
Abstract
Single case research is a viable way to obtain evidence for social and psychological interventions on an individual level. Across single case research studies various analysis strategies are employed, varying from visual analysis to the calculation of effect sizes. To calculate effect sizes in studies with few measurements per time period (<40 data points with a minimum of five data points in each phase), non-parametric indices such as Nonoverlap of All Pairs (NAP) and Tau-U are recommended. However, both indices have restrictions. This article discusses the restrictions of NAP and Tau-U and presents the description, calculation, and benefits of an additional effect size, called the Typicality of Level Change (TLC) index. In comparison to NAP and Tau-U, the TLC index is more aligned to visual analysis, not restricted by a ceiling effect, and does not overcompensate for problematic trends in data. The TLC index is also sensitive to the typicality of an effect. TLC is an important addition to ease the restrictions of current nonoverlap methods when comparing effect sizes between cases and studies.
Introduction
In intervention studies on complex human behavior in the field of, for example, social work (Wong, 2010), forensic psychology (Spreen et al., 2010), special education (Horner et al., 2005), and counseling practices (Lenz, 2015), Single Case Research (SCR) has been applied. SCR is a viable alternative when between-group studies, such as Randomized Controlled Trials (RCTs), are not possible (Hein & Weeland, 2019). Due to practical reasons, such as difficulties to include sufficient respondents, finding adequate control groups and reluctant patients as forensic patients (Spreen, 1992), the assumptions of between-group studies are sometimes difficult to meet in intervention studies. In such situations, SCR can serve as an alternative, as causal associations can be assessed within the context of an individual or a small group of individuals. SCR enables systematic evaluation of interventions by repeated measurement of an outcome variable in typically one participant (Vannest & Ninci, 2015). The effect of interventions is then defined by the difference in outcomes between the phases in the experimentally controlled conditions. Typically, these conditions comprise A-phases (baseline or control) and B-phases (intervention or treatment) in reversal designs and multiple baseline designs, different conditions B (treatment 1) and C (treatment 2) in alternate treatment designs, or different criterions B (treatment 1) and B’ (reinforced treatment 1) in changing criterion designs (Heyvaert et al., 2015).
Analysis of SCR data usually starts with visual analysis that refers to reaching a judgment about the reliability or consistency of intervention-effects by eye (Kazdin, 2011). Six aspects of the graphical data are to be considered: the difference in mean values between phases (level), the stability of the measure during the phases (variability), the tendency of increasing or decreasing values within phases (trend), the consistency of change between two phases (overlap), the immediacy of the effect (intercept gap), and the replicability of the effect within the design (consistency) (Franklin et al., 1996; Kratochwill et al., 2013; Lane & Gast, 2014). Visual analysis can lead to type I errors when the effects are small to moderate and when data are autocorrelated (Barton et al., 2019; Brossart et al., 2006). Therefore, it is recommended to proceed with statistical analysis for more reliable and standardized decisions about the existence and size of an effect (Kratochwill et al., 2013; Parker & Brossart, 2003; Swann & Pustejovsky, 2018).
For SCR designs with statistical sufficient measurements in all phases, parametric analysis techniques such as standard t or F tests (Barlow et al., 2009), time series analysis (Yaffee & McGee, 2000), Standardized Mean Difference (Busk & Serlin, 1992), Bayesian analysis (Rindskopf, 2014a), multilevel analysis (Baek et al., 2014), randomization tests (Heyvaert & Onghena, 2014), regression analysis (Swaminathan et al., 2014), Generalized Least Squares analysis (GLS; Swaminathan et al., 2014), Hierarchical Linear Modeling (HLM; Gage & Lewis, 2014), and d-statistics (Shadish et al., 2014) can be used. For a more complete picture there are overviews of statistical techniques that can be used in SCR designs (see Manolov & Moeyaert, 2017). Most parametric tests are valid if strict distributional assumptions are met. Severe outliers, unbalanced variance between phases, no variance in one or more phases, or an insufficient number of measurements in the study or in one of the phases, would make it doubtful to use most parametric tests to provide valid results (Heyvaert & Onghena, 2014).
Current What Works Clearinghouse standards (WWC-standards) recommend reporting a d-statistic as effect size in SCR designs (What Works Clearinghouse [WWC], 2020). This is useful because the d-statistic is comparable across designs and the results are comparable to effect sizes in group designs (Shadish et al., 2014). To obtain this parametric statistic, the standard deviation across participants is used, rather than the standard deviation within participants (Odom et al., 2018).
In many SCR intervention studies, the assumptions to validly compute parametric effect sizes cannot be met because of too few data points. As mentioned earlier, this causes problems for parametric testing due to severe outliers, unbalanced variance between phases, or no variance in one or more phases. For research situations where less than 40 data points with a minimum of five data points are collected in each phase, non-parametric effect size indices are recommended. Percentage of Nonoverlapping Data (PND; Scruggs et al., 1987) has been one of the most widely used non-parametric effect sizes in SCR for a long time (Heyvaert & Onghena, 2014). However, this index does not always reflect the correct effects for outliers or because adverse effects due to treatment and trend are present. Also, PND cannot discriminate when there is complete nonoverlap. To address these limitations, modifications of PND have been developed, such as the Nonoverlap of All Pairs (NAP; Parker & Vannest, 2009) and Tau-U (Parker et al., 2011).
Both NAP (e.g., Abrahamsson et al., 2018; Baldwin & Powell, 2015; Collier-Meek et al., 2019; Jamieson et al., 2019; Spauwen et al., 2020) and Tau-U (e.g., Brodhead et al., 2019; Erhardsson et al., 2020; Kunze et al., 2021; McGoldrick et al., 2021) are frequently used in SCR designs with small data sets. Both measures include one or two of the six aspects of the data that are assessed in visual analysis (Tanious et al., 2020). Because of the emphasis on nonoverlap and trend, other aspects of visual analysis of the data, such as immediacy of the effect and level change, are unweighted in the effect size (Dart & Radley, 2017) or only indirect by nonoverlap.
To tackle these restrictions, we introduce the Typicality of Level Change (TLC) index that does consider all six aspects of visual analysis. First, we discuss the restrictions NAP and Tau-U have in correctly differentiating effect sizes between cases and studies. Next, we introduce the concept of Typicality of Level Change (TLC). Based on a hypothetical example of a non-concurrent multiple baseline design and an ABAB-design, we argue how TLC complements visual analysis regarding the restrictions of NAP and Tau-U. Although our example comprises two designs, TLC can be applied in any of the SCR designs that have two-phase comparison as the basic unit of analysis.
Restrictions of Nonoverlap Indices: Nonoverlap of All Pairs (NAP) and Tau-U
NAP uses the degree of overlap of data between two phases to express effect sizes (Parker & Vannest, 2009). NAP compares all data in the baseline phase with all data in the intervention phase. Whenever values in the intervention phase (B) exceed the values in the baseline phase (A), values of “1” are assigned; whenever values in B are smaller than values in A, values of “0” are assigned, and when values in both phases are identical, values of “0.5” are assigned. The assigned values for each pair of A- and B-data are added and divided by the total number of pairs between the two phases (Vannest & Ninci, 2015). Consequently, NAP is a value that varies between 0 and 1 (0 = decline without overlap between phases, 0.5 = as much overlap as nonoverlap between phases, 1 = increase without overlap between phases).
