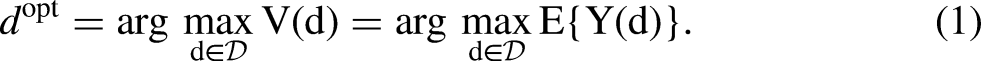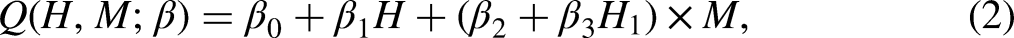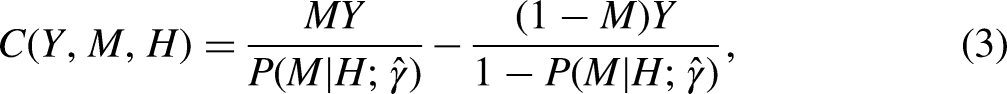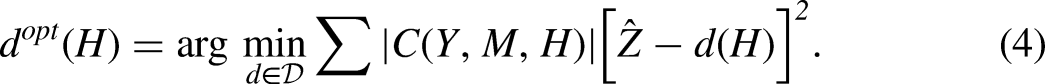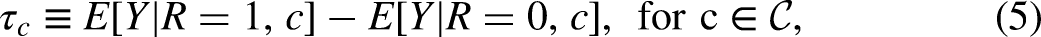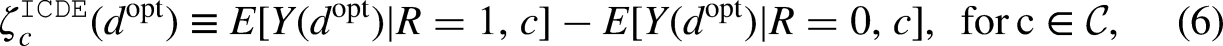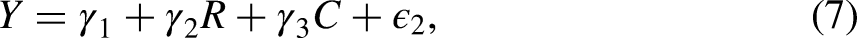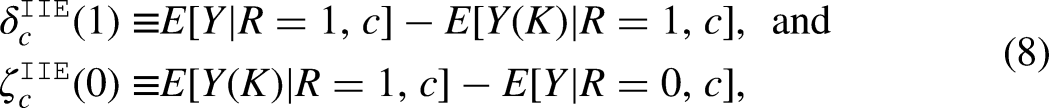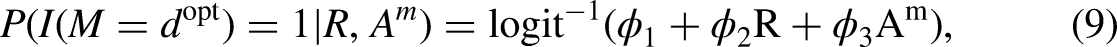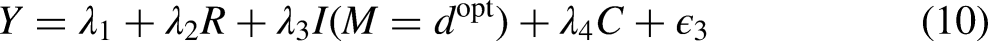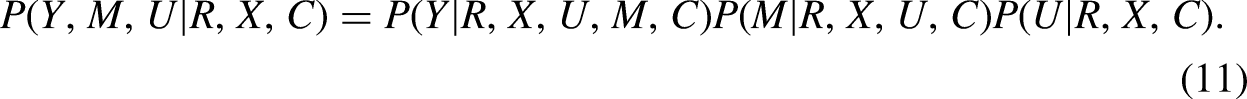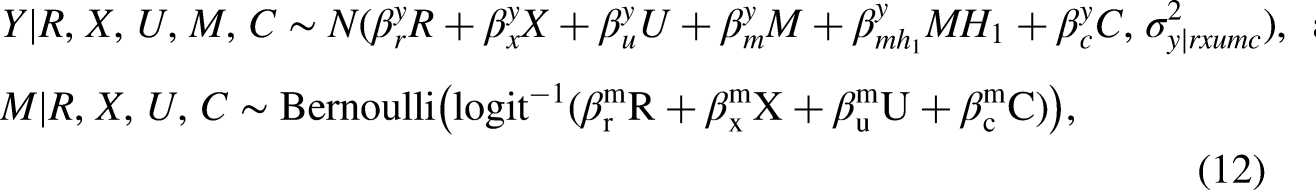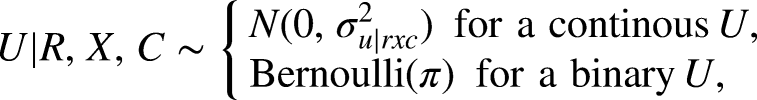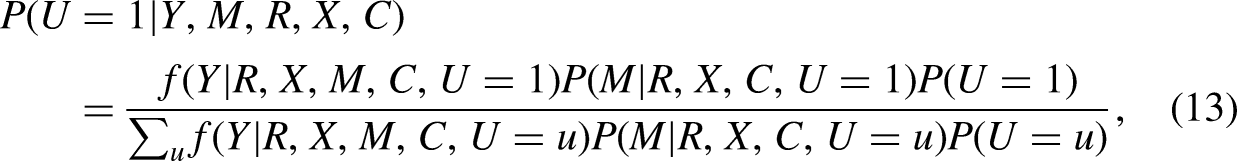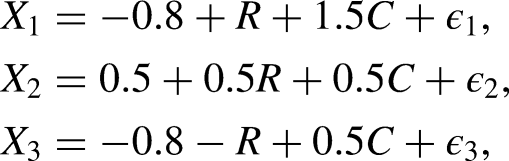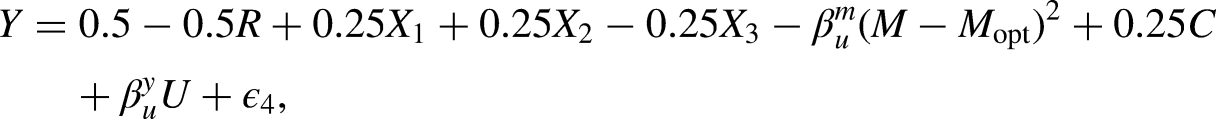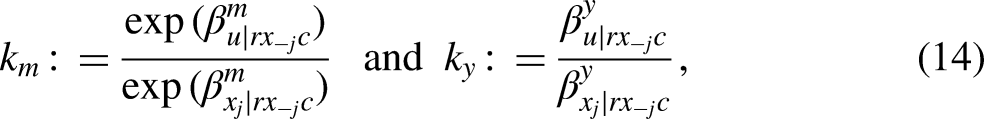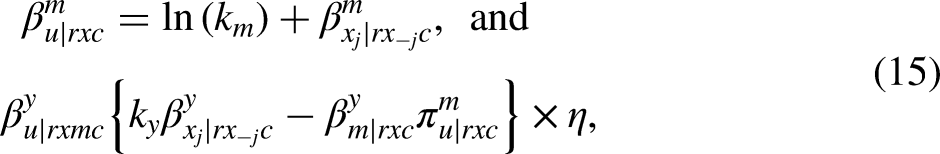Causal decomposition analysis aims to assess the effect of modifying risk factors on reducing social disparities in outcomes. Recently, this analysis has incorporated individual characteristics when modifying risk factors by utilizing optimal treatment regimes (OTRs). Since the newly defined individualized effects rely on the no omitted confounding assumption, developing sensitivity analyses to account for potential omitted confounding is essential. Moreover, OTRs and individualized effects are primarily based on binary risk factors, and no formal approach currently exists to benchmark the strength of omitted confounding using observed covariates for binary risk factors. To address this gap, we extend a simulation-based sensitivity analysis that simulates unmeasured confounders, addressing two sources of bias emerging from deriving OTRs and estimating individualized effects. Additionally, we propose a formal bounding strategy that benchmarks the strength of omitted confounding for binary risk factors. Using the High School Longitudinal Study 2009 (HSLS:09), we demonstrate this sensitivity analysis and benchmarking method.
Substantial disparities in educational, economic, and health outcomes persist across social groups in the United States, including those based on race/ethnicity, class, and gender. Traditional decomposition approaches, such as difference-in-coefficients analysis or Oaxaca-Blinder decomposition, have been employed to identify risk factors, such as educational attainment, that explain these disparities. However, these approaches have limitations: they do not define clear causal estimands and fail to specify the assumptions required for causal interpretation (e.g., no omitted confounding). Causal decomposition analysis (Jackson and VanderWeele 2018; VanderWeele and Robinson 2014) has addressed these issues by defining causal estimands, such as disparity reduction and disparity remaining, and by clarifying assumptions within a counterfactual framework.
