
Abstract
A recurring finding of research on the L2 acquisition of coda obstruent voicing is that, in terms of the phonetic parameters that serve to realize the voicing contrast, learners are overwhelmingly more accurate with duration than the voicing of the obstruent itself. The current work expands our understanding of this asymmetry in two ways. First, as previous studies have focused almost exclusively on learners of English, we investigate here whether L2 learners’ superior production of duration is also found among learners of other target languages via a study of Mandarin-speaking learners’ production of French stop and fricative codas. Results from 18 Mandarin-speaking learners of French, primarily of beginner and intermediate proficiency who completed a sentence reading task, parallel those of previous studies with greater accuracy observed for vowel duration than the laryngeal voicing of the obstruent. Second, we explore potential sources of this asymmetry, in particular, the roles of L1 experience as well as of universal factors, namely, the relative perceptual salience of duration versus voicing, and the articulatory difficulty of voicing obstruents.
Keywords
1 Introduction
One of the challenges of acquiring a new phonological contrast is mastering the different phonetic parameters that serve to realize it. In the case of coda voicing contrasts, two of the main parameters used crosslinguistically are the laryngeal voicing of the obstruent and the relative duration of the preceding vowel and the obstruent: the vowel–obstruent ratio is higher with voiced stops. A recurrent finding of previous research on the L2 acquisition of coda obstruents is that learners generally approximate native speaker vowel duration more closely than obstruent laryngeal voicing (e.g., Baker, 2010; Crowther & Mann, 1992; Flege, 1988; Flege et al., 1987; Smith et al., 2009). While this finding is consistent, there are at least two outstanding issues related to the duration-voicing asymmetry relevant to L2 speech learning more generally. The first is the language-specific versus universal nature of the asymmetry. Given that most previous research has investigated the acquisition of English, it is unclear to what extent learners’ greater facility with duration is related to properties of this particular target language or whether duration is generally somehow inherently easier to acquire. The second issue involves the potential sources of the acquisition asymmetry including L1 experience, the relative perceptual salience of the two phonetic parameters, and articulatory difficulty. Indeed, with a few exceptions (Laeufer, 1996a), researchers have not sought to explain why L2 learners approximate duration more closely.
In the present study, we explore these two issues via a study of Mandarin-speaking learners’ acquisition of the French syllable-final obstruent voicing opposition (bec /bɛk/ “beak,” bègue /bɛg/ “stammer”; dix /dis/ “ten,” dise /diz/ “say”). This particular language pairing allows to build on and compare findings with previous research, which, as highlighted above, has mainly been conducted with learners of English including those with Mandarin as a first language (Flege et al., 1987, 1992). It also promises insights into some of the potential explanations for the asymmetry as, in terms of coda obstruent voicing, English and French differ in several ways. In particular, English has relatively longer preceding vowels (Laeufer, 1996a and references therein) and less variable vowel duration differences (Mack, 1982). Moreover, English speakers regularly (partially) devoice obstruent codas (e.g., head /hɛd/ is often realized as [hɛːd̥] or even [hɛːt]; e.g., Davidson, 2016; Docherty, 1992), whereas French speakers do not (Laeufer, 1996b). As such, if differences between the current study and previous research are observed, they may be related in part to properties of the target language.
2 Phonetic parameters of coda voicing
Crosslinguistically, phonological contrasts are typically realized via multiple phonetic parameters. In the case of syllable-final obstruent voicing, relevant parameters include properties of both the consonant itself and the preceding vowel. As concerns the obstruent, previous research has demonstrated the importance of laryngeal voicing and consonant duration as well as the presence and duration of the release burst in the case of stops (see the references in 2.1 and 2.2). With the vowel, the voiceless-voiced contrast may be realized via differences in duration as well as through vowel-to-consonant F1 offset frequency and rate of frequency change (e.g., Byrd, 1993; Chen, 1970; Fisher & Ohde, 1990; House & Fairbanks, 1953; Wolf, 1978). While a variety of phonetic parameters of phonological voicing exist, those most widely investigated for both L1 and L2 speech are consonant laryngeal voicing as well as vowel and following consonant duration.
2.1 Consonant laryngeal voicing
One of the primary parameters used to realize the phonemic voiceless–voiced contrast in obstruents is the presence versus absence of laryngeal voicing during the production of the consonant (e.g., Lisker, 1978). While languages differ in terms of the absolute percentage of voicing, voiced obstruents tend to involve a longer period of vocal fold vibration during the constriction interval. Figure 1 illustrates such a difference between the word-final, stressed /p/ and /b/ of French attrape /atʁap/ “catch” and syllabe /silab/ “syllable.”
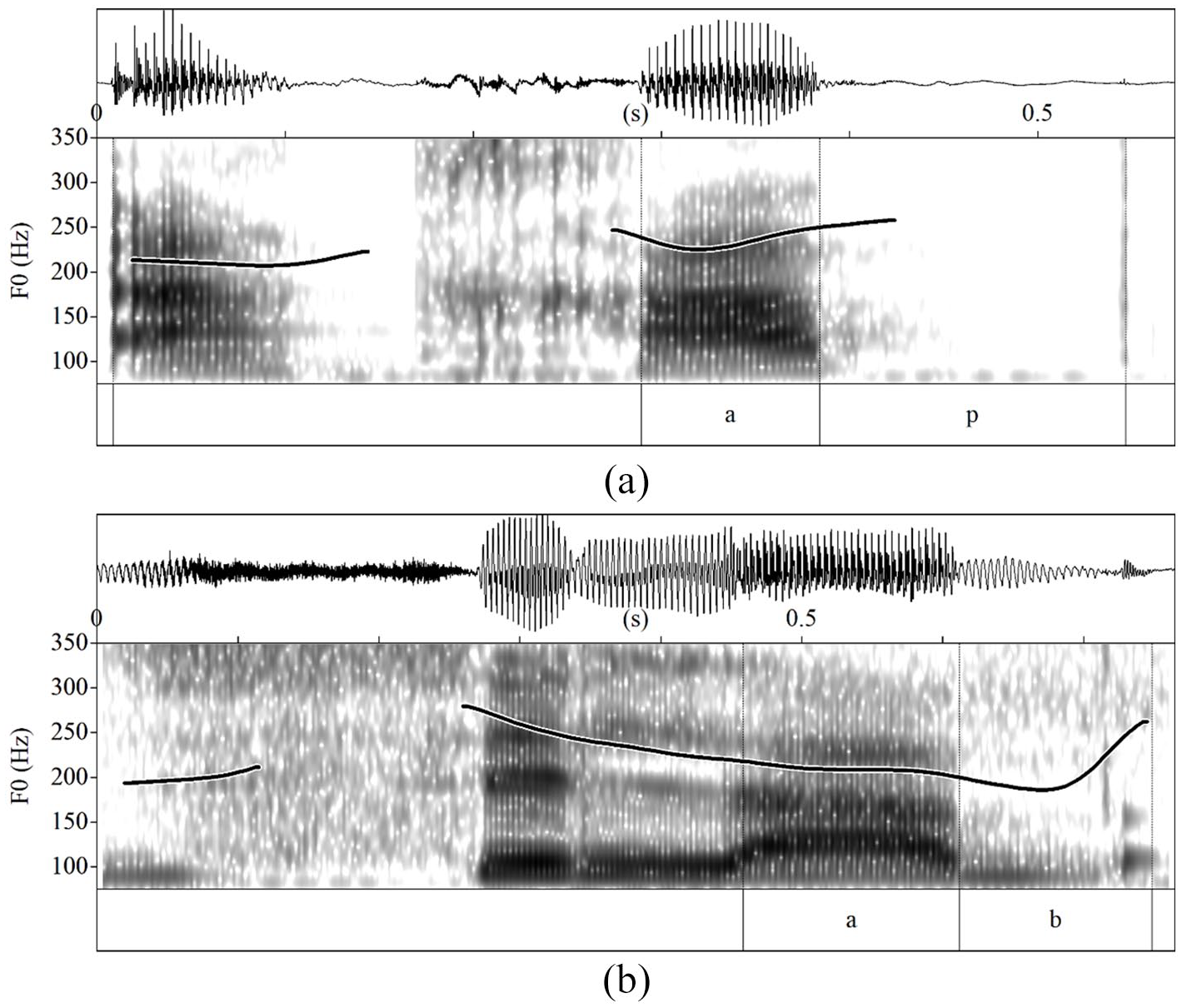
Laryngeal voicing of coda: (a) /p/ in attrape /atʁap/ “catch” versus (b) /b/ in syllabe /silab/ “syllable” as realized by a female Quebecois French speaker.
Whereas the realization of /p/ in Figure 1(a) involves only a brief presence of initial voicing as measured by the F0 line following the stop’s closure, voicing is present throughout the entire closure interval of the voiced stop /b/ (1b).
Given the importance of English as the target language in the previous research to be discussed here, Figure 2 provides a parallel English voiceless–voiced pair in which the coda stops /p/ and /b/ also occur in stressed position (tip /tɪp/, web /wɛb/). The between-language differences in voicing are clear, particularly in the case of the voiced stop. Whereas the voiceless /p/ of English tip resembles its French counterpart in terms of involving little to no laryngeal voicing, in contrast to French, the phonemically voiced English /b/ of web is voiceless throughout the majority of its closure.
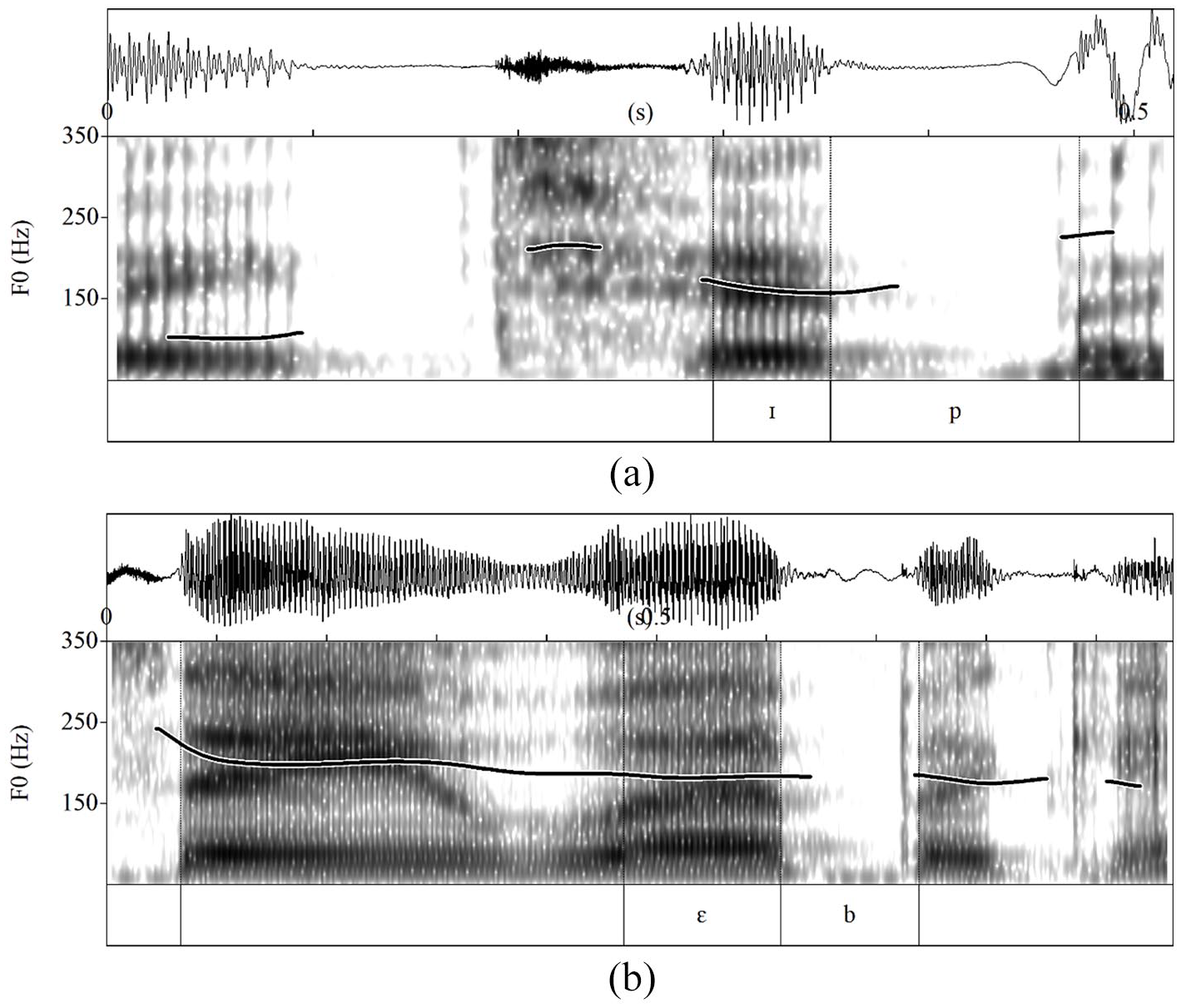
Laryngeal voicing of English coda: (a) /p/ in tip /tɪp/ versus (b) /b/ in web /wɛb/as realized by a female Canadian English speaker.
