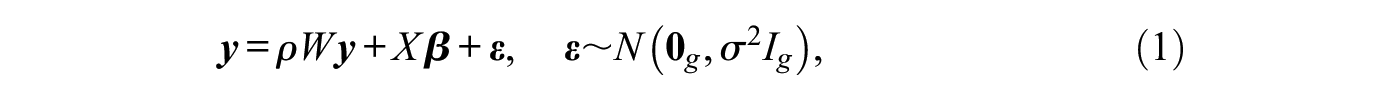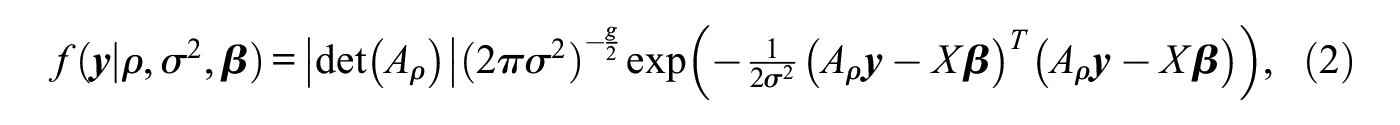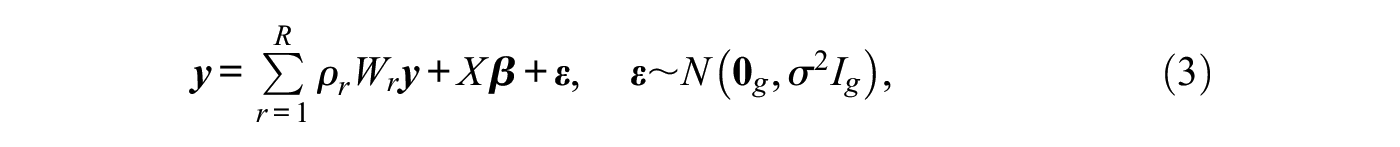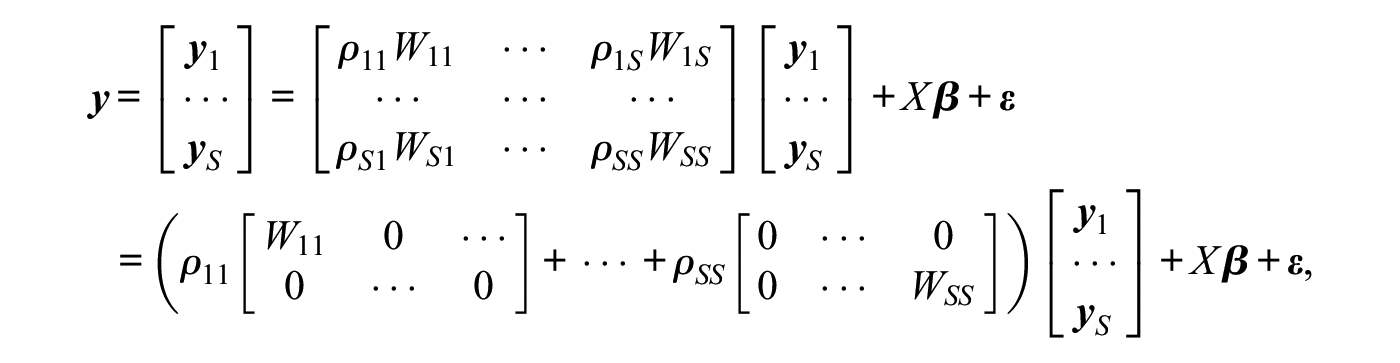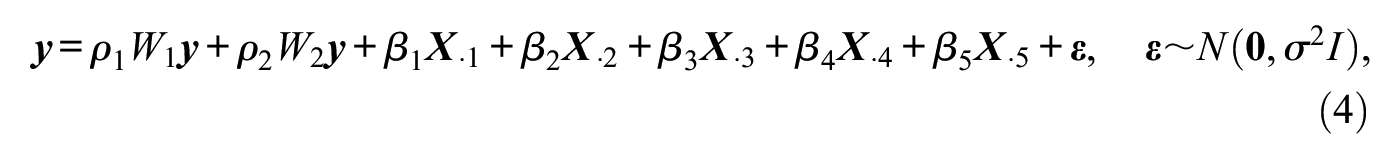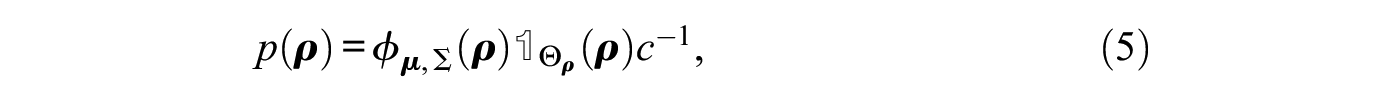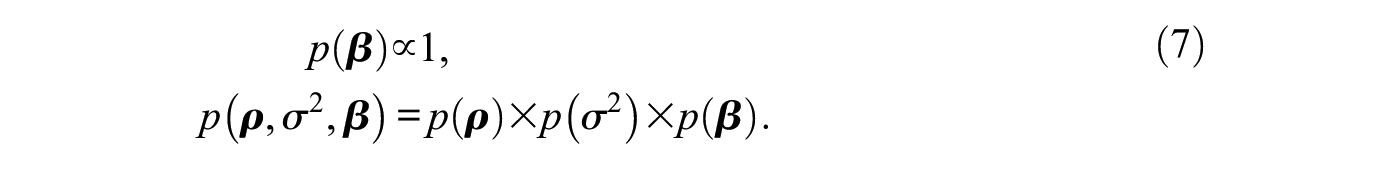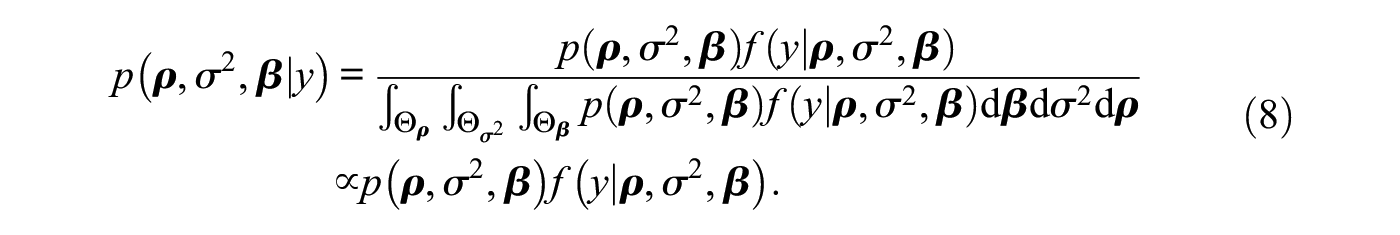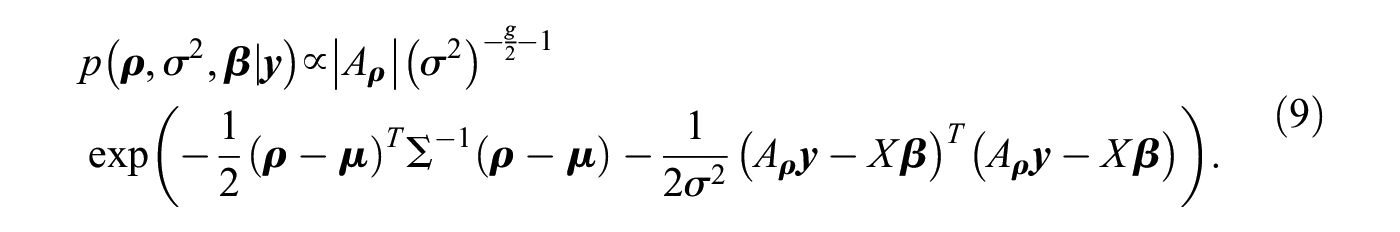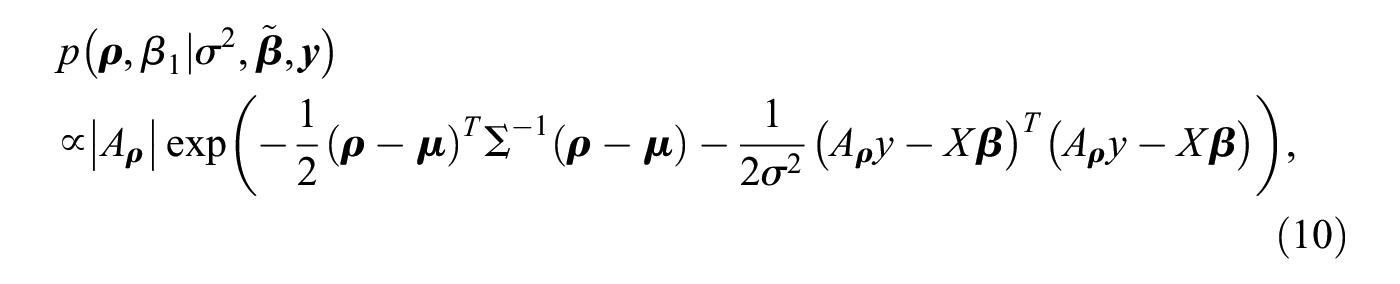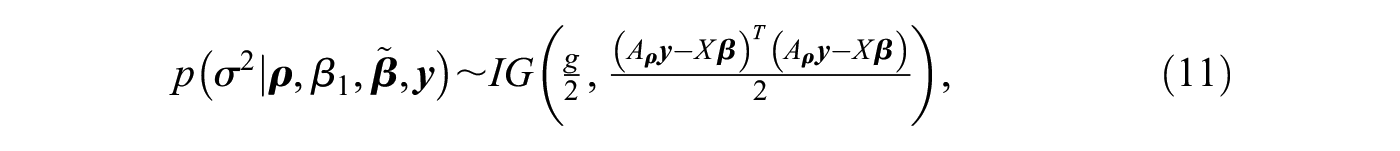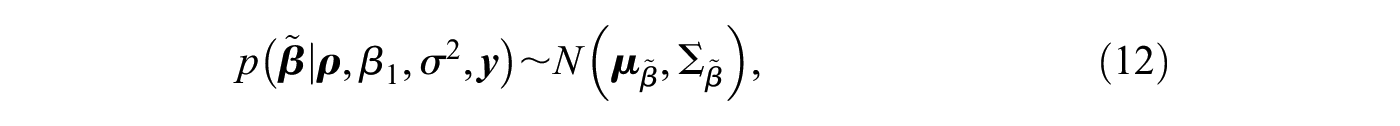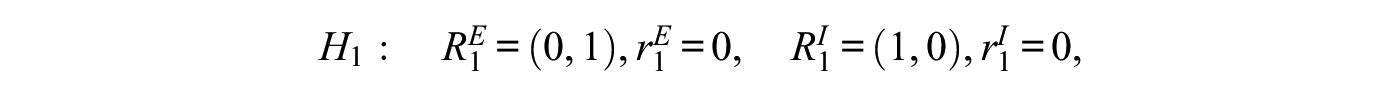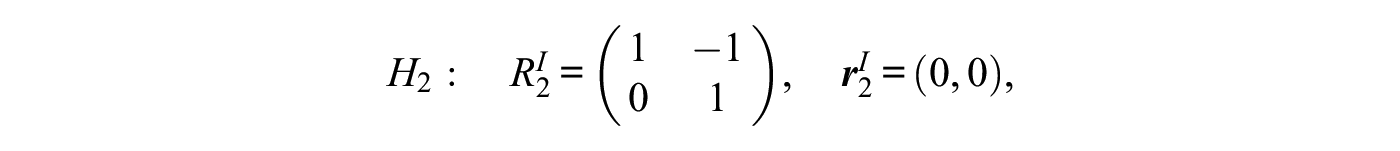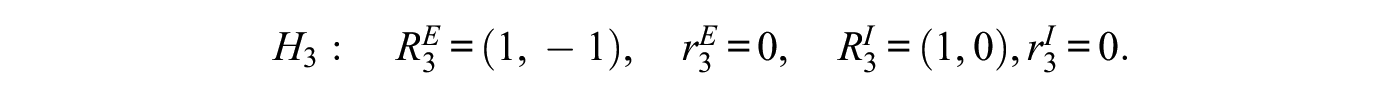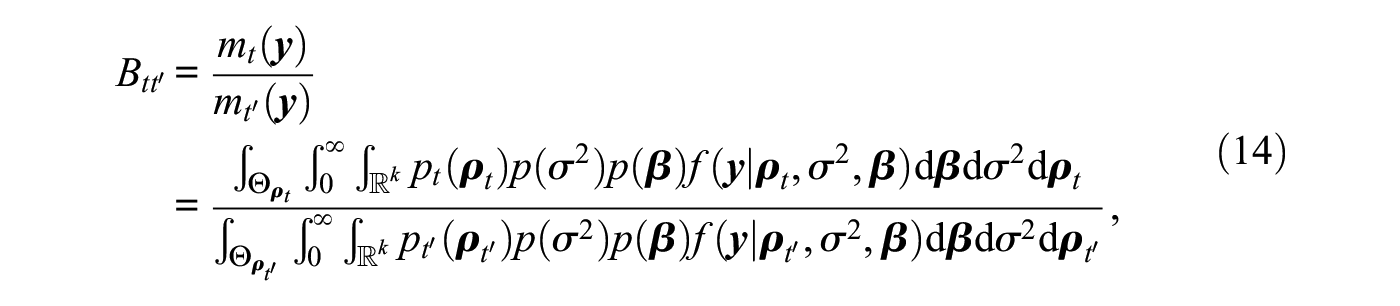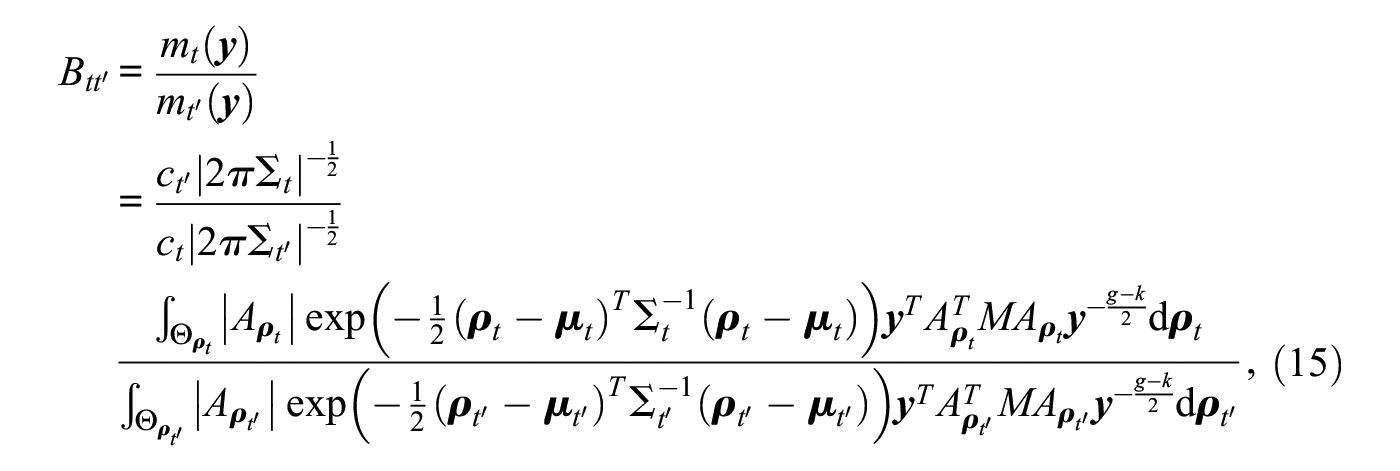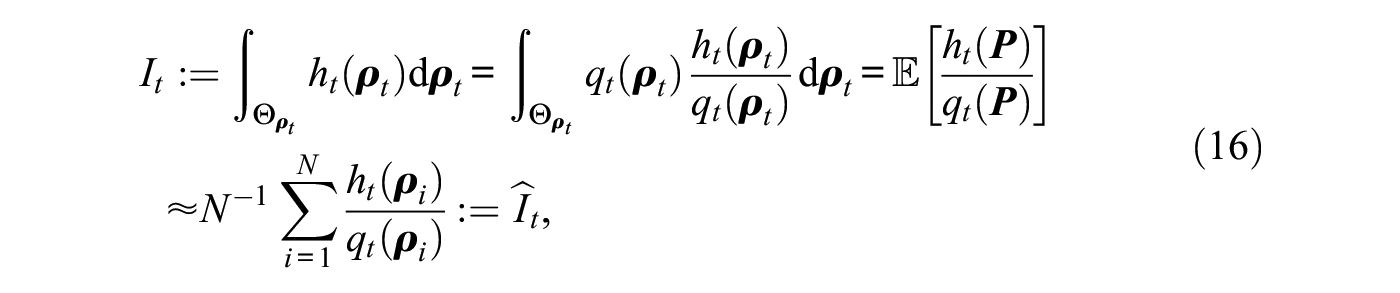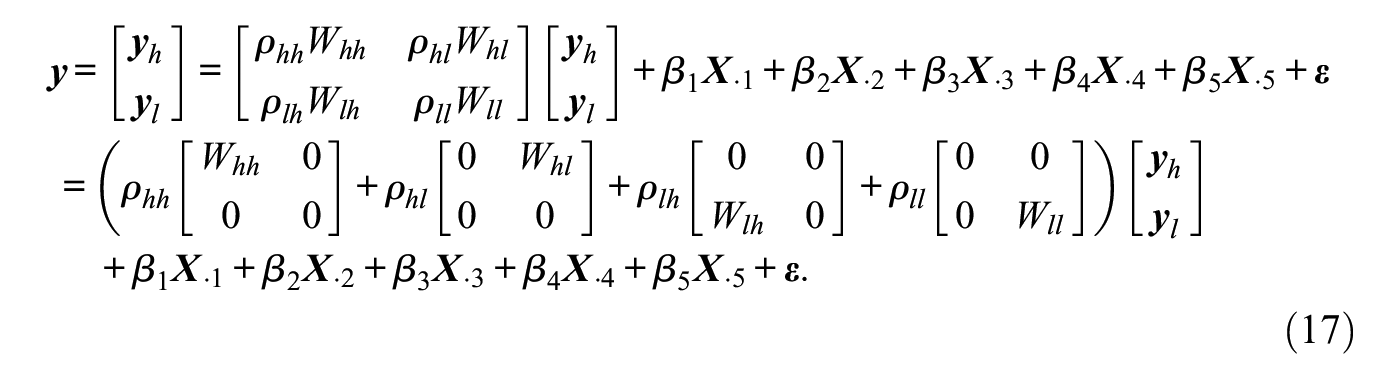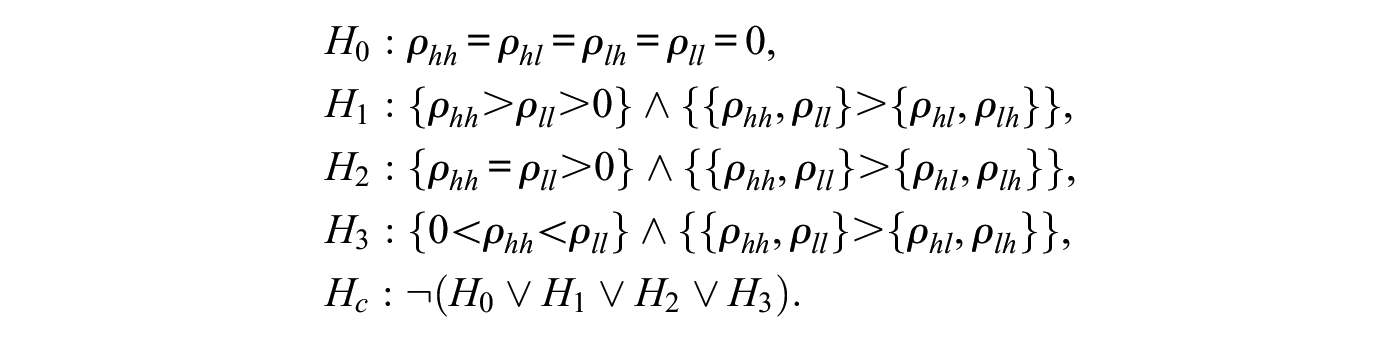The network autocorrelation model has been the workhorse for estimating and testing the strength of theories of social influence in a network. In many network studies, different types of social influence are present simultaneously and can be modeled using various connectivity matrices. Often, researchers have expectations about the order of strength of these different influence mechanisms. However, currently available methods cannot be applied to test a specific order of social influence in a network. In this article, the authors first present flexible Bayesian techniques for estimating network autocorrelation models with multiple network autocorrelation parameters. Second, they develop new Bayes factors that allow researchers to test hypotheses with order constraints on the network autocorrelation parameters in a direct manner. Concomitantly, the authors give efficient algorithms for sampling from the posterior distributions and for computing the Bayes factors. Simulation results suggest that frequentist properties of Bayesian estimators on the basis of noninformative priors for the network autocorrelation parameters are overall slightly superior to those based on maximum likelihood estimation. Furthermore, when testing statistical hypotheses, the Bayes factors show consistent behavior with evidence for a true data-generating hypothesis increasing with the sample size. Finally, the authors illustrate their methods using a data set from economic growth theory.
Social network research plays an important role in understanding how countries, organizations, and persons influence one another’s behavior, decision making, and well-being. The network autocorrelation model (Doreian 1981; Ord 1975) has been the workhorse for estimating and testing the strength of social influence with respect to a variable of interest in a given network (Fujimoto, Chou, and Valente 2011). In the network autocorrelation model, actors’ behavior, decision making, or well-being is assumed to be correlated, and a network autocorrelation parameter is estimated, representing the strength of a social influence mechanism in the network. The network autocorrelation model has been used to analyze network influence on individual behavior across many different fields, such as criminology (Tita and Radil 2011), ecology (McPherson and Nieswiadomy 2005), economics (Kalenkoski and Lacombe 2008), geography (Mur, López, and Angulo 2008), organization studies (Mizruchi and Stearns 2006), political science (Gimpel and Schuknecht 2003), and sociology (Burt and Doreian 1982).
Even though the network autocorrelation model has yielded many useful findings, the standard, or first-order, specification of the model implicitly assumes the presence of only a single network influence mechanism. However, this may be too restrictive in many cases, as different types of social influence are likely to be present simultaneously. For example, an actor is often a member of multiple distinct but potentially overlapping networks, such as a collaboration network, a friendship network, or an information-sharing network. Similarly, ties need not only be defined by social interaction but can also refer to geographical proximity, joint memberships, or money flows. Each of these networks may have some connection to the variable of interest; hence, a model that ignores multiple influence mechanisms might be overly simplistic. Besides the fact that individuals are often members of multiple, potentially overlapping, networks, it is also the case that many networks are characterized by subgroups. For example, children in school classes may belong to different social classes. We might ask if, with respect to school performance, children of socially disadvantaged backgrounds influence one another on the basis of the same influence mechanism, say friendship, stronger than do children from more privileged backgrounds. Another example of grouping can be found in economic growth theory: with respect to economic growth, central nations are expected to be subject to different processes than are peripheral developing nations (Dall’erba, Percoco, and Piras 2009; Leenders 1995).
In this article, we develop a fully Bayesian framework that allows the inclusion of external prior information for estimating higher-order network autocorrelation models and for simultaneously testing multiple non-nested constraints on the relative order of network effects, such as , , , or , where and quantify the strength of different influence mechanisms, respectively. Using a Bayesian approach for estimating and testing higher-order network autocorrelation models has several advantages compared with classical methods such as maximum likelihood estimation and null hypothesis significance testing. First, in contrast to maximum likelihood estimation of higher-order models, Bayesian estimation does not rely on asymptotic theory for computing standard errors of the network autocorrelation parameters, potentially resulting in a more accurate quantification of parameter uncertainty in small networks. Second, unlike null hypothesis significance testing, Bayes factors allow researchers to quantify relative evidence in the data in favor of the null, or any other, hypothesis against another hypothesis (Kass and Raftery 1995), and Bayes factors can be easily extended to test more than two hypotheses against each other simultaneously (Raftery, Madigan, and Hoeting 1997). Hence, this enables researchers to precisely test multiple network operationalizations against one another. Third, Bayes factors have been proven to be very effective for testing hypotheses with order constraints on the parameters of interest (Braeken, Mulder, and Wood 2015; Klugkist, Laudy, and Hoijtink 2005; Mulder 2016; Mulder and Wagenmakers 2016).
