
Abstract
Sustainable and inventive city design is becoming more and more dependent on the use of cutting-edge technology as smart cities develop further. Energy efficiency optimization in residential structures is an essential part of the puzzle as it helps conserve resources and keeps the planet habitable. An enhanced Deep Neural Network (DNN) model for household energy efficiency predictions is presented in this research. Our model uses a large dataset of building features, weather, occupancy patterns and energy usage histories. Data is preprocessed, features are engineered and hyperparameters are tweaked to improve DNN prediction. Scalable, easy-to-understand models are essential, as are shifting urban areas and energy landscapes. In this work, the authors have evaluated the proposed model with basic model with different optimizers. Initially, the Stochastic Gradient Descent optimizer applied that gained 91.02% Recall, 93.47% Precision, 93.28% F1-Score, 0.0153 MSE, 0.0166 RMSE and 0.0165 MAE. The proposed model gained 99.52% Recall, 98.91% Precision, 99.09% F1-Score, 0.0140 MSE, 0.0137 RMSE and 0.0139 MAE. By monitoring, analyzing and making decisions in real time, smart city systems can help planners understand energy usage trends. The optimized DNN model advances smart city development by promoting sustainability and resource optimization. Predicting residential buildings’ energy efficiency provides proactive energy savings, cost reduction and environmental impact mitigation. The suggested DNN model shows how smart cities use cutting-edge urban planning to become more sustainable, efficient and resilient.
Keywords
Introduction
Due to urbanization and population growth, home electricity consumption has risen. To meet this need, one must understand the many elements that determine household energy use. Residential architecture and design affect energy usage (Chuan and Ukil, 2015; Yoon et al., 2014). Building orientation, window quantity and placement and materials affect heating, cooling and illumination. Well-planned passive solar design and energy-efficient insulation reduce energy usage. Location dramatically impacts household energy needs. Due to climate change, heating and cooling methods must alter. Natural ventilation and shade can reduce cooling needs in warmer climates, whereas effective heating systems and insulation are needed in colder climes. For efficiency and lifespan, energy solutions must be regionally tailored (Zhang and Baillieul, 2016; Zvaigznitis et al., 2015).
One of the biggest energy consumers in a home is the Heating, ventilation, air conditioning (HVAC) system. Maintenance and efficiency of heating and cooling systems affect energy use. Energy recovery ventilation, smart thermostats and zonal heating improve HVAC performance and reduce energy use (Charai et al., 2018). The building's appliances and lighting greatly impact energy use. Energy Star appliances cut electricity use significantly. LED lighting reduces energy use and saves money and the environment (Guzman et al., 2019; Sava et al., 2018; Ucheaga et al., 2018). Residential energy demands are increasing, making renewable energy source integration essential. Solar panels, wind turbines and other renewable energy sources can generate electricity on-site to encourage a more sustainable energy mix. Dependence on traditional electricity networks may decrease. Smart home technologies enable residential energy optimization. Homeowners may cut energy use using smart thermostats, lighting controls and energy monitoring systems. This boosts efficiency (Al-Rakhami et al., 2019; Touili et al., 2019; Vishwamitra and Nidhish, 2020).
A home's energy needs depend on its occupants’ habits. Promoting energy-saving habits such as turning off lights and using appliances off-peak can reduce usage. Understanding and managing domestic energy needs requires a multifaceted approach. Every facet of a home's energy profile matters, from architecture and climate to appliances and renewable energy use. Raising awareness, adopting new technology and using strategic design concepts can help residential structures meet their energy needs responsibly and sustainably (Hassan et al., 2020; Imran et al., 2020; Maurya et al., 2021).
Problem formulation
Rising household energy consumption is the core of the issue, which affects design, technology, behaviour and the environment. As more people move to cities and electricity needs rise, residential buildings use more energy (Gao et al., 2021). We must identify effective strategies to lower residential buildings’ rising energy consumption without compromising occupants’ comfort, well-being or functionality (Amasyali et al., 2022; Khan et al., 2022; Nakkorn et al., 2022; Nikkhah et al., 2022).
Critical Components of the Problem:
Poor insulation, improper orientation and insufficient window placement are inefficient building design elements that lead to higher energy usage. Different climates call for additional heating, cooling and ventilation strategies, affecting a building's energy use. Inefficient HVAC systems, obsolete technology and poor maintenance cause excessive energy usage for heating and cooling. Unnecessary power utilization is contributed to by appliances and lighting fixtures that are either obsolete or inefficient, which substantially impacts residential buildings’ energy consumption (He et al., 2022). There is a pressing need to incorporate renewable energy sources into residential structures because reliance on conventional energy systems adds to resource stresses and environmental issues (Geske, 2022). An essential factor in energy usage is the habits and behaviours of residents since wasteful activities can counteract the benefits of improved technology and design. Legislative hurdles, technological limitations and economic concerns have hindered renewable energy integration and the broad adoption of energy-efficient technology (Slabe-Erker et al., 2022).
To create a sustainable and energy-conscious living environment for current and future generations, it is necessary to address these components and pursue the stated objectives to develop a thorough and successful plan for reducing the energy needs of residential structures.
Research motivation
Due to increased global energy demand and climate change, new residential construction energy efficiency methods are needed. Traditional energy management methods can't always optimize usage and reduce environmental impact. AI has revolutionized building energy efficiency solutions due to these challenges. As urbanization accelerates, residential buildings consume more of the world's energy. Heating, ventilation, air conditioning systems, electronics and other power-hungry devices need more electricity. Dynamic factors including weather, occupancy patterns and user preferences challenge traditional energy management systems. Static scheduling and rule-based systems may not adapt quickly enough to energy use's many linked elements. AI and machine learning redefine the paradigm by allowing strategies to learn from data, adapt to new conditions and make intelligent decisions without programming. Artificial intelligence algorithms simplify energy efficiency optimization by analyzing large amounts of data, identifying trends and predicting future demands (Adly and El-Khouly, 2022; Farrokhifar et al., 2023; Hernández et al., 2022; Kadrić et al., 2022; Tarek et al., 2022).
AI integration allows smart sensors and IoT devices to collect and evaluate data in real time. Past energy usage, future estimates and user behaviour patterns are needed to create trustworthy models for intelligent decision-making. AI-powered energy efficiency models may alter HVAC, lighting and appliance settings. Because predictive analytics estimate energy needs, the system can optimize comfort and reduce waste. By understanding user preferences, AI can customize the energy efficiency model. Smart home assistants use artificial intelligence to deliver real-time energy usage data and cost-cutting advice. AI allows solar panels and wind turbines to be seamlessly integrated by optimizing their use based on weather and energy demand. Carefully managed energy storage devices can store surplus electricity during off-peak hours. AI's reinforcement learning interactiveness allows the energy efficiency model to improve constantly. The model is updated depending on user feedback and system performance data to stay effective and adaptive (Sood et al., 2023).
Cloud computing is moving closer to data generating and consumption areas via fog computing, sometimes termed edge computing. Instead of the cloud, fog computing moves workloads from remote data centres to edge devices including routers, switches, gateways and IoT nodes. Being proximate to data sources and end-users allows for decreased latency, more efficient bandwidth consumption, better privacy and security and real-time application support. Fog computing brings computational resources closer to data sources, speeding processing and reducing latency for edge applications. Fog computing distributes computing resources across edge devices and cloud servers rather than data centres. Fog computing processes data near the source for real-time apps and services that demand quick insights and reactions. Offloading data processing to edge devices optimizes bandwidth and reduces network congestion. This reduces data sent to centralized servers. Fog computing scales and distributes resources according to application needs by using edge device processing power. By eliminating the need to transport sensitive data to remote computers for processing, keeping it at the edge improves privacy and reduces data breaches. Fog computing makes distributed systems more fault-tolerant and resilient by reducing centralized infrastructure.
User-friendly AI-powered dashboards track energy usage, expenses and system performance in real time. Users receive notifications and alerts about abnormalities and productivity opportunities. AI-based energy efficiency models work with intelligent grid initiatives to optimize grid and demand responsiveness. AI integration aids sustainability by encouraging resource conservation, carbon reduction and energy efficiency. AI-based residential energy efficiency models are an innovative approach to complex energy management issues. AI can help us meet energy needs and establish a more robust, eco-friendly future by creating more adaptive, user-friendly and sustainable solutions (Ali Yildirim et al., 2023; Aneli et al., 2023; Gal and Nimrod Kutasi, 2023; Kalidindi et al., 2023; Yan et al., 2023).
The proposed model has contributed significantly to the development of new approaches to urban planning research and practice:
This study contributes to the development of a more accurate model for energy efficiency prediction by allowing for the meticulous customization of the Deep Neural Network (DNN) architecture through feature engineering and hyperparameter manipulation. The model may be simply adjusted to fit various types of smart city housing. By incorporating it into smart city systems, the DNN model has been utilized to monitor the energy efficiency of residential buildings in real time. One step closer to the ultimate goal of sustainable urban planning is the model's capacity to assess and improve residential energy consumption. Methods for dealing with dynamic and multidimensional data can be advanced with the use of this suggested model, which can forecast urban energy efficiency.
The complete article is organized as follows. Section 1 covers the introduction, Section 2 covers the related work, Section 3 covers the materials and methods, Section 4 covers the implementation results and discussion. Section 5 covers the conclusion and future works.
Related work
A control technique for HVACs that responds to real-time pricing for peak load reduction is the main emphasis of Yoon et al. (2014). DDRC considers the user's comfort level while adjusting the set-point temperature so the user has less pain. Using the BCVTB, our suggested DDRC is linked to the EnergyPlus model in MATLAB/SIMULINK. The current wholesale price in the ERCOT market in Texas is the basis for the real-time retail price. According to the study, applying DDRC to home HVAC systems may drastically cut power expenditures and peak loads with only a little change in thermal comfort.
Passive systems, conversion devices, methods of service control and levels of service sought are the four categories of energy efficiency interventions studied by Marshall et al. (2016) in their investigation of the supply of heated thermal comfort with lower energy demand. Compared here, the three home occupancy patterns are those of a working couple, a daytime-present couple and an active family. We look at energy efficiency measures alone and in combination to see whether we can get the same results with cheaper measures as with more expensive ones. Using data retrieved from literature, scenarios are simulated using the engineering building modelling program TRNSYS. Regardless of the occupancy level, the most cost-effective solution was to insulate the walls and roof better.
Baniasadi et al. (2018) aim to create a smart home thermal energy management system (TEMS). The main contribution is a novel control method for combined heat and power systems (GSHPs) and water source thermal technology that uses building identification to reduce energy usage and costs. In addition, this article suggests a real-time pricing tariff-based interior dynamic temperature set-point technique to improve heat pump loads during peak-load shifting while allowing for a reasonable amount of thermal comfort fluctuation. According to simulation and experimental findings, the suggested TEMS shows great promise for real-time peak-load turning.
Al-Rakhami et al. (2019) suggested using an ensemble learning method in this study. The proposed method uses the XGBoost algorithm to prevent overfitting issues and construct an effective prediction model. The output answers are heating load (HL) and cooling load (CL). Results from experiments show that the suggested method provides the best forecast performance, which is helpful for engineers and building managers to decide how much energy to use in a building.
