
Abstract
Several studies have reported algorithm aversion, reflected in harsher judgments about computers that commit errors, compared to humans who commit the same errors. Two online studies (N = 67, N = 252) tested whether similar effects can be obtained with a referential communication task. Participants were tasked with identifying Japanese kanji characters based on written descriptions allegedly coming from a human or an AI source. Crucially, descriptions were either flawed (ambiguous) or not. Both concurrent measures during experimental trials and pre-post questionnaire data about the source were captured. Study 1 revealed patterns of algorithm aversion but also pointed at an opposite effect of “algorithm benefit”: ambiguous descriptions by an AI (vs. human) were evaluated more negatively, but non-ambiguous descriptions were evaluated more positively, suggesting the possibility that judgments about AI sources exhibit larger variability. Study 2 tested this prediction. While human and AI sources did not differ regarding concurrent measures, questionnaire data revealed several patterns that are consistent with the variability explanation.
Introduction
As we are entering an age of algorithms, humans increasingly interact with computer technologies that are fueled by machine learning. Many of these agentic technologies exhibit behaviors that are commonly ascribed with notions of (human) intelligence—they perform complex computations, classify data, draw inferences, are capable of processing natural human language, and they may engage in social acts such as making predictions, giving feedback, or providing recommendations. In many fields, such as playing games (Silver et al., 2017), diagnosing skin cancer (Salinas et al., 2024), or assessing personality (Youyou et al., 2015), algorithms outperform the judgments and abilities of human experts. And yet, ever since Meehl (1954) first outlined the potentials of algorithms, their capabilities were met with skepticism. This has led to the widespread notion that humans, particularly in professional decision-making contexts, exhibit an aversion to algorithms (Burton et al., 2020). A seminal series of experiments brought increased attention to the concept of algorithm aversion (Dietvorst et al., 2015). In their studies, participants were given an incentivized prediction task (e.g., predicting student grades based on various indicators) that they could either delegate to an algorithm or to a human (which could have been oneself or a different person). Crucially, though the algorithm’s prediction performance was not perfect, relying on the algorithm would have led to superior performance in this task. And yet, it was the imperfection of algorithms which shaped human delegation decisions the most. In other words, those who had seen the algorithm err, were more likely to delegate the task to a human. The notion of algorithm aversion therefore suggests that algorithmic errors are penalized more than comparable human errors. These findings have garnered a lot of attention in the scientific community (Jussupow et al., 2020). Experts in the field of judgment and decision making believed that humans will follow algorithmic device less than human advice (Logg et al., 2019, Study 1D), and many other experts took the findings of Dietvorst and colleagues as evidence that humans generally are aversive to algorithms (e.g., Bigman et al., 2023). This would indeed be problematic in societies that increasingly rely on algorithms which should be trusted by those who use them and those who are affected by them.
However, the empirical evidence for a generalized algorithm aversion is far from clear. For instance, algorithm aversion is difficult to reconcile with the observation that many professionals exhibit an over-reliance on algorithmic support (automation bias; Goddard et al., 2011; Skitka et al., 1999). Even the original studies on algorithm aversion (Dietvorst et al., 2015) would not permit to assume a generalized aversion. In fact, participants in their studies who did not see the algorithm perform (and err), were more likely to delegate to the algorithm than to a human. This was further corroborated in a series of studies which consistently showed that without prior experience of algorithmic failures, humans preferred to delegate to the algorithm rather than to a human (algorithm appreciation; Logg et al., 2019).
In sum, and accounting for these disparate findings, it might be better to speak about algorithm ambivalence than algorithm aversion. According to this notion, algorithms are at least as likely to be trusted as humans when (a) a person hasn’t seen the algorithm perform or (b) when the person has experienced a flawless performance. However, once a person has experienced flaws in algorithmic performance, evaluations for this algorithm are more negative than experiencing comparable flaws in human performance (algorithm aversion).
Based on these findings, our present studies aim to extend existing knowledge on algorithm aversion and algorithm ambivalence with two contributions. First, in our Study 1 we explore whether the key finding of the algorithm aversion literature (harsher penalties for algorithmic vs. human errors) can be found in a different field: collaborating with an agent—supposedly an AI or a human—in a referential communication task (Brennan & Clark, 1996; Krauss & Weinheimer, 1964; Yule, 2013). Knowing whether increased penalties for algorithmic errors can also found beyond classical delegation tasks would broaden the scope of fields of application.
Second, based on findings in our first study, in Study 2 we explore the possibility that aversion represents only one side of the coin with regard to human responses to algorithms. Just as a flawed performance from an algorithm will be penalized harshly, there is a distinct possibility that a surprisingly good performance will yield better evaluations of an algorithm over a human. The general mechanism behind increased negative and increased positive responses to algorithms could be lack of experience with computers (compared to experience with humans), leading to judgments about algorithms that are more susceptible to change quickly—a concept we dub variability. Variable judgments about algorithms, compared to more crystallized judgments about humans, could also explain the ambivalence that people experience when it comes to algorithmic performance.
Extending the Scope of Algorithm Aversion
To recap, studies by Dietvorst et al. (2015) showed that seeing an algorithm err increased the likelihood to delegate to a human rather than to the algorithm. Our first goal was to explore whether an increased penalty for algorithmic errors can be found in a quite different domain. Our Study 1 departed from the classical setup of algorithm aversion studies in three ways. First, typical algorithm aversion studies involve a context of delegation in which participants are given a choice to either enlist the help of an algorithm or rely on their own judgment (or that of another human). In contrast, we explore algorithm aversion in a collaboration context. Humans increasingly interact with algorithms in a collaborative fashion (i.e., repeatedly interacting with output from large language models; Collins et al., 2024). A key feature of collaboration is that it requires reliance: humans have to make do with algorithmic output, irrespective of whether it is flawless or erring. We therefore investigate a scenario in which participants must rely on input from an agent (human or algorithm) to make a decision. Crucially, we varied whether this input from an agent contained errors or not. Second, while most algorithm aversion studies are about computational competence (e.g., mathematical accuracy of prediction), our studies focused on a communication scenario that requires linguistic competence. In particular, we made use of the referential communication paradigm (Brennan & Clark, 1996; Krauss & Fussell, 1991) in which one communicator (so-called matcher) is tasked with identifying a visual stimulus from several candidate stimuli. The other communicator in this paradigm (director) must verbally describe which stimulus should be chosen next. In our studies, participants were in the matcher role and had to rely on the descriptions by an agent (either a human or an AI). Third, algorithm aversion studies vary in terms of the errors that agents make (e.g., false or inaccurate predictions). In our studies, the “errors” introduced by an agent refer to violations of the Gricean maxim of manner (Grice, 1975), particularly the maxim to avoid linguistic ambiguities. Concretely, in our studies participants in each experimental trial had to identify a Japanese kanji character based on the description from an agent source (human or AI). In some trials, the descriptions by the agent were non-ambiguous, thus allowing participants to easily identify the correct stimulus. However, in other trials the descriptions of the agent were ambiguous, thus making it impossible to clearly identify the intended stimulus (see Table 1 for examples). Having an algorithm exhibit sub-optimal performance in a referential communication task is relatively realistic as the actual capability of current AI systems to take contextual factors of referential communication into account is still in its infancy (Corona Rodriguez et al., 2019).
Example Stimuli Used in Both Experiments.

Note. In the bottom row is the description (supposedly composed by a human or an AI). This description would be non-ambiguous regarding the set of stimuli on the top left (fitting only to the first kanji) but ambiguous regarding the set of stimuli on the top right (the description fits to both the first and second kanji).
In sum, our Study 1 tested predictions from the algorithm aversion paradigm in a setting that was based on collaboration rather than delegation, relied on linguistic rather than computational competence, and involved the use of ambiguous language rather than numerical errors. We assessed markers of algorithm aversion both via concurrent measures and post-interaction measures. The concurrent measures tapped into a trial-by-trial evaluation of the agent (the quality of the received description) and of oneself (confidence in one’s choice). The post-interaction measures tapped into source credibility of the agent (McCroskey & Teven, 1999). Based on results from the algorithm aversion literature, we derived the following hypotheses:
H1: Ratings about description quality (H1a) and confidence in one’s choice (H1b) will not differ between a human source and an AI source when the descriptions are non-ambiguous. In contrast, flawed (ambiguous) descriptions from an AI will be evaluated as lower in quality (H1a) and yield lower confidence (H1b) than ambiguous descriptions from a human (interactions of source and ambiguity).
We also hypothesized that having mixed experiences with either human or AI agents in the referential communication task will be more penalized in an overall, post-interaction evaluation of source credibility for the AI.
