While examples have been clearly attested in the literature, the reversal of a merger is an uncommon occurrence that apparently contradicts principles underlying sound change. Understanding the implications of merger reversal therefore requires understanding of their implementation: whether there was a full merger in the first place, what the phonetic path taken to separate the merger was, and whether there was a social motivation behind the reversal. I take this approach in a case study of the traditional start-north merger of St. Louis English, which has reversed in recent decades. I show that the merger was most likely a near merger, that the reversal was achieved by raising north and fronting start, and that the reversal, at least the raising of north, was socially motivated. I argue that the data highlights the role of perceptual salience in reversing mergers and illustrates that merger reversal can at times be chain shift-like in appearance, if not execution.
One of the more strongly stated principles relating to language variation and change is that phonemic mergers cannot be reversed by linguistic means (Labov 1994). And yet, that phonemic apparent mergers do reverse is attested across varieties of English (Trudgill et al. 2003; Baranowski 2006; Bowie 2012; Maguire, Clark & Watson 2013) and in fact cross-linguistically (Kochetov 2006; Yao & Chang 2016; Sloos 2018). Such reversals are noteworthy for their seeming rarity. Given this, in order to develop a better understanding of how and why phonemic mergers reverse, we should take note any time we find one.
One such apparent reversal is found in the English of white speakers in St. Louis, Missouri. Here, a traditional urban feature was the merger of /ɑr/ and /ɔr/, which the community retreated from during the mid- to late-twentieth century (e.g., Murray 2002; Gordon & Majors 2006; Labov 2007). In the following pages, I refer to these vowels, using Wells’ (1982) lexical sets, as start (/ɑr/; e.g., barn, card) and north (/ɔr/; e.g., forty, cord) respectively. These sets enable comparison of vowels across English dialects even when they differ acoustically to a large degree.
Previous work on the reversal of the start-north merger in St. Louis has mostly amounted to noting it happened.1 I suggest, however, that we should take further interest in it, as a corpus of sociolinguistic interviews from this area is capable of illustrating merger reversal in apparent time. As such, sociolinguistic data from St. Louis can help to shed light on how mergers can be reversed. To that end, I aim to contribute to our understanding of the implementation of the start-north merger reversal in St. Louis. This involves consideration of three questions: what was the status of the vowels prior to separation? How did the phonetic change progress? Why did the reversal occur?
Through analysis of sociolinguistic interview data, I show that production of the start and north vowels constituted a near merger, rather than a complete merger, prior to their separation. As such, they were able to separate because they remained slightly distinct; speakers maintained knowledge of which lexical items were in each vowel class. Although the start-north merger originated due to the raising of start (Labov, Ash & Boberg 2006), the phonetic changes contributing to reversal involved both fronting the start vowel and raising the north vowel. Comparison of vowel production in informal conversation to formal contexts like a minimal pair task reveals that speakers target a higher north and larger distance between start and north in formal contexts. Responses to the minimal pair task only partially align with linguistic production. I suggest that these findings indicate that the raising of north was socially motivated. However, in these same contexts, speakers target a backer start vowel. I suggest that the fronting of start was not socially motivated and in fact predates north-raising.
Once I establish how the merger reversal in St. Louis was implemented, I then consider what the implications are for our understanding of such phenomena. I suggest, following Sloos (2018), that the movement of north was motivated by perceptual salience of the relative difference between white St. Louis English and varieties it is in contact with. Because these varieties typically merge north and force, the position of north within the back pre-rhotic vowels marks a key difference between white St. Louis English and other varieties. As such, speakers with the social motivation to reverse the merger targeted north for change. A lack of word frequency or orthography-based effects on north-raising and start-fronting indicate that the vowels changed as a class rather than via lexical diffusion (cf. Nycz 2013). I hypothesize that start-fronting is what enabled the reversal; by occurring concurrent with or shortly after the initial raising of start to match north, start-fronting maintained the distinction between the vowel classes enough for them to be eventually fully separated when the social motivation to do so arose.
This paper proceeds as follows. In section 2, I review background literature on the start-north merger in St. Louis and elsewhere, as well as merger reversals more generally. Section 3 introduces the sampling methodology, while section 4 reports results that show the start-north merger to be a near-merger and its reversal to be socially motivated. Section 5 discusses how the results show a role for perceptual salience in merger reversal.
2. Background
2.1. Start-north Merger in St. Louis
The set of lexical items corresponding to the start and north vowel classes largely correspond with orthography. The start class usually has <ar>, while north usually is spelled <or>. However, there are exceptions to this pattern. In many American English varieties, including that of St. Louis, (to)morrow, borrow, sorrow, and sorry are in the start class, while lexical items with /w/ preceding <ar>, such as quarter, war, and wharf, are in the north class. There is some cross-dialectal variation as to the complete distribution of lexical items across the classes. Some English varieties, like New York City English, place <or> items in open syllables in the start class (h[ɔ]rse, but h[ɑ]rrible; see Newman 2014). Because the start-north merger in St. Louis appears to pre-date widespread audio recording, it is unclear which distribution of lexical items operated prior to the attested neutralization of the vowels.
According to Labov, Ash, and Boberg (2006), St. Louis is the only urbanized area in North America in which this merger occurs. This description does not mean St. Louis is entirely unique in having the merger even within North America; Labov, Ash, and Boberg note that it may be found in rural areas left unsampled by The atlas of North American English. They suggest, however, that St. Louis is unique in the implementation of the merger. Whereas most communities with such a merger achieve it by lowering north, St. Louis does so by raising start. It is unclear whether this merger in St. Louis was complete or partial in production. Labov, Ash, and Boberg (2006:53) suggest it was a fully complete merger, but the example they give of a speaker who merges the vowels in production and perception shows substantial overlap but slightly distinct mean productions. If this speaker’s production is representative of the variety at large, this may mean that the vowels are only partially merged.
In contrast to the claims of Labov, Ash, and Boberg (2006), St. Louis is not the only urbanized area in which the start-north merger occurs. The merger is widely attested in Utah (Bowie 2003, 2008, 2012), and we would have expected it to be found in the Atlas’ sample of speakers from the urbanized areas of Ogden, Provo, and Salt Lake City.2 That it is not is surprising. Bowie (2008) notes that researchers throughout the twentieth century described the Utah merger in different ways, although most suggest that it involves north lowering. His conclusion is that the Utah articulation of the merger involves both lowering and unrounding of the north vowel (Bowie 2003), although he notes that even this description is overly simplistic given correlations of F1, F2, and F3 with perception of the vowel (Bowie 2008). St. Louis, while not alone in having the start-north merger, thus apparently stands alone in implementation of the start-north merger. However, it should be noted that an absence of documentation does not mean an absence of speakers with a similarly implemented merger. Whether the merger is unique to St. Louis is not particularly important for our purposes. Regardless of uniqueness, it is a highly enregistered and commodified (see Agha 2003; Johnstone 2009) feature of St. Louis English as spoken by whites.
Start-raising in and of itself is not uncommon in North American Englishes. The Back Chain Shift, found in the South, the Mid-Atlantic, and Pittsburgh, involves raising of this vowel (Labov, Ash & Boberg 2006). As such, start-raising is sometimes considered to be part of the Southern Vowel Shift (Dennis Preston personal communication 5 January 2018). There is a key difference between start-raising in St. Louis and elsewhere, however. In the Back Chain Shift, there is no period in which start and north overlap. The common incidence either does not reflect a common origin, or St. Louis diverged from the chain shift pattern at some point.
Recent work across the United States has found a general pattern of retreat from urban features (Dodsworth & Kohn 2012; Driscoll & Lape 2015; Labov et al. 2016; Wagner et al. 2016).3 The start-north merger in St. Louis appears to be no different in this regard (Murray 2002; Goodheart 2004; Gordon & Majors 2006; Labov, Ash & Boberg 2006). Dialect contact due to in-migration or urban-suburban contact may play a role. Duncan (2018), for example, observes that the merger is largely absent from an apparent time sample of a middle/upper-middle class inner-ring suburb, and contact with these speakers would provide an opportunity to learn the contrast. It is generally suggested that St. Louis is adopting the merger of north and force common across many North American Englishes, although the new configuration is often left unspecified (Murray 2002; Goodheart 2004; Gordon & Majors 2006; Labov, Ash & Boberg 2006). How exactly the change was implemented remains an open question. The community could lose the start-north merger by simply lowering start. If, as the literature suggests, the community did adopt the north-force merger, this could be achieved either by lowering start and raising north, or by raising north alone. Labov, Ash, and Boberg (2006) find one speaker with the north-force merger in St. Louis who both raised north and lowered start in comparison to other speakers, but it is unknown whether this speaker is representative of the community at large. It should be noted that among all speakers discussed in the following pages, St. Louisans who do separate the two vowels have the distribution of lexical items in which <or> words in open syllables are generally in the north class, with only a limited set of <or> words falling into the start class.
2.2. Merger Reversal
This section outlines why merger reversal is unexpected and discusses three possible explanations for why such reversals occur: that the phones constitute a near merger in production, that speakers have non-phonological knowledge of phones, and that contact effects reintroduce the distinction. One or more of these likely explains why start and north were able to separate in St. Louis.
A phonemic merger is quite simply the loss of a distinction between two phonemes in both linguistic production and perception (Maguire, Clark & Watson 2013). This can be thought of in synchronic terms—a speaker with a merger in their phonemic inventory does not make a distinction between phones that other speakers of their language have historically made and currently do—as well as diachronic terms—a change over time that results in the loss of distinction within a community. Maguire, Clark, and Watson (2013) note that a merger can occur either when production of one phone changes to match that of another, or when two phones converge upon a new place in the vowel space. Either way, the lack of distinction makes apparent why two principles regarding mergers are said to hold. As summarized in Labov (1994:311-313), Herzog’s Principle is that mergers expand, and Garde’s Principle is that mergers cannot be reversed by linguistic means.
Herzog’s Principle follows if we consider a language learner who interacts with some speakers who do merge a pair of phonemes and some speakers who do not. Particularly because mergers tend to occur among phoneme pairs that are not distinguished by many minimal pairs, especially in the same lexical category (Wedel, Jackson & Kaplan 2013), it is simpler for the learner to not posit a distinction, as they will be able to communicate effectively with both merged and unmerged speakers with minimal information loss. Garde’s Principle follows when we consider that a merger results in a complete loss of distinction between phonemes. In the absence of cues as to which lexical items are associated with which phoneme, a speaker attempting to separate two merged phonemes would have to select lexical items at random, which all but rules out successful reversal.
It is apparent, then, that when we say that mergers cannot be reversed, we mean that two phonemes cannot merge and then separate with the same sets of lexical items associated with each phoneme. Garde’s Principle does not rule out a subsequent split, whether into allophones based on a new cue, or new phonemes. However, even under a conservative approach to the concept of a merger reversal in which a merger is reversed if and only if the same lexical items are in their original categories, there appear to be examples of such a reversal. There are three main explanations for this.
The first explanation of a merger reversal is simply that the phonemes in question were never actually merged in the first place. Labov, Karen, and Miller (1991) describe “near mergers,” in which two phones are produced similarly, but measurably differently. In such cases, however, speakers perceive the two phones as merged. For example, in a minimal pair task, speakers would label a pair of lexical items involving the phones as pronounced the same, even if they make a distinction between them in informal conversation. Despite perceiving no difference, the speakers at some level of their linguistic knowledge must know the difference between the phones in order to produce the slight distinction. Labov (1994) suggests that near mergers can be separated; over time, speakers in a community may bring two phonemes quite close together before moving one or both in a different direction. He offers this explanation for the apparent reversal of the mate-meat merger in Early Modern English (Labov 1994:36). Written evidence points to a loss of distinction, yet the vowels were later separated perfectly. If these vowels merely constituted a near merger, this would explain both the separability and the description of the vowels as identical in the written record. Somewhat similarly, Kochetov (2006:104) notes that in a Northern Russian variety, /ʂ/ and /ʃ/ were “incompletely” merged to /ʂ/ in that differences in manner and place of articulation were neutralized, but a length distinction was maintained. Although we cannot know that this situation constituted a near merger without perception data, the slight distinction between the two phones nevertheless enabled their subsequent separation.
There are some attested merger reversals, though, in which the phones in question appear to truly have been merged. This could mean that these instances are still near mergers and that researchers have simply not found the distinguishing phonetic cue. However, it could also mean that there was indeed a complete merger, and that there is some non-phonological factor which speakers rely on as a cue to determine which lexical items fall into which class. One such cue may be orthography. If the phones that merged in production and perception historically have different spellings, literate speakers could perhaps rely on this difference to separate them. For example, in the Russian example described by Kochetov (2006), separation of /ʂ/ into /ʂ/ and /ʃ/, while enabled by the length distinction, is eased by /ʂ/ corresponding to <ɰ> and /ʃ/ corresponding to <ш>. One could imagine that a clear correspondence such as this could enable literate speakers to learn to separate phones even in the absence of a phonological cue.
Relying on orthography to reverse a merger may not be a linguistic means of reversing it per se. However, scholars such as Maguire, Clark, and Watson (2013) suggest that Labov’s (1994) interpretation of Garde’s Principle is too strong, and that some (complete) mergers can be reversed by linguistic means. Yao and Chang (2016) offer a potential example of merger reversal driven by linguistic means. In Shanghainese, /e/ and /ɛ/ came to be in a state of merger or near merger for many speakers. This has recently begun to reverse, with /e/ gaining a glide. Yao and Chang (2016) attribute this change to contact with Mandarin, which has /ej/ in the set of lexical items cognate to the original Shanghainese /e/. As evidence, they note that Shanghainese-Mandarin bilinguals lead monolinguals in the change, and that phone separation is largest in experimental tasks which force speakers to engage in translation-like exercises. Merger reversal by L2 transfer, as they argue, certainly appears to be reversal by linguistic means. However, note that because these vowels are in near merger for many speakers, the Shanghainese example may instead be an example that falls into our first category of reversal explanation: reversal of a merger occurring because it was not a full merger in the first place. Suppose, however, that L2 transfer or orthography were to be shown to lead to reversal of a complete merger. In such potential cases, neither cue to reversal would involve speakers’ knowledge of phonetic or phonological rules. As such, the principle that mergers cannot be reversed by linguistic means may be more conservatively stated that mergers cannot be reversed by phonological means.
The possibility of reversal through L2 transfer points to the final explanation of merger reversal in the literature, which is that reversal occurs due to contact with other varieties of the same language. There are social and linguistic reasons for this. A socially motivated reason is that contact with an unmerged variety may lead to negative evaluation of the merged variety.4 Such negative evaluations are especially well attested for mergers of historically pre-rhotic vowels across English varieties, regardless of whether the variety is rhotic in the present day. There are attestations of negative evaluation of a merger of the near and square vowels in New Zealand English (Warren & Hay 2006). In a perception task, Watson and Clark (2013) find that speakers from the North West of England who merge the nurse and square vowels are evaluated as of a lower status than speakers who do not.
In multiple cases, contact and the evaluations resulting from it are implicated in socially motivated merger reversal. One such example comes from Baranowski’s (2006) work in Charleston, South Carolina. Whereas a traditional feature of Charleston English is a merger of the near and square vowels, Baranowski (2006) finds that the vowels separate in apparent time. Qualitative data from his interviews suggests that the traditional feature may be negatively evaluated socially. Another example comes from Utah, where the start-north merger is separating (Bowie 2012). Bowie (2012) notes that the merger is highly stigmatized, as Utahns see the merger as stereotypically representative of the region. Sloos (2018) suggests something similar for Austrian German, where the bären and beeren vowels had been merged but are separating. She suggests that contact with northern German varieties, which are seen as prestige varieties and do not completely merge these vowels, led to Austrian speakers targeting a distinction.
Contact-derived merger reversal does not necessitate social evaluation, however. There is evidence that speakers who merge two phones may separate them as a result of extended contact with unmerged speakers. For example, Canadian migrants to New York City show some separation of the low back lot and thought vowels, which are merged in Canada but not in New York (Nycz 2013). Nycz (2013) notes that these speakers report the vowels as being the same in minimal pair tasks, suggesting that the separation observed in conversation and read word lists is due to contact, but not conscious awareness of the feature. In this case, vowel production is correlated with word frequency; more frequent words are closer to the extremes of production. Nycz (2013) suggests that this finding indicates that contact is resulting in lexical diffusion. Somewhat similarly, Trudgill et al. (2003) suggest that the contact-induced reversal of a merger of /v/ and /w/ in the English of South East England had an intermediate stage in which the merger was lexically restricted. Such an account appears to imply contact-induced lexical diffusion.
