
Abstract
This study explores the distribution of modals and quasi-modals in the twenty English dialects represented in the Global Web-based English Corpus (GloWbE). Intervarietal trends are observed across and within the Englishes of the “Inner circle” and “Outer circle.” Ratios calculated for onomasiological pairings of modal expressions suggest that Inner circle varieties tend to be associated more closely than Outer circle varieties—and “epicentral” varieties more so than non-epicentral ones—with trends of frequency change that have been identified in previous diachronic studies of the reference varieties, British and American English. A further type of change is revealed by semantic analysis: Inner circle varieties tend to embrace epistemic modality more readily than Outer circle varieties. Possible explanations considered for intervarietal differences include areal proximity, epicentrality, evolutionary status, and colloquiality.
1. Introduction
The aim of the present study is to provide a more comprehensive and explanatorily adequate account of the modals and quasi-modals in World Englishes (WEs) than has hitherto been published. The principal means by which modality—which embraces such notions as possibility, necessity, ability, obligation, and permission—is expressed in English is the class of modal auxiliaries (often referred to simply as “modals”), but increasingly commonly by “quasi-modals” (periphrastic expressions of the type
(1) I’m going to leave the discussion here (GloWbE, NZ)
(2) Oh no, I’m going to Paris this year (GloWbE, AU)
English modals and quasi-modals have attracted a great deal of scholarly interest, with synchronic corpus-based and corpus-informed descriptive studies mostly targeting the “reference” varieties, British English (BrE) and American English (AmE) (e.g., Coates 1983; Westney 1995; Krug 2000; Leech, Hundt, Mair & Smith 2009; Collins 2009a). More recently, the regional/varietal scope has been expanded in studies both of sets of WEs (e.g., Collins 2009b; Collins & Yao 2012; Deuber, Biewer, Hackert & Hilbert 2012; van der Auwera, Noël & de Wit 2012; Loureiro-Porto 2019) and of specific WEs (e.g., Diaconu 2012; Collins 2014; Collins, Borlongan & Yao 2014; van Rooy & Wasserman 2014; Noël & van der Auwera 2015).
Most commonly used as a source of data in the WEs-focused studies are the parallel corpora of the International Corpus of English (ICE) collection. However, the ready availability since 2014 of the Global Web-based English corpus (GloWbE) online (Davies 2013) has opened up new possibilities—exploited in the present study—for the intervarietal study of modality in English world-wide, with its twenty subcorpora each representing a different WE. GloWbE unquestionably has the advantage of size over ICE: GloWbE’s subcorpora range in size from 35 to 387 million words compared to the one-million words of each ICE corpus. However, it is important to be aware of its limitations and deficiencies (discussed in section 3).
The structure of the paper is as follows. Section 2 locates the study in its scholarly context. Section 3 outlines the features and composition of the primary data-source, GloWbE, and introduces the methodology used in the study. Section 4 provides and discusses the findings for fourteen pairs of modal expressions. Finally, section 5 presents the conclusion.
2. Background
The scholarly context for the present study is the WEs paradigm. Accordingly, it appeals to influential models of WEs which legitimize the formulation of predictions to test against the study’s findings: Kachru’s (1985) “Concentric circles” model; Schneider’s (2003, 2007) “Dynamic” model; and Mair’s (2013) “World system of Englishes” model. Factors invoked in these models that are relevant to interpreting the findings of the study include “areal proximity,” “epicentrality,” and “evolutionary status.” In addition to these I outline three considerations which, despite not being concerned specifically with WEs, have the potential to provide insights into the study’s alternation-based findings: diachronic trends, genre distribution, and modal semantics.
Kachru’s (1985) Concentric circles model warrants the prediction that the first -language or “native” varieties of the Inner circle (IC) will share structural properties that may differ from those that are found in the institutionalized second-language varieties of the Outer circle (OC), where they are subject to factors such as second-language acquisition processes and differential norm orientations. Within Kachru’s (1985) IC and OC, there are subgroupings of varieties determined by their areal proximity (e.g., the Englishes of India, Pakistan, Sri Lanka, and Bangladesh in South Asia). The member varieties of these regions may exhibit similarities that differentiate them from varieties of other geographical regions, no doubt a by-product of the role of language contact in driving the spread of linguistic innovations and usages. Areal proximity is furthermore related to the phenomenon of epicentrality in language, the attainment by a variety of demographic, historical, and sociolinguistic prominence, thereby enabling it to serve as a normative model for speakers of other—typically neighboring—varieties (cf. Peters 2009; Hundt 2013; Gries & Bernaisch 2016). The notion of epicentrality underpins Mair’s (2013) World system model of WEs, in which he posits a hierarchy of relationships between WEs in a globalized world, a hierarchy in which varieties higher up are more likely to influence those lower down than vice versa. According to Mair (2013), AmE has become a “hypercentral” model in English world-wide today (ousting the merely “supercentral” BrE), and there are further cases of epicentrality lower in the hierarchy, in areal zones of the type mentioned above.
A further source of hypotheses is the evolutionary status of varieties, a concept famously associated with Schneider’s (2003, 2007) Dynamic model of postcolonial Englishes. Schneider (2003, 2007) posits five developmental phases (“foundation,” “exonormative stabilisation,” “nativisation,” “endonormative stabilisation,” and “differentiation”), with the evolutionary status of OC varieties being determined by the positions they occupy along the cycle of phases, or of IC varieties by the time when they completed their passage through the cycle. Differences in the evolutionary status of varieties may be reflected in their linguistic similarities to and differences from the parent variety.
Consider now the three more general sources of explanation for the study’s findings that were introduced above. The first consideration is diachronic variation with the modals and quasi-modals (see further Ziegeler 2016). Research by Leech, Hundt, Mair, and Smith (2009) based on the Brown family of corpora provided evidence of a declining tendency in the frequency of the modals and a concomitant rise in the frequency of quasi-modals, in BrE and AmE writing between the early 1960s and 1990s. These findings, presented in Table 1 (BrE and AmE data from Leech, Hundt, Mair & Smith 2009:74, 97), furthermore indicate a tendency for the higher frequency modals (notably will, would, can, and could) to have undergone smaller changes than lower frequency modals such as must, shall, ought, and need. Leech, Hundt, Mair, and Smith’s (2009) research has prompted quantitative synchronic investigations of the distribution of the modals in other English varieties, in which a relative paucity of modal tokens and a relative abundance of quasi-modal tokens are sometimes interpreted as conveying an apparent-time implication of change (Collins 2009b; Collins & Yao 2012). Accordingly, I explore the potential relevance of attested diachronic trends observed in the literature to the frequency findings of the present synchronic study.
Percentage Change of the Modals in Various Corpora
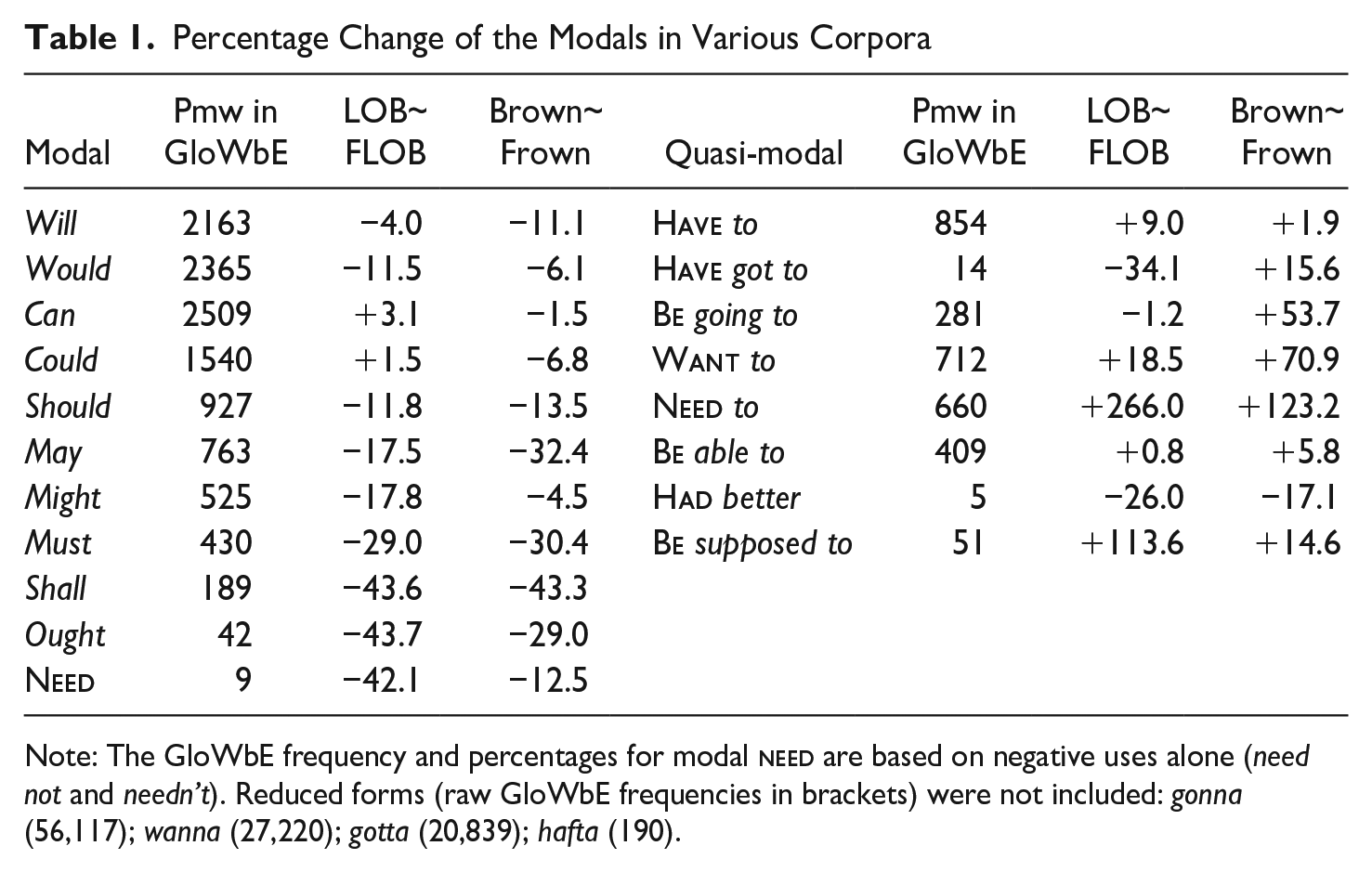
Note: The GloWbE frequency and percentages for modal
It is necessary to enter a caveat regarding the extrapolation of putatively diachronic generalizations from frequencies extracted from a synchronic corpus such as GloWbE: all such extrapolations must be considered provisional, ultimately requiring empirical validation in future research using real-time historical WEs corpora. As argued in section 3, comparisons of frequencies from the two text categories of “Blogs” and “General” in GloWbE offer some insights into apparent-time change, albeit less compelling than extrapolations made on the basis of comparisons of speech versus writing frequencies in the ICE corpora. Another caveat is that rates and directions of change in BrE and AmE, as identified by Leech, Hundt, Mair, and Smith (2009) and others, may differ from those under way in other varieties (see, e.g., Mukherjee & Schilk 2012).