H2: Source credibility will be lower after interacting with an AI than after interacting with a human.
Beyond Algorithm Aversion: The Role of Variability
Algorithm aversion occurs when algorithmic errors are penalized more harshly than comparable human errors. Study 2 sought to better understand algorithm aversion conceptually by testing two competing hypotheses that both are centered on the expectations that humans typically have about algorithms (or more generally, about computers). The first hypothesis (elevated expectation) assumes that individuals expect computers to exhibit superior performance compared to humans on specific tasks. Extant theories are relatively vague about comparative expectations. The CASA approach (Computers Are Social Actors; Nass & Moon, 2000) asserts that humans apply similar schemata to humans and computers, suggesting similar expectations toward these agents. In contrast, the mind perception approach (Waytz et al., 2010) argues that humans expect computers to be excellent in tasks that require thinking and acting (agency) but do not expect computers to sense and feel (experience). In direct support of this notion, a study by Hertz and Wiese (2019) found that people are more likely to seek assistance of computers on analytical tasks (adding numbers), but more likely to seek assistance of another human when the task required experience (recognition of emotions). Competence of computers (giving good vs. bad hints) is also associated with higher compliance of participants (Lee & Liang, 2016). While these studies suggest high expectations about the performance of computers, there is some evidence that expectations about computers might be even higher than for humans. In a survey study on vehicle safety, it was found that respondents expect autonomous vehicles to be four to five times as safe as humans to receive comparable levels of acceptance (Liu et al., 2020), suggesting that an autonomous vehicle that commits as many driving errors as a human is deemed unacceptable. In sum, the elevated expectation hypothesis predicts that for tasks that require agency (such as describing kanji characters) humans expect more from a computer than from humans, thus leading to more negative judgments about AI performance (particularly after failure).
However, a second hypothesis assumes that algorithm aversion is only one part of a broader causal mechanism: heightened variability of judgments about computer agents. In other words, as humans typically have only limited experience with computer agents, they might be adjusting their impressions about computer agents more quickly and extremely than their impressions about human agents.
Study 2 sought to differentiate between the elevated expectation hypothesis and the variability hypothesis. In this study, judgments about agents (human and AI) were measured both before (initial expectations) and after (updated expectation) interaction. To decide among the competing hypotheses, we compared two conditions. In one condition, we had participants interact with an agent whose performance exhibited a downward trend over time (adapted from de Visser et al., 2016). Both the elevated expectation hypothesis and the variability hypothesis predict that an AI will be penalized more than humans for performance degradation (algorithm aversion). However, in the second condition, participants interacted with an agent whose performance increased over time (upward trend). The elevated expectation hypothesis would predict that evaluations for an improving AI would still be lower than for improving humans. Crucially, however, the variability hypothesis predicts that an upward-trending performance would lead to more positive evaluations for an AI than for a human. Initial evidence for such a pattern comes from a vignette study showing that an autonomous vehicle which rescued a man by driving him to a hospital received more praise than a human who accomplished the same thing (Hong et al., 2021), presumably because the performance of the vehicle surpassed expectations.
Like in Study 1, evaluations about agents (human vs. AI) were assessed with concurrent measures (satisfaction with the agent) and questionnaire measures (pre-interaction evaluations to capture expectations and post-interaction evaluations to measure updated judgments). Based on our assumption that variability will lead to more extreme (positive and negative) evaluations of algorithms, we posited the following hypotheses:
H3: Satisfaction with an AI (vs. a human) source is decreasing faster over time when the performance exhibits a downward trend, but satisfaction with an AI (vs. a human) source is increasing faster over time when agent performance exhibits an upward trend (three-way interaction between source, time, and trend).
H4: Ratings on source credibility (H4a), source perceptions (H4b), and competence/warmth (H4c) will exhibit a stronger decrease from pre-interaction to post-interaction measurements for an AI (vs. human) when the source performance is downward-trending, and these ratings will exhibit a stronger increase from pre-interaction to post-interaction measurements for an AI (vs. human) when the source performance is upward-trending (three-way interaction between source, measurement time, and trend).
Both studies were approved by the local ethics board. Study 2 was pre-registered at https://aspredicted.org/g8pn-hydc.pdf
Study 1
Study 1 sought to extend the scope of algorithm aversion studies by using a scenario that relies on collaboration rather than delegation, requires linguistic rather than computational competence of an agent, and introduces ambiguous language (violations of the Gricean maxim of manner) rather than numerical errors.
Methods
Participants and Design
Study 1, conducted in July 2020, was based on an analysis of 94 student participants, recruited through mailing lists at the local university. Participants could choose between partial course credit or participation in a raffle as compensation. After the exclusion of participants that did not meet manipulation checks (see below), the final sample consisted of 67 participants (64% female). Participants were, on average, 23.0 (SD = 3.7) years old.
Study 1 used a 2 × 2 mixed two-factor design with the factor source (human vs. AI agent; between-subjects variation) and the factor description quality (ambiguous vs. non-ambiguous; within-subjects variation).
Materials
Studies employing the referential communication task often use realistic depictions of physical objects (Brennan & Clark, 1996) or depictions of abstract “nonsense figures” (Krauss & Fussell, 1991). To provide a mixture between realism and abstraction, we developed new material involving 20 sets of descriptions about kanji characters (see Table 1). Each description was trying to describe one target character among four kanji characters. For the 10 non-ambiguous trials, descriptions were formulated in a way that only one kanji characters matched the description. The position of the correct kanji character was random. To create 10 ambiguous trials, we used the same 10 descriptions as in the non-ambiguous trials but replaced one of the distractor stimuli with a second kanji that also matched the description. Consequently, two out of four kanji characters (in random positions) matched the description in ambiguous trials.
Measures
For the concurrent measures, we adapted ideas from de Visser et al. (2016) who measured trust in agents by tapping into perceptions of source as well as perceptions of the self (confidence). Similarly, we measured subjective quality of descriptions (a proxy for the ability component of trustworthiness; Mayer et al., 1995) to capture source perception and confidence in the correctness of one’s judgment to capture self-perception. For both measures, 7-point Likert scales were used (from 1 = low to 7 = high for perceived quality, and 1 = very unconfident to 7 = very confident for confidence).
For the post-hoc questionnaire, we used the Source Credibility Scale developed by McCroskey and Teven (1999). It measures the credibility of perceived sources of messages on three subscales. The subscales are competence, trustworthiness, and goodwill. The scale uses a 7-point semantic differential. Cronbach’s alpha for the whole scale was .89. The alpha for the subscales was for competence 0.90, trustworthiness 0.86, and goodwill 0.80.
Procedure
The study was conducted online. After receiving informed consent and measurement of demographic data participants were instructed on the task during the experiment. The task was to identify one kanji symbol among four, through a written description of the target symbol. One group of participants was informed that the descriptions were created by a member of the scientific staff, the other half were told that all descriptions were generated by an AI that uses a novel algorithm. The experiment continued with 20 trials where the order of presentation (ambiguous vs. non-ambiguous trials) was random. To make the source salient, a photo of a young woman (human source) or a stylized depiction of a robot (AI source) was accompanied with each description. In each trial, participants had to choose one of the four kanji characters that they believed best fit to a description, upon which they received feedback about correctness. Subsequently, they had to rate subjective quality of the description as well as the confidence in their choice. After going through 20 trials, participants filled out the Source Credibility Scale. Afterward, participants were asked if they have experience with Japanese writing and if they correctly remember the source of the descriptions. Participants who indicated an ability to read kanji, and participants who misremembered the source were later excluded from analyses. At the end, participants were thanked, debriefed, and were given an opportunity to withdraw their data.
Analysis
We analyzed the data using R (R Core Team, 2021), tidyverse (Wickham et al., 2019), and the lme4 library (Bates et al., 2015). p-Values were calculated using the lmerTest library (Kuznetsova et al., 2017). To analyze the subjective quality and confidence ratings from the experiment, we used a linear mixed model with the specific rating as the dependent variable. The source of the description and description quality were independent variables. The intercepts for each participant and each trial were allowed to vary randomly.
To analyze the questionnaire data, we used a simple t-test between both experimental groups. We used post-hoc t-tests to identify the differences between sources on each subscale.
Results
Concurrent Measures
H1 states that the AI descriptions are rated worse than the human descriptions on ambiguous trials but similar on non-ambiguous trials with regard to quality of the description (H1a) and confidence in the decision (H1b). We used a linear mixed model with the rating as dependent variable, the description’s source and ambiguity as fixed effects and random intercepts of participant and item. In accordance with the hypotheses, we expected an interaction effect of source and ambiguity. Descriptive data are shown in Table 2.
