
Abstract
This article presents a dynamic reservoir characterization using a new multi-objective optimization algorithm to quantify the reservoir uncertainties in history matching. The proposed method formulated Pareto-optimality with preference-ordering to derive multiple trade-off history-matched reservoir models for probabilistic production estimation. The integration of linear programming with multi-objective genetic algorithm enhances the efficiency of a multi-directional search by prioritizing the reservoir models that satisfy the aspiration levels on the discrepancy between the observed and the calculated production data. The preference levels are automatically adjusted in correspondence to the quality of the reservoir models for facilitating the model update process during optimization. An oil-field application result indicates the method outperforms the conventional multi-objective optimization method in terms of the relative average error for the production data despite a small loss of diversity-preservation among the reservoir models.
Keywords
Introduction
In the petroleum industry, history matching based on multi-objective optimization has been investigated as a means of handling the inter-well interference. Unlike the traditional single-objective history matching approaches based on reducing the objective-sum (Ballester and Carter, 2007; Cheng et al., 2008; Nævdal et al., 2005), the optimization concept of multi-objective history matching has an advantage where its mathematical formulation is free of an obligation to pre-determine the weight factors connecting the objective functions (Nicklow et al., 2010). The goal of multi-objective history matching is to generate multiple trade-off reservoir models that are Pareto-optimal in posterior space for probabilistic production forecasts. Pareto-optimality is the state of the optimal allocation of resources. The optimal domain composed of Pareto-optimal solutions is called the Pareto-optimal front (POF) (Deb et al., 2002).
Multi-objective history matching approaches have adopted a variety of evolutionary multi-objective optimization (EMO) methods (Hajizadeh et al., 2011; Han et al., 2011; King et al., 2013; Min et al., 2013; Mohamed et al., 2011; Schulze-Riegert et al., 2007; Shelkov et al., 2013). Most of these previous studies focused on compromising only two or three conflicting objective functions; because their methods had difficulty in approximating the POF, of which the structure became complicated in proportion to the number of objective functions. LM data points would be needed to describe the M-dimensional POF in the case that L data points are necessary to delineate one dimension of the POF. For this reason, combining preference information on the objective functions with EMO methods is considered a practical compromise for resolving the increasing complexity to deteriorate convergence toward the POF (Hannan, 1980; Ishibuchi et al., 2008; Kollat and Reed, 2006; Long, 2014; Mezura-Montes and Coello, 2011; Rao et al., 1988; Reed and Minsker, 2004; Reed et al., 2007; Thiele et al., 2009). This computational intelligence method prioritizes the solutions by reflecting the decision maker’s preferences, and finds favorable solutions on a specific part of the POF with significant improvement in convergence despite the small loss of diversity-preservation. The preferences can be articulated as follows: assigning different ranks to solutions; eliminating redundant solutions; using indicator functions; scalarizing objective functions for fitness evaluation; or using decision maker’s preference information (Ishibuchi et al., 2008).
This study proposes a history matching procedure using a newly developed EMO method. Dynamic Goal Programming (DGP) as the decision maker’s preferences was newly implemented and integrated with a multi-objective genetic algorithm (MOGA). The proposed scheme articulates the preferences for enhancing the convergence by prioritizing the reservoir models. The levels of preferences are automatically modified in accordance with the quality of the reservoir models during optimization.
Formulation of multi-objective history matching
Equation (1) generalizes history matching as a multi-objective problem

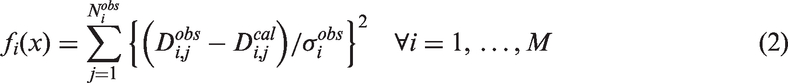
Mathematically, Pareto-optimality is defined as the best non-domination. Non-domination is a state of equivalence, in which no objective can be improved without adversely affecting other objectives (Deb et al., 2002). A reservoir model, f(x1), is said to dominate a reservoir model, f(x2), only if equation (3) is satisfied
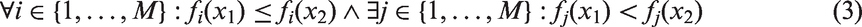
Figure 1 illustrates posterior space for a minimization problem with two conflicting objective functions. For history matching, the origin is the ideal solution that refers to the true earth yielding the observed production data. In reality, it is impossible to mimic the true earth perfectly due to reservoir uncertainties. This aspect highlights the importance of stochastic approaches to generate multiple Pareto-optimal reservoir models of which performances are similar to that of the true earth. The degree of reservoir uncertainties defines the characteristics of the POF, e.g. dimension, shape, and distance from the origin.
Schematic diagram of multi-objective optimization based on Pareto-optimality.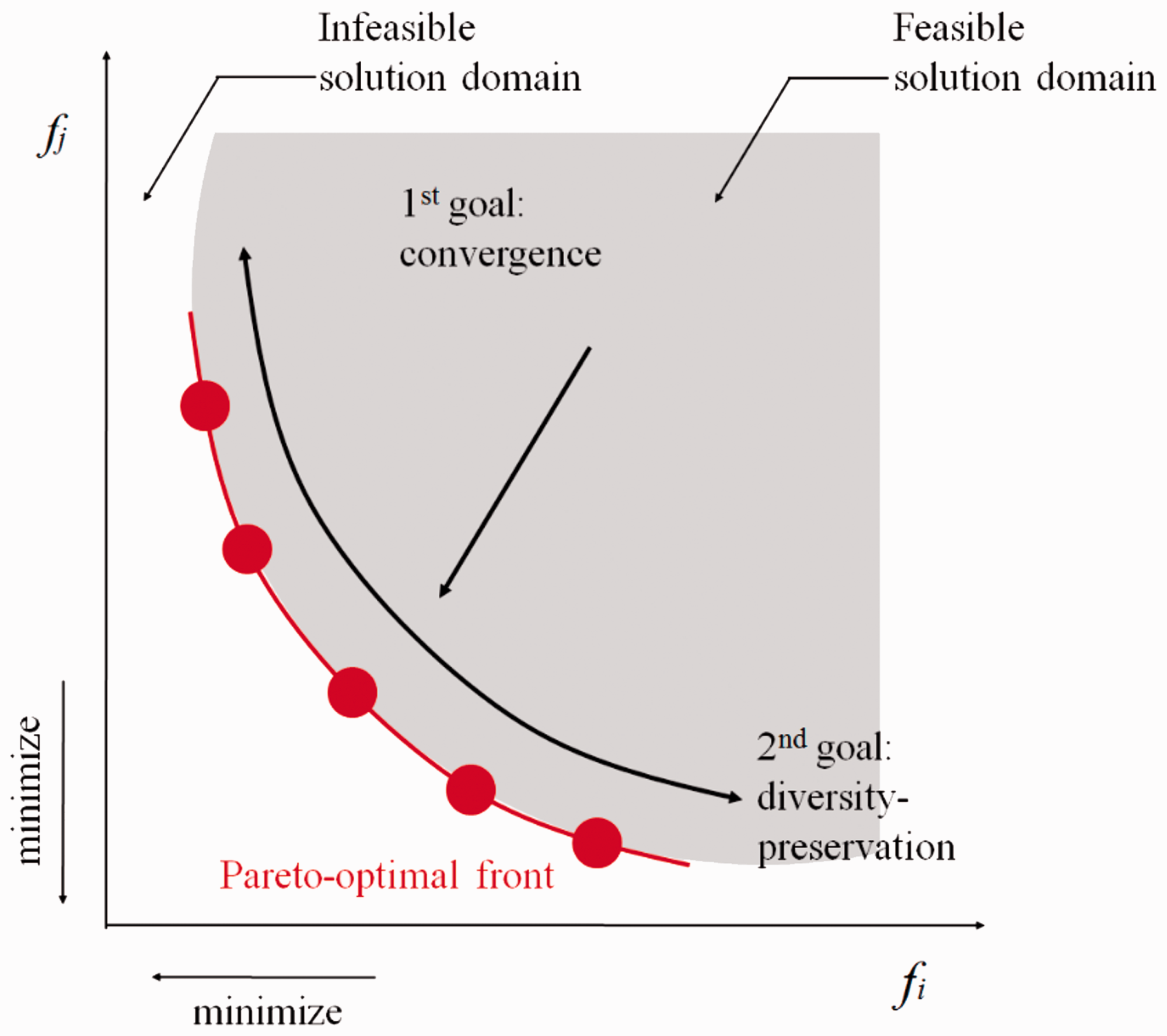
To obtain the representative of the POF, multi-objective history matching has to fulfill two orthogonal goals simultaneously. The characterized reservoir models are desired to be not only as close to the POF as possible but also uniformly distributed along the POF (Min et al., 2013). It is noted that the global minimum in single-objective optimization is the Pareto-optimal reservoir model that is the nearest from the origin under the given specific weights.
