
Abstract
While nearly all dialects on the British Isles have undergone the
1. Introduction
Nearly all dialects in the British Isles have undergone the
The article is organized as follows. Section 2 provides a review of the literature describing the pronunciation of the
2. nurse Merger in Scottish English
While there is agreement that /ɪr/, /ɛr/, and /ʌr/ vary in Scottish English speech between their traditional distinct realizations and vowels approaching a full merger upon the lexical set defined by Wells (1982) as
However, despite such descriptions in the literature, empirical evidence for the observed variation or
Apart from the realization of the following syllable coda /r/, two more factors emerge in Lawson, Scobbie, and Stuart-Smith’s (2013) study as potential influencing factors of the realization of
In sum, very little empirical evidence substantiates claims of either merged or separate vowels for words such as fir, fern, and fur in Scottish English: the
What are the acoustic properties of the
What effect do phonological (realization of following /r/), orthographic, and social factors (here, gender and age) have on realizations of the
How different or similar are the patterns produced by individual speakers, and with what frequency do different types of
3. Data and Method
3.1. Corpus Data
The data for this study were drawn from ICE-Scotland, the Scottish component of the International Corpus of English (Schützler, Gut & Fuchs 2017). Corpora from the ICE-family follow a uniform sampling scheme (see Nelson 1996; Nelson, Wallis & Aarts 2002), with 600,000 words collected from fifteen spoken genres (or text types) and 400,000 words sampled from seventeen written genres.
In our analyses we include material from five spoken genres: four categories of scripted speech, including broadcast news (“bnew”), broadcast talks (“btal”; e.g., scripted speeches given in the Scottish parliament by invited speakers), legal presentations (“leg”; e.g., legal sentencing) and non-broadcast talks (“nbtal”; e.g., scripted speeches given at university such as inaugural lectures on any topic), as well as unscripted speeches (“unsp”; e.g., conference presentations in any field). If the general design of ICE is to lean intentionally towards the standard end of language use by including only highly educated speakers (e.g., comments in Greenbaum 1996:177), these genres could be said to be particularly formal and most likely to evoke the use of the standard variety of Scottish English, as compared to face-to-face conversations or telephone calls, for example. All speakers in this study are users of SSE, including university lecturers, journalists, lawyers, university students, and ministers. It should be noted that, although they are considered to be middle-class speakers due to their current occupations, their original social class is largely unknown. This of course has consequences for the generalizability of our data, as we will discuss in the final section.
The total number of speakers is ninety-two; the breakdown by gender and genre is shown in the left-hand part of Table 1 (dataset A). For most of the analyses, a smaller dataset was derived from this dataset A, one that includes only those speakers for whom information regarding both gender and age was available (dataset B). Further, a third subset of the data was used to inspect the relationship between the acoustic quality of the vowel and the phonetic realization of the following /r/ (dataset C). Since this analysis was based on a time-consuming auditory analysis, a smaller dataset was chosen (see section 3.3). Rhoticity is a highly sensitive feature that is subject to a series of language-internal and external factors; dataset C is based solely on broadcast talks rather than a cross-section of genres to rule out potential effects of speech rate, text type, and orthography on the realization of /r/. As Table 1 shows, the genre of broadcast talks is strongly overrepresented in our sample in terms of speaker numbers, particularly so in dataset B. Moreover, in all datasets the gender distribution within most genres is uneven.
