
Abstract
This study reports the results of a Give-X task investigating the comprehension of ordinal and cardinal numbers in monolingual Russian-speaking children. Data collected from 36 children between the ages of 4;06 and 5;10 provided evidence that Russian learners follow the well-attested pattern for cardinal acquisition, but that children use a language-specific approach to ordinal acquisition. Lower ordinals elicited more correct responses than higher ordinals, and several cardinal subset-knowers comprehended the irregular lower ordinals vtoroj ‘second’ and tretij ‘third’. This suggests that Russian-speaking children initially learn ordinals lexically, unlike English- and Dutch-speaking children, who have previously been shown to use a rule-based approach. The authors argue that this is explained by the irregularity of the Russian ordinal system, which makes the threshold for rule-learning too high for an initial rule-based approach. Future research should clarify whether lexical learning of ordinals leads to the same underlying knowledge of ordinals as rule-based learning does.
Introduction
Over the past decades, a growing body of research has provided insight into the acquisition of numerical knowledge in children and its interaction with linguistic knowledge. Many of these studies focused on the acquisition of cardinals, but recently Meyer (2019) has argued that the ordinal domain shows the interaction between language and numerical acquisition even more clearly. Not only are ordinals often productively derived from cardinals in adults, Dutch- and English-speaking children do actually use this rule to acquire ordinals, learning regular ordinals (such as fourth) before irregular forms (such as second).
This pattern might not be universal, however, as we argue here that some language systems could be too opaque for rule-based learning. Russian, for example, has an ordinal system with even more irregularities than English. We report results from a Give-X task (Wynn, 1992) with Russian learners, who exhibit a different learning strategy than children acquiring Dutch and English (Meyer, 2019). This novel pattern provides fresh insight into how language can influence numerical development.
Number acquisition
The acquisition of numerals begins with the acquisition of cardinals. Cardinal acquisition has been investigated in many different studies and for many different languages, which demonstrate a universal developmental pattern (e.g., English in Le Corre & Carey, 2007; Wynn, 1992; Dutch and English in Meyer, 2019; Japanese and Russian in Sarnecka et al., 2007; Slovenian and Saudi-Arabic in Almoammer et al., 2013). Children generally acquire the first four cardinals in a slow, tiered fashion, passing through so-called ‘knower-levels’. A child at one of these knower-levels only knows the exact meanings of the cardinals up to the highest cardinal of their level (e.g., one, two and three for three-knowers), and interprets all higher cardinals as a random higher quantity than that cardinal. Collectively, children at these stages are usually labeled as subset-knowers, because they only know a subset of the numerals in their count list (Le Corre & Carey, 2007). Most studies attest maximally four subset knower-levels.
After children have gone through the first four knower-levels, they reach the final stage of cardinal acquisition, which is the Cardinal Principle (CP)-knower stage. CP-knowers can use their count list to interpret meanings higher than four, having thus acquired at least three of the principles described by Gelman and Gallistel (1978): the cardinality principle (the label applied to the last counted item in a set represents the total number of items in the set), the one-to-one-correspondence principle (when counting a set, only one numeral can be assigned to each item) and the stable-order principle (numerals used in counting should always be used in the same order). English-speaking children generally reach this stage by the age of four, but there are many timing differences within and between languages (e.g. Le Corre & Carey, 2007; Meyer, 2019). These cross-linguistic differences could be due to the availability of certain linguistic cues: e.g., singular-plural marking, the use of quantifiers and count-mass syntax have all been argued to help children in the acquisition of numerical meanings (for an overview, see Meyer, 2019).
Despite these timing differences, all languages show the same distinction between subset-knowers and CP-knowers. This pattern could be explained by two innate cognitive representation systems: the Object Tracking System (OTS) and the Approximate Number System (ANS). The OTS is an system that can be used for the precise representation of quantities up to three or four, which is also the limit of the subset-stages. The ANS can be used for larger quantities, but is much more imprecise. It seems that in order to become CP-knowers, children need to merge the two systems (e.g., Le Corre & Carey, 2007; Meyer, 2019).
This combinatory system may also be necessary for ordinal learning, which trails behind cardinal acquisition and follows a markedly different pathway. Not only do children score much lower on ordinal tasks than on cardinal tasks (e.g., Colomé & Noël, 2012; Fischer & Beckey, 1990; Hamburger & Crain, 1984; Meyer, 2019; Miller et al., 2000), ordinals also do not seem to be acquired in a tiered fashion. Building on Wynn’s well-known Give-X tasks (1992), Meyer (2019) investigated cardinal and ordinal acquisition in both Dutch and English. The results of all three studies, testing children between the ages of 3;03 and 6;04, indicated that ordinal acquisition in these languages follows a different pattern than cardinal acquisition: Dutch- and English-speaking children acquire regular forms first and all at the same time (fourth, sixth in English, tweede ‘second’ and vierde ‘fourth’ in Dutch), before acquiring irregular forms (English second, third and fifth; Dutch derde ‘third’). 1 This indicates that children use the ordinal derivation rule to acquire ordinals, and may also explain timing differences found across languages: speakers of regular languages such as Cantonese, Mandarin and Dutch (Lei, 2019; Meyer, 2019; Miller et al., 2000) learn ordinals earlier than children acquiring less-transparent ordinal systems such as English or French (e.g., Colomé & Noël, 2012; Meyer, 2019; Miller et al., 2000).
The question is, however, to what extent Meyer’s rule-based pattern is generalizable to languages with an even more opaque ordinal system than English. In line with Yang (2016), we argue that the greater the amount of irregularity, the more regular forms a child needs to know to recognize the derivation rule (Yang, 2016), which could make a rule-based approach less appealing. This is compounded by where in the count list the evidence for the rule can be found, as ordinals higher than fifth are generally very infrequent and conceptually more difficult: Meyer (2019) has argued that it might be cognitively too taxing for some CP-knowers to apply the ordinal formation rule at the same time as co-activating the OTS and ANS, which would explain why Dutch-speaking children in her study made more mistakes on regular higher ordinals than on the regular lower ordinals (Meyer, 2019). The present study will put pressure on the rule-based approach by focusing on Russian, a language with a much less transparent ordinal system than Dutch and English.
Russian ordinals
Russian ordinal numbers are derived from cardinals through the adjectival suffix. Like adjectives, ordinals agree in case, gender and number with the nouns they modify. They all share the declension pattern of hard-stem adjectives, except for tretij, which has a mixed declension pattern (Timberlake, 2004). It is important to note that the suffix of hard-stem masculine adjectives has two allophones in the nominative and accusative case: -oj and -yj. The suffix -oj is used in stress-ending adjectives and ordinals, while -yj is used in stem-stressed words. Table 1 presents the masculine citation forms of the first 10 ordinals.
Russian cardinals odin ‘one’ through desjat’ ‘ten’ and their corresponding ordinals.
