
Abstract
The net output power of biomass, influenced by proximate analysis factors, is pivotal for enhancing efficiency in bioenergy applications, necessitating accurate predictive tools. This study employs a gradient boosting machine (GBM) model, refined through four advanced optimization methods: batch Bayesian optimization (BBO), evolution strategies, Bayesian probability improvement (BPI), and Gaussian process optimization (GPO). The model is constructed using a dataset comprising 980 experimental samples, with 90% allocated for training and 10% for testing, incorporating key input variables such as temperature, moisture content, fixed carbon, volatile matter, and air-to-fuel ratio to forecast biomass net output power. To prevent overfitting, k-fold cross-validation is applied during the training phase. The performance of each optimization method is assessed via computational runtime and metrics such as R2), mean-squared error, and average absolute relative error. Correlation analysis reveals that temperature exhibits the strongest positive correlation with net output power (correlation coefficient: 0.62), followed by fixed carbon (0.14), while moisture content (−0.29), volatile matter (−0.01), and air-to-fuel ratio (−0.06) show negative correlations. Among the optimization techniques, GBM–BPI delivers the highest accuracy, achieving an R2 of 0.998521 for the training set and 0.9947336 for the test set, outperforming other approaches. Regarding computational speed, GPO is the most efficient, requiring 212.54 s, whereas BBO is the slowest at 521.14 s. Sensitivity analysis elucidates the influence of each input variable on net output power, underscoring the strength of data-driven methods in addressing intricate systems. These models offer reliable tools for predicting biomass net output power, reducing reliance on expensive, time-consuming, and labor-intensive experimental processes.
Keywords
Introduction
Amid growing concerns about energy security and environmental impacts, policymakers are increasingly prioritizing renewable energy sources to meet escalating energy demands (Begum et al., 2014; Dinca et al., 2018; Pettinau et al., 2013). Biomass, as a sustainable energy resource, has emerged as a cornerstone of eco-friendly energy production (George et al., 2018; Safarian et al., 2020b). It stands out as the only renewable energy source capable of effectively substituting fossil fuels, supporting continuous power generation while also enabling the production of transportation fuels and chemical products (Puig-Arnavat et al., 2013; Safarian et al., 2018, 2019a; Safarian and Unnthorsson, 2018). Biomass gasification, a highly efficient and environmentally friendly technology, transforms a variety of biomass feedstocks into versatile products for diverse applications (Puig-Arnavat et al., 2013). These systems emit significantly lower levels of air pollutants, and their byproducts are nontoxic with commercial utility. A key advantage of this technology is its compatibility with decentralized power generation units, making it an ideal solution for energy supply in remote regions lacking access to centralized grids, where localized heat and power production are essential (Safarian et al., 2020a, 2020d).
Biomass gasification is a thermochemical process involving the partial oxidation of carbon-rich solid materials at elevated temperatures, using agents such as steam, carbon dioxide, oxygen, nitrogen, air, or their combinations, to produce syngas. This gas mixture comprises hydrogen, carbon monoxide, carbon dioxide, methane, light hydrocarbons, tar, char, ash, and trace impurities (Mikulandrić et al., 2014). Roughly half of the syngas's energy content is derived from hydrogen and carbon monoxide, with the remainder from methane and heavier aromatic hydrocarbons. Biomass typically has a moisture content of 5–35%, which is reduced to below 5% during the drying phase. In pyrolysis (200–700 °C with limited oxygen), volatile components are converted into H2, CO, CO2, CH4, tar, and water vapor, leaving behind carbon-rich char.
During the oxidation phase, oxygen reacts with combustible materials to form CO2 and H2O. These compounds are subsequently reduced back to CO and H2 upon interaction with char from pyrolysis. Some hydrogen in the biomass also oxidizes to form water. The endothermic reduction phase, driven by combustion energy from char and volatiles, produces combustible gases such as H2, CO, and CH4 (Safarian et al., 2019b). Extensive research on biomass gasification systems has identified feedstock characteristics, reactor design, and operational conditions as critical determinants of gasifier efficiency, syngas composition, and overall system performance (Damartzis et al., 2012; Safarian et al., 2020c; Safarianbana et al., 2019). Key feedstock properties include ash content, moisture content, volatile matter, thermal conductivity, fixed carbon, and organic/inorganic compositions. Given the complexity of thermochemical reactions within reactors, empirical optimization is often labor-intensive and costly. In contrast, predictive modeling offers a more efficient and cost-effective approach to determining optimal conditions and selecting suitable feedstocks (Baruah et al., 2017).
Standard experimental techniques for assessing the net output power of biomass through proximate analysis are typically resource-heavy, requiring advanced equipment and significant time investments. Conversely, data-driven strategies have risen as an effective substitute, offering substantial promise for high-precision predictions across multiple domains. Despite the rising need for reliable biomass power output data under diverse conditions, the application of cutting-edge machine learning (ML) methods to predict this attribute remains largely untapped. ML techniques have repeatedly proven their exceptional accuracy and versatility in a wide range of applications. Thus, employing ML to forecast biomass net output power presents a valuable opportunity for researchers and practitioners. This research utilizes an advanced gradient boosting machine (GBM) model, optimized using four state-of-the-art algorithms: batch Bayesian optimization (BBO), evolution strategies (ES), Bayesian probability improvement (BPI), and Gaussian process optimization (GPO). Essential operational parameters, including temperature, moisture content, fixed carbon, volatile matter, and the air-to-fuel ratio, are incorporated into the model to estimate net power output. A detailed sensitivity analysis is subsequently carried out to assess the individual and combined effects of these inputs on the model response. Data reliability is maintained through approaches aimed at identifying potential anomalies. The model's performance is thoroughly evaluated using critical metrics, including R2, mean squared error (MSE), and average absolute relative error (AARE%), as well as optimization runtimes. To ensure a comprehensive assessment of the model's capabilities, a variety of performance measures and visualization tools are applied. The approach is thoroughly illustrated in Figure 1.
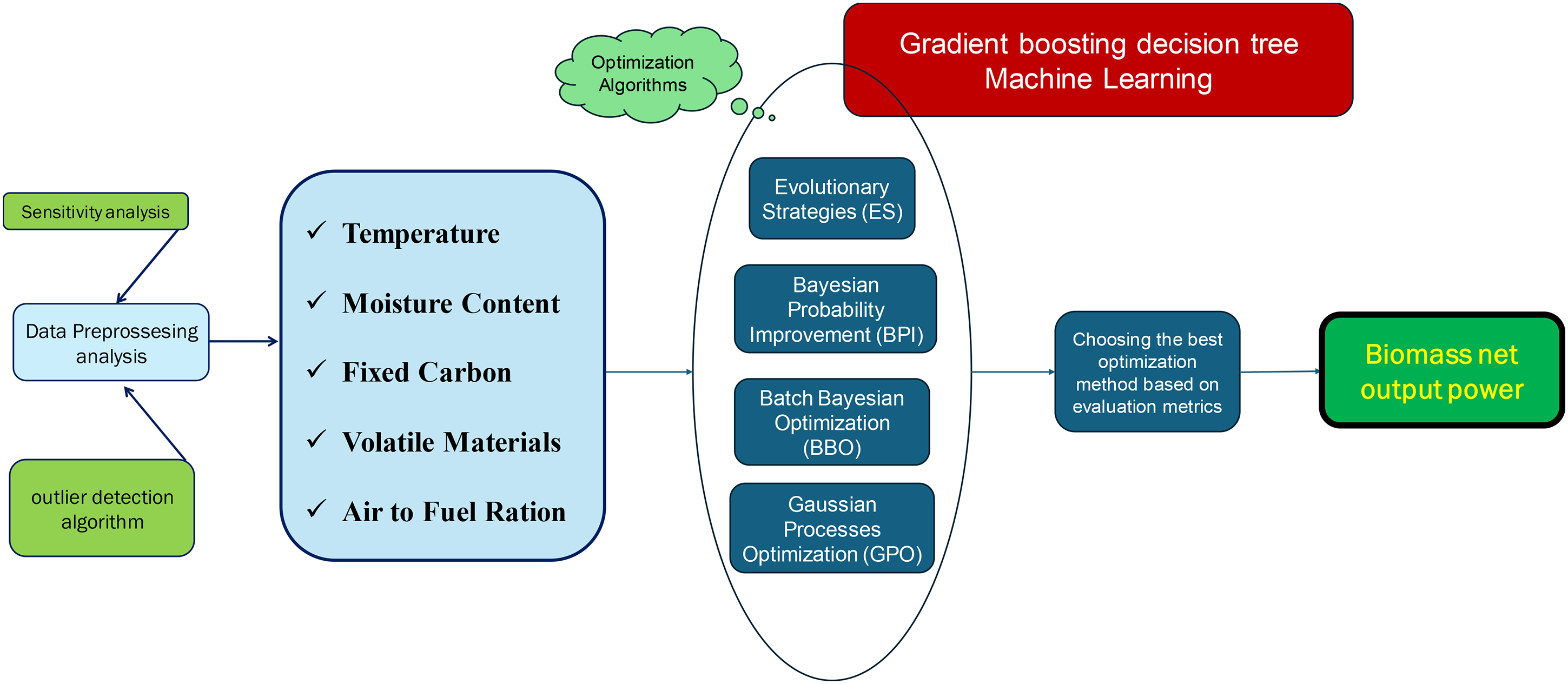
The step-by-step procedural framework adopted in this study.