An efficient method for the modelling and optimization of a structure with several housing units, including electric cars, energy storage and local shared renewable power generation, is presented by Rezaei and Dagdougui (2020). Our goal is to assist decision-makers in a multi-unit building with their energy consumption by creating a model predictive control that can efficiently regulate the HVAC system in each unit. This will lower the building's electric bill and improve the matching performance of local generation and consumption. A housing complex in the Montreal region has found a solution to their difficulty. The findings demonstrate how practical the suggested approach is.
A new fully convolutional denoising auto-encoder (dAE) architecture is proposed by Garcia-Perez et al. (2021) as an easy-to-use NILM system for big non-residential buildings. It is contrasted with earlier dAE methods that used actual hospital power consumption data, focusing on specific features of big buildings. Additionally, we demonstrate via three use cases that our method offers additional beneficial functionalities for energy management chores in significant buildings, including meter replacement, gap filling and novelty identification.
Siddique et al. (2022) investigate the advantages of combining detailed building typology with measured heat demand data to allocate rehabilitation subsidies effectively. We create an optimization model to measure the effect of inaccurate heat demand estimations on subsidy distribution and quantify the missing CO2 emissions. We discover systematic bias in heat demand estimations that, when applied to the case study of Lyngby-Taarbaek municipality in Denmark, give older houses a more considerable heat need than they have and, conversely, give newer family residences a lower heat demand. This prejudice distorts 40% of the overall subsidy and causes 39% of the CO2 emissions to be misallocated. We hope that governments will use our findings to prioritize decarbonization efforts based on which buildings will have the most impact.
Research by Es-Sakali et al. (2022) is focused on determining how various types of glazing impact the amount of energy required for heating and cooling a structure. A structure situated in a semi-arid area was utilized as a real-life case study. The OpenStudio simulation engine was used to perform the building energy model. We used ASHRAE's statistical indexes to calibrate the inside temperature of the building. The next step was to compare seven distinct window types, including air and argon-filled triple, double and single-paned windows. Windows with argon space, whether triple- or double-glazed, may save yearly energy costs by 37% and 32%, respectively. The technique presented in this work has the potential to inform future research on how to maximize the energy efficiency of buildings through the use of carefully glazed windows.
The feasibility of making geopolymer bricks from ferrosilicon and aluminium slag, two types of industrial waste, was investigated by Tarek et al. (2022). The physico-mechanical characteristics of the bricks demonstrate their compliance with several regulations and guidelines. An even lower thermal conductivity of 0.28 W/mK is attained, in comparison to regular bricks. At last, we used the simple payback time (SPP) to evaluate the bricks’ financial feasibility. The created brick samples had a return on investment estimated at 8.76–15.79 years. Consequently, geopolymer bricks are acknowledged by many as a notable advancement in eco-friendliness.
Using the response surface methodology (RSM), Kadrić et al. (2022) want to investigate the possibility of energy reduction in a typical building from the country's residential construction stock. Using a home listed in Bosnia and Herzegovina's national TABULA register, This research work models the energy savings linked with energy-efficient retrofit measures using RSM in conjunction with EnergyPlus and DesignBuilder, two energy modelling tools. To maximize energy-efficient retrofit design options for decreasing heating and cooling energy consumption in residential buildings, this research work presents a unique energy consumption model. In addition, a nationwide survey on energy usage in Bosnia and Herzegovina was used to validate the created model. Consequently, the created model is adaptable and works well for the fast forecasting of residential building stock energy savings and consumption connected to energy-efficient retrofits.
Adly and El-Khouly (2022) offer a multi-objective approach to evaluating the energy efficiency of luxury homes in arid zone gated communities. Energy efficiency is enhanced by the implementation of building energy rules. There is a lack of implementation of the successful approaches identified by energy codes for attaining energy efficiency on the size of existing urban communities, despite these codes identifying building-scale energy efficiency measures. For residential gated communities to become more energy efficient, this article suggests a way to combine renewable energy sources with energy retrofitting methods. This research work uses simulation analysis to find out how well these tactics work with various construction materials according to the Egyptian Energy Code for Residential Buildings standards. The findings provide a blueprint for improving the energy efficiency of pre-existing structures and neighbourhoods and demonstrate an 88.68% reduction in the overall energy consumption of the gated community.
In their 2023 publication, Rathnayake and Pushpakumara create a grading mechanism for both new and existing structures that are based on priority weights. This research work presents a grading method for building valuations that are based on the Fuzzy Analytical Hierarchy Process. Integrating fundamental engineering, sustainability and adaptation concepts into a building's appraisal process is an additional innovative aspect of this article. Using numerical descriptors also removes any subjectivity from this approach. To build this model, we averaged the thoughts of one hundred experts and kept the consistency ratio of their ideas below 10%. Lastly, a residential structure value is carried out as an example to demonstrate the numerical capabilities of the suggested approach. In real estate transactions, insurance, taxes and investment choices, the proposed model has been utilized to assess both new and old residential structures.
Building envelopes in semi-arid climate zones has been optimized for thermal comfort, energy efficiency and comfort using an integrated framework proposed by Mousavi et al. (2023). This Meta Additive Regression demonstrated greater confidence when analyzing the output variables in green buildings. The findings show that an optimized building envelope may reduce yearly energy use by 50 kW/m2 per household.
The impact of proposed renovation techniques on the energy flexibility reserve of all buildings is quantified by Mugnini et al. (2023) up to 2050. There are flexibility curves that link the cluster's demand to a penalty signal (such as a price signal) and flexibility indicators that compare situations with and without energy flexibility turned on. The findings provide a numerical assessment of how various techniques for refurbishing Italy's building portfolio affected efficiency goals and flexibility reserves. It is projected that by 2050, the total electrical power that can be adjusted (upwards and downwards) by utilizing the energy flexibility of all buildings might reach 17.9 GWe. These amounts correspond to approximately 2% of the current electricity consumption in Italy.
In their quantitative study, Altieri et al. (2023) used a one-of-a-kind dataset consisting of 92 residential structures to determine the combination of measures that resulted in the greatest reductions in energy use. A black-box model of the complicated connection ‘Optimization measures-Energy Saving’ is created by training an Artificial Neural Network over a particular dataset. By calculating sensitivity indices, we can examine and measure how each optimization measure affects the energy consumption variability. LICOMs may produce a median savings of around 2%. By efficiently employing the selected metamodel-based technique, one may model each input–output link and do sophisticated sensitivity assessments with synthetic data. For focused decision-making, it is crucial to be able to estimate the anticipated energy savings of an optimization measure and its likelihood of success.
Research gaps
Deep learning–based household energy efficiency prediction models have advanced in recent years; however, many questions remain and additional research is needed in these areas:
Smart meters, IoT devices and building management systems are providing more data, but accessibility, granularity and quality are still issues. Researchers should address data sparsity, missing values and inconsistencies to improve prediction models. Feature engineering must be efficient to generate reliable prediction models. However, discovering relevant features and generating meaningful representations from disparate data sources is difficult. Future research in automated feature engineering, dimensionality reduction and domain-specific information may improve model performance. Deep learning models are opaque, making it difficult to decipher their forecasts and find the true causes of high home energy expenditures. Model interpretability methods including feature importance analysis, attention mechanisms and model visualization can help stakeholders comprehend energy consumption trends and improvement opportunities. Predictive models constructed and tested utilizing data from certain areas, building types or periods may be limited in their applicability. Researchers should use domain adaptation, transfer learning and model fine-tuning to deploy energy efficiency models across geographies and building types. Climate, occupancy patterns and socio-economic position affect household energy use. Integrating external data sources improves predictive model accuracy and resilience. Future research should examine deep learning model training methods that incorporate complex interactions and dependencies such as weather predictions, demographic data and other contextual information. Many predictive models cannot quantify the uncertainty of their energy consumption point estimates. Risk and uncertainty management decisions require uncertainty estimation. Probabilistic modelling, Bayesian deep learning and uncertainty quantification techniques may improve stakeholder projections and decision-making.
Moving from research prototypes to real-world deployment involves model scalability, processing efficiency and infrastructure interaction. Energy efficiency models in residential buildings can be implemented using distributed learning, edge computing and lightweight designs to reduce computational overhead and resource restrictions.
Material and method
Dataset
Both the CL and the HL are components of thermal energy that are controlled by the HVAC system of a building. For optimal indoor air quality, the HVAC system is programmed to calculate the space's HL and CL. In this regards, several research has concentrated on assessing livable, environmentally friendly interiors (Cárdenas-Rangel et al., 2023).
Figure 1 demonstrates the data distribution of the dataset. The fundamental criteria that are used to determine the cooling and heating capabilities that are required are the building's attributes, how it is used and the weather (Palladino, 2023; Zahedi et al., 2023). An efficient evaluation of the building's energy performance (EPB) and well-planned HVAC system may guarantee less wasteful energy use. Despite these efforts by many nations, energy consumption is high and expected to rise worldwide. In light of the above, a great number of engineers have worked on various predictive and evaluation methods, with the main objective of creating an ideal estimate of building energy use.
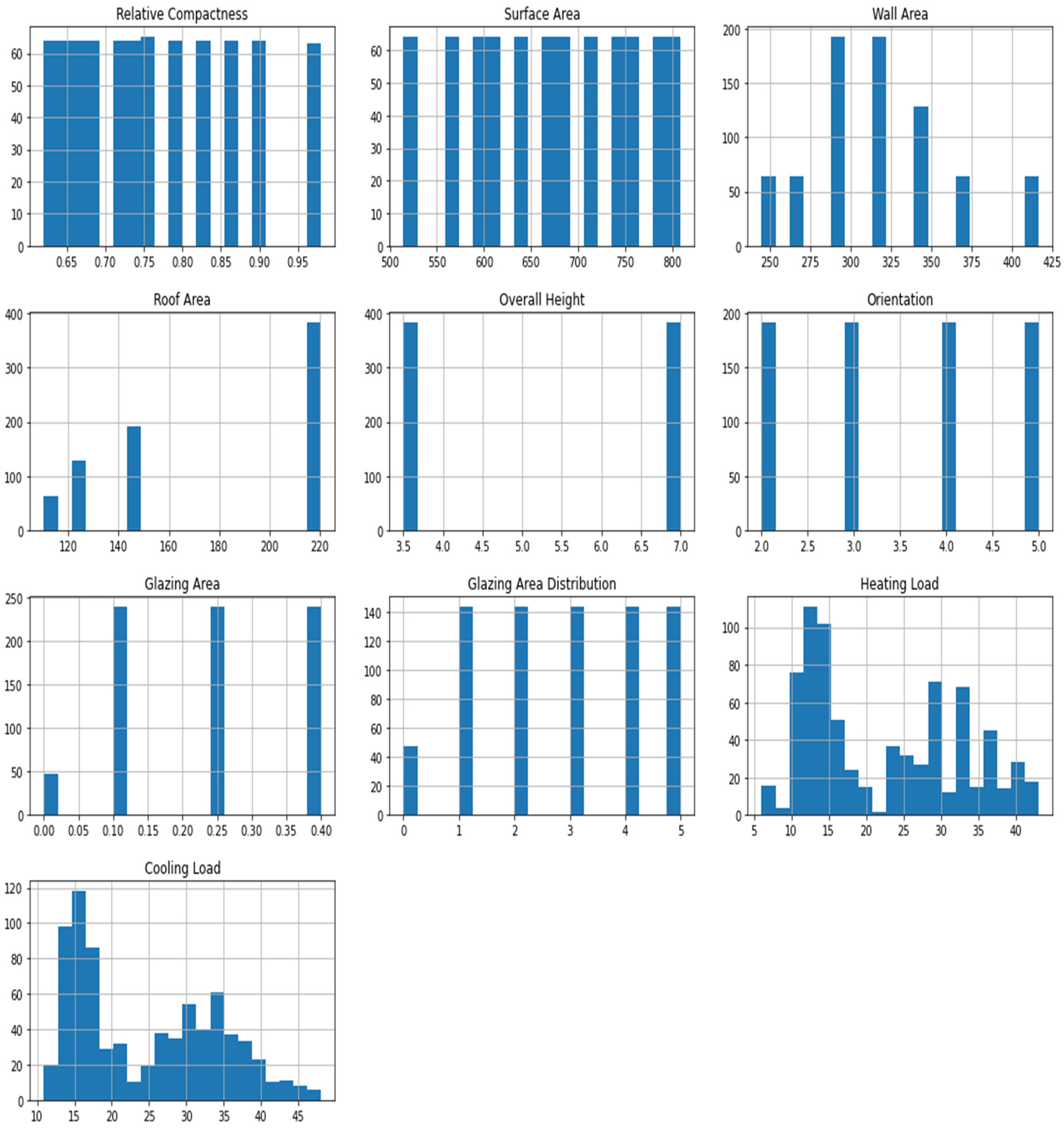
Data distribution of energy dataset.
