
Abstract
Children across the world acquire their first language(s) naturally, regardless of typology or modality (e.g. sign or spoken). Various attempts have been made to explain the puzzle of language acquisition using several approaches, trying to understand to what extent it can be explained by what children bring to language-learning situations as well as what they learn from the input and the interactive context. However, most of these approaches consider only speech development, thus ignoring the inherently multimodal nature of human language. As a multimodal view of language is becoming more widely adopted for the study of adult language, a multimodal approach to language acquisition is inevitable. Not only do children have the capacity to learn spoken and sign language equally easily, but spoken language acquisition consists of learning to coordinate linguistic expressions in both modalities, that is, in both speech and gesture. To provide a step forward in this direction, this article aims to synthesize findings from research studies that take a multimodal perspective on language acquisition in different sign and spoken languages, including the development of speech and accompanying gestures. Our review shows that while some aspects of language acquisition seem to be modality-independent, others might differ according to the affordances of each modality when used separately as well as together (either in sign, speech, and/or gesture). We argue that these findings need to be integrated into our understanding of language acquisition. We also identify which areas need future research for both spoken and sign language acquisition, taking into account not only multimodal but also cross-linguistic variation.
There is a growing consensus in the language sciences that human language is inherently multimodal in nature and in its primary face-to-face context (e.g. Hagoort & Özyürek, 2024; Holler & Levinson, 2019; Perniss, 2018). When both the auditory and visual modalities are accessible, languages use both vocal and visual articulators (i.e. head, hands, face, torso). When hearing and speech are not accessible (i.e. in the case of deafness), the visual modality alone can be recruited to subserve all structures and functions of language, as in the case of sign languages. That is, the human language faculty can be expressed in both modalities and even simultaneously.
An interesting consequence of this multimodal nature of language is that no language uses only speech and that all languages used in face-to-face communication involve the visual modality. That is, expressions in the visual modality (e.g. signs, co-speech gestures) are intrinsic to both sign and spoken languages. Co-speech gestures are meaningful and visible communicative movements that universally accompany spoken languages and are aligned with expressions in speech. Deaf communities use systematic and conventionalized movements of the hands, face, and body for all levels of linguistic expression in sign languages (e.g. Goldin-Meadow & Brentari, 2017; Özyürek & Woll, 2019; Perniss et al., 2015). While most theories of adult language have been based on structures expressed mostly in the spoken (and/or written) modality, it is now becoming accepted that a new multimodal language framework is needed to account for not only speech but also sign languages and co-speech gestures used in spoken languages (e.g. Hagoort & Özyürek, 2024; Kita & Emmorey, 2023; Özyürek & Woll, 2019; Vigliocco et al., 2014). For example, there is mounting evidence in the study of adult spoken language that co-speech gestures recruit language-specific brain areas of speech and sign (Özyürek, 2018; Özyürek & Woll, 2019). Yet, such a view of adult language also needs to be integrated into our understanding of language acquisition, which is mostly dominated by investigations of linguistic structures expressed in speech only. In order to contribute toward such a multimodal perspective on language acquisition in this article, we review studies that have begun to reveal what role multimodality plays in first-language acquisition both for sign languages and for co-speech gestures.
In particular, our review focuses on modality-specific aspects of visual-spatial expressions and how they are acquired as co-speech gestures and in sign languages. Our chosen focus reflects our belief that these modality-specific aspects need to be integrated into our models of language and its acquisition. Expressions in the visual modality, as in co-speech gestures or sign languages, share some unique language features and differ from expressions in speech. These features include visual indexicality (e.g. pointing to a bottle saying ‘this’), visual iconicity (e.g. a drinking gesture to mean bottle or the drinking action itself), and simultaneity in the form of using speech with gestures in spoken languages and the concurrent use of different articulators (hands, face, and body) to represent multiple referents or arguments in sign languages (Slonimska, 2022; Slonimska et al., 2020). These modality-specific features allow different ways to express information (e.g. in indexical, iconic, and simultaneous ways) than those of the sequential and arbitrary nature of most expressions in speech. Thus, how they are recruited during language acquisition allows them to provide different insights into the language-acquisition process.
These modality-specific features of expressions in co-speech gestures and signs might have different consequences for language acquisition than for speech alone. For example, as infants begin to express their first words in speech they can already point to objects and places related to what is expressed in speech (e.g. pointing to a bottle and saying ‘drink’) showing that children can express two arguments instead of one when the multimodal utterance is taken into account. Similarly, a signing baby might point to a bottle by hand and produce a negation sign by shaking their head at the same time. Taking such visual modality-specific expressions into account in language acquisition might portray a different (or similar) account of how children go about acquiring a language (Goldin-Meadow, 2014). For example, some expressions or language structures might appear earlier in the visual modality or in different ways than in speech, such as in the development of vocabulary, syntactic, morphosyntactic, and pragmatic expressions or narrative structure (e.g. Karadöller et al., 2025; Sümer, 2015; Sümer et al., 2014, 2017), as we will discuss further in the current article.
As multimodal language acquisition is already a relatively big field, in this review, we will only focus on the aspects of first-language acquisition where modality-specific aspects of visual expressions might modulate (or not) the language-acquisition process when pointing, iconicity, and simultaneity are considered. For example, acquiring iconic structures in the visual modality with or in place of arbitrary spoken language structures might occur early in the acquisition process. Furthermore, simultaneity might provide children with different ways to express linguistic structures that are different from the sequential structures of spoken language, which needs to be accounted for in language acquisition.
This review focuses on typical first-language acquisition in production, leaving out second-language acquisition, multimodal input, interactive features of the acquisition process, atypical cases of language acquisition, as well as language comprehension due to space limitations. However, we believe that a unified multimodal view of language acquisition might be foundational for other types and aspects of language acquisition. Below, we first synthesize the literature on language acquisition when both speech and co-speech gestures are taken into account, and then we move on to sign language acquisition, focusing on pointing, iconicity, and simultaneity.
Gestures in spoken language acquisition
Gestures are the actions of the hands, body, and face used as part of communication and mostly accompanying speech (Kendon, 2004). Gesture use is universal, and all children and adults in every speaking community are considered to use gestures as no evidence to the contrary has yet been encountered. Interestingly, the universality of gesture use in communication and in language acquisition is independent of the frequency of gestures in the input (e.g. evidence for the similar trajectory of the emergence of pointing in different cultures, Liszkowski et al., 2012). Furthermore, the ability to gesture does not need gestural input, as children and adults who are congenitally blind also use gestures to accompany speech (Iverson & Goldin-Meadow, 1997; Mamus et al., 2023; Özçalışkan et al., 2016). Gestures have also been shown to play a crucial role in communication and cognition and are part of adults’ language structures–albeit they show variation across individuals (Özer & Göksun, 2020) and languages (Özyürek et al., 2008).
Despite being an essential part of cognition, communication, and language, linguistic studies and theories often overlook the role of gestures in spoken language acquisition and focus solely on examining spoken linguistic structures. Initial attempts to understand the role and extent of gestures in language have focused on whether gestures are entirely independent of speech (i.e. the free imagery hypothesis, de Ruiter, 1998, 2000; Krauss et al., 2000) or whether they are closely linked to speech and are limited to expressing information expressed in speech in visual-spatial ways (e.g. Butterworth & Hadar, 1989). More recently, the synthesis of findings from many languages has shown that gestures are not entirely independent of language; and at the same time, they are linked to imagery and are embodied (embodied cognition: the notion that cognition is deeply rooted in the body’s interaction with the world; Hostetter & Alibali, 2019; Kita & Özyürek, 2003; Özyürek, 2018). Gestures may even be a precursor to language and thought processes (i.e. the gesture-for-conceptualization hypothesis, Kita et al., 2017; also see the article by Avcılar et al., 2022 for a discussion). Therefore, achieving a complete picture of language acquisition is impossible without understanding the role and functions of gestures in language acquisition.
Taking these functions of co-speech gestures into account, in this part of the review, we synthesize the accumulated evidence on the role of gestures in language acquisition, focusing on pointing and iconicity. We review these roles in the context of first-word acquisition, sentence production, vocabulary development, and the expression of complex conceptual domains such as relational language. Before this, we briefly review the types of different gestures accompanying speech.
Types of gestures accompanying speech
Gestures have many types and communicative functions (Kendon, 2004; McNeill, 1992, 2005). These types include pointing, iconic, emblem, and beat gestures. Although pointing and iconic gestures are typically meaningful only in the context of the speech, emblem gestures have a meaning on their own and can be used in the absence of speech. Finally, beat gestures are the rapid hand movements produced following the rhythm of speech (McNeill, 1992).
Pointing gestures are typically formed by extending the arm, hand, and index finger. They are often used to indicate locations, directions, persons, and objects and are often accompanied by demonstrative and/or personal pronouns (e.g. Peeters & Özyürek, 2016) or by a full noun, or sometimes they are used in isolation (see the articles by Azar et al., 2019; Kita, 2003 for more information). For example, a pointing gesture accompanying the sentence ‘I want the apple over there’, which refers to one apple among many others, conveys the information about which apple is being referred to in the sentence and its location in the immediate environment. Pointing to an empty gesture space might be associated with pronouns or locations in narrative space.
