
Abstract
Infant-Directed Speech (IDS) and Adult-Directed Speech (ADS) are two registers that can differ across multiple linguistic domains and social contexts. In languages where the phonemes’ acoustic clarity is modified, there is a typical assumption in the literature that these phonemes are either hyper- or hypo-articulated. These modifications have received considerable attention in language research, serving as the basis of proposals concerning the potential didactic and communicative (e.g., affective) functions of IDS. The current study adds to this literature by examining how vowels and consonants are modified in IDS in a previously unstudied African language with an unusual phoneme inventory: Tashlhiyt Berber. Seven caregivers were recorded interacting with: (a) infants between the ages of 0;6 and 1;5, and (b) an adult experimenter who is a native speaker of Tashlhiyt. In IDS, we found longer vowel duration for content words and exaggerated pitch levels across the board, successfully replicating cross-linguistic patterns. Counter to the hyper-articulation hypothesis, there was more vowel overlap in IDS, while no differences were observed between IDS and ADS for overall vowel space size. We additionally found that speakers tend to completely neutralize certain consonant contrasts in IDS, rendering them indistinguishable to the infant. Our results are most consistent with the proposal that caregivers use IDS to guide and maintain their infant’s attention and to convey positive affect.
Keywords
Introduction
One of the first tasks facing infant language learners is to identify a phonological system – the building blocks of language (Cutler, 2012). Human languages make use of the high flexibility of the vocal tract to make functional distinctions between sounds and assemble them to build larger, meaningful units of language (e.g., morphemes, words). Yet, how languages do this varies widely (Moran & McCloy, 2014). Polynesian languages, for instance, have very small phonological inventories (fewer than 20, Lynch, 1998). Other languages, such as Tashlhiyt Berber, which we study here, have an inventory of over 70 phonemes, most of which are consonants. Infants have no trouble negotiating the acquisition of typologically different phonological systems, but how they do so is still unclear. This is because our understanding of how and whether input is modified cross-culturally and in response to typologically different systems is very limited. In the current paper, we report on infant-directed speech (IDS) in Tashlhiyt Berber, investigating if and how caregivers modify their speech to infants.
Infant-Directed Speech
It is well established that speakers adapt to the needs of their interlocutor, including in speech directed to children. In many communities around the world, caregivers regularly use a special register when addressing children, which has been referred to in the literature as motherese (Newport & Gleitman, 1984), baby-talk (Ferguson, 1964), parentese (Ferjan Ramírez et al., 2024), IDS (Cox et al., 2023), and infant-directed language (Heymann et al., 2020). Many differences in multiple linguistic domains set IDS 1 apart from Adult-Directed Speech (ADS). Most obvious to naïve listeners, IDS is characterized by higher pitch (Cristia & Seidl, 2014), more repetitions (McRoberts et al., 2009), and shorter, less complex utterances (Genovese et al., 2019; Martin et al., 2016). More fine-grained differences include hyper-articulated (Lovcevic et al., 2025) and longer vowels (Marklund & Gustavsson, 2020), though these are not observed across the board (Cristia & Seidl, 2014).
IDS characteristics, and hyper-articulation in particular, are often argued to support language acquisition, where tokens in the input act as high-quality exemplars of the target segments and allow children to distinguish contrasts (e.g., corner vowels; Johnson et al., 1993). Additionally, syllable repetition and reduplication can scaffold word segmentation, one of the first challenges facing infants breaking into language (Ota & Skarabela, 2016, 2018; Stärk et al., 2022). It has also been shown that IDS carries more positive vocal affect linked to exaggerated prosody (Kalashnikova & Burnham, 2018; Kitamura & Lam, 2009) and accompanying facial gestures (Green et al., 2010). This may serve to capture and maintain the infant’s attention, with demonstrations that it successfully does so in newborns (Cooper & Aslin, 1990; Dunst et al., 2012). However, the role IDS plays in language acquisition continues to be debated, especially with regards to facilitating phonological development and specifically phonemic acquisition.
Although IDS exhibits some consistent crosslinguistic patterns, individual languages and cultures rarely show identical patterns of features (Kidd et al., 2025). There are likely many reasons underlying variability in IDS, but one possible source derives from typological variation. That is, differences in structural properties across languages (e.g., phoneme inventories) can lead to different modifications of the input and acquisition trajectories. Wang et al. (2016), for example, suggested that phonological structure might not only influence modification patterns in IDS, but also their extent. Pitch, for example, is the most salient IDS feature cross-linguistically, but is modified differently based on the language’s prosodic type (e.g., tonal, stress, or pitch-accented language). Thus, it is more exaggerated in stress-timed languages such as English than in tonal languages such as Mandarin, since allowing the caregiver to freely modify pitch in tonal languages risks impeding the transmission of tonal cues. Another common IDS feature is speech rate, which has also been shown to vary cross-linguistically. For example, Dutch-speaking but not Mandarin-speaking (Han et al., 2021) or Tamil-speaking mothers (Narayan & McDermott, 2016) slow down significantly when unfamiliar words are introduced. This could again be attributed to phonological characteristics (e.g., rhythmic class) or alternatively to cultural conventions (Han et al., 2021). Thus, it is important to consider language-specific phonological structure as well as culture-specific caregiving behaviors when studying the shape of IDS across different populations.
Another major way caregivers adapt their speech in IDS is by manipulating the degree of acoustic clarity. Evidence suggests that, when modified in IDS, phonemic categories can either be over- or under-specified (Lovcevic et al., 2025). This is observed in vowels, when they are pushed into more peripheral positions of the vowel space (Kuhl et al., 1997), in consonants where the durational differences in Voice Onset Time are exaggerated (Englund, 2005), and in tones (Xu Rattanasone et al., 2013). Such findings suggest that caregivers may attempt to maximize the salience of phonetic differences to facilitate phonemic perception (Kuhl et al., 2007), allowing infants to lay the foundations of their native language. This view is supported by findings that link hyper-articulation to later linguistic development (Kalashnikova & Burnham, 2018; Lovcevic et al., 2024), and by its manifestation when speakers address foreigners (Piazza et al., 2022), pets with some vocal ability (e.g., parrots, Xu et al., 2013), or under sub-optimal listening conditions (Garnier et al., 2018).
However, hyper-articulation in IDS has not been consistently observed cross-linguistically. Caregivers may not increase the salience of phonemes and might even hypo-articulate them instead. This has been observed for both salient (Norwegian /g/-/k/) and less salient (Nepali /ɡ/-/ɡʱ/-/k/-/kʱ/) consonant contrasts, as well as in larger (Cantonese) and smaller (Mandarin) vowel inventories (Benders et al., 2019; Rosslund et al., 2025; Tang et al., 2017; Xu Rattanasone et al., 2013). Much speculation has been put forward regarding the relationship between language-specific phonology and inventory size (Lovcevic et al., 2025), not only for IDS but also for other forms of hyper-speech (e.g., such as foreigner-directed speech, Piazza et al., 2022). Additionally, while cross-linguistic studies fail to reveal a consistent influence of phonological complexity on hyper-articulation’s emergence, it is possible that their mixed findings could be attributed to cultural or methodological variables (Wang et al., 2016). Indeed, any influence of language-type on IDS is filtered through a system of cultural practices related to child rearing. In sum, it seems that, unlike pitch, which is modified differently in IDS across languages based on structural features, the relationship between phonological structure and segment hyper/hypo-articulation patterns is unclear. Its variability across languages and cultures makes it important to study on a wider scale, if it is to be better understood (Lovcevic et al., 2025) and to overcome the challenges posed by the insufficient language coverage in the study of child language acquisition (Kidd & Garcia, 2022).
The Current Study
The goal of this paper is to contribute to the expansion and diversification of the range of languages covered in the IDS literature by describing the segmental characteristics of Tashlhiyt Berber’s IDS. Tashlhiyt is spoken in south-western Morocco. It is famous for its complex phonological system (Ridouane, 2014), comprising a large inventory of 71 consonants and a small vocalic system (three vowels: /a/, /i/, /u/) (Moran & McCloy, 2014). It also has a typologically rare syllable structure, which allows any segment to be in the syllable nucleus position. As a result, vowelless words (e.g., /tdːztstː/ “you compressed it”) comprise around 22% of all syntactic words in Tashlhiyt (Ridouane, 2008). Despite being well-described, Tashlhiyt remains understudied from a developmental perspective (but see Lahrouchi & Kern, 2018), and its complex phonological system represents an untouched corner of the linguistic design space in studies of acquisition (Passmore et al., 2025). Here, we ask whether the vowels and consonants of Tashlhiyt are modified by caregivers in IDS, and if so, how. That is, we ask (a) do caregivers hyper-articulate segments, and (b) do they modify vowels and consonants similarly? We pay particular attention to the role of phonological structure and whether it leads to different behavior by taking inventory size as a proxy of complexity. Our study represents an important addition to the literature: in research investigating hyper-articulation in IDS, Tashlhiyt is simultaneously the language with the largest consonant inventory (Table 1) and the smallest vowel inventory examined to date (Lovcevic et al., 2025).
Tashlhiyt’s Consonant Inventory Adapted From Ridouane (2014), Gray Areas Represent Neutralized Phonemes in a Maximally Reduced Inventory. a .

