
Abstract
Background:
Online crowdsourcing platforms, such as Amazon Mechanical Turk (MTurk), have become popular alternatives to the ubiquitous student samples used in psychology research. r/SampleSize, an alternative pool on the website Reddit, allows for online participant recruitment without compulsory or immediate payment, making it potentially useful for students, research trainees, and course instructors.
Objective:
The current study sought to assess the viability of using r/SampleSize as a participant pool by comparing its data characteristics to MTurk and existing lab samples.
Method:
Two hundred and fifty-six MTurk workers and 277 r/SampleSize participants completed identical questionnaires on demographics, participation motivations, and standard psychology scales.
Results:
Participants recruited through r/SampleSize reported diverse ages, education levels, income, and employment, although White ethnic background and US residence were predominant. r/SampleSize participants were more internally motivated than MTurk to participate in research and had greater need for cognition but did not differ significantly in altruism or motivation to gain self-knowledge. r/SampleSize data reliability and quality were comparable to MTurk and lab samples across most analyses.
Teaching Implications:
r/SampleSize can be used to recruit relatively large and diverse samples for undergraduate research projects with minimal setup, labor, and cost.
Conclusion:
The findings suggest that r/SampleSize is a diverse and viable participant pool.
Online crowdsourcing has become a popular method of recruiting research participants for studies in psychology. The ease and timeliness of data collection online as well as access to relatively large samples make this recruitment strategy particularly attractive for students, research trainees, and course instructors in psychology (Sciutto, 2015). Unlike traditionally used university student samples that suffer from problems with generalizability and representativeness (Hanel & Vione, 2016), online recruitment offers greater demographic diversity and data quality (Buhrmester et al., 2011; Peer et al., 2017; Rouse, 2015; Sciutto, 2015). These features can offer trainees the opportunity to pose more diverse research questions and enable improved training in research methodology by accounting for factors such as sufficient samples for statistical power (Vankov et al., 2014), as well as generalizability and representativeness in data collection (Henrich et al., 2010). The importance of training students to promote better research practices is particularly relevant in the context of the replicability crisis in psychology (Morling & Calin-Jageman, 2020; Perlman & McCann, 2005).
Most dedicated online crowdsourcing platforms, such as Amazon Mechanical Turk (MTurk), are designed for participant recruitment in return for financial compensation (i.e., pay-per-survey). The cost of online recruitment (e.g., $6 an hour recommended for MTurk studies; Moss, 2019) reflects increasing demands for higher compensation rates (Keith et al., 2017; Peer et al., 2017; Rouse, 2015). This recruitment strategy is thereby financially prohibitive for in-class projects, independent studies, and other research training where supervisors and trainees do not typically have access to considerable funds (e.g., Kierniesky, 2005). The use of social media platforms, such as Facebook or Twitter, is one accessible alternative; however, this recruitment approach poses some ethical and methodological limitations. For example, Sciutto (2015) indicates that Facebook participants are known to the researchers, which may increase risks of socially desirable responding and coercion.
Another avenue for a more financially accessible online recruitment platform is Reddit, a social news and media aggregation website where users can browse and post content anonymously. Based on a review of preliminary studies which recruited participants through specific communities on Reddit (subreddits), Shatz (2017) suggested that Reddit can be a potential source of fast, reliable, and diverse data. In addition, researchers have the option to provide compensation to Reddit participants through flexible compensation methods, such as gift card raffles, which have the benefit of minimizing financial losses to researchers. One subreddit known as r/SampleSize is a dedicated community of over 165,000 registered members who voluntarily complete online surveys (“r/SampleSize,” 2012). r/SampleSize regularly moderates the posted surveys based on standardized guidelines, creating an infrastructure that supports equal opportunities for researchers. r/SampleSize therefore appears to show unique promise as a large, broadly accessible, and moderated participant pool that may be particularly attractive for students, research trainees, and course instructors in psychology.
Several recent studies have provided insights into the characteristics of the r/SampleSize participant pool, including greater demographic diversity in terms of age, educational level, and equal gender representation compared to traditionally-used samples (Brickman & Silva, 2017; Jamnik & Lane, 2017; Luong et al., 2019; Record et al., 2018). Brickman and Silva (2017) also reported that r/SampleSize participants completed surveys largely due to internal motivations over external motivations. Furthermore, Jamnik and Lane (2017) demonstrated that scale reliabilities were similar between r/SampleSize and an undergraduate sample. The responses of r/SampleSize participants also successfully replicated previous findings on psychological well-being (Jamnik & Lane, 2017) and the fundamental attribution error (Luong et al., 2019).
Although promising, the above studies are limited in their scope regarding the psychological and psychometric qualities of the r/SampleSize sample, which may discourage its use by psychology instructors, students, and research trainees. The psychological implications of the greater internal motivations of the sample observed by Brickman and Silva (2017) need to be investigated to facilitate the accurate interpretation of studies using r/SampleSize samples when they are compared to other samples that may not share these psychological characteristics. Specifically, altruism may underlie the internally motivated and voluntary participation of r/SampleSize participants (e.g., Burns et al., 2006), which would suggest that they are more altruistic than the externally motivated participants from a pay-per-survey platform like MTurk. Moreover, voluntarily seeking out research studies without compensation, which typically involve complex thought or tasks, appears characteristic of greater need for cognition (Cacioppo et al., 1984). It is important that researchers investigating any of the numerous commonly-studied constructs associated with altruism and need for cognition, such as personality traits (e.g., Furnham et al., 2016; Sadowski & Cogburn, 1997), know about such differences—or lack thereof—when interpreting findings from r/SampleSize.