For example, in a simple research design in which regions are divided into higher-productivity and lower-productivity regions, it would be reasonable to expect differing levels of influence within and between the two sets of regions. In such a setup, one could hypothesize that higher-productivity regions might influence one another’s policies more strongly than lower-productivity regions would influence one another. Moreover, one could argue that the influence of higher-productivity regions on lower-productivity ones is likely higher than that of lower-productivity regions on higher-productivity regions. Of course, one could formulate competing hypotheses, such as that all network autocorrelations are zero, that they are nonzero but equal to one another, or that there is neither influence of lower-productivity regions on higher-productivity ones nor influence among lower-productivity regions themselves. This cannot be done using classical tests and is of particular importance in higher-order network autocorrelation models, as in this setting, researchers often have expectations about the order of strength of different network effects. Such expectations are implicit in most research and Bayes factors permit researchers to state them as actual hypotheses and then test them in a precise and straightforward manner. Beyond allowing researchers to test the more interesting hypotheses they may already have, we hope the availability of this approach will also stimulate researchers to theorize more creatively and more precisely about social influence phenomena, knowing their hypotheses can be easily and correctly tested against one another.
Thus, we propose Bayes factors for testing multiple hypotheses on the relative importance of network influence in a given network. The presented methodology not only allows a researcher to conclude if there is evidence in the data for, or against, nonzero network autocorrelations in the network, but it also grants the researcher the opportunity to simultaneously test any number of competing hypotheses on the relative strength of the network effects against one another. Subsequently, we conduct an extensive simulation study to investigate and show the desirable numerical properties of the new procedures, which we then use to reanalyze a data set from the economic growth literature. In addition to motivating and introducing new methodology, another main goal of this article is to make the methods easily available to researchers by providing ready-to-use R code.
We proceed as follows. In the next section, we present higher-order network autocorrelation models in detail before introducing Bayesian estimation and hypothesis testing techniques for the model in Sections 3 and 4. Concomitantly, we provide efficient implementations for estimating higher-order network autocorrelation models and for computing Bayes factors involving order hypotheses on the network autocorrelation parameters. We assess the numerical behavior of the proposed methods in Section 5. In Section 6, we illustrate our approaches with an empirical example, and Section 7 concludes.
2. The Network Autocorrelation Model
2.1. The First-Order Network Autocorrelation Model
Building on a standard linear regression model, the network autocorrelation model relaxes the assumption of independence of observations and allows correlation between them by explicitly using the underlying network structure. More precisely, an actor’s response is modeled as the weighted sum of the actor’s neighbor responses and a linear combination of actor attributes. In mathematical notation, the first-order network autocorrelation model is given by
where is a vector of length containing the observations for a variable of interest for the actors in a network, is a standard design matrix (possibly including a vector of ones in the first column for an intercept term), is a vector of regression coefficients as in standard linear regression, comprises the error terms that are assumed to be independent and identically normally distributed with zero mean and variance of , is a vector of zeros of length , and denotes the identity matrix. Furthermore, is a connectivity matrix, where a nonzero entry amounts to the influence of actor on actor and for all . Typically, is row-standardized; that is, all rows sum to 1, which in this case means that the term represents the vector of the actors’ neighbor average responses. Finally, is the network autocorrelation parameter and quantifies the magnitude of the network influence with respect to a variable of interest in a given network as induced by . For a substantive interpretation of the model, see Leenders (1995, 2002).
The model’s likelihood is multivariate normal and can be written as
where (see, e.g., Doreian 1981). Usually, the parameter space of is chosen as the interval around for which is nonsingular (Hepple 1995a; LeSage and Parent 2007; Smith 2009). The bounds of this feasible range of are determined by the eigenvalues of with the smallest and largest real part, respectively, which means that must be contained in , where denote the eigenvalues of with (Hepple 1995a). The model’s overall parameter space of is then given by .1
2.2. Higher-Order Network Autocorrelation Models
The standard, or first-order, network autocorrelation model in equation (1) is limited to a single network autocorrelation parameter and a single connectivity matrix . Hence, in this model the network influence is assumed to be homogeneously distributed across the network on the basis of a single influence mechanism. Extending the first-order model to higher-order network autocorrelation models allows a richer dependence structure by including multiple connectivity matrices, representing different influence mechanisms (e.g., geographic adjacency and social similarity).2 This amounts to the functional form
where are distinct connectivity matrices, and the corresponding network autocorrelation parameters denote the strength of the different influence mechanisms.
In practice, there can be overlap between connectivity matrices; that is, different connectivity matrices may share common ties. Partially overlapping connectivity matrices do not pose identification problems as long as there is no complete overlap (Elhorst et al. 2012), but overlap does make interpretability of the network autocorrelation parameters more difficult (Elhorst et al. 2012; LeSage and Pace 2011). In particular, partial overlap may result in empirically unlikely negative network autocorrelations (Dittrich et al. 2017a; Elhorst et al. 2012). We analyze the numerical effect of overlapping connectivity matrices on the estimation of and hypothesis tests on in more detail in a simulation study in Section 5.
