
Abstract
Karadöller et al. give a comprehensive review of first language acquisition in the vocal and especially bodily modalities, but they do not explicitly model a multimodal framework. The multimodal parallel architecture provides such a theoretical model that can explain both unimodal and multimodal communication. We will discuss this model, how it distinguishes what is innate and what is acquired, and how modalities relate to each other in acquisition. This approach, therefore, offers a ‘grand unified model’ situating all modalities and their acquisition into a common architecture.
Introduction
We applaud the rich depth of detail of the comprehensive review by Karadöller et al. (2025), hereafter KSO (Karadöller, Sümer, and Özyürek), of first language acquisition in a multimodal framework for the vocal and especially bodily linguistic systems. Although the authors state the necessity of situating language acquisition broadly within a multimodal framework, they do not explicitly describe a model of multimodality. The multimodal parallel architecture (MPA; Cohn & Schilperoord, 2024), expanding on Jackendoff (2002), provides exactly the type of framework that is required to explain both unimodal and multimodal communication across all modalities. In this contribution, we will discuss this model, how it distinguishes what is innate and what is acquired, and how modalities relate to each other in acquisition.
Multimodal parallel architecture
Traditional models of language span across three primary areas of structure – phonology, syntax, and semantics – but the MPA further generalizes these to account for greater richness and multimodality by using the terms ‘modality’, ‘grammar’, and ‘meaning’ (see Figure 1(a)).
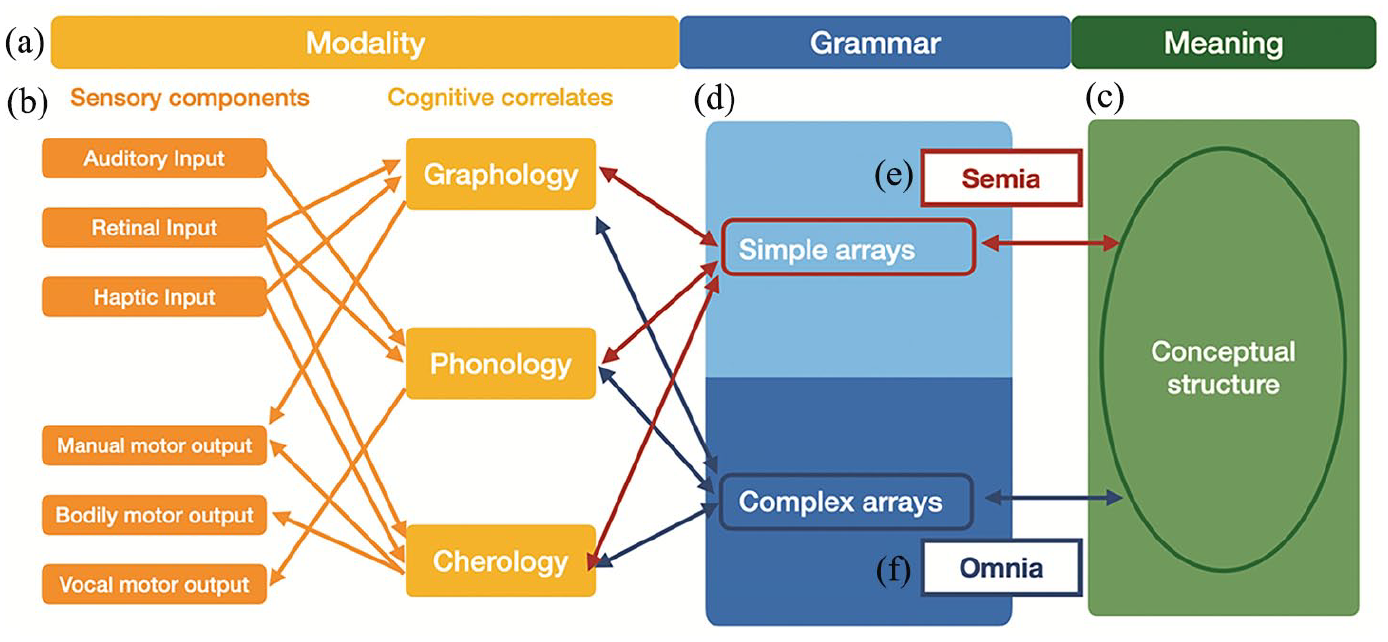
(a–d) The Multimodal Parallel Architecture With Highlights of Correspondences for (e) Semia and (f) Omnia Systems.
‘Modalities’ are a combination of both sensory signals (visual, auditory), their reception (vision, audition), and their articulation (vocal folds, hands) and the cognitive correlates abstracting across those signals, called ‘formologies’ (see Figure 1(b)). All these components are necessary for properly characterizing modalities. For example, KSO refer to gestures and sign language as the ‘visual modality’, but mostly all modalities involve visual signals. Vision is involved in seeing bodily motions (which can also be felt), just as perceiving the sounds of speech is influenced by seeing mouths move. In fact, all modalities are multisensory, making formologies a better way to distinguish them.