However, NAP has at least three restrictions. Firstly, NAP suffers from a ceiling effect. Beyond the point where there is complete nonoverlap between two phases the magnitude of level change is ignored (Parker et al., 2011). Parker et al. (2011) found that of the 176 data sets from a convenience sample of published articles using AB designs, 25% of these data sets yielded a maximum NAP (NAP = 1.00). The level change, immediacy of effect and trends differ between the studies despite a NAP of 1.00. With respect to level change, this means that a client whose condition improved from very dissatisfied to very satisfied and a client whose condition improved from very dissatisfied to dissatisfied can both receive a NAP of 1.00, while the magnitude of change in their conditions is clearly different. Secondly, because trend is not fully adjusted for by NAP, NAP is susceptible for overestimating the size of effects when trend is present (Parker et al., 2011). For a client already improving before the start of the intervention and continuing to improve during the intervention, NAP would lead to an overestimation of the size of the effect. Thirdly, there is the problem that we refer to as the problem of typicality. NAP does not account for the varying probabilities on nonoverlap between cases due to different baseline scores. When a client already has a relatively high score at baseline, it is statistically more difficult to improve compared to a client who has a relatively low score at baseline. Thus, it becomes more difficult or even impossible to exceed baseline data when scores are relatively close to the optimum at baseline. This means that the amount of possible change depends on baseline levels. The ceiling effect, problems to adjust for trend, and the problem of typicality, restrict NAP to properly compare the size of effects between studies or cases.
In contrast to NAP, Tau-U (Parker et al., 2011) adjusts for trend in the data in the baseline and intervention phase based on nonoverlap (Vannest & Ninci, 2015) and has different versions. The version used in this study is the initial version, called Tau-UAB, that adjusts for trend in both the baseline and intervention phase (Vannest & Ninci, 2015). Other versions contain an adjustment for baseline trend only (Davis, 2014; Parker et al., 2011; Rakap, 2015). All versions are computed in the same way as the NAP and correct for trend in the baseline and/or intervention phase. This means that NAP is extended with comparisons of ties within phases, in the same way as is used in the calculation of Kendall’s Rank Correlation (KRC). Overlap between phases, positive trend during baseline and negative trend during intervention hinder the validity of the argument that behavior has changed because of the intervention. The three counterparts (nonoverlap between phases, the absence of positive trend during baseline phase, and the absence of negative trend during intervention phase) are aggregated and divided by the sum of pairs to obtain Tau-UAB (Supplement 1 illustrates the computation).
By taking both nonoverlap and trend into account, two of the restrictions of NAP do not apply to Tau-U: (1) it discriminates between effect sizes beyond the point of nonoverlap, making the ceiling effect less problematic (Parker et al., 2011), and (2) it corrects for trend. However, known restrictions include dependency on phase length with respect to its correction of trend, doubtful alignment with visual analysis, vague or inconsistent terminology in SCR publications related to Tau-U, and the difficulty of graphing (Brossart et al., 2018; Tarlow, 2017). By adjusting for trend in situations with immediate and large level change, the correction can lead to counter-intuitive results. Consequently, Tau-U underestimates effect sizes when large immediate level changes occur in combination with a moderate trend. Like the NAP, the problem of typicality is also not covered by Tau-U.
The Typicality of Level Change Index
The Typicality of Level Change (TLC) index was developed to ease the restrictions of NAP and Tau-U. TLC is based on the logic of combinatorial inference in typicality tests (Rouanet et al., 2000). In such tests, from a known reference distribution of some statistic (such as the mean of a variable) a particular subset of size n is compared with all other samples of size n that are possible from the reference distribution. The proportion of samples that exceed the value of the particular sample expresses its typicality within the reference distribution. The smaller this proportion, the more atypical the particular sample. The TLC index can be computed for single case studies in which measurements of some numerical outcome variable is compared between two phases. The reference distribution is then defined as the combination of all possible values of the outcome variable between the n measurements (Figure 1).
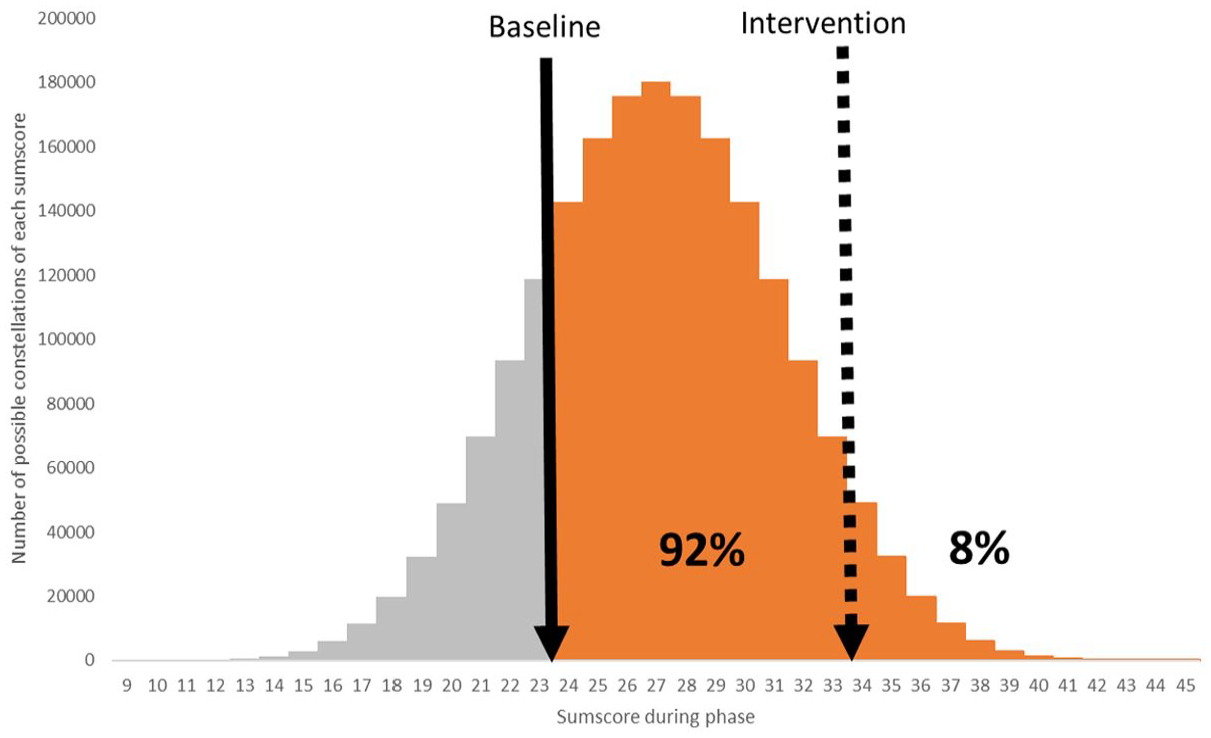
Visual illustration of a TLC of 0.92. The complete distribution of possible sum scores is the reference distribution, in this example based on five measurements with an outcome variable on an ordinal measurement scale from 1 to 9. The baseline sum score was 23 and the intervention sum score improved to 34, achieving 92% of the maximum possible improvement.