Additionally, no published research to date has directly investigated the data quality obtained from r/SampleSize. More importantly, no research to date has compared r/SampleSize to paid platforms like MTurk that are already used as reliable alternatives to undergraduate pools. The purpose of the current study was to examine the demographics of the r/SampleSize participant pool and assess the viability of r/SampleSize as an alternative participant pool to MTurk by addressing two research questions: R1. Participant motivations: What are the motivations for participating on r/SampleSize compared to MTurk? In accordance with the rationale presented above, we hypothesized that r/SampleSize participants would be more internally motivated to participate than MTurk workers, more altruistic compared to MTurk workers, and have a higher need for cognition compared to MTurk workers. R2. Data quality: How does the quality and reliability of data collected from r/SampleSize compare to MTurk?
Method
Participants
Two hundred and seventy participants responded to the MTurk survey of which 14 were excluded for withdrawal from the study as they did not reach the debriefing page of the survey. Four hundred seventy-eight participants responded to the r/SampleSize survey, of which 194 were excluded for withdrawal and seven for being under 18 years old. Of withdrawn participants, 193 did not reach the debriefing page, while only one withdrew their data at debriefing. Missing data were excluded from the final dataset on a case-wise basis (indicated per analysis if applicable).
Power analyses conducted prior to data collection using G*Power 3.1.9.2 (Faul et al., 2009) indicated that our planned sample sizes of 250 in each group were sufficient to detect, at a minimum, conventionally small effects (ds > 0.34; Cohen, 1988) across all planned participant motivations and data quality analyses at β = .20 and α = 0.00278, excluding the reliability analyses. This minimum is based on the participant motivation analyses, which were the least sensitive among the planned analyses. For the reliability analyses, these sample sizes were sufficient to detect, at a minimum, a difference ratio in Cronbach’s α of approximately 1.30 at β = .20 and α = .003 (corrected for 15 potential pairwise comparisons) as per Bonett (2002).
Measures
All measures, analysis scripts, data, and preregistration details for the study are available on the Open Science Framework (OSF; see Transparency and Openness Statement).
Demographics
We asked participants about their gender, age, ethnicity, country of residence, household income (USD), employment status, education, and marital status. To measure political orientation, we used the 12-item Social and Economic Conservatism Scale (SECS; Everett, 2013) to measure two dimensions of social and economic political conservatism. Participants were asked to rate their positivity or negativity toward an issue (e.g., abortion). Scores of 0 indicated greater negativity toward the issue (i.e., less conservatism), whereas scores of 100 indicated greater positivity toward the issue (i.e., greater conservatism).
Participation motivations
We measured internal and external participation motivations by adapting five questions from Buhrmester et al. (2011) for use with r/SampleSize (“Why do you use r/SampleSize?”) regarding interest, passing time, having fun, making money, and gaining self-knowledge. We also added an additional item on helping with research (“To help with research”). Participants rated each motivation on 7-point Likert scales (1 = Strongly Disagree to 7 = Strongly Agree).
Altruism
We measured altruism using the 10 altruism questions from the 300-item International Personality Item Pool (IPIP-NEO; Goldberg, 1999; Goldberg et al., 2006). Participants were asked to rate how accurately each item described them (e.g., “I love to help others”) on 5-point Likert scales (1 = Very Inaccurate to 5 = Very Accurate). We also added 10 randomly selected items from the IPIP-NEO to reduce hypothesis guessing (see OSF materials).
Need for cognition
We measured need for cognition using the 18-item Need for Cognition Scale (NFC; Cacioppo et al., 1984). Participants were asked to rate how well each statement described them (e.g., “I would prefer complex to simple problems”) on 5-point Likert scales (1 = Extremely Uncharacteristic to 5 = Extremely Characteristic).
Data quality
Reliability
Based on Peer et al. (2017), we used the IPIP-NEO, Rosenberg Self-Esteem Scale (RSES; Rosenberg, 1965) and NFC as standard scales for reliability analysis due to their ubiquity and demonstrated reliability in standardized samples. Similarly, we conducted reliability analyses on the 16-item version of the Social Desirability Scale-17 (SDS-17; Stöber, 2001) and four-item Perceived Awareness of the Research Hypothesis Scale (PARH; Rubin, 2016) due to their known reliability in previous samples.
Attention checks
We interspersed three attention check questions, one in each of the SECS, IPIP-NEO, and NFC respectively as measures of data quality. Participants were asked to respond how the question asked (e.g., “To validate your continuing participation, please select 70.”).
English fluency
We assessed self-reported English fluency using a 5-point Likert item on English comprehension (1 = Not well at all, 5 = Extremely Well).
Social desirability and demand characteristics
Self-report measures can be affected by social desirability (e.g., Holtgraves, 2004) and demand characteristics (e.g., Sharpe & Whelton, 2016), so we measured social desirability using the SDS-17 and demand characteristics using the PARH.
Participant naivety
After each standardized scale (SECS, IPIP-NEO, RSES, NFC), we asked participants if they had ever answered that questionnaire before. We also asked participants if they were familiar with MTurk or r/SampleSize and if they had ever completed academic studies on that platform before.
Procedure
All procedures were approved by the University of Toronto Mississauga Research Ethics Board. Participants accessed their version of the questionnaire through links posted on the MTurk task list and r/SampleSize subreddit. MTurk data collection was split into three time blocks between July 27–31, 2018 (5 days). r/SampleSize data collection was performed between July 27–August 22, 2018 (27 days). Following r/SampleSize guidelines, we reposted the questionnaire every 24 hours if the post had fallen off the front page. Participants from either participant pool were restricted from duplicate responses through the Qualtrics ballot stuffing feature and MTurk worker ID verification.
Participants completed the survey questions in the following order: motivations, SECS, IPIP-NEO altruism items, RSES, NFC scale, SDS-17, demographics questions, PARH scale, and open-ended questions on their thoughts on the research. Participants were then debriefed and received compensation. MTurk participants were paid $1.50 USD whereas r/SampleSize participants were eligible to enter a raffle for one of five $75 USD gift cards.
