
Abstract
Studies of early lexical development have examined children’s vocabulary composition with the aim of quantifying early preference in the acquisition of nouns, predicates (verbs, adjectives, and adverbs), and closed-class/function words. Their findings show that a noun bias is common, suggesting it could be a universal aspect of early language development. However, only a small percentage of the world’s languages have been investigated. This paper examines whether children acquiring Xitsonga, a Bantu language spoken in Southern Africa, exhibit a noun bias in their early acquisition of lexical items. Data were collected from caregivers of 95 monolingual Xitsonga-speaking children aged 16 to 32 months in Limpopo Province, South Africa, using the MacArthur-Bates Communicative Development Inventories (MB-CDI) adapted for Xitsonga. Xitsonga-speaking children’s vocabularies showed a positive noun bias in relation to predicates and function words, similar to findings for most languages. However, separating predicates into verbs and adjectives showed that while there is still an early noun bias, children begin to favour verbs when their vocabularies exceed 400 words. The proportion of nouns and verbs aligns with findings for other Bantu languages, suggesting that languages that share typological similarities may have similar trajectories in early acquisition of lexical categories.
Keywords
Introduction
Child language acquisition research lacks diversity, with approximately only 1.5% of the world’s 7000 languages represented in publications (Kidd & Garcia, 2022). This imbalance challenges the development of comprehensive theories of language acquisition. There is a growing consensus on the need for diversification, including studying language acquisition in non-Western and rural societies, particularly by indigenous scholars (Cristia et al., 2023; Kidd & Garcia, 2022; Pascoe et al., 2024).
One understudied language is Xitsonga, part of the Tswa-Ronga Bantu subfamily in South Africa, Mozambique, and Zimbabwe. As part of the Bantu family, Xitsonga is a tonal language characterised by a noun class system with affixes modifying noun and verb roots. Verbs are particularly complex, as they distinguish between-subject and object noun classes (Demuth et al., 1986; Lee et al., 2022). The rich morphology, complex syntax, and tonomorphology of Xitsonga have been the focus of some studies (Kubayi et al., 2023; Lee & Burheni, 2014), most focused on adult speakers rather than children’s acquisition.
One area that lacks investigation in under-researched Bantu languages such as Xitsonga is the “noun bias” in early acquisition. In many languages, children’s early vocabularies show a larger proportion of words for tangible objects and people’s names than other word categories (Gentner, 2006; Gentner & Boroditsky, 2001). This noun bias is theorised to be a universal aspect of language development because discrete objects are hypothesised to be easier to recognise and learn than predicates (Jackson-Maldonado et al., 1993; Tardif, 1996). Piccin and Waxman (2007) argue that nouns are conceptually easier to learn than other syntactic categories (i.e. predicates and function items) because the concepts they refer to are more accessible. However, research on the Mayan languages of Tseltal and Tsotsil (Casillas et al., 2024), Korean (Choi & Gopnik, 1995), and Mandarin Chinese (Tardif, 1996) shows little evidence for a noun bias. Given the limited research into Xitsonga-speaking children’s early language acquisition, the existence of a noun bias – or whether the language’s rich verb morphology or other characteristics give rise to a different pattern of early word learning – remains to be investigated.
This study investigated the vocabulary composition and potential noun bias in Xitsonga-speaking toddlers (16–32 months) using the MacArthur-Bates Communicative Development Inventories (MB-CDI): Words and Sentences, a parent report tool adapted for over 100 other languages (Jarůšková et al., 2023). Data for this paper were collected as part of a multilingual research project investigating children’s early language development in South Africa’s 11 official languages, of which Tsonga is one (Brookes et al., 2025). The first author was responsible for leading the adaptation of the MB-CDI for Xitsonga-speaking children.
We first review studies of noun bias in early language acquisition, including research on Bantu languages and other languages with similar linguistic characteristics. Then we give details of our methodology and results, examining the proportion of nouns, predicates (verbs and adjectives), and function words in the vocabulary of Xitsonga-speaking toddlers. Our aim is to establish whether a noun bias holds in Bantu languages such as Xitsonga, characterised by rich morphology and a noun class system. Specifically, we compare the distribution of lexical categories across discrete vocabulary-size bands in 16 to 32-month-old children and track how these distributions shift as vocabulary grows.
Noun Bias in Early Productive Vocabulary
Nouns are reported to be acquired earlier than verbs due to their concreteness and direct link to perceptual experience. As a result, noun dominance in early lexical development has often been attributed to cognitive constraints (Gentner & Boroditsky, 2001; Kueser & Borovsky, 2024). By contrast, verbs denote actions, events, and states that are less bounded, with their meaning derived from participant actions in context. Similarly, relational words, such as pronouns and prepositions, take their meaning from the linguistic connections among referential words. Because function words rely on linguistic rather than perceptual grounding, their acquisition highlights the interaction between cognitive maturation and language-specific structures (Alcock, 2017; Bassano, 2000).
Early productive vocabulary studies indicate context-dependent and complex noun-verb bias across languages, with support for noun bias in many Indo-European languages such as English, Dutch, German, Swedish, Italian, French, and Spanish (Bassano, 2000; Bates et al., 1994; Bornstein et al., 2004; M. C. Caselli et al., 1995; Jackson-Maldonado et al., 1993; Kauschke & Hofmeister, 2002). Cross-linguistic research using the Wordbank database, which includes vocabulary data from over 26 languages, demonstrates that early lexical composition patterns vary substantially across languages (Frank et al., 2021). Rather than reflecting universal cognitive constraints, these patterns appear to be shaped by an interaction of language-specific factors, including typological features (such as word order and morphological transparency), input frequency and salience, and culturally influenced patterns of caregiver-child interaction (Braginsky et al., 2019; Tardif et al., 1997). This suggests that while some aspects of early vocabulary development may be universal, the relative prominence of different lexical categories is significantly influenced by linguistic and cultural context. Some languages, such as English, require overt nominal subjects in most clauses, potentially making nouns more salient in the input children receive (Tardif et al., 1997). In contrast, some languages, such as Xitsonga, have rich agreement system characteristics, and it is possible to use clauses that consist of verbs with affixes only (Kubayi et al., 2023).
Other languages, such as Navajo (Athabaskan-Eyak-Tlingit) and Kaluli (Trans-New Guinea), also show a noun bias (Gentner, 2006; Gentner & Boroditsky, 2001). However, Mayan languages Tseltal and Tsotsil appear to have a verb bias (Brown, 1998; De León, 1999). Mandarin and Cantonese studies show that Chinese-speaking children produce verbs earlier and more often than English-speaking children, depending on the context. In naturalistic parent-child interactions, verbs predominate, while nouns dominate picture-book evaluations (Tardif et al., 1997, 1999). Korean (Choi & Gopnik, 1995) and Japanese (Imai et al., 2008) noun-verb ratios differ substantially from English patterns. In Kigiriama and Kiswahili, Alcock (2017) found that nouns largely dominate vocabulary production, although verb and noun comprehension were similar. Hence, she argues that production scores alone could misrepresent children’s lexical knowledge because comprehension measures show distinct patterns from production measures. Similarly, for Ngas spoken in Nigeria, no significant difference between nouns and verbs was reported in production, although parents reported that the children comprehended more verbs than nouns, especially older toddlers (Childers et al., 2007). Children aged 1;0–1;5 showed a trend towards more verbs than nouns, and older toddlers (1;7–2;7) showed a verb preference that was statistically significant. Childers et al. (2007) suggest that the observed patterns of noun and verb acquisition may result from a combination of social context and language-specific structural properties, with the linguistic properties of Ngas favouring verbs and being supported by cultural practices that support verb learning, for example frequent use of directive speech, and routine-based activities.