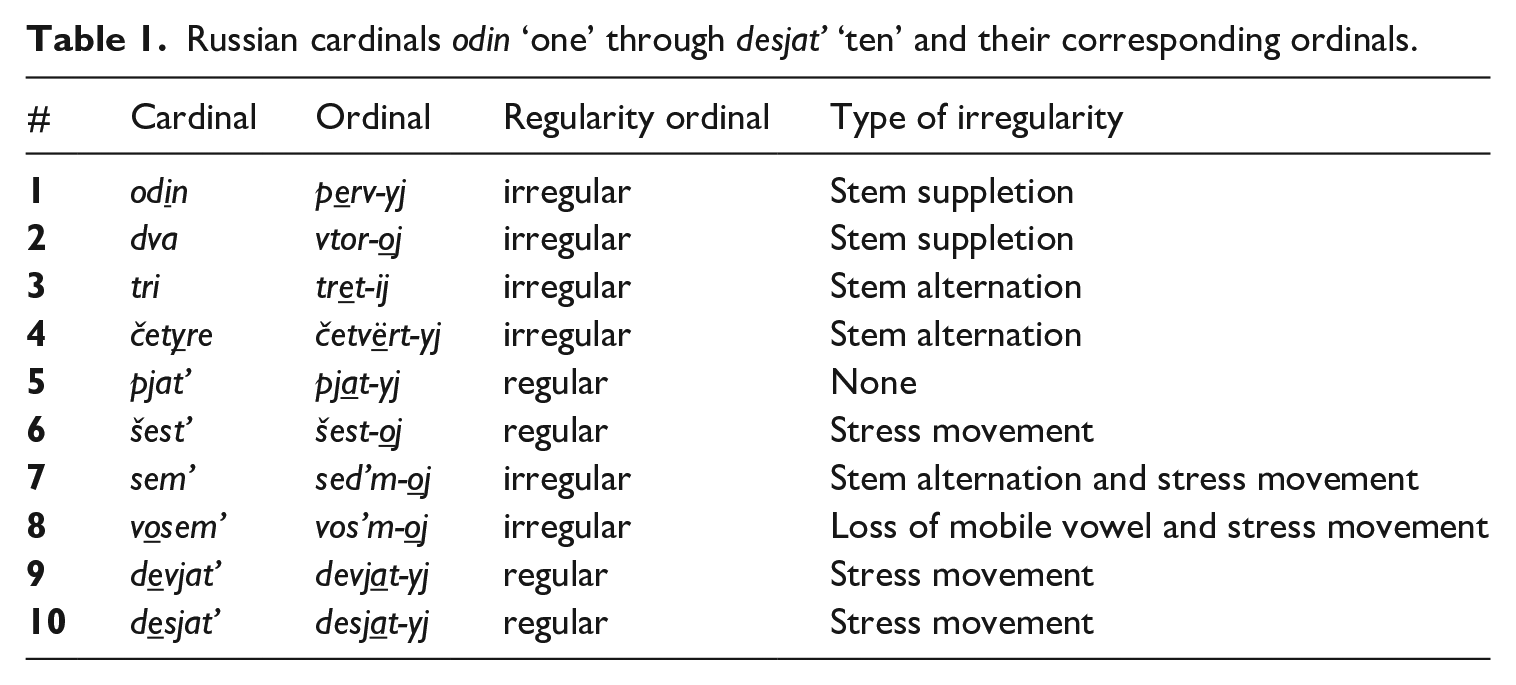
It is clear from Table 1 that the Russian ordinal system is very opaque. All the ordinals within the OTS-boundary are irregularly derived from their corresponding cardinals. The higher ordinals pjatyj ‘fifth’, šestoj ‘sixth’, devjatyj ‘ninth’ and desjatyj ‘tenth’ show more regularity, although in some cases we do see stress movement. Since such cases of stress movement are ubiquitous in the Russian language, we do not consider these ordinals to be irregular, especially because they are also highly transparent: despite stress movement, the cardinal stem remains intact. Sed’moj ‘seventh’ and vos’moj ‘eighth’ are irregular. 2 This brings the total number of irregular ordinals in Russian to five (if we exclude pervyj ‘first’), and makes the Russian ordinals system less regular than English, which has three irregular ordinals above first. 3 This total number of irregular forms could be an issue for the initial learnability of the Russian derivation rule.
Yang’s Tolerance Principle and Sufficiency Principle offer a measure to help determine how many ordinals Russian children need to know in order to overcome these five exceptions (Yang, 2016). The Tolerance Principle, provided in (1), states that a rule (R) is productive if the number of exceptions (e) is lower than the number of items in the category N, divided by the natural log of N (Yang, 2016, p. 64). According to Meyer (2019) this means that English-speaking children need to know only five ordinals to learn the English derivation rule, if first is excluded (if N = 5, then θ5 = 3.1, which is greater than 3), but at least nine if first is included (if N = 9, then θ9 = 4.1, which is greater than 4). Russian-speaking children would need to know even more ordinals: 13 if pervyj ‘first’ is excluded from the list (if N = 13, then θ13 = 5.07, which is greater than 5), and 18 if we do take pervyj ‘first’ into account (if N = 18, then θ18 = 6.23, which is greater than 6).
(1) Tolerance Principle Let R be a rule applicable to N items, of which e are exceptions. R is productive if and only if: e < θN where (Yang, 2016, p. 64)
While the Tolerance Principle determines how many exceptions are tolerable for a rule to be productive, the Sufficiency Principle (2) concerns the amount of positive evidence needed to generalize a rule. In the case of ordinals, this comes down to the same calculation: if N = 13, and M = 8, then (N–M = 5) is smaller than θ13 = 5.07. But if N = 12 and M = 7, then N–M = 5, which is not smaller than θ12 = 4.83.
(2) Sufficiency Principle Let R be a generalization over N items, of which M items are attested to follow R. R can be extended to all N items if and only if: N – M < θN where (Yang, 2016, p. 177)
Both formulas thus show that Russian-speaking children need to know at least 13 ordinals in order to acquire the derivation rule, a much larger number than the five ordinals English-speaking children need to learn. This could make rule-learning difficult, especially since all evidence for the derivation rule is above the OTS-boundary: these higher ordinals are not only cognitively more taxing (as argued in the previous section), but also much less frequent than lower ordinals. This is illustrated by Table 2.
Frequency data for the Russian ordinals pervyj ‘first’ through desjatyj ‘tenth’ as taken from (Lyashevskaya & Sharov, 2009). The frequency in ipm represents the occurrences per million words, the relative frequencies are presented as percentages.
