
Abstract
In today’s economic environment, performance and efficiency assessment is essential for organizations in order to survive and raise their market share. Energy efficient consumption is a major issue in the energy planning of each country which is a big concern of managers, hence, exploitation of a strong approach for efficiency evaluation and assessment seems necessary in the energy section. In this study, a novel performance assessment model is proposed based on the concept of trust, using two popular fuzzy operators called T-norm and S-norm. The developed model is applied for a real case study of energy consumption efficiency assessment for 36 countries. An adaptive network based fuzzy inference system (ANFIS) is used to measure the efficiencies. Also, to predict efficiency rates of the future time periods, a regression model is applied as a time series model. The obtained results indicate the superiority and applicability of the proposed methodology. To the best of our knowledge, this is the first study that proposes a novel performance measurement approach based on trust context by using fuzzy T-norm and S-norm operators.
Keywords
Introduction
In today’s changing world, severe competitiveness among economic entities (decision making units (DMUs)) persuades them to constantly improve their performance. In such a complex situation, managers require some measures to evaluate the current conditions of organizations in order to monitor the performance and make right decisions. Besides, in order to have a better prediction of the future trend, the available historical data of the organization’s performance should be taken into consideration. It makes the performance and efficiency assessment of any organization to be important remarkably (Azadeh et al., 2007a).
Energy is one of the key economic elements of a nation that should be considered to provide economic growth and consequently community development. Energy efficiency is the goal to reduce the amount of energy required to provide products and services which concerns energy planners. Hence, efficiency assessment of energy use is an essential issue to improve the performance of energy section, especially in developing countries.
In the field of efficiency assessment, there are a vast number of methodologies that can be applied to determine the boundaries of efficiencies (Velicer and Fava, 2003). The approach of each methodology has some positive and some negative characteristics. The main shortcoming of these approaches is providing purely numerical values in which a wide evaluation is needed to make the results meaningful and applicable (León et al., 2003). In this situation, using the concept of trust in the field of performance assessment would be appropriate to cover some of the weaknesses. It provides explicit qualitative scales rather than just providing purely numerical data which would be more tangible and apprehensible for end users. This attitude makes trust a key component in the efficiency assessment process that enhances the efficiency and effectiveness of the managers in making decisions. Before explaining the definition of trust, some concepts should be defined as follows:
Trust agent is an entity that believes in another entity for a specific context and in a specific timeslot. Trusted agent is an entity that gives a specific context in a specific timeslot in which other entities have belief. Timeslot is a time duration between two time pints in which the trust value for a specific context and between two entities is determined. In the above definitions, context relates to the essence of the service given by an entity.
A comprehensive definition of trust is provided by Chang et al. (2006) as follows: “The belief that the trusting agent has in the trusted agent’s willingness and capability to deliver a mutually agreed service in a given context and in a given timeslot”.
Unlike general beliefs about the similarity of security and trust, they have different meaning; security makes a safe environment without unconfident agents, while trust aids the trusting agent to select a trustee agent. In contrast to objective measurable scales, trust is the subjective idea of trusting agent about the trusted agent which shows the possibility of continuing their interaction (Chang et al., 2006; Luo et al., 2009a).
Two major attitudes can be considered in the trust modeling: trust prediction and trust determination. Trust prediction is the process of determining trust value of an entity, either qualitatively or quantitatively, at a point of future time and trust determination is the process of establishing trust value of an entity, either qualitatively or quantitatively, either during the current time or in the past (Jamasb and Pollitt, 2001).
Prediction and forecasting have two categories: (1) prediction of whether interactions between two parts have been formed and therefore the trust between two agents will exist. (2) Predicting trust values and prediction of the level of trusting agent satisfaction (Azadeh et al., 2015b; Raza et al., 2011). Prediction and forecasting is a necessary research challenge and miscellaneous approaches have been proposed to forecast future values in different areas such as health system (Wu et al., 2010), earthquake magnitude prediction (Panakkat and Adeli, 2007), software reliability (Tian and Noore, 2004), failure time (Tahir et al., 2014), climate prediction (Pangburn, 2010), and energy (Aras, 2008; Azadeh et al., 2015a; Balat, 2004; Das et al., 2011; Fan et al., 2014; Zhao et al., 2015). A most valuable case to select a suitable partner is by predicting trustworthiness of an agent.
Numerical scales to quantify the amount of trust.

To the best knowledge of the authors, it is the first time that these two fuzzy operators are used in the area of trust for the performance assessment of real entities.
The remainder of this study is organized as follows: in the next section, the previous works related to this study are reviewed. In “Results” section, the proposed methodology for efficiency assessment is described. In “Discussion” section, a real case study is presented to show the application of the proposed methodology. Finally, in “Conclusions and policy implications” section, the conclusions of the study are discussed.
Literature review
The related literature can be categorized into three sections: performance assessment, energy consumption, and trust. Performance measurement and efficiency assessment is of great importance for optimal management and control activities of complex systems. There are a vast number of methodologies with different approaches in the literature which are used to determine the efficiency boundaries (Jamasb and Pollitt, 2001). These approaches are classified into parametric and non-parametric approaches. The parametric methodologies include the estimation of both deterministic and stochastic boundary functions (SFF) and they are based on the econometric regression theory which has been widely accepted in the econometrics field while the non-parametric ones comprise data envelopment analysis (DEA) and free disposal hull (FDH) which are based on a mathematical programming approach (Azadeh et al., 2011).
All the proposed methodologies have some strengths and some weaknesses. Although the efficiency frontier assessment methods are known as reliable analysis tools and they have been used widely in previous studies (Cook and Green, 2005; Golany et al., 1994; Goto and Tsutsui, 1997; Knittel, 2002; Lam and Shiu, 2001; Olatfubi and Dismukes, 2000; Park and Lesourd, 2000; Sanhueza et al., 2004; Sueyoshi and Goto, 2001), the required assumptions for some of these methods are restrictive and conflicting conclusions of efficiency are often resulted by using different methods due to the unsuitability of the assumptions (Azadeh et al., 2011). For example, the DEA frontier is so sensitive to the presence of the outliers and statistical noise which indicates that the frontier derived from DEA analysis may be warped if the data are contaminated by statistical noise (Bauer, 1990).