Methods
Adaptation of MB-CDI for Xitsonga
Instrument adaptation involved translation, inclusion of culturally specific concepts and relevant syntactic features, followed by an expert review with two focus groups of child language professionals and parents to ensure. Pilot testing included 40 toddlers (50% rural and 50% semi-urban; i.e. local settlements attached to small towns that represent an intermediate stage between rural and fully urban environments). Items were removed, replaced or improved if they: (a) showed a significant correlation with age, (b) had an occurrence rate of at least 10% to avoid floor effects, (c) had an occurrence rate of 90% or lower to avoid ceiling effects, and (d) had a correlation of ⩾.3 with the overall scale (Brookes et al., 2025).
The instrument contained 737 lexical items and 21 categories. The “helping verbs” category was excluded because it is not applicable to Xitsonga. Some Germanic function words are fulfilled by affixes in Bantu languages; thus, the adapted Communicative Development Inventories (CDI) have fewer function word categories (Brookes et al., 2025).
Participants
Participants were recruited from the Greater Giyani municipality in Limpopo Province, South Africa. As monolingual environments are rare in large metropolitan areas, children were selected from rural villages and semi-urban populations in predominantly Xitsonga-speaking areas through district clinics and non-governmental organisations (child-care centres). 1 One hundred and thirteen caregivers completed the MB-CDI. Eighteen were excluded: two for exposure to another language for more than >4 hr per day; two for hearing/communication concerns; two for language delays; six children were outside the 16 to 32 months range; four for vocabulary scores identified as extreme outliers, and two used for training and practice. Data analysis was conducted on the remaining ninety-five (95) participants (See Table 1).
Child Participants’ Age, Sex, and Area (n = 95).

Data Collection
We used an electronic version of the MB-CDI on Qualtrics (2020–2023) that could be used offline in rural areas. Fieldworkers, who were employees of child development organisations, two third-year social work university students, and one second-year speech-language pathology student were trained to help parents/caregivers fill out the MB-CDI due to varying levels of literacy and skill with technology. The questionnaire took approximately 60 min to complete. Questionnaires were screened for inclusion/exclusion if: (a) they were completed in 30 min or less, (b) lexical items typically acquired much later, such as quantifiers, were checked, but early acquired words for familiar items were not, and (c) the Words section score exceeded other good scores by several hundred at the age level. Questionnaires were removed from the analysis if incomplete, completed in under 18 min, or if a child was exposed to another language for more than 4 hr a day (Brookes et al., 2025).
Reliability and Validity
Internal consistency, measured by Cronbach’s alpha, indicated levels of >.98 for the entire form (each section by age group). Due to data distribution variability, Spearman’s coefficient assessed the correlation between the scores of the two sections and the correlation of each section with age. There were moderate but significant correlations with age for vocabulary production (r = .428, p < .001) and sentences and grammar (r = .494, p < .001), indicating age sensitivity. Content validity was ensured through expert consultation and piloting.
Statistical Analysis
Data analysis was conducted using R (version 4.4.2). We plotted the average composition of nouns, predicates, and function words against the total vocabulary size. To investigate the differences in word categories at specific vocabulary sizes of 16 to 32-month-olds, we conducted a mixed-design analysis of variance. To examine bias for each lexical category, we adopted Bates et al.’s (1994) approach, plotting a generalised linear model with third-order polynomials to show how the proportion of words in different categories changes with vocabulary growth. We also calculated the relative representation estimates for each lexical category.
We focused on the vocabulary composition of the three categories: Common Nouns included animal names, vehicles, toys, clothing, body parts, household items, food, and furniture, excluding games and routines, sound effects, names for people, and places, which follow a different developmental trajectory according to Bates et al. (1994). Predicates comprised verbs and adjectives. Function words included pronouns, prepositions, question words, quantifiers, and connectives. Modal/auxiliary verbs were excluded as they are bound morphemes. Articles were excluded since Xitsonga expresses definiteness through context, word order, and demonstratives. Adverbs were excluded from the CDI as there are very few in Bantu languages.
Results
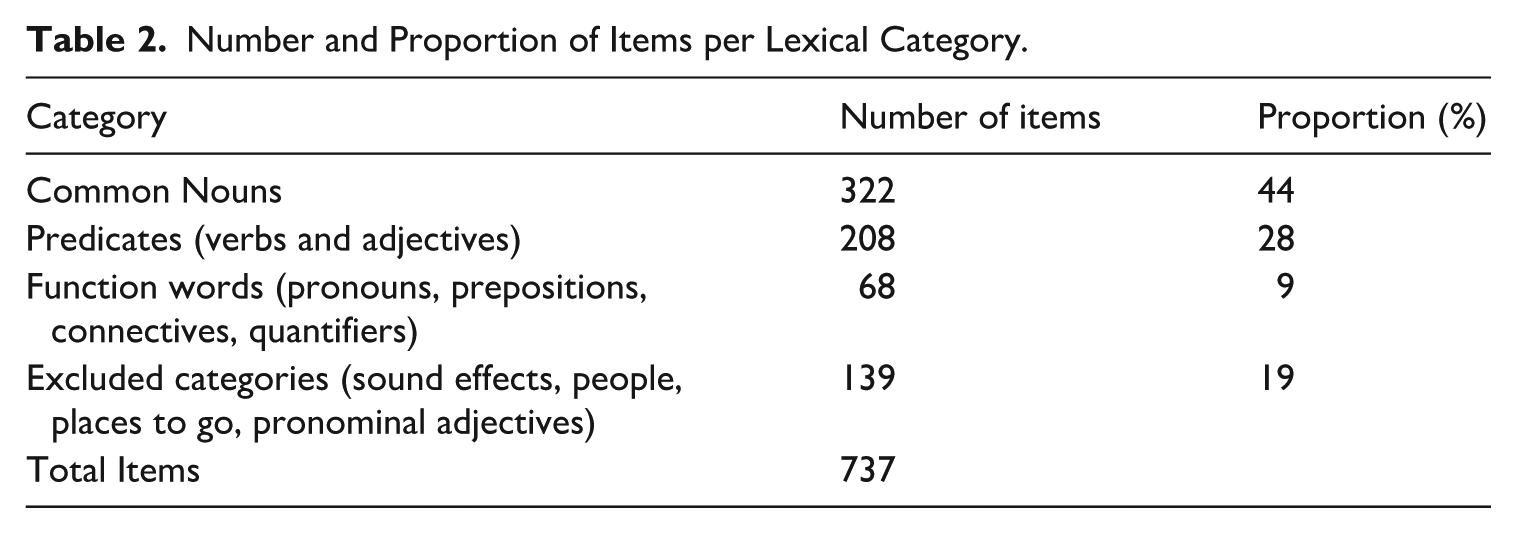
Table 2 provides the number and proportion of nouns, predicates, and function words in relation to the total number of lexical items in the Xitsonga MB-CDI.
