
Abstract
Introduction
Middle ear surgery, one of the most delicate and complex surgical procedures, plays a crucial role in the treatment of patients with chronic mesotympanum otitis media, cholesteatoma, or otosclerosis, and so on. In addition to the chronic inflammation, the middle ear surgery might be necessary for patients with characteristic symptoms of conductive hearing loss and tinnitus.1,2 During the middle ear surgeries, a surgeon’s extensive training and detailed anatomical knowledge are essential to avoid intraoperative complications.
Chorda tympani, the significant branch of facial nerve, contains the gustatory fibers dominating the anterior two-thirds of the tongue, parasympathetic fibers to the submandibular and sublingual salivary gland, and somatosensory branches of the facial nerve. Patients undergoing tympanoplasty, a common procedure for treating chronic otitis media, are susceptible to postoperative symptoms related to chorda tympani damage, which has been reported for over a century and remains.3-5 Unfortunately, studies have shown that postoperative taste disturbances, mouth dryness, numbness or tingling of tongue, dysphagia, and dysphonia occur in a significant percentage of patients after tympanoplasty.6-9 The complexity of the endoscopic surgical environment further compounds the challenges, as the surgical fields are complex and confined to a narrow field of view and limited space. Additionally, the anatomical location of the chorda tympani makes it particularly vulnerable to traction, stretching, and inadvertent cutting during tympanoplasty, often encountered when elevating the annulus.10-13 Consequently, preserving the chorda tympani during endoscopic middle ear surgery presents a formidable challenge.
In recent years, artificial intelligence (AI) has made remarkable advancements in the field of endoscopy, achieving significant successes. Convolutional neural networks (CNNs) have been utilized in various diagnostic endoscopic studies, such as fundoscopy for diabetic retinopathy,14,15 dermoscopy for melanoma detection,16,17 otoscopy for eardrum classification and segmentation,18-20 and nasal endoscopy for classifying nasal polyps and varus papilloma.21,22 However, applying CNNs to surgical data poses several challenges and limitations. These include background noise, suboptimal image quality, inadequate lighting conditions, and the presence of blood and artifacts (eg, liquids, and instruments; Figure 1). Consequently, research on the role of computer vision in endoscopic surgery, especially in the complex and delicate endoscopic middle ear procedure, remains relatively limited. Miwa et al. 23 developed an AI system for cholesteatoma lesion detection during endoscopic middle ear surgery, achieving the identification of cholesteatoma stroma compared to non-otologists (42.3% vs 38.5%), although the algorithm’s overall detection accuracy remained somewhat limited.
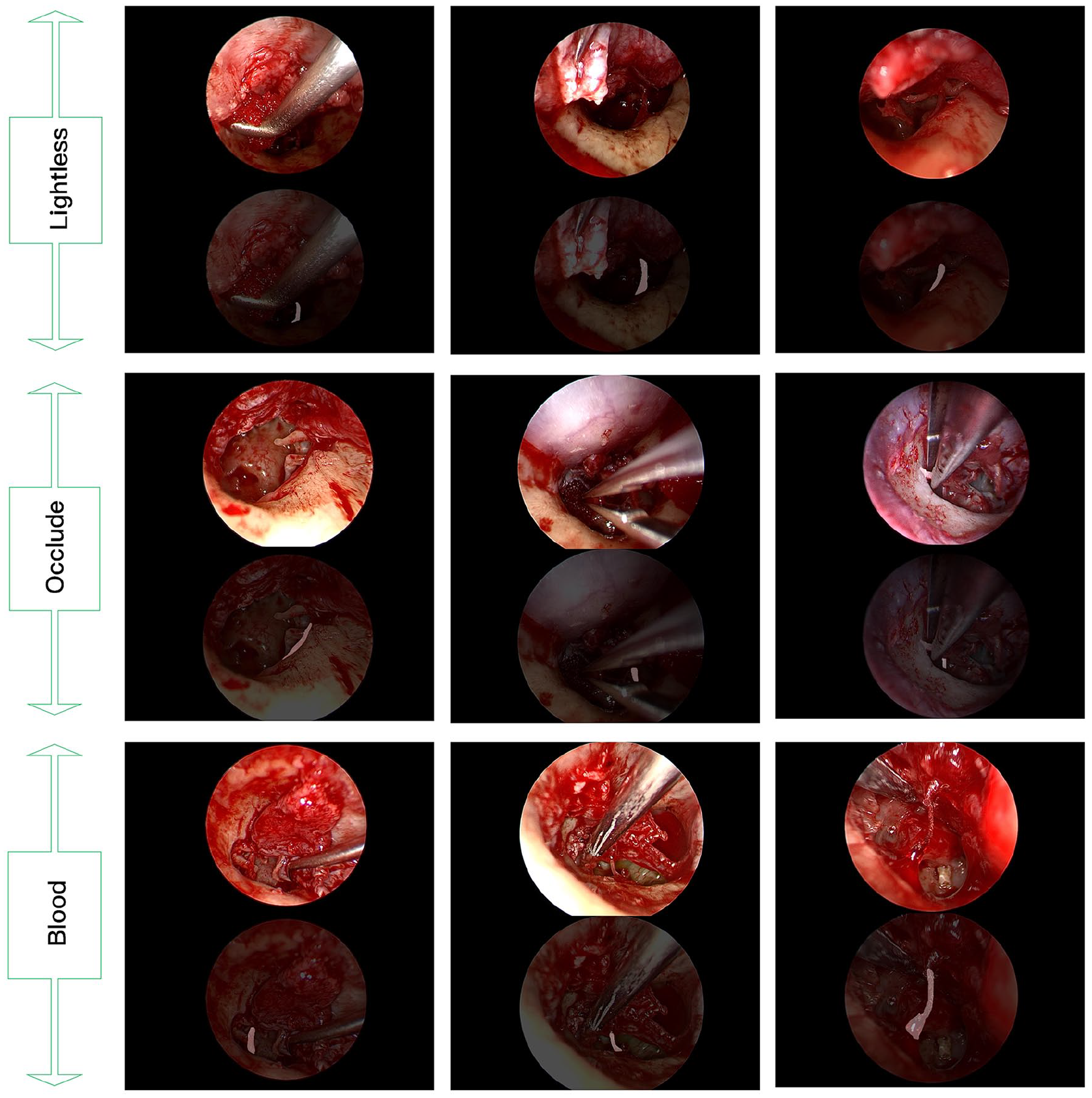
Examples of challenging endosurgical situations and chorda tympani segmentation results by the proposed multistage transfer learning algorithm based on U-net.
To address the aforementioned challenges, we present the first dataset aimed at validating the potential of deep learning (DL) semantic segmentation of the chorda tympani through DL in endoscopic middle ear surgery. In this study, we employed multistage transfer learning techniques to train the chorda tympani datasets and achieved automatic segmentation during endoscopic middle ear surgery. Our work aims to enhance the ability of otologists to recognize and preserve the chorda tympani during endoscopic middle ear procedures, laying the foundation for future translational research to provide computer vision-based real-time surgical guidance and decision support in endoscopic middle ear surgery.