Number of Speakers per Genre
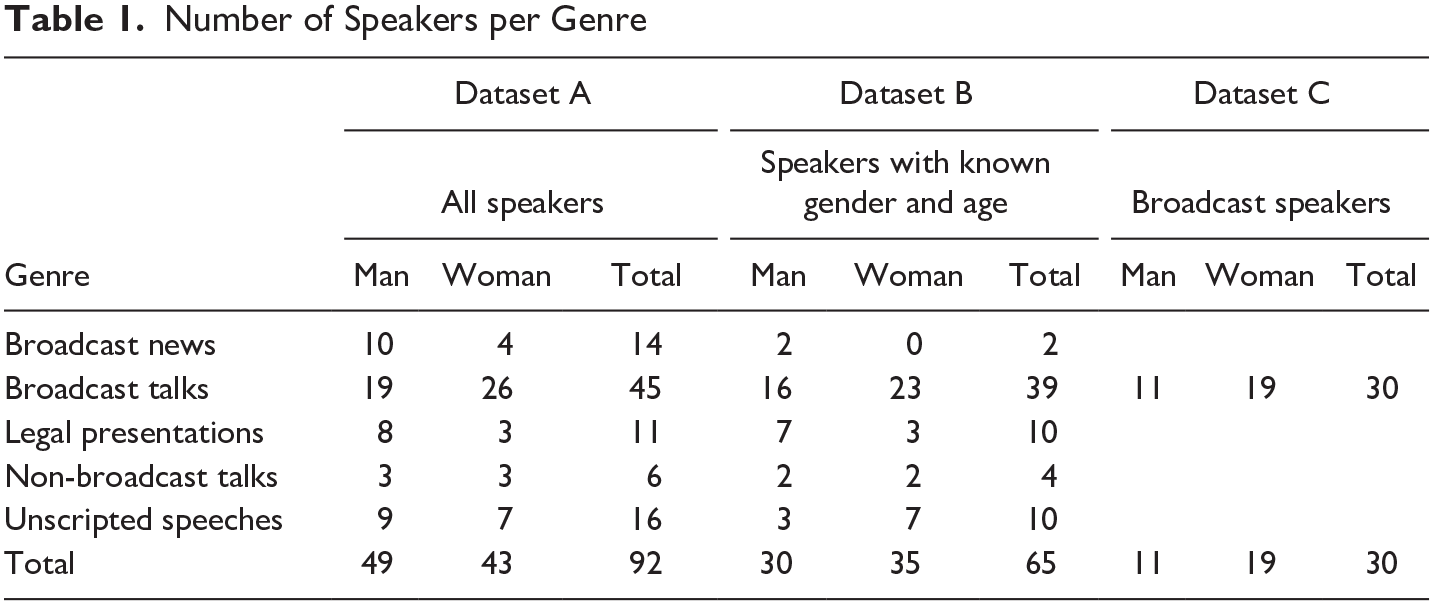
The total number of target words containing the vowels we consider here was 64,616 in dataset A, 51,576 in dataset B, and 23,640 in dataset C. We include
3.2. Extraction and Acoustic Analysis of Vowels
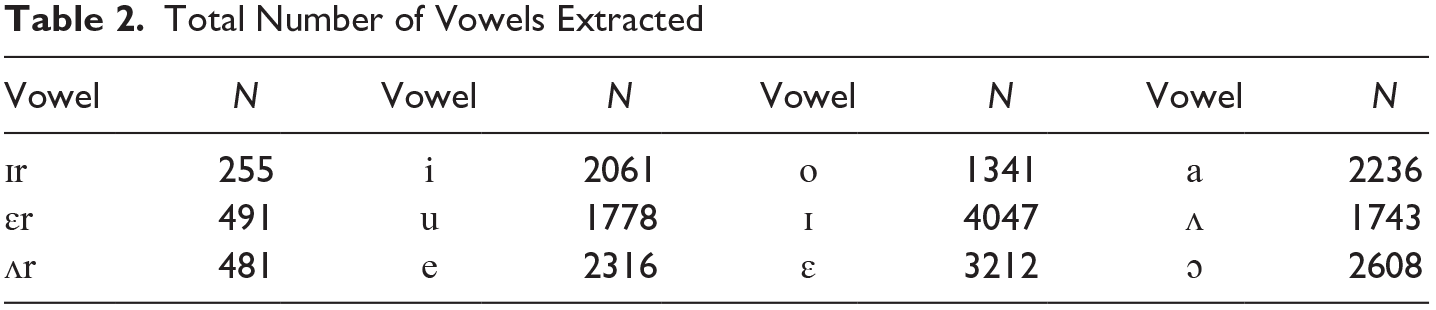
ICE Scotland contains automatic phonemic transcriptions that were created with WebMAUS (Schiel 2004). This is a web service that creates phonemic transcriptions via forced alignment of orthographic transcriptions and sound files. These transcriptions were subsequently corrected manually for both phoneme transcription and location of phoneme boundaries in Praat (Boersma & Weenink 2017). For the present study, we created TextGrids that were based on the automatically generated annotations and contained twelve vowel categories in the stressed position (three
Total Number of Vowels Extracted
Using Praat, the F1 and F2 values of all target vowels were extracted automatically in Bark (Traunmüller 1990), averaging across a section of the vowel that extended from 20-70 percent of its total duration. Based on Sönning and Schützler (2018), we then applied an adapted form of Lobanov’s (1971) z-score normalization procedure. Based on the raw data, we first determined the midpoint of the acoustic vowel space for each speaker by calculating median values of F1 and F2 for each of the eight normalizer categories for that speaker, and by calculating their mean, again separately for each formant. Next, the respective mean was subtracted from each individual vowel measurement, creating values centered around zero. For all vowels, these negative and positive values of F1 and F2—effectively deviations (in Bark) from the midpoint of the space—were then divided by the standard deviation of the sixteen centered median values of normalizers for the respective speaker across both F1 and F2. While the original Lobanov normalization procedure measures formants in Hz and divides centered values by a standard deviation of normalizers that is different for F1 and F2, using a single standard deviation in both dimensions preserves relative positions and distances between vowels and thus respects the psychoacoustic scaling introduced by the Bark-scale.
3.3. Auditory Analysis of the /r/ Variant
For the thirty speakers in dataset C (see Table 1), an auditory analysis was carried out to determine the realization of the /r/ variant (if present) in all /ɪr/, /ɛr/, and /ʌr/ words. Two phonetically trained raters assessed whether /r/ was realized as a tap/trill ([ɾ r]), an approximant ([ɹ Vɹ]), or whether no constriction was perceived (coded as Ø). These three categories were employed in order to capture variation along a continuum ranging from the “traditional” Scottish tap/trill realization via the modern standard realization as an approximant to a vocalized, unconstricted variant (following Schützler 2013, 2015:59). Unlike /r/-vocalization in working-class speech, the latter is interpreted as possibly due to anglicization in middle-class speech.
We refrained from using a more fine-grained distinction of rhotic realizations because it would have made it difficult to achieve sufficient interrater reliability (as in Dickson & Hall-Lew 2017). Following this method, we achieved good interrater reliability of about 89 percent between the first and the second rater for identification of /r/ variants. In case of disagreement between the two raters, a third rater, also phonetically trained, made the final decision. The auditory analysis was complemented with a visual spectrographic analysis using Praat (Boersma & Weenink 2017) for less clear tokens or when in doubt.