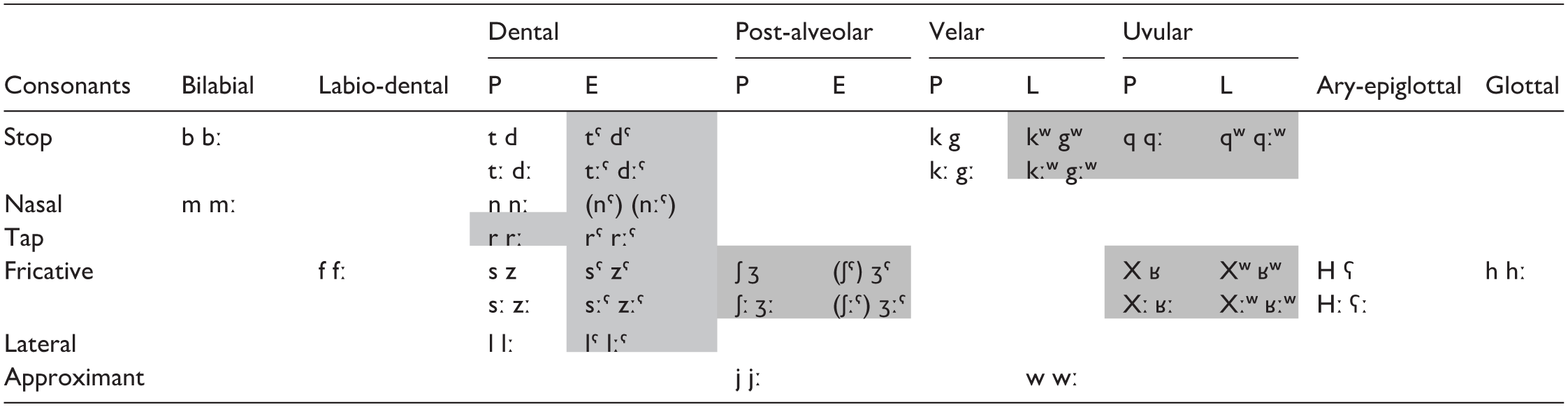
Note. P = Plain; L = Labialized; E = Emphatic (Pharyngealized); IDS = Infant-Directed Speech.
Gray areas in the inventory represent the contrasts that may or may not be (subject to individual differences among caregivers) neutralized in IDS. Some caregivers, for example, may neutralize Emphatic dental consonants only, while others may neutralize all contrasts in gray.
There are at least two, mutually exclusive, possibilities in how Tashlhiyt-speaking caregivers could modify IDS in comparison to ADS. First, if phonological complexity drives the emergence of hyper-articulation, as discussed above, this should be (a) less pronounced in the comparatively smaller vocalic system but (b) more pronounced in the consonant system (to emphasize the differences between the less salient consonant contrasts). In contrast, if hyper-articulation is driven by convenience and is more likely to emerge when there is less risk of overlap between phonemic categories (Lovcevic et al., 2025), we expect the opposite pattern: consonant hypo-articulation and vowel hyper-articulation. Since there is no previous work on this topic in Tashlhiyt, we cannot make firm predictions and must be content with mapping out the hypothesis space in this manner.
We present several analyses bearing upon these predictions. For vowels, we asked whether vowels are acoustically more salient in IDS compared to ADS. We focused on a number of acoustic dimensions: pitch, duration, Vowel Space Area (VSA) size, vowel overlap, and individual formant characteristics. Observing a higher pitch in IDS would replicate cross-linguistic results and would be consistent with the suggestion that the register serves attention-getting and affective functions. With respect to vowel duration, we followed Bundgaard-Nielsen et al. (2023) in examining whether it is similarly modified in content words compared to function words, as well as in nouns compared to other word classes, controlling for word position. If longer vowel durations in IDS are observed, this would suggest that the register might serve a didactic function by enhancing vowel clarity, which could promote phonemic acquisition. Regarding VSA, a larger VSA and less vowel overall for IDS would indicate hyper-articulation, lending more support to the hyper-articulation hypothesis (Kuhl et al., 1997), while a smaller VSA and more vowel overlap would both suggest that vowels are less salient (e.g., hypo-articulated), going against the idea of facilitating perception and learning. Regarding formants, an overall increase in values would suggest that IDS is better understood as a means to convey vocal affect and/or imitation of infant vocalizations (Benders, 2013).
For consonants, we asked whether consonants are modified in IDS, similarly to vowels, in ways that could either increase or decrease their perceptual salience. We therefore compared the target phonemes to the actual phonemes produced by the caregivers and whether the phoneme’s surface realization matched its underlying form. We report that certain sets of contrasts in Tashlhiyt are systematically neutralized. That is, we find no evidence in favor of hyper- or hypo-articulation, but a completely different behavior that does not pattern with vowels in the language. Although “neutralization” is used in phonology to refer to the lack of phonetic contrast between phonemic categories in specific environments, we use this term to refer to neutralization regardless of context. To our knowledge, modifications such as the ones reported here have only been documented previously for IDS in Australian languages: Warlpiri (Laughren, 1984) and languages within the Arandic language family (Central Anmatyerr, Kaytetye, and Alywaar, Turpin et al., 2014).
Methods
Participants
Seven caregivers participated in this study (five females): two fathers, two mothers, two aunts, and one grandmother were recorded addressing three infants (one female) aged 6, 7, and 15 months. All caregivers lived in the same household as the infant, and none were first-time parents. No infants or caregivers had any reported health issues or language-related difficulties. All caregivers grew up as monolingual Tashlhiyt speakers. Three of them acquired Darija (Moroccan Arabic) after the age of 15 years, while others had no to very limited second language proficiency. Their education level ranged between illiterate (no formal schooling) and 6 years of schooling. The average household had six members, with at least two stay-at-home caregivers as well as one main breadwinner. The three participating infants all had at least one older sibling. All caregivers reported speaking only Tashlhiyt at home.
Materials
The caregivers were recorded using a head-worn cardioid microphone connected to a Dell XPS 15 laptop through a Focusrite Scarlett 2i2 audio interface. The recordings were saved as uncompressed WAV (i.e., Waveform Audio File Format) files at a sampling rate of 44.1 kHz. Videos depicting familiar objects and animals were used to elicit IDS and ADS, taken from open online sources.
Procedure
Each participant took part in two audio recording sessions in succession: one for IDS and another for ADS. Sessions took place in a quiet room in Agadir, Morocco. Infants took part in multiple sessions, but on different days to avoid fatigue and boredom, except for one infant who participated in two sessions with 30 min in between. Each session lasted 10 min, and recordings lasted, on average, 4 min per session. During the IDS sessions, infants sat on their caregiver’s lap facing a screen where a silent video was played. The video contained scenes of animals, babies, and cartoon animations. The caregivers were asked to draw the child’s attention to the video and describe what they saw to the child. Caregivers often engage in such “point and describe” activities in their daily life with their children, drawing their attention to objects or animals (e.g., “oh look, it’s a kitten! It’s playing with the ball”). During ADS sessions, infants were absent, and caregivers were asked to describe what they saw in the video to a Tashlhiyt-speaking adult male experimenter (the first author). The order of the sessions was counterbalanced. Four participants started with the IDS session, while the others started with the ADS.
Acoustic Analysis
Vowels
All recordings were annotated and analyzed in Praat (Boersma, 2001). We manually identified the onset and offset of target vowels (a/u/i) based on auditory information as well as visual inspection of the spectrogram. Vowels that were affected by noise (e.g., baby vocalizations), clipping issues, disfluencies, or were too short to establish a stable point for reliable formant estimation were not segmented. We also avoided segmenting vowels that were adjacent to labialized consonants, glides, and other vowels. These contexts can affect the F2 of the adjacent vowels, making it difficult to identify the vowel boundary or resulting in phonetically longer vowels, which might have skewed our durational measures. We coded each vowel for Word Position within the utterance (Initial, Medial, Final) and its word class (Content, Function). See Table B1 in Appendix B for the number of tokens for each condition.
A Praat script was used to automatically calculate the mean Pitch (f0), Duration, F1, F2 and F3 values from the middle 40% of each vowel to avoid any artifacts from the surrounding segments (e.g., nasals). Vowel durations were log-transformed for statistical analyses, while f0 values were converted to semitones, which better represent the logarithmic nature of the human perception of pitch. In Praat, we kept the default settings by setting formant ceilings at 5500 for Females and 5000 for Males. The formant values were normalized per speaker using Lobanov Transformation, which reduces the effects of talker-specific characteristics (e.g., vocal tract size) on the data. After normalization, we identified and excluded 38 vowel tokens as outliers because they fell outside the Inter-Quartile Range (IQR) by 1.5*IQR. Additionally, vowel tokens (N = 75) with a mean f0 higher than 350 Hz were excluded from the final dataset because they can potentially affect formant estimation accuracy in Praat. The final dataset included a total of 1051 vowel tokens.
Consonants
The recordings were transcribed for a second time in broad IPA (International Phonetic Alphabet) using Phon (Rose & MacWhinney, 2014), a software designed to analyze phonological data. Each target utterance was transcribed followed by its actual realization. We extracted all instances of the contrasts in gray in Table 1 (no tokens were excluded). A total of 1609 consonants were transcribed and analyzed. In this part of the study, we have based our results on transcriptions of two trained Tashlhiyt-speaking transcribers. Phon was then used to compute the extent of consonant neutralization using the Percentage of Consonants Correct score (PCC) analysis. The software returns the accuracy of each phoneme as well as how it was substituted. Agreement between the two transcribers was 100% for all contrasts except pharyngealized ones, which reached 79%.
Results
All statistical analyses were conducted in R (R Development Core Team, 2024) using the lme4 package (Bates et al., 2015). Emmeans (Lenth, 2024) was used for post-hoc tests. The ggplot2 (Wickham, 2011) and PhonR (Mccloy, 2012) packages were used to compute VSA size and visualize all plots. All code and data are available at https://osf.io/as98u/.
Vowels
In our first set of analyses, we focus on vowels, asking whether they are acoustically more salient in IDS compared to ADS. We describe several acoustic measures, including pitch, duration, VSA size, vowel overlap, and individual formant characteristics.
Pitch
We first asked whether Pitch was consistently different in IDS vowels compared to ADS. We fitted a linear mixed effects model with Pitch as the dependent variable (see Table 2 for model summary statistics), and with Register, Word Class, and Word Position included as fixed effects, Vowel identity and Speaker as random effects and with sliding-difference (repeated) contrast coding used for Word Position (Initial vowels were first compared to Medial vowels, then Medial vowels were compared to Final vowels). The only significant effect was Register (β = 7.72, SE = 0.57, t = 13.37, p < .001); pitch was consistently higher for IDS.
Summary of Statistical Models Estimating the Effect of Register, Word Class, and Vowel’s Word Position on Vowel Duration and Pitch.
