
Abstract
When the written language that children learn to read and write is distinct from the oral language they acquired as their mother tongue, they may encounter substantial challenges. The linguistic distance between two varieties of the same language could have an impact on the literacy acquisition journey. The present study focuses on Arabic, a prototypical case of diglossia, where the distance between the spoken and standard varieties has been intensively examined phonologically and lexically. However, a paucity of studies has addressed their morphological distance. This study takes one step in this direction by describing, analyzing, and quantifying the distance of morphemes in content words from spoken Palestinian dialect (SPD) to Modern Standard Arabic (MSA). It is the first to map this distance by form and function in the three predominant systems: derivation, inflection, and clitics in nouns and verbs. All morphemes were arranged on an axis targeting four main levels that varied in the extent of the morphological distance from SPD to MSA, beginning with ‘identical’ morphemes (same form, same function), followed by ‘strongly overlapping’ morphemes (morpho-phonological difference in form, same function), then ‘partially overlapping’ morphemes (different form, same function), and ending with ‘unique’ morphemes (unique form, same/different function). The mapping showed significant findings indicating that most morphemes are non-identical between SPD and MSA, comprising 81.4% of the total. Most of these non-identical morphemes (64.9%) were assembled to the ‘partially overlapping’ and ‘unique’ levels, appearing mainly in the verb inflection category. Implications for the possible impact of morphological distance on reading acquisition are discussed.
Introduction
Linguistic distance between spoken and written language
When the written language that children learn to read and write is distinct from the oral language they had spontaneously acquired as their mother tongue, they may encounter considerable challenges when commencing their literacy acquisition journey (e.g. Myhill, 2014). This linguistic distance between two language versions can be described as a continuum in terms of degrees across different languages, representing various discrepancies between them (Daniels & Share, 2018). Thus, it could have a different impact on literacy acquisition and development in each language, depending on the distance of the spoken variety from the written one (Myhill, 2014).
For some pairs, the written and spoken languages are considered bilingual as two first languages, demonstrating the most extreme situation of linguistic distance (Daniels & Share, 2018). In this case, children learn to read and write in a completely different language from the one they speak. For example, in South Africa, most of the young readers who speak one or another of the African languages (such as Zulu, Xhosa, Swati [or Swazi]) as their mother tongue, are taught in a second language (mostly English). English is considered the language of learning and teaching from the third or fourth year of school (Alexander, 2001). In contrast, the indigenous African languages are not used in education but only as the home language. Thus, this instance poses these multilingual speakers of African languages at educational risk compared to their minority peers, English and Afrikaans speakers, who got the opportunity to learn literacy in their own language (Makalela, 2017). Sign languages are also worth mentioning. Some deaf children use a sign language as their first language, but sign languages have no written form. Therefore, when they acquire reading, these deaf children learn a written form not of their sign language but of a spoken language that they might not yet know (Gärdenfors et al., 2019; Haptonstall-Nykaza & Schick, 2007).
On the other side of the linguistic distance, continuum is placed more worldwide dialectal variation phenomena (Daniels & Share, 2018). Taking English for an example, in Britain, each dialect of the language (e.g. Scottish, Yorkshire) is distinct according to its geographical background and differs from the ‘standard’ English written variety targeted for education, by one of the linguistic domains, such as phonology (different accents), syntax (complex vs simple constructions) or lexicon (high- vs low-status varieties). Although the spoken and written forms in this phenomenon are situated in close proximity to the initial point of the distance continuum, they are still not identical and might impede literacy acquisition to varying degrees (see Daniels & Share, 2018; Myhill, 2014; Washington & Seidenberg, 2022).
Somewhere in between these two cases of linguistic distance is diglossia. Ferguson first introduced this term in 1959, referring to using two varieties from different status that exist side by side in a single community: The colloquial (vernacular) low-status variety of a language is acquired from birth and used in everyday speech; and the standard high-status variety is learned by formal education and used in a formal context (Ferguson, 1959). The present study focuses on Arabic, a Semitic language, which is a prototypical case of diglossia.
Diglossia in Arabic: linguistic distance between Spoken and Modern Standard Arabic
Diglossia is considered one of the most conspicuous features of the Arabic language, in which the same native Arabic speakers use the two forms of spoken and written language for distinct functions (Maamouri, 1998). Spoken Arabic (SpA), the sixth most spoken language in the world, is spontaneously acquired as the mother tongue of approximately 274 million people (Eberhard et al., 2022). However, it is not a single dialect. Instead, it encompasses a large number of Arabic vernaculars, each region and geographical area having its own specific vernacular, with dialectal differences varying in proportion to the geographical distance from one another (Ryding, 2005). In contrast, the modern descendant of Classical Arabic and Literary Arabic, MSA, is considered the only language variety with a conventional written form. However, it is not the mother tongue of any Arabic speaker (Saiegh-Haddad, 2022). Although children are exposed to MSA early on through storybooks, children’s songs, digital media, or prayer (Saiegh-Haddad & Henkin-Roitfarb, 2014), formal exposure to MSA commences only when the child begins elementary school. At that time, they are required to master the use of MSA as a linguistic system remote from their everyday SpA (Laks & Berman, 2014). Thus, despite different dialects, all native Arabic speakers read the same orthography (Saiegh-Haddad & Henkin-Roitfarb, 2014).
Moreover, unlike other diglossic languages and dialectal variation, the linguistic disparities between SpA and MSA exist in all language domains – semantics, phonology, morphology, and syntax (e.g. Holes, 2004; Saiegh-Haddad, 2018). These disparities represent two forms of the same language that are distant and fundamentally distinct (Ferguson, 1959; Saiegh-Haddad & Henkin-Roitfarb, 2014). Therefore, native Arabic speakers could be considered as bilinguals (Eviatar & Ibrahim, 2000; Khateb & Ibrahim, 2022). This case of diglossia poses a serious obstacle to literacy (e.g. Feitelson et al., 1993; Saiegh-Haddad, 2003, 2004, 2007, 2012), including significant effects on reading and writing acquisition, teaching instructions, and conducting effective intervention programs (e.g. Myhill, 2014). Notably, it even affects the simpler joy of children, from very early stages, to experience listening to an adult reading them stories in a language they understand, since nearly all children’s books are written in the standard form of Arabic that they do not master until later stages of schooling (Shendy, 2019).
The degree of the linguistic distance between a spoken dialect and MSA varies from one region to another. According to the work of Saiegh-Haddad and Spolsky (2014), this affects how easily the same MSA word may be identifiable by children from different SpA backgrounds. For example, the MSA word for car is /sayya:ra/, which in spoken Egyptian dialect is /ʕarabiyya/ compared with other dialects, such as in spoken Palestinian dialect (SPD) /siyya:ra/ or /sayya:ra/.
Over the last decade, the linguistic distance between SpA and MSA varieties and its impact on early literacy learning has been intensively examined, mostly the phonological and lexical distance by Saiegh-Haddad (2003, 2004, 2005; Saiegh-Haddad et al., 2011; Saiegh-Haddad & Haj, 2018; Saiegh-Haddad & Spolsky, 2014). The phonological distance between the two language varieties appears in the syllabic structure and phonemic inventory (Saiegh-Haddad, 2018). For example, at the syllabic level, the SpA permits initial consonant clusters (e.g. /kta:b/ ‘a book’), but MSA does not (e.g. /kita:b/ ‘a book’). At the phonemic level, MSA includes both voiced and unvoiced interdental fricatives (/ð/ and /θ/, respectively), whereas, in some of the dialects, these phonemes do not exist (Saiegh-Haddad, 2003). These and other phonological discrepancies between the two forms of the language have been found to interfere with MSA reading acquisition and development; for example, standard phonemes are more difficult to isolate in comparison with phonemes that exist in both spoken and standard Arabic (Saiegh-Haddad, 2003). As for the lexical distance between the two forms, Saiegh-Haddad and Spolsky (2014) distinguished three types of words that were collected from a corpus of preliterate Arabic-speaking children (at age 5) who speak the central Palestinian dialect: (1) ‘unique words’ that have distinct forms in SpA and MSA, (2) ‘cognate’ words, which keep partially overlapping phonological forms in SpA and MSA, and (3) ‘identical words’, which maintain their surface phonological form in SpA and MSA. The results showed that the most common type of lexical item in the child’s lexicon is ‘cognates’ (40.6%), followed by ‘unique words’ (38.2%), and finally, ‘identical words’ (21.2%). In essence, SpA and MSA lexicons overlap only partially, a matter that may pose a serious obstacle for young children when listening to simple sentences or stories, and when acquiring reading at school (Saiegh-Haddad & Spolsky, 2014).
This linguistic distance between the different SpA vernaculars and MSA variety has been characterized by degrees of overlapping or absence of it, ranging on a continuum (Maamouri, 1998; Saiegh-Haddad, 2018). Recently, Saiegh-Haddad and Haj (2018) investigated the phonological distance effect between SpA and MSA on phonological representation. They ranged this distance on a continuum targeting three classes in MSA words (1) ‘identical words’ with identical phonological forms in both SpA and MSA; (2) ‘cognate’ words which consist of four subclasses varying in the degree of their phonological distance or overlapping between SpA and MSA forms: (a) ‘1-phoneme distant cognates’ which includes two types, namely, ‘1-vowel distance cognates’ and ‘1-consonant distant cognates’, (b) ‘2-phoneme distant cognates’ of vowel and consonant, and (c) ‘more than 2-phoneme distant cognates’; and (3) ‘unique words’ with forms in MSA that are completely different from their forms in SpA. They have shown that the phonological representation accuracy of MSA words in the lexicon varies relative to their type and degree of distance from SpA. The ‘identical words’ displayed a higher level of representational accuracy, as opposed to the cognates and unique MSA forms, which revealed lower levels.
