
Abstract
In this paper, we examine young children’s acquisition of the prefixal noun class system of Eegimaa, a Jóola language spoken in Senegal (Atlantic family, Niger-Congo). The analysis is based on spontaneous, spoken data representing a mixed design (longitudinal and cross-sectional), with –9.5 hr of recordings, including nine children, aged between 1;10 and 3;2. The data yielded 967 spontaneously produced noun tokens. Across the group of children, accuracy is already high at age 2 years, at 73%, and increases to 94% by age 3. Two children’s productions are examined more closely through a series of longitudinal recordings, which show that the majority of nouns are produced accurately, with target-like noun class prefixes already present from the earliest ages, a finding that differs from earlier research on the distantly related Bantu languages. Non-target-like nouns, produced with omitted, substituted or filler prefixes, amount to less than one fifth of the overall noun tokens produced in the transcribed recordings. We discuss the types of errors made by the children and possible reasons for them, and the implications of the learning trajectories for understanding morphological acquisition.
Keywords
Introduction
Research on the acquisition of African noun class systems has been conducted almost exclusively in Bantu languages. In this paper, we investigate the acquisition of noun class morphology in Niger-Congo languages using data from Eegimaa, an Atlantic language of the Jóola cluster spoken in the south of Senegal, with an estimated 13,000 speakers (Lewis et al., 2016). Eegimaa is distantly related to Bantu languages, and its noun class system is structurally similar to the ones found in these languages. In Bantu languages, children have been reported to learn the noun class systems through three ‘partially overlapping stages’ (Demuth, 2003; Demuth & Weschler, 2012; Kunene, 1979, for a summary), which consist of first producing nouns without any prefix, followed by the use of a ‘shadow’/ ‘dummy’ prefix, which may function as a placeholder. Only later are they reported to produce the full nouns with the accurate prefix.
With only a few exceptions, nouns in Eegimaa must combine with a noun class prefix (NCP). These prefixes indicate the morphological class to which a noun belongs, as well as expressing grammatical number information, distinguishing singular and plural. Nouns in Eegimaa, as in Bantu, also trigger alliterative agreement 1 in most cases. In this study, we focus on the acquisition of noun prefixes only, leaving aside the agreeing elements.
There are different ways to account for children’s acquisition of noun class morphology. When a child learns a noun early in the acquisition process, before having acquired generalised knowledge of the morphological system, they are likely to learn the noun together with its prefix as an unanalysed chunk, since they reliably occur together. The child will learn to segment the nominal morphemes later, as the recurring patterns in the language lead to more abstraction and generalised categories (Ambridge & Lieven, 2011). Yet the descriptions of the acquisition of noun class systems in Bantu, as noted above, suggest that children learn the noun stems first, with vague or unspecified representations of the nominal class prefixes, such that they initially do not even attempt them, but rather produce prefixless noun stems. Note that in Eegimaa, prefix-taking nouns always occur with their prefixes in the adult language, and hence, children are unlikely to encounter bare noun stems in the input. Constructivist approaches expect children to acquire complex morphological structures by first learning items piecemeal, as unanalysed wholes, before learning to segment them into their components and using abstract morphology more productively (Diessel, 2019; Lieven et al., 1997; Tomasello, 2000). Before gaining command of the morphophonology and morphosyntax of the target system, however, children produce non-target-like forms as well as target-like chunks, either omitting the nominal prefix or replacing it with a different form. Our research questions (in section ‘Research questions’) address both the issue of productivity and the extent to which we can observe different stages in the acquisition process. In Bantu languages, children are reported to show morphophonological underspecification before gaining an understanding of how the morphological system works (Demuth, 2003; Demuth & Weschler, 2012; Demuth et al., 1986; Kunene, 1979; Suzman, 1980; Tsonope, 1987). The emergence and increasing mastery of the morphological system can be seen in the growing accuracy of prefixes and contrastive use, although the development may follow a U-shaped curve, if initial accuracy is followed by a decline in accuracy in service of increased productivity. As enunciated by Pye et al. (2017, see also Pye, 2019), cross-linguistic comparison across unrelated languages as well as groups of closely and more distantly related languages is crucial in order to identify patterns that hold broadly across languages as well as to better understand individual differences.
Despite early claims that complex morphological systems like that of Polish are learned early and without error (Slobin, 1985; Smoczynska, 1985), more recent studies have shown that less frequent lexemes and less frequent grammatical categories are more error-prone than these initial descriptions captured (e.g. in Spanish, Aguado-Orea & Pine, 2015; Finnish, Räsänen et al., 2015; and Lithuanian, Savičiūtė et al., 2018). The generally early acquisition of the more frequent forms of early- acquired lexemes has been tested across several morphologically complex languages (e.g. Granlund et al., 2019, including Estonian, Finnish and Polish), but it has also been found that the mastery of gender can be prolonged in particular languages, for example, in Germanic (German, Dittmar et al., 2008; Danish, Kjaerbaek et al., 2014) and Slavic (Polish and Russian: Janssen, 2016). Ivanova-Sullivan et al. (2024), comparing Bulgarian and Russian children, acquiring related Slavic languages with similar three-way gender systems, found that Bulgarian children were better able to use cues from gender marked adjectives in predictive processing. A key implication of their study is the need to compare the acquisition of similar systems in typologically related languages (see also Kidd & Garcia, 2022; Pye, 2019).
This study examines new data on the acquisition of the noun class morphology in Eegimaa, analysing both cross-sectional and longitudinal corpus data. We examine 9.5 hr of spontaneous production data from nine children aged 1;10 to 3;2. We investigate the use of NCPs in a cross-sectional study drawing on spontaneous production data from all nine children across three age points: 2;0 (1;10 to 2;2), 2;6 (2;4 to 2;8) and 3;0 (2;9 to 3;2), followed by a closer look at longitudinal data from two children.
The analysis of the Eegimaa data presented below reveals that children’s language productions are predominantly target-like even in the earliest recordings at 1;11, with non-target-like usage comprising about one quarter of noun tokens at age 2 years. We will compare the Eegimaa data with previous results from Bantu, the genealogically and typologically closest language branch for which we have data on the acquisition of noun classes, pointing out methodological challenges.
This paper begins with an overview of the Eegimaa noun class/gender system in section ‘Linguistic background: Eegimaa and its system of noun morphology’. In section ‘Method’, we present our data collection methods, the data used in this paper and the participants in our study. We discuss our results in sections ‘Results: Group analysis’ and ‘Individual trajectories’, linking them to previous studies on the acquisition of noun class systems in Niger-Congo noun class systems, and we discuss theoretical implications in the discussion in section ‘Discussion’.
Linguistic Background: Eegimaa and Its System of Noun Morphology
The Language Background
Eegimaa (bqj ISO 639) is a language of the Jóola cluster—a continuum of closely related languages spoken in Gambia, southern Senegal and Guinea-Bissau—belonging to the Atlantic family of the Niger-Congo language phylum. The Eegimaa villages are located to the west of the city of Ziguinchor in the former Casamance region in the south of Senegal. Similar to the majority of villages in Casamance, the Eegimaa-speaking villages are monoethnic and monolingual villages, where daily communication between villagers is done through a single default language of communication (Sagna & Hantgan, 2021). They differ from multiethnic and multilingual villages, often referred to as cosmopolitan villages, which are composed of ethnolinguistically diverse neighbourhoods where daily communication requires the use of several different languages (Sagna & Hantgan, 2021).
Noun Morphology
We focus in this paper on the morphology that appears on nouns. This means that we look at the acquisition of the nominal prefixes that express the singular-plural distinction. We refer to these as NCPs. It should be borne in mind that the term ‘noun class’ can be confusing. On the one hand it can be understood as referring to what appears on the noun—the way that we are using it when talking of NCPs—while on the other it can be used to refer to the classification of a noun in terms of its agreement patterns: nouns in the singular that trigger the same agreement pattern are said to belong to the same class, while nouns in the plural that trigger the same agreement will be assigned to another class. This also means that, under the ‘noun class’ construal of agreement, the singular and plural of the same noun belong to different classes. While it is not the focus of this paper, the approach that we take to agreement is to see it as a gender: nouns that share agreement patterns across singular and plural belong to the same gender. There is, of course, a link between the NCP system and the gender system. This work, where we look at NCPs, is part of a larger programme where we investigate (a) NCPs, (b) gender agreement and (c) the interaction of (a) and (b). Our programmatic aim is deliberately to look at these separately before bringing them together, in order to achieve a better understanding of how they interact. Table 1 provides a complete list of Eegimaa NCPs along with their corresponding genders.
Noun class prefixes (NCPs) for singular (SG) and plural (PL) and genders in Eegimaa, with examples.
