al., 1986; S. M. Smith & Shaffer, 1991, 1995). Nonetheless, cognitive psychologists have shown that speakers naturally use falling (rising) intonation more frequently when they believe they are making correct (incorrect) statements (Brennan & Williams, 1995; V. L. Smith & Clark, 1993). People may naturally signal lower confidence, such as by raising their vocal intonation at the ends of sentences, to avoid appearing incompetent for confidently asserting false statements (given that higher projected confidence increases the social cost of making false statements; Vullioud et al., 2017). Because the validity of a target can influence a person’s motivation to acquire more knowledge about the target and because people are motivated to hold correct attitudes, the belief that the speaker is sharing valuable and accurate information should enhance people’s elaboration of the content—that is, the message (Chaiken et al., 1989; Petty et al., 1997; Petty & Cacioppo, 1979).
If falling intonation signals a confident speaker, enhancing recipient message elaboration, we would expect increased persuasion with strong messages but no increase or even decreased persuasion with weak messages. This would form a boundary condition for the intuitive traditional findings whereby vocal confidence signals generally boost persuasion (e.g., Guyer et al., 2021; Guyer, Fabrigar, et al., 2019; Van Zant & Berger, 2020). Surprisingly, in certain conditions, more vocal confidence might fail to boost persuasion, or even reduce persuasion, by highlighting the message’s weakness, as it motivates recipients to process the message more critically.
Although other approaches exist (see Experiment 2), processing levels are commonly tested by examining the impact of argument quality on attitudes (Clark & Wegener, 2013; Petty & Cacioppo, 1986). The rationale is that careful processing of a persuasive message should result in a significant influence of argument quality on attitudes. Conversely, if argument quality has a limited impact on attitudes, this implies that the recipient is using more superficial cognitive strategies to assess the message. Therefore, significant differences in the effect of argument quality on post-message attitudes are expected when the recipient is carefully evaluating the message, whereas these differences should be weaker when the recipient is not carefully evaluating the message.
The Present Work
In three experiments, we crossed vocal intonation (falling vs. rising) with argument quality (weak vs. strong) using between-participant designs. We introduced several variations for greater generalizability across different attitude topics and populations. The extremity of vocal intonation was operationalized differently in Experiments 2 and 3, and the experiments used a mix of men and women speakers. Elaboration likelihood was assessed through two distinct tests: moderating the effect of argument quality (Experiments 1–3) and thought/attitude consistency (Experiment 2). Crucially, all experiments explored whether changes in vocal intonation impact listener perceptions of speaker confidence, enhancing the processing of persuasive messages. Importantly, elaboration conditions were consistently kept moderate by maintaining ambiguity about the personal relevance of the proposal and avoiding steps that could undermine processing ability (e.g., through distraction; see Guyer, Fabrigar et al., 2019).
Experiment 1
Experiment 1 had several goals. First, we sought to replicate past work by demonstrating that communicators are perceived as more confident when they finish their sentences with falling versus rising vocal intonation. Second, and most critically, we tested whether the effects of manipulated vocal confidence (i.e., falling vs. rising intonation) on persuasion could be moderated by the quality of the arguments (i.e., strong vs. weak), such that a confident-sounding speaker (i.e., falling intonation) can elicit more persuasion when delivering strong arguments but less persuasion when delivering weak arguments.
Methods
Participants
We recruited 277 participants from IE University (Madrid, Spain) who completed materials online in exchange for course credit. Participants were 58.8% women, 41.2% men; and were primarily young adults, Mage = 25.1, SDage = 13.0. We followed time-based stopping rules, stopping at the end of a semester when at least 50 participants/cell had been obtained. In our power analysis, we anticipated that falling intonation would bolster the benefit of strong > weak messages on attitudes by d = .50, and that rising intonation would reverse this effect. We obtained 83% power to detect this interaction (see SOM-2). We report all manipulations, measures, and exclusions in these studies. Data and code are available on OSF at https://osf.io/24rbp/?view_only=1202b80986124efebec8ed0fcfe7cb5a. No studies in this manuscript were preregistered.
Procedure and Materials
We randomly assigned participants to one of four between-participant conditions in a 2 (Vocal Intonation: Falling vs. Rising) × 2 (Argument Quality: Strong vs. Weak) design. After being seated at a computer, we gave participants headphones and asked them to listen to an audio message that discussed the possibility of implementing a junk food tax. We informed participants that “some provinces in Spain are considering the legislation” to ensure that the personal relevance of the message was ambiguous (i.e., unclear if it would affect the listeners themselves or not), thus creating conditions under which participants were more likely to process the message with a moderate (vs. high or low) level of elaboration. This contrasts with past research by Guyer, Fabrigar et al. (2019), which deliberately promoted high elaboration (e.g., by emphasizing personal relevance) or low elaboration (e.g., by distracting participants). That is, instead of making personal relevance too high or too low to begin with, in this study, we kept that variable somewhere in between since it was not specified whether the proposal would be implemented in their current location or somewhere else. 1
After participants listened to the audio passage, we then asked them to rate the junk food tax using an attitudes scale. Next, participants were asked several questions about the speaker’s stylistic delivery (e.g., the speaker’s age, accent, and gender; how complex the vocabulary and well-organized the message was) to help mask our goals and thus reduce demand characteristics. We also asked several exploratory questions about how focused participants felt (e.g., “To what extent were you focused on what the speaker was saying” rated 1 = Not at all to 7 = Completely) and how credible the speaker seemed (e.g., “To what extent did the speaker sound like a person who knew what he was talking about” rated 1 = Not at all to 7 = Definitely), analyzed in SOM-3, as well as how able participants were to understand the speaker (“To what extent were you able to understand what the speaker was saying?” rated 1 = Not at all to 7 = Completely). Mixed into these questions was a manipulation check (“did the intonation in the speaker’s voice mostly rise at the end of each sentence, or mostly fall at the end of each sentence,” rated 1 = mostly fall to 7 = mostly rise), and a rating of the speaker’s confidence level (“to what extent does the speaker seem confident” from 1 = Not at All Confident to 7 = Very Confident).
Independent Variables
Argument Quality
We gave participants a message containing strong or weak arguments justifying the implementation of a new junk food taxation policy.
In the weak arguments condition, we gave participants information that sounded superficially convincing, but upon closer reflection were unconvincing. For example, one argument stated that junk food taxes would generate only enough money to “partially fund programs for a small number of citizens.” Arguments in this condition attributed facts to sources with unclear credibility such as an unnamed college student.
In the strong arguments condition, we gave participants reasonably strong, logically connected information. For instance, this message argued that the tax would “fund a number of healthy lifestyle programs” without substantial adverse consequences for junk food companies. Arguments in this condition attributed facts to reputable scientists (a professor at Oxford University) and organizations (e.g., the Spanish Diabetes Association).
Vocal Intonation
The message was recorded by the same male speaker in both audio versions and was digitally edited using PRAAT®. To manipulate vocal intonation, we first selected 12 of 22 sentences per condition that were similarly placed within the strong and weak versions of the passage. The entire text consisted of declarative sentences. Importantly, we spread out the sentences in which intonation was manipulated, so that in both conditions, the respective manipulation was evenly distributed throughout the text. Next, we either raised (for rising intonation) or lowered (for falling intonation) the speaker’s vocal pitch on only the last word of the chosen sentences (i.e., such that 4.4% of words were changed). Relative to the speaker’s baseline, pitch was raised or lowered by 35 hertz on these words. These manipulations were selected because we believed that the differences in intonation were sufficiently distinct to the untrained ear but also did not exceed natural variation in intonational fluctuation (e.g., see Chen et al., 2001). 2
Dependent Variables
Attitudes
Our dependent variable was participants’ attitudes toward the implementation of the new taxation policy. Specifically, we asked participants to rate their attitudes toward the implementation of the new policy on a set of eight, seven-point semantic differential scales (e.g., good, bad, like, dislike). These specific items have been previously validated for assessing attitude change (Crites et al., 1994). Ratings on these items were highly reliable (α = .90), so we computed an overall attitude index by averaging scores across all items.