GBM and optimization algorithms background
Gradient boosting machine
This study develops a predictive model utilizing the GBM framework to forecast the net output power of biomass based on proximate analysis, incorporating key input variables such as temperature, moisture content, fixed carbon, volatile matter, and air-to-fuel ratio. GBM model's hyperparameters are fine-tuned using four advanced optimization methods: BBO, ES, BPI, and GPO. The following sections describe the GBM approach and offer a brief overview of the optimization techniques applied. The GBM is a robust ML technique that combines multiple weak decision trees to form a highly accurate predictive model. Belonging to the family of boosting algorithms, GBM builds models iteratively, with each new model correcting the errors of its predecessors (Dou et al., 2025; Xiang et al., 2025). Commonly utilized for both classification and regression tasks, GBM is highly regarded for its precision and capability to model intricate, nonlinear patterns (W. Liu et al., 2022). GBM process initiates with a basic model, and in each successive iteration, a new model is incorporated into the ensemble to correct errors from prior models. These errors, known as residuals, are determined by computing the gradient of the loss function, with each new tree trained to reduce this gradient based on the ensemble's existing predictions.
Initial model: The process starts with a rudimentary model, often a constant value, defined as follows:

Residual calculation: For each iteration (m = 1, 2, …, M), residuals, or negative gradients, are computed using the below expression (Alcolea and Resano, 2021):
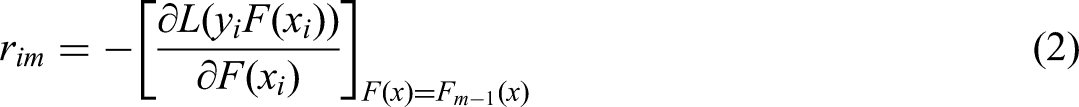
Training: A new decision tree, hm(x), is constructed to fit the residuals rim:
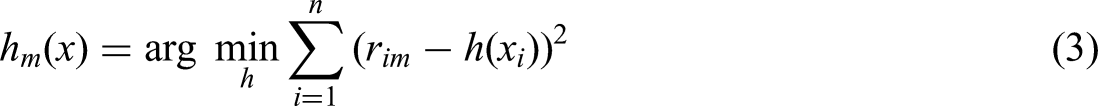
Ensemble update: The model is refined by incorporating the new tree, weighted by a learning rate η:

The learning rate η regulates the influence of each tree, helping to mitigate overfitting.
Final model: After M iterations, the complete predictive model is obtained by aggregating all trees:
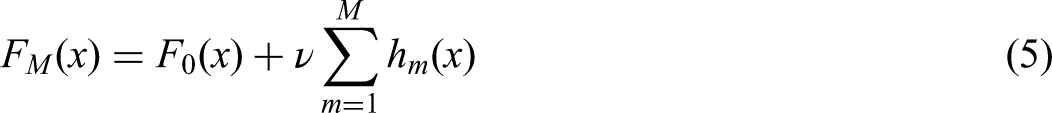
Optimization algorithms
Batch Bayesian optimization
BBO improves upon traditional Bayesian optimization by addressing the challenge of optimizing expensive black-box functions through the concurrent evaluation of multiple points, or batches, rather than sequential assessments. This approach capitalizes on parallel computing resources, making it particularly effective in distributed systems and high-performance computing environments where simultaneous evaluations are practical. By employing parallelism, BBO substantially reduces the total optimization time while preserving the robustness of Bayesian optimization in identifying the global optimum (González et al., 2016).
BBO evaluates several points at once instead of one by one. This demands adjustment of the acquisition function to consider how each point's evaluation may influence the others within the batch. Typically, BBO uses a Gaussian process (GP) as a surrogate model to estimate the target function, offering a probabilistic framework for predicting function behavior and quantifying uncertainty (Ren and Sweet, 2024).
BBO commonly uses acquisition functions that balance exploration and exploitation across batches. The parallel expected improvement (q-EI), an extension of EI for multiple points, estimates the expected gain over the current best value for q correlated points modeled by a GP. It is formulated as:
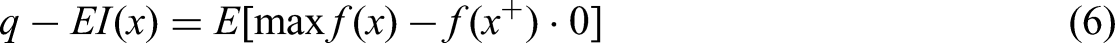
Here, X = [x1, x2, …, xq] denotes the batch of q concurrently evaluated points, f(X) the corresponding function values, and f(x+) the current best observed value. The expectation E is taken over the joint posterior of the GP. Another approach in BBO is Thompson sampling, which entails sampling from the posterior distribution of the GP and selecting a batch of points that optimize the sampled function. This method effectively balances exploration and exploitation, making it well-suited for scenarios involving parallel evaluations (J. Liu et al., 2021a).
In summary, BBO enhances Bayesian optimization by leveraging parallel computing to assess multiple points simultaneously. It employs specialized acquisition functions, such as q-EI and Thompson sampling, to select batches of points that efficiently balance exploration and exploitation, ensuring robust optimization (Miyata et al., 2023). BBO excels in environments where parallel evaluations are feasible, significantly reducing optimization time while retaining the ability to locate the global optimum. Its capacity for parallel optimization positions BBO as a potent tool for tackling costly black-box functions across various applications (Tamura et al., 2025).
Bayesian probability improvement
BPI is a pivotal optimization technique within Bayesian optimization frameworks, designed to address intricate, computationally intensive functions where analytical solutions are unfeasible. This method excels in scenarios involving costly function evaluations, effectively minimizing computational overhead while proficiently locating optimal solutions (Y. Liu et al., 2021b). BPI guides optimization by balancing exploration of uncertain zones and exploitation of regions with high improvement potential.
BPI aims to raise the probability of finding points better than the current best. Unlike EI, it focuses solely on the likelihood of improvement, making it well-suited for problems where maximizing discovery chances outweighs optimizing expected gains (Jiang et al., 2018).
The theoretical foundation of BPI centers on calculating the probability that a new point x will surpass the current best value f(x*), leveraging the posterior distribution derived from GP models. These models, integral to Bayesian optimization, provide predictive mean μ(x) and variance σ2(x) across the search space. The probability of improvement is determined using the cumulative distribution function of the standard normal distribution (Y. Liu, Su et al., 2021b). The mathematical expression for BPI is given as:

The BPI acquisition function is designed to select the next points for evaluation, with higher values indicating a greater probability of exceeding the current best solution. This approach ensures consistent progress with each evaluation by prioritizing the likelihood of improvement over the scale of potential gains. As a probability-driven strategy, BPI capitalizes on the predictive uncertainties provided by GPs to steer the search for optimal solutions (Farid and Rahman, 2010). BPI focuses on improvement probability, making it a key tool in Bayesian optimization, especially when function evaluations are expensive and the aim is to maximize the chance of better results.
Evolutionary strategies
ES are optimization methods inspired by natural evolution, designed to tackle continuous optimization problems. These algorithms evolve a set of candidate solutions over generations through processes like mutation, recombination, and selection (Chen et al., 2022). Each population member is expressed as (x, σ), where x is the solution vector and σ defines the mutation step size for each variable. The process starts by initializing a population of μ individuals, with each x randomly sampled within the problem's bounds and each σ set to a small positive value, such as: xi ∼ Uniform(xi min, xi max) and σi ∼ Uniform(σmin, σmax). In each generation, λ offspring are generated via mutation, which alters both the solution vector x and the strategy parameters σ. The new strategy parameters (σ′) are obtained as follows (Hansen et al., 2015):
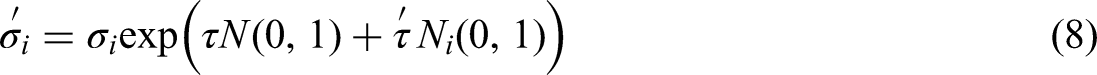

When recombination is used, it integrates information from multiple parents. For example, in intermediate recombination, the offspring (x′, σ′) is computed as the weighted average of μ parents:


After offspring are created, selection identifies the next generation. The (μ + λ)-ES scheme picks the best μ from both parents and offspring, while the (μ, λ)-ES approach selects μ only from the offspring (λ ≥ μ). ES's key strength is its self-adaptive ability to adjust the mutation parameters (σ) during optimization (Glasmachers et al., 2010). This feature enables ES to effectively balance exploration and exploitation, making it well-suited for complex, high-dimensional optimization challenges. Additionally, ES can be enhanced with advanced techniques like covariance matrix adaptation to boost its performance. In summary, ES iteratively apply mutation, recombination, and selection to refine a population of solutions. The algorithm's ability to autonomously tune its strategy parameters makes it a powerful and adaptable tool for continuous optimization. The algorithm initializes a population, generates offspring through mutation and recombination, evaluates fitness, and selects the best individuals until the stopping condition is reached. The final output corresponds to the best solution identified (X. Li et al., 2025; Mezura-Montes and Coello, 2008).