Iconic gestures have semantic content, mostly specified in the particular context of the speech with which they co-occur. They are used to represent an object, person, place, or event visually through the shape or movement of the hand or the relative positioning of the two hands (e.g. McNeill, 1992). Iconic gestures bear visually-motivated similarities between the handshapes they depict and the objects, events, event components, or locations they represent (Furman et al., 2014; Göksun et al., 2010; Karadöller et al., 2025). For example, a stirring motion made with the hand while talking about cooking is visually and structurally similar to the stirring action (see Figure 2 for more iconic gesture examples). Although iconic gestures are visually motivated, the meaning they express is mostly based on the speech they accompany. Indeed, experimental studies have shown that the meaning of these gestures is quite ambiguous in the absence of speech (Krauss et al., 1995).
In emblem gestures, a relatively arbitrary relationship exists between the gesture form and its meaning. Due to this relationship, emblem gestures are similar to words in spoken languages. For example, there is no similarity between the conventional gesture (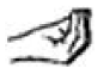 ) and the meaning it represents in the Turkish context, i.e. ‘delicious’.). Therefore, even when emblem gestures do not accompany speech, the meaning they represent is known by most language users (McNeill, 1992).
) and the meaning it represents in the Turkish context, i.e. ‘delicious’.). Therefore, even when emblem gestures do not accompany speech, the meaning they represent is known by most language users (McNeill, 1992).
Finally, beat gestures (Figure 1) serve important roles in pragmatics, information structure, and phrasal organization. They are used to emphasize parts of speech at the information structure level to express prominence on these parts (McNeill, 1992).
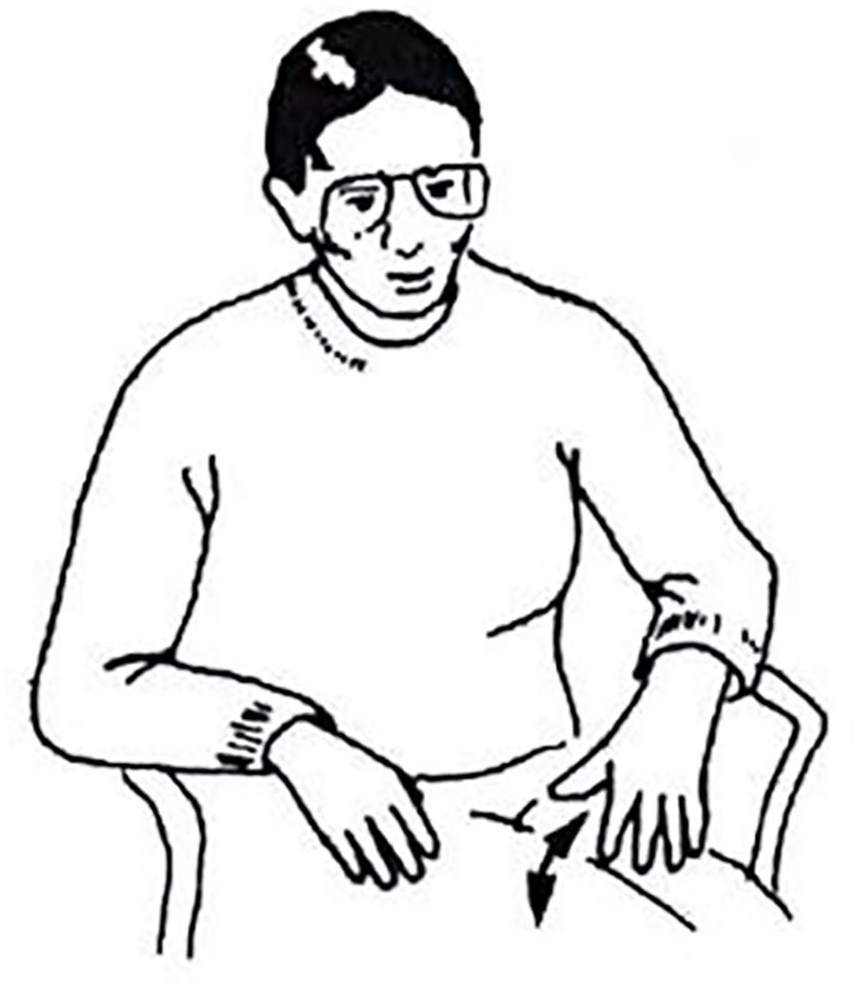
Example of a Beat Gesture.
Although all these gesture types are present in everyday multimodal communication and may play a role in language acquisition, the role of pointing and iconic gestures has been more extensively studied than that of beat and emblem gestures (but see the work of Esteve-Gibert et al., 2022; Rohrer et al., 2022). In the sections to come, we review what is known about the role of pointing and iconic gestures in language acquisition, including how they are simultaneously used with speech, by focusing on the emergence of first words, first sentences, vocabulary development, and the acquisition of specific terminology to communicate about specific domains such as spatial and causal relationships, motion event descriptions, and narrative recall.
Role of pointing gestures in spoken language acquisition
Pointing gestures are essential to children's first-language acquisition (e.g. Kirk et al., 2022; McGillion et al., 2017). Pointing as a communicative act appears around infants’ first birthday, regardless of the culture they are born into (Bates, 1979; Bates & Dick, 2002; Rüther & Liszkowski, 2023). Infants use pointing to signal their needs and interests to their caregivers (e.g. Guevara & Rodríguez, 2023; Tomasello et al., 2007), and points carry an antecedent role in delivering their social motivation for communication (e.g. Matthews et al., 2012). Pointing is used across a range of diverse cultural settings, likely constituting a gestural universal (Liszkowski et al., 2012). Moreover, using pointing gestures for communication is a crucial milestone for language development, as they are the most reliable indicators that the first words are on their way (e.g. Colonnesi et al., 2010). Delays in index-finger pointing have been associated with language delays (e.g. Lüke et al., 2017) and even atypical development (e.g. Sansavini et al., 2019).
Considering the importance of pointing gestures in language development, Rüther and Liszkowski (2023) investigated the ontogenetic origins of pointing gestures by following dyadic interactions between 31 infants and their parents when children were 8–13 months of age through a ‘decorated room paradigm’ (Liszkowski et al., 2012; Liszkowski & Tomasello, 2011). In this paradigm, parents and infants wander around a room decorated with 20 interesting objects (e.g. photos of animals, flowers, etc.) hung on the walls and ceilings. Parents are asked to look at the objects together with their infant while holding them on their hips. Researchers video-recorded these dyadic interactions and later coded for the presence of parent pointing and infants’ earlier emerging showing, hand-pointing, and point-following frequencies. Results showed an increase in all pointing behaviors as a function of age. Moreover, caregiver pointing and infants’ earlier pointing behaviors longitudinally predicted the age of emergence of index-finger pointing. This study advances our understanding of the ontogeny of human pointing by demonstrating the role of early interactional behaviors between parents and children in the emergence of index-finger pointing (see also the study by Liszkowski & Rüther, 2021 for extended discussion).
Once children start using pointing gestures, these gestures predict future language skills. Several studies on infant pointing have demonstrated that children use pointing gestures before they say their first words (e.g. Iverson & Goldin-Meadow, 2005). Before children can say the word ‘ball’, they point to a ball to indicate their need and desire to communicate about it. For instance, Iverson and Goldin-Meadow (2005) followed 10 children longitudinally between the ages of 10 and 24 months by videotaping their 30-minute interactions with their caregivers at home every month. Researchers later coded these interactions for the presence of communicative gestures and speech. Results showed that children’s early pointing gestures have a positive relationship with the early words that they subsequently utter. Pointing use seems to provide alternative ways for children to refer to objects in the visual modality when they do not yet produce words for those objects.
Pointing gestures are the most dominant communication strategy before words appear, but they are not restricted to this period. Children continue to use pointing gestures after they begin to express their first words. Children use speech-pointing gesture combinations before forming two-word utterances or combining words into sentences (Butcher & Goldin-Meadow, 2000; Capirci et al., 1996; Goldin-Meadow & Butcher, 2003; Greenfield & Smith, 1976; Iverson & Goldin-Meadow, 2005; Özçalışkan & Goldin-Meadow, 2005, 2009). For instance, before they start using two words (e.g. ‘my ball’), they point to themselves and say ‘ball’ to express that the ball belongs to them. In the same study, Iverson and Goldin-Meadow (2005) further explored whether children use speech-gesture combinations either in a supplementary or complementary fashion and whether using these multimodal compounds relates to using two-word utterances. Results showed that all children used speech-gesture combinations of either nature for a couple of months before forming two-word utterances. Overall, these studies showed that pointing gesture use is not only a precursor to the emergence of spoken words but also an indicator of the formation of two-word utterances (e.g. Iverson & Goldin-Meadow, 2005; Özçalışkan & Goldin-Meadow, 2005, 2009).