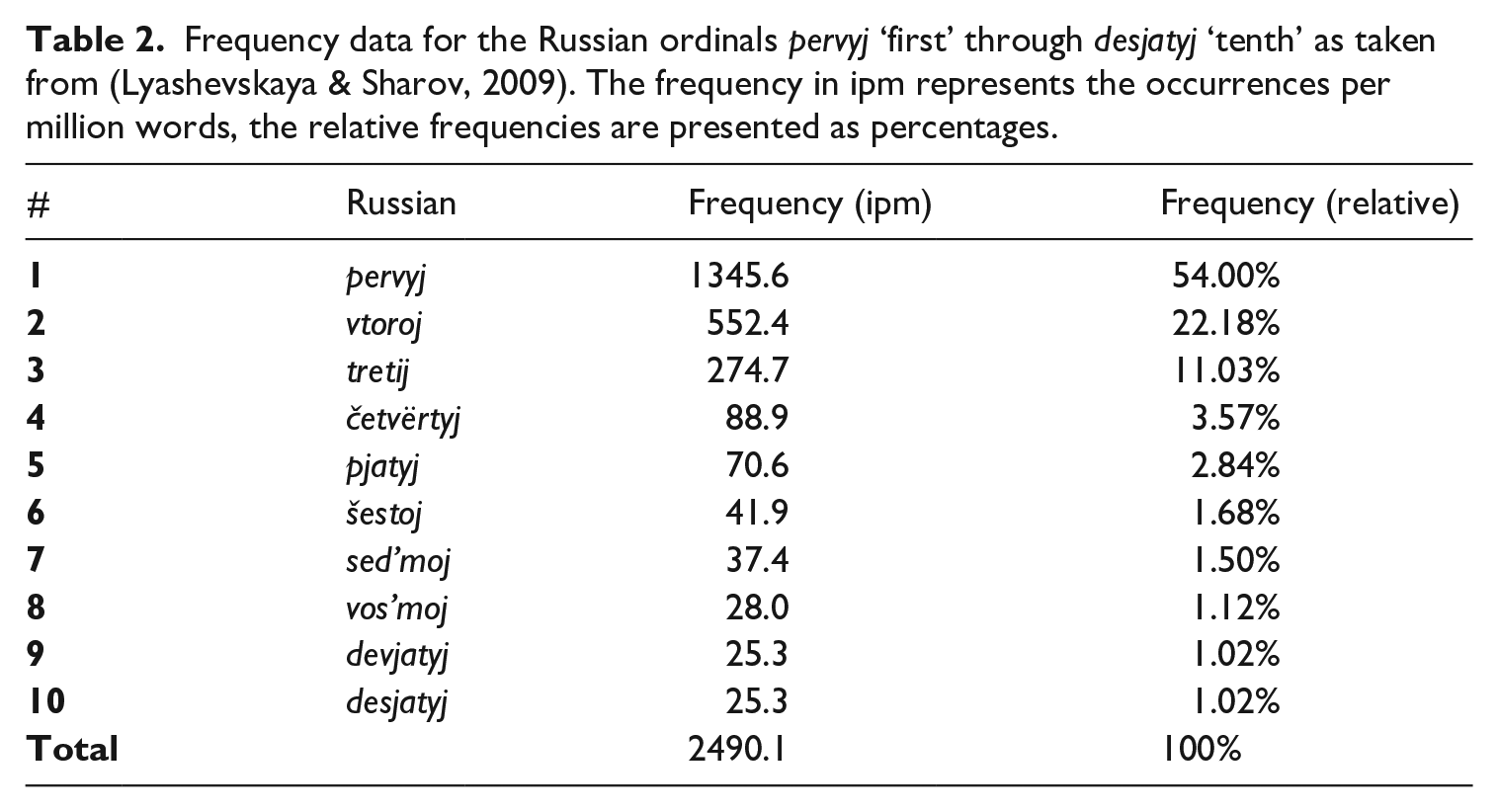
Table 2 indicates that pervyj ‘first’ is by far the most frequent ordinal, and that after tretij ‘third’ the frequency of the ordinals rapidly drops: there is practically no difference in usage frequency between šestoj ‘sixth’ and desjatyj ‘tenth’. This frequency pattern, similar to those in Dutch and English (Meyer, 2019), shows that all regular ordinals are relatively infrequent. It will thus take a relatively long time for Russian-speaking children to learn enough ordinals to master the derivation rule, which makes it less likely for children to use a rule-based approach.
Hypotheses and predictions for Russian ordinal acquisition
This study investigates whether the acquisition of Russian ordinals follows the rule-based pattern attested for Dutch and English by Meyer (2019). Based on the discussion above, we can formulate separate predictions for the acquisition of pervyj ‘first’, on the one hand, and other ordinals on the other hand. Just like in Dutch and English, pervyj ‘first’ is likely to be acquired before the other ordinals due to its separate status (Meyer, 2019). If the acquisition of the other ordinals also follows the same acquisition pattern as in those two languages, we would find that children learn regular ordinals pjatyj ‘fifth’ and šestoj ‘sixth’ before irregular ordinals. This would indicate a rule-based learning strategy.
However, we have discussed at least two reasons to suspect that Russian-speaking children might initially resort to lexical learning for ordinal acquisition. First, Russian does not have any regular ordinals within the OTS-domain. This might pose a problem for a rule-based approach, as the frequency of ordinals rapidly drops after tretij ‘third’. Moreover, this evidence is only found on higher ordinals, which might further complicate the acquisition of rule: as argued earlier, higher ordinals are cognitively more taxing, since children need to co-activate the ANS and OTS to interpret them (Meyer, 2019).
Second, the total number of irregular forms might form a problem as well. It was argued in the previous section (following Yang, 2016), that Russian-speaking children would have to learn a total of 13 ordinals in order to acquire the ordinal formation rule. This process might take a lot of time, especially since many of these higher ordinals are extremely infrequent. In the meantime children are thus likely to receive more evidence for the more frequent lower irregular ordinals vtoroj ‘second’ and tretij ‘third’ than for the higher regular ordinals. The question of this study is whether Russian-speaking children would be able to learn some of these ordinals lexically before they master the ordinal formation rule, or whether ordinal knowledge requires understanding of the formation rule.
A secondary question concerns the ability of subset-knowers to acquire ordinals. Under both hypotheses, we expect subset-knowers to lack the advanced or deeper knowledge of cardinals and of the relevant counting principles required to fully understand ordinality. Russian-speaking children thus most likely need to be CP-knowers in order to learn and apply the ordinal suffix to the appropriate stem, and thus to master the derivation rule. This is most certainly the case in a rule-based approach, as all evidence for the ordinal formation rule is above the OTS-boundary, which is still inaccessible for subset-knowers. Under a lexical approach, however, it is conceivable that some subset-knowers already learn lower ordinals lexically, just like they have learned some of the lower cardinals without full understanding of the counting principles. It is still important to note, however, that their representation of these ordinals would most likely still be incomplete.
The discussion above has brought forward two different hypotheses, which both yield different predictions regarding the order of acquisition. Russian-speaking children either use a rule-based approach to initial ordinal acquisition, or they learn their first ordinals lexically. The following section will present the methods and materials used to test these two hypotheses.
Methods and materials
This study compared children’s comprehension of Russian cardinal and ordinal numbers using an adapted computer-version of Meyer’s (2019) Give-X task. This type of task, also known as a ‘Give me’ or ‘Give Me X’ task has been used in many studies investigating cardinal development (e.g., Almoammer et al., 2013; Colomé & Noël, 2012; Le Corre & Carey, 2007; Meyer, 2019; Wynn, 1992) and more recently also ordinal acquisition (Colomé & Noël, 2012; Meyer, 2019).