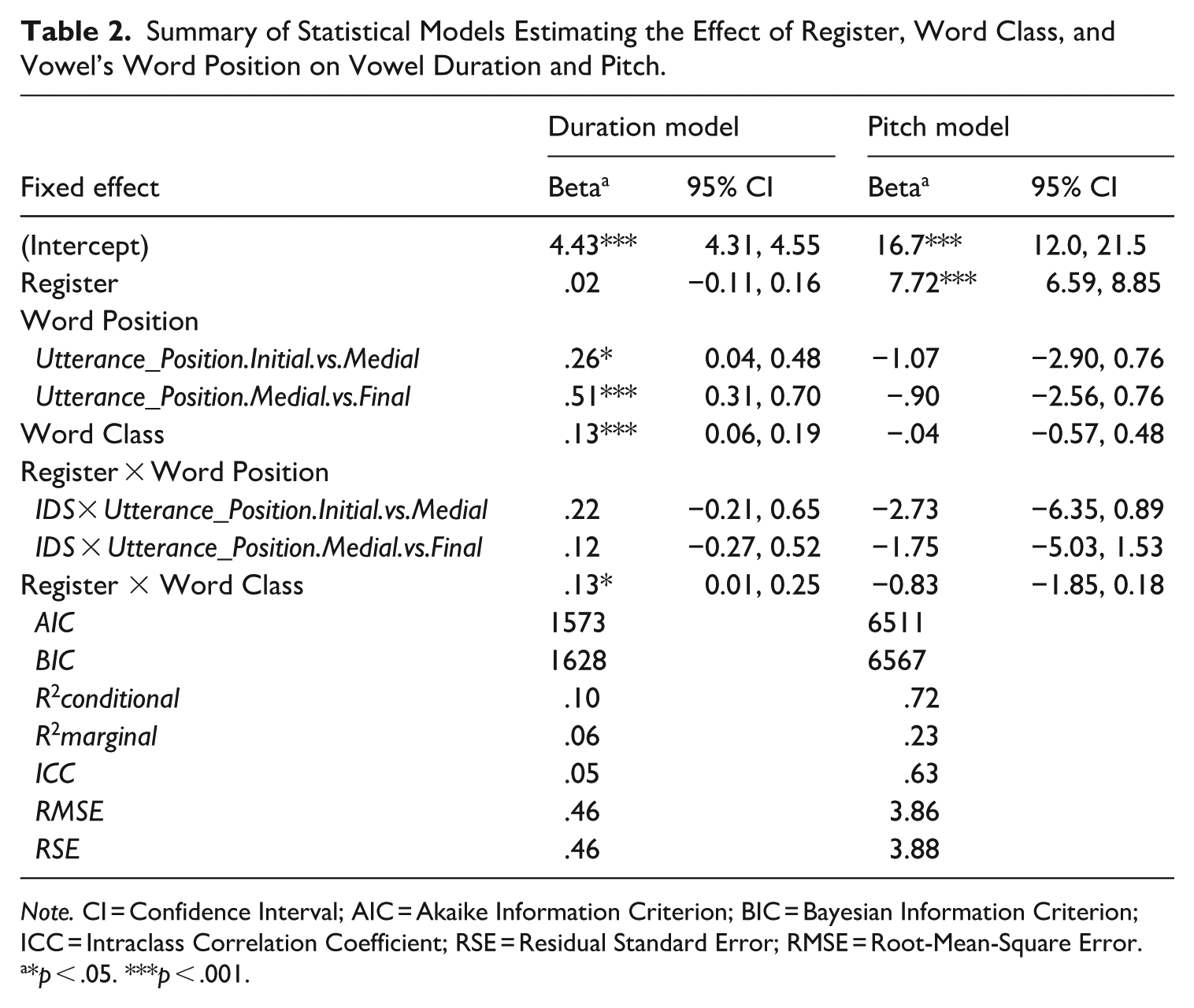
Note. CI = Confidence Interval; AIC = Akaike Information Criterion; BIC = Bayesian Information Criterion; ICC = Intraclass Correlation Coefficient; RSE = Residual Standard Error; RMSE = Root-Mean-Square Error.
*p < .05. ***p < .001.
Duration
Here we compare vowel duration in IDS and ADS, and whether this is mediated by word class and word position (Table 3). We fit a mixed effects model with vowel duration (log-transformed) as the dependent variable, and with Register (sum-coded; ADS: −0.5, IDS: +0.5), Word Class (sum-coded; Content words: +0.5, Function words: −0.5), and Word Position (Initial/Medial/Final) included as fixed effects. Sliding-difference (repeated) contrast coding was used for Word Position (Initial compared to Medial and then Medial compared to Final). Vowel identity and Speaker were included as random effects. Table 2 presents the model summary results. There was no significant main effect of Register (β = .02, SE = 0.06, t = 0.33, p = .73), but there was a significant interaction between Register and Word Class (β = .13, SE = 0.06, t = 2.15, p = .03), suggesting that vowels in content words were longer in IDS than in function words. There was also a main effect of Word Position, indicating that word-final vowels were longer than word-medial vowels (β = .26, SE = 0.11, t = 2.33, p = .02) and that the latter were, in turn, longer than word-initial vowels (β = .51, SE = 0.10, t = 5.05, p < .001). However, there was no interaction with Register, suggesting that the final lengthening is not exaggerated in IDS compared to ADS.
Descriptive Statistics for Duration and Pitch Values (in ms and Hz) for Vowels in ADS and IDS Across Register, Word Class (Content and Function Words), and Word Position.
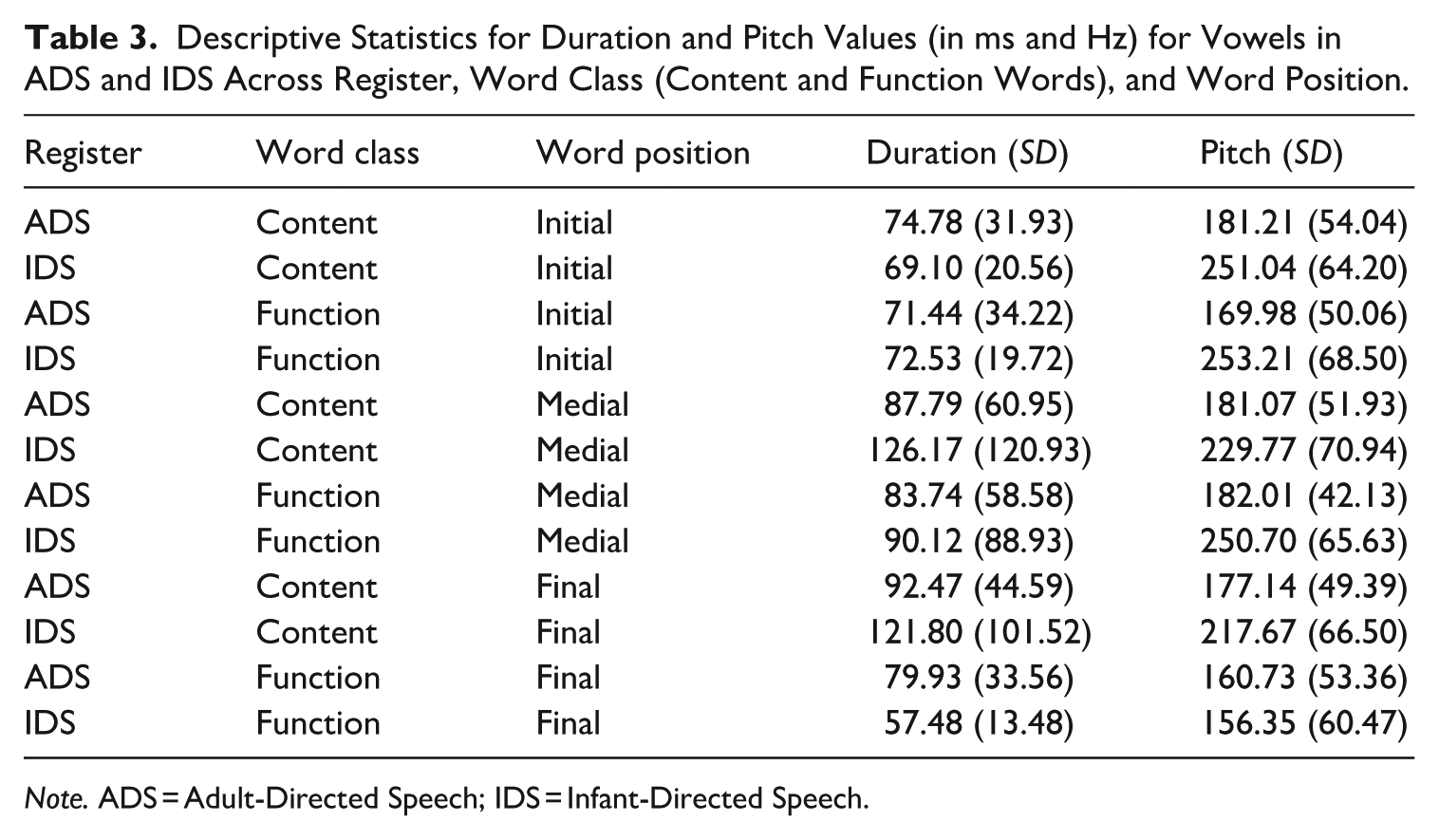
Note. ADS = Adult-Directed Speech; IDS = Infant-Directed Speech.
To explore these differences further, we investigated whether vowels in nouns were different in duration from those in other content words. Note that the latter category mostly consists of verbs because Tashlhiyt has very few adjectives. On a subset of data that only contained content words (see Table 4), we fitted a linear mixed effects model with Register (sum-coded; ADS: −0.5, IDS: +0.5), Content word class (sum-coded; Noun: +0.5 vs. Other content words: −0.5), and Word position (same coding structure as the previous model) as fixed effects, and with Speaker and Vowel Identity as random effects (see Table 5 for model summary statistics). A significant interaction between Register and Word Class (β = 0.27, SE = 0.07, t = 3.93, p < 0.001) showed that vowels in nouns in IDS were longer than those in Other Content words.