Number and Proportion of Items per Lexical Category.
Following Bates et al. (1994), we grouped children based on their level of lexical production rather than chronological age in increments of 100 words, with an additional division between 0 and 50 words and 51 and 100 words. Table 3 provides the descriptive statistics (i.e. mean, standard deviation, minimum, and maximum scores) for each category produced at each development stage.
Mean Number of Nouns, Predicates, and Function Words of Xitsonga-Speaking Children per Vocabulary Level.
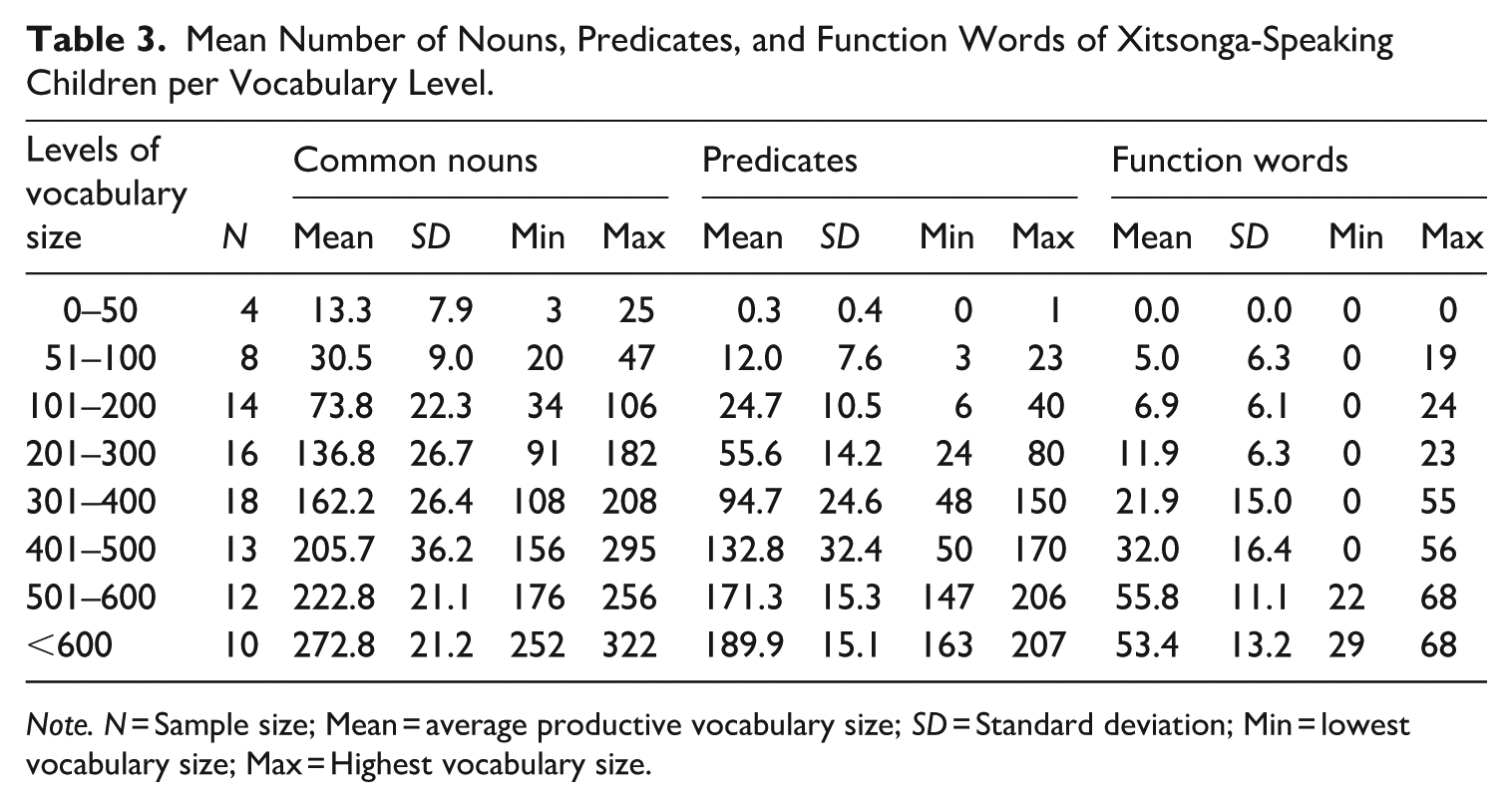
Note. N = Sample size; Mean = average productive vocabulary size; SD = Standard deviation; Min = lowest vocabulary size; Max = Highest vocabulary size.
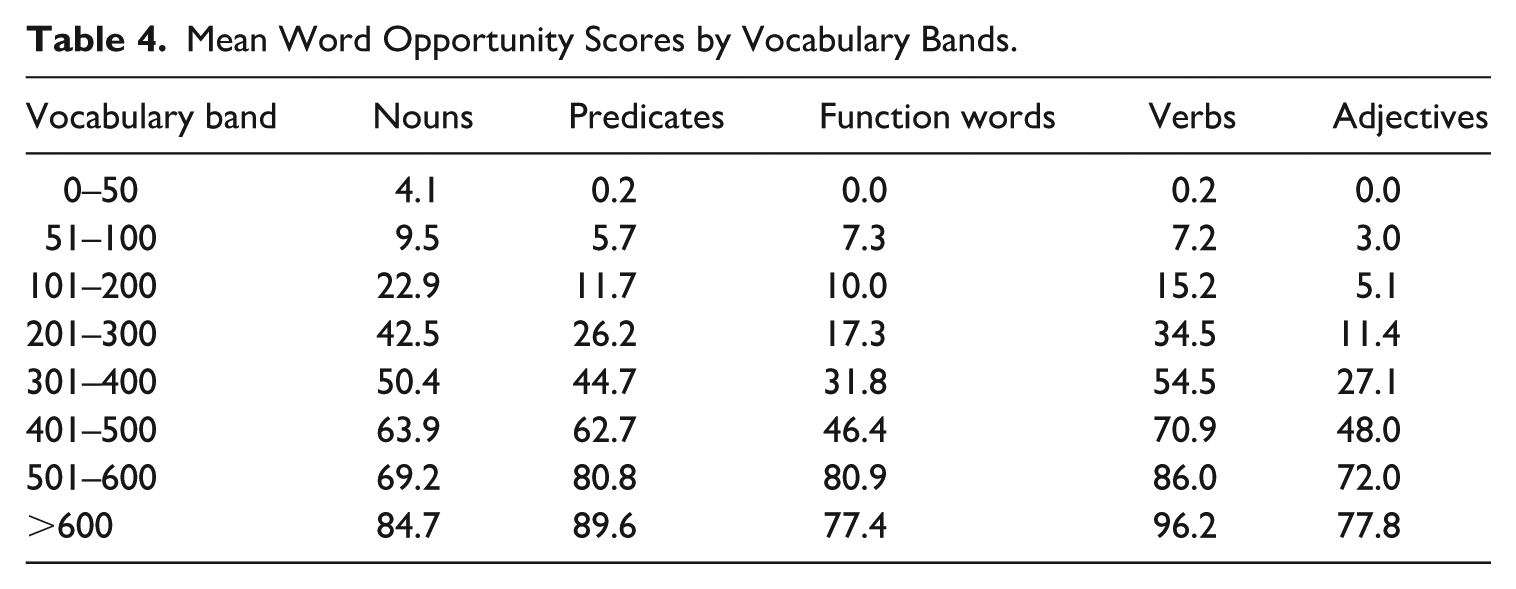
Because there were more nouns on the checklist than verbs, we calculated word opportunity scores (i.e. relative proportions) to enable fair comparisons across word categories (Bornstein et al., 2004; Childers et al., 2007). In other words, these scores were derived by calculating the proportion of words a child produced relative to the total number of possible words in each category. Table 4 shows the average word opportunity scores for each lexical category (i.e. nouns, predicates, and function words). In addition, it also presents the word opportunity scores for verbs and adjectives, following the separation of the predicate component into these two categories.