Pointing gesture use also indicates children’s future vocabulary size (e.g. Acredolo & Goodwyn, 1988; Goldin-Meadow & Butcher, 2003; Rowe & Goldin-Meadow, 2009a, 2009b; Rowe et al., 2006; Salo et al., 2018; but see the article by Blake et al., 2003). In most of these studies, gestures that children used were mostly but not exclusively in the form of pointing. Although few in number, some children started to use iconic gestures in addition to points. In one of these studies, Rowe and colleagues (2006) recorded daily home activities of 53 parent-child dyads every 4 months when children were aged between 14 and 34 months. They also administered the Peabody Picture Vocabulary Test (PPVT) at 42 months. Results showed that children’s gesture use at 14 months predicts their vocabulary size at 42 months. These results were robust and held even after controlling for children’s early vocabulary knowledge and demographics such as SES (Socio-Economic Status) and parental gesture use.
Nevertheless, more recent studies investigating the potential correlates of infant pointing frequency have underlined the importance of SES (e.g. Ger et al., 2023; Rowe & Goldin-Meadow, 2009a) and parental gesture use (Ertaş et al., 2023). For instance, Ger and colleagues (2023) followed 56 Turkish-speaking infants monthly from 8 to 12 months of age to measure the frequency of index-finger pointing along with several candidate correlates, such as SES, mothers' pointing production, and infants' point-following to targets in front of and behind them. Results showed that infants' pointing frequency increases as they age, and their abilities to track and follow their parent's pointing (i.e. point-following abilities) were positively associated with their own pointing frequency. Moreover, high-SES infants had a steeper increase and a higher pointing frequency than the low-SES infants from 10 months onwards, possibly due to higher-SES parents having more responsive and less controlling behaviors (Koşkulu et al., 2021; see also the article by Liszkowski & Rüther, 2021 for alternative mechanisms that potentially moderate the relationship between SES and infant pointing such as caregiver-responsiveness). Maternal pointing frequency was not associated with infant pointing frequency at any age. Another study (Ertaş et al., 2023) investigated the same infants at a later time point in development (14 and 18 months of age) and measured infants’ and parents' index-finger-pointing frequency as well as their direct (lexical processing efficiency via looking while listening task) and indirect (parent-completed Turkish Communicative Development Inventory; Aksu-Koç et al., 2019) vocabulary proficiency. They found that infants’ index-finger-pointing frequency at 14 months predicted their vocabulary development prospectively at 18 months when measured directly via a looking while listening task. Moreover, neither maternal pointing nor infants’ own pointing predicted their vocabulary when measured indirectly via parent-completed inventory. These recent studies extend the evidence on the relationship between pointing and language acquisition with more direct measures of vocabulary (Ertaş et al., 2023), shedding more light on the relationship between early pointing and later language abilities (Ger et al., 2023).
The contribution of pointing gestures to language acquisition continues during preschool (see the study by Cameron & Xu, 2011 for the use of pointing in narrative recall) and school-age periods (see the study by Karadöller et al., 2019, 2025 for the use of pointing gestures to abstract space in describing spatial relationships between objects). During these periods, the relationship between pointing and speech seems to change from pointing being a precursor to speech to pointing being a facilitator. To investigate the role of gestures in narrative recall, Cameron and Xu (2011) investigated 30 children aged between 49 and 58 months in recalling narratives and their use of pointing gestures. Results showed that children who were instructed to point to the locations on the map while retelling the narrative narrated more details about the story than children who were asked to keep their hands still. Cameron and Xu (2011) discussed the possible underlying mechanisms for using gestures to lighten the cognitive load (e.g. Goldin-Meadow et al., 2001; Wagner et al., 2004) and facilitate lexical search (Krauss et al., 1996). Overall, these results underline the scaffolding role of pointing gestures in preschool children’s narrative recall.
Finally, pointing gestures to abstract spaces are also used as a visual-spatial compensatory mechanism to missing speech. For example, school-aged children use pointing gestures to provide spatial information that is missing in their speech when expressing information in cognitively challenging domains, such as when describing relative locations for objects that are in a left-right relationship to one another other (Karadöller et al., 2019, 2025). However, pointing gestures are not the only visual expressions used by children; they also employ iconic gestures, which we review in the next section.
Role of iconic gestures in spoken language acquisition
As children develop in their language use and cognition, they communicate beyond indexicality and can gesture about objects and concepts. Sometime between 17 and 36 months of age, they begin to use iconic gestures that depict semantic and visual characteristics of objects, actions, and events (e.g. Capirci et al., 2005; Furman et al., 2014; Özçalışkan et al., 2014). A tight link has been established between early action representations and the appearance of gestures and/or first words (Capirci et al., 2005; see also the article by Volterra et al., 2017). A longitudinal study investigating action, gesture, and word use of Italian-speaking children between 10 and 23 months of age showed that children demonstrate their understanding of meanings by initially practicing actions associated with specific objects (e.g. pushing a little car) and then using iconic gestures and/or words semantically related to these actions (Capirci et al., 2005).
The order between iconic gesture use and the appearance of words related to these gestures seems to be somewhat different from that for pointing. Although pointing gestures consistently precede children’s first words, the appearance of iconic gestures does not precede speech but rather develops together with the children’s use of verbs that correspond to these gestures (Özçalışkan et al., 2014). For instance, Özçalışkan and colleagues (2014) investigated spontaneous speech and gesture use of 40 American English-speaking children from 14 to 34 months of age in their daily interaction with their mothers. Later, they coded these interactions for the presence of gestures representing actions and action verbs in children's repertoire. They found that children produce their first iconic gestures 6 months later from their first verbs related to these actions. Moreover, iconic gestures increased in frequency together with the use of verbs, and over time, these gestures began to convey meanings that were not yet expressed in speech. Therefore, rather than preceding verbs, gestures possibly allow children to represent actions iconically while they produce these verbs. Iconic gestures might also compensate for the lack of specific semantic knowledge in verbs representing these actions only after children acquire a verb system.
Acquiring a verb system is not the only challenge children face in their language-acquisition journey. They need to learn language terms to talk about conceptually-challenging domains such as expressing causal relationships (e.g. Göksun et al., 2010) or spatial relations between objects (e.g. Karadöller et al., 2025). Iconic gesture use precedes the acquisition of terms to communicate about complex conceptual domains, such as spatial relations between objects, events, and/or event components, causal relationships, and so on. Several studies have demonstrated that children capitalize on using iconic gestures to compensate for the lexical terminology they lack when communicating about these domains. As a result, they use gestures more frequently than adults (e.g. Austin & Sweller, 2014; Church et al., 2000; Karadöller et al., 2025; Sauter et al., 2012). The main factor underlying children's high frequency of gesture use is that gestures support speech by creating an alternative communication channel (Krauss et al., 2000; Melinger & Levelt, 2004). This is especially the case when the development of language structures for complex conceptual themes lags behind cognitive development for these concepts (Church & Goldin-Meadow, 1986; Perry et al., 1992). In these instances, gestures convey conceptual information that language structures cannot yet express. This is often seen in the expression of conceptually-challenging categories such as spatial relationships or causal events (Austin & Sweller, 2014; Calero et al., 2019; Furman et al., 2014; Göksun et al., 2010; Karadöller et al., 2019, 2025; Karadöller, Sümer, & Özyürek, 2021; Karadöller, Sümer, Ünal, & Özyürek, 2021). For instance, children use gestures to convey information that is missing from their speech when they cannot express spatial terms such as ‘Left-Right’ (e.g. Karadöller et al., 2019, 2025; Karadöller, Sümer, & Özyürek, 2021; Karadöller, Sümer, Ünal, & Özyürek, 2021) or the grammar structures used to talk about causal events (e.g. Göksun et al., 2010).
Even though children start to communicate about spatial relations between objects using spatial terms very early in life, such as ‘In-On’ appearing at age 2, followed by ‘Front-Behind’ at the age of 5 years (e.g. Johnston & Slobin, 1979), using spatial terms to refer to left-right relations between objects does not usually appear until children are 8 years or older (Clark, 1973). Children do not often use ‘Left-Right’ in the early stages of their language development; instead, they use somewhat ambiguous spatial terms, such as ‘Side’ or ‘Next to’ (Figure 2). In these instances, they resort to gestures to indicate the exact relationship they want to convey, which is missing in their speech (Karadöller et al., 2019, 2022; Karadöller, Sümer, & Özyürek, 2021; Sümer, 2015). These findings reveal that gestures support their communication about spatial relationships that are known at a conceptual level but not yet expressed in speech. Moreover, these findings also highlight the importance of multimodality's crucial role and function in language acquisition.

Spatial Description of an 8-Year-Old Turkish-Speaking Child Using a General Spatial Term (Side) in Speech and Iconic Hand Placement Gestures that Depict More Specifically the Relative Locations of Objects to Each Other.