Model development
Workflow of proposed history matching approach
Figure 2 shows a flow chart of the proposed method, D-MOGA (DGP with MOGA). The reservoir models are improved by tuning the reservoir properties. New reservoir models, which are called children, are generated by recombining old reservoir models, which are called parents, using genetic operators: crossover and mutation (Goldberg, 1989). The calculated production data for computing the fitness values are obtained using numerical reservoir simulation. Then, the old and new reservoir models are ranked to select high-quality reservoir models with respect to the relative superiority of fitness values using three ranking evaluation modules: non-dominated sorting for Pareto-ranking, DGP for prioritization, and crowding-distance sorting for diversity-preservation. The selected reservoir models in the current generation become the parents for the next generation. This evolutionary process is repeated until the iteration reaches the maximum number of generations.
Flow chart of the proposed history matching procedure using D-MOGA.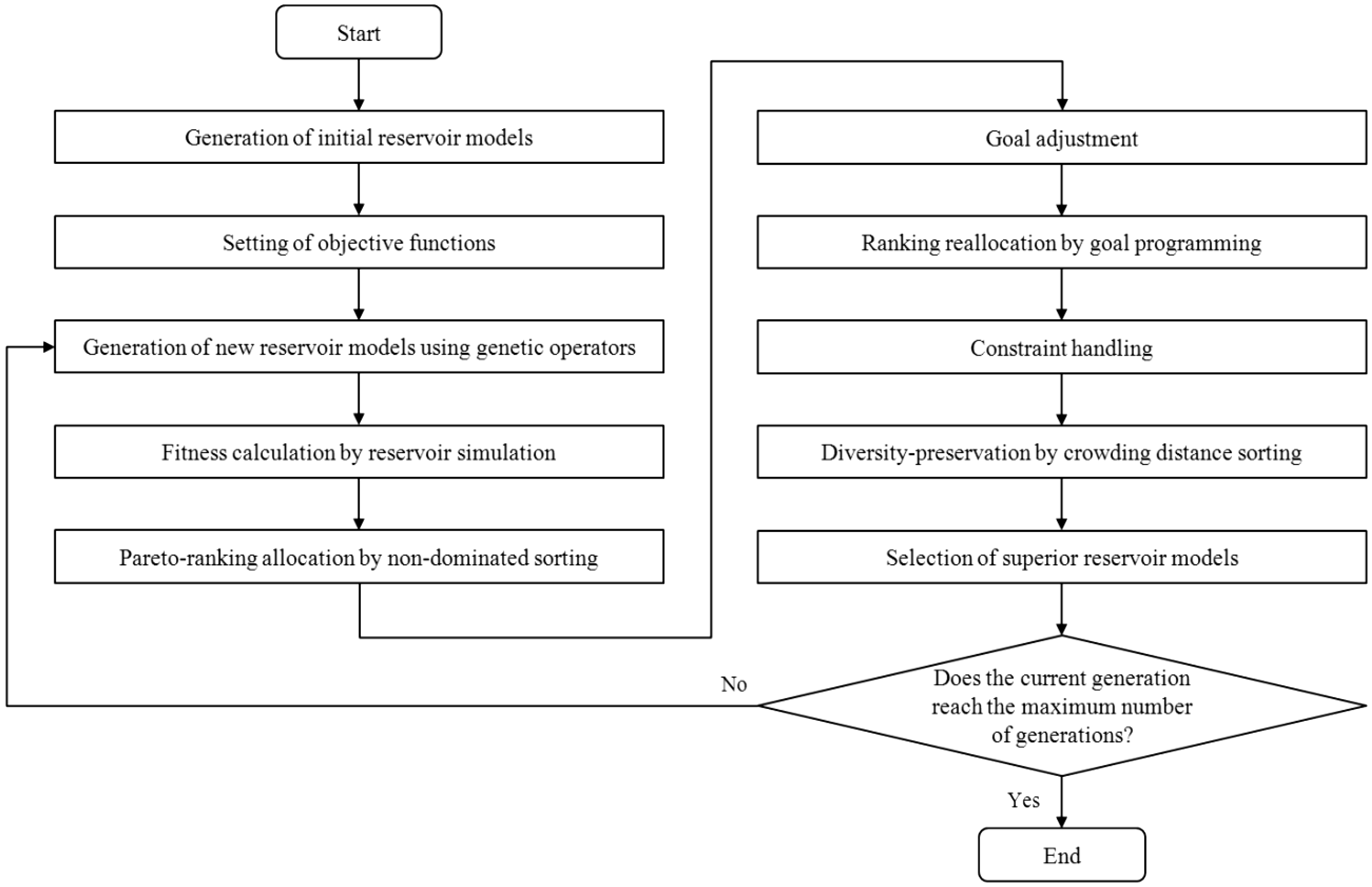
Pareto-ranking using non-dominated sorting
Figure 3(a) shows non-dominated sorting to evaluate the reservoir models in two-dimensional (2D) posterior space. In this figure, the number of non-dominated fronts, n, is three. The black circle refers to the best non-dominated reservoir models given the first rank R1. The reservoir model, y1, dominates y2. y3 also dominates y4 and y5. y1 and y3 on the same non-dominated front are equivalent to each other as the superiority in f1 accompanies the inferiority in f2. In other words, the reservoir models in the ith rank Ri (gray rectangular) are inferior to the reservoir models in the upper ranks from R1 (black circle) to Ri−1, but superior to the reservoir models in the lower ranks from Ri+1 to Rn (open triangle). The upper rankers are assigned higher probabilities to survive in the evolutionary process.