Results
Demographics
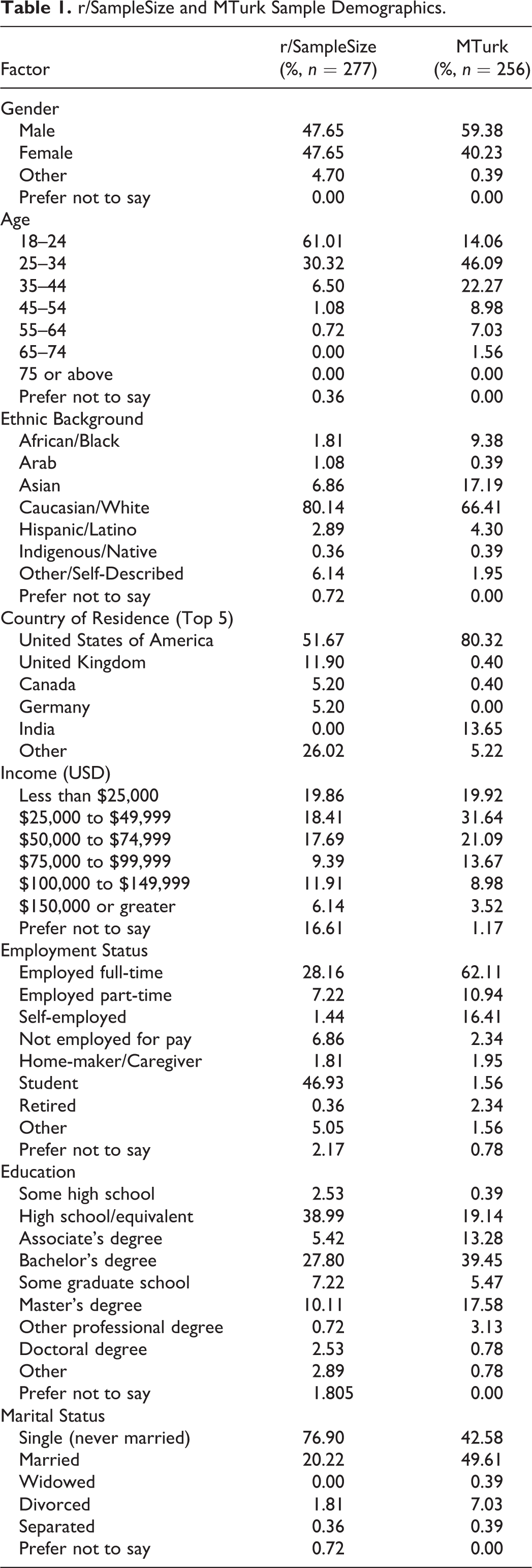
Descriptive statistics of demographics for both samples are reported in Table 1. r/SampleSize participants reported equal male-female gender representation and diverse ages, education levels, and income ranges. They also reported predominantly Caucasian/White ethnic backgrounds and residence in the United States.
r/SampleSize and MTurk Sample Demographics.
Preregistered Planned Analyses
Participant motivations
One-way ANCOVAs were conducted to compare the motivations of MTurk and r/SampleSize participants, controlling for social desirability and demand characteristics and correcting for multiple comparisons using the Bonferroni correction (adjusted α = 0.00278). We used conventional guidelines from Cohen (1988) to guide interpretation of effect sizes. As shown in Figure 1, r/SampleSize participants indicated greater motivation than MTurk participants to complete interesting tasks F(1, 523) = 35.88, p < .001, ηp2 = .06, d = 0.47, 95% CI [0.29, 0.64], to pass time F(1, 523) = 163.75, p < .001, ηp2 = .24, d = 1.13, 95% CI [0.95, 1.31], have fun (F(1, 523) = 177.01, p < .001, ηp2 = .25, d = 1.11, 95% CI [0.94, 1.30]), and help with research (F(1, 523) = 78.73, p < .001, ηp2 = .13, d = 0.70, 95% CI [0.53, 0.88]). Conversely, r/SampleSize participants indicated much less motivation for participating to make money than MTurk participants (F(1, 523) = 1584.67, p < .001, ηp2 = .75, d = −3.51, 95% CI [−3.78, −3.24]). The difference in motivation for gaining self-knowledge was not significant (F(1, 523) = 2.81, p = .0940, ηp2 < .01, d = 0.095, 95% CI [0.075, 0.27]). Social desirability was a significant covariate only of motivation to help with research (p < .001, ηp2 = .02). Demand characteristics were a significant covariate of motivation to complete interesting tasks (p < .001, ηp2 = .08), have fun (p < .001, ηp2 = .04), gain self-knowledge (p < .001, ηp2 = .06), and help with research (p < .001, ηp2 = .05). Mann-Whitney U tests, which were conducted to address normality and homoscedasticity violations for the analyses of motivations to pass time and make money, converged with the results from the one-way ANCOVAs.
