This study investigates the social evaluation of linguistic variation and the cognitive monitoring processes involved. Recognizing the need for cross-regional research that keeps experimental factors constant, we focus on (ing) and (t)-deletion. We investigate frequency evaluation as managed in England, UK (N = 200), and in Pennsylvania, US (N = 150). Results for (ing) indicate no significant effect of [ɪn]-frequency in England, while in Pennsylvania the frequency of [ɪn] significantly affects ratings regarding perceived professionalism. We also found evidence for listeners’ awareness of the attitude target (N = 15) to affect their ratings regarding perceived professionalism. Variation in (t)-deletion did not prompt any significant differences.
Research in the sociolinguistic tradition is based on the assumption that variation is a normal feature of any language. Most research also makes assumptions about the cognitive abilities of speakers and hearers. For the majority of sociolinguistic research, this socio-cognitive theorizing has occurred mostly implicitly, for example when discussing how aware speakers are about certain types of variation and their respective ability to style-shift (Labov 1972). However, more recent research has tested some of the cognitive mechanisms involved in processing variable speech (e.g., Campbell-Kibler 2011; Levon & Buchstaller 2015; Vaughn & Kendall 2019; Vaughn 2022a, 2022b; García, Walker & Beaton 2023). One strand of research in this tradition revolves around the notion of ‘sociolinguistic monitoring’ as introduced by Labov, Ash, Baranowski, Nagy, and Ravindranath (2006) and Labov et al. (2011). In this paradigm, authors hypothesize that many sociolinguistic assumptions about language variation and social meanings can be explained if we assume that a monitoring process takes place during speech production and perception. In particular, researchers working in this paradigm have investigated how and why speakers and listeners track the speech signal for socially meaningful cues of variable features and monitor the frequency of these forms.
Much of this work has been perception- rather than production-oriented, in line with the original experiments carried out by Labov et al. (2011). In order to find out whether listeners are able to evaluate the fine-grained variation patterns that production studies have documented for (ing), they conducted a series of matched-guise experiments using a test passage consisting of short news items (164 words) with ten evenly-distributed progressive {-ing}-suffixes. Recordings were made with a female speaker of Standard American English, who articulated the focus words with two typical (ing)-variants: [ɪŋ] with a velar nasal and [ɪn] with an apical nasal (Labov et al. 2011:436-437). Seven guises were created by replacing none (0 percent), some (10 percent, 20 percent, 30 percent, 50 percent, 70 percent), or all of the [ɪŋ]-realizations (100 percent) with [ɪn] (Labov et al. 2011:436-437). Participants were told they would listen to seven versions of a trial newscast by a journalism student applying for a job with a local radio station. They were asked to rate each recording on a professionalism-scale, ranging from ‘perfectly professional (1)’ to ‘try some other line of work (7).’ Labov et al. (2011) found that guises with a larger number of [ɪŋ]-variants were judged to be more professional-sounding; recordings with more [ɪn]-variants were associated with lower professionalism-ratings.
Labov et al. (2011:434) remain “neutral” to the question of whether the tracking of sociolinguistic variation is carried out by “a separate processing and storage module” or is, for instance, done “‘on the fly’ at any time by an inspection of remembered tokens.” Instead, they elaborate on the characteristics of sociolinguistic monitoring conceptualized as listeners’ sensitivity to frequency variation in the production of linguistic variants and its influence on social evaluation. In describing these characteristics, Labov et al. (2011) focused on three issues: the time period across which frequency assessment accumulates, the number of tokens it is sensitive to and the distribution of the response. Regarding these three points, they found the time window to be at least fifty-seven seconds long. Listeners are sensitive to frequency differences of even one [ɪn]-token, and many listeners’ responses follow a logarithmic rather than a linear pattern, that is, evaluation is attenuated as more tokens of a form occur—each individual token has a reduced effect compared to the previous one. Wagner and Hesson (2014:656), who also focused on variation in (ing), implemented a similar research design and used the same audio-files as Labov et al. (2011), found a similar response pattern.
Levon and Fox’s (2014) replication of Labov et al.’s study in London is particularly relevant to our study because of its interest in regional differences in the evaluation of (ing)-based frequency variation between the US and the UK. Despite using a slightly longer, adapted test passage, they followed Labov et al.’s original study design and also focused on professionalism ratings. As listener evaluations were entirely unaffected by how many [ɪn]-tokens a guise included (Levon & Fox 2014:197-198), the authors conclude that “listener attitudes to (ing) on the professionalism-dimension are weaker in Britain than in the United States” (Levon & Fox 2014:199) and that listener attitudes toward (ing) are more automatically accessible in the US than they are in Britain (Levon & Fox 2014:199).
Any conclusions that relate to cross-regional patterns and attitude strength, however, remain speculative to some extent. While results from similar experiments in different locales may suggest general tendencies, Labov et al.’s (2011) original study and replications in the US context (Wagner & Hesson 2014) on the one hand and the British experiments on the other (e.g., Levon & Fox 2014) are not directly comparable. The speakers, the test passages, and the placement of (ing) all differed between these studies. What is needed for a balanced comparison of listener evaluation of quantitative variation in (ing) across different locales is a cross-regional study that keeps the speaker, test passage and recordings, as well as the overall survey design constant.
In order to address this research gap, we conducted a cross-regional study with the same adapted news-report and speaker throughout to compare listener evaluations of (ing)-based quantitative variation in three different locales: Pennsylvania (in the US) and the North as well as the South of England. In addition to (ing), we included (t)-deletion (Wells 1982; Labov 2001; Hazen 2006) as a further stable variable that is also found to be involved in style-shifting. It also creates a backdrop against which the evaluation of (ing) can be compared, as we suspect that participants are less likely to become aware of (t)-deletion during experimentation. Variation in (ing), in turn, is much more likely to raise participants’ awareness since it continues to receive overt public comment (Labov 1972). Vaughn (2022b:517), for instance, who also worked in the sociolinguistic-monitoring paradigm, reports that most of her participants guessed that her experiments focused on variation in (ing). Of course, repeated exposure to highly similar guises, as implemented in this paradigm, may increase the likelihood of listeners becoming aware of the attitude target. In Austen and Campbell-Kibler’s (2022) real-time study, which did not involve listening to multiple similar versions of a test passage, participants did not become aware of (ing) as the attitude target.
Experimenting with stereotypical features such as (ing) presents researchers with a methodological problem as study participants’ awareness of the experimental target may influence evaluation. Much attitude research actually recommends removing participants who have realized what the study is about (e.g., Kircher 2016). However, the extent to which experimental participants become aware of the attitude target (be it a stereotyped feature or not) and how this varies from region to region is not known. This is why we will explore participants’ awareness of the attitude target, as indicated by listeners’ ability to name the attitude target when asked to do so (see section 3.3) and analyze the effects their (un)awareness has on the evaluation of variants.
By doing so, this study contributes to a better understanding of the listener characteristics that may impact evaluation as it investigates the impact of listeners’ regional background and their potential awareness of the feature under scrutiny. In particular, we explore
(1) whether there is a significant effect of quantitative variation in (ing) and (t)-deletion on listener evaluation in several regions (i.e., Pennsylvania, the North of England, and the South of England),
(2) what the nature of the response pattern is (i.e., is it logarithmic or linear), and
(3) in how far listeners’ (un)awareness of the attitude target affects their evaluation.
Thus, our motivation for this study is, first and foremost, of a comparative nature. We conduct a cross-regional replication study in the tradition of sociolinguistic-monitoring experiments to provide alternative explanations for the contradictory findings made in previous research.
Although our focus is a cross-regional comparison that relates to Labov et al.’s (2011) original study, our own view about sociolinguistic monitoring differs somewhat from that of Labov et al. (2011:434) whose conception relates to both speech production and perception. During the last decade, research has provided evidence of the disjunct of production and perception (e.g., Levon 2014; Schleef 2023), in particular when approaching language variation from a third-wave perspective. While research on style production has argued that features cluster into styles to create social meanings (Eckert 2012), it is by no means clear that listeners can actually perceive all features equally and recognize the intended meanings. In addition, Campbell-Kibler (2016; also Austen & Campbell-Kibler 2022) has been critical of Labov et al.’s (2011) proposal for being unrealistically broad in covering both self-regulation and other-perception. Instead, sociolinguistic monitoring of production and perception may be two distinct (although possibly interrelated) processes that are impacted by various systems to differing degrees. This is why our own conception of sociolinguistic monitoring in this paper is limited to perception, without making assumptions about production. Particularly, we agree with Campbell-Kibler (2016; also Austen & Campbell-Kibler 2022), who argues that there is no need for specialized cognitive modules to explain sociolinguistic behavior and that cognitive structures proposed elsewhere are capable of accounting for it (see Austen & Campbell-Kibler 2022:128).