Descriptive Data of the Concurrent Measures (Study 1).

Ratings on subjective quality of the descriptions were significantly higher in non-ambiguous trials than in ambiguous ones: B = 1.71, t(20.90) = 8.80, p < .001, suggesting that participants responded aversely to linguistic inaccuracies. The interaction of source and description quality was in the expected direction, but did not yield significance, B = −0.25, t(1253) = −1.72, p = .085, thus providing no support for H1a.
In contrast, confidence ratings were higher in non-ambiguous trials than ambiguous ones: B = 1.96, t(22.27) = 8.80, p < .001. Consistent with H1b, this main effect was further qualified by the expected interaction between source and description quality: B = −0.60, t(1253) = 4.17, p < .001 (Figure 1). The interaction effect stems from a comparatively lower rating of confidence for ambiguous descriptions by the AI (vs. human): d = −0.29, t(83.3) = −1.38, p = .517, and a comparatively higher rating for non-ambiguous descriptions by the AI (vs. human): d = 0.31, t(83.3) = −1.48, p = .456. Even though neither of these differences individually is statistically significant, together they create a significant interaction effect indicating a larger difference between ambiguous and non-ambiguous descriptions of the AI: d = −1.97, t(22.3) = −8.80, p < .001, compared to the difference between ambiguous and non-ambiguous descriptions of the human: d = −1.36, t(22.6) = −6.09, p < .001.
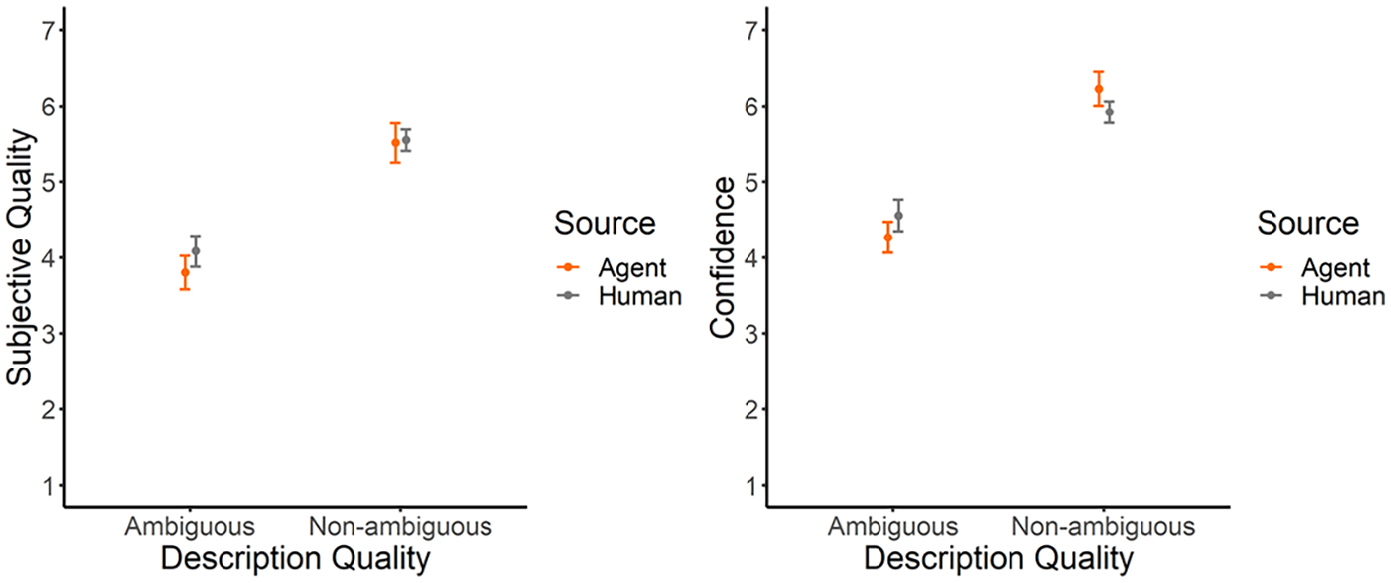
Results (±SE) for concurrent measures (left: subjective quality; right: confidence) in Study 1.
Together, these results suggest a larger gap in confidence ratings (and, to a lesser degree, in quality ratings) between non-ambiguous and ambiguous descriptions if participants believed these descriptions to be produced by a machine rather than a human.
Questionnaire Data
For H2 we expected that the AI would have a lower overall rating of source credibility when compared to the human. We used Bernoulli-corrected t-tests to compare source credibility ratings and its subscales between human and AI sources.
The t-test on the source credibility data showed a descriptive, but non-significant difference between human sources (M = 4.68, SD = 1.33) and AI sources (M = 4.31, SD = 1.42): t(65) = −1.96, p = .054, suggesting slightly higher ratings of source credibility for human than for AI sources. On this basis, H2 cannot be supported by the data. Similarly, neither the subscales of competence (AI: M = 4.62, SD = 1.40, Human: M = 4.96, SD = 1.39): t(65) = −1.24, p = .218; nor of trust (AI: M = 4.45, SD = 1.29, Human: M = 4.85, SD = 1.24): t(65) = −1.73, p = .088; nor of goodwill (AI: M = 3.85, SD = 1.44, Human: M = 4.23, SD = 1.25): t(65) = −1.60, p = .114 yielded significant differences. Results are illustrated in Figure 2.
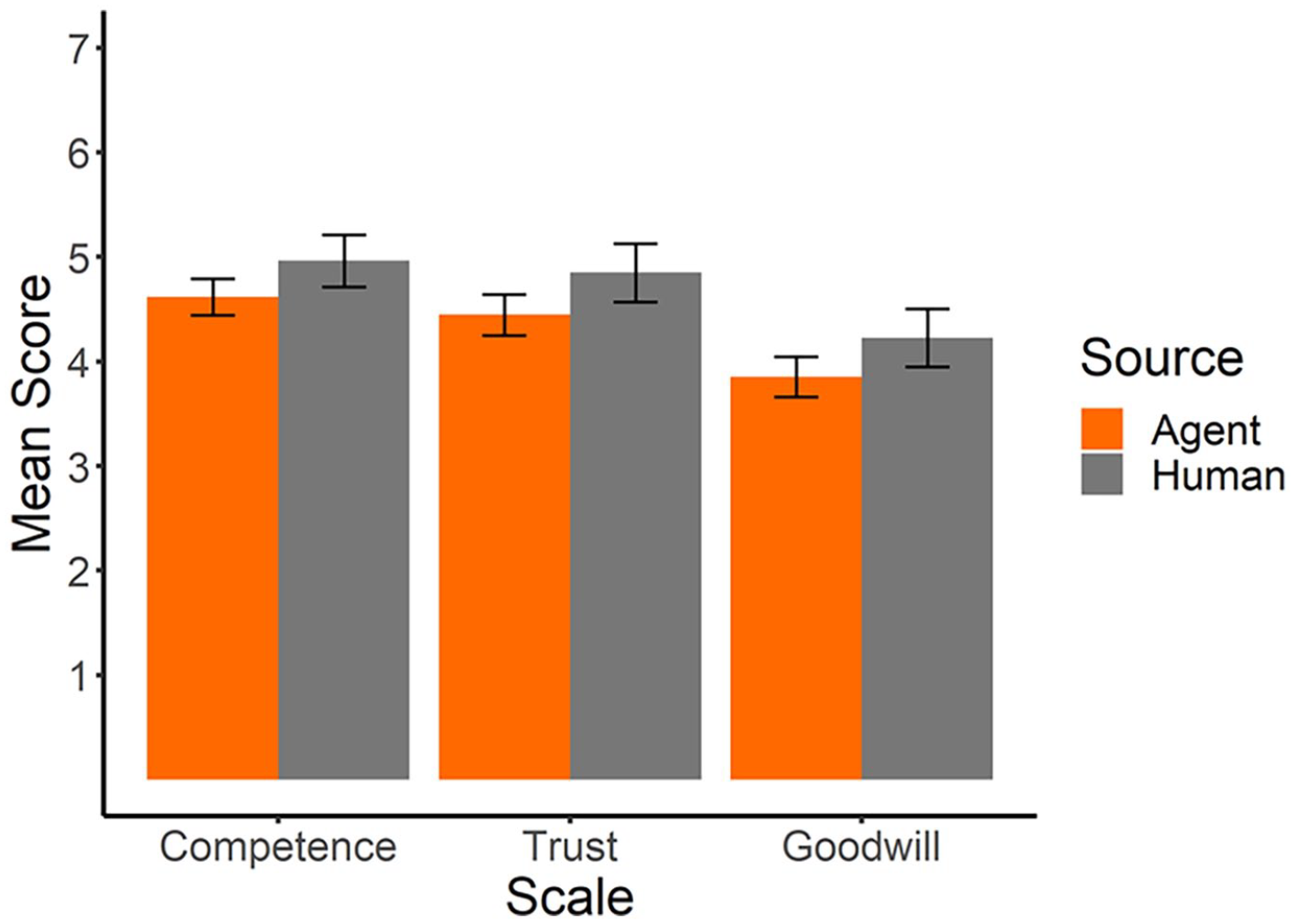
Results (±SE) for questionnaire data (source credibility subscales) in Study 1.