Behavioral Intentions
We included two items to assess participants’ behavioral intentions toward the tax policy: how likely it was that they would vote for such a policy, and how likely it was that they would collect signatures to support the policy, each rated 1 (Not at All) to 7 (Definitely). These items were internally consistent, α = .67, and thus were averaged to form a behavioral intention index.
Results
Manipulation Check: Perceived Vocal Intonation
Our analysis was a 2 (Argument Quality: Weak vs. Strong) and Vocal Intonation (Falling vs. Rising) ANOVA. Starting with effects on perceived vocal intonation, we found the hypothesized main effect of vocal intonation, F(1, 273) = 29.39, p < .001, ηp2 = .10 [.05, .16], such that people perceived intonation as rising more in the rising (M = 4.85, SE = .10) than in the falling (M = 4.05, SE = .11) conditions.
There was no main effect of argument quality on vocal intonation, F(1, 273) = 3.35, p = .068, ηp2 = .01 [.00, .04]. However, we did detect an unexpected interaction of Argument Quality × Vocal Intonation, F(1, 273) = 4.17, p = .042, ηp2 = .02 [.00, .05]. Rising intonation was perceived as rising more than falling intonation in both argument quality conditions, but the difference was somewhat more pronounced in the weak argument condition, Mdiff = 1.1, F(1, 273) = 27.41, p < .001, than in the strong argument condition, Mdiff = .50, F(1, 273) = 5.80, p = .017. However, since the interaction effect was not replicated in other datasets (and did not manifest in an integrated data analysis combining the three experiments; see SOM-4), we do not comment on this further, other than to address it briefly in the discussion of Experiment 1.
Manipulation Check: Ability to Understand the Speaker
Part of the novelty of our research is that we examine whether a vocal signal might influence message processing by affecting motivation (perceived speaker confidence) without changing ability to process the message. Thus, our second manipulation check seeks to confirm that falling and rising intonation did not differ with respect to how this manipulation affected self-reported message comprehensibility. Indeed, ability to understand the speaker was not affected by argument quality, F(1, 273) = 2.68, p = .103, eta = .01, vocal intonation condition, F(1, 273) = .21, p = .644, eta = .00, nor their interaction, F(1, 273) = .60, p = .440, eta = .00.
Perceived Speaker Confidence
We employed the same 2 × 2 ANOVA specified above, now predicting speaker confidence. We found the hypothesized main effect of vocal intonation on speaker’s perceived confidence, F(1, 273) = 14.25, p < .001, ηp2 = .05 [.02, .10], such that people thought the speaker with falling intonation (M = 5.55, SE = .14) sounded more confident than the speaker with rising intonation (M = 4.82, SE = .13). We did not anticipate nor detect any main effect of argument quality, F(1, 273) = 2.81, p = .095, ηp2 = .01 [.00, .04], nor an interaction, F(1, 273) = .25, p = .619, ηp2 < .01. Thus, congruent with past research (e.g., Experiment 1 of Guyer, Fabrigar, et al., 2019), ratings of speaker confidence were higher for those conditions in which the speaker’s vocal intonation was digitally manipulated to fall versus rise at the end of a sentence.
Persuasion
Once again, we used a 2 × 2 ANOVA, now to examine persuasion effects. Expectedly, and confirming the validity of our argument quality manipulation, we found a main effect of argument quality, F(1, 273) = 12.06, p = .001, ηp2 = .04, such that strong arguments led to more favorable opinions of the junk food tax (M = 5.28, SE = .10) relative to weak arguments (M = 4.77, SE = .11). Vocal intonation had no main effect on persuasion, F(1, 273) = .28, p = .599, ηp2 = .00, which is consistent with our perspective that falling intonation should only benefit persuasion given strong arguments, but undermine persuasion given weak arguments.
As predicted, the hypothesized interaction effect was significant, F(1, 273) = 4.18, p = .042, ηp2 = .02 [.01, .09], as seen in Figure 1. Simple slopes analyses confirmed that although falling intonation marginally boosted persuasion given strong arguments, Mdiff = .38, F(1, 273) = 3.36, p = .068, ηp2 = .01 [.00, .04], the same pattern of falling intonation was unrelated to persuasion given weak arguments, Mdiff = −.24, F(1, 273) = 1.13, p = .288, ηp2 = .00 [.00, .03]. This is captured in Figure 1: falling intonation (left square) is more persuasive than rising intonation (right square) given strong arguments (in blue), but this benefit is eliminated given weak arguments (in red). Alternatively considered, argument quality substantially and significantly benefited persuasion given falling intonation, Mdiff = .82, F(1, 273) = 14.76, p < .001, but argument quality did not benefit persuasion given rising intonation, Mdiff = .21, F(1, 273) = 1.05, p = .306.
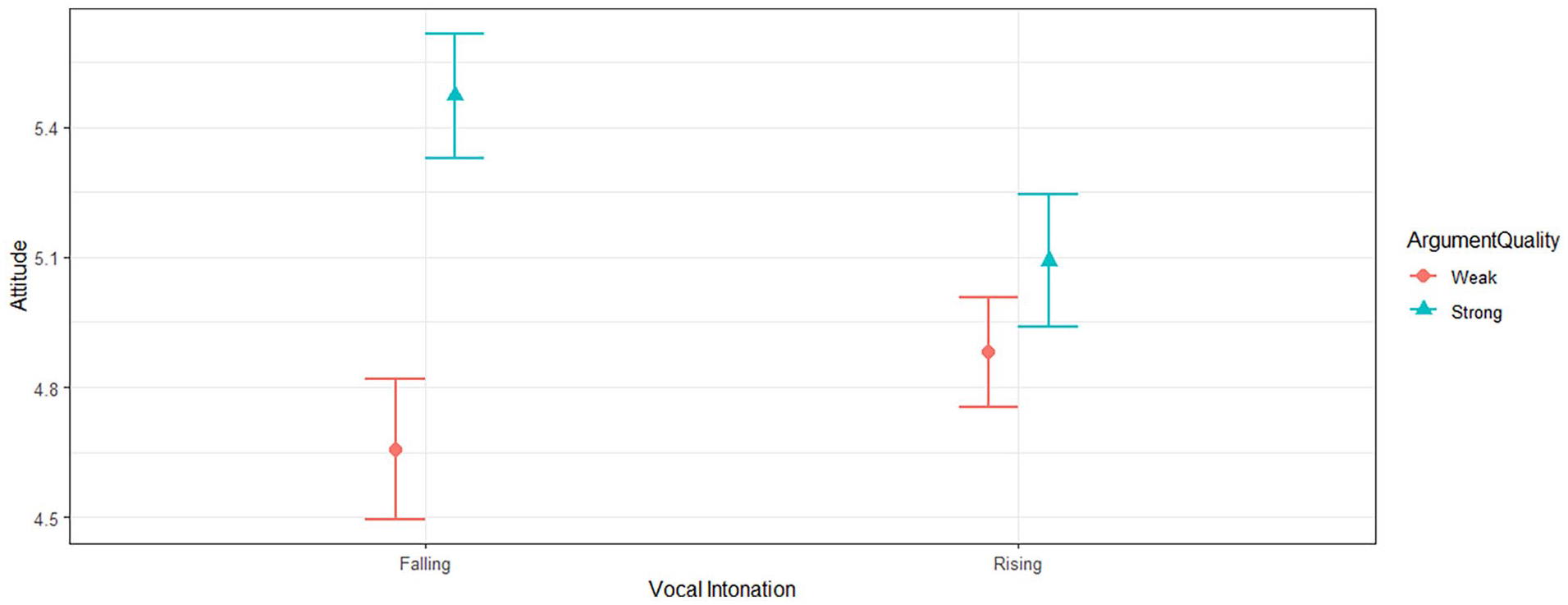
Effect of Argument Quality and Vocal Intonation on Persuasion.