Gaussian process optimization
GPO is a powerful Bayesian optimization technique that models the target function through a GP. A GP is defined by its mean function μ(x) and covariance kernel k(x, x′), where x represents the input parameters (Majumdar et al., 2025). The covariance kernel typically adopts the squared exponential form:
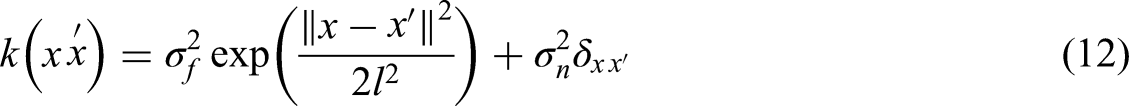
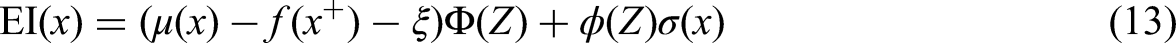

Methodology
Analysis of the collected database
The dataset employed to construct the ML models in this research is derived from experimental investigations into the net output power of biomass energy systems under varied conditions. Consisting of 980 data points, the dataset includes essential input variables such as temperature (°C), moisture content (%), fixed carbon (%), volatile matter (%), and air-to-fuel ratio (kg/kg), compiled from multiple sources (Safarian et al., 2020e). These parameters are critical in influencing the power output of biomass systems, making them indispensable for precise predictive modeling. The dataset captures the maximum, minimum, and average values for each variable. Of the 980 experimental samples, 90% are designated for training and validation, utilizing k-fold cross-validation with 5-fold, while the remaining 10% are set aside to evaluate the performance of the developed models.
To enhance the clarity and comprehensiveness of the dataset description, it is important to provide additional background on the biomass types included in this study. The dataset was derived from a downdraft biomass gasification–power production system modeled in Aspen Plus, incorporating 86 distinct biomass feedstocks from diverse categories. These feedstocks encompass wood and woody biomasses (e.g. pine, oak, and forest residues, accounting for approximately 35% of samples), herbaceous and agricultural biomasses (e.g. rice husk, wheat straw, sugarcane bagasse, and corn stalks, about 30%), animal-origin biomasses (e.g. poultry litter and manure, about 10%), mixed and processed biomasses (e.g. refuse-derived fuel and paper waste, about 15%), and contaminated or industrial by-product biomasses (e.g. sludge and food-processing residues, about 10%).
This diverse dataset was compiled from the thermodynamic simulation results based on the elemental and proximate analyses reported by Vassilev et al. (Adhab et al., 2025), ensuring a wide coverage of biomass compositions across different origins and processing conditions. Such diversity enables the developed ML models to capture a broad range of thermochemical behaviors, thereby improving their robustness, generalizability, and predictive reliability when applied to real-world biomass gasification systems operating under varied feedstock and process conditions.
Furthermore, Figure 2 illustrates raincloud plots for each variable, offering a comprehensive visual representation of their distributions.
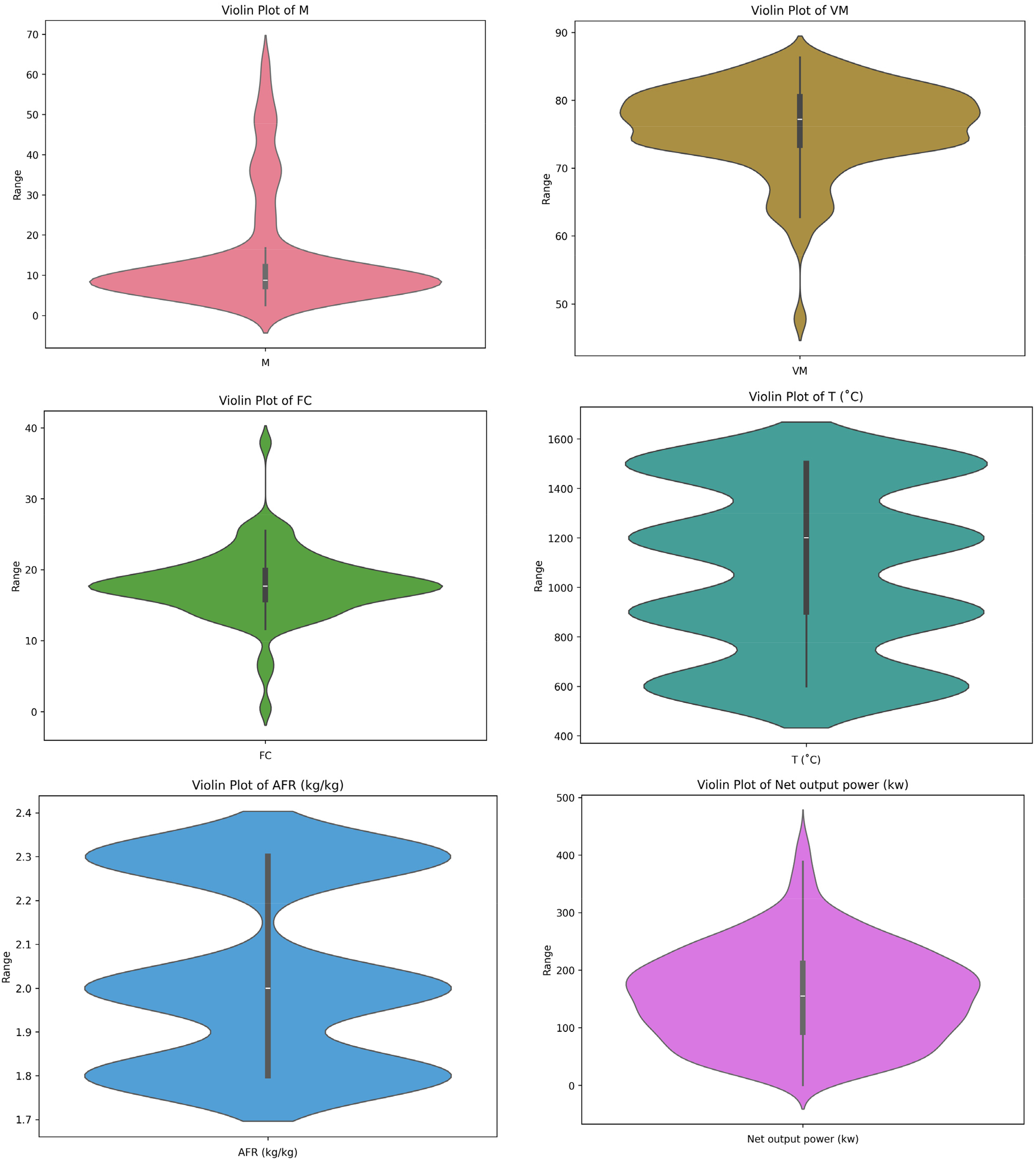
Visualization of frequency distribution and cumulative distribution for input and output data. Note that AFM means air-to-flow mass flow ratio, T is the temperature (°C), VM is the volatile materials (%), FC is the fixed carbons (%), and M is the moisture content (%).
The experimental data used for model development were generated through a thermodynamic equilibrium-based simulation of a downdraft biomass gasification integrated power production system using ASPEN Plus software. The simulated system parameters and equipment configuration were benchmarked against typical small- to medium-scale downdraft gasifiers with a thermal input capacity ranging from 25 to 250 kW. This range reflects the operational specifications of experimental and pilot-scale units reported in prior studies. For validation and data comparison, temperature measurements within the simulation framework were calibrated based on experimental findings that typically employ K-type thermocouples (chromel–alumel) with an accuracy of ±1 °C and a measurement range up to 1300 °C. The moisture content of biomass feedstocks was determined in accordance with ASTM E871-82 standard test methods for moisture analysis, while proximate and elemental analyses were performed following ASTM D3172-13 and ASTM D5373-16, respectively. These standard-based definitions and validated parameters were incorporated into the simulation to ensure the physical and chemical accuracy of the generated dataset and to maintain consistency with real-world biomass gasification operations.
Evaluation of models
The algorithm initializes a population, generates offspring through mutation and recombination, evaluates fitness, and selects the best individuals until the stopping condition is reached. The final output corresponds to the best solution identified. This approach is favored for its simplicity and ability to produce dependable, unbiased results, making it an ideal choice for various ML tasks. Its systematic structure and equitable data distribution enhance its applicability across diverse predictive modeling scenarios.
To demonstrate the k-fold cross-validation process, consider an example with 5-fold. The dataset is split into five equal parts. During the first iteration, the first fold is set aside as the validation set, with the other 4-fold used for training. In the next iteration, the second fold becomes the validation set, while the remaining folds support training. This process repeats sequentially until each fold has served as the validation set exactly once (He et al., 2025; Vujović, 2021).