Figure 2 demonstrates the count of CL vs. Surface Area. The true represents that the attack exists otherwise it is false. Figure 3 highlights the count of CL vs. overall height.
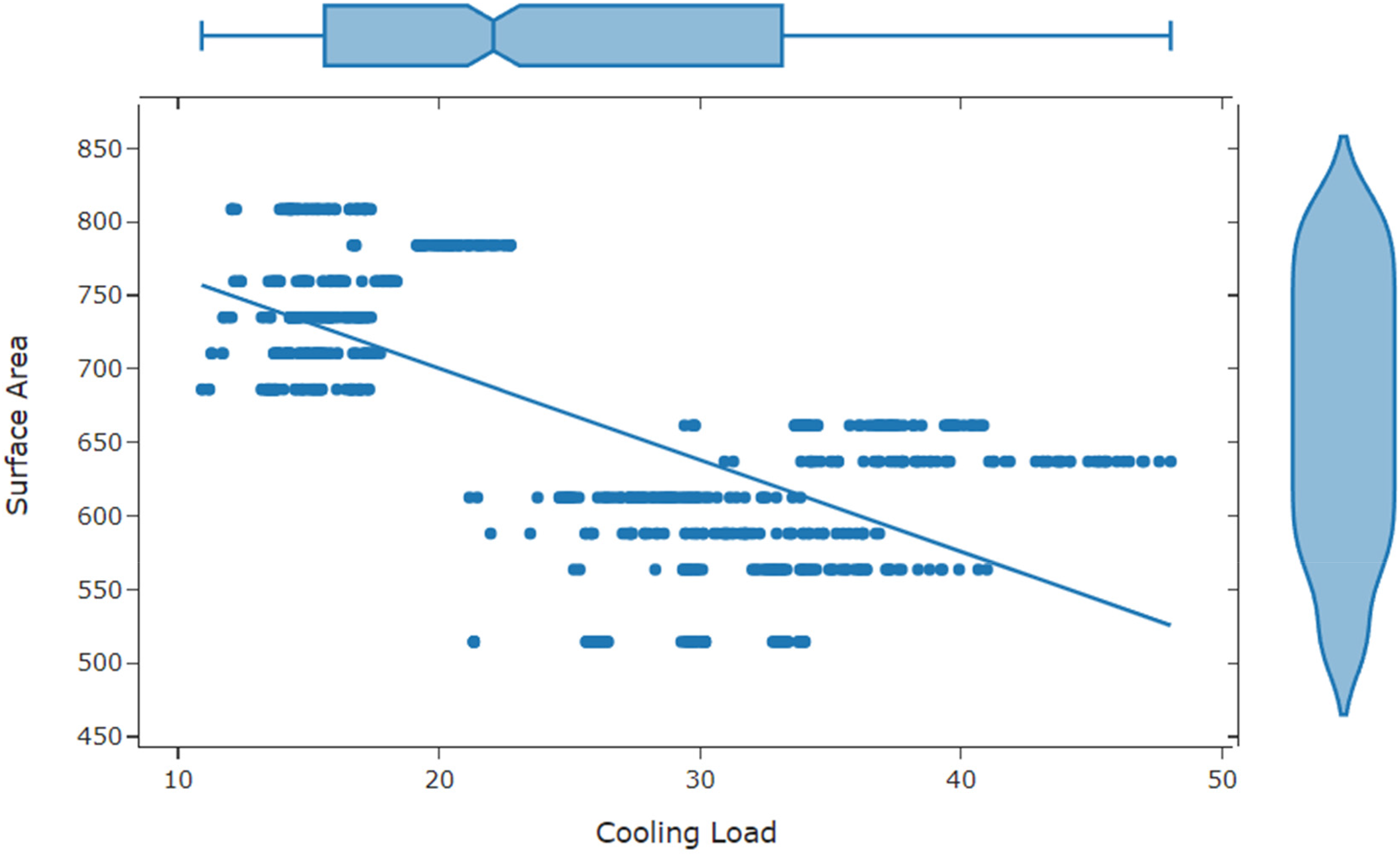
Comparison between cooling load and surface area in energy dataset.
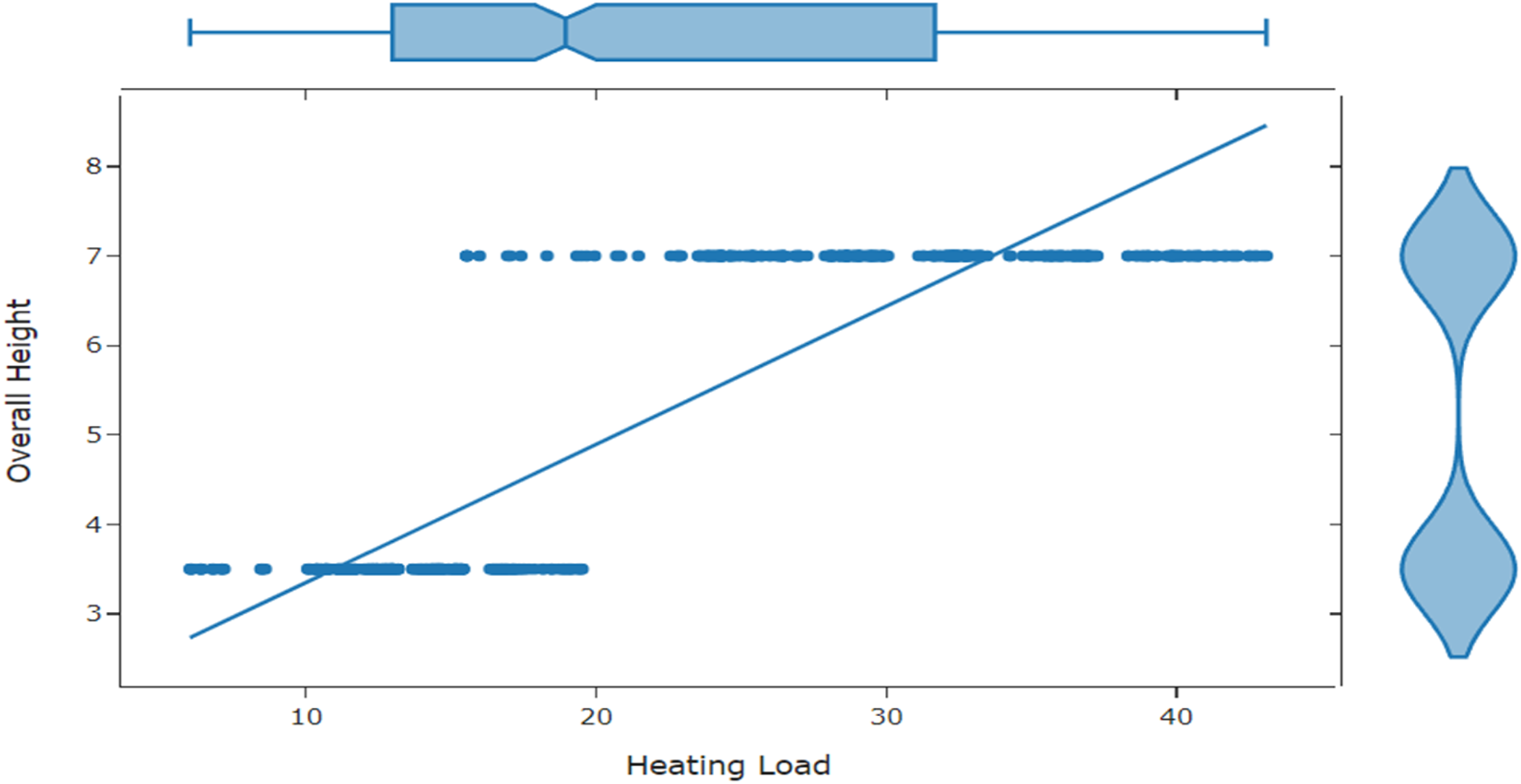
Comparison between cooling load and overall height in energy dataset.
Missing values, a common data analysis issue, can skew dataset insights. To provide accurate analysis and informed decision-making, missing values must be carefully handled, whether they are caused by human error, equipment failure or data-gathering process features. Deleting missing values from the dataset is a simple solution. The listwise elimination or complete-case analysis method ensures that only whole cases are analyzed. Incorrectly distributed missing values might skew results from deletion methods, which are easy to apply and preserve data. In datasets with many missing values, deletion may lose vital information. Imputation algorithms estimate missing values using existing data. The average of observed variable values is used to impute missing values in mean imputation. Mode and median imputation use the middle value to fill in missing variables. Imputation reduces deletion-induced bias while maintaining sample size. They risk oversimplifying the data distribution and overlooking variability, especially with outliers. Imputed values may not accurately represent missing data.
Finding outliers, or observations that don't fit the trend, is crucial to data analysis. Outliers can skew statistical analysis, machine learning models and decision-making, leading to inaccurate predictions and conclusions. Outliers must be identified and managed for data-driven studies to be accurate. Deep neural networks discover outliers by finding data points that behave differently or statistically. Z-score, isolation forests and k-means clustering are good outlier detection approaches, but deep learning provides significant advantages for complex, high-dimensional data with non-linear interactions.
Method
Deep Neural Networks rule AI, revolutionizing technology and industries. These complex networks, inspired by the human brain's dense neuron network, are successful in image identification and natural language processing (NLP). Every DNN has a hierarchical arrangement of artificial neurons, or nodes, that create layers. Processing and feature extraction from data helps each layer depict increasingly complex patterns as the network grows. Common architectural components include input, concealment and output layers. Information passes through the network and is transformed at each neuron based on its biases and weights. This is forward propagation. The network's output is then compared to the target using a loss function. Backpropagation and gradient descent optimize the network's weights and biases based on error propagation during training.