Behavioral Intentions
We also analyzed behavioral intentions with the same two-way ANOVA. We detected a main effect of argument quality, F(1, 273) = 5.24, p = .023, ηp2 = .02 [.00, .05], whereby strong arguments (M = 4.29, SE = .13) prompted more favorable behavioral intentions toward the policy than did weak arguments (M = 3.88, SE = .13). Consistent with our reasoning, there was no main effect of vocal intonation, F(1, 273) = .27, p = .607, ηp2 = .00 [.00, .02]. However, contrary to expectations, the interaction also was non-significant, F(1, 273) = .46, p = .498, ηp2 = .00 [.00, .02]. Falling intonation was unrelated to behavioral intentions given strong arguments, Mdiff = −.03, SEdiff = .26, p = .909, and also was unrelated given weak arguments, Mdiff = .22, SEdiff = .25, p = .395. Therefore, we do not have a basis to make claims about vocal intonation’s moderating effect on behavioral intentions in Experiment 1.
Mediation by Perceived Speaker Confidence
Our theory suggests that falling intonation leads recipients to process messages more carefully, polarizing the persuasive effects of strong (vs. weak) arguments, at least in part because falling intonation is a signal of speaker confidence. Rising intonation, however, undermines speaker’s perceived confidence, leading recipients to respond similarly to strong and weak arguments. Importantly, these claims imply a process above and beyond the observed effect, such that confidence should help to account for how vocal intonation affects persuasion.
To this end, we constructed a moderated mediation model using model 14 of PROCESS (v3.5, 10,000 bootstrapped iterations; Hayes, 2022), such that the independent variable (manipulated intonation) predicts the mediator (speaker confidence), which predicts the dependent variable (attitudes), but the path from perceived confidence to attitudes is moderated by argument quality. Specifically, we would expect falling intonation to positively affect confidence (i.e., the “a path”), and then expect perceived confidence to moderate the effects of strong versus weak messages onto attitudes (i.e., moderate the “b path”). Although the a path was significant, B = .72 [.34, 1.10], SE = .19, t(275) = 3.73, p < .001, the moderation of the b path was non-significant, B = .14 [−.04, .32], SE = .09, t(272) = 1.57, p = .119. The moderated mediation index was consequently non-significant, MMI = .10, as indicated by a 95% confidence interval that crosses zero, CI95 = [−.03, .27]. Because this same pattern of significance/non-significance occurred for Experiment 2, we return to this issue in Experiment 3, which successfully obtained a stronger vocal intonation manipulation, and in the general discussion with a meta-analytic test aggregating over all datasets.
Discussion
Experiment 1 replicated prior research (Experiment 1 of Guyer, Fabrigar, et al., 2019), showing that changes in vocal intonation have systematically different effects on listeners’ perceptions of speaker confidence. Specifically, speakers who finished their sentences with falling intonation were perceived as significantly more confident than those who finished with rising intonation. In addition, for the first time, we demonstrated that vocal intonation can influence cognitive elaboration of messages. The two-way interaction between intonation and argument quality showed that the persuasive effects of strong versus weak arguments on attitude change were heightened when a speaker used falling intonation, indicating confidence, compared to rising intonation, indicating uncertainty.
Experiment 1 has limitations, including an unexpected interaction effect that suggested the intonation manipulation had higher construct validity in the weak argument quality condition. However, this pattern is unlikely to explain the detected interaction effect on persuasion. Despite a less successful manipulation of vocal intonation in the strong message condition, our hypothesis and data supported the idea that vocal intonation should enhance persuasion more in the strong versus weak message condition. Experiment 2, which used different messages and a different population, was designed to further validate and replicate our results across diverse populations and contexts.
Furthermore, Experiment 1 deployed only two levels of intonation: rising and falling. It may be illustrative to explore a broader range of intonation intensities. Considering ecological validity, speakers may naturally deploy relatively pronounced or relatively modest dynamics in their intonation patterns. In addition, examining a broader range of vocal intonation may more thoroughly allow us to understand its causal relationship to elaboration and persuasion. Thus, in Experiment 2 we broadened our range of intonation dynamics.
Experiment 2
One important goal of Experiment 2 was to further investigate the effects of vocal intonation on persuasion under moderate elaboration by examining a broader spectrum of this variable. Conceptually, the “intensity” of vocal intonation can range along at least two dimensions. First, one could increase the magnitude of intonational variation (i.e., changes in pitch) at the end of a given sentence (e.g., falling/rising by 25 Hz vs. 75 Hz). Second, one could increase the percentage/proportion of sentences in a persuasive appeal that ends with either falling or rising intonation (e.g., falling/rising on 25% vs. 75% of sentences). In Experiment 2, we considered magnitude of intonation extremity, whereas Experiment 3 considers frequency.
Second, in Experiment 2 we analyzed elaboration by three methods. First, we compared the effect of strong versus weak messages on persuasion, as in Experiment 1. We also considered two additional pieces of evidence relating to the contents of participants’ thoughts; therefore, in Experiment 2, we employed a thought listing procedure to assess participants’ cognitive responses to the communication (Cacioppo & Petty, 1979). Specifically, we analyzed the proportion of participants’ thoughts that were message-relevant (vs. irrelevant). One might anticipate that rising intonation, for instance, might draw participants to think about the source, as for example rhetorical questions may do (e.g., Swasy & Munch, 1985), which would decrease participants’ degree of message-relevant processing. However, we also tested the degree to which the favorability of thoughts can predict attitudes, a method of demonstrating cognitive elaboration often used by attitude scholars (Chaiken, 1980; Petty & Cacioppo, 1979). That is, if falling intonation prompts more elaboration, it should increase the association between pro-message thoughts and pro-message attitudes. Thus, we would expect an interaction effect: more favorable thoughts should always align with more favorable attitudes, but this thought/attitude correspondence should be stronger given falling versus rising vocal intonation.
In addition, we sought to enhance the generalizability of our research by sampling from a very different population than we used in Experiment 1: Canadian versus Spanish participants. We had no theoretical basis to predict differences in our key effects between our samples, and therefore expected our effects to generalize across different populations. Establishing such generalizability is important for demonstrating the external validity of our claims (Campbell & Cook, 1979; Findley et al., 2021).
Methods
Participants
We recruited 321 participants from a Canadian university to participate in the laboratory for course credit. We followed time-based stopping rules, originally aiming for 50 participants/cell but stopping early due to practical reasons (see SOM-2 for a discussion of statistical power, which we calculated after data collection based on Experiment 1’s effect size estimate). Although we did not collect demographic data from this sample, our sample was drawn without restriction from a participant pool comprised of 22.7% men, 76.6% women, .4% non-binary/other, and .1% prefer not to answer; 70.8% white, 12.3% East Asian, 7.3% mixed, 4.2% south Asian, 3.3% other, 1.5% black, .7% Hispanic; Mage = 18.1, SDage = 1.1.
Procedure and Materials
The general procedure was comparable to Experiment 1 except where noted. First, we changed the topic from junk food tax to a student tuition plan that encouraged students to work part-time for their university in exchange for money to cover tuition (see, e.g., Priester et al., 1999). Experiment 2’s speaker was a woman, whereas Experiment 1’s speaker was a man.
Second, after listening to the audio recording, unlike in Experiment 1, participants now completed a cognitive response task in which they listed up to 10 thoughts prompted by the persuasive passage. Next, participants rated each thought as positive, neutral, negative, or topic-irrelevant. Finally, participants rated their attitude toward the topic. We then subtracted each participants’ number of negative thoughts from their number of positive thoughts, and divided by that participant’s total relevant thoughts to create an index representing average thought valence. We then had two expert judges, blind to condition, code all participant thoughts with respect to message-relevance; these codes were reliable, r(319) = .70, p < .001.
Third, due to time constraints incurred by adding the cognitive response task, we reduced the number of items used to rate the speaker to include only the key manipulation check (intonation), the rating of confidence, and three distractor items (i.e., the clarity, complexity, and the organization of the speaker’s speech).