These three explanations of merger reversal—near merger in production, speakers having non-phonological knowledge of phones, and contact phenomena—are by no means mutually exclusive. Broadly speaking, we therefore expect that reversal of the start-north merger in St. Louis will fall into one or more of these patterns. If the feature was only ever a near merger, separation would have always been possible. If it was a complete merger, we expect to find evidence of non-phonological knowledge of vowel classes and/or a contact effect of some sort. Extended contact with unmerged speakers would yield frequency effects on vowel production whereby high-frequency words lead the change. Contact may also result in negative evaluation of the feature, which could motivate reversal. Because orthography is a general cue to vowel class, we may find that speakers use this to separate them. However, given that there are exceptions to any orthography-based rule, we would expect to find temporary orthography effects on production. Namely, <ar> north words should lag in any change to north, while <or> start words should lag in any change to start or briefly participate in change to north.
3. Methods
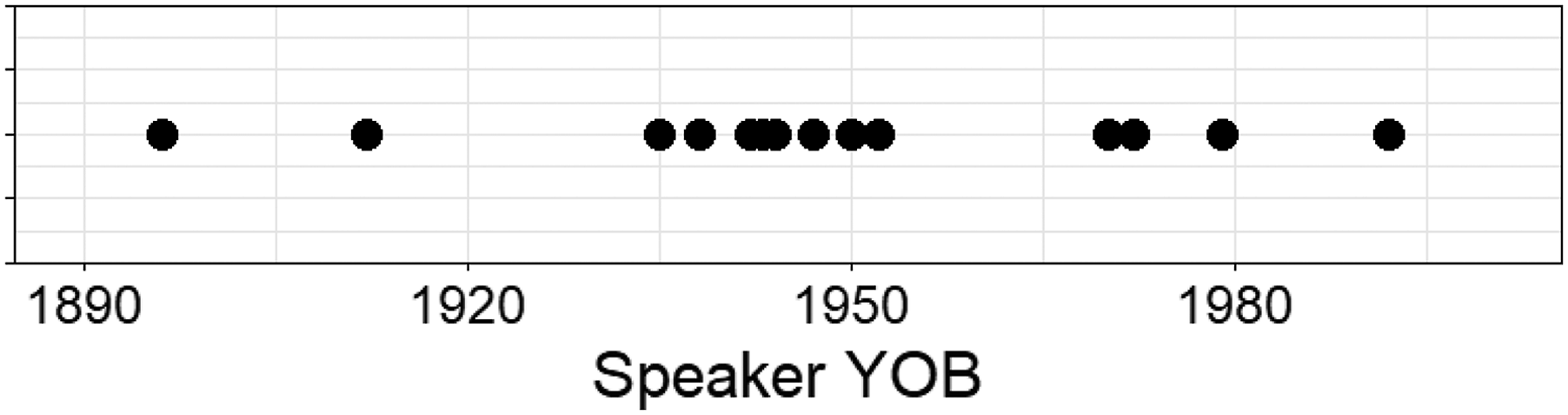
The data in this paper is drawn from a subset of a 2017 project investigating the role of suburbanization in language variation and change in three field sites within Greater St. Louis (N = 98 one-on-one interviews). Because post-WWII suburbanization is widely perceived as a migration pattern of the white middle class in the United States, this project focused on sampling white middle-class speakers. In order to keep data collection manageable across the multiple field sites, other social factors were further controlled for. As such, the sample focused particularly on interviewing women with the reasoning that controlling for speaker sex in this way would illustrate the leading edge of language change in the region (Labov 1972; see Duncan [2018] for further motivation). The speakers included here fit into this category as a result. This larger project found that the status of the start-north merger differed between the City of St. Louis and some of its upper-middle-class suburbs, in that the vowels were completely separated in the speech of interviewees of any age who grew up in high-prestige suburbs like Kirkwood and Webster Groves (Duncan 2018). One view of this would be that the merger was variable throughout the region. However, Duncan (2019) suggests that whether cities and their suburbs constitute cohesive dialect regions is a more complex question than meets the eye. This means that it is an open question as to whether suburban speakers where the merger was not present are members of the same speech community as the urban speakers where the merger was present. For this reason, this paper focuses on the socially and geographically cohesive subset of speakers who grew up in the City of St. Louis (N = 17 white, middle-class women born 1935-1992; no speakers in this subset excluded), where the start-north merger was historically attested. I supplement this sample with two one-on-one oral histories recorded with white women born in 1896 and 1912 who grew up in the city (Communications class oral history project 1987). This takes advantage of the comparability in format and topic of a semi-structured conversation in a sociolinguistic interview to an oral history interview (cf. Becker 2010), and follows the methodology of others (e.g., Friedman 2014) who use oral histories to fill in gaps or extend the range of an apparent time sample. The range of speaker ages and how they distribute across the sample can be seen for all nineteen speakers in Figure 1.
Speaker Birth Years in Sample
Interviews were conducted as a traditional sociolinguistic interview (Becker 2013), with a semi-structured conversational section (40-120 minutes depending on participant’s talkativeness) followed by increasingly formal tasks: a reading passage, word list, and minimal pair task. In the minimal pair task, speakers rated the pairs cord-card, born-barn, morning-mourning, and horse-hoarse as being pronounced the “same,” “different,” or “close.” The two former pairs involve lexical items containing start and north, while the latter two involve lexical items containing north and force. Interviews were recorded at either the participant’s home or a quiet public place such as a library. All recordings were .wav files taken at a 16-bit, 44.1 kHz sampling rate. The equipment used to record changed partway through the project. Of the interviews used in the current study, seven interviews were conducted with a Zoom H4 recorder placed in front of the speaker, using the built-in XY microphone; one with a Zoom H5 recorder placed in front of the speaker, using the built-in XY microphone; and nine with a Zoom H5 recorder, connected to a Shure SM93 omnidirectional lavalier microphone. Although there is some evidence that differences in recording equipment may influence measurements (Švec & Granqvist 2010), the recordings here are comparable as the same fieldworker collected each sociolinguistic interview in the same manner otherwise. Because of this, any perturbations across speakers are likely to be minor and immaterial to the analysis.
An undergraduate research assistant transcribed the conversation section of the interviews, beginning ten minutes into the recording in order to ensure the collection of casual speech data and continuing for fifteen minutes. I transcribed the reading passage, word list, and minimal pair tasks.5 The transcriptions and audio were then forced aligned using the FAVE program (Rosenfelder et al., 2014). A customized script was used to extract F1 values at 40 percent of the vowel in Praat (Boersma & Weenink 2017). Formants were Lobanov normalized (Lobanov 1971) and rescaled using the overall mean and overall standard deviations of the speaker set analyzed in Duncan (2018).6
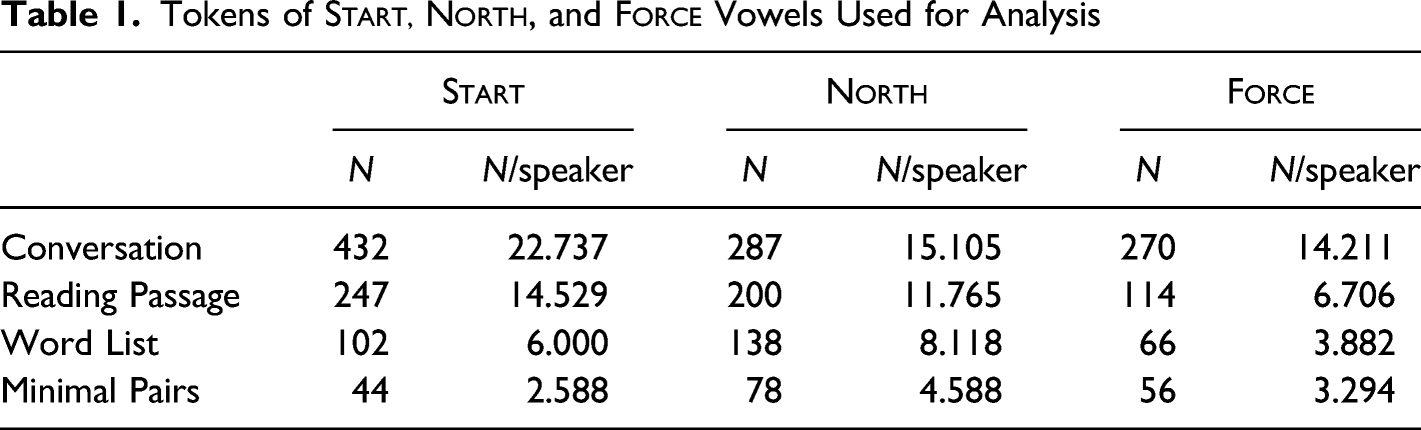
FAVE assumes that speakers have a north-force merger when labeling vowels. To separate the vowel classes, I followed the practice established by Labov, Ash, and Boberg (2006) of coding lexical items for vowel based on the pronouncing dictionary of Kenyon and Knott (1953). In the dictionary, lexical items in the force class are given a pronunciation of /ɔ/ or /o/, while the north class only has a production of /ɔ/. Table 1 summarizes the token counts per section of the interview that this process yielded.
Tokens of Start, North, and Force Vowels Used for Analysis
START
NORTH
FORCE
N
N/speaker
N
N/speaker
N
N/speaker
Conversation
432
22.737
287
15.105
270
14.211
Reading Passage
247
14.529
200
11.765
114
6.706
Word List
102
6.000
138
8.118
66
3.882
Minimal Pairs
44
2.588
78
4.588
56
3.294
There is little reported evidence of phonological conditioning on production of these vowels. Because following nasals often affect vowel production, particularly when it comes to vowels in the lower back of the vowel space (Baranowski 2015), I considered the possibility that this pattern will apply here, and coded tokens for the following environment (word-internally): nasal, other consonant, or none. Tokens in which the vowel occurs word-medially in an open syllable were coded as having no following consonant. Although such conditioning is not attested in St. Louis, this coding system would thus show us if St. Louisans had phonological conditioning of the vowels as in New York City English (h[ɑ]rse, but h[ɑ]rrible; see Newman 2014). Tokens were also coded for the preceding phonological context. Voicing (none, voiceless, voiced), place of articulation (none, coronal, labial, velar), and manner of articulation (none, stop, fricative, nasal, approximant) were included as factors, with affricates treated as stops and /h/ and /j/ treated as velars. Additionally, tokens were coded as to whether they were function words (for, or) or not. Function words were only included in the analysis if they had primary stress.
As discussed in section 2.2, potential outcomes related to merger reversal may include frequency-driven separation (see Nycz 2013) or orthographically guided separation (see Kochetov 2006). Tokens were additionally coded to test for these outcomes. Frequency was coded using data from SUBTLEX-US (Brysbaert & New 2009), a corpus of subtitles from American TV and film designed for obtaining naturalistic word frequencies. Frequencies were Zipf-scaled by taking the base-10 logarithm of the word’s frequency per billion words. For both the start and north vowels, spelling was coded as <ar> or <or>.7
4. Results
Understanding the implementation of the start-north reversal in St. Louis involves three elements. The first consideration is whether the overlap in the vowels constituted a complete merger or not: is there any way to distinguish the vowels even among speakers with a large amount of overlap? The second and third considerations both concern potential effects of dialect contact. The second consideration is to identify the phonetic path of the reversal: in tracing this path, were there frequency and/or orthographic effects on production? The third consideration is to determine to what extent, if any, the reversal appears to be socially motivated. I now explore each of these points in turn.
4.1. Merger Status
A first step in determining whether the vowels were completely merged is to determine the degree of overlap between them. I do so using the Pillai-Bartlett trace of a MANOVA (also called a Pillai score), which is a measure of overlap between categories. This has been used to test whether a pair of vowels are merged (following Hall-Lew 2010; Hay, Warren & Drager 2006), because the measure includes both F1 and F2 in addition to preserving more of the information about the distribution of tokens than other measures do, such as the Euclidean distance between means. Although scores seldomly reach these values, a Pillai score of zero would indicate complete overlap between categories, while a Pillai score of one would indicate complete separation.