Higher-order network autocorrelation models not only allow one to consider multiple influence mechanisms, but they also allow researchers to partition a network into several subgroups. In the latter case, possible heterogeneity in network influence strength is included in the model by allowing for different levels of network autocorrelation within and between subgroups for a given influence mechanism (e.g., geographic adjacency). Dividing actors in a network into subgroups, with sizes and , a model with multiple subgroups can be expressed using the representation in equation (3) by writing
where is a vector of length containing the observations for the actors in the th subgroup of the network, is a connectivity matrix defining the influence relationships between members of subgroup and members of subgroup , and is a network autocorrelation parameter representing the strength of the network influence of the actors in subgroup on the actors in subgroup . Because the sizes of the subgroups potentially differ, each is typically row-standardized separately, which removes scale effects and eases direct comparison between the network autocorrelation parameters (McMillen, Singell, and Waddell 2007).
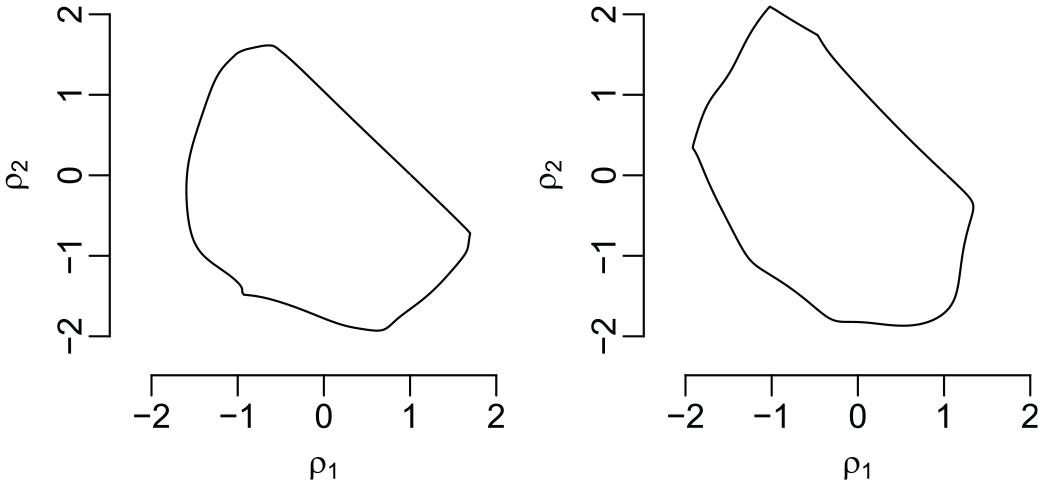
The structure of the likelihood function of higher-order network autocorrelation models remains the same as in the first-order model in equation (2), with being replaced by . As in the first-order model, we define the -dimensional parameter space of as the space containing the origin for which is nonsingular. Elhorst et al. (2012) provided a simple procedure for checking if a point R, given , lies in the corresponding feasible parameter space .3Figure 1 shows two exemplary feasible parameter spaces of in a second-order network autocorrelation model for simulated data based on nonoverlapping matrices (left) and with 40 percent overlap (right).
Feasible two-dimensional parameter space for simulated data based on nonoverlapping connectivity matrices (left) and connectivity matrices with a 40 percent overlap (right).
2.3. Application of a Higher-Order Network Autocorrelation Model: Economic Growth of Labor Productivity
In this subsection, we introduce a data set from the economic growth literature that prompts questions that can readily be answered using the proposed Bayes factor approach. Here, we merely describe the data set and the research questions; in Section 6, we provide solutions to the posed questions.
Dall’erba et al. (2009) used a second-order network autocorrelation model to explain the growth rates of labor productivity in the service industry across 188 European regions in 12 countries from 1980 to 2003. To adequately deal with interregional spillovers, the authors introduced two different spatial weight matrices, and , “under the assumption that economic interactions decrease very substantially when a national border is passed” (p. 337). They constructed using a region’s three nearest neighbors within the same country, and was based on the three nearest neighbors in bordering countries. The authors then row-normalized these raw binary connectivity matrices. In addition to an intercept term, Dall’erba et al. (2009) considered four more explanatory variables: the growth rate of market service output in a region, the initial labor productivity gap between the region and the leading region, a measure of the region’s urbanization, and a measure of the region’s accessibility. Thus, their model is given by
where is the vector of growth rates of labor productivity in the service industry across the 188 regions, represents the vector of the four regression coefficients plus an intercept term, contains the values for the explanatory variables for the 188 regions, where , denotes the th column of , is a vector of zeros, and represents the corresponding identity matrix.
The authors found that the estimate of , reflecting interactions within the same country, is positive and statistically significant, indicating the presence of positive spatial within-country spillover effects. On the other hand, the estimate of is very close to zero and statistically not significant. Dall’erba et al. (2009) concluded by saying that “the results obtained also confirm the hypothesis that economic interactions decrease very substantially when a national border is passed (indeed, the coefficient reflecting external spillovers is not statistically significant)” (p. 342). However, to draw this conclusion, one needs to directly test a corresponding hypothesis, for example, , against a (set of) competing hypothesis (hypotheses), such as , , or (and) . These four hypotheses correspond to the notion of “no network effects” (), “a positive within-country network effect only” (), “positive but decreasing network effects after a national border is passed” (), and “positive and equally strong within-country and between-country network effects” (). Currently, no formal statistical method is available to directly test such hypotheses on multiple network autocorrelations. In the remainder of this article, we develop a Bayesian framework for testing and quantifying the evidence in the data for such hypotheses involving equality as well as order constraints on the network effects. We come back to this empirical example and test these hypotheses against one another using Bayes factors in Section 6. Finally, Dall’erba et al. (2009) stated that “there is evidence that the coefficients in a growth model are potentially varying for different subsets of the total sample” (p. 342). In Section 6, we investigate if there is such evidence in this data set by considering a network autocorrelation model with two subgroups, allowing for differing levels of network autocorrelation within and between the two subgroups.
3. Bayesian Estimation of Higher-Order Network Autocorrelation Models
3.1. Prior Specification
Bayesian estimation starts with formulating prior expectations about the parameters in a model in terms of prior distributions, or priors. These priors summarize the (lack of) information about the model parameters before observing the data. If such prior information is available (e.g., on the basis of previous literature), informative priors for the parameters of interest can be formulated. For the first-order network autocorrelation model, Dittrich et al. (2017a) performed a literature study, looking at the distribution of reported network autocorrelations across many different fields. On the basis of their results, most of the analyzed data in the literature exhibit positive network autocorrelation between 0 and 0.5, and it seems highly unlikely to observe negative network autocorrelation estimates (as previously noted by, e.g., Neuman and Mizruchi 2010). This information could then be used to formulate an informative prior for in a first-order network autocorrelation model, as Dittrich et al. (2017a, 2017b) did. On the other hand, if such prior information is missing, or a researcher deliberately refrains from adding additional information to the model through the prior, noninformative priors are often used (Gelman et al. 2003). In the network autocorrelation model, and are commonly assigned the standard noninformative priors and (Hepple 1995a; Holloway, Shankar, and Rahman 2002; LeSage 1997b). These priors assume that all possible values for and are equally likely a priori. We also do so throughout this article. Note that these priors are not proper in the sense that they do not integrate to a finite value, which does not affect estimation of the model.
We use a general -variate normal prior for , , where denotes the probability density function of a multivariate normal distribution with prior mean and prior covariance matrix , is the standard indicator function, and is a normalizing constant representing the probability mass of contained in the network autocorrelation parameters’ space . If researchers have sufficient prior information about the network autocorrelations, they can specify and directly. Alternatively, when specifying vaguely enough, that is, with very large diagonal elements, the prior becomes essentially identical to a proper uniform distribution for on the bounded parameter space .4
In summary, we use the following priors for the model parameters, which we assume to be a priori independent from one another:
3.2. Posterior Computation
After having specified a prior distribution for the model parameters, the information contained in the observed data is used to update the prior distribution and to arrive at the posterior distribution, or simply posterior. The posterior is used for all Bayesian inference in the model, for example, to obtain point estimates of model parameters (the posterior mean or the posterior median), to construct Bayesian credible intervals (i.e., intervals in the domain of the posterior), or to determine other statistics of interest, such as the probability that one network effect is stronger than another one for given data, . In this subsection, we specify the posterior in higher-order network autocorrelation models on the basis of the priors from Section 3.1, and we provide an automatic and efficient scheme to sample from this posterior.
First, Bayes’ theorem gives that the posterior is proportional to the prior multiplied by the likelihood, more precisely
The denominator of equation (8) is called the marginal likelihood and ensures that the posterior integrates to unity. The marginal likelihood does not depend on any model parameters and can be ignored in Bayesian estimation of the model. On the other hand, when testing hypotheses, the marginal likelihood does play a central role, as it quantifies how plausible the data are under a specific hypothesis, which we discuss in the following section.
Next, using the priors in equations (5), (6), and (7), and the likelihood function in equation (2), we can express the posterior in higher-order network autocorrelation models as
However, the posterior in equation (9) does not belong to a family of known probability distributions, so we cannot directly infer its posterior mean, its quantiles, or other quantities of interest.5 In this case, it is common to sample random draws from the posterior and to use these posterior draws to approximate any desired statistic. An efficient method is to sequentially draw from the conditional posteriors, that is, the posterior of one parameter (block) given the remaining parameters and the data (Gelfand and Smith 1990; Geman and Geman 1984).6 Extending the proposed method for the first-order network autocorrelation model in Dittrich et al. (2017a) to higher-order models, we sample the model parameters according to the following blocks: , and , where denotes the model’s intercept and contains the remaining regression coefficients. By simultaneously sampling and , we can better capture potential posterior correlation between the network effects as well as potential correlation between the network effects and the intercept (Dittrich et al. 2017a). The conditional posteriors for the proposed blocks are then given by (see, e.g., LeSage 1997a)
where denotes the inverse gamma distribution, and and are given in Appendix A.
Drawing from the conditional posteriors in equations (11) and (12) can be done using standard statistical software. In contrast, the conditional posterior in equation (10) does not have a well-known form and cannot be directly sampled from. Instead, we use the Metropolis-Hastings algorithm (Hastings 1970; Metropolis et al. 1953) to generate draws from the conditional posterior for . In short, the algorithm generates candidate values for the conditional posterior from a candidate-generating distribution that can be easily sampled from and subsequently accepts, or rejects, the draws with a certain probability. The algorithm’s efficiency mainly depends on the shape of the proposed candidate-generating distribution; if possible, exploiting the form of the conditional posterior and specifying a candidate-generating distribution that closely approximates it results in efficient solutions (Chib and Greenberg 1994, 1995, 1998).
We first approximate by a quadratic polynomial in by virtue of Jacobi’s formula and the Mercator series (see Appendix A). Next, we observe that the logarithm of the exponential in equation (10) can also be written as a quadratic polynomial in . Hence, the logarithm of the conditional posterior itself can be approximated by a quadratic polynomial in . Finally, by equating coefficients of this quadratic polynomial with the log-kernel of the probability density function of an -variate normal distribution, the density in equation (10) can be approximated by an -variate normal candidate-generating density for that is tailored to the conditional posterior for .7 All details and the full sampling scheme can be found in Appendix A.
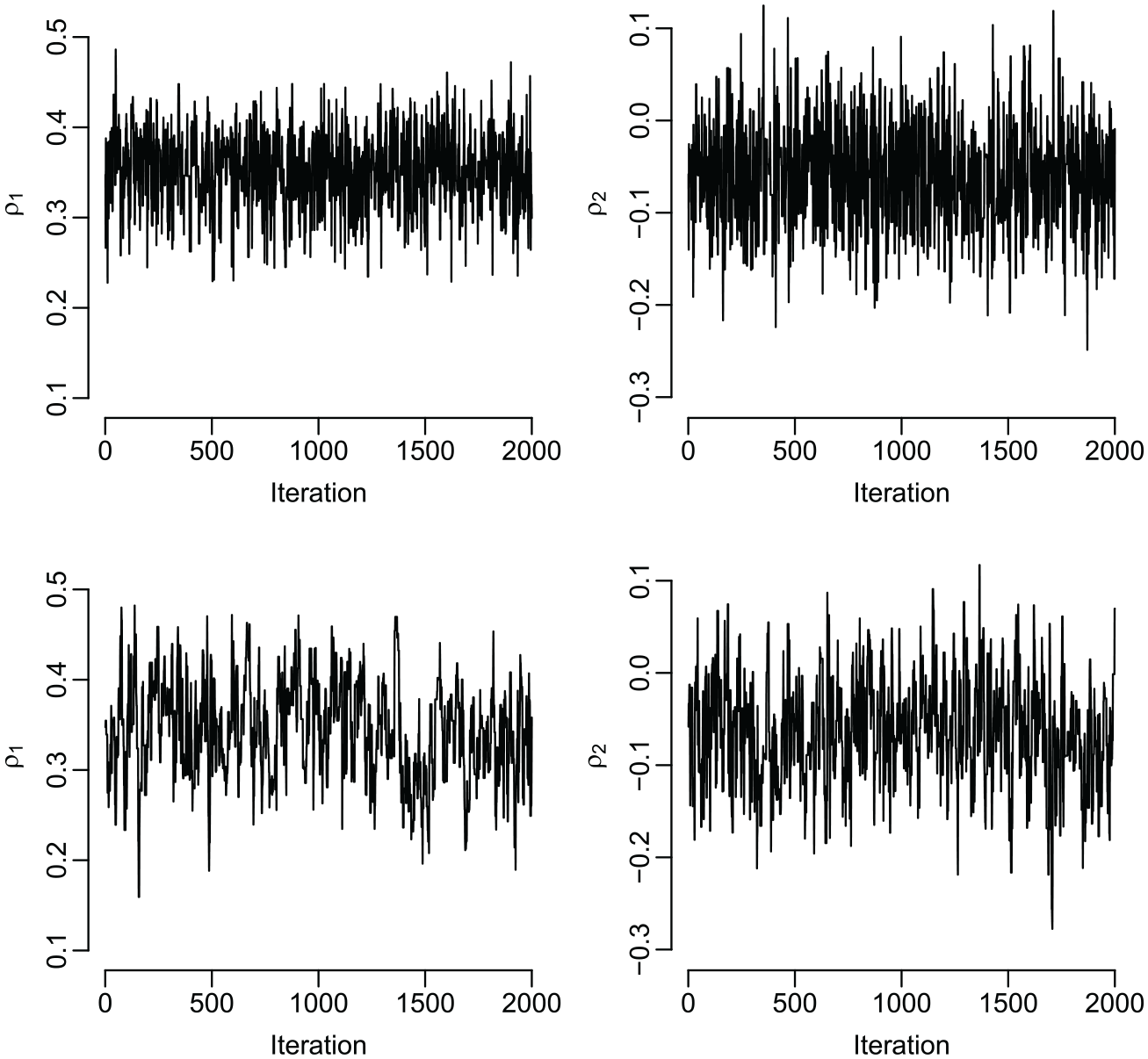
We implemented our proposed approach in R (R Core Team 2017) and compared its performance with a sampling scheme that does not block the network autocorrelation parameters and the intercept but uses one-dimensional random walk algorithms to generate draws for each network effect sequentially, as in Zhang et al. (2013). Figure 2 shows exemplary trace plots of posterior draws for and on the basis of the two sampling schemes and the data in Dall’erba et al. (2009) with model (4). We see that our method results in a more efficient implementation than drawing each network effect separately, as it generates Markov chains that explore the corresponding parameter space of much faster. Finally, our approach is fully automatic in the sense that there are no parameters to be tuned in the Metropolis-Hastings algorithm, such as the variance of candidate-generating distributions.