The differences between French and English illustrated here are typical of the languages. For example, Laeufer (1996b) compared the production of the final stops of monosyllabic minimal pairs (e.g., English tap /tæp/-tab /tæb/; French bac /bak/ ‘bin/ferry’-bague /bag/ “ring”) as realized by five speakers, each of American English and European French. The percentage of voicing reported for /bg/ differed greatly between the two languages. In English, on average, 53% of these phonemically voiced stops (range: 31%–70% among the five speakers) were realized with voicing during 50%–100% of the stop’s closure. In contrast, the rate in French was 95% (range: 81%–100%). Similarly, there was a stark difference in the percentage of fully voiced coda stops (Group M: English /b/ 28%, /g/ 25%; French /b/ 76%, /g/ 68%).
2.2 Consonant and preceding vowel duration
In many languages including French and English, voiceless obstruents are typically longer than their voiced counterparts (e.g., Klatt, 1976; Lisker, 1957 but see, for example, Flege & Port, 1981; Smith et al., 2009 for a lack of such asymmetry in Arabic and German coda stops, respectively). In the case of coda obstruents, this has a consequence for the duration of the preceding vowel. Due to timing constraints on syllable rhymes, vowels preceding voiceless obstruents tend to be shorter than those preceding voiced obstruents. The consequence is that the overall duration of the vowel–consonant (VC) interval is somewhat similar (e.g., Kohler & Künzel, 1978; Port, 1981) although relatively larger with voiced stops; this asymmetry has been shown to be a relevant perceptual cue to final obstruent voicing (e.g., Denes, 1955; Port & Dalby, 1982; Raphael, 1971).
To illustrate with French and English, returning to the examples presented in Figure 1, the VC duration ratio 1 of the /ap/ sequence in French attrape is 0.58 (95/163 ms) as compared with 0.90 in the /ab/ sequence in syllabe (137/153 ms). Similarly, in Figure 2, the VC duration ratio of the /ɪp/ sequence in English tip is 0.47 (57/121 ms) compared with 1.13 in the /ɛb/ sequence in web (142/126 ms). These particular examples illustrate an important difference between the two languages. While in both languages vowels are proportionally longer preceding the relatively shorter voiced obstruents, the absolute size of the difference is much larger in English (here, 0.47 vs. 1.13 for vowels before voiceless and voiced stops, respectively, compared with 0.58 and 0.90 in French). This particular example is representative of a general trend for the vowel duration difference preceding voiceless versus voiced obstruents to be relatively smaller in French, up to half that observed in English (e.g., Delattre, 1965; Laeufer, 1996b). Indeed, Flege et al. (1992) highlight that the English difference is larger than in many languages (p. 129). The French difference has also been reported to be more variable (Mack, 1982). In contrast, the difference in coda stop duration is larger in French (Laeufer, 1996b). The sum effect is that vowel duration differences before voiceless versus voiced stops should be more salient in English than in French. This raises the question as to whether the asymmetry in mastery of duration versus voicing observed in previous L2 studies focusing overwhelmingly on English is potentially related to properties of the target language and whether, with a target language having a smaller contrast, a similar asymmetry will be observed.
Having reviewed how coda obstruent voicing contrasts are realized phonetically, including the presence of quantitative interlinguistic differences between English and French, we now turn to a review of previous research that has investigated the extent to which L2 learners are capable of acquiring such differences.
3 Previous research on the L2 acquisition of obstruent coda voicing
Two strong tendencies emerge in previous research on the L2 acquisition of obstruent coda voicing. The first is the asymmetry in the degree of learners’ target-likeness with duration versus voicing. The second relates to the effects of learners’ overall linguistic experience, namely, the presence of persistent L1-based influence and, in some cases, a positive correlation between target-like phonetic production and L2 experience.
3.1 Asymmetries in the mastery of duration versus voicing
As highlighted multiple times already, compared with consonant duration and, even more so, consonant voicing, learners are relatively more successful in matching target language vowel duration 2 (Baker, 2010; Flege et al., 1992). However, their performance is not always target-like. In particular, differences in vowel length may be very small (e.g., Crowther & Mann, 1992; Flege et al., 1987). To illustrate such research, consider Flege et al. (1987) who investigated the effect of experience on the production of English /p b/ by L1 Mandarin learners (n = 8) with an average of 13 years of English immersion experience in the United States. Based on data from a word reading task, while the Mandarin-speaking learners produced a statistically significant difference in stop closure duration conditioned by stop voicing, the difference was small compared with that of the native speakers (10 vs. 36 ms). Furthermore, while their voiceless stops were target-like in length, their voiced stops were overly long and a duration difference was produced in only 46 of 72 tokens. As concerns stop voicing, the Mandarin-speaking learners produced a minimal contrast, especially when compared with their English peers (7 vs. 89 ms)—both /p/ and /b/ involved little closure voicing.
Asymmetries in vowel duration versus stop voicing are observed not only for learners with an L1 like Mandarin that lacks coda obstruents. Smith et al. (2009) studied the realization of English voicing by native speakers of German (n = 13) who had resided in the United States for 3.8 years on average. German has a syllable-final phonological contrast between voiceless and voiced obstruents. This said, due to a final devoicing rule, coda obstruents are devoiced with the degree of devoicing being greater than that observed in English. Indeed, syllable-finally, the production of German voiced obstruents typically involves little to no laryngeal voicing. Smith et al. tested participants on the production of minimal word pairs differing only in the final obstruent (/td/ or /k g/) in carrier sentences in both their L1 German and L2 English. The speakers produced proportionally significantly longer vowels before voiceless versus voiced coda stops (L1 German 9%; L2 English 24%) with their English difference resembling that of the native English speakers (20%). Stop duration differences were characterized by another pattern. In their L1 German, no difference was observed between voiceless and voiced stops whereas in their L2 English, voiceless stops were 17% longer than voiced stops. This voiceless–voiced difference was significantly less than that of the L1 English speakers (67%). Finally, as concerns stop voicing, their production of L1 German and L2 English voiceless stops was identical (22% vs. 21% laryngeal voicing), but there were differences with voiced stops (25% vs. 45% laryngeal voicing). However, the voicing asymmetry did not match that of the native English speakers who voiced phonemically voiceless stops less (10%) and voiced stops much more (74%). 3 In summary, even when learners’ L1 permits coda obstruents and has a voicing contrast in this position, greater accuracy is observed with the realization of duration than obstruent voicing.
3.2 Effects of L1 and target language experience
Previous research has also demonstrated the importance of effects of L1 influence and target language experience. When acquiring the phonetic parameters of obstruent coda voicing, there is strong L1-based influence (Baker, 2010; Crowther & Mann, 1992; Flege, 1988; Flege & Port, 1981; Laeufer, 1996b), sometimes even after many years of immersion in the target language. This said, with the exception of the Arabic-speaking learners of English in Flege and Port (1981), 4 many learners move—to some extent—away from their L1 realizations toward more target language-like production of the phonetic parameters, especially those with considerable L2 experience (Laeufer, 1996b).
To illustrate, consider Flege et al. (1992) who investigated the production of English word-final /t d/ in minimal CVC pairs (e.g., beat-bead) produced in a carrier sentence by Mandarin- and Spanish-speaking learners as well as by American English native speakers. Within each group of L2 learners, there was a less and more experienced group (n = 10 each) that differed in years of residency in the United States (Mandarin: 0.9 vs. 5.5; Spanish: 0.4 vs. 9.0) as well as their age of arrival (Mandarin: 23 vs. 27; Spanish: 20 vs. 26 years). At the group level, both the L1 Mandarin and Spanish speakers produced significantly smaller vowel duration differences than the native English speakers (Mandarin: Inexperienced 32 ms [23%], Experienced 37 ms [25%]; Spanish: Inexperienced 30 ms [22%]; Experienced 55 ms [36%]; English: 87 ms [48%]). Nonetheless, 11 of the 40 L2 learners produced vowel duration differences that fell within the native speaker means—this included 1 inexperienced and 2 experienced L1 Mandarin speakers and 5 experienced and 3 inexperienced L1 Spanish speakers. To control for the confound of stress and rate of speech, the researchers calculated the ratio of the mean vowel durations before /t/ versus /d/. No significant difference was found between the L1 English and Experienced L1 Mandarin and Spanish speakers’ ratios; the difference between the native speakers and the inexperienced learners, in contrast, was significant. In terms of properties of the stops themselves, while all participants produced shorter voiced than voiceless stops, the differences were lesser than in the L1 English speakers’ realizations (Mandarin: Inexperienced 16 ms, Experienced 27 ms; Spanish Inexperienced 7 ms, Experienced 18 ms; English 39 ms); no significant between-group differences were found. Finally, as concerns closure voicing, all five groups produced a significant difference between /t/ versus /d/ with the L1 English group’s difference being significantly larger other than that of the experienced Spanish group (Mandarin: Inexperienced 10 ms, Experienced 11 ms; Spanish Inexperienced 18 ms, Experienced 40 ms; English: 54 ms). An individual speaker analysis revealed that 11 of the L2 learners did not differ significantly from the native speaker controls (4 inexperienced Spanish, 5 experienced Spanish, 2 Mandarin speakers 5 ). 6 One notices that, while the experienced Spanish-speaking learners differed from their inexperienced counterparts, no difference was observed between the two L1 Mandarin groups. Once again, a strong L1-based effect is observed: Spanish allows for coda /t d/, whereas Mandarin does not.
Given that the vast majority of previous research has focused on English as a target language, one might wonder to what extent the two general tendencies reviewed immediately above are universal. This question seems even more pertinent given that as outlined in section 2.2, the English vowel duration asymmetries before voiced and voiceless stops is larger than in many languages (Flege et al., 1992). To explore this issue further, we present next the details of our study of obstruent coda voicing production by Mandarin-speaking learners of French.
4 Method
4.1 Participants
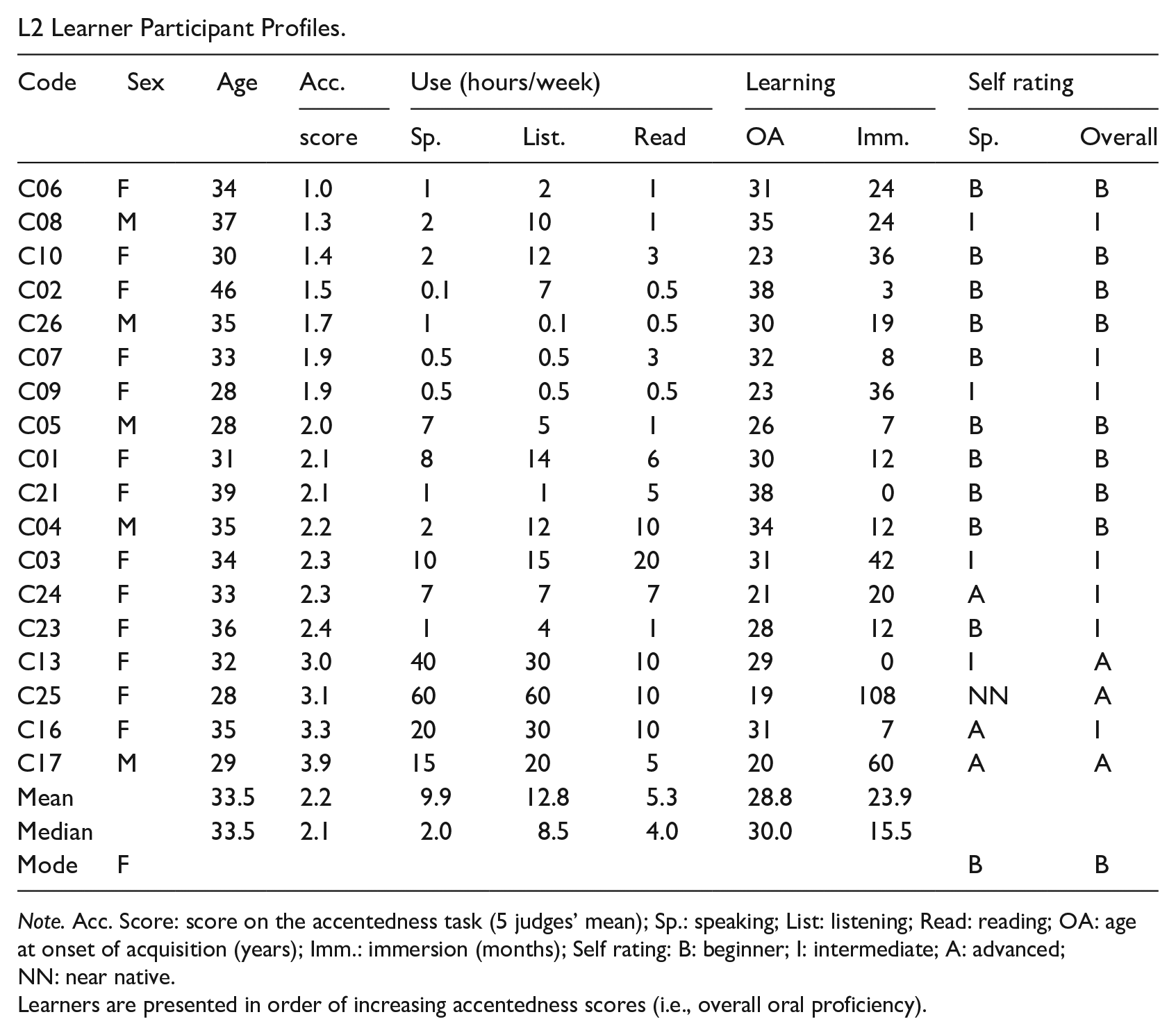
The participants in the present study included two groups: native French speakers (N = 10) and Mandarin-speaking learners of French (N = 18), 7 all of whom were recruited and tested in Montreal, Canada. The control group consisted of native Quebec French speakers (four male, six female), with an average age of 29 years (range: 21–52). The learner group consisted of 5 male and 13 female native Mandarin speakers (mean age = 34; range: 28–46) born and raised in China. On average, they had been speaking French for 5 years (range: 1–12) and had 24 months (range: 0–108) of immersion experience (see Appendix A for individual participant profiles).
