
Abstract
Accurate identification of water-inrush sources is critical for deep mining safety. This study proposes an entropy-weighted variable fuzzy set (EW-VFS) model, which uses information entropy to objectively determine the importance of different hydrochemical indicators, to discriminate complex mixed water sources in the Sunzhuang Minefield, North China. In this study, we analyzed 86 water samples from five key aquifers—Permian sandstone fractured aquifers, Ordovician limestone karst aquifers, and three thin-layer limestone aquifers—using nine hydrochemical parameters. Entropy weight analysis identified Mg²+ and HCO3− as the dominant indicators for source discrimination. The EW-VFS model achieved an overall accuracy of 83.33%, demonstrating high reliability, particularly for Permian sandstone fractured water and Ordovician limestone water. Furthermore, a time-series analysis of the model's rank feature value (Hi) revealed a dynamic evolution of the inrush source, showing a clear transition between different thin-layer limestone aquifers during mining operations. This study's findings demonstrate the model's utility in identifying multisource water inrush. However, its performance in differentiating the highly similar thin-layer limestone aquifers shows potential for further enhancement, which could be addressed with more comprehensive hydrogeochemical data.
Keywords
Introduction
As one of the world's largest energy consumers, China has long maintained a coal-dominant energy consumption structure (Wu et al., 2024). To ensure stable coal supply, mining operations are progressively extending to greater depths (Yang et al., 2021). Under deep mining conditions, coal seams intersecting with multiple aquifers fundamentally alter natural groundwater flow paths, water-rock interactions, and hydrogeological structure (Hou et al., 2024). Mining-induced disturbances and high-pressure karst water cause extensive fractures in the surrounding rock. These disturbances can also activate faults and collapse columns, forming new water-conducting channels. This creates favorable conditions for groundwater inrushes into coal mining faces, severely threatening operational safety (Chen et al., 2023) and concurrently leading to environmental degradation, including groundwater depletion, water quality deterioration, and surface subsidence (Wang et al., 2022). These challenges are exacerbated under complex hydrogeological conditions involving great mining depths and high-pressure karst water, which often result in dispersed water-inrush points and mixed water sources (Hamed et al., 2011). Therefore, in the event of a water inrush, accurately identifying the source is the primary task for formulating effective control measures (Wang et al., 2019). This task is of critical importance for both ensuring mining safety and managing water resources sustainably (Yang et al., 2021).
To address water-inrush source discrimination in multi-aquifer systems under deep mining conditions, extensive studies have been conducted using hydrogeochemical characteristics, isotopes, trace elements, and hydrogeochemical modeling (Aris et al., 2007; Chen et al., 2011; Qian et al., 2018; Yang et al., 2021; Yu et al., 2022). These studies highlight the importance of vertical hydrogeochemical heterogeneity in deep mining. This characteristic provides a reliable foundation for distinguishing aquifers, understanding their hydraulic connections, and identifying water-inrush sources (Qu et al., 2023; Wang et al., 2024). However, with increasing mining depth and scale, aquifer mixing intensifies, leading to more similar hydrogeochemical signatures. Consequently, relying solely on these characteristics becomes insufficient for accurately identifying the sources and contribution ratios of mixed water inrushes (Chen et al., 2022). To overcome this limitation, researchers have begun to integrate multivariate statistical methods with hydrogeochemical data to establish more robust mathematical models for water source discrimination. For example, by integrating the complementary advantages of the Analytic Hierarchy Process (AHP) and Grey Relational Analysis (GRA), researchers developed a predictive model for comprehensive evaluation of roof water-inrush risks (Zhang et al., 2019). Chen and Gui (2021) used the Fisher discrimination model to identify inrush water sources based on five conventional hydrogeochemical parameters and δ¹⁸O-δD isotopic data from water samples. Principal component analysis (PCA) and Bayesian multiclass linear discriminant analysis (LDA) were employed to discriminate among four aquifer types (Xue et al., 2023). A fuzzy comprehensive evaluation model was developed using 18 water sample indicators, accurately determine the primary sources of total mine water discharge (Xu et al., 2018). Based on hydrogeochemical data, Huang et al. (2017) developed a water source identification model by combining Fisher discriminant analysis and gray correlation theory (Huang et al., 2017). While these combined statistical and mathematical models show advantages in processing large datasets (Belkhiri et al., 2010), they exhibit significant limitations when applied to the complex hydrogeological conditions of deep mining, where aquifer mixing is prevalent. For instance, Bayesian models are highly sensitive to static prior probabilities, which may become unreliable as mining activities dynamically alter groundwater chemistry (Zhang et al., 2020b). Gray relational models depend on preset reference sequences, limiting their adaptability to parameter shifts caused by aquifer mixing (Yang et al., 2023). More critically, existing fuzzy models lack the adaptability to parameter shifts caused by aquifer mixing (Liu et al., 2017). They typically employ rigid membership functions with fixed shapes and ranges, rendering them incapable of responding to the changing parameter distributions that result from mining disturbances (Wang et al., 2018). Therefore, a clear knowledge gap exists for a discrimination model that can dynamically adapt to the fuzzy and variable nature of mixed water sources under deep mining-induced stress. Developing such a flexible and robust model is the primary objective of this study.
To address this gap, this study proposes a novel Entropy Weight-Variable Fuzzy Set (EW-VFS) model and applies it to the Sunzhuang Minefield in the Fengfeng mining area (Figure 1). This approach first utilizes the entropy weight method to objectively determine the weights of different hydrogeochemical discrimination indicators (Chen, 2005). These weights are then integrated into a variable fuzzy set framework to build the discrimination model (Wang et al., 2019). The model identifies water-inrush sources by calculating the comprehensive relative membership degree of a water sample to each potential aquifer and classifying it based on the principle of maximum membership and rank feature values (Chen, 1993). By dynamically adapting to the fuzzy characteristics of mixed water, the proposed EW-VFS model demonstrates enhanced flexibility and discrimination accuracy, providing a robust new methodology for water source identification under complex deep-mining conditions.
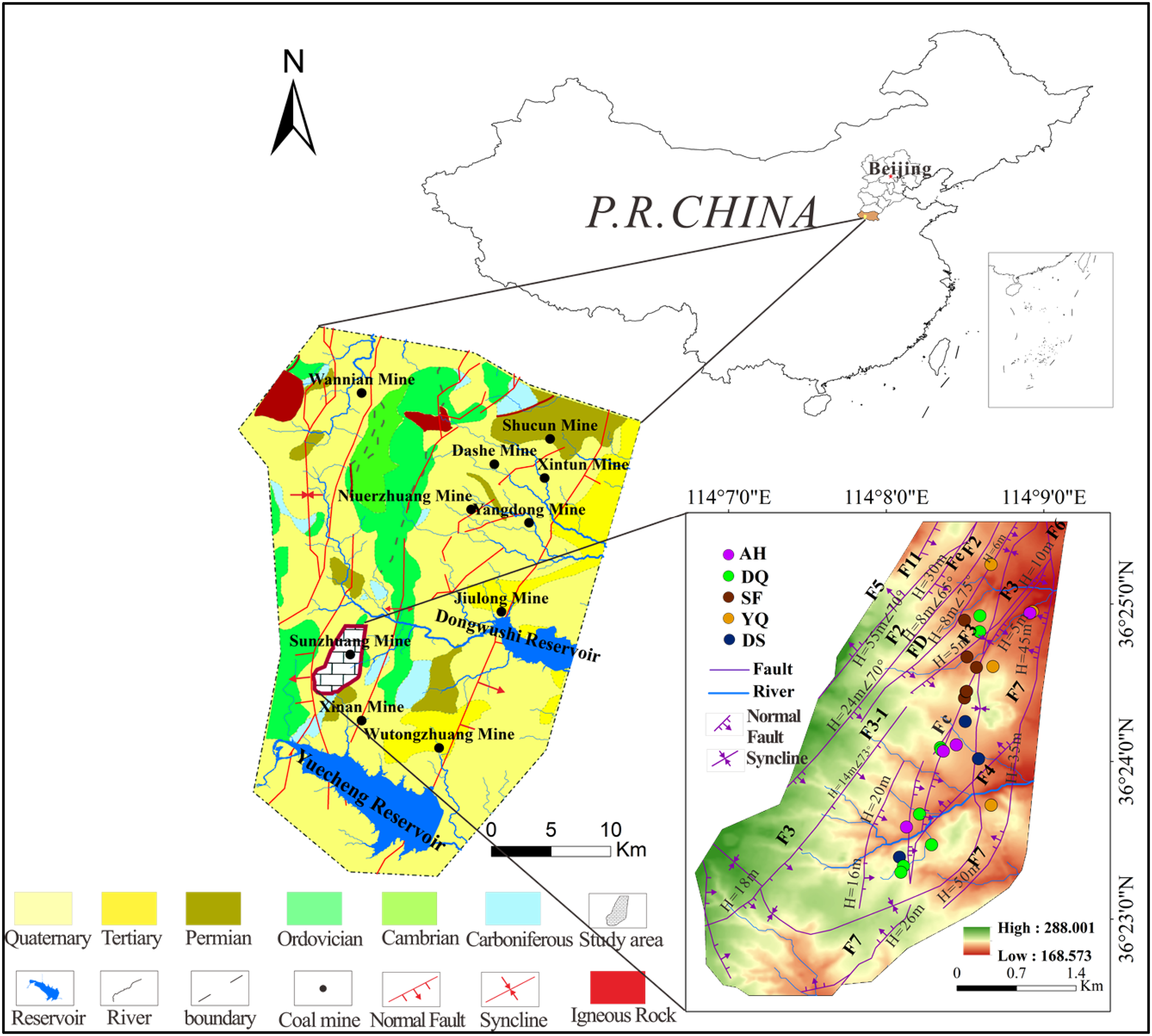
Overview of the study area and sampling point distribution.