Material and Methods
Patients
A total of 25 patients (Female: 13, Male: 12; Left: 13, Right: 12; Age Range: 8-70, mAge: 44) diagnosed with otitis media were enrolled at the Department of Otolaryngology of Peking Union Medical College Hospital between August 2020 and April 2023. All the patients were confirmed as otitis media patients with clear surgical indications after perfecting audiological examination, including the pure tone audiometry and acoustic immittance as well as computed tomography imaging examination of temporal bone before surgery. Among them, 3 cases were pathologically proved to be patients with cholesteatoma of middle ear, and the other 22 cases were patients with chronic otitis media.
Images
A Storz 0.3 cm × 14 cm HOPKINS® endoscope and an IMAGE1 S camera head (Karl Storz SE & Co. KG, Tuttlingen, Germany), in conjunction with a high-definition video recorder offering a resolution of 1920 × 1080 pixels, were used for recording. The recorded videos were subsequently extracted into still images at a rate of 1 frame per second (fps). In total, we randomly collected 8240 images from the 25 patients, which were divided into 3 sets: a training set (20%, 1648 images), a validation set (5%, 412 images), and a test set (75%, 6180 images). To ensure consistent labeling accuracy across the datasets, 2 medical residents with prior labeling experience independently performed the initial labeling. Two board-certified ear specialists provided labeling instructions and conducted a final examination of the labeled dataset to ensure accuracy. The Labelme software (https://github.com/wkentaro/labelme) was utilized for image annotation. Additionally, data enhancement techniques were employed to increase the number of samples in the training and validation sets by a factor of 5 (training set: 8240 images and validation set: 2060 images). These techniques aimed to mimic actual surgical scenarios and prevent overfitting. Enhancements included spatial brightness transformations, horizontal or vertical rotations, the addition of noise or random points, parallel motion, and combinations of the aforementioned techniques.
Analysis
AI refers to instructing machines to have the ability of human intelligence. As a form of AI, Machine Learning (ML) uses statistical methods to enable machines to learn tasks and get best-fitted mathematical models without the need for explicit programming. DL extends the concept of ML and means that the mathematical models used are more complex and detailed. CNNs, one of the representative algorithms of DL, has obtained great performance especially in image processing tasks such as image classification, object detection, and semantic segmentation. In this article, we used the special training method of 2-stage transfer learning to train the model and used the FullGrad method to verify the model logics. Moreover, we used the intersection over union (IOU) and pixel accuracy (PA) metrics obtained in the validation set and the true positive (TP), false positive (FP), true negative (TN), and false negative (FN) metrics obtained in the test set to evaluate the segmentation performance of the model. Finally, we further verified the segmentation performance of the model in a real surgical video.