Discussion
Using a variant of the referential communication task, Study 1 sought to provide evidence for algorithm aversion (Dietvorst et al., 2015) in a novel, collaborative setting. Indeed, we could find the expected interaction effect between source and description quality: when a stimulus description was ambiguous (i.e., faulty), participants evaluated the quality of AI descriptions slightly more poorly and showed significantly less confidence than with an ambiguous description allegedly stemming from a human. Interestingly, and unexpectedly, we also found that the interaction effects could partly be attributed to the fact that for non-ambiguous stimuli the AI descriptions were evaluated even more positively than comparable descriptions from a human source, at least for the confidence variable. In other words, Study 1 showed some evidence for algorithm aversion (for an under-performing AI), but also some evidence for an “algorithm benefit” (for an AI that exhibits good performance). This could be interpreted as a general effect of variability. Humans are likely to have less experience with AI agents and therefore will more quickly adapt their impressions and judgments of these agents, thus leading to a quicker adjustment to both flawed performance (algorithm aversion) and flawless performance (“algorithm benefit”).
Partially in line with the literature on algorithm aversion, Study 1 provided evidence that after the interaction, AI agents were evaluated slightly more poorly on variables of source credibility than human agents—the effect was only marginally significant, but this can be attributed to a lack of statistical power. Taken together, the results of Study 1 do not only show that an erring (ambiguous) computer agent is judged more harshly than an erring human agent, but also offer the interesting possibility that a well-performing computer agent might be judged more positively than a comparable human agent. Study 2 was designed to test for this possibility.
Study 2
In Study 2, conducted in late 2020, we tested for the possibility that different evaluations of computer agents versus humans might simply reflect lower levels of experience with computer agents. If that were the case, humans would have to update their impressions about computer agents based on current experiences with this agent to a larger degree (increased variability) which might not only occur for underperformance of an agent, but also for overperformance. Study 2 was similar to Study 1 in many respects: participants again received 20 written descriptions of kanji characters, and they were made to believe that the descriptions stemmed from a human or an AI. However, to test for variability of judgments, the distribution of computer agent errors (ambiguous trials) in Study 2 changed over trials. In one condition (downward trend), the quality of descriptions decreased over five blocks of four trials each (similar to de Visser et al., 2016). However, in a complementary condition (upward trend), quality of descriptions increased over time. Evaluations of the agent were assessed with concurrent measures during interaction and with questionnaire items (measured before and after interaction).
Methods
Participants and Design
For the second study, we used the Prolific platform to recruit participants. Participants were paid 2.88 £ for an estimated 23 min to complete the study. This amounts to an equivalent of 7.51 £ per hour. Three hundred participants completed the survey. After excluding data that did not meet the pre-registered inclusion criteria, the dataset consisted of 252 individual participants. The included participants were on average 29.7 (SD = 9.1) years old and 39% female.
Study 2 used a 2 × 2 × 5 mixed two-factor design with the factors source (human vs. AI agent), trend (upward vs. downward) as between-subjects factors, and time (experimental blocks 1 through 5) as within-subjects factor.
Materials
Study 2 used the same material as Study 1 (20 trials of description about sets of four kanji characters). Stimuli were randomly assigned to five blocks of four trials each, with the addition that the number of non-ambiguous descriptions per block either decreased from 4 to 0 (downward trend) or increased from 0 to 4 (upward trend).
Measures
For concurrent measures, we used different variables than in Study 1, for two main reasons. First, the concurrent measures in Study 1 (quality and confidence) were highly correlated (multilevel r = .74, t(1600) = 45.41, p < .001), thus overlapping substantially in spite of having different conceptual heritage (quality as agent evaluation, confidence as self-evaluation). For Study 2, we decided to measure satisfaction with agent explanations as concurrent measures, based on the ground that satisfaction captures both elements of agent evaluation (expressing satisfaction with an agent) and elements of self-evaluation (satisfaction as a subjective and personal feeling of favorability). 1 Second, to better track how satisfaction develops over time, we had participants indicate (1) their satisfaction with descriptions in the preceding block and (2) their satisfaction with descriptions over all preceding blocks.
In contrast to Study 1, questionnaire data were taken both before and after the referential communication task. Three types of scales were used. First, we used the same Source Credibility Scale as in Study 1 (McCroskey & Teven, 1999) which captures competence, trustworthiness, and goodwill with 7-point semantic differentials. Cronbach’s alpha of the subscales varied between α = .75 for the trust subscale (prior to interaction) and α = .90 for the competence subscale (after interaction). Second, we used four subscales of the Godspeed questionnaire (Bartneck et al., 2009) which are frequently used in literature on the perception of technologies (Weiss & Bartneck, 2015), and originally captured attributes of robots. The subscales used measure anthropomorphism, animacy, likeability, perceived intelligence, and we excluded the subscale of perceived safety as it uses different instructions that did not align with our setup. The original questionnaire used a 5-point-scale, but we extended it to a 7-point-scale to fit the other questionnaires. Cronbach’s alpha of the subscales varied between α = .73 for the perceived intelligence subscale (prior to interaction) and α = .91 for the anthropomorphism subscale (both prior to and after interaction). Third, we used items taken in the context of the Stereotype Content Model (Fiske, 2018) (again, frequently measured in studies that compare humans and technologies; e.g., Spatola & Wudarczyk, 2021) that measure competence and warmth, the two basic variables in person perception. We added the opposite of each attribute to create semantic differentials that are similar to the other scales. Again, we used a 7-point-scale and translated the items to German. Cronbach’s alpha of the subscales varied between α = .75 for both subscales (prior to interaction) and α = .91 for the competence subscale (after interaction). As all three scales were constructed to capture pairs of adjectives, presentation order was random for both times of measurement.
Procedure
The study was conducted online via Pavlovia. After receiving informed consent, demographic attitudes were captured. Participants then received a short description about the source (depending on condition, either a human source or an AI agent). Subsequently, participants were requested to rate the assigned source on source credibility, via the Godspeed questionnaire, and on stereotype content (warmth and competence). After this, participants went through 20 trials of the referential communication task, separated into five blocks of four trials each. Depending on condition, the number of non-ambiguous descriptions per trials either increased or decreased over successive blocks. After each block, participants indicated their satisfaction with the source, both on the preceding block and all preceding blocks together. After 20 trials, items from the three questionnaires (source credibility, Godspeed, stereotype content) were administered again. Afterward, participants were asked if they had experience with Japanese writing and if they correctly remembered the source of the descriptions. At the end of each experimental run, participants were thanked, debriefed, and were given the opportunity to withdraw their data.
Analysis
We analyzed the data following the pre-registration (with one exception, noted below). For the analysis of concurrent measures, we calculated a linear mixed model. As software, we used R (R core team) and the lme4 library (Bates et al., 2015). Within the model, to analyze the satisfaction with the source in general and in the last block, we used the ratings as dependent variables. As independent variables, we used the the alleged source of the descriptions (human vs. AI), the quality trend of the blocks (downward vs. upward), and the temporal placement of the block (block 1–5). As random variables, we used a random intercept per participant and a random slope for each participant over time. p-Values were estimated using Satterthwaite’s method implemented in the library lmerTest (Kuznetsova et al., 2017).
For the questionnaire data, we originally pre-registered to analyze these data on difference scores between post-interaction and pre-interaction measures. However, we decided that it is statistically sounder to introduce time (pre-interaction vs. post-interaction) as an additional factor. Consequently, the hypothesis for questionnaire data should be manifest in a three-way interaction between time (pre-interaction vs. post-interaction), source (human vs. AI), and trend (downward vs. upward). This was evaluated using a set of repeated-measures ANOVAs (one for each questionnaire) with combined ratings of subscales as dependent variables. Exploratorily we individually analyzed the subscales of the questionnaires, again using a repeated-measures ANOVA.