The second general consideration concerns the potential impact on GloWbE frequencies of colloquialization, a powerful discourse-pragmatic agent of grammatical change in English that is characterized by Leech, Hundt, Mair, and Smith (2009) as a stylistic shift that has been operating to make written genres more like spoken ones since the mid-twentieth century. Collins and Yao (2013), who define colloquialization as the spreading of colloquial features from baseline casual face-to-face conversation to other—written and spoken—genres, show that grammatical developments in a number of WEs may be affected by differences in the degrees to which speakers are (in)tolerant of colloquialism and informality. Witness, for example, the contribution to the ongoing grammaticalization of the quasi-modals that is to be found in instances where the infinitival marker to is incorporated into the preceding verb. Such reductions are found not only in informal speech, but also in informal styles of writing (typically in representations of casual speech) where they are represented by non-standard spellings of the type gonna, gotta, wanna, and hafta (Huddleston & Pullum 2002:1616). In the present study, the source of quantitative information about the colloquiality of the modals and quasi-modals that is invoked in discussing putatively colloquialization-influenced variation is the generic division in GloWbE between General texts and Blogs.
The third general consideration is modal semantics. I operate here with a binary semantic distinction between “root” and “epistemic” modality, as used, among others, by Coates (1983, 1995) and Depraetere and Reed (2021). The distinction is exemplified by the different uses of must in (3) and (4), respectively root and epistemic.
(3) Imran Khan is the right choice and he must be given a chance. (GloWbE, PK)
(4) sometimes the things he says I think he must be crazy (GloWbE, PK)
Root modality deals with the necessity or possibility of the actualization of a situation, two major subtypes recognized by, for example, Palmer (1990), Huddleston and Pullum (2002), and Collins (2009a): (i) deontic modality (in which the factors impinging on the actualization involve some kind of authority, as when a person, rule, or convention is responsible for the imposition of an obligation or granting of permission); and (ii) dynamic modality (in which the factors are intrinsic to the subject-referent—such as ability or volition—or generally circumstantial). By contrast, epistemic modality deals with the speaker’s judgment that the proposition underlying the utterance is true, located on a scale ranging from weak possibility (“It may be so”) to strong necessity (“It must be so”). It is the distribution of epistemic modality that will be the focus of the meaning-based analysis in this study.
3. Data and Method
The data source for the present study is GloWbE, a web-based corpus comprising 1,885,632,973 words of both General texts (e.g., newspapers, magazines, company websites) and Blogs from 1.8 million web pages from twenty different countries (Davies & Fuchs 2015). The number of tokens of modals and quasi-modals for each variety far exceeds that available in studies based on the one-million-word ICE and Brown corpora (cf. Peters, Collins & Smith 2009; Leech, Hundt, Mair & Smith 2009); even relatively uncommon expressions such as modal need and quasi-modal
In the present study the distinction between Blogs and General texts in GloWbE has been exploited as a source of information about the colloquiality of the modals and quasi-modals and the potential influence of colloquialization. There is insufficient space in this paper for a comprehensive account of colloquialization effects for every alternation presented in section 4, so commentary will be limited to a selection of cases where there is a notable preference for Blogs over General texts.
Table 2 presents the macro-generic distribution of the modals and quasi-modals, with per-million-word (pmw) frequencies derived from the General and Blogs sections of GloWbE. What it shows is that the lower frequency modals tend to be favored more in General texts than Blogs, suggesting that their declining diachronic fortunes may be influenced by their “anti-colloquiality,” that is, their greater preference for features that are typical of writing than for those that are typical of speech (cf. Collins &Yao 2018; Kruger & Smith 2018). By contrast, the distribution of the higher frequency modals is skewed toward Blogs, their informality and colloquiality probably helping them to withstand the declining trend of their lower frequency counterparts. The distribution of the quasi-modals is also skewed more toward the Blogs, suggesting that colloquialization is an important factor in their rising fortunes.
Macro-Generic Distribution of the Modals and Quasi-modals in GloWbE (Frequencies pmw)
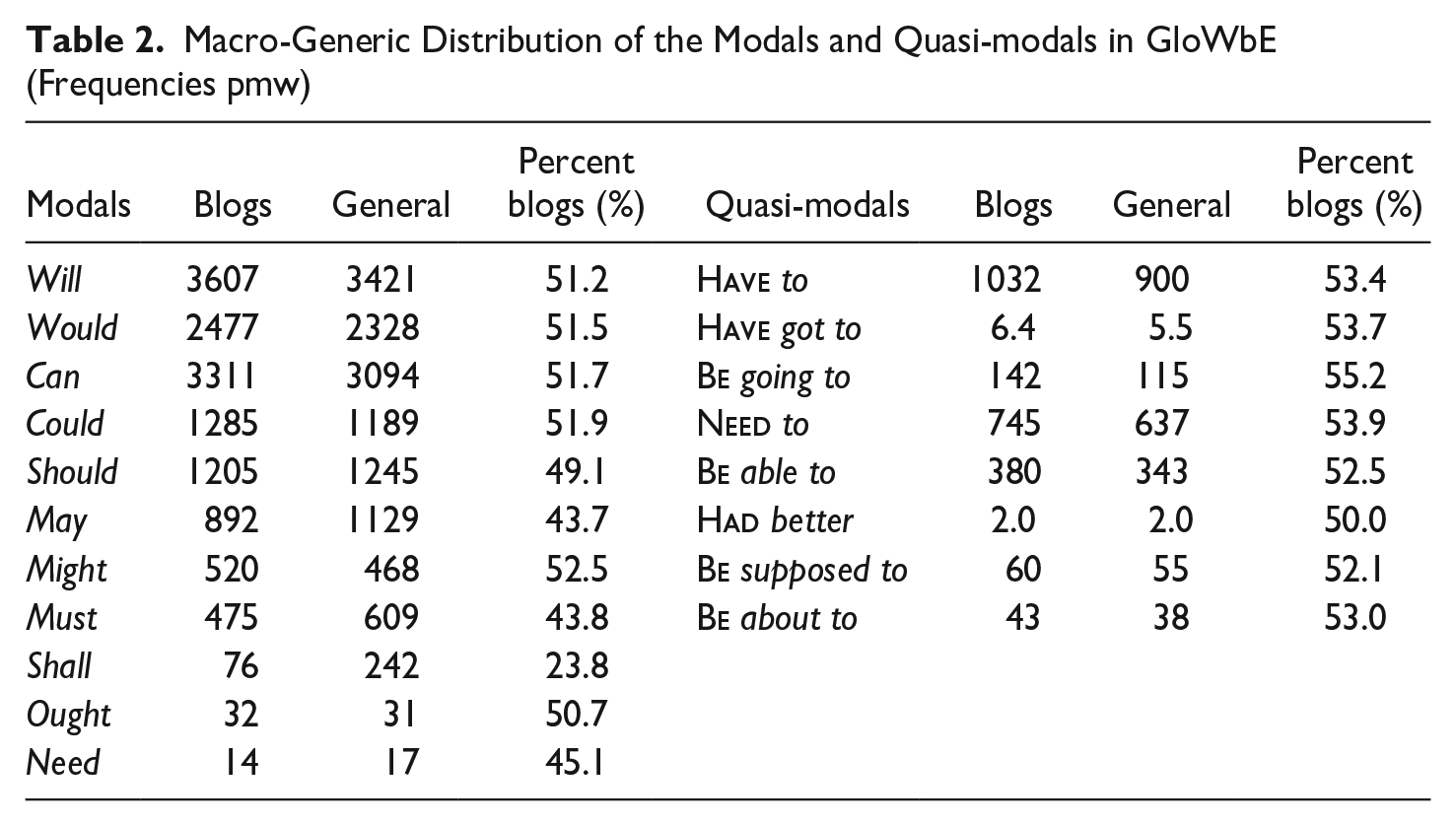
It is important to keep in mind that GloWbE is not designed to be a carefully curated and generically-representative corpus like the corpora of the ICE and Brown family collections. Despite inevitably being, as a web-based corpus, somewhat “quick and dirty” (Isingoma & Meierkord 2019:311), GloWbE is a highly attractive resource for studies of the present kind, with its massive size, its inclusion of a large number of WEs, the informality of its texts, and the user-friendliness of an online platform providing search tools that enable a wealth of quantitative information to be readily accessed. Most importantly, the relatively informal nature of the GloWbE texts is arguably conducive to the study of diachronically volatile categories such as the modals and quasi-modals, which as we shall see, are prone to the influence of drivers of change that are particularly associated with more informal language, notably colloquialization.