TLC is the percentage achieved improvement from the maximal possible improvement given the baseline score in the reference distribution. TLC can be calculated in an Excel spreadsheet (Supplement 3 provides a link to the sheet). Consider Figure 1, which shows the reference distribution of all sum scores which are possible by combining five measurements of an outcome variable having a scale of 1 to 9, resulting in a minimum score of 5 and a maximum of 45. Suppose in a single case study that the sum score of five measurements of the baseline phase was 23 and of five measurements during the intervention phase 34. The gray area in Figure 1 represents all sum scores that do not exceed the observed baseline sum score (maximal 23). The part of the reference population in which the sum scores exceed the baseline score and thus indicate an improvement is illustrated by the orange area (greater than 23). This improvement area can be divided into two parts. The orange area left to the intervention sum score, the numerator in the formula of TLC (Supplement 3), represents all sum scores between the baseline sum score and the achieved intervention sum score of 34. TLC is calculated as the percentage of the achieved improvement in the orange area. For Figure 1 TLC is 0.92, meaning that of the maximum possible change based on his baseline score, this participant achieved 92%. The remaining 8%, the orange area right to the intervention sum score, is what separates the participant from the optimal score.
Typical Values of TLC
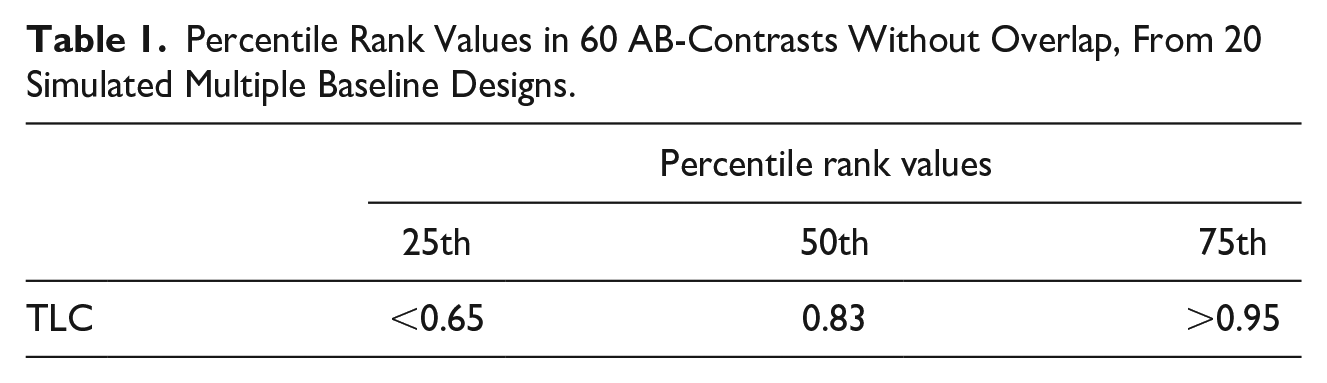
To explore what TLC outcomes may account for small, medium, or large effect sizes, we simulated data. In this study 20 SCR Designs having three nonoverlapping AB-contrasts each (multiple baseline designs with three participants) were simulated. The simulated designs had a phase length of minimum 3 and maximum 10 in each phase (meeting WWC-standards with reservations at least [Kratochwill et al., 2013]), and a measurement scale varying from a 5 point scale to a 12 point scale. All contrasts were completely nonoverlapping (NAP = 1). From the simulation we deduced typical values for small, medium, and large effect sizes of TLC. We used the same critical intervals as for benchmarks of NAP were obtained (Parker & Vannest, 2009). Figure 2 shows how TLC discriminates between samples without any overlap, with typical values of the percentiles being 0.65 for 25th, 0.83 for 50th, and 0.95 for 75th (Table 1).
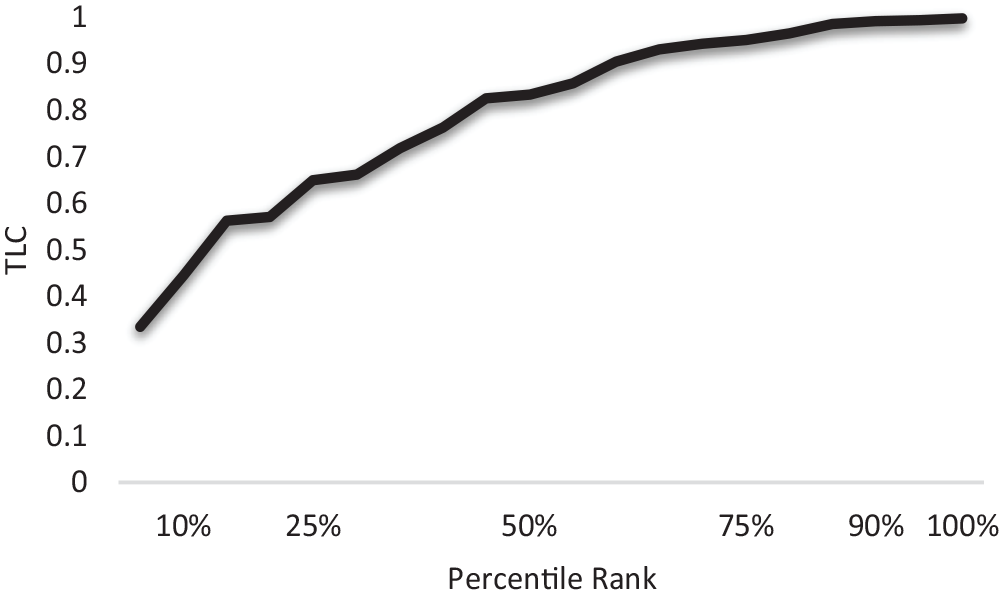
Uniform probability plot for TLC of 60 AB-contrasts without overlap, from 20 simulated multiple baseline designs.
Percentile Rank Values in 60 AB-Contrasts Without Overlap, From 20 Simulated Multiple Baseline Designs.
Confidence Intervals of TLC
To obtain confidence levels to estimate the precision of the effect size (Vannest & Ninci, 2015), a modified jack-knife principle can be employed (Snijders & Borgatti, 1999). The basic idea of the jack-knife principle is to create a number of Ni artificial data sets from N sample elements, by excluding the i-th element. If a sample consists of elements A, B, C, D, and E, then one of the five artificial data sets consists for example of elements A, B, D, and E. The variability between the artificial data sets indicates the variability that may be expected when new data is collected from replicated studies. TLC is not calculated from one sample with size N but from two samples, consisting of size N1 and N2, respectively belonging to the baseline and intervention phase. Jack-knife would result in calculating the TLC for all different combinations of n1 possible samples of size N1−1 and n2 possible samples N2−1, such that n = n1 × n2. If the standard error of TLC, for example, is calculated by comparing five baseline samples and five intervention samples, 25 sample contrasts are made to calculate the standard error:

This routine would mean that n1 × n2 calculations have to be made, which is very intensive especially when the number of measurements and the number of answer categories grow. Therefore, one could alternatively look at the 2.5 and 97.5 percentiles of the empirical distributions from the sample produced by the simulation of n1 × n2 samples. This technique is often used with Markov Chain Monte Carlo simulations (Rindskopf, 2014b). Since in the distribution of the example, 25 sample contrasts are created, the 2.5 and 97.5 percentiles are given by the minimum and maximum of these samples. The confidence interval (CI) of the TLC (0.92) in Figure 1 is [0.81, 0.95]. Calculating the confidence levels gives an indication of the precision of the effect and makes it possible to compare effects across cases. Calculation of the CI is shown in Supplement 2.