Trace plots of posterior draws for and on the basis of our proposed scheme (top row) and a random walk algorithm (bottom row) for the data in Dall’erba et al. (2009) with model (4).
To conclude, the presented sampling algorithm allows researchers to automatically and efficiently draw from the posterior on the basis of a general multivariate normal prior for the network autocorrelation parameters, including informative as well as noninformative specifications. Such efficient sampling is essential for performing any Bayesian estimation of the model, which solely relies on the generated posterior draws. An R program that implements our scheme is available at https://github.com/DittrichD/BayesNAM.
4. Bayesian Hypothesis Testing in Higher-Order Network Autocorrelation Models
In many network studies, researchers have competing theories about the specific order of different network effect strengths. These theories can be formulated as hypotheses on the network autocorrelation parameters, for example, as , , or , and can include as many network autocorrelation parameters as relevant to one’s theory. The focus of interest then lies on which substantive theory, or hypothesis, is most plausible and most supported by the data and how strongly. In this section, we consider constrained hypotheses on the network effects, where a hypothesis , , contains equality and inequality constraints on , that is,
where and are a matrix and a vector of length , respectively, containing the coefficients of the equality constraints under hypothesis . Equivalently, the matrix and the vector contain the coefficients of the inequality constraints. For example, the constraints induced by the three hypotheses , , and can be represented by equation (13) as8
The Bayes factor is a comparative Bayesian hypothesis testing criterion that directly quantifies the relative evidence in the data in favor of a hypothesis. The Bayes factor of hypothesis against hypothesis , , is defined as the ratio of the marginal likelihoods under the two hypotheses, that is, in the network autocorrelation model as
where are the network autocorrelation parameters under hypothesis , denotes their prior density, and is the corresponding parameter space (Kass and Raftery 1995). We assume common priors for and under both hypothesis and hypothesis as they are seen as nuisance parameters in the presented framework. The exact form of the priors for these nuisance parameters typically does not alter the magnitude of the Bayes factor (Kass and Raftery 1995).
The marginal likelihood under hypothesis , , is a weighted average likelihood over the parameter space under hypothesis , with the prior under hypothesis acting as a weight function. Therefore, it can be interpreted as the probability that the data were observed under hypothesis . Hence, the Bayes factor, as the ratio of two marginal likelihoods, quantifies the relative evidence that the data were observed under hypothesis rather than hypothesis . For example, when , this indicates that the data are five times more likely to have occurred under hypothesis compared with hypothesis . Conversely, when , it is five times more likely to have observed the data under hypothesis than under hypothesis .
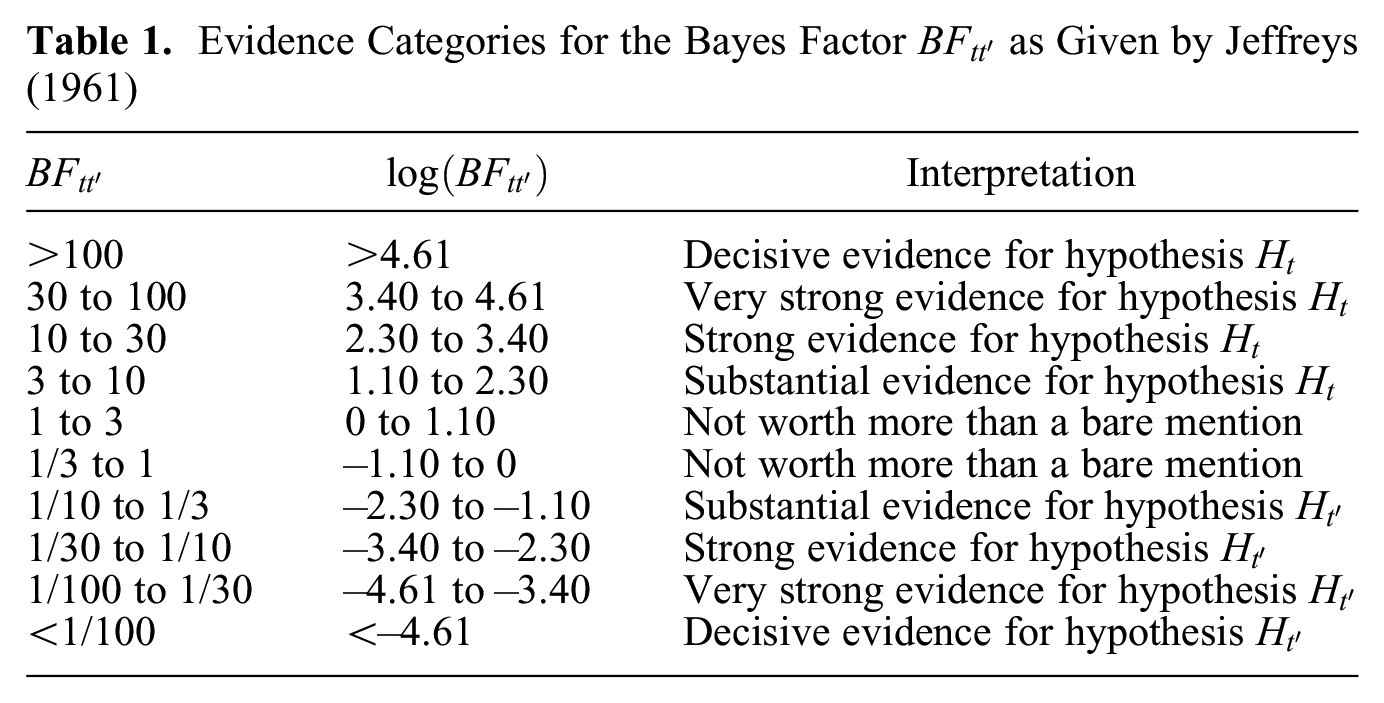
To facilitate interpretation of the Bayes factor, Jeffreys (1961) proposed a classification scheme that groups Bayes factors into different categories (see Table 1). For example, there is “strong” evidence in the data for hypothesis , relative to hypothesis , when and, equivalently, “strong” relative evidence in the data for hypothesis when . This grouping provides verbal descriptions and rules of thumb when speaking of relative evidence in the data in favor of a hypothesis, but it is still somewhat arbitrary. Ultimately, the interpretation of the magnitude of a Bayes factor should hinge on the context of the research question (Kass and Raftery 1995). For some introductory texts on Bayes factor testing in social science research, we refer the interested reader to Braeken et al. (2015), Raftery (1995), van de Schoot et al. (2011), or Wagenmakers (2007).
Evidence Categories for the Bayes Factor as Given by Jeffreys (1961)
Interpretation
>100
>4.61
Decisive evidence for hypothesis
30 to 100
3.40 to 4.61
Very strong evidence for hypothesis
10 to 30
2.30 to 3.40
Strong evidence for hypothesis
3 to 10
1.10 to 2.30
Substantial evidence for hypothesis
1 to 3
0 to 1.10
Not worth more than a bare mention
1/3 to 1
−1.10 to 0
Not worth more than a bare mention
1/10 to 1/3
−2.30 to −1.10
Substantial evidence for hypothesis
1/30 to 1/10
−3.40 to −2.30
Strong evidence for hypothesis
1/100 to 1/30
−4.61 to −3.40
Very strong evidence for hypothesis
<1/100
<–4.61
Decisive evidence for hypothesis
4.2. Bayes Factor Computation
In this section, we present efficient methods to compute marginal likelihoods and Bayes factors in higher-order network autocorrelation models. Using a multivariate normal prior for under hypothesis , , , the noninformative prior for the nuisance parameters and , and after analytically integrating out and , the Bayes factor of hypothesis against hypothesis in equation (14) reduces to
The normalizing constants and in equation (15) correspond to the prior probabilities that the unconstrained priors for under hypothesis and for under hypothesis , and , are in agreement with the constraints imposed under the two hypotheses. They can be approximated by simple rejection sampling, that is, by sampling draws from the unconstrained priors and recording the proportions of draws that are in agreement with the constraints. The remaining integrals in the numerator and denominator of equation (15) do not have closed-form solutions and have to be evaluated numerically. For this purpose, we rely on an importance sampling procedure (Owen and Zhou 2000) that is explained next.
Let denote the integrand in the numerator of equation (15) (all steps apply equivalently to ). Then, we can write for the numerator of equation (15)
where is a random variable with probability density function known as the importance density, denotes the expected value for , and are draws from , forming realizations of . The specification of the importance density is crucial for the algorithm’s efficiency, where we aim to construct a density that closely follows the actual integrand but has heavier tails than the latter and is easy to sample from (Owen and Zhou 2000).
As in Section 3.2, we approximate by a second-order polynomial in at its maximum, the origin. This results in a normal approximation of . We apply the same rationale to the third term in , . Hence, can be approximated by the product of three multivariate normal densities that itself is a multivariate normal density, which we use as importance density in equation (16).10 Finally, as approaches the boundary of , the proposed normal importance density has heavier tails than , because in this case decreases toward zero, but the normal importance density does not. This ensures a finite variance of the importance sampling estimate and reliable estimation of the associated Bayes factors. All details can be found in Appendix B.
4.3. A Default Prior for
When testing multiple hypotheses against one another, a prior for the tested model parameters has to be specified under each hypothesis. Arguably, eliciting a prior under each hypothesis directly can become difficult and cumbersome, especially with a large number of hypotheses at hand. As an alternative, we propose an automatic empirical Bayes procedure (Carlin and Louis 2000) for constructing a default prior under each hypothesis such that the marginal likelihood under every hypothesis is maximized.
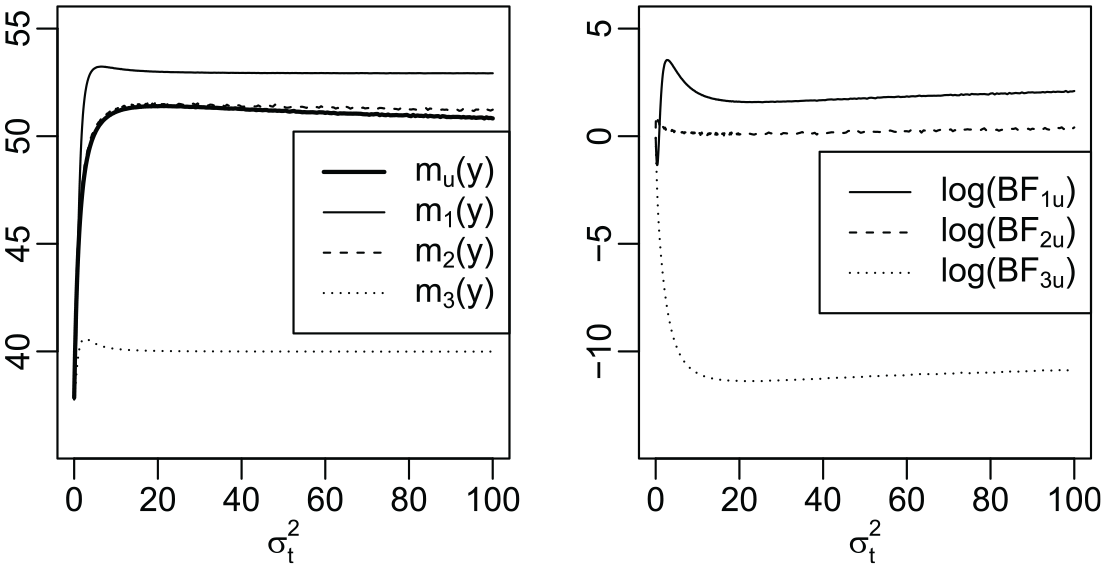
First, we center the multivariate normal default prior under hypothesis around the origin. The motivation for this choice is that the origin is located at the boundary of typical (in)equality constrained hypotheses in the network autocorrelation model, such as , , or , and previous literature on order constrained hypothesis testing suggests “there is a gain of evidence for the inequality constrained hypothesis that is supported by the data when the unconstrained prior is located on the boundary” (Mulder 2014:452). Second, in contrast to Bayesian estimation, assigning very large values to the diagonal elements of the prior’s covariance matrix is not feasible in hypothesis testing. In hypothesis testing, we need to explicitly calculate the normalizing constant , and a vague formulation of makes this computation either unstable or tremendously time consuming because of the fairly small parameter space .11 Instead, we set the prior covariance matrix of the free network autocorrelation parameter(s) under a hypothesis, for example, under hypothesis , to the product of the corresponding asymptotic variance-covariance matrix of the maximum likelihood estimate of and a hypothesis-specific scaling factor , similar to Zellner’s g-prior (Zellner 1986). In mathematical notation, , where denotes the submatrix of the network autocorrelation model’s Fisher information matrix . Hence, there is only one free parameter in the prior specification of left, . Following Hansen and Yu (2001) and Liang et al. (2008), we use a local empirical Bayes approach and choose such that the associated marginal likelihood is maximized, avoiding arbitrary prior specification. Because there is no analytic solution to this maximization problem, one way to approximate the maximum of is to compute the marginal likelihood on a grid of increasing values for until a stopping rule is reached, for example, until the marginal likelihood is not increasing anymore, or until it is not increasing by more than some tolerance factor.12
Figure 3 shows the marginal likelihoods under the three constrained hypotheses , , and ; the marginal likelihood under an unconstrained hypothesis ; and the logarithm of the Bayes factors of the three constrained hypotheses against the unconstrained hypothesis as a function of , , for the data in Dall’erba et al. (2009) with model (4). All of the marginal likelihoods sharply increase for smaller values for before they gradually decrease after having reached their respective maxima. The associated Bayes factors, in which we are ultimately interested, appear fairly robust to the choice of , except for extremely small values for . For the vast majority of data sets we looked at, we observed essentially the same pattern, with almost all the optimal values for lying between 2 and 10.
Marginal likelihoods , , under the hypotheses , , , and as a function of (left), and the logarithm of the Bayes factors and as a function of (right) for the data in Dall’erba et al. (2009) with model (4).
In summary, we showed how Bayes factors can be used to quantify the evidence in the data for hypotheses with order constraints on the network autocorrelation parameters. In addition, we provided methodology to efficiently compute such Bayes factors without any need to subjectively elicit priors for the network effects. This ultimately allows network scholars to test and verify any kind of expectations they have about the strength of different network effects. An R program that implements our methodology will be available at https://github.com/DittrichD/BayesNAM.