In this context of Arabic diglossia, the linguistic distance between the two varieties exists in morphology and not merely in phonology and the lexicon (Saiegh-Haddad & Henkin-Roitfarb, 2014). Morphology – the study of how morphemes are created and combined into words – has been recently considered as another significant component, beyond phonology, in literacy development (Berthiaume et al., 2018; Breadmore & Deacon, 2018; McBride, 2017; Rastle, 2018). It is often regarded as one of the three cornerstones of literacy development together with phonology and orthography (Harm & Seidenberg, 2004; Kirby & Bowers, 2017; McBride, 2017; Seidenberg & McClelland, 1989). However, it can vary widely across languages (Aronoff & Fudeman, 2011; Duncan, 2018; Gonnerman, 2018; Ravid, 2019). For instance, Arabic is based mainly on non-concatenative word-building procedures (Holes, 2004). These contrast sharply with the concatenative (stem + suffix) procedures that dominate word formation in Indo-European languages (Shalhoub-Awwad, 2020).
Although morphology is considered the predominant hallmark of Arabic, the linguistic distance in the morphological domain has received little attention in research (e.g. Holes, 2004). Hence, our interest is directed to the morphological distance between SPD and MSA. It is the first to explore the extent of this distance by ranging it on a continuum that could begin with identical morphemes between SPD and MSA, followed by partially overlapping morphemes, and might end with very different morphemes. For example, 1 the word /matɁbax/ ‘kitchen’ is identical in SPD and MSA because the singular noun is marked by an identical word-pattern maCCaC, in both varieties. However, the words /bi:dɁa/ in SPD and /baydɁa:Ɂ/ in MSA ‘white’ are partially overlapping since they share the exact morphological category, an adjective describing qualities, yet they differ in their nominal patterns, C1i:C3a in SPD versus CaCCa:Ɂ in MSA (addition of /-a-/ and /-Ɂ/, and transformation of /-i:-/ to /-y-/ and /-a/ to /-a:-/). By contrast, /ʔatʔibbaʔ/ ‘doctors’ is unique to MSA, because the broken plural is marked by the unique pattern ʔaCiCCa:ʔ that is used in MSA only. The latter example might display the most considerable discrepancy on the continuum.
The current study is grounded on the morpheme-based (or root-and-pattern) approach, which presumes that every Semitic surface form is constructed by the interleaving root consonants and word-pattern bound morphemes one within the other to form a specific lexical word (e.g. Cohen, 1951; Hilaal, 1990; McCarthy, 1982). This model stands in sharp contrast with the stem-based (or word-based) approach, which utilizes for Semitic morphology the same set of universal constraints or rules applied across the world languages by assuming that the Arabic lexicon is made up of different processing, which conceives the stem as a basic unit to which prefixes and suffixes are appended linearly (e.g. Benmamoun, 2003; Heath, 2003; Ratcliffe, 2004). Empirical evidence from priming research in Semitic languages (Arabic and Hebrew) supports mainly the former approach revealing strong priming effects by roots and word-patterns (e.g. Boudelaa & Marslen-Wilson, 2005, 2011; Deutsch et al., 2018; Deutsch & Malinovitch, 2016; Frost et al., 1997; Shalhoub-Awwad, 2020, 2022; Shalhoub-Awwad & Leikin, 2016). Hence, these studies attest to the role of root and word-pattern as internal morphological units in processing in contrast to the stem-based approach (e.g. Bat-El, 2017). The present study aims to understand the depth of the morphological distance from SPD to MSA based on the morpheme-based approach due to the crucial role of root-and-pattern structure in organizing the mental lexicon of the Arabic speaker (Boudelaa, 2014).
Notably, SPD is the mother tongue of approximately two million Arabs who live in Israel (Horesh, 2021). It has sub-varieties of dialects, including three ‘ecolinguistic’ groups classified by Cadora (1992) as urban, rural, and Bedouin. The focus of this study was on northern Palestinian Arabic, which is the native dialect of its authors. Note that although Hebrew is the formal and dominant language in the country and is used in daily communication and business, Arabic speakers are ethnically separated, and most of them live in Arab towns or villages (Horesh, 2021). They use Arabic exclusively for teaching at school. In contrast, they begin to learn reading and writing Hebrew as a second language only in third grade (Saiegh-Haddad & Everatt, 2017). Contrary to their Hebrew-speaker peers who speak and learn to read and write in a single language, the Palestinian-speaker child is challenged with a diglossic phenomenon from a very early stage of school (Myhill, 2014).
Arabic morphological structure
Arabic is a synthetic language with rich morphology. Its morphological structure comprises three predominant systems: Derivation, inflection, and clitics (Saiegh-Haddad & Henkin-Roitfarb, 2014).
Derivational morphology
Derivational morphology in Arabic is primarily a non-concatenated process (non-linear) which is considered the heart of word formation in the uniquely Semitic root-and-pattern system (Hilaal, 1990; Holes, 2004; McCarthy, 1981; Saiegh-Haddad & Henkin-Roitfarb, 2014). Most content words are composed of at least two underlying abstract morphemes: a root and a word-pattern. The root is an unpronounceable bound morpheme, usually represented by three consonants, conveying the semantic meaning. The word-pattern is also an unpronounceable bound morpheme – a fixed prosodic template with slots for the root consonants. ‘Intertwining the root consonants within the word-pattern forms a specific lexical bi-morphemic word with a particular meaning and a well-defined grammatical category directly discernible by the specific word-pattern’ (Saiegh-Haddad & Henkin-Roitfarb, 2014, p. 9). For instance, the word /ma
Arabic words can also be derived by a concatenated process, in which the morphemes are added linearly. For example, the adjective
Inflectional morphology
Inflectional morphology in Arabic is mostly a concatenative process in which affixes, like English suffix ‘es’ as in ‘buses’, are added to the stem by appending morphemes linearly according to three basic categories: gender, number, and person (Ryding, 2005). For example, the noun /basɁ
Clitics
The Arabic morphological system contains an extensive system of clitics (Saiegh-Haddad & Henkin-Roitfarb, 2014). The clitics are morphemes that are pronounced (in Arabic also written) like affixes attaching to the word as prefixes (proclitic), suffixes (enclitic), or both, resulting in a complete one-word phrase or clause. The clitic system includes prepositions, conjunctions, direct object pronouns, and so on (Saiegh-Haddad & Henkin-Roitfarb, 2014, p. 14). For example, the one-word phrase وَسَأَرْسُمُها /wa-sa-Ɂarsumu-ha:/ ‘and I will draw it’ includes the conjunction /wa-/ ‘and’ and the future marker /-sa-/ ‘will’ as proclitic and the pronoun /-ha:/ ‘her’ as enclitic.
Morphological distance in learning to read Arabic
The study on morphological distance in learning to read Arabic has only recently begun to receive attention. Most of the studies that have examined the morphological impact on early reading acquisition have focused mainly on the spoken variety. These studies have consistently reported that morphological awareness plays a significant role in word recognition and spelling development (e.g. Saiegh-Haddad, 2013; Taha & Saiegh-Haddad, 2017; Tibi et al., 2020; Tibi & Kirby, 2017). In addition, recent research has supported the early emergence of morphological processing in reading (e.g. Shalhoub-Awwad, 2020, 2022; Shalhoub-Awwad & Leikin, 2016) and spelling (e.g. Saiegh-Haddad, 2013; Taha & Saiegh-Haddad, 2017).
Few other studies have considered the linguistic distance in discussing their results. Shalhoub-Awwad and Leikin (2016) found a significant root priming effect among second and fifth graders, with an advantage in priming effect for second grade. The authors attributed this superiority to the diglossic situation, precisely the phonological and lexical distance, which promoted young readers’ reliance on the root morpheme in second grade compared to the more skilled readers (fifth grade) who were found to rely less on the root morpheme due to their developed mental lexicon and orthographic knowledge (Shalhoub-Awwad & Leikin, 2016). Another study by Laks et al. (2019) has indirectly investigated the linguistic distance between the two varieties of Arabic in the verbal system in spoken Palestinian Arabic text production among adults. Their results showed that among the system of ten potentially active patterns that are used for verb formation, CaCaC is revealed to be the most frequent one used by the adult corpus. The following productive patterns were CaCCaC and taCaCCaC, whereas the remaining patterns were hardly used by adults. However, future studies should examine these features among young children to understand the usage of oral verbal patterns and compare it to the written forms in MSA to clarify its distance effect on their reading acquisition process.
The issue of morphological distance in learning to read Arabic has been directly probed by Schiff and Saiegh-Haddad (2018). They compared Arabic-speaking children’s phonological awareness, morphological awareness, and word reading in spoken and standard language varieties. One of the most important findings revealed that morphological awareness for shared morphological units in both SpA and MSA was greater than for units used only in MSA. In addition, they found an advantage for word reading accuracy and fluency of items in SpA over items in MSA throughout development, suggesting a long-term effect of linguistic distance on word reading.