2. The Variables
2.1. (ing)
Variation in (ing) generally refers to the varying spoken realization of the progressive {-ing}-suffix as either [ɪŋ] or [ɪn], as in making. These two main variants occur in almost all varieties of English. Both in the UK and the US context, variation in (ing) is constrained by a combination of internal and external factors (e.g., Trudgill 1974; Labov 2001; Hazen 2006; Schleef, Meyerhoff & Clark 2011). Previous research shows that there are phonological environments that favor the velar variant [ɪŋ] (Houston 1985; also Hazen 2006:583; Schleef, Meyerhoff & Clark 2011:235). Based on her British data, Houston (1985:19-20) concludes, for instance, that [ɪŋ] is more likely to be produced when the following segment begins on a velar sound. With regard to previous segments, a preceding velar stop or apical is the strongest predictor of an apical realization of (ing). Hazen (2006:583, in ref. to Houston 1985:22) also collates arguments for stress placement as a predictor of [ɪŋ] or [ɪn], respectively. In multi-syllabic words, unstressed syllables tend to be realized as [ɪn], whereas a secondary stress tends to correlate with a velar realization of (ing). Moreover, due to the historical development of (ing), there is also grammatical conditioning with regard to the morphological class of the {-ing}-form. Verbs have been shown to favor the [ɪn]-variant, whereas [ɪŋ] usually occurs in nouns (Houston 1985; Labov 2001:86-87; Vaughn 2022b:513; Tagliamonte 2004).
The sociolinguistic constraints operating on (ing) have been relatively well described (e.g., Campbell-Kibler 2007, 2009, 2011; Labov et al. 2011; Schleef & Flynn 2015; Schleef, Flynn & Barras 2017; Bailey 2019). Generally, the apical variant [ɪn] is more frequent in informal styles, male and working-class speech. However, there are more specific patterns that result from interactions with region and the baseline frequency of [ɪn] in a particular area (e.g., Labov 2001:90). In the UK, especially, we find regional differences in the use of (ing). Based on VARBRUL probabilities, Houston (1985:108) suggests there are two dialect groups: the southern/internal group, favoring [ɪŋ], and the northern/peripheral group, favoring [ɪn]. Houston (1985:103), focusing on working-class speech, cites [ɪŋ]-values of 20-42 percent for London, 21 percent for Manchester, and 18 percent for Edinburgh. This resonates with findings by Tagliamonte (2004), who attests little symbolic social value attached to (ing) in the Northern English city of York. Social class is the only social factor that reaches statistical significance, and its effect size is not particularly strong. For a number of socio-historical reasons, the use of (ing) is more socially conditioned in southern varieties of British English (Schleef & Flynn 2015:52; Schleef, Flynn & Barras 2017:32-33, in ref. to Tagliamonte 2004:401), where the [ɪŋ]-variant is the prestigious form and tends to be used by middle- and upper-class speakers (Levon & Fox 2014:195). Similar cases of a stronger sociolinguistic conditioning have been reported for the US context (Tagliamonte 2004:401).
Perception-oriented research on the evaluation and social meanings of (ing) has been equally prolific. Campbell-Kibler (2007:32-33, 2011:423) found that US speakers who produce [ɪŋ] are normally rated as significantly more intelligent, educated, articulate, and less likely to be a student. The use of [ɪn], in turn, was associated with informality and speakers were rated as less educated, more likely to be from the country, and less gay-sounding. In the UK context, such patterns have also been shown to interact with social class as well as region. Middle-class listeners, independent of region, agree on the formality of [ɪŋ] (Schleef, Flynn & Barras 2017:46). However, working-class participants in different locales in the UK may hold different attitudes for some social-status scales. Research within the sociolinguistic-monitoring paradigm mentioned above has also contended that the evaluation of [ɪn], regarding professionalism, is less negative in London (Levon & Fox 2014) than in the US context (Labov et al. 2011).
2.2. (t)-Deletion
(t)-deletion refers to the presence or elision of the morpheme-final plosive /t/, which, for example in a word like best, results in two main pronunciation variants, namely best [bɛst] and bes’ [bɛs]. As with variation in (ing), (t)-deletion occurs in almost all varieties of English (Tagliamonte & Temple 2005:282). Studies investigating the UK context show that [t] is regularly deleted in locales such as York (24 percent, Tagliamonte & Temple 2005:287-288) and Manchester (37 percent, Baranowski & Turton 2020:15). Likewise, Pavlík (2017) attests the deletion of /t/ in 26 percent of words ending in -n’t or -nt in the Standard British English of BBC newscasters. In the US, usage rates are generally similar, at 33 percent (Guy 1991). The variability of (t)-deletion, however, is conditioned by a diverse set of internal and external factors. Not least for this reason, (t)-deletion is among the most extensively studied variables in sociolinguistic research (Pavlík 2017:195; Baranowski & Turton 2020:1), typically in combination with a focus on (d)-deletion as a closely related phenomenon.
Phonological environment has been found to be one of the strongest predictors of (t)-deletion. The variant deleted-[t] typically occurs when preceded by sibilants (then stops, nasals, other fricatives, and liquids, see Labov 1989). Further phonological environments that favor deleted-[t] are following consonants or non-sonorous segments; following vowels and sonorants inhibit deletion-processes (Labov 1989; Guy 1991; Tagliamonte & Temple 2005; Smith, Durham & Fortune 2009; Hazen 2011).
The variability in (t)-deletion may also be a function of higher-level linguistic constraints such as the morphological structure and class of a word (Guy 1980, 1991; Tagliamonte & Temple 2005; Baranowski & Turton 2020), with underived, mono-morphemic words favoring deleted-[t] (summarized in Tagliamonte & Temple 2005:284, 290) and inflected verb forms disfavoring it (Guy 1991; also Pavlík 2017:197). While numerous studies attest these patterns for the US context (Baranowski & Turton 2020:3, 4; see e.g., Guy 1991), results for the UK context paint a more complex picture. Tagliamonte and Temple (2005:290), for instance, did not find a significant effect of word class on (t)-deletion in York. In a large-scale replication study in Manchester, however, Baranowski and Turton (2020) did find morphological class to predict (t)-deletion in ways similar to the US context.
Among the sociolinguistic factors that have been found to condition (t)-deletion are ethnicity (Fasold 1972; Hazen 2011), age (Hazen 2011), social class (Fasold 1972; Hazen 2011), and gender (Tagliamonte & Temple 2005), though the impact of these factors varies. In data from York, for instance, male participants were found to delete slightly more frequently (Tagliamonte & Temple 2005), while there was no gender difference in Manchester (Baranowski & Turton 2020:15-16). Social class and age were also not significant in Manchester, but stylistic differences were found with less deletion associated with more formal styles.
As this brief survey suggests, despite the comparably rich description of the variability of (t)-deletion in English overall, much less is known about (t)-deletion in British English (Tagliamonte & Temple 2005; Pavlík 2017; Baranowski & Turton 2020) compared with American English (e.g., Wolfram 1969; Fasold 1972; Guy 1980; Labov 1989; Bayley 1994; Santa Ana 1996; Coetzee & Kawahara 2013). This situation calls for further work on (t)-deletion in the UK context as well as comparative studies across regions. In addition, it is aspects of style and the social evaluations of (t)-deletion, which seem to demand much closer attention. Our study seeks to explore both avenues of research.
2.3. Hypotheses
In this study, we first explore the effect of quantitative variation of token frequency on listener evaluation across several locales. As both (ing) and (t)-deletion are reported to be involved in style-shifting, we expect that there is a significant effect of frequency differences in all regions. However, given the indication of weaker attitudes in Britain (see Levon & Fox 2014), the effect size will likely be smaller for (ing) in England. Our review of variables also suggests that the difference in social stratification and general commentary is less pronounced for deleted-[t] than for use of [ɪn] in both Britain and the US. As a result, we would expect a smaller effect of variant frequency for (t)-deletion than for (ing).
Secondly, we investigate the nature of the response pattern in the three different locales. Given previous findings for the UK and the US context, we also expect differences in the nature of the response pattern for (ing), but not necessarily for (t)-deletion. For (ing), a linear pattern seems to be most likely for responses from UK listeners and a more logarithmic distribution for responses in the US as it has been argued that attitudes toward variation in (ing) are weaker in Britain than they are in the US.
We thirdly investigate in how far listeners’ (un)awareness of the attitude target affects their evaluation. We hypothesize that, in the case of (ing) especially, individuals who have become aware of the attitude target (i.e., what the experiments are testing) will evaluate quantitative variation differently from those participants who have not. In order to test these hypotheses, we conducted experiments on the perception of (ing) and (t)-deletion in England and Pennsylvania.
3. Methods
3.1. Test Passages
The design of our research and test materials closely follows Labov et al.’s (2011) original study. We also chose the social context of a news broadcast and kept the token number at 10 progressive {-ing}-suffixes. At ca. 1.2 minutes, our test passage was slightly longer than the original passage. The text that was used (see Appendix, section “Test Passages”) was inspired by an actual on-site news report (aired as part of BBC Breakfast in 2018, see Fritz 2018), which focused on prefabricated housing, a relatively neutral topic. The original script, however, was changed considerably to ensure that [ɪn] and deleted-[t] occur in plausible and consistent linguistic environments.
Looking at the linguistic contexts more specifically, variation in (ing) was limited to unique bi- or tri-syllabic present-participle forms, for example, testing, working, referring. The decision to focus on verb forms rather than nouns was motivated by previous research that has found the realization of (ing) as [ɪn] to be more likely in present-participle forms than in nouns that end in {-ing} (Houston 1985; Labov 2001:86-87; Vaughn 2022b:513; Tagliamonte 2004). As some words in English can occur as a present-participle and also as a noun, for example, being (but cf. putting), all relevant token words were checked for frequency of occurrence in the spoken BNC (see Vaughn 2022b:513). Only those words that are more commonly used as verb-forms in spoken British English were considered when creating the test passage; word-forms that are predominantly used as nouns, for example, building, were avoided entirely. We selected non-velar consonants (i.e., /b/, /f/, /ð/, /θ/, /s/, /h/) as following phonological segments, which are contexts that favor [ɪn] (Houston 1985:19-20; also Hazen 2006; Schleef, Meyerhoff & Clark 2011:235) or show no significant effect (Tagliamonte 2004:399). In addition, we spaced out target tokens in relatively equal distances of at least twelve word-forms and avoided other words ending in {-ing}.