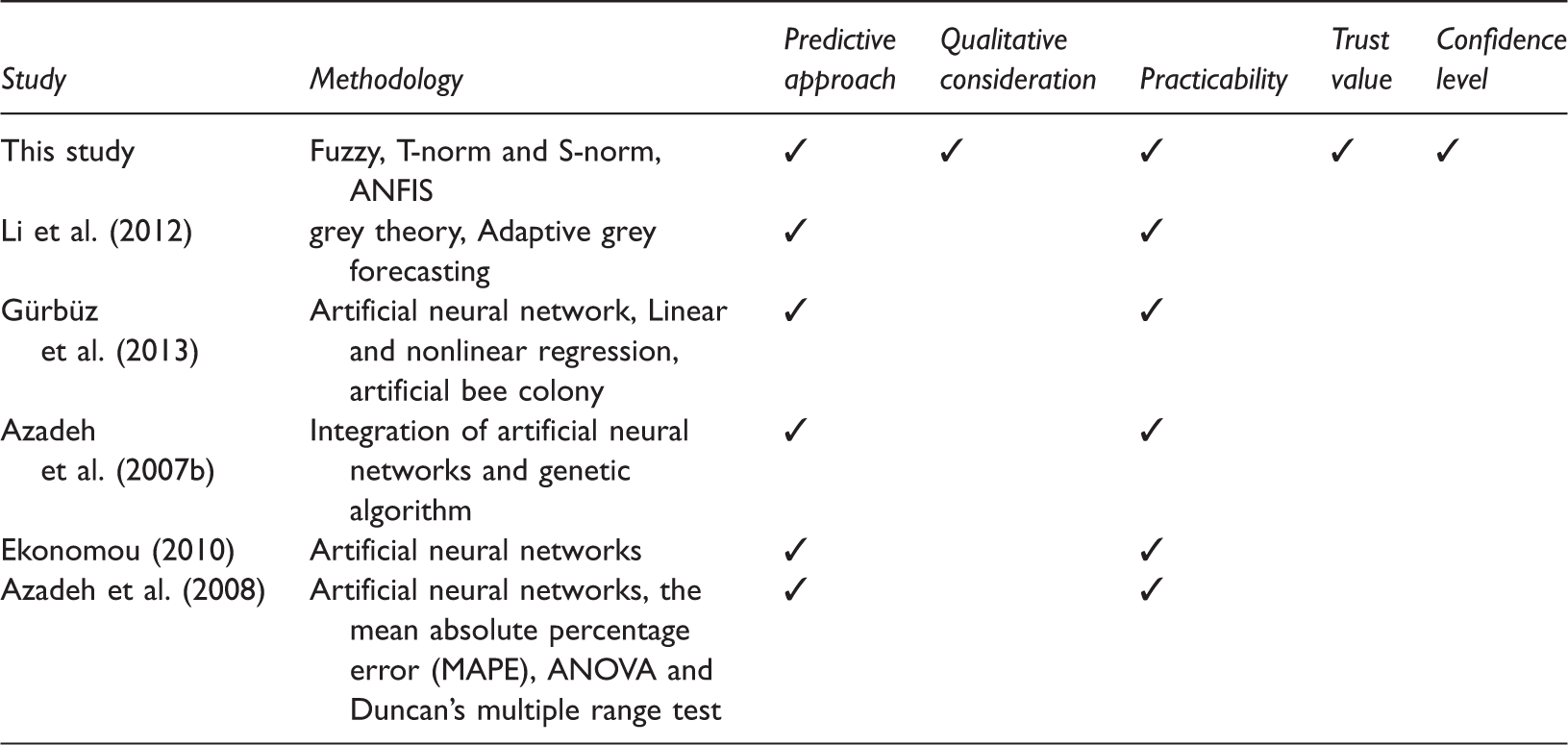
A review of the energy consumption literature shows that there are a vast number of studies on the energy consumption (Jorgenson et al., 2014; Wang, 2014). Some of them about energy prediction are reported here. Gürbüz et al. (2013) used classical and neural network approaches to predict energy consumption of Turkey based on artificial bee colony algorithm. Kavaklioglu (2011) used support vector regression methodology to predict and model Turkey’s electricity consumption. Azadeh et al. (2008) focused on prediction of the annual electricity consumption in energy intensive manufacturing industries. In their study, they showed that artificial neural network can be used for long-term prediction. Ekonomou (2010) described an artificial neural network method for the long-term prediction of Greek energy consumption.
Trust is a concept that has been taken into consideration in a number of areas especially electronic commercial fields. In this context, making decisions depends on the expectations created due to the information of former behaviors that is called reputation (Carbo et al., 2003). Abdul-Rahman and Hailes (2000) prepared a trust model based on a reputation mechanism, or word-of-mouth that would allow agents to decide which other agents’ opinions they trust more and would allow agents to progressively adapt their understanding of another agent’s subjective recommendations. Azadeh et al. (2015c) presented an efficient model for the analysis of outputs of performance measurement methodologies, using trust that provides explicit qualitative scales rather than pure numerical data. They introduced implementing the concept of trust in terms of performance assessment and measurement. Singh and Sinha (2010) presented a statistical predictive Trust model based on the Local Learning technique and famous methodologies of the Markov model. Carbo et al. (2003) developed a trust management mechanism tackling with uncertain information to apply it for a multi-agent system of merchants, recommenders, and buyers, using fuzzy set theory. They represented the benefits of using fuzzy sets to manage reputation in multi-agent systems.
Luo et al. (2009b) developed a model of trust based on fuzzy recommendation similarity, to evaluate and to quantify the trustworthiness of nodes, which consists of five kinds of fuzzy trust recommendation relationships. Siegrist et al. (2003) proposed a dual-mode model of social trust and confidence which was examined in the applied context of electromagnetic field risks. Structural equation modeling procedures and data from a random sample of 1,313 Swiss citizens between 18 and 74 years old were exploited. The obtained results delineated that the dual-mode model of social trust and confidence could be used as a common framework in the field of trust and risk management. Guo et al. (2011) presented a novel extensible trust evaluation model. The contribution of their paper is a formal general Extensible Trust Evaluation Model for Cloud computing environments (ETEC Model) with a method of comprehensive time-variant evaluation for calculating direct trust and a method of space-variant evaluation for expressing recommended trust. Teacy et al. (2005) developed a model of trust and reputation to ensure good interactions among software agents in large scale open systems. To compute trust, probability theory was applied with respect to the past interactions between agents. In the absence of sufficient personal experiences, the model used reputation information gathered from third parties. Kim et al. (2010) developed a model of trust for efficient allocation and reconfiguration of computing resources satisfying various user requests. They analyzed reliability based on historical information of servers in a Cloud data center.
Wang et al. (2012) presented a general model of trust, called RLM; they applied the Robust Linear Markov model to trust aggregation and representation. Huynh et al. (2006) proposed a trust and reputation model called FIRE which integrated a number of information sources to produce a comprehensive assessment of an agent’s likely performance in open systems. The model incorporated interaction trust, role-based trust, witness reputation, and certified reputation to provide trust metrics in most circumstances.
Comparison between studies of energy consumption.