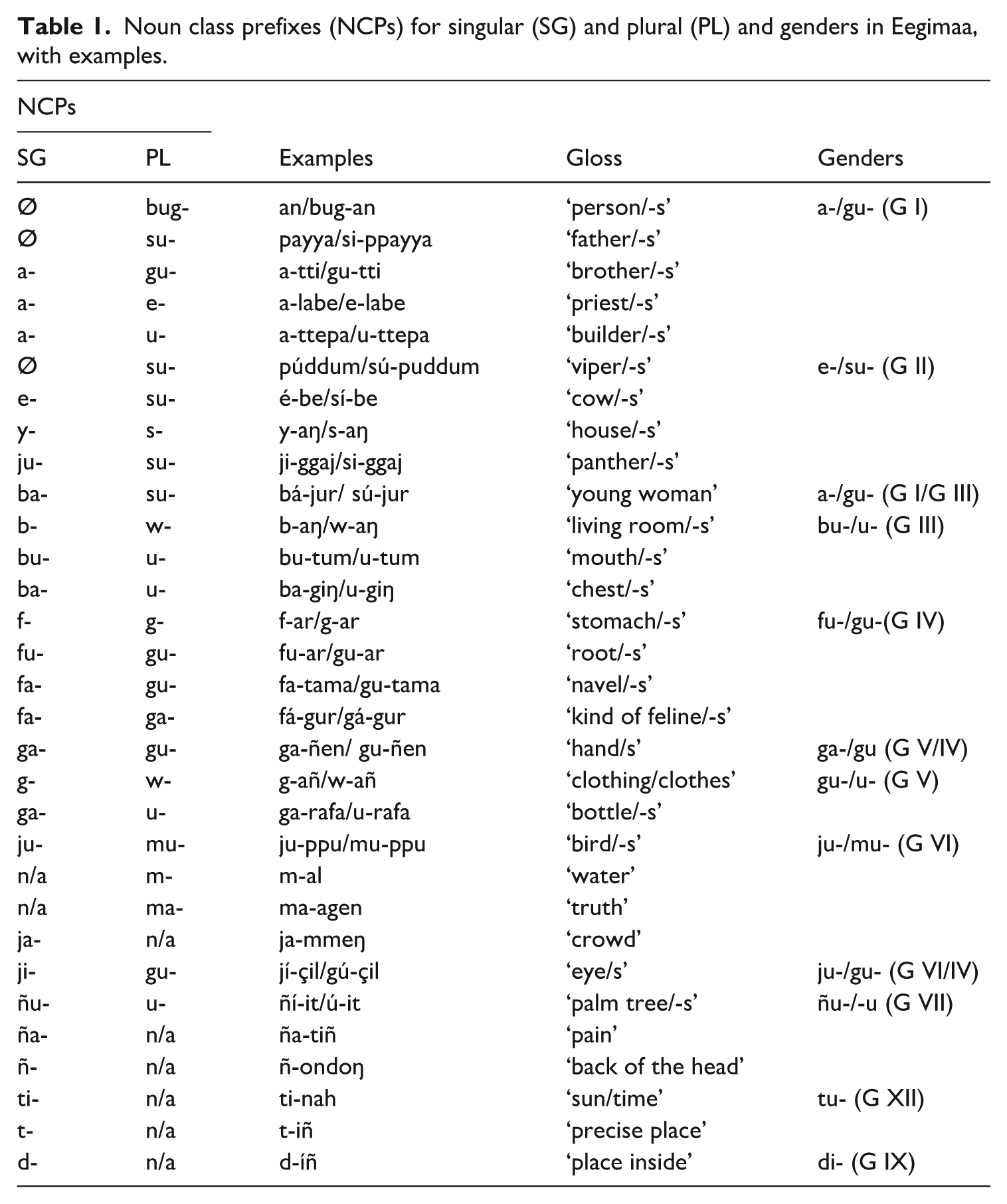
The basic structure of a noun in Eegimaa and other Jóola languages consists of an NCP, a stem and an optional suffix. Examples (1a–b) illustrate the singular NCP a-, which combines with the stem -ññol ‘child/offspring’ and the possessive suffix -om ‘1SG.POSS’ in (1a). Example (1b) shows another instance of the use of the singular prefix a-, which combines with the stem -labe ‘priest’. NCPs indicate the grammatical number of the nouns to which they attach. The examples in (1) also show that plurality is expressed by prefixation, and that nouns that have the same singular prefix need not have the same corresponding plural prefix. Example (2) illustrates another frequent singular prefix, ga-, with its corresponding plural marker u- on two different nouns.
b. b.
Eegimaa NCPs have the following shapes: V- (e.g. C- (e.g. CV (e.g. CVC- (e.g.
Some nouns, like an ‘person’ do not take a prefix in the singular; they are said to have a zero prefix. Zero prefixes are, however, not what is normally expected. The shape of the prefix, in particular whether a consonant appears in the target language prefix, is important for our understanding of phonological processes in early acquisition of NCPs, as discussed in section ‘NCP usage by age group’.
Count nouns in Eegimaa form singular-plural nominal pairs (e.g. a-/gu- in example (1a)). We consider these pairs to be part of a system of noun paradigms (nominal morphological classes, or NMCs). In acquiring the noun morphology system, the task for the child is to learn the alternation between associated prefixes. In the target language, non-count nouns can combine with either singular or plural prefixes. For example, ga-jjo ‘mead’ takes the singular prefix ga- while mí-i ‘milk’ takes the plural prefix mi-.
Agreement Morphology
Eegimaa nouns in the NMCs discussed above control agreement-taking elements such as definite articles, demonstratives, adjectives and verbs. In traditional approaches to analysing noun class systems in Niger-Congo languages, the singular and plural forms of the same noun are assigned to different classes. This is exemplified in the first line of glossing in (3) to (6).
(trad.) ‘The plank is broken.’ ‘The branch is broken.’ ‘The planks are broken.’ ‘The branches are broken.’
In contrast to the traditional system, our classification treats combinations of singular and plural agreement patterns as genders. While the gender category in our analysis remains the same in (3) to (6) irrespective of number, the prefixal number contrast itself is represented directly (
Research Questions
Questions that arise for a language having a nominal morphological system like Eegimaa include the following. Are prefixes and stems initially learned together as unanalysed units? If so, when do children begin to show signs of awareness that these are separable units? One may also ask whether children learn nominal stems separately first, omitting prefixes before showing an awareness of nominal prefixes and their functions. These questions have been investigated in Bantu languages like Siswati (Kunene, 1979) and Sesotho (Demuth, 2003; Demuth & Weschler, 2012), which provide good material for comparison with Eegimaa.
The analysis we present in this paper investigates children’s production of NCPs, excluding the agreeing elements. The overarching question guiding this study is: How do children learn the nominal class morphology of Eegimaa? The specific research questions addressed are the following:
The following section describes the collection and coding of the corpus data used in the analysis. This is followed by analyses of the group data in ‘Results: Group analysis’ and individual children’s longitudinal data in ‘Individual trajectories’.
Method
The data used in this paper come from a naturalistic corpus of spontaneous child language collected in 4 of the 10 Eegimaa-speaking villages between 2017 and 2021. In total, 16 children aged 1;10 to 4;0 were recorded in the project. Six of those children were recorded according to a dense longitudinal scheme, with recordings planned every 15 days from age 1;10 to 4;0. 2 Ten other children were recorded at two time points, once at age 3;0 and once at 4;0.
Children were recorded mostly at home, but also around the school nursery, which they join around 3 years of age. At home, children were recorded playing outdoors with multiple playmates and interacting with various adults, including their primary caregivers, older relatives and other adult members of the community. This is a standard socialisation environment for children in rural areas in Senegal and Africa, but such a learning environment is atypical of first language research, which is mostly carried out in industrialised countries where children interact with a limited number of people at home (Lieven & Stoll, 2013). During the recording sessions, children were recorded from up to 50 m away using a camera and wireless microphone with little or no interference from the recording team.
Naturalistic data from spontaneous interactions have the advantage of revealing general developmental trends; they are ideal for investigating productivity and uncovering individual variation (Demuth, 1996; Pye, 2019). However, processing such data is labour-intensive, especially due to the lack of linguistically trained transcribers, and the unavailability of software for analysis of low-resource languages like Eegimaa. This poses particular challenges for obtaining sufficient annotated data for quantitative analysis. What’s more, the forms targeted for analysis may not be frequent, making it difficult to carry out statistical analyses with predictive power
In this study, we analyse 9 hr and 31 min of production data from the recordings of nine children aged 1;10 to 3;2. First, we analyse data from several children grouped in three age groups: 2;0, 2;6 and 3;0 (Section ‘Results: Group analysis’). Next, in our analysis of individual trajectories, we examine two children’s productions of nouns and their prefixes across several age points: transcribed recordings at 1;11, 2;0.6, 2;4 and 2;6 for Sanum, and 2;0, 2;6 and 3;0 for Jandy. Table 2 presents an overview of the recordings included in the analysis, with the age group, the children’s pseudonyms and code, age at recording and the number of noun tokens they produced. The age groups are distinguished by shading, and Sanum and Jandy, whose longitudinal data we analyse in section ‘Individual trajectories’, are highlighted to distinguish them. Altogether, the dataset includes a total of 967 nouns produced by the children.
Summary of the data used in this study, including each recording of all nine children.