Variation in (t)-deletion was restricted to mono- or bisyllabic words, for example, best, grant, strongest, and limited to /t/ in word-final position. Given the phonological contexts that favor deleted-[t] in this position (Baranowski & Turton 2020:9-11; also Labov 1989; Guy 1991; Tagliamonte & Temple 2005; Smith, Durham & Fortune 2009; Hazen 2011), all target tokens have either /s/ or /n/ as a preceding sound. The onset of the following word was limited to certain obstruents (i.e., /k/, /p/, /f/). Moreover, the onset of the following word had to differ from the new coda of the target token (once [t] is deleted), that is, constructions such as bes’ suggestions were avoided. As with the (ing)-tokens, we excluded other word-forms ending in /t/ and ensured a minimum distance of thirteen word-forms between (t)-deletion tokens.
3.2. Speaker Profiles and Guise Construction
To create the main set of guises, test passages were recorded with a male L1 speaker of British English with a southern accent. We also recorded a male L1 speaker of Standard American English from Rhode Island, who grew up in New Jersey and lived in Pennsylvania for several years. This guise was used only with US listeners to explore the effect of accent on evaluation. Both speakers were in their mid-thirties. For the recordings, both speakers produced a first version of the text with consistent use of [ɪŋ] and then again realizing all (ing)-tokens as [ɪn]. The procedure was repeated for both (t)-variants, first with word-final [t] and then with deleted-[t]. All recordings were made in a sound-attenuating booth at the University of Salzburg. Guises were constructed through digital splicing in Praat (Boersma & Weenink 2022), which involves replacing a given pronunciation variant, for example, [ɪŋ], with an alternative variant, for example, [ɪn]. In case of the news-reporting experiments, guise construction involved replacing either none (0 percent) or one (10 percent), two (20 percent), three (30 percent), five (50 percent), seven (70 percent), or all (100 percent) standard variants with the non-standard ones.1 In all cases, splicing concerned the sounds in question; only in very few cases did we have to replace small parts of the immediate phonetic environment. All recordings were scaled to 70 db.
3.3. Procedure and Questionnaire
The data was collected October-December 2023 through paid web-based experiments using Lime Survey (LimeSurvey GmbH 2023). In each news-reporting experiment, participants evaluated the seven different versions of the (ing) or the (t)-deletion test passage. Following established practice (e.g., Labov et al. 2011:444), the 50-percent guise was always heard first as a point of reference; all other guises were randomized and set to auto-play from start to finish. Participants could only proceed to the next page once a recording had played through and was scored. Similar to the original study, scores were recorded using a 7-point rating scale ranging from try some other line of work (1) to perfectly professional (7).
This section was followed by items assessing respondents’ awareness of the attitude target. Participants were given the question prompt If we told you this study was about a specific language feature, which one would you think it was? and asked to respond to it by entering a short answer into a textbox. Responses were subsequently jointly coded by two researchers, who considered any instances of participants explicitly mentioning the attitude target as an indication of awareness (e.g., I’d say the “ing” sound. Throughout these recordings the speaker has often said it as “in” instead, or also Including or dropping the ‘g’ sound at the end of a word such as reporting, thinking, etc.). Whenever responses did not explicitly mention the feature under scrutiny (e.g., participants stating that the study was about inflection and pacing, or about the construction industry, or responded with don’t know), the respective participant was considered unaware of the attitude target. Unclear cases were discussed with a third researcher to support the decision-making process.
The surveys also included identification tasks, which tested participants’ ability to identify the variants in focus. Listeners were presented with short test sentences (e.g., She was running in order to catch the bus.) after being told that a given focus word (e.g., running) would be produced with either one variant or another (e.g., [ɪŋ] or [ɪn], see also Schleef, Roth, Mackay & Pflaeging forthcoming).2 Listeners heard the recording of the sentence, and they were asked to identify the variant in the recording. The questionnaires also contained questions relating to participants’ own use of (ing)- and (t)-deletion variants, along with three psychometric tests. The Revised Self-Monitoring Scale (SMS, see Cramer & Gruman 2002) assesses study participants’ self-monitoring habits (subscale “Ability to Modify Self-Presentation,” i.e., amsp) and their “Sensitivity to the Expressive Behavior of Others” (subscale sebo). We believe that these participant characteristics are related to processes of sociolinguistic monitoring. The Broad Autism Phenotype Questionnaire (BAPQ, see Hurley, Losh, Parlier, Reznick & Piven 2007) collects information on listeners’ cognitive style, e.g., their preference for patterns and repetitions. It contains subscales, such as pragmatic language, which assesses an individual’s ability to communicate effectively in social situations and to hold a fluid, reciprocal conversation (Hurley, Losh, Parlier, Reznick & Piven 2007:1681). The BAPQ has been implemented in other studies within the sociolinguistic monitoring paradigm as the skills it tests are assumed to be implicitly involved in forming social judgments on language variation (see Wagner & Hesson 2014:655, also Levon & Buchstaller 2015). The third psychometric test was the Motivation to Control for Prejudiced Reactions survey (MCPR, see Dunton & Fazio 1997), which also tests for listener characteristics that may equally be linked to social evaluation processes. Finally, we also collected participant demographics. The full survey with question prompts and answer options is reproduced in the Appendix (section “Questionnaire”). Further information on the psychometric tests implemented in this study can be found at Schleef, Mackay & Pflaeging 2025.
3.4. Participants
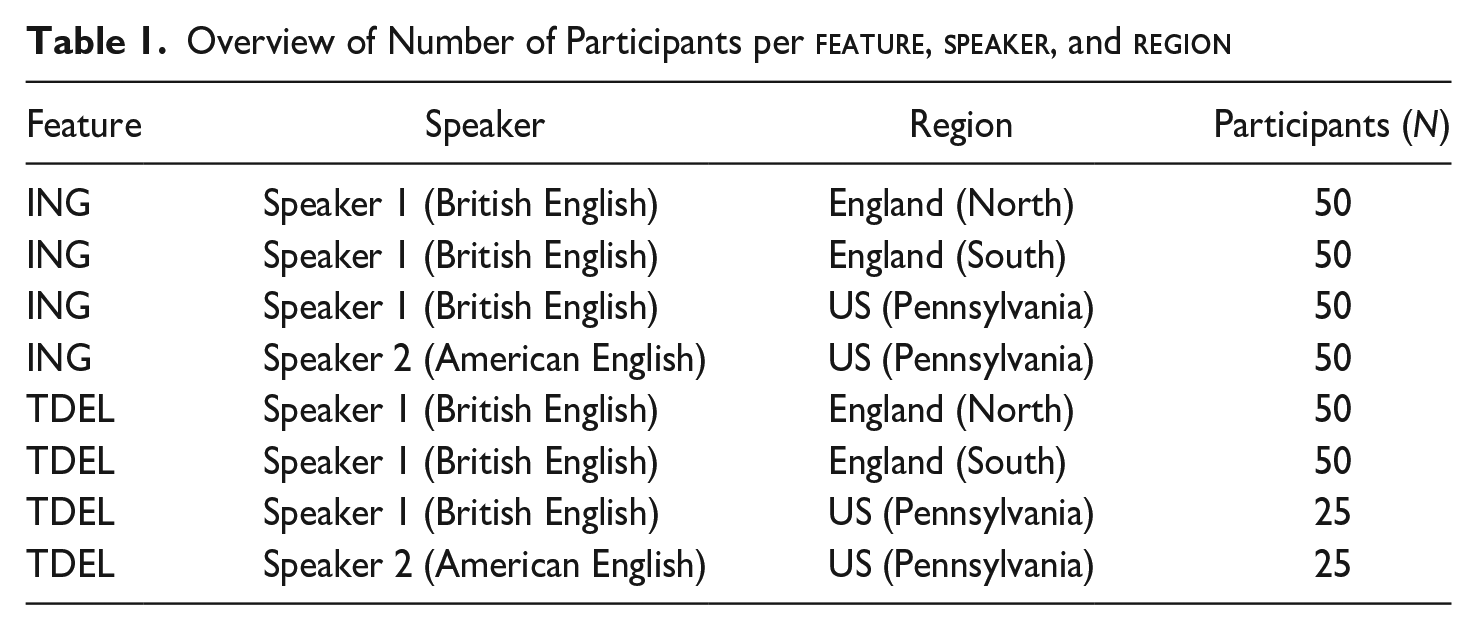
Experiments involved 350 participants across all surveys (see Table 1), who were recruited through Prolific (www.prolific.com). Participants from the North of England (N = 100) were either from the North East, North West, or Yorkshire and the Humber. Respondents from the South of England (N = 100) were from London, the South East, and the South West. US participants were from Pennsylvania (N = 150), to match the main region studied in Labov et al.’s (2011) original experiment.3 Using Prolific’s in-built screening function, we also filtered the pool of available participants further to ensure that all respondents were born and still live in these areas and that their first language was English. We also screened for respondents who, before turning eighteen, had spent most of their time in the respective locales. Participants in our experiments were 41.9 years of age on average (SD = 13.7), ranging from eighteen to eighty-three years, balanced for gender (based on Prolific’s categories), and with various employment statuses (e.g., not a student, full- or part-time employment, retired).