Two-stage transfer learning: The pretraining phase of the study comprised 2 steps, as depicted in Figure 2. In the first step, the pretrained U-net model was applied to the IEEE International Symposium on Biomedical Imaging (ISBI) cell tracking challenge dataset, which consisted of 30 training and 30 testing samples. Likewise, the DeepLabV3 + and Pyramid Scene Parsing Network (PSPnet) models were pretrained using the VOC2012 + Semantic Boundaries Dataset (SBD) dataset, comprising 12,031 images annotated with 21 categories, including “background” (SBD refers to the augmented dataset). The primary objective of this step was to transfer knowledge from natural images to surgical images. In the second step, microsurgical images were utilized for chorda tympani segmentation. This 2-step approach served for 2 purposes: first, it helped to further bridge the interdomain gap and minimize the disparity between natural and surgical images. Second, it offers valuable guidance for chorda tympani by leveraging similar image features between endoscopic and microsurgical images. To obtain the final pretrained weights, we employed a chorda tympani dataset consisting of 5817 images obtained from 36 patients with otosclerosis, which helped mitigate cross-domain disparities and provided essential information about adjacent regions. Finally, employing the weights obtained from the chorda tympani microsurgical dataset, CNNs were trained using the chorda tympani endoscopic surgery dataset to develop a robust algorithmic system.
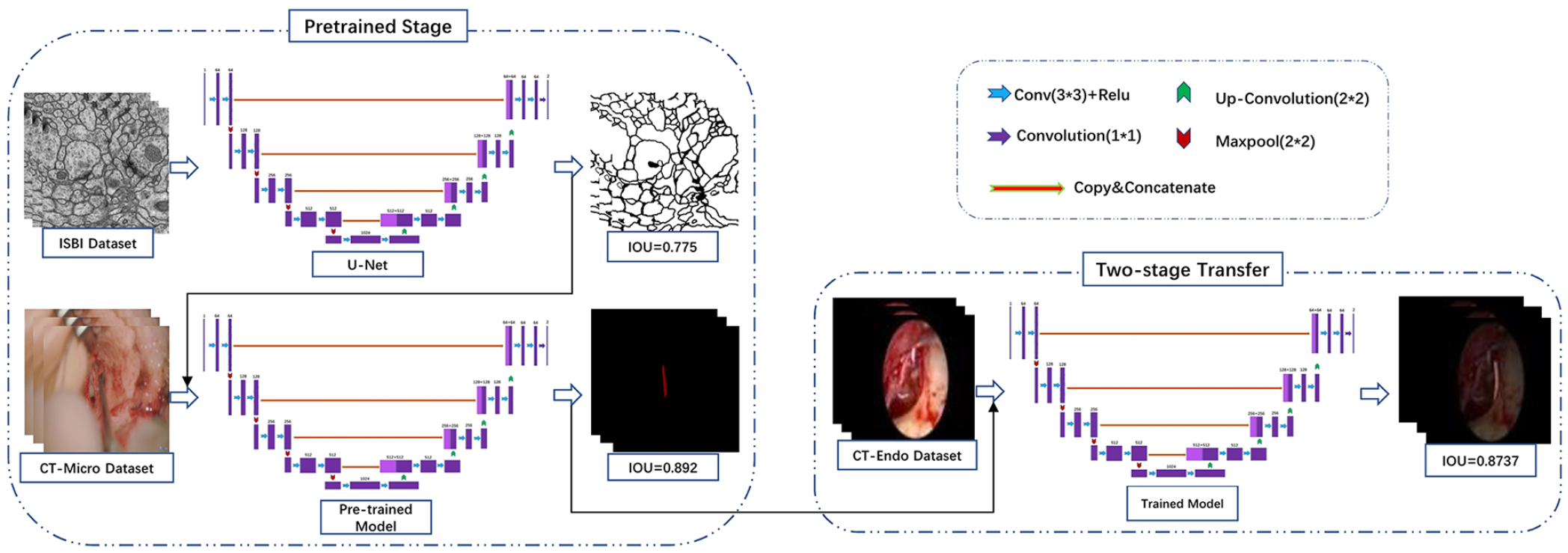
Overview of U-net’s architecture and multistage training process.
Heat maps generation: Gradient-weighted Class Activation Mapping (Grad-CAM) is a widely used technique for visualizing the pixel-wise contribution of an image to a classification outcome, eliminating the need for architectural modifications or additional network components.24,25 However, in this study, we took advantage of FullGrad, a technique that provides enhanced visualizations and instills greater confidence in the underlying model for human users compared to the visualizations produced by Grad-CAM. 25 The heat maps generated by FullGrad served not only to enhance trust in human users but also to provide guidance to clinicians during imaging examinations in clinical settings.
Metrics for validation dataset: To assess the performance of various neural networks, we employed commonly used evaluation metrics in computer vision, specifically the IOU and PA. These metrics are utilized to quantify the degree of overlap between the actual object location and the segmented object predicted by the AI models.