To date, however, we could hardly locate any specific investigation mapping the morphological distance between the two forms of the Arabic language in its inflectional, derivational, and clitic systems. Only one study examined the morphological distance between SPD and MSA at the level of form (word-patterns and roots) in the nominal system among young children ages 3–6 (Shalhoub-Awwad & Khamis-Jubran, 2021). In their study, they classified this distance into five different categories, showing that the most frequent category is ‘common word-patterns and roots’ which comprised about 47.6% of their speech (e.g. /ʔakbar/ ‘bigger’ in SPD and MSA, has the same word-pattern ɁaCCaC and the same root /k.b.r/). The following category is the ‘partially different word-patterns with common roots’ accounting for 29.1% of their speech (e.g. /kbi:r/ in SPD and /kabi:r/ in MSA ‘big’, has partially different word-patterns CCi:C in SPD and CaCi:C in MSA with the same root /k.b.r/). In addition, 13.1% of the nouns are with ‘different word-patterns and different roots’ (e.g. /xitya:r/ in SPD and /ʕaʒu:z/ in MSA ‘old man’ have different word-patterns CitCa:C and CaCu:C with different roots /x.w.r/ and /ʕ.ʒ.z/, in SPD and MSA, respectively), and 7.5% are nouns with ‘different word-patterns and common roots’ (e.g. /ʒuʕa:n/ in SPD and /ʒa:ʔiʕ/ in MSA ‘hungry’ have different word-patterns CuCa:n in SPD and Ca:CiC in MSA with the same root /ʒ.w.ʕ/). The authors proposed that if more steps are taken to raise the awareness of preschoolers about these differences, the impact of these diglossic structures (i.e. the distance between the morphemes of spoken and written variety, for example, CCi:C in SPD as in /kbi:r/ versus CaCi:C in MSA as in /kabi:r/ ‘big’) on their reading acquisition processes could be reduced (Shalhoub-Awwad & Khamis-Jubran, 2021). This is an assumption that should be determined in future studies.
In response to the need to understand the depth of the morphological distance between SpA and MSA, based on the morpheme-based approach (e.g. Boudelaa, 2014; Cohen, 1951; Hilaal, 1990; McCarthy, 1982), the present study aimed to (a) map the morphological distance levels from SPD to MSA in content words by form and function and to (b) map these distance levels by the three predominant morphological systems (derivation, inflection, and clitics) and lexical categories (nouns and verbs).
Method
Procedure
Mapping the morphological distance levels of content words from SPD to MSA required several steps. First, we mapped the morphological structures in MSA, based on Holes (2004), and analyzed their counterparts in SPD by morphological derivations, inflections, and clitics in both verbal and nominal systems. This mapping yielded five categories: (1) verb derivation, (2) noun derivation, (3) verb inflection, (4) noun inflection, and (5) clitics. The following analyses were based on common trilateral roots between SPD and MSA. 2
Derivational morphology
(1)
(2) (a) Participles. Nineteen word-patterns of triliteral roots of active (10) and passive (9) participles were included, as shown in Table 2. (b) Verbal noun. The following verbal word-patterns of triliteral roots (13 unaugmented and 13 augmented patterns) were included as follows (note that some of the patterns include more than one possible derived form):
(c) Other nominal word-patterns. This study included as well other nominal word-patterns by suffixation or pattern modification (reflecting a specific semantic class), as shown in Table 5.
Triliteral verbal word-patterns I–X and examples.
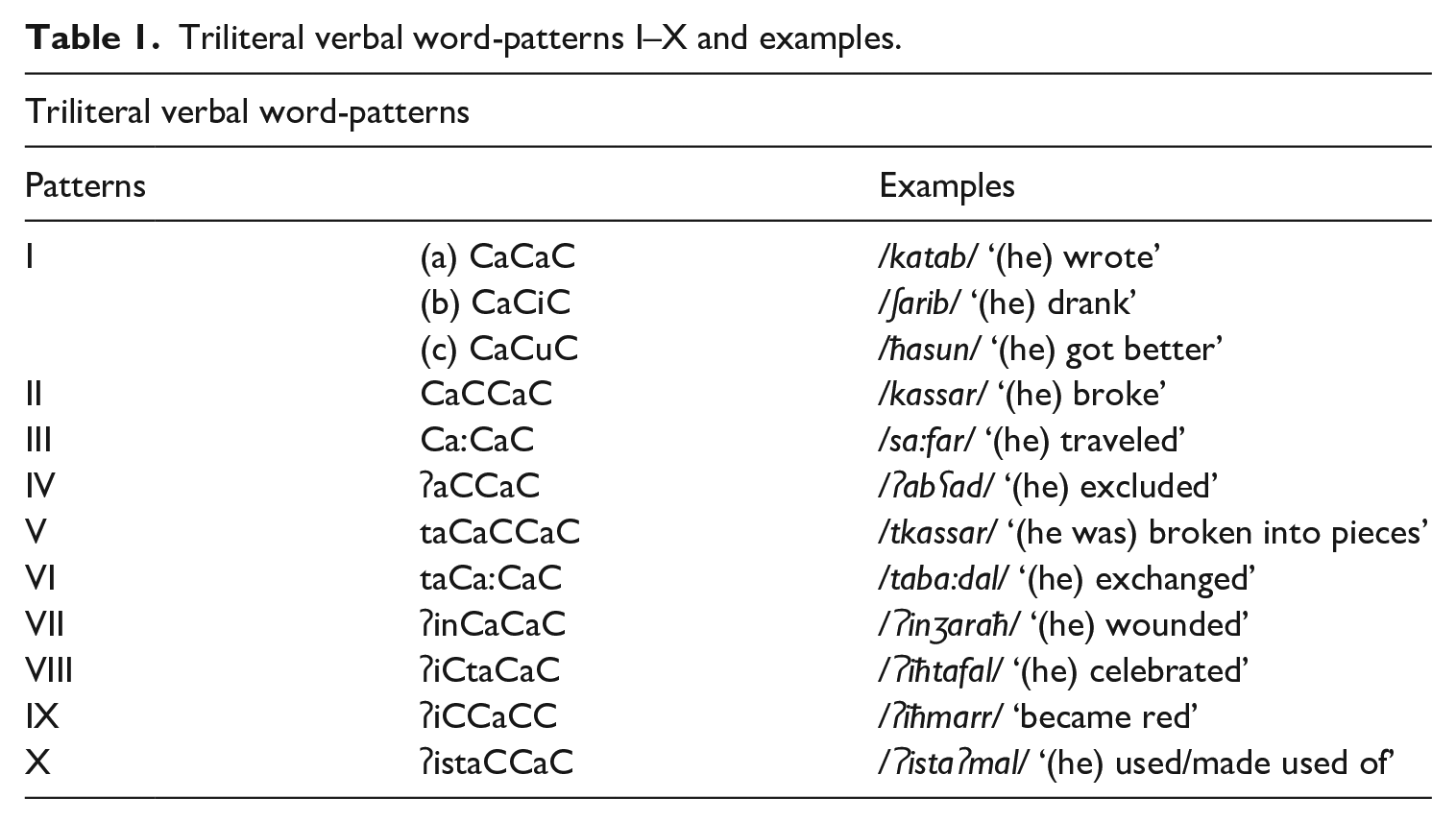
Active and passive patterns of participles of triliteral roots and examples.

Patterns and samples of verbal noun derived from pattern I, and examples.
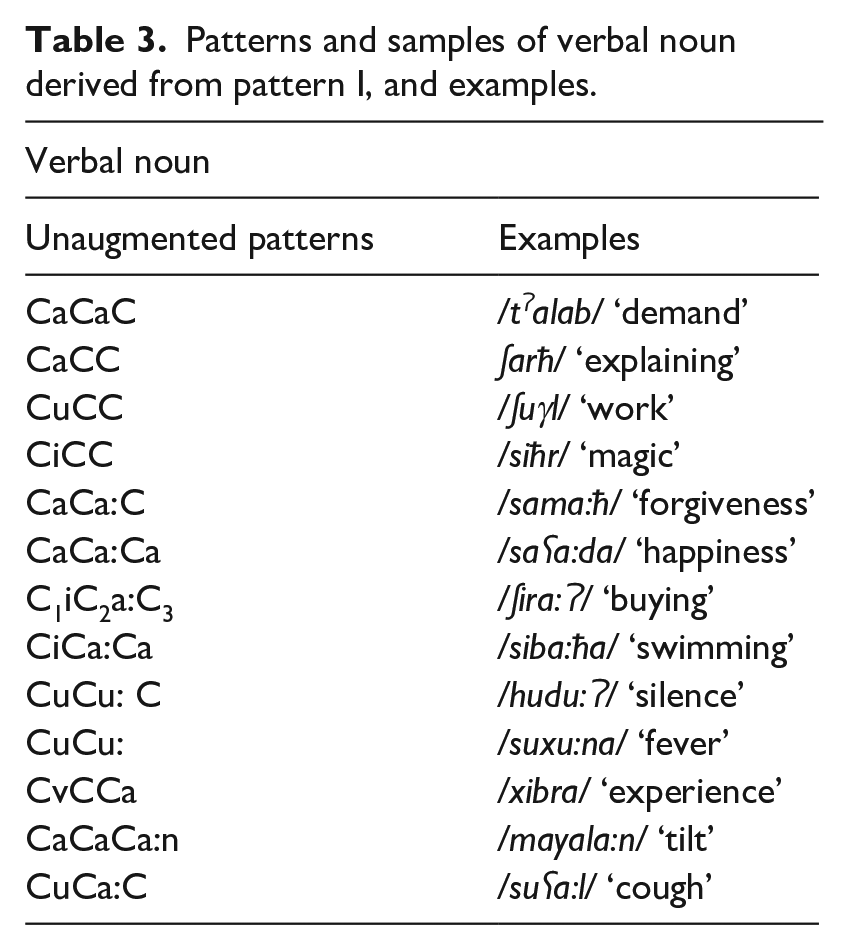
Patterns and samples of the verbal noun derived from patterns II–X, and examples.