Overview of Number of Participants per feature, speaker, and region
Feature
Speaker
Region
Participants (N)
ING
Speaker 1 (British English)
England (North)
50
ING
Speaker 1 (British English)
England (South)
50
ING
Speaker 1 (British English)
US (Pennsylvania)
50
ING
Speaker 2 (American English)
US (Pennsylvania)
50
TDEL
Speaker 1 (British English)
England (North)
50
TDEL
Speaker 1 (British English)
England (South)
50
TDEL
Speaker 1 (British English)
US (Pennsylvania)
25
TDEL
Speaker 2 (American English)
US (Pennsylvania)
25
3.5. Data Analysis
Professionalism ratings were submitted to linear mixed-effects regression models built using the lmerTest package (Kuznetsova, Brockhoff & Christensen 2017) run in R (R Core Team 2022). A maximal model containing all relevant dummy-coded categorical factors (including e.g., gender, age group, class) and continuous factors (e.g., mood) was manually stepped down, using R’s anova() function to compare models, with only those factors which improved the model fit being kept in the final model.4 The following overview is a full list of the factors considered when fitting the models (in alphabetical order); levels are given as they were included in the models.
usage: Yes, regularly. | Yes, sometimes. | No, never.
For the linear models, professionalism ratings were predicted as professionalism rating ~ guise. The logarithmic models were fit using R’s log() function: professionalism ratings were predicted as professionalism rating ~ log(guise).5 The final models included random intercepts for respondent. We also checked for interactions between guise and all other predictors. Model-fit checks were carried out through the check_model() function from the performance package (Lüdecke, Ben-Shachar, Patil, Waggoner & Makowski 2021) and the report package (Makowski, Ben-Shachar, Patil & Lüdecke 2021).
Results are based on SpeakerRegion-specific data sets, which reflect which speaker (British or American) was heard in which geographical region (North of England, South of England, Pennsylvania). We refer to them as BritNorth, BritSouth, BritPenn, and AmPenn, respectively. Following common practice in attitudes research (e.g., Kircher 2016), we initially excluded those participants from the data sets who had become aware of the attitude target. In a second step, we deliberately included these participants in the statistical analysis but tested for an interaction effect between guise and awareness to determine if participants’ awareness impacts their evaluation as the number of non-standard tokens increases.
4. Results
4.1. (ing)