Material and Methods
To illustrate the usefulness of the TLC-index as an additional effect measure to NAP and Tau-U, consider the following two hypothetical studies. Study 1 consists of a non-concurrent multiple baseline design (MBD) to assess the functional relationship between intervention X and the quality of life in individuals with dementia. Participants are three elderly people, named Anne, Bob, and Chris. During a baseline period of 5, 7, and 9 weeks, baseline data is collected by weekly administration of a simple Quality of Life (QoL) question. The participants are asked “Taking everything in your life into account, please rate your overall Quality of Life on the following 10-point scale,” with 1 meaning “very distressing,” 5 to 6 “so-so,” and 10 “great.” After the baseline phase, the intervention period that lasts for the remaining of the 14 weeks started. For the sake of argument, it is assumed that further criteria for causal inference according to WWC-standards (WWC, 2020) are met.
Study 2 consists of an ABABAB withdrawal design to assess the functional relationship between intervention X and quality of life in individuals with dementia. The intervention X in study 2 is the same intervention as in study 1. In this case there is only one participant, an elderly lady called Jennifer. During the study, data is collected weekly by taking the same QoL-question during six phases: a baseline period of 5 weeks, a first period of intervening of 9 weeks (the first B), withdrawals of the intervention (the second and third A), and re-introductions of the intervention (the second and third B). Intervention X is supposed to have no learning effect: the withdrawal of the intervention should lead to a decline of quality of life back to baseline level, allowing for ABABAB design.
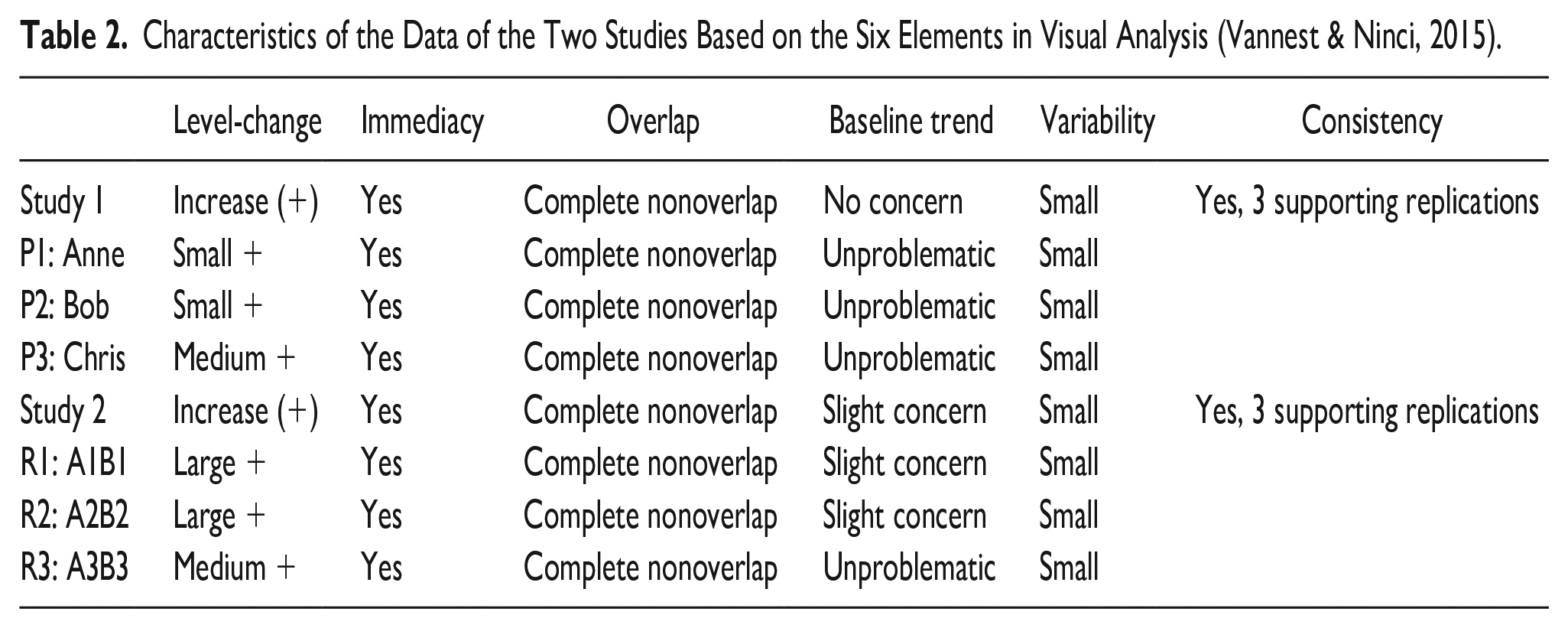
We constructed data for each case in the two studies, in a way that would show (a) how TLC can be used in different high validity designs, such as ABABAB designs and MBDs, and (b) how TLC deals with the restrictions of the NAP and Tau-U. Both studies contained at least three AB-replications: each of the participants in the MBD-study (Anne, Bob, Chris) and five phase changes in the ABABAB-study (of which we analyze A1B1, A2B2, and A3B3; B1A2 and B2A3 are ignored because of comparability of the two designs). We constructed data so that those replications are similar, but with subtle differences in pairs of replications with respect to the mean difference and trend. The first pair (Anne vs. A1B1) and the second pair (Bob vs. A2B2) differ with regard to mean level and trend in the first phase, and the third pair with regard to the typicality of the change (Chris vs. A3B3).
In Table 2, the manipulated characteristics of the data for each of the participants are shown. As an illustration, for case Bob, this means that his scores on QoL increases from baseline to intervention (small positive level change), with no overlap between phases and no large deviations within the phases (small variability). During baseline, scores did not show an upward or downward tendency (no positive trend). Also, there is an instant gap between baseline and intervention, (immediate change). The designs contain multiple phase shifts that show replications of an effect (consistency) between (MBD-study) and within participants (ABABAB-study).
Characteristics of the Data of the Two Studies Based on the Six Elements in Visual Analysis (Vannest & Ninci, 2015).
The effect sizes NAP, Tau-U, and TLC are calculated for each of the participants. Averaging the measures gives an indication of the functional relation between the intervention and QOL. Next, we focus on how the indices differentiate effect sizes between the participants. NAP, Tau-U, and TLC are compared on the three theoretical restrictions mentioned before: ceiling effect, correction for trend, and typicality. Computations were performed in Excel. Pairs of participants are compared to show how the indices differ from each other. The differences are compared with the conclusions from visual analysis, in which all relevant characteristics of the data can be justified.
Results
The change in QoL of the three participants in Study 1 and over phases in Study 2, divided into three AB contrasts, is illustrated in Figure 3. Trend lines are only included in the top four panels, the two panels in the bottom row do not have trends.