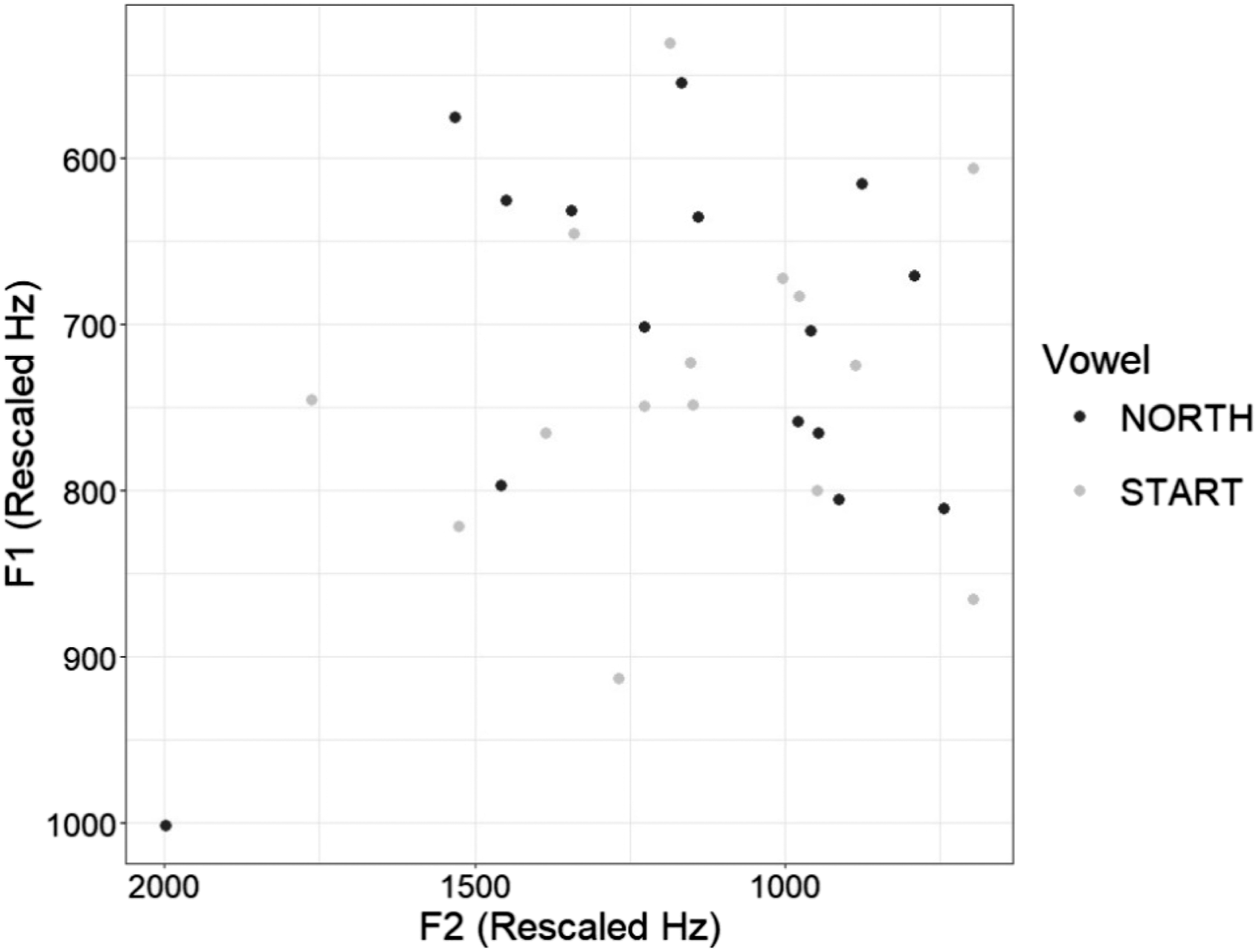
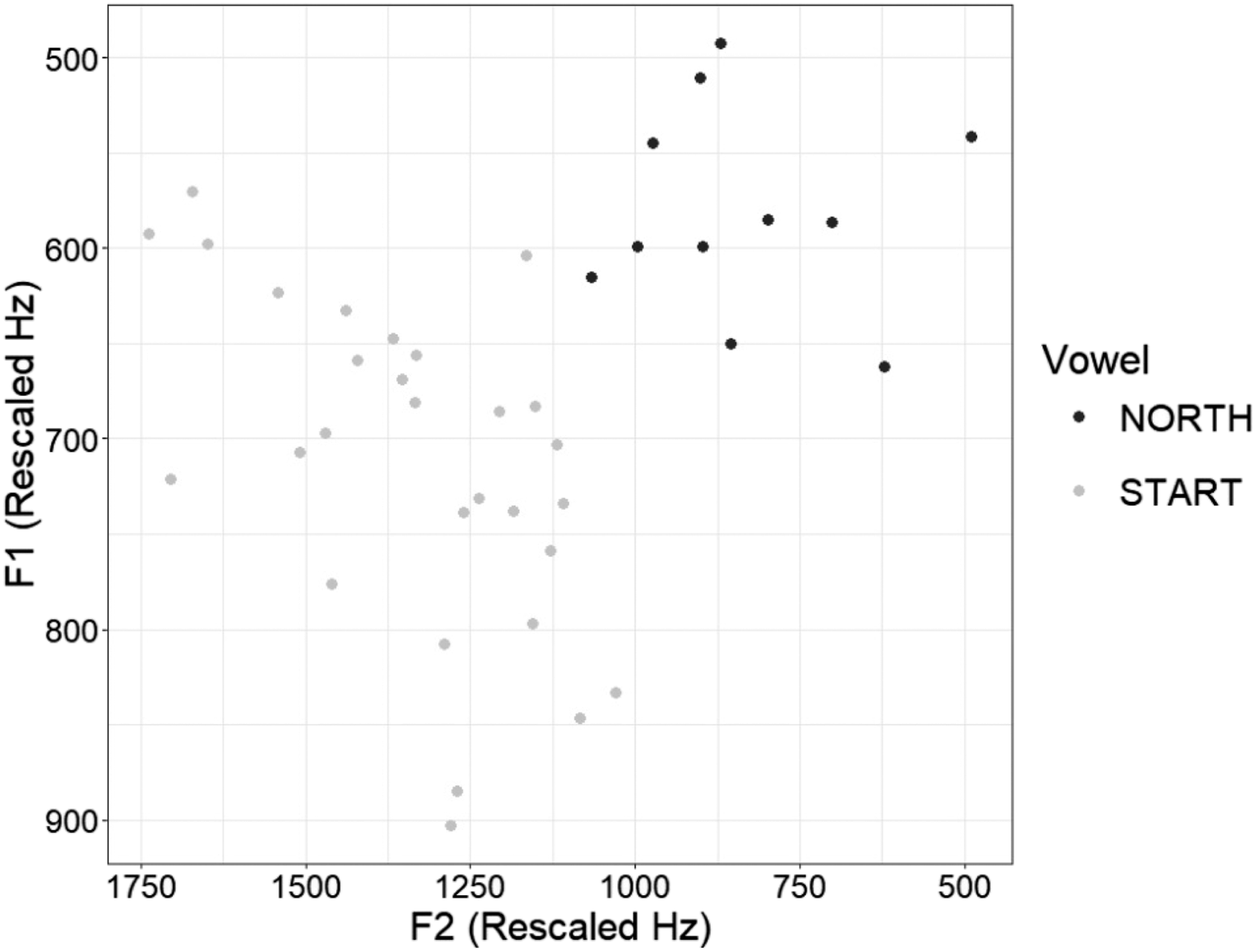
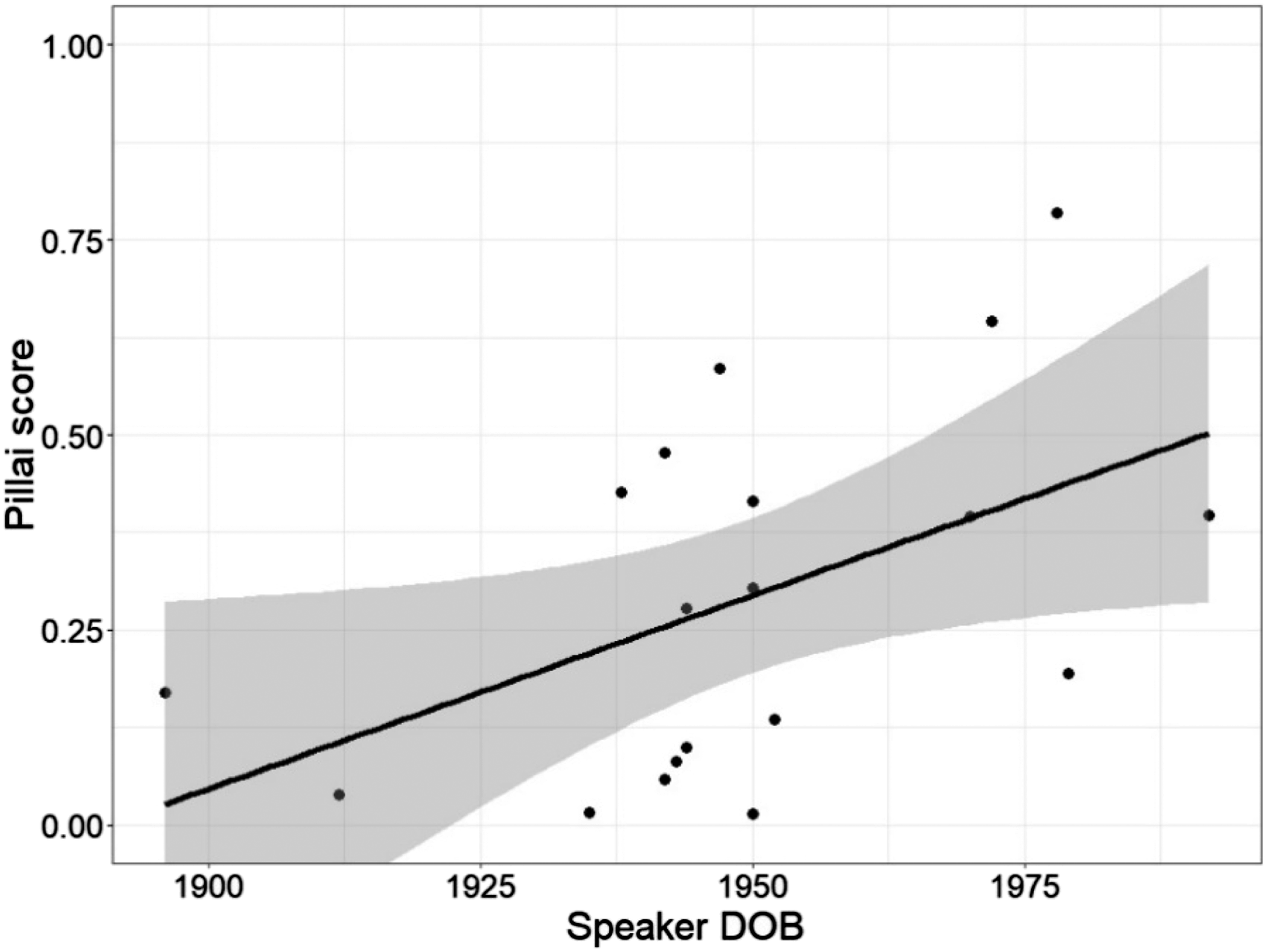
I calculated the Pillai score for start and north in informal conversation for each speaker. Pillai scores ranged from 0.015 (STLWFCB1,8 born 1950; Figure 2) to 0.784 (STLWFNC2, born 1978; Figure 3).
Distribution of Start-North Tokens for Speaker STLWFCB1
Distribution of Start-North Tokens for Speaker STLWFNC2
The very low scores are quite close to zero; several speakers nearly completely overlap in production of the two vowels. Given that in a small sample we would expect some variability, this result would suggest that these speakers almost certainly have a full merger between the vowels. The highest Pillai scores, on the other hand, indicate a large degree of separation between them. Linear regression of Pillai score against speaker age finds a significant effect of age (Intercept β = .626, p = 0.0007; Age β = -.005, p = 0.0329, adjusted r2 = 0.1963); Pillai scores have increased in St. Louis over time (see Figure 4).
Change in Start-North Pillai Scores over Time
Pillai scores indicate, then, that overlap between start and north was essentially total for many St. Louisans born as late as 1950. This, however, does not necessarily mean that the vowels were in complete merger. It is possible, for example, that a slight degree of non-overlap is systematic and indicative of a small difference in the distribution of vowel production. It is also possible that by focusing on an overlap in the overall distribution of tokens, we overlook a difference in mean production. At the same time, it is possible that an acoustic measure other than F1/F2, such as vowel duration, distinguishes the pair. For these reasons, determining merger status requires looking beyond individuals’ Pillai scores.
One way to analyze this further would be to conduct t-tests for each speaker’s F1 and F2 between the vowels. This is problematic; given relatively low token counts per speaker and the need to account for repeated measures, we would likely find many non-significant results. While non-significance could indicate complete merger (i.e., no difference in mean production), it could also simply reflect a lack of power. Instead, I pool data from the speakers with the lowest Pillai scores in order to test for any differences. I use as a cut-off point a Pillai score of 0.1, yielding six speakers (Nstart = 141, Nnorth = 103).9 I maintain my focus on F1 and F2 but also add vowel duration, z-score normalized by speaker, to this set of variables. Combining these three measures into a MANOVA yields a Pillai score of 0.054, which indicates extensive overlap. This is unsurprising, as each of these speakers showed extensive overlap in F1/F2, but it is useful to observe that the distribution of tokens in the pooled data reflects individual speakers’ distributions. Despite the low Pillai score, the MANOVA shows a significant effect of vowel (F = 4.5357, p = 0.0041). This means that while the overlap in production is near total, there is still a mean difference in production. Within this model, the vowels significantly differ in F1 (F = 5.2577, p = 0.0227) and F2 (F = 4.3662, p = 0.0377), but not duration (F = 1.9077, p = 0.1685). This closer examination of the data indicates that start and north had distinct mean productions even among speakers whose vowel production overlapped extensively. If the popular description of start and north as merged is backed up by perception data, the slight distinction in production between start and north would seem to indicate near merger rather than complete merger.
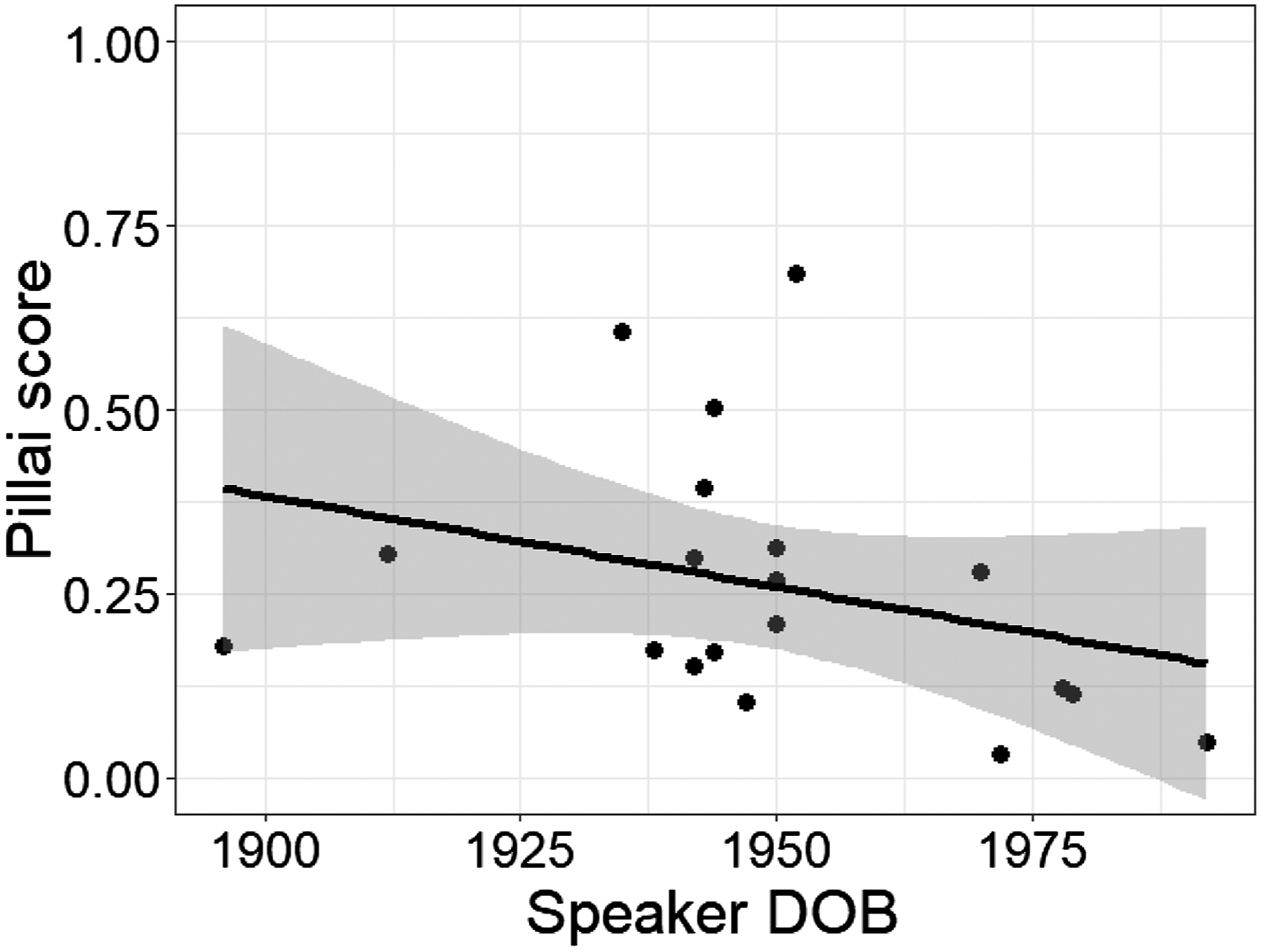
While it is apparent from the data that there was extensive overlap of start-north and that the distributions of the two vowels separated, it is less clear whether that separation causatively led to the merger of north and force. Pillai scores range from 0.034 (STLWFNC1, born 1972) to 0.686 (STLWFCB3, born 1952). Looking at this pair of extremes alone may suggest an apparent time shift from separation to overlap, as the speaker with the most separation is twenty years older than the speaker with the most overlap, but the general picture is less clear, as seen in Figure 5.
Change in North-Force Pillai Scores over Time
Linear regression of north-force Pillai score against year of birth finds no significant effect of age. A separate regression model does find a significant correlation between north-force Pillai score and start-north Pillai score (Intercept β = 0.396, p < ATB 0.0001; start-north Pillai β = -0.465, p = 0.0075, adjusted r2 = 0.3132). This indicates that speakers with a complete separation of start and north have overlap of north and force, and that speakers with a near complete overlap of start and north maintain some level of distinction between north and force. Because start-north Pillai score is correlated with age, we can construct a syllogism that suggests that St. Louis is probably in fact moving toward a merger of north and force over time, if it has not yet already been completed. However, a direct change to a complete merger of north and force with a complete loss of contrast is not supported by the data. Any progression toward this merger should therefore be explored in further research.