Methodology
For the efficiency assessment, a methodology is developed based on fuzzy T-norm and S-norm operators as illustrated in Figure 1. The main steps and sub-steps of the methodology are as follows:
T-norm and S-norm calculation.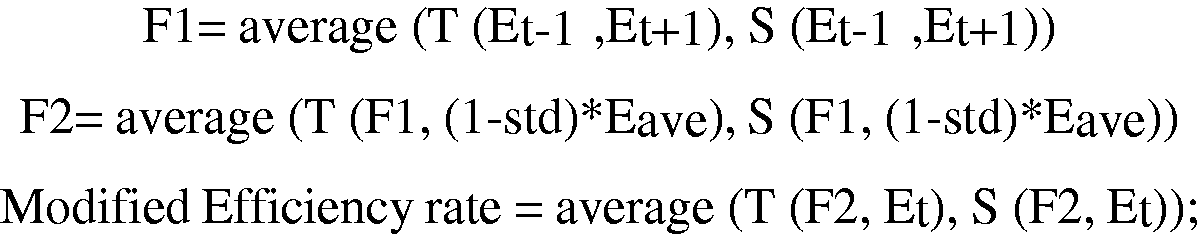
Step 1: Data collection
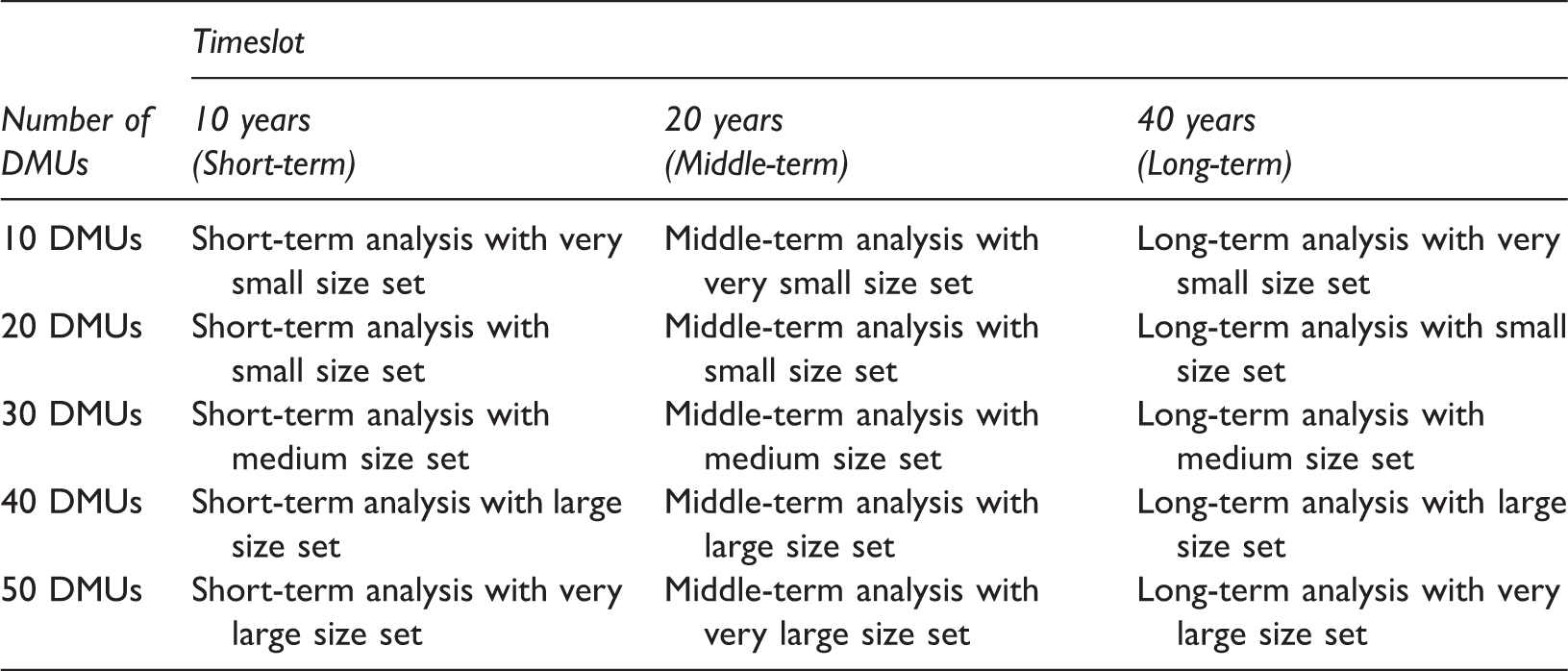
In order to characterize the structure of the problem, the scenarios should be determined with regard to the number of DMUs and the duration of each timeslot. On the basis of the number of DMUs, the following classes of data sets are defined:
Class 1: Very small data sets which contain 10 DMUs
This type of data sets is defined for a very small organization or an organization with very little importance for the analyzer.
Class 2: Small data sets which contain 20 DMUs
This type of data sets is defined for a small organization or an organization with low importance for the analyzer.
Class 3: Medium data sets which contain 30 DMUs
This type of data sets is defined for a medium size organization or an organization with mediocre importance for the analyzer.
Class 4: Large data sets which contain 40 DMUs
This type of data sets is defined for a large size organization or an organization with high importance for the analyzer.
Class 5: Very large data sets which contain 50 DMUs
This type of data sets is defined for a very large size organization or an organization with very high importance for the analyzer. On the basis of the duration of the timeslots, the following classes of data sets are defined:
Class 1: Short-term data set
This type of data sets contains the efficiency rate of 10 years (T = 10).
Class 2: Middle-term data set
This type of data sets contains the efficiency rate of 20 years (T = 20).
Class 3: Long-term data set
This type of data sets contains the efficiency rate of 40 years (T = 40).
Fifteen different scenarios.
Step 2: Efficiency calculations
To measure each DMU’s efficiency rate, an input oriented non-parametric efficiency frontier analysis method based on adaptive network-based fuzzy inference system (ANFIS) is applied. To implement this method, following steps are necessary:
Determine input(s) and output(s) for each DMU. Use ANFIS method to estimate relation between input(s) and output(s). Calculate weigh of DMUi (Wi) as follows:
Calculate the error between the real output (
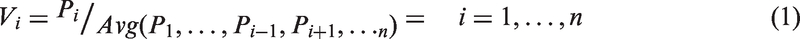


Shift frontier function from ANFIS for obtaining the effect of the largest positive error which is one of the unique features of this algorithm:

The largest 
Therefore, the value of the shift for each of the DMUs is different and is calculated by:
The efficiency scores take values between 0 and 1 which are calculated as follows: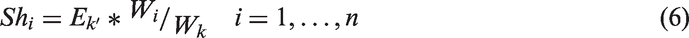
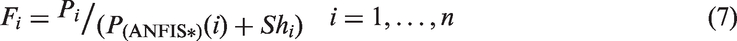
Step 3: Prediction
Efficiency rates of the current, previous, and following years (predicted), along with the average efficiency and standard deviation, are the five main inputs in trust modeling, however, in different situations their relation with final trust value varies. To predict the efficiency of the following years will be calculated using linear regression as a time series modeling.
The trust value of a specific year depends on a number of factors, including the efficiency rates of the current and previous years, the average efficiency rate of the timeslot, and the standard deviation of the timeslot. The required efficiency rates are calculated in the prior step using ANFIS method. After calculating the average efficiency rate and the standard deviation of the timeslots, the efficiency rate of the following year is predicted by an appropriate regression model using Wolfram Mathematica 9.0.
Time series analysis is a statistical method of analyzing data from repeated observations of a single unit or individual at regular intervals over a large number of observations; and time series forecasting is the use of a model to predict future values based on previously observed values (Mirtalaei et al., 2012).
In statistics, the definition of linear regression is a method to model the relationship between a numeral dependent variable y and one or more expositive variables X. One expositive variable is named simple linear regression. For more than one expositive variable, it is named multiple linear regression (This case differs from multivariate linear regression where multiple dependent variables are predicted rather than one scalar variable).
In linear regression, datum is modeled using linear predicting functions, and unclear model parameters are guessed and estimated from the datum. Such models are named linear models. Most widely, linear regression points to a model in which the contingent mean of y given the quantity of X is an affine function of X. Less widely, linear regression could point to a model in which the median, or some other quintile of the contingent distribution of y given X is declared as a linear function of X. Similar to all types of regression analysis, linear regression concentrates on the conditional probability distribution of y given X, rather than on the joint probability distribution of y and X, which is the amplitude of multivariate analysis.
Step 4: T-norm and S-norm
In this step, two fuzzy operators, i.e. S-norm and T-norm are applied to model trust in the assessment of efficiency rates. These two operators have some characteristics as follows:
The operator ^ is an S-norm, if it satisfies four conditions:
Commutativity: Monotony: Associativity: Neutrality of 0:
And the operator ^ is a T-norm, if it satisfies four conditions:
Commutativity: Monotony: Associativity: Neutrality of 1:
T-norms and S-norms.

Then, the modified efficiency rate (M.E) is calculated as shown in Figure 1. The conceptual framework of this step is illustrated in Figure 2.
Conceptual framework of step 4.
Step 5: Trust value calculation
This step consists of two main steps as follows:
Step 5.1: Initial trust value calculation
The M.E which was computed in step 4 is used to calculate the trust value. The value can be proposed in the scale, as shown in Table 1. Then, the procedure depicted in Figure 3 is applied to calculate the trust value.