The IOU is defined as:
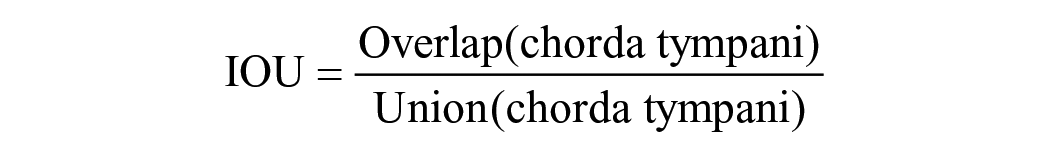
PA is defined as:
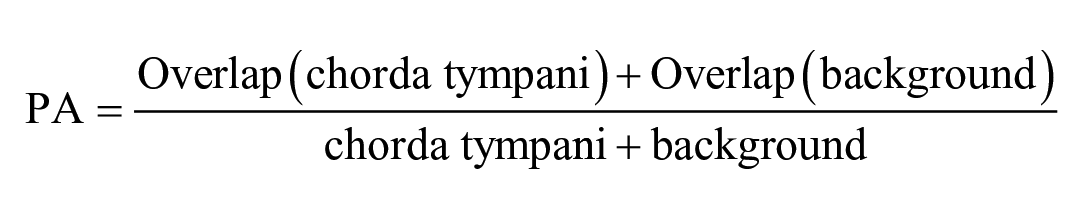
Metrics for test dataset: In this study, a trained network was utilized to predict the chorda tympani in the test set consisting of 6180 images, which were subsequently evaluated by 2 otologists. The accurate detection and localization of landmarks are essential criteria for a reliable neural network. To assess the network’s performance, a confusion matrix was employed by comparing the predicted results with the ground truth, enabling the calculation of correct and incorrect predictions for each category.
If the predicted landmark fell within the true location of the chorda tympani, it was considered a correct output and called a TP. FP occurred when the predicted output fell outside the true location of the chorda tympani, indicating that the predicted chorda tympani fell within the background. If there was no predicted output in the chorda tympani image, it was designated as FN. On the other hand, if there was no predictive output on an image without the chorda tympani at all, it was defined as TN. Based on these definitions, 4 typical evaluation metrics, including Accuracy, Precision, Sensitivity, and Specificity were calculated using the following equa-tion:

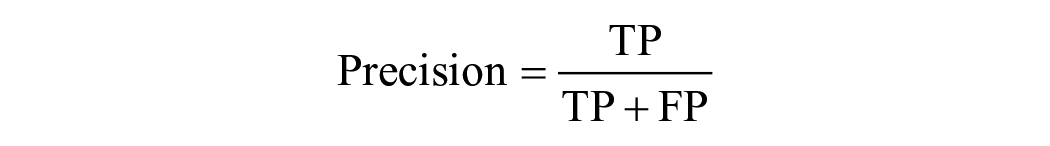
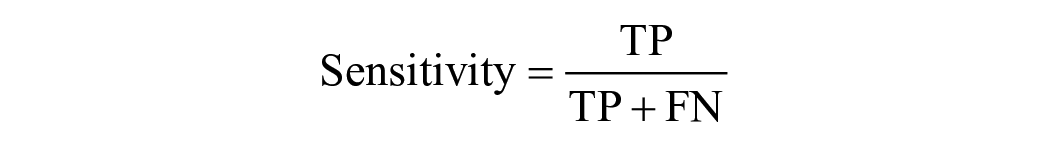
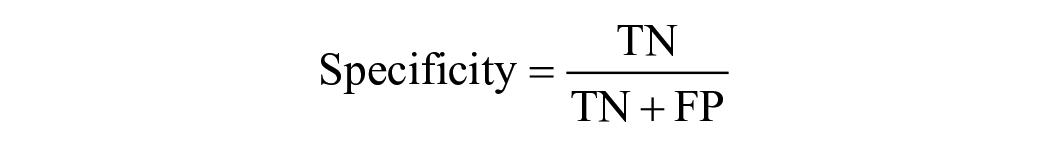
Video: In addition to accuracy, we also considered the speed of recognition. In this case, we utilized fps as a metric to measure the recognition speed. fps is defined as:
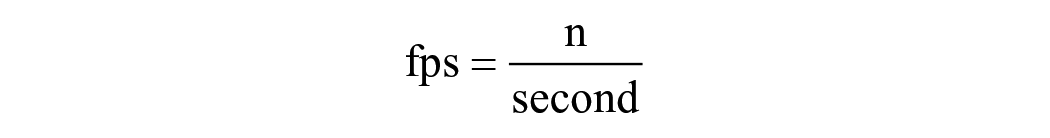
When predicting the segmented output for a given input video, n represents the number of frames, and sec refers to the unit of time, specifically per second.