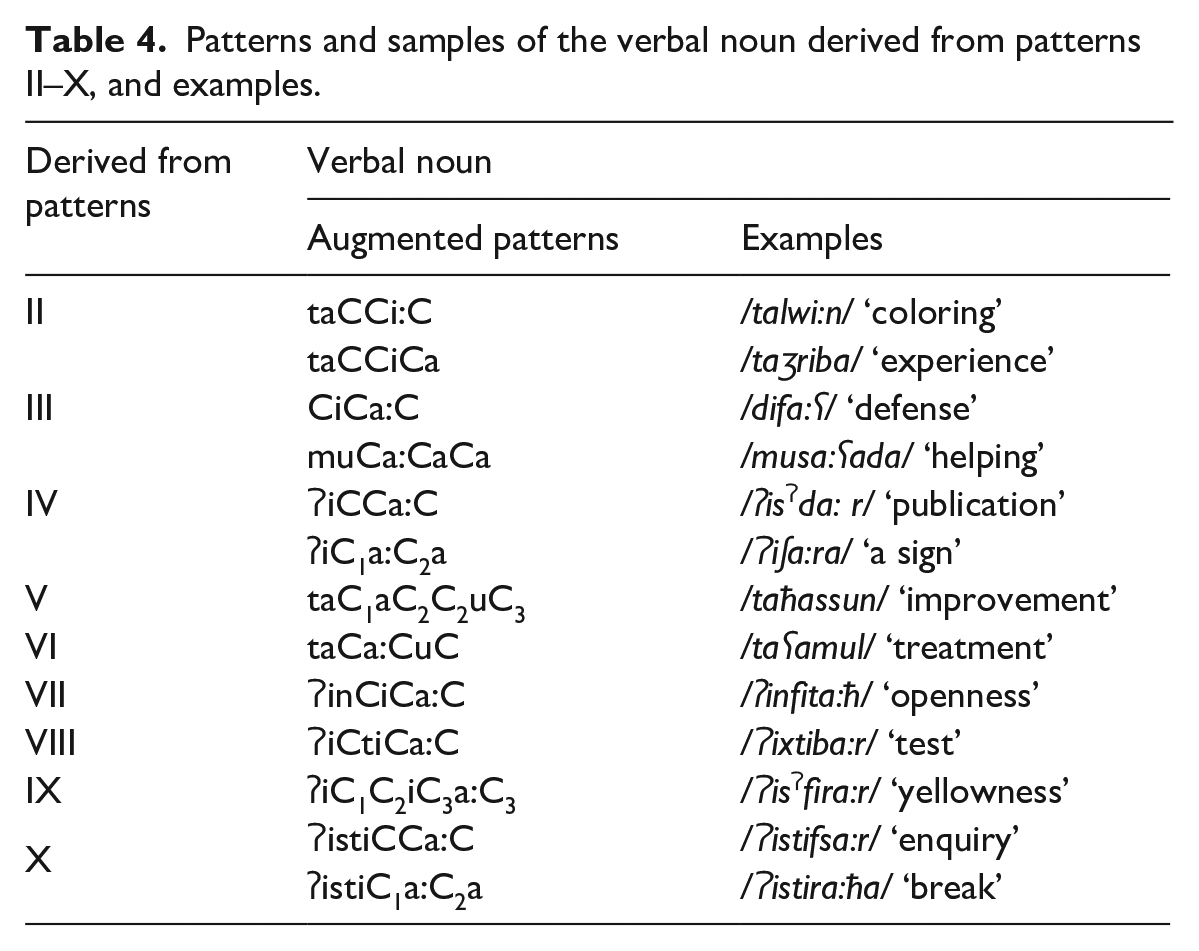
Nominal word-patterns by semantic class, suffixation or pattern modification, and examples.
Inflectional morphology
(3) (a) Past tense. Based on the concatenative procedure, inflectional suffixes are added to the root and pattern surface word according to the categories mentioned above. For example, the verb /katab-ta/ ‘(you (s. masc.)) wrote’ is conjugated by adding the suffixed inflectional morpheme /-ta/ to the surface word /katab/ ‘(he) wrote’ linearly. (b) Present tense. Uses non-concatenative and concatenative procedures in its conjugation. For example, /taktub-u:n/ ‘(you are (pl. masc.)) writing’ is formed by both non-concatenative and concatenative procedures, the k.t.b root consonants, were conjugated in a non-concatenative procedure into the morpheme taCCuC (inflected from past tense CaCaC /katab/ ‘(he) wrote’), as well as the inflectional morpheme /-u:n/ referring to number (pl.), gender (masc.), and person (second person) were added in a concatenative procedure. Note that the active voice of the unaugmented verbal word-pattern (pattern I; C1v1C2v2C3),
4
has three types of internal vowel patterns (C1aC2aC3, C1aC2iC3, C1aC2uC3), in which it has some changes in the present tense (Holes, 2004): (1) v1 is parallel to /a/; (2) v2 is parallel to /u/ or /i/ (e.g. /ras
(4) (a) Dual. The suffixes /-a:n/ and /-ayn/ as in /kita:b-
(b) Sound masculine plural. The suffixes /-i:n/ and /-u:n/ are added to nominal forms, as in /dahha:n-
(c) Sound feminine plural. The suffix /-a:t/ (could be suffixed to both feminine and masculine nouns; see Holes, 2004, p. 167), which are added to nominal forms, as in, /ba:sɁ-
(d) Broken plural. Fifty-one different broken plural patterns were recruited based on research with Arabic-speaking children (Boudelaa & Gaskell, 2002; Ravid & Farah, 1999; Ravid & Hayek, 2003; Saiegh-Haddad et al., 2012), first-grade textbooks, and children’s book stories (by ‘/maktabat Ɂalfa:nu:s/’ project in kindergarten). Both high and low frequencies of broken plural patterns were included, such as CaCa:Ci as in /kara:si/ ‘chairs’. (e) Collective.
5
Eleven collective patterns were included. For example, the word-pattern CaCaC as in /ʃaʒar/ ‘trees’.
Clitics
(5) (a) Proclitics. Consist of the prepositions /bi-/ ‘in’, /ka-/ ‘as’, /li-/ ‘to’, conjunction, subordinating /fa-/ ‘then’, /wa-/ ‘and’, definite article /Ɂal-/ ‘the’, and future verbal particle /sa-/ ‘will’. (b) Enclitics. Consist of the following enclitics: Possessive pronoun, first person /-i:/ (s., masc./fm.); objective pronoun, first person /-ni:/ (s., masc./fm.); possessive/objective pronouns, first person /-na:/ (pl.); possessive/objective pronouns, second person: /-ka/ (s., masc.), /-ki/ (s., fm.), /-kuma:/ (dual, masc./fm.), /-kum/ (pl., masc.), and /-kunna/ (pl., fm.); possessive/objective pronouns, third person: /-hu/ (s., masc.), /-ha:/ (s., fm.), /-huma:/ (dual, masc./fm.), /-hum/ (pl., masc.), and /-hunna/ (pl., fm.).
Next step, we have classified the morphological distance by form and function ranging them on a continuum targeting four main levels that varied in the extent of the morphological distance from SPD to MSA. 6 This classification included morphological derivations, inflections, and clitics, in the nominal and verbal systems (see Supplemental Material).
(1)
(2)
(3)
(4)
The following step was mapping each of the five morphological categories by the distance levels as follows:
Derivational discrepancies in the verbal system from SPD to MSA by verbal word-patterns (I–X of triliteral roots);
Derivational discrepancies from SPD to MSA in the nominal system by nominal word-patterns;
Inflectional discrepancies from SPD to MSA in the nominal system by type of pluralization (dual and plural);
Inflectional discrepancies from SPD to MSA in the verbal system (by tense, person, number, and gender);
Morphological distance from SPD to MSA in the nominal and verbal systems, by types of clitics (proclitic and enclitics).
The last step was to assemble the mapped morphological categories to the four distance levels: ‘identical’, ‘strongly overlapping’, ‘partially overlapping’, and ‘unique’. We manually classified in an Excel file each of the morphemes by giving 1 point to the distance level it refers to, as shown in the following examples in each of the levels: (1) the word-pattern CuCuC, as in /kutub/ ‘books’ got 1 point in the ‘identical’ distant level since it shares the same form and function; (2) the word-patterns CCa:C in SPD as in /sɁħa:b/ and ɁaCCa:C in MSA as in /ɁasɁħa:b/ ‘friends’, got 1 point in the ‘strongly overlapping’ distance level, since they differ in their form in two morpho-phonological parameters (addition of CV /Ɂa-/); (3) morphemes with different form in both varieties got 1 point in the ‘partially overlapping’ distance level. However, if the word included both non-linear and linear formations, it got 2 points for each formation, as in /katab-u/ in SPD and /katab-tum/ in MSA ‘(they (pl., masc.)) wrote’: 1 point assembled to the ‘partially overlapping’ distance level (degree 3) due to the differences between the two varieties in the linear formation (the affixation /-u/ in SPD versus its counterpart MSA affixation /-tum/), and another 1 point was assembled to the ‘identical’ distance level for the non-linear formation of the same word-pattern CaCaC /katab/; (4) morpheme with unique form in MSA got only 1 point in the ‘unique’ distance level. For example, the morpheme /-tunna/ as in the past tense verb /katab-tunna/ ‘(you (pl., fm.)) wrote’, got 1 point in the ‘unique’ distance level (degree 2).