Initial trust value calculation.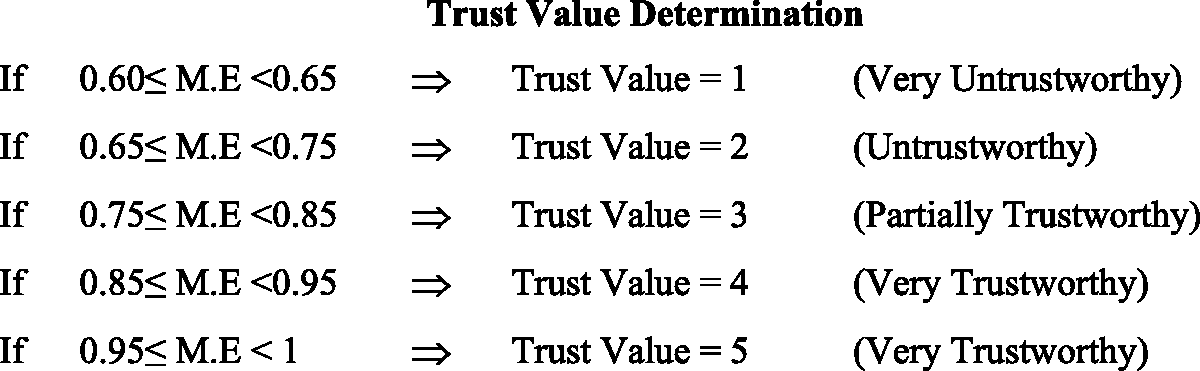
Step 5.2: Confidence level computation and determining modified trust value
Maturity, tendency, and density are here metrics for the confidence level that will be used in order to calculate the modified trust value. Each of them can have a value of 1, 2 or 3, where 1 is the lowest value, 2 is the normal value, and 3 is the highest one.
Maturity (M): Maturity refers to the total life span of an entity for which efficiency rates are provided (Raza et al., 2011). Tendency (Te): Tendency is a metric projecting the time to which the largest data belongs. It means that for each data set, we determine the k-th largest data (k = 1,…,j) and then examine the year to which the data belongs (Raza et al., 2011). Density (D): Density is the metric that compares the mean and median of the data set. It determines whether or not our data set contains any low rates. Imagine the median is larger than mean value; this means that there a number of data whose values are very low that have decreased the value of mean (Raza et al., 2011). Then, the confidence level is calculated as follows:
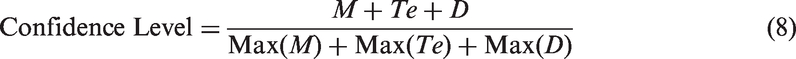
OR
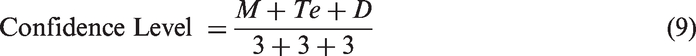
This value to determine the modified trust value as: Modified Trust Value = Confidence Level × Trust Value. Figure 4 projects the mentioned procedure.
Modified trust value determination.
Results
To show the applicability of the proposed methodology, assessment of energy consumption efficiency is implemented as a real case study.
Step 1
Energy consumptions.

Step 2
Efficiency rates by ANFIS.
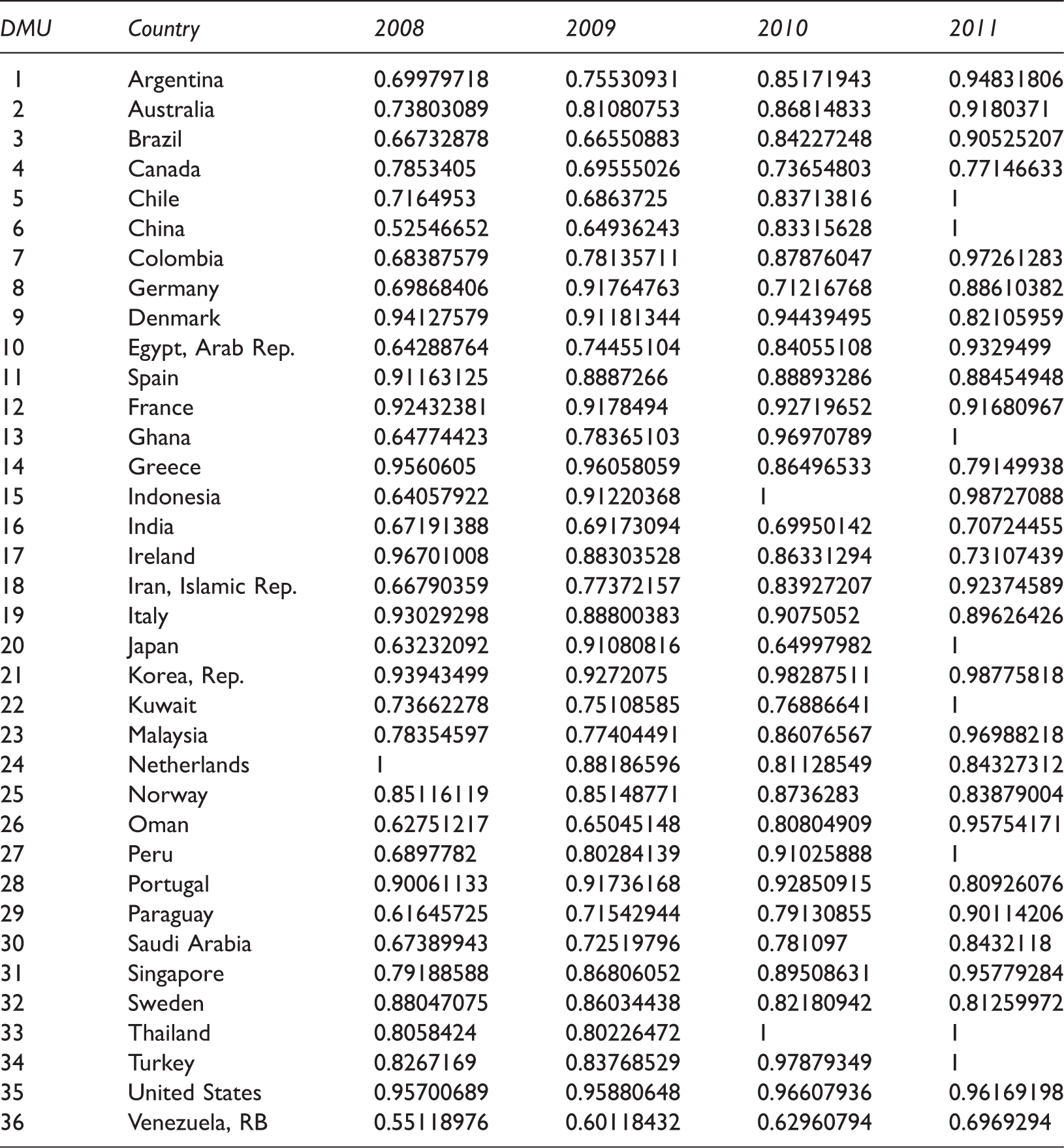
Step 3
Predicted efficiency rates.