The composition of GloWbE is presented in Table 3, with labels for the country of origin of each of the twenty subcorpora, the English varieties they represent, and the number of words each one contains. Also included are subclassifications used in the study: Kachru’s (1985) IC versus OC distinction, along with further primarily regionally-based subgroupings (of the IC into American, European, and Oceanic countries; and of the OC into South Asia [SA], South-East Asia [SEA], Africa [Afr], and the Caribbean [Carib]). The neatness of this picture is complicated to some extent by the OC untypicality of JamE, SingE, and SthAfrE, all of which enjoy a good representation of first-language English speakers. I henceforth use the GloWbE “country labels” when referring to the findings for the particular GloWbE subcorpora, as opposed to the abbreviated “variety labels,” which I use when extrapolating from the findings for subcorpora to varieties in general.
GloWbE Composition and Word-Count
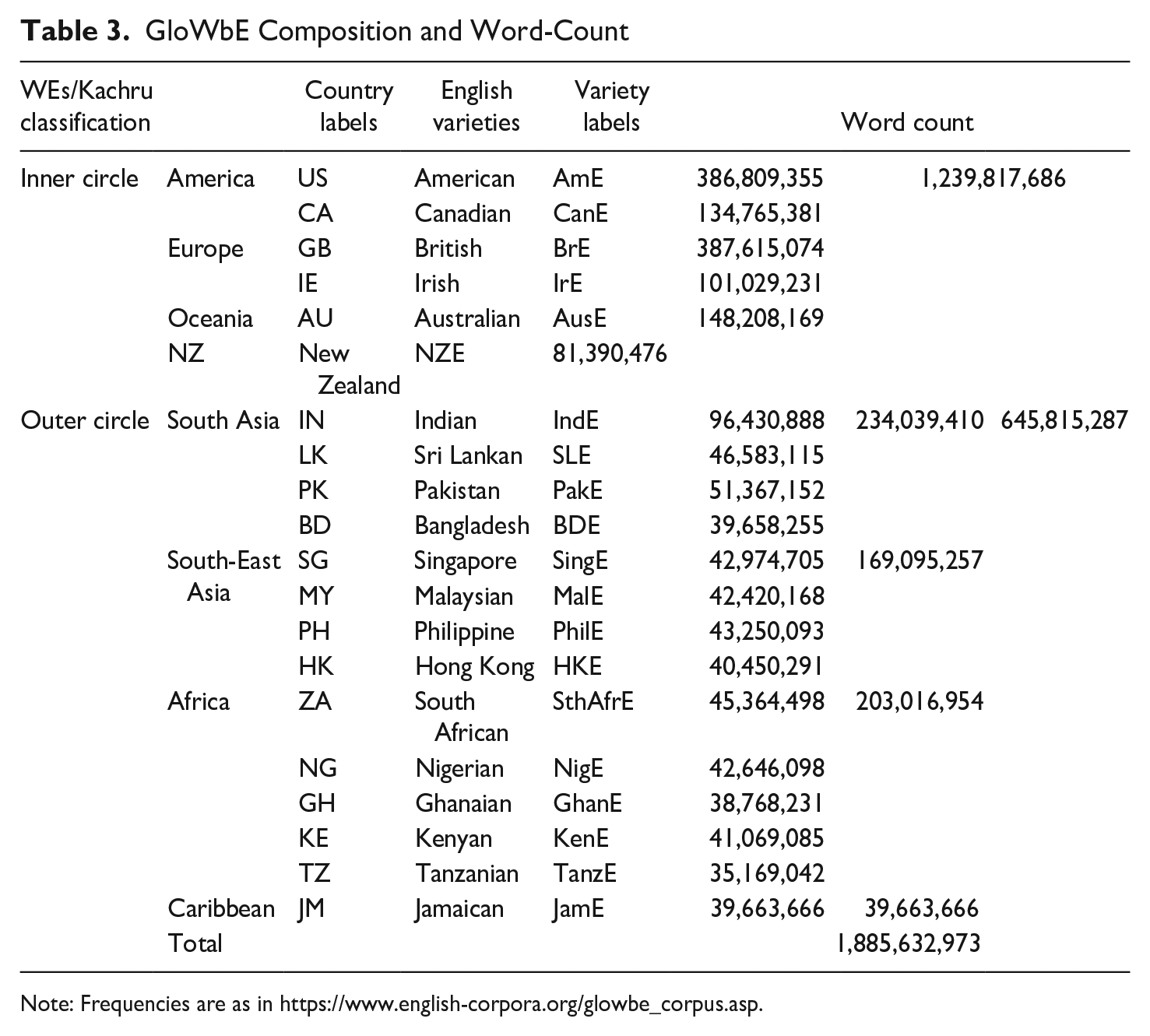
Note: Frequencies are as in https://www.english-corpora.org/glowbe_corpus.asp.
The reference varieties, BrE and AmE, exert influence that extends well beyond their geographical neighbors, IrE and CanE respectively. The linguistic sway of BrE reflects its historical status as colonial “parent” in the evolution of postcolonial English varieties, while that of AmE reflects the status of the USA latterly as an international superpower. The remaining two IC varieties, AusE and NZE, have closely related histories and are well-established in the Southern Hemisphere. Each of the three multivariety OC subgroups—SA, SEA, and Afr—contains an extensively standardized, influential, and internationally well-known epicentral variety: IndE, SingE, and SthAfrE, respectively. Extended discussion of fourteen of the postcolonial Englishes represented in GloWbE is provided in Schneider (2007), and a subset of these in Schneider (2014).
Turning to methodology, the analytical approach adopted in the present study is premised on the concept of “alternation” between competing grammatical items and categories. Such alternates are understood to be semantically overlapping in the sense that they compete with, and can usually be substituted for, one another. This does not mean that they are semantically identical in every respect, a situation that—even if it were possible—would result in a level of redundancy that would be intolerable in any natural language. In cases of mutual substitutability, one generally finds a difference, even if subtle or elusive, in connotative and/or associative meaning, as in the almost identical contexts of (5) and (6) where may arguably has a slightly more formal overtone than the otherwise semantically equivalent might.
(5) In addition, they may possibly want to slow down some of the lead follicles. (GloWbE, IN)
(6) Not a route to everything they might possibly want to do that the device or software is capable of. (GloWbE, BG)
My alternation-based approach is thus congruent with research—mostly informed by the Labovian “language variation and change” and the “corpus-based variationist linguistics” models (Szmrecsanyi 2017)—which has been conducted on such phenomena as dative alternation and genitive alternation in language use and acquisition (e.g., Heller, Szmrecsanyi & Grafmiller 2017; Szmrecsanyi et al. 2017), and with research on recent diachronic variation involving “onomasiological” competition between alternating constructions (e.g., Aarts, Close & Wallis 2013; Mair & Leech 2021). Accordingly, in this study I eschew the approach customarily followed in corpus-based WEs studies of generalizing from normalized frequencies, in favor of one based on ratios representing the proportionalities for putatively competing modal expressions. Tables 4 to 17 display these ratios and, in keeping with the shading system used in the frequency tables generated by the GloWbE tools—where the cells for high frequency tokens are shaded—such frequencies are bolded in this and all subsequent tables. 2
Should versus Ought to in GloWbE
Should versus
Should versus
May versus Might in GloWbE
Could versus Might in GloWbE
Can versus May in GloWbE
Can versus
Will versus Shall in GloWbE
Will versus
The study includes both a (primary) form-based component and a (secondary) meaning-based component. For the former, search routines were formulated in accordance with the online BYU platform. For the modals, as single form categories, both raw and pmw frequencies were readily obtainable using the modal form in conjunction with the tag “.[vm*],” as for example in “will.[vm*].” However, for the quasi-modals, as multi-form lexeme-based categories, normalized frequencies had to be calculated from the raw frequencies provided. In cases where exhaustive searches were not possible for a category, frequencies based on a set of the most frequent tokens—typically the 1000 most common—of the category in question were obtained. For example, the search for
(7) [ . . .] and his organisation represent a totally failed political ideology. All they have to offer is a return to the gun and the bomb. (GloWbE, IE)
For the meaning-based analysis I had to address the problem that the GloWbE platform provides only for form-based searches. This being so, an exhaustive semantic description of the modals and quasi-modals would have required manual inspection of the almost seventy million modal and quasi-modal tokens in the corpus. In view of the practical impossibility of such an undertaking, two alternative possibilities were considered. One was to manually process smaller sets of randomly sampled tokens. The other was to exploit the fact that—as recognized by, for example, Coates (1983) and Wärnsby (2006)—there are a number of contextual syntactic features that can be used to identify modal meanings, especially epistemic ones. I have pursued the latter alternative in this study, anticipating that it might shed further light on Collins’s (2022) finding that epistemic comment markers are more commonplace in IC than OC varieties (by a ratio of 1.53:1).
Selective use was made of the six identifying features claimed by Coates (1983:244-245) to be associated with epistemic modality: perfect aspect, progressive aspect, existential there subject, state verb, quasi-modal, and inanimate subject. Wärnsby (2006:49-51) not only quantifies and exemplifies Coates’s (1983) features, but also proposes a number of explanations for their applicability. For example, Wärnsby (2006) argues that the incompatibility of the perfect aspect with non-epistemic modality derives from the fact that directed or permitted actions can normally only be posterior, and that of the progressive aspect from the fact that one cannot permit something that is already happening and therefore is beyond the agent’s control. The high strength of the correlations reported by Coates (1983) and Wärnsby (2006) are undoubtedly a by-product of the size of their databases (3460 times smaller than GloWbE for Coates 1983, and 2670 for Wärnsby 2006). Infrequent as they may be, non-epistemic examples are not entirely excluded by the identifying features. For example, while must and may cannot be used subjectively to oblige or permit someone to do something in the past, anteriority with the perfect aspect is nevertheless possible if they are used objectively in a general requirement or granting of permission, as in (8) and (9).