Descriptive Statistics for Duration (in ms) for Vowels in ADS and IDS Across Register, Word Class (Content Words Only), and Word Position.
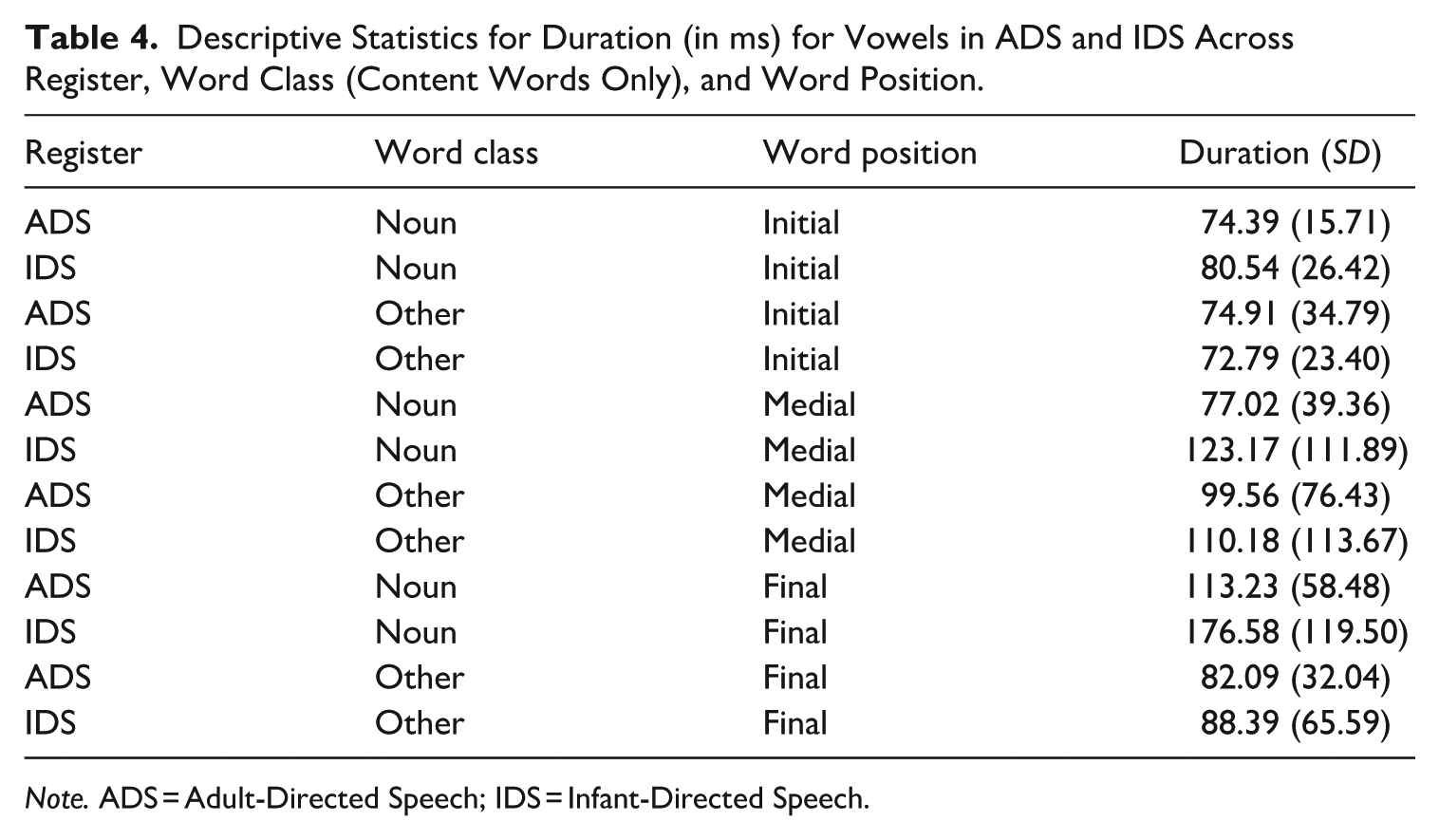
Note. ADS = Adult-Directed Speech; IDS = Infant-Directed Speech.
Summary of Statistical Models Estimating the Effect of Register, Word Class, and Vowel’s Word Position on Vowel Duration in Content Words.
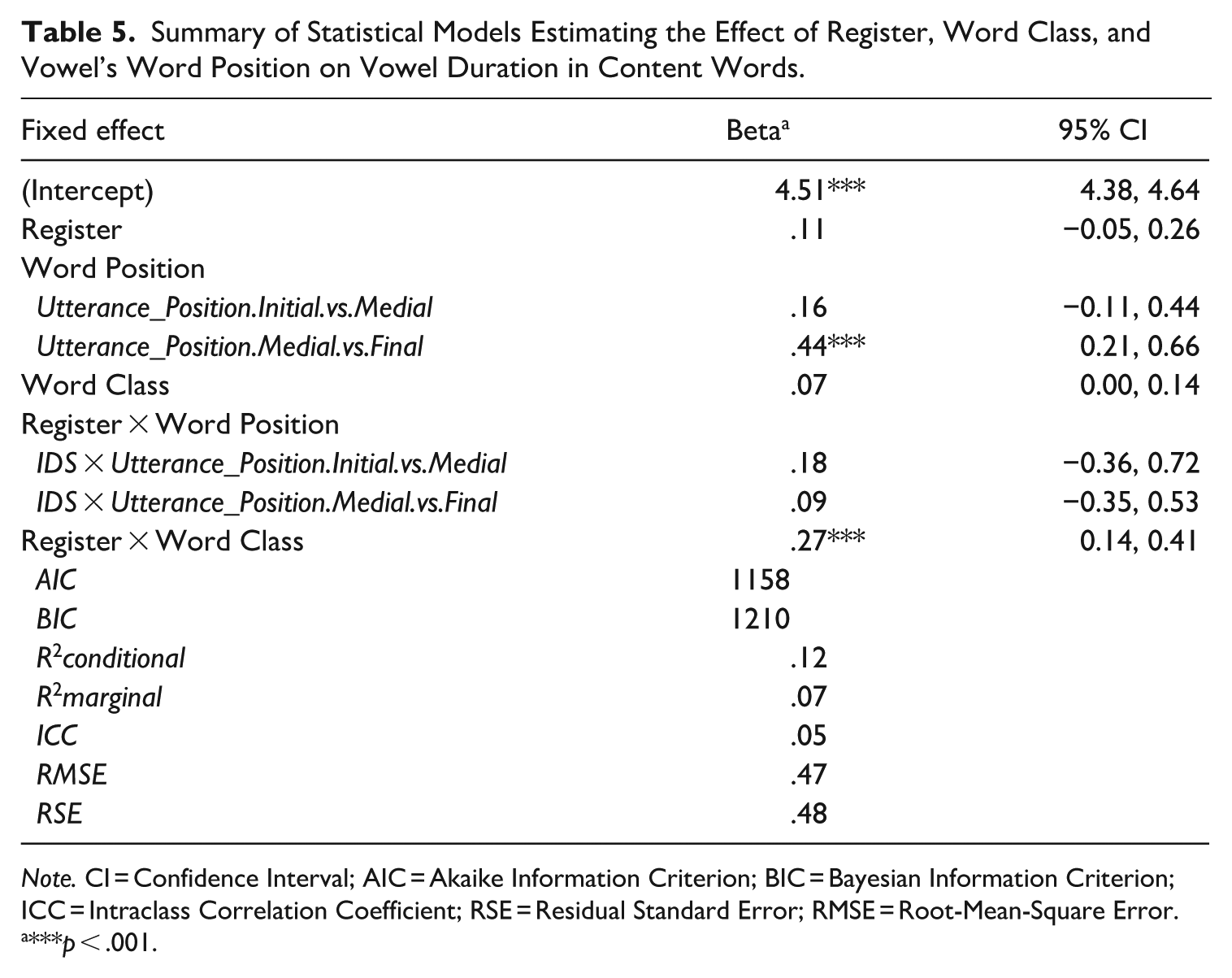
Note. CI = Confidence Interval; AIC = Akaike Information Criterion; BIC = Bayesian Information Criterion; ICC = Intraclass Correlation Coefficient; RSE = Residual Standard Error; RMSE = Root-Mean-Square Error.
***p < .001.
Vowel Space Area
Our third analysis evaluated the hyper-articulation hypothesis by examining whether Tashlhiyt-speaking caregivers expanded their VSA in IDS. A bigger VSA in IDS would indicate that caregivers hyper-articulated their vowels. The opposite pattern would instead suggest hypo-articulation. The descriptive statistics for mean formant values for each vowel across the two registers are shown in Table 6 (Raw) and Table 7 (Lobanov-normalized). We used the PhonR package (Mccloy, 2012) to compute and visualize the VSA (see Figure A1 in Appendix A for individual VSA plots). Figure 1 shows the acoustic vowel space triangle averaged across all caregivers for both registers (IDS vs. ADS). A 2-tailed paired-samples t-test with Register as the independent variable and VSA (Lobanov-normalized) as the dependent variable did not reveal any significant differences (t(6) = 0.29, p = 0.77, d = 0.12, 95% CI [−0.69, 0.92]) between the ADS (M = 1.57, SD = 0.23) and the IDS VSA (M = 1.52, SD = 0.34). These results do not support either of the previous predictions, revealing no evidence for either hyper-articulation or hypo-articulation of vowels in IDS. VSA expansion occurs when vowel formants are modified in ways that make the vowel triangle bigger (see Figure 1). However, these formants can be modified in other ways that do not make the triangle different in size but are still informative about IDS.
Descriptive Statistics of F1, F2, and F3 Values (in Hz) for All Vowels in ADS and IDS.