Mean Word Opportunity Scores by Vocabulary Bands.
To investigate the differences in word categories at specific vocabulary sizes, we conducted a mixed-design analysis of variance (ANOVA). Following Bates et al. (1994), we focused on the vocabulary composition of three-word categories (i.e. nouns, predicates, and function words). Vocabulary band (0–50, 51–100, 101–200, 201–300, 301–400, 401–500, 501–600, and >600 words) was used as a between-subject factor, and word category (i.e. nouns, predicates, and function words) as a within-subjects factor. Figure 1 shows the developmental trends in vocabulary composition for nouns, predicates, and function words.
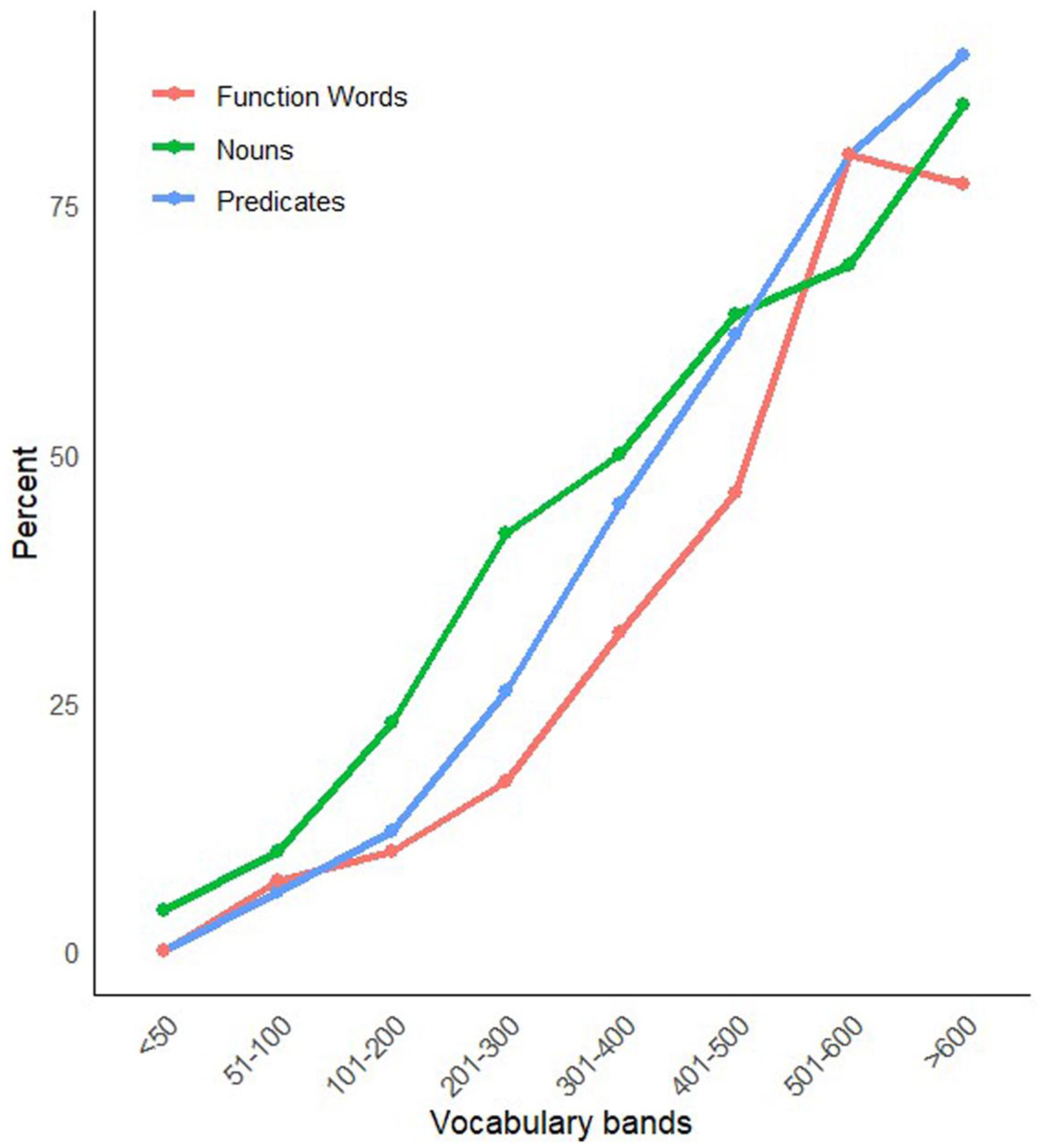
Developmental trends in vocabulary composition for nouns, predicates and function words.
The ANOVA revealed a significant main effect of vocabulary band, (F(7, 87) = 213.7, p < .001, partial η2 = .9), word category, (F(1,46) = 11.34, p < .001, partial η2 = .2) and a significant interaction between vocabulary band and word category, (F(10, 23) = 3.39, p < .001, partial η2 = .2), indicating that the effect of vocabulary band on the outcome variable varied across word categories.
Pairwise comparisons after applying Bonferroni corrections indicated no significant differences between word categories for children in the 0–50, 51–100, and >600 vocabulary bands. For the 101–200 vocabulary band, children produced significantly more nouns than predicates (estimate = 0.11, t = 2.78, p = .020). For the 201–300 level, children produced significantly more nouns than function words (estimate = 0.25, t = 4.45, p < .001), and predicates (estimate = 0.16, t = 4.29, p < .001). For the 301–400 vocabulary band, children produced significantly more nouns than function words (estimate = 0.19, t = 3.48, p = .002), and fewer function words than predicates (estimate = −0.13, t = −3.72, p = .001). For the 401–500 vocabulary band, children produced significantly more nouns than function words (estimate = 0.18, t = 2.78, p = .020), and fewer function words than predicates (estimate = −0.16, t = −4.00, p = .001). For the 501–600 vocabulary band, children produced significantly fewer nouns than predicates (estimate = −0.12, t = −2.95, p = .029), and differences between nouns and function words were not statistically significant.