Results
The first aim of the present study was to map the morphological distance levels from SPD to MSA by form and function. This mapping yielded a total of 420 morphemes that was broken down into four distance levels as follows (see Figure 1):
‘identical’ level included 78 morphemes (same form, same function) accounting for 18.6% of all morphemes, for example, CuCuC in both SPD and MSA as in /kutub/ ‘books’ encoding the same function (broken plural);
‘strongly overlapping’ level consisted of 120 morphemes (slightly different forms, same function) making up 28.6% of all morphological structures, for example, CCa:C in SPD as in /sɁħa:b/ ‘friends’ versus ɁaCCa:C in MSA as in /ɁasɁħa:b/ ‘friends’ encoding the same function (broken plural);
‘partially overlapping’ level included 106 morphemes (different forms, same function) making up 25.2% of all morphemes, for example, the different morphemes/-u/ in SPD and /-u:n/ in MSA as in the present tense /btikitb-u/ and /taktub-u:n/ ‘(you (pl., masc.) are writing’, respectively, encode the same function; and
‘unique’ level comprised 116 morphemes (unique form, same/unique function) accounting for 27.6% of all morphemes, for example, ɁaCCuC in MSA only as in /Ɂaðruʕ/ ‘arms’ encoding the same function (broken plural).
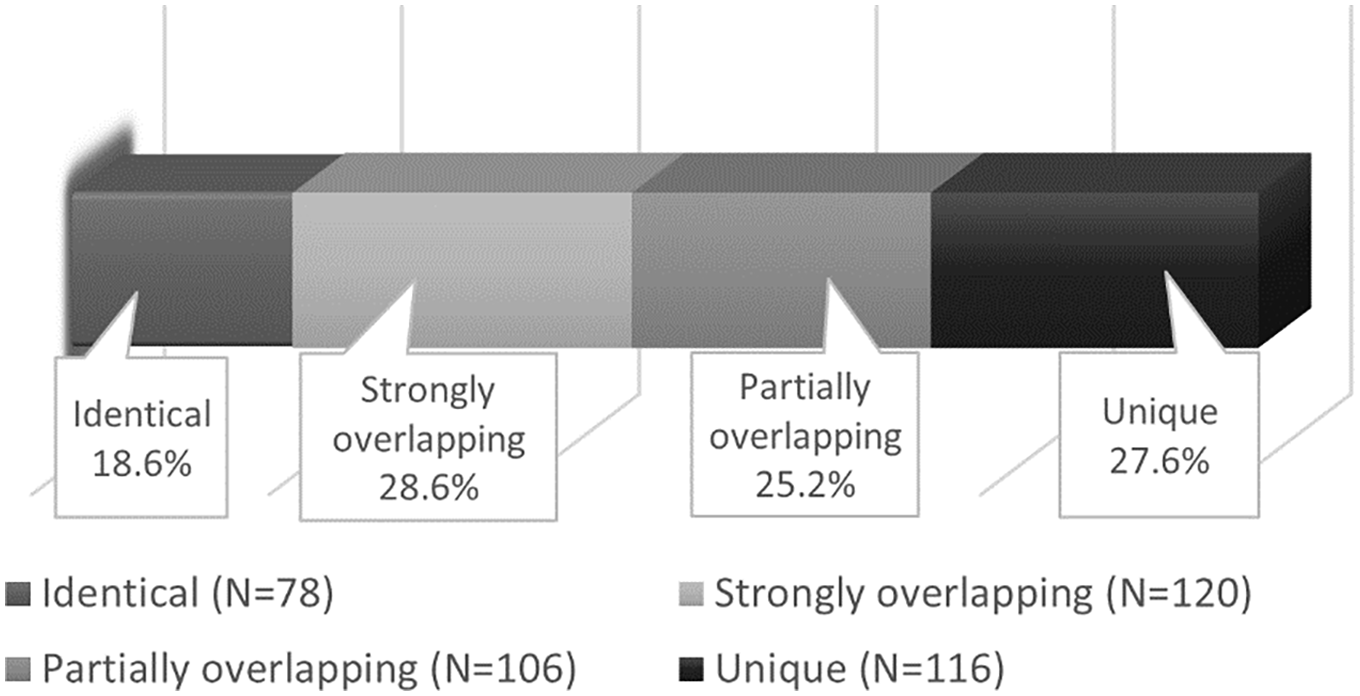
Distribution (in Percentage) of the Four Distance Levels.
Following the similar distribution of the three distance levels, ‘strongly overlapping’ (N = 120), ‘partially overlapping’ (N = 106), and ‘unique’ (N = 116), it was interesting to take a closer look at each of them on the continuum of degrees to understand the depth of the distance. This raised the following results in each of the distance levels:
The ‘strongly overlapping’ distance level, which has been classified into two degrees, revealed nearly comparable percentages, as follows: (1) ‘Strongly overlapping – degree 1’ (morphemes with morpho-phonological differences in one parameter; N = 65) comprising 54.2% of the morphemes in this level and (2) ‘Strongly overlapping – degree 2’ (morphemes with morpho-phonological differences in two parameters; N = 55) making up 45.8%.
The ‘strongly overlapping – degree 1’ has been classified into two subsets (see Figure 2): (a) one vowel change/addition/deletion (N = 57), covered the highest frequency reaching 87.7% of this degree; for example, maCCaCi in SPD as in /madrasi/ ‘a school’ versus maCCaCa in MSA as in /madrasa/ ‘a school’ (one vowel change); (b) one consonant change/addition (N = 8), covering the remaining portion of this degree comprising 12.3%; for example, baCCaC in SPD as in /baʃraħ/ ‘(I am) explaining’ versus ɁaCCaC in MSA as in /Ɂaʃraħ-u/ ‘(I am) explaining’ (one consonant change).
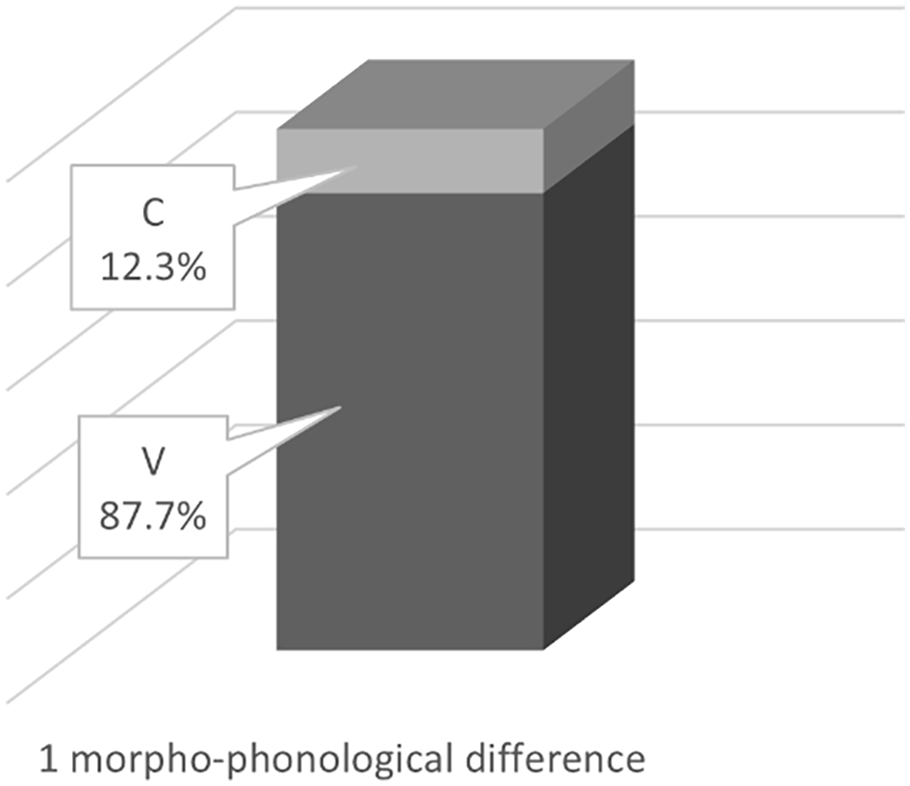
Percentages of Subsets in the ‘Strongly Overlapping – Degree 1’.