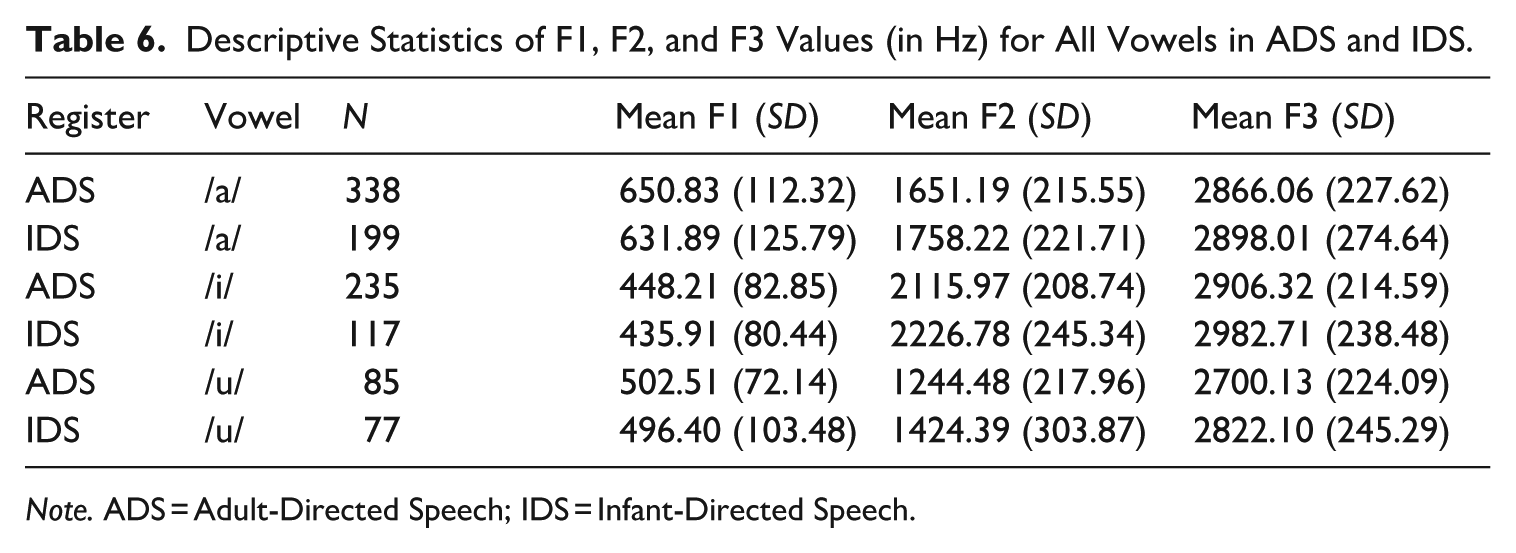
Note. ADS = Adult-Directed Speech; IDS = Infant-Directed Speech.
Descriptive Statistics of F1, F2, and F3 Values (Lob-Normalized) for All Vowels by Register.
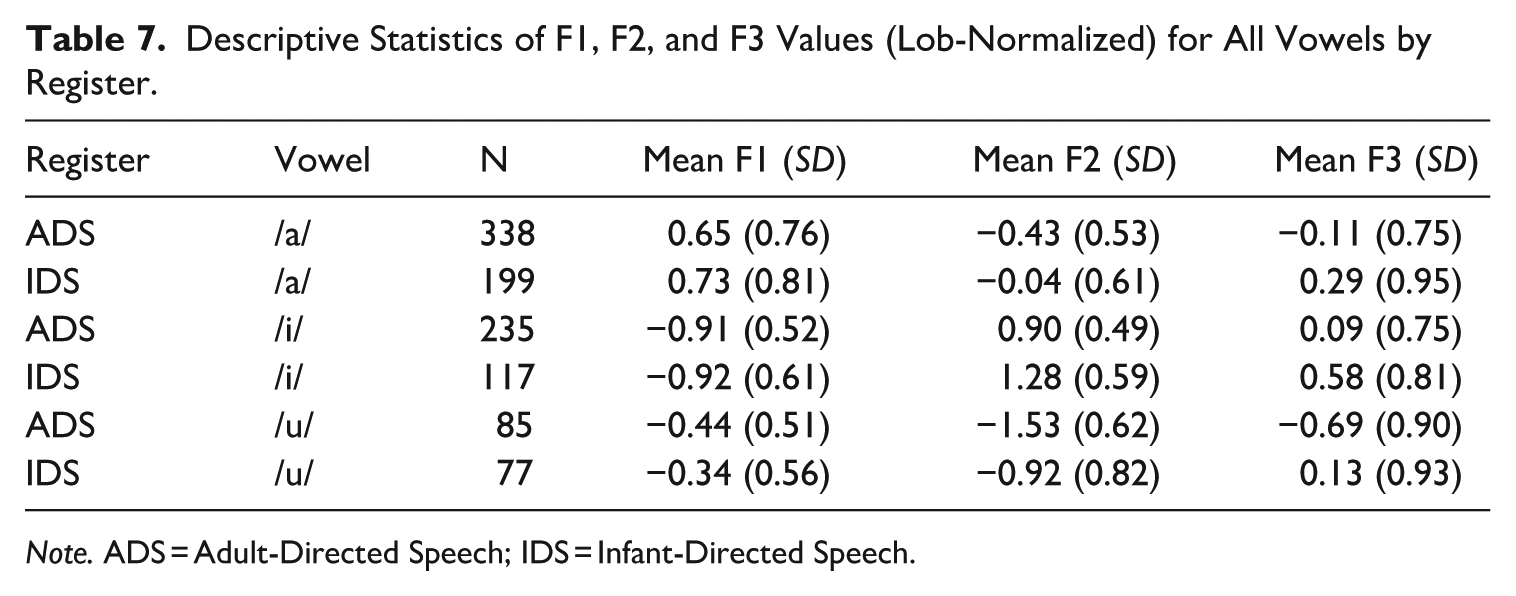
Note. ADS = Adult-Directed Speech; IDS = Infant-Directed Speech.
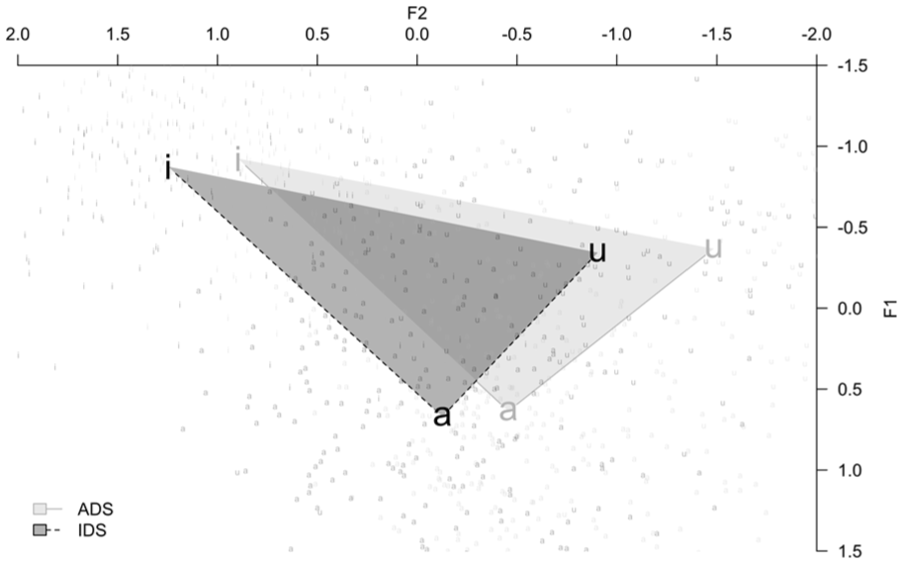
Vowel space area (Lobanov-normalized) for IDS (Dark Gray) and ADS (Light Gray).
Formant Analysis
Since we found no evidence for hyper- or hypo-articulation in the previous analysis, we asked whether vowel formants are modified in ways that indicate that caregivers are modifying affect instead of attempting to hyper-articulate vowels. To answer this question, we fitted three linear mixed models with, respectively, F1/F2/F3 (Lobanov-normalized) as the outcome variables (see Table 8 for model summaries). We included Register as a fixed effect (sum-coded; ADS: −0.5 vs. IDS: +0.5), while Speaker and Vowel Identity were added as random effects. There was a significant main effect of Register for the F2 (β = .44, SE = 0.03, t = 11.58, p < .001) and F3 models (β = .50, SE = 0.05, t = 9.46, p < .001), suggesting that, for all vowels, the second and third formant frequencies were higher across the board in IDS. For F1, however, the effect of Register was not significant (β = .06, SE = 0.04, t = 1.30, p = .19).
Summary of Statistical Models Estimating the Effect of Register on Vowel Formant Values.