In addition, we separated the predicate component into verbs and adjectives to allow a direct comparison between nouns and verbs, as several studies focus on this contrast rather than on nouns and predicates. As explained above, Bantu languages have very few adverbs and are not included in the Xitsonga CDI. Frank et al. (2021) also excluded them from their comparison of nouns, verbs, and adjectives, as there are very few in their sample. As shown in Table 4 above, the children in this study produced an average of 4.1% of nouns with a vocabulary size of 0–50 compared to zero function words at the same stage. When predicates are divided into verbs and adjectives, verbs overtake nouns earlier, while the proportion of adjectives is much lower but similar to that of function words. The children started showing a slightly higher proportion of verbs than nouns (verbs at 54% compared to nouns at 50%) in the 301–400 vocabulary size range. However, with a vocabulary size exceeding 401 words, children produced an average of 71% of verbs compared to 48% of adjectives and 64% of nouns. The proportion of verbs continued to increase compared with adjectives and nouns. There was an increase in the proportion of adjectives and function words after 500 words.
Figure 2 shows the developmental trends in vocabulary composition for nouns, predicates, function words, verbs, and adjectives, as well as the point at which 50% of the lexical items are produced on average for each lexical category.
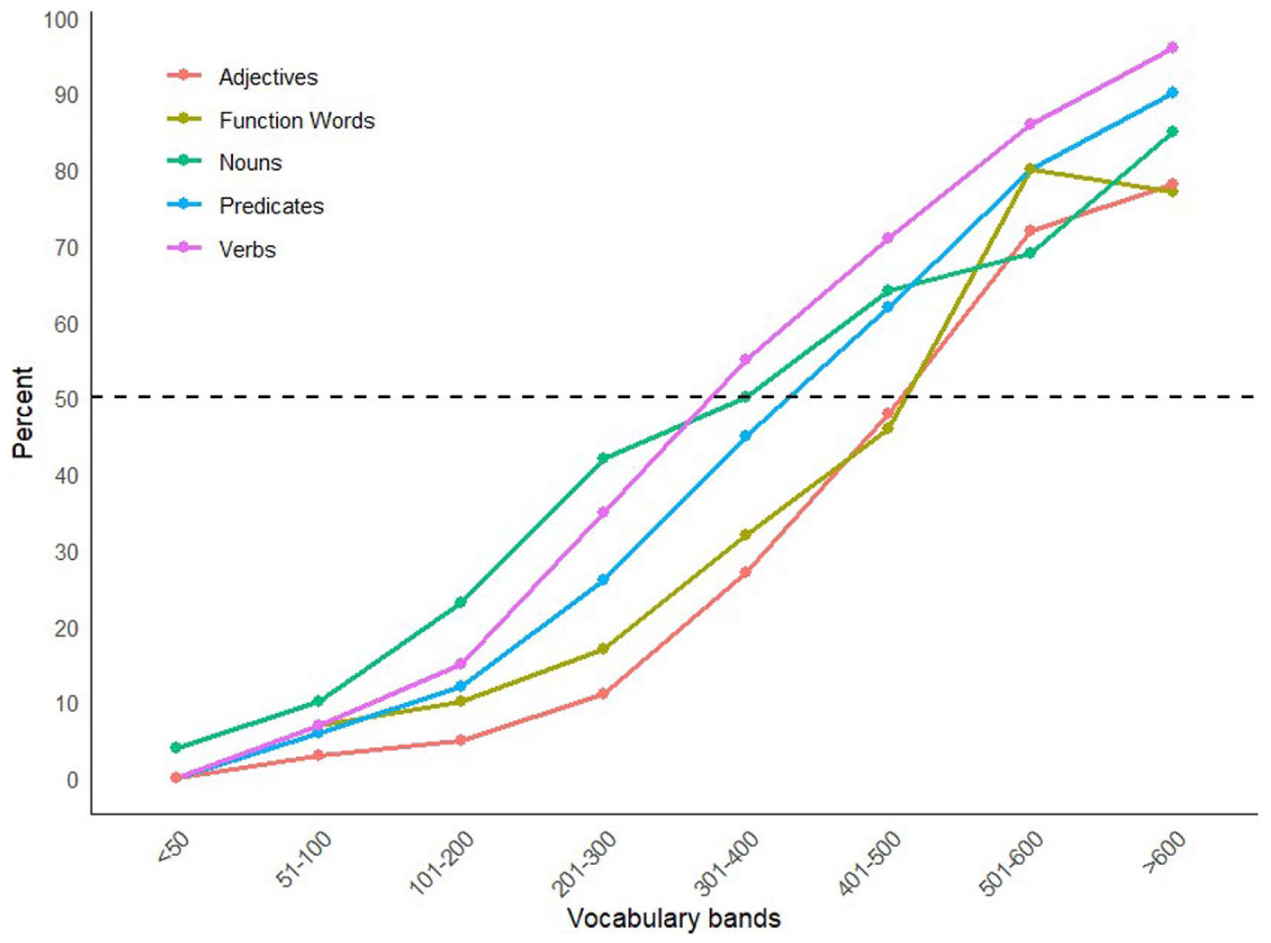
Proportion of nouns, verbs, adjectives, and function words.
On average, 50% of nouns have been checked when the total vocabulary nears 400 words. If verbs and adjectives are combined as predicates, predicates reach 50% when the overall vocabulary size is between 401 and 500 words. Considering verbs and adjectives separately, 50% of verbs are recorded when the total vocabulary reaches almost 400 words, which is similar to nouns. Adjectives reach 50% between 501 and 600 words. Lastly, function words also reached 50% when the total vocabulary is between 501 and 600. Figure 2 also shows that both adjectives and function words are the least represented in the vocabulary composition of the four categories.
To investigate how categories change across vocabulary growth, we plotted a generalised linear model with third-order polynomials that shows how the proportion of words in different categories changes as the overall vocabulary size increases (Bates et al., 1994; Frank et al., 2021). Figure 3 shows the bias estimates for each lexical category calculated as a function of the total vocabulary size. Each data point shows an individual child’s vocabulary. The curves represent the association between each lexical category and the total vocabulary, showing category proportion as a function of total production. If most data points fall above the diagonal line, it shows a positive bias and therefore overrepresentation of a category. If most data points fall below the diagonal line, it shows a negative bias and therefore underrepresentation.