3.4. Statistical Modeling
For the statistical analysis, Bayesian linear (Gaussian) mixed-effects regression models with
Variables in the Statistical Models
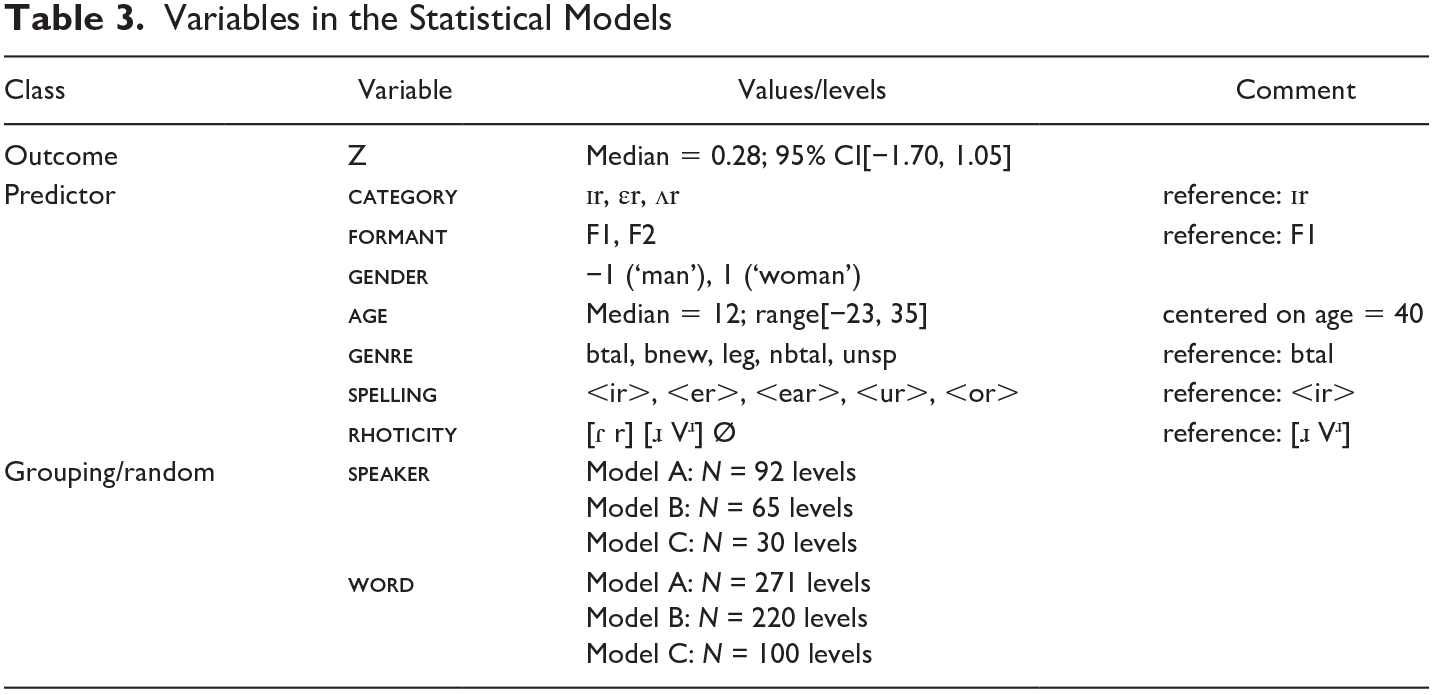
As summarized in Table 4, three models were fitted to datasets A, B, and C; they were analogously labeled “Model A,” “Model B,” and “Model C.” Model A and Model B differ only in the latter having
Model Syntax for Linear Mixed-effects Regression Models

The outcome variable in all models is the formant value Z, which is a z-score calculated as described in the previous section. In the fixed part of Model A,
4. Results
4.1. Realization of nurse Vowels
In the following discussion of the results, predictors that are not of interest in a particular display are constrained to take their normal/average values. For example, if there is no focus on genre differences, predictor values of the four predicted categories of
Figure 1 displays the estimates of the speaker means of F1 and F2 for /ɪr/, /ɛr/, and /ʌr/, based on dataset A. The thicker, central parts of the crosses placed on each vowel position represent 50 percent uncertainty intervals, while their thinner and longer parts represent 95 percent uncertainty intervals. The high threshold of confidence was chosen because of the large number of speakers (N = 92) and because
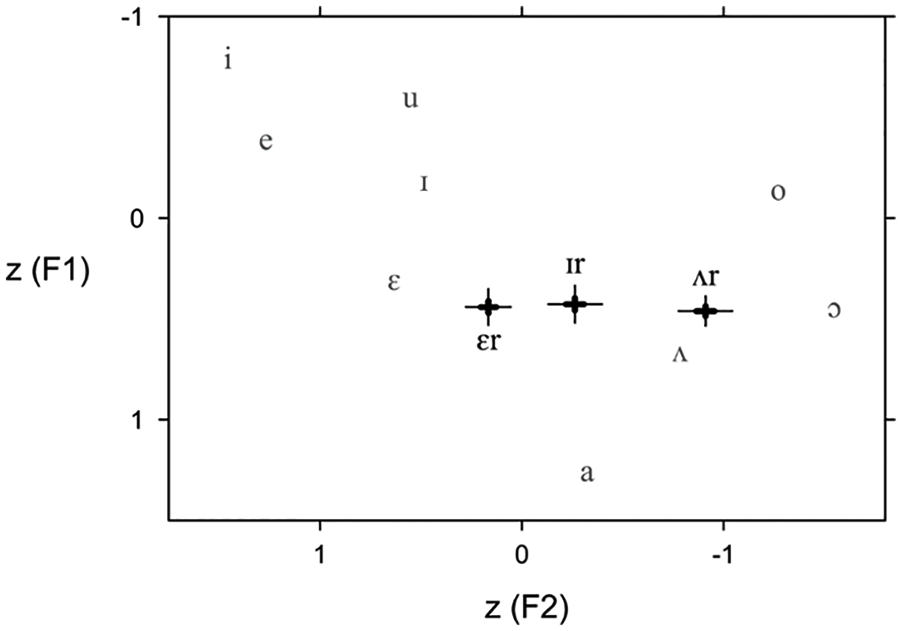
Position of /ɪr/, /ɛr/, and /ʌr/ in the Acoustic Vowel Space (Dataset A)
As can be seen from Figure 1, in SSE the
While Figure 1 presents the mean F1 and F2 values of /ɪr/, /ɛr/, and /ʌr/ averaging across all speakers in dataset A on the basis of the statistical model, Figure 2 zooms into the realizations of /ɪr/, /ɛr/, and /ʌr/ by the individual speakers. Token numbers differ between the three panels of the plot because we excluded speakers for whom the respective vowel category was represented by less than two tokens (thus, N = 57 for /ɪr/, N = 73 for /ɛr/, and N = 70 for /ʌr/). Individual speakers’ average positions for the three categories form “clouds” in the vowel space that are centered roughly on the average positions shown in Figure 1. However, considerable inter-speaker variation can be observed for all three