(8) Excise Duty must have been paid before the goods are sent otherwise goods may be seized (GloWbE, GB)
(9) The world is increasingly becoming a small place. Today, job opportunities are not just limited to India alone, although you may have completed your education here. A whole lot of other countries have Indian workers employed in scores. (GloWbE, IN)
There is a second type of indicator of epistemic meaning in modal expressions to which appeal is made in the study, namely adverbials functioning either as “harmonic” expressions or as “hedges.” Harmonic adverbials are congruent with the type of epistemic modality expressed by the (quasi-)modal. For example, in must surely, the adverb surely is compatible with the speaker’s strong confidence in the logical necessity of the proposition, and in may perhaps, perhaps is compatible with the speaker’s inference that the proposition is logically possible. By contrast, hedges are semantically non-harmonic expressions: in must presumably, the adverb serves to pragmatically weaken the speaker’s confidence; and in surely may, the weak may and strong surely express independent modal meanings (‘surely it is the case that it is possible’). 3
4. Results
Fourteen pairs of semantically similar modal expressions are identified, associated with three broad semantic groupings: necessity and obligation; possibility, permission, and ability; and prediction and volition.
4.1. Necessity and Obligation
4.1.1. Must versus Have to
Must and
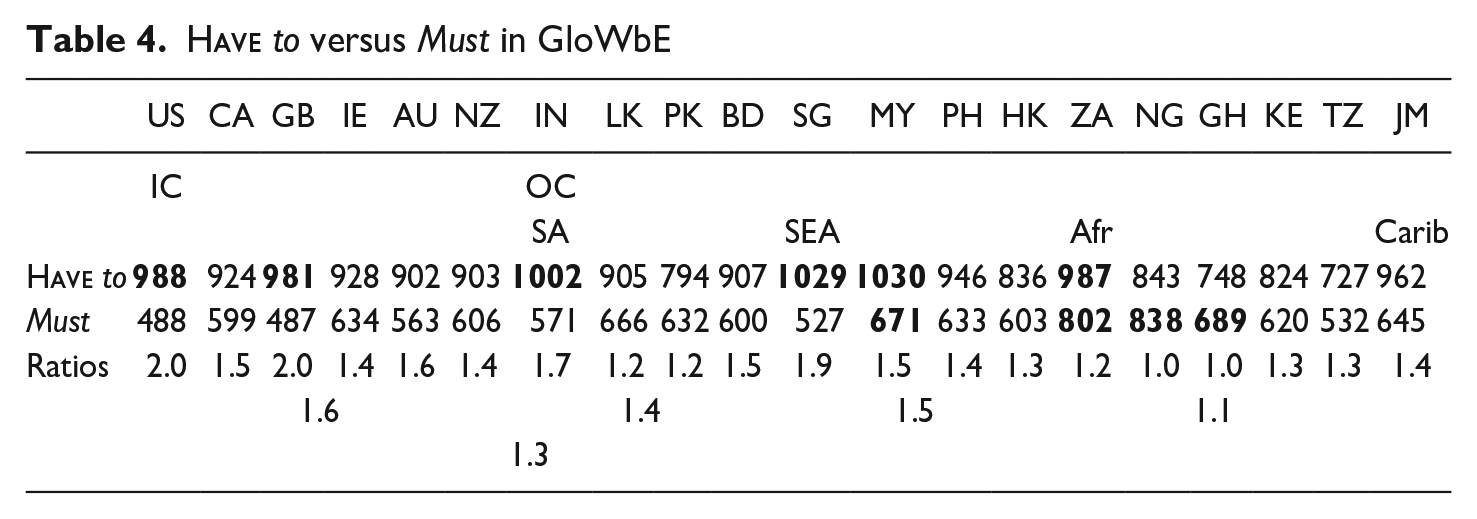
The pmw frequency-based ratios presented in Table 4 show the relative preference for the quasi-modal over the modal to be stronger in the IC than the OC, an unsurprising finding in view of the evidence that the IC varieties tend to be more advanced than the OC in current grammatical change, and especially in colloquialization-driven changes (Collins & Yao 2018; Collins 2023). It is notable that a mere comparison of IC versus OC average frequencies for
Further evidence of the role of colloquialization in the IC versus OC results can be found in the distribution of the informal reduced form hafta, which is precisely twice as popular in the IC (and particularly so in AmE) with 0.12 tokens pmw, as it is in the OC (where the AmE-influenced variety PhilE has the highest number of tokens) with 0.06 pmw. Another factor that appears to be exerting an influence in the ratio-based findings presented in Table 4 is epicentrality: hypercentral AmE and supercentral BrE have the strongest ratios overall; IndE has the strongest ratio in SA; and SingE in SEA. Another finding consistent with that of other studies is that the most IC-like of the OC subgroups is SEA, a finding supported by the relatively evolutionarily-advanced status of the SEA varieties (Collins 2022, 2023).
Finally, consider the expression of epistemic modality by must, as in (10). Application of the relevant tests discussed in section 3 revealed that epistemic must is more common in the IC than the OC. For must have
(10) He must be having a lot of new experience in the school on first day. (GloWbE, SG)
(11) Any actor who could accurately depict that backstabbing jerk would have to be good. (GloWbE, AU)
4.1.2. Have to versus Have got to
The quasi-modals
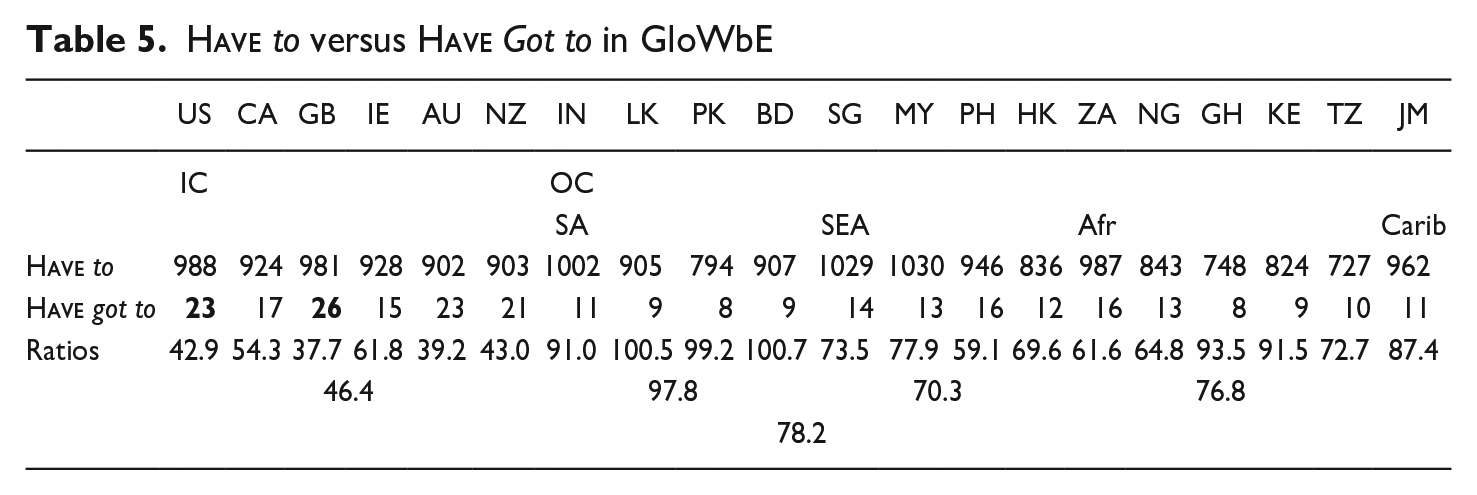
As Table 5 indicates, the preference for
Like
(12) You have got to be joking when you say, “Islam discourages outsiders from enquiry.” (GloWbE, AU)
4.1.3. Should versus Ought to
Should and ought to are semantically close and often interchangeable, as suggested by mutually-reinforcing examples such as (13) and (14).
(13) Something ought to and should yield in the interest of a harmonious existence. (GloWbE, NG)
(14) In sum, the court should and ought to dismiss this petition for the foregoing reasons (GloWbE, KE)
According to Huddleston and Pullum (2002:186), “[i]n its most frequent use should expresses medium strength deontic or epistemic modality and is generally interchangeable with ought (+ to).” However, ought to is far less common than should, and, like other low frequency modals, is in rapid decline (see Table 1).