Results
Training Details
All experiments conducted in this study were carried out on DL workstations equipped with an Intel®Xeon® Platinum 8172 M CPU @ 2.60 GHz (Die = 52, RAM = 64 G) and a NVIDIA GeForce RTX 3080 Ti GPU. The CNN model training framework was implemented using PyTorch 1.9.1 of Python 3.6.13. We employed several common DL models, including U-net with VGG16 as the backbone, U-net with ResNet50 as the backbone, DeepLabV3+ with MobileNetv2 as the backbone, DeepLabV3+ with Xception as the backbone, PSPnet with MobileNetv2 as the backbone, and PSPnet with ResNet50 as the backbone.
Model Performance on Images
Validation dataset: As shown in Table 1, the VGG16-based U-net model achieved the best performance among the various tested models, obtaining a mIOU of 0.8737 and mPA of 0.9263 with the validation set. In contrast, when the VGG16 framework was replaced with the ResNet50 model, the performance slightly decreased, yielding a mIOU of 0.8231 and mPA of 0.8771.
Summary of Quantitative Experimental Results on the Validation Set with the Given CNNs.
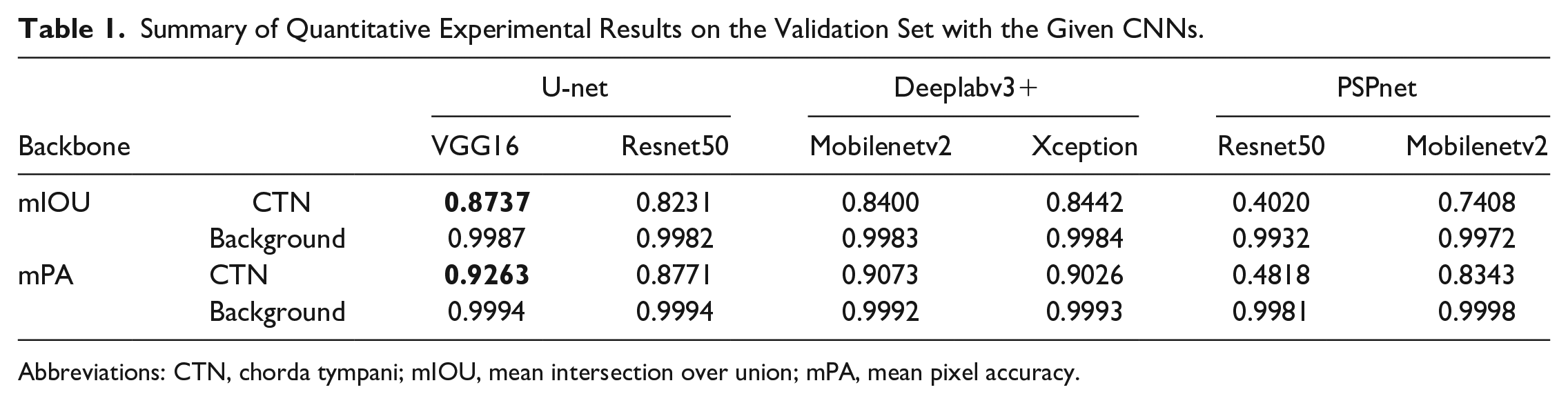
Abbreviations: CTN, chorda tympani; mIOU, mean intersection over union; mPA, mean pixel accuracy.
The DeeplabV3+ network, utilizing the Xception model as its backbone, achieved a mIOU of 0.8442 (Table 1) in the validation set. However, by replacing Xception with Mobilenetv2 as the backbone framework for DeeplabV3+, some advantages were observed. The required training time was reduced to approximately half of the time required with Xception and as shown in Table 2, the fps increased from 8.97 to 12.97, while maintaining a mIOU of 0.84.
Summary of the Quantitative Experimental Results.

Abbreviation: mfps, mean frames per second.
Additionally, we explored modifications to the PSPnet model using ResNet50 and Mobilenetv2 as the backbones. During pretraining, the PSPnet model demonstrated excellent performance in recognizing the chorda tympani under microscope vision using a dataset comprising 5817 images from 36 patients with otosclerosis (training set: validation set = 9:1). Specifically, the ResNet50-based PSPnet achieved a mIOU of 0.8655 and mPA of 0.9251, while the Mobilenetv2-based PSPnet achieved a mIOU of 0.7773 and mPA of 0.8641. However, when applied to the endoscopic middle ear surgery scenario for chorda tympani identification, the mIOU of the Mobilenetv2-based PSPnet and ResNet50-based PSPnet models decreased to 0.7408 and 0.402, respectively, which were lower compared to the results obtained by the U-net and DeeplabV3+ models.