Similar to what has been found for gestures aiding the communication of spatial relations between objects, studies show that children use gestures to compensate for missing information when describing causal relationships related to events. For instance, Göksun and colleagues (2010) asked 64 preschoolers aged between 2.5 and 5 years to describe an action in which the experimenter pushed a ball across a small pool with a stick. Results show that younger children produced noncausal sentences and location gestures to refer to the goal of the action. However, older children also used gestures that conveyed missing information in speech about the instrument and the direction of the action. These results underscore not only a close relationship between action representations (e.g. Capirci et al., 2005) and children’s manifestation of these representations via the use of gestures but also the role of gestures in carrying causal information before children can form complete sentences to describe causal relationships related to these events.
In addition to gestures aiding the communication of conceptually-challenging domains, narrative development stands as another domain that demonstrates the role of iconic gestures in language acquisition, especially when referring to character viewpoints. Although previous work on character introduction in narratives suggests that children start to introduce characters around 6 years of age (e.g. Bower & Morrow, 1990), recent studies investigating multimodal referent introduction in narratives found that children can already understand character viewpoint and can introduce characters via gestures before doing so in speech (e.g. Demir et al., 2015; Stites & Özçalışkan, 2017). For instance, Stites and Özçalışkan (2017) asked 36 children between 4 and 6 years of age to watch and tell a cartoon that depicted Sylvester climbing up a drainpipe to catch Tweety, then swallowing a bowling ball thrown by Tweety and rolling into a bowling alley with the ball in his stomach. Results showed that 5-year-olds can introduce the character with a pronoun along with iconic gestures that show the character from the character's point of view (e.g. raising the body and bringing the hands to the side of the face like cat claws when saying, ‘He is climbing up the pipe’). These results provide multimodal evidence that children acquire character viewpoints in narratives and can introduce characters together with their perspectives via speech-gesture combinations before expressing them exclusively in their speech.
Overall, gestures accompanying speech are not only an alternative communication channel that supports the acquisition of linguistic structures (e.g. Alibali et al., 2009; Church et al., 2000; Colletta et al., 2010; Karadöller et al., 2025), but they are also a communication strategy that is frequently used by adults (McNeill, 1992). As children progress in their cognitive skills and can employ linguistic terminology to refer to their thought processes, the role and functions of gestures may shift from being complementary (i.e. conveying information missing in speech) to being co-expressive (i.e. conveying information that is already present in speech) (e.g. Karadöller et al., 2019, 2025). The frequency and the role of gestures (complementary or co-expressive) in adulthood may vary across individuals (see the article by Özer & Göksun, 2020 for a review).
Finally, it has been shown that iconic gestures show variability in different languages, varying with different typological structures (see the article by Ünal et al., 2024 for a review). Several studies demonstrated a language-specific patterning of gesture use early in development as a function of age, especially when conveying information related to event components that show cross-linguistic variability (e.g. Furman et al., 2006, 2010, 2014; Gullberg et al., 2008; Özyürek et al., 2008). Semantic elements of motion events (agent, action, figure, path, manner, etc.) are mapped onto lexical and syntactic structures differently across languages (Talmy, 2000). These differences lead to variations in the constructions preferred by the speakers of different languages (Kita, 2009; Ünal et al., 2024). Iconic gestures have also been found to be sensitive to cross-linguistic differences. For instance, in caused-motion events (e.g. she put the toy away), the main semantic elements of caused-motion (action and path) can be encoded in the verb (e.g. kaldır- put.away) in verb-framed languages such as Turkish. Elements of the same event can also be represented by encoding the action in the verb (e.g. put) and path in the satellite (e.g. away) in satellite-framed languages such as English. Previous research has shown Turkish-speaking children’s speech and iconic gestures to manifest this linguistic specificity (Furman et al., 2014). Specifically, Turkish-speaking children encoded the semantic elements of caused-motion in the verb in their speech. Moreover, their gesture also reinforced or supplemented their speech by encoding these semantic elements in language-specific ways, although these types of gestures were scarce in English-speaking children’s repertoire. The authors argue that the language children learn has the potential to shape the amount and the type of gestures they use in their first years of life from 14 and 19 months onward, respectively (Furman et al., 2014). These results suggest that the emergence of iconic gestures (i.e. involving actions) might be facilitated in languages where verbs are more central and allow for verbs and iconic gestures to emerge together early in development.
Cross-linguistic differences in motion event descriptions (e.g. Boy run down the stairs) are also present in how manner and path are encoded. For instance, Japanese and Turkish encode the manner and the path of a motion event in separate verbs and clauses (e.g. koşarak indi, run descent) in speech, and speakers of these languages also use separate gestures for them. Whereas in other languages, such as English, these elements are encoded in a single clause (using a verb and a satellite) (e.g. run down) in speech, and speakers of English also use a single gesture to represent these elements (e.g. Kita & Özyürek, 2003). Özyürek and colleagues (2008) investigated 3-, 5-, and 9-year-old children and adults from two typologically different languages (English and Turkish) in encoding event components via speech and their iconic gesture use. Participants watched and retold 10 videoclips of motion events (e.g. Tomato Man slides up a hill after being pushed by Green Man). Although children use adult-like linguistic structures in speech to encode these elements from 3 years onwards, their adult-like gestural representations take longer to emerge (about 9 years of age). That is, both groups of children start in similar ways (using separated gestures for manner and path), but English-speaking children, over time, start using conflated gestures. These findings demonstrate that language-specific encoding of events develops earlier in speech than in gesture. This development requires considerable time until gestures are shaped by language over time, especially for languages where more than one event component is expressed in one clause.
Interim summary: gestures in spoken language acquisition
Gestures are integral to language (Kendon, 2004) and are used by speakers across all communities (Liszkowski et al., 2012), including blind speakers who have never seen gestures (Mamus et al., 2023). In this part of the article, we summarized the role and functions of gestures in first-language acquisition by synthesizing the evidence focusing on pointing and iconic gestures. This synthesis demonstrated several pieces of evidence that both pointing and iconic gestures have an important role in providing a visual-spatial scaffold for the emergence of words and language structures. It also showed that since gestures are closely linked to spoken languages, they are embedded into and develop in tandem with spoken components of language as children age.
Many studies reviewed here show clear evidence for gestures preceding spoken language acquisition. First, pointing gestures have been found to be a precursor to and predictor of several domains of language acquisition, such as the appearance of first words, first two-word utterances (e.g. Iverson & Goldin-Meadow, 2005), and vocabulary size (Rowe et al., 2006). Moreover, iconic gestures have been found to be a precursor to the acquisition of terms and linguistic structures concerning conceptually-challenging relational domains such as spatial (e.g. Karadöller et al., 2025) and causal (e.g. Göksun et al., 2010) relationships, and narrative recall (e.g. Stites & Özçalışkan, 2017).
Gestures, however, cannot always be considered a precursor to speech as, in some cases, they seem to develop in tandem with speech and are sensitive to language specificity. Empirical evidence for gestures to follow speech development centers mostly around iconic gestures. Specifically, iconic gestures for actions have been found to follow the development of the verbs or emerge together, allowing children to express the semantic specificity of the actions (e.g. Özçalışkan et al., 2014). However, the emergence of iconic gestures might be facilitated in languages where verbs are more central and where verbs and iconic gestures might emerge together early in development (Furman et al., 2014). Moreover, iconic gestures encoding motion event components are closely tied to the cross-linguistic variation in encoding these components (e.g. Özyürek et al., 2008) and might look language-specific after language specificity emerges in speech (but see the article by Özçalışkan et al., 2024 for showing language specificity for cases when speech and gesture might develop together).
Therefore, the development of pointing and iconic gestures goes hand in hand with language development. When gestures are considered together with what is expressed in speech, it becomes clear that children have more expressive capabilities than can be expressed in their speech. Thus, what children know and can express as they acquire language might be very limiting when one focuses only on speech. Gestures also reveal language-specific developmental trajectories, such as the early action and verb bias that we see in the development of Turkish causal events. This part of the review therefore calls for revisiting current language and cognitive development theories across different languages with a multimodal viewpoint.
Sign language acquisition
The studies discussed earlier in this article provide robust evidence for the intricate relationship between gesture use and first-language acquisition at different stages and for different domains of language. Speaking children employ all mediums available to them to communicate their message and interact with their interlocutors. For deaf children, however, the visual modality is the primary modality accessible to them, and they mainly use their hands and body (including eye gaze and facial expressions) to construct meaning and produce language structures. Thus, the linguistic organization of sign languages hinges on the affordances of the visual modality in a systematic way. In this part of our review, we shift our focus to sign languages and review the evidence on whether and how the visual affordances of sign languages (especially pointing, iconicity, and simultaneity) modulate sign language acquisition for different domains such as vocabulary and morpho-syntax as used in encoding spatial relations and narrating events.