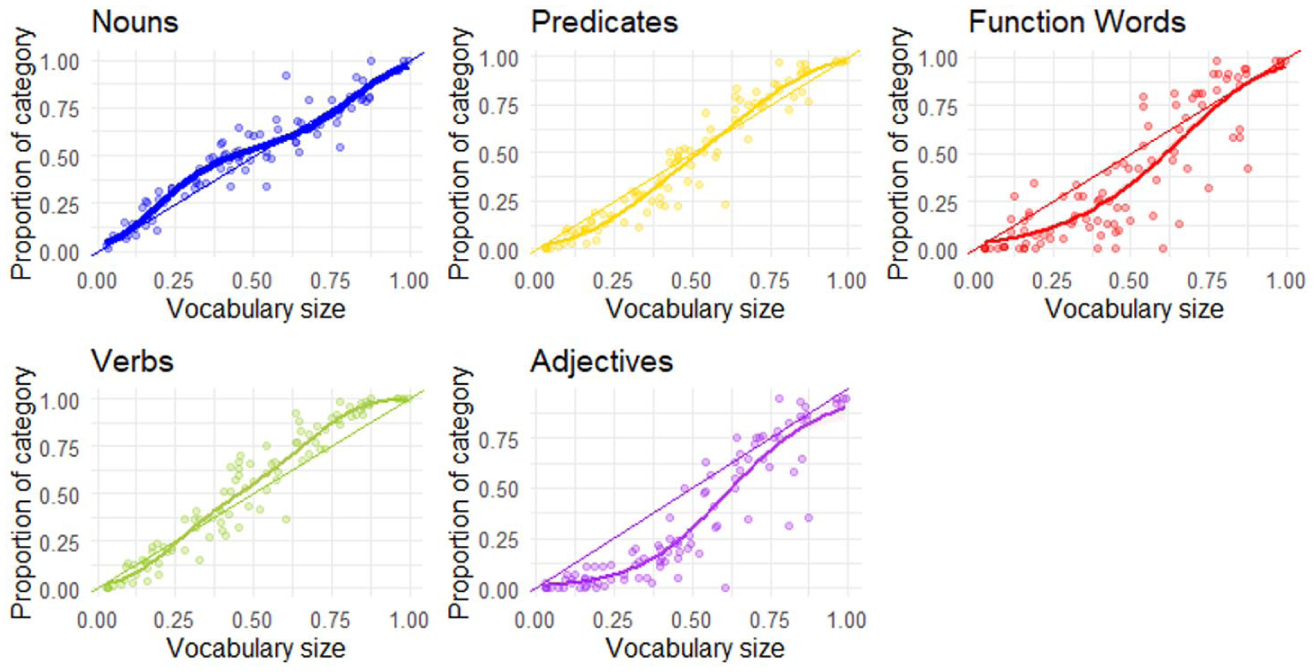
Proportion of total noun, predicate, verbs, adjectives, and function word items on Xitsonga-MB-CDI at each vocabulary level.
The findings from the generalised linear regression model show a positive noun bias from the 0–50% vocabulary range and a negative predicate bias. From 50% to around 80%, most of the data points fall below the diagonal, showing a slight negative noun bias, but at the ceiling, nouns are equally represented. With predicates, we see a positive bias after 50% with overrepresentation at the ceiling, as most data points fall above the diagonal line. Verbs show a negative bias up to the 25% vocabulary range but start to show a positive bias after 25%, while adjectives show a negative representation as most data points fall below the diagonal line as vocabulary increases. There is a clear underrepresentation of function words up to the 75% vocabulary range. After the 75% range, the points converge towards the diagonal, and there is an overrepresentation of function words, as most of the data points fall above the diagonal line.
Figure 4 highlights the degree to which each lexical category contributes to overall vocabulary development.
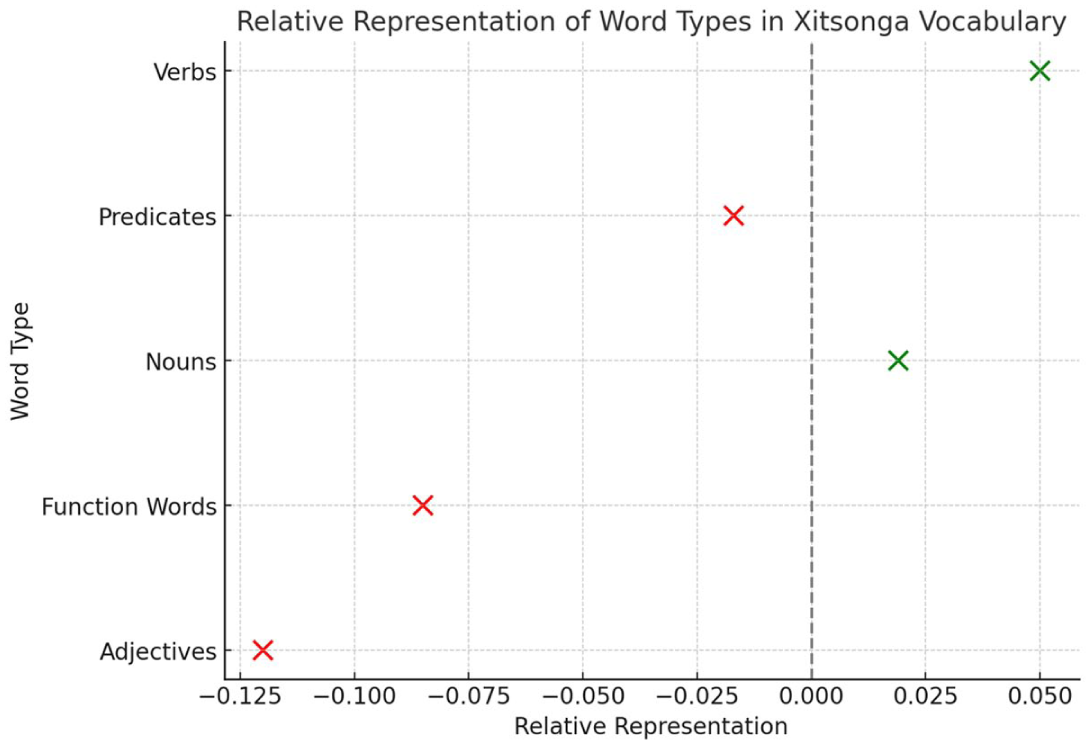
Relative representation of lexical categories.
Figure 4 displays the relative representation of different word types in children’s vocabularies, adjusted for the number of opportunities each word type had on the CDI checklist (i.e. word opportunity scores). The x-axis represents the proportional difference between observed usage (how often children used words of a certain type) and expected usage (how many such words were available on the checklist). A value of 0 indicates perfect alignment: children used that word type in proportion to how often it appeared on the checklist. Positive values (i.e. points that appear to the right of the vertical dashed line) indicate overrepresentation: children used more words of that type than expected based on the number of items available. We see that nouns (relative representation = 0.02) and verbs (relative representation = 0.04) are overrepresented in early lexical development, with verbs having an overall higher representation than nouns. Verbs show the highest relative overrepresentation, implying that children produced a greater proportion of the available verbs than other word types, suggesting that verbs were particularly salient or accessible in their early vocabularies. Negative values (i.e. points that appear to the left of the dashed line) show underrepresentation: children used fewer words of that type than would be expected given the number of available items. Function words (relative representation = −0.09) and adjectives (relative representation = −0.12) are underrepresented. Adjectives are most underrepresented, implying that children either knew fewer of them or used them less frequently relative to their availability. Measuring only predicates (relative representation = −0.02) obscures the representation of verbs in early vocabulary.
Discussion
This study investigated early lexical development in Xitsonga-speaking children aged 16 to 32 months using an adapted version of the MB-CDI. Our aim was to establish whether noun bias holds in Xitsonga, a Bantu language characterised by rich morphology and a noun class system, and to examine how vocabulary composition changes as children’s vocabularies develop.