Results for (ing) are based on four related experiments: using the same general research design throughout, we collected responses of fifty participants from the North of England, fifty respondents from the South of England, and another group of fifty participants from Pennsylvania, US. These experimental groups all heard and rated the British speaker (i.e. BritNorth, BritSouth, BritPenn). In addition, we collected responses from another fifty participants from Pennsylvania, who heard and evaluated the American speaker (i.e. AmPenn). Based on our assessment of participants’ awareness of the attitude target, we excluded fifteen participants altogether who had realized what the study was about (BritSouth: three listeners removed; BritNorth: six listeners; BritPenn: one; AmPenn: five).
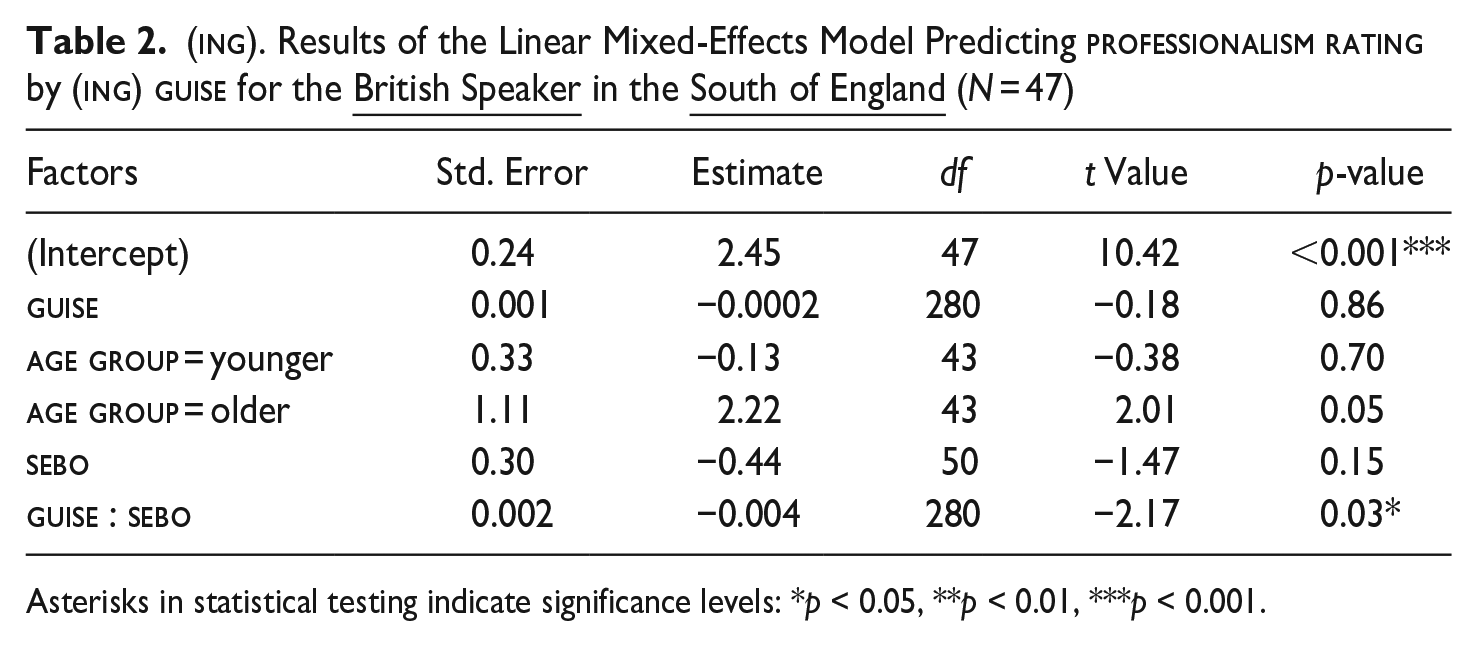
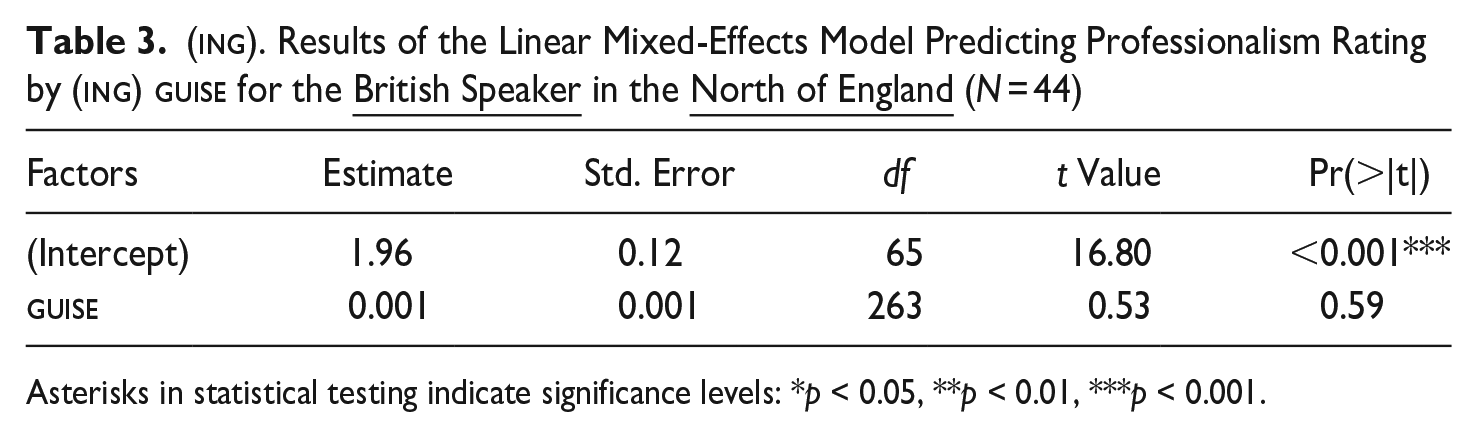
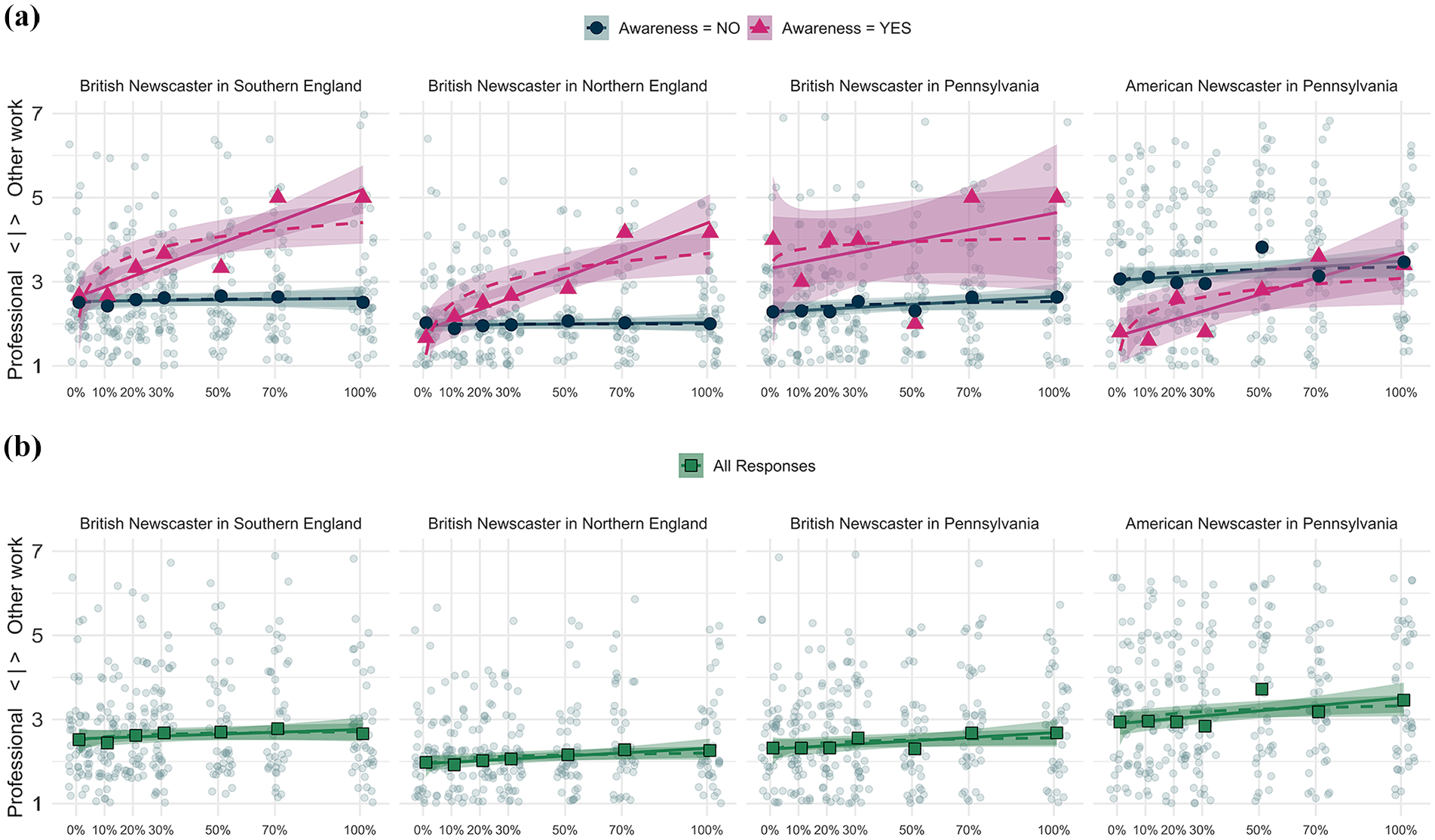
Results indicate that listener evaluations in England were unaffected by guise, regardless of the locale in which guises were heard: both in the South of England (Est. = −0.0002, p = .86, see Table 2) and in the North of England (Est. = −0.001, p= .59, see Table 3), an increase in [ɪn]-tokens did not have an impact on perceived professionalism. The response patterns in both regions are flat (see Figure 1, upper graphs (a), dark blue lines with circles), which is further supported by non-significantly lower AIC values for the linear models for each locale (linear model for BritSouth: AIC = 832, r2 = 74.00; logarithmic model for BritSouth: AIC = 834, r2 = 74.00 and the linear model for BritNorth: AIC = 755.8, r2 = 45.00; logarithmic model for BritNorth: AIC = 756.1, r2 = 45.00).
(ing). Results of the Linear Mixed-Effects Model Predicting professionalism rating by (ing) guise for the British Speaker in the South of England (N = 47)
(ing). Results of the Linear Mixed-Effects Model Predicting Professionalism Rating by (ing) guise for the British Speaker in the North of England (N = 44)
Professionalism rating by (ing) guise per SpeakerRegion. Upper Graphs (a): Pink Triangles = Mean Evaluations per Guise for Those Who Became Aware That (ing) was Being Targeted (N = 15). Blue Circles = Evaluations From Those Who Were Not Aware (N = 185). Linear Model Fits Are Shown With the Unbroken Lines and Logarithmic Fits With Dashed Lines. Lower Graphs (b): Green Squares = All Responses
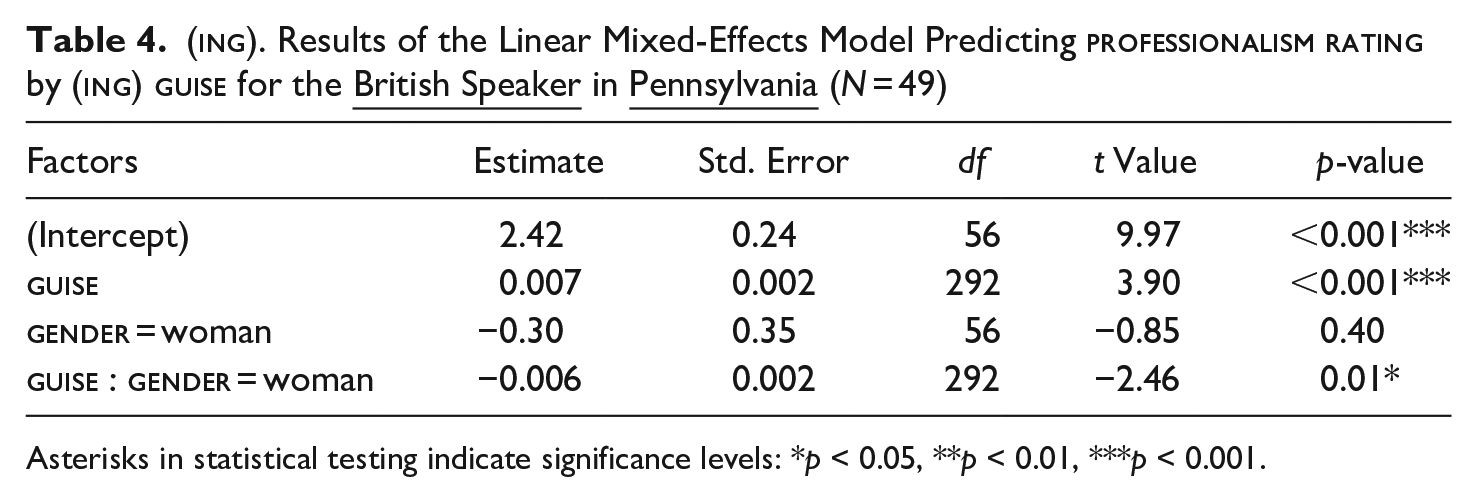
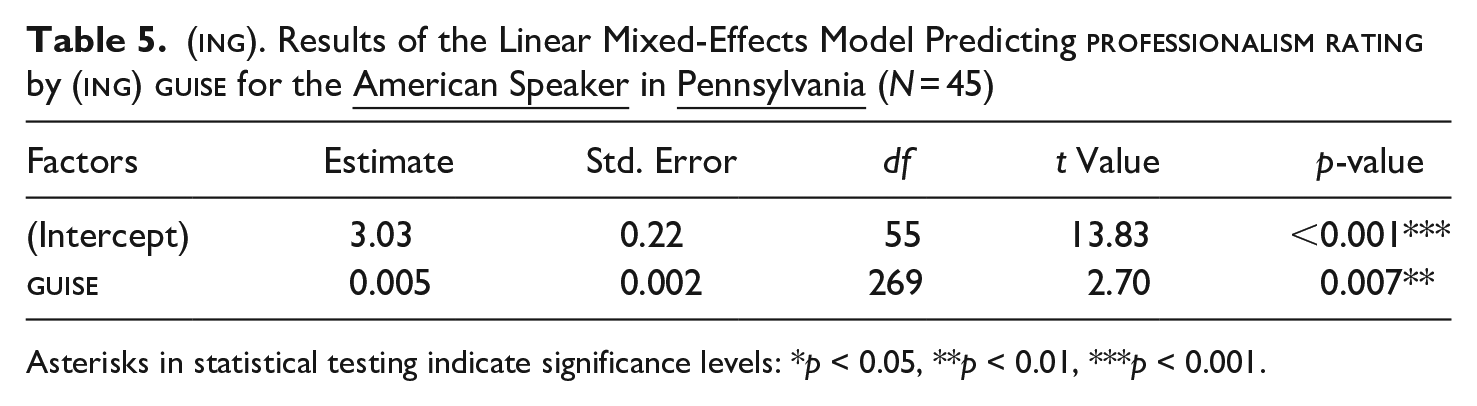
In Pennsylvania, in turn, guise did have a significant main effect on listener evaluations, regardless of which speaker participants heard. A relatively higher number of [ɪn]-tokens resulted in significantly more negative ratings of the British (Est. = 0.007, p < .001, see Table 4) as well as the American speaker (Est. = 0.005, p < .001, see Table 5). A positive value indicates that an increase in [ɪn]-tokens results in more negative professionalism ratings. As indicated by non-significantly lower AIC values (BritPenn: linear: AIC = 920, r2 = 71.00, logarithmic: AIC = 925, r2 = 71.00 and AmPenn: linear: AIC = 1018, r2 = 64.00, logarithmic: AIC = 1020, r2 = 64.00), the response patterns are best described as linear, rather than logarithmic, for both SpeakerRegion-groups in the US context (see Figure 1, upper graphs (a), dark blue lines with circles).