Results
Concurrent Measures
We hypothesized (H3) that source, time, and trend will interact in a way that satisfaction with an AI (vs. a human) is decreasing faster over time when the source performance is decreasing (downward trend), but that satisfaction with an AI (vs. a human) is increasing faster over time when the source performance is increasing (upward trend). Descriptive data for satisfaction ratings are listed in Table 3.
Descriptive Data of the Satisfaction with the Description (Study 2).

The analysis of the satisfaction data collected during the experiment shows that the manipulation of the quality of each block worked. The satisfaction follows a clear trend in accordance with the manipulation. This can be seen in the interaction effect of time and trend on the satisfaction with the partner in general, B = 0.37, t(248) = 7.20, p < .001 and with the partner during the last block, B = 0.68, t(248) = 9.67, p < .001. However, there was no main effect of source, neither for judgments on all preceding blocks: B = −0.24, t(248) = −1.02, p = .307; nor for judgments on the preceding block: B = −0.32, t(248) = −1.39, p = .165. Most importantly, no interaction effects including source materialized, including the predicted 3-way interaction between source, time (blocks), and trend: B = −0.01, t(248) = −0.20, p = .840 for overall satisfaction and B = −0.03, t(248) = −0.29, p = .776 for satisfaction with the last block, respectively (see Figure 3). In that regard, Study 2 lent no support for H3.
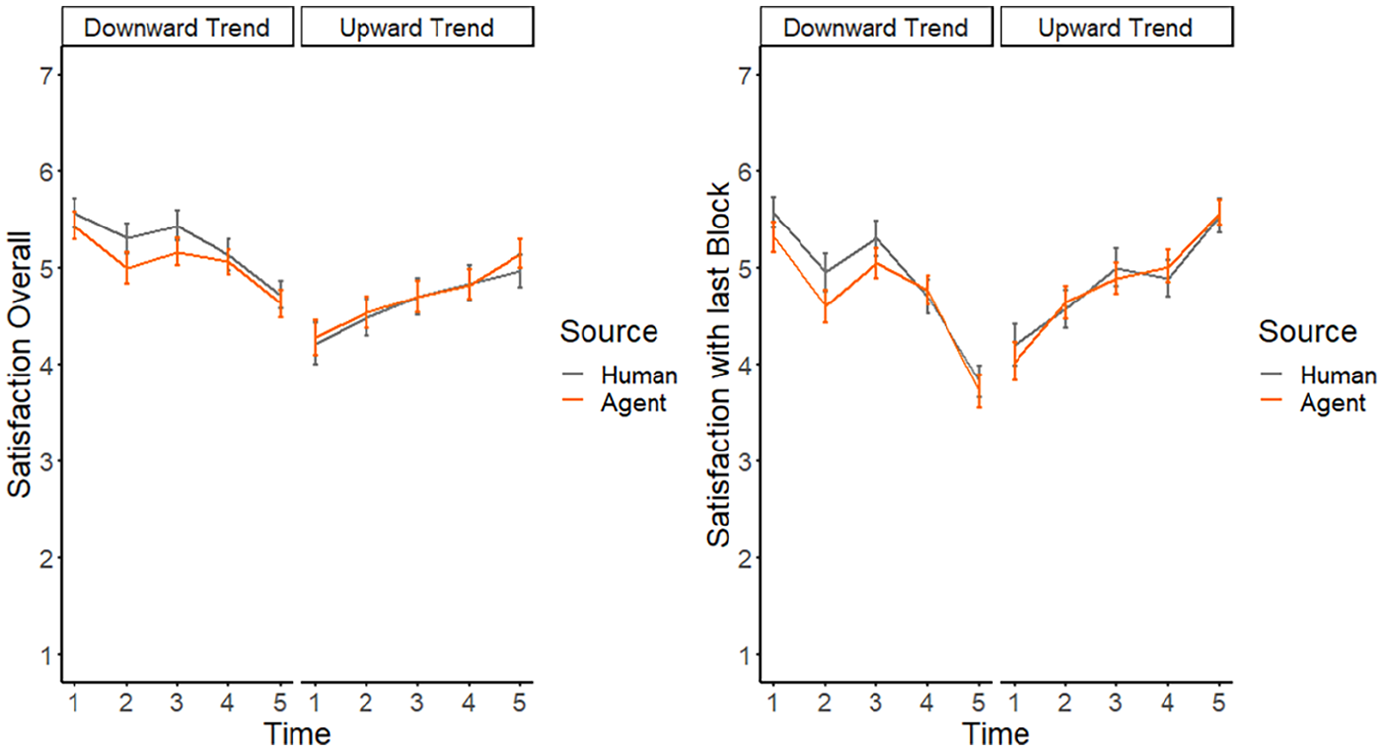
Results (±SE) for concurrent measures (left: satisfaction overall; right: satisfaction with the last block) in Study 2.
Questionnaire Data
Main Analysis
H4 predicted a significant 3-way interaction between source (AI vs. human), time (before vs. after interaction), and trend (upward vs. downward) for source credibility (H4a), the Godspeed questionnaire (H4b), and competence/warmth ratings from the Stereotype Content Model (H4c). Based on our variability assumption, the predicted interactions would mean that a downward trend in performance would lead to lower ratings for the AI (vs. human) agent whereas an upward trend would lead to higher ratings for the AI (vs. human) agent.
Results for the Source Credibility questionnaire (H4a) revealed a significant main effect for source: F(1) = 28.90, p < .001, indicating that source credibility for human sources was rated higher than for AI sources. Main effects for trend: F(1) = 2.67, p = .104 and time F(1) = 3.01, p = .083 did not reach significance. In addition, there were significant interactions between source and time: F(1) = 7.13, p = .008, as well as time and trend F(1) = 3.92, p = .048. Crucially, the three-way interaction of source, time, and trend was significant F(1) = 5.02, p = .025, consistent with H4a. As can be seen from Figure 4, ratings for the human source went down over time, irrespective of trend. In contrast, perceived credibility for the AI agent decreased with a downward trend but increased with an upward trend.
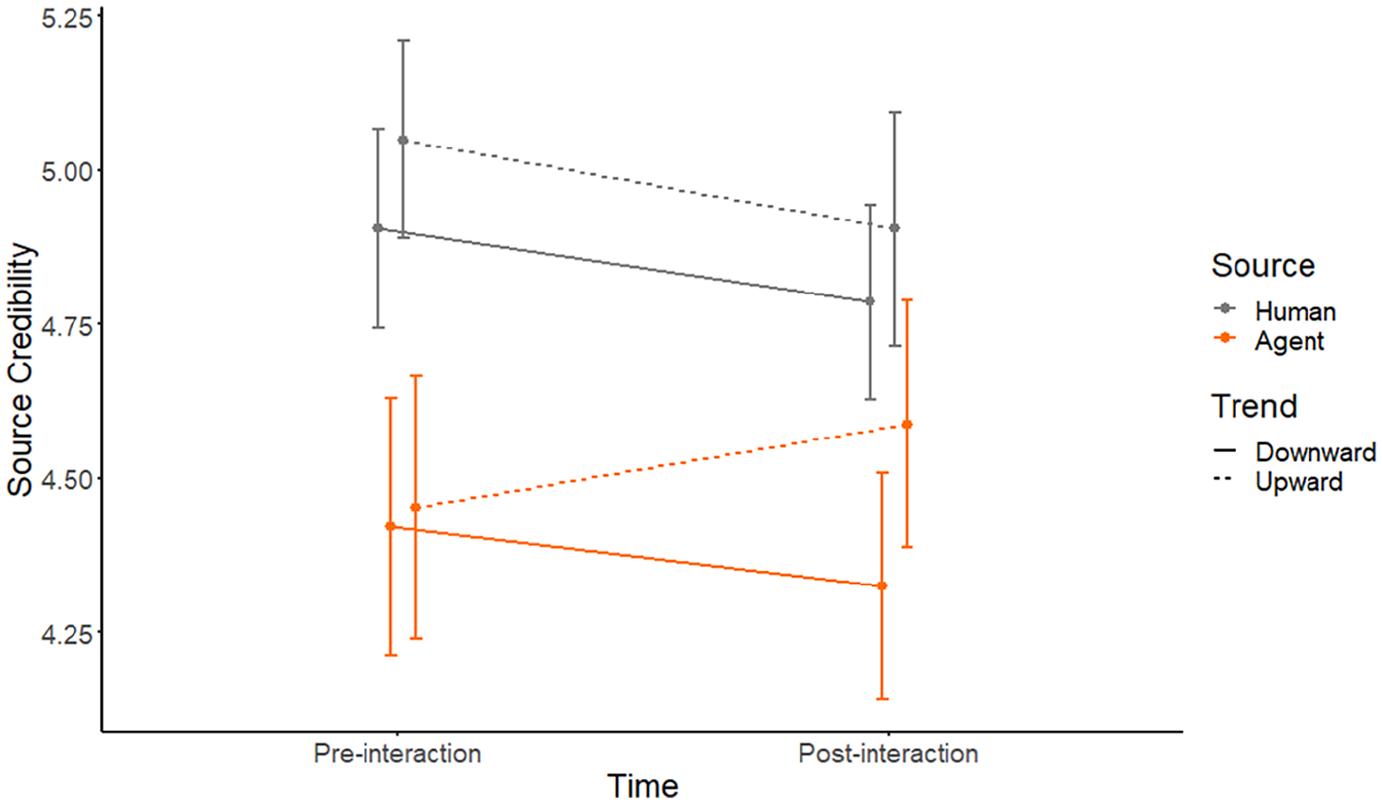
Results (±SE) for source credibility in Study 2.