Fourth, we shifted the design to a 2 (Vocal Intonation Direction: Falling vs. Rising) × 2 (Argument Quality: Strong vs. Weak) × 2 (Vocal Intonation Extremity: Moderate vs. Strong) between-participants design. To create these conditions, we first selected 15 sentences that were similarly placed within both versions of the passage (i.e., strong vs. weak arguments). Next, we either digitally raised or lowered the intonation in the speaker’s voice on the last word in each of the chosen sentences (i.e., 3.3% of total words were manipulated). Thus, relative to the speaker’s baseline, we created two conditions that, on average, raised the speaker’s intonation by either a moderate (35 hz) or strong amount (75 hz). Similarly, relative to the speaker’s baseline, we created two conditions that, on average, lowered the speaker’s intonation by either a moderate (15 hz) or strong amount (20 hz) on the chosen words.
Results
Manipulation Check: Perceived Vocal Intonation
We conducted a 2 (Argument Quality: Strong vs. Weak) × 2 (Vocal Intonation Direction: Falling vs. Rising) × 2 (Vocal Intonation Extremity: Moderate vs. Strong) ANOVA on perceived vocal intonation. We found no evidence for the expected two-way interaction of Vocal Intonation Direction × Vocal Intonation Extremity, F(1, 313) = .00, p = .964, ηp2 = .00 [.00, .00]; thus, we had no basis to expect that the extremity of vocal intonation was detected by participants. We did, however, find the expected main effect of Vocal Intonation Direction, F(1, 313) = 54.91, p < .001, ηp2 = .15 [.10, .23]. That is, falling intonation was perceived as falling more (M = 4.56, SE = .11), and rising intonation was perceived as falling less (M = 3.40, SE = .11), regardless of how extreme the falls/rises in pitch were. Remaining effects in the three-way ANOVA were unexpected, weak/non-significant, and not replicated in other experiments, and so are reported in SOM-4.
Perceived Speaker Confidence
Once again, we ran a 2 × 2 × 2 ANOVA as described above. As with perceived intonation, there was no evidence that Vocal Intonation Extremity moderated the effect of Vocal Intonation Direction on confidence, F(1, 313) = .65, p = .420, ηp2 = .00 [.00, .02]. We once again obtained a main effect of Vocal Intonation Direction, F(1, 313) = 11.46, p = .001, ηp2 = .04 [.01, .08], such that falling intonation voices were judged as more confident (M = 5.25, SE = .09) than rising intonation voices (M = 4.82, SE = .09). No further effects reached significance. The full ANOVA table is reported in SOM-4.
Persuasion
We again employed a 2 × 2 × 2 ANOVA, this time on attitudes. The data from the perceived vocal intonation and perceived speaker confidence tests both suggested that listeners distinguished between falling and rising intonation, but were unable to distinguish between the strong and moderate forms of each. Obviously, our expectations for the remaining variables were informed by these analyses. Whereas we had originally hypothesized a three-way interaction on attitudes, at this point, we now expected only a two-way interaction of Vocal Intonation Direction × Argument Quality on attitudes, essentially replicating Experiment 1 but across a broader range of intonational extremities.
Confirming the validity of our argument quality manipulation, we found a main effect of argument quality on persuasion, F(1, 313) = 76.92, p < .001, ηp2 = .20 [.14, .26], whereby strong arguments prompted more favorable views of the work program (M = 5.09, SE = .09) relative to weak arguments (M = 3.95, SE = .09). Vocal intonation had no main effect on persuasion, F(1, 313) = .13, p = .719, ηp2 = .00 [.00, .01], once again consistent with our theory that vocal intonation should only bolster persuasion given strong arguments, and impair persuasion given weak arguments.
Most importantly, we replicated Experiment 1’s interaction effect of vocal intonation direction × argument quality, F(1, 313) = 10.88, p = .001, ηp2 = .03 [.01, .07]. Breaking down the simple effects, we found that although falling intonation significantly boosted persuasion given strong arguments, Mdiff = .38, F(1, 313) = 4.36, p = .038, ηp2 = .01 [.00, .04], falling intonation significantly reduced persuasion given weak arguments, Mdiff = −.47, F(1, 313) = 6.63, p = .010, ηp2 = .02 [.00, .05]. This is captured in Figure 2: falling intonation (left square) is more persuasive than rising intonation (right square) given strong arguments (blue squares), and this is reversed given weak arguments (red squares). Alternatively expressed: given falling intonation, the benefit of strong over weak arguments was relatively pronounced, Mdiff = 1.57, SE = .18, p < .001. However, given rising intonation, this effect was diminished to less than half the original effect size, Mdiff = .71, SE = .18, p < .001.
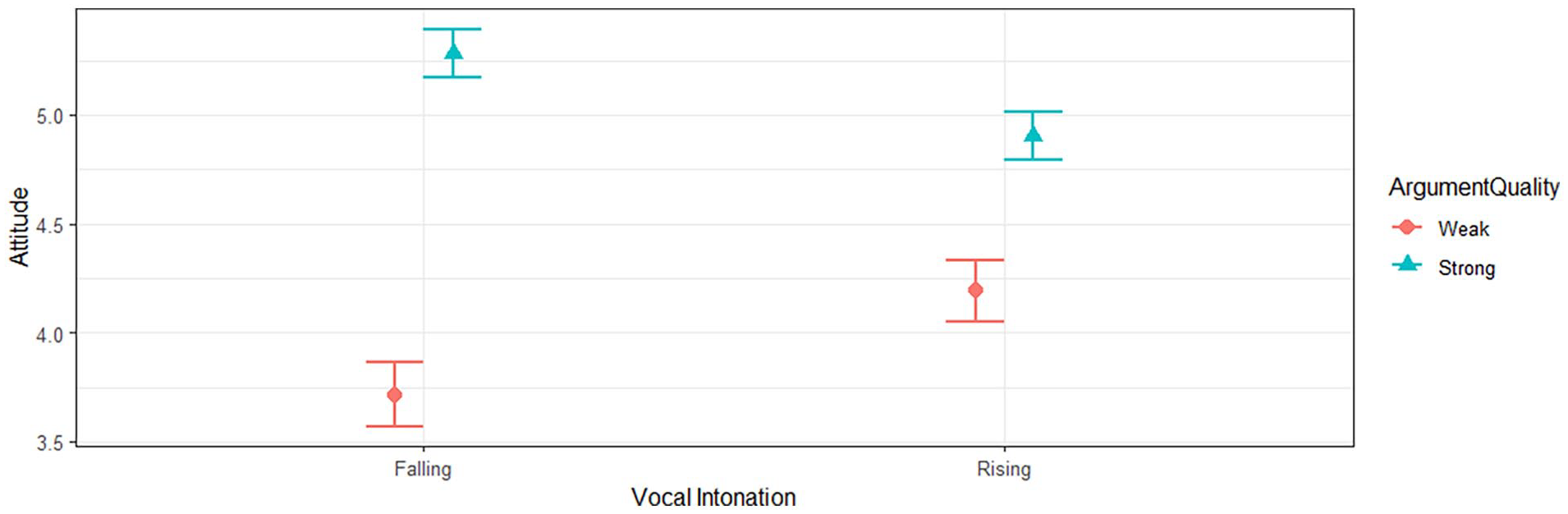
Effect of Argument Quality and Vocal Intonation on Persuasion.
Proportion of Relevant Thoughts
As previously mentioned, the ELM positions “moderation of argument quality on persuasion effects” as a methodological tool to identify when participants are elaborating carefully, but it is only one among several pieces of relevant evidence (Petty & Cacioppo, 1999). A second way of identifying when people are elaborating more carefully can be observed through analyzing the proportion of their thoughts that are relevant (vs. irrelevant) to evaluating the attitude object. We used the same three-way ANOVA model explained above in the persuasion subsection, with proportion of relevant thoughts as the dependent variable. We detected only the expected main effect of Vocal Intonation Direction, F(1, 313) = 10.99, p = .001, ηp2 = .03 [.01, .07], such that falling intonation voices prompted more relevant thoughts (M = 75.8%, SE = 2.0%) than rising intonation voices (M = 66.5%, SE = 2.0%). No further effects reached significance. The full ANOVA table is reported in SOM-4.