Ranking evaluation modules of the developed D-MOGA: (a) non-dominated sorting, (b) goal programming, (c) constraint handling, and (d) crowding-distance sorting.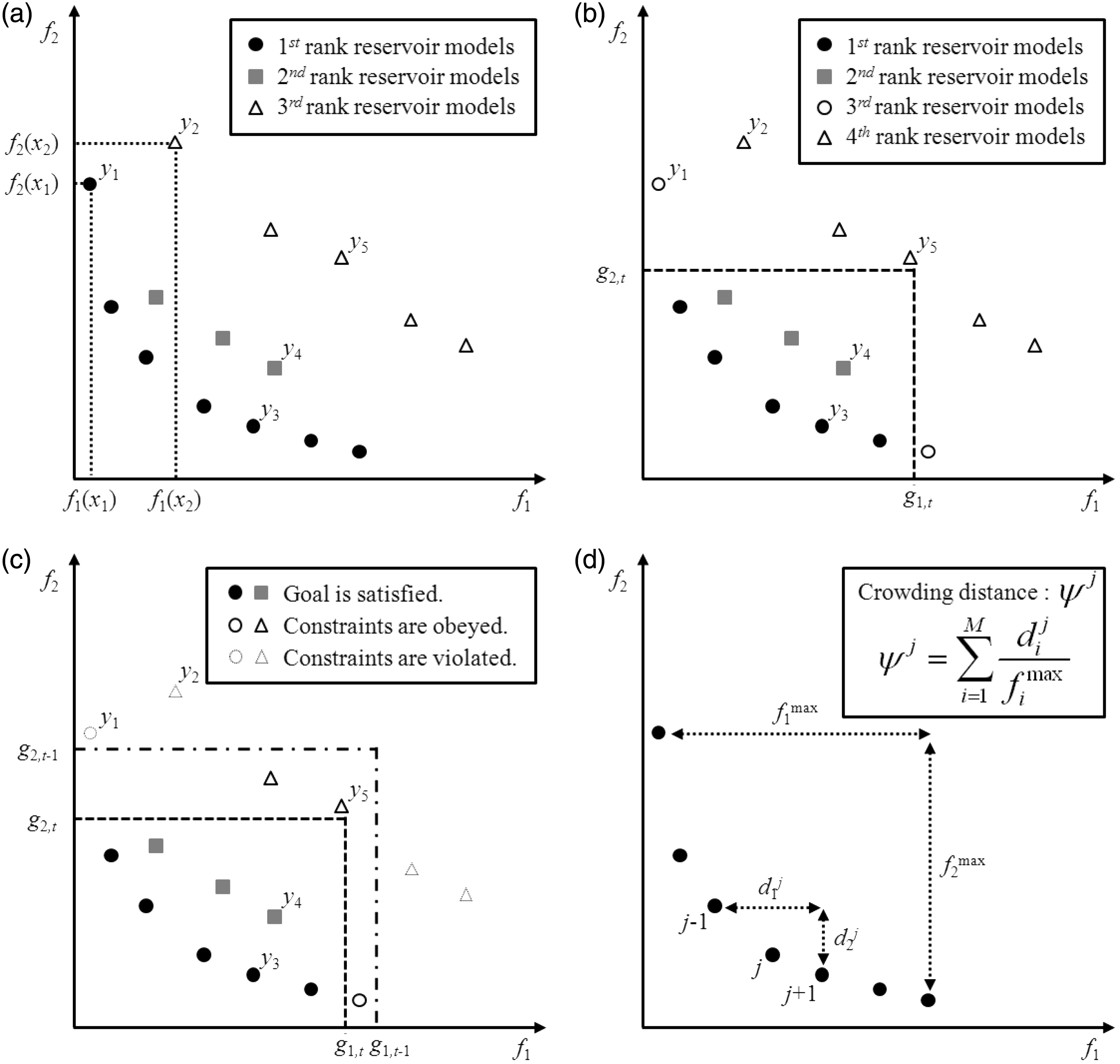
Ranking reallocation using DGP
DGP prioritizes the reservoir models that satisfy the preferences on the objective functions. This preference-ordering is composed of three consecutive stages: goal programming, goal adjustment, and constraint handling. Figure 3(b) presents the ranking reallocation with the goal expressed as a dash line. The goal is the intersection of all aspiration levels. The ith aspiration level, gi, t , is the fitness value desired to be achieved at least for fi in the tth generation. The reservoir model, y4, satisfying the goal, is regarded as superior to y1, not satisfying the goal, even though y1 lies on the upper non-dominated front than y4. Let n1 denote the number of fronts on which all reservoir models satisfy the goal, n2 denote the number of fronts that partially satisfy the goal, and n3 denote the number of fronts where no reservoir model satisfies the goal. Goal programming increases the number of ranks from n to n1+2n2+n3. By non-dominated sorting, the reservoir models inside the goal reallocate their ranks from R1 to Rn1 +n 2, and the reservoir models outside the goal from Rn1 +n 2 + 1 to Rn1 + 2 n 2 +n 3. For example, the number of ranks in Figure 3(b) increases from three to four because n, n1, n2, and n3 are 3, 1, 1, and 1, respectively.
The efficiency of the traditional preference-ordering approach with the fixed goal diminishes without a priori information on the shape of the POF. If the goal is set up too tightly, there would be no solution satisfying the goal, then the goal programming does not work properly. On the contrary, setting the goal up loosely cannot contribute to the optimization any more in case most of solutions satisfy the goal in the non-optimal domain at the early stage of exploration. To overcome these problems, DGP is designed to induce solutions toward the optimal domain by continuously adjusting the goal with consideration of the current values of the objective functions. The initial aspiration level is set to the maximum value for each objective function in the initial population. The aspiration levels are adjusted by the quality check on the reservoir models in every generation. Equation (4) updates the next aspiration level, gi,t+1, if the proportion of reservoir models that satisfy the current aspiration level, gi,t, is equal to or greater than the goal adjustment threshold
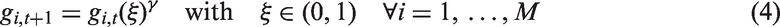
Figure 3(c) depicts the constraint handling with the constraint expressed as a dot-and-dash line. The previous aspiration level, gi, t −1, becomes the constraint to suppress the divergence of reservoir models by non-dominated sorting. Only the reservoir models within the constraint can be candidates to be parents of the next generation. Both y3 and y4, satisfying the goal, are preferred. y5 also obeys the constraint although it fails to satisfy the goal. On the contrary, both y1 and y2 violate the constraint. Therefore, y3, y4, and y5 are qualified, whereas y1 and y2 are unqualified as the parents for the next generation.