To assess the precision and reliability of the models developed in this study, a robust array of performance metrics was applied (Zhou, 2025). These include Relative Error percent or RE%, AARE%, MSE, and R2. Each metric offers a unique perspective on the model's performance, as detailed in subsequent sections (Bassir and Madani, 2019; Hasanzadeh and Madani, 2024; Madani et al., 2017; Madani and Alipour, 2022):
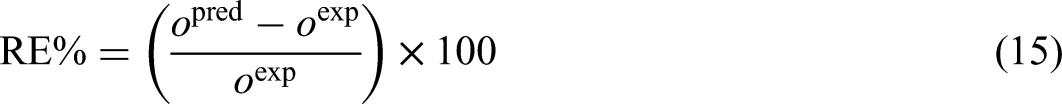
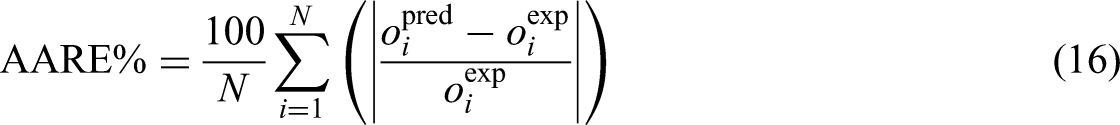
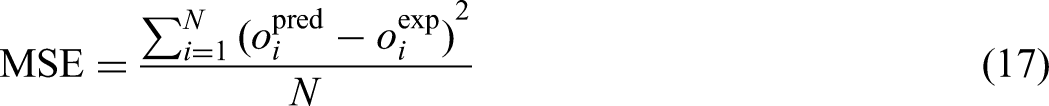
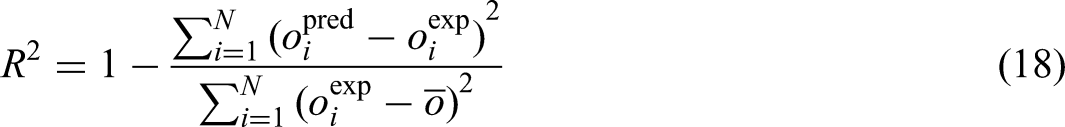
The dataset for this research includes 980 data points, offering a substantial sample size for ML applications, though careful measures are still required to prevent overfitting and enhance model generalizability. To ensure balance, the distribution of the target variable (biomass net output power) was analyzed using statistical measures and visualized via density plots, revealing a broad and continuous range of output values. k-Fold cross-validation, with k = 5, was implemented to assess model performance across various data subsets, minimizing biases from training-test splits. Additionally, leverage-based outlier detection and sensitivity analysis were performed to evaluate the representativeness and impact of individual data points. Despite the advantages of a larger dataset, the use of ensemble learning through the GBM, combined with iterative cross-validation and multiple optimization techniques, ensures robustness against data variability and bolsters model stability. These integrated approaches significantly enhance the reliability of the proposed predictive framework, effectively addressing challenges related to dataset characteristics.
Results and discussion
Outlier detection
The leverage algorithm identifies data points that diverge from model expectations by combining standardized residuals with the hat matrix (H), defined as follows (Abbasi et al., 2023; Bemani et al., 2023; Madani et al., 2021):


This analysis is depicted through a Williams’ plot, which differentiates between trustworthy and questionable regions based on leverage values and residuals. The trustworthy region encompasses data points with low leverage (below H* = 0.0184) and small residuals, while the questionable region highlights points with either high leverage or significant residuals. Points in the questionable region warrant closer scrutiny due to their potential to compromise model accuracy. As illustrated in Figure 3, the majority of data points fall within the trustworthy region below the leverage threshold of 0.0184, labeled as Valid Data in blue. However, approximately 10 points, marked as Suspect Data in orange, exceed this threshold and are flagged as potentially problematic. This visualization tool aids in assessing data quality and the influence of anomalous points on the modeling process. Nevertheless, all points are retained in the model development to enhance the generalizability of the predictive models.
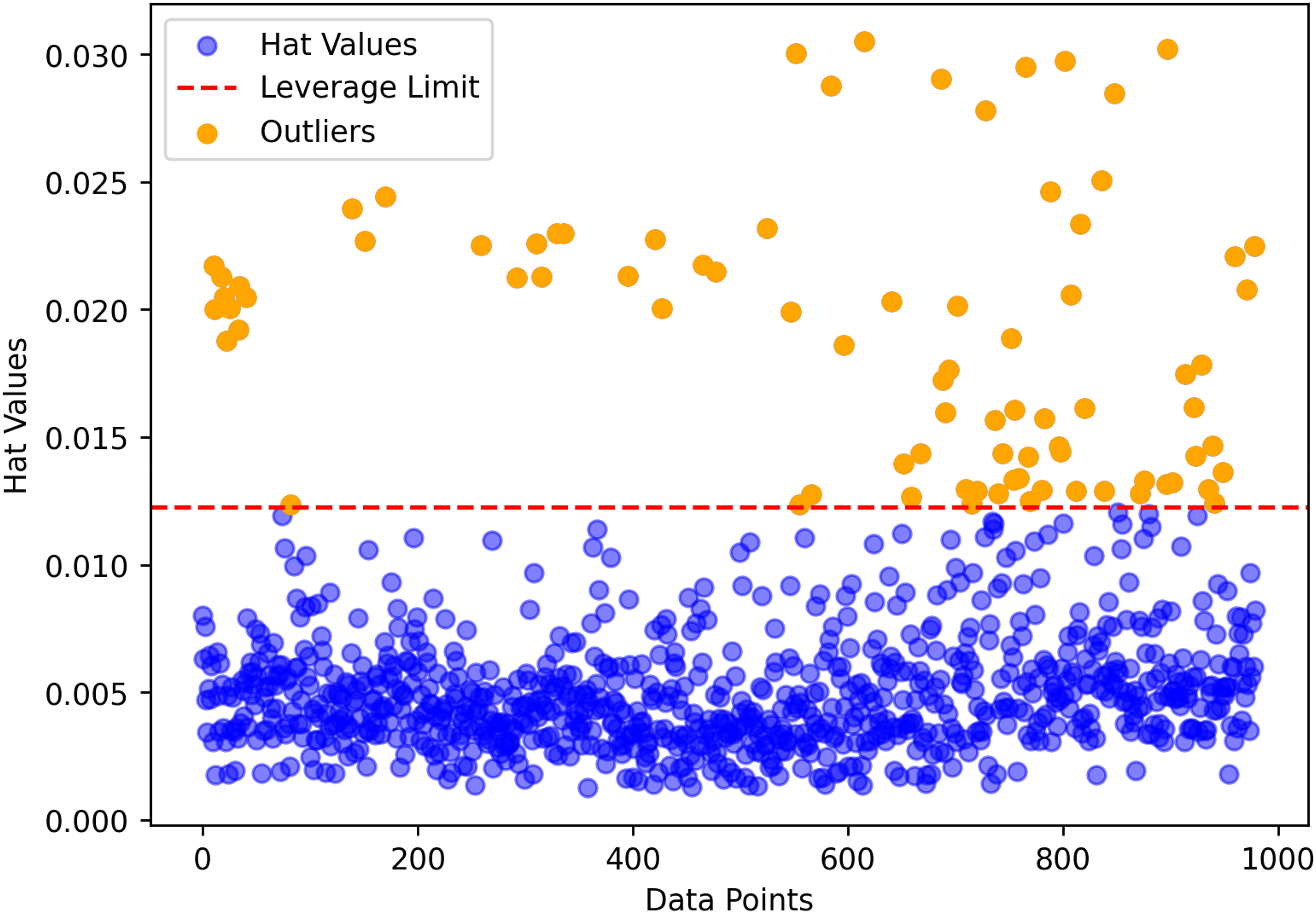
The leverage approach, a well-established technique, identifies potential outlier observations.
Sensitivity study
This section analyzes the relative impact of input variables including temperature, moisture content, fixed carbon, volatile matter, and air-to-fuel ratio on the prediction of biomass net output power based on proximate analysis. The significance of each variable is evaluated, and the correlation coefficient is calculated using the methodology described below (Bemani et al., 2023):
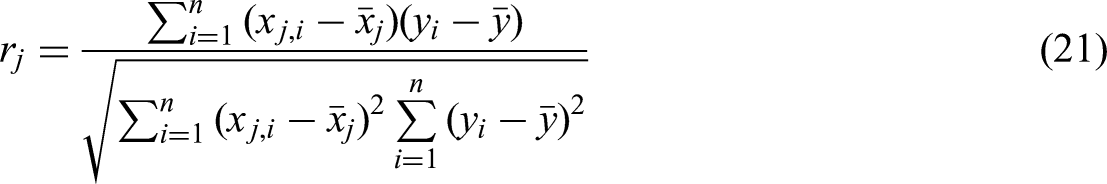
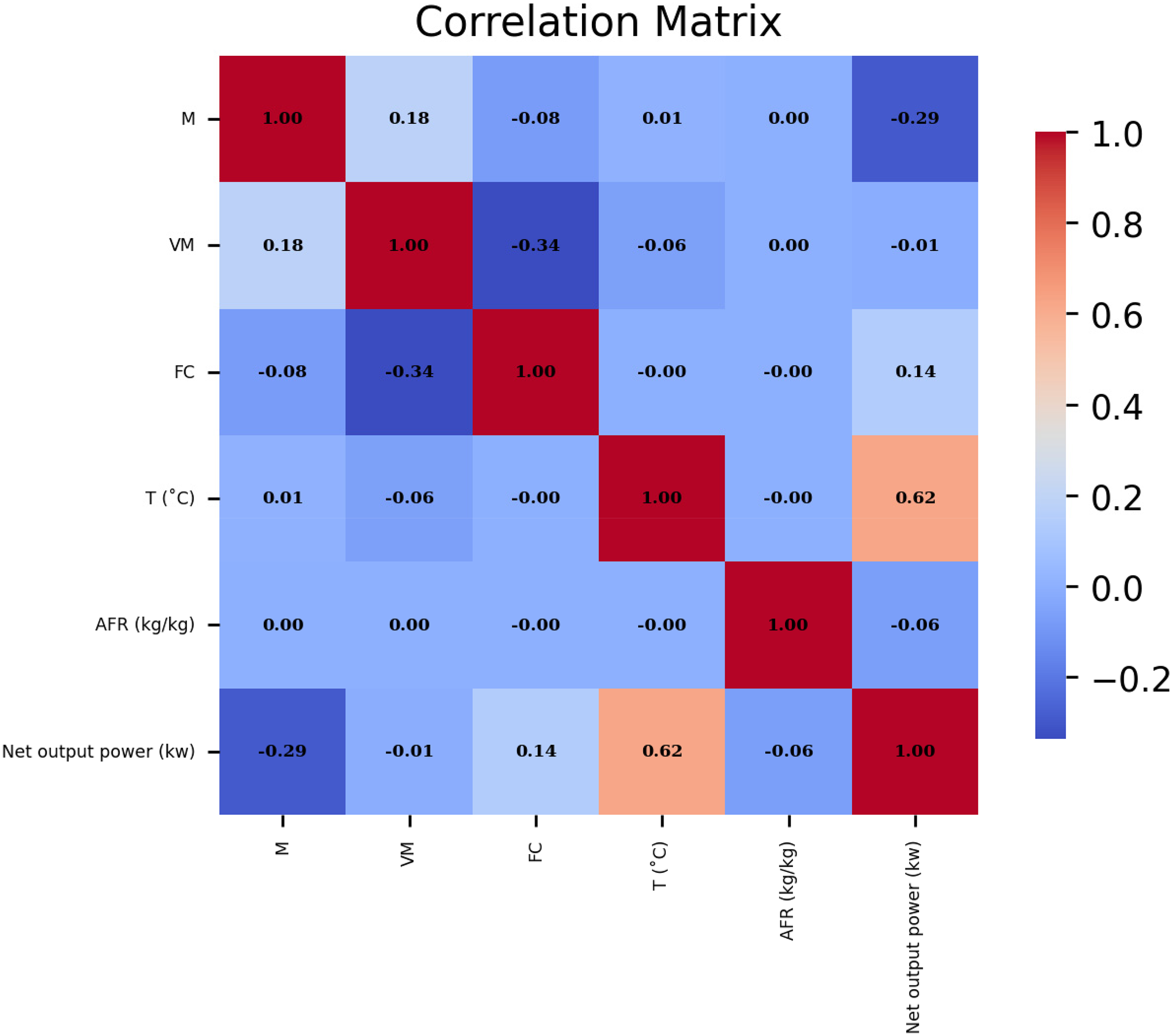
The interrelationship dynamics between paired variables as revealed through correlation analysis.