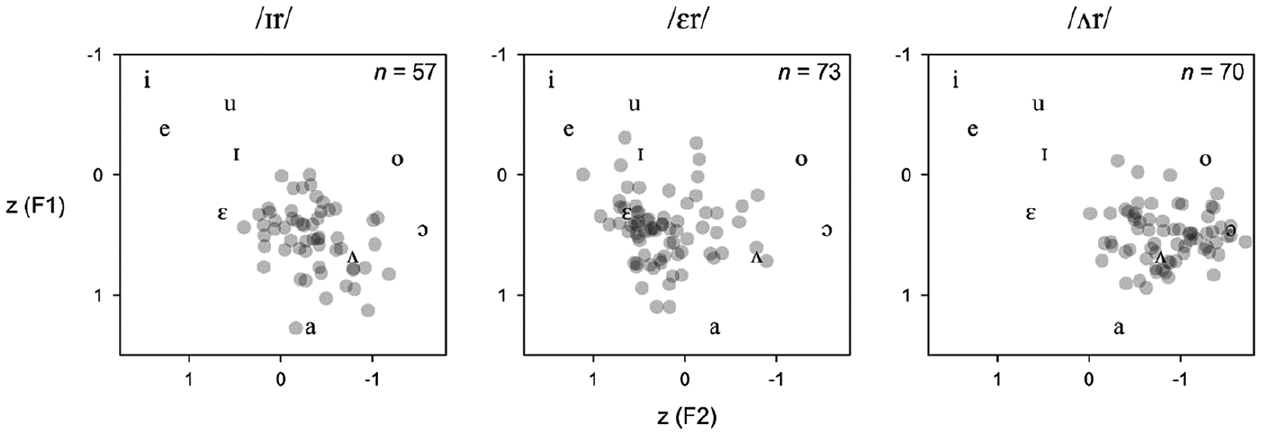
Positions of /ɪr/, /ɛr/, and /ʌr/ by Individual Speaker (Dataset A)
Figure 3 presents estimated mean transformed F1 and F2 values for the different gender and age groups, based on dataset B: women are shown in the top panel (using 50 percent and 90 percent uncertainty intervals) and men are shown in the bottom panel. For the respective older groups, estimates are based on the assumption of sixty-year-old speakers; for younger groups, speakers are assumed to be twenty years old.
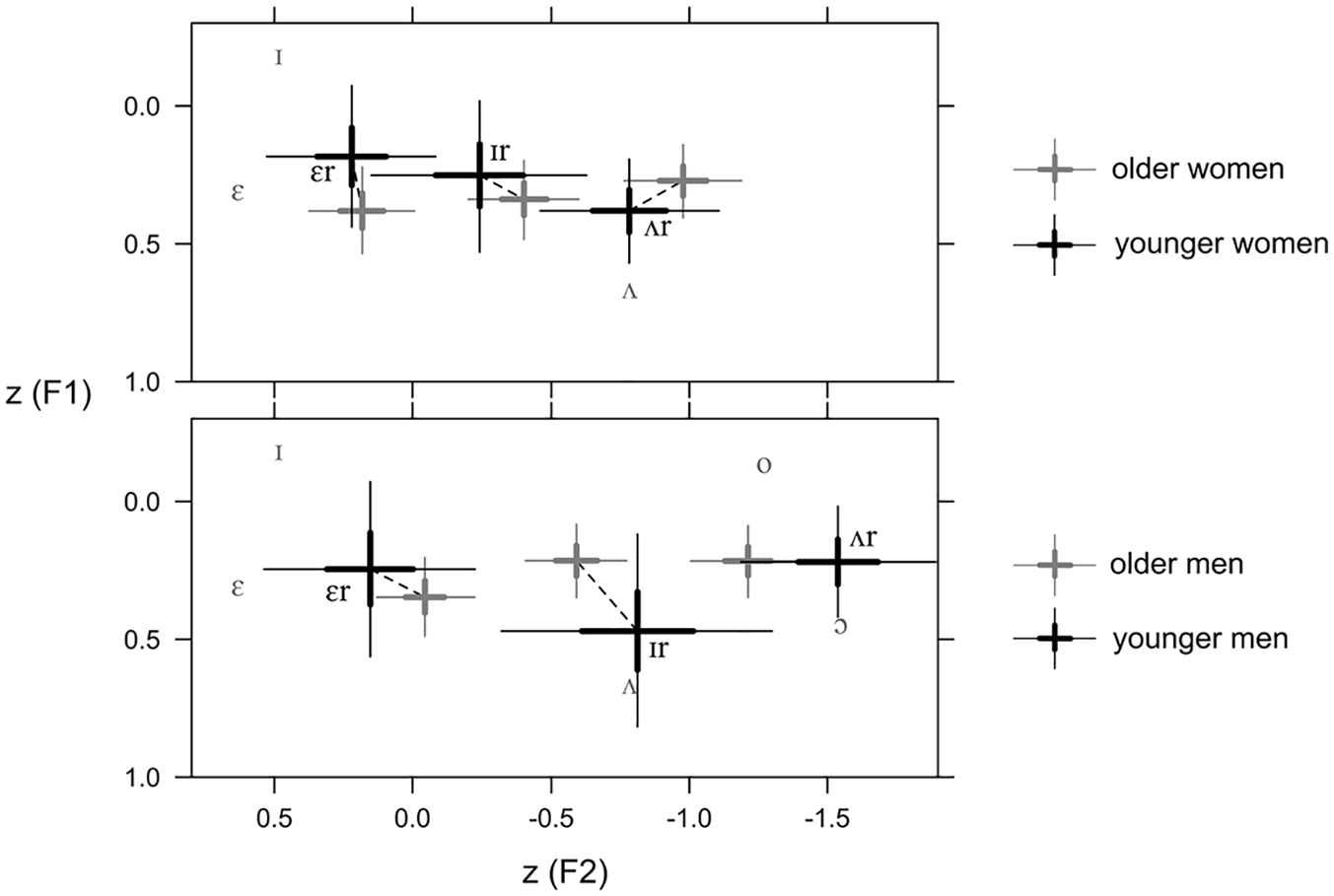
Position of /ɪr/, /ɛr/, and /ʌr/ by Age and Gender (Dataset B)
The figure shows that there are no substantial differences between groups established on the basis of
Concerning age patterns, results are inconclusive. For both men and women, differences between age groups are moderate with regard to most pre-rhotic vowels. If we assume an ongoing change in the direction of centralization and/or merger, this is only partially supported, e.g., by the tendency of younger men to centralize the vowel in /ɪr/ more than older men, or a similar (albeit very slight) tendency of the same kind that affects /ʌr/ between younger and older women. However, these tendencies appear to be sporadic and are not part of a more general pattern. For example, it is the younger women and the younger men who produce acoustically more peripheral variants of /ɛr/, and /ʌr/ is realized further towards the back with a lower F2 by younger men compared to their older counterparts, while younger women have a slightly increasing F2 than older women do. In other cases, there is no correlation between age and the centralization of vowels, for example concerning the realization of /ɪr/ by women.