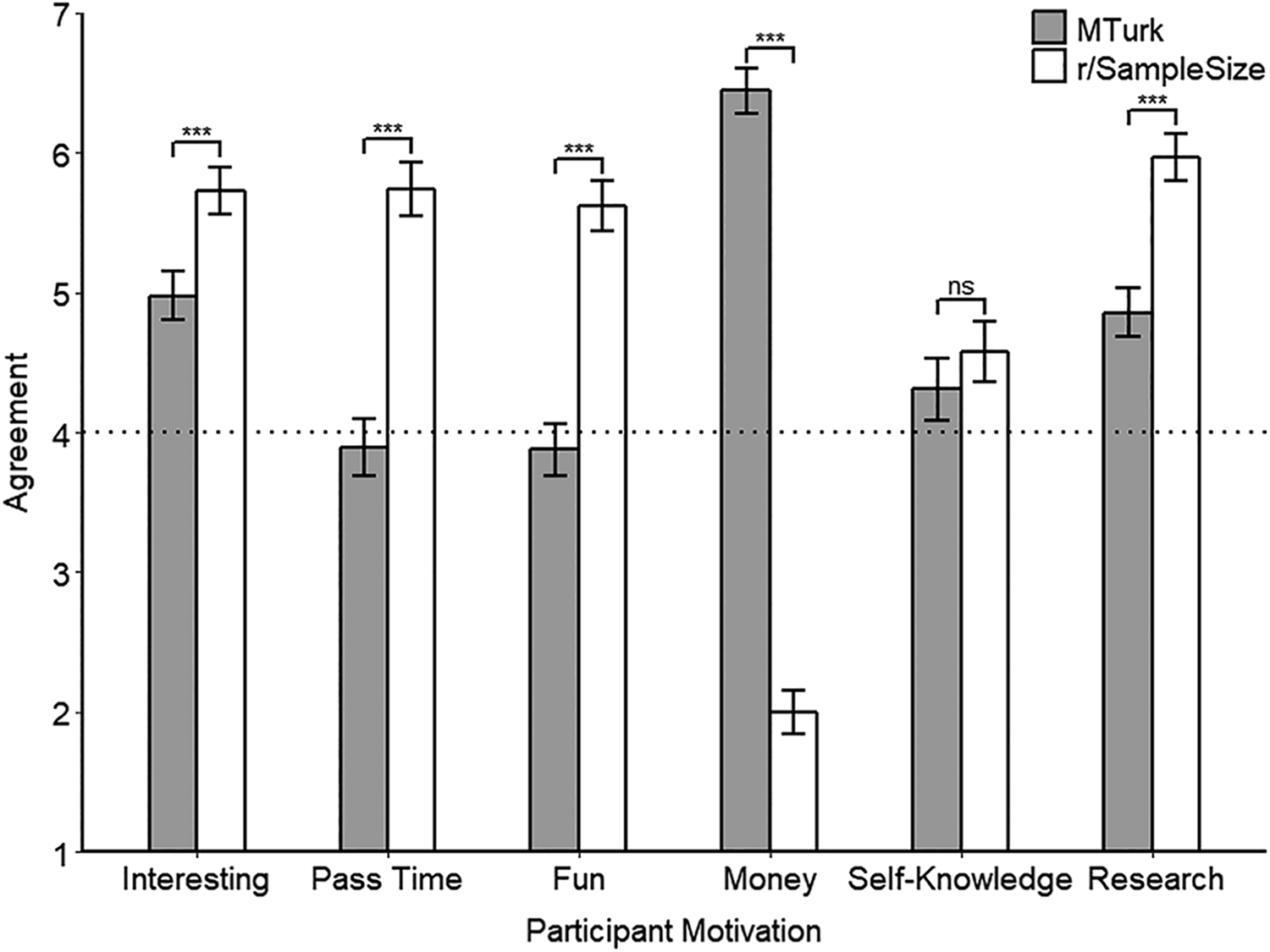
Estimated marginal mean motivations between r/SampleSize and MTurk participants, controlling for social desirability and demand characteristics. Error bars represent 95% CIs. The dotted line represents the midpoint of the agreement scales. ***p < 0.001.
Altruism
One-way ANCOVAs revealed that the difference between r/SampleSize and MTurk participants in self-reported altruistic personality was not significant, F(1, 522) = 1.54, p = .215, ηp2 < .01, d = 0.035, 95% CI [−0.14, 0.21], but with social desirability being a significant covariate (p < .001, ηp2 = .04; Figure 2A).
Need for cognition
r/SampleSize participants reported slightly higher need for cognition than MTurk participants, F(1, 522) = 8.56, p = .004, ηp2 = .02, d = 0.23, 95% CI [0.058, 0.40], with only demand characteristics as a significant covariate (p = .007, ηp2 = .014; Figure 2B).
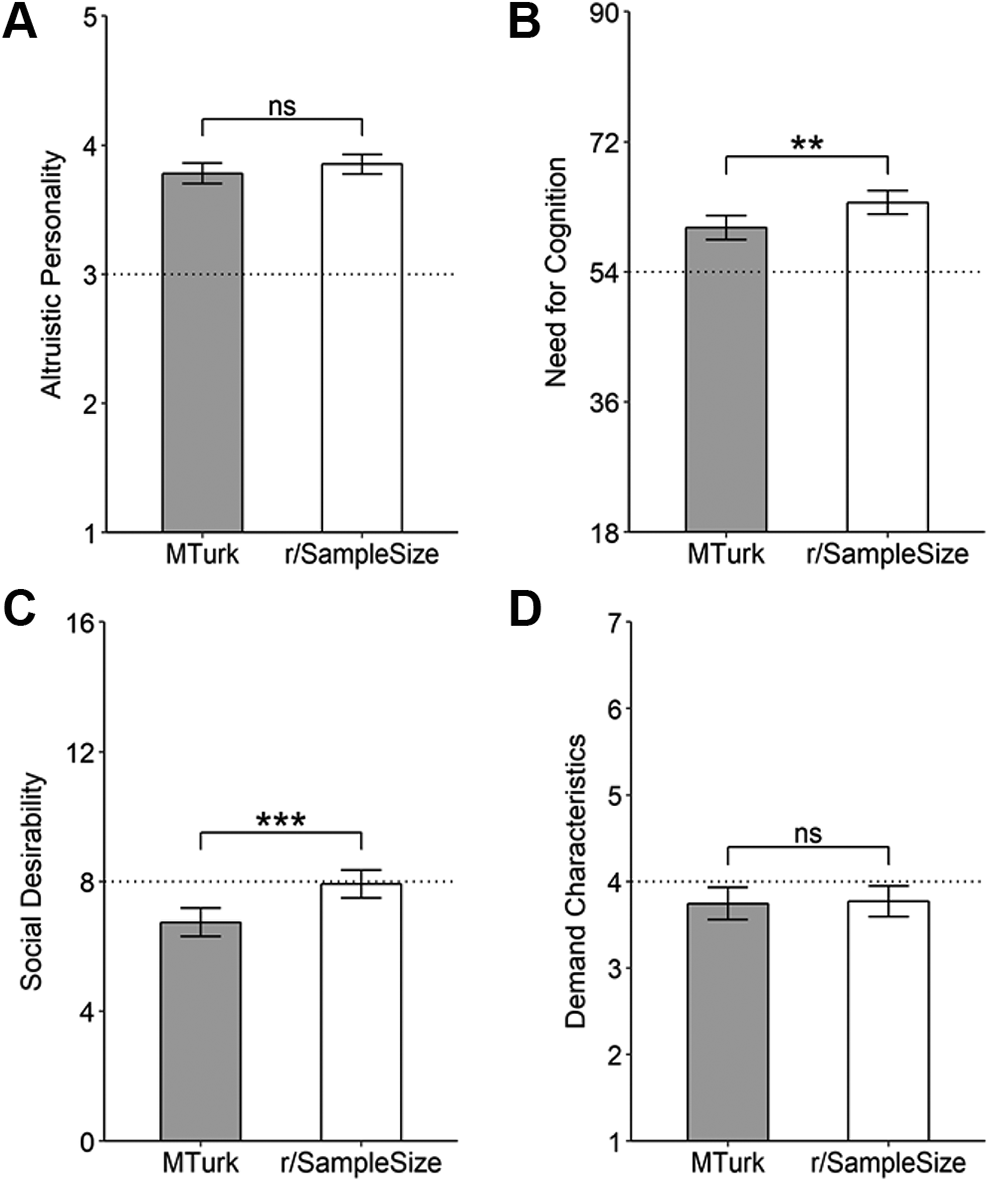
Estimated marginal means for altruistic personality (A) and estimated sum scores for need for cognition (B) between MTurk and r/SampleSize participants, controlling for social desirability and demand characteristics. Social desirability sum scores (C) and mean demand characteristics scores (D). Error bars represent 95% CIs. The dotted lines represent the midpoints of the scales. **p < 0.01, ***p < 0.001.
Data quality
Reliability analyses