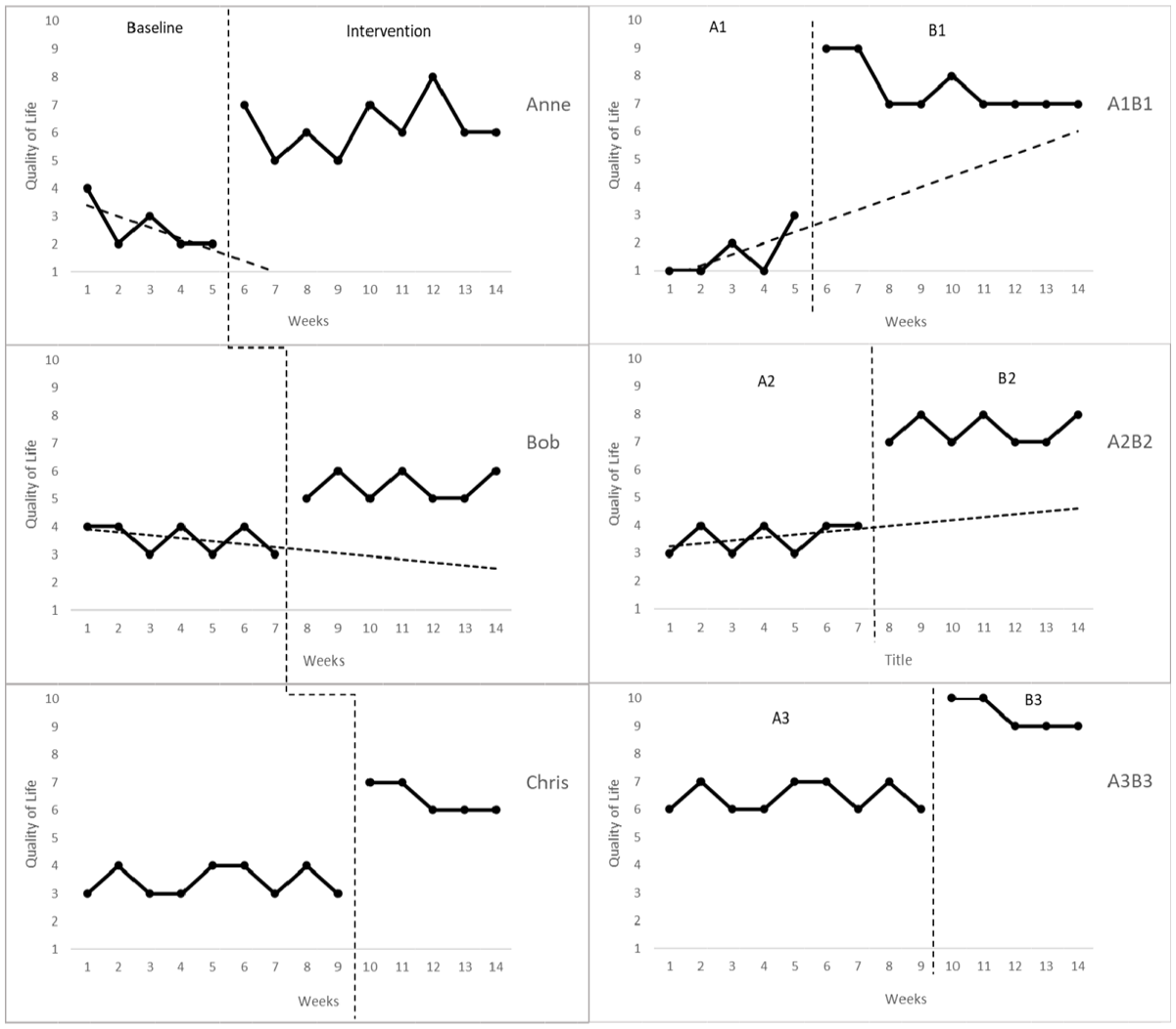
Three replications of the effect in the multiple baseline design (study 1, left panels) and the ABABAB-design (study 2, right panels).
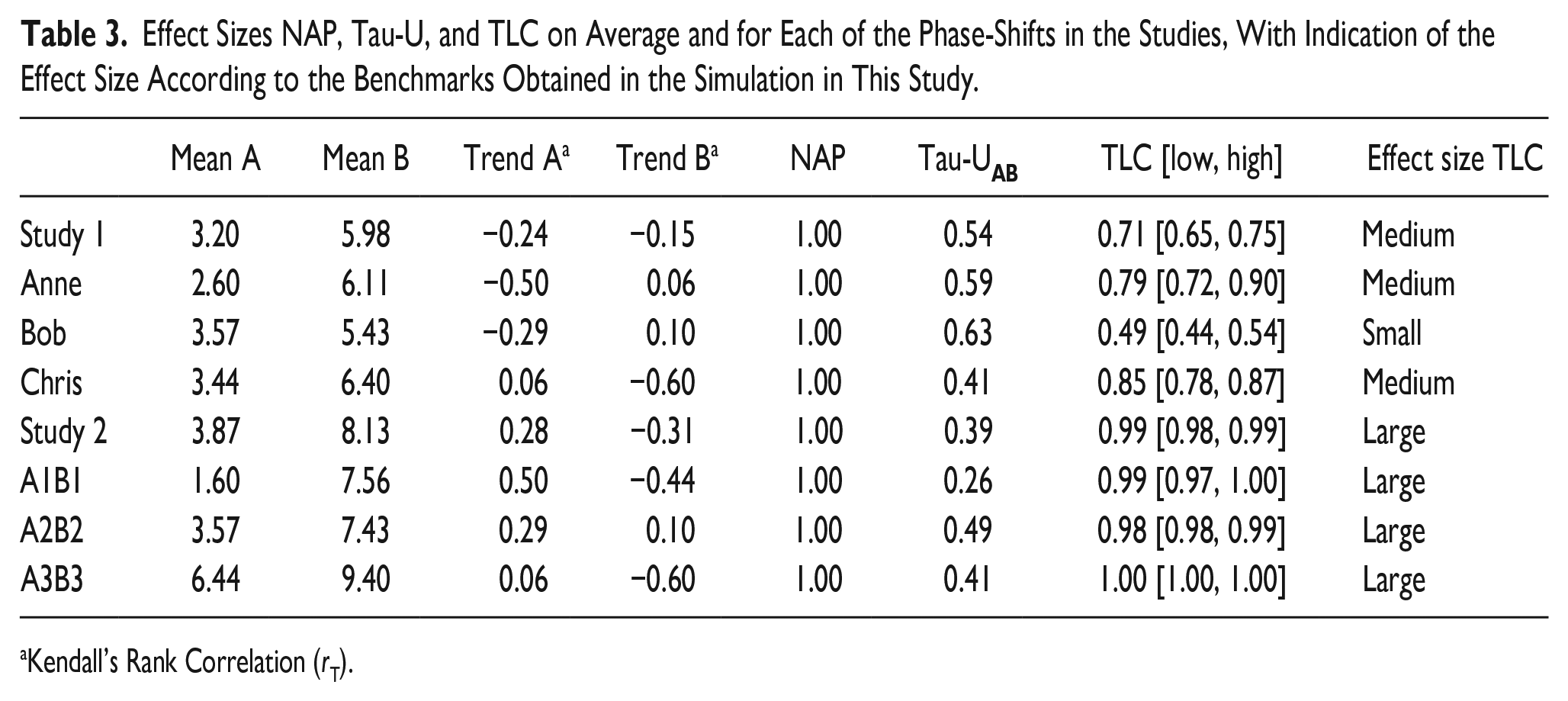
To compare the magnitude of effects between the participants, NAP, Tau-U, and TLC are calculated for each of the phase shifts (Table 3). We rather compare two phases than the whole design, because each replication should reflect evidence, and the design could be hard to comprehend without looking to the individual phase shifts first.
Effect Sizes NAP, Tau-U, and TLC on Average and for Each of the Phase-Shifts in the Studies, With Indication of the Effect Size According to the Benchmarks Obtained in the Simulation in This Study.
Kendall’s Rank Correlation (rT).
The QoL of the three participants in study 1 improves between phases. The effect sizes NAP, Tau-U and TLC support the evidence that change in QoL can be attributed to intervention X (average ESs: NAP = 1.00; Tau-U = 0.54; TLC = 0.71; Table 3). Jennifer’s QoL (study 2) improved when the intervention was introduced (A1B1) and decreased when the intervention was withdrawn (B1A2). QoL improved again due to the intervention (A2B2). This pattern occurred again with the second reversal (B2A3 and A3B3). The effect sizes support the evidence of the study for the functional relationship between intervention X and QoL in study 2 as well (average ESs: NAP = 1.00; Tau-U = 0.39; TLC = 0.99; Table 3).