Test Dataset: In this study, the trained U-net model was utilized to predict the chorda tympani in 6180 images, given its excellent IOU results. Two experts thoroughly examined these predicted images and constructed a confusion matrix to evaluate the performance using 4 evaluation metrics: TP, TN, FP, and FN. The results, as shown in Figure 4, demonstrated that the CNN achieved excellent performance, with an Accuracy of 0.911, Precision of 0.9823, Sensitivity of 0.8777, and Specificity of 0.9714. These findings indicated the model’s ability to accurately recognize the chorda tympani. In addition, FullGrad was employed to predict a large number of images from the test set. As shown in Figure 3, the generated heatmaps effectively highlighted the localized landmarks and the key structures identified by the U-net model. These visualizations were beneficial for decision-making processes. FullGrad’s ability to highlight the pixels around the chorda tympani landmarks indicated the model’s accuracy.
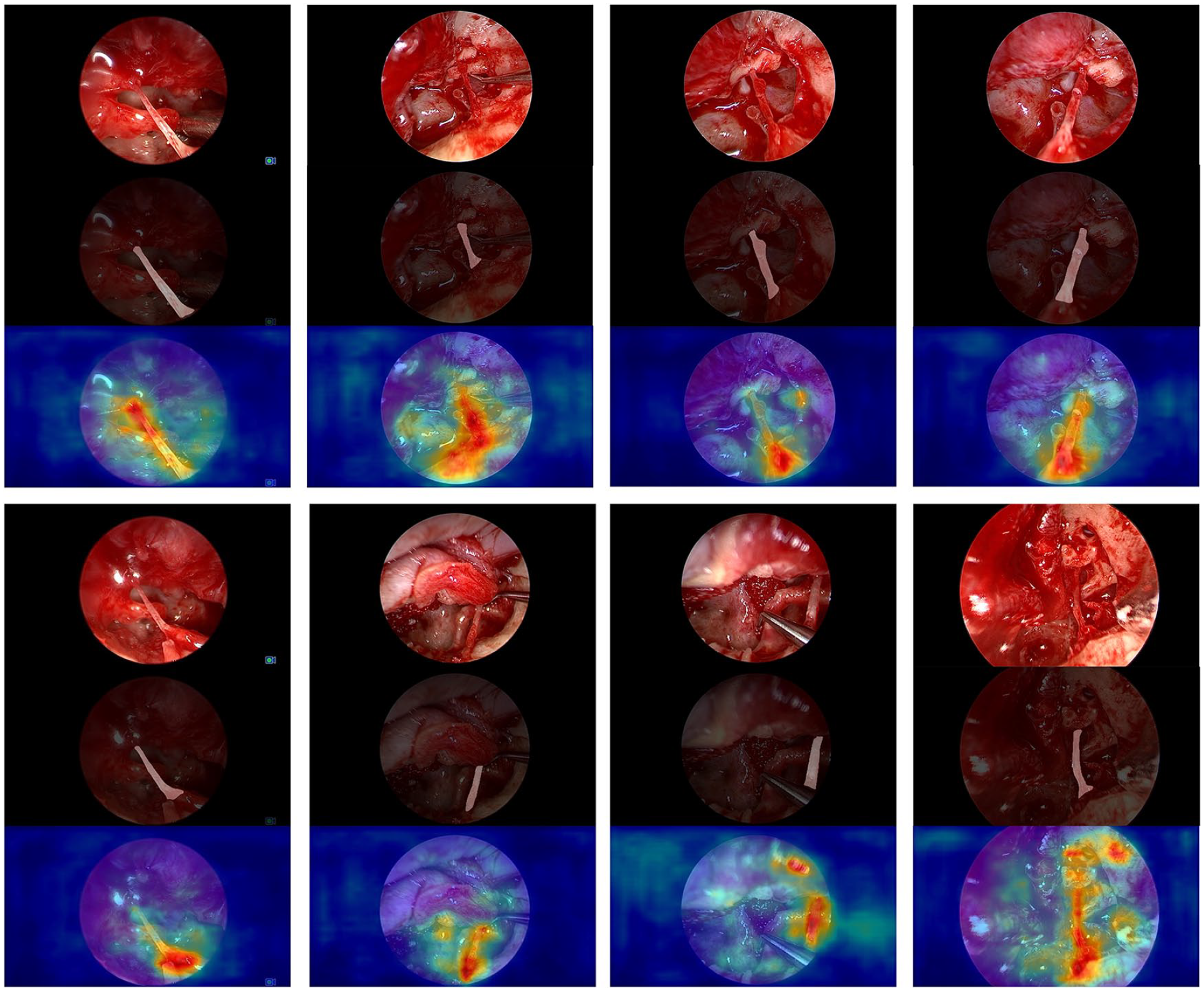
Representative chorda tympani segmentation and FullGrad obtained by DeepLabv3+ (backbone = Mobilenetv2). Attention maps are displayed as heatmaps overlaid upon the original images, where warmer colors indicate a higher contribution to the segmentation decision.
Model Performance on Video
To assess the performance of surgical videos, we randomly selected 30-second raw video clips containing camera movement, magnification, and demagnification. The U-net model exhibited excellent performance in this evaluation. Our evaluation criteria not only focused on accuracy but also on recognition speed. We compared the recognition speed of different networks and the results were presented in Table 2. As depicted in the Table 2, the Mobilenetv2-based model demonstrated an average speed increase from 8.97 fps to 12.97 fps compared to the initial CNN model.