In many respects, the trajectory of sign language acquisition is similar to that of speech. For example, similar to the appearance of first words, first signs appear at around 12 months of age; a vocabulary spurt typically occurs roughly at 18 months; two sign combinations appear at 24 months; the 500-sign stage is reached by 36 months; grammar emerges between 2 and 3 years of age; and the acquisition of discourse functions continues up to school age (Chamberlain & Mayberry, 2000; Lillo-Martin & Henner, 2021; Morgan & Woll, 2002). This parallelism between sign and speech development is observed if children interact with fluent language users, who can provide them with rich linguistic input in sign language from early on. However, this is only the case for a minority of deaf children (around 10%) since most of them are born into families where there are no proficient signers (Mitchell & Karchmer, 2004). To make this part of our review comparable to speaking children’s multimodal language development as described above, we will focus on sign language acquisition in deaf children who receive early sign language input. Despite the universal patterns of language development shown for early signing children and speaking children, there has also been accumulating evidence showing how modality-specific aspects of sign languages, such as pointing, iconicity, and simultaneity, modulate different domains of language acquisition.
Pointing in sign language acquisition
The use of pointing is one of the first ways to communicate about the world and is key to achieving joint-attention behavior, a necessary component of language acquisition (e.g. Colonnesi et al., 2010; Goldin-Meadow, 2007; Tomasello et al., 2007). All children, deaf or hearing, point at objects, people, places, or sometimes an event to get the attention of their interlocutors. Indeed, several studies have reported that signing children use pointing more frequently than their non-signing peers (Cormier et al., 1998 for American Sign Language (ASL); Hoiting, 2009; Hoiting & Slobin, 2007 for Sign Language of the Netherlands (NGT), Kanto et al.,2015, 2024 for Finnish Sign Language (FinSL), Morgenstern et al., 2010 for French Sign Language (LSF); Wille et al., 2018 for Flemish Sign Language (VGT)). For example, the study by Morgenstern and her colleagues (2010) presented evidence for the earlier and more frequent use of pointing by making direct comparisons between a deaf child acquiring LSF, a hearing bimodal bilingual child acquiring French and LSF, and a hearing child acquiring French across 7–24 months of age. Overall, it was the deaf child who produced more pointings than her hearing peers. Furthermore, the children who were acquiring LSF (both the deaf child and hearing child) started to produce them 3 months earlier than the French-acquiring hearing child, whose first pointings emerged around 11 months.
However, deaf children point in different ways than speaking children, and in the case of sign languages, pointing progressively gains grammatical functions such as personal reference (i.e. pronouns) (Cooperrider et al., 2021; Cormier et al., 2013), unlike what we see for pointing in speaking children. For example, deaf children usually point toward their chest to mean ‘I’ (first-person singular) or to their addressee for ‘you’ (second-person singular). One prediction could be that such transparency (e.g. the direct link between pointing and the reference ‘I’) might facilitate the acquisition of pronominal pointing behavior in deaf children. Despite the earlier and more frequent use of pointing in sign compared to speech development, several studies with deaf children acquiring sign language reported a discontinuity in using pointing to refer to people (i.e. as a pronoun): deaf children freely pointed at people and objects up to 12–15 months of age. However, they later stopped pointing at people (including themselves) while continuing to point at objects and places till 18 months of age. When these children started to point at people again at 20 months of age, it was mainly self-pointing, and pointing at other people (including their addressees) emerged at 24–25 months of age. The reappearance of pointing to people has been interpreted as showing that pointing to people might have a special status in a child's linguistic system, that is, pronominal function (Caët et al., 2017; Hatzopoulou, 2011 for Greek Sign Language (GSL); Petitto, 1987 for ASL; Pizzuto, 1990 for Italian Sign Language (LIS)). Thus, signing children need to differentiate functions of pointing (e.g. deictic, pronominal), which might be a reason for the observed discontinuity in the use of this type of pointing in sign language acquisition.
Another interesting observation about pointing to people by deaf signing children relates to their predictive role for sign language development in other domains of language. More specifically, the disappearance of pointing (especially self-pointing) is related to acquiring other linguistic aspects. When signing children stopped pointing at people, they started using more sign tokens (i.e. number of signs) as well as more sign types (i.e. sign categories such as predicates [e.g. WANT], lexical signs, classifier constructions, etc.; Caët et al., 2017; Petitto, 1987). Furthermore, when they re-started using self-points with pronominal functions, they could produce more complex syntax, combining an average of three signs or more (Blondel & Tuller, 2008; Caët et al., 2017; Petitto, 1987). For example, at about 2 years of age, an LSF-acquiring deaf child was able to produce combinations such as
Most of the research on pointing in signing children focuses on pointing to refer to people. However, the few studies that explored pointing from an interactional perspective in parent-child contexts report its use to refer to objects. For example, Wille et al. (2018) report the use of pointing and lexical signs by a deaf girl acquiring VGT at around 18 months of age. Furthermore, Kanto et al. (2024), comparing data from KODAs (hearing Kids of Deaf Adults) and hearing children with hearing parents, observed differences in the use of pointing and language development, that is, the more KODAs produced signs in FinSL at the age of 1, the more they produced pointing at the same age. On the other hand, the more hearing children produced words in Finnish at the age of 3 years, the less they produced pointing at the same age. Furthermore, the frequency of pointing of the KODAs was rather stable across the different data points, even though their language skills developed over time, whereas the pointing frequency of hearing children decreased over time while their language skills developed further.
The studies reviewed here depict an intriguing developmental trajectory for pointing in sign languages, as in sign languages, pointing is used for several functions, unlike in spoken languages. The affordances of the visual modality of sign languages for the representation of referents for pointing to external objects as well as for pronominal functions seem to encourage the earlier and more frequent use of pointing by signing children compared to their speaking peers.
Iconicity and simultaneity in sign language acquisition
In sign languages, many (but not all) signs are visually motivated since they depict their referents, actions, or events in iconic ways (Karadöller et al., 2025; Karadöller, Sümer, & Özyürek, 2021; Perniss et al., 2010, 2015; Taub, 2001). Sign languages also allow for the simultaneous use of multiple articulators in order to depict more complex relations (e.g. spatial relations between objects) or actions (Slonimska et al., 2022). These modality-specific features of sign languages potentially modulate the acquisition of vocabulary and linguistic structures.
Iconicity in sign language forms is mainly defined as the visually-motivated mapping between a language form and its referent (Perniss et al., 2010; Slonimska & Özyürek, in press; Taub, 2001). This link is modulated by relevant cognitive abilities (e.g. being able to make analogies between language forms and their referents), conceptual knowledge, and world experience (Emmorey, 2014; Pizzuto & Volterra, 2000; Sevcikova Sehyr & Emmorey, 2019). In this part of the review, we first illustrate iconicity and simultaneity in the form of lexical signs and linguistic structures. Next, we review the literature on whether and how they modulate sign language acquisition.
Iconic signs bear visually-motivated resemblance(s) to what they refer to in the real world. However, how these signs resemble their referents shows variation across sign languages because iconicity in a lexical sign can be motivated by different properties of a referent. We see different correspondences between visually perceptible features of the signs and their referents (i.e. imagistic iconicity, Russo, 2004; Taub, 2001). For example, the lexical sign for
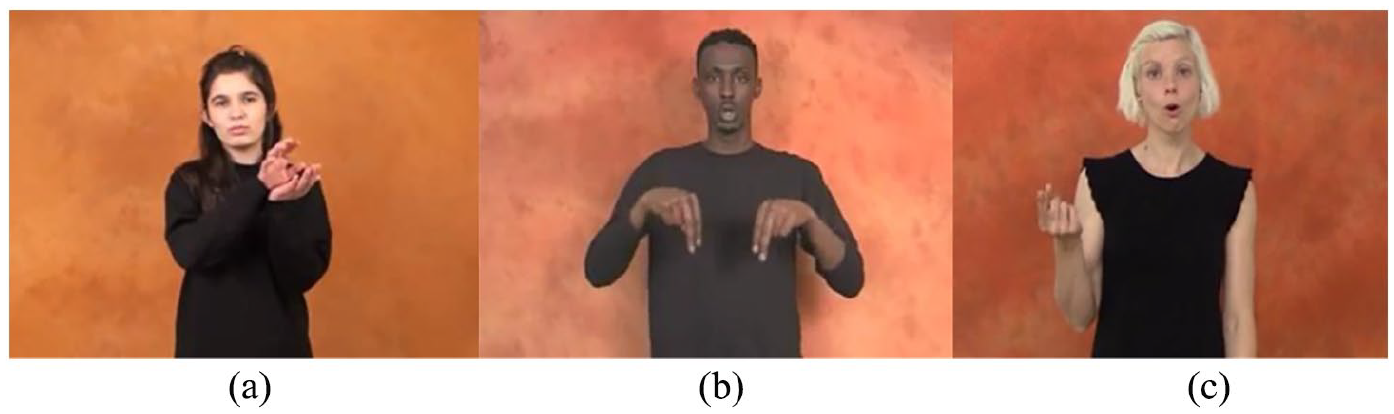
Lexical signs for
Iconicity in sign languages is not only restricted to lexical signs but also observed in linguistic structures that depict the location or motion of referents in space. One of the language forms with this type of iconicity is classifier constructions (see the article by Schembri, 2003 for the use of terminology). In these forms, the handshapes and their location/movement in relation to each other in signing space are associated with the size, shape, and location/motion of the referents being encoded (Brennan, 1990; Emmorey, 2002; Perniss, 2007). For instance, a signer of LIS in Figure 4 depicts a pen located to the right of a book (from his own perspective) using a classifier construction. While his left hand represents the flat surface of the book, his right hand shows the elongated shape of the pen, both of which reflect the perceptual features of these referents. The signer locates both of his hands in the signing space to depict the spatial relations between them simultaneously (Slonimska, 2022). Along with spatial relations between objects, these forms can be used to depict different components of an event, such as agents involved and/or their movement by employing multiple body articulators simultaneously to refer both to their perceptual features and their relations with respect to each other (i.e. diagrammatic iconicity, Cuxac, 1999; Perniss, 2007; Slonimska, 2022).