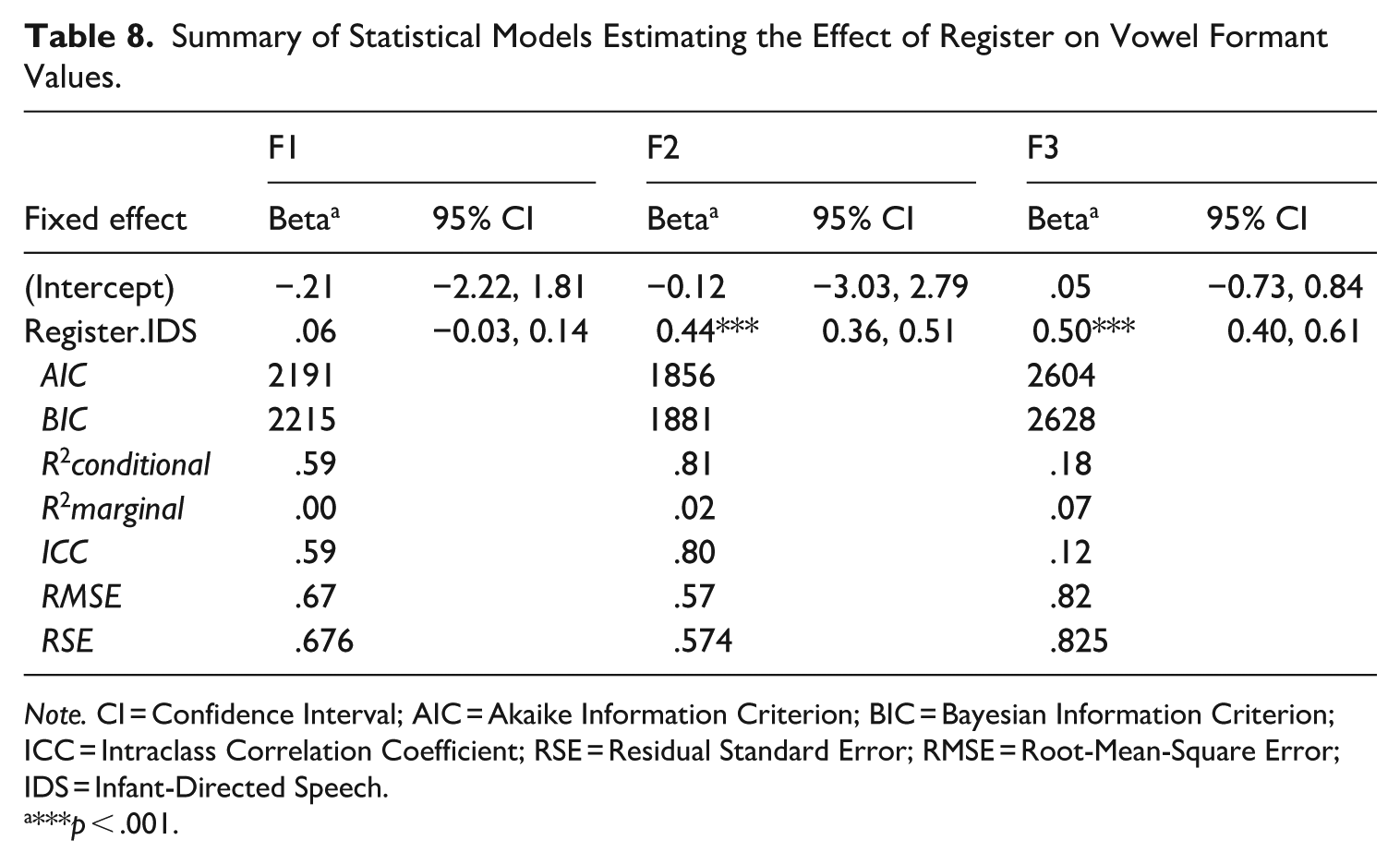
Note. CI = Confidence Interval; AIC = Akaike Information Criterion; BIC = Bayesian Information Criterion; ICC = Intraclass Correlation Coefficient; RSE = Residual Standard Error; RMSE = Root-Mean-Square Error; IDS = Infant-Directed Speech.
***p < .001.
Vowel Overlap
The next analysis tested whether vowel categories are more distinct in IDS by computing the degree of the overlap between any two given vowels. More overlap between vowels would be evidence for hypo-articulation, while less overlap indicates that the vowel contrasts are more salient in IDS. Both Pillai (computed through a MANOVA test) and Bhattacharyya scores in Figure 2 (Computed using the adehabitatHR package, Calenge, 2015) showed a greater mean overlap between the /u/-/i/ and /a-u/ contrasts in IDS than ADS (see Figure 3).
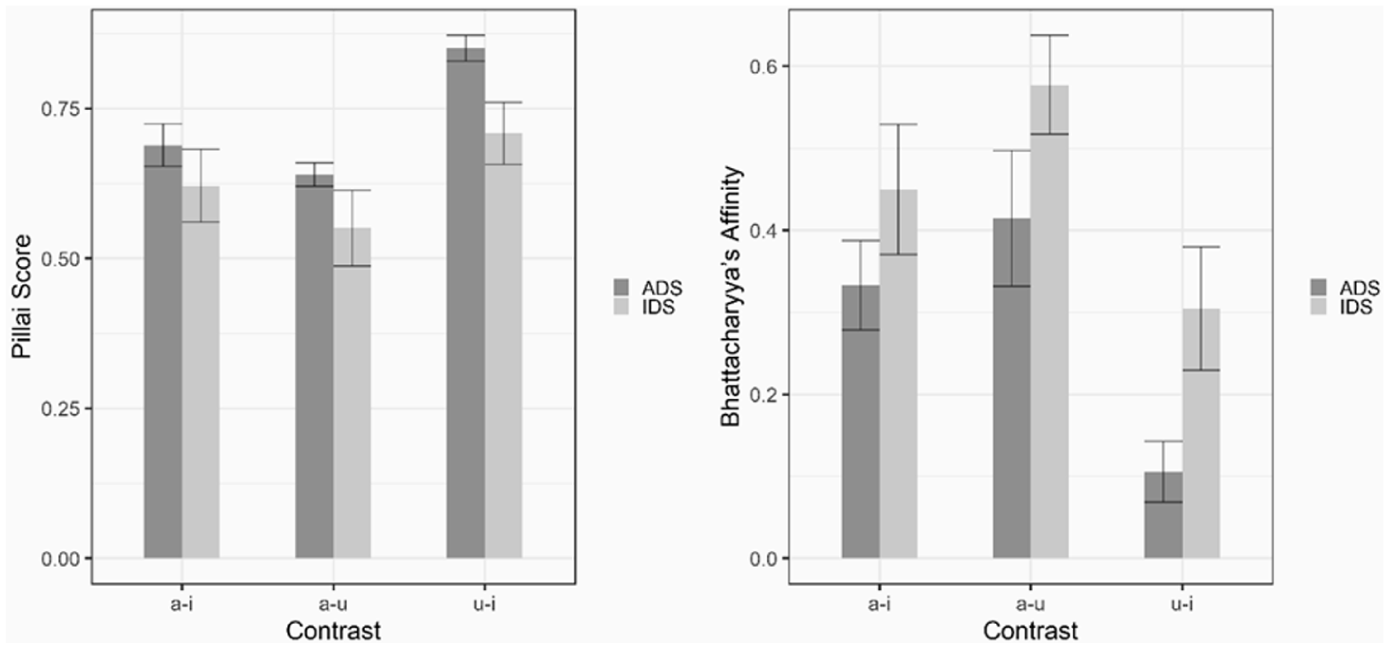
Vowel category overlap scores for IDS and ADS: Higher Pillai scores indicate less overlap, while higher Bhattachariyya’s Affinity scores indicate more overlap.
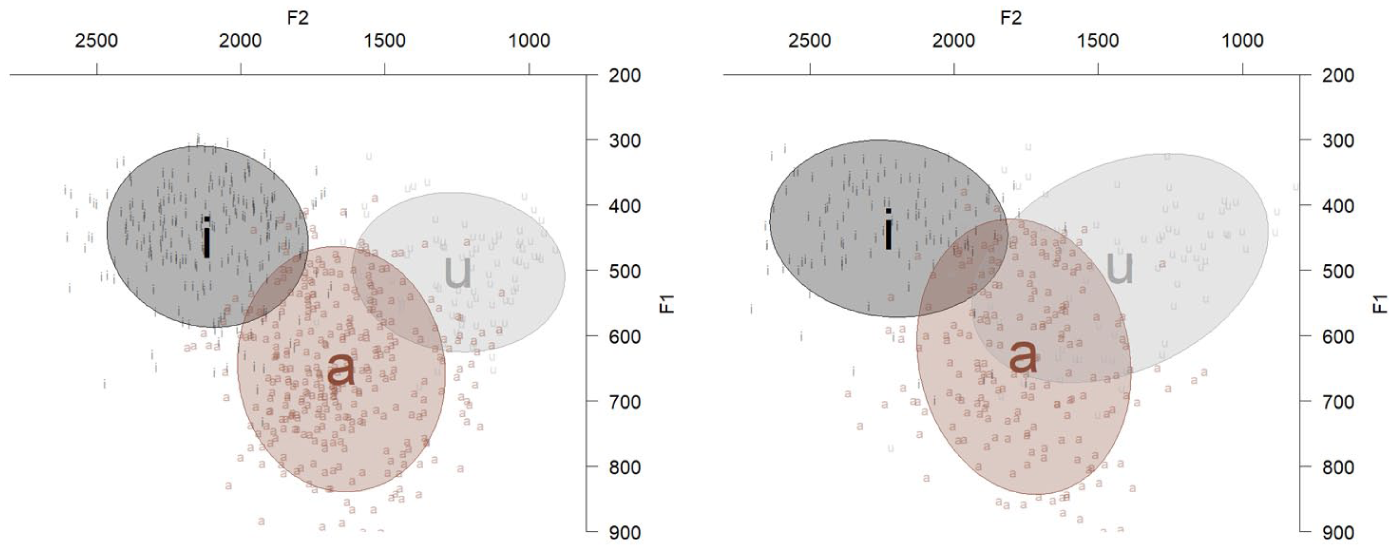
Ellipse plot visualizing mean vowel formant distributions for each of the three vowels in ADS (left plot) and IDS (right plot).
Consonant Contrasts
In our second set of analyses, we explore IDS modification in consonants. In particular, we report on a consonant neutralization behavior that characterizes IDS in Tashlhiyt, whereby caregivers seem to modify a set of phonemic contrasts (Figure 4) in IDS. These contrasts are phonemes that caregivers neutralize to varying degrees in the register. For example, one caregiver produced no /ʒ/ and /q/ tokens throughout the recordings, where they simply surfaced as /z/ and /k/, respectively. This behavior never occurred in the ADS recordings and is thus likely a property of Tashlhiyt IDS. When asked, all speakers indicated their awareness of this modification and said that they did it subconsciously, although it could be elicited as well.
We used Phon to calculate how often contrasts were neutralized. Since our transcriptions contained the target utterances as well as the actual utterances, we calculated how often a consonant’s surface realization matched its underlying representation (excluding mismatches resulting from other morpho-phonological processes). Our analyses in Phon returned an overall PCC of 65% (SD = 35%), which is the percentage of target phonemes that surfaced non-neutralized. Consonant contrasts varied in how often they were neutralized. As shown in Figure 4, average PCC scores for different contrasts ranged from 50% (SD = 31%) for the /r − l/ contrast to 87% for the /χ − ʜ/ contrast (SD = 17).