(ing). Results of the Linear Mixed-Effects Model Predicting professionalism rating by (ing) guise for the British Speaker in Pennsylvania (N = 49)
In sum, these results show a regional difference between England (no significant effect of guise) and Pennsylvania (significant effect of guise on professionalism ratings), which provides further substantiation of previous findings by Labov et al. (2011) for the US context and Levon and Fox (2014) for the UK context. In contrast to Labov et al. (2011), however, a logarithmic distribution did not prove a significantly better description of the response pattern observed in the data.
Considering that our main focus is the effect of guise or interactions with it, we also tested for significant interaction terms in each of the four SpeakerRegion-specific models. We found that the British speaker in the South of England (see Table 2, Est. = −0.004, p < .03) is rated significantly better, as [ɪn]-tokens increase, by participants who show a high sensitivity to the expressive behavior of others (as indicated by a high score on the sebo-subscale of the Self-Monitoring Scale (SMS). Also, the British speaker is rated significantly better by women in Pennsylvania (Est. = −0.006, p < .01, see Table 4). Predictors which were not found to be significant but improved the overall model fit were included in the final model, for example, listeners’ pragmatic language ability (pragmatic_language:Est. = −0.002, p = .10).
The upper graphs (a) in Figure 1 not only include the distribution pattern for those respondents who did not become aware of the attitude target (blue lines), they also plot the response pattern for those participants who did identify the attitude target correctly (light pink lines with triangles). For all four SpeakerRegion-groups, distributions differ visibly between the ‘aware’ (light pink with triangles) and ‘unaware’ (dark blue with circles) listener groups. Unfortunately, responses are technically too few to include an interaction term between guise and awareness in a meaningful way in individual models. Nonetheless, we experimented with a second set of models and, this time, included all participants (see Tables A5-A8). An interaction term between guise and awareness was meant to reveal if the significant main effect for guise remains a significant predictor and provide statistical evidence for the factor of awareness, which it did. awareness is significant in interaction with guise in three out of four models (it is not significant in the model with only one aware participant, see Table A7). This indicates that participants who became aware of the attitude target rate the increase in [ɪn]-tokens significantly more negatively than those who did not realize what the study way about.
4.2. (t)-Deletion
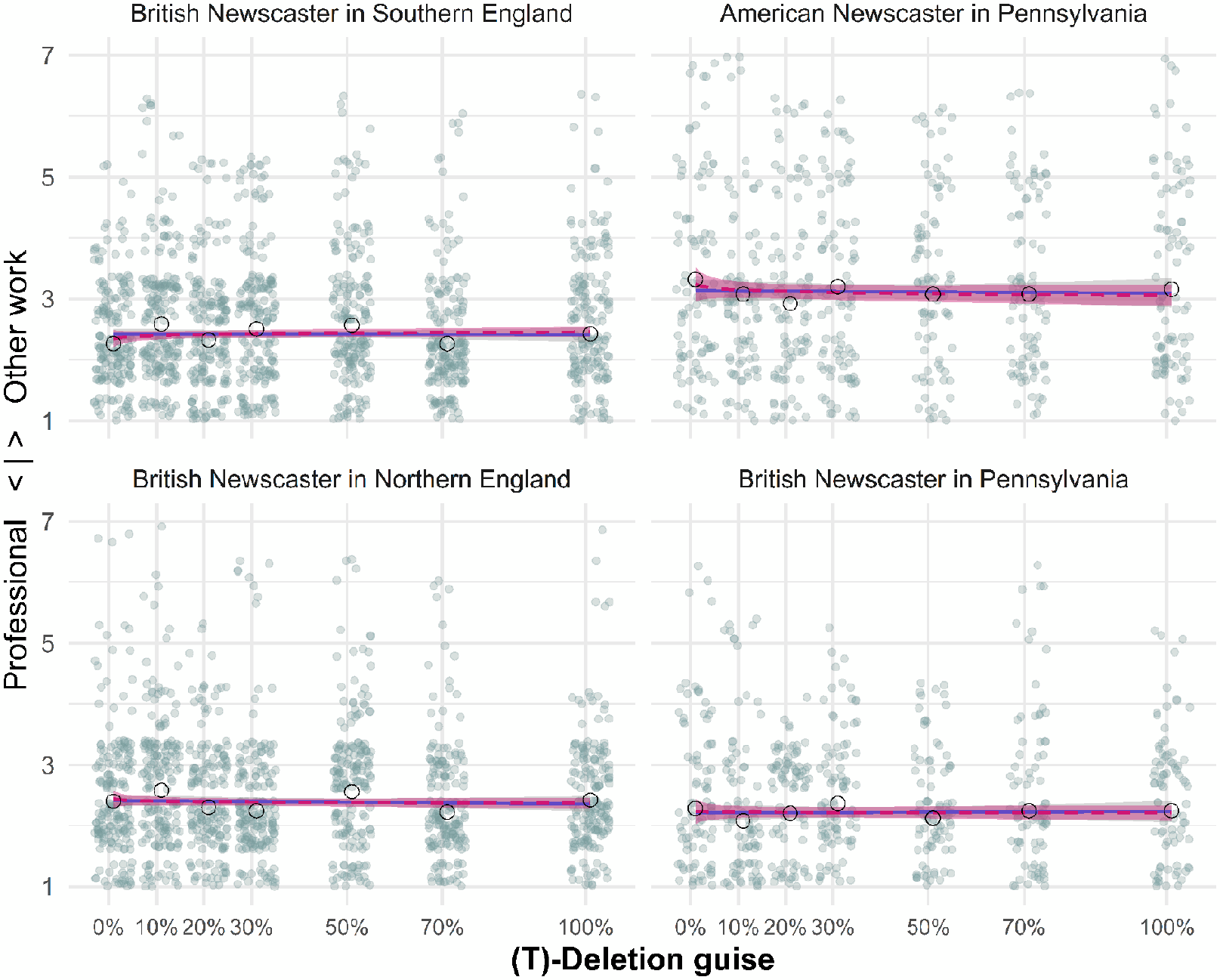
Similar to the experiments on (ing), results for (t)-deletion are based on four related experiments: using the same test passage and research design, we collected responses of fifty participants from the North of England, fifty participants from the South of England, and twenty-five participants from Pennsylvania, who all heard the British speaker. We also collected responses from another group of twenty-five participants from Pennsylvania, who heard and rated the American speaker. The number of participants was smaller for experiments in the US context since initial experiments did not indicate any significant effect of frequency differences of deleted-[t] on listener evaluation, which made it unlikely that further experiments with more participants would change this picture.
We found no significant main effect for guise in our models (see Appendix, section “Further Results of Mixed-Effects Models,” Tables A1-A4). We observe a flat response pattern in all regions (see Figure 2). None of the respondents became aware of the attitude target. Thus, results for (ing) and (t)-deletion are markedly different.
professionalism rating by (t)-Deletion guise for Each SpeakerRegion Constellation. Linear Model Fits Are Shown With the Unbroken Lines and Logarithmic Fits With Dashed Lines
5. Discussion
These results now allow us to make some generalizations and answer our research questions regarding the evaluation of quantitative differences in the use of [ɪn] and deleted-[t] in England and Pennsylvania. In particular, we explored (1) whether there is a significant effect of token-frequency in these regions, (2) what the nature of the response pattern is, and (3) how awareness of the attitude target affects evaluation.
As for (ing), our results indicate that [ɪn]-frequency affects listener evaluation in Pennsylvania significantly, regardless of which speaker was heard. In England, however, this effect was not attestable. These results thus substantiate findings from previous studies, for example, Labov et al. (2011), who found [ɪn]-frequency to be a significant predictor in the US, and Levon and Fox (2014), who did not find a significant effect of [ɪn]-frequency on professionalism ratings in the British context. While there are clear parallels between our results and previous findings, there are also a number of important differences, which offer fresh perspectives on the study of sociolinguistic monitoring in different locales.
First, conclusions in previous research about the social meanings of variation in (ing) in the US context as opposed to the UK are based on studies with similar research designs, but with slight divergences in their implementation. Levon and Fox (2014:196) used a test passage for their monitoring experiments that resembled the structure of Labov et al.’s (2011) original text but differed from it in length (thirty-six words longer) and with regard to the topics of the headlines (adapted to the British context); naturally, they also used a different speaker. Our study, in turn, is the first to offer a direct comparison of listener evaluations regarding variation in (ing) as we used the same set of guises across all three locales. In that sense, it offers robust conclusions about cross-regional patterns of listener evaluations and the social meanings of (ing). It attests clearly to British listeners’ insensitivity toward variation in (ing), whereas US listeners seem to track and evaluate varying [ɪn]-frequencies differently, even when produced by a British speaker.
Second, Labov et al. (2011) are often cited for having found a logarithmic response pattern in listener evaluation. While a logarithmic model did indeed prove to be the best fit for 38 percent of their data (all listeners, regardless of age group), a substantial share of their data (31 percent) were best described by a linear model and another 31 percent showed neither a linear nor a logarithmic pattern (see quantitative overview by Levon & Fox 2014:192; see also Labov et al. 2011:453). Their results are, thus, less straightforward than originally assumed, which makes finding a linear distribution quite plausible. In fact, our results indicate that neither the logarithmic nor the linear model are a significantly better fit for our data; they are very similar.
Third, the regression lines for the US participants (excluding those who became aware) only show a slightly increased slope and do not span across several evaluation points as it did in Labov et al. (2011) where it ranged from below two to above five. However, once we consider the response patterns of those participants who became aware of the attitude target (see Figure 1, upper graphs (a), pink lines with triangles), the response patterns are much more in line with those found by Labov et al. (2011).