Although the immediacy of the effect is not as clear for each phase shift and there are some positive baseline trends, these two studies with both three demonstrations of the intervention effect point to evidence for the effectiveness of intervention X. NAP, Tau-U, and TLC differ with respect to which study shows more evidence (Table 3). NAP does not discriminate (1.00 = 1.00), Tau-U prefers study 1 (0.54 > 0.39), while TLC prefers study 2 (0.71 < 0.99). This shows that NAP, Tau-U, and TLC discern differently between the effect sizes. Closer inspection can reveal which of the three is most in line with an intuitive understanding based on all relevant aspects of a visual analysis of the data.
Ceiling Effect
In study 1 and 2, NAP clearly suffers from a ceiling effect, while Tau-U and TLC do not. NAP is 1.00 for all comparisons and therefore does not discriminate between the size of effects between the studies. Tau-U and TLC do discriminate between the two studies, albeit in a different order. The different order of effects by TLC and Tau-U occurs because they differ in how they deal with (over)compensating for trend and taking typicality into account. There is some undesirable trend in study 2 (Table 3 shows the upward trend during baselines (rT = 0.28) and downward trend during intervention phases (rT = −0.31) in study 2. In study 1 there is no undesirable trend in baseline rT = −0.24) and less in intervention phase (rT = −0.15). Therefore, Tau-U is higher in study 1. According to TLC however, there is a large effect in study 2, and a medium effect in study 1.
This is due to the greater level-change in study 2 (8.13−3.87 = 4.26) in comparison to study 1 (5.98−3.20 = 2.78), TLC is higher for study 2.
Correcting for Trend
Looking only at the upper panels of the two studies in Figure 3, the trend differs between the two studies. In the multiple baselines design, Anne’s baseline shows downward trend: her QoL declines over time and an improvement during the intervention phase would break this trend. Study 2 (ABABAB-design) starts with a slightly positive trend: Jennifer’s QoL seems to be improving gradually during the baseline phase, meaning the data shows a positive baseline trend. Even when no intervention was performed, this could hypothetically continue.
Tau-U may overcorrect for trend, as becomes apparent when we look closer in the pairwise comparisons. Although Anne (Tau-U = 0.59; TLC = 0.79) shows less positive trend during baseline than Jennifer’s first baseline A1 (Tau-U = 0.26; TLC = 0.99), the difference in immediacy and amount of level-change might be more important here in determining, which effect is stronger. The large consistent difference between the end of the baseline and the beginning of the intervention in Jennifer’s data (from maximally 3 during baseline to consistently more than 7 during intervention), indicates change while the modest trend that occurs can be relaxed, because of the convincing immediacy of the effect.
Also, when we compare the panel of Bob (Tau-U = 0.63; TLC = 0.49) with the panel of A2B2 (Tau-U = 0.49; TLC = 0.98), just looking at trend might lead to believe the phase-shift of Bob is more convincing. However, the change of QoL is less than 2 points in the case of Bob compared to over 3 in A2B2, while both having rather stable measurements in both phases. To interpret the increase in QoL from A2 to B2 as a consequence of a continued trend, is not plausible and one better ignores the problematic trend here in calculating an effect size after inspecting it in visual analysis.
TLC does not adjust for trend, making it prone to error when problematic trends occur. To detect a problematic trend, we propose an indirect technique that avoids the risk of overcompensation like Tau-U does. To investigate whether trend causes problems in the interpretation of the effect, two TLCs can be calculated from the data using a split-half technique when the design consists of phases with a length of at least five. If there is no trend, the split-half TLCs should be equal. Figure 4 shows situations in which there is no trend and trend: in the upper panel of Figure 4 there is no trend in both phases, because the short term effect (A2B1) does not differ from the long term effect (A1B2). The short term or immediate effect is reflected by TLCS for the second half of data points during baseline (A2) and the first half of data points during intervention phase (B1). The long term effect is reflected by TLCL for the first half of data points in baseline (A1) and the second half of data points during intervention (B2). In the second panel of Figure 4, there is a positive trend in both phases, so the long term difference in level will be much larger, and is reflected by TLCL > TLCS.
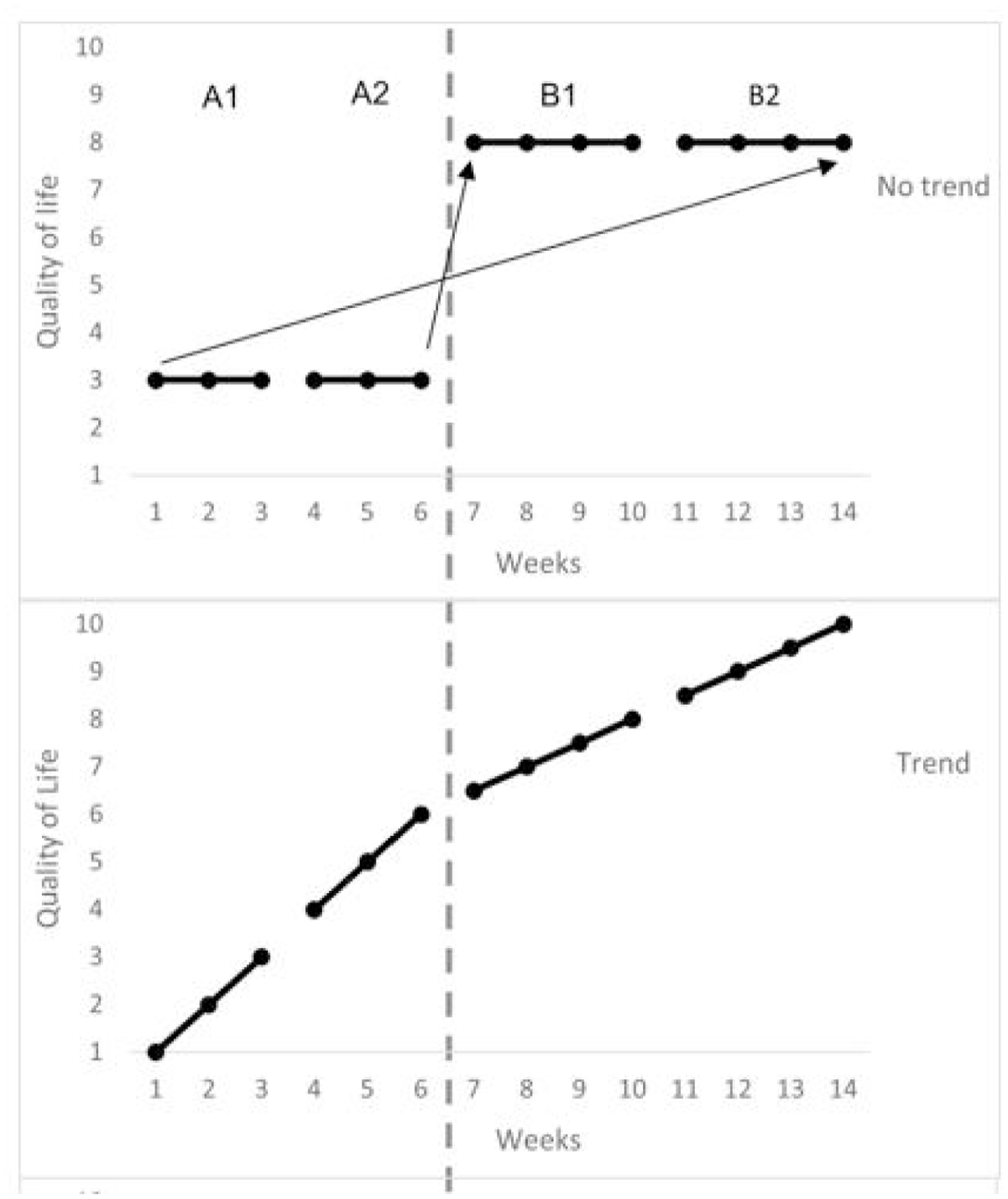
Examples of split-half techniques to detect problematic trend. No indication of trend (TLCS = TLCL) in panel 1, indication of trend (TLCS < TLCL) in panel 2.