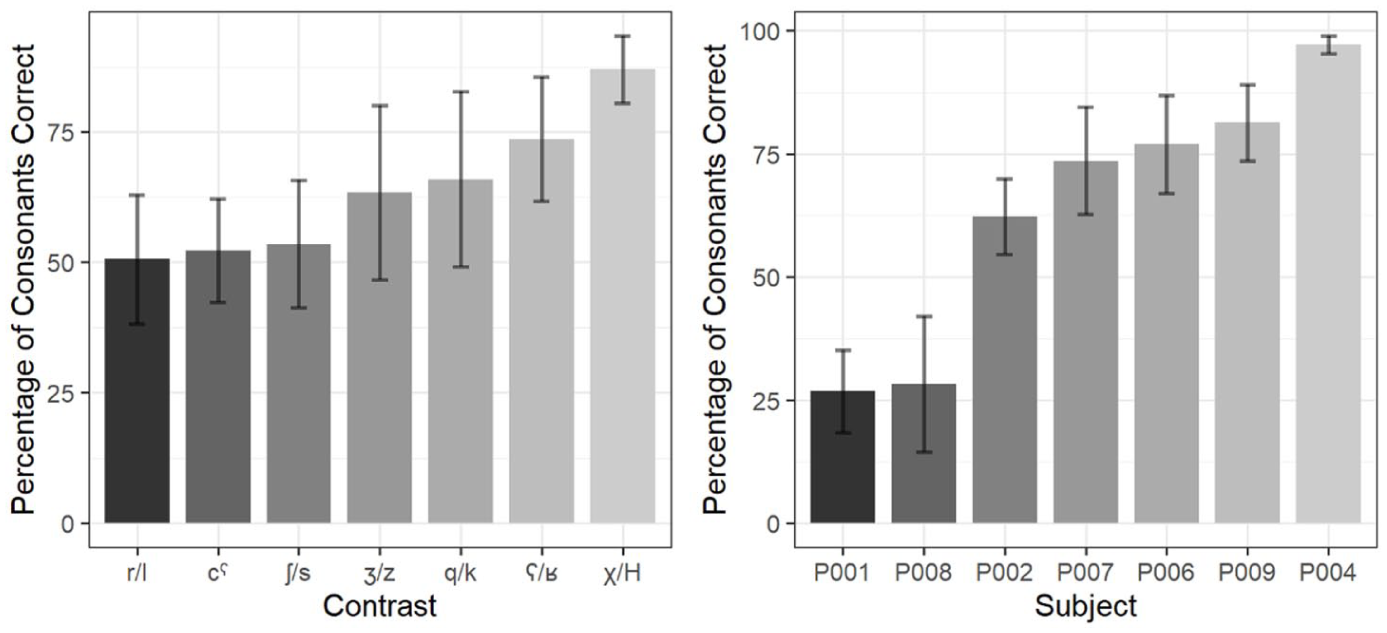
Percentage of Consonant Correct for each consonant contrast (left panel) and speaker (right panel) in IDS. Higher PCC values indicate less neutralization occurrences.
Consonant contrast neutralization also varied by caregiver and ranged from 2% (SD = 2.5%) to 77% (SD = 22%), as can be seen in Figure 4. Similarly, speakers did not neutralize to the same extent across all contrasts. While two speakers completely neutralized /ʒ/ whenever it occurred in target words, another completely neutralized the /q/ phoneme. Additionally, pharyngealization (shown as “cˁ” in Figure 4), a secondary articulation that is distinctive in Tashlhiyt, was also subject to neutralization with an average PCC score of 52% (SD = 26%), with speakers ranging from 6% to 87% of pharyngealized phonemes. Regardless of the extent, all speakers engaged in some neutralization, which was never the case in ADS.
Discussion
In this paper, we asked whether segments – vowels and consonants – were realized differently in IDS compared to ADS in Tashlhiyt. With regards to vowels, we compared IDS and ADS vowels on measures of pitch, duration, VSA, vowel overlap, and individual vowel formants. Our results showed that vowels had consistently higher f0, making this the most salient marker of vowels in IDS in Tashlhiyt, in line with cross-linguistic findings (Cox et al., 2023). Additionally, vowel duration was longer in IDS, especially for content words and, within content words, especially for nouns. While VSA was constant across registers, Pillai and Bhattacharyya’s Affinity scores indicated that two of the three vowel Tashlhiyt contrasts have slightly more overlap in IDS. Our analysis of individual formant values also showed that F2 and F3 were consistently higher in IDS. With regards to consonants, we showed that caregivers neutralized certain consonant contrasts. These results indicate that caregivers adjust their speech when talking to infants, modifying vowels and consonants in different ways within the language.
Vowels
We found that VSA did not expand during IDS in Tashlhiyt, but that two out of three vowel categories showed more overlap. The result adds to the small number of studies showing that, in some languages, there is no clear-cut vowel hyper-articulation when caregivers engage with their infants (for English and Japanese, see Dodane & Al-Tamimi, 2007; and for Cantonese, see Xu Rattanasone et al., 2013). The lack of VSA expansion and increasing overlap does not support the hyper-articulation hypothesis, which argues that IDS is driven by the need to facilitate language development and that vowels should consequently be maximally distinct in the child’s input (Kuhl et al., 1997). Our VSA and vowel overlap results also suggest that hyper-articulation might not occur in systems with small vowel inventories, contrary to Lovcevic et al. (2025), who suggested that these languages are more likely to be hyper-articulated because they can afford to do so without risking too much overlap between categories. Instead, we found evidence for more overlap, even without VSA expansion, which is more consistent with the idea that acoustic salience in small vowel systems, and three-corner vowel systems specifically, does not necessarily increase in IDS. These results are consistent with vowel modifications in Warlpiri IDS, another language with a small vowel system (Bundgaard-Nielsen et al., 2023).
Cross-linguistically, vowels are often longer in IDS across all tokens. However, this might be simply because most studies only included content words in their data. We therefore compared content and function words. Indeed, vowels were longer in content words, which we followed up with a comparison of nouns to other content word classes. Interestingly, our results showed longer vowel durations in IDS for nouns than for other content words, which again replicates findings from Warlpiri (Bundgaard-Nielsen et al., 2023), a language with a similar vowel system. Cross-linguistically, noun production is associated with slower speech rates, which is argued to be due to their higher processing demands (Seifart et al., 2018). Warlpiri IDS also exhibits an expanded VSA for nouns, which we currently cannot directly examine for Tashlhiyt due to data limitations (e.g., not enough observations to calculate VSA for all conditions). Thus, considering that vowel duration and VSA expansion measures are highly correlated in IDS (Hartman et al., 2017; Shochi et al., 2009), it is very likely that vowels will also be hyper-articulated in Tashlhiyt IDS nouns, a result that would generally be consistent with a weaker version of the hyper-articulation hypothesis, where caregivers selectively adapt their speech to highlight the contrasts that children may struggle with instead of increasing acoustic salience across the board. Tashlhiyt and Warlpiri both have a compact vowel space with small inventories, which likely constrain, in comparable ways, the extent to which caregivers are able to modify speech when addressing children.
Our results also show an overall increase in pitch, F2 and F3 for all vowels in IDS. Increases in F2 and F3 are typically linked to a more advanced tongue position and more rounded lips, respectively. The literature suggests that these modifications result from speakers shortening their vocal tract, either in an attempt to mimic child speech or to seem non-threatening (Kalashnikova & Burnham, 2018). These modifications have also been argued to maintain infants’ attention (Segal & Newman, 2015; Trainor & Desjardins, 2002) and convey positive emotion (Benders, 2013; Trainor et al., 2000). Taken together, the VSA size, vowel overlap, pitch, duration, and vowel formant results are consistent with the view that, overall, the purpose of IDS is mainly to serve communicative (attentional and affective) functions.
Consonants
Our analysis of consonant modification in Tashlhiyt revealed an as-yet undocumented feature of IDS outside Australian languages (Laughren, 1984), in which some contrasts (e.g., /r/ and /l/) are completely neutralized to varying degrees by caregivers. For instance, when the underlying phoneme /r/ occurred in a word (e.g., /takurt/ “ball”), it was often realized as [l] (e.g., /takult/). This surprising behavior may result in the elimination of certain phonemes from the input, which in principle poses challenges for the acquisition of the full native inventory by the infant, at least through IDS. Note that there were considerable differences in consonant contrast neutralization behavior between contrasts and speakers (Figure 4). While contrasts such as /ʜ/ − /χ/ were only neutralized half of the time on average, others, such as /z/ − /ʒ/, were neutralized by some speakers all the time. In addition to the neutralization of these contrasts, secondary articulations such as pharyngealization were affected. Up to 92% of pharyngealized consonants were “de-pharyngealized” by some speakers. These results, similar to those of Benders et al. (2019) show that even when the phonological space is crowded (as is the case with the Tashlhiyt consonants), caregivers may avoid hyper-articulation.
This behavior in Tashlhiyt-speaking caregivers seems, at face value, to be incompatible with the idea of a listener-oriented didactic function of IDS. An alternative explanation could be that caregivers are imitating how infants (mis-)produce these sets of contrasts, a common form of caregiver-infant play. However, this behavior is present in IDS addressed very young infants, long before the infants’ first attempt at vocalizations. At the same time, neutralization appears to be a feature of IDS, since all the caregivers engaged in it to some degree. This may then reflect an implicit cultural understanding of the complexities of Tashlhiyt’s consonant inventory, with caregivers selectively neutralizing contrasts thought to be the most challenging sounds to their infant.