5. Simulation Study
We performed a simulation study to investigate the performance of the proposed Bayesian estimator and Bayes factors in a second-order network autocorrelation model. First, we compared the Bayesian estimator from Section 3.2 with the maximum likelihood estimator in terms of bias of the network effects and frequentist coverage of the corresponding credible and confidence intervals. Here, we use the term coverage to indicate the proportion of times in which the true, that is, data-generating, network effects were contained in the credible and confidence intervals. Second, because researchers are generally interested in testing whether (some) network effects are zero or whether one network effect is larger than another, we considered a multiple hypothesis test with the following five hypotheses: , , , , and . We investigated if and how fast the different Bayes factors converge to a true data-generating hypothesis and how robust these findings are to various degrees of overlap between two connectivity matrices.
5.1. Study Design
In our simulation study, we generated data via , for four network sizes (), three levels of overlap between and (0 percent, 20 percent, and 40 percent), and both and having an average degree of four. We simulated random nonsymmetric binary connectivity matrices using the rgraph() function from the sna package in R (Butts 2008), randomly rearranged ties when accounting for overlap, and subsequently row-standardized the raw connectivity matrices. Furthermore, we drew independent values from a standard normal distribution for the elements of (excluding the first column which is a vector of ones), , and .
In our first experiment, we set the two network effects to and simulated 1,000 data sets for each of the 12 scenarios (four network sizes × three levels of overlap × one network effects size).13 For the Bayesian estimator, we used the standard improper prior for the nuisance parameters and a noninformative bivariate normal prior for , , which essentially corresponds to a uniform prior for . We drew 1,000 realizations from the resulting posteriors relying on the methods described in Section 3.2, taking the maximum likelihood estimate of as the starting value in the sampling algorithm (see Appendix A). We used the marginal posterior median as point estimator and the 95 percent equal-tailed credible interval for coverage analysis. We obtained the maximum likelihood estimates as well as their standard errors and associated asymptotic confidence intervals applying the lnam() function from the sna package in R.
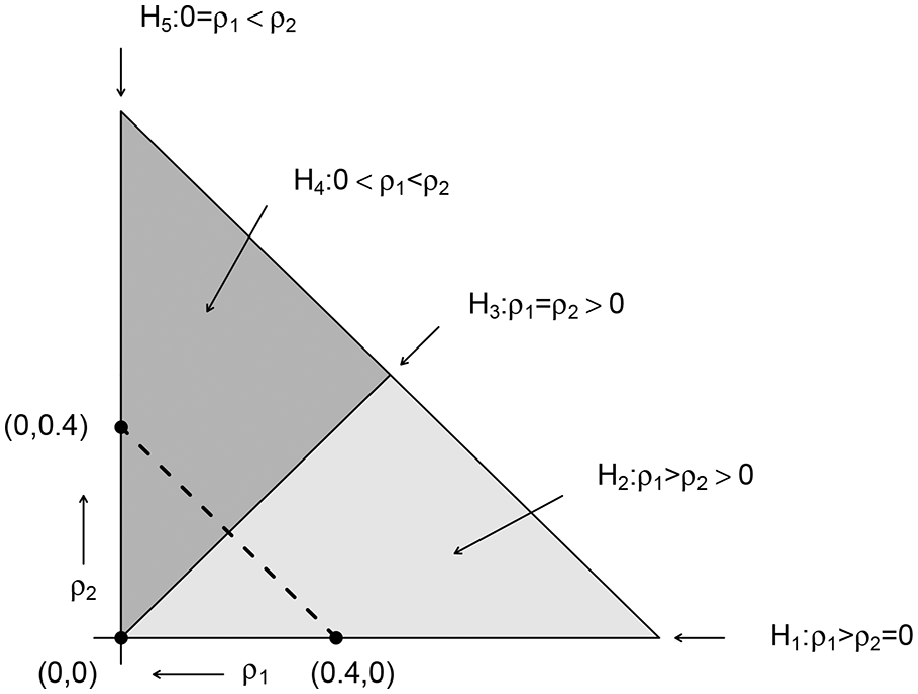
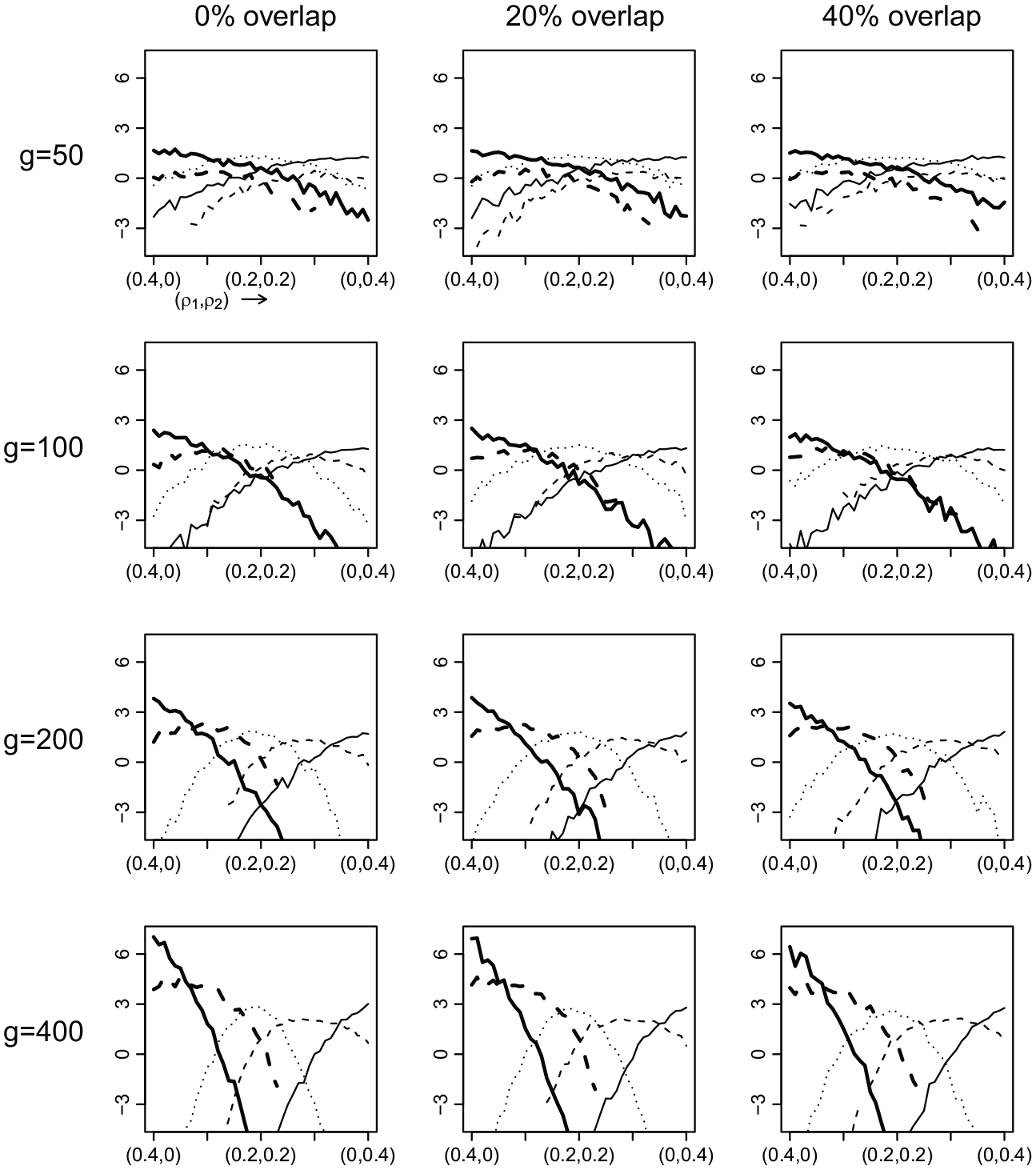
In our second experiment, we considered 41 network effects sizes () and simulated 100 data sets for each of the 492 scenarios (four network sizes × three levels of overlap × 41 network effects sizes). Figure 4 shows the trajectory of the network effects and depicts the five tested hypotheses, , , , , and . We specified the prior under each of the five hypotheses on the basis of the proposed empirical Bayes procedure in Section 4.3.14 To compute the normalizing constants and , we generated draws from the unconstrained bivariate normal prior for until we obtained 1,000 draws in agreement with the constraints imposed under hypothesis and hypothesis , respectively. Then, we approximated the normalizing constants by the reciprocals of the proportion of the total number of draws in agreement with the constraints. For the hypotheses with only one free network autocorrelation parameter, that is, , , and , we directly obtained the corresponding normalizing constants by using the pnorm() function in R, as the bounds of the feasible range of a single free network autocorrelation parameter are known exactly (see Section 2.1). Finally, for all hypotheses we drew 1,000 realizations from their (unconstrained) importance densities and computed the logarithm of the Bayes factor of each constrained hypothesis against an unconstrained reference hypothesis .15
Admissible subspaces of under the five constrained hypotheses and the trajectory of the data-generating network effects (dashed line).
5.2. Simulation Results
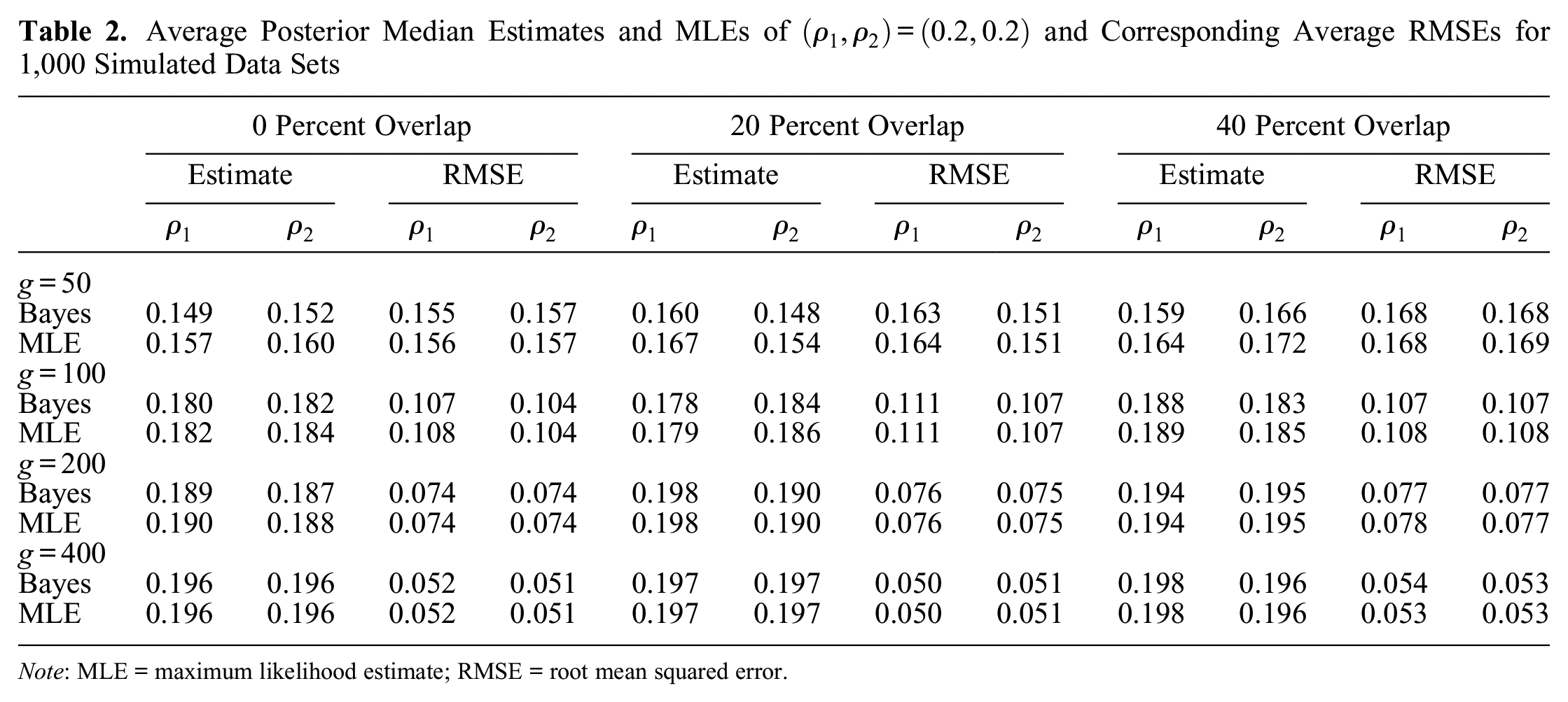
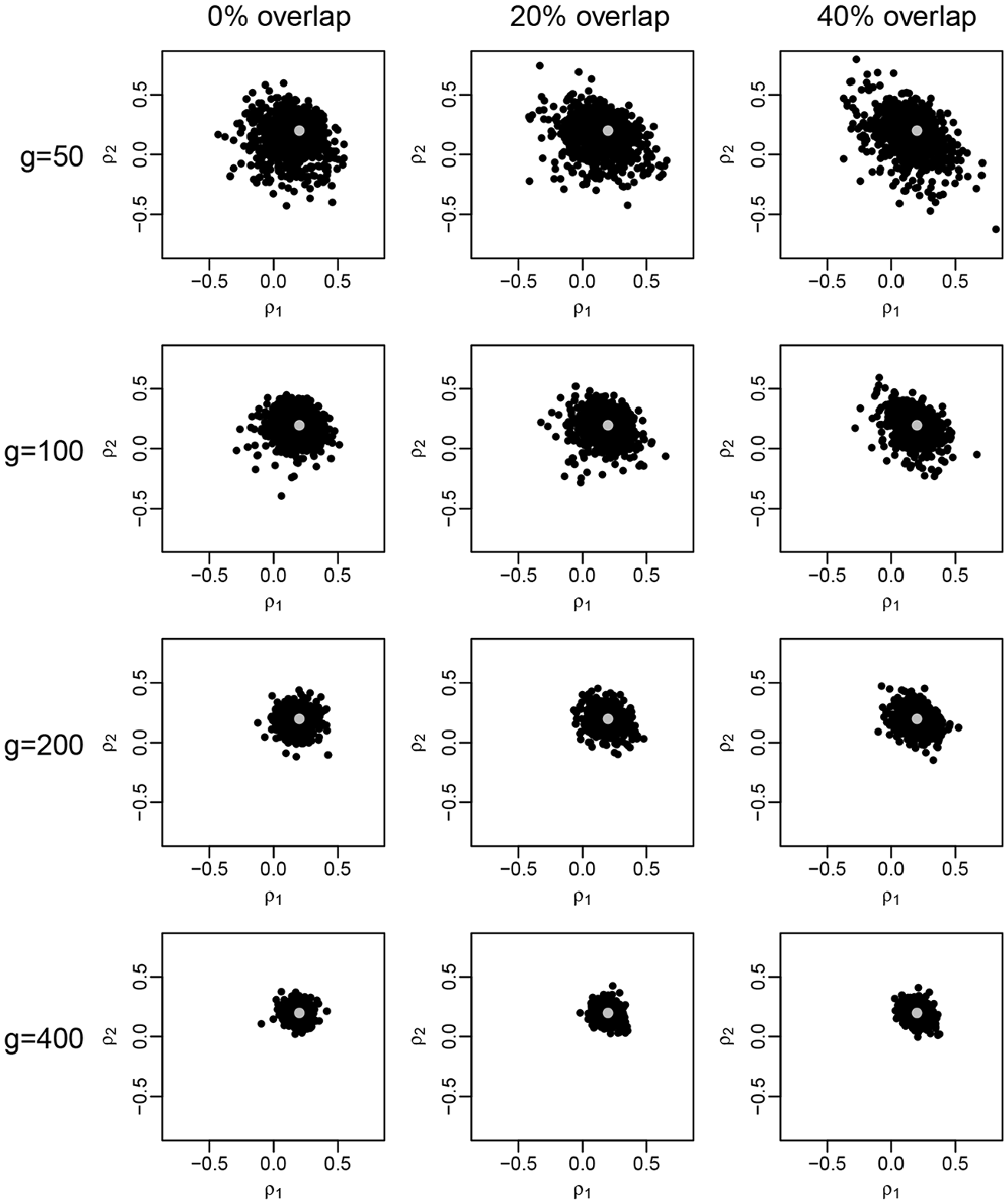
Table 2 shows the average estimates and root mean squared errors of and for the Bayesian as well as the maximum likelihood estimator. Overall, the two estimators yield nearly identical results for all considered scenarios. As expected, the (negative) bias in the estimation of the network effects and the associated root mean squared errors are decreasing with the network size, the bias being virtually nonexistent for . Introducing 20 percent and 40 percent overlap between two connectivity matrices does not appear to affect the estimation results, even if there is mild negative correlation between the estimated network effects in these cases (see Figure 5).