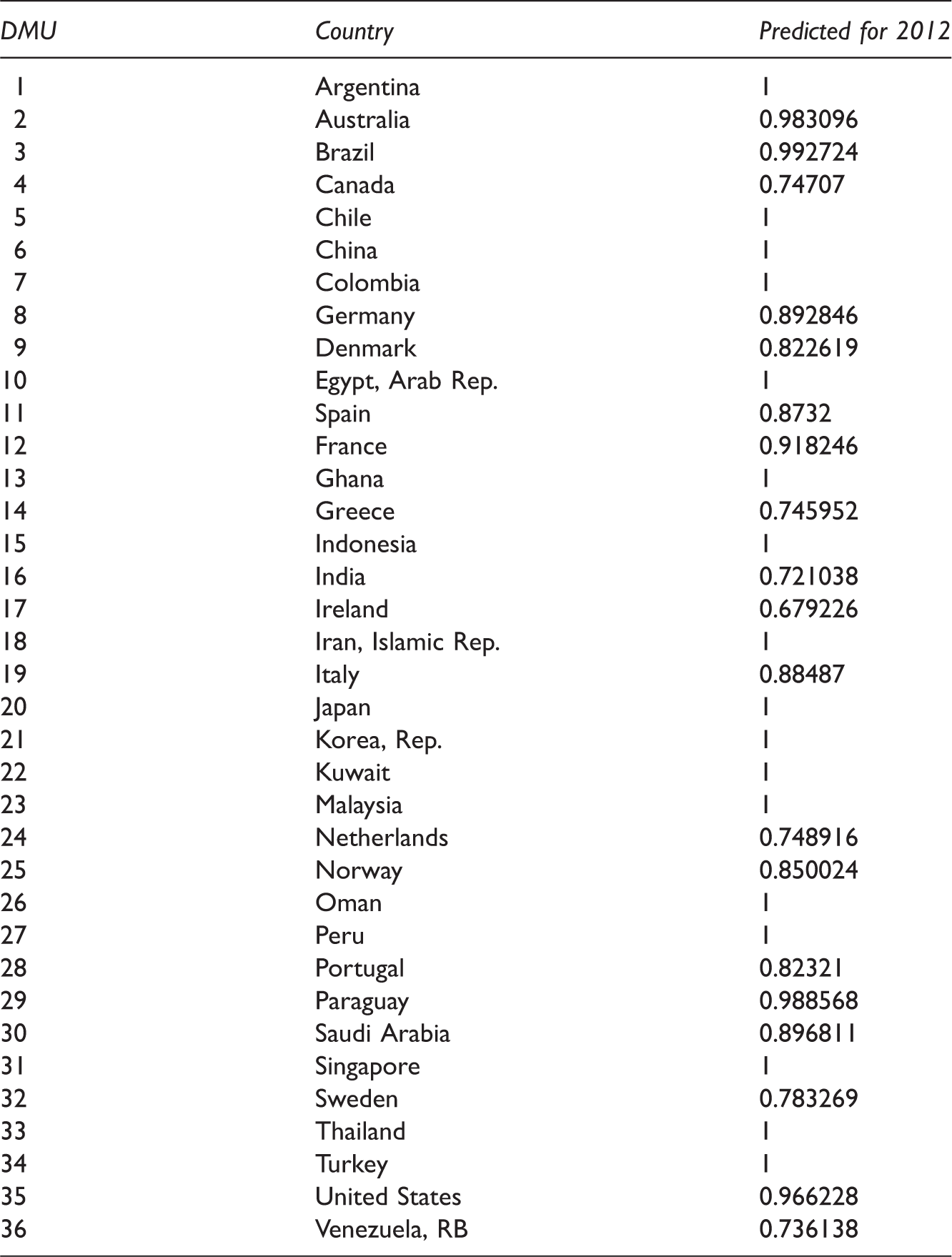
For example, the fitted regression model for Argentina is developed using the efficiency rates of the previous four years from Table 6. The related results obtained by Wolfram Mathematica 9.0 are illustrated in Figure 5.
The fitted regression model for Argentina.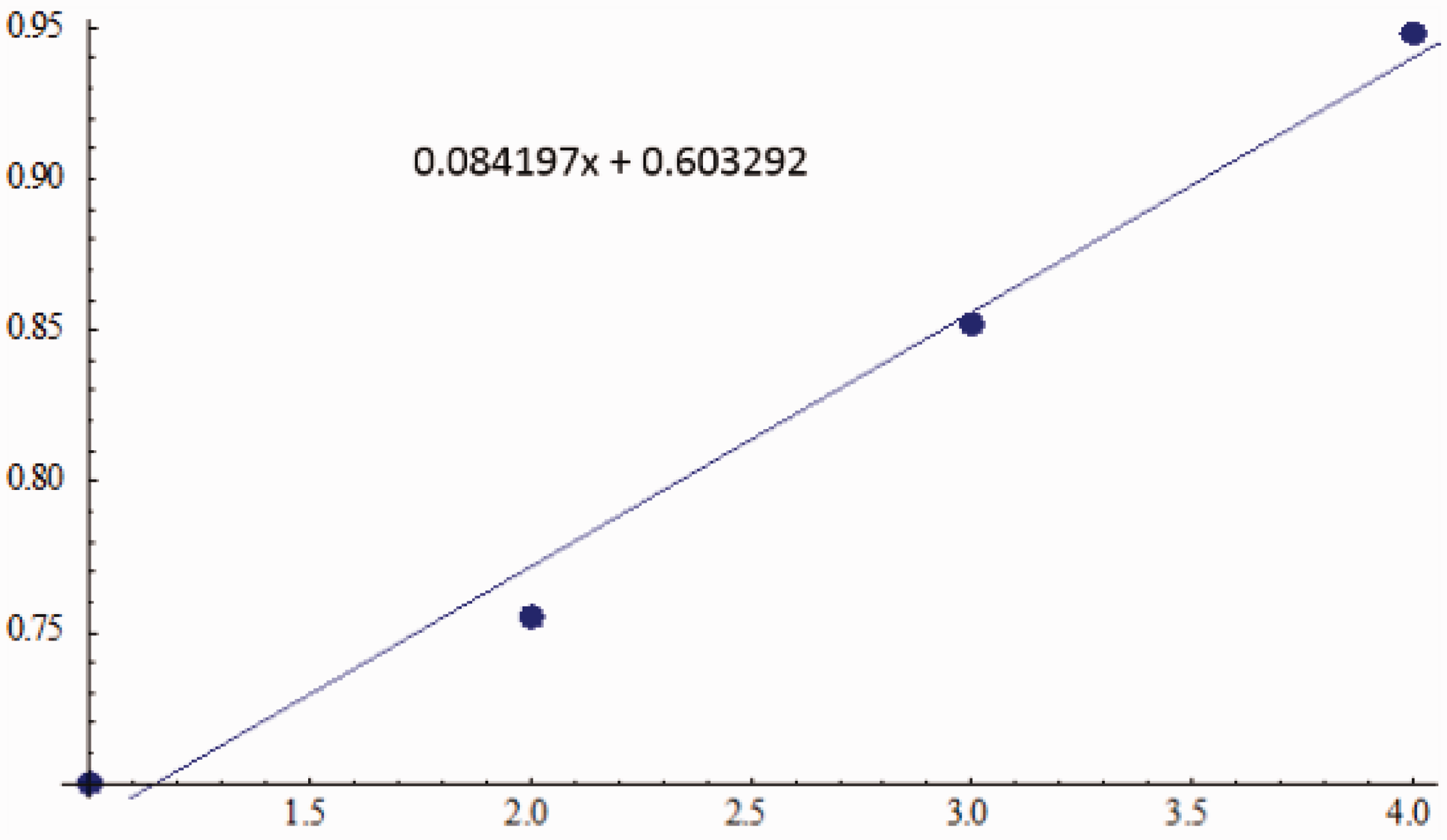
ANOVA results.

Step 4
Average and standard deviation for DMUs.