Description of a spatial scene in which there is a pencil next to a book by a signer in Italian Sign Language (LIS).
Despite a considerable body of research showing similar language-acquisition trajectories for both signing and speaking children under comparable input conditions (e.g. Lillo-Martin & Henner, 2021), it has also been questioned whether the prevalence of iconic forms in sign languages modulates language development for signing children differently compared to their speaking peers. Research investigating how visual affordances of sign languages, such as iconicity and simultaneity, modulate their acquisition has mainly focused on three areas: vocabulary use, expressing location and motion, and narrating events.
In early studies of sign language acquisition, the potential effects of iconicity on early vocabulary development were defined as being either weak or none (e.g. Orlansky & Bonvillian, 1984). Nevertheless, even these early studies suggested that signing children produce their first signs as well as their first 10 signs 2–4 months earlier than speaking children (e.g. Bonvillian et al., 1990). These findings were initially framed as a biological advantage for signing over speaking children since the hand muscles involved in producing signs mature earlier than the muscles in the vocal tract (Meier & Newport, 1990). However, despite this early maturation of muscles of main articulators, sign language acquiring children still make several phonological errors in the signs that they produce, with handshape in particular being notoriously challenging to acquire (Conlin et al., 2000; Gu et al., 2022; Karnopp, 2008). Furthermore, recent studies have challenged the ‘biological advantage’ view by emphasizing the facilitating role of iconicity on vocabulary development (e.g. Caselli & Pyers, 2017; Novogrodsky & Meir, 2020; Sümer et al., 2017; Thompson et al., 2012) and the development of linguistic structures to communicate in other domains such as spatial relations (e.g. Karadöller et al., 2025; Perniss & Vigliocco, 2014; Sümer, 2015; Sümer et al., 2014, 2017).
The current line of sign language acquisition research has yielded strong insights into the predictive role of iconicity for early vocabulary development. Studies that examined parental report data (MacArthur-Bates Communicative Development Inventory [CDI]) on the production of lexical signs have revealed that signs with greater iconicity are acquired earlier than less iconic ones (Caselli & Pyers, 2017 for ASL; Novogrodsky & Meir, 2020 for Israeli Sign Language [ISL]; Sümer et al., 2017 for TİD; Thompson et al., 2012 for BSL). Most of these studies, however, report a clear link between age and the effect of iconicity on lexical sign development. Namely, older children benefit from iconicity more than younger ones during vocabulary learning (Novogrodsky & Meir, 2020; Sümer et al., 2017; Thompson et al., 2012). However, the facilitating effect of iconicity for early vocabulary development is still observed even at the age of 10–12 months. Greater benefits from iconicity in older children could be due to greater cognitive understanding or enhanced environmental and cultural experiences that help them understand and establish motivated links between meaning and form.
It is possible that, despite being iconic, lexical signs can also be complex, involving simultaneity and several movements (Figure 5[a]). Sometimes lexical signs might also have a non-manual component, as shown in Figure 5(b), in which a signer of Danish Sign Language (DSL) is producing the lexical sign for

Lexical sign for (a)
There might be different sources for the iconicity in a language form (e.g. Ortega et al., 2017; Padden et al., 2014; Thompson, 2011). Lexical signs for tools, for example, may employ a certain set of handshapes (i.e. handling), while the ones for bulky objects such as houses will employ another set (i.e. object). Thus, one group will be more action-based since they depict how we handle/hold objects, while the other group will be based on the perceptual features of their referents (e.g. whether the referent is round or flat). It is also possible that the same objects can be expressed by two different lexical signs that differ in the type of iconicity (Figure 6). Ortega and his colleagues (2017) were interested in whether and in which ways having two variants that differ in how iconicity is represented (action-based vs perceptual-based) modulates the acquisition of lexical signs. Here, they showed pictures of objects to 10 TİD signing adults and two groups of deaf children (4–6 years and 7–9 years) and asked them to produce lexical signs for these objects. The analysis of lexical sign productions revealed differences in the preferences of the use of different variants across groups. More specifically, adults preferred perceptual-based variants (Figure 6[b]) more frequently than action-based (Figure 6[a]) ones, while both groups of children mainly used action-based variants.

Action-based (a) and perceptual-based (b) variants for
One might argue that action-based signs are preferred by signing children because they are more iconic than perceptual-based ones. Thus, the higher degree of iconicity in action-based signs, rather than the motoric/embodied representations in them, drives early lexical sign acquisition. If this is the case, iconicity would explain such preferences of signing children better than an embodied view of language acquisition. Caselli and Pyers (2019) addressed the same issue by focusing on the interaction between degree and type of iconicity in lexical signs by analyzing parental reports from 58 ASL signing deaf parents with deaf children. They did not find an effect of iconicity type but rather observed a strong effect of the degree of iconicity on modulating early lexical sign acquisition. However, the average age of children in their study was 24 months, thus including a much younger group of children compared to the ones in the study by Ortega et al. (2017). It is likely that these ASL-acquiring children have not yet had enough motoric/bodily experiences, cognitive capacity, or world knowledge to fully build the links between the form of the signs and their meanings. Thus, at younger ages, signing children may benefit more from the degree of iconicity regardless of its type (i.e. action or perceptual). When they get older, they are better able to distinguish types of iconicity and benefit more from those related to their motoric/bodily experiences. This explanation aligns with other studies showing that iconicity seems more advantageous for lexical sign acquisition when children are older than 24 months of age (Sümer et al., 2017; Thompson et al., 2012 see also the article by Ortega et al., 2017 for a review).
So far, the above-mentioned studies have mainly focused on the acquisition of lexical signs and how they are modulated by iconic features in these signs. However, iconicity is not only restricted to the form of lexical signs but is also seen in classifier constructions, which are mainly employed to encode spatial relations between objects and motion event descriptions. In these descriptions, signers across several sign languages mainly employ classifier constructions (Emmorey, 2003; Perniss, 2007), as depicted in Figure 4. Despite their iconic properties, the production of these language forms can be challenging for signing children since they need to select appropriate classifier handshapes (e.g. a flat–but not a round–handshape to refer to book in Figure 4) as well as simultaneously coordinate manual articulators in signing space to refer to each referent. Thus, this domain can be quite relevant to understanding the effects of iconicity in sign language development due to its visual properties and structural complexities, thereby allowing us to explore whether and how these factors (iconicity and simultaneity) play a role in the acquisition of these forms by signing children.
Despite the universal tendency reported for the emergence of spatial terms in speech (i.e. spatial relations without a viewpoint such as ‘In’ and ‘On’ are produced earlier than the ones with a viewpoint such as ‘Left’ and ‘Right’), recent studies with signing children present quite a different picture and reveal a strong role of language modality in the order of their acquisition. Studying spatial descriptions (‘In’, ‘On’, ‘Under’) elicited from 20 deaf children (between 4 and 9 years of age) acquiring TİD and comparing them to those elicited from hearing children acquiring Turkish, Sümer (2015) and Sümer et al. (2014, 2020) found that both signing and speaking children were on par when they acquired adult target forms. However, the pattern was surprisingly different for expressing spatial terms that require taking a viewpoint (i.e. ‘Left’, ‘Right’). While encoding the spatial relation between the objects located on a lateral axis (e.g. pen left to paper), even the signing children at the age of 4 years were adult-like in how frequently they used locative forms such as classifier constructions (Figure 7). This was not the case for similarly-aged speaking children, who were still struggling to provide adult-like target forms for similar descriptions in their speech, even when their co-speech gestures were considered (Karadöller et al., 2025). Furthermore, TİD acquiring children, even at the age of 3–4 years, were able to produce simultaneous classifier constructions while describing object locations, in contrast to the difficulties that were suggested by earlier studies on the acquisition of these constructions (e.g. Engberg-Pedersen, 2003; Newport & Meier, 1985; Newport & Supalla, 1980; Slobin et al., 2003; Supalla, 1982; Tang et al., 2007). However, it is important to note that these earlier studies focused on the expression of motion events, which consist of more event components compared to encoding location. In the next paragraph, we shift our attention to the domain of motion events.

Description of a spatial scene in which there is a pen next to a paper by a 5-year-old TİD signer.