Hydrogeological conditions of the study area
The Fengfeng mining area, a critical energy and industrial base in North China, is located in southwestern Handan City, Hebei Province, as a part of the Handan-Xingtai hydrogeological unit (Qu et al., 2018). Over half a century of intensive mining has significantly altered the in situ stress, displacement, seepage, and hydrogeochemical fields of the surrounding rock, leading to complex hydrogeological conditions and frequent water-inrush incidents (Zhang et al., 2022). Sunzhuang Minefield has achieved a peak annual output of 120 Mt. Its operations, which mine three main coal seams at depths down to approximately −500 m, face significant water-inrush threats from multiple aquifers. Previous research on this minefield has predominantly focused on prevention measures against Ordovician limestone confined water (Sun et al., 2019; Hao et al., 2021; Kai et al., 2023). Limited studies have investigated vertical hydraulic connections among multiple aquifers or water-inrush source identification. Particularly, thin-layer limestone aquifers have often been treated as generalized units without further subdivision in most existing studies (Guo et al., 2017; Sun et al., 2023).
The Sunzhuang Minefield, located in the southwestern part of the mining area, is characterized by low mountainous and hilly topography, with elevations ranging from +288 to +168 m and a general slope from southwest to northeast. During deep mining operations, three major water-inrush aquifer types are encountered: (1) Quaternary weathered bedrock porous aquifers, (2) Permian sandstone fractured aquifers, and (3) Carboniferous and Ordovician limestone karst-fractured aquifers. Years of hydrogeological exploration and mining exposure have revealed nine distinct aquifers from top to bottom (Figure 2). The Quaternary weathered bedrock aquifer and Shihezi sandstone aquifer are excluded from this study as they exhibit weak water-bearing properties and maintain considerable distances from working faces during deep mining operations. The Permian sandstone aquifer primarily consists of the Shanxi Formation fractured sandstone aquifer. The Carboniferous limestone karst-fractured aquifers include five subunits: Yeqing limestone, Shanqing limestone, Fuqing limestone, Xiaoqing limestone, and Daqing limestone aquifers. Due to their spatial contiguity and hydrogeochemical consistency, the Shanqing and Fuqing limestone aquifers are combined into a single unit, the Shanfuqing limestone aquifer. The Xiaoqing limestone aquifer is excluded from this study due to its weak water yield capacity. The Ordovician limestone karst aquifer, which forms the bedrock of the coal seams, exhibits an exceptionally strong yet heterogeneous water yield capacity.

Comprehensive histogram of strata in the study area.
Materials and methods
Sampling and test methods
The distribution of water sampling points is presented in Figure 1. Some sampling locations overlap due to their close proximity. All polyethylene bottles were triple-rinsed with source water at each sampling point. Water samples were collected in bottles filled to capacity (no headspace) and immediately sealed with caps, and labeled on-site. No preservatives were added, with samples being stored at 4 °C and transported to the laboratory within 24 hours for conventional component analysis. Due to hydrogeological constraints in field sampling, the number of collected samples was insufficient for systematic characterization of major water-inrush aquifers in Sunzhuang Minefield. Therefore, supplementary hydrogeochemical data from the past decade were obtained from the mine operator. To ensure data validity, ionic balance verification was performed for each sample (equation (1)), where E represents the charge balance error (%); mc and ma the molar concentrations of cations and anions (mol/L), respectively; and Z the ionic charge number. Samples with a charge balance error exceeding the range of ±5% were discarded.
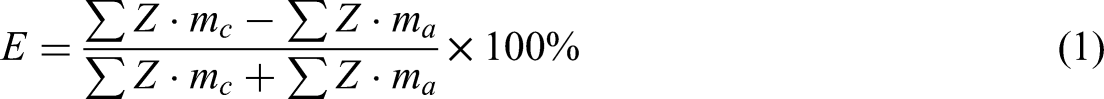
After eliminating disqualified data, a total of 86 groundwater samples were retained for analysis. This dataset included 16 samples from the Permian sandstone fractured aquifers (DS), 13 from Yeqing limestone aquifer (YQ), 16 from Shanfuqing limestone aquifer (SF), 20 from Daqing limestone aquifer (DQ), 15 from Ordovician limestone karst aquifers (AH), and 6 from water-inrush samples. Discrimination indicators included six major ions (Ca²+, Mg²+, K+ + Na+, HCO₃−, SO₄²−, Cl−) and three physicochemical parameters: electrical conductivity (EC), total dissolved solids (TDS), and total hardness (TH).
Entropy weight: Variable fuzzy set theory
Weight determination
Weight determination is crucial for calculating comprehensive relative membership degrees, as appropriate weight allocation directly impacts the accuracy of identification results. To achieve this objectively, we employed the Entropy Weight Method (EWM). In this context, entropy is a measure of the data dispersion for a given indicator. Its value reflects the amount of useful information that indicator provides. The core principle is that the greater the variability of an indicator's data across samples, the more valuable it is for classification. Specifically, an indicator with a small entropy value exhibits high data variation, making it highly effective for distinguishing between samples, and it is thus assigned a high weight. Conversely, an indicator with a large entropy value has more uniform data, offers less discriminatory power, and is therefore assigned a low weight. By determining weights based on the inherent variability of the data itself, the EWM provides a robust and objective foundation for our multi-indicator evaluation. The weight calculation procedure is as follows:
Construct the mean matrix A = (aij)m
×
n. Based on actual measurement data, establish a normalized table with m rows representing evaluation objects and n columns representing evaluation indicators. For m evaluation objects classified into k categories, each element aij in matrix A represents the mean value of corresponding evaluation objects (i = 1, 2, …, m; j = 1, 2, …, n). Data standardization: The range method was applied to normalize the measured data, eliminating dimensional and scale differences among variables. The standardized values for n indicators (x₁j, x₂j, …, xmj) are denoted as zij, as expressed in equation (3): Probability matrix calculation: For the j-th indicator of the i-th sample, probability normalization was performed with non-negative translation to determine proportion weights, as shown in equation (4): The entropy value calculation formula for evaluation indicators is given by equation (5): Determination of evaluation indicator weights. The entropy weight wj for each indicator essentially represents the proportional information utility value dj among different indicators within the same sample, where a higher dj value corresponds to a greater weight. The calculation formulas are given by equations (6) and (7):
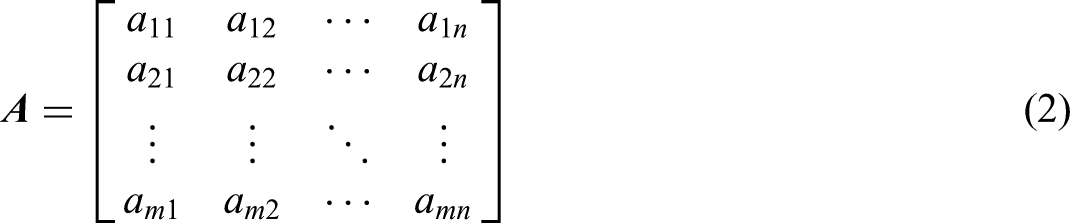
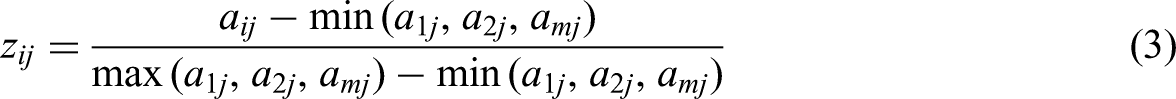

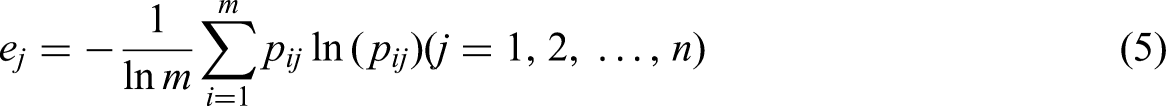


Relative membership degree
Let A be a fuzzy concept set on the universe of discourse U. Fuzzy sets are mathematical constructs designed to represent vague conceptual categories, where u denotes any element in
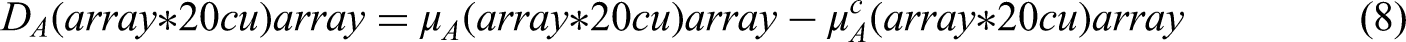
DA(u) is the represents the relative difference degree of u to fuzzy set A, µA(u) ∈[0,1], µAc(u) ∈[0,1], and µA(u) + µAc(u) = 1. When defining the relative difference degree of u to A as a mapping,
DA:D→[−1,1], u|→DA(u) ∈[−1,1], the relative membership degree µA(u) can be derived by equations (9) to (11).