Overall ratings on source perception (Godspeed questionnaire, H4b) exhibited a similar pattern to source credibility data. All main effects were significant, with higher ratings for human than for AI sources: F(1) = 219.41, p < .001; higher ratings for the first measurement than for the second measurement: F(1) = 12.29, p < .001, and higher ratings for the upward trend than the downward trend: F(1) = 3.92, p = .049. In addition, there was a significant two-way interaction between source and time: F(1) = 21.53, p < .001. Most importantly, and in support of H4b, main effects and two-way interactions were qualified by the predicted three-way interaction between source, time, and trend: F(1) = 6.22, p = .013. As can be seen from Figure 5, ratings for the human source decreased over time (irrespective of trend) while ratings for the AI source showed the expected pattern of variability (increase with an upward trend, decrease with a downward trend).
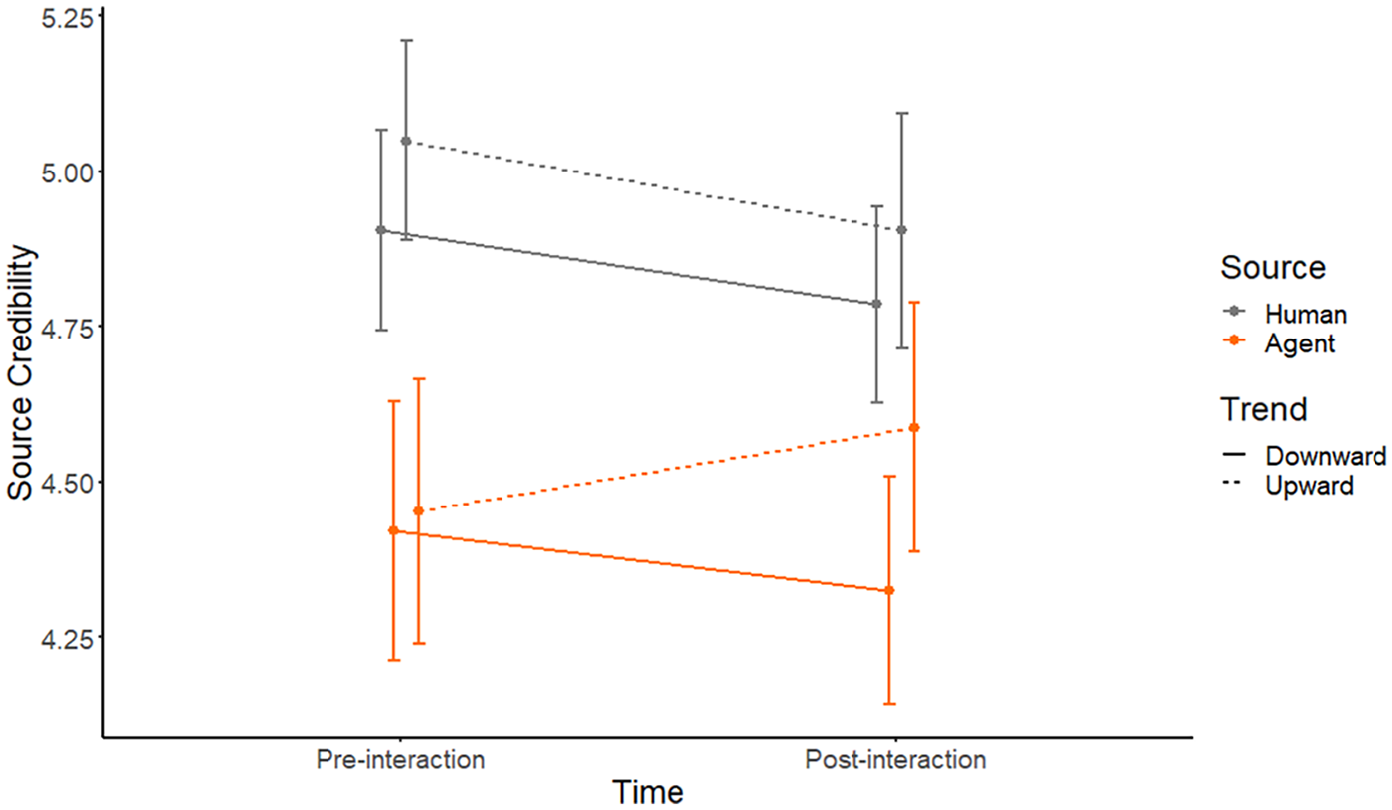
Results (±SE) for the godspeed questionnaire in Study 2.
In contrast, results for warmth and competence from the Stereotype Content Model did not mirror findings from the other questionnaires. While human sources received higher ratings than AI sources: F(1) = 8.81, p = .003, and while ratings prior to interaction were higher than post-interaction ratings: F(1) = 21.27, p < .001, only the two-way interaction between source and time was significant: F(1) = 7.41, p = .006. Crucially, the 3-way interaction did not materialize: F(1) = 0.54, p = .463, thus failing to support H4c. As can be seen from Figure 6, both upward trend and downward trend decreased ratings of stereotype content for human source and AI source.
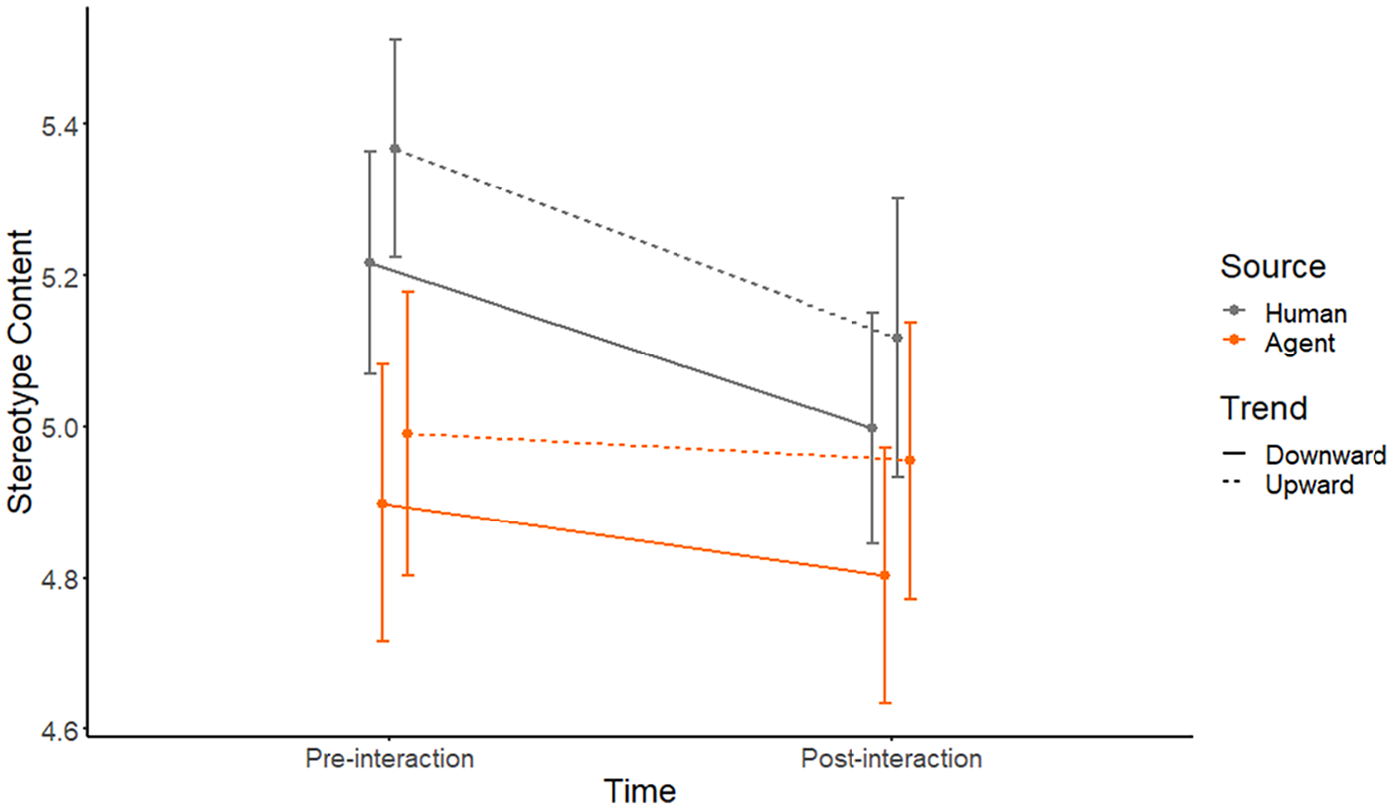
Results (±SE) for stereotype content in Study 2.