Deep neural networks need large amounts of labelled data to train, therefore, they require a lot of processing power. Deep Neural Network effectiveness depends on training data quantity, quality, network design and hyperparameters. Data augmentation, regularization and dropout reduce overfitting and promote generalization. GPUs and TPUs, which speed up training, allow researchers to tackle more complex issues. Deep neural networks are widely used in numerous industries due to their versatility. CNNs have revolutionized computer vision by excelling at object detection, face recognition and image classification. Recurrent neural networks (RNNs) and transformer designs in NLP such as BERT and GPT have automated machine translation, sentiment analysis and text synthesis. Deep neural networks are used in medical image processing, medication discovery, algorithmic trading, driverless automobiles and finance. Deep neural networks have transformed industries, spurred innovation and increased productivity. AI-powered diagnostics technologies improve healthcare outcomes by detecting diseases early. Financial institutions use algorithms to optimize investment strategies and reduce risk. The democratization of AI tools and frameworks has allowed people and companies to use DNNs to solve many problems, fostering creativity and entrepreneurship (Akin et al., 2023; Kınay et al., 2023). Deep neural networks have made considerable strides but still confront challenges. AI, algorithmic bias and data privacy ethics must be considered. Deep Neural Network explainability and interpretability can be improved, especially in sectors that require transparency and trust. Continuous research into self-supervised learning, neuromorphic computing and lifetime learning will improve DNNs by expanding their capabilities and overcoming their limits (Krarti et al., 2023; Lee et al., 2023; Prades-Gil et al., 2023; Wilczynski et al., 2023). They are versatile and capable of learning intricate data patterns for use in many fields. However, they are notoriously difficult to train and need copious amounts of data.
Deep neural networks architecture
Deep neural networks bring in a new era of AI and ML by imitating the human brain to solve challenging issues. Deep neural networks can handle enormous amounts of data, learn complicated patterns and make accurate predictions due to their design (Altieri et al., 2023). The characteristics of a model are introduced in the input layer of a DNN that is used to forecast residential buildings’ energy efficiency. The model takes these characteristics as input and utilizes them to forecast future energy usage. Important information affecting energy efficiency has been considered below:
Building Size Number of Rooms Daily Average Temperature Occupancy Patterns Appliance Usage Historical Energy Consumption Location Solar Panel Output Energy-Efficient Features
It is possible to normalize and encode these characteristics before feeding them into the neural network's input layer. Each feature is represented by a node in the input layer, and the values of these nodes make up the input vector for a particular data point (such as a day in time series data). The accuracy of the model's predictions is heavily dependent on the characteristics used and their quality. The selection of pertinent features that represent the intricacies of household energy consumption relies heavily on feature engineering and domain expertise (Galvin, 2023; Mousavi et al., 2023; Mugnini et al., 2023).
Hidden layers
It is the problem's complexity and the amount of data that determine the number of hidden layers and the number of neurons in each layer. Starting with a moderate-sized network and making adjustments as necessary is a frequent strategy. It is necessary to adjust a hyperparameter called the amount of neurons in each hidden layer. The model can learn more complicated representations with more neurons, but overfitting becomes more likely with more neurons.
To avoid overfitting, the authors select the Rectified Linear Unit (ReLU) activation function for the hidden layers and take into account the L2 regularization approach. After that, to make the training more stable and the convergence faster, the authors add batch normalization layers. The loss function for energy efficiency prediction has been selected as mean squared error (MSE).
The core of a DNN is its layered architecture of interconnected nodes. Input, concealed and output layers are most prevalent. Data is entered into the input layer, where each node represents a variable or characteristic. One or more hidden layers help the network extract hierarchical representations of input data after the input layer. These hidden layers’ neural circuits process data, store outcomes and send them to the next layer. Based on hidden layer representations, the output layer makes the final prediction or classification. Each layer processes data with neurons or nodes. Each DNN neuron is connected to all neurons in the layer above and below it, creating a complex network. A neuron's effect over another is governed by its connection weights. The training step involves iteratively changing these weights using gradient descent and backpropagation to reduce the discrepancy between the target and predicted output. Non-linear activation functions help DNNs understand complex data relationships. Common activation functions include ReLU, Sigmoid, Tanh, Leaky ReLU and Exponential Linear Unit. These functions provide non-linearities by mapping input data to an output range, allowing the network to represent real-world data.
Different activities and domains require different DNN topologies. Computer vision and image recognition often use customized architectures like the Convolutional Neural Network. CNNs analyze spatial input efficiently by utilizing convolutional layers that gather information at many sizes using filters or kernels. Recurrent neural networks handle sequential data like time series or natural language and have recurrent connections to preserve information. Neural networks’ depth—the number of hidden layers—is crucial to their construction. Deeper networks may learn more complicated features and representations from input, but can also cause training challenges including bursting or disappearing gradients, which can slow convergence. New methods include batch normalization, residual connections and skip connections attempt to simplify deeper network training. Recent neural network architecture advances include attention mechanisms, transformers and graph neural networks. These advances enable complex modelling in drug development, recommendation systems and NLP. The DNNs are shown in Figure 4.
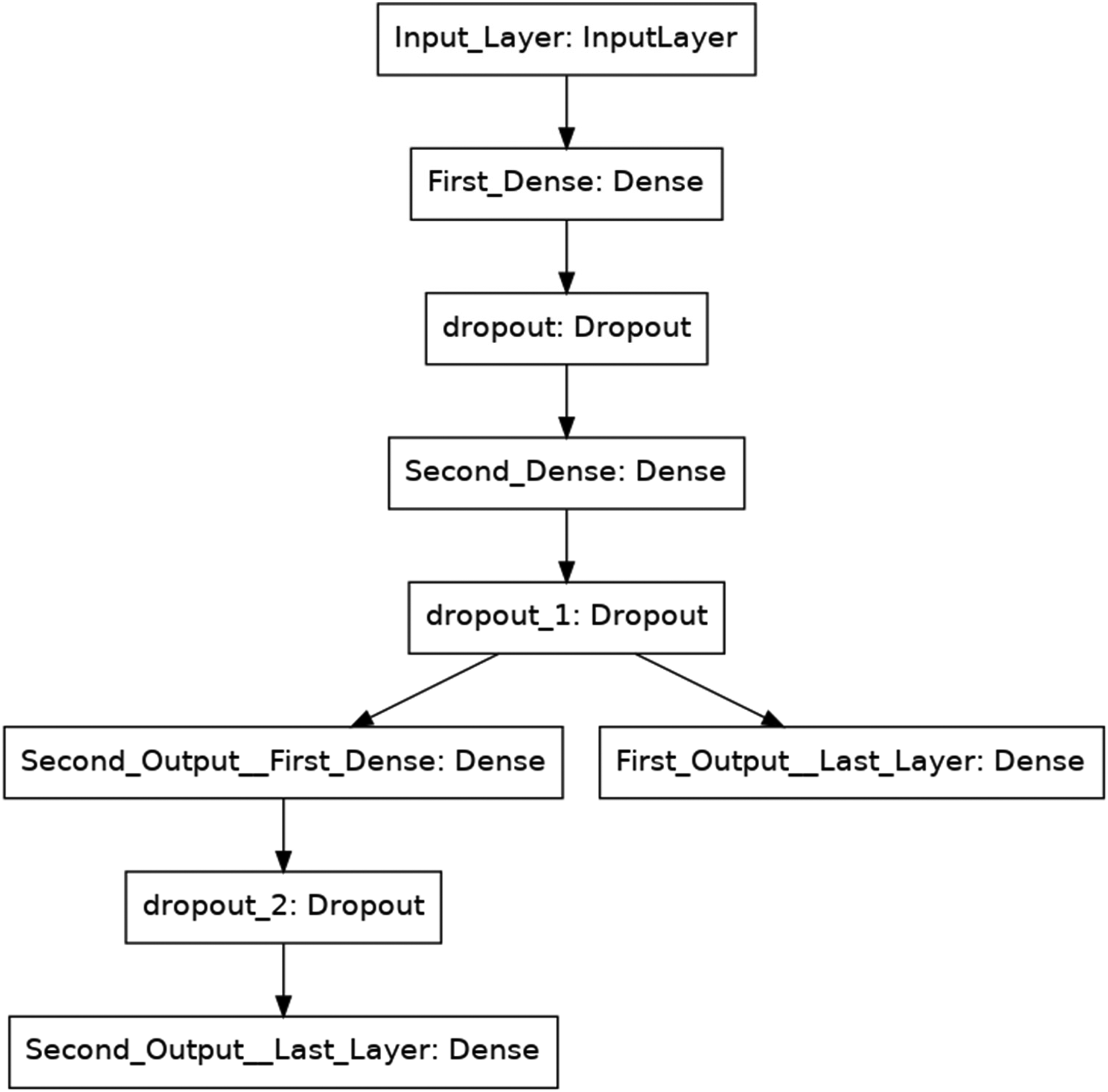
Deep Neural Networks (DNNs) for the current problem.
Dropout is used by DNNs to improve generalization and avoid overfitting. It involves ‘dropping out’ (i.e. setting to zero) a fraction of neurons at random during training to reduce neural reliance and improve network representation robustness. In each training iteration, dropout randomly deactivates a portion of the network's neurons with a predefined probability (dropout rate). Each training cycle eliminates a different neuron. Dropout prevents neuronal co-adaptation and adds noise to training. Dropout is usually disabled, and the complete network is used for prediction during testing or inference. Randomly removing neurons and feature detectors from the network reduces overreliance. This encourages the network to develop more robust and generalizable features, improving its performance on new data. The architecture of DNNs allows them to learn complex patterns from input. The network's ability to understand and interpret input depends on its layers, neurons, activation functions and specialized topologies.
Working
Undoubtedly, several processes can be broken down into sub-steps and depicted in a thorough flow chart to describe the process of creating and executing a DNN for cyber attack prediction. The process is outlined in text form below:
# Step 1: Data Preparation
LOAD dataset containing features of residential buildings (such as insulation, window type and orientation) and their known energy efficiency ratings PREPROCESS data
- Normalize or standardize features - Split data into training and testing sets DEFINE a neural network structure
- INPUT layer with several neurons equal to the number of features - Several HIDDEN layers with the desired number of neurons (using activation functions like ReLU) - OUTPUT layer with a single neuron (for regression task) COMPILE the neural network model
- Choose an optimizer (like Adam) - Choose a loss function (like MSE for regression) - Choose metrics (like mean absolute error) TRAIN the model using the training dataset
- Define the number of epochs - Define batch size EVALUATE the model on the testing dataset to check its performance USE the model to predict energy efficiency for new residential buildings PERFORM hyperparameter tuning if necessary RETRAIN the model if required.
# Step 2: Building the DNN Model
# Step 3: Compile the Model
# Step 4: Train the Model
# Step 5: Model Evaluation
# Step 6: Prediction
# Step 7: Fine-tuning and Optimization (optional)
This section shows a dense layer activation function utilizing a ReLU and 128 neurons. The ReLU is often used in neural networks. Printing input as positive and 0 otherwise renders the model non-linear. The ReLU activation function is chosen based on deep learning model success. Over sigmoid and tanh activation functions, ReLU accelerates stochastic gradient descent (SGD) convergence during training. The ReLU also avoids saturation for positive inputs, which helps train deeper networks and avoid the vanishing gradient problem. The ReLU activation in this layer makes the model non-linear to learn complex data patterns and connections. Thus, our residential building energy efficiency projection model improves.