The ‘strongly overlapping – degree 2’ has been categorized into four subsets as follows (see Figure 3): (a) ‘
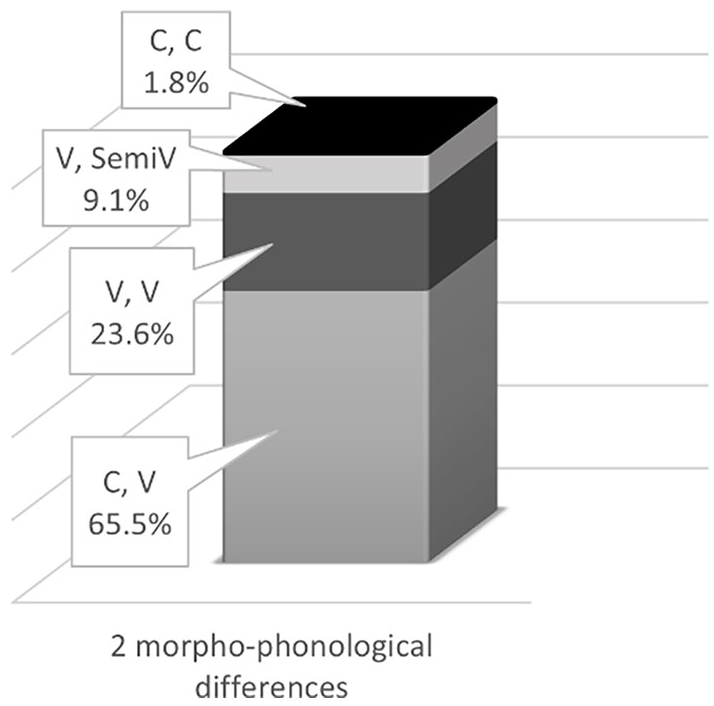
Percentages of Subsets in the ‘Strongly Overlapping – Degree 2’.
As for the ‘partially overlapping’ distance level, which has been classified into four degrees, the results revealed that ‘partially overlapping – degree 4’ (N = 80) is the most frequent degree, covering 75.5% of the morphemes in this level (e.g. the enclitics suffix /-ku/ as in /kta:b-ku/ ‘your (pl., masc.) book’ exists only in SPD, whereas /-kum/ as in /kita:ba-kum/ ‘your (pl., masc.) book’ exists only in MSA). It is followed by ‘partially overlapping – degree 3’ (N = 16) comprising 15.1% (e.g. the morpheme /-u/ in SPD as in the present tense /btikitb-u/ is used in both SPD and MSA, and the morpheme /-u:n/ in MSA as in /taktub-u:n/ ‘(you (pl., masc.) are writing’ is used only in MSA). However, ‘partially overlapping – degree 1’ (N = 6) and ‘partially overlapping – degree 2’ (N = 4) were less frequent, covering only 5.7% and 3.8%, respectively (see Figure 4). The results regarding the ‘unique’ distance level showed that the ‘unique – degree 2’ (N = 103) reached 88.8% of the morphemes in this level (e.g. the morpheme /-tunna/ as in the past tense verb /katab-tunna/ ‘(you (pl., fm.)) wrote’ marks the feminine plural only in MSA). Whereas the ‘unique – degree 1’ covered only 11.2% (e.g. the word-pattern ɁaCiCCa:Ɂ as in /ɁatɁibba:Ɂ/ ‘doctors’, which exists only in MSA) (see Figure 5).
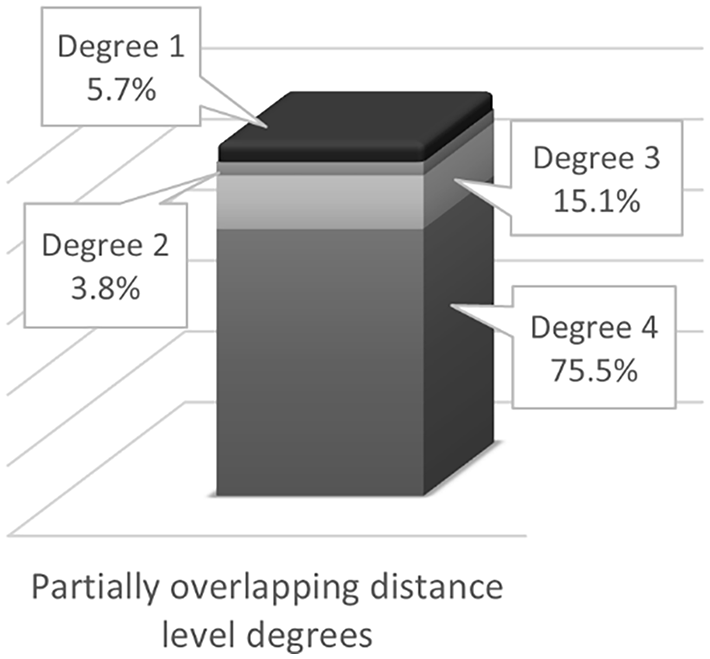
Percentages in the ‘Partially Overlapping’ Distance Level by Degrees (1–4).
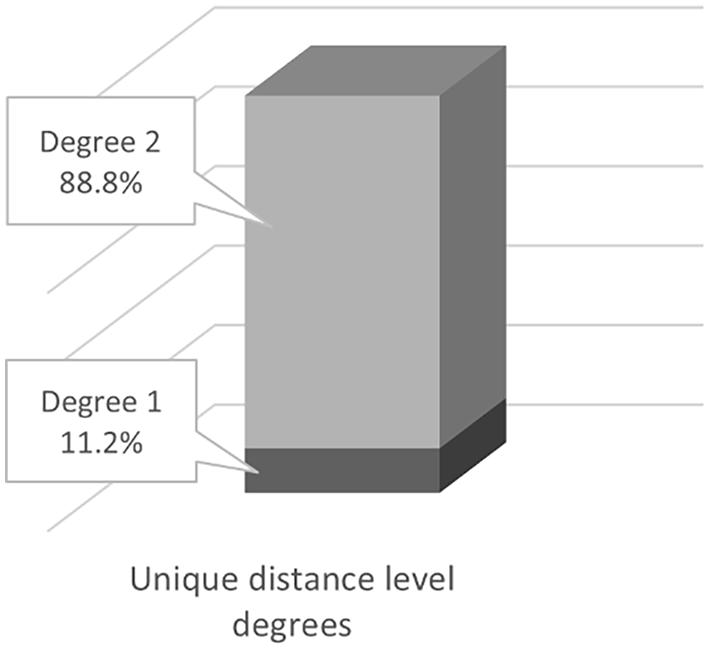
Percentages in the ‘Unique’ Distance Level by Degrees (1–2).
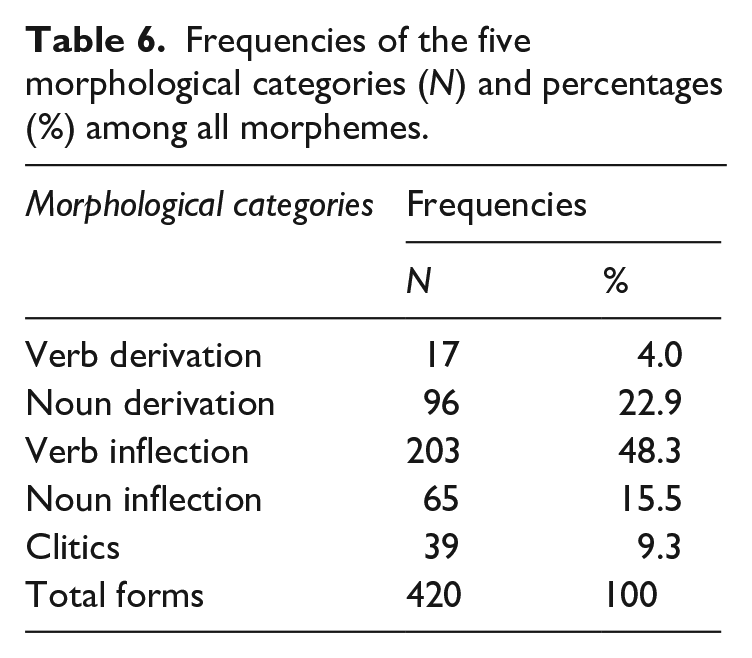
The second aim of the study was to map the morphological and lexical categories (derivations, inflections, and clitics in the nominal and verbal systems) in each of the four distance levels. Two steps were taken to achieve this goal. First, we categorized the 420 morphemes into five categories (see Table 6). The verb inflection was the most frequent category, making up 48.3% (N = 203) of all morphemes. The second most frequent category is noun derivation, which comprised 22.9 % (N = 96) of the total. This is followed by the noun inflection category, making up 15.5% (N = 65). The following category is the clitics, accounting for 9.3% (N = 39) of all morphemes. The lowest frequency was found in the verb derivation category, making up 4% (N = 17) of the total.
Frequencies of the five morphological categories (N) and percentages (%) among all morphemes.
Second, we mapped the five morphological categories in each of the four distance levels. As shown in Figure 6, the most frequent morphological category in the ‘identical’ distance level is the noun derivation (N = 44), covering 10.5% of all morphemes. The second frequent category is the noun inflections (N = 20), accounting for 4.8%. These categories are followed by the verb derivation category (N = 8), making up only 1.9%, followed by verb inflection (N = 3) and clitics (N = 3) categories comprising an equal portion, 0.7% of all morphemes. In the ‘strongly overlapping’ distance level, the verb inflection (N = 40) and noun derivation (N = 38) categories, accounted for a close portion making up 9.5% and 9% of all morphemes, respectively. The following categories are noun inflection (N = 27), making up 6.4%, while verb derivation (N = 8) and clitics (N = 7) covered only 1.9% and 1.7% of the total, respectively. In the ‘partially overlapping’ distance level, the most prevalent category is the verb inflection (N = 66), accounting for 15.7% of all morphemes, followed by clitics (N = 17), making up 4%. The noun inflection (N = 13), noun derivation (N = 9), and verb derivation (N = 1) covered the remaining proportion of the morphemes in this level as shown: 3.1%, 2.1%, and 0.2%, respectively. In the ‘unique’ distance level, the most frequent category is the verb inflection (N = 94), accounting for 22.4%, followed by the clitics category (N = 12), comprising 2.9% of all morphemes. The next categories are noun inflection (N = 5) and noun derivation (N = 5), accounting for a similar proportion of 1.2%. However, the verb derivation category does not exist at this distance level.