The Mandarin-speaking learners had varying levels 8 of spoken as well as overall French proficiency, with the majority (n = 14) of self-reported values for their spoken French being beginner or intermediate (Beginner: 10, Intermediate: 4, Advanced: 3, Near-native: 1). In keeping with other L2 phonetic production studies (e.g., Colantoni & Steele, 2007), a more objective measure of overall French-speaking ability was included in the form of an accentedness task. This involved participants reading the North Wind and the Sun in French. Accentedness scores were obtained by intermixing the learner recordings with those of 22 other L2 learners and 7 native French speakers then presenting all recordings in one of five random orders to five native speaker judges. These naïve assessors were asked to assess the speakers’ accentedness using a 5-point scale where “1” was labeled with the French equivalent of certainly not native, very strong foreign accent and “5” as certainly native, no foreign accent. The learner group’s mean accentedness score was 2.2 (with “2” corresponding to The speaker has a strong accent) with a range of 1.0-3.9 and standard deviation of 0.7.
French was the learners’ third language with all of them speaking English with varying degrees of proficiency. The participants’ self-evaluation of their spoken English proficiency included a range of abilities (Beginner: 1; Intermediate: 10; Advanced: 6; Near-native: 1). The group’s mean score for a parallel English accentedness task was slightly higher than that of their French at 2.6 (between “2”—The speaker has a strong accent and “3”—The speaker has a medium accent ; range 1.0-3.9, standard deviation 0.7)). While it has been established that L2-to-L3 crosslinguistic influence on consonant production may occur (e.g., Domene Moreno, 2021; Hammarberg & Hammarberg, 2005; Llama et al., 2010), given that the greater facility with consonant duration over laryngeal voicing is understood to be a universal constraining L2 speech learning due in part to articulatory constraints on human speech production, regardless of learners’ level of spoken L2 English proficiency, one should expect the asymmetry, if it indeed exists, to hold for their L3 French. Moreover, as detailed in section 1, English and French differ substantially in their implementation of coda obstruent voicing with English having longer preceding vowels, less variable vowel duration differences, and regular (partial) obstruent coda devoicing. As such, even for Mandarin speakers who have mastered the phonetic parameters of coda voicing in their L2 English, L2-to-L3 transfer can only be of limited assistance in acquiring the phonetic implementation of French obstruent coda voicing. Finally, given that our participants’ English was rated as being strongly to moderately accented on average, we argue that the potential contribution of their L2 English to mastering French coda voicing is limited.
4.2 Stimuli
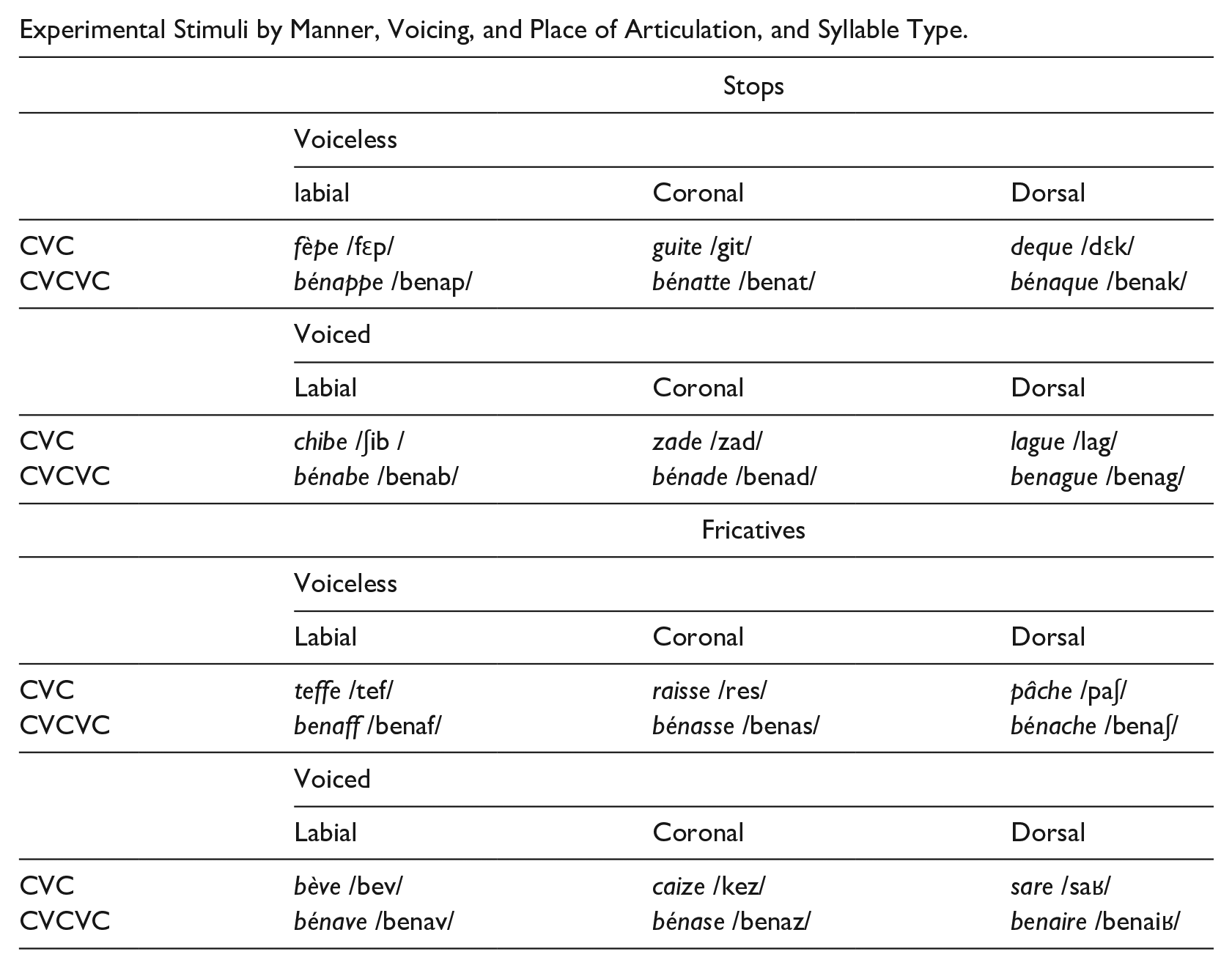
A total of 24 target final obstruent stimuli were included in the present study (Appendix B). These stimuli varied by place of articulation (labial, coronal, dorsal), voicing (voiced, voiceless), manner of articulation (stop, fricative), and syllable structure (CVC, CVCVC); the coda obstruent was always stressed and word-final in the target. While most previous studies have focused on coda stop voicing alone, we include fricatives here given that this manner class patterns with stops in terms of the phonetic implementation of preceding vowel duration and obstruent laryngeal voicing. There were 12 stimuli per manner of articulation; within each group of 12, there were 2 stimuli (1 CVC, 1 CVCVC) at each place of articulation. The target stimuli were intermixed with 106 additional words included to test other hypotheses for the larger study from which the data are taken. All stimuli were nonce French words. Nonce words were chosen to minimize frequency effects, which could be quite different for French native speakers and French learners, particularly those of lower proficiency. As language experience is a core predictor of speech learning (e.g., Best et al., 2011; Munro & Derwing, 2008), the use of nonce words ensured that both the L1 and L2 participants were equally (un)familiar with pronouncing the targets.
4.3 Tasks
The data from the present study were collected to answer multiple research questions, and for this reason, participants completed several tasks—one perception 9 and two production tasks in French, and one production task in English. The two French production tasks are the only tasks directly relevant to the present study, thus they are the ones that will be discussed here. The first task was the accentedness task already described in section 4.1. The second task, which was employed to elicit production of the target stimuli, consisted of reading the target words in the carrier sentence Je dis [TARGET] encore une fois “I say [TARGET] again.”
All subjects were tested individually in a quiet room or sound attenuated chamber. The entire stimuli set was presented twice to the learners, in random order each time. All productions from the carrier task were recorded using a Marantz CDR300 CD recorder (44,100 Hz; 16-bit; mono) and a unidirectional AudioTechnica AT803B lavaliere microphone.
4.4 Data preparation and analysis
Target words containing the final obstruents were extracted from the carrier sentence. The sound files were then labeled in Praat (Boersma & Weenink, 2019), segmenting the vowel (V) and consonant boundaries (C) in the /VC#/ sequence (Figure 3). The duration of the vowel and consonant, as well as the voicing of the consonant during the constriction interval as measured by the presence of F0, was extracted using a modified Praat script based on Shigeto Kawahara’s voicing script (version 4, February 2010). The voice report in Praat was used to determine the percentage of voiced frames. Default values were used for running the report, except for the pitch floor (set to 70 Hz for males, 100 Hz for females), the pitch ceiling (set to 250 Hz for males, 300 Hz for females), and the time step (set to 0.001 s) following the recommendations in Eager (2015) to obtain the most accurate voicing values. The results of the script were subsequently imported into Excel and two dependent variables were created. The first of these was the VC duration ratio (duration of the vowel/duration of the final obstruent). As indicated earlier, the use of this ratio as opposed to absolute vowel duration allowed to normalize for differences in speech rate. The % obstruent voicing was calculated by dividing the duration of the presence of F0 of the obstruent by the entire duration of the obstruent. This measure allowed for comparison of voicing in both stop and fricative codas.
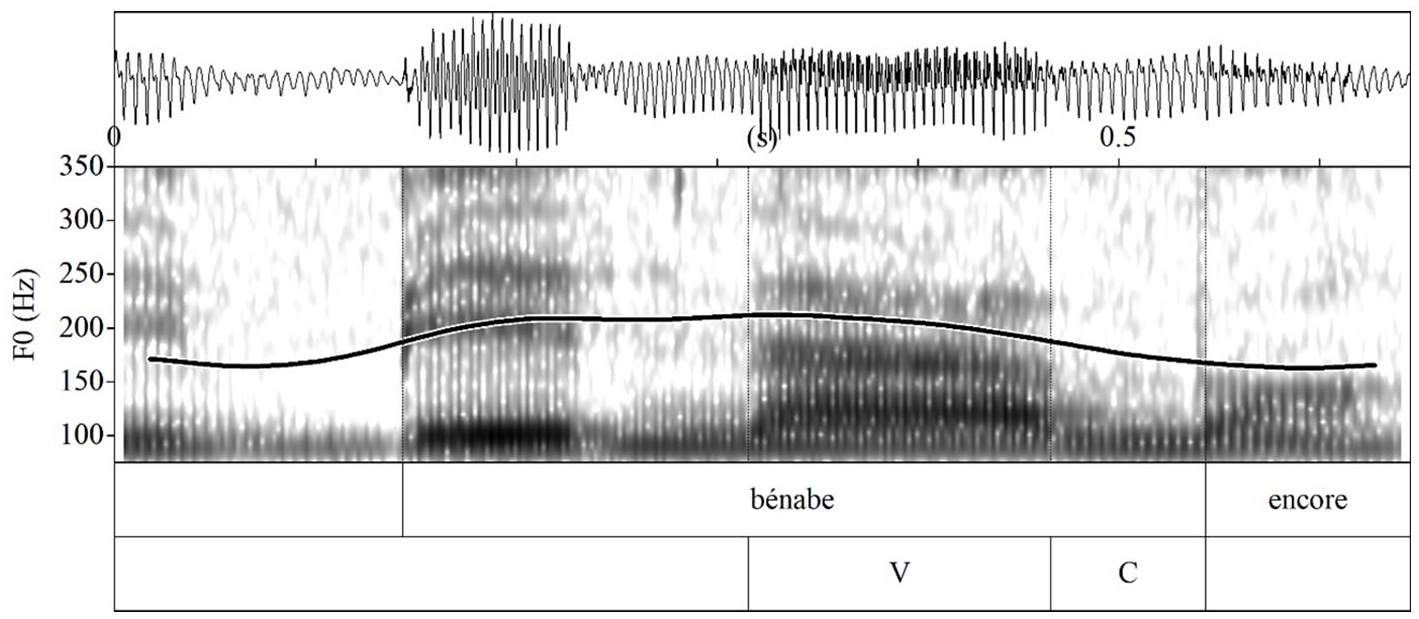
Segmentation of the /VC#/ sequence in the nonce word bénabe /benab/ as produced by a native French speaker (F11).