Participants
A total of 36 typically developing monolingual Russian-speaking children (18 boys, 18 girls, mean age = 5;01 years, range = 4;06–5;10 years) were tested. The children were recruited at three different kindergartens in the center of Saint Petersburg. An additional 13 children were excluded from the results for being bilingual (11 children) or failing to complete the test (2 children). The children’s parents signed an Informed Consent form that was approved by the Ethics Committee of the Faculty of Humanities at the University of Amsterdam.
Materials
To ensure the comparability of this test to other Give-X tasks, the items and the procedure were made very similar to those used by Meyer (2019). Children were tested on the first seven cardinals and ordinals. This selection follows Meyer’s work, but is also most suited for the present purposes given the distribution of (ir)regular ordinals in Russian. As discussed earlier, pjatyj ‘fifth’ and šestoj ‘sixth’ are both completely regular in Russian, but the numerals pervyj ‘first’ through četvërtyj ‘fourth’ and sed’moj ‘seventh’ are irregular. The comparison between the lower irregular forms vtoroj ‘second’ through četvërtyj ‘fourth’ and sed’moj ‘seventh’ with pjatyj ‘fifth’ and šestoj ‘sixth’ therefore makes it possible to investigate the effect of regularity on the acquisition order of ordinals. Two trial items (posdlenij ‘last’ and vse ‘all’) were used to introduce the test to the children.
Each of these 14 numerals appeared three times in the task, combined with feminine or masculine nouns. This brought the total number of items to 42. Neuter nouns were excluded, as they are less frequent than masculine and feminine nouns and therefore harder to select. Moreover, neuter nouns and congruent adjectives or ordinals are often less transparent due to the vowel reduction of unstressed endings, and therefore acquired later (Janssen, 2016). Similarly, only feminine nouns ending in -a were included in the study, excluding less transparent feminine nouns ending in a palatalized consonant (Timberlake, 2004). Ordinals and cardinals were combined in the same test and presented in a randomized order.
The test was administered on a touchscreen laptop computer and all the questions in the test were pre-recorded. The software registered all the answers, which improved the ease of coding, but audio-recordings were made as well to register children’s verbal behavior (such as their counting strategies). Since all the questions in the computer-task had been recorded by a native speaker of Russian, there was minimal variability between each session: all children were presented with exactly the same questions, which were formulated and pronounced in an identical way. The experimenter repeated the question in the few cases where a child did not hear the question.
In line with Meyer (2019), formulaic variations such as Čeburaška govorit ‘Čeburaška says’ were recorded to keep the task as naturalistic and entertaining as possible, and all stimuli offered the numeral as a full nominative subject DP (determiner phrase). This means that the children always heard the nominative form of the numeral, and that they always received evidence for the singularity or plurality of the numeral on the verb form in addition to the marking on the noun. For ordinals, the agreement of the numeral with the noun served as a third piece of evidence for singularity. The examples below show how the items were introduced to the children for cardinals (3) and ordinals (4).
(3) Dva telefona mogut pomestit’sja two.NOM telephone.GEN.SG. can.3PL fit.INF v čemodan k Čeburaške. Ty možeš’ in suitcase.ACC.SG to Čeburaška.DAT.SG you can.2SG upakovat’ dva telefona? pack.INF two.ACC telephone.GEN.SG ‘Two telephones can fit in Čeburaška’s suitcase. Can you pack two telephones?’ (4) Sed’maja utka očen’ xočet poexat’ seventh.NOM duck.NOM really want.3SG go.INF s Čeburaškoj. Ty možeš’ upakovat’ with Čeburaška.INSTR you can.2SG pack.INF sed’muju utku? seventh.ACC.SG duck.ACC.SG? ‘The seventh duck really wants to come with Čeburaška. Can you pack the seventh duck?’
Procedure
The children were tested individually at their daycare center in Saint Petersburg by one experimenter. This experimenter introduced the children to Čeburaška, a Russian cartoon figure, and told them that they were going to play a computer game in which they were asked help Čeburaška to pack his suitcase. The test started with an introductory story based on Meyer (2019, p. 26), translated into Russian. The children then completed two training items. Each trial showed a line of nine identical pictures, and the children were asked to first pack the last item in the row and then to pack all the items. Figure 1 gives an example of this screen layout.

Screen layout of the test items
Both training items helped the children to understand the proceedings of the task. They learned how to pack one or multiple items, and that they could correct their mistakes by deselecting pictures before packing them (something they usually grasped intuitively). The remaining part of the test was very similar. Children were asked to put a specific number of items or a certain item in the row of nine pictures (e.g., three balls, the second chicken) in the suitcase. Children were allowed (but not required) to count items out loud.
A possible concern regarding computer tasks could be that some children might enjoy the ‘clicking’ procedure too much, resulting in the child packing more items than necessary. This behavior was indeed observed for four children who regularly packed more than one item on the ordinal trials. However, as these children did give correct answers for pervyj ‘first’ and (some of) the cardinal trials, they most likely only resorted to this strategy when they did not know the correct answer. For 13 other children a different grabbing pattern was observed. Three children had a clear preference for either the first or the last item, while 10 children had a clear preference for the middle of the screen (the fourth, fifth and sixth position). This may be explained by the experimental setting: children sat right in front of the computer, which made it easiest for them to reach for the middle of the screen.
At the end of the task, the experimenter asked all children to count to desjat’ ‘ten’ and desjatyj ‘tenth’. For ordinals, the children were asked to count a row of cups in order, and the experimenter helped them by asking ‘if this is the first, then the next is . . .?’ This made the task clearer. The children were also asked to count odin samolët-
Coding and analysis
This study followed Meyer’s (2019) method of analysis for ordinals and cardinals. First, the children were linked to a specific knower-level based on their performance on the cardinal trials: one-knower, two-knower, three-knower, four-knower or CP-knower. If a child scored correctly on at least two out of three occurrences of a certain cardinal n, and did not give an n-number of items more than once when asked for a different number, the child was assumed to have exact knowledge of this number, and thus to be an n-knower. These criteria are in line with those reported in many studies on cardinal acquisition, e.g., Le Corre and Carey (2007) and Meyer (2019). The tool provided by Negen et al. (2012) was used as well. This tool estimates knower-levels by approximating a Bayesian inference of a child’s knower-level. In all except for eight cases the results of both methods were the same.
These eight cases were analyzed carefully not only based on the results of the two estimation methods, but also on the child’s behavior during the test: for example, did the children count, showing knowledge of the cardinality principle, or did they consistently grab (cf. ‘grabbers’ in Wynn, 1990)? This led us to the decision to describe seven children as CP-knowers, even though they made too many mistakes on the cardinal sem’ ‘seven’ and occasionally on šest’ ‘six’ as well. One child was estimated to be a two-knower based on the criteria of Le Corre and Carey (2007), but as a four-knower according to the tool provided by Negen et al. (2012). This child was eventually described as a four-knower: he scored correctly on četyre ‘four’ multiple times, and his two mistakes on tri ‘three’ seemed to reflect problems with his attention span.