Discussion
CNNs among a variety of deep neural networks, have been widely used in the medical image analysis and achieved result comparable to a level of specialist in the diagnosis of skin diseases,26,27 retinal diseases,28,29 laryngeal diseases,30,31 otitis media disease,32-34 and obstructive sleep apnea disease.35,36 However, there are many limitations and complexities of using middle ear endoscopic surgery data, including the frequent camera motion, lighting, camera angle and surgical approach, and so on. Therefore, the application of CNNs in the middle ear endoscopic surgery, has been limited thus far. In this study, we demonstrated the feasibility of CNNs-based computer vision to identify chorda tympani within the middle ear endoscopic surgical field. Specifically, various CNN models were developed and proven to perform automatic chorda tympani detection and semantic segmentation with high levels of performance. This type of model will not only serve as a tool to assist surgeons in efficiently identifying and tracking chorda tympani for improving surgical safety and avoiding postoperative complications but also probably shorten the learning time of new trainees when applied to medical training.
We conducted experiments with various CNN models, including DeeplabV3+, PSPnet, and U-net. Among those architectures in this study, VGG16-based U-net achieved the best performance on the validation set (mIOU = 0.8737, mPA = 0.9263). For the aim of decreasing the computational resources needed while retaining relatively high accuracy, we replaced the backbone of both PSPnet and Deeplabv3+ with Mobilenetv2, a basic backbone architecture tailored for mobile and resource-constrained environments. As a result, the Mobilenetv2-based Deeplabv3+ achieved excellent performance (mIOU = 0.8400) almost similar to the Xception-based Deeplabv3+ (mIOU = 0.8442) on the validation dataset. However, the performance of the Mobilenetv2-based PSPnet (mIOU = 0.7408) and Resnet50-based PSPnet (mIOU = 0.4020) was much worse than the Mobilenetv2-based DeeplabV3+ (mIOU = 0.8400) and Resnet50-based U-net (mIOU = 0.8231). It indicated that PSPnet may not be so suitable for the semantic segmentation of chorda tympani in the middle ear endoscopic surgery task.
Moreover, with test dataset of 6180 raw images, we evaluated the VGG16-based U-net which performed best on the validation set. As shown in Figure 4, with the 6180 images, 487 images with chorda tympani were identified by our CNN as images with no chorda tympani (FN = 487), while only 63 images without chorda tympani were identified by our CNN as images with chorda tympani (FP = 63). With a higher specificity and a slightly lower sensitivity (Sensitivity 0.8777, Specificity 0.9714), it indicated that our CNN performed slightly better at accurately identifying images without chorda tympani than images with chorda tympani. But overall, the accuracy and sensitivity of our model were both higher than 85% (Accuracy 0.911, Precision 0.9823, Sensitivity 0.8777, and Specificity 0.9714), indicating that it could recognize chorda tympani accurately.
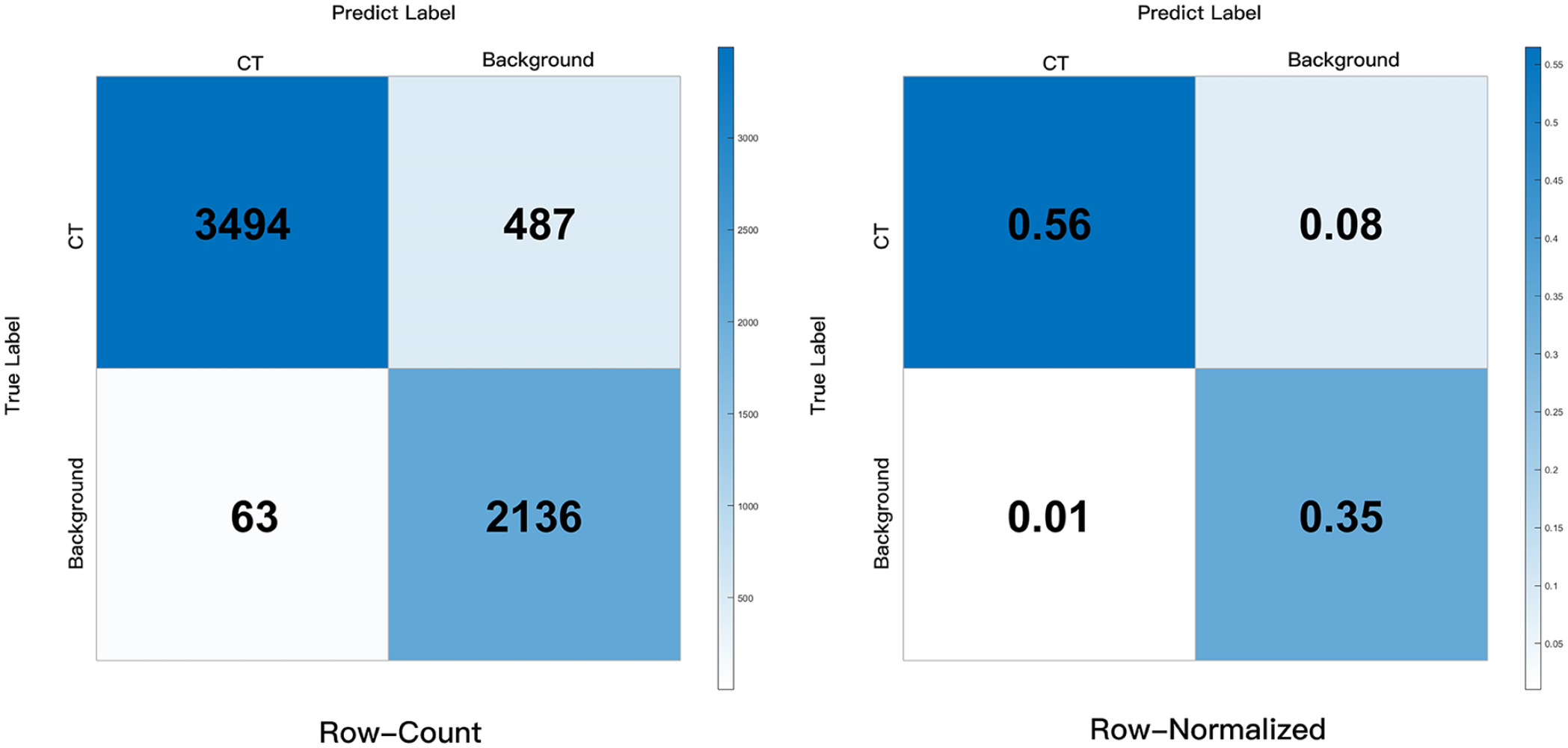
Confusion matrix obtained by our U-net model.