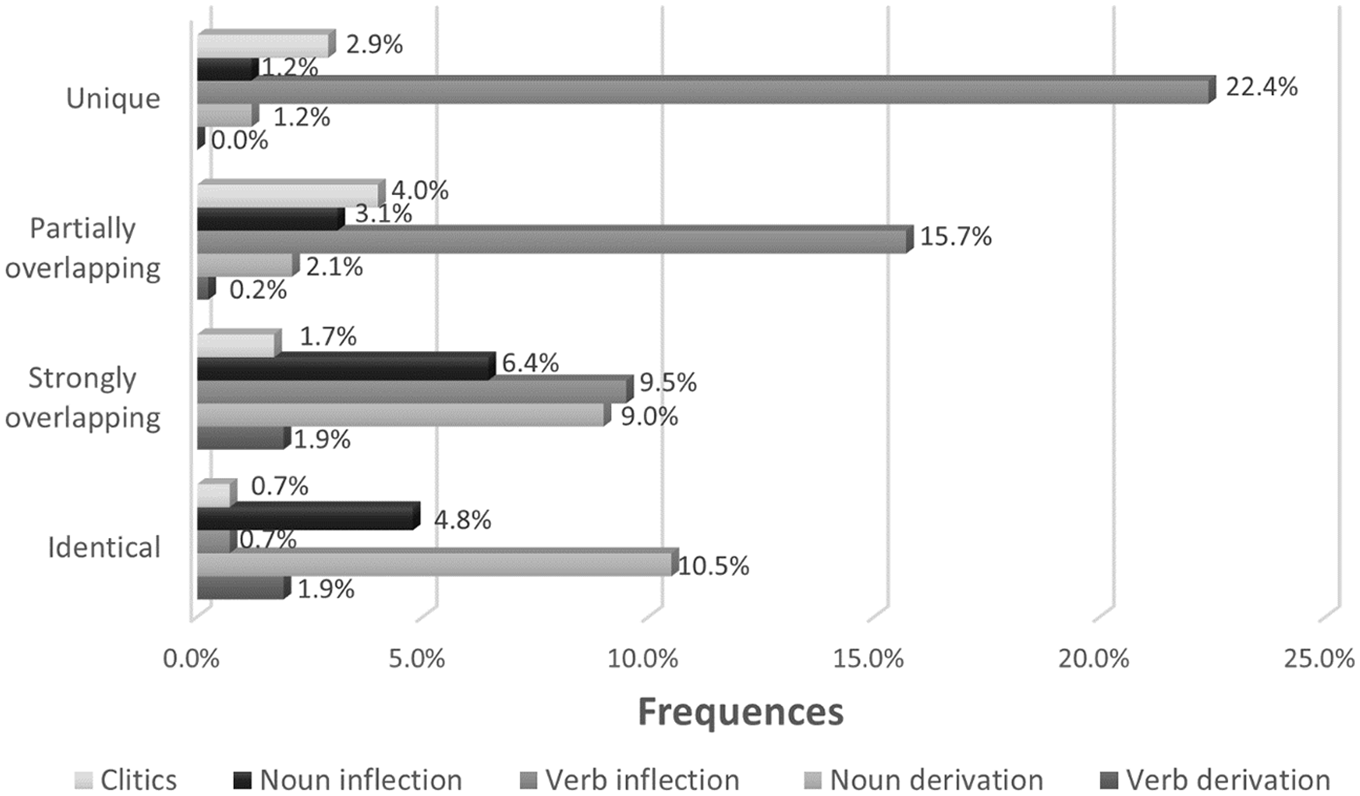
Percentages of Morphological and Lexical Categories in Each of the Four Distance Levels.
Discussion
The present study is the first to map the morphological distance from SPD to MSA in content words. This mapping was grounded on the morpheme-based approach (e.g. Cohen, 1951; Hilaal, 1990; McCarthy, 1982), suggesting that every Semitic content word is represented in the lexicon as comprised morphological units. An overview on the mapping of the morphological structures in the current study supported this claim and showed that both varieties of the words in SPD and MSA preserved the two basic morphological constituents of root-and-pattern (or more when the affixations are added).
Our first aim was to map the distance levels from SPD to MSA of the morphemes in content words by form and function. This mapping included derivations, inflections, and clitics in nominal and verbal systems. Several steps have been taken to attain this aim. First, we ranged these morphemes on an axis that varied in the extent of the distance from SPD to MSA, targeting four main levels: beginning with ‘identical’ (same form, same function), followed by ‘strongly overlapping’ (slightly different form, same function), then ‘partially overlapping (different form, same function), and ending with ‘unique’ (unique form, same/unique function). The mapping indicated that most of the morphemes are non-identical between SPD and MSA, covering 81.4%. These morphemes were distributed across three distance levels: ‘strongly overlapping’, ‘partially overlapping’, and ‘unique’, comprising 28.6%, 25.3%, and 27.6% of all morphemes, respectively. A closer look at these non-identical morphemes between SPD and MSA shows that the source of the distance stems from morphological or morpho-phonological differences. Yet, the difference of approximately two-thirds of these morphemes (N = 216, 63.2%) is morphological and placed at the extreme distance of the axis (‘partially overlapping’ and ‘unique’ distance levels), attesting very clearly that the main and conspicuous source of the distance between SPD and MSA morphemes is morphological. However, only 36.8% (N = 126) of them are situated on the axis at the closest proximity between SPD and MSA (mainly at the ‘strongly overlapping’), 8 differing in their morpho-phonological parameters. These findings are consistent with the claim that diglossia traverses all linguistic domains (Schiff & Saiegh-Haddad, 2018) and are in line with Maamouri (1998), who argued that a comparison of MSA with any existing Arabic dialects will show a situation that exhibits phonological, morphological, syntactical, and lexical differences. The current study shows for the first time that linguistic differences are remarkable in morphology.
These findings steered us to understand more in-depth the characteristics of the morphological and morpho-phonological differences. Hence, in the second step, we ranged the morphological structures in each of the three distance levels on a continuum in terms of distance degrees. This mapping revealed several significant findings. The most interesting and important finding is related to the location and type of the degrees in the ‘partially overlapping’ and ‘unique’ distance levels, where the distance is remarkable and more profound in the morphological domain, mainly at the form level. The most frequent degree in the ‘partially overlapping’ distance level, which was mapped into four distance degrees (see Figure 4), was the ‘partially overlapping – degree 4’ comprising 75.5% of the structures in this level, where the SPD morphemes exist only in SPD, while their counterparts in MSA exist only in MSA. The second most frequent degree in this level was the ‘partially overlapping – degree 3’ covering up to 15.1% of this level where the morphemes in SPD exist in both varieties, while their counterparts in MSA exist only in this variety. These two degrees are located at the extreme end of this level, close to the ‘unique’ distance level, making up together 90.6% of it. Whereas the most frequent degree in the ‘unique’ distance level, which has been mapped into two distance degrees (see Figure 5), was ‘unique – degree 2’ situated at the most extreme end of the axis, covering 88.8% of this distance level, where the morphemes exist only in MSA encoding a unique function with no parallels of morphemes and function in SPD.
These findings regarding the most frequent morphological distance degrees leave us with unanswered questions that need to be explored: To what extent do these degrees of morphological distance interfere with reading skills? Which reading abilities are sensitive to these degrees: word reading accuracy, speed, fluency, or reading comprehension? Although the effect of morphological distance on literacy development has recently begun to receive empirical attention (e.g. Schiff & Saiegh-Haddad, 2018; Tibi & Kirby, 2017), there is still much to be explored while considering the effect of this axis, which is vital for a theory of reading acquisition under a diglossic context. One of the plausible directions is that these findings may pose a serious obstacle to readers across the developmental trajectory, assuming that the more extreme the distance between SPD and MSA is, the more challenging the reading mission would be. This assumption is congruent with Saiegh-Haddad and Haj’s (2018) study, which investigated the phonological distance effect between SpA and MSA on phonological representation. They showed that children in grade 6 still found it difficult to reach an accurate phonological representation for ‘unique’ words (with completely different lexical-phonological forms between SpA and MSA) and even for ‘cognate words’ (that differ in more than ‘2 phonemes’). Similar implications can be obtained when the readers deal with written words that are located at the extreme end of the morphological axis with a remarkable distance between SPD and MSA morphemes, such as morphemes with unique forms and functions that exist in MSA only. It requires future studies that systematically examine the impact of this distance on reading throughout the developmental trajectory.
The second most important finding is related to the ‘strongly overlapping’ distance level where the differences are morpho-phonological. The results showed nearly comparable percentages of two distance degrees: ‘strongly overlapping – degree 1’ (one morpho-phonological difference) comprising 54.2% and ‘strongly overlapping – degree 2’ (two morpho-phonological differences) making up 45.8% of this level. These two degrees are initially phonological, which roamed to the morphological domain, causing a distance in the internal structure between SPD and MSA forms.