4.2. Phonetic Path
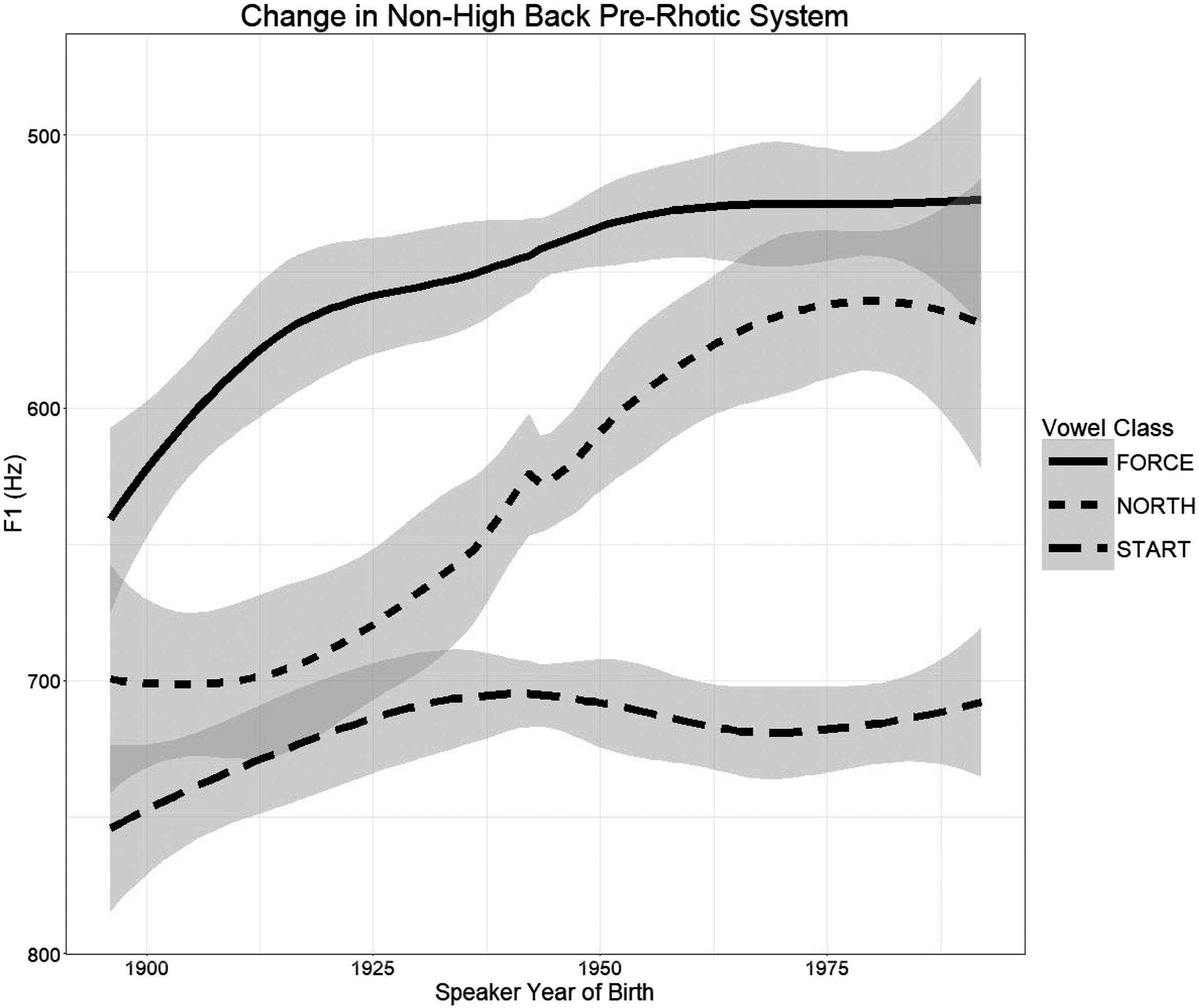
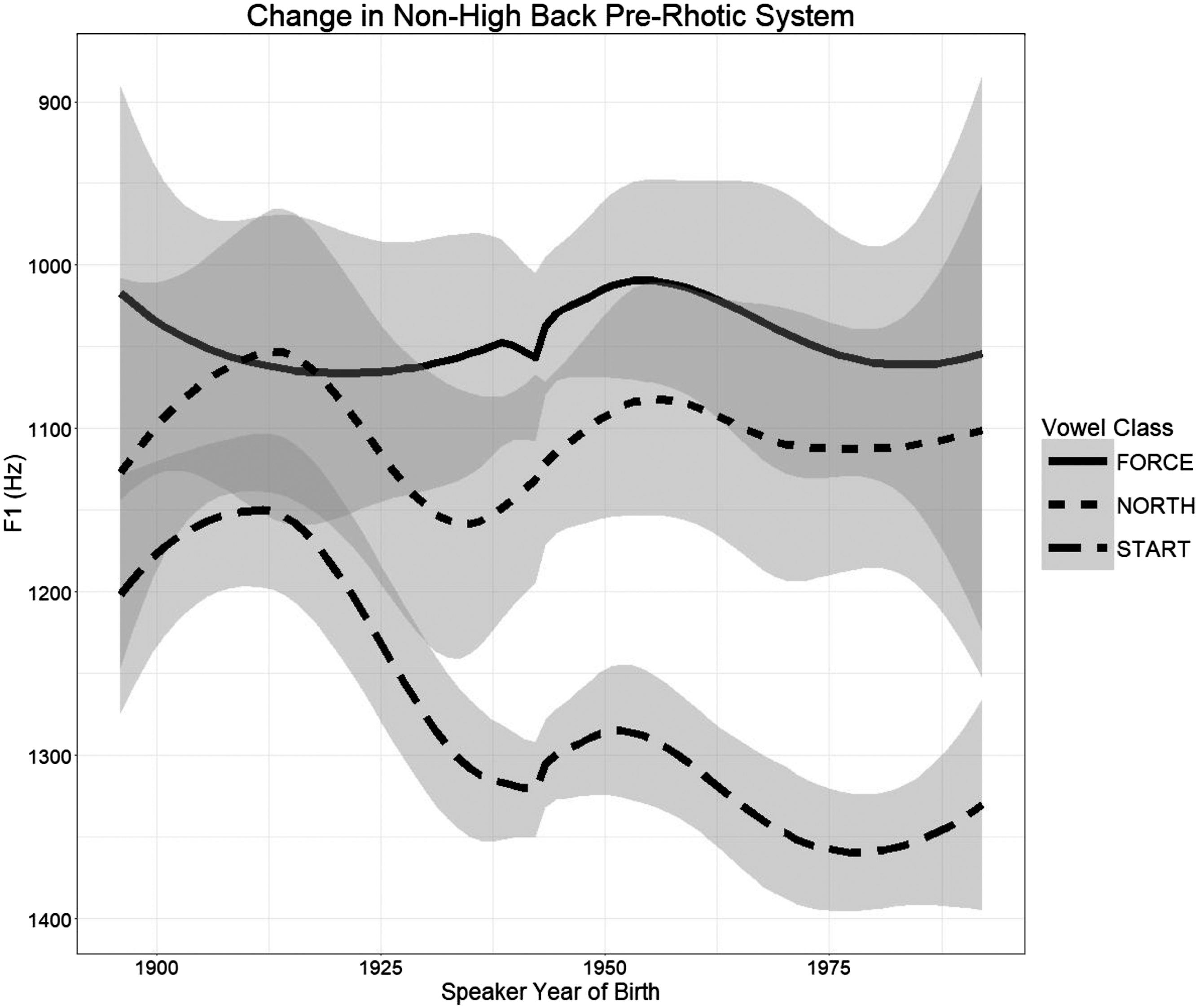
Given that we can see from Pillai scores alone that the start and north vowels separated, the next issue to consider is which vowel(s) changed in which way(s) in order to do so. I begin by considering the three non-high back pre-rhotic vowels within the informal conversation data. Figure 6 shows a loess regression of F1 of each vowel by speaker age. As seen, the start vowel had reached a similar height to that of north before the oldest speaker included in the sample was born, and it did not appear to change much over the following century. The force vowel is similar, showing raising in the early twentieth century before remaining roughly stable over the remainder of the century. It is unclear whether the early raising reflects an actual change or oversensitivity to limited data. In any case, the north vowel stands in contrast to both start and force. This vowel began the twentieth century overlapping with start in F1 (indicated by the non-separation of error bars) and raised in the mid-twentieth century to approach force. Visual inspection thus indicates that the reversal of the start-north merger, and movement toward a potential merger of north and force, was due at least in part to raising of the north vowel.
Change in F1 of Non-high Back Pre-rhotic System in St. Louis
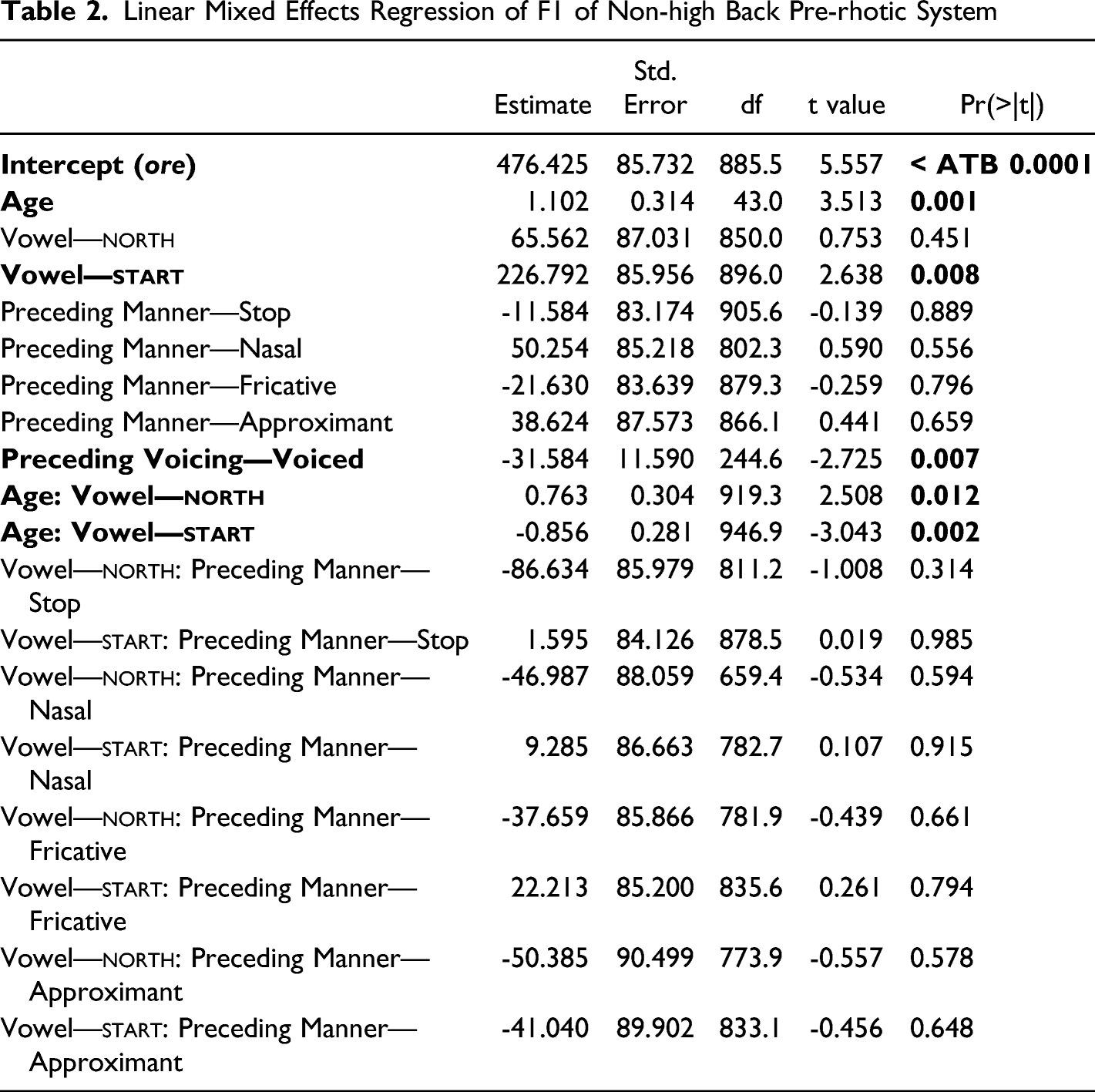
Linear mixed effects regression (Bates et al. 2014) corroborates this initial inspection. A mixed effects model was initially run in which following environment, preceding manner of articulation, preceding place of articulation, preceding voicing, vowel, word frequency, function word, and speaker age were fixed effects, and speaker and lexical item were random effects. Interactions between vowel and the other fixed effects were also considered as possible fixed effects in the initial model. We may only expect frequency effects to occur when a vowel is changing. As such, I also tested a model in which word frequency was a random slope by speaker, as opposed to a fixed main effect. Because there are relatively few exceptional <ar> north items and <or> start items, testing for an orthographic effect in the conversation data was not possible. A final model was selected via stepdown process using the step function in R (R Core Team 2017); the final model eliminated word frequency (whether as fixed effect or random slope), following environment, preceding place of articulation, and function word, both as main effects and their interactions with vowel, as factors. Preceding voicing was kept only as a main effect, and preceding manner of articulation was kept both as a main effect and interaction with vowel.
Table 2 shows the results of the final model, using as a baseline the force vowel with no onset (ore). As expected, there is a main effect of vowel, as start has a different height than force for all speakers. There is no significant difference between north and force in this main effect. There is also a main effect of age, indicating that the raising of force seen in Figure 6 is significant. The vowel is higher when preceded by a voiced consonant. There is one significant interaction between age and vowel. North significantly interacts with age, with the overall effect that north raises faster than force. This interaction shows that north is indeed raising over time. While start also significantly interacts with age, the interaction has the effect of canceling out much of the age effect. This suggests that start is not raising to the same degree as north or force in apparent time. The interaction between vowel and preceding manner of articulation was kept in the final model but is not statistically significant. Overall, the model suggests that the main change to the system of pre-rhotic back vowels in F1 was the raising of north away from start and toward force.
Linear Mixed Effects Regression of F1 of Non-high Back Pre-rhotic System
Estimate
Std. Error
df
t value
Pr(>|t|)
Intercept (ore)
476.425
85.732
885.5
5.557
< ATB 0.0001
Age
1.102
0.314
43.0
3.513
0.001
Vowel—NORTH
65.562
87.031
850.0
0.753
0.451
Vowel—START
226.792
85.956
896.0
2.638
0.008
Preceding Manner—Stop
-11.584
83.174
905.6
-0.139
0.889
Preceding Manner—Nasal
50.254
85.218
802.3
0.590
0.556
Preceding Manner—Fricative
-21.630
83.639
879.3
-0.259
0.796
Preceding Manner—Approximant
38.624
87.573
866.1
0.441
0.659
Preceding Voicing—Voiced
-31.584
11.590
244.6
-2.725
0.007
Age: Vowel—NORTH
0.763
0.304
919.3
2.508
0.012
Age: Vowel—START
-0.856
0.281
946.9
-3.043
0.002
Vowel—NORTH: Preceding Manner—Stop
-86.634
85.979
811.2
-1.008
0.314
Vowel—START: Preceding Manner—Stop
1.595
84.126
878.5
0.019
0.985
Vowel—NORTH: Preceding Manner—Nasal
-46.987
88.059
659.4
-0.534
0.594
Vowel—START: Preceding Manner—Nasal
9.285
86.663
782.7
0.107
0.915
Vowel—NORTH: Preceding Manner—Fricative
-37.659
85.866
781.9
-0.439
0.661
Vowel—START: Preceding Manner—Fricative
22.213
85.200
835.6
0.261
0.794
Vowel—NORTH: Preceding Manner—Approximant
-50.385
90.499
773.9
-0.557
0.578
Vowel—START: Preceding Manner—Approximant
-41.040
89.902
833.1
-0.456
0.648
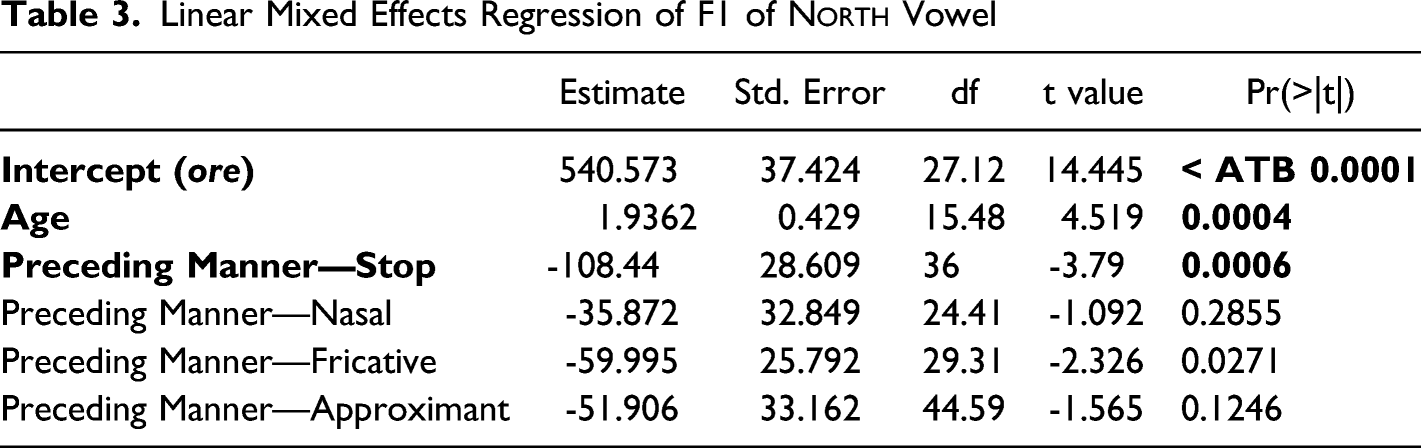
These findings are replicated when considering the north vowel individually. The same initial model, minus the interactions with vowel, was run on north tokens, with a final model selected via stepdown process using the step function. Here, speaker age and preceding manner of articulation are again selected as significant effects, with frequency, following environment, preceding place of articulation, and function word eliminated by the stepdown process (see Table 3). Unlike the previous model, preceding voicing was also eliminated. Frequency was again eliminated when considered as a random slope.