We used the cocron package in R (Diedenhofen & Musch, 2016) to conduct significance tests for Cronbach’s alphas between r/SampleSize, MTurk, and existing samples as done previously (e.g., Peer et al., 2017). As shown in Table 2, the differences in Cronbach’s alphas across r/SampleSize, MTurk, and existing samples for the IPIP-NEO, NFC, or SDS-17 were not significant, but the PARH and RSES did differ significantly. As shown in Table 3, post hoc analyses for the PARH showed that the differences between r/SampleSize, MTurk, and the adult sample were not significant, but MTurk was significantly lower than the adult sample. For the RSES, differences between r/SampleSize and MTurk or MTurk and the student sample were not significant, but r/SampleSize was significantly greater than the student sample.
Omnibus Tests for Cronbach’s α Across r/SampleSize, MTurk, and Community Samples.
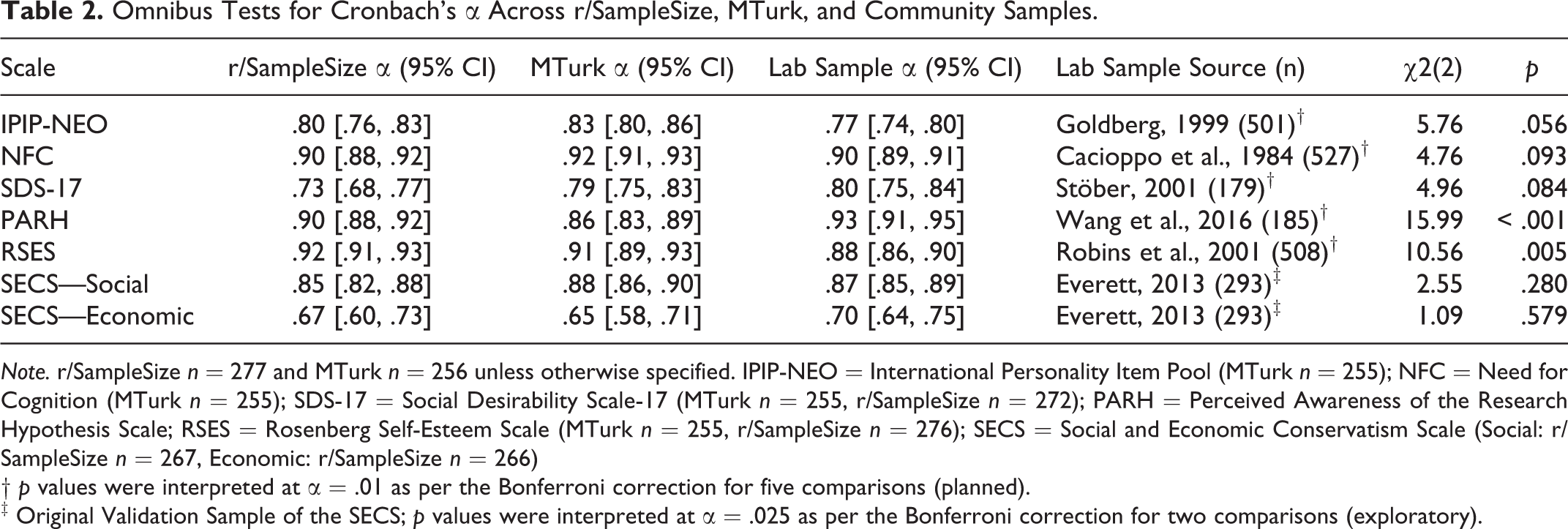
Note. r/SampleSize n = 277 and MTurk n = 256 unless otherwise specified. IPIP-NEO = International Personality Item Pool (MTurk n = 255); NFC = Need for Cognition (MTurk n = 255); SDS-17 = Social Desirability Scale-17 (MTurk n = 255, r/SampleSize n = 272); PARH = Perceived Awareness of the Research Hypothesis Scale; RSES = Rosenberg Self-Esteem Scale (MTurk n = 255, r/SampleSize n = 276); SECS = Social and Economic Conservatism Scale (Social: r/SampleSize n = 267, Economic: r/SampleSize n = 266)
† p values were interpreted at α = .01 as per the Bonferroni correction for five comparisons (planned).