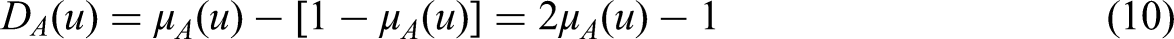

Determining the relative difference degree DA(u) becomes pivotal for computing the relative membership degrees.
Relative difference degree
According to the definition of variable fuzzy sets, let X0 = [a,b] be the attractive domain on the axis where the relative difference degree satisfies 0 < DA(u) ≤ 1. Let X = [c,d] be an extended interval containing X0 (X0⊂X), where subintervals [c,a] and [b,d] represent the repulsive domain with −1 ≤ DA(u) < 0. Point M within [a,b], typically the midpoint of the interval, satisfies DA(u) = 1. The positional relationships among M, [a,b] and [c,d] are illustrated in Figure 3.

The positional relationships among M, [a,b] and [c,d].
Let any value x within the interval X, when x lies to the left of point M, the relative difference function model is given by equation (12):
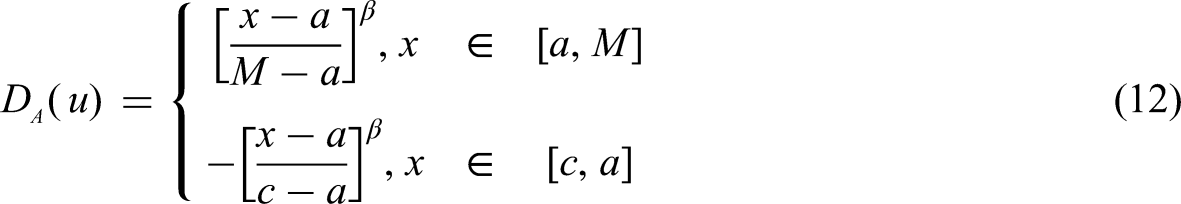
When x lies to the right of point M, the relative difference function model is given by equation (13):
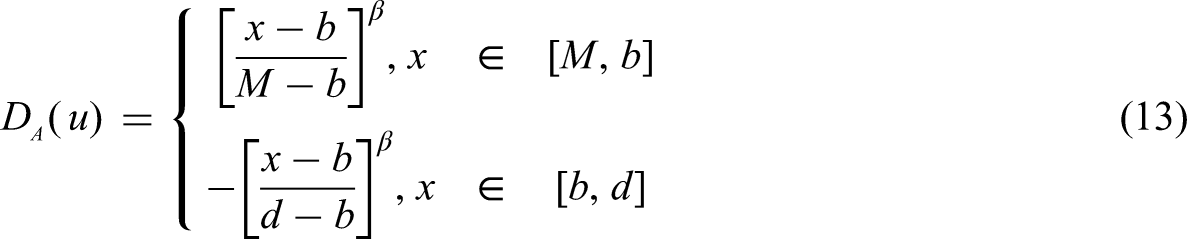
When
Comprehensive relative membership degree
For the s-th sample to be identified, let ush represent its comprehensive relative membership degree with respect to rank variable h, the weight wj of the j-th indicator is determined by the entropy weight method and μA(jh) denotes the relative membership degree of indicator j to rank variable h. The comprehensive relative membership degree ush can then be calculated using the variable fuzzy set recognition model, as shown in equation (14):



In equations (14)–(16), a denotes the optimization criterion parameter (with a = 1 for least absolute deviations and a = 2 for least squares), n the number of indicators; p the distance parameter (where p = 1 indicates Hamming distance and p = 2 Euclidean distance); dhg the dissimilarity between sample s and water source h, while dhb denotes their similarity.
Rank feature value
To transform fuzzy membership degrees into continuous quantitative indices, we define the sample's rank feature value Hi, as equation (17):

The Hi comprehensively integrates all information regarding the h and the μsh, thereby enabling a more holistic and objective determination of the classification level for sample s. Consequently, Hi serves as an effective predictor of the membership relationship of sample s. Moreover, Hi is a numerical descriptor of fuzzy conceptual levels, typically noninteger valued and bounded by 0 ≤ Hi ≤ i. Geometrically, within the h-μsh coordinate plane, Hi corresponds to the centroid position of the figure formed by the h and µsh. Therefore, this study employs Hi for predictive classification, rather than relying solely on the maximum membership principle for direct level assignment (Chen and Guo, 2005).
Integer distance evaluation
In water source discrimination, the ideal rank feature value Hi for sample si should closely approximate the aquifer category. Hi should approach integer values (e.g. 1, 2, 3,…) to clearly indicate which class the sample belongs to. The distance between each sample's Hi value and its nearest integer category is calculated under different parameters, with smaller distances indicating more accurate classification results. The absolute difference between Hi and their nearest integers under varying parameters is computed as shown in equation (18):

The mean value

A smaller
To provide a clear overview of the entire process, the computational procedure of the EW-VFS model is visualized in the schematic flowchart in Figure 4.