Fourth, our study suggests that the question of whether those participants who became aware of the attitude target respond differently to varying [ɪn]-frequencies is crucial. Excluding the British speaker in Pennsylvania, where only one person became aware of the attitude target, all other models show a significant interaction term between guise and awareness, indicating that those participants who realized what the study was about rated the guises significantly differently as [ɪn]-frequencies increased (see Tables A5–A8 in the Appendix, section “Further Results of Mixed-Effects Models”). This is, perhaps, not surprising as it allows those participants to react knowingly to frequency differences and select a wider spread of ratings. As emphasized in section 4.1, the number of participants who did become aware is very low, which makes it difficult to include awareness in the statistical analysis in a meaningful way. If the four models for the unaware respondents (Tables 2–5) are compared with an equivalent set of models where all participants are included—without an interaction term for guise and awareness—results look decidedly different, indicating a significant or near-significant effect for Guise for all locales (see Tables A9–A12, in the Appendix, section “Further Results of Mixed-Effects Models,” see also Figure 1, lower graphs (b)). Thus, it becomes apparent that assessing listeners’ awareness and accounting for it in the statistical analysis is an indispensable move to make in future attitudes research.
Our conclusion raises an important question: despite the parallels in results, why do we observe differences in our data from the findings of Labov et al. (2011) regarding the range of professionalism-ratings and distribution in the US? We believe there are two reasons for this. In contrast to Labov et al. (2011), whose respondents were primarily students, our participants are of varying ages and backgrounds and are predominantly not students. Thus, our participant base differs from previous studies. Furthermore, Labov et al. also found evidence of a linear distribution pattern for parts of their data (see Labov et al. 2011:453; Levon & Fox 2014:192).
The logarithmic distribution documented in Labov et al. (2011) is not a side effect of the method used, that is, listening to multiple versions of a similar test passage. Instead, the logarithmic distribution they found may be idiosyncratic to their data: the methodological procedure may have differed in unpublished details from ours, which may have resulted in more participants in the original study to have become aware of the attitude target. This would explain the more prominent logarithmic distribution found by Labov et al. and that of participants who have become aware of the attitude target in our study.
Let us next consider results for (t)-deletion. While our findings for (ing) generally align with what we would expect based on production research and some previous perception studies, results for (t)-deletion were not in line with our expectations. As (t)-deletion was found to be subject to style-shifting (e.g., Baranowski & Turton 2020:16-17), one would expect sociolinguistic monitoring to take place, allowing speakers and listeners to track the frequency of standard/non-standard features accordingly. At the same time, our review of variables suggested that the difference in social stratification and general comment is less pronounced for deleted-[t] than for use of [ɪn]. As a result, we would expect a smaller effect of variant frequency for (t)-deletion than for (ing), which is indeed the case—at least for the US data.
Our finding that the frequency of deleted-[t] had no significant effect on listener evaluation across locales can be explained by the observation that, acoustically, deleted-[t] is harder to notice than [ɪn]. This can be seen in identification tasks implemented in the present study and in a further related set of experiments that looked more holistically at the noticeability, identification, and discrimination of sociolinguistic variants in England (Schleef, Roth, Mackay & Pflaeging forthcoming). Results for the present groups of respondents show that they are generally able to identify variants of (ing) and (t)-deletion correctly in read-out sentences and when presented with respective answer options: 86.2 percent of all participants identified the (ing)-variants correctly; 83.2 percent of all participants identified the variants of (t)-deletion correctly. If results for the individual variants are considered, however, it becomes apparent that the identification of deleted-[t] proved the most difficult: only 68.3 percent of deleted-[t]-tokens were identified correctly, whereas 98 percent of [t]-tokens were heard correctly. In contrast, the results for the two variants of (ing) were very similar to one another ([ɪn] 88.2 percent correct, [ɪŋ] 84.2 percent correct). The fact that the response pattern for (t)-deletion is flat and that not a single participant became aware of deleted-[t] in the present study is in line with these results.
Still, this raises the question of how speakers manage style-shifting—for (t)-deletion as well as (ing) in Britain—when sociolinguistic monitoring is not sensitive to such stylistically variable features? For one, production and perception may not necessarily align in monitoring processes. In addition, Vaughn (2022a) has argued that the kinds of matched-guise experiments as used in most previous studies on sociolinguistic monitoring, including our own, are run in incongruent styles, that is, informal features are spliced into otherwise formal language. Vaughn and Kendall (2019) found that read-out [ɪn]-sentences differed from [ɪŋ]-sentences in several vowel and consonant realizations. Thus, informal features naturally occur together with other informal features. Vaughn (2022a) compared stylistically congruent and incongruent guises with respect to (ing) and found that guises where [ɪn] appears in a congruent style are rated as most accented. Most other studies in the sociolinguistic monitor paradigm have used guises that seem incongruent in style. In the current study, the effect of [ɪn] versus [ɪŋ] could be captured even in stylistically incongruent guises in the US context. However, given the results of our study, such a research design may not be sufficient for (ing) in Britain and (t)-deletion in England and Pennsylvania. In these locales, [ɪn] and pre-consonantal deleted-[t] appear to fall under the radar in incongruent guises when they occur without other informal features.
6. Conclusion
Campbell-Kibler (2016) argues that the Labovian cognitive model is much too simple to account for the insights of third-wave variationist sociolinguistics and calls for an urgent update. Nonetheless, dynamics observed in the tradition of the sociolinguistic monitor must be incorporated into this new model. In order to achieve a tight integration of findings on sociolinguistic monitoring, contradictions and open questions in this paradigm must first be addressed and explained. It is relatively clear that “socially informed monitoring” is occurring (Campbell-Kibler 2016:142), although the monitoring process may not necessarily be language-specific. Speakers do monitor their own speech in production. To what extent this applies to perception and in how far production- and perception-related monitoring inform each other remains an open question.
We believe we have achieved two goals in this study that further work on sociolinguistic monitoring should consider. First, this study has been able to address the question of cross-regional comparability, and we were able to substantiate previously observed patterns, using the same test passage and speaker in different locales. Results suggest that frequency-based professionalism-ratings of (ing) and (t)-deletion are similar in the UK, but are different in the US context. Of course, when considering other genres and other evaluative scales, results may differ. After all, evaluation and social meaning are multidimensional (Eckert 2008), and our analysis focused on perceived professionalism only. Thus, we cannot speak to whether the variables may index any other social meanings. Second, we have also collected some first evidence that the factor of awareness of the attitude target may affect the response rate; different awareness states seem to result in different evaluative distributions. While more data is needed for a more robust description of this pattern, our results stress the importance of eliciting whether participants in experiments have become aware of the attitude target and of incorporating this information into the analysis. Different awareness states may very well explain the different findings in studies conducted within the sociolinguistic monitoring paradigm and exploring them represents a crucial area of future investigation.
Footnotes
Appendix
Acknowledgements
We would like to thank two anonymous reviewers and the editors of Journal of English Linguistics for their helpful comments on an earlier version of this manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded in whole by the Austrian Science Fund (FWF) [10.55776/P33846]. For open access purposes, the author has applied a CC BY public copyright license to any author accepted manuscript version arising from this submission.
ORCID iD
Jana Pflaeging
Notes
Author Biographies
Erik Schleef is Professor of English Linguistics at the University of Salzburg, Austria. His research focuses on variation and change in dialects of the British Isles, the acquisition of variation, sociolinguistics and perception, as well as language and gender. He is co-editor of the Routledge Sociolinguistics Reader and co-author of Doing Sociolinguistics: A Practical Guide to Data Collection and Analysis.
Bradley Mackay is a Postdoctoral Research Fellow at the University of Michigan, USA. His research interests include language, gender, and sexuality, and he is currently involved in projects which examine the ways ethnicity and gender are entwined with language variation and change in Afrikaans.
Jana Pflaeging is a post-doctoral researcher in English and Applied Linguistics at the University of Salzburg, Austria. She works in variationist sociolinguistics and speech perception research, as well as in multimodal discourse analysis. She is co-editor of the book series Pathways to Multimodality (De Gruyter).
References
1.
AustenMarthaCampbell-KiblerKathryn. 2022. Real-time speaker-evaluation: How useful is it, and what does it measure?Language98(2). 108-130.
2.
BaileyGeorge. 2019. Emerging from below the social radar: Incipient evaluation in the North West of England. Journal of Sociolinguistics23(1). 3-28.
3.
BaranowskiMaciejTurtonDanielle. 2020. td-deletion in British English: New evidence for the long-lost morphological effect. Language Variation and Change32(1). 1-23. doi:10.1017/S0954394520000034.
4.
BayleyRobert. 1994. Consonant cluster reduction in Tejano English. Language Variation and Change6(3). 303-326. doi:10.1017/S0954394500001708.
5.
BoersmaPaulWeeninkDavid. 2022. Praat: Doing phonetics by computer [Computer program]. Version 6.2.12, retrieved Apr 2022 from http://www.praat.org.
6.
Campbell-KiblerKathryn. 2007. Accent, (ING), and the social logic of listener perceptions. American Speech82. 32-64. doi:10.1215/00031283-2007-002.
7.
Campbell-KiblerKathryn. 2009. The nature of sociolinguistic perception. Language Variation and Change21. 135-156. doi:10.1017/S0954394509000052 .