When preparing the data, we hypothesized that the French rhotic /ʁ/ might pattern differently from the other fricatives for two reasons. First, this fricative does not contrast with a voiceless counterpart as do the other French voiced fricatives. Second, previous work has demonstrated that /ʁ/ is particularly difficult to acquire for L2 learners (Colantoni & Steele, 2007, 2008). Accordingly, we compared the average VC duration ratios and % obstruent voicing of /ʁ/ versus the other voiced fricatives for the L2 speakers using paired sample t-tests. As expected, a significant difference between /ʁ/ and the other fricatives was observed: /ʁ/ had a smaller VC duration ratio, /ʁ/ = 1.31, /v z/ = 1.72; t(17) = 6.51, p < .001, and a lower mean % voicing, /ʁ/ = 24%, /v z/ = 52%; t(17) = 5.82, p < .001. Due to these differences and the fact that the rhotic is not contrastive with a voiceless counterpart (making the acquisition of the voicing parameters unnecessary for successful communication), we omitted /ʁ/ from further analysis. We also omitted 63 tokens that were not analyzable, due to sound quality issues (e.g., presence of laughing, incorrect production). Once all such tokens were excluded, the VC duration ratio and obstruent voicing analyses involved 1,169 tokens (Mandarin learners n = 742 tokens; French controls n = 427 tokens).
Statistics were run in R (v. 4.1.3). For the mixed-effects models presented in section 5, we attempted to fit each model with the maximum random effects structure. However, in all cases, this resulted in convergence errors. We therefore followed the recommendations in Barr et al. (2013) to progressively remove less informative intercepts and slopes to reach a random effects structure that converged. The final random effects structure is specified individually for each model. The lme4 R-package (Bates et al., 2015) was used for the mixed-effects models; p-values were obtained using the lmerTest package (Kuznetsova et al., 2017). Post hoc pairwise comparisons were run with the emmeans package (Lenth, 2020), using a Bonferroni adjustment. All categorical variables were sum coded to facilitate the interpretation of interactions (Singmann & Kellen, 2019).
5 Results
We begin by comparing the mean values observed for each of the two main parameters, VC duration ratio and % obstruent coda voicing, grouped by language as well as the underlying voicing and manner of articulation of the obstruent. Given that fricatives may be relatively more difficult to voice (Ohala, 1983), we wished to verify the existence of any manner-conditioned differences. To determine whether the influence of the three predictors on either of our outcome variables (VC duration ratio, % obstruent voicing) was significant, we ran linear mixed-effects models.
5.1 VC duration ratio
We begin with the VC duration ratio. Figure 4 displays the mean ratios for underlying voiceless compared with voiced obstruents, grouped by manner of articulation and speakers’ L1. Both groups produced relatively longer vowels and larger VC duration ratios for both underlying voiced stops (L1 Mandarin—voiced 1.54, voiceless 0.76; L1 French—voiced 1.70; voiceless 0.58) and fricatives (L1 Mandarin—voiced 1.73, voiceless: 0.95; L1 French—voiced 2.14; voiceless 0.79). The Mandarin values fell well within the range of those of the French controls including for voiced fricatives where, despite differences in means, 96% of the Mandarin-speaking learners’ values fell within 2 SDs of those of the French controls.
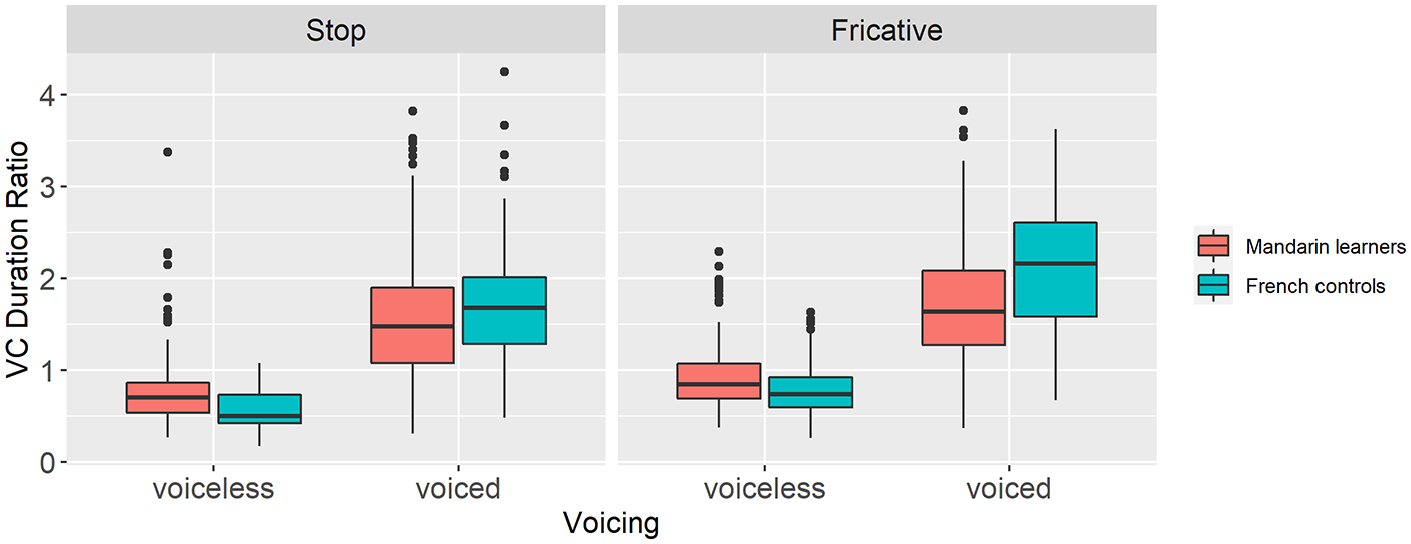
Mandarin learner-French control group comparison of the mean VC duration ratio by obstruent manner (stop [left]; fricative [right]) and underlying voicing (voiceless [left], voiced [right]).
We ran a linear mixed-effects model to examine the effects of language group, voicing, manner, and their interactions on the VC duration ratio. It consisted of random intercepts for participant and item, voicing and manner by participant slopes, as well as a group-by-item slope. The model revealed effects of voicing and manner, and an interaction between group and voicing (Table 1).
Linear Mixed-Effects Model Examining the Effect of Language, Underlying Voicing, and Manner, on the VC Duration Ratio.
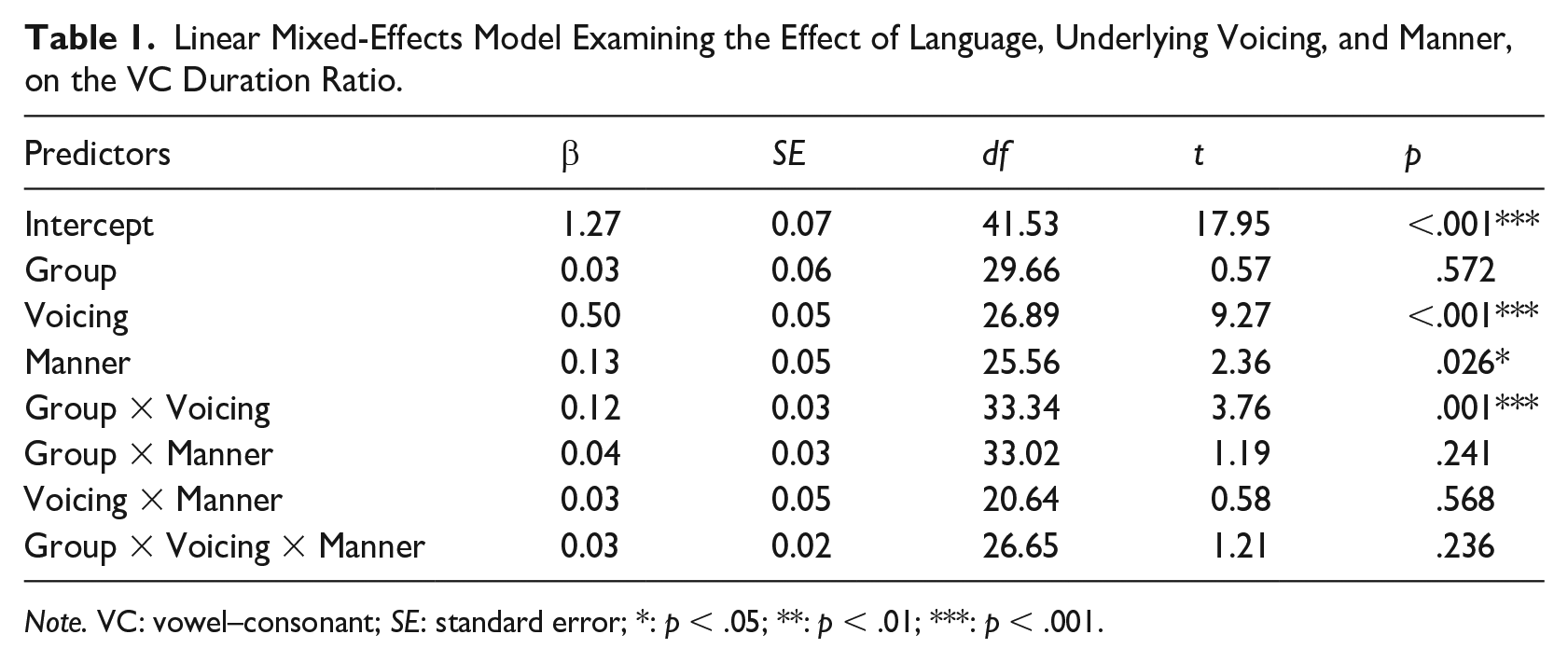
Note. VC: vowel–consonant; SE: standard error; *: p < .05; **: p < .01; ***: p < .001.
A post hoc pairwise comparison of the language group-by-voicing interaction was performed, to examine in greater detail in which condition(s) differences occurred (Table 2). While no group differences were found between the Mandarin-speaking learners and French controls in either condition, the language group-by-voicing interaction was primarily driven by the underlying voiced obstruent condition, in which group differences approached significance; the Mandarin learners produced a relatively smaller duration ratio (M = 1.62) than the French controls (M = 1.87).
Results of a Post Hoc Pairwise Comparison of Mandarin-Speaking Learner-French Control Mean VC Ratio Differences in the Interaction of Language Group and Underlying Voicing.
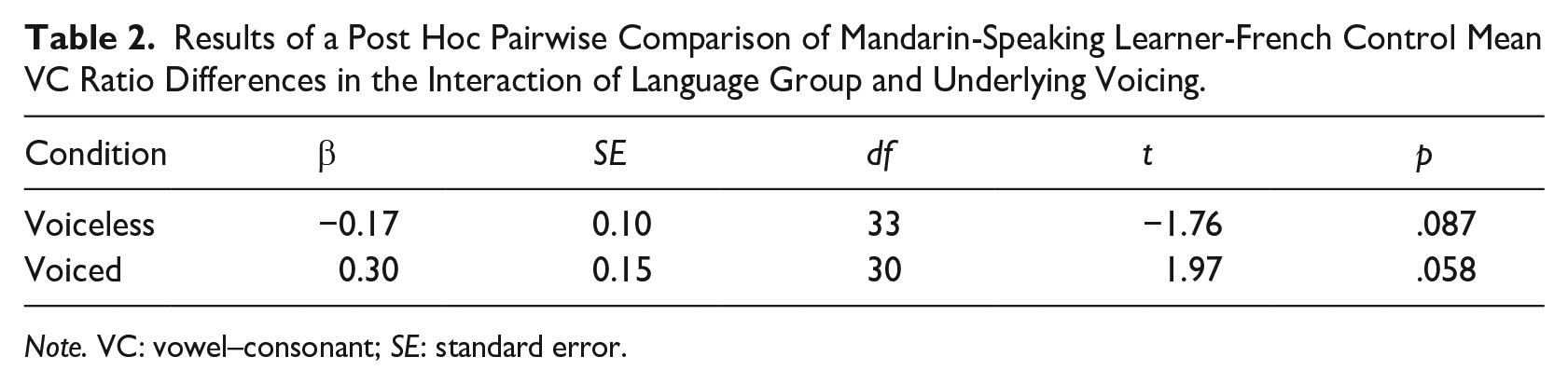
Note. VC: vowel–consonant; SE: standard error.
5.2 Percentage of obstruent coda voicing
Figure 5 provides an overview of the Mandarin-speaking learners’ and French controls’ percent of obstruent coda voicing.