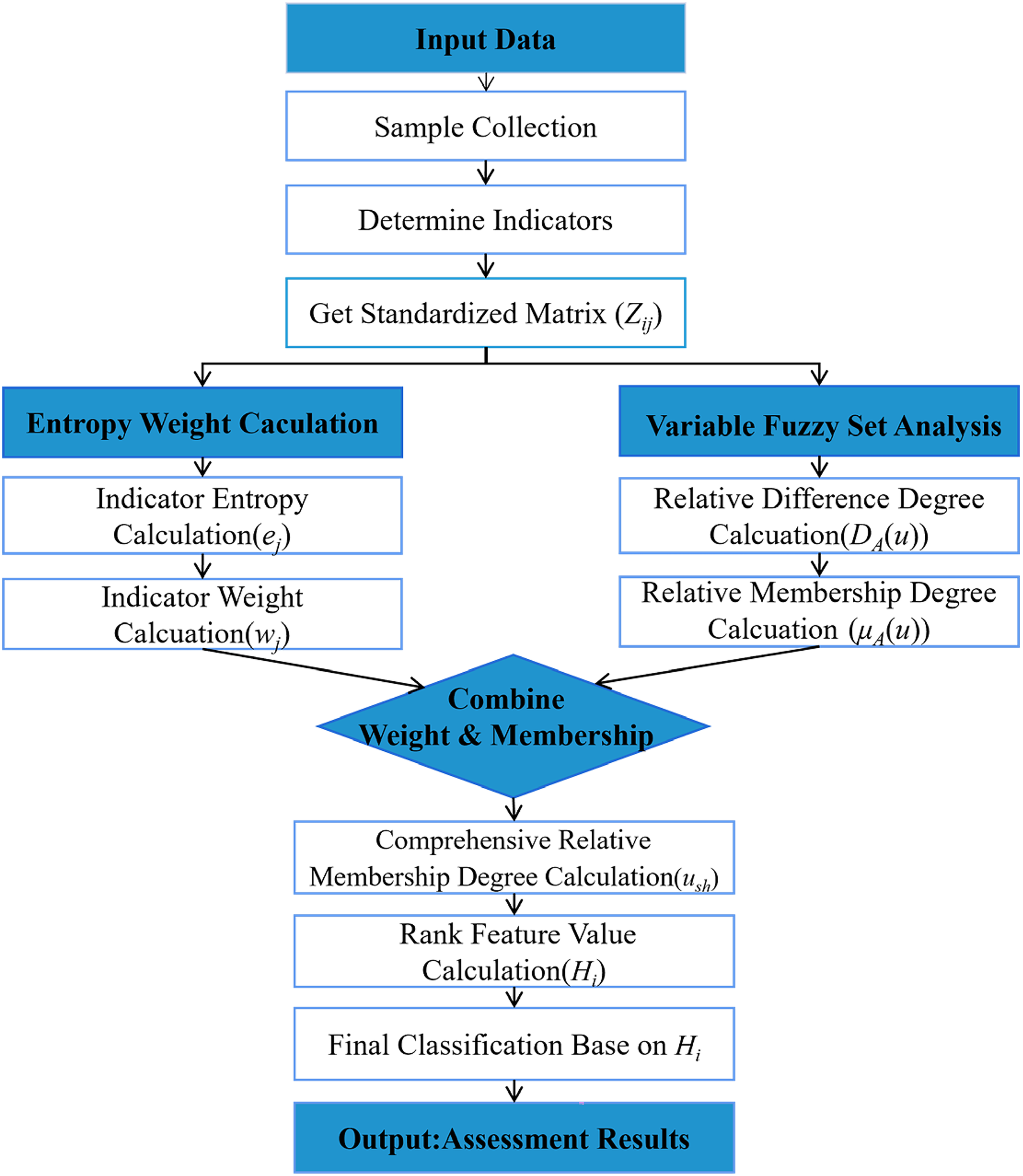
Schematic flowchart of the EW-VFS model steps.
Result and discussion
Descriptive statistical analysis of indicator
A statistical analysis was performed on conventional hydrogeochemical components and physicochemical parameters from 80 groundwater samples collected in the Sunzhuang Minefield, with the original mass concentrations of each indicator presented as box plots (Figure 5). In box plots, the left and right boundaries of the rectangular boxes correspond to the 25th (Q1) and 75th percentiles (Q3), respectively (Qian et al., 2018), while the central line represents the median. Square markers indicate mean values, and the whiskers extend to the minimum and maximum concentrations, with data points outside this range classified as outliers. Figure 5 can clearly demonstrate the distribution patterns of each parameter across the five aquifers and distinct variations of the same parameter among different aquifer types.
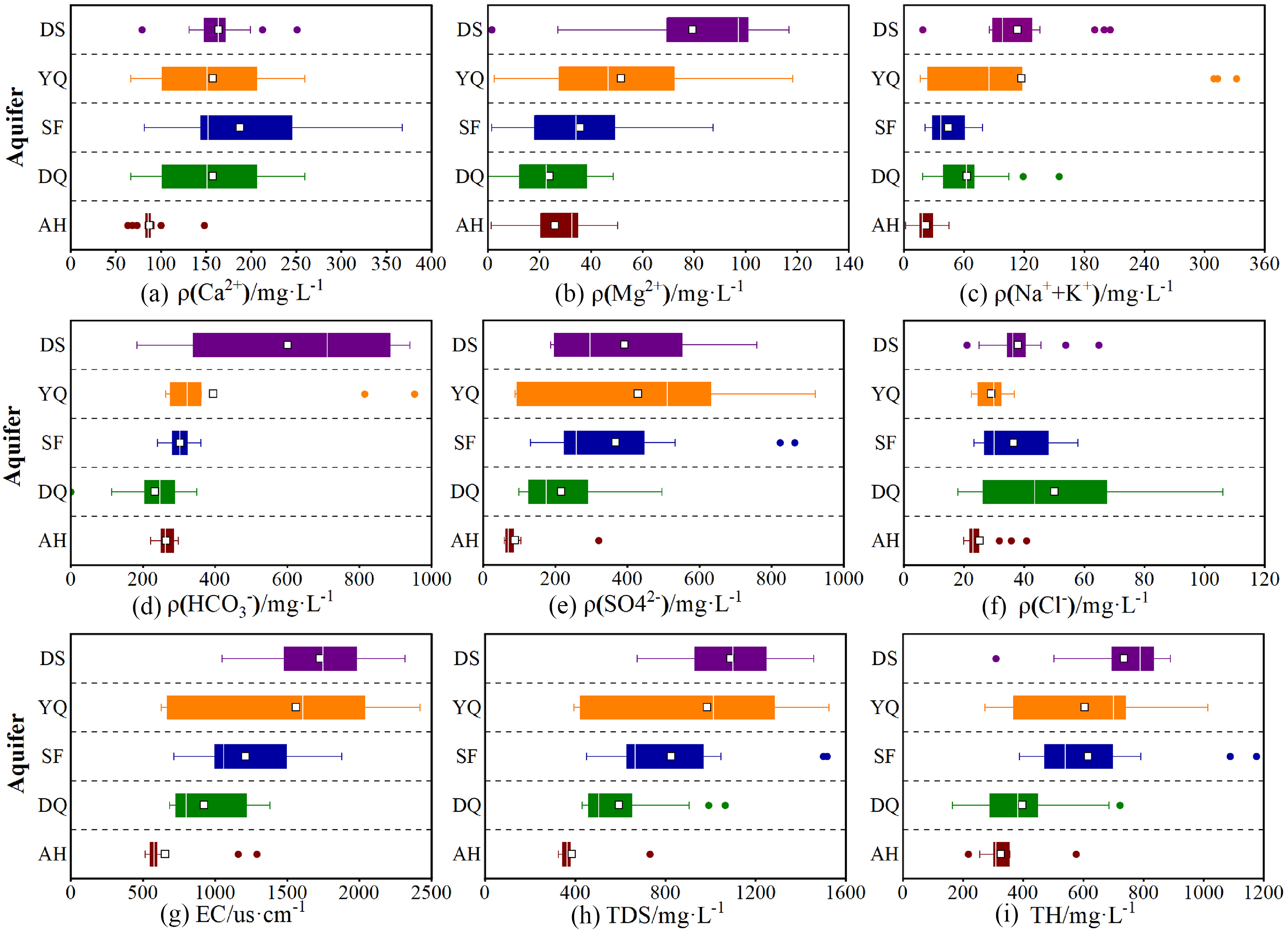
Box plots of conventional components and physicochemical parameters.
As evidenced by box plots B and D, the DS aquifer exhibits the highest mean concentrations of Mg²+ and HCO₃−, which serve as effective discriminators to distinguish it from other aquifers. The YQ aquifer shows higher SO₄²− concentrations, while the SF aquifer contains the maximum Ca²+ levels. The DQ aquifer is characterized by elevated Cl− concentrations coupled with depressed HCO₃− levels, whereas the AH aquifer displays the lowest concentrations of Ca²+, Na+ + K+, SO₄²−, and Cl− among all aquifers. These hydrogeochemical characteristics of the five aquifers are intrinsically linked to their host rock lithologies. The three physicochemical parameters (EC, TDS, and TH) exhibit a decreasing trend with increasing aquifer depth. Although parameter variations exist across aquifers, their values consistently cluster within specific ranges, showing higher probabilities near median values. This distribution pattern aligns with variable fuzzy set theory, where proximity to characteristic values enhances attraction (identification capability), whereas deviation increases repulsion (reduces identifiability). To enhance data robustness, the interquartile range (25%–75%) was adopted for analysis, with identified outliers being excluded.