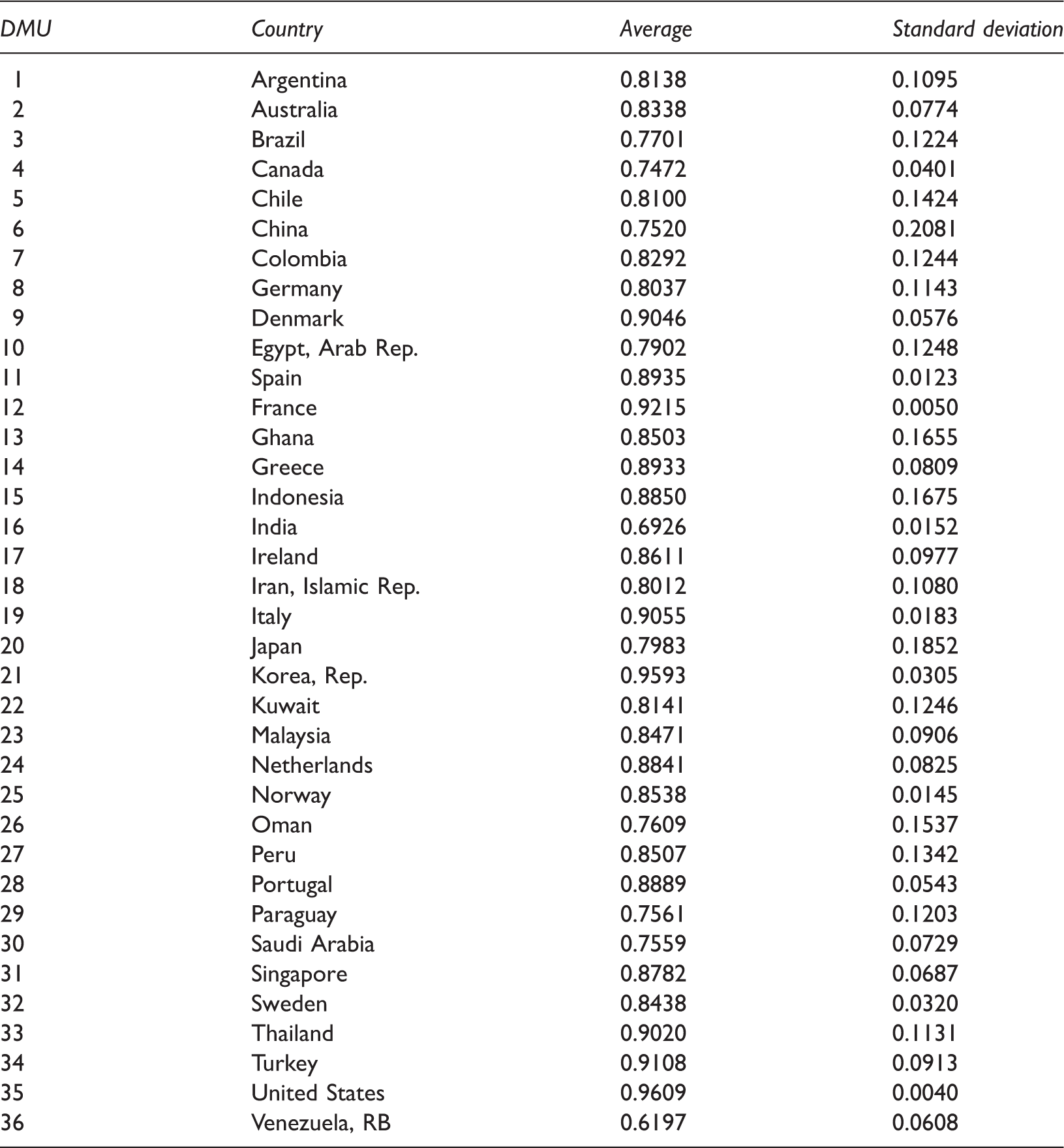
Step 5
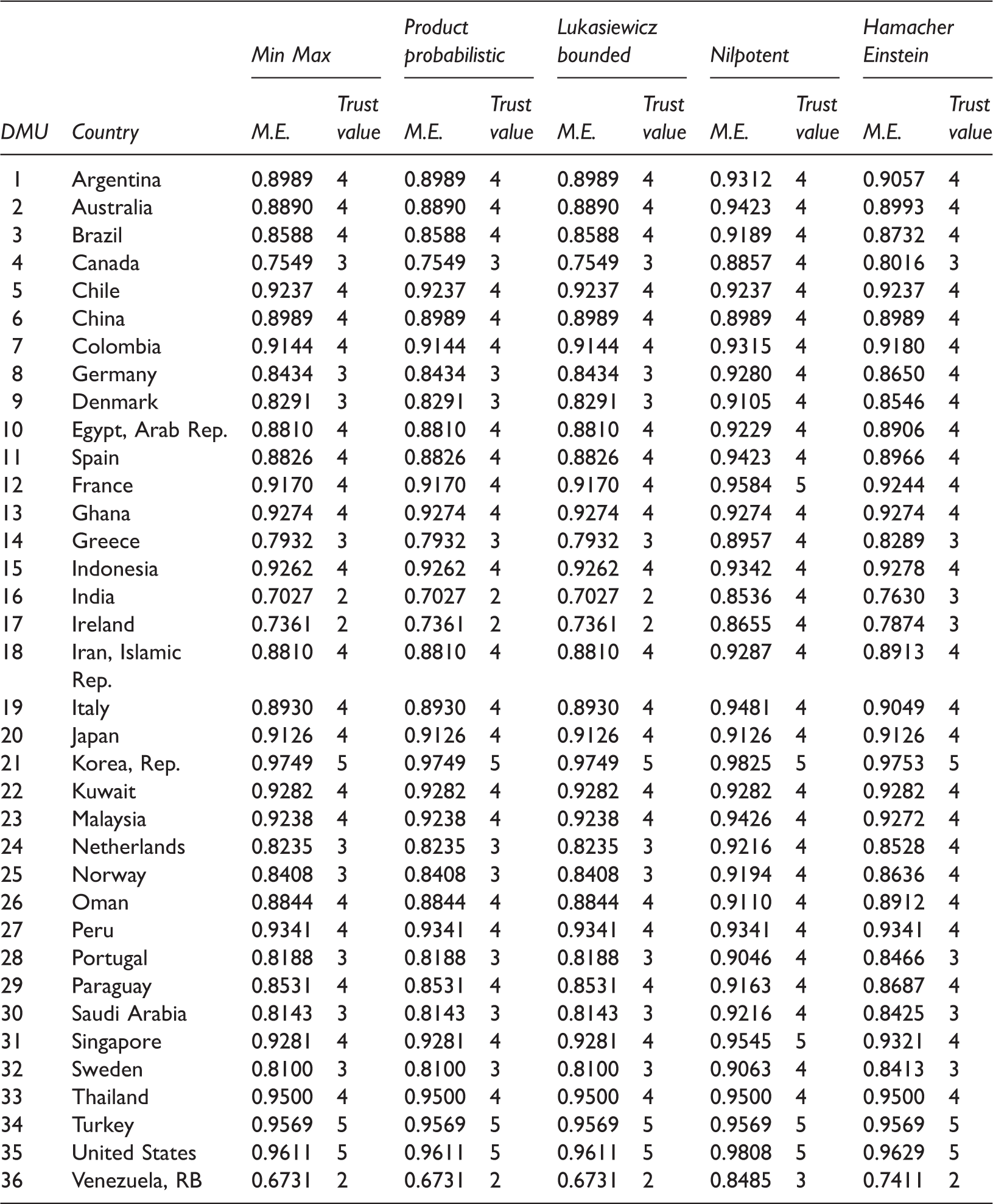
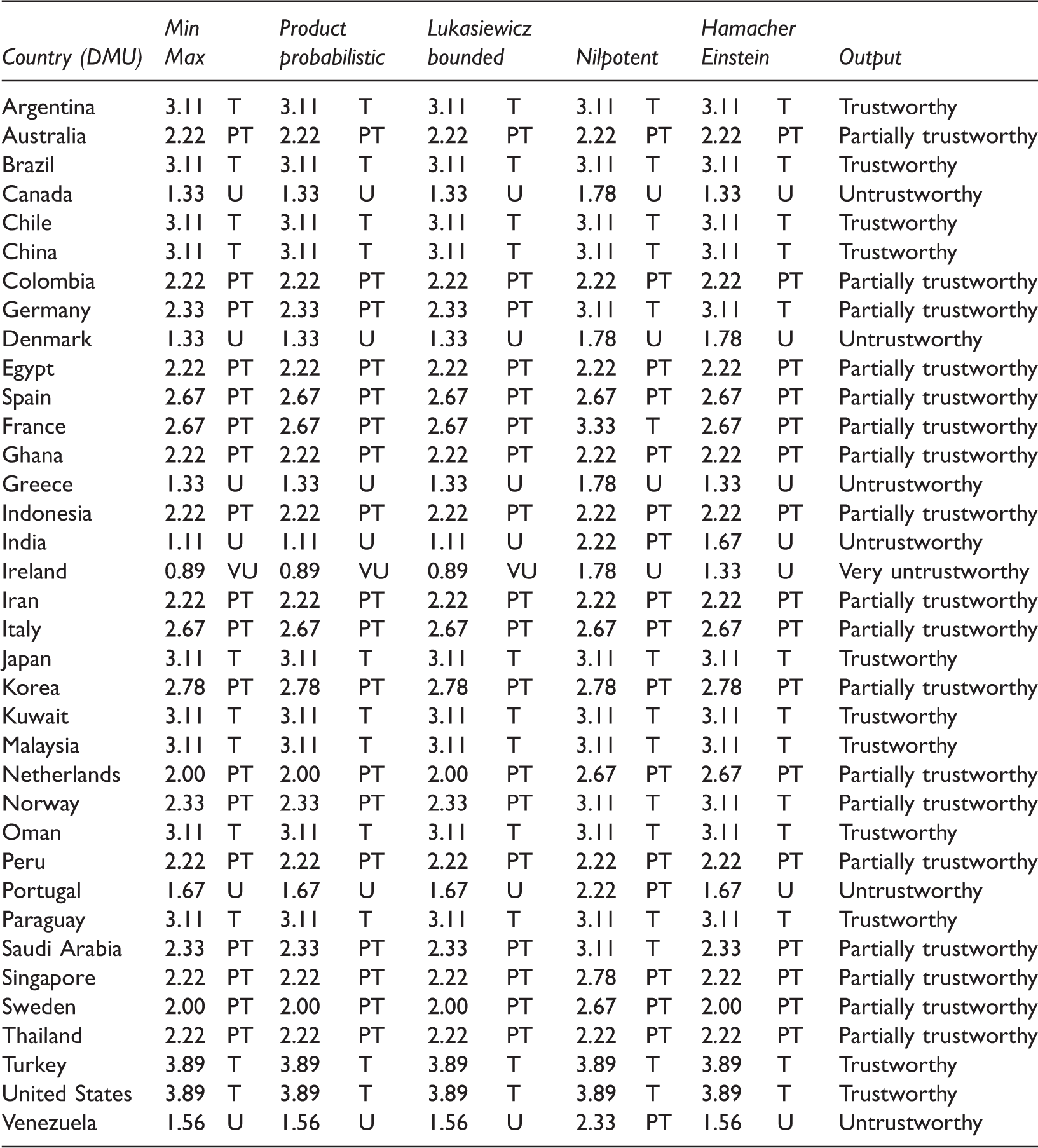
Modified efficiency and