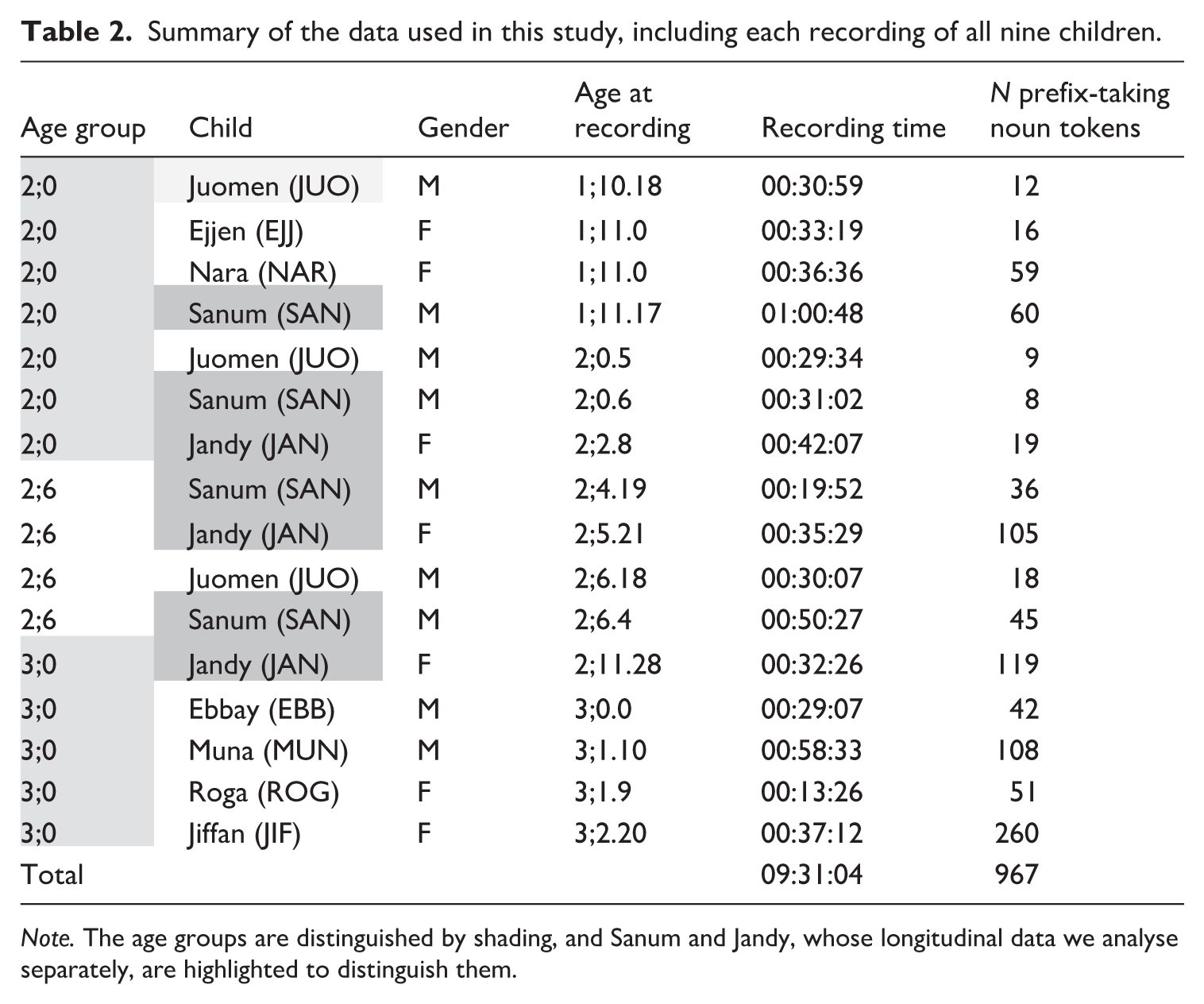
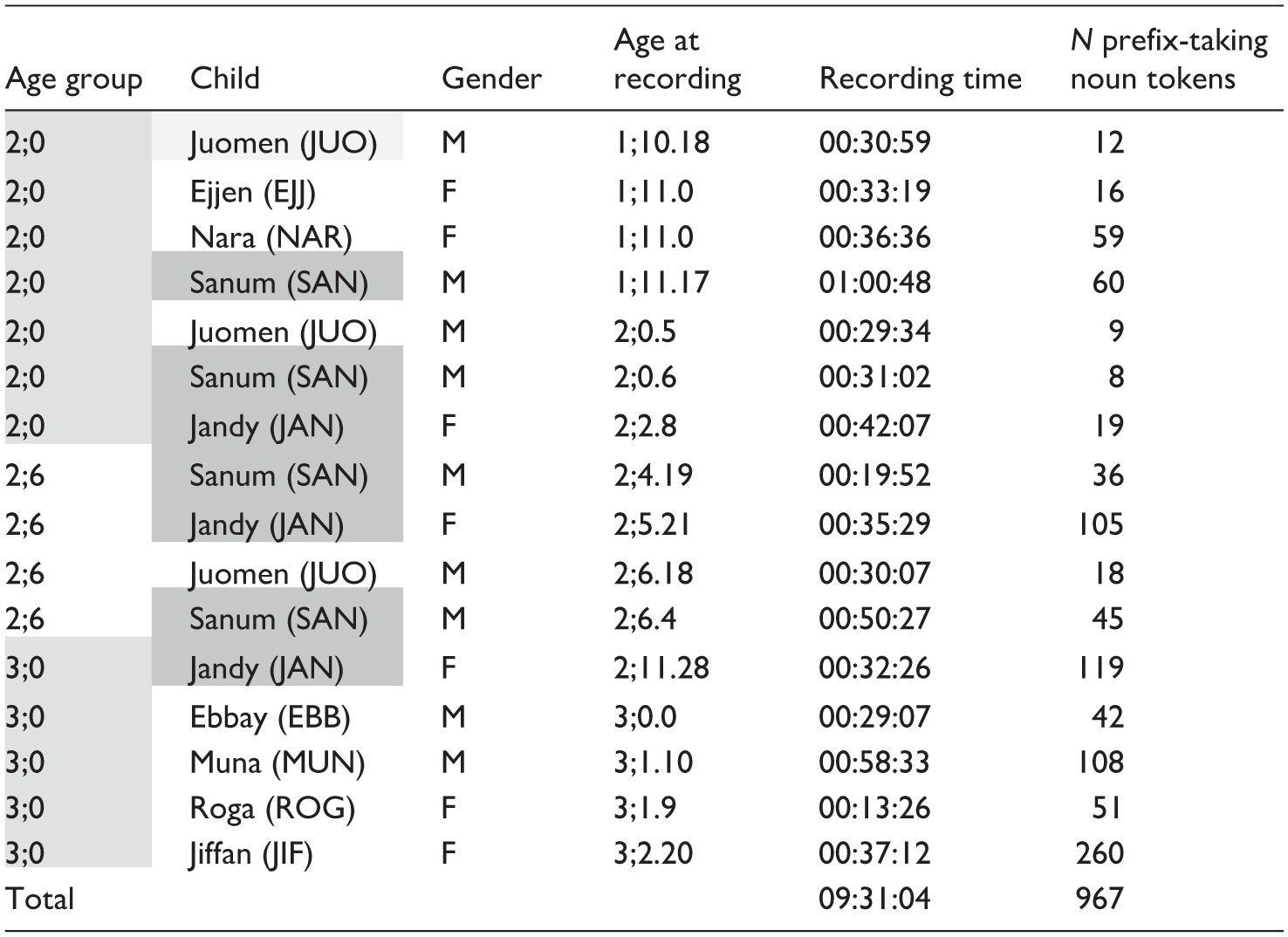
Note. The age groups are distinguished by shading, and Sanum and Jandy, whose longitudinal data we analyse separately, are highlighted to distinguish them.
Children’s recordings were transcribed using the ELAN linguistic annotation software developed by the Max Planck Institute for Psycholinguistics. We extracted all the nominals that trigger agreement and all agreement-taking elements (not analysed in this paper) for coding in Excel. Nominals, which include nouns, proper names and pronouns that can control agreement, were coded for the stem, part of speech, use of prefixes by adults and children, accuracy, grammatical number and type of error in the case of non-target-like uses. In our analysis for this paper, we exclude proper names and other nominals that do not combine with NCPs.
The categories we use to characterise the children’s use of nominal marking are presented in Table 3.
Codes for categorising children’s use of nominal marking.
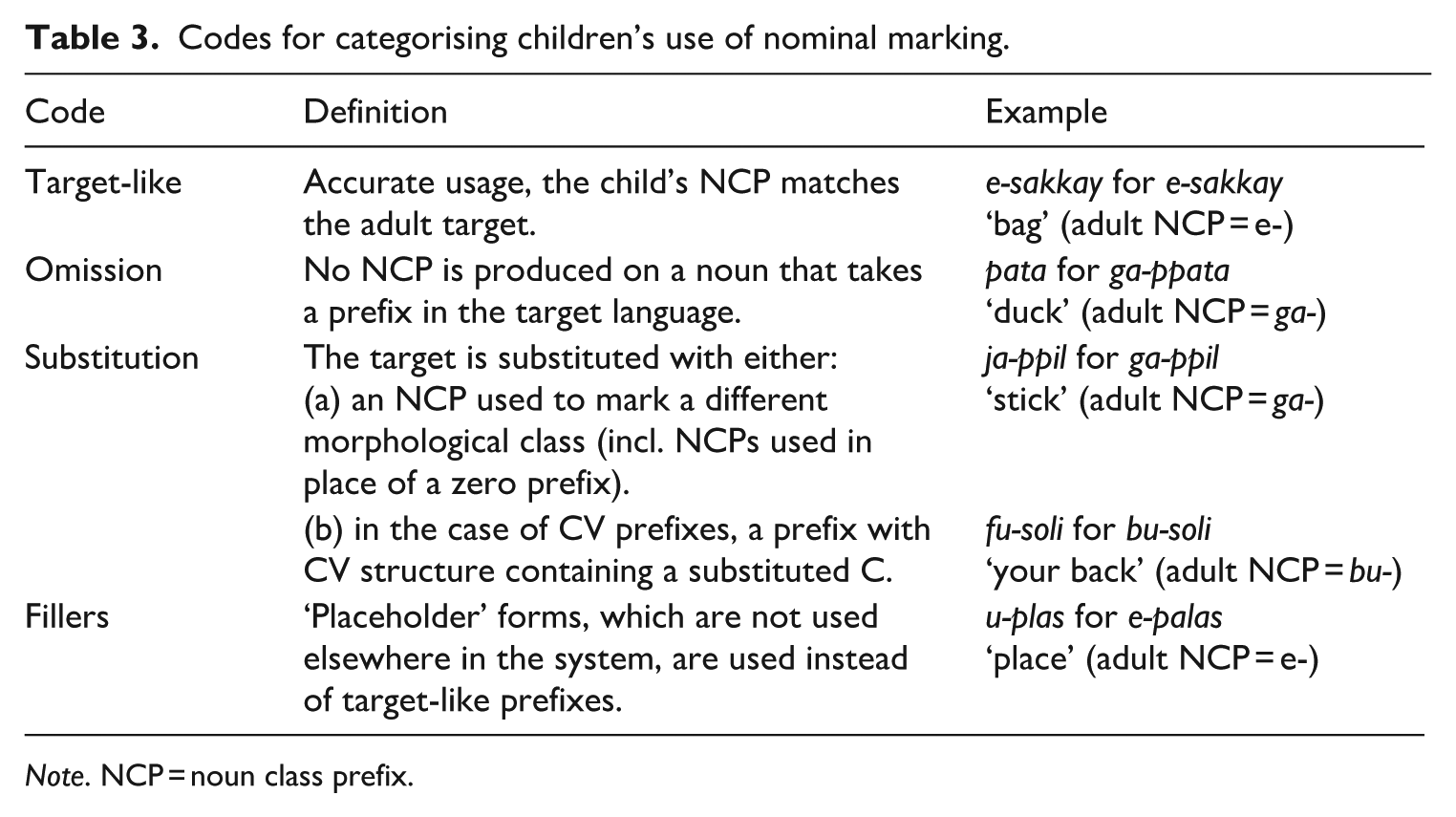
Note. NCP = noun class prefix.