Average Posterior Median Estimates and MLEs of and Corresponding Average RMSEs for 1,000 Simulated Data Sets
0 Percent Overlap
20 Percent Overlap
40 Percent Overlap
Estimate
RMSE
Estimate
RMSE
Estimate
RMSE
Bayes
0.149
0.152
0.155
0.157
0.160
0.148
0.163
0.151
0.159
0.166
0.168
0.168
MLE
0.157
0.160
0.156
0.157
0.167
0.154
0.164
0.151
0.164
0.172
0.168
0.169
Bayes
0.180
0.182
0.107
0.104
0.178
0.184
0.111
0.107
0.188
0.183
0.107
0.107
MLE
0.182
0.184
0.108
0.104
0.179
0.186
0.111
0.107
0.189
0.185
0.108
0.108
Bayes
0.189
0.187
0.074
0.074
0.198
0.190
0.076
0.075
0.194
0.195
0.077
0.077
MLE
0.190
0.188
0.074
0.074
0.198
0.190
0.076
0.075
0.194
0.195
0.078
0.077
Bayes
0.196
0.196
0.052
0.051
0.197
0.197
0.050
0.051
0.198
0.196
0.054
0.053
MLE
0.196
0.196
0.052
0.051
0.197
0.197
0.050
0.051
0.198
0.196
0.053
0.053
Note: MLE = maximum likelihood estimate; RMSE = root mean squared error.
Posterior median estimates (black) of (gray) for 1,000 simulated data sets.
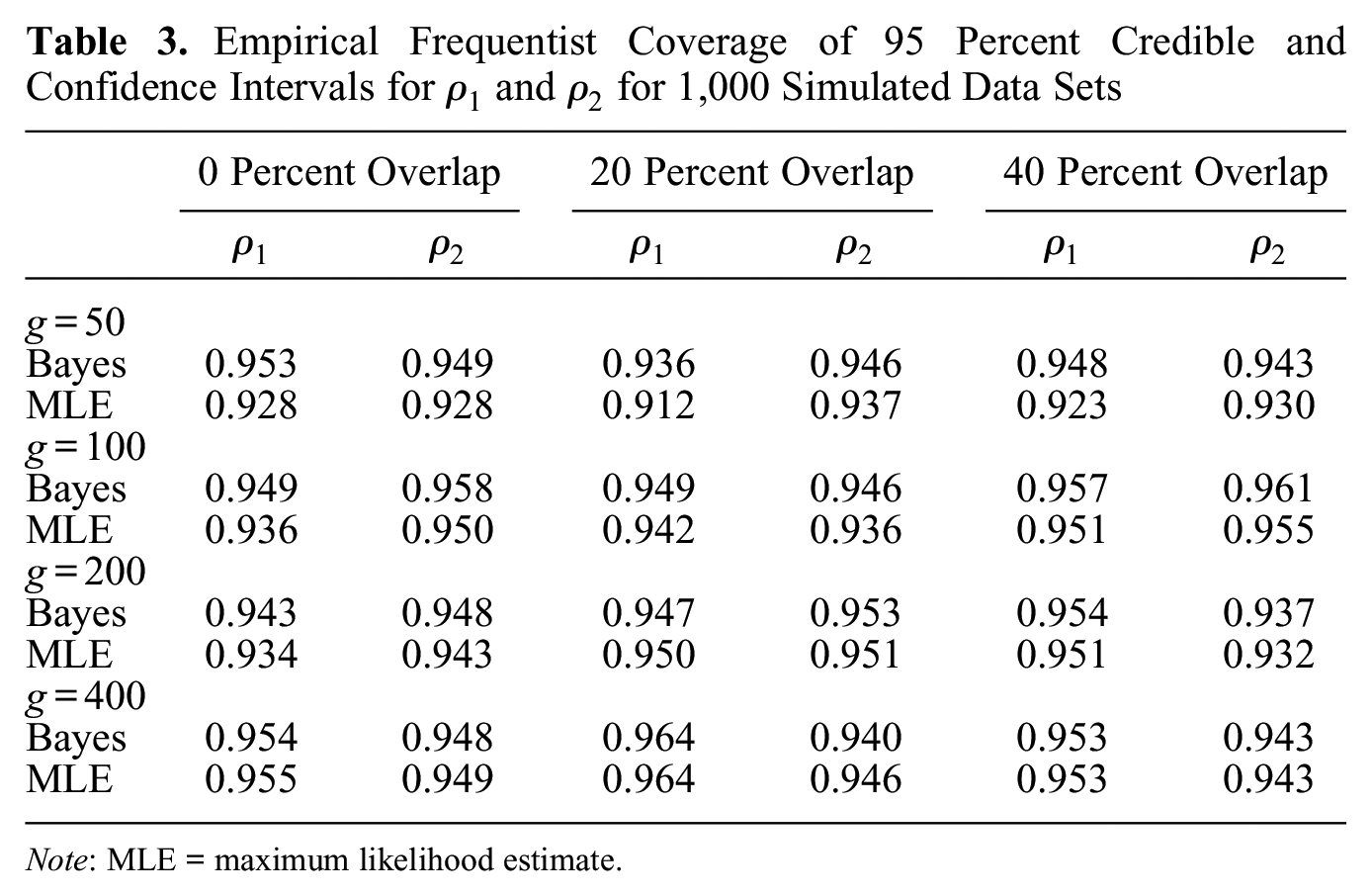
Table 3 reports the empirical frequentist coverage of Bayesian equal-tailed 95 percent credible intervals and asymptotic 95 percent maximum likelihood-based confidence intervals for and . The coverage of Bayesian credible intervals is very close to the nominal 0.95 for all considered scenarios, and the coverage of confidence intervals is below nominal for network sizes of 50. These observations are in line with the subpar coverage of maximum likelihood-based confidence intervals for small samples in the first-order network autocorrelation model reported by Dittrich et al. (2017a).
Empirical Frequentist Coverage of 95 Percent Credible and Confidence Intervals for and for 1,000 Simulated Data Sets
0 Percent Overlap
20 Percent Overlap
40 Percent Overlap
Bayes
0.953
0.949
0.936
0.946
0.948
0.943
MLE
0.928
0.928
0.912
0.937
0.923
0.930
Bayes
0.949
0.958
0.949
0.946
0.957
0.961
MLE
0.936
0.950
0.942
0.936
0.951
0.955
Bayes
0.943
0.948
0.947
0.953
0.954
0.937
MLE
0.934
0.943
0.950
0.951
0.951
0.932
Bayes
0.954
0.948
0.964
0.940
0.953
0.943
MLE
0.955
0.949
0.964
0.946
0.953
0.943
Note: MLE = maximum likelihood estimate.
On the basis of results from our first simulation experiment, we draw two main conclusions. First, we recommend using the Bayesian estimator over the maximum likelihood estimator, as both estimators yield nearly identical network effect estimates, but the coverage of Bayesian credible intervals appears accurate, whereas for smaller network sizes the coverage of maximum likelihood-based confidence intervals is much less accurate. Second, estimating second-order network autocorrelation models with moderately overlapping connectivity matrices, that is, with up to 40 percent shared ties, does not affect estimation of the network effects. This second finding is of particular importance to social network researchers who often encounter distinct but partially overlapping networks in empirical practice.
Figure 6 displays the average logarithm of the Bayes factor of hypothesis (thick solid line), (thick dashed line), (dotted line), (dashed line), and (solid line) against an unconstrained reference hypothesis, , respectively, as a function of network effects from to . Overall, the results indicate that the Bayes factor shows consistent behavior, that is, there is the most evidence for the data-generating hypothesis if the network size is large enough. This evidence monotonically increases with network size. In particular, there is little discrimination between the five hypotheses for , whereas there is clear support for the data-generating hypothesis for network sizes of 200 and 400. Two lines in Figure 6 are discontinued for numerical reasons: when computing the Bayes factor, we need to calculate the probability mass of the unconstrained importance density contained in the parameter space imposed by the constraints under a hypothesis (see Appendix B). For the Bayes factors involving the purely inequality constrained hypotheses and , we approximated these probabilities numerically by the proportion of 1,000 draws from the unconstrained importance densities that were in agreement with hypothesis and hypothesis , respectively. For some data sets, however, none of the draws were in agreement with hypothesis , or hypothesis , in which case we set the corresponding marginal likelihood to . If this happened for at least one of the 100 simulated data sets, then the average logarithm of the Bayes factor was as well. Finally, as in our first simulation experiment, these findings are robust to moderate degrees of overlap between two connectivity matrices.
Average logarithm of the Bayes factors , , of the hypotheses (thick solid line), (thick dashed line), (dotted line), (dashed line), and (solid line) against as a function of network effects from to for 100 simulated data sets.
6. Application Revisited
In this section, we reanalyze a data set from the economic growth literature initially studied by Dall’erba et al. (2009) and address the questions raised in Section 2.3. First, we reestimated the second-order network autocorrelation model in equation (4) on the basis of noninformative priors for all model parameters and compared the results with those coming from maximum likelihood estimation. Second, we used Bayes factors to quantify the relative evidence in the data for different competing hypotheses of interest with respect to this data set. Finally, we considered a network autocorrelation model with two subgroups, assuming only one dominant common influence mechanism within and between the two subgroups.
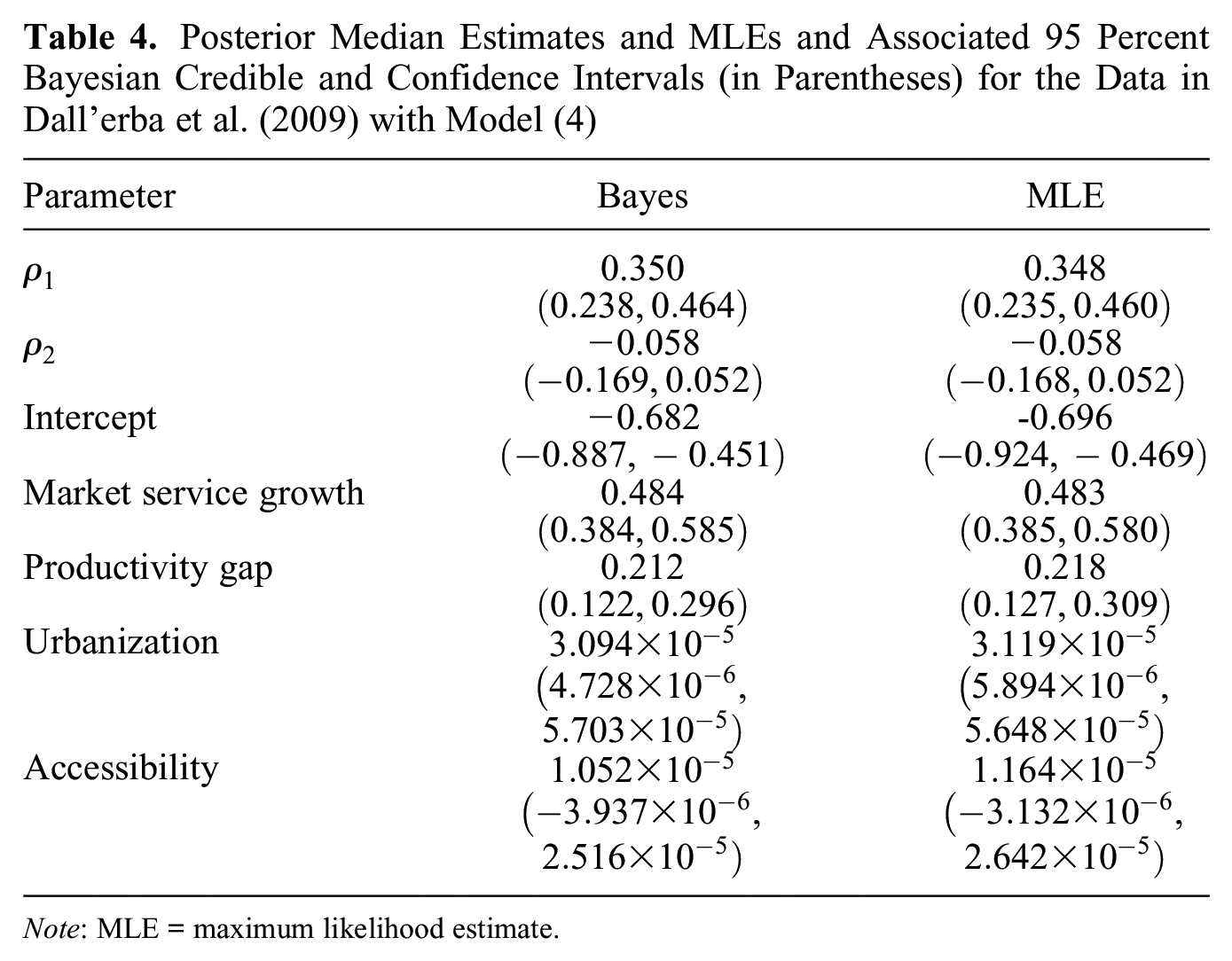
6.1. Bayesian Estimation of a Second-Order Network Autocorrelation Model
Table 4 displays the results of a Bayesian estimation of the second-order model in equation (4), along with the corresponding maximum likelihood estimates.16 The Bayesian and the maximum likelihood estimates of all parameters are similar to each other, in line with results from our simulation study in Section 5.2. In particular, the (Bayesian) estimate of , reflecting interactions within the same country, is of large positive magnitude (0.350), and the (Bayesian) estimate of , reflecting spillovers from regions in neighboring countries, is much smaller and close to zero (–0.058).17Dall’erba et al. (2009) concluded by saying that “the results obtained also confirm the hypothesis that economic interactions decrease very substantially when a national border is passed (indeed, the coefficient reflecting external spillovers is not statistically significant)” (p. 342).