To this extent, the MPA specifies formologies for each specific modality, connected to various inputs and outputs for sensory signals. The ‘vocal modality’ involves sounds that are received through the auditory system and produced through the vocal folds and mouth. These speech sounds are abstracted cognitively as phonemes that are organized by phonology. The ‘bodily modality’ used to produce gestures and sign language has an independent cherology (e.g. Sandler, 2017), with visual and tactile sensory signals, received through vision and/or haptic perception, produced through bodily motions, and abstracted into cheremes and cherology.
Alongside the vocal and bodily modalities, our model also includes the ‘graphic modality’ naturally characteristic of drawing. Graphic expression has persisted for millennia, interacts in substitutive multimodal interactions in natural ways (Cohn & Schilperoord, 2024; Storment, 2024), exhibits the same neurocognitive markers as semantic and syntactic processing (Cohn, 2020), and exhibits a similar developmental trajectory (discussed below). Graphic expressions are perceived through vision, articulated through traces left by bodily motions, and abstracted into graphemes and graphology. These graphics are also extended in learned cross-modal correspondences with phonology, creating writing systems.
‘Meaning’ characterizes the conceptual structure associated with communication, that is, semantic memory (see Figure 1(c)), a supramodal hub accessed by numerous modalities (Ralph et al., 2016). Different types of signification (i.e. iconicity, indexicality, symbolicity) characterize the mapping between modalities and meanings, an inherent property of the MPA. ‘Grammar’ characterizes the principles by which elements combine. Following Jackendoff and Wittenberg (2014), we distinguish between simple grammars (i.e. with single units and linear arrays) and complex grammars (i.e. with hierarchy and/or parts-of-speech).
Various expressive behaviors emerge as interactive activation states within the MPA. Spoken languages are an interaction between the vocal modality, complex syntax (see Figure 2(a)), and meaning, while sign languages maintain a similar interaction but with the bodily modality (see Figure 2(b)). Drawn visual languages likewise use the same interactions but with the graphic modality (see Figure 2(c)). Multimodal interactions have several emergent behaviors at once. Co-speech gesture (see Figure 2(d)), for instance, combines spoken language with gesture – which uses the bodily modality and a simple grammar – to converge on a common conceptual structure. Thus, the MPA accounts for both unimodal behaviors and their various combinations.
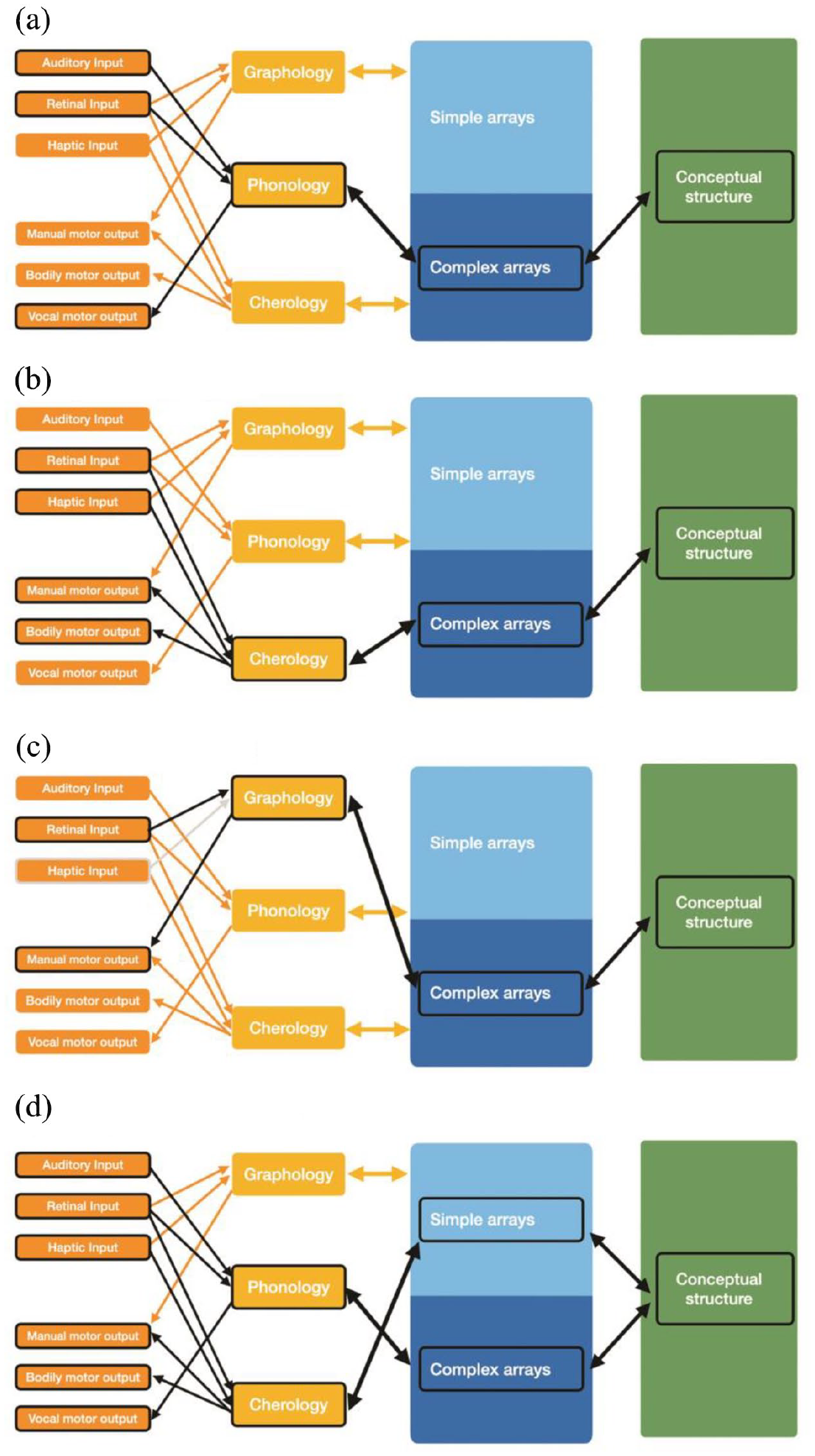
Emergent Interactions of Unimodal and Multimodal Expressive Behaviors in the Multimodal Parallel Architecture of (a) Spoken Language, (b) Sign Language, (c) Visual Language, and (d) Co-Speech Gesture.
Intrinsic to the MPA is that the affordances of modalities have consequences on the structure of their meaning and grammars, such as their relative prevalence of signs that use iconicity or indexicality. Such affordances also extend to acquisition processes, as hinted at by KSO.
Acquisition