Defining criteria for coding fillers is important for comparing our data with previous findings. However, the criteria for the filler category are unclear in the literature. Peters (2001) describes phonological (‘premorphological’) fillers as devoid of meaning, with their phonological shape being determined by phonology rather than morphology. She proposes as a criterion for recognition that they ‘are not readily mappable onto target adult morphemes, have no systematic morphosyntactic function (however idiosyncratic)’ (Peters, 2001, p. 234). She also notes that ‘the ultimate decision about the status of a given child’s early fillers must be made post hoc: if they just disappear, they were purely phonological; if they evolve continuously into identifiable morphemes they were (or became) protomorphemic’ (Peters, 2001, p. 234). For Peters (2001), protomorphological fillers ‘show some of the distributional and phonological attributes of adult functors’ (p. 234). Demuth defines fillers as being phonologically reduced placeholders, which are sometimes (arguably) categorised as overgeneralisation errors (see Demuth & Weschler, 2012, p. 73). Demuth’s categorisation seems to rest partly on the use of possessive and demonstrative agreement being used several months before nouns being ‘consistently marked with fully formed prefixes’ (see Demuth & Weschler, 2012, p. 73). We will return to the question of defining fillers in the Discussion.
The most frequently occurring form in the filler category is u (e.g. u-çulol pro su-hulol ‘chickens’), which occurs as a plural NCP in the target system. We nevertheless categorise this as a filler, because the children using it are not producing any plurals at the age at which they begin to use the u. Moreover, since the u occurs in the system only as a plural NCP, it is unlikely to be an instance of overgeneralisation for singular nouns, as a less frequent morpheme and a less frequent category. This filler category is taken up again in the discussion.
Results: Group Analysis
In this section, we discuss the group data across the three ages and note the general trends in NCP usage across all nine children. We describe the children’s use of NCPs and the types of errors they make. The emergence of productivity is traced by examining contrastive use of NCPs for plural formation and evaluative morphology and NCP alternations with the dummy stem -nde ‘thingy’. We also describe two types of overgeneralisation found in the data.
The pooled group data, summarised in Table 4, show considerable development in the age range we have included in the analysis, from age 2;0 (including children ranging from 1;10 to 2;2), 2;6 (2;4 to 2;6) and 3;0 (2;11 to 3;2). The total tokens of noun production are not equivalent across the age groups, both because of the differing amounts of transcribed data available, as well as the children becoming more voluble with increased proficiency. In the youngest group, non-target-like production makes up over a quarter (27% across all three non-target-like categories) of the spontaneous production of nouns, with substitutions accounting for 13%, NCP omission for 9% and fillers comprising 5% of the tokens. At 2;6, non-target-like use is reduced by more than half (totalling 11.5% of all noun tokens), and at 3;0, it is again reduced by half, to 6%. At 2;6, omission and substitution make up similar proportions of the data, and at 3;0, omissions have become rare. Fillers are only used with any notable frequency at age 2;0. The following sections examine the non-target-like usage more closely.
NCP usage by all nine children.
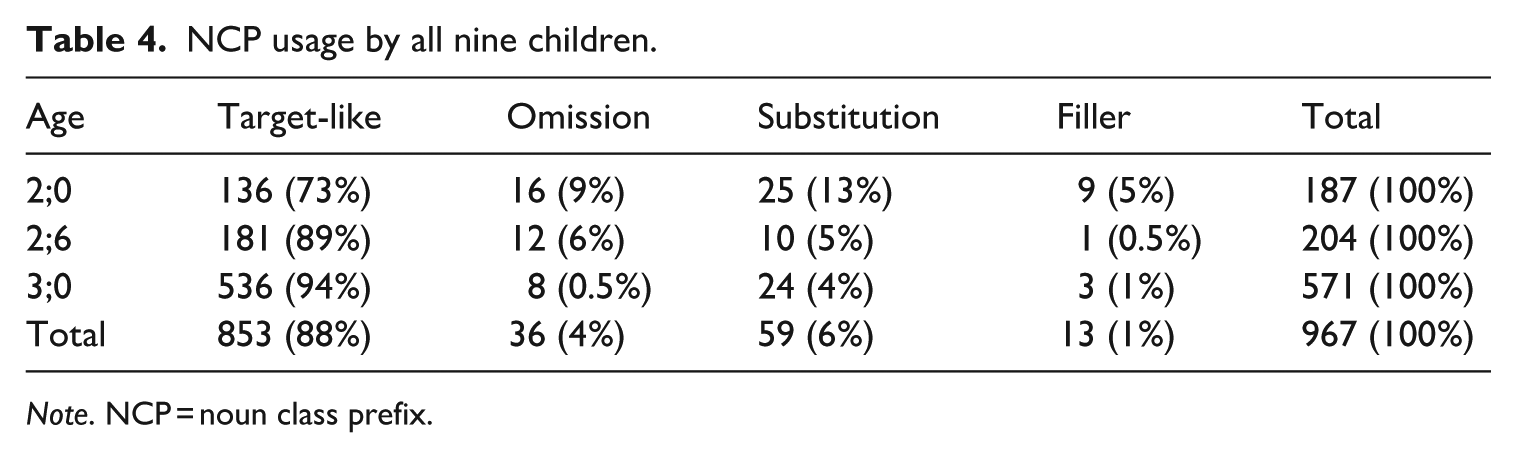
Note. NCP = noun class prefix.
NCP Usage by Age Group
The most frequent NCP used by the 2-year-olds is the prefix e-, produced in a target-like fashion in 55 out of 78 tokens (71%). This includes 23 unique nouns (types) produced accurately with e-, such as e-humba ‘pig’ and French loan words like e-classe ‘class’ and e-sakkay ‘the backpack’. This is the singular prefix of the morphological class with the largest number of nouns also in the adult language (Sagna, 2022, p. 81). Moreover, it is not associated with any specific semantic properties in the adult language and so is considered a default prefix. This is followed in frequency of use by prefixless nouns. Although the children omit target prefixes in 5% of the tokens (N = 16), the zero prefix is used accurately 29 times, with 13 unique nouns, at age 2;0. Following these in frequency at age 2;0 are ga- and fu-, with similar frequencies but very different profiles. Nouns taking the NCP ga- are used 25 times by the children, but only 6 of these have the target prefix (6 target-like uses with 6 different nouns), whereas fu- is used 22 times, but all with the same noun, fu-how ‘head’.
The NCPs ga- and fu- are the second and third largest morphological classes in Eegimaa. Semantically, ga- is associated with flat shapes, and fu- is associated with round shapes (Sagna, 2012, 2022). All the tokens of production of ga- and fu- by the 2-year-olds are accurate, and so we cannot say whether these reflect an understanding of the semantics of these nominal morphological classes or learning of the noun with the prefix as a whole chunk. However, the data also include 20 tokens (7 types) of nouns taking ga- used with substitutions, that is, used with other prefixes.
Most of the substitutions for ga- at age 2;0 can be accounted for by the phonological process of consonant harmony, typical for this age. Importantly, ga- is the most frequent consonant-initial NCP, following only e- and zero in frequency. Fourteen of the 20 substitutions involve consonant harmony, and all of the examples of substitution have the target vowel and either an adapted or omitted consonant. Examples of harmonic patterns, using either a consonant identical to a consonant in the noun stem (as shown in 7) or harmony in place of articulation, as in 8 (showing bilabial harmony), and 9, (alveolar/palatal harmony).
Child production Target form (7) da-dala-á (SAN 1;11.17) ga-ddalla-om NCP-sandal-1.SG NCP-sandal-1SG.POSS ‘my sandal’ (8) ba-ppi-am (NAR 1;11.0) ga-ppil-om NCP-stick-1.SG.POSS NCP-stick-1.SG.POSS ‘my stick’ (9) da-ñen (EJJ 1;11.0) ga-ñen NCP-hand NCP-hand ‘hand’
Example (10) shows two different attempts by one child at producing the same noun, both from the same recording. In (10a), the child adapts both the stem and the prefix, seeming unsure of the target or lacking articulatory control to produce it, but in (10b), he resolves this via consonant harmony, again adapting both the stem and the prefix to harmonise with the -d- in the second syllable of the stem.