We further appraised the U-net on raw videos and U-net maintained high accuracy with a recognition speed of about 6.56 fps. Additionally, as shown in Figure 3, for one thing, the obtained Mobilenetv2-based DeeplabV3+ can accurately segment chorda tympani in various challenging surgical scenes, including inadequate lighting conditions, the presence of blood, and the occluding of artifacts. For another, heat maps generated by FullGrad further validated the accuracy of Mobilenetv2-based DeeplabV3+. Attention maps are displayed as heatmaps overlaid upon the original images, where warmer colors indicate a higher contribution to the segmentation decision. FullGrad highlighted the pixels around the end part of the chorda tympani, but not elsewhere, indicating that our model’s decision on this image was focused on the pixels around the end part of the chorda tympani. Besides, when applied to the same video clips, the Mobilenetv2-based DeepLabv3+ not only exhibited high accuracy but increased processing speed to about 12.97 fps. These findings suggest that DeepLabv3+ with Mobilenetv2 as its backbone may be more suitable to detect and track the chorda tympani for real surgical applications than the U-net model.
However, there are certain limitations in this study that need to be addressed in future research. First, conducting multicenter studies with a larger dataset will enhance the accuracy and robustness of the CNN segmentation algorithm. Second, there is a need to explore and develop new CNNs with lighter architectures that maintain high accuracy, thus improving their practicality and applicability. Finally, expanding the CNN model’s training to encompass images with chorda tympani from other surgical procedures can broaden the range of segmentation scenarios it can handle.
Conclusion
In our study, we have demonstrated the potential of DL-based computer vision in the field of endoscopic middle ear surgery, specifically for the identification of chorda tympani. The developed DL models showcased their capability to automatically detect and segment chorda tympani with a high level of performance. Such models can serve as valuable tools to assist surgeons in effectively identifying and tracking the chorda tympani for improving the surgical safety and avoiding postoperative complications. Moreover, these models hold promise in medical training by potentially reducing the learning time required for new trainees.
Footnotes
Acknowledgements
None.
Author Contribution Statement
Xin Ding: Designing research direction, organizing materials, and writing articles. Yu Huang: Helping to design research direction and organize materials. Yang Zhao and Xu Tian: Helping to design research direction and to write articles. Guodong Feng and Zhiqiang Gao: Review and revise articles and guidance of research direction and article writing.
Availability of Data and Material
If you want to obtain the data and material, you can contact with the author at the email
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is supported by ‘National key research and development program’ (Grant number: 2019YFB311801) and ‘the Fundamental Research Funds for the Central Universities’ (3332021010).
Ethical Approval and Consent to Participate
The authors assert that all procedures contributing to this work comply with the ethical standards of Ethics Committee of Peking Union Medical College Hospital and with the Helsinki Declaration of 1975, as revised in 2013. The study was approved by the Ethics Committee of Peking Union Medical College Hospital, Beijing, China.
Consent for Publication
All of the authors consent for the publication on Ear, Nose & Throat Journal.