Again, the considerable scatter of individual speakers’ vowel positions for all three
Figure 4 presents differences in vowel realization across the four genres broadcast talks (btal), non-broadcast talks (nbtal), legal presentations (leg), and unscripted speeches (unsp), again showing 50 percent and 90 percent uncertainty intervals. The text category broadcast news (bnew) was not plotted since data are rather sparse and included no tokens from women (see dataset B in Table 1). As discussed above, predictors that are not in focus are constrained to take their “normal” values (
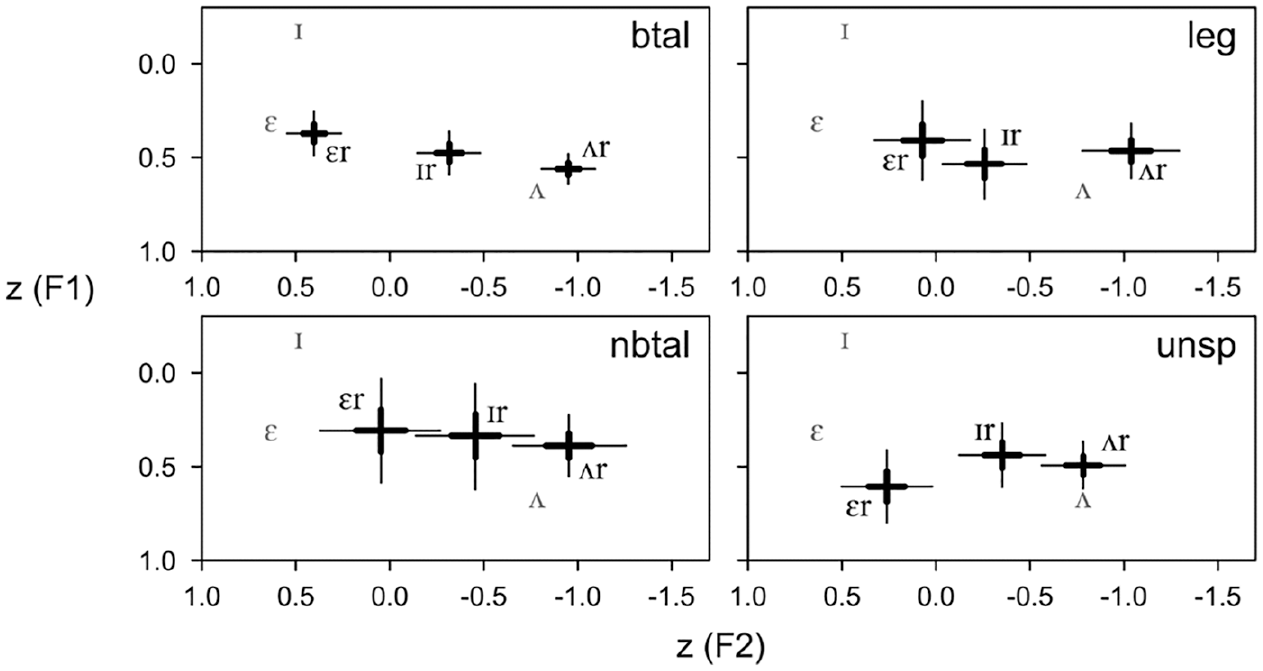
Genre Differences in the Realization of /ɪr/, /ɛr/, and /ʌr/ (Dataset B)
Figure 4 shows that in the category non-broadcast talk, arguably the least formal of the categories analyzed here, /ɪr/, /ɛr/, and /ʌr/ are most similar, with /ɪr/ and /ɛr/ close to merging and /ʌr/ being further apart. No difference between scripted and unscripted speech can be seen. The same caveat as above holds with regard to this analysis as well: if we are interested in the average positions of the three vowels for groups of speakers (in this case arranged by the genres in which language was produced), we arrive at results that are only subtly different and not always easy to interpret. The approach followed thus far produces idealized abstractions based on the potentially more radically different and therefore more revealing underlying individual patterns.