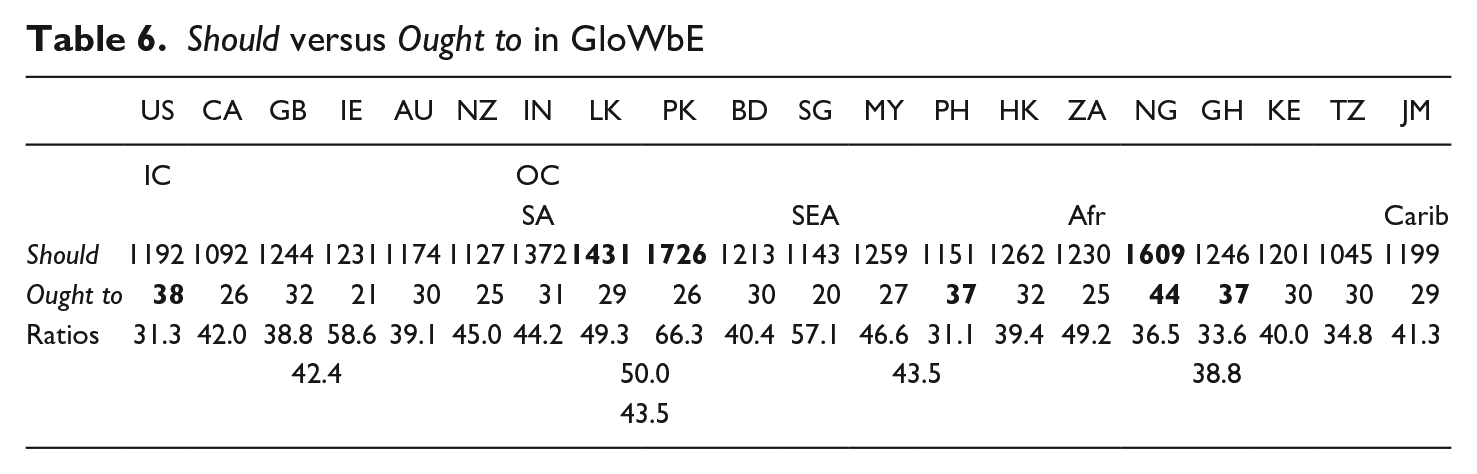
The ratios in Table 6 indicate a dispreference for ought to, relative to should, that is very similar in the IC and OC, and is stronger in BrE than AmE (as the contrasting Brown family percentages in Table 1 would lead us to expect). The relative tolerance of ought to in AmE is shared by the AmE-influenced OC variety, PhilE. Strong epicentrality is evidenced by SingE in SEA and by SthAfrE in Afr. Finally, it may be noted that our alternation-based account paints a different picture of the fortunes of should in the IC than an account based on (average) pmw frequencies alone. In the latter it is not only ought to that enjoys more support in the OC than the IC, but also should, with ratios of 1.06:1 and 1.09:1 respectively, calculated by comparing the average frequency of the six IC countries with that of the fourteen OC varieties.
Another explanation for why should is holding its ground better, and more so in the IC than ought to, is that it is one of the few necessity/obligation modal expressions apart from must and
(15) Playing with Moulson and Tavares should hopefully bring out Boyes old scoring touch from a few seasons ago. (GloWbE, CA)
(16) Spanish goalkeeper David De Gea should presumably also be in contention after missing out against Norwich (GloWbE, GB)
4.1.4. Should versus Had Better
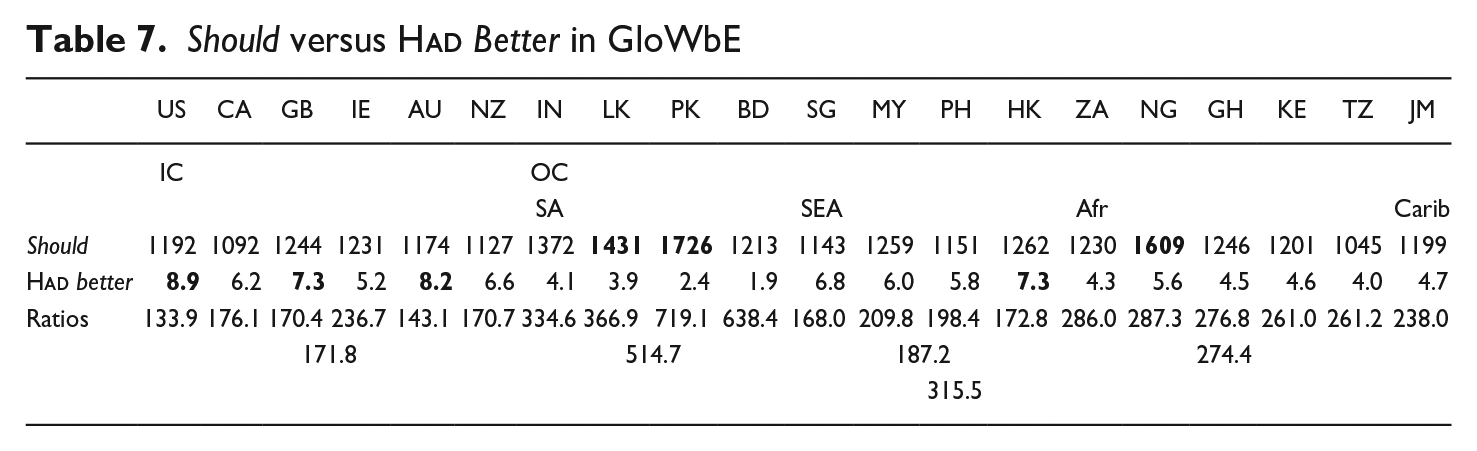
What factors could outweigh the typical intervarietal pattern of IC-leadership noted elsewhere in this study to be associated with diachronically volatile modal expressions? One possibility is the comparative syntactic complexity of
(17) Clearly a Muslim had better be absent than to show up in school during mass and be playing hide-and-seek (GloWbE, GH)
4.1.5. Should versus Be Supposed to
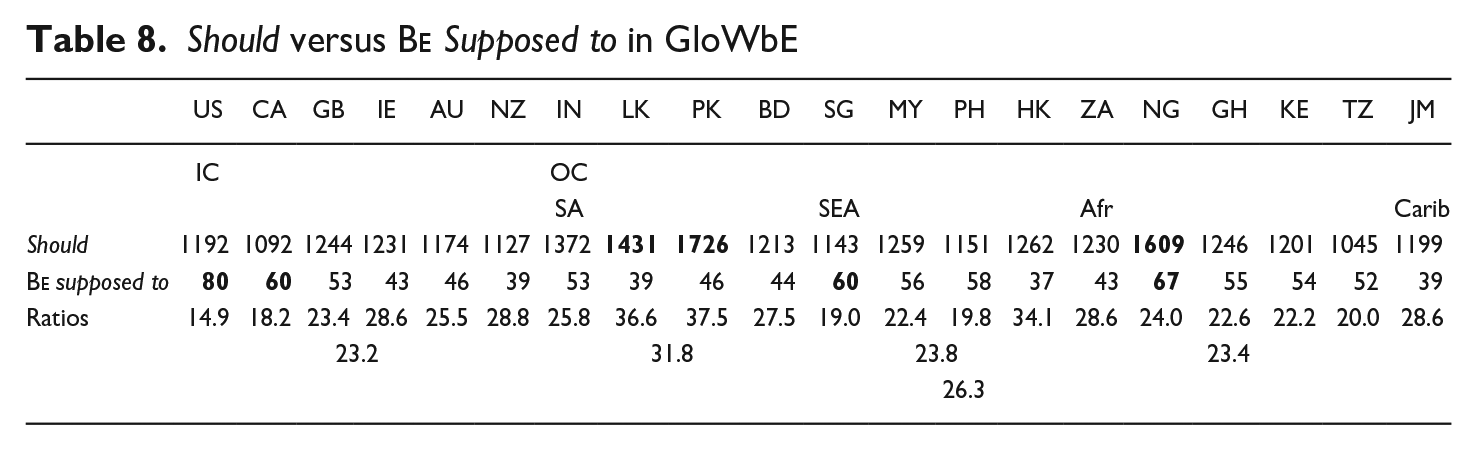
Another factor in the relative frequency of
(18) AT THE FEET OF THE MASTER, is supposed to have been written by him when he was thirteen years of age (GloWbE, IN)
(19) your prediction about what will happen this November will be as disastrously wrong as your prediction about what was supposed to happen in November of 2008 (GloWbE, US)
4.1.6. Need to versus Need
I have operated with the principle that modals have no non-tensed forms and no separate third person singular present tense form or regular past tense form with -ed as suffix (cf. Quirk, Greenbaum, Leech & Svartvik 1985:138-139; Huddleston & Pullum 2002:109; Collins 2009a:12-13). By these criteria, indeterminate cases such as (20) and (21) are understood to contain quasi-modals, the absence of the to-infinitive a matter of secondary importance (e.g., van der Auwera, Noël & de Wit 2012).
(20) But really, this needs not be our destiny; it need not be our collective fate (GloWbE, NG)
(21) she feels that she needed not give men ‘chance’ (GloWbE, GH)
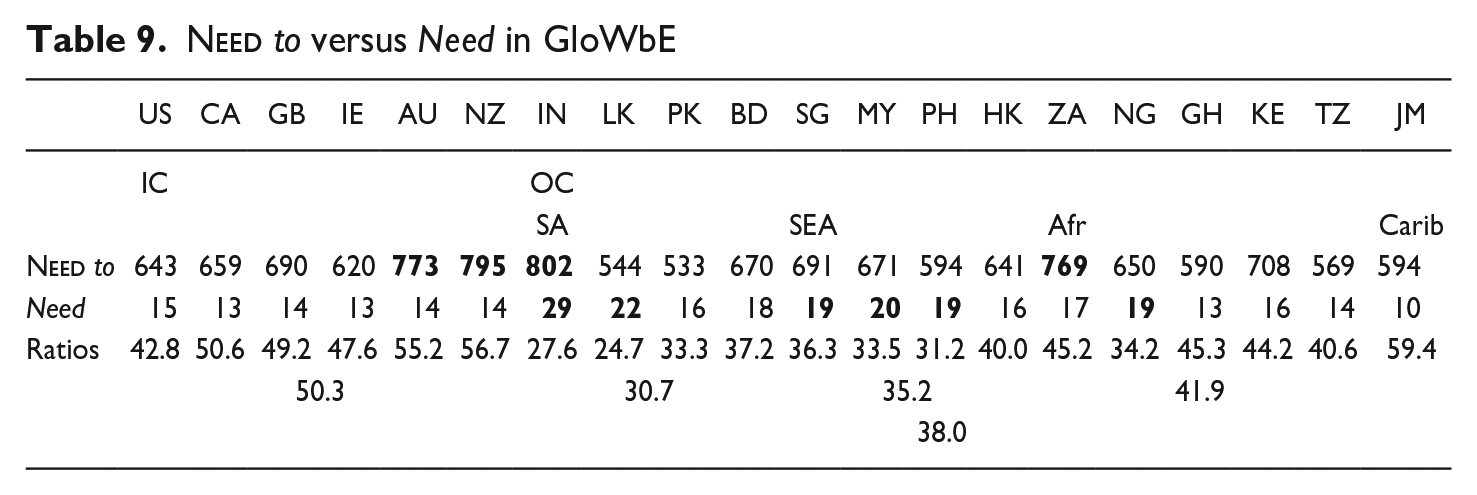
Table 9 presents the results of the search for modal need (via the query “need.[vm*]”) and for the quasi-modal (
The relationship between the modal need and the quasi-modal
While its capacity to express epistemic modality is not sufficient to save need from decline, it is notable that—as is commonly the case with epistemic modality—epistemic need, as marked by its collocation with necessarily in (22), is more frequent in the IC than the OC, by a ratio of 1.59:1.