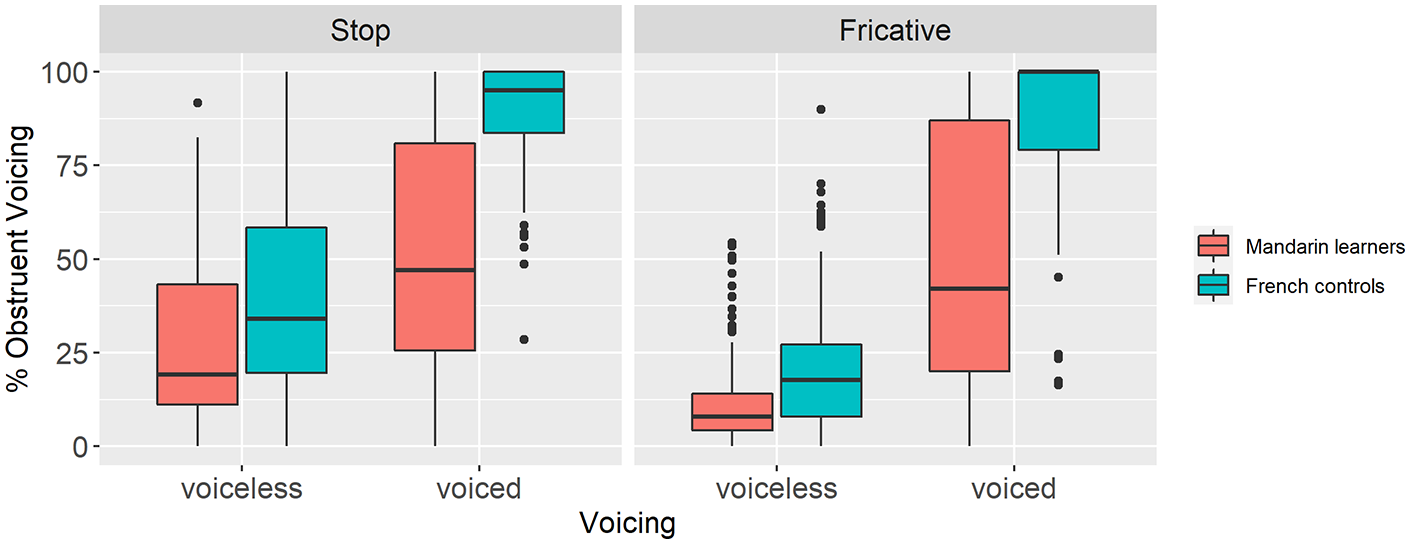
Mandarin learner-French control group comparison of the mean % obstruent voicing by obstruent manner (stop [left]; fricative [right]) and underlying voicing (voiceless [left], voiced [right]).
For both groups, underlying voiced obstruents were relatively more voiced than their voiceless counterparts although differences were larger in the native French speakers’ production, regardless of whether the targets were stops (L1 Mandarin—voiced 52%, voiceless 27%, difference = 25%; L1 French—voiced 90%, voiceless 41%, difference = 49%) or fricatives (L1 Mandarin—voiced 52%, voiceless 11%, difference = 41%; L1 French—voiced 87%, voiceless 21%, difference = 66%). We further investigated possible between-group differences by running a linear mixed-effects model examining the effects of underlying voicing, manner, and language group on mean % obstruent voicing (Table 3). The model included the same random effects structure as the previous mixed-effects model. There was an effect for all three predictors (all p-values < .001). The interactions of underlying voicing by group and underlying voicing by manner were also significant (p < .001 for both interactions). We performed a post hoc analysis on the underlying voicing by group interaction, given that we were primarily interested in differences in % obstruent voicing between the two groups. The results revealed that the French controls realized the underlying voiced obstruents with a much greater degree of voicing than the Mandarin learners (L1 Mandarin: 52%; L1 French: 89%; β = 37.00; SE = 7.31; df = 28; t = 5.06; p < .001). The underlying voiceless obstruents were also produced with more voicing by the French controls, although the group differences were smaller (L1 Mandarin: 19%; L1 French: 31%; β = 11.6; SE = 4.92; df = 29; t = 2.36; p = .025).
Results of a Linear Mixed-Effects Model Examining the Effect of Language Group, Underlying Voicing, and Manner on % Obstruent Voicing.
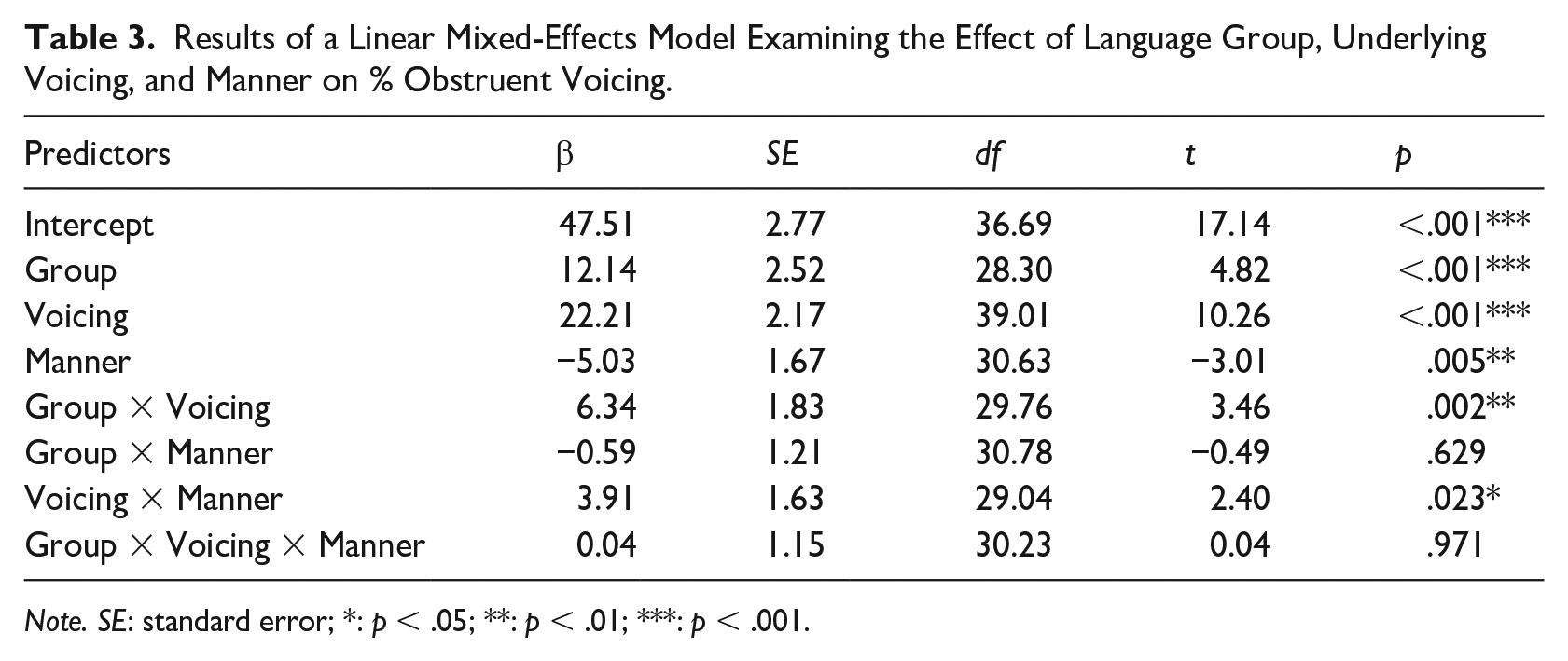
Note. SE: standard error; *: p < .05; **: p < .01; ***: p < .001.
In addition to the group differences, there were differences in the amount of variability observed for each group. With voiced obstruents, variability was much higher for the Mandarin learners. For stops, the interquartile range of the French controls was 16% (Q1 = 84%; Q3 = 100%) versus 55% for the Mandarin-speaking learners (Q1 = 26%; Q3 = 81%). The results for voiced fricatives were similar. The French control values had an interquartile range of 21%, compared with an interquartile range of 67% (Q1 = 20%; Q3 = 87%) for the Mandarin learners. This degree of variability was not observed with the VC ratio.
To examine potential individual differences in variability, Figure 6 displays the L1 Mandarin and L1 French speakers’ individual mean % obstruent voicing results for underlying voiced obstruents (Mandarin speakers in red, French speakers in green). Within each group, speakers are organized in increasing order of mean % voicing. Given that variability was similar for stops and fricatives, we do not separate by manner here.
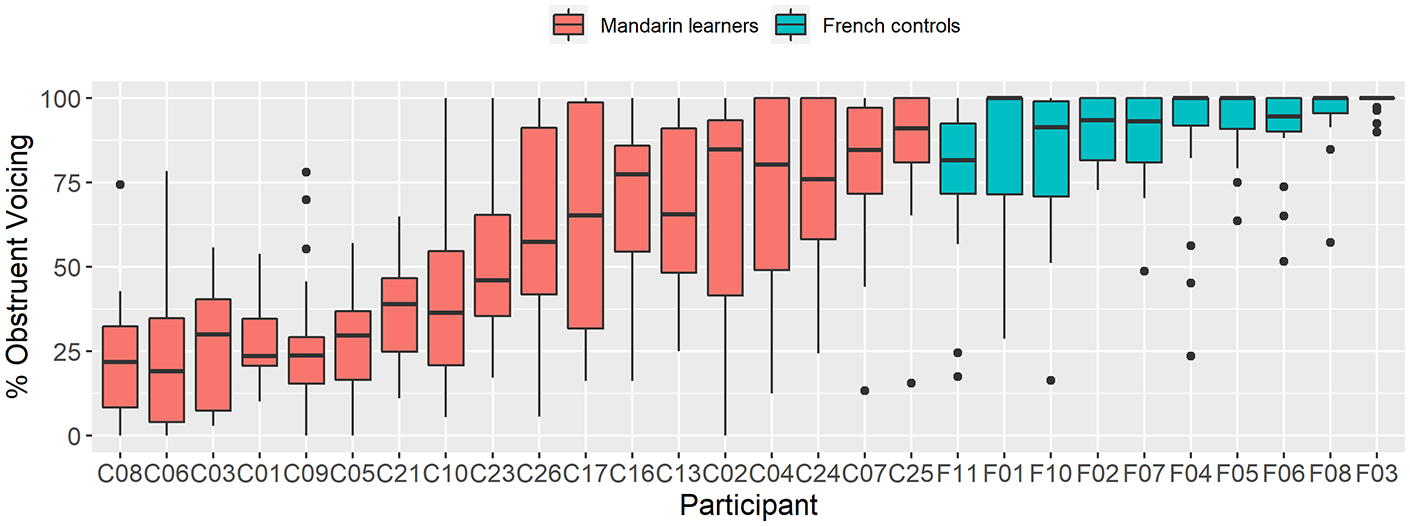
Mandarin learner-French control comparison of the % obstruent voicing for voiced obstruents by participant. Within each group, participants are presented by increasing mean % obstruent voicing from left to right.
Regarding the Mandarin learner results, it is possible to distinguish three groups in terms of the similarity of their voicing compared with the native French speakers. Speakers C25 and C07’s (the two rightmost participants within the L1 Mandarin group) production resembles the native French control patterns—mainly voiced obstruents realized with a small degree of variability. The second subgroup of learners (C26, C17, C16, C13, C02, C24) displays a high degree of variability with % obstruent voicing values ranging from less than 50% to fully voiced. The remaining learners display a lower degree of variability, and generally low % obstruent voicing values. The French control values were similar across speakers and were less variable when compared with the Mandarin speakers, with the exception of C25 and C07 singled out above.
Overall, the individual results reveal that the variability observed in the group analysis (Figure 5) was due to both inter- and intra-speaker variability. Regarding the former, the Mandarin learners varied greatly in their relative success in realizing obstruent voicing. Some achieved voicing values similar to the French controls, but the majority did not. Regarding intra-speaker variability, many Mandarin learners displayed a large degree of variability in their individual % obstruent voicing, with values for some individuals ranging from less than 50% to close to 100% (e.g., C02, C17, C26).
The large degree of variability and the similar patterns displayed by the three groups of speakers raise the question of whether the variability across speakers is due partly to differences in French proficiency. To answer this question, we examined whether the % obstruent voicing values were greater in the speakers with a higher oral proficiency, 10 using a correlation analysis (Figure 7). The analysis revealed no overall significant correlation between the two variables (p = .057). While there was a general trend for a higher % obstruent voicing with increased oral proficiency particularly at the lower and upper ends of the scale, participants with an oral proficiency in the range of “2” displayed both high (C02, C26, C07, C04, C24) and low degrees of obstruent voicing (C09, C05, C01, C21, C03).