Thought/Attitude Correspondence
Recall that falling intonation was expected to increase the association between thought valence and attitudes (Chaiken, 1980; Petty & Cacioppo, 1979). To test this possibility, we ran an interaction of relevant thought valence × vocal intonation direction on attitudes, using model 1 in PROCESS. We detected a significant interaction, B = .47 [.13, .81], t(314) = 2.72, p = .007, indicating that thought valence was more strongly associated with attitudes given falling versus rising intonation. Specifically, more positive thought valence predicted more positive attitudes moderately when intonation was rising, B = 1.16 [.92, 1.40], t(314) = 9.60, p < .001, but thought valence predicted attitudes much more substantially when intonation was falling, B = 1.63 [1.39, 1.87], t(314) = 13.29, p < .001. This provides additional evidence that falling intonation, with its implications of speaker confidence, bolstered recipients’ tendency to process the source’s information rigorously. This result is also depicted in Figure 3, where we see that the red line indicating falling intonation shows a relatively sharp relationship between thought positivity and attitudes, showing that a confident speaker leads recipients to rely more on their thoughts (i.e., as part of their greater cognitive elaboration). Although the blue line, which indicates, rising intonation, still shows a marked association between thought positivity and attitudes (people who think favorably about the work program naturally also liked it more), the effect is attenuated compared to falling intonation, as reflected by the less sharply sloped line. This suggests lower elaboration likelihood, which should result in people being less guided by their thoughts when appraising the work program.
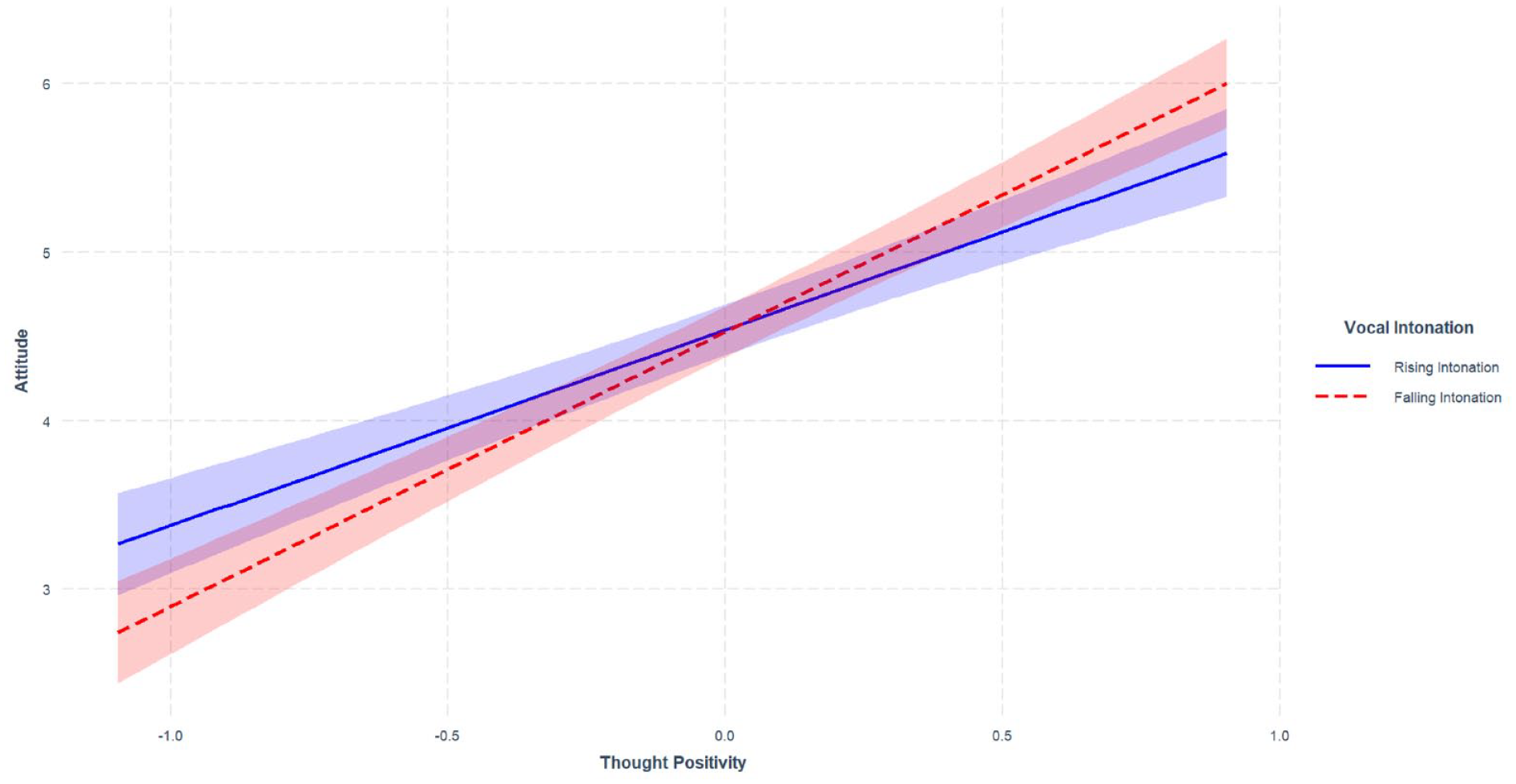
Effect of Thought Positivity and Vocal Intonation on Persuasion.
Discussion
Our exploration of a wider range of vocal intonation replicated the effects on perceptions of speaker confidence from Experiment 1. Speakers who finished their sentences with falling intonation were consistently seen as significantly more confident than those who finished with rising intonation. Despite changing the population, topic, gender of the speaker, persuasive message, and the operationalization of vocal intonation, our results replicated the key patterns found in Experiment 1. We also extended our findings by demonstrating that two different measures of tracking elaboration likelihood—proportion of relevant thoughts, and thought/attitude consistency—aligned with the hypothesized direction based on the speaker’s vocal intonation patterns.
Although accumulating evidence from the first two experiments support our conceptualization that falling versus rising intonation increases elaboration of arguments, one might argue that Experiment 2 failed to test whether intensity of intonation patterns affects persuasion, because participants failed to notice the difference between the moderate versus strong versions of the falling and rising conditions. Thus, in Experiment 3, we attempted to vary a different aspect of vocal intonation that we introduced earlier: frequency.
Experiment 3
As noted in Experiment 2, there are at least two ways in which falling/rising intonation patterns can be manipulated. One could either manipulate the intensity of the intonational variation on the last word in a sentence, or increase the proportion of sentences within a passage that contains falling/rising intonation on the last word in a sentence. In Experiments 1 and 2, the proportion of sentences that contained an intonation manipulation (i.e., pitch change on the last word in the sentence), was approximately 50% relative to the total number of sentences in the passage. However, this proportion could be varied to any arbitrary value. It might be the case that the effect of intonation change on listener perceptions of speaker confidence and cognitive elaboration may vary as a function of the proportion of sentences that contain changes in intonation, with downstream consequences for persuasion. That is, a higher proportion of intonation change may more strongly signal high (or low) confidence. To test this idea, in Experiment 3, we manipulated the proportion of sentences in the audio recording (25% vs. 75%) that contained either falling or rising intonation on the last word in the sentence. We also reintroduced a measure of behavioral intentions in Experiment 3, anticipating the possibility that the “stronger” vocal intonation manipulation might produce effects on this variable.
In addition, we sought to replicate the patterns demonstrated in Experiments 1 and 2 via a new population with broader demographic characteristics than our first two studies: paid workers on Mechanical Turk.