‡ Original Validation Sample of the SECS; p values were interpreted at α = .025 as per the Bonferroni correction for two comparisons (exploratory).
Post Hoc Tests for Cronbach’s α Across r/SampleSize, MTurk, and Community Samples.
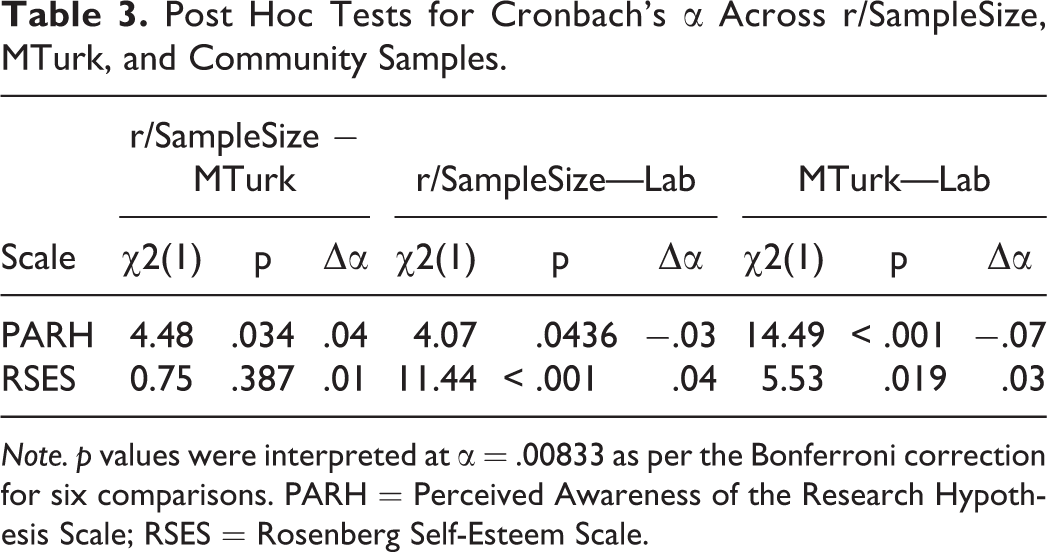
Note. p values were interpreted at α = .00833 as per the Bonferroni correction for six comparisons. PARH = Perceived Awareness of the Research Hypothesis Scale; RSES = Rosenberg Self-Esteem Scale.
Attention checks
Welch’s t-test indicated that r/SampleSize participants (M = 2.92, SD = 0.28) correctly answered more attention checks on average than MTurk participants (M = 2.77, SD = 0.60), t(352.73) = 3.60, p < .001, d = 0.32, 95% CI [0.15, 0.49].
Social desirability and demand characteristics
Welch’s t-tests indicated that socially desirable responding was slightly greater for r/SampleSize than MTurk participants t(509.92) = −3.80, p < .001, d = 0.33, 95% CI [0.16, 0.50] (Figure 2C), and differences in demand characteristics scores between r/SampleSize and MTurk participants were not significant, t(511.67) = 0.20, p = .845, d = 0.02, 95% CI [−0.15, 0.19] (Figure 2D).
English fluency
A one-way ANCOVA indicated that the differences in self-reported English comprehension scores between r/SampleSize and MTurk participants were not significant, F(1, 523) = 0.31, p = .578, ηp2 < .01, d = −0.046, 95% CI [−0.22, 0.12], with no significant contribution of social desirability or demand characteristics.
Non-Preregistered Exploratory Analyses
Duration of questionnaire completion
Examination of histograms and boxplots of questionnaire completion times revealed multiple upper outliers. Such outliers were plausible as the questionnaire was not intended to force completion times. A Mann-Whitney U test (without outlier removal) indicated that the median completion time for r/SampleSize participants (Mdn = 13.02 min) was nearly five minutes greater than MTurk participants (Mdn = 8.02 min), U = 55488, p < .001, 95% CI [3.98, 5.70].
Social and economic conservatism
Welch’s t-tests indicated that social conservatism was largely greater for MTurk than r/SampleSize participants, t(495.45) = 11.89, p < .001, d = 1.04, 95% CI [0.86, 1.23], and economic conservatism was moderately greater for MTurk than r/SampleSize participants, t(509.91) = 7.61, p < .001, d = 0.67, 95% CI [0.49, 0.84]. As shown in Table 2, differences in Cronbach’s alphas across r/SampleSize, MTurk, and Everett’s (2013) original SECS validation sample were not significant.
Participant naivety
Sixteen percent of MTurk participants reported familiarity with r/SampleSize, with 75% reporting no familiarity and 9% unsure. Of the MTurk participants who reported familiarity with r/SampleSize, 67% reported completing academic studies on r/SampleSize, 31% reported not completing studies, and 2% were unsure. Thirty percent of r/SampleSize participants reported familiarity with the MTurk platform, whereas 66% reported no familiarity and 5% were unsure. Of the r/SampleSize participants who reported familiarity with MTurk, 13% reported completing academic studies on MTurk and 87% reported not completing studies.