Table 1 presents the statistical results after outlier removal for each aquifer. The data reveal that all aquifers in the study area exhibit high water hardness, classified as very hard water (TH > 180 mg/L). While the DS aquifer shows brackish characteristics (1000 mg/L < TDS < 3000 mg/L), the remaining aquifers maintain average TDS concentrations below 1000 mg/L, qualifying as freshwater. The coefficient of variation (CV), which quantifies data dispersion, exceeds 30% for HCO₃− and SO₄²− in the DS aquifer, Mg²+, Na+ + K+ and SO₄²− in the YQ aquifer, Ca²+ and SO₄²− in the SF aquifer, and Mg²+ in the DQ aquifer, indicating relatively high data variability. Other parameters across aquifers demonstrate lower CV values (<30%), reflecting more concentrated distributions within specific ranges (Zhang et al., 2020a).
Statistical results of aquifer parameters after outlier removal.
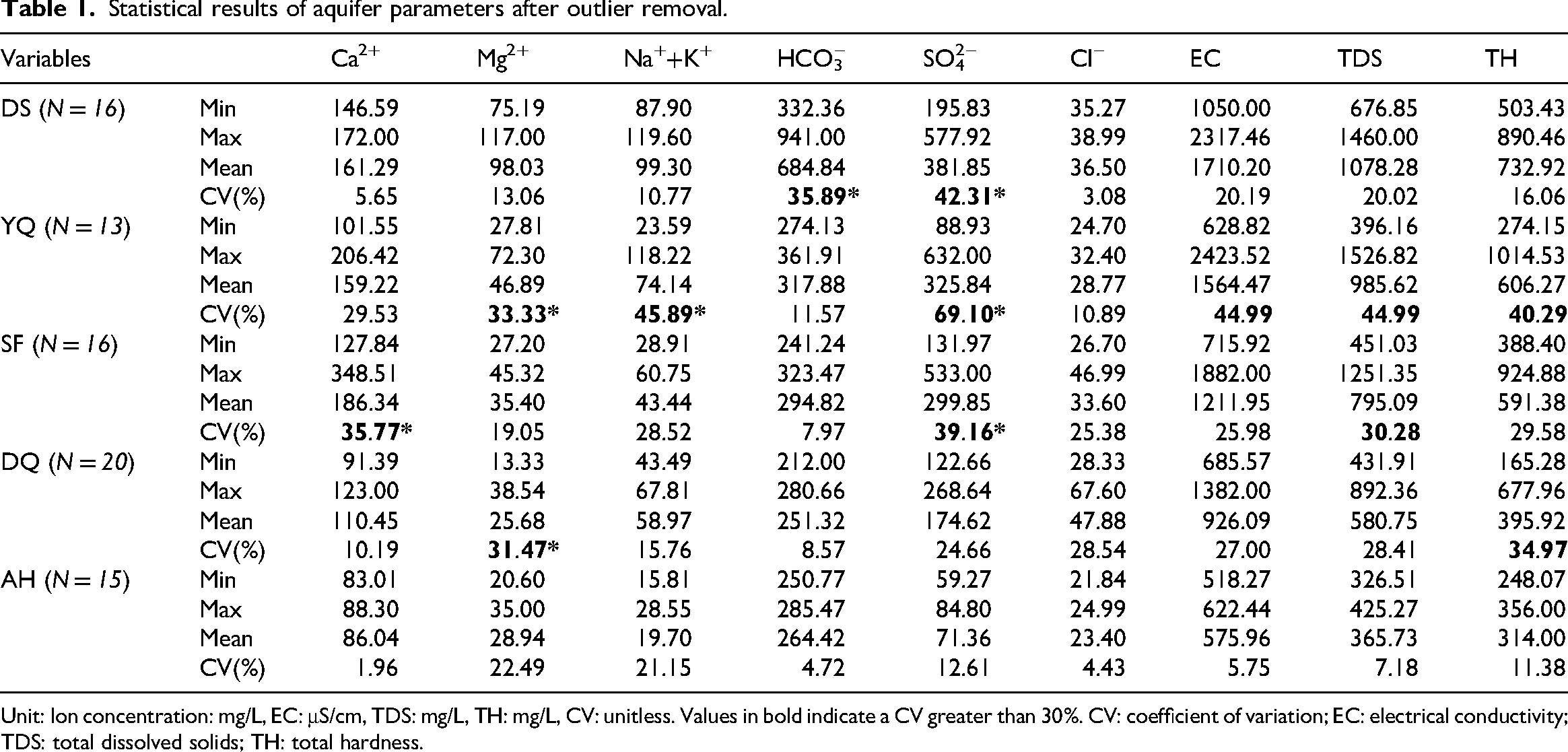
Unit: Ion concentration: mg/L, EC: μS/cm, TDS: mg/L, TH: mg/L, CV: unitless. Values in bold indicate a CV greater than 30%. CV: coefficient of variation; EC: electrical conductivity; TDS: total dissolved solids; TH: total hardness.
Outliers in hydrogeochemical indicators for each aquifer were determined using box plot analysis, with subsequent data processing conducted, six conventional ions were selected to form the basis for developing the water source identification model. Since EC, TDS, and TH are linear combinations of these conventional ions (Hussain et al., 2019), to prevent data redundancy and maintain model discriminative performance, these parameters were retained solely for statistical characterization.
Development of discrimination model
In this study, we established identification intervals using 80 water samples from 5 types of aquifers as the training set. For this set, the influence of outlier values within each indicator was addressed by using the mean-standard deviation classification method (Wang et al., 2017) to determine threshold parameters: [a, b] = [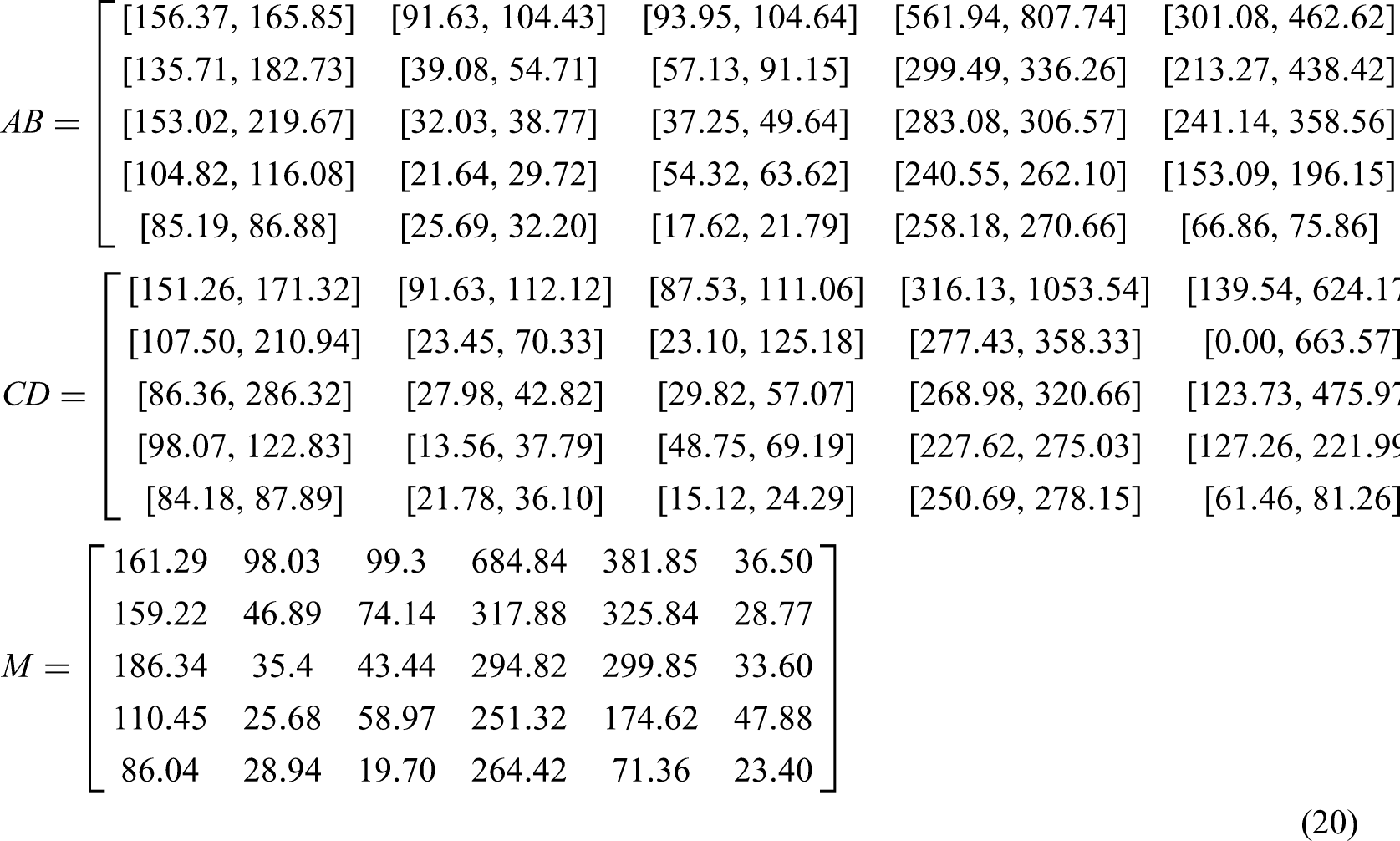
Based on the positional relationships among matrices AB, CD, and M, equations (12) to (13) were applied to calculate their relative difference degrees, while equation (10) was used to determine the relative membership degrees.