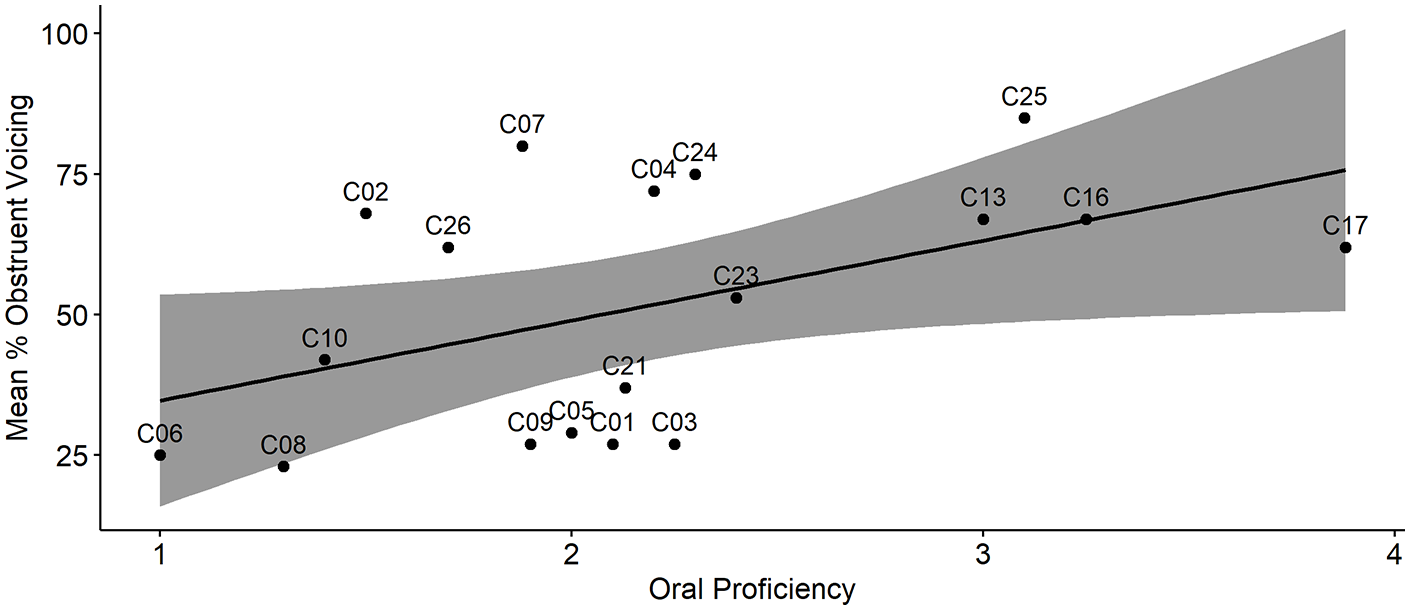
Correlation between Mandarin-speaking participants’ oral proficiency as measured by accented ratings using a 5-point scale and their mean % obstruent voicing. The gray shading indicates the 95% confidence interval.
Both groups of speakers sometimes produced a brief pause after the target word, although these disfluencies were more common among the L2 learners (following underlying voiced obstruents: L1 Mandarin n = 158 [47%] tokens, L1 French n = 17 [9%] tokens: voiceless obstruents: L1 Mandarin n = 363 [90%] tokens; L1 French n = 101 [44%] tokens). In the other more fluent realizations, they produced utterances with no pause between the target obstruent and the following word of the carrier phrase (encore /ɑ̃kɔʁ/ “again”) or rather an epenthetic vowel following the target voiced consonant (number of epenthetic vowels directly following underlying voiced obstruent: L1 Mandarin n = 179 [53%], L1 French n = 178 [91%]; following voiceless obstruents: L1 Mandarin n = 42 [10%], L1 French n = 131 [56%]). Whether the obstruent was realized before a pause or a vowel was expected to influence the degree of voicing, as intervocalic contexts should facilitate the voicing of the preceding obstruent. Indeed, when comparing the mean % obstruent voicing values for underlying voiced obstruents, both groups realized underlying voiced obstruents with a greater degree of voicing pre-vocalically (L1 Mandarin: prevocalic 64%, pre-pausal 38%; L1 French: prevocalic 90%, pre-pausal 71%).
Based on these differences, it was plausible that the lower degree of voicing observed in the Mandarin learner productions was due in part to their larger number of pre-pausal realizations of voiced obstruents (47% by the Mandarin controls compared with 9% by the French controls). We therefore performed a second analysis comparing the % obstruent voicing of the Mandarin learners and French controls by following context (pre-vocalic, pre-pausal). Due to the small number of tokens for underlying voiced obstruents produced with a following pause by the French native speakers, and similarly, the small number of underlying voiced obstruent tokens produced with a following vowel by the Mandarin learners, the data were not separated by manner. As the mixed-effects model reported above did not reveal a language-by-manner interaction, manner was not expected to play a role.
Figure 8 displays the % obstruent voicing results comparing the Mandarin learner and French control groups’ realization of underlying voiced and voiceless obstruents in pre-pausal versus pre-vocalic contexts. In the former context, the Mandarin learners realized underlying voiceless obstruents with a mean % obstruent voicing of 17%, which was similar to the mean observed in the French controls (22%). In the case of underlying voiced obstruents, a clear between-group difference was observed (Mandarin learners 38%, French controls 71%).
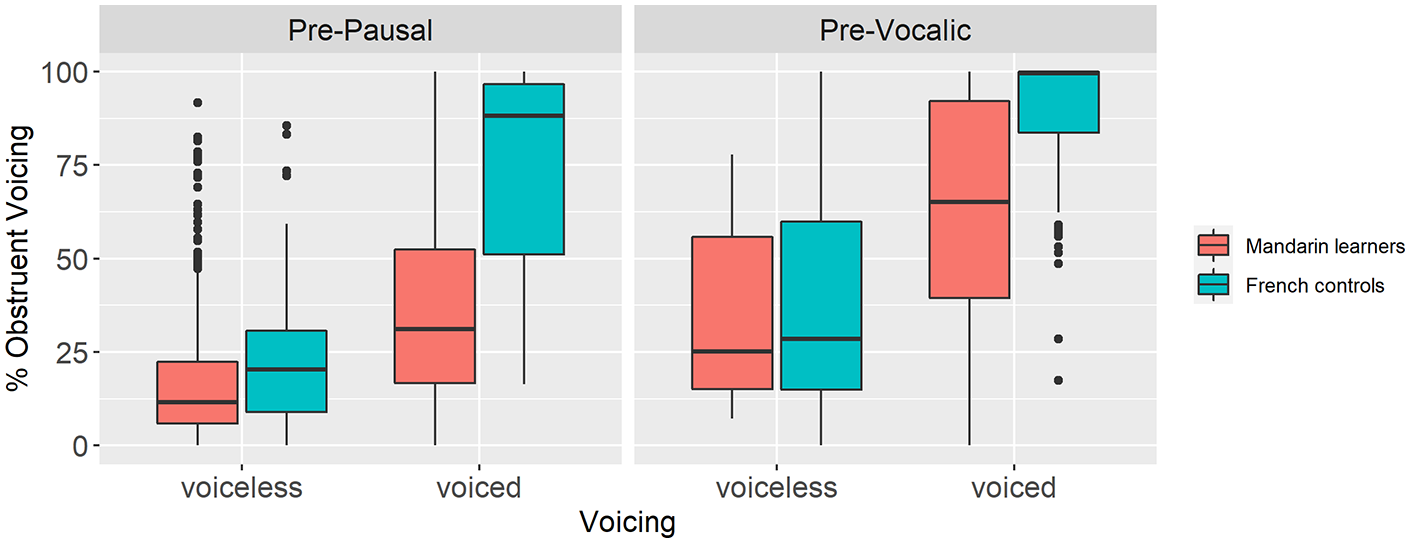
Mandarin-speaking learner-French control group comparison of the mean % obstruent voicing by context (pre-pausal [left]; pre-vocalic [right]) and underlying voicing (voiceless [left], voiced [right]).
We ran a mixed-effects model to examine in greater detail the effect of language group and underlying voicing on % obstruent voicing as a function of the following context. Note that due to the small number of tokens in two of the conditions, the results should be considered with a degree of caution, as they may underemphasize between-group differences. We included random intercepts for group and item, by participant random slopes for following context, voicing, and their interaction, and by group random slopes for group, following context, and their interaction. The mixed-effects model revealed an effect of group (β = 10.90 SE = 2.66; df = 25 t = 4.09; p < .001), voicing (β = 21.95; SE = 2.70; df = 35 t = 8.12; p < .001), following context (β = −4.48; SE = 1.61; df = 23 t = −2.79; p < .001), and a group-by-voicing interaction (β = 5.00; SE = 1.79; df = 25; t = 2.80; p = .009). These results suggest that, while differences in voicing were observed depending on whether the obstruent preceded a pause or a vowel, the differences were similar for speakers of both L1s. A post hoc pairwise comparison of the group-by-voicing interaction revealed no difference between the Mandarin learners and French controls in the voiceless condition (β = 6.80; SE = 4.52; df = 38; t = 1.50; p = .141). However, a significant difference was found in the voiced condition (β = 30.40; SE = 4.85; df = 50; t = 6.26; p < .001). While the results in Figure 8 suggest that a following vowel facilitated voicing for the French controls more than the Mandarin learners, the absence of a three-way interaction between group, voicing, and following context reveals that this was not the case. However, the lack of an effect may be due to the small number of tokens in some contexts. Nevertheless, regardless of whether the following context was a vowel or a pause, the Mandarin learners voiced underlying /b d g v z / less than their French-speaking peers.
5.3 Comparing the accuracy of duration versus laryngeal voicing
While the analysis in the previous section revealed that the Mandarin learners differed from the French controls for both voicing parameters, the first goal of the current study was to investigate the relative difficulty of the two parameters for the Mandarin learners. To quantify the degree of difficulty, for each group of speakers, we calculated the mean values of the two obstruent voicing parameters (VC duration ratio, % voicing; see Figure 9) by underlying voicing, for both stops and fricatives.
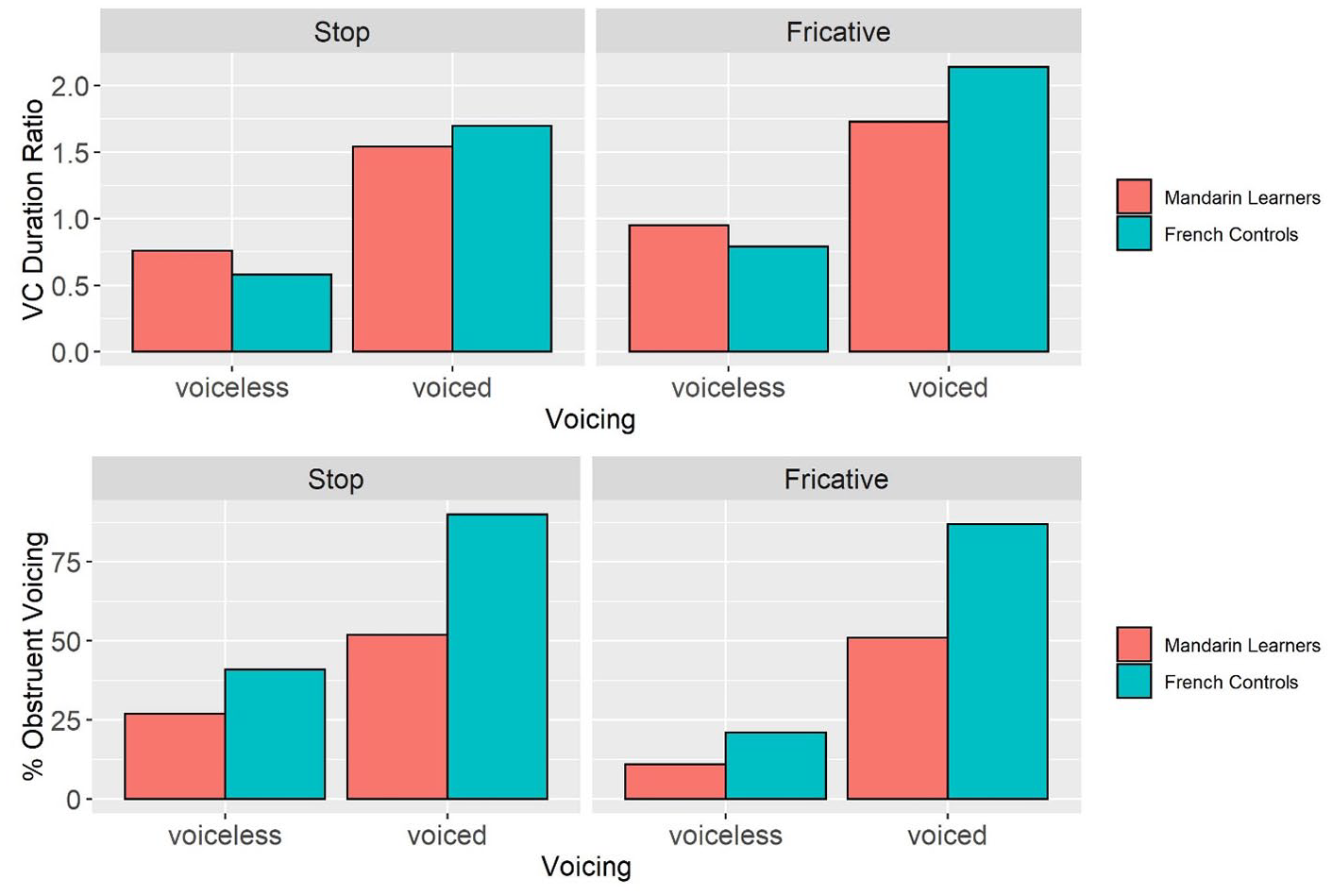
Bar graphs representing the mean VC duration ratio (top) and % obstruent voicing (bottom) values in the Mandarin learners’ and French controls’ production of underlying voiceless (left) and voiced (right) obstruents, grouped by manner (Stop [left], Fricative [right]).