Diversity-preservation using crowding-distance sorting
Crowding-distance sorting is an auxiliary method of non-dominated sorting for maintaining the variety of solutions (Deb et al., 2002). Figure 3(d) depicts the diversity-preservation scheme that cuts off the densely distributed reservoir models in Rk if the number of cumulative reservoir models from R1 to Rk is greater than the population size. Equation (5) calculates the crowding-distance, ψ j, for the jth reservoir model

Results and discussion
Field description and experimental setting
Reservoir properties of the reference reservoir model.

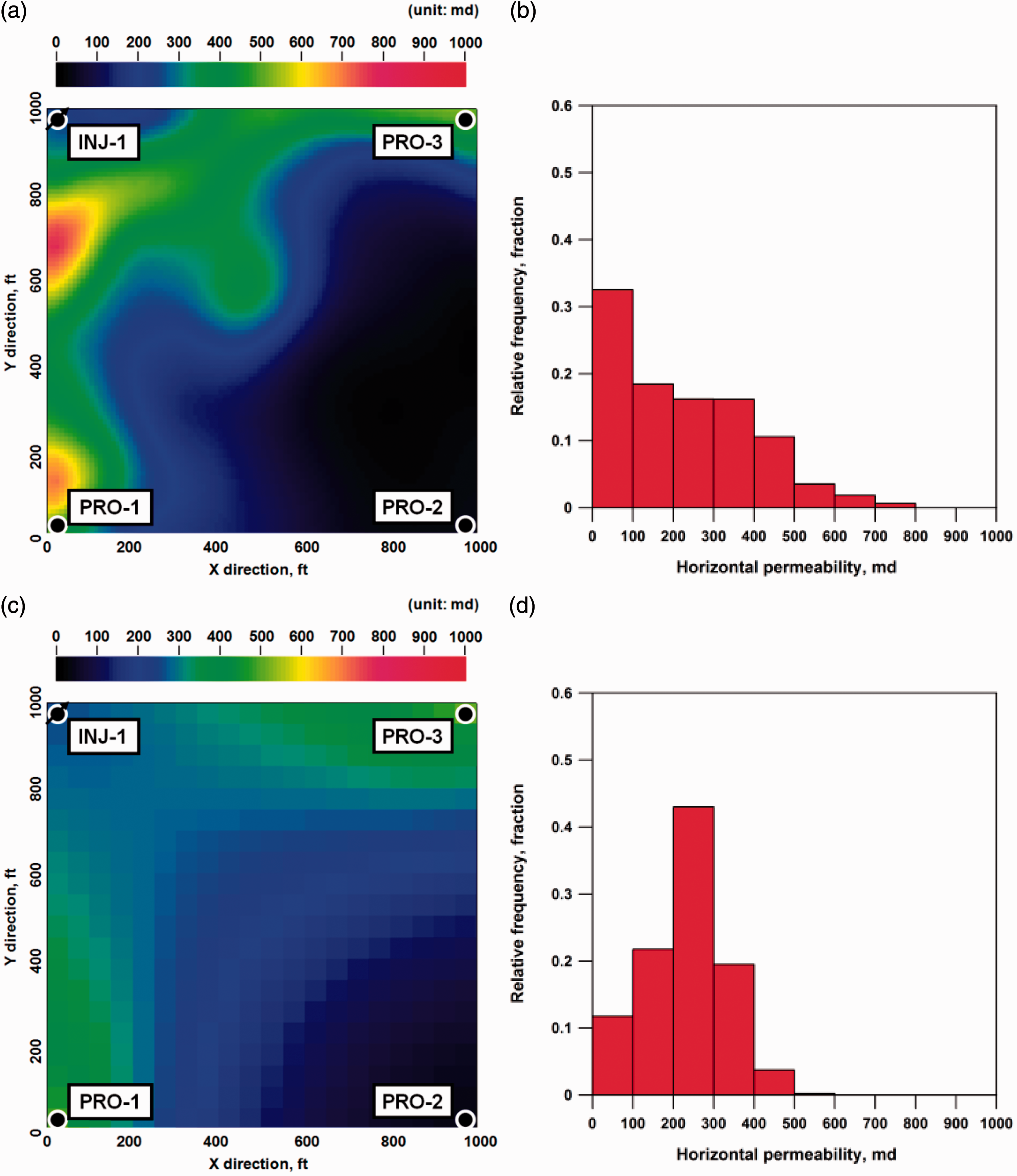
Distribution of horizontal permeability before history matching: (a) map of the reference reservoir model, (b) histogram for the reference reservoir model, (c) map of an initial reservoir model, and (d) histogram for the initial reservoir model.