Within the MPA, modalities and their interfaces with meaning are innate, resulting in ‘semia systems’ (i.e. gestures, doodles, etc.) which use only simple grammars and a limited lexicon. The potentiality for complex grammars is also innate, but must interact with exposure and practice with an external system to develop an ‘omnia system’ (i.e. full ‘languages’). Omnia are acquired, but all modalities persist as semia. Thus, only people with exposure and practice develop a sign language (omnia), but gestures (semia) persist for everyone, including fluent signers.
The MPA has two implications for acquisition. First, modalities are not independent, but concurrently interact in a holistic multimodal development. For example, though KSO adopt a multimodal perspective, they describe that ‘pointing . . . gestures predict future language skills’ (p. 679). This suggests that these behaviors develop independently, instead of that pointing gestures ‘precede’ vocal development within a shared system.
Second, since they are not independent, developmental trajectories should be similar across modalities. In fact they are, as highlighted by KSO, for the vocal and bodily modalities and for graphics as well. Children begin with a scribbling stage playing with graphemes (0–3 years), then map graphics onto spatial volumes (3–10 years), and only later start using lines to depict contours (8–11 years; Willats, 2005). In addition, sequencing progresses from recognition of the parts of single images (0–3 years), to basic sequencing (4–6 years), to complex patterns (5–11 years; Cohn, 2020).
Most work on graphic development has focused on the mapping between graphics and spatial concepts, but little study has been made of the acquisition of conventionalized ‘visual languages’ and their developmental trajectory. However, as in all modalities, imitation is crucial for acquisition. Children who imitate established conventions are rated as more proficient drawers and more creative (Huntsinger et al., 2011; Okada & Ishibashi, 2017), and imitation occurs at different rates based on the relative exposure to graphic omnia (Wilson, 2016). Further exploring the development of conventionalized graphics is ripe for future research. Like for other modalities, graphic development occurs across a critical learning period that apexes at puberty, with the absence of acquisition resulting in a resilient innate capacity, that is, when people ‘can’t draw’, it reflects their persisting semia of doodling (Cohn, 2012).
Abstracted across modalities, there appears to be a generalized pattern of acquisition that begins with sorting out the formology and establishing an inventory of conventionalized units (i.e. a lexicon). In addition, sequencing grows from single units to linear arrays, to complex combinatorics using stored constructions. These trajectories are layered, so development of the formology will be happening concurrently to acquiring units, which also overlaps with sequencing. However, this generalized trajectory of each modality does not factor in how modalities also interact with each other, and both are crucial to gain a complete understanding of acquisition.
Altogether, as stressed by KSO, an accurate characterization of acquisition within, across, and between all modalities requires a multimodal framework and to be discussed in those terms. The MPA does provide such a ‘grand unified model’ in that it situates all modalities, their interactions, and their acquisition into a common architecture.
Footnotes
References
 lexicon? The linguistic status of pro-text emojis
lexicon? The linguistic status of pro-text emojis