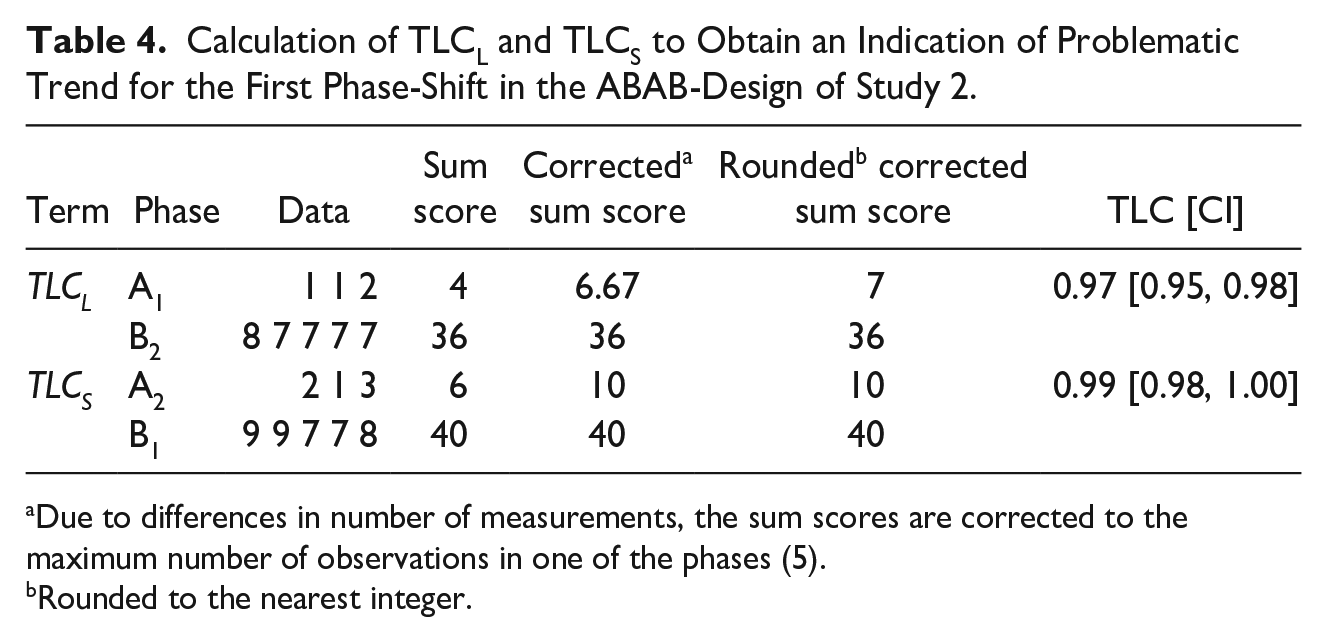
For the A1B1-phaseshift in our example, TLCL > TLCS, but there is overlap between the confidence intervals (Table 4). Demonstration of an effect is not doubtful in this phase shift: if this applies to the other replications as well, it is plausible that the change in QoL was caused by the intervention. The calculation of the TLCS and TLCL of A1B1 is illustrated in Table 4.
Calculation of TLCL and TLCS to Obtain an Indication of Problematic Trend for the First Phase-Shift in the ABAB-Design of Study 2.
Due to differences in number of measurements, the sum scores are corrected to the maximum number of observations in one of the phases (5).
Rounded to the nearest integer.
Taking Typicality Into Account
Finally, when trend and difference in level between phases are identical, but the baseline value differs between participants, considering typicality of change helps to differentiate between effects. In the bottom panels of Figure 3, the development of Chris and Jennifer’s final replication A3B3 is depicted and shows that Jennifer consistently scores a point more than Chris. NAP (1.00) and Tau-U (0.41) are the same for both. The question remains whether Chris’ replication is as convincing as this phase shift in Jennifer: Jennifer could not have improved much more, because the measurement scale limits this. Her quality of life is almost as good as it can be in A3. Chris’ quality of life though could have been improved more (5.7 during the intervention). The concern here is that an improvement in the mean on a scale of 1 to 10, from 3.4 to (at least) 6.4 is not as typical as an improvement from 6.4 to (at least) 9.4, although the magnitude of difference in level between the phases is the same (3). When the data of Chris and Jennifer’s final replication A3B3 are presented alternatively (Figure 5), where the lowest score at baseline is recoded to 0% (3 for Chris and 6 for Jennifer) and the highest possible value (10 in both cases) would be recoded 100%, the graphs show the typicality of improved quality of life of both. From a typicality point of view, Jennifer’s development should be reflected with a larger effect size. Chris (TLC = 0.85) and Jennifer (TLC = 1.00) are ordered in a way that the change is greater for Jennifer when TLC is used as an effect measure.
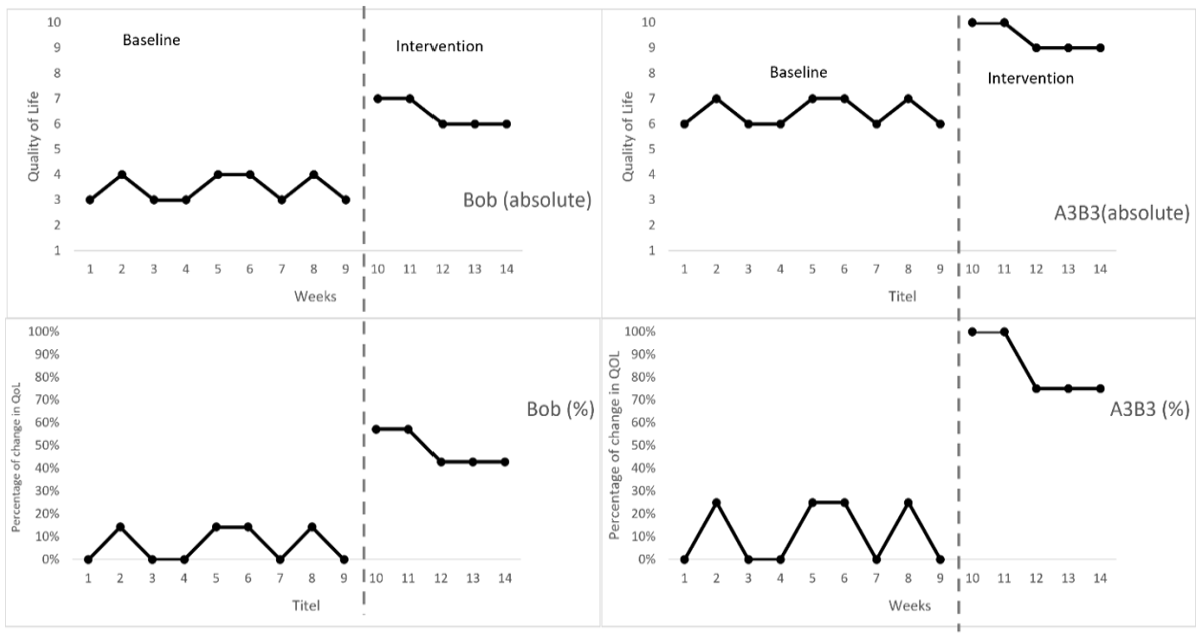
Comparison between Chris and Jennifer’s A3B3-phases, with respect to their percentage of improvement in comparison to their own lowest measured quality of life (bottom two panels): the improvement in the QOL is more typical in Jennifer’s phase-shift.