Methods
Participants
We recruited 447 UK participants from Mechanical Turk (MTurk) to complete these materials for US$0.70 each. Sample size was determined by budgetary considerations, but a power analysis suggested better statistical power given similar assumptions that we used to guide Experiment 2 (see SOM-2). Participants were slightly majority men (57.2%) with 42.8% women; and were generally young adults, Mage = 29.8, SDage = 9.99, after removal of two erroneous responses (“1” and “420”), however their age range (18–66) covered a somewhat broader span than our previous student samples, with 20% of the sample being over 37 years old. 3
Procedure and Materials
The experimental design was comparable to Experiment 2 except where specified. The design was altered to a 2 (Vocal Intonation Direction: Falling vs. Rising) × 2 (Vocal Intonation Frequency: 75% vs. 25% of sentences) × 2 (Argument Quality: Weak vs. Strong) between-participants design. The frequencies equated to 7.1 to 7.4% (2.3–2.4%) of words in the high-frequency (low-frequency) conditions. We used the junk food tax topic, with the reasoning that this was more understandable than the student work plan for non-university students (i.e., Experiment 3’s MTurk workers). The audio recording was delivered by the same male speaker used in Experiment 1. We also reintroduced the behavior intention items from Experiment 1 to determine if greater statistical power and the introduction of the more extreme intonation conditions might begin to exert downstream influences on behavior intentions. The exploratory items introduced in Experiment 1 were again included and are reported in SOM-3.
Results
Manipulation Check: Perceived Vocal Intonation
We performed three-way (2 × 2 × 2) ANOVAs analyzing the effects of argument quality, vocal intonation direction, and vocal intonation frequency on perceived intonation. Most importantly, we anticipated and detected a two-way interaction of vocal intonation direction × vocal intonation frequency, F(1, 439) = 11.31, p = .001, ηp2 = .03 [.01, .05]. As expected, even at 25% frequency, we found that falling intonation was seen as less rising (M = 3.78, SE = .12) than rising intonation (M = 4.83, SE = .12), Mdiff = 1.04, SE = .17, p < .001. However, at 75% frequency, this difference was amplified such that falling intonation was seen as much less rising (M = 4.07, SE = .12) than rising intonation (M = 5.90, SE = .12), Mdiff = 1.83, SE = .17, p < .001. Remaining effects were either subsumed by this interaction (i.e., main effects of vocal intonation and frequency of intonation), or were non-significant, and for brevity’s sake are reported in SOM-4.
Manipulation Check: Ability to Understand the Speaker
Once again, there was no effect of vocal intonation direction or magnitude, nor argument quality, nor their interactions, on ability to understand the speaker, all Fs < 3.17, ps > .075 (complete statistics in SOM-8).
Perceived Speaker Confidence
We once again analyzed the 2 × 2 × 2 factors by means of an ANOVA analysis. Crucially, we anticipated and found a two-way interaction of vocal intonation × frequency of intonation, F(1, 439) = 3.06, p = .081, ηp2 = .01 [.00, .03]. Breaking this down at each level of frequency, we found that falling intonation was seen as more confident (M = 5.50, SE = .13) than rising intonation (M = 4.84, SE = .14), Mdiff = .66, SE = .19, p = .001, even at the modest frequency of 25% of sentences. However, at 75% frequency, this difference was marginally amplified such that falling intonation was seen as much more confident (M = 5.43, SE = .13) than rising intonation (M = 4.30, SE = .13), Mdiff = 1.13, SE = .19, p < .001. Thus, the confidence-boosting effects of falling intonation were almost doubled by the shift from 25% to 75% frequency. All remaining effects are subsumed by the above interaction or are non-significant (see SOM-4).
Persuasion
Turning to attitudes, we anticipated a three-way interaction: argument quality’s effect on attitudes should be greater given falling versus rising intonation, but this in turn should depend on frequency of intonation. That is, as the frequency of intonation change (falling vs. rising) increases from 25% to 75%, the effect of each intonation type on persuasion should also increase.
Indeed, a three-way interaction was detected, F(1, 439) = 4.50, p = .034, ηp2 = .01 [.00, .03]. To decompose this interaction, we examined the two-way interaction of argument quality × vocal intonation at each level of frequency of intonation. Starting with the 75% frequency level, we detected a two-way interaction effect, F(1, 224) = 5.27, p = .023, ηp2 = .02 [.00, .06]. Falling intonation marginally boosted persuasion (M = 5.27, SE = .16) versus rising intonation (M = 4.87, SE = .17) given strong arguments, F(1, 224) = 2.94, p = .088, ηp2 = .01 [.00, .05]. However, falling intonation (M = 4.58, SE = .17) did not increase persuasion compared to rising intonation (M = 4.94, SE = .16) given weak arguments, F(1, 224) = 2.34, p = .127, ηp2 = .01 [.00, .04]. This can be seen in Figure 4A, in which we see a familiar pattern to that observed in Experiments 1 to 2: falling intonation increases persuasion given strong arguments (blue squares) but is unrelated to persuasion given weak arguments (red squares).
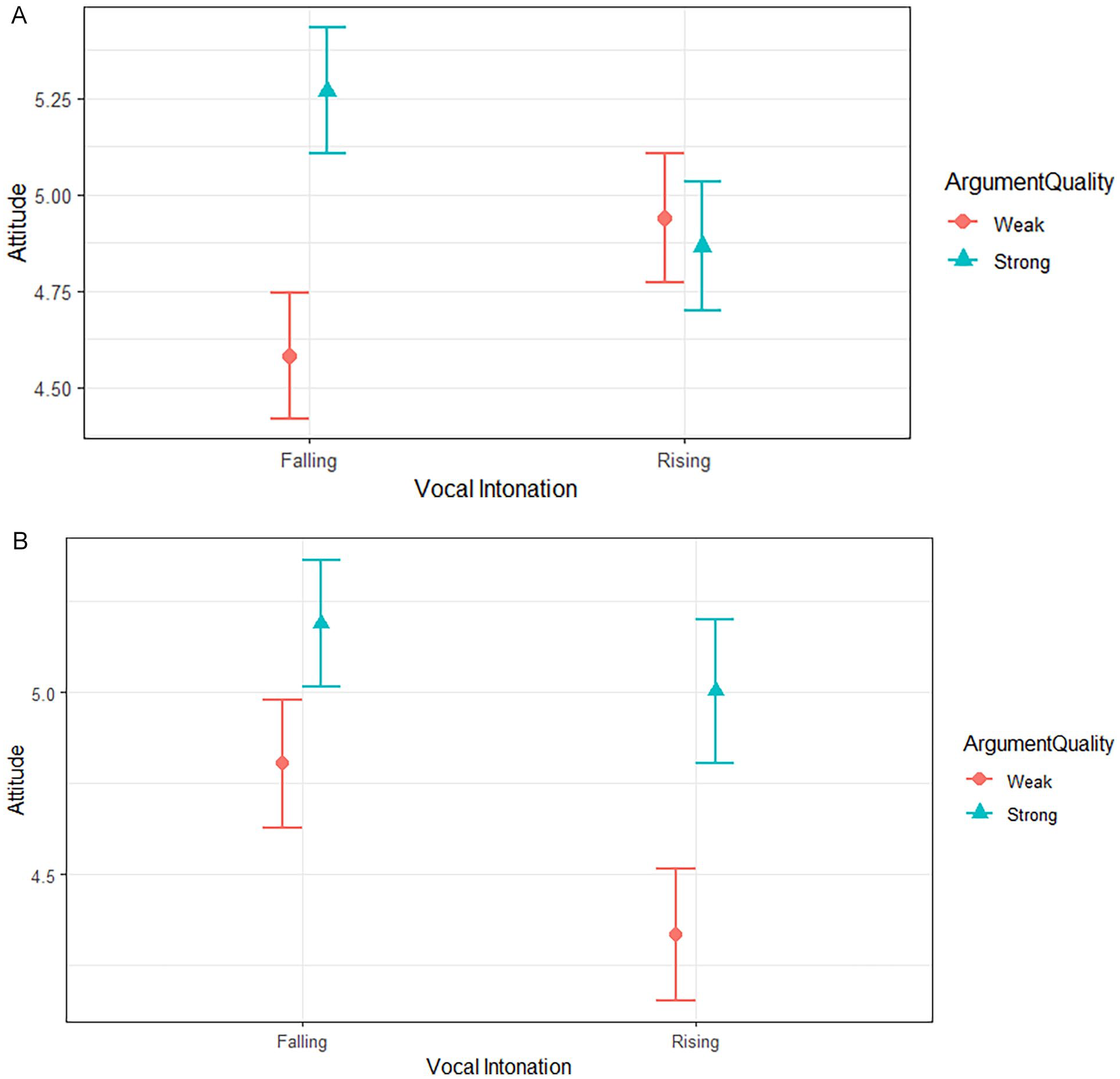
(A) Vocal Intonation and Argument Quality Influence Persuasion at 75% Intonation Frequency (B) Vocal Intonation and Argument Quality Influence Persuasion at 25% Intonation Frequency.