The ‘strongly overlapping – degree 1’ was classified into two subsets (see Figure 2): (1) One vowel change/addition/ deletion covering the highest frequency of this subtype reaching 87.7% of it (13.6% of all morphemes). For example, /kt
The main finding regarding the highest frequency of the one vowel difference may lead to the assumption that it is marginal and should be merged with the ‘identical’ distance level making together 32.1% of all morphemes. This assumption can be supported by Saiegh-Haddad and Haj’s (2018) claim that a distance of one vowel does not undermine lexical representation. In this study, they showed that the ‘identical’ and ‘1 vowel distant cognate’ words behaved similarly with no significant differences in their phonological representation accuracy. However, this assumption begs a pertinent question regarding the extent to which this distance is considered significant in the literacy acquisition journey. This leads to an opposite claim suggesting that the one vowel difference may pose an obstacle for novice and disabled readers that stems from the difficulty connecting words encoded in MSA to their corresponding spoken words in the reader’s mental lexicon. This difficulty may hinder the word encoding process by blocking the possibility of automatically reaching sufficient lexical identification, albeit the high degree of decipherability of the Arabic transparent mashkoul 9 script that enables accurate reading (Share, 2008). In addition, the results of the ‘strongly overlapping – degree 2’ which has been classified into four subsets (see Figure 3), revealed that the most frequent subset is ‘C, V’ covering 65.5% of this degree; followed by ‘V, V’ subset, comprising 23.6% of it. The third frequent subset, ‘V, semi-V’, covered 9.1% of this degree. The remaining ‘C, C’ subset, was less frequent, covering only 1.8%. We assume that this degree in its two morpho-phonological differences may pose challenges among novice and disabled readers similar to what has been argued previously regarding the one morpho-phonological differences.
As for the more skilled readers who are more exposed to the non-mashkoul script version (phonologically opaque script [with no short-vowel diacritics] and morphologically transparent) (Bar-On et al., 2018; Saiegh-Haddad, 2013; Saiegh-Haddad & Henkin-Roitfarb, 2014), it is believed that it encourages them to rely more on the morpho-orthographic structure of the written words (Bar-On et al., 2018; Shalhoub-Awwad, 2020). Hence, this ‘strongly overlapping’ distance level in its two distance degrees may negatively affect them in two possible ways. The first is related to both of the vowels’ subsets (one or two short vowels change/addition/deletion). This distance may hinder reading accuracy since it may lead more skilled readers to recover phonological information of the SPD word-pattern instead of its parallel in MSA. It also may impede reading fluency since it confronts them with competition between two lexical readings that stem from the overlapping between similar word-patterns, a matter that may delay recovering the MSA phonological information. Support for this explanation comes from Schiff and Saiegh-Haddad’s (2018) study showing higher word reading accuracy and fluency for SpA words (identical word forms in SpA and MSA) compared to MSA words (that exist in MSA but not in SpA) even in the non-mashkoul version. To illustrate some of the manifestations of this possibility, it is informative at this point to consider a specific example: the non-mashkoul orthographic form MTʕAWN /mutaʕa:win/ ‘cooperator’ is orthographically deep because the three short vowels /u/, /a/, and /i/ are missing. However, the first consonant /m/ and the long vowel /a:/ represented by the letters M and A are supposed to indicate the word-pattern to the reader, a matter that should enable recovering the missing phonological information by using the word-pattern mutaCa:CiC. However, due to the distance between this word-pattern in MSA and its parallel in SPD mitCa:CiC, the reader may recover the phonological information of the SPD instead of the MSA, leading to lower accuracy/fluency rates. Yet it is also possible that these more skilled readers may not recover the phonological information based on SPD during reading. These two alternatives await future studies. The second possible way is related to the ‘strongly overlapping’ distance of one or two morpho-phonological differences including at least one consonant or long vowel. We argue that this distance can have a more severe effect on reading accuracy and fluency among novice, disabled, and skilled readers. This assumption is motivated by Saiegh-Haddad and Haj’s (2018) results, which showed that the ‘identical’ phonological forms in SpA and MSA and words with ‘1 vowel distant cognates’ were the most accurate. However, the other types of ‘cognate words’ (words with ‘1 consonant distant cognates’, ‘2 phoneme distant cognates’, and more) reached lower accuracy levels, whereas the ‘unique words’ scored the lowest, across all graders (K, grades 1, 3, and 6). These findings suggest that children may still have difficulties recognizing a word that is familiar to them, though it has one consonant distance (or more) between the SpA and MSA.
The second aim of the present study was to map the five morphological and lexical categories: (1) verb derivation, (2) noun derivation, (3) verb inflection, (4) noun inflection, and (5) clitics in each of the four distance levels. The findings from this mapping provide several insights. An overall look at the distribution of the five morphological categories along the distance axis showed that the two derivational categories (verbs and nouns) and the noun inflection category are situated at the closest proximity between SPD and MSA. These categories have been scattered between the ‘identical’ and ‘strongly overlapping’ distance levels. The most significant portion was in favor of noun derivation, followed by noun inflection and verb derivation, covering 56.4%, 25.6%, and 10.3% of the ‘identical’ level, and 31.7%, 22.5%, and 6.7% of the ‘strongly overlapping’ level, respectively. The findings from the other side of the distance axis showed that the bulk of the distance between SPD and MSA appears mainly in the verb inflection category (see Figure 6), situated at the most extreme distance level. It reached a substantial portion of 81% of the ‘unique’ level, (22.4% of the total structures), in addition to the ‘partially overlapping’ comprising 62.5% of it (15.7% of the total). The clitics category was the following category after the verb inflection at the ‘unique’ level covering 10.3% of it (2.9% of the total structures), and at the ‘partially overlapping’ level, accounting for 16% of it (4% of the total). These findings provide empirical evidence for the claim that morphological differences between the dialects and MSA are marked in inflectional categories, whereas derivational morphology reveals relatively minor differences (Holes, 2004; Laks & Berman, 2014; Saiegh-Haddad, 2018).
The distribution of the verb inflection and clitics at the ‘unique – degree 2’, corroborates the frugal and efficient use of the SPD compared to MSA. We will illustrate this through the following example. In MSA, the verb in the past tense, third person has four conjugation options to mark the number (dual and plural) and gender (masculine and feminine): /katab-
Conclusion
The present study is the first to explore the morphological distance from SpA to MSA. It described the diglossic context and the remarkable orality-literacy gap of the morphological domain in general. More importantly, it points to the source of the differences in morphological categories and structures in which the distance is more extreme and profound. Mapping these differences is essential to gain a more in-depth insight into the dimension of distance and its possible effect on literacy acquisition. Hence, future research regarding the impact of the morphologically different distance levels on various reading skills (accuracy, fluency, and reading comprehension) and spelling is warranted. Schiff and Saiegh-Haddad’s (2018) study was the sole study that investigated the difference between morphological awareness in SpA versus MSA on reading performance. However, the SpA morphological awareness tasks included morphological units that existed in both varieties, whereas the MSA tasks targeted morphemes that are used only in MSA. In terms of the present study, their tasks were selected from ‘identical’ and ‘unique’ distance levels and did not include ‘strongly overlapping’ and ‘partially overlapping’ levels that covered 53.8% of all morphological structures. Thus, our thorough analysis of the morphological distance between the specific SPD and MSA is relevant to task design.
Furthermore, our findings regarding the morphological distance axis have important implications for morphological instruction and intervention. This is because reading instruction in Arabic is agnostic of the linguistic distance between SpA and MSA (Saiegh-Haddad, 2020). The Arabic curriculum in Israel for literacy preparation in preschool (3- to 6 year-olds [Ministry of Education, 2008]) relies on the assumption that the starting point in developing basic literacy skills in Arabic is spoken language, so that, it focuses solely on the spoken variety. Whereas the Curriculum for Arabic Language Education: Language, Literature and Culture, for the elementary school: Grades 1–6 (Ministry of Education, 2009) refer extensively to the linguistic distance between SpA and MSA. However, it does not provide clear guidance on the structure type in each linguistic domain and the teaching methods that need to be taken in dealing with linguistic distance. Hence, our findings can provide a clear scientific basis on which to rely and help update the curricula for both preschools and elementary schools and translate the distance levels into teacher training and appropriate materials for teaching morphology in this diglossic context. It also should assist in designing any scientifically sound, evidence-based language/reading educational program. An additional implication that may stem from our findings is the need to consider the effect of linguistic distance in the assessment of dialect speakers with dyslexia. The linguistic distance needs to be examined as a possible additional linguistic risk factor that might affect these individuals. If it turns out to have an effect, then it is essential to consider and neutralize its effects and prevent misdiagnosis of the source of dyslexia. To ensure appropriate assessment and intervention, there is a need to develop suitable tools that are sensitive and tailored to the specific dialect that the child speaks (Khamis-Dakwar & Makhoul, 2014). Our findings could provide a basis for developing such tools specified to the morphological distance from SPD to MSA and for mapping this distance in other vernaculars or other diglossic languages.
Supplemental Material
sj-docx-1-fla-10.1177_01427237221145375 – Supplemental material for Morphological distance between spoken Palestinian dialect and standard Arabic and its implications for reading acquisition
Supplemental material, sj-docx-1-fla-10.1177_01427237221145375 for Morphological distance between spoken Palestinian dialect and standard Arabic and its implications for reading acquisition by Nancy Joubran-Awadie and Yasmin Shalhoub-Awwad in First Language
Footnotes
Acknowledgements
The authors thanks Prof. David Share for his assistance in preparing this manuscript.
Author contributions
Data availability statement
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.