Ordinals were not analyzed in the same way as cardinals because the knower-level method could underestimate children’s knowledge of the ordinal rules. If a child understands the relation between the cardinal pjat’ ‘five’ and the regular ordinal pjatyj ‘fifth’, they can determine which picture to pick. However, if a child hears vtoroj ‘second’, and cannot find this item in the row, because they only know the incorrect but regular form *dvatyj ‘two-th’, then the child has to pick a random incorrect item. If this randomly chosen item overlaps with pjatyj ‘fifth’, this does not necessarily mean that the child does not understand pjatyj ‘fifth’. For this reason we decided to analyze ordinal knowledge more extensively, by dummy-coding children’s scores on each ordinal (0 = correct, 1 = incorrect) in order to be able to see the effects of age, cardinal knowledge, regularity and the place of the ordinal in the count list. Pervyj ‘first’ will be analyzed separately due to its different morphosyntactic status.
Results
Cardinals
Table 3 displays the final distribution of the five knower-levels related to age and the size of the count lists. Ten was the maximum score on the counting task, even though in some cases children were able to count to a higher number.
Knower-levels, ages and length of count lists of all subjects. Age range and mean age are presented in months and years, standard deviations are presented in months.
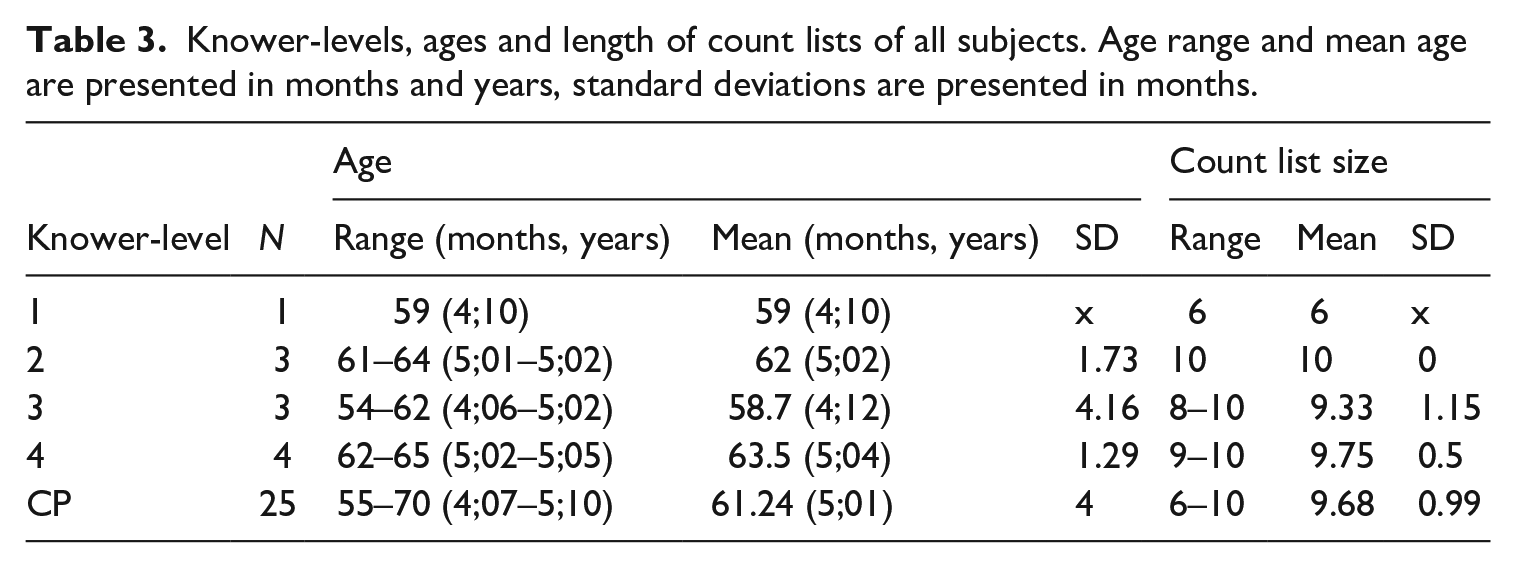
Table 3 shows that children were generally able to count to a higher number than they could comprehend, which is in line with previous studies. Some of the subset-knowers were older than some of the CP-knowers, and vice versa, but a Spearman’s correlation test did indicate a correlation between children’s knower-levels and their age in months (rs = .875, p < .001). No correlation was found between knower-level and the count list length (rs = –.006, p = .971), nor was there a detectable relation between age and count list length (rs = –.119, p = .488).
The data also suggest that Russian-speaking children go through the subset-stages at a relatively late age. Although only children above the age of four were tested, 11 out of 36 children (mean: 5;01, range: 4;06–5;05) were still at the traditional subset-stages up to four. This is quite old if we compare this to English data, as English-speaking children generally reach the CP-knower stage by the age of four (e.g., Huang et al., 2010; Le Corre & Carey, 2007; Meyer, 2019). This does not appear to be in line with Sarnecka et al. (2007), who did not find a significant difference between English-speaking children and Russian-speaking children. However, as they tested younger children than the present study (2;09–3;07), it is hard to compare the results.
Ordinals
Quantitative results
The children in this study generally performed worse on the ordinal tasks than on the cardinal tasks. Ordinal count lists were typically shorter than cardinal count lists. While 30 out of 36 children could count to ten, only 10 children were able to count up to tenth, and four children were not able to count ordinals at all. We did not find any overgeneralizations of the regular derivation rule.
The Give-X task revealed a similar delay in ordinal comprehension compared to cardinal knowledge. Although 12 CP-knowers showed (near-)ceiling performance, there were 13 CP-knowers who still made mistakes on ordinals (see Figure 2).