Exploratory Analysis
In a number of exploratory analyses, again using repeated-measures ANOVAs, we also inspected rating patterns for all subscales that were measured. While the three-way interaction that we found for the overall Source credibility and Godspeed scale only carried over to a single sub-scale (animacy), subsequent analyses revealed a striking pattern of two-way interactions between source and time. These patterns are illustrated in Figure 7. Six of the nine subscales exhibited a significant two-way interaction between source and time: goodwill (source credibility): F(1) = 8.14, p = .004; trust (source credibility): F(1) = 5.71, p = .017; animacy (Godspeed): F(1) = 5.61, p = .018, anthropomorphism (Godspeed): F(1) = 34.62, p < .001; likeability (Godspeed): F(1) = 7.51, p = .006; and warmth (stereotype content): F(1) = 9.66, p = .002. In contrast, three subscales (in the left column of Figure 7) did not exhibit these interactions between source and time: competence (source credibility): F(1) = 0.01, p = .940; perceived intelligence (Godspeed): F(1) = 1.63, p = .202; and competence (stereotype content): F(1) = 0.76, p = .384; all of which only yielded significant main effects for time. Descriptively, these three subscales cover judgments about cognitive ability of a source whereas the other six subscales arguably cover judgments on non-cognitive or social abilities. In other words, the analysis of subscales revealed that ratings on cognitive subscales were decreasing over time for both types of sources (irrespective of trend) whereas ratings on non-cognitive/social subscales showed a pattern of convergence: ratings of the AI source became more similar to ratings of human sources over time. This finding could also be interpreted as variability of judgments about AI agents.
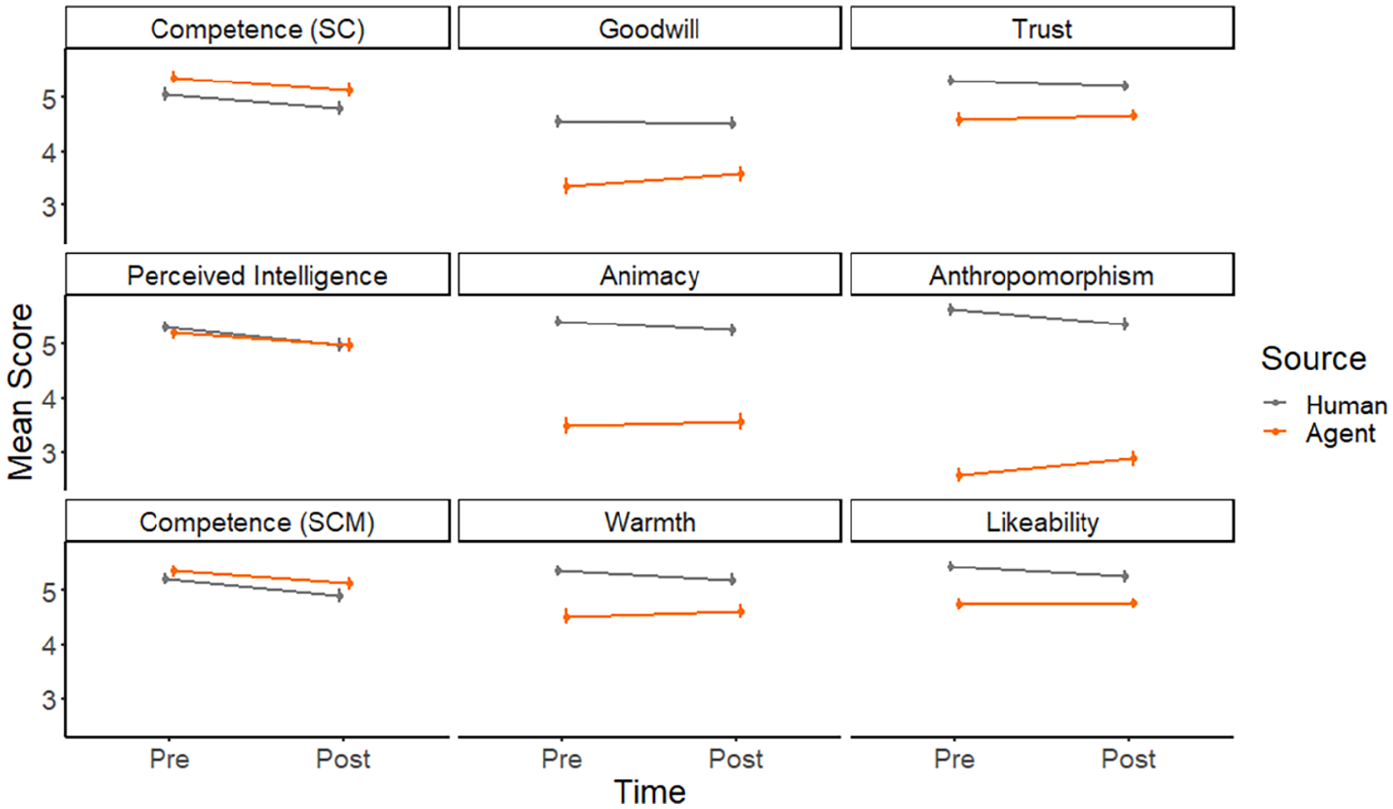
Results (±SE) for the subscales used in Study 2. Subscales covering judgments on cognitive capability are depicted in the leftmost column.
Discussion
Study 1 reported a larger gap for concurrent AI evaluations between correct (non-ambiguous) and flawed (ambiguous) descriptions than for evaluations on a human agent. Descriptively, that significant result was partially driven by a (non-significant) algorithm aversion (lower AI than human ratings in ambiguous trials), but also partially driven by an “algorithm benefit” (higher AI than human ratings in correct trials). These findings offer the conceptually interesting possibility that both algorithm aversion and “algorithm benefit” are just two complementary aspects pointing at an increased variability of social judgments about computers (vs. humans). To explore this possibility, Study 2 measured expectations before interaction, and also introduced trends of description quality as an independent, between-subjects variable, with the expectation that a downward trend will lead to particularly low ratings of an AI (vs. a human) source over time, whereas an upward trend will lead to particularly high ratings of an AI (vs. a human) over time. The results of concurrent measures indicate that the trend manipulation by itself was functioning properly. On both concurrent measures, satisfaction with a source decreased with a downward trend of quality but increased with an upward trend in quality. However, the concurrent measures of Study 2 did not find any evidence that these patterns were affected by source at all: Both human sources and AI sources were evaluated similarly on concurrent measures. This contrasts with studies on algorithm aversion. A key difference between those studies and Study 2 is that algorithm aversion experiments always gave participants an opportunity to compare their own performance to the performance of a computer (predicting grades in algorithm aversion experiments). In contrast, our Study 2 did not permit for such a comparative standard between self and computer, thus making potential differences less salient. However, the results on concurrent evaluations in Study 2 also differed from results of Study 1. In the first study, source differences were apparent, but they were absent in Study 2. It can be speculated that concurrent ratings of a source might be different when participants have already evaluated the source prior to interaction (Study 2), compared to a situation where participants have not made general evaluations prior to interaction (as in Study 1). It might be the case that participants adjust their concurrent evaluations based on their previous evaluations to appear consistent, a possibility that is worthwhile to follow up on in subsequent studies.