Linear Mixed Effects Regression of F1 of North Vowel
Estimate
Std. Error
df
t value
Pr(>|t|)
Intercept (ore)
540.573
37.424
27.12
14.445
< ATB 0.0001
Age
1.9362
0.429
15.48
4.519
0.0004
Preceding Manner—Stop
-108.44
28.609
36
-3.79
0.0006
Preceding Manner—Nasal
-35.872
32.849
24.41
-1.092
0.2855
Preceding Manner—Fricative
-59.995
25.792
29.31
-2.326
0.0271
Preceding Manner—Approximant
-51.906
33.162
44.59
-1.565
0.1246
Examining F2 shows a different pattern altogether. Figure 7 shows a loess regression of force, north, and start by age. As seen, there is considerable variance in this. It appears that north and force overlap in large part and have not changed in apparent time. Start, on the other hand, appears to have fronted over time, and has been clearly distinct from the other two vowels for some time.
Change in F2 of Non-high Back Pre-rhotic System in St. Louis
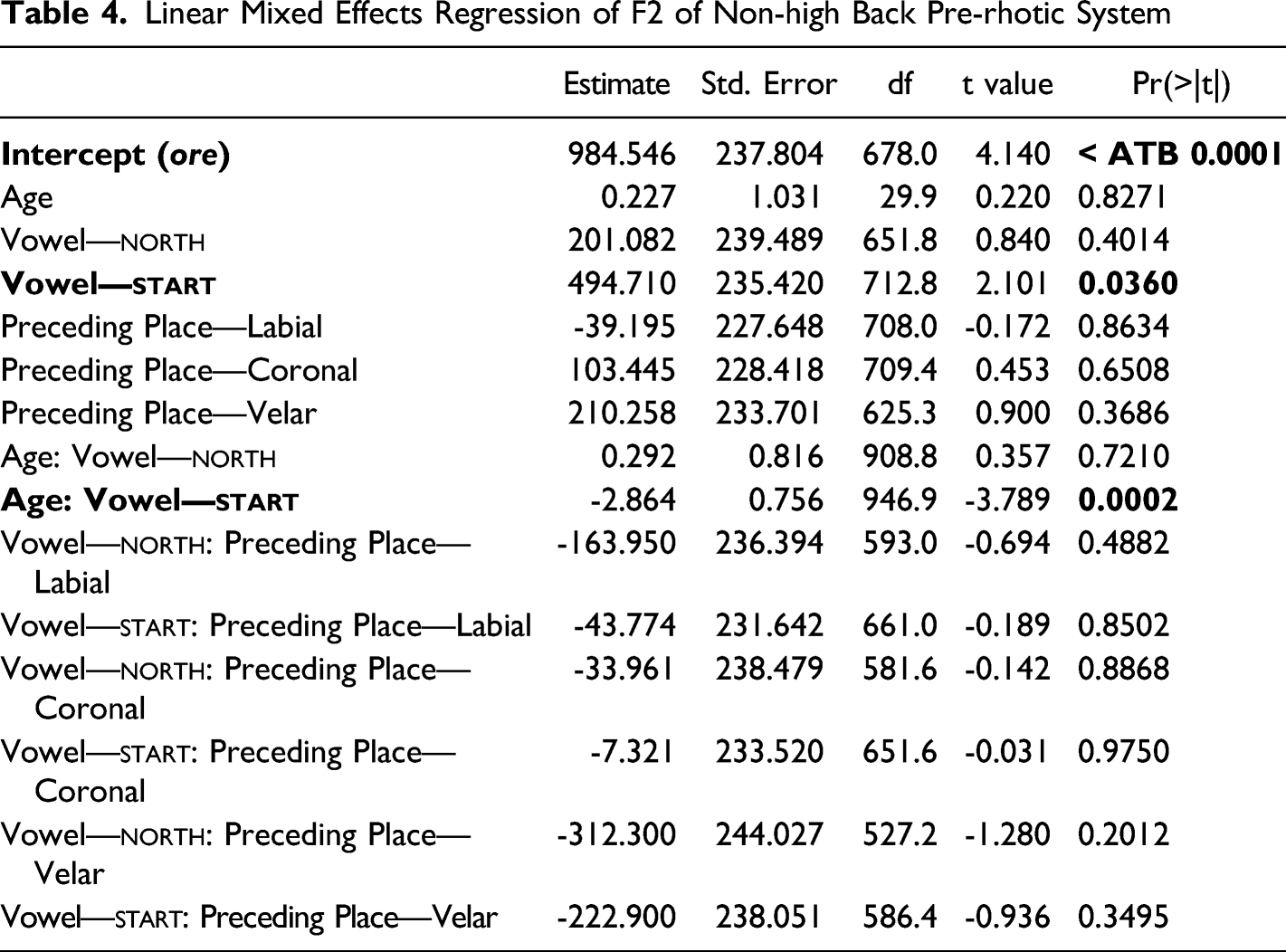
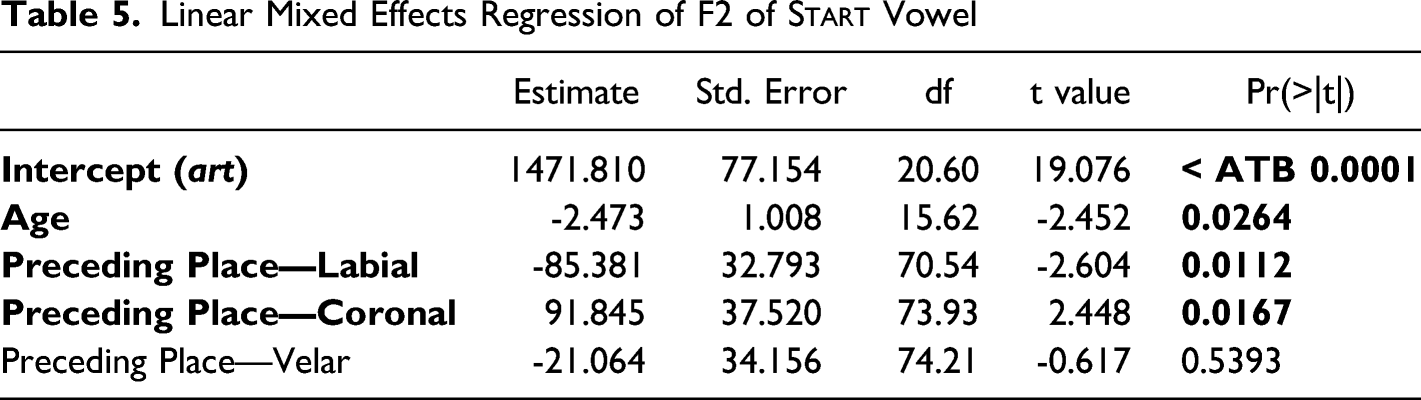
This visual inspection is corroborated by regression analysis. A linear mixed effects regression model was created as above for all three pre-rhotic vowels with the same baseline, fixed effects, interactions, and mixed effects. A final model was again arrived at using the step function. The final model included age, vowel, and preceding place of articulation as fixed effects, as well as the interaction between vowel and preceding place of articulation (see Table 4). Both speaker and lexical item were kept as random intercepts. In this model, the only significant effects are a main effect for vowel (start is fronter than force) and an interaction between age and vowel (start has fronted over time). The interaction between vowel and preceding place of articulation was kept but non-significant. These findings are replicated when considering start alone. Applying the step function to the same initial model, minus interactions, yields a model with age and preceding place of articulation as fixed effects (as shown in Table 5). The age effect shows start to have fronted over time. The preceding place of articulation effect shows the vowel to be fronter when preceded by a coronal consonant and backer when preceded by a labial. Overall, we find that start and north have separated via two processes: north raised, while start fronted.
Linear Mixed Effects Regression of F2 of Non-high Back Pre-rhotic System
Estimate
Std. Error
df
t value
Pr(>|t|)
Intercept (ore)
984.546
237.804
678.0
4.140
< ATB 0.0001
Age
0.227
1.031
29.9
0.220
0.8271
Vowel—NORTH
201.082
239.489
651.8
0.840
0.4014
Vowel—START
494.710
235.420
712.8
2.101
0.0360
Preceding Place—Labial
-39.195
227.648
708.0
-0.172
0.8634
Preceding Place—Coronal
103.445
228.418
709.4
0.453
0.6508
Preceding Place—Velar
210.258
233.701
625.3
0.900
0.3686
Age: Vowel—NORTH
0.292
0.816
908.8
0.357
0.7210
Age: Vowel—START
-2.864
0.756
946.9
-3.789
0.0002
Vowel—NORTH: Preceding Place—Labial
-163.950
236.394
593.0
-0.694
0.4882
Vowel—START: Preceding Place—Labial
-43.774
231.642
661.0
-0.189
0.8502
Vowel—NORTH: Preceding Place—Coronal
-33.961
238.479
581.6
-0.142
0.8868
Vowel—START: Preceding Place—Coronal
-7.321
233.520
651.6
-0.031
0.9750
Vowel—NORTH: Preceding Place—Velar
-312.300
244.027
527.2
-1.280
0.2012
Vowel—START: Preceding Place—Velar
-222.900
238.051
586.4
-0.936
0.3495
Linear Mixed Effects Regression of F2 of Start Vowel
Estimate
Std. Error
df
t value
Pr(>|t|)
Intercept (art)
1471.810
77.154
20.60
19.076
< ATB 0.0001
Age
-2.473
1.008
15.62
-2.452
0.0264
Preceding Place—Labial
-85.381
32.793
70.54
-2.604
0.0112
Preceding Place—Coronal
91.845
37.520
73.93
2.448
0.0167
Preceding Place—Velar
-21.064
34.156
74.21
-0.617
0.5393
Although the start-north merger could be reversed because it was evidently an incomplete merger in production and potentially a near merger, I nevertheless briefly consider whether orthography could have also played a role. Given the above results, any role for orthography would involve <ar> north words lagging in north-raising, <or> start words lagging in start-fronting, and/or <or> start words briefly participating in north-raising. To test for an orthographic effect, I consider word list data. In addition to other start and north lexical items, orthographically exceptional items war, quarter, sorry, and tomorrow were included in the list. This means that while there are limited numbers of tokens overall in this context, there are enough tokens per speaker to test for an orthographic effect (roughly six start and eight north per speaker). I ran a linear mixed effects regression model for each vowel for both F1 and F2 (a total of four models). As there were very few tokens in this context, I set aside potential effects of phonological environment for the initial run. As such, each model initially included speaker age, spelling, and their interaction as fixed effects, and speaker and lexical item as random effects. As when testing frequency, I account for the possibility that any orthographic effect would only apply for a subset of speakers by also testing a model in which spelling is included as a random slope by speaker rather than a fixed effect. A final model was again arrived at via the step function. Spelling, whether included as a fixed effect or random slope, was dropped from each model. These results suggest no effect of orthography on vowel production.