Child production Target form (10) a. ka-didnay (JUO, 2;0.5) gá-jindol NCP-gecko NCP-gecko ‘gecko’ b. da-dindinay (JUO, 2;0.5) gá-jindol NCP-gecko NCP-gecko ‘gecko’
Moreover, we can also account for NCP omission patterns by phonological processes. Omission occurs most frequently on trisyllabic nouns at this age: Out of 16 instances of omission, 13 involve trisyllabic targets. The remaining omissions are all disyllabic nouns.
It is interesting to ask how phonological development feeds into or overlaps with the children’s emerging knowledge of semantics in the NCP system. We return to this question in the Discussion section. In relation to this we can ask whether we can associate the purely phonological basis of these substitutions with the lack of the semantic underpinnings required for a productive NCP system. The data for 2;0 barely shows any plural formation, with only one noun, si-ddadda [: si-ddalla] ‘sandals/shoes’, produced by Nara, with a target-like plural prefix. All the other attempts at plurals result in errors, including the use of both fillers and NCP omission. Other NCP substitutions at this age include u-hulol [: su-hulol ‘chickens’], which shows the use of an existing NCP of the V shape for one having a CV shape. Importantly, all the examples of substitution at this age seem to be phonological or articulatory in nature.
At 2;6, 89% of noun tokens are used with target-like NCPs. We see, again, the predominant use of the default prefix e-, with 45 target-like uses out of 54 tokens (83%), a slight increase from age 2;0. This is followed by prefixless nouns, used accurately in 45 instances, and representing the omission of target prefixes in 12 instances (where the prefixes e-, ga-, fu- and y- are omitted). The NCP ga- is used accurately in 22 instances, as well as 3 examples of omission and 2 substitutions. The substantial reduction in substitutions for ga- when compared with the 2;0 age group (from 20/26 to 2/27) is worthy of note; both examples at 2;6 can also be accounted for by harmony (kápolo pro gapolol and papata pro ga-ppata), just as the examples described above at age 2;0. The singular prefix a-, used for nouns with human denotation, was used in a target-like fashion in all 13 occurrences. The high accuracy with a- may well be attributed to the limited set of human nouns used (four types in the child production, an increase from two used at 2;0), all highly salient for this age group.
Five different plural NCPs are produced on 13 occasions at this age. Contrastive use of NCPs is observed with four different stems, including tangal ‘sweet/candy’, accurately used with both a zero prefix and the plural si- in si-tangal ‘varieties of sweets’ and the pro-form -nde ‘thingy’, which combines with four singular NCPs—e-, a-, ga- (flat shape and augmentative) and ji- (diminutive)—and the plural prefix si-. At age 2;6, NCP omissions make up 6% of uses (as shown in Table 5, while substitutions comprise 5%. Fillers make up a negligible proportion of NCP usage (with only one example, <1%).
Combination of the dummy stem -nde with the NCPs from gender I to VII.
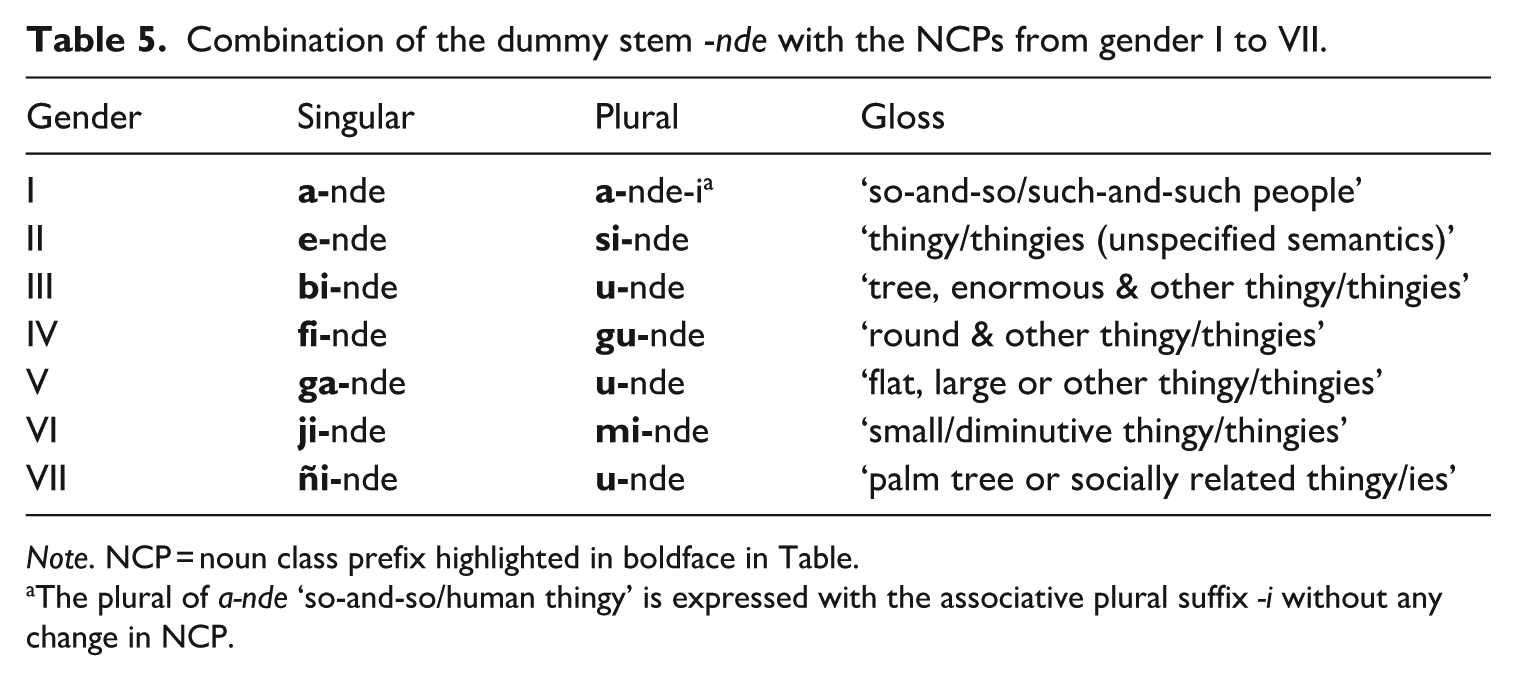
Note. NCP = noun class prefix highlighted in boldface in Table.
The plural of a-nde ‘so-and-so/human thingy’ is expressed with the associative plural suffix -i without any change in NCP.
At age 3;0, 94% of nouns are produced with accurate NCPs. Omissions only account for 1% at this point, with eight instances, and only three uses were coded as fillers. The most frequently used NCP continues to be e- with 192 target-like uses out of 205, and 72 noun types. As with the other age groups, prefixless nouns are next in frequency, with 100 tokens altogether, 10 of which (10%) are non-target-like. However, eight of these are produced by one child with one noun (e-ddãs ‘dance party’).
Beyond the general increase in accuracy, the change in usage with the NCP ga- is particularly informative. While this prefix has clear semantics associated with it in the target language, we only observe this affecting its usage by children at 3;0. The 3-year-olds accurately produce 52 instances of ga-: all attempts at nouns taking ga- are accurately produced. In addition, the children use ga- seven times with three noun lexemes which do not take ga- in the target language. Although the prefix can be used productively with augmentative semantics, this involves some degree of lexical restriction in the adult language (Sagna, 2012). In the children’s data, it is used in place of e- with e-jeŋ ‘thorn’, e-hulol fíttit ‘sea gull’ and e-bbodi ‘tight shirt/vest’, shown in (11–13).
(11) ga-jeŋ [: e-jeŋ] (MUN 3;1.10) NCP-thorn ‘(nasty, big) thorn’ (12) páijo [: pan i-joh] gahulokum [: e-hulol hum] fúttit [: fí-ttit] (JIFF 3;2.20) FUT.1SG-catch NCP-chicken.PART NCP-river ‘I will definite catch a seagull (lit. river chicken)’ (13) ga-bbodi [: e-bbodi] g-aa [: y-aa] (JIFF 3;2.20) NCP-vest(II.SG) II.SG-DEF ‘The vest/tight t-shirt’
Given the high frequency of the target prefix e- and its generally accurate usage by 3-year-olds, the production of ga-jeŋ by Muna (used four times in the same recording) would suggest semantically-based usage of the prefix, extending it beyond what would be expected for the adult lexicon in applying augmentative semantics. On the other hand, ga-hulol fíttit ‘seagull’ and ga-bbodi ‘tight shirt/vest’ in examples (12) and (13) are non-target-like uses which are interpretable as augmentative. Neither of these uses can be explained via phonological processes, but it is unclear whether semantic overextension underlies these uses or not. They both represent overuse of the prefix ga-, and both would be interpreted by a listener as augmentative. However, we cannot be sure whether Jiffan intended this use as augmentative (albeit non-target-like), based on context. Overextending this prefix, whether it is semantically based or not, indicates an emergent understanding of the productive way prefixes are used in the system more generally
The NCP a-, which combines with nouns of human denotation, is used accurately in all 41 of its occurrences. Plurals are used much more frequently and accurately than in the younger age groups. The plural NCP si- is used accurately in 24 out of 26 attempts, and the plural NCP u- is used accurately in 20 out of 20 attempts as a plural marker, in addition to its use as a substitute for si- and two uses of u- as a filler. Contrastive use, with NCP alternations on a single stem, is more frequent at 3;0. These uses include singular-plural contrasts, as in fu-mangu/gu-mangu ‘mango/es’, singular-plural-diminutive alternations, as in e-ssakk ‘backpack’, si-ssakk ‘backpacks’, ji-ssakk ‘small backpack’, and singular-plural- augmentative formations, as with e-pattaloŋ ‘pair of trousers’, si-pattaloŋ ‘pairs of trousers’, ga-pattaloŋ ‘pair of big/bad trousers’. Alternations of this type are also found with the pro-form -nde ‘thingy’: e-nde ‘thingy’, si-nde ‘thingies’, ga-nde ‘big/flat thingy’, discussed in the next section.