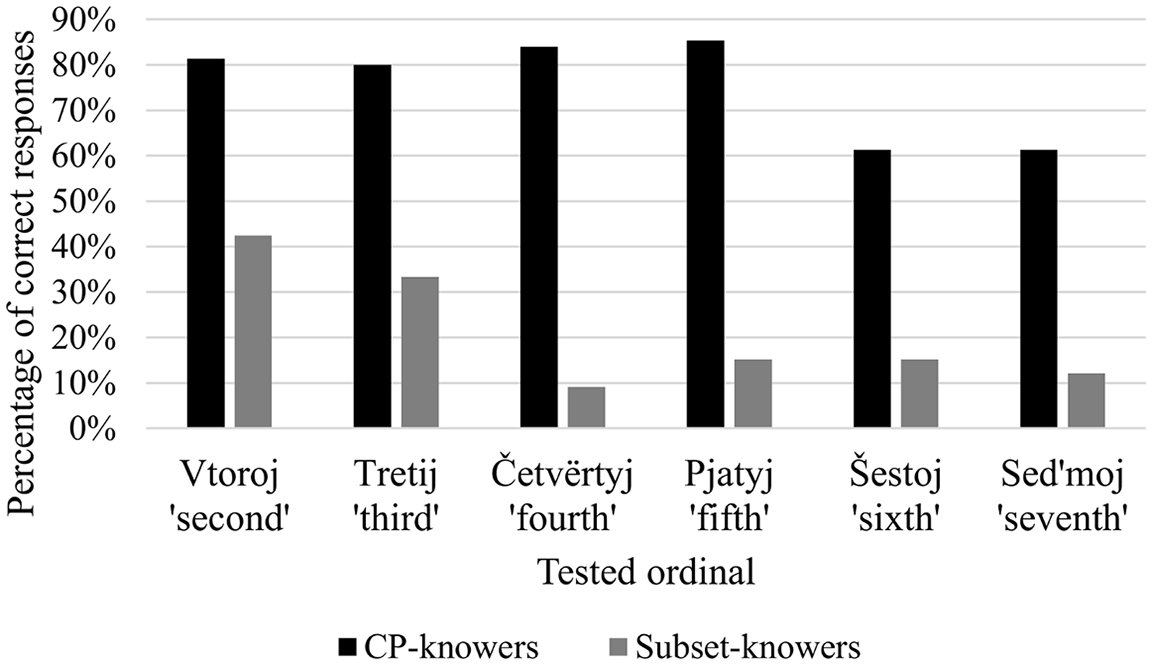
Percentage of correct response by subset-knowers (N = 11) and CP-knowers (N = 25).
Figure 2 not only suggests that CP-knowers perform better on ordinals than subset-knowers, but also that both groups performed worse on the ordinals above pjatyj ‘fifth’. This indicates that performance on the regular ordinals pjatyj ‘fifth’ and šestoj ‘sixth’ was not better than on irregular lower ordinals. To assess whether this observation can be generalized, we used R (R Core Team, 2016) for the statistical analysis, and fitted generalized linear mixed-effects logistic regression models with the lme4 package (Bates et al., 2015).
We first fit a model that included knower-level as a categorical variable with two levels (subset-knowers vs CP-knowers), followed by a second model including knower-level as a continuous factor. We then compared these two models: while treating knower-level as a continuous factor might be more precise, including it as a binary factor could lead to fewer degrees of freedom. The continuous factors age in months and place in the ordinal count list were centered before analysis, and the fixed categorical variables, (ir)regularity and knower-level (in the first model), were dummy-coded with explicit contrasts. Random intercepts were included for subject and item, with random slopes for place in the ordinal list by participant and knower-level and age by participant. The dependent variable was whether a child’s response on the ordinal trials was correct or incorrect. As the AIC and BIC were lower for the second model with knower-level as a continuous factor (AIC: 452.74 vs 451.77, BIC: 537.74 vs 536.77), this model was chosen for the rest of the analysis. The result summary of this model is given in Table 4.
Result summary for correct responses on tested ordinals in Russian. Coefficient estimates, confidence intervals, standard errors, associated Wald’s z-score and significance level (p) for all predictors in the analysis. Formula: Correctness ~ (Place + Regularity) + KnowerLevel * Age + (Place | Subject)+(KnowerLevel * Age | Item Ordinals considered irregular: pjatyj ‘fifth’; and šestoj ‘sixth’.
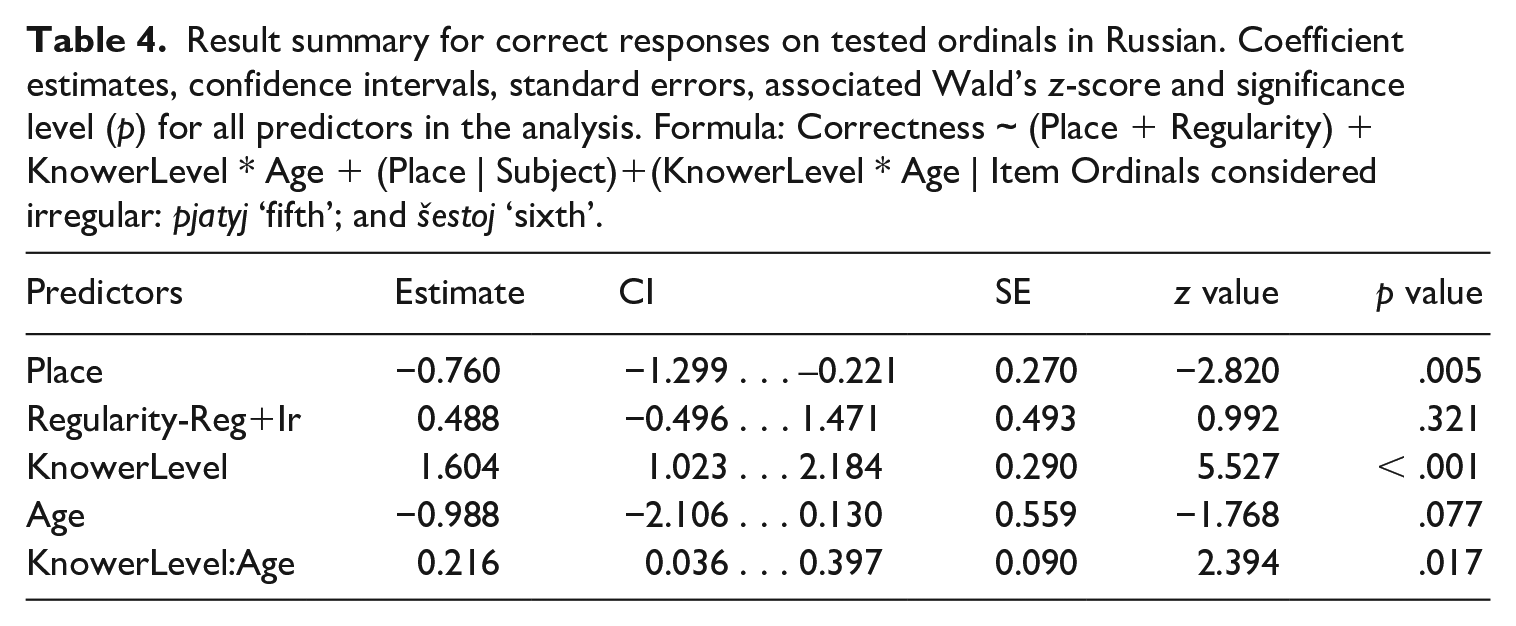
The overview of the model as presented in Table 4 indicates effects of place in the ordinal list and knower-level. The negative effect of place indicates that the odds for a participant to answer correctly were higher for lower ordinals than for higher ordinals. The probability that a child understood an ordinal significantly increased by knower-level, and a positive interaction between knower-level and age was found. This interaction effect means that the odds for older children to score better than younger children increased by cardinal knower-level. (More specifically, only CP-knowers seemed to really improve.) Significant effects of age and regularity were not found.
The results for pervyj ‘first’ were excluded from the discussion above. Pervyj ‘first’ behaves syntactically differently from the other ordinals (see also Barbiers, 2007; Meyer, 2019), and is also much more frequent. Because of this, it was predicted that despite its irregular form, scores on pervyj would be much higher than the scores on the higher ordinals. The data in Table 5 support this prediction. In fact, hardly any of the children made mistakes on pervyj, and thus the overall percentages were near-ceiling.