There was no evidence that familiarity with the SECS, RSES, or SDS-17 scales differed significantly between MTurk and r/SampleSize participants (Table 4). More MTurk participants reported familiarity with the IPIP-NEO altruism subscale than r/SampleSize, χ2(1, N = 466) = 23.26, p < .001, 95% CI [0.13, 0.31]. Conversely, more r/SampleSize participants reported familiarity with the NFC than MTurk, χ2(1, N = 482) = 37.42, p < .001, 95% CI [−0.36, −0.19]. Given multiplicity across the five analyses, results were interpreted at α = .01 after Bonferroni correction.
Scale Familiarity and Attention Check Performance of r/SampleSize and MTurk Participants.
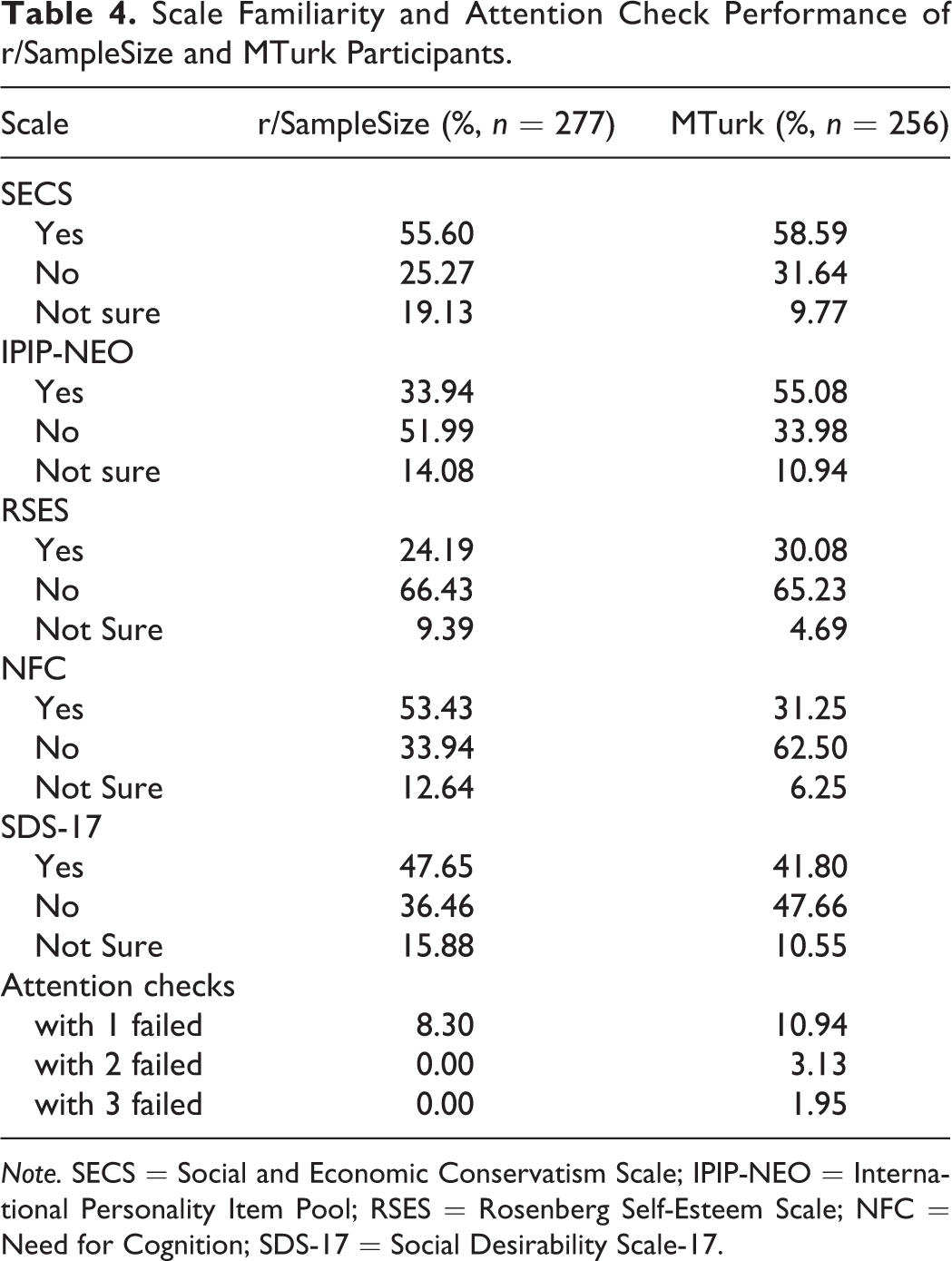
Note. SECS = Social and Economic Conservatism Scale; IPIP-NEO = International Personality Item Pool; RSES = Rosenberg Self-Esteem Scale; NFC = Need for Cognition; SDS-17 = Social Desirability Scale-17.
Table 4 shows the percentages of participants who failed one, two, or three attention checks. If participants were to be excluded due to their performance on the attention check, more MTurk participants would be excluded under any criteria than r/SampleSize participants.
Discussion
The current study assessed the viability of r/SampleSize as an online participant pool by comparing characteristics of the data obtained from this sample to MTurk and existing lab samples in terms of participant motivation, data quality, and demographics. The results demonstrate some differences in motivation and socially desirable responding between r/SampleSize and MTurk participants, but overall data quality and reliability is comparable between r/SampleSize, MTurk, and lab samples. The r/SampleSize participant pool also shows relative demographic diversity, with some differences compared to MTurk. These findings indicate that r/SampleSize is a diverse and viable option for participant recruitment and therefore provides an accessible alternative participant pool for psychology research courses and independent research projects.