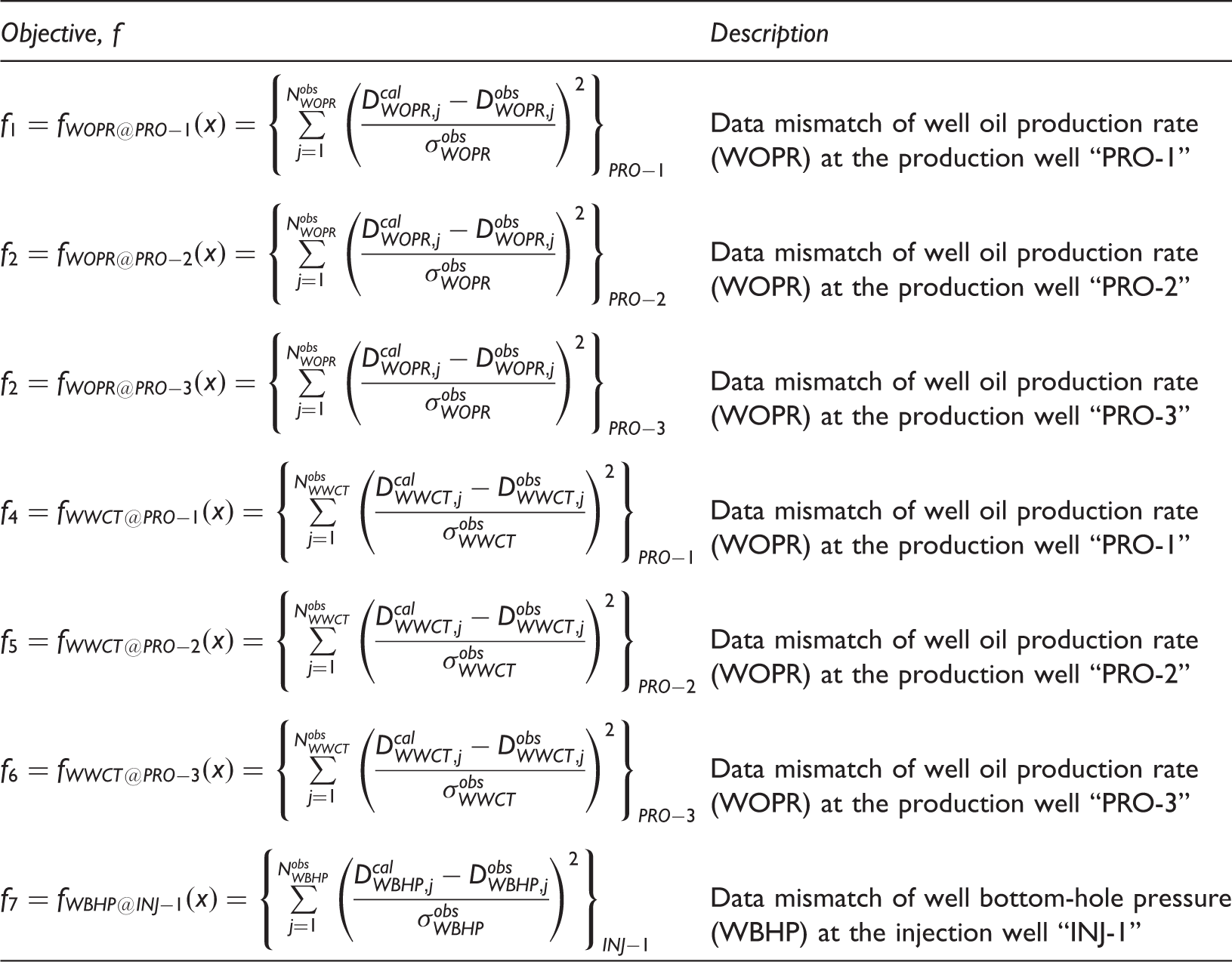
Objective functions for history matching.
History matching results
History matching was performed for 912-day waterflooding. Production behaviors were also predicted for the history-matched reservoir models up to 2282 days. The matching results of D-MOGA were compared with those from NSGA-II (Non-dominated Sorting Genetic Algorithm-II), which is one of the most widely utilized EMO algorithms in various engineering area (Deb et al., 2002).
Figure 5 shows the improvement of the objective functions in terms of the smallest, the median, and the maximum fitness values for f1 and for the objective-sum over the generations. D-MOGA decreased the fitness values of individual objective functions, thereby reducing the objective-sum consistently: the average proportion of the first-rank solutions was 45.4% of the population size of 100. On the contrary, NSGA-II focused resultantly on finding diversified solutions in the non-optimal domain as the number of first-rank solutions was larger than the population size from the fourth generation until the end of optimization process. In this case, the crowding-distance sorting made the diversity-preservation scheme dominate the optimization process, which resulted in the oscillation of the objective-sum since improving some objective functions worsened other objective functions.
Improvement of fitness values in each generation in the 20 × 20 grid system: (a) the smallest for f1, (b) the median for f1, (c) the maximum for f1, (d) the smallest objective-sum, (e) the median objective-sum, and (f) the maximum objective-sum.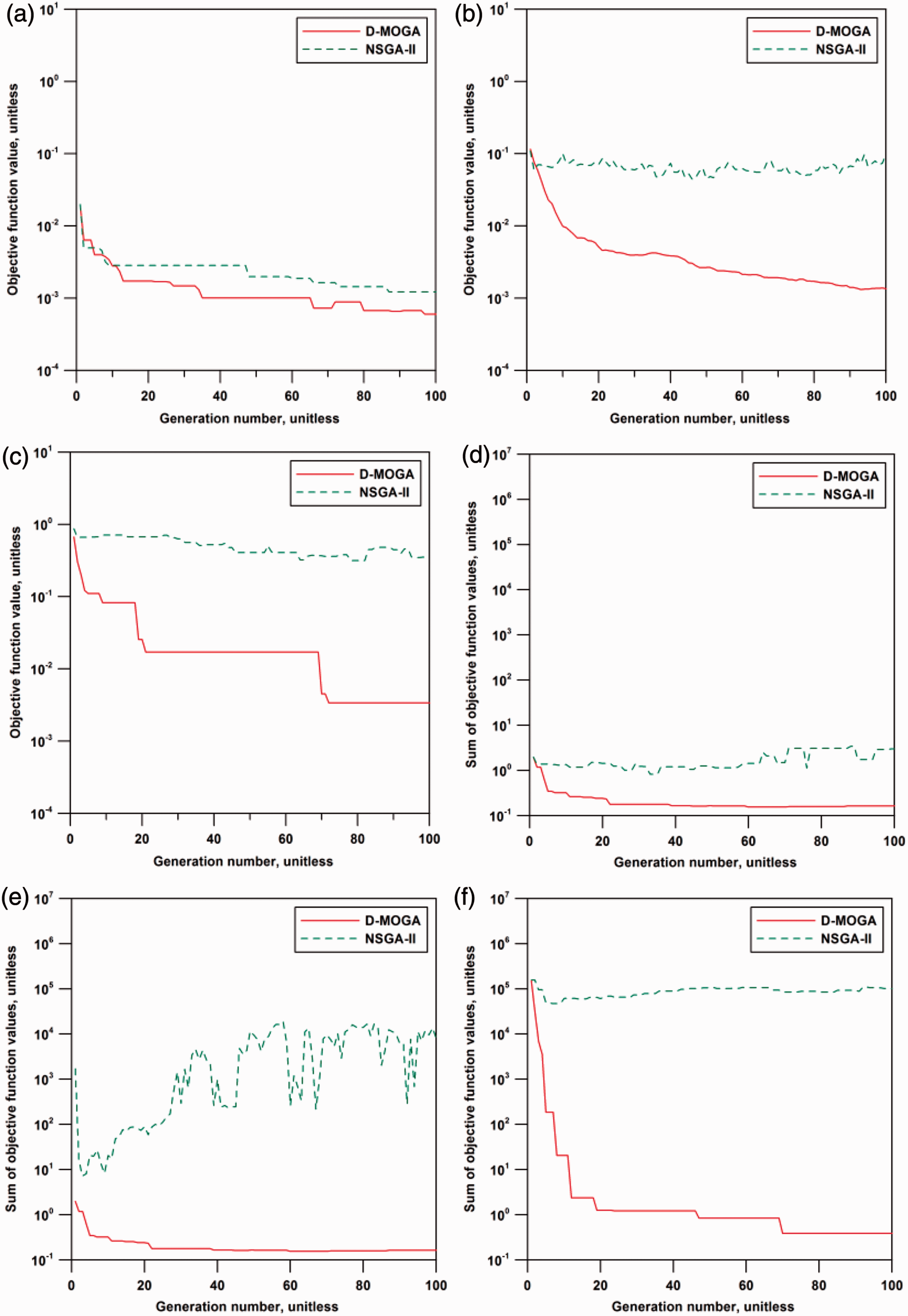
Figure 6 compares the production profiles at “PRO-2,” related to f2, in which the timing of water breakthrough was uncertain due to no water produced during history matching. Constant pressure condition was imposed for the production well. Note that shut-in conditions were considered: for 1 month during history matching and for 6 months during production forecasts, respectively. Red diamonds express the observed production data and solid gray lines express the calculated production data from the history-matched reservoir models. D-MOGA matched the production histories appropriately, and thereby resulted in the reliable production forecasts. Most production scenarios obtained from NSGA-II, however, were impractical owing to the failure in matching the timing of water breakthrough.