While results of Study 2 were inconclusive regarding concurrent measures, there were some signs in favor of the variability mechanism in our questionnaire data. For two of the three scales (Source Credibility, Godspeed questionnaire), we could observe the predicted 3-way interaction between source, time, and trend. A closer inspection of the data revealed that our design did only find limited evidence of algorithm aversion (the slopes for human and AI explanations with a downward trend are running parallel to each other), but conversely there was strong indication of an “algorithm benefit” (an upward trend of explanation quality led to decreased ratings of a human source, but to improved ratings of the AI source). In hindsight, it is not surprising that the predicted pattern did not materialize for stereotype content as the two subscales (competence and warmth) are regarded as completely independent from each other. In contrast, the subscales of the Source Credibility Scale and the Godspeed measure are designed to measure the same construct. Taken together, these patterns can be interpreted in a way that ratings of an AI are more variable, that is, they depended on whether the AI quality increased or decreased over time. In contrast, ratings of human sources were independent from trend, and tended to uniformly deteriorate over time.
In addition to this, exploratory analyses of Study 2 revealed some interesting pattern regarding the questionnaire subscales. Here, it makes sense to separately discuss those subscales that relate to cognitive properties of a source versus subscales capturing non-cognitive/social aspects. For the three cognitive subscales, two consistent patterns can be observed. First, initial ratings of an AI were at least as high as initial ratings of a human (even higher in case of the competence subscale from the Source Credibility scale). This is in line with the literature on algorithm appreciation (Logg et al., 2019) and also fits nicely with studies inspire by the mind perception approach (Hertz & Wiese, 2019). Second, post-interaction ratings for both human sources and AI sources were significantly lower than pre-interaction ratings. This pattern (which occurred across both upward and downward trends) suggests that participants were less convinced about the cognitive capabilities of sources (both human and AI) after interacting with them. In contrast to the evaluative decrement on cognitive subscales, a different picture emerged for those subscales that captured non-cognitive/social aspects of a source. On all these scales (goodwill, trust, anthropomorphism, animacy, likeability, warmth) significant interactions between time and source were found. While evaluations of human sources showed a small decrease from pre- to post-measurements, an AI was evaluated more positively after the interaction than before the interaction. As a result, differences between human sources and AI sources converged over time.
General Discussion
With an increasing proliferation of AI systems, it will become more common that humans interact with artificial agents. From a psychological point of view, getting a better understanding of how humans respond to such agents gains importance. Previous research on human responses to computer agents has uncovered that erring computers are judged more harshly than erring humans, leading to algorithm aversion. Theories like the mind perception approach suggest that computers are rated relatively high on agency and competence, but low on experience or warmth. If the only human-like benefit of computers (high agency/competence) is compromised by faulty computer behavior, aversion toward algorithms might arise.
With the present paper, we originally started to find evidence for algorithm aversion in a new context: referential communication between humans and machines, a linguistic interplay that helps to build common ground via grounding activities between stakeholders (Brennan & Clark, 1996). We compared human responses to human versus AI sources, both on concurrent measures during interaction and subsequent measures on questionnaires that capture source credibility, an essential aspect of communication and mutual understanding. In line with previous accounts of algorithm aversion, our first study indeed confirms the human tendency to penalize computer errors (ambiguous descriptions) more strongly than identical human errors, thus providing an extension of both algorithm aversion accounts as well as investigations into human-machine grounding. However, our first study also showed a complementary pattern, dubbed “algorithm benefit”: flawless (non-ambiguous) descriptions of an AI were accompanied by better evaluations than similarly flawless descriptions from humans. These results hint at a novel mechanism that could result in a re-interpretation of algorithm aversion effects. It could well be the case that algorithm aversion and algorithm benefit represent two sides of the same coin, a larger variability of human judgments about computers. It stands to reason that limited experience with AI technologies leads to more pronounced adjustments about their capabilities, based on the concrete experiences that humans make with these technologies. If these experiences are favorable, algorithm benefit may ensue; if the experiences are unfavorable, algorithm aversion may arise.
To further explore this possibility, we conducted a second study. Study 2 measured judgments about agents both prior to and after interaction. Crucially, the interaction was either with an agent whose performance degraded (downward trend) or improved (upward trend). This allowed us to test between two competing hypotheses: If performance expectations were generally higher for algorithms than for humans (elevated expectation mechanism), an upward-trending AI would not improve ratings as much as an upward-trending human. However, if judgments about algorithms are generally more extreme than for humans (variability mechanism), an upward-trending AI would improve ratings more than an upward-trending human.
While the results of Study 2 are not entirely conclusive, they offer at least some support for the variability hypothesis. Those participants who were confronted with a dynamic change in AI performance (decreasing or increasing), adapted their initial impressions correspondingly. In contrast, those who were confronted with exactly the same dynamic changes in human performance (decreasing or increasing) showed no corresponding adaptation of their judgments. Perhaps humans can come up with many reasons why a human source may dynamically increase in performance (e.g., via learning) or may decrease in performance (e.g., via fatigue). Conversely, for computer targets such dynamic changes in performance may seem unexpected, leading to corresponding adjustments of judgments.
Conceptually, the variability hypothesis can be construed through the lens of Expectancy Violations Theory (Burgoon, 2015; Burgoon & Jones, 1976). This theory holds that human judgments about other agents should be seen in relation to expectations about these agents. Not meeting these expectations leads to negative responses, whereas exceeding expectations leads to positive responses. Consistent with this view, the variability account predicts that low or degrading performance from a computer will constitute a negative violation of expectations (algorithm aversion) whereas high or increasing performance from a computer will constitute a positive violation of expectations (algorithm benefit).
Interestingly, the adjustments about AI sources that we observed were not made on those subscales where one might expect them the most (“cognitive” features like competence or perceived intelligence). Rather, dynamic changes in computer performances led to corresponding adjustments on non-cognitive subscales, such as goodwill, trust, anthropomorphism, animacy, likeability, and warmth. Many theories have suggested that both humans and computers are evaluated on two dimensions (agency/competence vs. experience/warmth), and some theories suggest that ultimately, experience/warmth counts more than agency/competence when accounting for essentials about humanity (Abele et al., 2021; Abele & Bruckmüller, 2011). Similarly, a recent study on collaborative robots showed that trust of factory workers was contingent on the description of robots as human-like and cooperative (Kopp et al., 2022). In that regard, one might conclude that the dynamic changes apparent in an AI with an upward or downward trend contributed to making a computer technology appear more human-like (higher variability on the experience/warmth dimension).
It should be noted that our conclusions about increased variability toward computer targets are still tentative and require further testing. The design of Study 1 did not permit to capture variability regarding questionnaire data (as we did not measure pre-interaction expectations), and results of Study 2 did find evidence for variability only for questionnaire data, and not on concurrent measures. Unfortunately, our decision to change concurrent measures from Study 1 (quality and confidence) to Study 2 (satisfaction) makes it impossible to clearly interpret these differences, thus representing a substantial shortcoming. Another limitation of our studies refers to the fact that we did not know in how far participants really believed that descriptions were coming from an AI versus a human. However, we see no strong reason to think that a substantial number of participants had doubts about the capabilities of AI to generate kanji descriptions (describing pictorial stimuli falls well within the range of AI performance; You et al., 2016). Moreover, it would be difficult to explain significant differences among conditions if participants systematically believed the AI-ascribed kanji descriptions to originate from humans or vice versa. As a final limitation, by using similar tasks in both studies we do not know whether similar findings can be obtained in other communication contexts. Among the key targets of future research in this area would be to generalize to different communication tasks, and to further test the variability mechanism. For instance, if variability can explain our patterns, participants with a lot of AI experience should exhibit less change after an AI fails to meet or exceeds expectations. Despite these limitations, we believe that investigations into the variability of human judgments of computers can make a valuable contribution to our understanding of human responses to increasingly human-like technologies.
AI has been likened to a moving target (Bartneck et al., 2021; Chui et al., 2018), a technology that always describes what computers currently are not yet capable of. Once a solution to a hard puzzle is found by AI researchers (e.g., accurate object character recognition), many humans no longer count these solutions as examples of artificial intelligence. Similarly, AI capabilities in translating text have been a laughingstock some years ago, and they can lead to very sudden changes in perceivers after brief encounters with software that exhibits excellent performance in machine translation. Currently, this phenomenon can be observed at scale with the frequently raving reviews and impressions that people throughout the world share about their experiences with large language models like ChatGPT. The associated attitude change about the capabilities of AI provides ample reason to think about the variability of human judgments surrounding computer technologies. The sudden mismatch of prior expectations and current experience can have strong effects on our perceptions of computers, and this dynamic nature of judgments is rarely addressed in conceptual accounts of human-agent interaction. We hope that our work can make a contribution toward a view that regards human judgments about technologies as something that can change quickly and decisively.
Footnotes
Credit Author Statement
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.