4.3. Social Motivation
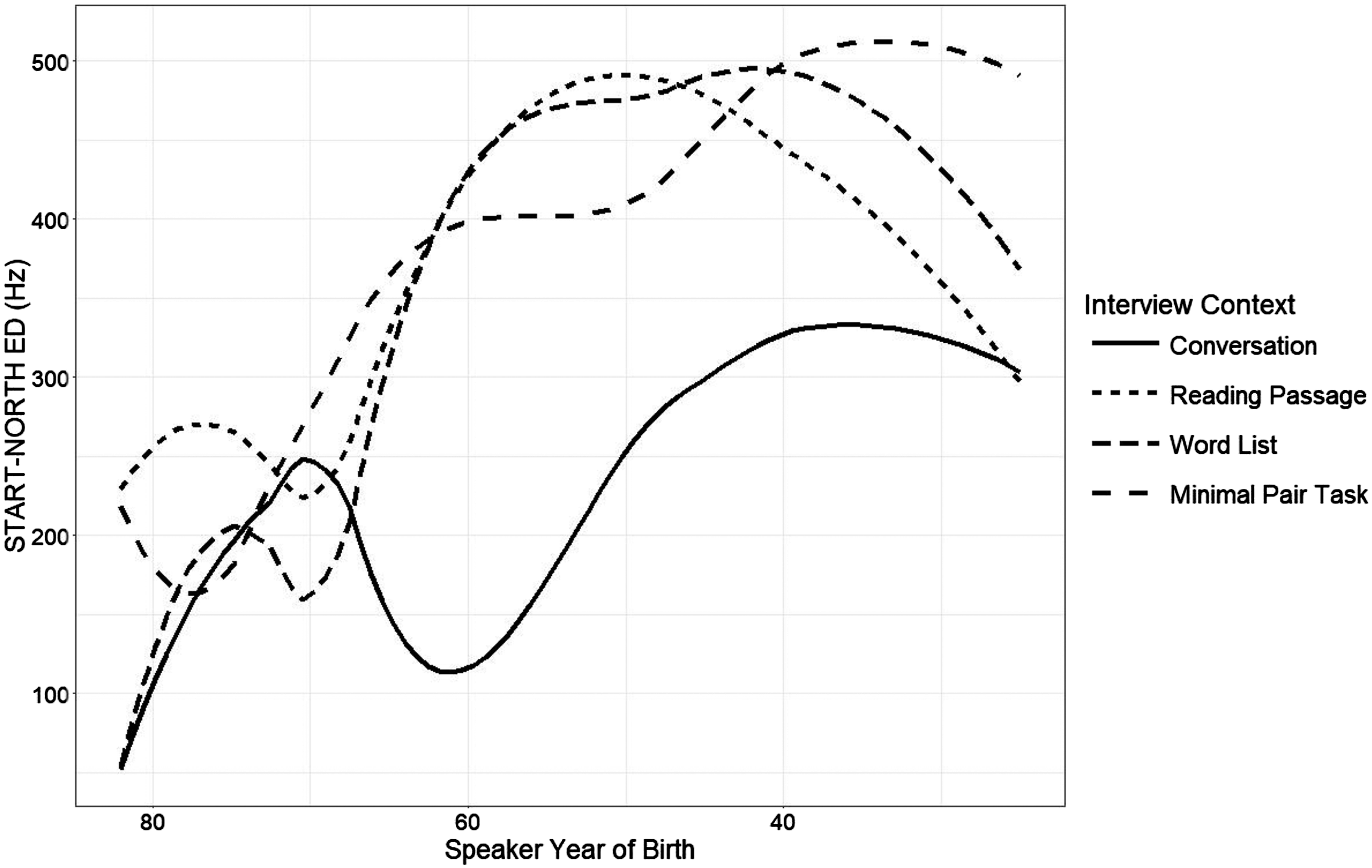
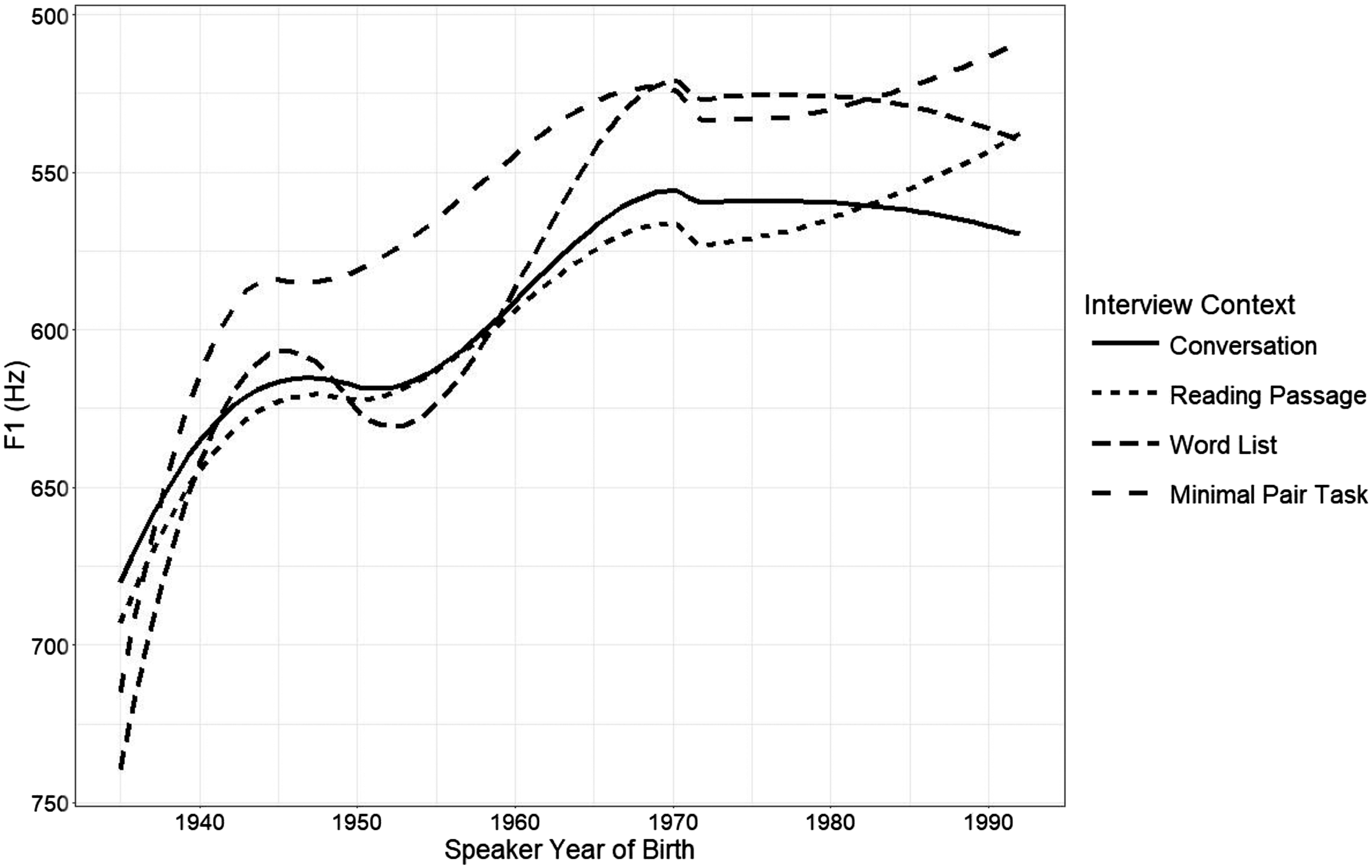
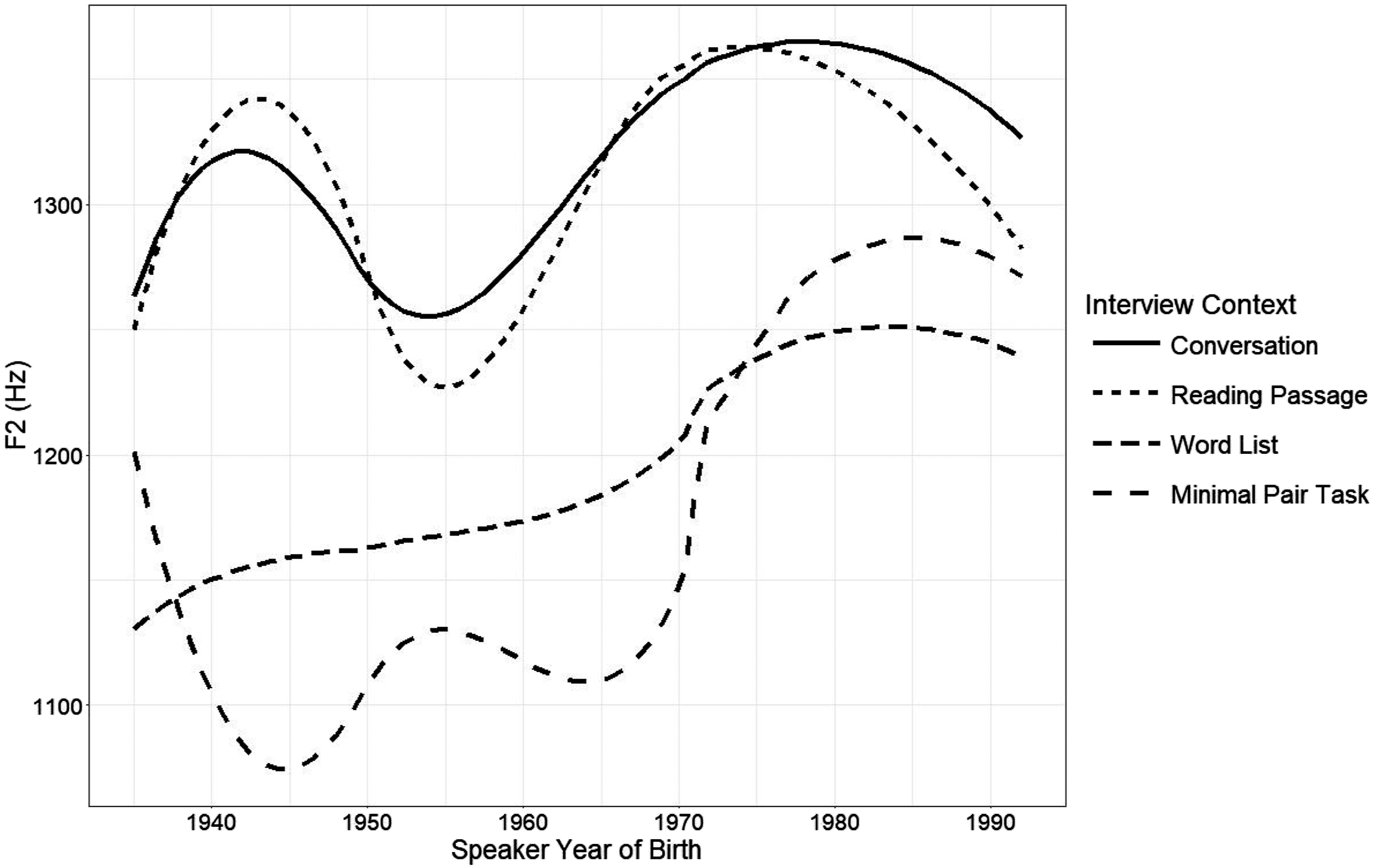
I now consider whether there is evidence of social motivation in reversal of the merger. I draw on three types of data: production differences across tasks that vary the level of attention-to-speech, responses on the minimal pair task, and qualitative commentary. I first examine how production differs between the different contexts of the sociolinguistic interview: conversation, reading passage, word list, and minimal pair task. Following Labov ([1966] 2006), I interpret the conversation as a relatively informal speech context, while the word list and minimal pair tasks are contexts calling for particularly formal speech in which speakers target linguistic norms. The attention-to-speech model has faced criticism for insufficiently accounting for the range of ways in which speakers style-shift; however, my interest in it lies not in how it theorizes style-shifting, but for the insights it offers into how speakers’ production changes across speech contexts. Typically, speakers use more of the prestige variant in more formal speech contexts. For example, Labov ([1966] 2006) finds that speakers of New York City English, which is a variably non-rhotic dialect, are more rhotic when reading a word list or participating in a minimal pair task than in conversation. We find patterns of production across contexts that are suggestive of prestige variants existing among the St. Louisans sampled with respect to start and north. The Euclidean distance (ED) between the two vowels is larger in the word list and minimal pair tasks (Figure 8), and the north vowel is higher in these tasks (Figure 9). Euclidean distance is used here rather than Pillai score in order to facilitate comparison to the minimal pair task. Here I calculate the Euclidean distance as the distance between a speaker’s mean start and north productions in a given context. There are thus four data points per speaker, one for each interview context. Interestingly, the start vowel is backer in the word list and minimal pair tasks than in conversation and reading passages (Figure 10).10 It is worth noting that the vowel does not show much change over time even in conversation here; the fronting change appears to be mostly complete when the oral histories have been removed from the analysis.
Euclidean Distance between Start and North by Age and Interview Context
F1 of North by Age and Interview Context
F2 of Start by Age and Interview Context
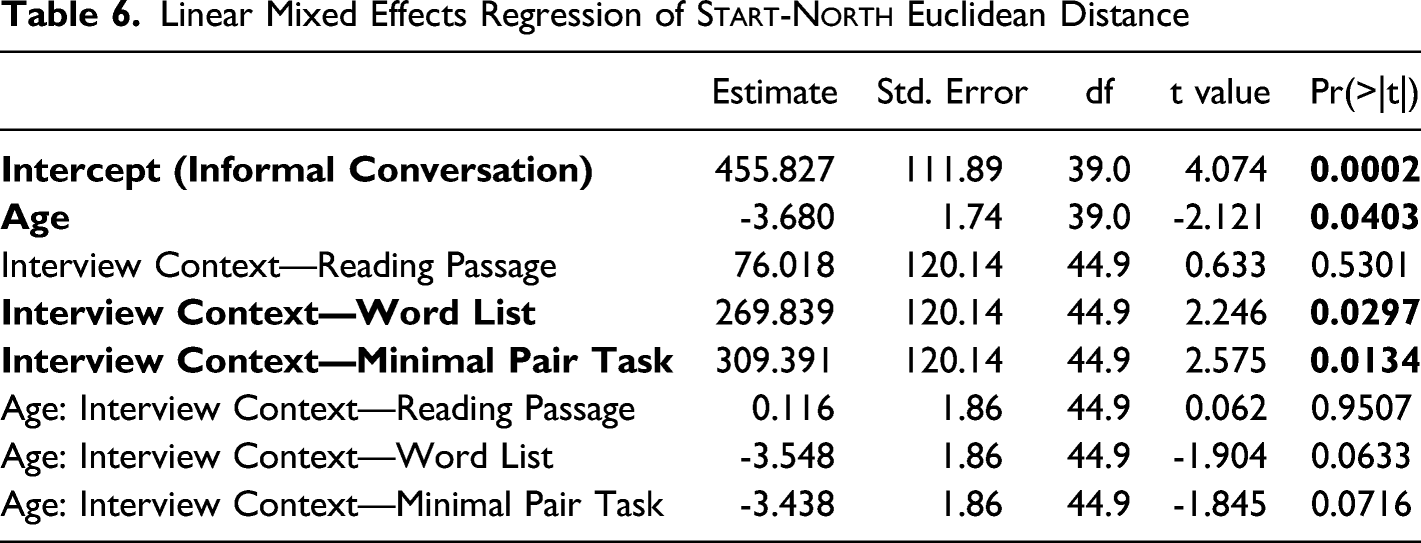
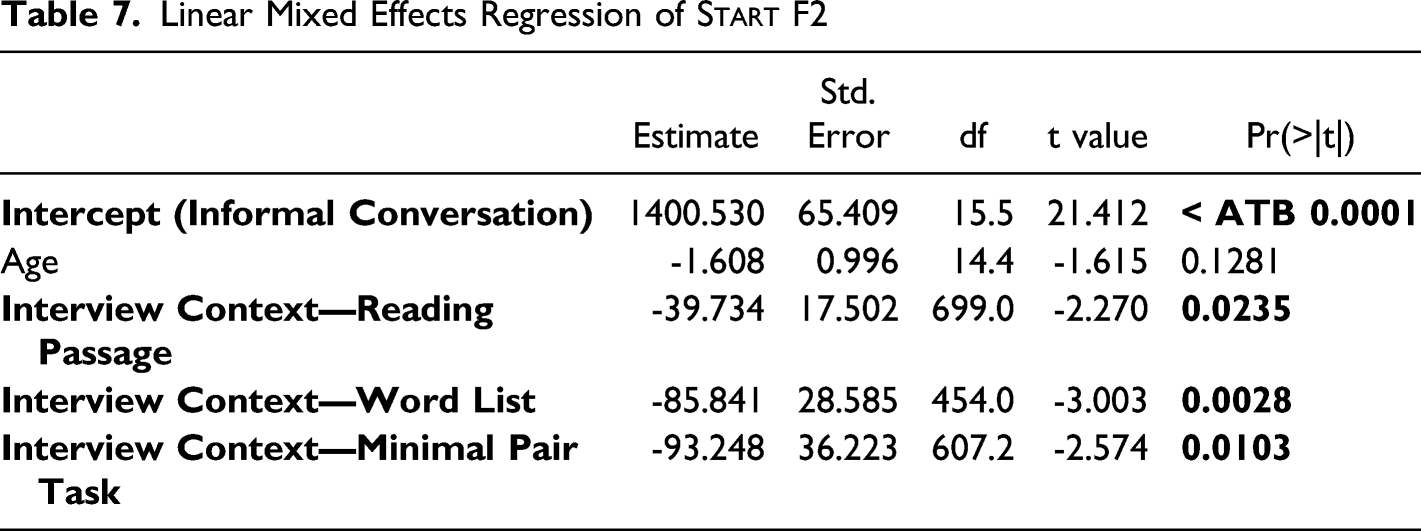
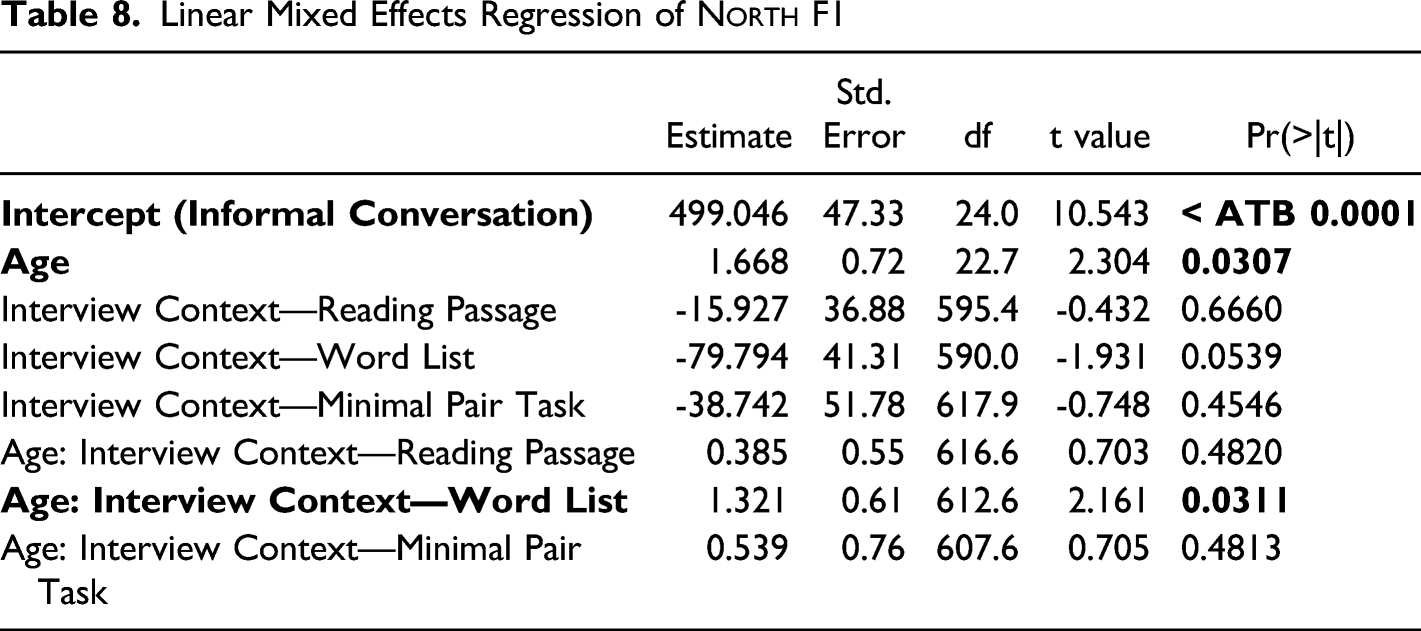
Linear mixed effects regression models show that the interview context effect is more consistent for the Euclidean distance between start and north (Table 6) and F2 of start (Table 7) than F1 of north (Table 8). All models reported use the informal conversation as a baseline and include speaker age, interview context, and their interaction as fixed effects, and speaker (and lexical item, in the case of the F1 model) as a random effect. As seen in Table 6, there is a significant effect of interview context in which the word list and minimal pair tasks show a larger Euclidean distance than in informal conversation. The interaction between speaker age and interview context, while not statistically significant, suggests that this effect has grown over time. It is unclear whether this interaction effect is real but not significant because of the limited number of Euclidean distance data points, or something illusory that would disappear with additional data.