We then calculated the ratio of the Mandarin-to-French means for each parameter. This ratio, which assesses the target-likeness of the Mandarin learners’ realization of both the VC ratio and % obstruent voicing, was then used to assess the relative degree of difficulty. A score of “1” corresponds to the learners matching the French controls perfectly. The further the value is from “1,” the less accurate the learners’ production (i.e., the more difficult the parameter).
As can be seen in Table 4, with the exception of voiceless stops where the Mandarin-speaking learners were equally successful in matching their native speaker peers with a divergence of 31% and 33% for the VC duration ratio and % obstruent voicing, respectively, for all three other comparisons, they were much more accurate with the VC duration ratio (voiced stops: 0.91 vs. 0.58; voiceless fricatives: 1.20 vs. 0.52; voiced fricatives: 0.81 vs. 0.59). In sum, the much larger difference between the Mandarin learner and French control values for % obstruent voicing in all contexts with the exception of voiceless stops suggests that voicing was the more difficult parameter.
Mean Mandarin Learner Values for Each Voicing Parameter, Expressed as a Proportion of the French Control Mean Values, Grouped by Obstruent Manner of Articulation and Voicing.
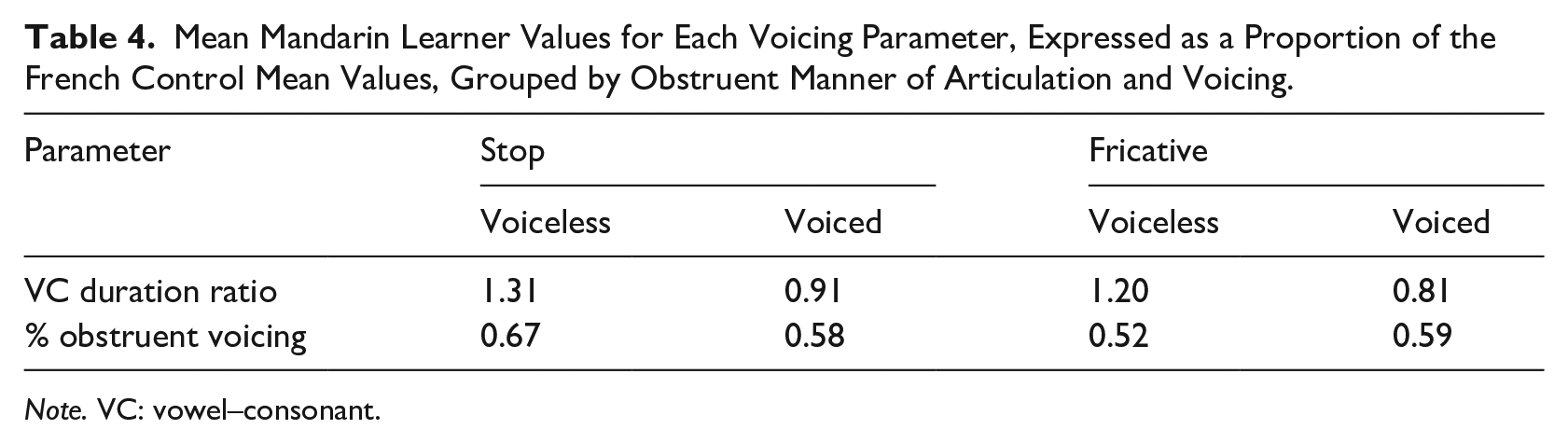
Note. VC: vowel–consonant.
6 Discussion: exploring the potential contributions of L1 experience, perceptual salience, and articulatory difficulty
In the present study, a clear asymmetry was observed with our Mandarin-speaking learners being more accurate with the production of the VC duration ratio. Not only were the learners unable to voice obstruents to the same degree as the French controls, the degree of voicing was relatively less target-like than their realization of vowel duration.
The L2 learners’ greater facility with duration observed here parallels the findings of the majority of previous studies having investigated the acquisition of coda voicing in Germanic languages, both English (e.g., Baker, 2010; Flege et al., 1987; Laeufer, 1996b) and German (Smith et al., 2009). That this pattern was found once again, this time for a Romance language like French in which obstruent voicing is potentially more perceptually salient given the language’s smaller, more variable VC ratio asymmetry and (more) fully voiced coda obstruents, provides further evidence for a general greater facility with duration during L2 acquisition. The relatively greater importance of duration has also been found for L2 vowel perception (e.g., Bohn, 1995). As Schertz et al. (2015) highlight, in the perception of the English /i-ɪ/ contrast, learners with a variety of L1s (Catalan, Mandarin, Russian, Spanish) attend to duration cues, whereas native speakers attend first and foremost to spectral cues. The question that begs to be asked is what are the sources of learners’ greater facility with this phonetic parameter? In the following sections, we explore three possible explanations, namely, L1 experience and the potential universality of duration as a cue to phonological contrasts, the relative perceptual salience of the two parameters, and the articulatory difficulty of realizing voicing in obstruents, particularly in syllable codas.
6.1 L1-based experience and universal use of duration as a phonetic cue
The first possible explanation for the duration-voicing asymmetry observed here and in previous research is that, even with speakers of an L1 lacking an obstruent coda voicing contrast such as Mandarin, duration is a parameter used to cue phonological contrasts and, thus, one with which learners have previous experience. In the case of Mandarin-speaking learners, their L1 consonant inventory /p pʰ t tʰ k kʰ f s ʂ x t͡s tsʰ t͡ʂ t͡ʂʰ m n ŋ l ɻ w j/ (Duanmu, 2007) includes no voiced obstruents, and codas are restricted to the nasals /n ŋ / (e.g., Wiese, 1988) as well as the liquid /ɻ/ in affixed forms (e.g., Cheng, 1966; Wiese, 1988; Yip, 1992). In contrast, native Mandarin speakers have experience using duration to realize phonological contrasts including stressed versus unstressed syllables (e.g., Duanmu, 2007; Shen, 1993) and focus (e.g., Chen & Gussenhoven, 2008; Lee et al., 2016).
It may be the case that all L2 learners come to the table with experience using duration as a phonetic cue to phonological contrasts. Indeed, duration is used widely crosslinguistically to signal phonological oppositions in consonants (e.g., the voiceless-voiced opposition discussed here), vowels (e.g., short-long contrasts such as those of English /i-ɪ, e-ɛ, o-ɔ, u-ʊ/), as well as prosodic phenomena including lexical stress (e.g., Cutler, 2005; Gordon & Roetgger, 2017) and phrasal boundary marking (e.g., Byrd & Riggs, 2008; Swerts, 1997). Crowther and Mann (1992), following Kluender et al. (1988), hypothesize specifically that vocalic duration is a universal perceptual cue to voicing in final stop consonants.
This proposal is consistent with several of the studies reviewed earlier whose researchers attributed L2 learners’ greater accuracy in the production of duration to properties of the L1 including the presence of a coda voicing contrast (L1 Spanish speakers in Flege et al., 1992) or contrastive vowel length (L1 Korean speakers in Baker, 2010). For example, in Baker (2010), all of the L1 Korean–L2 English learners, regardless of their age at onset of acquisition and amount of immersion experience, could produce target-like vowel duration before both voiceless and voiced stops. While all learners produced a significant difference in closure duration between voiceless and voiced stops, all values were greater than those of the native speaker controls even for learners with 10 years of immersion experience. Consistent with the proposal here, Baker highlights that the Korean-speaking learners’ greater facility with vowel duration may be related to both the presence of phonemic vowel length contrasts in their L1 and the greater salience of vowels (sonorants). We turn next to the potential role of perceptual salience in explaining the duration-voicing asymmetry in the current study.
6.2 Perceptual salience
Research on L2 acquisition regularly appeals to perceptual salience, proposing that more salient phenomena are acquired more readily (e.g., Baker, 2010; Bohn, 1995; Colantoni & Steele, 2007; Goldschneider & DeKeyser, 2001; Laeufer, 1996a; papers in Gass et al., 2018). While the construct of salience is intuitive, it has multiple operationalizations that vary by phenomenon and researcher (see Boswijk & Coler, 2020 for discussion with reference to linguistics in general). Schmid and Günther (2016) propose that linguistic salience “emerges from a comparison between an incoming linguistic cue and expectations that are activated from the interaction between current perception-based linguistic, situational, and social context, and long-term memory-based cognitive context (i.e., linguistic and encyclopedic knowledge)” (p. 4). In the particular case of second language acquisition, Dekeyser et al. (2018) propose the existence of three categories of salience—narrow, medium, and broad. Narrow salience refers to perceptual properties of a linguistic form such as the presence of stress, the number of phones, and its position in the utterance; this type of salience is not in a relationship with linguistic meaning. In contrast, the constructs of medium and broad salience both include meaning-related elements such as the clarity of meaning and transparency of form-meaning mappings. What differentiates the latter two categories is that broad salience also includes extra-linguistic factors related to the physical, psychological, and linguistic contexts.
Salience as discussed with respect to the acquisition of coda voicing is of the narrow type in Dekeyser et al.’s typology. In the case of phonetic perceptual salience in particular, certain features/phonetic parameters may be more perceptually salient than others. For example, all else equal, stressed syllables are more salient than their unstressed counterparts given their greater acoustic prominence due to their greater amplitude, duration and/or higher frequency (e.g., Cutler, 2005). As highlighted above, salience is an emergent property in part determined by previous linguistic experience. Indeed, L1 experience in both monolinguals and bilinguals shapes perceived salience by directing listeners’ attention to features that are information rich in terms of linguistic contrasts. The role of salience and the related concept of attention have been formalized in cue weighting theory (Francis et al., 2000; Francis & Nusbaum, 2002; Holt & Lotto, 2006) and the Automatic Selective Perception Model (Strange, 2011). Both of these models propose that listeners are more attentive to features relevant to phonological contrasts in their L1. For the particular case of L2 speech perception, these proposals have been borne out in various studies that have shown that, even at the level of speakers’ dialect, previous experience is relevant (e.g., Chládková & Podlipský, 2011; Escudero, 2005).
Returning to the present study, we argue here that duration may be relatively more salient than laryngeal voicing, both because of our Mandarin-speaking learners’ L1 experience and properties of the input. On the general assumption in L2 speech research that accurate perception is required for accurate production (e.g., Escudero, 2005; Flege, 1995), phonetic parameters that are more salient and thus acquired more readily in perception should also be the parameters that are mastered earlier in production, all else being equal. In the case of L1 Mandarin speakers, one should expect greater attention to be paid to duration than laryngeal voicing, as their L1 uses duration to signal phonological contrasts including the voiceless-voiced stop contrast via voice onset time as well as the primary phonetic cue to stress (Shen, 1993) and corrective versus broad focus (Wang et al., 2020). 11 Duration cues are also used to identify tones (Kong & Zeng, 2006) and as a salient marker of prosodic boundaries (primarily via pre-boundary lengthening; Shen, 1992; Yang, 2008). The sensitivities that Mandarin speakers have to duration in their L1 are also present when learning a non-native language. For example, using event-related potentials, Zeng et al. (2020) found that native Mandarin speakers with only limited English experience obtained through English classes at school were sensitive to lexical stress duration cues in their L2 English. The participants listened to the stimulus /de.de/, which was modified to have either a pitch cue, a duration cue or an intensity cue marking the first or second syllable. The authors examined the mismatch negativity responses to the changes in the stimuli to determine whether participants were sensitive to any of the three stress cues. The results revealed that the learners were sensitive to differences in duration and pitch when they were present on either the first or second syllables, and only sensitive to intensity when present on the first syllable.
With respect to voicing cues, Flege (1989) analyzed whether Mandarin speakers are sensitive to obstruent voicing cues in L2 English. This study examined the perception of words ending in either /t/ or /d/ by native English speakers and Chinese (Mandarin, Shanghainese, Taiwanese) learners of English, primarily graduate students and faculty at the University of Alabama. While the participants had been living for 2 years in the United States on average, they performed poorly on an English comprehension test administered by the author, indicating that the learners were not highly proficient. Participants performed a forced-choice identification task, in which they had to identify stimuli as ending either in /t/ or /d/. The stimuli were (a) unmodified, (b) had the closure voicing removed, (c) the stop burst removed, or (d) both the stop burst and voicing removed. Accurate identification of the stimuli occurred for 92% of all unmodified tokens. When the closure voicing was removed, accuracy dropped slightly to 88%. When the burst alone was removed, accuracy dropped by a much larger degree to 70%. When both voicing and the burst were removed, the accuracy was similar (69%).
The results from Flege (1989) suggest that the Mandarin speakers rely less heavily on the closure voicing cue, and that the stop burst is the most relevant cue to stop voicing. The relative importance of the stop burst is arguably an L1 effect, specifically, due to its importance in Chinese languages that have a laryngeal voicing contrast between voiceless plain and voiceless aspirated obstruents such as Mandarin /p pʰ t tʰ k kʰ t͡s tsʰ t͡ʂ t͡ʂʰ/. Given that the VC duration ratio was not modified in this study, it is difficult to know with certainty to what extent the vocalic duration cue played a role. However, the fact that the learners achieved a 69% accuracy rate without the voicing and stop burst cues suggests that the vowel duration cue was also very important.