Turning to the 25% frequency level, the analogous two-way interaction was non-significant, F(1, 215) = .60, p = .439, ηp2 < .01 [.00, .03]. This can be seen in Figure 4B, in which falling intonation was not significantly more persuasive (M = 5.19, SE = .19) than rising (M = 5.00, SE = .19) given strong arguments, F(1, 215) = .49, p = .486, ηp2 < .01 [.00, .02]. However, falling intonation was marginally more persuasive (M = 4.80, SE = .18) than rising (M = 4.33, SE = .18) given weak arguments, F(1, 215) = 3.56, p = .061, ηp2 = .02 [.00, .05]. Once again, other effects are reported in SOM-4.
Behavioral Intentions
We expected the same effects to emerge on behavioral intentions that we observed for attitudes, and so subjected behavioral intentions to the same three-way ANOVA test. For brevity’s sake, and because this analysis is highly redundant with the attitudes effect detailed above, we relegate full details to the supplement (SOM-4), and summarize briefly here. We again observed the critical three-way interaction, F(1, 439) = 3.99, p = .046, ηp2 = .01 [.00, .03]. Once again, this effect was driven by a significant two-way interaction at 75% frequency, F(1, 224) = 7.93, p = .005, ηp2 = .03 [.01, .08], such that falling intonation altered behavioral intentions more than did rising intonation given strong arguments, Mdiff = .55, SEdiff = .27, p = .042, but falling intonation shifted behavioral intentions marginally less than rising given weak arguments, Mdiff = −.52, SEdiff = .27, p = .054. At 25% frequency, no such interaction emerged, F(1, 215) = .03, p = .857, ηp2 = .00 [.00, .01]. Instead, we found only a main effect of argument quality, F(1, 215) = 4.06, p = .045, ηp2 = .02 [.00, .06], whereby strong arguments increased behavioral intentions (M = 4.15, SE = .10) more than weak arguments (M = 3.76, SE = .10). This parallels the attitudes interaction and our predictions precisely. 4
Mediation by Perceived Speaker Confidence
Recall that in Experiment 1, we predicted a mediated moderation model such that falling intonation should increase perceived confidence, which should be related to more positive attitudes but only given strong (vs. weak) arguments. In Experiment 1, this was non-significant. For Experiment 3, we ran the same model for attitudes and again for behavioral intentions, once again using PROCESS model 14 (Hayes, 2022). We used only the 75% frequency subset of conditions to maximize the power of the vocal intonation manipulation. 5 For the attitudes analysis, we expected and found that falling intonation positively affected confidence (i.e., the “a path”), B = 1.14 [.75, 1.52], SE = .19, t(226) = 5.85, p < .001. We then expected and found that argument quality moderated the effect of confidence onto attitudes (i.e., moderated the “b path”), B = .31 [.10, .51], SE = .10, t(223) = 2.97, p = .003. Specifically, confidence bolstered persuasion given strong arguments, B = .34 [.19, .50], t(223) = 4.42, p < .001, resulting in significant mediation of intonation through confidence, IE = .39 [.18, .64]; but confidence did not bolster persuasion given weak arguments, B = .04 [−.18, .11], t(223) = .50, p = .615, resulting in non-significant mediation, IE = .04 [−.13, .22]. The moderated mediation index was significant, MMI = .35, as indicated by a 95% confidence interval that does not cross zero, CI95 = [.09, .65].
We also found the same pattern for behavioral intentions. In this analysis, again, falling intonation positively affected confidence, B = 1.14 [.75, 1.52], SE = .19, t(226) = 5.85, p < .001. Argument quality moderated the confidence effect on behavioral intentions, B = .28 [.05, .51], SE = .12, t(223) = 2.35, p = .019. Again, confidence bolstered behavioral intention change given strong arguments, B = .38 [.20, .55], t(223) = 4.22, p < .001, resulting in significant mediation of intonation through confidence, IE = .43 [.20, .70]; however, confidence did not bolster behavioral intentions given weak arguments, B = .10 [.−.07, .26], t(223) = 1.15, p = .253, without significant mediation, IE = .11 [−.10, .33]. The difference between these patterns was significant, as revealed by the significant MMI of .32 [.06, .63]. In sum, we found that confidence can account for vocal intonation’s moderation of argument quality—given a suitably intense manipulation of vocal confidence in which 75% of sentences are affected.
Discussion
Experiment 3 replicated the predicted Intonation × Argument Quality interaction in another population—British online workers—while also revealing a crucial boundary condition. Once again, falling vocal intonation was more persuasive than rising intonation given strong arguments and less persuasive given weak arguments, but only when the proportion of sentences with varying intonation was high (75%). That is, falling intonation stimulated more processing (strong > weak argument benefits) than rising intonation, but only at a relatively high intonation frequency. These effects disappeared when the proportion of sentences with varied intonation was reduced (to 25%). Combining these findings with Experiments 1 to 2, where the moderating effect of intonation repeatedly occurred with 50% frequency, suggests that, at least in our paradigm, the critical mass point at which intonation has persuasive consequences falls between 25-50% frequency, thus providing greater specificity about the boundaries of our effect.
Furthermore, we found effects on behavioral intentions in Experiment 3, unlike Experiment 1, which may continue to signal the value of higher-frequency (i.e., 75% rather than 25-50% frequency) intonation to clearly signal confidence. Given that behavioral intentions have been shown to “bridge” between attitudes and behaviors (Ajzen, 1991; Conner & Armitage, 1998; Sheeran et al., 1999), these results are an exciting addition to Experiments 1 to 2, demonstrating clear behavioral implications of the present work. Furthermore, this helps to establish the generalizability of our findings, in this case to an alternative measure of how positively recipients evaluated the attitude topic—evidently, enough to be willing to vote for and collect signatures in support of it.
General Discussion
Across three experiments varying in attitude topics (junk food taxation, student work program), populations (Spanish university students, Canadian university students, British crowdsourced workers), operationalization of vocal intonation (varying across frequency and intensity), and outcome measures (effects on attitudes and behavioral intentions, thought relevance, thought-valence/attitude consistency), we consistently found that falling intonation signaled more confidence to participants than rising intonation, in turn prompting more careful processing of persuasive messages. Furthermore, falling intonation enhanced persuasion only with strong arguments, and was either unrelated to (Experiments 1 and 3) or even reduced persuasion with weak arguments (Experiment 2). These consistent findings have important theoretical and applied implications, which we will discuss shortly. First, we will address several outstanding issues through an internal meta-analysis.
Internal Meta-Analyses
We conducted an internal meta-analysis of our presented three experiments and an additional file drawer study. Full details are reported in SOM-6 for brevity’s sake, so we summarize the questions and results briefly here.
First, the meta-analytic effect supported the hypothesized interaction whether the file drawer study was excluded or included. That is important because the predicted interaction effect was not significant when the file drawer study was analyzed on its own.
Second, we noted in Experiment 1 that confidence was non-significant as a mediator of vocal intonation’s effects in Experiments 1 to 2 and was only significant as a mediator sometimes in Experiment 3. However, when studies were aggregated, the moderated mediation was significant overall, and remained significant whether the file drawer study was included or excluded. That is, vocal intonation significantly increased perceived confidence of the source; perceived confidence then interacted with argument quality to affect persuasion. 6
Insights and Future Directions
The core contribution of this work is demonstrating that vocal intonation, an example of the broader constellation of variables that convey vocal confidence, increases the elaboration of messages by those listeners. We demonstrate this in several ways: falling intonation increased the persuasive benefits of strong over weak arguments. Moreover, Experiment 2 showed both that thoughts were more relevant giving falling (vs. rising) intonation, and that thought valence corresponded more closely with attitudes given falling (vs. rising) intonation, showing converging evidence that falling intonation can bolster processing. In the present data, not only do we have some evidence that ability to process cannot account for the effects of vocal intonation (as vocal speed has been shown to do; e.g., S. M. Smith & Shaffer, 1991), but we also have evidence that the effects of falling intonation on persuasion are mediated by perceptions of speaker confidence.