Linear Mixed Effects Regression of Start-North Euclidean Distance
Estimate
Std. Error
df
t value
Pr(>|t|)
Intercept (Informal Conversation)
455.827
111.89
39.0
4.074
0.0002
Age
-3.680
1.74
39.0
-2.121
0.0403
Interview Context—Reading Passage
76.018
120.14
44.9
0.633
0.5301
Interview Context—Word List
269.839
120.14
44.9
2.246
0.0297
Interview Context—Minimal Pair Task
309.391
120.14
44.9
2.575
0.0134
Age: Interview Context—Reading Passage
0.116
1.86
44.9
0.062
0.9507
Age: Interview Context—Word List
-3.548
1.86
44.9
-1.904
0.0633
Age: Interview Context—Minimal Pair Task
-3.438
1.86
44.9
-1.845
0.0716
Linear Mixed Effects Regression of Start F2
Estimate
Std. Error
df
t value
Pr(>|t|)
Intercept (Informal Conversation)
1400.530
65.409
15.5
21.412
< ATB 0.0001
Age
-1.608
0.996
14.4
-1.615
0.1281
Interview Context—Reading Passage
-39.734
17.502
699.0
-2.270
0.0235
Interview Context—Word List
-85.841
28.585
454.0
-3.003
0.0028
Interview Context—Minimal Pair Task
-93.248
36.223
607.2
-2.574
0.0103
Linear Mixed Effects Regression of North F1
Estimate
Std. Error
df
t value
Pr(>|t|)
Intercept (Informal Conversation)
499.046
47.33
24.0
10.543
< ATB 0.0001
Age
1.668
0.72
22.7
2.304
0.0307
Interview Context—Reading Passage
-15.927
36.88
595.4
-0.432
0.6660
Interview Context—Word List
-79.794
41.31
590.0
-1.931
0.0539
Interview Context—Minimal Pair Task
-38.742
51.78
617.9
-0.748
0.4546
Age: Interview Context—Reading Passage
0.385
0.55
616.6
0.703
0.4820
Age: Interview Context—Word List
1.321
0.61
612.6
2.161
0.0311
Age: Interview Context—Minimal Pair Task
0.539
0.76
607.6
0.705
0.4813
Only the main effect of interview context is significant for F2 of start; the vowel is backer in more formal interview contexts than informal conversation. By contrast, there is no significant main effect of interview context on F1 of north, but there is a significant interaction term: younger speakers raise north in the word list task more than older speakers do.
While each of the three variables examined here show evidence that speakers are changing their targets in more formal environments, they are not behaving in the same way. The Euclidean distance between start/north and F1 of north show speakers to be targeting the direction of the sound change in more formal environments: the two vowels are further apart, and north is raised in comparison to conversational speech. If we take the target in formal contexts to represent a prestige variant, this would mean that a separation of start and north and raised north are evaluated as prestigious among the speakers sampled. Changing toward the prestige variant is indicative of a change from above, and suggests that speakers are targeting a vowel system that more closely approximates the system typical of American English varieties in formal contexts. The degree to which they target such a system appears to be increasing over time, even as the start‐north merger has been reversed in informal conversation. However, F2 of start shows the opposite pattern: where it had fronted, speakers target a backer production in formal contexts. In other words, the prestige variant appears to be what the community had changed from, rather than what the community is changing to. This is especially surprising given that backing start would put its production closer to that of north. It therefore appears that the fronting of start, while a key component of the separation of the two vowels in production, is not perceived in the same way as the raising of north.
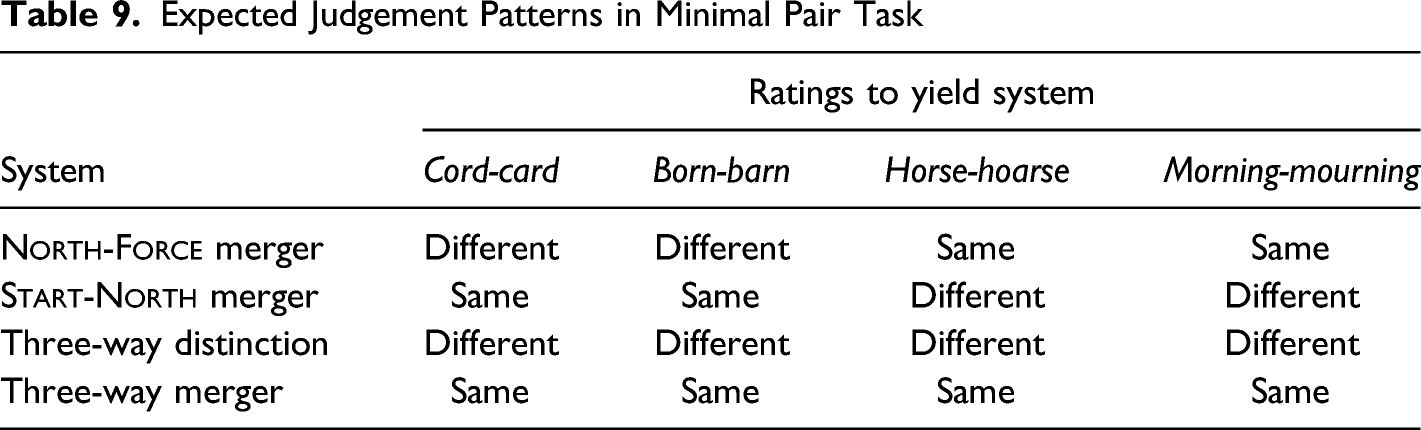
In addition to considering the read items as production data, I consider responses to the minimal pair task as perceptual data. It should be noted that these responses primarily reflect conscious perception. That is, participants in such a task are aware of what they are being asked and offer conscious introspection in their responses. As such, while minimal pair task judgements can correlate with other measures of subconscious perception, factors such as spelling differences between words and prescriptive norms can lead to a divergence between the measures. In the current task, speakers read a given pair of words out loud and then decided whether they pronounce the two the same, different, or close. Because the task tested both start-north and north-force pairs, there are a few patterns that we would expect to see in responses that correspond to different back pre-rhotic systems (as shown in Table 9). Namely, speakers could have one merger, the other merger, a three-way merger, or a three-way contrast.
Expected Judgement Patterns in Minimal Pair Task
Ratings to yield system
System
Cord-card
Born-barn
Horse-hoarse
Morning-mourning
North-Force merger
Different
Different
Same
Same
Start-North merger
Same
Same
Different
Different
Three-way distinction
Different
Different
Different
Different
Three-way merger
Same
Same
Same
Same
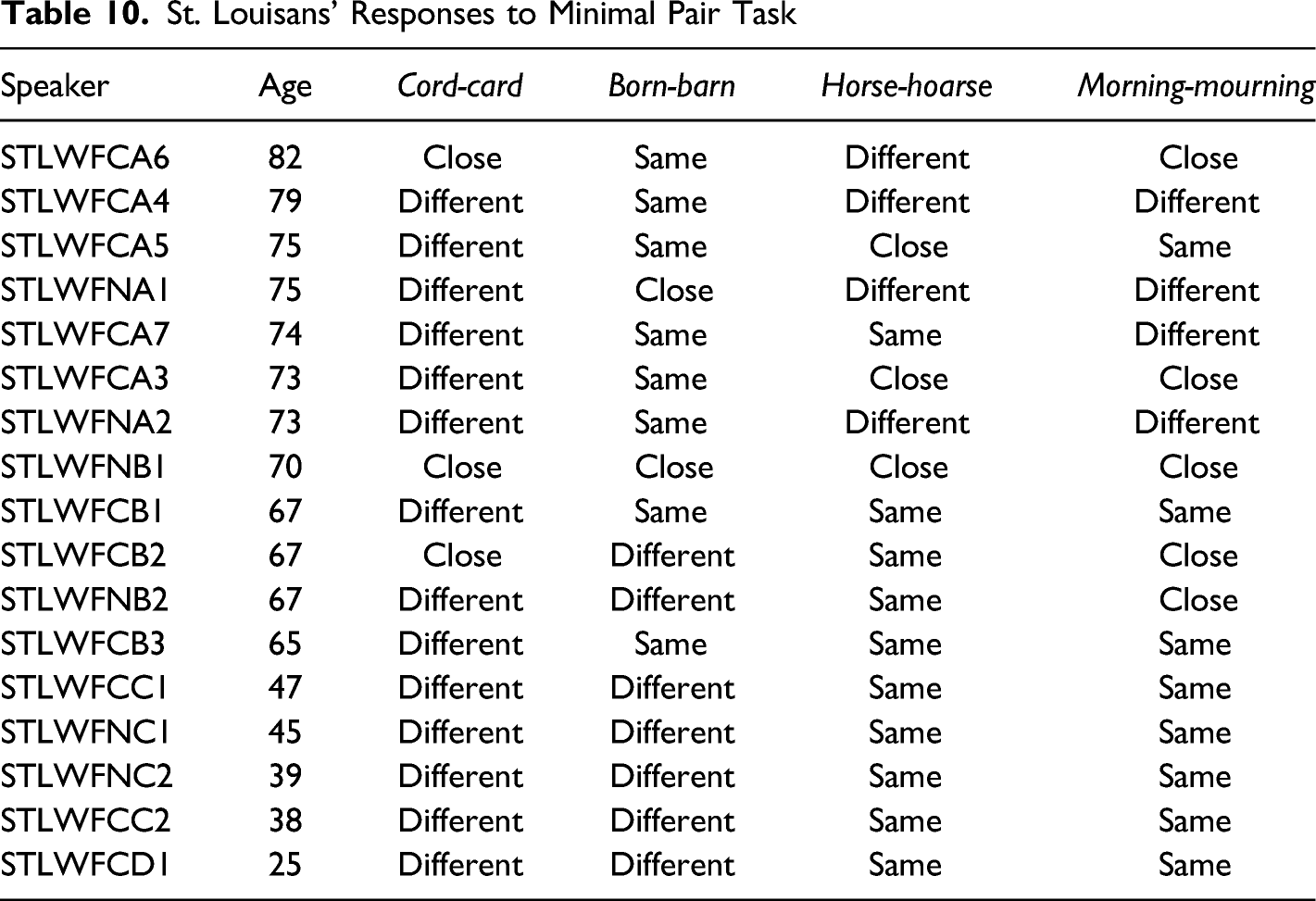
The expectation only somewhat holds. Overall, the minimal pair task judgements do appear to show change over time in which pair of vowels is perceived as merged, as illustrated in Table 10. Six speakers, five of whom were born in or after 1970, give ratings that suggest a perceived north-force merger. This makes sense; as St. Louis reversed the start-north merger, it progressed toward the north-force merger, and speakers perceived the two vowels as merged as a result. However, although change is evident, there is no clear-cut shift from start/north being the same to being different, nor is there a clear-cut shift from north/force being different to being the same. This is in large part because no speakers gave ratings that suggested a perceived start-north merger, despite, as seen in section 4.1, several clearly having extensive overlap between the two vowels in their informal speech.
St. Louisans’ Responses to Minimal Pair Task
Speaker
Age
Cord-card
Born-barn
Horse-hoarse
Morning-mourning
STLWFCA6
82
Close
Same
Different
Close
STLWFCA4
79
Different
Same
Different
Different
STLWFCA5
75
Different
Same
Close
Same
STLWFNA1
75
Different
Close
Different
Different
STLWFCA7
74
Different
Same
Same
Different
STLWFCA3
73
Different
Same
Close
Close
STLWFNA2
73
Different
Same
Different
Different
STLWFNB1
70
Close
Close
Close
Close
STLWFCB1
67
Different
Same
Same
Same
STLWFCB2
67
Close
Different
Same
Close
STLWFNB2
67
Different
Different
Same
Close
STLWFCB3
65
Different
Same
Same
Same
STLWFCC1
47
Different
Different
Same
Same
STLWFNC1
45
Different
Different
Same
Same
STLWFNC2
39
Different
Different
Same
Same
STLWFCC2
38
Different
Different
Same
Same
STLWFCD1
25
Different
Different
Same
Same
One reason why no speaker had a perceived start-north merger is quite straightforward: no speaker reported cord-card as being the same. Some speakers did, however, report born-barn as being the same. One may wonder whether this disconnect is related to phonological conditioning of production. As we saw earlier, although the following environment does not condition production, the preceding place of articulation does influence F2 of start such that the vowel is backed when following a labial in comparison to when following a coronal. One possible explanation of this is that speakers legitimately produced born-barn more similarly than cord-card, and accurately reported this.
However, reporting born-barn as being pronounced the same correlates with linguistic production in informal conversation in a way which suggests that more than phonological conditioning is at play. Linear regression of speakers’ start-north Pillai scores in informal conversation against their response to the born-barn pair shows that speakers who found them to be the same have significantly lower Pillai scores than those who found the pair to be pronounced differently (Intercept β = .448, p << 0.0001; “same” β = -0.257, p = 0.0321, adjusted r2 = 0.1864). This suggests that speakers’ perception of born-barn reflects their own production of the vowels: when produced close enough, speakers perceive the vowels as merged. As no speaker reported cord-card to be pronounced the same, this correlation does not hold for that pair. I suggest, then that something beyond fine-grained phonological conditioning explains the difference in responses to born-barn versus cord-card. If phonological conditioning alone explained responses, we would still expect the speakers with the greatest overlap between the two vowels to rate cord-card as pronounced the same. Instead, because no speakers report cord-card as pronounced the same, I suggest that speakers with a great deal of overlap between the vowels are reporting what they believe to be the socially “right” answer for cord-card, rather than what their actual perception is. In other words, I speculate that the difference in responses to these pairs indicates that overlap differs in salience for speakers by lexical items or phonological environment.11
Additional evidence that speakers’ responses to the minimal pair task involved at least some language attitudes may be seen in responses to horse-hoarse and morning-mourning. Younger speakers, as expected, rate these as the same. However, where we would expect older speakers to rate these as different (regardless of whether or not they perceive start/north as merged, these speakers’ north is much lower than their force), we find that many ratings are instead “same” or “close.” These ratings do not correspond with the informal conversation data reported in sections 4.1 and 4.2, which suggests that the speakers are responding based on what they believe the “correct” answer to be.
If the minimal pair task produced surprising results because speakers were responding based on prescriptive norms, we would perhaps expect to see overt negative evaluations. This is in fact the case, as seen in the excerpt in (1) from my interview with STLWFCA4, a seventy-nine-year-old woman. I use italics to indicate the low north vowel approximating start and underline to indicate the raised variant approximating force.
(1) STLWFCA4: […] and I've been there for I don't know forty, there I am saying “forty,” forty, {LG} How many times have you recorded that?
{LG} Forty-six years. {LG}
Interviewer: Not many, actually, only cause I’ve been interviewing people more my age or between us in age and it seems to have gone away real fast.
STLWFCA4: I would hope so, but boy, I'll tell you, if you grew up with it you have to think about it every time you say it.
While not every speaker expressed as negative an evaluation of the feature as this speaker did, most expressed awareness of it as a feature of St. Louis English. Like the speaker above, this awareness centered on non-standard production of north, with lexical items like forty, fork, etc., given as examples. Older speakers additionally reported that when they used the feature, younger relatives would often point the feature out and give negative evaluations of it.
I suggest that the evidence offered above clearly shows the raising of north to be a socially motivated sound change. Speakers target the raised variant and a distinction between start and north in formal speech contexts, which typically indicates a targeting of a linguistic norm. The low variant is overtly stigmatized, and responses to the minimal pair task appear to indicate a degree of social evaluation rather than perception alone. Combined, these paint a picture of a sound change resulting from awareness and stigmatization of a nonstandard form. The fronting of start does not appear to be socially motivated in the same way, as there is no overt evaluation of backer or fronter variants and the backer variant is in fact favored in production in formal speech contexts.