The Generic noun -nde
The generic noun -nde ‘thingy’ combines with all NCPs in the target language, depending on the referential semantics, as shown in Table 5, 3 which gives NCP pairs from Genders I to VII. In the adult language, its use is based on morphological and semantic knowledge and points to the productivity in the system. The children’s target-like use suggests an awareness of morphological class pairs, singular-plural number distinctions and semantic gender/class categorisation.
At age 2;0, -nde ‘thingy’ is used 13 times by 2 children. Nine of these uses are target-like, with two NCPs (e- and ga-); the other four uses include three substitutions and one omission. All these nouns are produced in singular form. The predominantly target-like uses of NCPs with the stem -nde may be taken to suggest a good command of prefix usage. However, the evidence for this is limited, and it may also be argued that children learn NCPs together with stems as a unit.
Of the 13 instances of -nde ‘thingy’ use at 2;6, 12, including one plural use, are accurate. Only one NCP omission appears as a non-target-like use. The use of five different NCPs, including the expression of diminutive meaning and the target-like use of plural, suggests emerging awareness of the semantic properties of the Eegimaa noun class system and knowledge of the productive functions of NCPs.
At age 3;0, the five different NCPs used with the -nde are all target-like in all 21 instances of use. These NCPs include two plurals, of which one is the diminutive plural NCP mu-. The target-like uses of various NCPs on the same stem indicate knowledge of the Eegimaa noun class system and emerging productivity.
Evidence of Overgeneralisation
We observe two types of overgeneralisations in the use of NCPs in children’s production data. The first one, mentioned above for the 3;0 age group, can be described as semantic overgeneralisation. We observe this with the non-target-like use of the NCP ga- in its augmentative function in contexts where evaluative morphology does not seem to be the intended target for the child, and where adults would use different NCPs. For example, ga-pattaloŋ ‘pair of big/bad trousers’ is used where e-pattaloŋ ‘trousers’ is expected; the child is talking about a pair of trousers she will be wearing to go to a dance party, rather than describing a large or damaged pair of trousers.
The second type of overgeneralisation is characterised by children adding NCPs to prefixless nouns. This has not been reported in previous research on African noun class systems. In fact, Demuth and Weschler (2012, p. 73) claim that there are no cases of ‘noun class prefixes being incorrectly added to nouns that have no prefix’ in Bantu languages.
However, NCPs are used with prefixless nouns in the Eegimaa corpus at ages 2;0 and 3;0 by three children. All of these instances are loanwords and involve the use of e-, the default NCP for nouns belonging to other classes. These are: one token each of *e-lekkol for lekkol ‘school’, *e-musik for musik ‘music’, *e-tangal for tangal ‘candy’ and eight instances of e-ddãs for ddãs ‘dance party/dancing’. The first two nouns never occur with NCPs in the adult language, so the addition of NCPs by children may be analysed as cases of morphological overgeneralisation. The noun tangal ‘candy’, on the other hand, does not occur with the NCP e-. It can occur without a prefix or with the singular and plural diminutive NCPs as in ji-tangal ‘small piece of sweets’ and mu-tangal ‘small pieces of sweets’. Hence, this non-target-like use of e- in *e-tangal may be seen as either the superfluous addition of an NCP in the context of a prefixless noun, or it can be analysed as an NCP substitution for singular NCPs ji-. Under either analysis, a process of analogical extension seems to underlie the child’s use of e-. The noun stem daans can occur in adult language either with an NCP, as in e-ddãs ‘dance party’, or without one, as in daans ‘dancing’. In most of its uses, the child erroneously adds the NCP to the stem in contexts where it denotes ‘dancing’ as an activity rather than a specific dance party. This may be analysed as both morphological and semantic overgeneralisation, where the child fails to distinguish the semantic difference reflected in the morphology.
In summary, in addition to morphological errors such as NCP omissions, we also find instances of semantic overgeneralisation and the superfluous addition of NCPs in contexts where adult speakers would use a prefixless noun. We analyse the use of e- with prefixless nouns as morphological overgeneralisation rather than semantic overextension because this NCP doesn’t carry any specific semantics. Since neither of the above overgeneralisations has been reported in previous research on African noun class systems, their occurrence in our data is an important finding both for describing the trajectory of acquisition of Eegimaa as well as for cross-linguistic comparison/ validity.
Individual Trajectories
In this section, we analyse the learning trajectories of two children with longitudinal data. We examine the accuracy of their NCP uses, the types of errors they make and the combinations of the stems they produce with these NCPs.
Sanum
This section presents NCP and noun usage in four recordings from a boy with the pseudonym Sanum, at ages 1;11.7, 2;0.6, 2;4.19 and 2;6.4. Because two of the recordings are within 1 month of each other, and only one of these (the younger one) has a significant number of NCP uses (57 at 1;11,7 and 8 at 2;0.6), we include both of these as a datapoint for age 2 years.
Sanum at Age 2
In the 2 recordings at age 2, Sanum produces 68 nouns (excluding proper names), including 2 nonfinite (nominalised) verbs (Sagna, 2022). He uses 10 different NCPs, including the ‘zero prefix’. Sanum uses 21 different types of nouns around age 2;0, but each noun stem combines with one prefix only (no NCP alternations observed on any stem), and all the NCPs are singular markers. The only targeted plural noun is su-hulol ‘chickens’, not produced accurately in any of four attempts. Some of these stems are used with fillers (see below), or the prefix realisation is unclear.
Sanum produces 33 target-like NCP tokens (49% of noun uses), showing less accuracy than the group mean at this age (73%). The non-target-like uses attested in his data include prefix omission (15%), substitutions (18%), use of fillers (10%) and one instance of uncertain/unclear use. He also produces words that may be classed as baby-talk (7%), and which do not take NCPs. These are addressed separately, since they do not take NCPs. Most of Sanum’s target-like productions are monosyllabic (10 nouns) and disyllabic (20) nouns, with only 3 longer nouns.
The 10 NCP omissions in Sanum’s production at 2;0 are all trisyllabic nouns, as mentioned above in the group analysis. Sanum’s omission of NCPs with lengthier targets forms the bulk of the omissions at age 2;0 (total 16). Sanum’s substitutions can be accounted for by limited articulatory-motor skills rather than morphology, as exemplified in (7) to (9) above with NCP ga- in ga-ddalla ‘sandal/shoe’ produced as da- in da-ddala [: ga-ddalla] 4 ‘sandal/shoe’; it also surfaces as pa- as in pa-piç [: ga-ppil] ‘stick’. *pa- and *da- are not nominal class prefixes in Eegimaa. These are clear cases of consonant harmony, related to either ease of production or representational simplification. Fillers make up 10% of NCP uses (seven tokens, four types) in Sanum’s age 2;0 data, and they are produced along with phonological errors, as in o-koba [: e-humba], u-çulol/u-hulol/u-çuhulol [: su-hulol] ‘chickens’.
The NCPs produced by Sanum in the 2-year-old recordings are almost all singular. For the noun su-hulol ‘chickens’, with a plural target NCP, Sanum uses fillers in three out of four uses (u-çulol/u-hulol/u-çuhulol [: su-hulol] ‘chickens’), and omits the prefix in one instance
In summary, at age 2;0, Sanum produces nouns with target-like, singular prefixes in half of his attempts, alongside NCP omissions and substitutions. There is no clear evidence of the productive use of noun class morphology at this stage, as there are no NCP alternations to express plurality, evaluative morphology, or to indicate knowledge of the regularities in the system.
Sanum at Age 2;4
Sanum produces 36 NCP-taking nouns at 2;4. The NCPs on these nouns were used in a target-like fashion in 26 instances (72%), showing development from age 2;0, albeit still lower accuracy than the group mean. Many of these nouns are produced with phonological errors not affecting the prefix, such as word-final consonant deletion in *u-ppi for u-ppil ‘still’ and *ga-se, for ga-ser ‘spoon’. Sanum produces 17 different noun stem types at 2;4. The most frequently used are -ser ‘spoon’ (with six tokens), -nnaŋ ‘cooked rice’ used five times, -pata ‘duck’ used four times and -ssakk ‘backpack’ used three times. Five stems (gab ‘dish up’, kanja ‘okra’, ol ‘fish’, -jammen ‘goat’ and pil ‘stick’) are used twice each, and the remaining eight stems are only used once. Crucially, none of these stems is used with alternating prefixes.
Non-target-like uses at this age include five (14%) NCPs omissions: three of these were with the noun ga-ppata ‘duck’, produced as pata, fata and patata, and twice with fu-kanja ‘okra’, produced as kanja and kanda. NCP substitutions, which include initial consonant substitution as in çi-nnaŋ for si-nnaŋ ‘rice’, account for 11% of errors (4/36). Only one use of a filler prefix was attested: u- used in place of e- in the loanword u-palas [: epalas] ‘place’.
In a notable advance from the earlier age point, Sanum uses two plural NCPs (u- and si-) at 2;4. The former is used twice with u-ppi [: u-ppil] ‘sticks’, and the latter is used with two different noun stems: twice with si-jjame [: si-jjamen] ‘goats’, and once with si-ddala ‘sandals/shoes’. No instances of NCP alternations are found with noun stems at 2;4. In addition, the NCP s-, an allomorph of the plural marker si-, is also used erroneously, once with a singularia tantum noun in s-ambun ‘fire’, and five times as a distributive plural marker in si-nnaŋ/çi-nnaŋ/si-nna [: si-nnaŋ] ‘cooked rice’. Again, no singular-plural alternations are observed on stems at 2;4, but the use of plural markers on different nouns, some of which were attempted with singular prefixes around 2;0, suggests that Sanum is beginning to acquire number distinctions.