There are certain limits to DNNs, notwithstanding their impressive performance in many applications, such as household energy efficiency prediction. To overcome obstacles and set reasonable expectations, it is essential to understand these constraints of the modelling process. For DNN training to be effective, a lot of data is needed. Overfitting and poor generalization can occur in datasets that are either biased or inadequate in representing a wide range of building types, climates and inhabitant behaviours. Many people think of DNNs as ‘black-box’ models since it's hard to understand how they make predictions. Understanding the elements affecting energy efficiency might be challenging due to a lack of interpretability.
The input data quality has a significant impact on DNN performance. Data that is either missing or has too much noise might make the model underperform. While essential, preprocessing procedures such as dealing with outliers and missing numbers have been difficult. It has been necessary to provide a lot of computer resources to train and deploy big DNNs. Applications requiring real-time forecasts or situations with limited resources may find this to be a constraint. Overfitting occurs when a DNN, particularly one with many parameters, learns too much from the training data and is unable to apply what it has learned to novel, unknown data. To fix this, regularization methods, validating and monitoring are required.
To get the most out of DNNs, you have to tweak hyperparameters (such as learning rate, layer count and neurons per layer). It takes time to find the ideal mix, and there is not a magic bullet. Despite DNNs’ pattern-learning capabilities, they may not be able to provide light on the relationship between variables. To get practical insights into energy efficiency applications, it is essential to understand the reasoning behind certain forecasts. Expertise in a particular topic is necessary for the development of efficient DNN models. It is difficult to construct a useful model without first gaining a thorough familiarity with the elements impacting residential building energy efficiency. Variables, such as weather, human actions and building maintenance, make residential structures dynamic systems. Without constant updates, DNNs may have trouble adjusting to these changing conditions. Because of the introduction of new technology or retrofits to existing buildings, it is possible that historical data will not be enough to capture changes in energy efficiency trends over time.
Careful data collecting, preprocessing, model adjustment and continuous monitoring are all necessary to overcome these obstructions. One possible solution to these problems is the use of hybrid methodologies, which integrate domain knowledge or combine DNNs with other modelling techniques.
Proposed methodology
Deep Neural Networks have solved tough problems in several fields, including computer vision, NLP and reinforcement learning. However, the optimization problem is non-convex, and the parameter space is extremely dimensional, making neural network training problematic. Optimizers help mitigate these issues by guiding optimization toward the optimal options. During training, optimizers change neural network parameters to minimize a loss function. Optimizers efficiently traverse high-dimensional parameter space to find the ideal parameters to minimize the loss function. Without effective optimizers, training DNNs, especially big models, is nearly impossible. During DNN training, bursting or disappearing gradients, delayed convergence rates and convergence to local minima occur. When backpropagation's gradients are too little or large, the optimization process stops or diverges, causing the disappearing or bursting gradients problem. This makes finding the global minimum harder because the loss landscape is not convex and can get caught in poor local minima. Optimizers stabilize training, prevent local minima and accelerate convergence using various methods.
Several optimization methods have been developed to solve DNN training problems. Some popular optimizers are:
Gradient descent
Gradient descent, a fundamental optimization approach, minimizes the loss function by iteratively altering parameters in the negative gradient. SGD, mini-batch and batch gradient descent have been proposed to enhance performance and efficiency. Vanilla gradient descent converges slowly and is learning rate-sensitive.
Momentum optimization
Momentum optimization solves the slow convergence problem by adding a momentum term that accelerates parameter updates in the direction of consistent gradients. Momentum optimization accumulates past gradients to accelerate and smooth convergence in highly curved regions.
AdaGrad
AdaGrad modifies the learning rate for each parameter based on past gradients to update infrequent parameters more and frequent ones less. This adaptive learning rate method improves sparse data performance and convergence.
RMSProp
Root Mean Square Propagation (RMSProp) overcomes AdaGrad's falling learning rate by using a moving average of squared gradients. To improve convergence and stability, RMSProp divides the learning rate by cumulative squared gradients’ square root. This scales learning by recent gradient magnitude.
Adam
Adam combines RMSProp and momentum optimization with adaptive learning rates and momentum terms. Adam converges quickly and performs well on various deep-learning problems by keeping parameter learning rates unique and adaptively updating momentum estimations.
Optimizers help train DNNs by solving optimization issues in multidimensional domains. Gradient normalization, adaptive learning rates and momentum updates help optimizers enhance training efficiency, stability and convergence speed. Understanding optimizers’ ideas and properties is essential to training DNNs efficiently and using them to solve complex real-world problems. Due to deep learning research, optimization strategies are expected to improve DNN training and performance.
Enhancing DNN efficiency: AdaHessian optimization with quantization and pruning
Deep Neural Networks have revolutionized many fields by excelling in reinforcement learning, image recognition and NLP. When implemented in real-world applications, these models often have computing resource, memory and energy efficiency difficulties. To solve these problems, researchers have developed quantization and pruning to compress DNNs and make them more computationally efficient. We examine how trimming, AdaHessian optimization and quantization can improve DNN performance.
Optimization with AdaHessian
The new AdaHessian optimization method uses the loss landscape's curvature information from the second-order Hessian matrix. AdaHessian employs second-order information and gradient information to change learning rates for specific parameters, unlike standard optimization methods. This adaptive learning rate method makes optimization more robust and cost-effective, especially in complex or steep curvature. AdaHessian uses gradient and curvature information to improve training, convergence and generalization.
Quantification
Quantization reduces neural network activations and weights’ precision to reduce computational complexity and memory footprint. By expressing parameters and activations with fewer bits, quantization reduces storage needs and inference times for resource-constrained hardware systems. Quantization errors may reduce model accuracy. Researchers developed quantization-aware training to mitigate these errors. This training tweaks the model so quantization barely affects performance.
Pruning
Pruning neural networks removes extraneous connections to build sparser, more efficient models. By deleting unneeded connections based on weight magnitude or sensitivity analysis, pruning reduces inference parameters and compute processes. Pruning can shrink models and expedite inference without affecting accuracy. Iterative pruning and fine-tuning can prevent aggressive trimming from deteriorating model performance.
Integrating AdaHessian optimization, quantization and pruning
Quantization, pruning and AdaHessian optimization boost DNN efficiency. AdaHessian optimization improves DNN convergence and generalization by finding a more efficient loss landscape path. AdaHessian optimization and quantization reduce computational cost and memory footprint for tiny DNN training and inference with reduced accuracy. AdaHessian optimization simplifies pruning schemes by optimizing training for sparsity-inducing limitations. The AdaHessian optimization method optimizes model parameters, quantization levels and pruning thresholds simultaneously to maximize efficiency and model correctness.
Quantization, pruning and AdaHessian optimization of DNNs may solve compute complexity, energy efficiency and model size issues. AdaHessian optimization uses second-order curvature information to train DNNs faster while improving model performance. Quantization and pruning can enable AdaHessian optimization to generate tiny, efficient DNNs for low-resource situations. Deep neural networks will become more efficient and scalable when optimization algorithms and compression methods are developed. This will allow widespread real-world use. In the proposed method, these methods can be coupled in Figure 5 as follows:
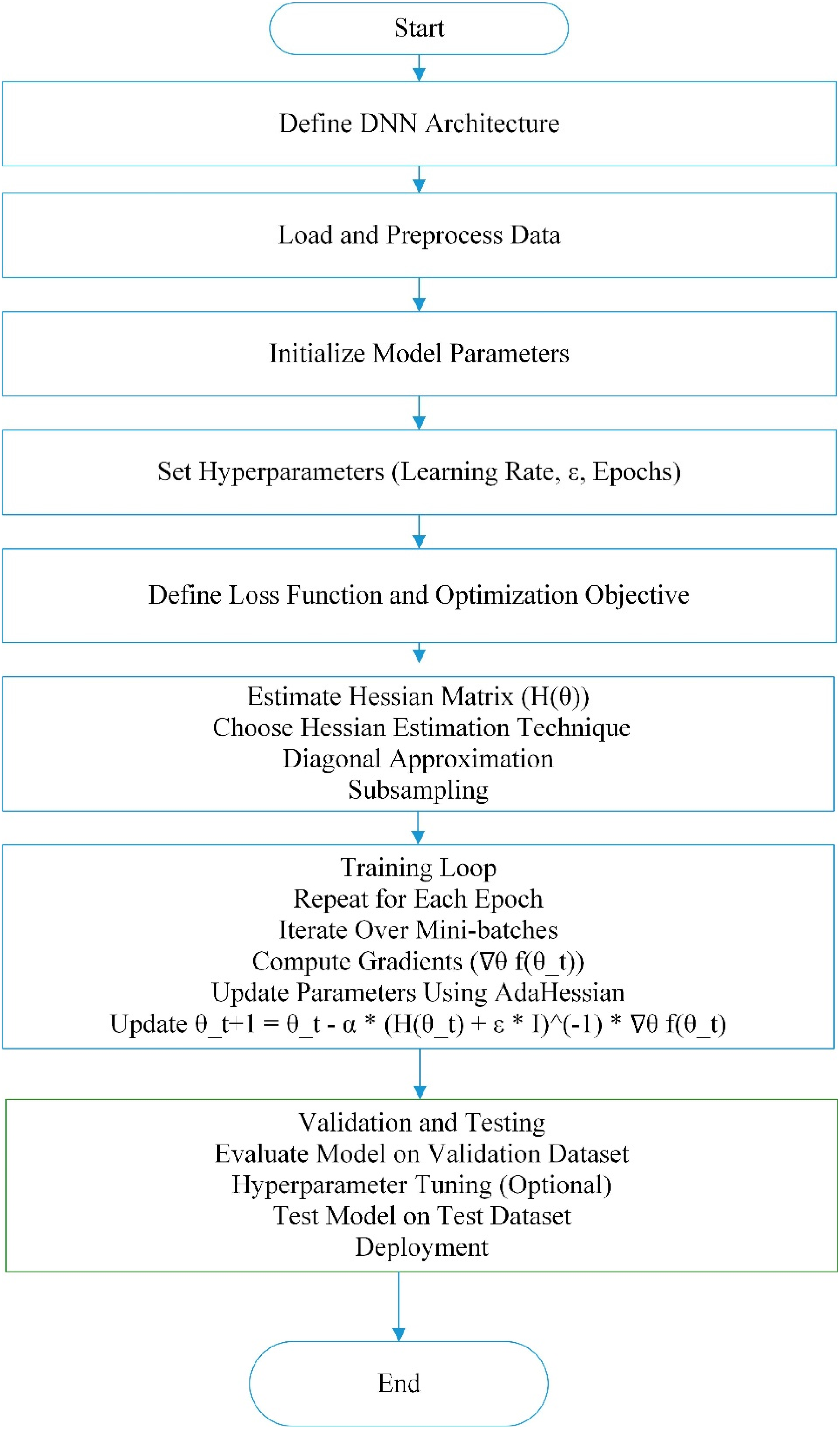
Working of the proposed model.