As predicted, the increased processing stimulated by falling intonation led to some interesting consequences. We found the first evidence that the benefits of vocal confidence (here, falling vs. rising intonation; also see Guyer, Fabrigar, et al., 2019) on persuasion can be completely eliminated by employing suitably weak arguments. This is crucial because speaker confidence is often thought to enhance trust and persuasion (Caballero & Pell, 2020; Guyer, Briñol, et al., 2019; Guyer et al., 2021, 2025; Guyer, Fabrigar, et al., 2019; Van Zant & Berger, 2020). However, the ELM contends that a variable beneficial under certain conditions may reduce persuasion under others (Petty & Cacioppo, 1986). Specifically, under moderate elaboration conditions, an otherwise persuasion-boosting variable might increase processing and thus reduce or at least not facilitate persuasion by weak messages.
Few variables are comprehensively studied across multiple roles of the ELM, yet the idea that variables can serve in diverse roles in the ELM depending on elaboration conditions is a core postulate of this framework (Petty & Cacioppo, 1986). When the present results are combined with findings that vocal confidence can serve as a cue under low elaboration and bias thinking under high elaboration (Guyer, Fabrigar, et al., 2019) and that vocal confidence can work metacognitively by validating previously generated thoughts (Guyer et al., 2025), we have cause to believe that vocal confidence can operate through most of the ELM’s multiple roles, providing some of the strongest data to date on the ELM’s multiple roles postulate. Thus, a seemingly simple property of a speaker—the confidence their tone communicates—can have radically different properties ranging from thoughtless to thought-biasing (Guyer, Fabrigar, et al., 2019) to thought-provoking (the present work).
The present work prompts exciting applied insights. People often advocate that speakers should always communicate with high (vs. low) confidence (Haas, 2019; Landrum, 2023)—a staple of self-improvement and self-empowerment programs (Booher, 2003; Carnegie, 1990; Carney et al., 2010; Cuddy et al., 2015). “Oracy” initiatives often educate young people to speak confidently to, be persuasive and feel confident (Heron et al., 2021; Holmes-Henderson et al., 2022; Stinson, 2015). Linguistics scholars have often characterized rising intonation as an exclusively ineffectual or disempowering speech pattern (Barr, 2003; Conley et al., 1978; Edelsky, 1979; Warren, 2016). Yet although enhanced vocal confidence will often be a boon (e.g., Guyer, Fabrigar, et al., 2019; Van Zant & Berger, 2020), our findings show that increased vocal confidence may not always be helpful given increased processing of sufficiently weak messages. Speakers may wish to consider whether their audiences might often be in moderate processing environments, and if so, to consider the extent to which the central merits of their arguments are compelling.
The present findings might also stimulate more research into why falling intonation (and potentially other prosodic properties that signal speaker confidence) may increase message processing. That is, what processes may be responsible? We have generally focused on one possibility: that confident speakers might be perceived as more worthy targets for devoting one’s finite cognitive resources because they are taking a social risk to advocate a position (Tenney et al., 2007; Vullioud et al., 2017). However, other possibilities may be responsible; for instance, vocal confidence might stimulate recipients to compare themselves against the speaker and feel a reciprocal, contrasting sense of powerlessness or doubt that could sometimes be channeled into increased processing (see Briñol et al., 2007; Tiedens & Fragale, 2003). Another possibility is that falling-intonation speakers are construed as more expert than rising-intonation speakers; sources viewed as expert can at least sometimes prompt more processing than those construed as inexpert (Clark et al., 2012; DeBono & Harnish, 1988; Karmarkar & Tormala, 2010).
Another interesting possibility is that the present effects could be attenuated or reversed under theoretically predictable circumstances. We expand on a key example in SOM-5.
Limitations and Constraints on Generalizability
One critical consideration is that the effects of confident speaking might depend on the meaning that recipients give to vocal intonation patterns. Most research, including our own, has focused on how a variety of vocal cues are interpreted by recipients as suggesting confidence (Jiang et al., 2017; Jiang & Pell, 2015; Pell & Kotz, 2021). However, one might imagine conditions under which confidence might instead signal that a speaker is trying hard to persuade a target, which might be interpreted as domineering or may trigger reactance motivation in recipients (Quick et al., 2015; Reynolds-Tylus, 2019). Under such circumstances, we might anticipate that falling (vs. rising) intonation, or other nonverbal signals suggestive of confidence, might decrease or at least not increase persuasion (also see Vaughan-Johnston et al., 2021). Indeed, in face-to-face conversations (as opposed to the present paradigm of prepared messages), a speaker who always confidently declares might be seen as pontificating or disinterested in the recipient’s perspective. Even if two speakers both issue exclusively declarative statements, one who uses occasionally rising intonation might be seen as more open-minded and interested in other people’s opinions, which might reduce reactance concerns. In addition, if one instance of a speaker sounding confidence is discredited (i.e., they speak confidently and are shown to be incorrect), their subsequent confident speech may no longer stimulate increased processing insofar as the perceived meaning of that confidence may shift (see Briñol et al., 2018; Tenney et al., 2019, for a related example). Finally, cultural variations likely lead listeners to interpret intonation differently; for example, in Australian English rising intonation does not necessarily imply low confidence and instead suggests a clarification of whether a listener has understood the speaker (Guy et al., 1986).
Although we have shown several pieces of evidence that falling intonation increases processing relative to rising intonation (i.e., moderation of argument quality effect on attitudes, increased thought valence/attitude correspondence), other forms of evidence only worked in Experiment 3 (i.e., moderation of argument quality effect on behavior intentions), or only on one dataset (i.e., higher attitude/behavior intention association given confident vs. non-confident speaker). Weaker effects on behavior intentions follow predictably from the fact that behavior intentions are formed from factors beyond only attitudes (e.g., social norms and perceived behavioral control; Ajzen, 1991). Thus, behavior intention effects are downstream from attitudes effects and are inherently multidetermined.
In principle, our hypothesis concerning how perceived speaker confidence can control processing is broader than only falling/rising intonation. Thus, one limitation of the present data is that we focused exclusively on intonation patterns, albeit we essayed to explore this variable somewhat broadly (i.e., across several parameters in Experiments 2–3). However, we would predict similar effects should emerge given other presentations of vocal confidence (e.g., high volume, faster vocal speed, low pitch) or even other confidence cues (e.g., eye contact, Brooks et al., 1986). What we see as the key variable is speaker confidence, whatever source behaviors prompt this inference in recipients. 7
Supplemental Material
sj-docx-1-psp-10.1177_01461672241262180 – Supplemental material for Falling Vocal Intonation Signals Speaker Confidence and Conditionally Boosts Persuasion
Supplemental material, sj-docx-1-psp-10.1177_01461672241262180 for Falling Vocal Intonation Signals Speaker Confidence and Conditionally Boosts Persuasion by Thomas I. Vaughan-Johnston, Joshua J. Guyer, Leandre R. Fabrigar, Grigorios Lamprinakos and Pablo Briñol in Personality and Social Psychology Bulletin
Footnotes
Authors’ note
The manuscript is not under consideration by any other journal.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The manuscript was supported by the third author’s SSHRC Insight grant (grant no. 435-2022-0034) and SSHRC Development grant (grant no. 430-2019-00099)
Ethical Approval
All data were collected in a manner consistent with the APA’s Ethical Principles in the Conduct of Research with Human Participants, and participants completed informed consent prior to participating. The data are open, are described in the manuscript.
Supplemental Material
Supplemental material is available online with this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.