To deepen the interpretation of the correlation analysis results, the physical mechanisms underlying the observed relationships between input parameters and biomass net output power are discussed in light of thermodynamic principles. The strong positive correlation between temperature and output power (correlation coefficient: 0.62) can be attributed to the enhancement of endothermic gasification reactions at elevated temperatures. Higher temperatures accelerate the decomposition of complex biomass compounds and volatile matter, promoting the formation of combustible gases such as hydrogen (H2), carbon monoxide (CO), and methane (CH4). These reactions increase the energy density of the produced syngas, leading to higher net power output. Moreover, elevated temperatures facilitate tar cracking and secondary reforming reactions, further improving gas quality and combustion efficiency.
Conversely, the moderate negative correlation between moisture content and output power (correlation coefficient: −0.29) is consistent with the thermodynamic limitations imposed by high moisture levels. Excess moisture requires additional heat for evaporation during the drying and pyrolysis phases, resulting in significant energy consumption that reduces the available thermal energy for gasification reactions. This endothermic heat absorption lowers the reactor temperature and diminishes the rate of conversion of carbonaceous materials into syngas, ultimately reducing system efficiency and net power output. Therefore, the correlation findings are closely aligned with the physical and thermochemical behavior of biomass gasification, validating the model's predictive insights through both data-driven and process-based reasoning.
Models’ optimization
In this research, the hyperparameter optimization of the GBM model was performed using four advanced optimization techniques: BBO, BPI, ES, and GPO. These methods were selected to assess their effectiveness and precision in fine-tuning complex models, providing enhanced performance over traditional methods like grid search or random search due to their capability to efficiently navigate high-dimensional parameter spaces with fewer iterations. BBO and GPO utilize probabilistic surrogate models, such as GPs, to intelligently explore the hyperparameter space, while BPI emphasizes maximizing improvement probability through Bayesian acquisition functions. Conversely, ES adopts an evolutionary strategy, iteratively refining parameters during optimization. Each technique optimized five critical GBM hyperparameters: learning rate, number of estimators, minimum child weight, maximum depth, and subsample ratio. The performance of these methods is evaluated based on predictive accuracy metrics and computational efficiency, as elaborated in later sections.
These optimization algorithms were applied independently and in combination with cross-validation to fine-tune the GBM model's hyperparameters, namely the learning rate, number of estimators, minimum child weight, maximum depth, and subsample ratio. The tested ranges and the optimal values identified for each algorithm are detailed in Table 1. Additionally, Figure 5 illustrates the evolution of MSE across multiple optimization cycles, with a total of 200 iterations conducted. The hyperparameter settings resulting in the lowest MSE are documented in Table 1 (Abdelfattah et al., 2025).
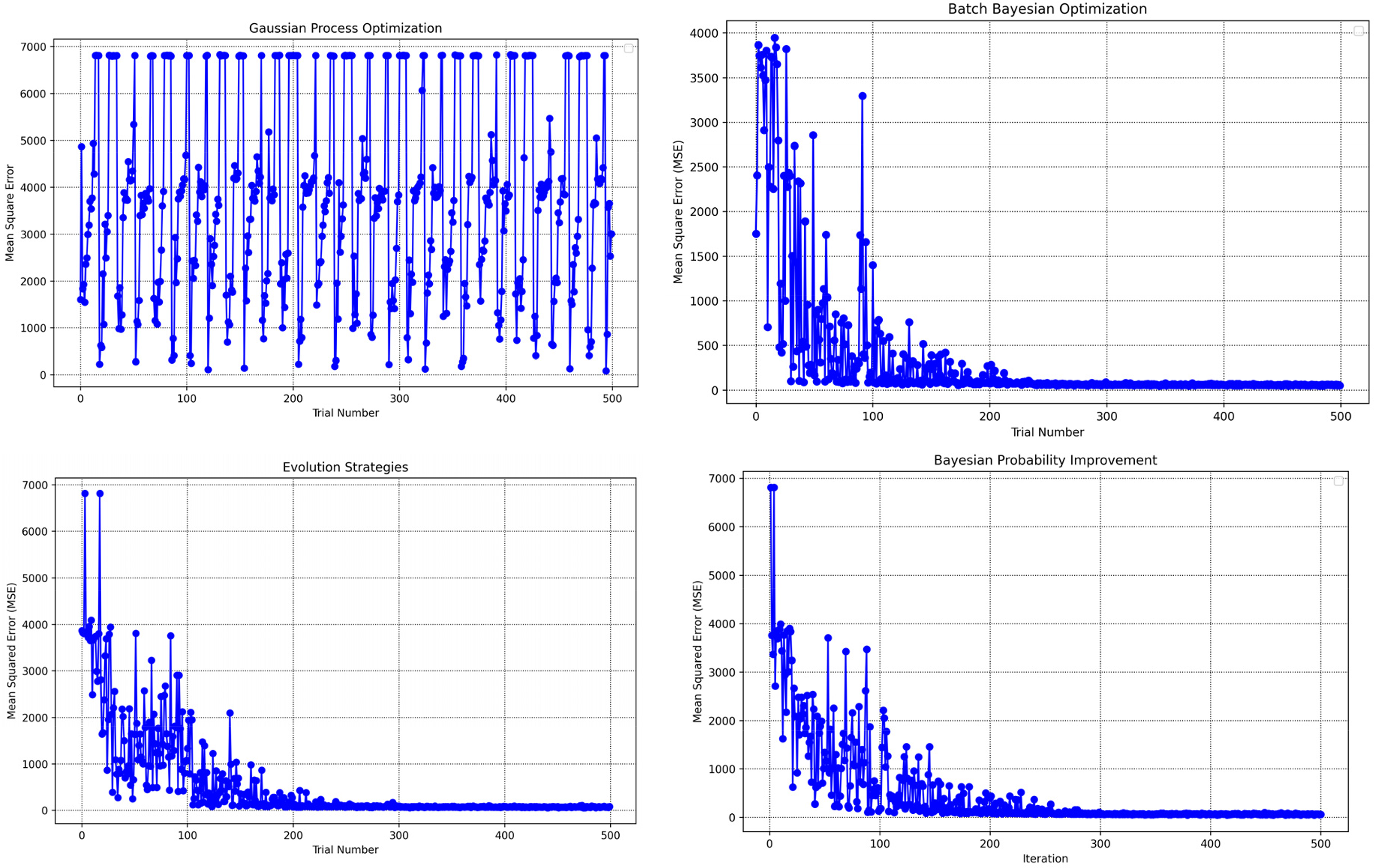
Training progression analysis: mean-squared error across iterations for various optimization approaches validated through k-fold cross-validation.
The random forest’s hyperparameter configurations: initial search spaces and optimized values.