Deep neural networks require many operations to combine pruning, post-training quantization and AdaHessian optimization. The goal of this approach is to produce a DNN that is as small and efficient as possible without sacrificing performance. Here is an approach that takes advantage of all these methods:
Step 1. Initialization:
Initialize the neural network model with random weights. Specify optimization hyperparameters, including learning rate, momentum and regularization parameters. Iterate over the training dataset in mini-batches. Forward pass: Compute predictions for the mini-batch. Compute the loss function based on the predictions and the ground truth labels. Backward pass: Compute gradients of the loss function concerning the model parameters using automatic differentiation. Update the model parameters using AdaHessian optimization: Compute second-order gradients (Hessian matrix or its approximation) to adaptively adjust learning rates for individual parameters. Update model parameters using the adaptive learning rates, incorporating gradient and curvature information. Perform quantization-aware training to train the model with awareness of quantization. During forward and backward passes, simulate the effects of quantization by applying quantization functions to weights and activations. Adjust the gradients to minimize the impact of quantization errors on model accuracy. Fine-tune the model to mitigate performance degradation caused by quantization, optimizing for both accuracy and quantization-induced errors. Apply pruning techniques to the trained model to remove redundant connections and parameters. Compute importance scores for weights based on criteria such as weight magnitude, sensitivity analysis or iterative pruning strategies. Prune weights with low importance scores, setting them to zero or removing corresponding connections. Fine-tune the pruned model to recover performance by adjusting the remaining parameters and connections.
Step 2. Training Loop:
Step 3. Quantization-aware Training:
Step 4. Pruning:
Efficiency and compactness make DNN models excellent for deployment in resource-constrained environments. A computational framework integrating AdaHessian optimization, quantization and pruning achieves this. Researchers and experimenters must use cutting-edge optimization and compression algorithms to improve deep-learning models. Only then will these models be suitable for many real-world applications.
Pseudo code of proposed hybrid model
The Pseudo code of the proposed hybrid model is as follows.

Results and analysis
Experimental setup
This section presents the simulation results obtained from analyzing the dataset of residential buildings. Our implementation of the proposed hybrid model and existing models utilizes the Python programming language along with essential libraries such as Numpy, Keras, Sci-kit, Matplot, Pandas and Tensorflow. The execution is carried out on a machine equipped with a Core-i7, 10700 processor, CPU @ 3.7Ghz, 16GB RAM and Windows 11 OS. Once the dataset was preprocessed, it was transformed into image datasets. The dataset is split into training and testing sets using k-fold cross-validation. Utilizing the suggested and current deep learning models, we have conducted a binary classification on the dataset. Here are the simulation parameters as shown in Table 1.
Parameters used for simulation.

Deep neural network training relies on the loss function. It guides the network to reduce errors and improve task performance. Loss functions depend on the challenge, such as classification, regression or generative tasks, and affect how well the network learns meaningful representations from data. The basic purpose of DNN training is to reduce the disparity between anticipated outputs and labels or targets. The loss function compares the network's predictions against the desired outcomes to measure alignment. Using optimization methods like gradient descent, the network improves its prediction accuracy. The right loss function influences DNN training's ability to learn meaningful representations and produce accurate predictions. Maximizing deep learning performance requires understanding loss functions and how they fit certain tasks. Practitioners can train DNNs to solve real-world problems by choosing the right loss function and model parameters.
Experimental results
The authors conduct an energy analysis with 12 simulated building forms in Ecotect. This software takes a structure's environmental context into account to determine the building's energy usage. Among other things, the buildings vary in terms of orientation, glazing area distribution and total glazing area. They get 768 different building forms by simulating different circumstances based on the aforementioned variables. With 768 samples and 8 characteristics, the dataset attempts to forecast two actual valued answers. Rounding the answer to the closest integer also makes it work as a multi-class classification issue. Figure 6 shows that A heatmap can indicate how environmental factors relate. While optimizing a DNN for energy efficiency prediction, a heatmap can show how model features or parameters effect prediction accuracy or efficiency.
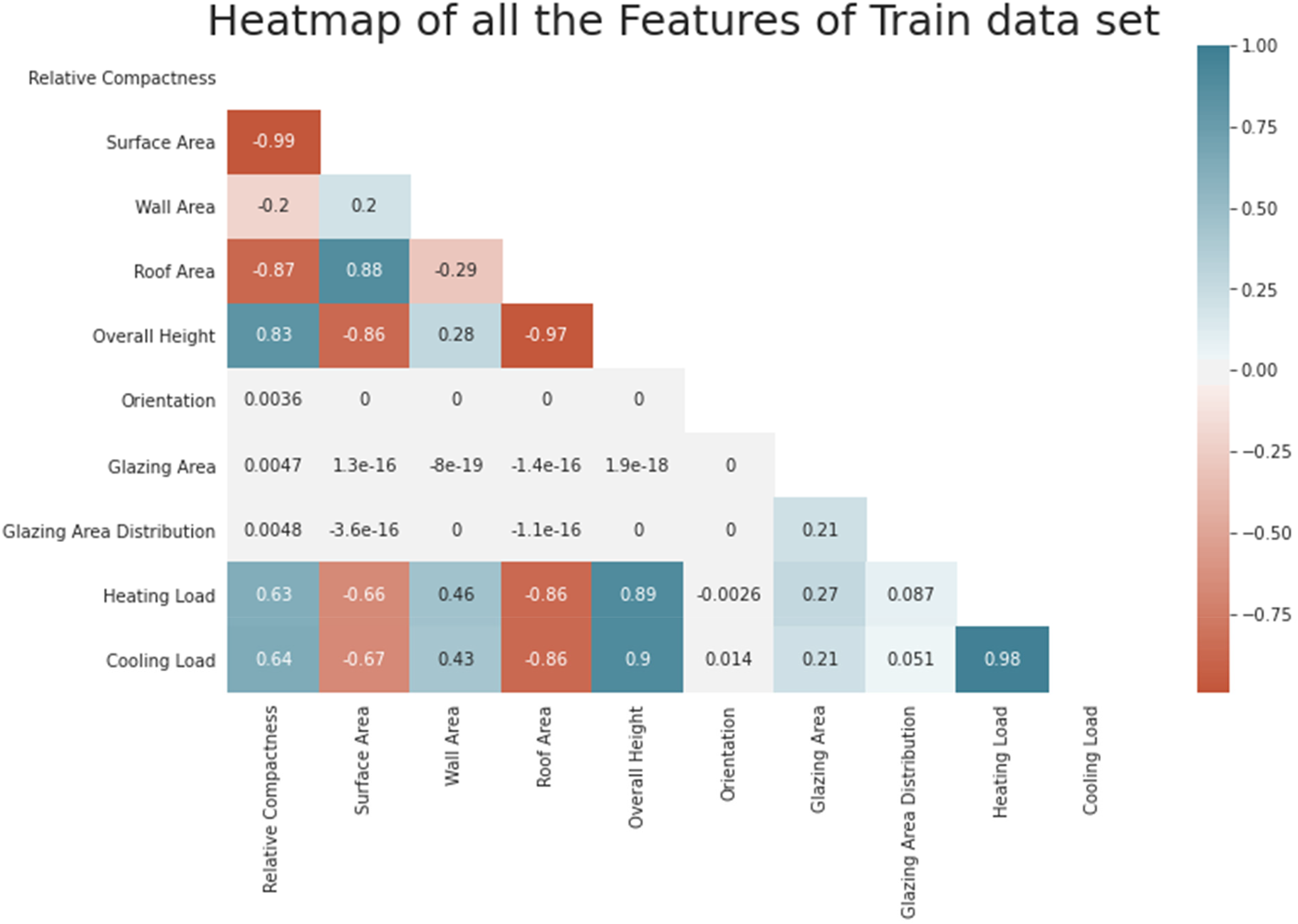
Heatmap of all features.
To test Heating and Cooling separately, the authors determined these parameters in Figure 7. They also created scatter plots of expected and actual values for each test, histograms of residuals and time series plots for the dataset.
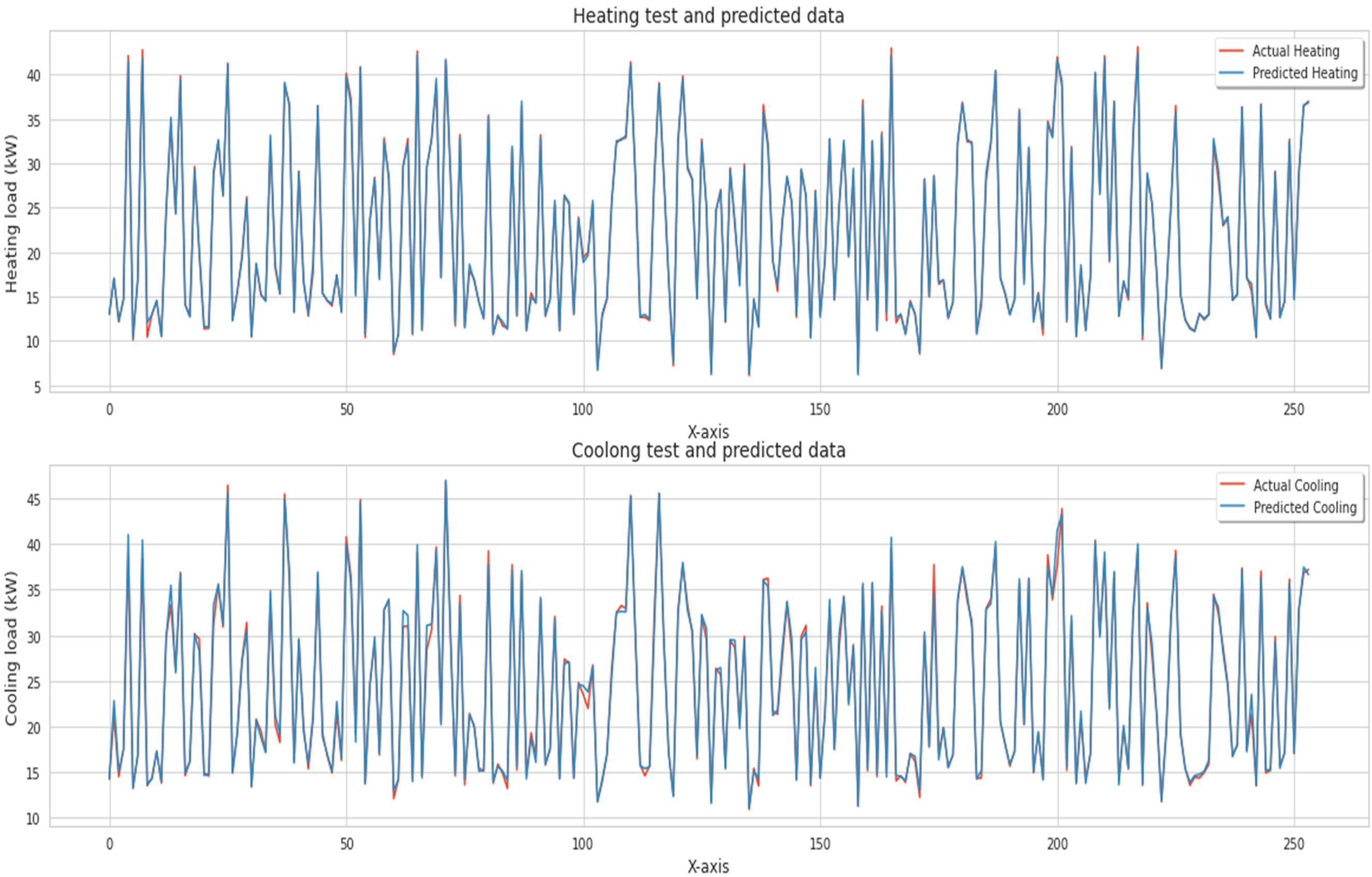
Evaluation of heating test and cooling test with predicted data.