8.
Campbell-KiblerKathryn. 2011. The sociolinguistic variant as a carrier of social meaning. Language Variation and Change22. 423-441. doi:10.1017/S0954394510000177.
9.
Campbell-KiblerKathryn. 2016. Towards a cognitively realistic model of meaningful sociolinguistic variation. In BabelAnna (ed.), Awareness and control in sociolinguistic research, 123-151. Cambridge: Cambridge University Press.
10.
CoetzeeAndries W.KawaharaShigeto. 2013. Frequency biases in phonological variation. Natural Language and Linguistic Theory31(1). 47-89. http://www.jstor.org/stable/42629730.
11.
CramerKenneth M.GrumanJamie A.2002. The Lennox and Wolfe Revised Self-Monitoring Scale: Latent structure and gender invariance. Personality and Individual Differences32. 627-637.
12.
DuntonBridget C.FazioRussell H.1997. An individual difference measure of motivation to control prejudiced reactions. Personality and Social Psychology Bulletin23(3). 316-326.
13.
EckertPenelope. 2008. Variation and the indexical field. Journal of Sociolinguistics12(4). 453-476.
14.
EckertPenelope. 2012. Three waves of variation study: The emergence of meaning in the study of sociolinguistic variation. Annual Review of Anthropology41. 87-100. doi:10.1146/annurev-anthro-092611-145828.
15.
FasoldRalph W.1972. Tense marking in Black English: A linguistic and social analysis. Washington, DC: Center for Applied Linguistics.
GarcíaChristinaWalkerAbbyBeatonMary. 2023. Exploring the role of phonological environment in evaluating social meaning: The case of /s/ aspiration in Puerto Rican Spanish. Languages8(3). 186. doi:10.3390/languages8030186.
18.
GuyGregory R.1980. Variation in the group and the individual: The case of final stop deletion. In LabovWilliam (ed.), Locating language in time and space, 1-36. New York, NY: Academic Press.
19.
GuyGregory R.1991. Explanation in variable phonology: An exponential model of morphological constraints. Language Variation and Change3(1). 1-22. doi:10.1017/S0954394500000429.
20.
HazenKirk. 2006. IN/ING variable. In BrownKeith (ed.), Encyclopaedia of language and linguistics, vol. 5, 581-584. Oxford: Elsevier. doi:10.1016/B0-08-044854-2/04716-7.
21.
HazenKirk. 2011. Flying high above the social radar: Coronal stop deletion in modern Appalachia. Language Variation and Change23(1). 105-137. doi:10.1017/S0954394510000220.
22.
HoustonAnn C.1985. Continuity and change in English morphology: The variable (ING). Philadelphia, PA: University of Pennsylvania doctoral dissertation.
23.
HurleyRobert S. E.LoshMollyParlierMorganReznickJ. StevenPivenJoseph. 2007. The broad autism phenotype questionnaire. Journal of Autism and Developmental Disorders37. 1679-1690.
24.
KircherRuth. 2016. The matched-guise technique. In HuaZhu (ed.), Research methods in intercultural communication: A practical guide, 196-211. Oxford: John Wiley.
25.
KuznetsovaAlexandraBrockhoffPer B.ChristensenRune H. B.2017. LmerTest package: Tests in linear mixed effects models. Journal of Statistical Software82(13). 1-26. doi:10.18637/jss.v082.i13.
26.
LabovWilliam. 1972. Sociolinguistic patterns. Philadelphia, PA: University of Pennsylvania Press.
27.
LabovWilliam. 1989. The child as linguistic historian. Language Variation and Change1(1). 85-97. doi:10.1017/S0954394500000120.
28.
LabovWilliam. 2001. Principles of linguistic change, vol. 2, Social factors. Oxford: Blackwell.
29.
LabovWilliamAshSharonBaranowskiMaciejNagyNaomiRavindranathMaya. 2006. Listeners’ sensitivity to the frequency of sociolinguistic variables. University of Pennsylvania Working Papers in Linguistics12(2). 105-129.
30.
LabovWilliamAshSharonRavindranathMayaWeldonTraceyBaranowskiMaciejNagyNaomi. 2011. Properties of the sociolinguistic monitor. Journal of Sociolinguistics15(4). 431-463. doi:10.1111/j.1467-9841.2011.00504.x.
31.
LevonErez. 2014. Categories, stereotypes and the linguistic perception of sexuality. Language in Society43. 539-566. https://www.jstor.org/stable/43904598.
32.
LevonErezBuchstallerIsabelle. 2015. Perception, cognition, and linguistic structure: The effect of linguistic modularity and cognitive style on sociolinguistic processing. Language Variation and Change27. 319-348. doi:10.1017/S0954394515000149.
33.
LevonErezFoxSue. 2014. Social salience and the sociolinguistic monitor: A case study of (ING) and TH-fronting in Britain. Journal of English Linguistics42. 185-217.
34.
LimeSurvey GmbH. 2023. LimeSurvey: An open source survey tool [Computer software]. Hamburg, Germany. http://www.limesurvey.org.
35.
LüdeckeDanielBen-ShacharMattan S.PatilIndrajeetWaggonerPhilipMakowskiDominique. 2021. Performance: An R package for assessment, comparison and testing of statistical models. Journal of Open Source Software6(60). 3139. doi:10.21105/joss.03139.
36.
MakowskiDominiqueBen-ShacharMattan S.PatilIndrajeetLüdeckeDaniel. 2021. Automated results reporting as a practical tool to improve reproducibility and methodological best practices adoption. CRAN. https://github.com/easystats/report.
37.
PavlíkRadoslav. 2017. Some new ways of modelling T/D deletion in English. Journal of English Linguistics45(3). 195-228. doi:10.1177/0075424217712358.
38.
R Core Team. 2022. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computingwww.r-project.org/ (June2022).
39.
Santa AnaOtto A.1996. Sonority and syllable structure in Chicano English. Language Variation and Change8(1). 63-89. doi:10.1017/S0954394500001071.
40.
SchleefErik. 2023. Mechanisms of meaning making in the co-occurrence of pragmatic markers with silent pauses. Language in Society52(1). 79-105. doi:10.1017/S0047404521000610.
41.
SchleefErikFlynnNicholas. 2015. Ageing meanings of (ing): Age and indexicality in Manchester, England. English World-Wide36. 47-89.
42.
SchleefErikFlynnNicholasBarrasWill. 2017. Regional diversity in social perceptions of (ing). Language Variation and Change29. 29-56.
43.
SchleefErikMackayBradleyPflaegingJana. 2025. Frequency-based professionalism evaluation of (ing) and (t)-deletion in England and Pennsylvania (supplementary materials). GitHub. https://github.com/jpflaeging/schleef-et-al-2025.
44.
SchleefErikMeyerhoffMiriamClarkLynn. 2011. Teenagers’ acquisition of variation: A comparison of locally-born and migrant teens’ realisation of English (ing) in Edinburgh and London. English World-Wide32(2). 206-236.
45.
SchleefErikRothEvelyn N.MackayBradleyPflaegingJana. Forthcoming. Noticing, identifying and discriminating sociolinguistic variants in England. English Language and Linguistics. doi:10.1017/S1360674324000625.
46.
SmithJenniferDurhamMercedesFortuneLiane. 2009. Universal and dialect-specific pathways of acquisition: Caregivers, children, and t/d deletion. Language Variation and Change21(1). 69-95. doi:10.1017/S0954394509000039.
47.
SteckerAmelia. 2020. Investigations of the sociolinguistic monitor and perceived gender identity. University of Pennsylvania Working Papers in Linguistics26(2). 119-128.
48.
TagliamonteSali A.2004. Somethi[ŋ]’s goi[n] on! Variable (ing) at ground zero. In GunnarssonBritt-LouiseBergströmLenaEklundGerdFidellStaffanHansenLise H.KarstadtAngelaNordbergBengtSundergrenEvaThelanderMats (eds), Language variation in Europe: Papers from the second international conference on language variation in Europe ICLaVE2, Uppsala, Sweden, 12th-14th June 2003, 390-403. Uppsala: Uppsala University.
49.
TagliamonteSali A.TempleRosalind. 2005. New perspectives on an ol’ variable: (t, d) in British English. Language Variation and Change17(3). 281-302. doi:10.1017/S0954394505050118.
50.
TrudgillPeter. 1974. The social differentiation of English in Norwich. Cambridge: Cambridge University Press.
51.
VaughnCharlotte. 2022a. The role of internal constraints and stylistic congruence on a variant’s social impact. Language Variation and Change34(3). 331-354. doi:10.1017/S0954394522000175.
52.
VaughnCharlotte. 2022b. What carries greater social weight, a linguistic variant’s local use or its typical use?Proceedings of the 44th Annual Conference of the Cognitive Science Society44(44). 512-518.
53.
VaughnCharlotteKendallTyler. 2019. Stylistically coherent variants: Cognitive representation of social meaning. Revista de Estudos da Linguagem27. 1787-1830.
54.
WagnerSuzanne E.HessonAshley. 2014. Individual sensitivity to the frequency of socially meaningful linguistic cues affects language attitudes. Journal of Language and Social Psychology33(6). 651-666. doi:10.1177/0261927X14528713.
55.
WellsJohn C.1982. Accents of English. Cambridge: Cambridge University Press.
56.
WolframWalter A.1969. A sociolinguistic description of Detroit Negro speech. Washington, DC: Center for Applied Linguistics.