We calculated the entropy values and corresponding weights of each hydrogeochemical indicator using the entropy weight method (equations (5) and (6)), with results summarized in Table 2. The analysis revealed that Mg2+ and HCO3− carried significantly higher weights of 0.2467 and 0.3079, respectively, compared to other indicators. Collectively, these two ions accounted for 55.46% of the total weighting, demonstrating their more dispersed distributions across the five aquifer types and highlighting their particular importance in discriminating water-inrush sources among different aquifers.
Entropy values and weights of each indicator.
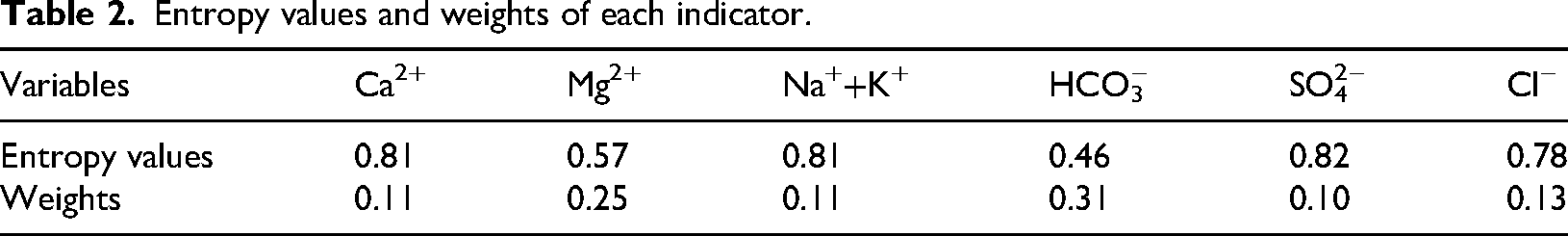
Following the calculation of relative membership degrees µA(u) and weight values wj, the comprehensive relative membership degree µsh and rank feature value Hi were determined using equation (14) and (17). The water source type was identified by optimizing the model through maximum membership degree and rank feature value analysis.
Water inrush source identification
The 12661 working face in Sunzhuang Coal Mine is the first mining panel of the No. 6 coal seam, located at a depth of 500 m below surface. Understanding its hydrogeological conditions during mining provides critical guidance for subsequent mining under pressure safe production. The SF limestone aquifer is the immediate roof of the working face, predominantly manifested roof water dripping and floor water seepage during extraction operations. When encountering structural fractured zones, the water inflow transient increased, causing measurable impacts on mining productivity. The DQ is confined aquifer in the floor, featuring developed karst fissures and hydraulic connectivity with the AH aquifer, demonstrated high water abundance. Its water-inrush coefficient of 0.06 MPa/m (Li et al., 2024) exceeded the critical threshold, indicating significant outburst risks. Prior to mining, surface-based regional groundwater grouting control was conducted on the DQ aquifer of working face 12661, with systematic slurry injection into fissure networks. Post-treatment verification confirmed the successful transformation of the DQ aquifer into a weakly permeable aquifer or relatively impermeable layer, significantly enhancing the floor aquiclude's water-resisting and pressure-bearing capacity. Investigation confirmed the working face is unaffected by atmospheric precipitation, goaf water, and fault water.
Water-inrush incidents occurred during formal mining operations after regional groundwater grouting control. To discrimination the water sources, six water samples were collected sequentially at the water-inrush point for hydrogeochemical analysis. The established discrimination model was then applied to predict the source aquifers of these inrush samples, with the measure parameters and corresponding results detailed in Table 3.
Water-inrush source identification results.
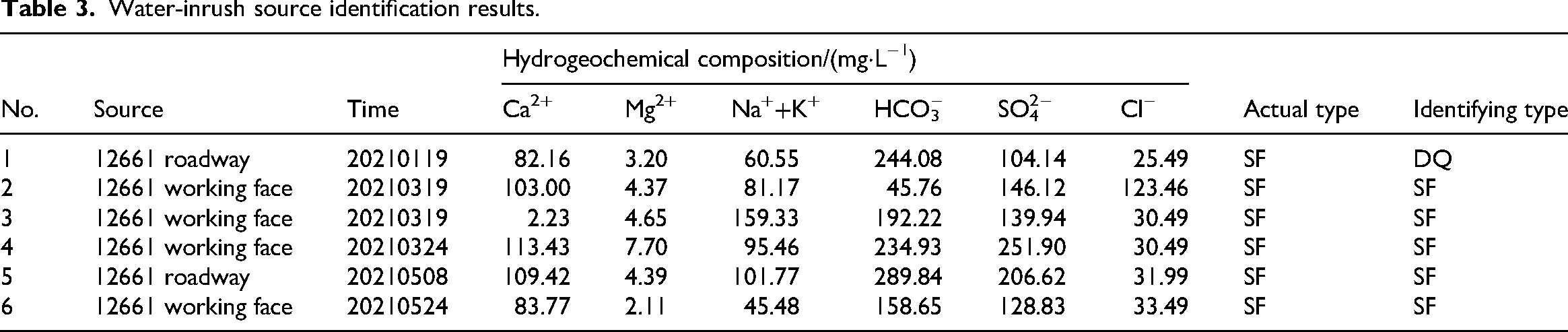
Taking water-inrush sample 1 s1j = (82.16, 3.20, 60.55, 244.08, 104.14, 25.49) as an example, the first parameter s11 (Ca2+ concentration) was compared with the corresponding Ca2+ values in matrices AB1h, CD1h, and M1h from equation (20) to determine their relative positions. For instance:
Given s11 = 82.16, a11 = [156.73, 165.85], c11 = [151.26, 171.32], and M11 = 161.29, the condition s11∉[c,d] therefore relative difference degree DA(s11) = −1. Subsequently, the relative membership degree µA(s11) = 0 was calculated using equation (11). Similarly, the relative membership degrees of s11 for other h-level intervals (representing different aquifers) were determined, forming the relative membership degree matrix U(s1).
The comprehensive membership degree vector μ1h for water-inrush sample s1 was calculated using the weights from Table 2 and equation (14), with the optimization criterion parameter set as α=2 and distance parameter p = 1.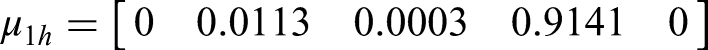
After normalization, the results are as follows: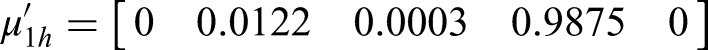
The rank feature values (Hi) were calculated using equation (17) as follows: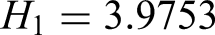
According to the evaluation criterion for rank feature values (Chen and Han, 2006): if H ∈ [h−0.5, h + 0.5] (h = 1, 2, 3, 4, 5), the evaluated sample is classified as grade h. In this study, the water sources DS, YQ, SF, DQ, and AH correspond to grades 1, 2, 3, 4, and 5, respectively. Since H₁ = 3.9753 ∈ [3.5, 4.5], it is conclusively identified as grade 4 water (DQ water).