Percentage of correct responses on pervyj ‘first’ per knower-level.

Qualitative results
The analysis presented above does not provide sufficient insight into children’s learning strategies to answer whether we see a lexical or rule-based learning pattern in Russian. We therefore also conducted a qualitative analysis of children’s responses, starting with CP-knowers. As mentioned earlier, some CP-knowers scored at ceiling level on most of the ordinals and did not make more than one mistake per ordinal. We will refer to this group (N = 12) as ‘strong CP-knowers’, and contrast them with ‘weak CP-knowers’ (N = 13). These are CP-knowers who made two mistakes or more on at least one of the ordinal numbers. In total two of the weak CP-knowers could count ordinals up to tenth without mistakes, compared to eight strong CP-knowers. Figure 3 presents their overall scores on the Give-X task.

Percentage of correct responses per ordinal given by weak CP-knowers (N = 13).
Figure 3 indicates that these CP-knowers generally experienced trouble with the ordinals sed’moj ‘seventh’ and šestoj ‘sixth’. Two children behaved differently: one of them only scored correctly twice on pjatyj ‘fifth’, while the other showed two correct scores on četvërtyj ‘fourth’ and two on šestoj ‘sixth’. Both children seemed to have a general preference for packing the items in the middle of the screen (so items fourth through sixth): the first child packed the fifth and sixth item relatively often, the other child packed the sixth item eight times, and the fourth item four times. It is thus unlikely that she had real knowledge of these ordinals, which means that none of the children had clearly acquired the regular ordinals pjatyj ‘fifth’ and šestoj ‘sixth’ before the other ordinals.
The group of subset-knowers can also be divided into a weak group (N = 6) and a strong (N = 5) group depending on their ordinal knowledge: weak subset-knowers did not score correctly on any of the ordinals above pervyj ‘first’, while children in the strong subset-group had knowledge of the ordinals vtoroj ‘second’ and tretij ‘third’. Figure 4 shows the scores of this latter group.
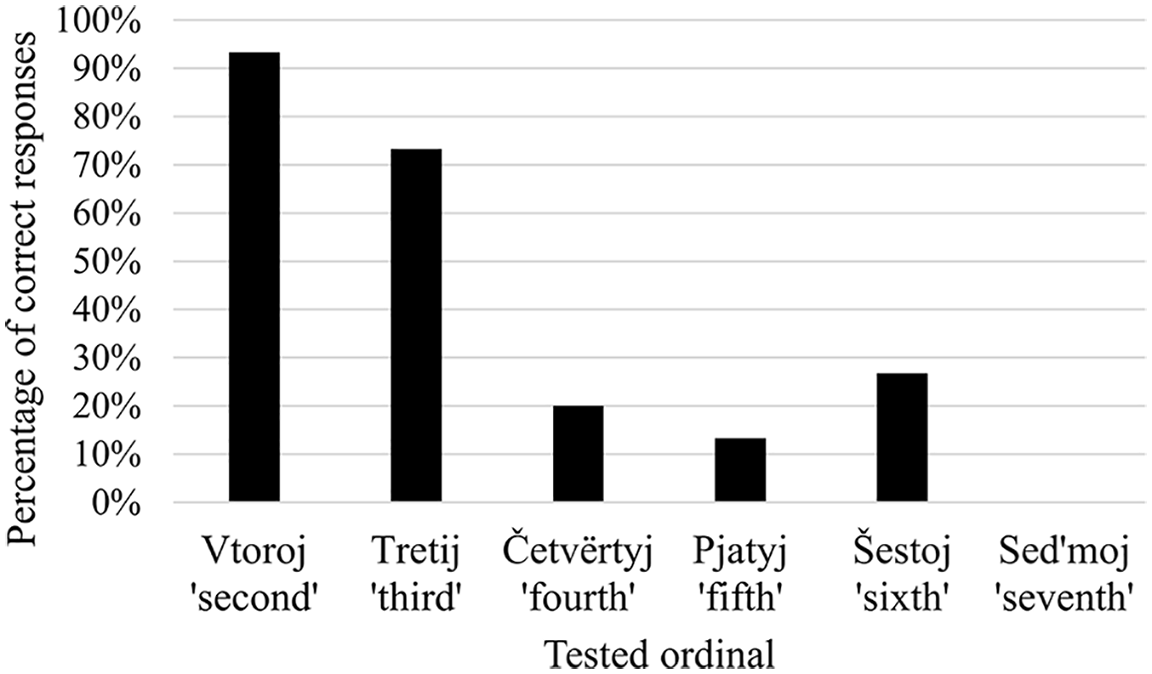
Percentage of correct responses per ordinal given by strong subset-knowers (N = 5).
It is clear from Figure 4 that these five subset-knowers scored high on the first two ordinals. One two-knower, three three-knowers and one four-knower (out of 11 subset-knowers) demonstrated knowledge of these ordinals in the Give-X task, while they did not know what to pack in the other trials. Figure 4 shows that there were also some correct responses on higher ordinals, but these responses are again unlikely to reflect knowledge of these ordinals: all of these five children preferred the middle of the screen when asked for ordinals they did not understand, which occasionally led to a correct response.
To summarize, the quantitative and qualitative analysis of the ordinal results have shown that knower-level is a predictor of ordinal knowledge and that higher ordinals are more difficult than lower ordinals, but that regularity does not seem to play a role. Although the absence of a significant effect of regularity cannot be interpreted on its own, the qualitative analysis showed that there are indeed no children in this study who clearly understood the regular ordinals pjatyj ‘fifth’ or šestoj ‘sixth’ before acquiring the ordinals vtoroj ‘second’ through četvërtyj ‘fourth’, while evidence was found that some subset-knowers already had knowledge of the irregular ordinals vtoroj ‘second’ and tretij ‘third’ before acquiring any (regular) higher ordinals. Moreover, some CP-knowers had knowledge of all the ordinals up to pjatyj ‘fifth’, but without knowledge of the regular ordinal šestoj ‘sixth’ and the irregular form sed’moj ‘seventh’. The ordinal pervyj ‘first’ yielded the most correct responses overall.
Discussion
This study investigated cardinal and ordinal acquisition in Russian. The results for cardinal acquisition were largely in line with previous research on Russian and other languages. Children were able to count higher than they could comprehend, and the children could be categorized in the traditional knower-levels. This supports the idea of a universal pattern of cardinal acquisition. Some of the Russian-speaking children in this study were relatively late to become CP-knowers compared to children acquiring English in previous studies: where English-speaking children usually reach the CP-level around the age of four (Almoammer et al., 2013; Huang et al., 2010; Meyer, 2019), 11 children (4;06–5;05) in the present study were still subset-knowers. This suggests that Russian-speaking children are slower in acquiring cardinal numbers than English-speaking children. Although it is hard to directly compare the two studies, a similar delay was found in Dutch by Meyer (2019) with respect to English. The present study does not provide any conclusive explanations for this apparent delay, but possible explanations could lie in, for example, education, input and linguistic factors (see also Meyer, 2019).