Figure 5 shows the realizations of /ɪr/, /ɛr/, and /ʌr/ according to the orthography of the word. In contrast to all previous analyses, the predictor
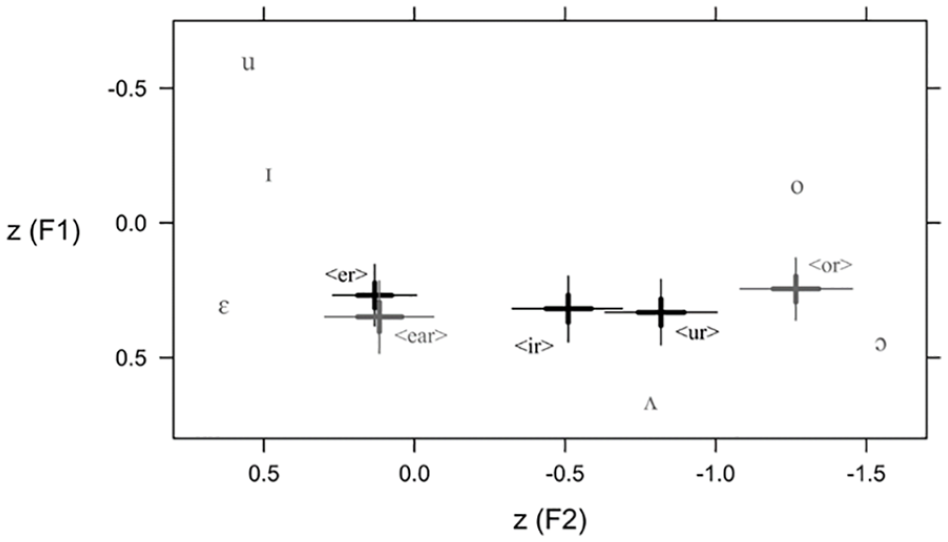
Position of /ɪr/, /ɛr/, and /ʌr/ by Spelling (Dataset B)
The figure shows that while the realization of /ɛr/ is not influenced by the spelling of either <er> or <ear>, spelling has a marked effect on the realization of /ʌr/: the vowel in words spelled with <or> such as in world is closer to /o/ and /ɔ/, while the vowel in words spelled with <ur> such as in burn is much more central and thus closer to the
Figure 6 presents the vowel realizations, based on dataset C and model C (broadcast talk only; see Tables 1 and 4) according to the realization of the following /r/. It offers two perspectives on the same data: the three panels at the top show differences within each of the three vowel categories, depending on which variant of /r/ follows. The three panels at the bottom show complete constellations of /ɪr/, /ɛr/, and /ʌr/ in combination with each of the three /r/-variants. There is a clear tendency for vowels followed by approximants to be grouped more closely together in the mid-central area of the acoustic vowel space than vowels followed by the traditional tap/trill and vocalized variants of /r/. In the top half of Figure 6, a following approximant always correlates with the most central vowel realization. Furthermore, the realization of the following /r/ as a tap/trill promotes the partial merger of /ɪr/ and /ʌr/, which, by contrast, are shown to be more distinct when followed by a vocalized /r/ variant. In fact, if we look at the effect of zero-variants of /r/, we see that the preceding vowel either has a quality intermediate between the ones associated with tapped or approximant /r/ (for /ɛr/ and /ʌr/), or it takes a different position altogether (for /ɪr/). In other words, there is no evidence in these data that the historical trajectory of change affecting /r/ ([ɾ]→[ɹ]→Ø), which may be assumed at least in middle-class Scottish accents, correlates with a continuum of variation and change between less centralized and more centralized (and eventually merged) qualities of
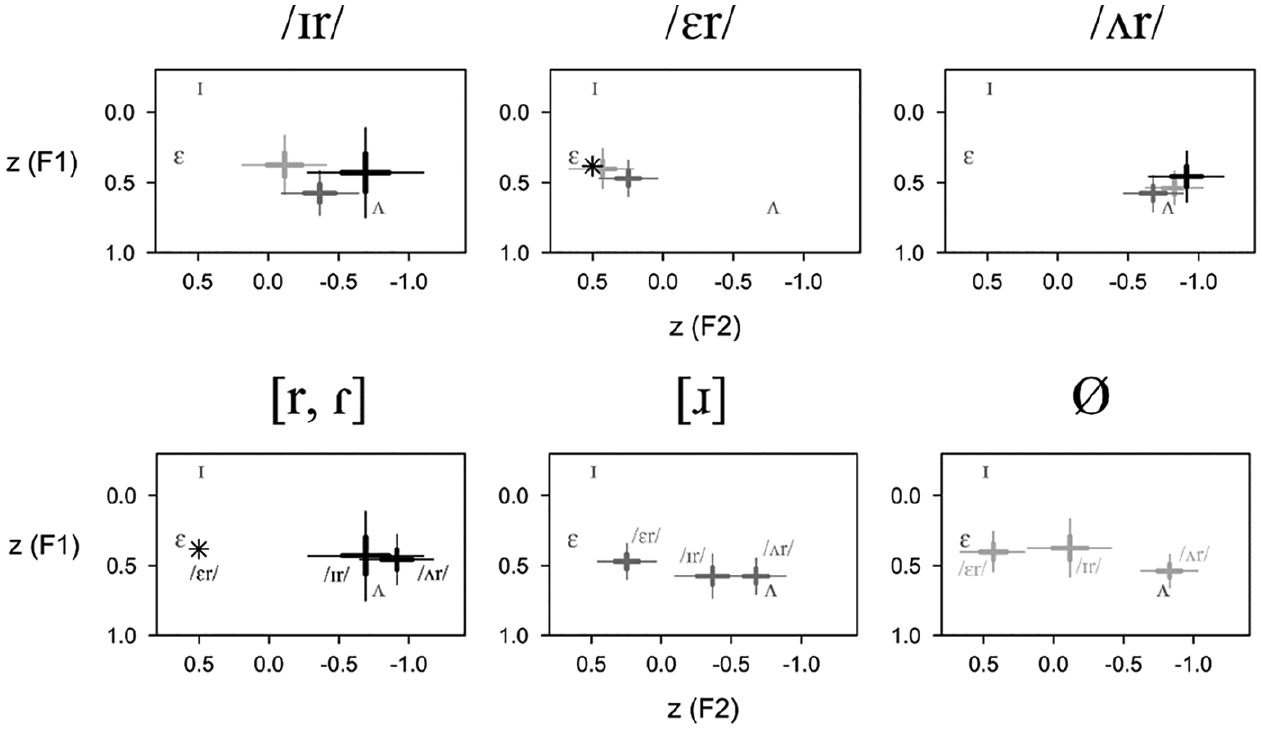
Relationships between Tap/Trill (Black), Approximant (Dark Gray), and Vocalized or Deleted (Light Gray) Variants of Coda /r/ and the Acoustics of /ɪr/, /ɛr/, and /ʌr/ (Dataset C) 3
4.2. Types of nurse Merger
As indicated in Figure 2, there is not only considerable inter-speaker variation in the position of each of the three categories /ɪr/, /ɛr/, and /ʌr/ but also substantial overlap of the areas occupied by each of them. On the basis of our results thus far, it therefore seems perfectly possible for individual speakers to have merged at least two of the three categories, which our earlier perspective on the data had not been able to reveal. Based on vowel plots for thirty-eight speakers in dataset A who produced each of the
Type 1: Unmerged. Three separate vowel spaces for /ɪr/, /ɛr/, and /ʌr/ are observed. The traditional three-way distinction of
Type 2: Merger of /ɪr/ and /ʌr/. The realizations of /ɪr/ and /ʌr/ are centralized and merged, while /ɛr/ is realized close to its non-pre-rhotic counterpart and retained as a distinct category.