(22) Furthermore, money given to poor country governments needn’t necessarily end up going to infrastructure or healthcare. (GloWbE, GB)
4.1.7. Must versus Need to
As noted in sections 4.1.1 and 4.1.6 must predominantly expresses deontic necessity, typically used with speaker-oriented subjectivity,
(23) Here in Australia you must wear a helmet when you ride on the road (GloWbE, CA)
(24) Anyways, you
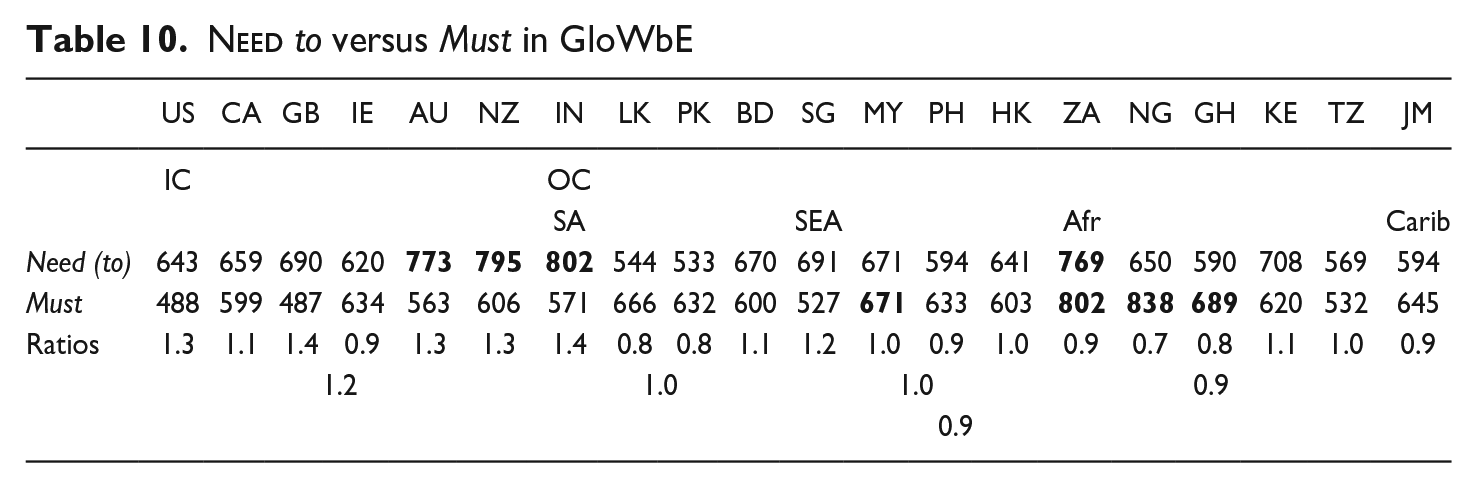
The frequencies in Table 1 indicate the diachronic fortunes for must and
As the ratios in Table 10 show, the (apparently rising) popularity of
4.2. Possibility, Permission, and Ability
4.2.1. May versus Might
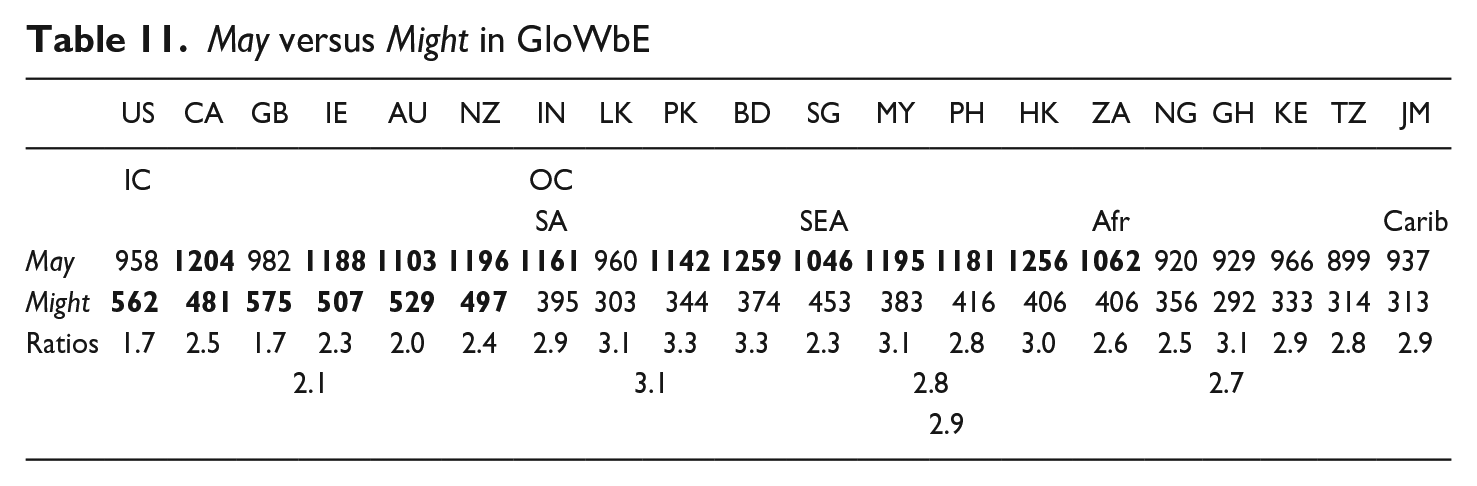
The dominant meaning of both may and might in Contemporary English is epistemic possibility. Opinions differ as to the degrees of likelihood they express. Some claim that the degrees are the same, including Coates (1983:152) and Collins (2009a:111), and others argue that may expresses a greater degree of likelihood, including Hermerén (1978) and Palmer (1990). May has shown a greater declining tendency than might (see Table 1). One likely factor in this trend is the anti-colloquiality of may (whose higher frequency in General over Blogs [1.28:1] contrasts with might’s higher frequency in Blogs over General texts [1.10:1]; see Table 2).
Unsurprisingly, as Table 11 shows, it is the typically more advanced “hypercentral” AmE, along with “supercentral” BrE, which show the strongest relative preference for might and dispreference for may, in both the IC and overall. The same relative preference is evidenced by the IC over the OC, by IndE in SA, by SingE in SEA, and by SthAfrE in Afr.
Are there semantic factors influencing the findings presented in Table 11? It is arguable that might is becoming the primary exponent of epistemic possibility. One piece of evidence for this is that collocations of might with the progressive aspect represent 2.75 percent of all tokens of might in GloWbE, compared with only 1.59 percent for may. A further piece of evidence is that coordinative sequences in the GloWbE data where the speaker switches from epistemic may to epistemic might, as in (25), are more common than those from epistemic might to epistemic may (21 versus 7 tokens respectively).
(25) These footwear may or might possibly not have beads, gems etc. (GloWbE, CA)
The differences between may and might that we have observed—when combined with the further finding that the IC versus OC ratio of might be
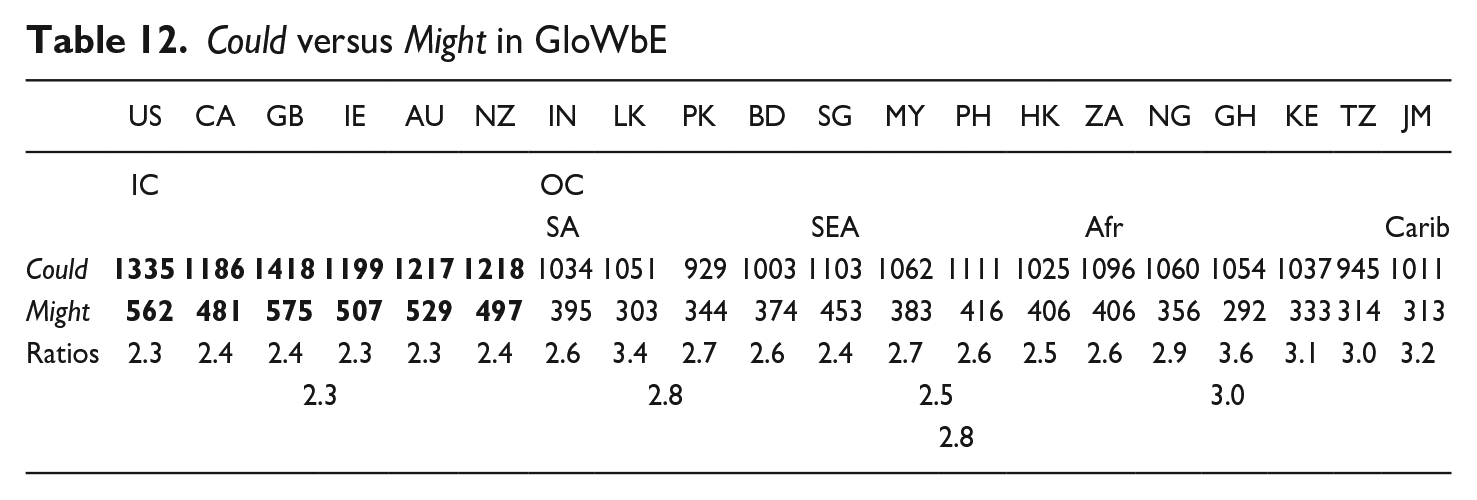
4.2.2. Might versus Could
The past tense modals might and could differ from their present tense counterparts, may and can, in having two broad uses: temporal and hypothetical. As Table 2 indicates, the more frequently occurring of the two, could, is also the more diachronically stable. The frequencies in Table 2 suggest that these two modals have comparable levels of colloquiality. The ratios in Table 12 present might as more frequent in the IC than the OC, relative to could, as it is in SEA within the OC. Possible explanations are that epistemic possibility is more commonly expressed by might than could, and epistemic might is more speech-friendly than is epistemic could (Collins 2009a:109, 176-177). In the present study, the use of both might and could in the existential-there construction, as in (26), where they predominantly express epistemic meaning, was found to be more frequent in the IC than in the OC (might 1.33:1 versus could 1.05:1).