Sanum at Age 2;6
At 2;6, Sanum produces 45 nouns. Of these, 36 (80%) are used in a target-like fashion. Here again, nouns are produced with some phonological errors, including deletion of segments in the stem as in e-potau [: e-pportabul] ‘mobile phone’, deletion and lengthening as in gaafa [: ga-raf] ‘breastfeeding’. There are also instances of target-like NCP production with neologisms, as in ji-kkaba [: jí-ppupe] ‘doll’. Out of 45 nouns, Sanum produces 31 singular nouns and attempts only one plural (ammay [: u-moy] ‘eyebrows’). The remaining 13 nouns are non-count nouns such as bomboŋ ‘sweets’, used nine times and ba-raj ‘rice porridge’, used twice. The data at 2;6 show no evidence of further advance in the use of number distinctions.
The most frequent error is NCP omission, occurring with seven nouns (16%). These nouns include bomboŋ ‘sweets’, used four times and produced as mboŋ and bomboŋ, as well as awoŋ/avoŋ [: avion] ‘plane’, produced twice, and aan [: y-aŋ] ‘house. Sanum produces one noun with a filler (ammay [: u-moy] ‘eyebrow’), by replacing its prefix with another one existing in the language. Finally, Sanum uses the prefixless baby-talk form ñámñam ‘food’. This is not used in adult speech, but it is attested in child-directed speech.
In this recording, Sanum produces NCP alternations on the generic stem, the pro-form -nde ‘thingy’ for the first time (see section ‘The generic noun -nde’), with three different NCPs, demonstrating constrastive usage. These uses, a-nde ‘so-and-so’ (about a person), ji-nde ‘small thingy’, e-nde ‘thingy’, are produced accurately, indicating productive use of contrasting NCPs at 2;6. The stem -nde is the only one, out of the 20 that Sanum produces at 2;6, that is used with different NCPs. The most frequent of all the stems in Sanum’s data at this age are bomboŋ ‘sweets’ (nine tokens), -pportabul ‘mobile telephone’ (four tokens, with phonological errors discussed above), -nde ‘thingy’ (4) and -raf ‘breastfeed’ (4).
Overall, Sanum’s data show considerable development, from half of the targets produced accurately at 2;0 to 80% target-like use at 2;6, along with the first contrastive usage. NCP omission, substitutions and fillers decrease with age, but at no point do they exceed one-fifth of uses. Sanum also shows some initial attempts at plural marking at 2;4, but he barely produces any plurals at 2;6. Signs of productive use emerge with contrastive use of three different NCPs on the pro-form -nde ‘thingy’.
Jandy
Jandy at Age 2;2.8
In this section, we examine the individual trajectory of a female child we call Jandy at ages 2;2, 2;6 and 3;0. In the recording at 26 months, Jandy produces 19 nouns, 16 (84%) of which were target-like, including either the target prefix or accurate prefixless usage. As in Sanum’s data, a number of these target-like nouns are produced with phonological errors on the noun stem. This includes consonant substitution as in e-çakk [: e-ssakk] ‘backpack’, the use of gemination to replace consonant clusters from French loans as in tatte [: salite (pronounced [salte])] ‘dirt’ and syllable addition as in gá-mbukulu [: ga-mburu] ‘bread’. Jandy uses only one filler in u:kkutu [: e-jukkutul] ‘your seat’ and produces a single case of NCP omission with the noun bumboŋ [: e-bomboŋ] ‘sweets’. She shows no signs of systematically distinguishing number, as the NCPs she uses include 11 singular prefixes, 6 prefixless non-count nouns like tatte [: salite] ‘dirt’ and 2 instances of the collective noun tange ‘candy’. She uses the noun bomboŋ both with the target prefix, as e-bomboŋ, and without a prefix (bomboŋ), a non-target-like production. At this age, Jandy does not alternate target-like NCPs with any of the 12 stems she produces.
Jandy at Age 2;5.21
Three and a half months later, Jandy produces 101 noun tokens, including nonfinite verbs and the generic noun -nde ‘thingy’. NCP omission is found in only a single token, nde-i [: e-nde-i] ‘your thing’ and only two tokens of NCP substitution as used in fu-sol-i [: bu-sol-i] ‘your back’ and ka-polo [: ga-polol] ‘his/her skin’, where there is NCP-initial consonant substitution (consonant harmony) and final consonant deletion. All the remaining 98 nouns are produced with target-like NCPs, though with phonological errors on some of the stems, as in ju-bbus [: ju-mbus] ‘plastic bag’, where a geminate is produced instead of a prenasal consonant cluster.
Number distinctions are shown in the use of four plural NCPs with four noun types, as shown in example (14). Jandy also produces 24 non-count noun tokens in target-like fashion. Of these three nouns, s-ambun ‘fire’ (used twice), m-al ‘water’, and w-al ‘hair’ are pluralia tantum nouns, 6 are prefixless nouns, for example, singom [: çingom] ‘chewing gum’ and 15 are nonfinite verbs like ji-geç ‘teasing’, which use singular NCPs. The majority of nouns (71/71% in total) are, however, singular.
(14)
Jandy produced 37 noun types in the recording at 2;5, three of which show NCP alternations expressing evaluative morphology with the use of the diminutive prefix, as in (15). Alternations are also found on the pro-form -nde ‘thingy’, shown in example (16) with three different NCPs, including two singular NCPs and one plural, and with the stem tangal ‘sweet’ in (17), which also takes a singular and a plural NCP.
(15) (16) (17)
Overall, Jandy’s data at just under 2;6 shows the use of plural prefixes and NCP alternations to form diminutive, augmentative and plural formation. This suggests that Jandy’s knowledge of the Eegimaa noun class system is becoming increasingly productive and generalisable and shows a clear advance from the earlier recording.
Jandy at Age 3;0
Jandy produces a total of 119 NCP-taking nouns at age 3;0. The vast majority of these NCPs (116) are produced in a target-like fashion, with the stems still produced with various phonological errors. Examples include é-uto [: é-otor] ‘car’ and ga-ççe [: ga-ser] ‘spoon’, which are produced with the target prefix, but with non-target-like pronunciation on the stem. Jandy uses only one filler, /u/, once with the word u-ploverol [: e-ppiloverol] ‘pullover/sweater’ and omits an NCP once with the word ótto [: e-otor] ‘car’.
Number contrasts are used, although the vast majority of nouns (98 tokens) occur with singular NCPs. Jandy also uses pluralia tantum (plural only) nouns (nine tokens), singularia tantum nouns (7) and three plural nouns. The plural nouns are produced with three different NCPs: u-ser ‘spoons’, mu-ol ‘fish’ and gu-solans [: gu-sorans], only the first of which is used in both singular and plural (Example 11).
Jandy uses 51 different nominal stems, the most frequent being -humba ‘pig’ (9 tokens), -ppilover ‘pullover/sweater’ and -ññil ‘child’ (7 tokens each). Some stems are also produced with different NCPs expressing semantic contrast. For example, personification of non-human entities with the prefix ja- is expressed in example (18), while evaluative morphology is shown in example (19) with the use of NCP ga- in its augmentative function. Jandy alternates prefixes in (20) to form a plural and uses two prefixes, which can be used alternatively to form the nonfinite verb eat (21). In adult language, the use of these different prefixes expresses a difference in the individuation versus non-individuation of the object. However, this distinction is difficult to ascertain in Jandy’s data, which only attests this nonfinite verb used without any object. The alternations suggest an awareness of the functions of NCP in the Eegimaa grammatical system.
(18) ‘pig’ ‘pig (personified)’ (19) ‘big/damaged car’ ‘car’ (20) ‘spoon’ ‘spoons’ (21) ‘eat/eating’ ‘eat/eating’
Discussion
In our study of corpus data from nine Eegimaa-speaking children, we investigated the use of nominal class morphology from age 2;0 to 3;0, through the lens of both group-wide and individual analyses. In both approaches, children in this age group show development in the range of production targets, the accuracy of nominal morphology and contrastive usage showing productivity. Across the group, average levels of target-like forms rose from 73% at age two to 94% at age three. At 2;0, non-target-like forms involve both omission and substitution, as well as a non-trivial amount of forms coded as fillers (5%, more on fillers below). By age 3;0, not only are children producing more noun tokens and a more diverse range of noun types, but omissions and fillers cease to be attested in any significant amount in the data. The only error type occurring with noteworthy frequency is substitutions, at 4%.
The same overarching trajectories can be seen in the two individual children’s longitudinal data, Sanum and Jandy. Sanum has a greater proportion of non-target-like forms than the group average at age 2;0, with ample tokens of omissions and substitutions as well as fillers, and a jump to much greater accuracy at 2;4 and 2;6. Jandy has a higher proportion of target-like uses already at 2;2, but neither of the two children begins to use the nominal morphology contrastively in the earliest recordings. Jandy uses a handful of nouns with contrastive (diminutive, augmentative, or plural) prefixes at 2;5. By 3;0, the children overall are producing many more plurals and showing signs of greater productivity.
However, the Eegimaa data resist analysis by way of Demuth’s (2003) and Demuth and Weschler’s (2012) description of Bantu acquisition, in which children are said to follow partially overlapping stages: NCP omission, use of fillers and finally production of the target-like NCPs. While these stages are admitted to be overlapping, they are predicted to come in a clear order in Bantu. In contrast, examples of omitted prefixes are certainly attested in the Eegimaa data, but they are under 10% of nouns produced even at age 2;0, and they are used alongside a much greater proportion of nouns used accurately, from the earliest recordings included in this study. Fillers are also attested and will be discussed below. It is possible that noun tokens produced at younger ages than 2;0 will reveal more examples of omitted or filler prefixes. However, the children at 2 years of age are at quite differing levels of linguistic development, some of them having just begun to combine words, yet none of them indicate a tendency to omit prefixes as a preferred approach to noun production.