initial trust value of T-norms/S-norms.
Confidence levels for each pair of T-norm and S-norm.
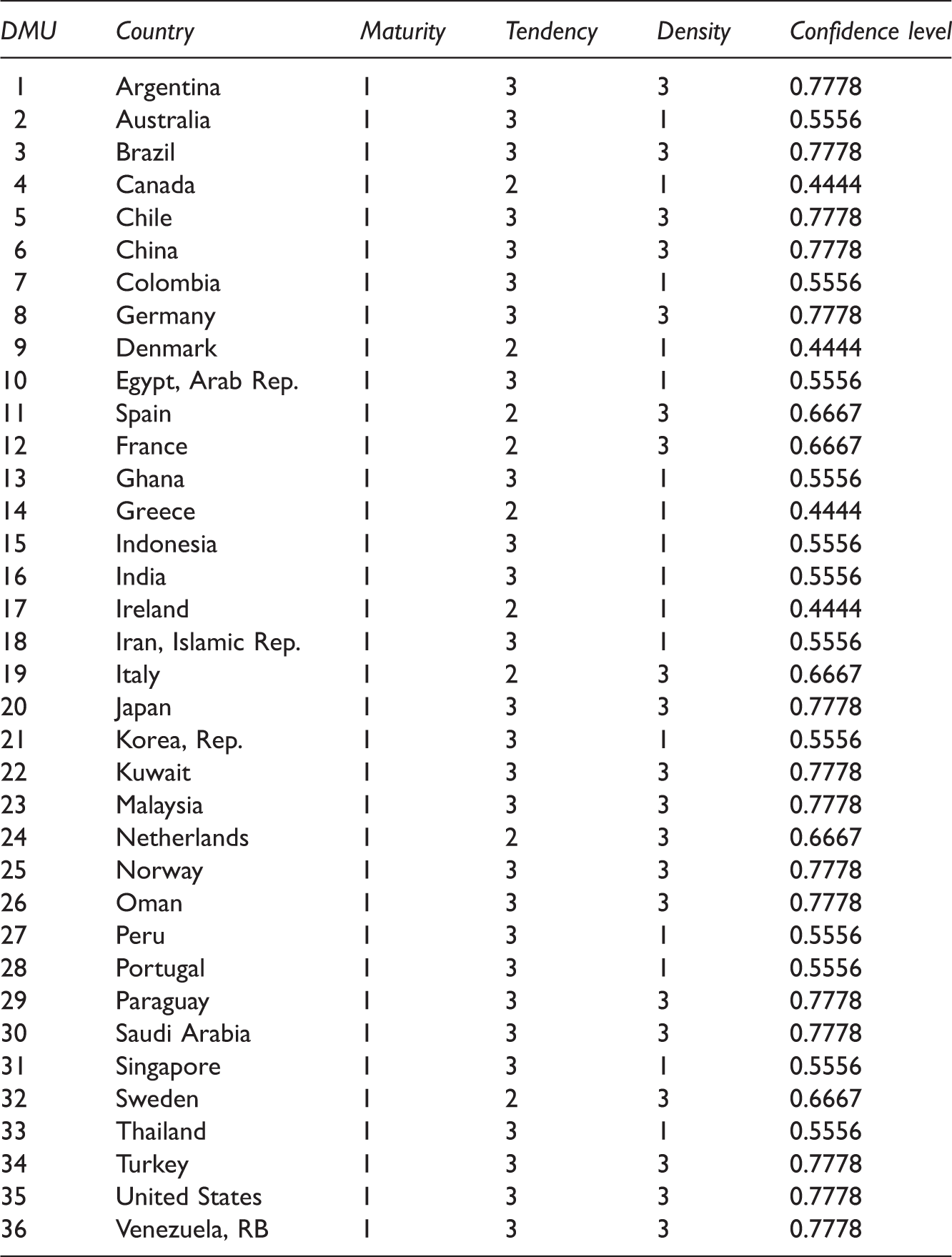
Modified trust values.