Analysis of results
Based on the above content, the sources of the other five water-inrush samples were successfully identified, with classification results presented in Table 4. The entropy-weighted fuzzy variable set model achieved an overall accuracy of 83.33%, correctly identifying five of the six test samples. This result demonstrates both the advancement and reliability of our model. Specifically, it surpasses the 75.86% accuracy achieved by traditional fuzzy methods in the same study area (Guo et al., 2017). Furthermore, it is consistent with the 87.5% accuracy reported for this method in other contexts (Wang et al., 2017). As evident from Table 4, the model demonstrates particularly strong performance in discriminating DS and AH aquifers.
Comprehensive relative membership degrees and rank feature values.
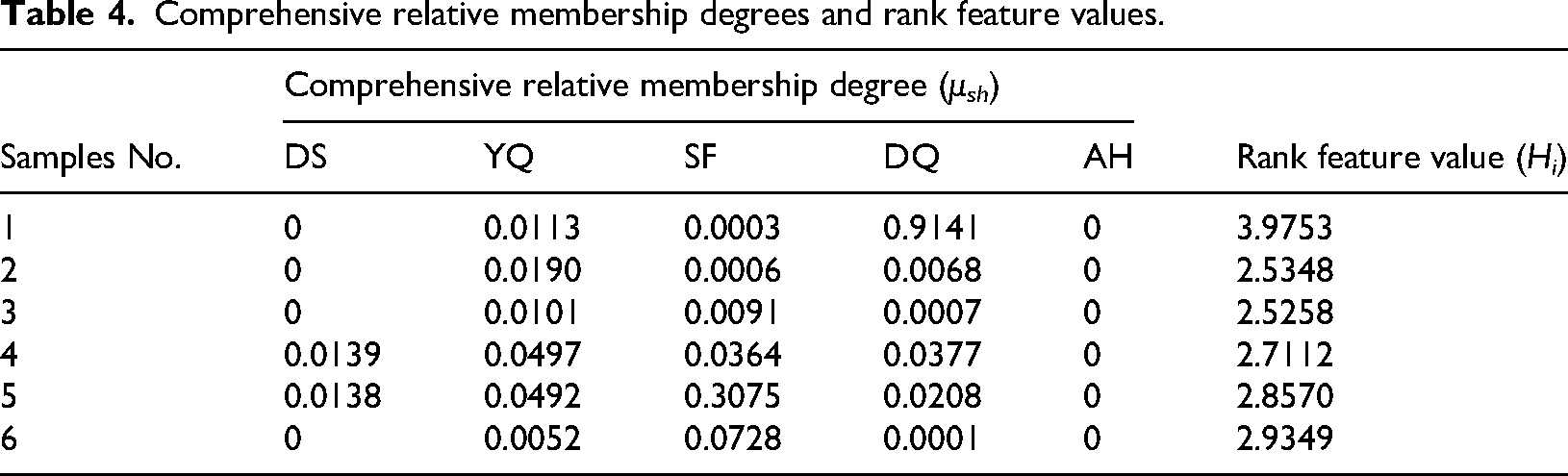
Figure 6 plots the data from Table 4 as a line chart, using the Hi values of six water samples to quantify the dynamic transition of the inrush source. This transition shows a shift from water predominantly from the DQ aquifer to water dominated by the SF aquifer due to mining disturbances. Figure 7 presents the conceptual model illustrating this mining-induced water source evolution. As shown in Figure 7(a) illustrating the postgrouting and premining stage. Surface-based regional groundwater grouting control was conducted in the mining area, including sealing of primary fractures and other water-conducting pathways, as well as reinforcement and thickening of the aquiclude, to reduce the risk of water inrush from the DQ confined aquifer into the working face. Figure 7(b) illustrating mixed inflow stage dominated by DQ aquifer. Mining-induced disturbances have generated secondary fractures in the roof and floor strata, which establish hydraulic connections with aquifers. Despite prior regional groundwater grouting control, localized residual inflows of DQ confined water may still reach the working face. This initial stage, water sample 1 (Hi = 3.9753) indicates absolute dominance of DQ water in the inrush source. Figure 7(c) illustrating the SF aquifer groundwater becomes the dominant water-inrush source. With time the pressure and flow rate of the DQ confined aquifer gradually decrease. Water samples 2 and 3, collected subsequently at the same time point, exhibit Hi values of 2.5348 and 2.5258, respectively. This marks the beginning of a transitional phase in the inrush source composition from DQ to SF water. Subsequent samples 4 to 6 demonstrate a continued trend with Hi values rising from 2.7112 to 2.9349, ultimately confirming SF water as the primary inrush source under mining-induced stress conditions.
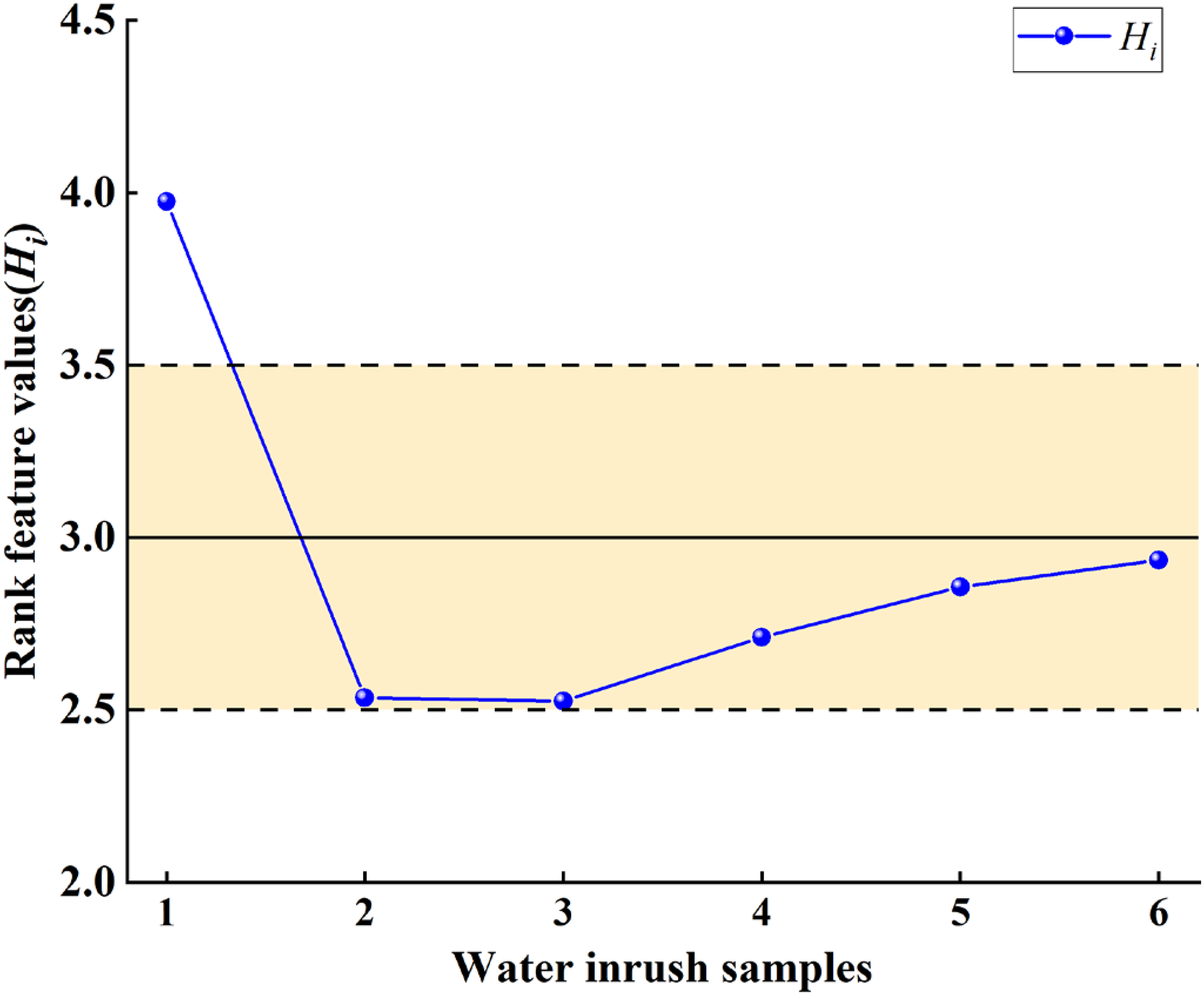
Variation curve of rank feature values (Hi).