More problematic from the point of view of applying Demuth and colleagues’ analysis to the Eegimaa data is the temporal relation between the use of omission and fillers. While nouns with omitted prefixes make up 9% of all the nouns produced by the group at age 2 years, filler prefixes only make up 5% at that age, and never increase to comprise a greater proportion of nouns than those with omitted prefixes, as would seem to be predicted by the overlapping stages of Demuth (2003; Demuth & Weschler, 2012). Instead, fillers decrease to a much lower proportion of noun usage (0.5%) by 2;6. The filler category is further discussed below. Here, suffice it to say that the Eegimaa data does not support the pattern of staged acquisition with omission followed by fillers and target-like NCPs. Even if some of what we have categorised as substitutions were seen as fillers in Demuth’s terms, these still cannot be described as increasing following a period of omission. Instead, they continually decrease throughout the observed period from 13% at age 2;0 to 5% at 2;6 and 4% at 3;0.
We discuss the types of errors children make below, tying them in to both our research questions and their broader implications.
The Role of Phonology and Semantics
In both the pooled group data and the individual trajectories, we found that the bulk of errors made at the age of 2;0 can be explained by phonological processes. The most prevalently used noun forms in the children’s data use either the prefix e- or no prefix, but following these in usage frequency is a prefix of interest with a CV structure. The prefix ga- lexically marks nouns with a flat shape, as well as augmentative or pejorative semantics. Target nouns marked by ga- are produced by the children with prefixes either substituting or omitting the consonant. The attested forms exhibit harmonic patterns, adapting the prefix as well as the stem, as can be expected by children at this age (Vihman, 2019). Phonology and the form of words can also be seen to play a role in the omitted prefixes at 2;0, as omissions occur much more frequently with trisyllabic targets, followed by disyllabic targets.
Some production is attested at 2;6, which indicates consonant harmony, but during the developmental period covered by the longitudinal frame of the dataset, phonology strongly accounts for only the earliest age point. After this, the children show increasing proficiency in both the morphological system and the semantics underlying it.
The change in use of the prefix ga- is notable: the non-target-like uses associated with ga- at 2;0 are mostly instances of consonant substitution (with prefixes containing -a-), whereas at age 3;0, ga-marked target nouns are all produced accurately. In place of the phonological inaccuracies, ga- is extended to nouns unlikely to occur with it in adult production. Whether this is driven by the semantics associated with ga- or an analogical overextension based on morphological form, this reveals a very different cognitive process than at age 2;0. In the younger data, the children may still have unstable representations of the prefixes, or simply inadequate articulatory control, but they clearly have difficulty stably producing the ga- where required. At age 3;0, they are drawing on paradigmatic relations and showing an understanding of prefixal form that goes beyond lexically learned chunks.
Productivity
The first signs of productivity are observed between 2;4 and 2;6, with plural formations and the alternation of several different NCPs on the same stems. We see these uses as early signs of system building, where children begin to show an understanding of the noun class system more generally. The children are using prefixes contrastively on nouns by age 3,0. Of particular interest is the generalised noun stem -nde, which is used with contrastive prefixes at ages 2;6 and 3;0. Not only is -nde a useful tool for the linguist investigating emerging productivity among children, it is also a handy tool for the child learning the system. While lexical nouns are slower to show evidence of contrasting usage, -nde is available as a pro-form to stand in for other nouns and combine with any of the NCPs. As such, it is extremely flexible morphologically, as well as being phonologically undemanding and semantically non-compositional and unspecific. It provides a convenient hook to practice NCP alternation with.
Research Questions
Returning to the research questions, we are in a better position at this point to venture answers. First, we asked when children show evidence of morphological productivity in nouns. Although the data are sparse, and children vary considerably in their pace of linguistic development, we can say that a major linguistic advance occurs in the third year of life, between the onset of children’s word combinations, broadening noun usage, and more productive, semantically attuned usage of the NCPs by their third birthday. This can be seen in the change in proportion and type of non-target-like forms as well as in an increase in productive and contrastive usage of NCPs in both the group and individual data.
Secondly, we asked whether there is evidence in the acquisition of Eegimaa to support the stages described for NCP acquisition in Bantu by Kunene (1979) and Demuth (2003). As noted above, our study failed to find data corroborating a similar developmental path in Eegimaa as has been found in Bantu. Children use target-like prefixes already at age 2;0 in half of the nouns they produce, unlike Demuth and Weschler’s (2012, p. 73) finding that Bantu-acquiring children do not produce target-like nouns in the first stage. Although the children in our study do omit prefixes, they do so in a minority of instances, even at age 2;0, alongside both target-like usage and substitutions of target prefixes, indicating that at this age they are developing awareness of the existence of word-initial nominal morphology.
Demuth and Weschler (2012) also claim that children never produce prefixes on prefixless nouns (p. 73). Our data do not contain many instances of this, but out of 11 examples of children’s production of prefixal noun forms for prefixless nouns (with 4 different noun stems), 10 are produced at age 3;0. A prefix provided when none is needed is a kind of overgeneralisation, not based on semantics, but on the morphological expectations of the language overall. The children in our study seem to have a grasp of the prefixal system by age 3;0, although details are still being learned at that point, especially regarding the less frequent NCPs and the lexical restrictions on productivity.
Methodological Issues
The primary methodological limitation of our study is the availability of sufficient data to analyse longitudinal development. The recruitment and recording process is challenging with a language with so few speakers, but the transcription process is even more so, considering the dearth of trained linguists available to assist in the process. Nevertheless, our corpus contains a sufficient amount of transcribed data that we can observe developmental patterns in individuals and in the group. Yet the coding of the data is far from straightforward.
For a comparison with previous research, the investigations of the acquisition of Bantu morphology are most pertinent. However, we ran into some difficulty providing comparable data for the fillers posited by Kunene (1979) and Demuth and Weschler (2012). Demuth and Weschler (2012) refer to ‘filler syllables (vowel) or nasal prefixes’ (p. 73), but in the same paragraph note that Tsonope (1987) and Suzman (1980) have proposed that these ‘fillers’ may instead represent the overgeneralised use of a different NCP. To avoid this, we attempted to clearly define what would count as a filler and what would count as a substitution (prefixes used with other nouns in the system or a substituted consonant). With our coding system, we may have reduced the chance of a child production being counted as a filler, but we also ensured a systematic approach to the coding of prefixes as one or the other. Yet even with such clear definitions, we found exceptions in NCP usage, such as the prefix u-, which did not seem to be appropriately marked as a substitution before children were using any plural prefixes, as it occurs only as a plural marker in the system.
Yet, coding fillers cannot solely rely on what else the child is producing at the time, as this would be circular. Since the children in our study are producing target-like forms alongside the fillers and substitutions, coding children’s prefixes as fillers is problematic in various ways, especially for lack of a solid definition and in light of the risk of underestimating the child’s knowledge of the system and its available forms. The most common filler in our data is /u/ (used 7 times), which is phonologically identical to one of the plural NCPs. This is followed by the nasal /m/ (used twice), which is not used as an NCP in Eegimaa. The less frequent fillers are /a/, identical to the human singular prefix a-, and /o/, which does not exist as an NCP. Overall, however, the number of tokens which could be deemed fillers is negligible.
Implications
As has been found in languages with plentiful morphological marking, such as Slavic and Finnic (e.g. Granlund et al., 2019), rich use of morphology in the child-directed speech leads to early use of morphology by children (Xanthos et al., 2011), but the path to fully adult-like production is lengthy. In particular, forms that are either infrequent or complex require more exposure and follow a slower trajectory to accurate production. In the Eegimaa data, we find that phonology explains most of the errors in the nouns produced by 2-year-olds. Phonological form is the most accessible aspect of the input, and the forms children use follow phonological processes which have been amply described across numerous languages. Between the ages of 2;0 and 3;0, the children in our study develop a fuller understanding of the semantic underpinnings of the system and the morphological paradigms expressing it. In order to learn the ways in which the form and the semantics interact, the child needs to master phonological representation and articulation alongside the semantic and structural information encoded in the nominal morphology.
During this period, semantic productivity emerges bit by bit, shown mostly in contrastive use and some instances of overgeneralisation. Certain properties of the system need to be in place before they can be extended and surpassed, in order to acquire both the productivity in the system and the constraints on productive affix usage. Although Eegimaa is distantly related to Bantu languages, it is clear that the trajectory proposed for Bantu does not fit the Eegimaa data.
Hence, the process of acquisition of nominal morphology is not generalisable across African languages. Which linguistic differences underlie these divergent acquisition trajectories remains to be explored in further research, which will have to provide a fuller picture of the acquisition of noun usage in Eegimaa. The nominal morphology investigated here is acquired in the context of syntactic agreement, which is often alliterative and operates both within the noun phrase and across larger clausal constituents. The importance and interaction of the morphosyntactic, semantic and pragmatic context in acquiring the language await future attention.
Footnotes
Acknowledgements
The authors would also like to thank the reviewers and the editors of the special issue for their invaluable comments, which helped to improve this paper. We are indebted to Marilyn Vihman for her insightful contributions to earlier versions of the analysis present here, particularly on consonant harmony. Finally, we thank Catherine Laing for her feedback on some aspects of our phonological analysis.
Author Contributions
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The support of the Economic and Social Research Council and Arts and Humanities Research Council (ESRC & AHRC, ES/P000304/1) is gratefully acknowledged.