Discussion
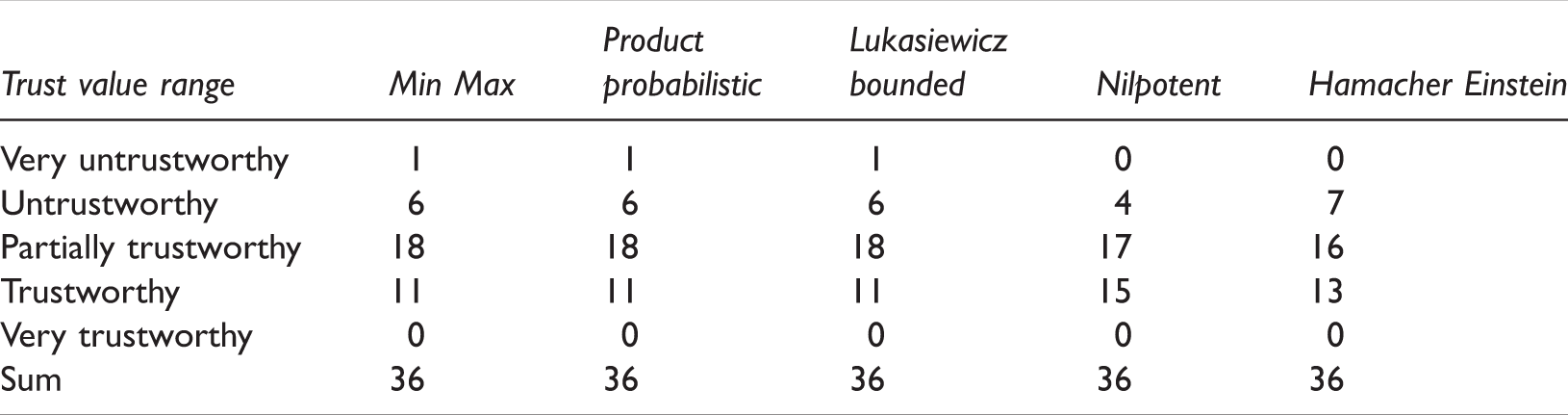
Some significant facts can be inferred from the obtained results. In this study, five different classes of T-norm and S-norm operators (i.e. Min Max, product probabilistic, Lukasiewicz bounded, nilpotent, and Hamacher Einstein) were applied for the trust value computations. These five sets were taken into consideration due to the role of personality in trust value calculation. As can be seen in Table 12, the results obtained by the first three sets are exactly the same, while Nilpotent and Hamacher Einstein sets provide different values which are greater in some cases. Also, the results of Nilpotent are the largest ones. Figure 6 represents the mentioned outcomes as well. It should be noted that the first three sets are different in calculating F1, F2, S(F2, Et), and T(F2, Et) but the M.E. rates are the same.
Modified trust values of different T-norms/S-norms.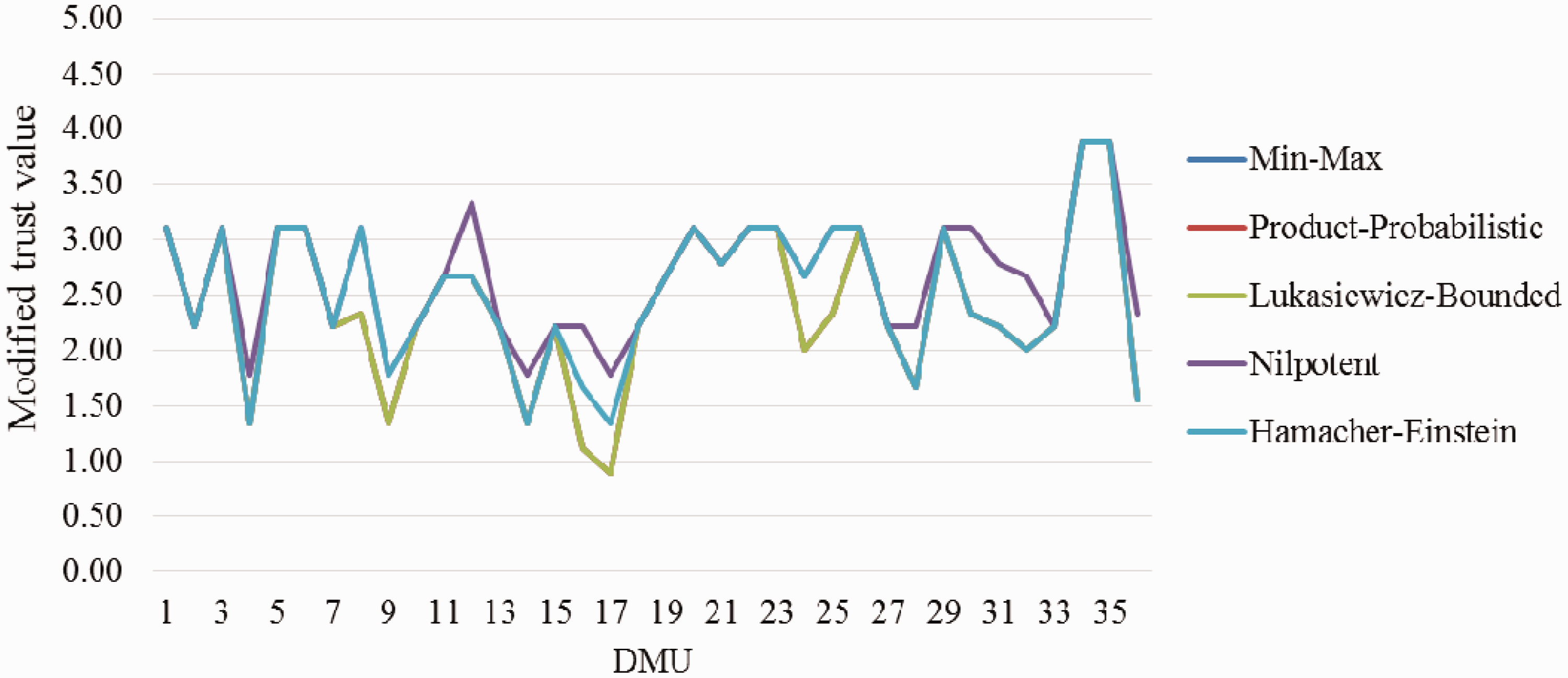
The number of trust value ranges for different T-norms /S-norms.
Conclusions and policy implications
In this paper, a trust-based model for performance assessment which provides explicit qualitative scales instead of representing purely numerical data was proposed to determine the trust value in energy consumption efficiency. The developed model was used for real data of 36 countries as DMUs. To the best knowledge of the authors, it is the first study that proposes an integrated trust model for assessing the performance of real DMUs, based on their size and degree of significance. The use of historical data, current values, prediction, and central and dispersion factors made the trust value determination model to be a comprehensive approach in which more reliable results are obtained by the utilization of the concept of confidence level. The proposed model can be practically used in different fields, such as sociology, business, etc.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was partially supported by a grant from University of Tehran [No. 8106013/1/20]. The authors are grateful for the support provided by the College of Engineering, University of Tehran, Tehran, Iran.