The use of classifier constructions while expressing motion events (e.g. a man walking toward a car) has been found to be challenging for signing children, who are not usually able to use them in adult-like ways until around 12 years of age (e.g. Engberg-Pedersen, 2003; de Beuzeville, 2006; Kantor, 1980; Schick, 1990; Slobin et al., 2003; Supalla, 1982; Tang et al., 2007). These challenges have been mainly reported for the use of appropriate classifier handshapes (Kantor, 1980) and the simultaneous representation of different event components, such as manner (e.g. walk) and path (e.g. toward) (Newport, 1981; Newport & Supalla, 1980; Supalla, 1982). Signing children tend to omit certain components at the early stages of language acquisition, but they express them simultaneously soon after (Newport, 1981; Newport & Supalla, 1980; Sallandre et al., 2018; Supalla, 1982). For example, Sallandre et al. (2018) found that deaf children (aged 5–10 years) acquiring LSF encoded both path and manner from early on, as opposed to hearing children acquiring French, who frequently produced path-only descriptions and fewer path + manner utterances in their motion event encodings with various paths and manners. However, when these children encoded these types of events, they had a tendency to express path and manner components separately, as shown in Figure 8. Here, a 5-year-old deaf child is describing a ‘swim across’ event by expressing manner (swim) and path (across) in two different forms. These findings suggest that signing children do not acquire these constructions in an analog or holistic fashion, despite the visual resemblance between their linguistic forms and the real motion event (Newport, 1981; Newport & Meier, 1985; Newport & Supalla, 1980; Supalla, 1982).
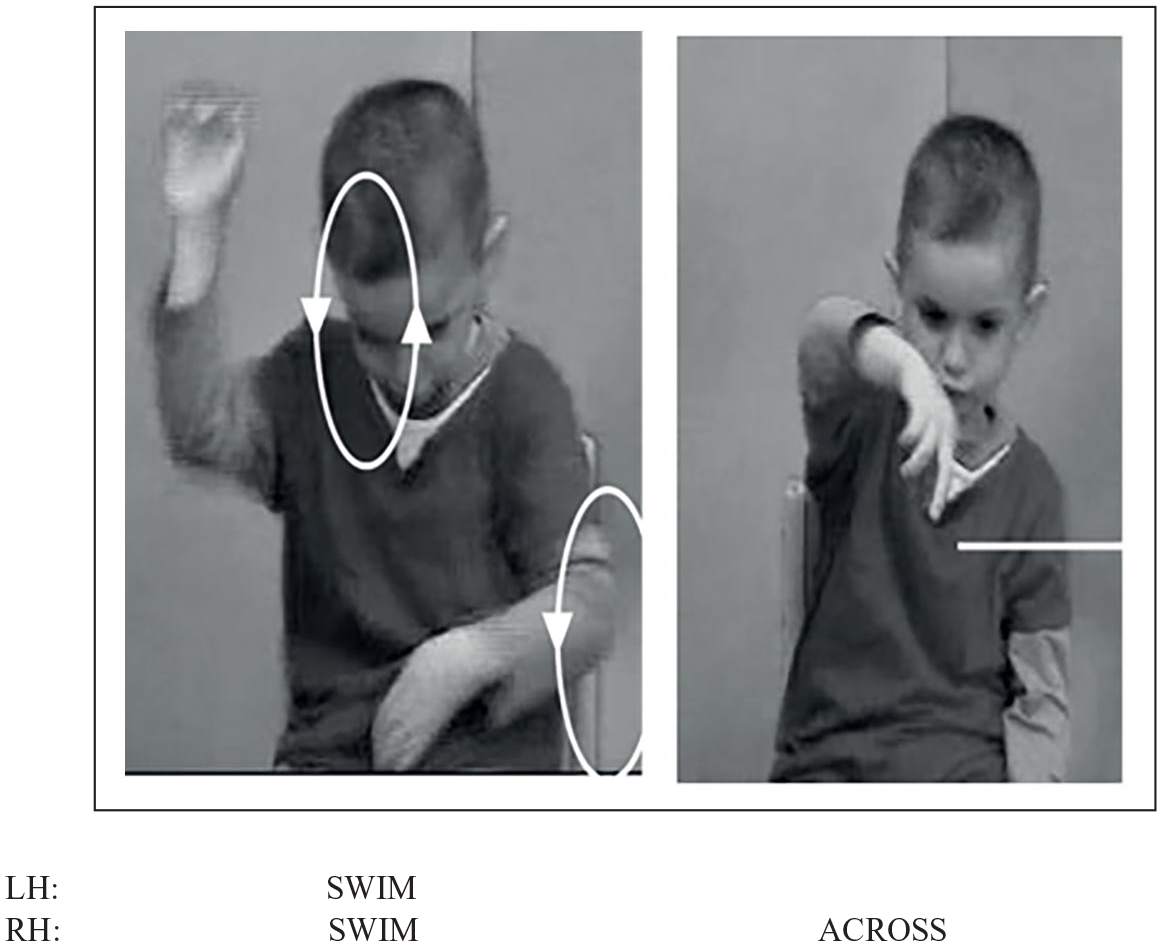
Description of a motion event by a 5-year-old signer of LSF, in which he encodes manner and path components in different language forms.
Simultaneity is not only confined to encoding path and/or manner in classifier constructions but also involves the expression of ground (bigger and usually stationary objects) and figure (smaller objects whose location and/or motion is encoded with respect to grounds) in expressing motion events (e.g. Aronoff et al., 2003; Perniss, 2007; Sümer, 2015; Supalla, 1982). In recent work, Sümer and Özyürek (2022) observed that TİD acquiring children (aged 4–10 years) omitted one of these components of a motion event more frequently than signing adults (Figure 9). Reporting similar findings from similar-aged Turkish acquiring children, the authors suggest this tendency to be a pervasive feature of children’s motion event descriptions (Engberg-Pedersen, 2003; Hickmann, 2005; Morgan et al., 2008; Slobin et al., 2003; Supalla, 1982; Tang et al., 2007) and might be derived from general cognitive tendencies in children regardless of the language modality that they acquire.

Description of a motion event (man walking toward a car) by a 4-year-old signer of TİD, in which he drops the mention of the car, which is the ground in this event description.
Finally, another domain where the effects of iconicity and simultaneity have been studied is narrative development. In narrating events, several factors, such as providing background information (e.g. Berman, 2001; Berman & Slobin, 1994) and marking the identifiability of the referents that are introduced and maintained during the discourse, are taken into account (e.g. Küntay, 2002). Studies with children acquiring speech revealed that the younger the children are, the less information they provide to set the scene in their narratives (Berman, 2001; Peterson, 1990; Peterson & McCabe, 1983; Umiker-Sebeok, 1979). However, these studies are conducted with children who are required to translate events presented usually in visual-spatial form (as in the case of picture-story narrations) into sequential segments of verbal output, thus causing a particular kind of cognitive demand (Berman & Slobin, 1994). Thus, it might be interesting to ask whether signing children encode more information in their narrations than their speaking peers due to the similarity between the referent and the linguistic form. Previous studies that compared these two groups of children proposed similar developmental trajectories: using linguistic forms for reference in an unclear manner up to the age of 3 years and not being able to maintain the characters introduced at the beginning consistently throughout the narration (Anthony, 2002; Hickmann et al., 1996; Karmiloff-Smith, 1981; Morgan, 2000, 2002; Morgan & Woll, 2003; Niederberger, 2004; Sümer, 2016; Vercaingne-Menard et al., 2001). Furthermore, signing children (around 3–4 years of age), similar to their speaking peers, usually start with direct quotations (i.e. using one’s words verbatim); only later do they use role-shift, which is a sign language–specific strategy in which they take the perspective of the person whose thoughts, utterances, or actions are being reported (Ely & McCabe, 1993; Lillo-Martin, 2012; Lillo-Martin & Quadros, 2011).
Interim summary: sign language acquisition
The affordances of the visual modality, such as indexicality, iconicity, and simultaneity, seem to influence sign language development in modality-specific ways at different stages of acquisition and for different language domains. There are also areas of language acquisition where these modality-specific aspects do not affect the trajectory.
It seems that the transparent nature of the link established between the pointing form and its meaning encourages signing children to employ it earlier and more frequently than speaking children (Cormier et al., 1998; Hoiting, 2009; Hoiting & Slobin, 2007; Morgenstern et al., 2010). Pointing is also employed more frequently by signing parents than by non-signing parents, which makes it more frequent in the input that signing children receive. Thus, an abundance of pointing in language input for these children might also modulate their acquisition in language-specific ways (e.g. Kanto et al., 2024; Morgenstern et al., 2010; Wille et al., 2018). However, when it comes to acquiring different functions of pointing (deictic vs personal reference), signing children do not seem to benefit immediately from this transparent link but instead require time to figure out how to embed the function of pointing into grammatical structures. When the pointing behavior is re-analyzed by signing children and integrated into their linguistic system, it seems to play a facilitating role in the acquisition of more lexical sign tokens and types as well as in the acquisition of more complex syntax (e.g. Caët et al., 2017; Hatzopoulou, 2011; Kanto et al., 2024; Morgenstern et al., 2010; Petitto, 1987; Wille et al., 2018). However, it is also important to keep in mind that deaf parents produce more pointing signs while interacting with their deaf or hearing children. The frequency of their pointing behavior seems to be stable across time as opposed to hearing parents with hearing children (Kanto et al., 2024; Wille et al., 2018). Thus, it is quite possible that more-frequent and extended exposure to pointing signs modulates their acquisition by signing children.