In the present study, r/SampleSize participants were more motivated to participate by internal factors (e.g., interest, fun) with slightly higher need for cognition and were largely less motivated by making money than MTurk participants. However, both r/SampleSize and MTurk participants were generally internally motivated to participate in research, were altruistic, and had high need for cognition as responses in both groups were greater than the midpoint of the scales. These results are consistent with previous research on r/SampleSize and MTurk participant motivations (Brickman & Silva, 2017; Buhrmester et al., 2011). Furthermore, social desirability did not influence most motivations, but demand characteristics did significantly influence the majority of motivations. Social desirability did have a small influence on self-reported altruism as would be expected from the altruism measurement literature (e.g., Erten, 2015). Both participant pools exhibited low socially desirable responding and demand characteristics, indicating acceptable data quality for both r/SampleSize and MTurk. However, socially desirable responding was slightly higher for r/SampleSize participants, highlighting the need to control for social desirability when using r/SampleSize.
Most analyses showed no evidence of reliability differences when comparing r/SampleSize, MTurk, and in-person samples. Importantly, all scales but the SECS-Economic demonstrated acceptable reliability as per the .80 guideline for basic research tools (Nunnally, 1978) across MTurk and r/SampleSize. For the PARH, only MTurk participants demonstrated lower reliability than the lab sample, replicating past research (Rouse, 2015). Furthermore, the RSES scale reliability was higher for r/SampleSize participants than the student sample. These results and the comparable levels of demand characteristics suggest that r/SampleSize data can match and even exceed MTurk data quality. Additionally, MTurk workers completed the questionnaire 5 minutes faster than the r/SampleSize participants and showed poorer performance on attention checks, suggesting that MTurk participants were less attentive.
Exploratory findings on participant naivety suggest that r/SampleSize data quality is generally high. Most of the r/SampleSize participants were unaware of MTurk and vice versa, suggesting that MTurk and r/SampleSize are largely independent participant pools. Furthermore, across the five tested scales, there was no evidence that r/SampleSize participants differed in familiarity with the scales from the MTurk participants, with the exceptions of the IPIP-NEO, with which MTurk participants were more familiar, and the NFC, with which r/SampleSize participants were more familiar. However, across both samples, a considerable proportion of participants demonstrated familiarity with most of the scales.
Consistent with previous studies (Luong et al., 2019; Record et al., 2018), the present sample has equal gender representation as well as large age, educational, and income ranges. However, as in previous studies, participants largely reported being Caucasian/White and residing in the United States. There were meaningfully higher levels of social and economic conservatism among MTurk workers compared to both r/SampleSize participants and the neutral point of the SECS, but we caution that this finding was exploratory, and the SECS-Economic showed reliability values far below the .80 guideline for basic research tools (Nunnally, 1978). Nevertheless, the combination of demographic characteristics indicates a diversity of participants that are otherwise underrepresented in traditional psychological research with undergraduate student samples (Hanel & Vione, 2016).
Limitations and Future Research
In the present study, compensation was necessary for r/SampleSize participants to ensure fairness across the two recruitment platforms, which limits the generalizability of our findings to “truly voluntary” participants. However, the form of compensation for r/SampleSize was an optional raffle which did not guarantee compensation. Indeed, we found that only approximately half of r/SampleSize participants had opted into the raffle. r/SampleSize participants also reported greatly lower financial motivation and higher internal motivations, suggesting that any sample-selection effects from providing financial compensation would be mitigated by these characteristics. Future studies concerned with the influence of financial motivation should disclose information regarding compensation after study completion rather than in the study description. Future studies should also collect r/SampleSize demographics to assess the replicability of the demographic makeup because it may change over time, as with all participant panels. Participant withdrawal rates might also vary from study to study. Although withdrawal is naturally expected for volunteers, it may depend on factors not investigated here such as study content, which could have implications for the representativeness of a given r/SampleSize sample. Ongoing validation of these sample characteristics is thus essential, and future research can use the characteristics and effect sizes observed here as a starting point for study planning.
Educational Implications
r/SampleSize provides course instructors and research supervisors with an accessible online participant recruitment platform that can be used to enhance the research training of students in psychology while maintaining acceptable data quality and addressing the limitations frequently observed with traditional university student samples. r/SampleSize allows for recruitment of relatively large and diverse samples in a short period of time. Although not as fast as MTurk data collection, in the present study it took under one month to collect our sample of 277 participants, a time period that would easily fit into a single-term psychology lab course or undergraduate research project. The platform also allows for optional compensation and flexible alternatives, such as gift card raffles, which is especially appealing given the financial constraints faced by many instructors and research supervisors.
Overall, the current study supports r/SampleSize as an alternative participant pool that matches data quality levels of MTurk and lab participants. The findings emphasize the usefulness of controlling for social desirability and demand characteristics when using this participant pool. We hope that psychology instructors, students, and trainee researchers can harness the potential of this online platform.
Supplemental Material
Supplemental Material, sj-pdf-1-top-10.1177_00986283211020739 - Evaluating Reddit as a Crowdsourcing Platform for Psychology Research Projects
Supplemental Material, sj-pdf-1-top-10.1177_00986283211020739 for Evaluating Reddit as a Crowdsourcing Platform for Psychology Research Projects by Raymond Luong and Anna M. Lomanowska in Teaching of Psychology
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Transparency and Openess Statement
All measures, analysis scripts, and data are available on the Open Science Framework at https://osf.io/n6vhx. Preregistration details are also available at ![]() . Preregistration occurred shortly after data collection began due to technical issues. Data were not examined or analyzed prior to preregistration.
. Preregistration occurred shortly after data collection began due to technical issues. Data were not examined or analyzed prior to preregistration.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.