Some conclusions with respect to which effect is larger might be open to discussion, such as those regarding the typicality of level change, but from visual analysis of Figure 5, ordering the right panels over the left panels, favoring superior level changes over slightly troubling trends during the baseline phase, seems hardly doubtful. For Tau-U, this ranking is entirely different, consistently favoring the phase shifts in the MBD over the ABABAB-design. For NAP, this leads to no ranking at all because all NAPs are maximum due to the ceiling effect. With TLC, the ordering of effects fits the conclusions of the results of visual analysis.
Discussion
In SCR statistical effect sizes are used to formally decide the degree to which an intervention has worked. Conclusions based on visual analyses are sensitive for subjective interpretations, especially when the effects are visually difficult to discern. In a standardized visual analysis six aspects of the data are considered to formulate a decision. Statistical effect sizes must therefore as much as possible be in line with the categories of visual analysis. Violation of assumptions of parametric effect size indices and tests are not uncommon in SCR due to small amount of measurement points. For such situations nonoverlap methods, such as NAP and Tau-U, are recommended. Both indices partly cover the six categories of visual analyses. By not explicitly weighing the size of level-change in the effect size, nonoverlap methods are prone to three restrictions: a ceiling effect, ignoring or overcompensating trend, and not taking into account the typicality of the level-change. In this study, we introduced TLC as a statistical effect size index that can be used in situations where properties of the data in a SCR do not allow the use of parametric alternatives, and a researcher still wants to acquire, besides visual interpretation, formal information about the effect size for each change of conditions in the single case design. Other than NAP and Tau-U, TLC is explicitly computed from level-change: the first of six variables that is taken into consideration in a visual analysis (Kratochwill & Levin, 2010; Ray, 2015).
In SCR, typically the goal is to find or refute evidence for interventions. A ceiling effect or overcompensated trend is not much of a problem as these binary decisions do not often lead to Type I- and Type II-errors when using nonoverlap methods. Tau-U and NAP are sufficient if establishing evidence is the purpose of the study. Also, one could use a parametric alternative as recommended by the WWC (2020). However, if we want to obtain more detailed information about the size of effect of each replication, TLC does not assume normal distribution of the data and weighs in more relevant characteristics of the data, which enables to differentiate more in small data sets.
Limitations and Future Research
There are some limitations to the current study. Benchmarks for small, medium, and large effects have been obtained by simulation but are not yet validated by field data. Also, to calculate TLC, the measurement scale must have an absolute minimum and maximum value, which is not the case for count data. To use TLC for count data, the data should first be recoded into ordinal scale categories. Whether this is always possible and desirable depends on the research situation and the properties of the data.
Several directions for future research of this effect size index are recommended. Firstly, it would be interesting to reanalyze published data with TLC, to see if taking into account typicality of an effect leads to different results and different nuances to the effects that were found. For instance, Parker et al. (2011) found 25% from a convenience sample of published articles using AB designs, yielded a NAP of 1.00. Analyzing this data again with TLC would lead to more differentiated conclusions from this data. The simulations in this study to find typical values of TLC already showed that TLC can discriminate when there is complete nonoverlap between phases.
Secondly, the principle of TLC is quite easy to understand, but calculation can be hard, even in cases with few data. Syntax in SPSS or R are not yet available, but calculation of TLC is possible in Excel for a variety of designs (ABAB, alternate treatment and multiple baseline) by using the available link to the spreadsheets in Supplement 3. The use of TLC is not limited to these designs. TLC can be used in any single case design that has two-phase comparison as the basic unit of analysis. It could be worthwhile to expand the opportunity to calculate TLC to a greater variety of designs.
Also, simulations need to consider the possible influence of the length of phases and the type of measurement scales on benchmarks as well. In addition, TLC should be compared to other effect sizes such as standardized mean difference (Busk & Serlin, 1992), log response ratio (Swann & Pustejovsky, 2018), and d-statistic (Shadish et al., 2014). Also, the relative robustness of TLC to autocorrelation has not yet been clarified, but is an important threat to any effect-measure in the field of SCR (Franklin et al., 1996). Finally, TLC needs to be field-tested to show what results would be generated in practice.
Despite most SCRs are underpowered when insufficient randomization was built into the design (Ferron & Onghena, 1996), in SCR, the goal is usually to find large effects that can hardly be discarded (Kazdin, 2011). The TLC is a distribution free index, which can be applied to any data set that meets the WWC (2020) guidelines, despite that these designs may not have the statistical power to find rather small effects. The WWC guidelines instruct to include three replications in MBDs or Reversal Designs, with at least three data points in each phase to meet standards with reservations, and at least five data points in each phase to meet standards.
Conclusion
This article introduced a non-parametric effect size index TLC for small data in single case research designs. While visual analysis is prone to subjectivity, distributional properties of small data often rule out parametric approaches, and existing nonoverlap methods NAP and Tau-U do have restrictions, TLC gives a standardized indication of the size of an effect between phases in SCR designs with small data. We illustrated with two hypothetical studies that, unlike NAP and Tau-U, TLC differentiates effects more in line with the outcomes of visual analysis. The TLC enables researchers to compare effects between participants and between studies based on typicality, offering a more precise measure of effect than NAP and Tau-U.
Supplemental Material
sj-docx-1-bmo-10.1177_01454455231190741 – Supplemental material for Typicality of Level Change (TLC) as an Additional Effect Measure to NAP and Tau-U in Single Case Research
Supplemental material, sj-docx-1-bmo-10.1177_01454455231190741 for Typicality of Level Change (TLC) as an Additional Effect Measure to NAP and Tau-U in Single Case Research by Willem Landman, Stefan Bogaerts and Marinus Spreen in Behavior Modification
Supplemental Material
sj-docx-2-bmo-10.1177_01454455231190741 – Supplemental material for Typicality of Level Change (TLC) as an Additional Effect Measure to NAP and Tau-U in Single Case Research
Supplemental material, sj-docx-2-bmo-10.1177_01454455231190741 for Typicality of Level Change (TLC) as an Additional Effect Measure to NAP and Tau-U in Single Case Research by Willem Landman, Stefan Bogaerts and Marinus Spreen in Behavior Modification
Supplemental Material
sj-docx-3-bmo-10.1177_01454455231190741 – Supplemental material for Typicality of Level Change (TLC) as an Additional Effect Measure to NAP and Tau-U in Single Case Research
Supplemental material, sj-docx-3-bmo-10.1177_01454455231190741 for Typicality of Level Change (TLC) as an Additional Effect Measure to NAP and Tau-U in Single Case Research by Willem Landman, Stefan Bogaerts and Marinus Spreen in Behavior Modification
Footnotes
Author’ s Note
Stefan Bogaerts is also affiliated to Fivoor, Academy of Research Innovation and Development, Poortugaal, The Netherlands.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.