Similar consonant neutralization has been reported for IDS in some Australian languages. We again draw similarities with Warlpiri, which collapses all coronal Places of Articulation (PoAs) into a single category (Laughren, 1984). Warlpiri’s consonant inventory is not comparable in size to Tashlhiyt, but the coronal PoAs that are subject to neutralization can be perceptually challenging. It might then be the case that inventory size per se is not responsible for segmental modification in IDS, but rather the phonetic salience of specific contrasts. In addition to Nepali, which shows evidence for hypo-articulation, Warlpiri and Tashlhiyt IDS contain the most challenging consonants examined so far. All these contrasts, despite being less salient, were subject to hypo-articulation and even complete neutralization. And while we do not currently consider neutralization to be an extreme case of hypo-articulation (e.g., not a relative reduction of salience), but rather an example of a phonological substitution process (i.e., phonetic differences are made absent), acoustic data is needed to better understand how these phonemes surface in IDS. This is especially true for less salient contrasts, since they are difficult to judge impressionistically (e.g., agreement on pharyngealized consonants was 79%). Regardless of the nature of these modifications, the way these phonemes are realized in Tashlhiyt goes against a didactic view of IDS, which would only be supported by evidence for hyper-articulation, especially for challenging contrasts.
There were also differences in the amount of neutralization across individuals and phonemes. We do not know whether there are also such differences in Warlpiri’s IDS, since these were not reported, but we think it is likely that modification patterns, like neutralization, will also show variability between speakers and possibly phonemes in other languages beyond Tashlhiyt (Figure 4). This alters the input characteristics in different ways, including the frequency of phonemes (if at all) and even whole phoneme classes (e.g., rhotics). And while both languages similarly avoid rhotics, Tashlhiyt extends the neutralization behavior to PoAs other than coronals (e.g., uvulars). Despite these differences, the commonality is that caregivers from both language groups seem sensitive to the articulatory effort some phoneme contrasts place on infants and modify their productions by keeping the most peripheral of PoAs (Table 1). That is, modifications made in IDS may be influenced by both infants’ perceived biomechanical limitations and their perceptual ones. For Tashlhiyt, this is especially true with the neutralization of articulatorily complex pharyngealization and labialization contrasts (Buech et al., 2022), which, in addition to the consonant set in Figure 4, could (maximally) reduce the inventory size in Table 1 from 71 down to 32 phonemes when neutralized.
Prior findings link hyper-articulation to better language outcomes (Kalashnikova & Burnham, 2018; Lovcevic et al., 2024), while others do not find evidence for detrimental hypo-articulation effects (Rosslund et al., 2025). This poses the question of how neutralization might affect consonant acquisition in Tashlhiyt (and, indeed, Warlpiri). Undoubtedly, the behavior of Tashlhiyt caregivers may completely or partially neutralize certain consonants from the input. However, this does not mean Tashlhiyt-style IDS might not serve a facilitative role in learning. One possibility is that the temporary reduction in the number of consonant categories in the input allows children to break into the system more easily, and this early knowledge is used to bootstrap into the full adult system. The suggestion is that this pattern could be another example of how caregivers adapt to the developmental needs of their infants. In Cantonese, which has six tones, mothers show evidence for tone hyper-articulation before their infants reach 4 months of age, but stop doing so when they reach 11 months (Xu Rattanasone et al., 2013). Similarly, it could be that in Tashlhiyt, parents try to adapt to their infant’s perceived abilities by allowing them to acquire a certain number of segments before introducing them to the rest of the inventory.
Limitations
Our study has some limitations that may have affected participants’ behavior. Our experimenter was a male native speaker of Tashlhiyt and a community member. However, despite his status as an in-group member, in rural areas of Morocco, it is socially normative for males and females to exercise a degree of social distance, especially if they are not related. Thus, the experimenter’s gender might have inhibited IDS elicitation. This was clear in the audio recordings of one female caregiver, who was not related to the experimenter and who sporadically inhibited what they called “silly talk” throughout the recording (P002), unlike female caregivers who were close relatives of the experimenter (P008). The relatively formal nature of the recording context may have also influenced our results. Specifically, we anecdotally observed that caregivers engage in neutralization more during intimate moments with their infants, which further reinforces the possibility that it may have an affective function. However, the opportunity to engage in such intimate moments was limited in our study, where dyads were largely engaging in triadic communication via their focus on the video. Thus, our recording context may have inhibited neutralization due to the lack of face-to-face interaction between the caregiver and the infant and may have underestimated the extent of the neutralization phenomenon.
This leads to a suggestion for future research that is rarely incorporated into studies of IDS – the influence of non-verbal behavior. That is, if neutralizations are more frequent in face-to-face contexts that have distinct affective valency, they may also co-occur with non-verbal signals (e.g., haptic cues like touch and facial expressions like smiling) that cue children to language. This suggestion awaits further research. At the same time, our elicitation method was not without value: although it may have impacted the segmental characteristics and elicited IDS exhibiting less consonant neutralization than usual, we do not believe it impacted other features of IDS, such as prosody. This is because the point-and-describe interaction is a daily activity in the lives of Tashlhiyt-acquiring infants. Finally, it is worth noting that because we measured pitch on vowels, this meant that vowelless words, which Tashlhiyt allows, were automatically excluded. Therefore, the pitch results do not present the whole picture of how pitch is implemented in Tashlhiyt’s IDS using other pitch-bearing elements, as is the case with Tashlhiyt’s ADS (Grice et al., 2015).
Conclusion
In this paper, we have presented the first study of IDS in Tashlhiyt Berber, a language that is typologically interesting in the context of phonological acquisition due to the contrast in the size of its vowel (small) and consonant (very large) inventories. Thus, the language represents an important data point for the field, which has consistently studied languages from a narrow typological range (see Passmore et al., 2025). We found a number of notable results. Firstly, Tashlhiyt-speaking caregivers do not hyper-articulate vowel categories when addressing infants, despite (or perhaps, due to) the language having a compact vowel space. The size of vowel space was similar across IDS and ADS registers, suggesting that vowels are not particularly clearer in IDS. Rather, our results revealed evidence for more overlap in IDS, suggesting that the opposite pattern (hypo-articulation) may be true. Overall, the pattern of results suggested that, for vowels, modifications in IDS may be more geared to direct attention and convey positive emotion rather than to help children distinguish between different vowels. For consonants, our findings revealed a surprising pattern of modification where caregivers neutralized certain consonants from the input. These findings suggest that caregivers do not always hyper-articulate phonemic segments regardless of the inventory size and phonetic salience, and may choose to modify vowels and consonants differently within the same language. The lack of VSA expansion, the increasing vowel overlap, and in particular, the consonant neutralization provide strong evidence against the hyper-articulation hypothesis. However, possible facilitative strategies (e.g., the temporary reduction of the consonant inventory size) could still lend support for the view that IDS may have a didactic function even without hyper-articulation. Finally, the contrast neutralization behavior raises questions about the challenges infants face during consonant acquisition, as well as what motivates caregivers to follow such behavior.
Footnotes
Appendix A
Appendix B
Number of Tokens for Each Vowel, Register, and Word Class.
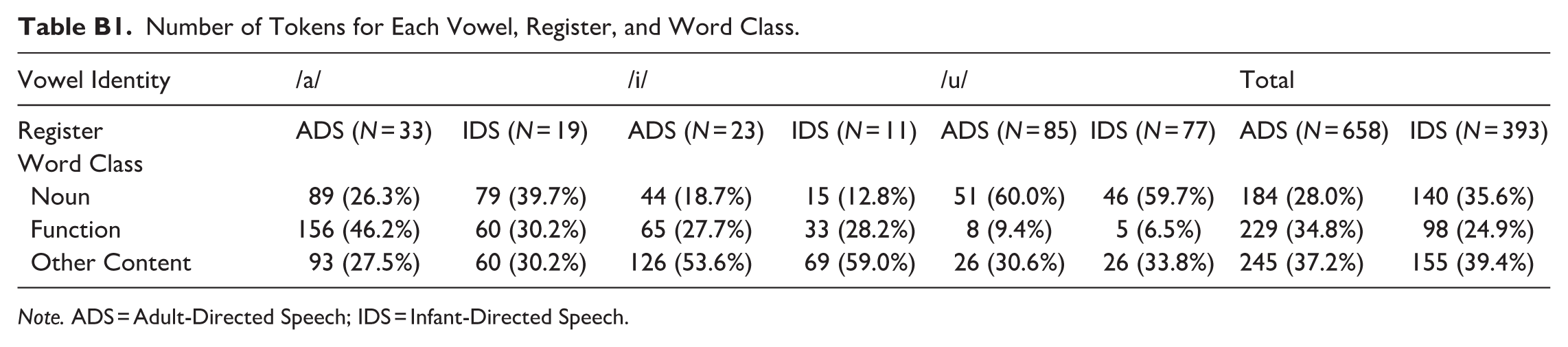
| Vowel Identity | /a/ | /i/ | /u/ | Total | ||||
|---|---|---|---|---|---|---|---|---|
| Register | ADS (N = 33) | IDS (N = 19) | ADS (N = 23) | IDS (N = 11) | ADS (N = 85) | IDS (N = 77) | ADS (N = 658) | IDS (N = 393) |
| Word Class | ||||||||
| Noun | 89 (26.3%) | 79 (39.7%) | 44 (18.7%) | 15 (12.8%) | 51 (60.0%) | 46 (59.7%) | 184 (28.0%) | 140 (35.6%) |
| Function | 156 (46.2%) | 60 (30.2%) | 65 (27.7%) | 33 (28.2%) | 8 (9.4%) | 5 (6.5%) | 229 (34.8%) | 98 (24.9%) |
| Other Content | 93 (27.5%) | 60 (30.2%) | 126 (53.6%) | 69 (59.0%) | 26 (30.6%) | 26 (33.8%) | 245 (37.2%) | 155 (39.4%) |
Note. ADS = Adult-Directed Speech; IDS = Infant-Directed Speech.
Acknowledgements
We thank Esther Janse, Janine Berns, and Zara Harmon for their comments, and Salah Eddine Hafed for helping with IPA transcription. We would also like to thank the families who participated in this study.
Ethical Considerations
The Faculty of Social Sciences Ethics Review Committee at Radboud University approved our study (Approval Registration Number: ECSW-2022-052) on June 24th, 2022.
Consent to Participate
Respondents gave written and/or verbal (recorded) informed consent and signature before starting the recording session.
Author Contributions
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the Max Planck Society.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.