We also observe an influence of the visual modality in other domains of language acquisition. For example, iconicity in lexical sign forms seems to facilitate signing children’s vocabulary development, especially after 16–18 months of age (Caselli & Pyers, 2017; Novogrodsky & Meir, 2020; Sümer et al., 2017; Thompson et al., 2012). Such facilitating effects were also observed for object locations and especially for acquiring spatial terms with viewpoint (i.e. ‘Left’, ‘Right’) in sign language, which are notoriously challenging for speaking children (Karadöller et al., 2021, 2025; Sümer, 2015; Sümer & Özyürek, 2020; Sümer et al., 2014). Signing children also, in general, prefer to express both path and manner of motion early on, which might be considered a general modality effect through iconicity.
However, we do not see convincing evidence for such a facilitating role of iconicity for all domains. For example, the acquisition of spatial relations without viewpoint (‘In’, ‘On’, ‘Under’) seems to be similar for both signing and speaking children (Sümer, 2015; Sümer & Özyürek, 2020; Sümer et al., 2014). When we look at event descriptions in general, signing children do not acquire different aspects of these events holistically but go through stages of segmentation of, for example, path and manner (Newport, 1981; Newport & Meier, 1985; Newport & Supalla, 1980; Sallandre et al., 2018; Supalla, 1982). Similarly, encoding other event components such as figure and ground seems to be related to children’s general cognitive development rather than the language modality being acquired (Engberg-Pedersen, 2003; Hickmann, 2005; Morgan et al., 2008; Slobin et al., 2003; Sümer & Özyürek, 2022; Supalla, 1982; Tang et al., 2007).
Finally, regarding narrative development, signing children also seem to be on par with speaking children in their timeline and milestones of learning how to use different linking elements and cohesion strategies to form meaningful and connected narratives (Anthony, 2002; Ely & McCabe, 1993; Hickmann et al., 1996; Karmiloff-Smith, 1981; Lillo-Martin & Quadros, 2011; Morgan, 2000 & 2002; Morgan & Woll, 2003; Niederberger, 2004; Sümer, 2016; Vercaingne-Menard et al., 2001).
Conclusion and discussion
Human language is inherently multimodal in nature. That is, language can be expressed in either the auditory or the visual modality, and when both are accessible, language users prefer to use them simultaneously and/or in coordination with each other. Visual-spatial expressions used in sign languages employ linguistic structures and functions, and gestures accompanying speech are considered integral to spoken languages. Recent research on adult language encompasses a unified multimodal view of language where expressions in the visual modality can be explained in both spoken and sign languages. This unified multimodal language view also needs to be adapted to language acquisition. The studies reviewed earlier illustrate the role of modality-specific aspects of language as factors modulating language acquisition. This is the case not only for sign language but also when considering spoken language acquisition and gestures. Below, we discuss the specifics of this modulatory effect for both spoken languages, considering co-speech gestures, and for sign languages regarding pointing, iconicity, and simultaneity. We also point out which aspects of the language-acquisition process seem to be modality-independent. Finally, we conclude by suggesting new avenues for research in these domains and an even broader focus by encompassing all aspects and domains of language.
Pointing is an integral and frequently-used component of both spoken and sign language–acquisition processes (Cooperrider et al., 2021; Cormier et al., 2013; Sandler & Lillo-Martin, 2006), employed in similar as well as different ways in both types of languages. In spoken language acquisition, children’s pointing gestures are considered to be one of the first communicative acts (e.g. Rüther & Liszkowski, 2023), which later facilitates early vocabulary (e.g. Iverson & Goldin-Meadow, 2005) and syntactic (e.g. the appearance of the two-word stage; Goldin-Meadow & Butcher, 2003) development. In sign language acquisition, pointing has also been found to be the most frequent and dominant communication form for deaf children in the early stages of their language acquisition and even more so than for hearing children (Cormier et al., 1998; Hoiting & Slobin, 2007; Morgenstern et al., 2010). However, deaf children undergo a period in which the use of pointing decreases while the functions of pointing change and become more pronominal (Caët et al., 2017; Hatzopoulou, 2011; Petitto, 1987; Pizzuto, 1990). Moreover, during this period, more lexical signs (both in terms of token and type) appear in deaf children’s lexicon, and deaf children start using complex syntax and pointing signs with different functions (Blondel & Tuller, 2008; Caët et al., 2017; Petitto, 1987). This also looks similar to the emergence of the combined use of points with verbs in spoken language development and expressions of spatial relations in speech, and it also considers the facilitating effects of pointing in speaking children for vocabulary size. However, no research has yet directly compared how pointing combines different grammatical aspects in sign and spoken language acquisition.
Iconicity also plays a prominent role in language acquisition through gestures in both sign and spoken language. It aids language acquisition while producing signs/gestures to refer to individual referents as well as locative/spatial relations among several referents. In spoken languages, iconic gestures might appear in tandem or later than verbs, at around 15 months of age. In sign languages, children are reported to benefit from iconicity as early as 10 months and even more after 30 months and older. This shows that children need to be cognitively mature enough to benefit from and understand iconic representations in gestures and signs. When cognitively apprehended, iconic representations in signs seem to provide an advantage for signing children when learning new signs (i.e. action representations). Sign language vocabularies usually consist of many iconic signs, which vary in degree and type. These aspects of iconicity (i.e. degree, type) might be an additional factor in modulating the acquisition of certain lexical signs compared to others. In spoken languages, iconic gestures might specify the semantic content of the verbs produced by children or ease their production when they emerge together.
Iconicity also seems to facilitate the acquisition of more complex structures in both spoken and sign languages. In spoken languages, iconic gestures precede linguistic forms on the relational level when expressing cognitively challenging concepts (e.g. spatial relations with viewpoints, causal relations, and narrative recall). In sign languages, relational concepts that are linguistically expressed via iconic forms such as classifier constructions (e.g. spatial relations between objects, motion events, and narratives) can be acquired earlier than their spoken language counterparts.
It is also important to note that iconicity does not always facilitate the acquisition of all domains. For example, while the acquisition of some components of motion events (i.e. manner and path) can be easier to express in sign than in spoken languages, this does not hold for other components (i.e. figure and ground), which show similar acquisition patterns in both spoken and sign languages. It is possible that certain semantic elements might be more suited for the visually-motivated mapping of concepts to forms than others.
Future directions
It is clear that a multimodal view of language acquisition needs to develop a unified framework to understand how the visual modality modulates the language-acquisition process in sign as well as spoken language, considering co-speech gestures. The above-reviewed studies show that modality-specific expressions, both in sign and gesture, play a significant role in the acquisition of many language structures from words to grammar to narrative structures. In order to understand modality specificity for spoken and sign language acquisition, we need to shift from comparing sign language development to that of spoken language alone. Rather, we should compare sign language development to that of speech and gesture combined.
The fact that pointing and iconicity in both spoken and sign languages facilitate certain aspects of the language-acquisition process is in line with claims that children rely on sensorimotor simulations to acquire vocabulary and develop conceptual knowledge and interactions with the external world, including the physical, social, and broader cultural environment (Morgenstern, 2024, Reggin et al., 2023; Wellsby & Pexman, 2019, for reviews). In these frameworks, pointing and iconicity in gesture and sign help to simulate, conceptualize (Kita et al., 2017), and ground the concepts in the here and now and the child’s body. Further theoretical and empirical studies are needed to understand how pointing and iconicity facilitate the acquisition of certain concepts and language structures at different levels. Of course, it is also possible that mapping of referents and actions to the visual modality might show slightly different trajectories in sign versus speech-plus-gesture. In sign, the visual modality carries the full load of language structure, whereas gesture develops in tandem with speech, and sign and gesture may exchange different loads during development. There is little research in this direction (see the articles by Karadöller et al., 2025, 2024 for the comparisons across TİD and Turkish speech-gesture combinations and Morgenstern et al., 2010 for comparisons across LSF and French speech-gesture combinations). Future research that compares speech-gesture combinations to sign language acquisition can delineate these aspects of language development from a unified multimodal perspective.
Conducting studies in diverse spoken and sign languages (including sign languages with varying sizes of communities, sociolinguistic structures, and histories; German, 2023; Lutzenberger et al., 2023) is also important. This is essential to uncover whether visual patterns might develop in different or similar trajectories in spoken and sign languages with different typologies (e.g. word order, path-satellite framed, pro-drop vs no-drop languages).
Finally, although there is ample evidence on the role of iconicity and pointing in language acquisition from a production perspective, this role is relatively less studied for language comprehension and processing and needs further research. Moreover, in all aspects of language, production, comprehension, and processing, the visual-spatial modality plays a role in other domains, such as phonology which was not reviewed in this article. Focusing on all aspects of language and drawing evidence from each domain will likely unravel many novel ways in which the visual modality is integral to language acquisition.