Using a mixed-design ANOVA, we first explored the differences in word categories (nouns, predicates, and function words) at specific vocabulary sizes of 16 to 32-month-olds. The findings reveal a clear developmental increase in different word categories across vocabulary bands. At smaller vocabulary bands (below approximately 100 words), children’s vocabularies were relatively balanced across categories, showing no significant differences among nouns, predicates, and function words. This is consistent with research documenting substantial individual variation during initial stages of word learning (Bates et al., 1994; Nelson et al., 1993). However, between the 101 and 500 word range, nouns became increasingly dominant; children produced significantly more nouns than predicates or function words. This aligns with well-documented cross-linguistic patterns showing peak noun bias during middle vocabulary development (Bates et al., 1994; M. C. Caselli et al., 1999; Fenson et al., 1994). In contrast, beyond 500 words, predicates became more frequent than nouns. Overall, the results portray a developmental progression from early noun-dominated vocabularies to a more diversified vocabulary as children’s word knowledge expands. This developmental trajectory aligns with cross-linguistic patterns documented in typologically diverse languages (Bassano, 2000; Bates et al., 1994; M. C. Caselli et al., 1999), suggesting that vocabulary composition changes reflect universal developmental processes that interact with vocabulary size thresholds.
Second, we explored how categories change across vocabulary growth, using a generalised linear model with third-order polynomials. Overall, Xitsonga-speaking children show an initial positive noun bias, meaning they use more nouns when their vocabulary size is below 400 words, with predicates and function words underrepresented, and function words representing the smallest category. This pattern mirrors many other languages, as reported by Frank et al. (2021), who compared the production of nouns, predicates, and function words across 26 languages (including two Bantu languages – Kigiriama and Kiswahili) and reported a noun bias in almost all languages. Nonetheless, the degree of noun bias varies across languages, and this variability was also noted in Xitsonga-speaking children with an initial noun bias that changes to verb preference as vocabulary size increases.
Comparison of the relative representation of lexical categories in the languages reported by Frank et al. (2021) with Xitsonga, nouns have a relative representation of 0.02, and predicates −0.02. Xitsonga falls in the bottom third of languages with a lower positive noun bias, similar to that of Kiswahili and Cantonese. With predicates, Xitsonga falls in the top 40% of languages, close to Kigiriama. This comparison suggests that Xitsonga shows similar trends in terms of the acquisition of nouns and predicates to those of other Bantu languages.
When predicates are divided into verbs and adjectives, we found a positive verb bias once children reached approximately 50% of the words in each category. At this stage, children produced an average of 54% of verbs on the list compared to 27% of adjectives and 52% of nouns. Frank et al.’s (2021) comparison of 26 languages shows substantial variability in verb bias. More languages have a positive verb bias than a predicate bias, and both Kiswahili and Kigiriama have positive verb biases. Xitsonga has a positive verb bias of 0.04 that places it in the top three to four languages, with a similar verb bias to Kiswahili. In contrast to verbs, adjectives tend to be underrepresented in almost all languages. This is also observed in Xitsonga with adjectives (relative representation = −0.12), underrepresented, placing Xitsonga in the bottom three languages close to Kiswahili, Hebrew, and Spanish (Mexican).
In terms of function words, we found a clear underrepresentation of function words up to the 75% vocabulary range. As vocabulary size increases beyond the 75% range, the points start to converge towards the diagonal. Frank et al.’s (2021) comparison of function words in Figure 5 shows the underrepresentation of function words in all languages.
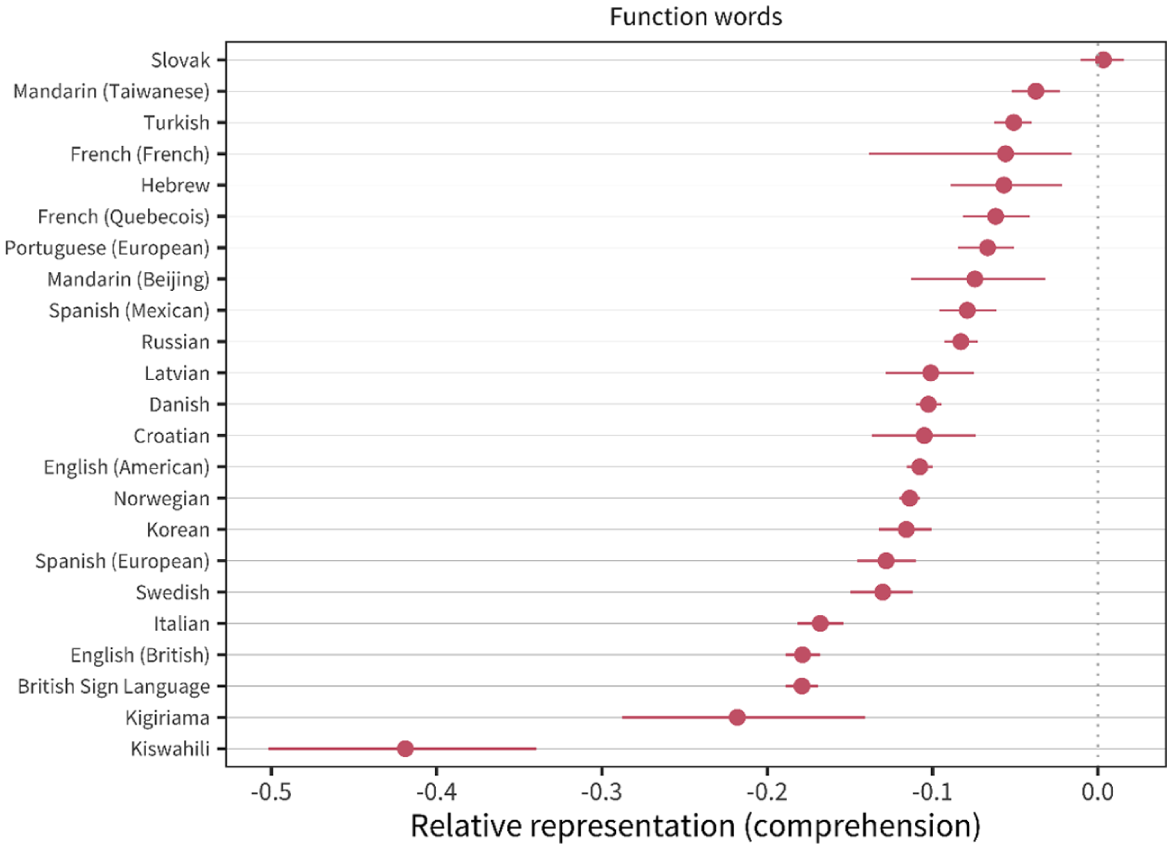
Relative representation in vocabulary compared to chance for function words for production data in each language (line ranges indicate bootstrapped 95% confidence intervals; Frank et al., 2021 – reproduced with permission from the author).