Production profiles at “PRO-2” obtained from 100 history-matched reservoir models in the final generation in the 20 × 20 grid system: (a) oil rate from D-MOGA, (b) water cut from D-MOGA, (c) oil rate from NSGA-II, and (d) water cut from NSGA-II.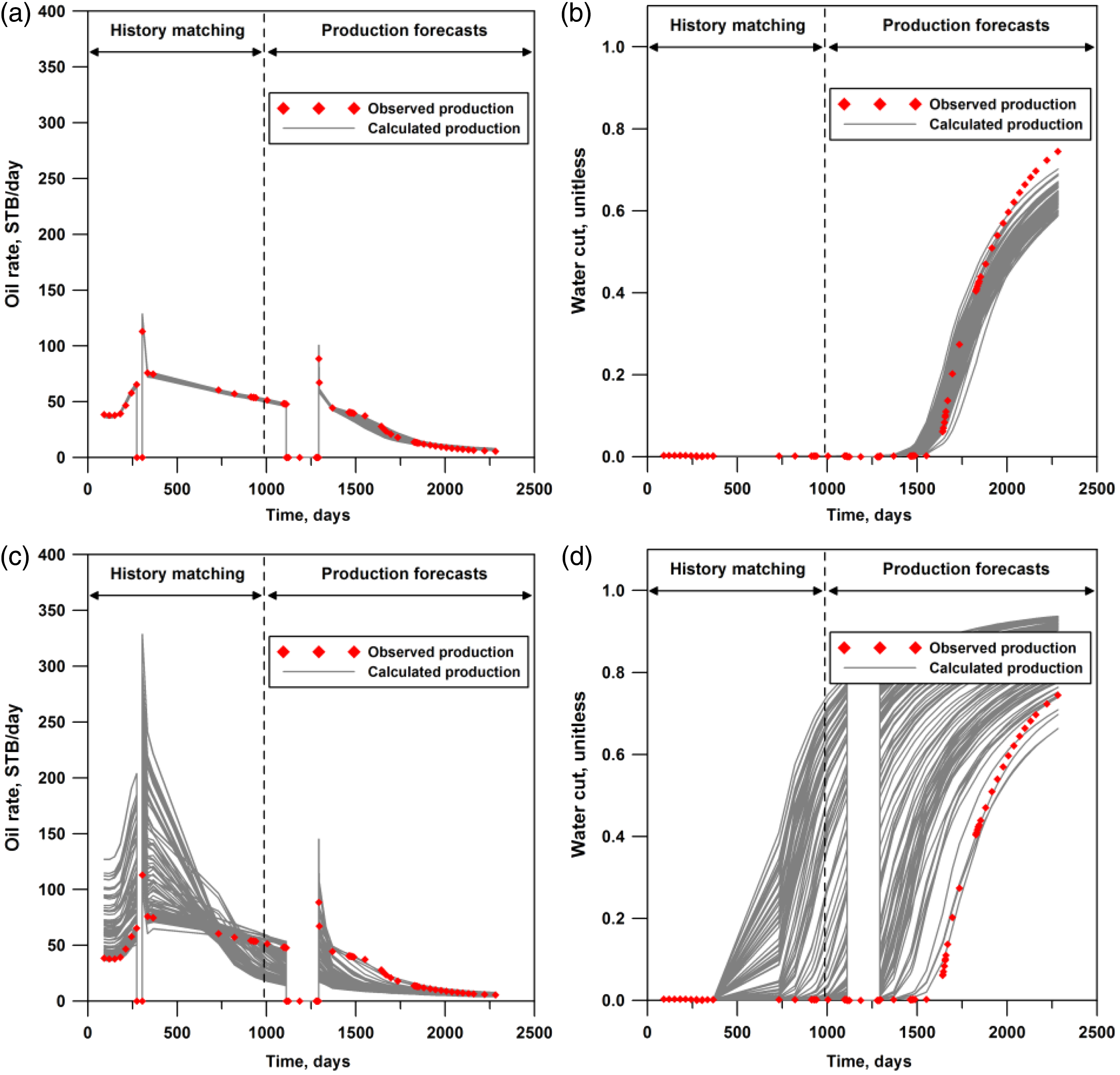
Figure 7 shows the spatial distribution of horizontal permeability for the reservoir model history-matched by D-MOGA, of which objective-sum is the smallest. The significant changes after history matching were a realization of a high permeable area between “PRO-1” and “INJ-1,” and an expansion of a low permeable region in the lower right quadrant to match a water breakthrough at “PRO-2.” The discontinuity among neighboring gridblocks resulted from the intrinsic characteristics of genetic operators, because both crossover and mutation modified the uncertain variables irrespective of neighboring variables by random sampling. Utilizing smoothing techniques that can consider the neighboring variables is expected to relieve this problem. When compared with the initial histogram shown in Figure 4(d), Figure 7(b) seemed to follow the lognormal distribution.