Ding et al. (2019) specifically examined Mandarin learners’ sensitivity to vowel duration in English. Fifty-six Mandarin speakers performed a forced-choice identification task in which they had to identify whether the final bilabial, alveolar or velar stop in /hVC/ words were voiceless or voiced. The vowels of each stimulus were modified to have one of seven different durations. The vowels in the voiced context had an average duration of 266 ms (range: 185–347 ms), whereas the vowels in the voiceless context had an average duration of 102 ms (range: 71–122 ms). The results revealed that as vowel length increased, so did participants’ tendency to identify the stimuli as ending in a voiced stop. In another study using a similar methodology, Wang and Wu (2001) also found a positive correlation between increased vowel length and voiced final stop identification. Taken together, the results from Flege (1989), Ding et al. (2019), and Wang and Wu (2001) suggest that, at least when perceiving English, Mandarin speakers are relatively insensitive to closure voicing as a cue to coda voicing, but that they are sensitive to vowel duration cues. As argued above, we attribute this to the fact that they are sensitive to duration cues for contrasts in their L1.
It should be noted that, in the particular case of L2 acquisition, as concerns salience, L1 experience and properties of the target do not operate in isolation. Indeed, Laeufer (1996b) proposes that learners are most successful with structures that are not only salient but also for which there exist L1 variants with similar phonetic implementation that can be used to approximate target language variants. In this study of French-speaking learners’ production of English word-final stops in monosyllabic minimal pairs read in a carrier sentence, 7 of the 10 participants matched the English speaker controls for absolute vowel duration which is salient 12 given that English vowels are relatively longer than those of French in both voiceless and voiced contexts (49 and 28 ms, on average, respectively, based on this study’s findings) and that, in the sentence-medial position tested, the durations are highly similar to those of L1 French sentence-final vowels. In contrast, only three speakers, in particular, those with the greatest amount of English-language immersion, were target-like with respect to the voiced-minus-voiceless vowel duration ranges and pre-voiceless-to-prevoiced duration ratios. All other learners remained close to their native French values. None of the learners matched the English controls for absolute or proportional consonant durations although several of them had moved away from their L1 French values (6 for voiced stops, 2 for voiceless). Laeufer attributes the learners’ lesser success with consonant duration to the fact that, compared with French, English coda consonants are relatively short and, consequently, the duration asymmetry between voiceless and voiced stops is relatively non-salient. Finally, the French-speaking learners were least successful with stop voicing. Only one of 10 had moved away from their L1 voicing patterns, and this individual’s percentage of voicing was lower than the majority of the native English speakers tested.
The studies reviewed in this section support our hypothesis that the vowel duration cue is easier to acquire due to its greater salience than final obstruent voicing. Moreover, Mandarin speakers are likely to be particularly sensitive to duration (but not voicing) cues, as a result of their experience with L1 Mandarin duration contrasts. While our proposal of salience is consistent with our learners’ greater success in mastering the duration of coda voicing, it remains to be substantiated directly. As we will outline in section 6.4, in future work, researchers should measure L2 learners’ perceptual sensitivity to the different parameters to substantiate the claim that certain parameters, such as vowel duration, are more salient than others including the percentage of consonant voicing.
6.3 Articulatory difficulty and laryngeal voicing
Whereas L1 experience, the arguable universal use of duration as a cue to linguistic contrasts, and differences in the relative salience of phonetic parameters are all potential explanations of L2 learners’ greater facility with mastering duration, a final factor may explain the learning asymmetry observed both in the present and previous studies, namely, articulatory difficulty. Previous work on L2 production has found that articulatorily complex structures are more difficult to acquire and are produced with lower levels of accuracy (Colantoni & Steele, 2007, 2008; Patience, 2022; Yavas, 1997). For example, in Patience (2022), L1 English–L2 Spanish-speaking participants performed an articulation task from which an articulatory difficulty hierarchy for five Spanish segments [β ɣ ɲ χ r] was derived; this hierarchy was found to be a predictor of accuracy of L1 English–L2 Spanish speech production in a picture description task. Other studies have also found evidence that articulatory complexity influences L2 speech production. Yavas (1997) and Colantoni and Steele (2007, 2008) examined the acquisition of word-final obstruents and the French rhotic /ʁ/, respectively, and found that the realization patterns in the data could be explained by aerodynamic voicing constraints. For example, Yavas (1997) found that obstruents were less voiced when following a high vowel, and when produced at velar as opposed to coronal and labial places of articulation. Both high vowels and more posterior articulations create a smaller oral cavity, which in turn causes an increase in the supraglottal air pressure. This hinders voicing, due to the fact that maintaining the transglottal pressure necessary for voiced obstruents (Catford, 1977) becomes more challenging as the supraglottal air pressure increases (Ohala, 1983).
Based on the findings of previous work revealing a clear role for articulatory constraints in L2 speech learning, we propose that our Mandarin speakers’ greater facility with realizing the VC duration ratio is also a consequence of the articulatory complexity of voicing obstruents. One word of caution is merited here. If articulatory difficulty indeed played a major role in the Mandarin learner-French control differences in the laryngeal voicing of voiced obstruents, we should also expect more relatively greater difficulty with voicing fricatives as opposed to stops. To create the turbulence in the air stream required for fricatives, a high supraglottal air pressure is needed. This requirement competes with the low air pressure (or relatively lower than the subglottal air pressure) required for voicing. As a result, the voicing of fricatives is considered to be even more complex than the voicing of stops (Ohala, 1983). However, we found no manner-conditioned L1–L2 differences, and the group differences were similar for both stops and fricatives.
On average, the learners’ voiced fricatives were considerably longer than their French peers’ (150 vs. 110 ms or a 40-ms difference) and the between-group difference was larger than for voiced stops (110 vs. 90 ms or a 20-ms difference). As discussed above, realizing both voicing and the constriction necessary for obstruents is articulatorily challenging, and the longer the constriction interval, the greater the difficulty. It is highly possible that our learners’ overly long fricatives explain in part their difficulties with voicing. The detrimental effect of excessively long consonants on voicing has previously been reported for English-speaking learners’ production of the French and Spanish rhotics /ʁ/ and /ɾ/ (Colantoni & Steele, 2007, 2008).
6.4 Follow-up study: experimental exploration of the relative contributions of L1 experience, perceptual salience, and articulatory complexity to the L2 acquisition of obstruent coda voicing
While the possible contributions of L1 experience, perceptual salience, and articulatory difficulty to explaining the duration-voicing asymmetry focused on here are well founded both theoretically and (indirectly) empirically, to be able to assess more directly their potential individual contributions to the L2 acquisition of obstruent coda voicing, further experimental research is required. We briefly outline here a two-part study of English, Mandarin, and Taiwanese-speaking beginner learners of French. These learners differ in their L1-based experience with syllable-final obstruents (none, Mandarin), voiceless codas alone (Taiwanese), and both voiceless and voiced syllable-final obstruents (English). 13
Experiment 1 would test the hypothesized greater relative sensitivity and ability to produce VC duration among all learners and would use these data to create an L1-based accuracy hierarchy (L1 English > Taiwanese > Mandarin) adopting the methodology in Schertz et al. (2015). Participants would first perform a forced-choice voiceless-voiced coda task. The stimuli would consist of French monosyllabic minimal pairs (e.g., /bak/ bac “bin,” /bag/ bague ‘ring’; /kas/ casse “break,” /kaz/ case “compartment/box”) varying from voiceless to voiced along a seven-step continuum for either the VC duration ratio cue or percent voicing cue. The learners would then produce the same stimuli in carrier sentences. The production data would be analyzed using a linear discriminant analysis to test the extent to which each of the two acoustic parameters predict category membership of each speakers’ productions.
Experiment 2, similar to the Yavas (1997) study discussed in section 6.3, would examine the hypothesized negative correlation between articulatory complexity (manipulated in terms of obstruent place of articulation and manner, preceding vowel height, and voicing of the following segment) and mean % obstruent voicing realization as well as the mitigating effect of L1-based experience (same expected hierarchy as in Experiment 1).
7 Conclusion
The present study contributes to our understanding of relative difficulty in L2 acquisition, once again demonstrating that not all target structures are acquired with equal facility. As with previous studies, we found that, when acquiring coda voicing contrasts, L2 learners more readily master duration compared with laryngeal voicing, including in a language like French where the voicing of syllable-final obstruents is arguably more salient. The Mandarin-speaking learners’ realization of coda obstruents / p t k f s ʃ b d g v z/ in the nonce word reading task matched that of the native speakers for the VC ratio with the exception of voiced fricatives. In contrast, these learners did not voice accurately either coda stops or fricatives. To explain this asymmetry, we appealed not only to the relative greater ease of acquiring duration due to both its universal use to realize phonological contrasts crosslinguistically but also to particular segmental and prosodic properties of Mandarin speakers’ L1. We also highlighted ways in which the relative perceptual salience of duration and voicing as well as the articulatory difficulty of realizing syllable-final voiced obstruents might underlie the asymmetry. In future research, these claims will need to be tested empirically. We have proposed one such study here, the results of which would allow us to understand even further the sources of relative difficulty in the acquisition of the phonetic parameters of obstruent voicing.
Footnotes
Appendix A
L2 Learner Participant Profiles.
| Code | Sex | Age | Acc. | Use (hours/week) | Learning | Self rating | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| score | Sp. | List. | Read | OA | Imm. | Sp. | Overall | |||
| C06 | F | 34 | 1.0 | 1 | 2 | 1 | 31 | 24 | B | B |
| C08 | M | 37 | 1.3 | 2 | 10 | 1 | 35 | 24 | I | I |
| C10 | F | 30 | 1.4 | 2 | 12 | 3 | 23 | 36 | B | B |
| C02 | F | 46 | 1.5 | 0.1 | 7 | 0.5 | 38 | 3 | B | B |
| C26 | M | 35 | 1.7 | 1 | 0.1 | 0.5 | 30 | 19 | B | B |
| C07 | F | 33 | 1.9 | 0.5 | 0.5 | 3 | 32 | 8 | B | I |
| C09 | F | 28 | 1.9 | 0.5 | 0.5 | 0.5 | 23 | 36 | I | I |
| C05 | M | 28 | 2.0 | 7 | 5 | 1 | 26 | 7 | B | B |
| C01 | F | 31 | 2.1 | 8 | 14 | 6 | 30 | 12 | B | B |
| C21 | F | 39 | 2.1 | 1 | 1 | 5 | 38 | 0 | B | B |
| C04 | M | 35 | 2.2 | 2 | 12 | 10 | 34 | 12 | B | B |
| C03 | F | 34 | 2.3 | 10 | 15 | 20 | 31 | 42 | I | I |
| C24 | F | 33 | 2.3 | 7 | 7 | 7 | 21 | 20 | A | I |
| C23 | F | 36 | 2.4 | 1 | 4 | 1 | 28 | 12 | B | I |
| C13 | F | 32 | 3.0 | 40 | 30 | 10 | 29 | 0 | I | A |
| C25 | F | 28 | 3.1 | 60 | 60 | 10 | 19 | 108 | NN | A |
| C16 | F | 35 | 3.3 | 20 | 30 | 10 | 31 | 7 | A | I |
| C17 | M | 29 | 3.9 | 15 | 20 | 5 | 20 | 60 | A | A |
| Mean | 33.5 | 2.2 | 9.9 | 12.8 | 5.3 | 28.8 | 23.9 | |||
| Median | 33.5 | 2.1 | 2.0 | 8.5 | 4.0 | 30.0 | 15.5 | |||
| Mode | F | B | B | |||||||
Note. Acc. Score: score on the accentedness task (5 judges’ mean); Sp.: speaking; List: listening; Read: reading; OA: age at onset of acquisition (years); Imm.: immersion (months); Self rating: B: beginner; I: intermediate; A: advanced; NN: near native.
Learners are presented in order of increasing accentedness scores (i.e., overall oral proficiency).
Appendix B
Experimental Stimuli by Manner, Voicing, and Place of Articulation, and Syllable Type.
| Stops | |||
|---|---|---|---|
| Voiceless | |||
| labial | Coronal | Dorsal | |
| CVC | fèpe /fɛp/ | guite /git/ | deque /dɛk/ |
| CVCVC | bénappe /benap/ | bénatte /benat/ | bénaque /benak/ |
| Voiced | |||
| Labial | Coronal | Dorsal | |
| CVC | chibe /ʃib / | zade /zad/ | lague /lag/ |
| CVCVC | bénabe /benab/ | bénade /benad/ | benague /benag/ |
| Fricatives | |||
| Voiceless | |||
| Labial | Coronal | Dorsal | |
| CVC | teffe /tef/ | raisse /res/ | pâche /paʃ/ |
| CVCVC | benaff /benaf/ | bénasse /benas/ | bénache /benaʃ/ |
| Voiced | |||
| Labial | Coronal | Dorsal | |
| CVC | bève /bev/ | caize /kez/ | sare /saʁ/ |
| CVCVC | bénave /benav/ | bénase /benaz/ | benaire /benaiʁ/ |
Acknowledgements
The authors thank the participants for their assistance.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work was supported by a Social Science and Humanities Research Council of Canada Standard Research Grant (410-2004-0925) to the second author.