Posterior Median Estimates and MLEs and Associated 95 Percent Bayesian Credible and Confidence Intervals (in Parentheses) for the Data in Dall’erba et al. (2009) with Model (4)
Parameter
Bayes
MLE
0.350
0.348
−0.058
−0.058
Intercept
−0.682
-0.696
Market service growth
0.484
0.483
Productivity gap
0.212
0.218
Urbanization
Accessibility
Note: MLE = maximum likelihood estimate.
6.2. Bayesian Hypothesis Testing in a Second-Order Network Autocorrelation Model
Using Bayes factors, we quantified the evidence in the data for two hypotheses representing the notion of decreasing economic interactions once a national border is passed, and , and tested them against two competing hypotheses, and .18 We also included a hypothesis that represents the complement of all other possible hypotheses on except hypotheses , and ; that is, hypothesis contains all the orders of network effects we did not hypothesize.
Table 5 provides the Bayes factors for every pair out of the set of the five considered hypotheses above using the prior specifications from Sections 4.2 and 4.3. Notably, is the hypothesis most supported by the data; it is approximately , 160.7, , and 14.1 times more supported than hypothesis , , , and , respectively. Moreover, we see the least evidence in the data in favor of the null. Consequently, regardless of the specification of alternative expectations about and , the hypothesis that both network effects are zero has to be strongly rejected. Although these implications seem in line with the authors’ claim that network effects decrease after a national border is passed, using Bayes factors provides us with much more extensive conclusions about the characteristic evidence in the data. Hence, we can now quantify how much more likely these conclusions are than competing conclusions (hypotheses) and how (un)likely it is that an entirely different mechanism generated the data. Ultimately, this data set contains the most and very strong evidence for a positive within-country network effect only.
Bayes Factors , , for Hypotheses , , , , and for the Data in Dall’erba et al. (2009) with Model (4)
Hypothesis
—
0.059
—
160.746
14.085
—
0.089
16.945
—
0.071
11.359
—
6.3. Bayesian Hypothesis Testing in a Fourth-Order Network Autocorrelation Model
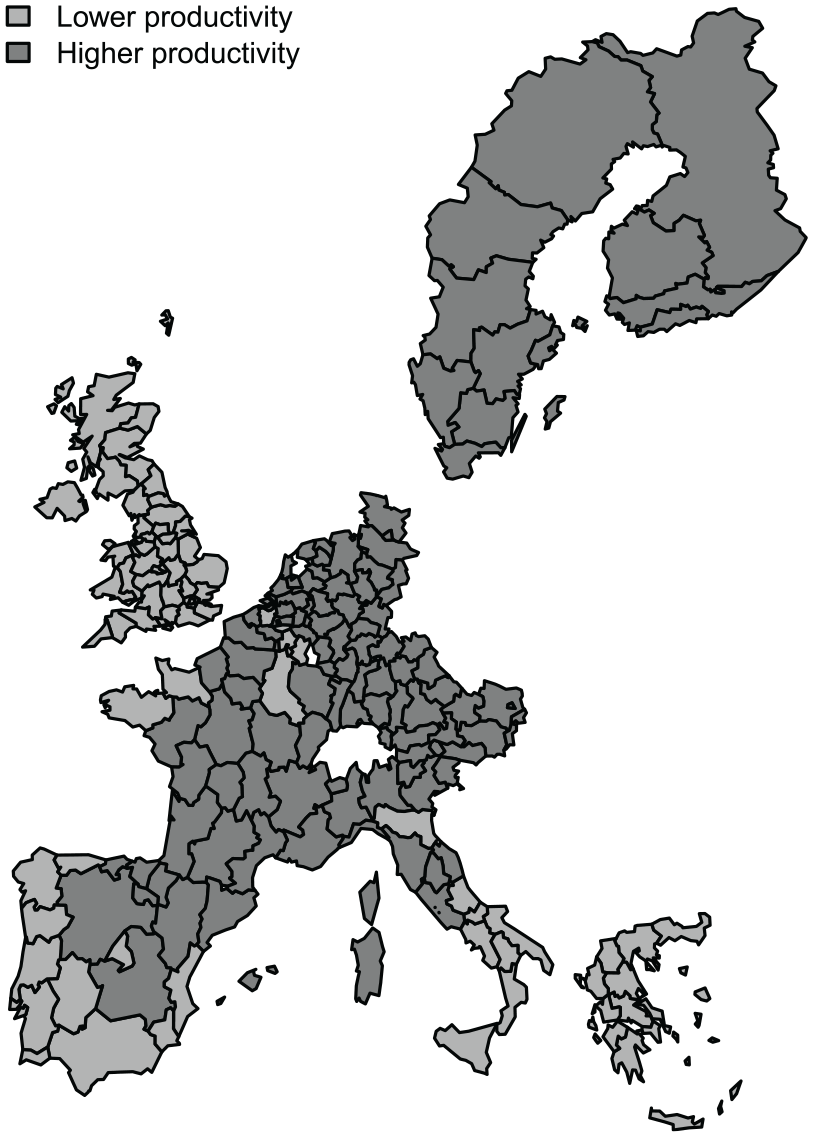
Dall’erba et al. (2009) pointed to potentially asymmetric growth rates across the regions, depending on a region’s initial productivity level. Thus, the authors proceeded by dividing the sample into two clusters: 111 initially more productive regions and 77 initially less productive regions, implying a core-periphery pattern (see Figure 7).19 Next, they separately estimated two second-order network autocorrelation models for the two clusters. Here, for illustrative purposes, we allowed for varying levels of network autocorrelation within and between the two clusters and consider a model with two subgroups instead. For example, we could expect network effects within regions of the same subgroup to be larger than network effects between regions of different subgroups, or we could expect initially more productive regions to influence initially less productive ones more strongly than the other way around.
Spatial distribution of productivity levels in 1980 across the 188 regions.
Our analyses in Section 6.2 suggest that there is very strong evidence in the data for a positive within-country network effect only; that is, and . Thus, we merely considered spillover effects within the same country, in other words, we assume only plays a role, not . We denote by , and the network effect within regions with initially higher productivity levels, the network effect of initially less productive regions on initially more productive regions, the network effect of initially more productive regions on initially less productive ones, and the network effect within regions with initially lower productivity levels, respectively. Accordingly, and contain the growth rates of labor productivity of the initially more and less productive regions, respectively, and we partitioned , the unstandardized connectivity matrix using the region’s three nearest neighbors within the same country, into the four submatrices , , , and , representing ties within and between the two subgroups.20 This results in the following fourth-order network autocorrelation model
We generally expect the network effects within the two subgroups to be larger than the network effects between subgroups, that is, , where the “>” sign holds pairwise for any two elements of the first and second set, respectively. Furthermore, hypotheses of substantial interest might be based on expectations of positive network effects within both subgroups but with potentially differing magnitudes. We translated these expectations to three hypotheses, , and , and supplemented them with the hypothesis of no network effects and the complement of all the orders of network effects we did not have hypotheses for.21 Formally,
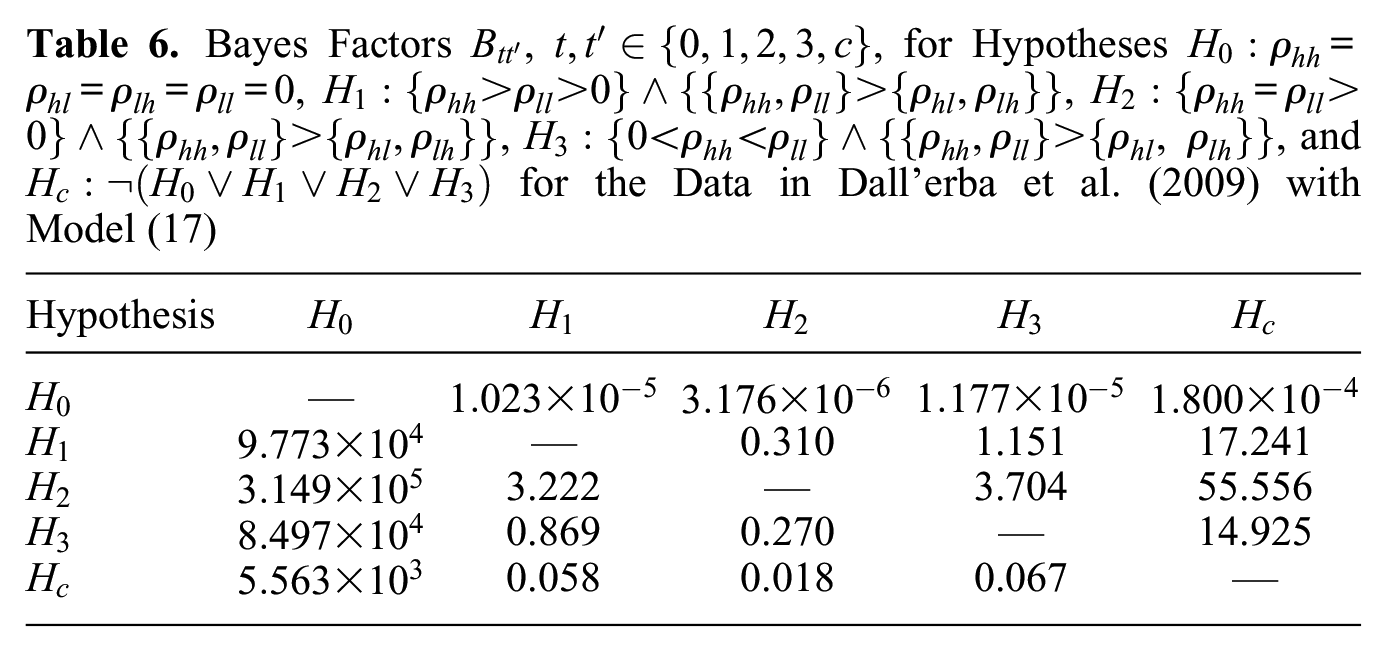
Table 6 shows the Bayes factors for every pair out of the set of the five considered hypotheses. We see that is the hypothesis most supported by the data; it receives approximately , 3.2, 3.7, and 55.6 times more support than do hypothesis , , , and , respectively. Hence, there is no evidence in the data for differing network effects within the initially more and less productive regions, but there is very strong evidence that network effects within the two subgroups are larger than network effects between subgroups.
Bayes Factors , , for Hypotheses , , , , and for the Data in Dall’erba et al. (2009) with Model (17)
Hypothesis
—
—
0.310
1.151
17.241
3.222
—
3.704
55.556
0.869
0.270
—
14.925
0.058
0.018
0.067
—
7. Conclusions
In this article, we developed Bayesian techniques for estimating and, primarily, testing higher-order network autocorrelation models with multiple network autocorrelations. In particular, we provided default Bayes factors that enable researchers to test hypotheses with order constraints on the network effects in a direct manner. The proposed methods allow researchers to simultaneously test any number of competing hypotheses on the relative strength of network effects against one another and to quantify the amount of evidence in the data for each hypothesis. This has not yet been possible using currently available statistical techniques for network autocorrelation models. Our proposed methods can straightforwardly be extended to test hypotheses on network autocorrelation parameters in heteroskedastic network autocorrelation models (LeSage 1997a) and network disturbances models (Leenders 2002).
We ran a simulation study to evaluate the numerical behavior of the presented Bayesian procedures for a number of different network specifications, including varying network sizes and network overlap. Our simulation study showed that, first, the Bayesian estimator and the maximum likelihood estimator yield similar parameter estimates of the network autocorrelation parameters for all scenarios. This was expected because we relied on noninformative priors for the network autocorrelation parameters. As a next step, it would be interesting to explore the use of (weakly) informative priors for multiple network autocorrelation parameters. Such priors can either be derived from published estimates in previous literature (similar to what Dittrich et al. [2017a] did for the first-order network autocorrelation model) or by eliciting experts on anticipated network effects in a given case study. Given previous findings in the literature when using a weakly informative prior for estimating a single network autocorrelation parameter (Dittrich et al. 2017a), we expect a carefully specified weakly informative prior for multiple network autocorrelation parameters will also decrease the negative bias of network autocorrelation parameters associated with maximum likelihood estimation of the model. Second, the Bayesian estimator exhibits nominal coverage of credible intervals and is more accurate than the maximum likelihood estimator, which is a strong argument in favor of the Bayesian approach, even when noninformative priors are used. Third, we found that the proposed Bayes factors always result in the largest evidence for the true data-generating hypothesis, with this evidence increasing further with network size. In other words, the proposed Bayes factors tend to point researchers to the correct (or best) hypothesis out of a set of competing hypotheses; these hypotheses can represent highly complex relations between the autocorrelation parameters, and the set of hypotheses tested against each other simultaneously can, in principle, be arbitrarily large.
The practical tools needed to perform the methods developed in this article are, or will be, freely accessible in an R package. Given the many, often implicit, expectations researchers have about the relative importance of different network effects, we hope that by enabling researchers to test these expectations directly and explicitly, higher-order network autocorrelation models will bring forth a more thorough understanding of social contagion processes that goes beyond the current state of the art.
Footnotes
Appendix A: Posterior Sampling
We outlined the procedure for sampling from the full posterior in higher-order network autocorrelation models in Section 3.2. However, the exact form of the candidate-generating distribution for the conditional posterior and the expressions and in equation (12) remain to be specified.
Appendix B: Bayes Factor Computation
In the following, we show how the integral in equation (16) can be effectively approximated by its importance sampling estimate ,
where are draws from a suitable importance density . We specify such that it closely follows the integrand but has heavier tails than the latter, which ensures a reliable estimation of .
As in Appendix A, we approximate by a quadratic polynomial in at its maximum value, the origin. This results in a normal approximation of , that is, , where , . In the case that is not positive definite, we use the nearest positive definite matrix to instead. The second term in the denominator of equation (B1) already equals the kernel of the probability density function of the normal distribution . Finally, we also approximate the logarithm of the third term in by a second-order Taylor polynomial at its maximum. It follows that , where and . Thus, can be approximated by the product of three multivariate normal densities that is multivariate normal itself, so , with , .