The main research question of this article concerned learning strategies used for ordinal acquisition. We hypothesized that Russian-speaking children would either use a rule-based approach to ordinal acquisition, or that they would initially learn the ordinals lexically. The statistical analysis showed an effect of place in the ordinal list, but did not indicate an effect of regularity. As higher ordinals are conceptually more difficult for both rule-based learners and lexical learners, this effect does not immediately answer the research question. We argue, however, that the qualitative analysis provided more evidence for a lexical approach than for a rule-based approach.
First of all, the findings indicated that at least five children had already acquired irregular vtoroj ‘second’ or vtoroj and tretij ‘third’ lexically, before understanding any of the other ordinals. The overall scores on šestoj ‘sixth’ and sed’moj ‘seventh’ were the lowest, and none of the children responded correctly to pjatyj ‘fifth’ and šestoj ‘sixth’ without knowledge of the first three ordinals. We can thus see evidence for a more gradual learning pattern, in which the most frequent lower ordinals are acquired before the less frequent higher ordinals. This is more in line with a lexical hypothesis than with a rule-based learning pattern.
It was nonetheless surprising that children did not seem to experience many difficulties with pjatyj ‘fifth’. Just like šestoj ‘sixth’ and sed’moj ‘seventh’, it is above the OTS-boundary and infrequent, and thus it seems strange that pjatyj ‘fifth’ did not elicit more mistakes. One possible explanation for this could be found in the fact that at least 10 out of 36 children had a clear preference for the items in the middle of the screen, which led to a number of occasional correct answers on pjatyj ‘fifth’. This could also explain why četvërtyj elicited relatively high scores compared to the more frequent vtoroj ‘second’ and tretij ‘third’. Another possibility is that numbers simply get more difficult the higher children have to count. As argued by Meyer (2019), the task of counting becomes more taxing both in terms of motor skills as well as in terms of working memory if a child has to count more items. This could explain why children struggled more with ‘sixth’ and ‘seventh’ (and CP-knowers even made some occasional mistakes on the highest cardinals).
A second argument for lexical learning is the fact that several subset-knowers showed knowledge of lower ordinals without exhibiting knowledge of the higher, rule-based, forms. It was argued that in a rule-based approach, Russian-speaking children cannot start learning ordinals before they reach the CP-knower-level, as they would need to use evidence from higher ordinals to learn and apply the ordinal formation rule. In a lexical approach, it was deemed possible for children to acquire some of the ordinals at the subset-stages of acquisition. This notwithstanding, it might still be considered surprising that subset-knowers were able to acquire ordinals, as Meyer’s (2019) findings suggested that Dutch-speaking children had to be CP-knowers (or very advanced four-knowers) to learn lower ordinal numerals. However, the Dutch subset-knowers in Meyer’s (2019) studies were all under the age of 4;00, while the Russian subset-knowers in the current study were between ages 4;06 and 5;05. Older children might be more cognitively mature than younger learners, which may help them to acquire ordinals at this stage with less linguistic support. Moreover, they are also more likely to have heard enough occurrences of the lower ordinals in their input at this stage than younger learners, which makes it more likely for older subset-knowers to have lexical knowledge of these ordinals. This may also explain why the strong subset-knowers scored better on ordinals than some of the CP-knowers: while all but one of the strong subset-knowers were older than 5;00 years old, seven of the weak CP-knowers were younger.
All in all, the results thus point more towards a lexical learning pattern than towards a rule-based approach in Russian ordinal acquisition. This suggests that Russian-speaking children acquire ordinals differently from Dutch- and English-speaking children (cf. Meyer, 2019). Our explanation for this lies in the irregularity of the Russian ordinal system. There are five irregular forms (vtoroj ‘second’, tretij ‘third’, četvërtyj ‘fourth’, sed’moj ‘seventh’ and vos’moj ‘eighth’), and only four regular forms (pjatyj ‘fifth’, šestoj ‘sixth’, devjatyj ‘ninth’, desjatyj ‘tenth’) in the first ordinals in the count list (excluding pervyj ‘first’). Following Yang’s Tolerance Principle and Sufficiency Principle (2016), we argued that the greater the number of exceptions, the greater the number of lexical items children need to know in order to generalize the rule: the calculations provided by these principles showed that Russian-speaking children need to know at least 13 ordinals (vtoroj ‘second’ through četyrnadcatyj ‘fourteenth’) to overcome these exceptions. Since these higher ordinals are highly infrequent, it takes a relatively long time for children to learn them. As children hear the irregular lower ordinals more frequently, this could explain why children learn some of these lexically before they master the derivation rule.
Conclusions
The main goal of this study was to determine which factors play a role in Russian ordinal acquisition, and how this relates to patterns previously found in other languages. As Dutch- and English-speaking children are aided by the rule underlying ordinal derivation from cardinals, the question was whether this would also apply to Russian, a language with even more irregular forms. The findings indicate that while Russian cardinal acquisition follows the same pattern attested for other languages in a large body of research, ordinal acquisition follows a different pattern, as Russian-speaking children initially seem to learn ordinals lexically. This is the first time that evidence has been found for lexical-learning in ordinal acquisition, which suggests language-specific learning patterns for ordinals.
This result implies that Russian-speaking children use a different acquisition strategy than the Dutch- and English-speaking children in Meyer’s study (2019). It was argued, in line with Yang’s Productivity and Sufficiency Principle (2016), that this can be explained by the fact that Russian has too many irregular forms: Russian-speaking children have to know at least 13 ordinals to apply the derivation rule to other ordinals (of which eight regular forms), while English-speaking only have to learn six ordinals, of which only two are regular (fourth and sixth). As the ordinals above fourth are very infrequent and cognitively demanding, the threshold for rule-learning might simply be too high for Russian-speaking children, especially since the lower irregular ordinals up to cetvërtyj ‘fourth’ are much more frequent and cognitively easier to process. This could explain why Russian-speaking children initially resort to a lexical-learning pattern.
We conclude that language can affect the way in which ordinals are learned, a finding that also has consequences for other languages. As we argue that the number of irregularities in the ordinal system plays a role, a similar learning pattern would be predicted for other languages with opaque ordinal systems. Examples of such languages are different Slavic languages or Romance languages, such as Spanish or Portuguese.
An important question that still needs to be answered is to what extent lexical learning initially entails the same representation of ordinals as rule-based learning. Our study reveals that there are Russian-speaking children who only know a subset of the ordinals in the count list lexically. These children most likely did not have a complete representation of ordinals and ordinality, as they had very limited knowledge of the ordinal count list, and thus the question is whether this knowledge can be compared to that of rule-learners.
Footnotes
Acknowledgements
We are grateful to Dirk-Jan Vet, the electronic engineer of the phonetics department of the ACLC, for helping us program the experiment.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research reported in this paper was supported by a travel grant from The Netherlands Institute in Saint-Petersburg.