Type 3: Merger of /ɪr/ and /ɛr/. The vowel spaces of /ɪr/ and /ɛr/ overlap, while /ʌr/ is further apart to the back and close to /ʌ/ and /ɔ/.
Type 4: Full merger. The realizations of /ɪr/, /ɛr/, and /ʌr/ are centralized and merged in terms of F1/F2 space.
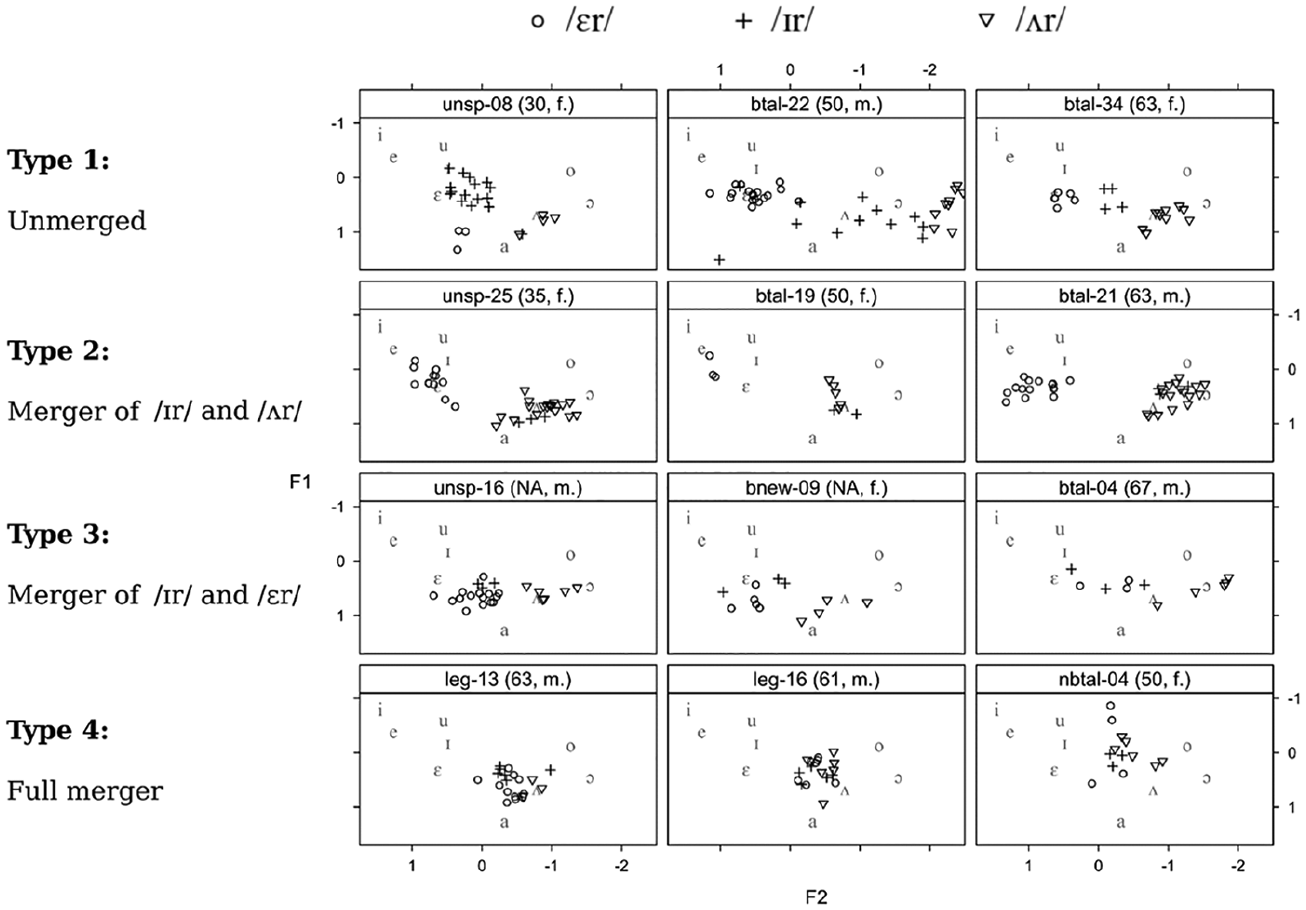
Four Types of Merger and Examples of Individual Vowel Spaces
Table 5 shows the classification of the speakers and information regarding their gender and age, if applicable. The individual vowel spaces for all thirty-eight speakers can be found in the Appendix.