To summarise, this pattern of initial noun bias followed by strong verb representation aligns with findings from other Bantu languages, particularly Kiswahili and Kigiriama (Alcock, 2017; Frank et al., 2021). However, even though verbs were initially underrepresented, there is a rapid change as children’s vocabulary increases. When comparing the proportion of nouns and verbs at a vocabulary size of above 400, Xitsonga has a positive verb bias. Similar verb biases have been found for Mandarin and Korean (Setoh et al., 2021; Tardif, 1996; Xuan & Dollaghan, 2013). Similarly, the Mayan languages Tseltal and Tsotsil show a verb bias (Brown, 1998; Casillas et al., 2024; De León, 1999). Findings of transitioning to verb bias were reported by Alcock (2017) in a study on Kigiriama and Kiswahili early language development. She reported that children’s first spoken words were predominantly nouns, with 75 to 95% being nouns compared to less than 10% being verbs. She observed that as children’s vocabulary size increased, the proportion of spoken words that were verbs also increased.
While a common noun bias supports the theory that early cognitive limitations result in the production of a higher proportion of nouns in early lexical development, the variation in noun, verb, predicate, and function word biases in different languages suggests that language typology and input are also key factors in shaping children’s vocabulary. Xitsonga shows similar trends to other Bantu languages such as Kigiriama and Kiswahili, suggesting that language typology may indeed be an important factor. The structure of Bantu languages, where prefixes on the verb refer to the noun class of the subject, means that verbs can be used without nominals to convey complete messages. This suggests that verbs may be more frequent and more prominent in input, a hypothesis that would need to be tested with data comprising spontaneous input to children in languages where verbs have a similar prominence, such as other Bantu languages, pro-drop languages such as Spanish and Italian, and Mandarin, where there is a stronger bias towards the earlier acquisition of verbs.
Xitsonga reveals one of the least negative biases for function words compared to other languages reported by Frank et al. (2021). This may be explained by the agglutinative nature of Bantu languages such as Xitsonga, where grammatical functions are expressed through bound morphemes rather than free-standing words. This can potentially reduce the number of function words that appear as independent items. Ninio (2019) suggests that function words are learned primarily through multi-word input, which necessitates an understanding of syntax. This is supported by Le Normand and Thai-Van (2022), reporting that 18 function words had a strong correlation with Mean Length of Utterance, indicating that these function words are predictive of syntactic development and sentence complexity in French-speaking children aged 2 to 4 years. This might be the case in Xitsonga. Herbert (1992) reported that the relationship between phonological and syntactic words, particularly the role of noun class prefixes, underscores the complexity of function words in the language’s morphosyntactic framework, as these prefixes interact with the entire noun phrase rather than just the noun itself. Kubayi (2022) further suggests that the role of function words is significant in the syntactic distribution and understanding of Xitsonga’s grammatical framework. He argues that traditional locative noun classes (16, 17, 18) function as prepositions and adverbs rather than nouns, thus challenging the traditional category distinctions. Their limited representation in the early stages may indicate their reliance on syntactic growth, as noted in other tonal languages (Choi & Gopnik, 1995; Tardif, 1996).
There might be two related aspects that could help clarify the significant verb bias observed in Xitsonga-speaking children with large vocabularies. First, Xitsonga’s agglutinative morphology means that verbal affixes always show tense, aspect, and agreement, making verbs more salient and easier to learn than languages with less regular patterns (Bornstein et al., 2004). Second, as children’s vocabularies grow beyond 400 words, their advancing cognitive and linguistic development allows them to process and form morphologically intricate verb forms (Tomasello, 2003). The interplay between transparent morphological structure and developmental readiness might clarify the distinct verb preference observed in the later stages of lexical development in Xitsonga.
In addition to its structural complexity, the acquisition of Xitsonga is likely influenced by sociocultural practices prevalent in Bantu-speaking communities. Further investigation of these contextual factors and their influence on language development is needed to determine how social practices affect children’s communicative interactions and early vocabulary composition, including the equilibrium between noun and verb acquisition.
Limitations
Our sample size was relatively small although other studies such as N. K. Caselli et al. (2020, N = 120), who used the MB-CDI, and Gatt et al. (2023, N = 44), and Nóro et al. (2015, N = 20) who both used recordings of spontaneous data, demonstrate that the acquisition of patterns of lexical categories may be obtained from small sample sizes. Nevertheless, future work on larger samples, particularly from speakers of Bantu languages, is needed to determine whether similar trends emerge. Analysis of naturalistic data across this age group would be an additional method of verifying what children are exposed to and what they produce. Tardif et al. (1999) contend that we also should take into consideration language structure, caregiver input, and contexts for reliable data collection when examining children’s early language. Further examination and comparisons with other languages that are agglutinative and morphologically complex, where bound morphemes are common (rather than separate function words), may shed light on the extent of the influence of linguistic structure on early acquisition.
The adaptation of the MB-CDI for Xitsonga required the omission of specific lexical categories, such as the helping verbs and some function categories, such as pronouns and definiteness, to align with Bantu morphology. These adaptations, while linguistically necessary, may limit direct comparisons with studies using the original MB-CDI or alternative adaptation approaches, potentially affecting the total vocabulary sizes or scores in certain categories. For example, a child might score 150 words on the original MB-CDI but only 130 on the Xitsonga adaptation because certain word categories were omitted, or a Xitsonga-speaking child at the 50th percentile might not be equivalent to a 50th percentile child in an English MB-CDI study.
Conclusion
The findings of this study enhance knowledge of theories of early lexical development in underrepresented languages such as Xitsonga and provide insight into the noun-verb bias within the vocabulary of Xitsonga-speaking children. The shift from noun to verb biases in children’s early word learning has the potential to provide insights into their inherent conceptual and perceptual predispositions during language acquisition. This corroborates narratives that highlight the interplay between universal cognitive factors and language-specific characteristics in influencing developmental trajectories. Exploring the variations in these biases can help us understand how formal language features and sociocultural factors influence early vocabulary development (Southwood et al., 2021). This argument becomes particularly compelling if the bias cannot be solely attributed to input factors, such as word frequency (Bloom et al., 1993; M. C. Caselli et al., 1995; Tardif, 1996). These findings underscore the necessity of employing culturally and linguistically suitable norms in the evaluation of vocabulary development within clinical practice. Standard expectations derived from English or other Indo-European languages may not sufficiently reflect typical development within Bantu language contexts.
Footnotes
Acknowledgements
Additional support was provided by Sefako Makgatho Health Sciences University. The authors acknowledge the input of Dr Michelle White and the support of the SA-CDI Team, the Child Language Development Node of SADiLaR hosted at Stellenbosch University, the field workers, and all participants who made the project possible.
Ethical Considerations
Faculty of Health Sciences Human Research Ethics Committee University of Cape Town, 166/2019.
Consent to Participate
Written informed consent was obtained from all participants prior to participation in the study.
Author Contributions
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the South African Centre for Digital Language Resources (SADiLaR). Communicative Development Inventories for all South Africa’s 11 official languages. (There is no grant number.) Additional funding: National Research Foundation of South Africa (NRF) (HSD170602236563). Preparatory funding: The British Academy Newton Fund (NG160093); NRF/Swedish Foundation for International Cooperation in Research and Higher Education (NRF/STINT160918188417).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data will be made available on the South African Centre for Digital Language Resources repository.
Disclaimer
The views and opinions expressed in this article are those of the author(s) and do not necessarily reflect the official policy or position of any affiliated institution, organisation, or funding agency. Any errors or omissions are solely the responsibility of the author(s).