5. Discussion and Conclusion
In section 4, we found that start-north Pillai scores suggest that the two vowels overlapped nearly completely in St. Louis, but further examination of the data shows that the vowels were not in complete merger. While they were certainly close enough to be considered a merger as a matter of shorthand in the dialectological literature, they were more likely in a state of incomplete merger in terms of phonetic production, and most likely near merger for a time. This near merger has reversed over time. An examination of F1 and F2 for each of start, north, and force shows that this reversal was implemented by raising north and fronting start. The lack of frequency or orthography effects, even as random by-speaker slopes, indicates that the entire vowel classes may have changed at once. The raising of north appears to be a clear instance of socially motivated sound change. Below I outline three implications of this finding. Firstly, I suggest that fronting of start predated the raising of north, maintaining the vowel distinction and enabling reversal of the merger. Secondly, I note the role of perceptual salience in explaining the reversal (Sloos 2018). Finally, I note that the change superficially resembles a chain shift.
As shown in section 4.2, the reversal of the start-north merger in St. Louis relied on two distinct changes in apparent time: start fronted and north raised. Only the raising of north appears to be socially motivated. This seems important: if the reversal has a social motivation, wouldn’t we expect to see all aspects of it show evidence of such motivation? I suggest that this may be because the two changes are not as equivalent as they initially seem. Evidence for this comes from comparing the conversation-only data to the data including all interview contexts. Because the two oldest speakers included in the conversation-only data were recorded in oral histories, they were dropped from the all-context data. This did not change whether we found a significant age effect for north-raising, as it occurred over the mid-late twentieth century. However, the age effect for start-fronting was only significant in the conversation-only data, which included the two oldest speakers. If we accept the age effect in the conversation-only model for start as indeed reflecting a change over time, this would imply that start-fronting had mostly completed by the early-mid twentieth century. I therefore suggest that there is a diachronic sequencing to the changes: start-fronting led north-raising.
Because these were distinct changes occurring at different points in time, there is no reason why we should expect start-fronting to have been socially motivated in the same way as north-raising. Rather, I hypothesize that start-fronting occurred to maintain the contrast between start and north. Instead of the vowel raising, completely merging with north, and subsequently separating, I suggest that start raised to overlap with north and (either concurrent with or soon after the raising) then fronted. This fronting served to put the vowels in near merger rather than complete merger, enabling their eventual separation. Note that the slight difference in production, combined with no speakers consistently reporting start and north to be the same in the minimal pair task, would seem at first glance to suggest wholly distinct vowels rather than a near merger. However, because responses to the minimal pair task appear to reflect prescriptive norms at least in part, I maintain that the extensive overlap of the two vowels is better characterized as a near merger, albeit a highly stigmatized one.
This account neatly explains how the reversal was possible while accounting for why start-fronting shows a different targeting pattern in formal contexts. As it was not a change from above, speakers would not target the fronter variant. The key problem with the account, of course, is that it is entirely hypothetical in the absence of recordings of speakers born in the mid-late nineteenth century, which at this point in time may render it rather unfalsifiable unless sufficient archival recordings are uncovered.
The implementation of the reversal offers independent evidence for Sloos’ (2018) account of perceptual salience playing a role in dialect contact-induced sound change. Sloos (2018) finds that Austrian German moves away from a merger of the bären and beeren vowels, while Swiss German moves toward this merger. Both changes are apparently due to contact with northern German varieties, which have variable overlap of the vowels. Sloos (2018) suggests that Austrian German speakers notice when northern German speakers produce a distinction, because it is different from their own speech. As a result, they target a distinction and separate the merger. The opposite occurs for Swiss German speakers: they notice the overlap as different from their own speech and target that overlap as a prestige form.
The same appears to happen in St. Louis. Speakers with the start-north near merger were in contact with speakers who merged north and force. As such, the position of the north vowel is the difference in speech that would be noticed by these speakers. Because the low position overlapping with that of start became stigmatized, St. Louisans had social motivation to change north and raised the vowel as a result. The perceptual salience account thus explains not only that the start-north merger reversed in St. Louis, but how that change was phonetically implemented as well. That St. Louisans I interviewed mostly called attention to north tokens when discussing the merger likewise shows the salience of the relative position of north.
While it appears clear that the contact-derived perceptual salience of the difference between start and north led to the raising of north and separation of the vowels in St. Louis, there is a question of which variety provides the model for St. Louisans to target. One possibility is that the model is a generic Northern or specifically Inland North variety. The English of white St. Louisans oriented towards Northern lexical items (Murray 2002) and phonological features like the Northern Cities Shift (NCS; Labov 2007) over the course of the twentieth century. As the Inland North merges north and force (Labov, Ash & Boberg 2006:52), the reversal of the start/north merger in St. Louis could be part of this broader reorientation. However, because the north/force merger is common to many American English varieties (Labov, Ash & Boberg 2006:52), it is also possible that white St. Louisans are responding to a perceived model of a general American English.
It is worth noting that in the absence of social context, the start-north merger reversal gives the appearance of a push chain shift: start raised to the position of north, which subsequently moved toward force. However, the progression of a chain shift is claimed to be a phonological process (Labov 1994; Gordon 2011). That is, while we should look to the social history of a community to better understand the actuation of the initial sound change, we would not expect a social factor to cause a chain shift to advance to a new stage. I distinguish here between “causing” and “leading.” We can and do find that advancement of a chain shift can be instigated, led, or adopted by different social groups. For example, the strut-backing of the NCS was famously led by burnout girls in Eckert’s (1988) study of Belten High in the Detroit suburbs. The change was community-wide, but some social groups were more advanced in it than others. It was not caused by those social groups, however; burnout girls did not innovate strut-backing to index an identity. By this standard, the observed sound changes in St. Louis do not constitute a chain shift because north-raising was socially motivated.
To claim otherwise would amount to a claim that progression of a chain shift can be driven by socially motivated sound change. Such a claim would mean that a phonological system can be socially evaluated (contra a large amount of evidence summarized in Eckert & Labov [2017]). However, I suggest that the St. Louis data, while not enough to conclusively point in this direction, is enough to warrant consideration of the position, particularly if we were to find a series of similar (near) merger reversals that resembled push chain shifts. It is unclear how common we would expect such patterns to be. In its historical and dialectological context, the pattern in St. Louis seems likely to be a special case. The reason for this is that the system of back pre-rhotic vowels changed in many American English varieties between the onset of the St. Louis merger and reversal from it. When St. Louis raised start, the typical configuration of the back pre-rhotic vowels was a three-way distinction. If this configuration remained the same, we might have expected that, once overlap of start and north became stigmatized, St. Louis would retreat from the overlap by lowering start and re-achieving a three-way distinction. However, the typical configuration changed, as north raised in most varieties to yield a merger of north and force. This meant that in order for St. Louis to retreat from its nonstandard configuration to the more typical one, it had to achieve a different configuration than it had prior to raising start. To do so, raising north to approach the position of force was necessary, yielding the change we observe. This contrasts even with the Utah reversal of the start-north merger; because north lowered to match start (Bowie 2003, 2008), retreat toward either the old or new typical configuration necessitates raising it back rather than moving start. The appearance of a chain shift in St. Louis, rather than constituting a true phonological chain shift, is therefore likely an artifact of this context. That said, if there are sufficient cases like the St. Louis example, the set of “chain shift-like” phenomena may nevertheless be worthy of further study.
The overall situation in St. Louis therefore appears to be as follows: the start-north vowels were initially in a state of near merger. Overlap between the vowels in production was substantial but did not quite amount to a complete merger. Reversal was therefore possible because the two vowels remained slightly distinct. This reversal appears to be socially motivated by contact with unmerged speakers and was implemented by raising the north vowel. I suggest that the data supports a view of contact-induced merger reversal in which perceptual salience of relative vowel positions drives phonetic implementation (Sloos 2018). Because the overall pattern of sound change resembles, but crucially differs from, a chain shift, I further suggest that reversal patterns like that in St. Louis may be worth considering as a set of chain shift-like phenomena.
Footnotes
Acknowledgments
Thanks to the editors, two anonymous reviewers, John Singler, Robin Dodsworth, Laurel MacKenzie, and the audience at the 2018 meeting of the American Dialect Society for helpful comments and suggestions.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is part of a project supported by NSF grant BCS-1651102 DDRI.
ORCID iD
Daniel Duncan
Notes
Author Biography
Daniel Duncan is Lecturer in Sociolinguistics at Newcastle University. His research focuses on the sociolinguistics of place, particularly the effects of suburbanization and public policy on language variation and change.
BoersmaPaulDavidWeenink. 2017. Praat: Doing Phonetics by Computer [Computer Program]. Version 6.0.28, retrieved February 2017 fromhttp://www.praat.org/
3.
R Core Team. 2017. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org(February 2017).
4.
RosenfelderIngridJosefFruehwaldKeelanEvaniniScottSeyfarthKyleGormanHilaryPrichardJiahongYuan. 2014. FAVE (Forced Alignment and Vowel Extraction). Program Suite v1.2.2, retrieved February 2017 fromhttps://zenodo.org/record/22281#.YW4ZQhrMJPY
5.
AghaAsif. 2003. The social life of cultural value. Language & Communication23(3-4). 231-273.
6.
BaranowskiMaciej. 2006. Phonological variation and change in the dialect of Charleston, SC. Philadelphia, PA: University of Pennsylvania dissertation.
7.
BaranowskiMaciej. 2015. Sociophonetics. In BayleyRobertCameronRichardLucasCeil (eds.), The Oxford handbook of sociolinguistics, 403-424. Oxford: Oxford University Press.
8.
BatesDouglasMartinMaechlerBenBolkerStevenWalker. 2014. lme4: Linear mixed-effects models using Eigen and S4. Journal of Statistical Software67(1). 1-48.
9.
BeckerKara. 2010. Regional dialect features on the Lower East Side of New York City: Sociophonetics, ethnicity, and identity. New York, NY: New York University dissertation.
10.
BeckerKara. 2013. The sociolinguistic interview. In MallinsonChristineChildsBeckyvan HerkGerard (eds.), Data collection in sociolinguistics, 91-100. New York: Routledge.
11.
BowieDavid. 2003. Early development of the card-cord merger in Utah. American Speech78(1). 31-51.
12.
BowieDavid.2008. Acoustic characteristics of Utah’s card-cord merger. American Speech83(1). 35-61.
13.
BowieDavid.2012. Early trends in a newly developing variety of English. Dialectologia8. 27-47.
14.
BrysbaertMarcBorisNew. 2009. Moving beyond Kučera and Francis: A critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for American English. Behavior Research Methods41(4). 977-990.
15.
DodsworthRobinMaryKohn. 2012. Urban rejection of the vernacular: The SVS undone. Language Variation and Change24(2). 221-245.
16.
DriscollAnnaEmmaLape. 2015. Reversal of the Northern Cities Shift in Syracuse, New York. University of Pennsylvania Working Papers in Linguistics 21(2). 41-47.
17.
DuncanDaniel. 2018. Language variation and change in the geographies of suburbs. New York, NY: New York University dissertation.
18.
DuncanDaniel. 2019. The influence of suburban development and metropolitan fragmentation on language variation and change: Evidence from Greater St. Louis. Journal of Linguistic Geography7(2). 82-97.
19.
EckertPenelope. 1988. Adolescent social structure and the spread of linguistic change. Language in Society17(2). 183-208.
20.
EckertPenelopeWilliamLabov. 2017. Phonetics, phonology and social meaning. Journal of Sociolinguistics21(4). 467-496.
21.
FriedmanLauren. 2014. The St. Louis Corridor: Mixing, competing, and retreating dialects. Philadelphia, PA: University of Pennsylvania dissertation.
22.
GoodheartJill C.2004. I’m no hoosier: Evidence of the Northern Cities Shift. St. Louis, Missouri. East Lansing, MI: Michigan State University MA thesis.
23.
GordonMatthew J.TivoliMajors2006. Arch rivalry: Urban sprawl and the St. Louis speech island. Paper presented at New Ways of Analyzing Variation 35, The Ohio State University, Columbus, OH.
24.
GordonMatthew J.2011. Methodological and theoretical issues in the study of chain shifting. Language and Linguistics Compass5(11). 784-794.
25.
Hall-LewLauren. 2010. Improved representation of variance in measures of vowel merger. Proceedings of Meetings on Acoustics9(1). 1-10.
26.
HayJenniferPaulWarrenKatieDrager. 2006. Factors influencing speech perception in the context of a merger-in-progress. Journal of Phonetics34(4). 458-484.
27.
JohnstoneBarbara. 2009. Pittsburghese shirts: Commodification and the enregisterment of an urban dialect. American Speech84(2). 157-175.
28.
KenyonJohn S.ThomasA. Knott. 1953. A pronouncing dictionary of American English. Springfield, MA: Merriam-Webster.
29.
KochetovAlexei. 2006. The role of social factors in the dynamics of sound change: A case study of a Russian dialect. Language Variation and Change18(1). 99-119.
30.
LabovWilliam. [1966] 2006. The social stratification of English in New York City. Cambridge: Cambridge University Press.
31.
LabovWilliam. 1972. Sociolinguistic patterns. Philadelphia, PA: University of Pennsylvania Press.
32.
LabovWilliam. 1994. Principles of linguistic change, vol. 1, Internal factors. Oxford: Blackwell.
33.
LabovWilliam. 2007. Transmission and diffusion. Language83(2). 344-387.
34.
LabovWilliamMarkKarenCoreyMiller. 1991. Near-mergers and the suspension of phonemic contrast. Language Variation and Change3(1). 33-74.
35.
LabovWilliamSharonAshCharlesBoberg. 2006. The atlas of North American English. New York: Mouton de Gruyter.
36.
LabovWilliamSabriyaFisherDunaGylfadottírAnitaHendersonBetsySneller. 2016. Competing systems in Philadelphia phonology. Language Variation and Change28(3). 273-305.
37.
LobanovBoris M. 1971. Classification of Russian vowels spoken by different listeners. Journal of the Acoustical Society of America49. 606-608.
38.
MaguireWarrenLynnClarkKevinWatson. 2013. Introduction: What are mergers and can they be reversed?English Language and Linguistics17(2). 229-239.
39.
MurrayThomas E.2002. Language variation and change in the urban Midwest: The case of St. Louis, Missouri. Language Variation and Change14(3). 347-361.
40.
NewmanMichael. 2014. New York City English. Berlin: Mouton de Gruyter.
41.
NyczJennifer. 2013. New contrast acquisition: Methodological issues and theoretical implications. English Language and Linguistics17(2). 325-357.
42.
SloosMarjoleine. 2018. Merger and reversal of the bären and beeren vowels: The role of salience. Studia Linguistica72(2). 282-296.
43.
ŠvecJan G.SvanteGranqvist2010. Guidelines for selecting microphones for human voice production research. American Journal of Speech-Language Pathology19(3). 356-368.
44.
TrudgillPeterDaniel SchreierDanielLongJeffreyP. Williams. 2003. On the reversibility of mergers: /w/, /v/, and evidence from lesser-known Englishes. Folia Linguistica Historica24(1-2). 23-46.
45.
WagnerSuzanne E.AlexanderMasonMonicaNesbittErinPevanMattSavage. 2016. Reversal and re-organization of the Northern Cities Shift in Michigan. University of Pennsylvania Working Papers in Linguistics22(2). 171-179.
46.
WarrenPaulJenniferHay. 2006. Using sound change to explore the mental lexicon. In Fletcher-FlinnClaireHabermanGus (eds.), Cognition, language and development: Perspectives from New Zealand, 101-121. Bowen Hills, QLD: Australian Academic Press.
47.
WatsonKevinLynnClark. 2013. How salient is the nurse∼square merger?English Language and Linguistics17(2). 297-323.
48.
WedelAndrewScottJacksonAbbyKaplan. 2013. Functional load and the lexicon: Evidence that syntactic category and frequency relationships in minimal lemma pairs predict the loss of phoneme contrasts in language change. Language and Speech56(3). 395-417.
49.
WellsJohn C.1982. Accents of English, vol. 1, An introduction. Cambridge: Cambridge University Press.
50.
YaoYaoCharlesB. Chang. 2016. On the cognitive basis of contact-induced sound change: Vowel merger reversal in Shanghainese. Language92(2). 433-467.