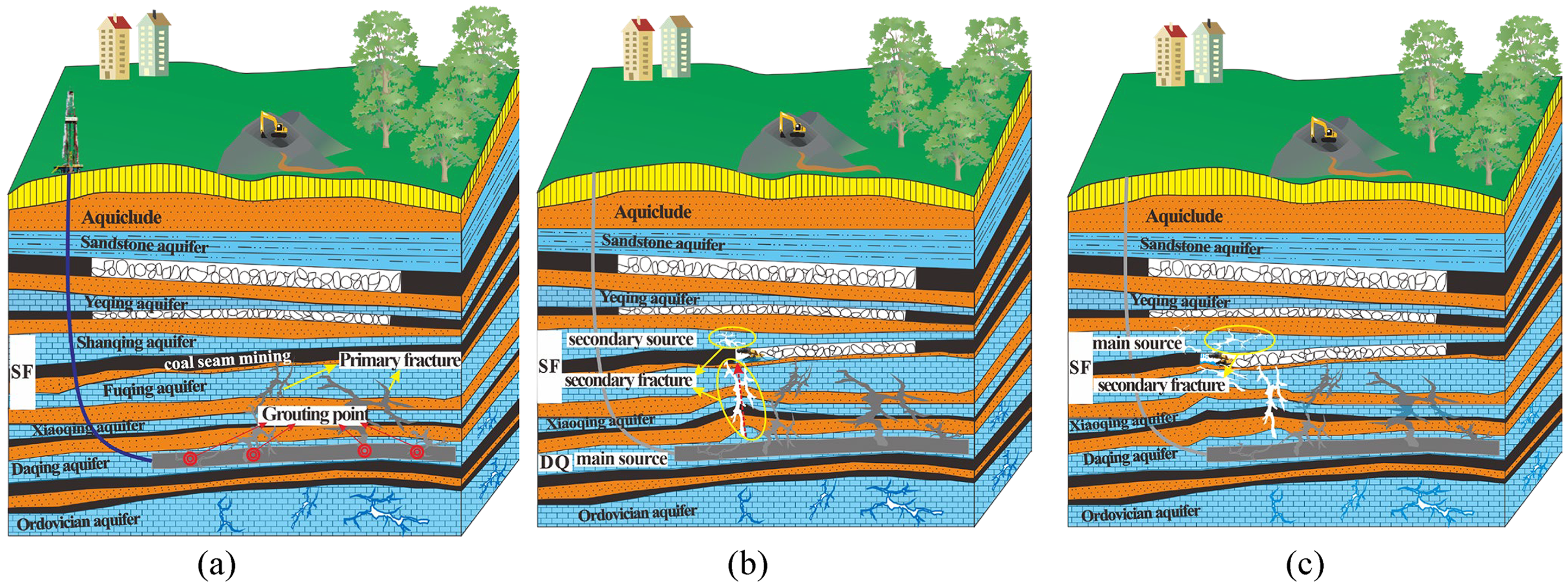
Model diagram of water-inrush process induced by mining. (a) postgrouting and premining preparation; (b) mixed inflow stage dominated by the DQ aquifer; and (c) the SF aquifer groundwater becoming the dominant source.
The misclassification of sample 1 as DQ water primarily stems from two factors: On the one hand, the limited number of reference samples for SF and DQ water led to imprecise discriminant intervals during model construction. For instance, the characteristic interval of threshold parameters [c, d] for Ca²+ in DQ water [98.07, 122.83] was found to be entirely contained within the broader range for SF water [86.36, 286.32]. This interval overlap meant that the model could not uniquely distinguish the two sources based on this key ion, contributing directly to the classification error. On the other hand, hydrogeological analysis revealed that both SF and DQ waters originate from adjacent thin limestone aquifers within the Carboniferous Taiyuan Formation. Combined effects of coal seam mining and confined aquifer pressure promoted the development of water-conducting fracture zones in surrounding rocks. Initial stage, the DQ water preferentially intruded into the working face through these dominant flow pathways, establishing it as the primary water source. Since premining regional floor grouting control effectively transformed the DQ aquifer into a weakly permeable zone. The residual water pressure was rapidly released and progressively diminished over time. Concurrently, SF water as the immediate roof and floor aquifer gradually assumed dominance through developing fracture networks, driving the hydrogeochemical transition from initial DQ water predominance to eventual SF water dominance in subsequent samples.
While the entropy-weighted variable fuzzy set model demonstrated superior performance in distinguishing DS and AH waters, further improvements are needed for accurate identification of thin limestone aquifers.
Table 5 presents the identification results of the entropy-weighted variable fuzzy set model based on equations (14) and (17) under different parameter configurations.
Identification results of the fuzzy variable set model under different parameters.

“*” indicates incorrect identification results.
It is evident that the model yields significantly higher errors in identification when the optimization criterion parameter α = 1 and distance parameter p = 1. The other three parameter combinations produce relatively consistent discrimination results. Using integer distance evaluation for the remaining groups, the calculated Hi values demonstrate that the parameter set α = 2, p = 1 achieves the minimal deviation from the nearest integer class in Table 6. This indicates its classification results best align with theoretical expectations, thus being selected as the final model parameters.
Calculation results of parameters.

The water source identification model developed in this study established discrimination intervals for five aquifer types during water-inrush analysis. Boxplot (Figure 5) visualization revealed overlapping ranges for certain hydrogeochemical indicators. Water samples falling within these overlap zones may decrease identification accuracy due to ambiguous classification boundaries. Therefore, future water source discrimination methods require further optimization based on existing historical data. Firstly, the sampling number should be expanded, for instance, by implementing stratified monitoring programs. Secondly, time-series analysis should be incorporated to study the dynamic hydrogeochemical variations that occur during inrush events. The discrimination thresholds M, [a b], and [c d] should be determined based on comprehensive spatiotemporal water quality monitoring datasets to further enhance the accuracy of water source identification.
Conclusions
Through systematic analysis of hydrogeochemical data from 80 water samples in the Sunzhuang mine field, this study achieved refined classification of aquifers. The boxplot statistical method effectively delineated characteristic indicator ranges for five distinct aquifer types. This analysis established a reliable data foundation for constructing the entropy-weighted variable fuzzy set model. In particular, the discrimination capability of each indicator was determined through coefficient of variation analysis.
The model employed the entropy weight method for objective weighting, identifying Mg²+ and HCO₃− as the most discriminative indicators with respective weights of 24.67% and 30.79%. Based on the entropy-weighted variable fuzzy set approach with dynamic membership functions and rank feature values quantification, it achieved 83.33% accuracy in water-inrush source identification. The model demonstrates effective discrimination between the DS and AH aquifers, but its accuracy in distinguishing thin limestone aquifers requires further improvement.
Temporal evolution analysis based on rank feature values (Hi) revealed a three-phase water-inrush pattern: (1) initial DQ water dominance (Hi = 3.98), (2) transitional mixing of DQ and SF waters (Hi≈2.5), and (3) stable SF water inflow regime (Hi = 2.71–2.93). This finding provides empirical evidence for understanding the evolutionary mechanisms of hydraulic connections among multiple aquifers under mining-induced disturbances.
Although the entropy-weighted variable fuzzy set model successfully achieved dynamic characterization of water source mixing patterns in this study area, the reliability and applicability of the model still heavily depend on the completeness of hydrogeological data. Therefore, it is critical to prioritize the collection and analysis of spatiotemporal water quality data from all major water-inrush aquifers to ensure accurate source identification.
Footnotes
Acknowledgements
We sincerely appreciate Sunzhuang Coal Mine for providing essential data support for this study.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: this work was supported by the Key Research and Development Program of Hebei Province (grant no. 22374204D).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The datasets supporting the findings of this study are available from the corresponding author on reasonable request