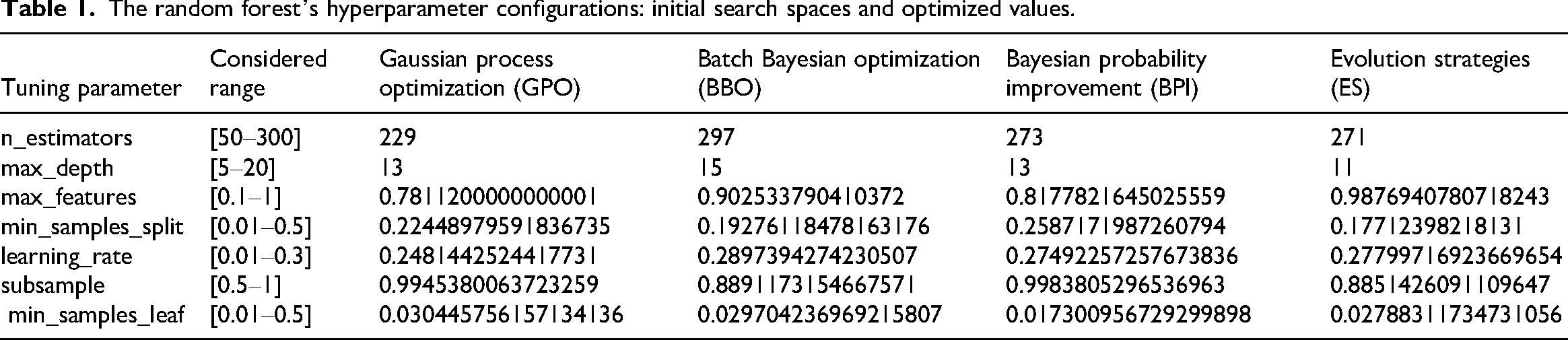
Table 2 outlines the computational time required for each optimization algorithm. BBO is the most computationally intensive, requiring 521.14 s to complete. In contrast, GPO is the most efficient, completing in 212.54 s. ES takes 437.6 s, while BPI requires 437.4 s. As indicated in Table 2, GPO achieves optimal performance relatively quickly, whereas BBO and BPI demonstrate slower but consistent improvements over iterations.
Assessment metrics identified for every optimization algorithm concerning training, testing, and total points.

GBM: gradient boosting machine; GPO: Gaussian process optimization; ES: evolution strategies; BPI: Bayesian probability improvement; BBO: Batch Bayesian optimization.
Table 3 provides a detailed summary of the performance metrics, including R2, MSE, and AARE%, for GBM models optimized using four distinct algorithms: BBO, BPI, ES, and GPO. As shown in Figure 6, test results confirm that the BPI algorithm provides the most accurate biomass power predictions, achieving R2 = 0.9947, MSE = 35.68, and AARE% = 4.5. These findings highlight BPI's capability to effectively capture the intricate relationships within the dataset while delivering robust predictive performance. In contrast, the GPO algorithm exhibits the lowest predictive accuracy, with an R2 of 0.992483, a higher MSE of 50.925478, and an AARE% of 5.9032663%, making it less effective than BPI. Although BBO systematically explores the parameter space, its prolonged optimization runtime (521.14 s) diminishes its computational efficiency. Notably, the GPO algorithm demonstrates the shortest optimization time (212.54 s), underscoring its efficiency in hyperparameter tuning.
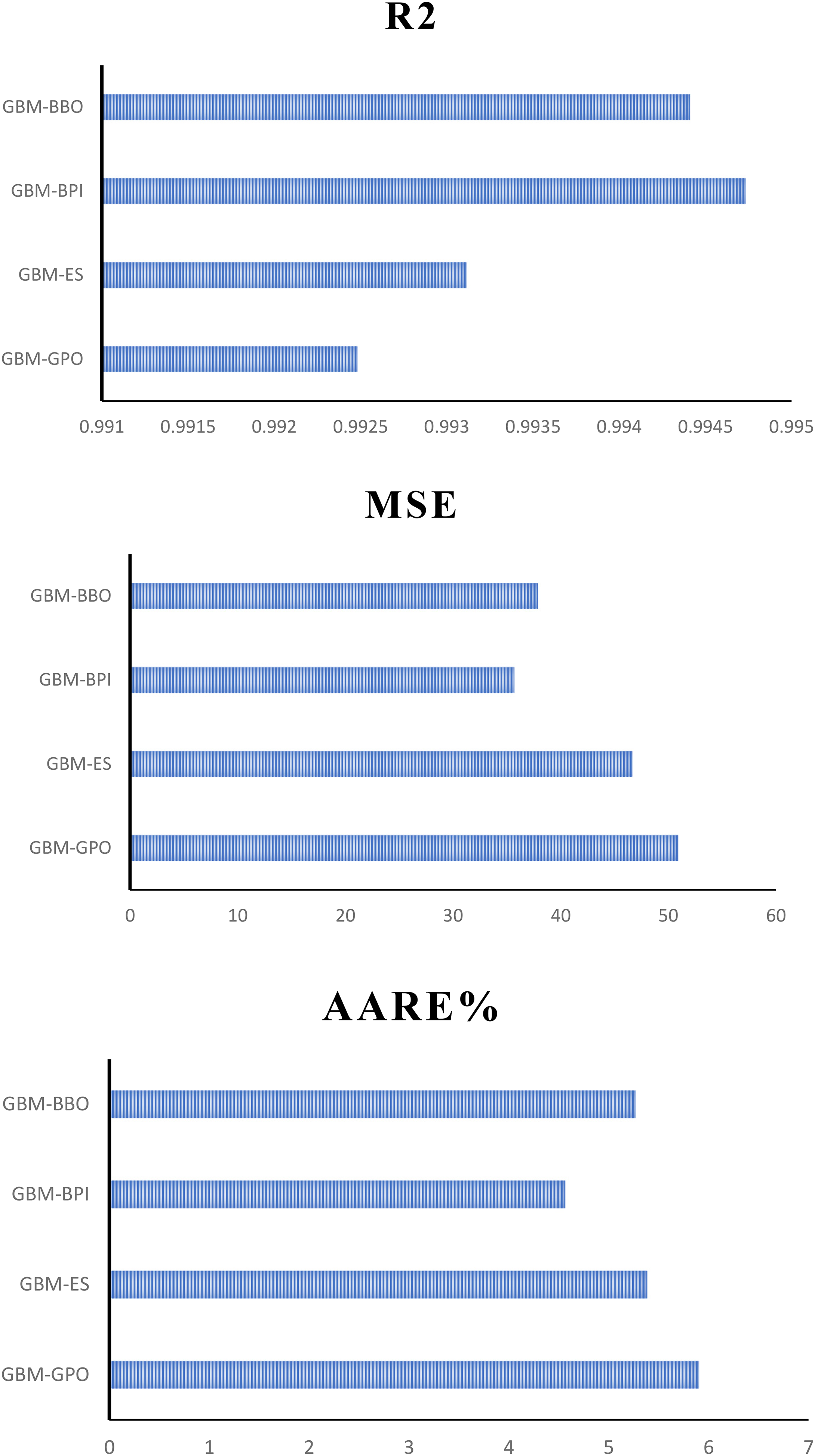
Performance assessment using R2, mean-squared error, and absolute average relative error percentage during testing across all optimization approaches.
Assessment criteria identified for every optimization method for training, testing, and total points.
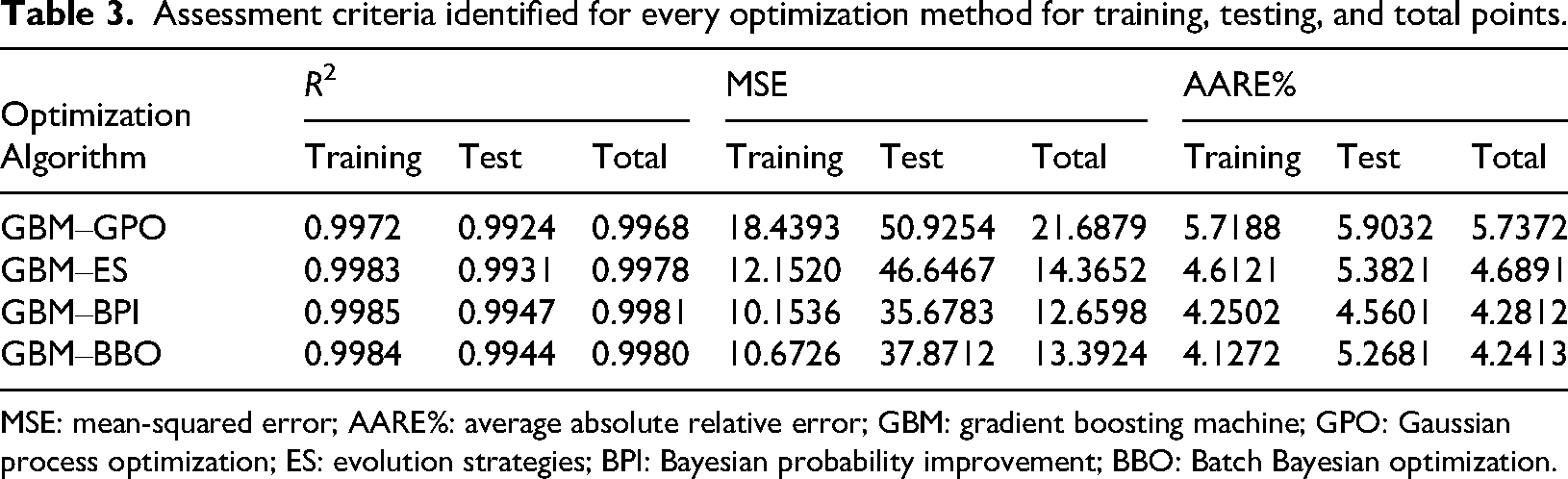
MSE: mean-squared error; AARE%: average absolute relative error; GBM: gradient boosting machine; GPO: Gaussian process optimization; ES: evolution strategies; BPI: Bayesian probability improvement; BBO: Batch Bayesian optimization.