Figure 8 demonstrates the technique to compare expected and actual data with relative deviation, sometimes termed relative error or percent mistake. The authors use a DNN optimizer to calculate the relative deviation of energy efficiency estimates to see how well they match real data.
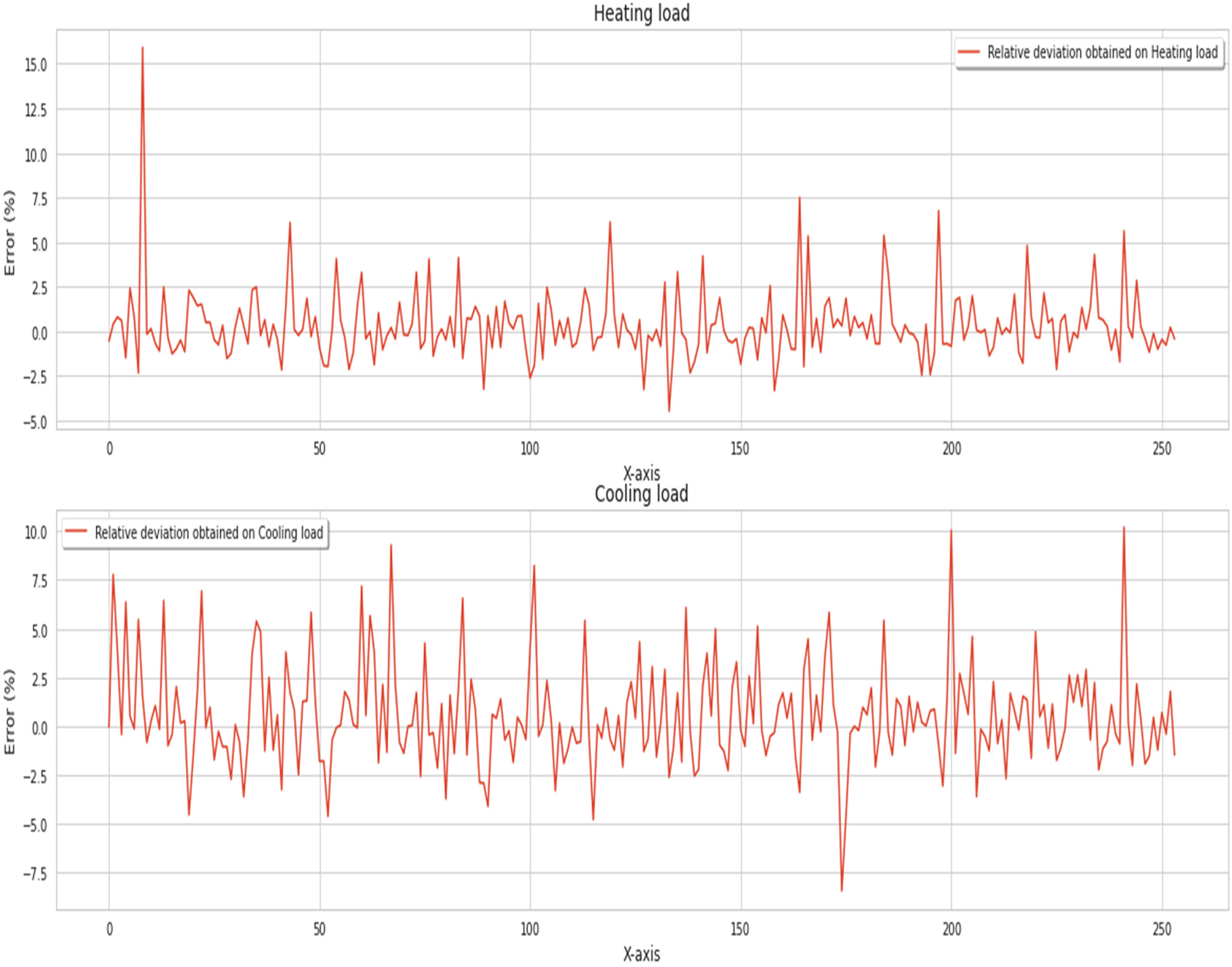
Relative deviation obtained by the proposed model.
Table 2 presents experimental results comparison for existing and proposed methods. A simple optimizer is Gradient Descent. It adjusts the neural network's parameters against the loss function's gradient. Despite being easy to build, it may converge slowly and get trapped in local minima. Stochastic Gradient Descent adjusts parameters by computing the gradient on a mini-batch of training data. It escapes local minima faster than classical gradient descent because it is stochastic. However, it may rock near the bottom. Adam, or Adaptive Moment Estimation, optimizes learning rates. For every parameter, it determines adaptive learning rates by preserving exponential moving averages of squares and gradients. Adam, which combines AdaGrad (adaptive learning rates) and RMSProp (squared gradients), is widely used for its efficiency and durability.
Experimental results comparison.
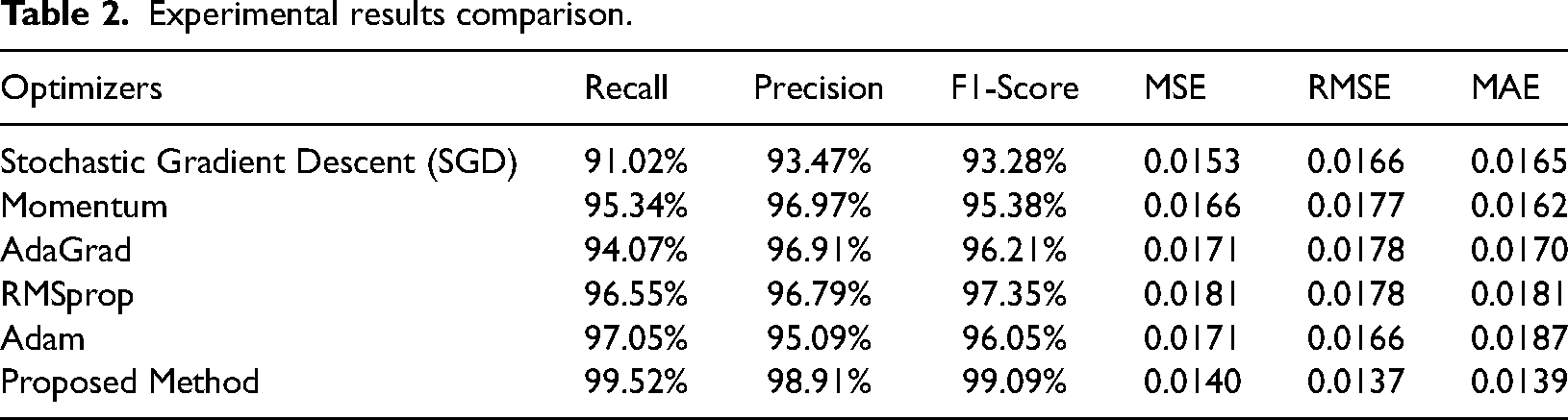
RMSProp, short for ‘Root Mean Square Propagation’, optimizes the learning rate by dividing the total of all recent gradients for a parameter by its root mean square. This approach solves gradient variance problems easily. Infrequently updated parameters receive larger changes using AdaGrad (Adaptive Gradient Algorithm) than often updated parameters. However, as training goes on, the learning rate monotonically lowers, which may slow convergence. The Adadelta improvement softens AdaGrad's harsh, monotonically falling learning rate. It limits the size of the window containing the collected past gradients instead of collecting them. Convergence becomes more stable.
Figure 9 depicts the root-mean-squared error (RMSE) values gained by various traditional machine learning models. The x-axis represents the RMSE value gained and y-axis represents the model applied. The model's predictions match observed data better as the RMSE approaches zero. Real-world energy efficiency forecast is better with a more accurate model. Root-mean-squared error is a valuable statistic for choosing an energy efficiency prediction model from numerous options. A reduced RMSE usually suggests better model prediction. Root-mean-squared error measures prediction accuracy but not model interpretability. Simpler models with slightly higher RMSE may be preferred for interpretability and implementation convenience. Figure 10 presents the accuracy results compared to the prescribed energy dataset for existing and proposed methods for different classes. This figure shows the comparison of various models based on different parameters, that is, MSE, RMSE and MAE. Figure 10 demonstrates the performance of various algorithms (K-NN, Decision Tree, Random Forest, Gradient Boosing model, etc.).
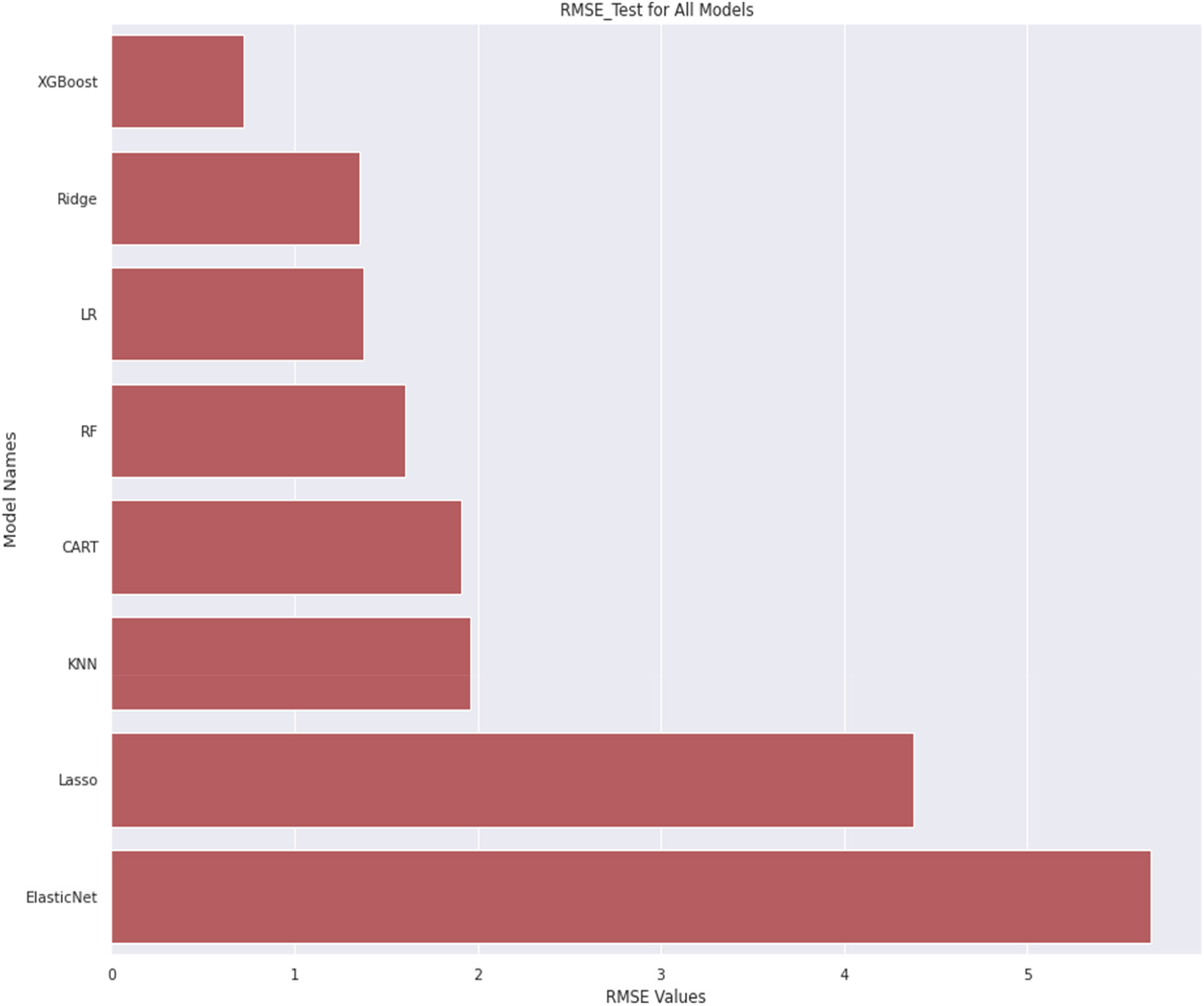
Root-mean-squared error (RMSE) value comparison obtained by existing algorithms.