Calculating directly might result in underflow in R, which is why we next show how to compute its logarithm only. We can write
where are draws from the unconstrained importance density and is an auxiliary constant, for example, , which is added to prevent the marginal likelihood to become too small to be distinguished from zero in R. The auxiliary constant is set in advance after generating the draws from the unconstrained importance density first.
Acknowledgements
We thank Sandy Dall’erba, Marco Percoco, and Gianfranco Piras for sharing their data with us.
Funding
J.M. was supported by a Veni Grant (451.13.011) provided by the Netherlands Organization for Scientific Research.
ORCID iD
Dino Dittrich
Notes
Author Biographies
Dino Dittrich holds a PhD in statistics from Tilburg University. His work centers on Bayesian estimation and hypothesis-testing techniques for social network models. Currently, he works as a data scientist at Health Care Systems GmbH.
Roger Th. A. J. Leenders is a professor at the Jheronimus Academy of Data Science and in the Department of Organization Studies at Tilburg University. He holds a PhD in sociology from the University of Groningen. He has published broadly on social network analysis, teams, innovation, and organization behavior in leading journals such as Organization Science, the Journal of Applied Psychology, the Journal of Product Innovation Management, Social Networks, and the Academy of Management Journal.
Joris Mulder is an associate professor in the Department of Methodology and Statistics at Tilburg University. He holds a PhD in applied Bayesian statistics from Utrecht University. His research focuses on Bayesian model selection and social network modeling.
References
1.
AnselinLuc. 2001. “Rao’s Score Test in Spatial Econometrics.”Journal of Statistical Planning and Inference97(1):113–39.
2.
BadingerHaraldEggerPeter. 2013. “Estimation and Testing of Higher-Order Spatial Autoregressive Panel Data Error Component Models.”Journal of Geographical Systems15(4):453–89.
3.
BartlettM. S.1957. “A Comment on D. V. Lindley’s Statistical Paradox.”Biometrika44(3–4):533–34.
BeckNathanielGleditschKristian S.BeardsleyKyle. 2006. “Space Is More Than Geography: Using Spatial Econometrics in the Study of Political Economy.”International Studies Quarterly50(1):27–44.
6.
BivandRogerKeittTimRowlingsonBarry. 2017. “rgdal: Bindings for the ‘Geospatial’ Data Abstraction Library.” Retrieved March9, 2020. http://CRAN.R-project.org/package=rgdal.
7.
Böing-MessingFlorianvan AssenMarcel A.HofmanAbe D.HoijtinkHerbertMulderJoris. 2017. “Bayesian Evaluation of Constrained Hypotheses on Variances of Multiple Independent Groups.”Psychological Methods22(2):262–87.
8.
BraekenJohanMulderJorisWoodStephen. 2015. “Relative Effects at Work: Bayes Factors for Order Hypotheses.”Journal of Management41(2):544–73.
9.
BurtRonald S.DoreianPatrick. 1982. “Testing a Structural Model of Perception: Conformity and Deviance with Respect to Journal Norms in Elite Sociological Methodology.”Quality and Quantity16(2):109–50.
10.
ButtsCarter T.2008. “Social Network Analysis with sna.”Journal of Statistical Software24(6):1–51.
11.
CarlinBradley C.LouisThomas A. 2000. “Empirical Bayes: Past, Present and Future.”Journal of the American Statistical Association95(452):1286–89.
12.
ChibSiddhartaGreenbergEdward. 1994. “Bayes Inference in Regression Models with ARMA (p, q) Errors.”Journal of Econometrics64(1–2):183–206.
13.
ChibSiddhartaGreenbergEdward. 1995. “Understanding the Metropolis-Hastings Algorithm.”American Statistician49(4):327–35.
14.
ChibSiddhartaGreenbergEdward. 1998. “Analysis of Multivariate Probit Models.”Biometrika85(2):347–61.
15.
Dall’erbaSandyPercocoMarcoPirasGianfranco. 2009. “Service Industry and Cumulative Growth in the Regions of Europe.”Entrepreneurship and Regional Development21(4):333–49.
16.
DittrichDinoLeendersRoger Th.MulderJoris. 2017a. “Bayesian Estimation of the Network Autocorrelation Model.”Social Networks48:213–36.
17.
DittrichDinoLeendersRoger Th.MulderJoris. 2017b. “Network Autocorrelation Modeling: A Bayes Factor Approach for Testing (Multiple) Precise and Interval Hypotheses.”Sociological Methods and Research48(3):642–76.
18.
DoreianPatrick. 1981. “Estimating Linear Models with Spatially Distributed Data.”Sociological Methodology12:359–88.
ElhorstJ. PaulLacombeDonald J.PirasGianfranco. 2012. “On Model Specification and Parameter Space Definitions in Higher Order Spatial Econometric Models.”Regional Science and Urban Economics 42(1–2):211–20.
21.
FujimotoKayoChouChih-PingValenteThomas W. 2011. “The Network Autocorrelation Model Using Two-Mode Data: Affiliation Exposure and Potential Bias in the Autocorrelation Parameter.”Social Networks33(3):231–43.
22.
GelfandAlan E.SmithAdrian F. 1990. “Sampling-Based Approaches to Calculating Marginal Densities.”Journal of the American Statistical Association85(410):398–409.
23.
GelmanAndrewCarlinJohn B.SternHal S.RubinDonald B. 2003. Bayesian Data Analysis. 2nd ed.Boca Raton, FL: Chapman & Hall/CRC Press.
24.
GemanStuartGemanDonald. 1984. “Stochastic Relaxation, Gibbs Distributions, and the Bayesian Restoration of Images.”IEEE Transactions on Pattern Analysis and Machine Intelligence6(6):721–41.
25.
GimpelJames G.SchuknechtJason E. 2003. “Political Participation and the Accessibility of the Ballot Box.”Political Geography22(5):471–88.
26.
GuptaAbhimanyuRobinsonPeter M. 2015. “Inference on Higher-Order Spatial Autoregressive Models with Increasingly Many Parameters.”Journal of Econometrics186(1):19–31.
27.
HallBrian C.2003. Lie Groups, Lie Algebras, and Representations: An Elementary Introduction. New York: Springer.
28.
HanXiaoyiHsiehChih-ShengLeeLung-Fei. 2017. “Estimation and Model Selection of Higher-Order Spatial Autoregressive Model: An Efficient Bayesian Approach.”Regional Science and Urban Economics63:97–120.
29.
HansenMark H.YuBin. 2001. “Model Selection and the Principle of Minimum Description Length.”Journal of the American Statistical Association96(454):746–74.
30.
HastingsW. K.1970. “Monte Carlo Sampling Methods Using Markov Chains and Their Applications.”Biometrika57(1):97–109.
31.
HeppleLeslie W.1995a. “Bayesian Techniques in Spatial and Network Econometrics: 1. Model Comparison and Posterior Odds.”Environment and Planning A: Economy and Space27(3):447–69.
32.
HeppleLeslie W.1995b. “Bayesian Techniques in Spatial and Network Econometrics: 2. Computational Methods and Algorithms.”Environment and Planning A: Economy and Space27(4):615–44.
33.
HighamNicholas J.2008. Functions of Matrices: Theory and Computation. Philadelphia: Society for Industrial and Applied Mathematics.
34.
HollowayGarthShankarBhavaniRahmanSanzidur. 2002. “Bayesian Spatial Probit Estimation: A Primer and an Application to HYV Rice Adoption.”Agricultural Economics27(3):383–402.
35.
JeffreysHarold. 1961. Theory of Probability. 3rd ed.Oxford, UK: Oxford University Press.
36.
KalenkoskiCharlene M.LacombeDonald J. 2008. “Effects of Minimum Wages on Youth Employment: The Importance of Accounting for Spatial Correlation.”Journal of Labor Research29(4):303–17.
37.
KassRobert E.RafteryAdrian E. 1995. “Bayes Factors.”Journal of the American Statistical Association90(430):773–95.
38.
KlugkistIreneLaudyOlavHoijtinkHerbert. 2005. “Inequality Constrained Analysis of Variance: A Bayesian Approach.”Psychological Methods10(4):477–93.
39.
LacombeDonald J.2004. “Does Econometric Methodology Matter? An Analysis of Public Policy Using Spatial Econometric Techniques.”Geographical Analysis36(2):105–18.
40.
LeeLung-FeiLiuXiaodong. 2010. “Efficient GMM Estimation of High Order Spatial Autoregressive Models with Autoregressive Disturbances.”Econometric Theory26(1):187–230.
41.
LeendersRoger Th. 1995. Structure and Influence: Statistical Models for the Dynamics of Actor Attributes, Network Structure and Their Interdependence. Amsterdam, the Netherlands: Thela Thesis.
42.
LeendersRoger Th. 2002. “Modeling Social Influence through Network Autocorrelation: Constructing the Weight Matrix.”Social Networks24(1):21–47.
LeSageJames P.PaceR. Kelley. 2008. “Spatial Econometric Modeling of Origin-Destination Flows.”Journal of Regional Science48(5):941–67.
47.
LeSageJames P.PaceR. Kelley. 2011. “Pitfalls in Higher Order Model Extensions of Basic Spatial Regression Methodology.”Review of Regional Studies41(1):13–26.
48.
LeSageJames P.ParentOlivier. 2007. “Bayesian Model Averaging for Spatial Econometric Models.”Geographical Analysis39(3):241–67.
49.
LiangFengPauloRuiMolinaGermanClydeMerlise A.BergerJim O. 2008. “Mixtures of g Priors for Bayesian Variable Selection.”Journal of the American Statistical Association103(481):410–23.
50.
LinTse-MinWuChin-EnLeeFeng-Yu. 2006. “‘Neighborhood’ Influence on the Formation of National Identity in Taiwan: Spatial Regression with Disjoint Neighborhoods.”Political Research Quarterly59(1):35–46.
51.
McMillenDaniel P.Singell Jr.Larry D.Jr.WaddellGlen R. 2007. “Spatial Competition and the Price of College.”Economic Inquiry45(4):817–33.
52.
McPhersonMichael A.NieswiadomyMichael L. 2005. “Environmental Kuznets Curve: Threatened Species and Spatial Effects.”Ecological Economics55(3):395–407.
53.
MetropolisNicholasRosenbluthArianna W.RosenbluthMarshall N.TellerAugusta H.TellerEdward. 1953. “Equations of State Calculations by Fast Computing Machines.”Journal of Chemical Physics21(6):1087–92.
54.
MizruchiMark S.StearnsLinda B. 2006. “The Conditional Nature of Embeddedness: A Study of Borrowing by Large U.S. Firms, 1973–1994.”American Sociological Review71(2):310–33.
55.
MoreyRichard D.RouderJeffrey N. 2011. “Bayes Factor Approaches for Testing Interval Null Hypotheses.”Psychological Methods16(4):406–19.
56.
MulderJoris. 2014. “Prior Adjusted Default Bayes Factors for Testing (In)equality Constrained Hypotheses.”Computational Statistics and Data Analysis71:448–63.
57.
MulderJoris. 2016. “Bayes Factors for Testing Order-Constrained Hypotheses on Correlations.”Journal of Mathematical Psychology72:104–15.
58.
MulderJorisFoxJean-Paul. 2018. “Bayes Factor Testing of Multiple Intraclass Correlations.”Bayesian Analysis14(2):521–52.
59.
MulderJorisHoijtinkHerbertKlugkistIrene. 2010. “Equality and Inequality Constrained Multivariate Linear Models: Objective Model Selection Using Constrained Posterior Priors.”Journal of Statistical Planning and Inference140(4):887–906.
60.
MulderJorisWagenmakersEric-Jan. 2016. “Editors’ Introduction to the Special Issue ‘Bayes Factors for Testing Hypotheses in Psychological Research: Practical Relevance and New Developments.’”Journal of Mathematical Psychology72:1–5.
61.
MurJesúsLópezFernandoAnguloAna. 2008. “Symptoms of Instability in Models of Spatial Dependence.”Geographical Analysis40(2):189–211.
62.
MurrayIainGhahramaniZoubinMacKayDavid J. 2006. “MCMC for Doubly-Intractable Distributions.” Pp. 359–66 in Proceedings of the Twenty-Second Conference on Uncertainty in Artificial Intelligence. Arlington, VA: AUAI Press.
63.
NeumanEric J.MizruchiMark S. 2010. “Structure and Bias in the Network Autocorrelation Model.”Social Networks32(4):290–300.
64.
NocedalJorgeWrightStephen J. 2006. Numerical Optimization. 2nd ed.New York: Springer.
65.
OrdKeith. 1975. “Estimation Methods for Models of Spatial Interaction.”Journal of the American Statistical Association70(349):120–26.
66.
OwenArtZhouYi. 2000. “Safe and Effective Importance Sampling.”Journal of the American Statistical Association95(449):135–43.
67.
R Core Team. 2017. “R: A Language and Environment for Statistical Computing.” Retrieved March9, 2020. http://www.R-project.org/.
68.
RafteryAdrian E.1995. “Bayesian Model Selection in Social Research.”Sociological Methodology25:111–63.
69.
RafteryAdrian E.MadiganDavidHoetingJennifer A. 1997. “Bayesian Model Averaging for Linear Regression Models.”Journal of the American Statistical Association92(437):179–91.
70.
SmithTony E.2009. “Estimation Bias in Spatial Models with Strongly Connected Weight Matrices.”Geographical Analysis41(3):307–32.
71.
TitaGeorge E.RadilSteven M. 2011. “Spatializing the Social Networks of Gangs to Explore Patterns of Violence.”Journal of Quantitative Criminology27(4):521–45.
van de SchootRensMulderJorisHoijtinkHerbertvan AkenMarcel A.DubasJudith S.CastroBram Orobio deMeeusWimRomeijnJan-Willem. 2011. “An Introduction to Bayesian Model Selection for Evaluating Informative Hypotheses.”European Journal of Developmental Psychology8(6):713–29.
74.
WagenmakersEric-Jan. 2007. “A Practical Solution to the Pervasive Problems ofp Values.”Psychonomic Bulletin and Review14(5):779–804.
75.
ZellnerArnold. 1986. “On Assessing Prior Distributions and Bayesian Regression Analysis with g-Prior Distributions.” Pp. 233–43 in Bayesian Inference and Decision Techniques: Essays in Honor of Bruno de Finetti, edited by GoelP. K.ZellnerA. Amsterdam, the Netherlands: North-Holland.
76.
ZhangBinThomasAndrew C.DoreianPatrickKrackhardtDavidKrishnanRamayya. 2013. “Contrasting Multiple Social Network Autocorrelations for Binary Outcomes, with Applications to Technology Adoption.”ACM Transactions on Management Information Systems3(4):18:1–21.