To thoroughly assess the predictive capabilities of GBM models optimized with different techniques, Figures 7 and 8 provide visual insights into their performance. Figure 6 presents scatter plots comparing predicted versus actual biomass net output power values, for GBM models tuned with BBO, BPI, ES, and GPO. For GBM–BPI, the data points closely align with the ideal line (y = x), achieving an R2 of 0.9947336 on the test set, indicating outstanding predictive precision and minimal deviations between the predicted and experimental values. Conversely, GBM–GPO (R2 = 0.992483) and GBM–ES (R2 = 0.9931145) show slightly more dispersed distributions, suggesting reduced accuracy, while GBM–BBO (R2 = 0.9944099) displays greater scatter, underscoring its limited capacity to model the dataset's complex relationships. The regression line equations in Figure 7 for GBM–BPI closely approximate the ideal bisector (e.g. slope ≈ 1, intercept ≈ 0), affirming its excellent fit.
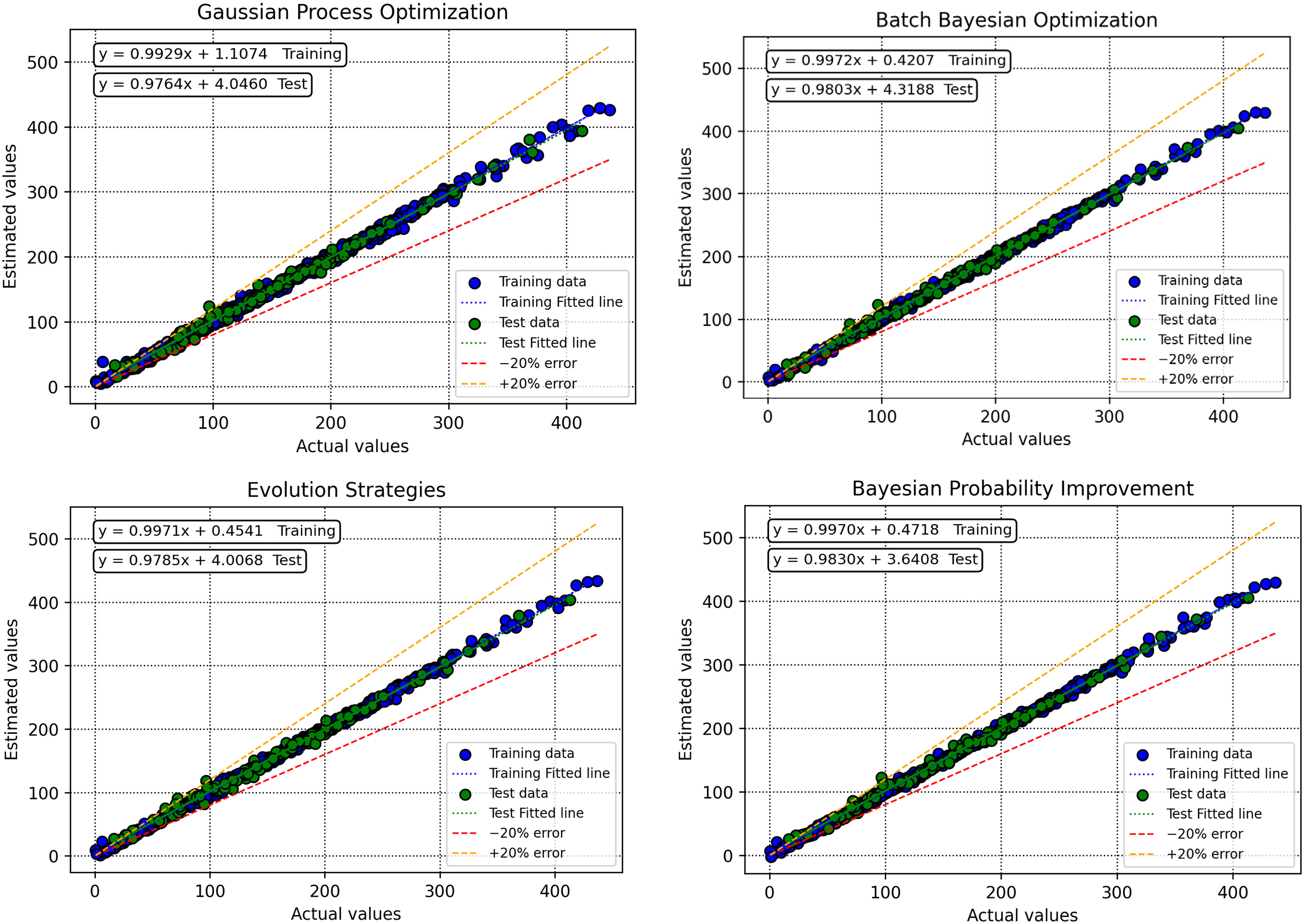
Comparison between predicted and actual values across all optimization methods during model development and evaluation.
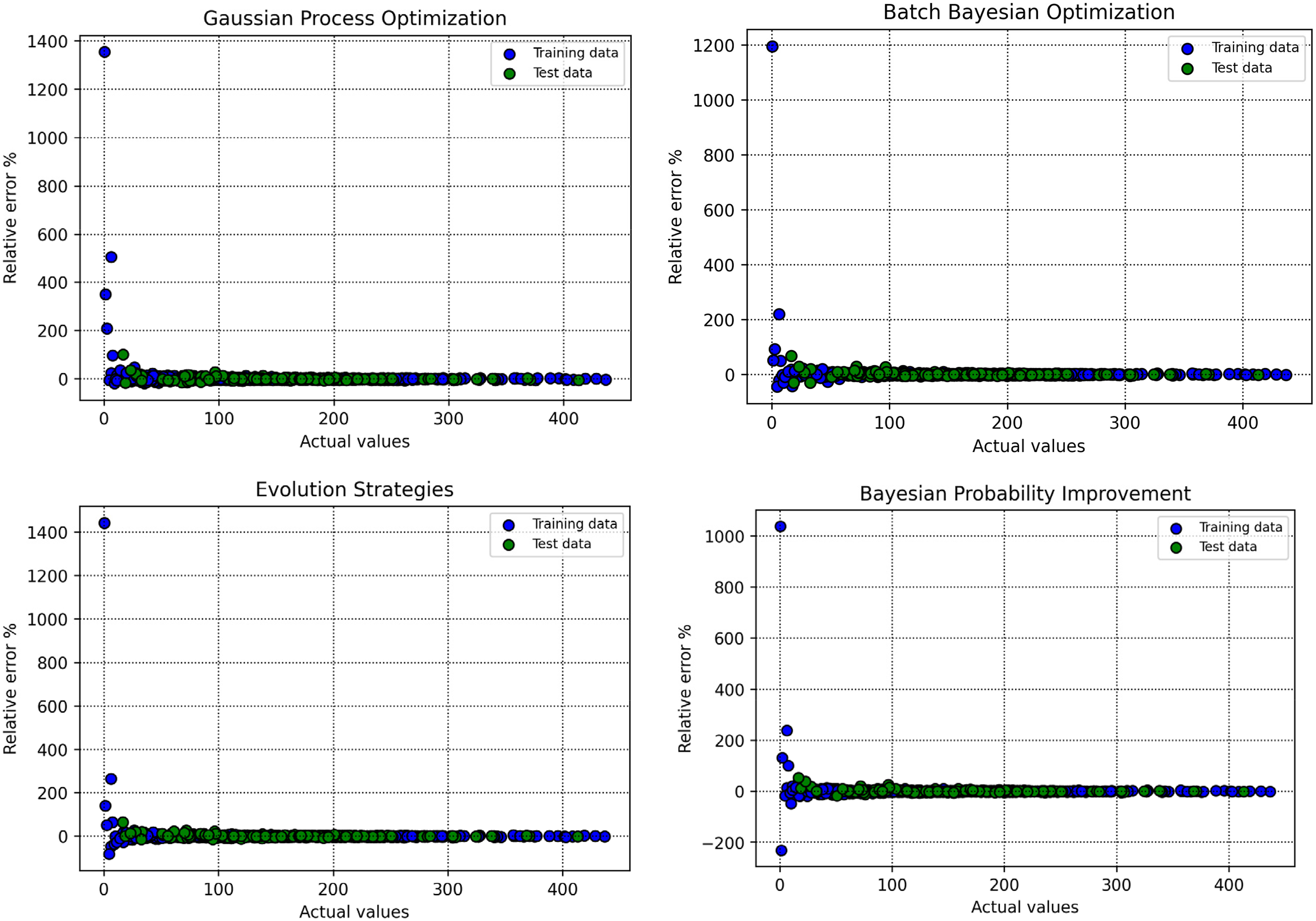
Percentage error relative to actual measurements across optimization methods during model development and validation.
Figure 8 complements this analysis by illustrating the distribution of relative errors (percentage deviations) for each optimization method. For GBM–BPI, the errors are tightly clustered around the y = 0 line, with a narrow spread and an AARE% of 4.560187% on the test set, reflecting consistent and low-error predictions. This compact error distribution underscores GBM–BPI's dependability in generating accurate biomass net output power estimates. In contrast, GBM–GPO (AARE% = 5.9032663%) and GBM–ES (AARE% = 5.3821186%) exhibit wider error ranges, while GBM–BBO (AARE% = 5.2681493%) performs less effectively. These visual trends corroborate the quantitative findings in Table 3, confirming that GBM–BPI offers the highest accuracy and reliability in predictions. This enhanced precision is particularly valuable for bioenergy applications, where accurate power output predictions can optimize system performance and minimize uncertainties in energy production. Additionally, Figure 9 compares predicted and actual data points across the four optimization algorithms.