Speakers of Different Types of
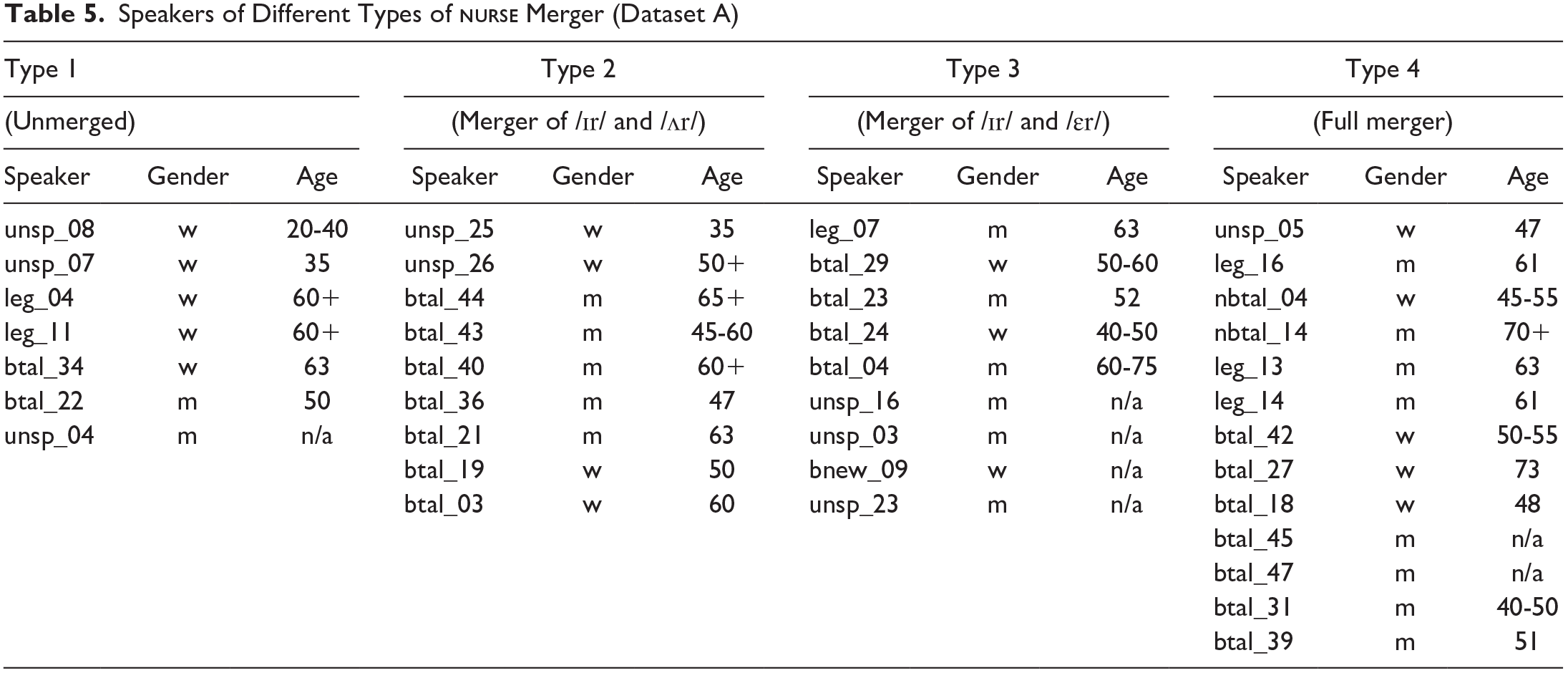
As Table 5 shows, full merger is the most frequent type (N = 13) among the speakers, while the unmerged type is the least frequent pattern (N = 7). Upon inspecting the speakers’ gender, the unmerged category seems more frequent among women, while the full merger type displays the opposite. However, any generalizations based on such a limited number of speakers should be treated with caution: all types occur across different age groups and genders. Patterned differences between groups of Scottish speakers may become more obvious when socio-economic background is considered. The social class of the speakers included in ICE Scotland is not available, however.
5. Discussion and Conclusion
This study investigated the acoustic properties of the
The second research aim was to explore possible social and linguistic constraints of the realization of the
Our results further show that in SSE the
The only genre effect found in this study was a more pronounced centralization and near-merger of /ɪr/ and /ɛr/ in non-broadcast talks. The tendency for a more closely spaced array of /ɪr/, /ɛr/, and /ʌr/ to emerge in the arguably less formal genre non-broadcast talks harmonizes with Wells’ (1982:407) association between the distinctness (of vowel categories) and more prestigious accents, particularly in the west of Scotland. We would argue that our findings reflect this tendency at a purely stylistic level, but the pattern will need to be investigated more rigorously across a broader range of genres.
A relatively strong effect on the realization of the
Our finding that /ɪr/ and /ʌr/ before a tapped or trilled /r/ are quite retracted and very close to each other fits one of the scenarios described by Stuart-Smith (2008:57-58), who says that, apart from the full three-way distinction and the mid-central merger, speakers may realize the contexts under investigation with a single vowel /ɪ/ or /ʌ/, or make a two-way distinction between /ɛ/ and /ʌ/. The latter seems to describe our findings quite well in combination with tapped or trilled realizations of /r/. Possibly, then, the relevant reference points for our data are not the three traditional vowels, but the two-way distinction between /ɪr/ and /ʌr/. These findings have potentially far-reaching consequences for assumptions concerning the history of vowel changes in the contexts under investigation: it is quite possible that in middle-class (or standard) accents the first target of the change was a two-way distinction as described above, with a later (incipient) merger in /ɜr/. At the moment, however, this can be no more than an interesting speculation.
Our comments in the preceding paragraph need to be tested in further research. We would like to suggest, however, that the underlying coherence of phonological features within individual speakers of SSE can to some extent account for the relationship between variants of /r/ and vowel realizations. At least for middle-class speakers of SSE, the realization of /r/ as a tap or a trill can be considered “traditional,” while the approximant [ɹ] has been established as the current standard variant. Likewise, there are traditional distinctions made between historically different members of present-day
In conclusion, our study has demonstrated the benefits of combining large-scale corpus-based quantitative data with fine-grained qualitative analyses of individual speakers. We were thus able to show that four distinct types of
Footnotes
Appendix
Individual Vowel Spaces (see Table 5)
Acknowledgements
We are grateful for the very helpful comments we received from our two reviewers and the editors on an earlier version of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the DFG (German Research Council; GU 548/13-1 and SCHU 3250/1-1).