(26) Given the results so far, there could be 20 to 50 tigers here. (GloWbE, GB)
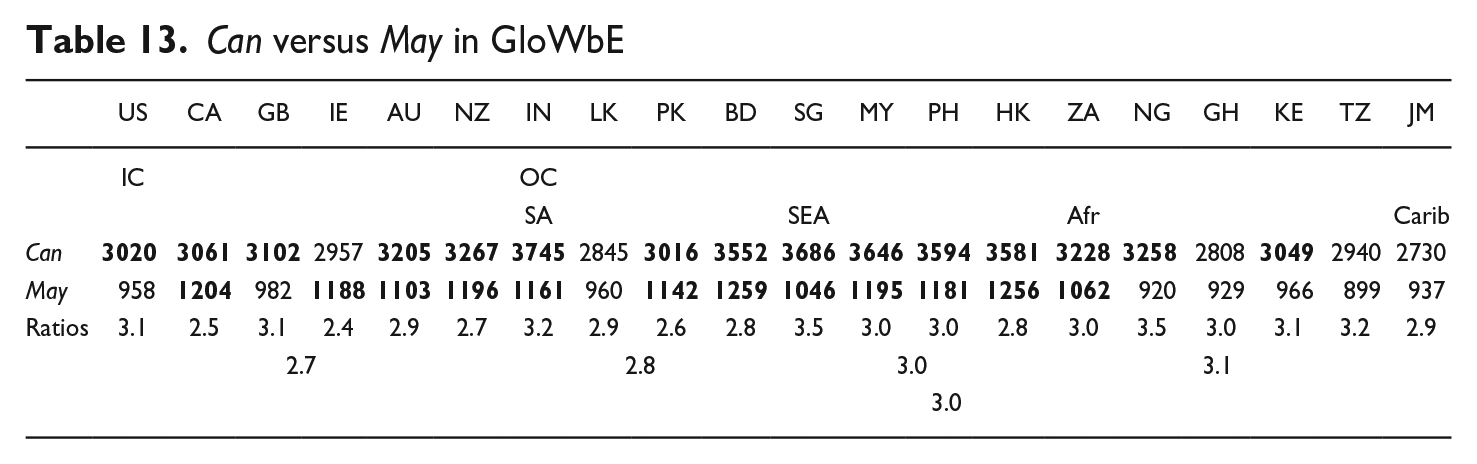
4.2.3. Can versus May
Can is a high-frequency, diachronically stable modal whereas may is a lower-frequency modal that is undergoing a strong decline (see Table 1). One factor in their contrasting fortunes is that may, as a predominantly epistemic modal, is encountering competition from epistemic might and could, whereas can has little competition as an exponent of dynamic possibility (including ability). Another is that the colloquiality of can (whose distribution is skewed toward Blogs: see Table 2) contrasts with the anti-colloquiality of may (skewed as it is toward General texts).
Table 13 indicates that the frequency of can relative to that of may is marginally stronger in the OC than the IC, with relative ratios suggestive of epicentrality in the three IC subgroups as well as in SA and SEA. The relatively stronger support for may in the IC may be attributable to the greater predilection for epistemic may in the IC than the OC, as noted in section 4.2.1.
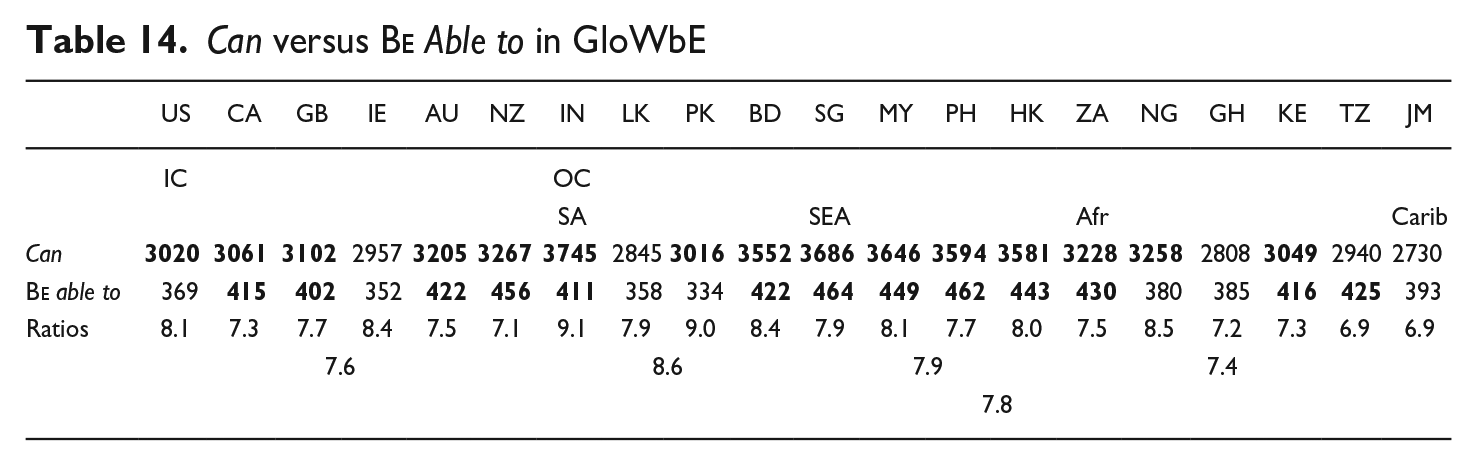
4.2.4. Can versus Be Able to
(27) Running some unencrypted performance tests. I was able to achieve 11.9MB/s (95.2 Mbit/s) throughput across the firewall. (GloWbE, CA)
4.3. Prediction and Volition
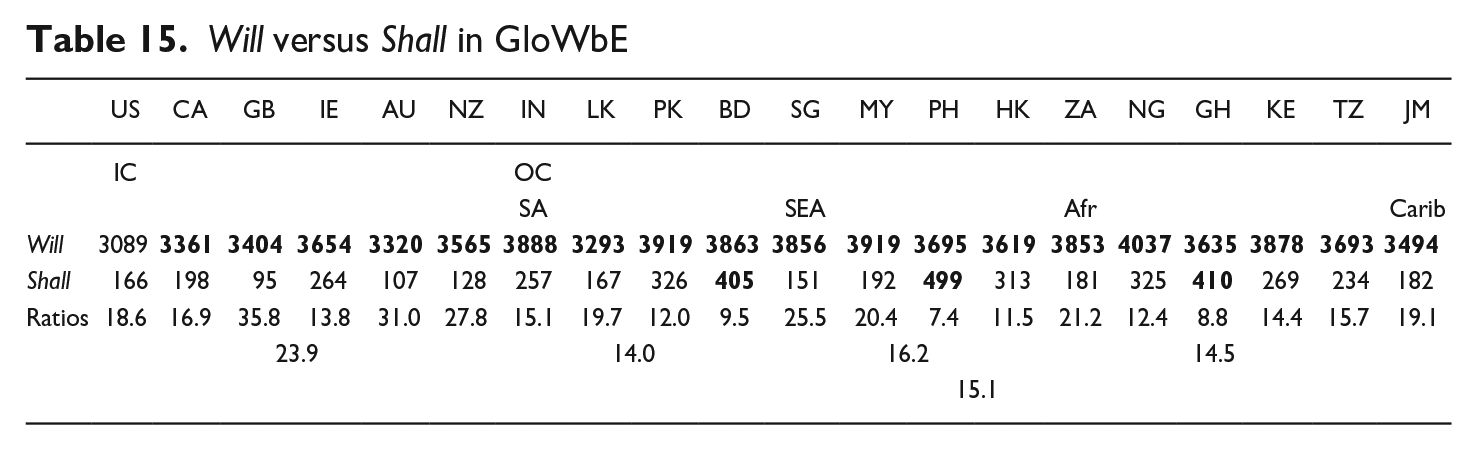
4.3.1. Will versus Shall
The high frequency modal will and the low frequency shall contrast markedly in their diachronic trajectories, the former undergoing a modest decline and the latter a major decline in Leech, Hundt, Mair, and Smith (2009) (see Table 1). One factor in the different fortunes of the two modals here may be their strikingly different generic distribution, as presented in Table 2, where will displays a Blogs versus General text ratio of 1.05:1, and by contrast shall is much more frequent in the General texts, with a ratio of 3.18:1.
Another factor is semantic: will is the primary exponent of epistemic predictability and prediction, while shall is no longer a viable competitor for will in this semantic area, having become predominately a marker of constitutive/regulative deontic modality (Collins 2009a:126, 135). Will tends strongly toward epistemic meaning when it collocates with hopefully, a combination that is more frequent in the IC (2.9 tokens pmw) than in the OC (1.9). This collocation contrasts with will gladly, which tends strongly to volitional meaning, and is less frequent in the IC (90.3 tokens pmw) than in the OC (101.4).