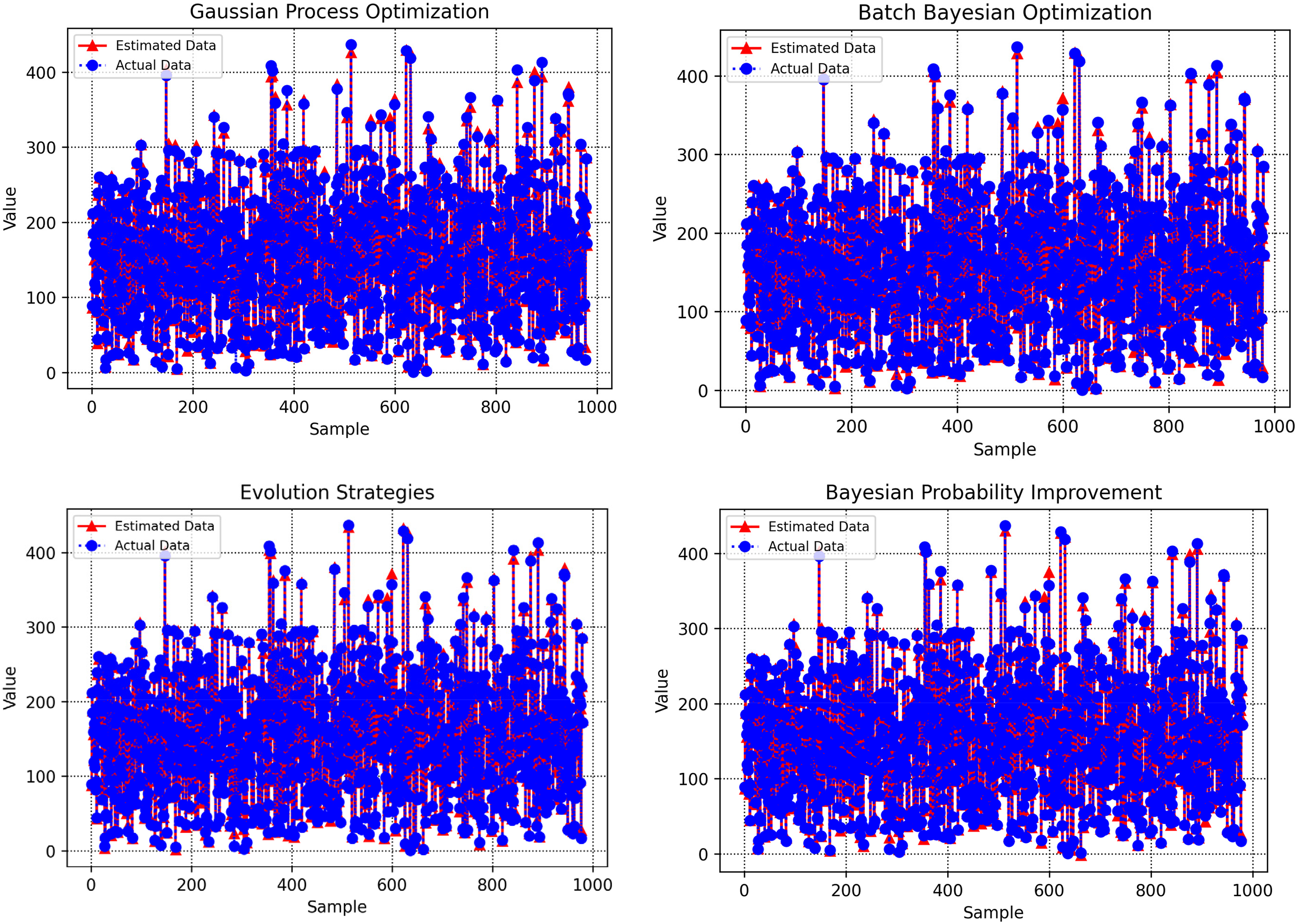
Estimated versus real data points visualization for all optimization algorithms.
Industrial applications
The predictive models established in this research, particularly the gradient boosting machine model optimized with Bayesian probability improvement (GBM–BPI), demonstrate significant potential for bioenergy applications involving biomass net output power prediction. These models provide a powerful tool for researchers and engineers to forecast power output with high precision (R2 = 0.9947336 on the test set), enabling advancements across multiple domains. In bioenergy and power generation, accurate predictions of biomass net output power under varying proximate analysis conditions support the design of efficient energy production systems, capitalizing on the combustion properties of biomass to optimize performance in applications such as electricity generation, cogeneration, and biofuel production. Reliable power output predictions are essential for enhancing boiler designs and turbine efficiencies, where biomass serves as a renewable fuel source. In agricultural and waste-to-energy sectors, these models facilitate the optimization of biomass feedstock selection by predicting power output, ensuring consistent energy yields during processing. These forecasts enable precise adjustments to operational parameters, improving system reliability and energy efficiency. Moreover, in sustainable energy initiatives, such as carbon-neutral power generation and renewable energy integration, the models assist in refining process conditions by predicting power output, thereby improving energy conversion efficiency and reducing environmental impact. By minimizing reliance on expensive and labor-intensive experimental measurements, these data-driven models foster innovation, reduce operational costs, and enhance scalability. Additionally, the sensitivity analysis identifying temperature as the primary influencing factor (correlation coefficient: 0.62) provides engineers with critical insights to prioritize key variables, streamlining system optimization. Collectively, these models enable industries to leverage the energy potential of biomass, driving improved performance, sustainability, and cost-effectiveness in alignment with global demands for renewable energy solutions.
Looking forward, several opportunities exist to further enhance the predictive modeling of biomass net output power. Incorporating a broader variety of biomass compositions, temperatures, and air-to-fuel ratios would make the model more robust and improve understanding of biomass behavior in diverse settings. Investigating alternative advanced ML approaches, such as deep learning or hybrid ensemble methods beyond GBM, may better capture intricate nonlinear patterns in the data. Incorporating additional input variables, such as ash content or biomass particle size, could further refine prediction accuracy. Finally, validating these models in real-world bioenergy settings, such as biomass power plants or waste-to-energy facilities, would bridge the gap between theoretical predictions and practical applications, promoting wider adoption of data-driven strategies in energy system design and optimization.
To clarify the applicability of the proposed models in real-world settings, it is essential to specify their relevance to different types of gasification systems and discuss their computational practicality. The predictive framework developed in this study is primarily applicable to downdraft and fluidized-bed gasifiers, which are widely used in small- to medium-scale biomass power generation systems. These reactors share similar thermochemical characteristics with the data used for model training, including partial oxidation, moderate temperature ranges, and mixed feedstock compositions. Consequently, the model can reliably predict the net output power under varying operational conditions in such configurations. For large-scale or fixed-bed updraft systems, however, additional calibration or retraining with system-specific data would be necessary to prevent prediction deviations caused by differing reaction zones, gas flow dynamics, and heat transfer mechanisms.
Regarding computational efficiency, the results indicate that the GPO-based model achieved the fastest optimization time of 212.54 s, which is satisfactory for most offline design, planning, and process optimization tasks. However, for real-time or online industrial regulation, where near-instantaneous predictions are desirable, further model refinement and lightweighting are recommended. Future work may incorporate strategies such as model pruning, parameter quantization, or hybrid reduced-order modeling to minimize computational overhead while maintaining predictive accuracy. These improvements would enhance the model's suitability for embedded control systems and adaptive process management in industrial biomass gasification applications.
Industrial applications
The proposed hybrid GBM framework optimized with BPI and GPO exhibits strong potential for generalization to other complex engineering systems. In future studies, this approach can be extended to domains where predictive modeling and optimization play critical roles. Additionally, future work may focus on adapting the proposed model for process and system optimization in mechanical, industrial, and energy domains.
Conclusions
In this study, the hyperparameters of GBM model are optimized using four sophisticated optimization methods: BBO, BPI, ES, and GPO. These hybrid models are developed to forecast the net output power of biomass based on proximate analysis, utilizing a dataset of 980 experimental samples, with 90% designated for training and 10% for testing. To mitigate overfitting, k-fold cross-validation is implemented during the training process. The performance of each optimization algorithm is evaluated through critical metrics, including R2, MSE, AARE%, and computational runtime. The results highlight varying degrees of influence among the input variables (temperature, moisture content, fixed carbon, volatile matter, and air-to-fuel ratio) on the target variable, net output power. Correlation analysis reveals that temperature has the most substantial effect on power output, followed by moisture content and fixed carbon, with volatile matter and air-to-fuel ratio showing minimal impact. Quantitatively, the GBM–BPI model exhibits the highest accuracy, achieving an R2 of 0.9947336 on the test dataset, surpassing other optimization approaches. Its MSE is 35.678312, with an AARE% of 4.560187%. Conversely, the GBM–GPO model demonstrates the lowest performance, with a test R2 of 0.992483. In terms of computational efficiency, GPO is the fastest, completing optimization in 212.54 s, compared to 521.14 s for BBO. These findings emphasize the robust potential of the proposed modeling framework for accurately and efficiently predicting biomass net output power. Future work should focus on expanding the dataset, exploring more advanced ML algorithms, and validating predictions in real-world bioenergy applications to further enhance the modeling of biomass power output.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Fujian Provincial Vocational and Technical Education Center Project (ZJGB2024049).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The datasets generated in this study are available upon request from the corresponding author, subject to providing a legitimate reason for access.