Distribution of horizontal permeability in the 20 × 20 grid system after history matching by D-MOGA: (a) map of the reservoir model with the smallest objective-sum and (b) histogram for the reservoir model with the smallest objective-sum.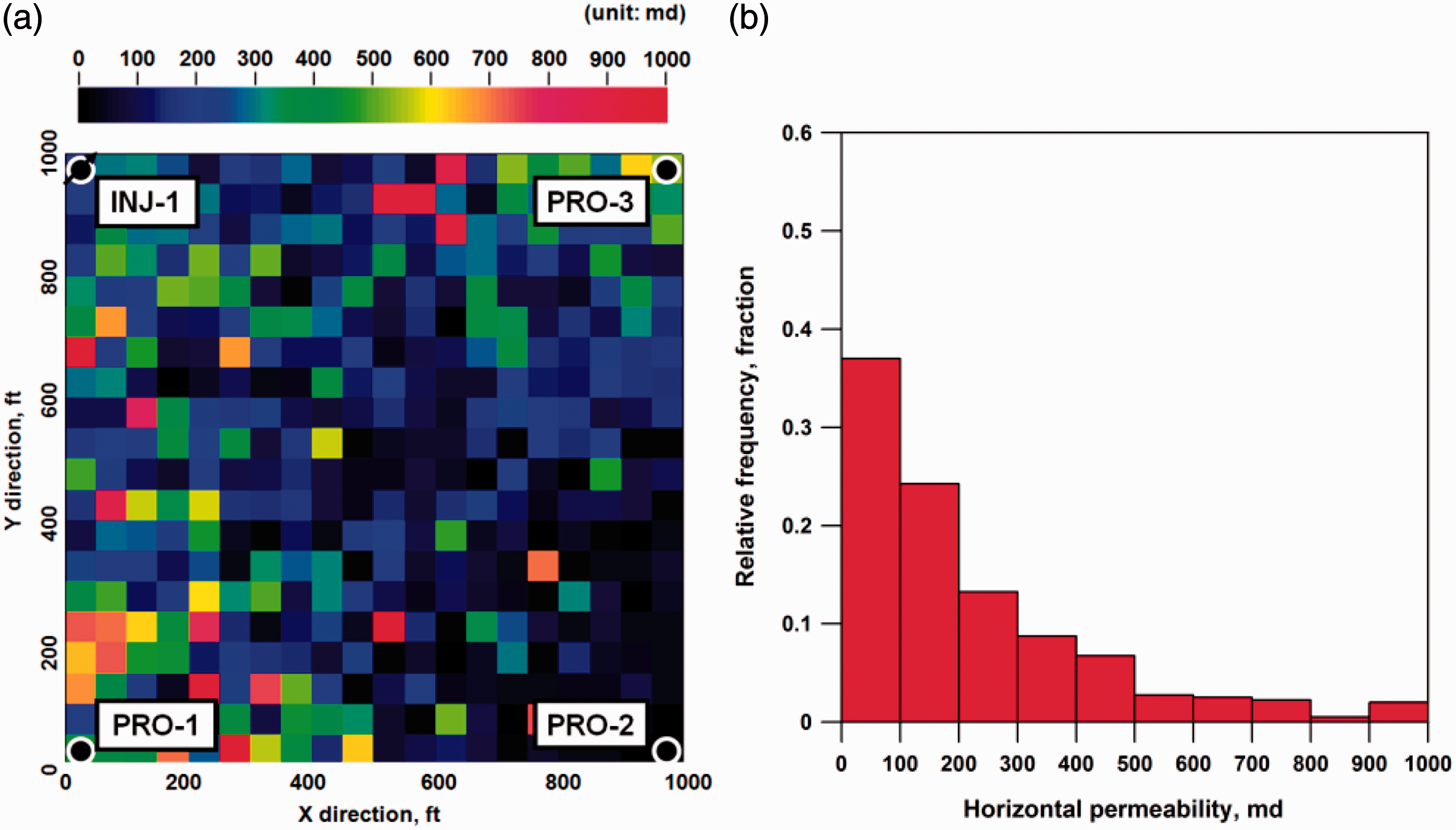
Sensitivity analysis of the effect of resolution on reservoir uncertainties
The field was also history-matched with the various numbers of gridblocks to investigate the effect of model resolution on the reservoir uncertainties: the 5 × 5 and the 10 × 10 grid systems. Figure 8 depicts the log–log scale plots that project the final reservoir models onto f1−f3 2D posterior space. The reservoir model with the smallest fitness value for each objective function was marked as the representative. Most of reservoir models from D-MOGA had shorter distances from the origin than NSGA-II. NSGA-II produced the convergent and the divergent reservoir models together despite yielding some representative solutions with smaller fitness values than D-MOGA.
Projection of the reservoir models in the final generation in f1−f3 2D objective space: (a) 5 × 5 grid system, (b) 10 × 10 grid system, and (c) 20 × 20 grid system.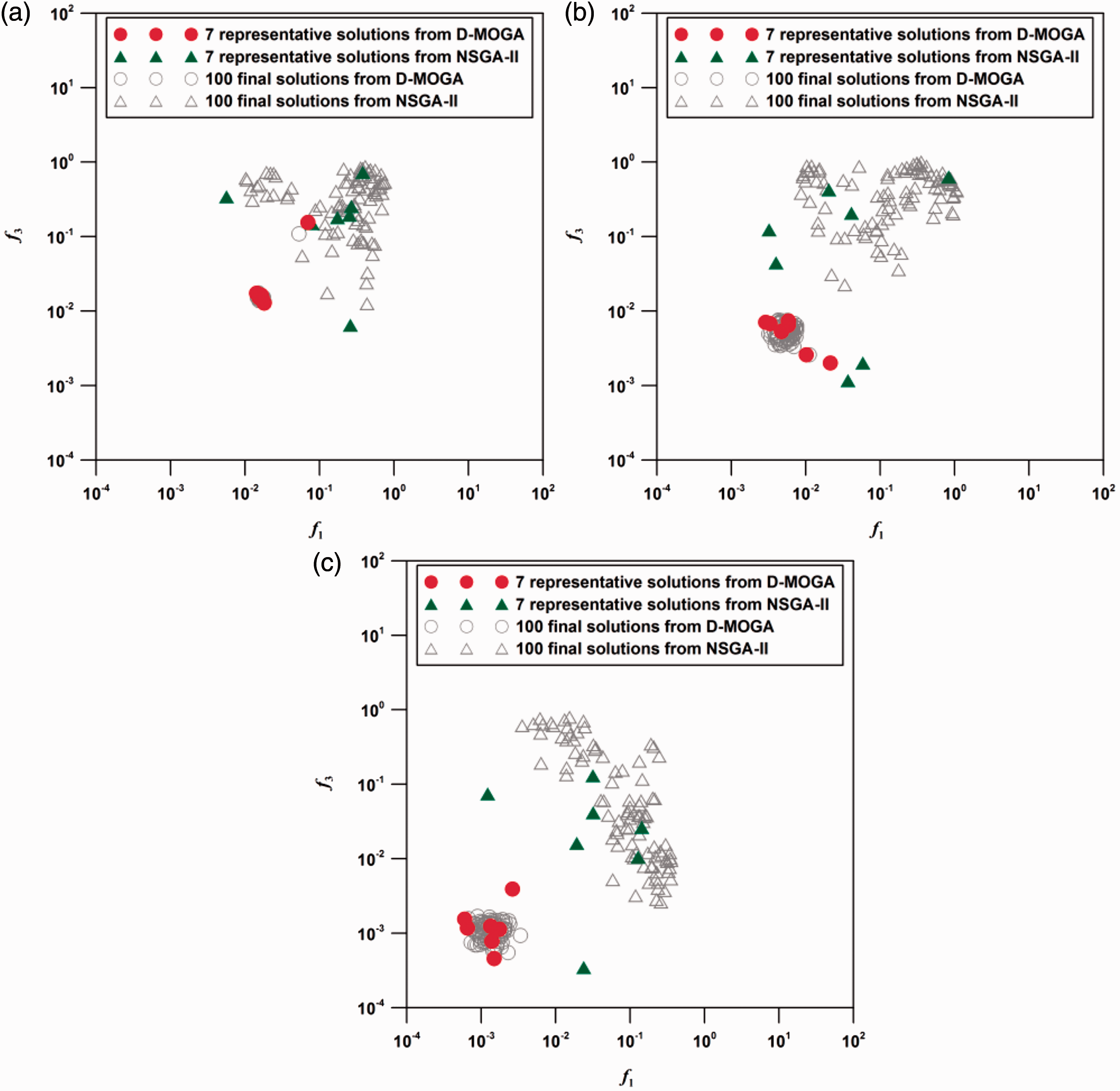
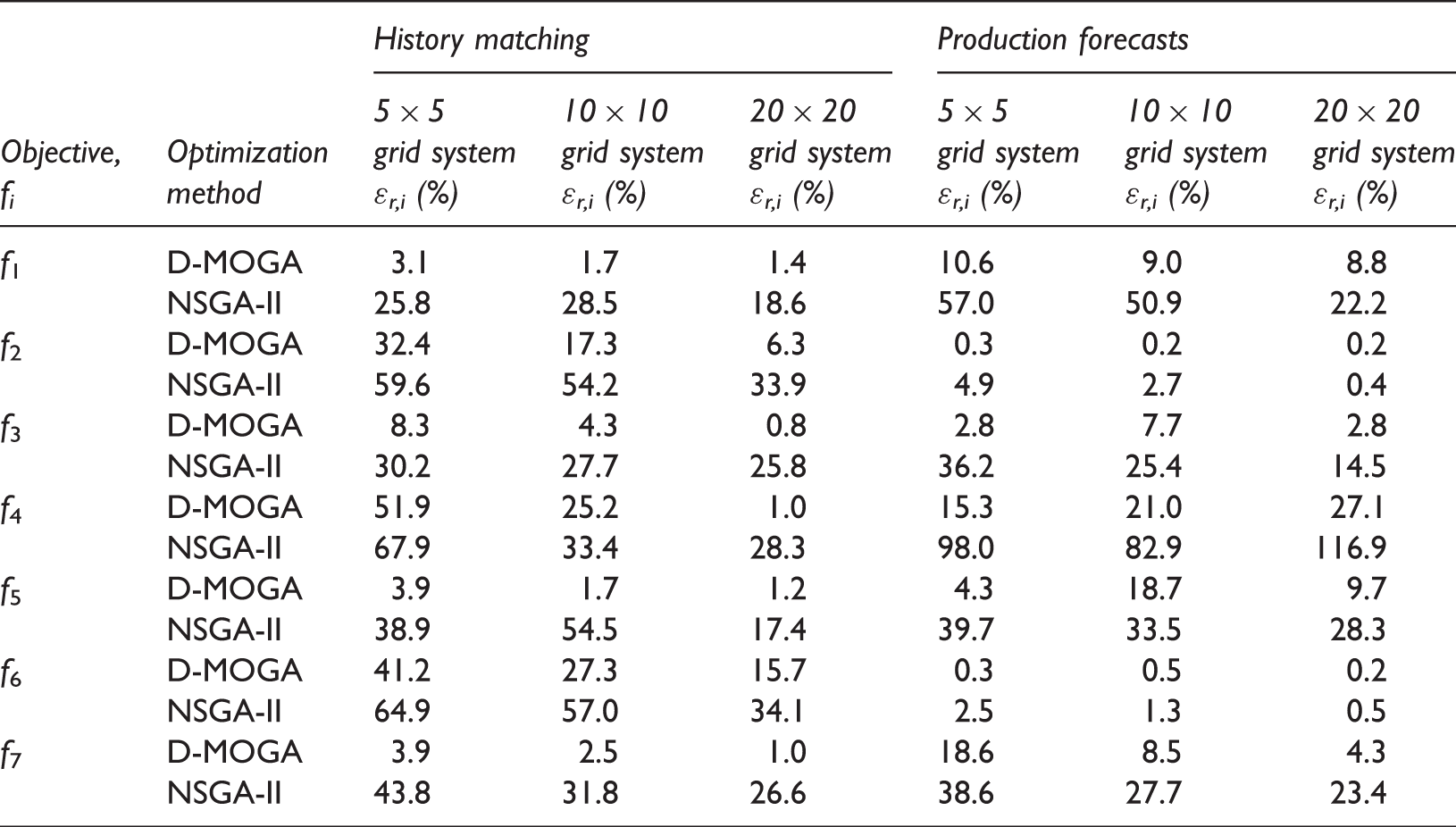
Model evaluation for 100 history-matched reservoir models in the final generation.
Conclusions
This article proposed the robust history matching scheme based on Pareto-optimality. Matching different production histories individually by articulating the preferences on the objective functions produced more reliable reservoir models than the conventional multi-objective optimization approach. The integration of preference-ordering with MOGA allowed the multi-directional analysis by pruning any unqualified reservoir model.
The results of oil-field application showed that developed methodology could be easily applied to solve the convergence problem and the unrealistic estimation caused by scale-difference and the complication among the multi-objective functions. This comparative study indicates that the developed well-based model is useful for the dynamic reservoir characterization of the heterogeneous fields by describing the irregular well performance successfully irrespective of different and complex operating condition of each well. The novelty of the approach can also contribute to a variety of decision making in oil-field development, e.g. response surface modelling in well placement optimization, by providing equi-probable, reliable, and diversified reservoir models. Furthermore, the developed methodology is being tested on the production design of heavy oil fields to compromise conflicting oil recovery and energy efficiency simultaneously. The results will be submitted in near future.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Korean government Ministry of Trade, Industry and Energy (Korea Energy and Mineral Resources Engineering Program) and Brain Korea 21 Plus Project (No. 21A20130012821). Also, the first author has been supported partially by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (NRF-2016R1A6A3A03012796).