The pmw frequencies and ratios for uncontracted will and shall in Table 15 indicate that shall is less frequent in the IC than in the OC. Epicentrality appears to be a factor in the demise of shall, as reflected in the ratios for AmE over CanE, BrE over IrE, AusE over NZE, SingE in SEA, and SthAfrE in Afr.
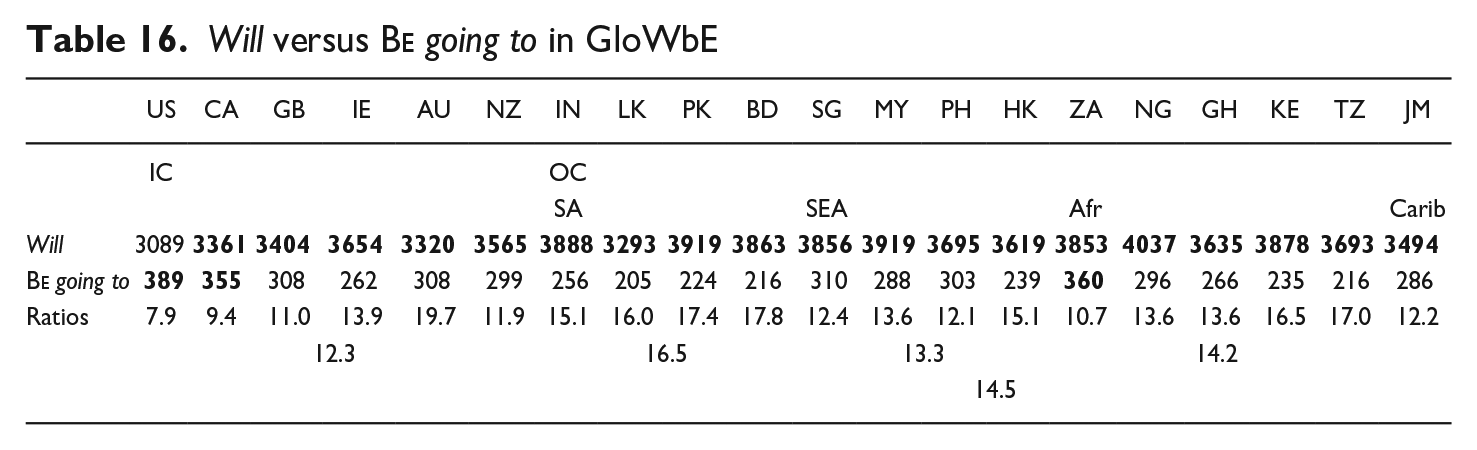
4.3.2. Will versus Be going to
Will and
The ratios in Table 16 suggest that
That semantic factors may be playing a role in the IC versus OC results is suggested by the frequencies for some epistemically-oriented collocations. When combined with the harmonic adverb probably, the pmw frequency of
4.3.3. Be About to versus Be Going to
(28) And Vonner...... if he was in any Premiership side as a regular- guess what? We wouldn’t get him!!...... or do you think Harry Rednapp and Joe Jordan are just about to arrive as well? (GloWbE, GB)
(29) Customers are more likely to ignore a deal if they know another one is going to arrive shortly. (GloWbE, ZA)
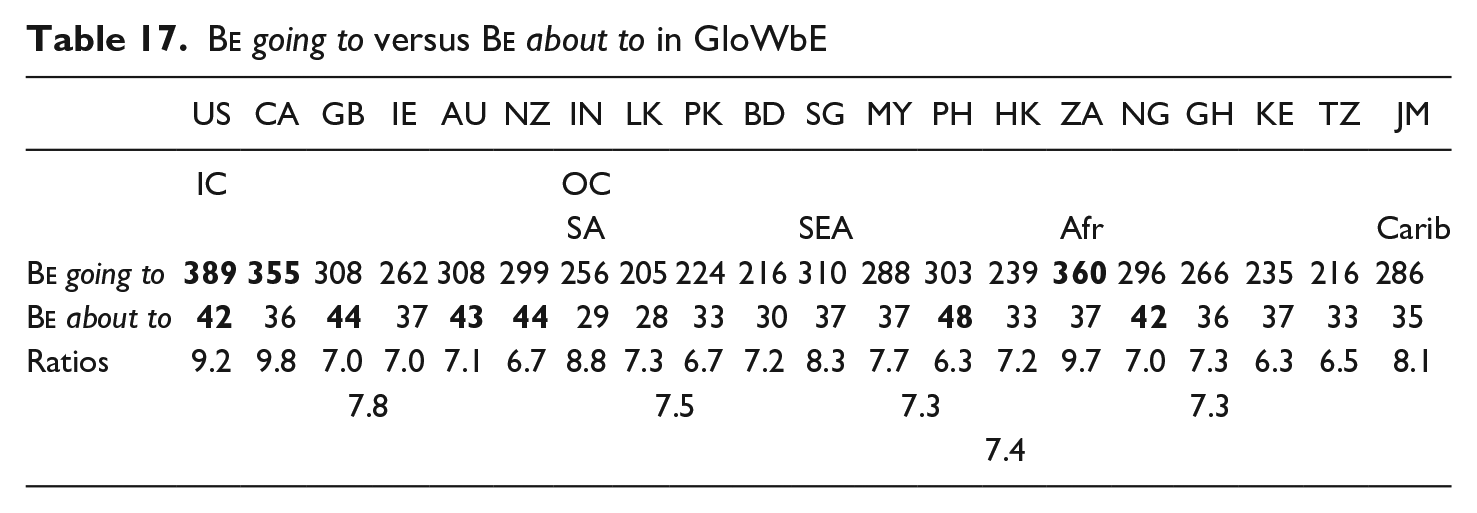
The ratios in Table 17 indicate that the frequency of
5. Conclusion
Let us review the study’s findings in light of the explanatory factors presented in section 2, beginning with Kachru’s (1985) Concentric circles typology of varieties. The IC varieties have been found here to typically have higher quasi-modal frequencies and lower modal frequencies than in the OC varieties, suggesting a tendency for the IC to be more advanced than the OC in diachronic trends that have been observed in the literature (notably the declining trajectories of most modals and the rising trajectories of most quasi-modals). Clear cases of this pattern are the relative dominance of
The influence of areal proximity is evident in many of the study’s findings. For example, the American, European, and Oceanian regional subgroups of the IC exhibit internal consistencies that are reflective of the historical and geographical ties between their constituent varieties. This tendency is particularly noticeable with the Oceanian varieties, AusE and NZE, whose similar and shared histories are reflected in their postcolonial evolutionary parallels (Schneider 2007:118-133). Co-patterning of AusE and NZE is found with
Linguistic epicentrality, the potential of a variety to influence neighboring varieties, is widely attested in the results. The epicentrality of IndE in SA, vis-à-vis SLE, PakE, and BDE, is suggested in the findings for
As we have seen, in Mair’s (2013) World system model a non-areally-driven concept of epicentrality is applied to the hierarchical interrelationships between WEs in a globalized world, with AmE ascribed “hypercentral” status and with “supercentral” BrE next in the pecking order of English world-wide. The findings of the present study strongly support the putative hypercentrality of AmE, which has the leading ratio overall with
Colloquialization has been postulated as a factor in many of the results, as reflected in the higher frequency of some expressions in “speechy” Blogs over more formal General texts, and anti-colloquialization in the case of several others where the reverse situation is in evidence (see further Collins & Yao 2013; Collins 2015). It is accordingly plausible to assume that colloquialism and informality exert influence, even if only indirectly, on such findings as the tendency for the IC varieties to be more receptive than the OC of the generally increasing use of speech-friendly quasi-modals and the decreasing use of the typically writing-friendly modals (Collins & Yao 2018). Some classic cases of (anti-)colloquialism-influenced findings are those for
Another finding of the study, that epistemic meanings are more frequent in the IC than the OC varieties, requires a different kind of explanation, one based in cognitive semantics. According to Sweetser (1990), the development of epistemic meanings in the English modal system occurs later than that of root meanings, via the process that she refers to as “subjectification.” There is furthermore some evidence that this pattern may be mirrored ontogenetically in the “history” of individual speakers, with epistemic uses of modals later-acquired than root uses (Le Bonniec 1970; Kukzaj & Maratsos 1975; Cournane 2014). More speculatively, it may be suggested that such correspondences extend to dialect formation as well, thereby providing an explanation for why epistemic meanings tend to be more frequent in the longer established IC varieties than in the developing OC varieties. This suggestion is reinforced by Collins’s (2022) finding that epistemic comment markers such as possibly, maybe, probably, presumably, supposedly, and undoubtedly have a distribution similar to the epistemic (quasi-) modals studied in this paper.
A number of the study’s results indicate that the ratios-based onomasiological approach achieves a level of descriptive adequacy that surpasses one based solely on pmw frequencies. For example, as we have seen, the relative strength of the IC ratios for the quasi-modals
In this study, historical modal and quasi-modal trajectories gleaned from corpus-based studies of BrE and AmE have been cited to support inferences of advanced and conservative modal trends drawn from synchronic multi-varietal GloWbE data. In the absence of available diachronic corpora representing all but a few of the GloWbE varieties, the status of such developmental inferences must ultimately be regarded as provisional, awaiting empirical substantiation via real-time diachronic data. I conclude by repeating my exhortation of 2015 to colleagues that they “address the ‘diachronic gap’ in the World Englishes paradigm” by the imaginative use of not only available corpora but also “newly-prepared purpose-built corpora” (Collins 2015:10). 5
Footnotes
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.