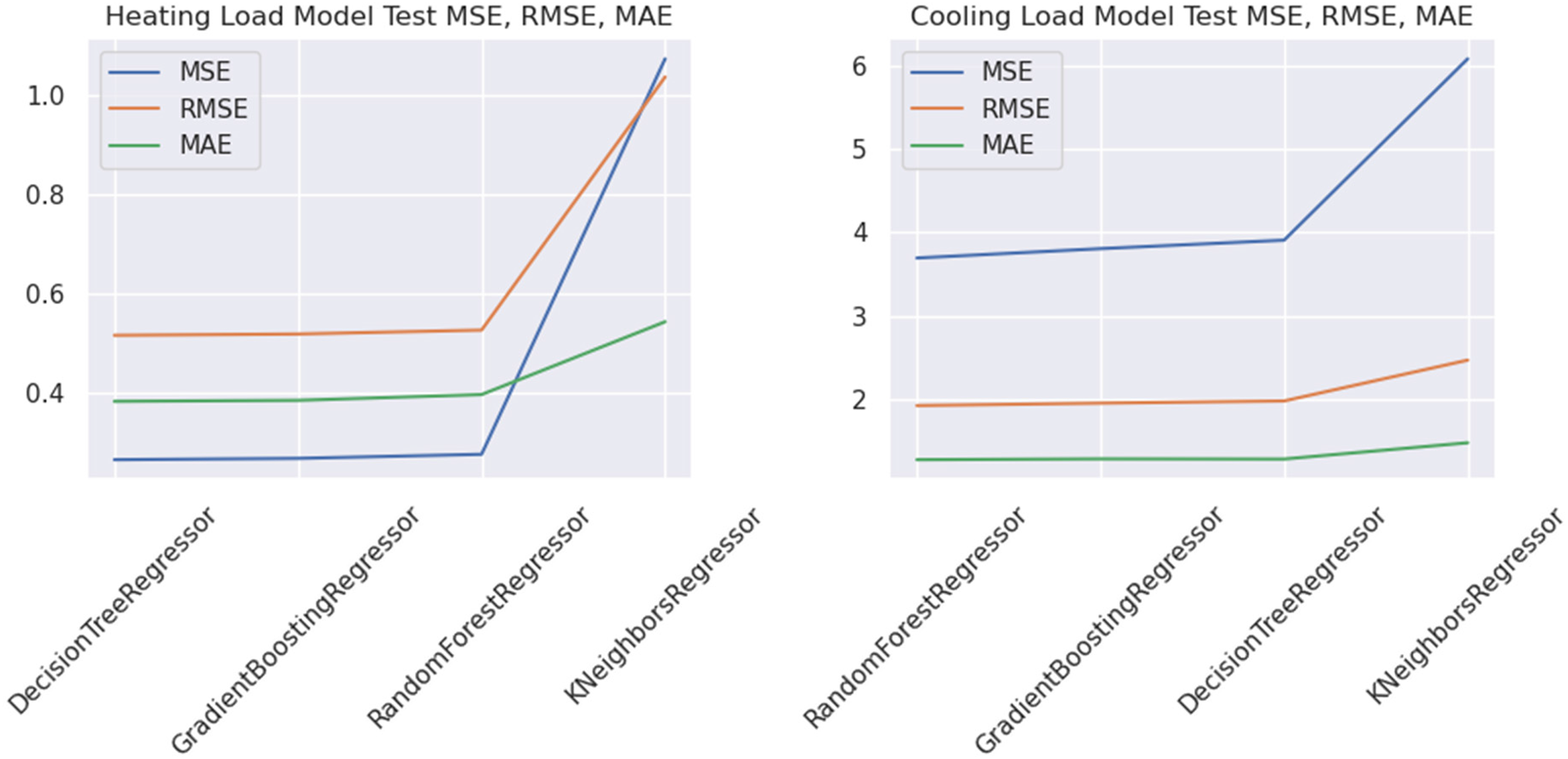
MAE and mean squared error (MSE) value comparison obtained by existing algorithms.
Discussion
It is critical to recognize and talk about the model's shortcomings, even though it offers a promising approach. The accessibility and accuracy of the training data greatly impact the model's performance. The capacity of the model to apply to various types of homes has been affected by data limitations in terms of quantity or representativeness. Since DNNs are notoriously difficult to understand and explain, they are sometimes referred to as ‘black-box’ models. Gaining end-user trust and comprehending the elements impacting energy efficiency projections has been challenged by a lack of interpretability.
Hyperparameter settings, especially those unique to AdaHessian optimization, may have a significant impact on the model's accuracy. It has been difficult to execute in real-world settings due to the high computing resources and knowledge needed to tune these hyperparameters. Changes in tenant behaviour, alterations to the structure or other external environmental factors are examples of dynamic changes that the model may find difficult to adjust to in residential settings. It has been difficult for a model that relies on past data to incorporate unexpected changes. It may take a lot of processing power to train DNNs using sophisticated optimizers like AdaHessian. This may restrict the model's usefulness in situations with limited computing resources, particularly during the early training period. There could be a compromise between accuracy and the size of the model that is reduced by post-training quantization, which improves deployment on edge devices. If quantization is used to an extreme degree, important information has been lost, which might impact the model's accuracy.
Climate, construction codes and energy usage habits can cause the model's efficacy to differ among areas. To guarantee the model's generalizability, it is crucial to test it in various environments. Economic circumstances, regulatory shifts and technology developments are examples of external variables that could impact energy usage; nevertheless, the model might not account for all of these aspects. The model's accuracy and relevance might be improved by including these parameters, which could be problematic. There are major findings of the results obtained by the proposed model as below:
More urban datasets have been included to boost our experimental evaluation. This extension shows the performance of our proposed model in several scenarios and confirms its generalizability. Sensitivity analysis assessed our prediction model's performance with different parameters and hyperparameters. Controlling these factors and understanding how they affect the model's accuracy and efficiency has helped us understand the mechanisms and where optimization is possible. We compared our deep learning–based forecasting model to conventional and cutting-edge methods. Our method is better, and this comparison shows how significant and useful it is for improving urban energy forecasting in the real world. We added simulation findings to our experimental data to show the scalability and robustness of our approach. Comprehensive simulations under varied scenarios and workload conditions have confirmed our approach's robustness and effectiveness in real-world deployment settings.
Using training data that includes personally identifiable information about people might cause ethical problems with the model's data security and privacy features. For the model to be used ethically, it is essential to resolve privacy concerns and ensure responsible data usage.
Limitations and challenges
Residential energy consumption data is private and must comply. Privacy concerns may limit model efficacy by restricting access to real-world data for training. Neural networks and other deep learning models are often called ‘black boxes’ due to their lack of interpretability. Understanding the model's predictions may hinder its incorporation into decision-making. Deep learning algorithms tend to overfit, especially on small or noisy datasets. Overfitting occurs when the model memorizes training data instead of generalizing patterns, resulting in poor performance on novel data. Training deep learning models, especially sophisticated ones like CNNs or RNNs, need powerful GPUs and lots of RAM. Not all research teams or organizations have such resources. Climate, building typologies, energy infrastructure and socio-economics vary greatly across cities. A model trained on data from one city or region may not be able to extend its knowledge to other cities or locations without changes or transfer learning. Cities are dynamic, with changing infrastructure, population and energy policy. Maintaining and updating the model to appropriately integrate these changes requires constant effort and resource allocation. Deep learning–based forecasting models must be integrated with energy management systems or infrastructure to work in real-world applications. Compatibility and technological issues may arise during integration.
Conclusion and future scope
To improve home energy efficiency, this research has proven that an optimized DNN using post-training quantization and the AdaHessian optimizer works. When it comes to forecasting patterns of energy usage in residential structures, the improved DNN shows much better accuracy. Energy management choices have been made with greater knowledge because of the model's improved prediction capabilities and its capacity to grasp intricate data linkages. Reducing the memory footprint and processing needs of the model is achieved mostly by post-training quantization. This helps with inference efficiency and makes it easier to deploy on edge devices with limited resources, which are typical in homes. By adjusting learning rates for certain parameters, the AdaHessian optimizer makes training even more efficient. By enhancing the model's total energy efficiency, this adaptive optimization strategy speeds up convergence during training. We present a novel deep learning algorithm for urban home energy usage prediction. To boost energy efficiency and sustainability. We tested and validated our model using real-world information to show that it accurately predicts energy demand trends over time. We found that deep learning models, such as LSTM networks, outperform conventional forecasting methods. Our approach captures detailed patterns and oscillations in energy use data using intrinsic temporal dependencies, improving projections. Feature engineering has also improved the model's interpretability by helping to comprehend energy utilization factors. This helps understand consumption patterns and helps policymakers and urban planners implement energy efficiency efforts. Our study helps create comprehensive urban energy management prediction models, which promote sustainable development and decrease residential buildings’ environmental impact. Future studies could focus on renewable energy, demand response and smart grid technology to improve urban energy efficiency. The proposed model is perfect for use on edge devices in real-world residential structures. These refined models can save computing power without sacrificing forecast accuracy, making them practical for use in the actual world. A dependable and effective method for optimizing residential building energy consumption is provided by this research work effort, which adds to the progress of sustainable energy management systems. In keeping with the overarching objectives of decreasing energy waste and encouraging environmentally conscious activities, the proposed model takes accuracy and efficiency into account.
Future scope
Intelligent and environmentally friendly energy management systems are within reach thanks to this model, which integrates state-of-the-art machine learning methods with an emphasis on real-world implementation. By including the forecasting model in real-time monitoring and control systems, proactive energy management strategies can be made possible. This might need developing algorithms that modify HVAC systems and other building elements in reaction to anticipated energy demands. Demand-response mechanisms can be improved and energy distribution in metropolitan environments optimized by integrating the forecasting model with smart grid technologies. Achieving this integration will need close collaboration with utility companies and rigorous adherence to relevant regulatory requirements. A wider acceptance depends on the model architecture and training methods being scalable and generalizable across different urban settings and building kinds. This could need creating domain adaptation strategies or transfer learning methods to use knowledge from one setting to another.
Footnotes
Author contributions
The authors confirm their contribution to the paper as follows: study conception and design: UR, ND and SK; data collection: SoK, SKR and UR; analysis and interpretation of results: NN, ST and AH; draft manuscript preparation: SoK, SaK, AS and PS. All authors reviewed the results and approved the final version of the manuscript.
Availability of data and materials
Publicly available datasets were analyzed in this study.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.