Disparity reduction and disparity remaining are defined as the extent to which social disparities (e.g., racial disparities in math scores) would be reduced or remain after hypothetically intervening to set risk factors (e.g., taking Algebra I by ninth grade) to a pre-specified value (Lundberg 2020) or equalize the distribution of risk factors across groups (Jackson and VanderWeele 2018). However, these hypothetical interventions often overlook individual characteristics (e.g., prior achievement or interest in math), which limits their real-world applicability. To address this limitation, Park et al. (2024) incorporated individual characteristics when intervening on risk factors by using optimal treatment regimes (OTRs). OTRs are decision rules that guide the assignment of treatments based on individual characteristics, with the goal of maximizing the expected outcome through leveraging heterogeneous effects (Murphy 2003). Utilizing this concept, Park et al. (2024) defined the individualized effects of disparity reduction and disparity remaining, aiming to investigate whether the intervention that maximizes the desired outcome also reduces disparities in the outcome between groups. The newly developed causal decomposition framework can serve as a critical tool for policymakers and educators to design interventions that balance excellence (effectively enhancing the desired outcome) and equity (reducing disparities between groups).
These newly developed individualized effects defined by Park et al. (2024), similar to other causal estimands, rely on unverifiable assumptions, such as no omitted confounding. Therefore, it is essential to develop a sensitivity analysis to assess the robustness of individualized effects against potential violations of the no omitted confounding assumption. While the bias originates from the presence of potential omitted variables, these variables may impact the estimation of both OTRs and disparity reduction/remaining. A difficulty in developing such a sensitivity analysis is uncertainty about whether these impacts are independent of one another. Although several studies have developed sensitivity analyses in the context of causal decomposition analysis (e.g., Park et al. 2023, 2022; Rubinstein et al. 2023), this specific challenge cannot be easily addressed with existing formula-based sensitivity analysis. Additionally, while the instrumental variables (IVs) approach has often been employed to address omitted confounding in the OTR literature, (e.g., Cui and Tchetgen Tchetgen 2021; Qiu et al. 2021), identifying suitable IVs in observational data remains a significant challenge, limiting their applicability.
By extending the simulation-based sensitivity analysis introduced by Carnegie et al. (2016), we aim to address the challenge of assessing the sensitivity of OTRs and individualized effects. The proposed approach simulates an omitted confounder given observed variables, allowing us to address both with and without interactions between the omitted variable and the risk factor. However, due to inferior performance observed in the simulation study, we focus on the case without interactions. Further discussion is provided in the Discussion section.
Most importantly, we enhance the sensitivity analysis by providing a method to formally benchmark the strength of omitted confounding. Sensitivity analyses typically evaluate the amount of omitted confounding required to alter study conclusions and whether such amounts of confounding are plausible within the research context. However, determining the plausibility of the amount can be difficult due to the lack of precise knowledge about it. To tackle this issue, Cinelli and Hazlett (2020) developed a novel bounding strategy to benchmark the strength of omitted confounding against observed covariates using . However, this approach is not suitable for simulation-based sensitivity analysis, especially when the risk factor is binary and the outcome is continuous. Therefore, we propose a strategy that benchmarks the strength of unmeasured confounding against observed covariates using original data scales, making it suitable for simulation-based sensitivity analysis even with binary risk factors.
To summarize, this study has two primary objectives: (1) to extend simulation-based sensitivity analysis to causal decomposition with individualized interventions, and (2) to enhance the sensitivity analysis by developing a method to benchmark omitted confounding against observed covariates applicable to simulation-based sensitivity analysis with binary risk factors. The structure of the remaining sections is as follows: the Running Example section introduces a running example and the Reducing Disparities With Individualized Interventions: Review section provides a review of causal decomposition with individualized interventions. The Simulation-Based Sensitivity Analysis for Causal Decomposition section introduces a simulation-based sensitivity analysis that is applicable to individualized interventions and demonstrates its performances through simulation studies. The Enhancing the Interpretability of Simulation-Based Sensitivity Analysis section proposes a method for benchmarking the strength of omitted confounding against observed covariates. Finally, we conclude with a discussion of the main contributions of the paper. Open-source software for R (causal.decomp) that implements the proposed method is available from https://cran.r-project.org/web/packages/causal.decomp/index.html.
Running Example
Our study is motivated by the following question: “How much of the Black-White disparity in math achievement would be reduced or remain if we intervened in students’ enrollment in Algebra I in 9th grade?” This example is drawn from the previous paper by Park et al. (2024). To explore this question, we used data from the High School Longitudinal Study 2009 (HSLS:09).
Although most U.S. students take Algebra I in the ninth grade, there are notable racial and ethnic differences in the timing of enrollment. Non-Hispanic White and Asian students are more likely to enroll before ninth grade, whereas Hispanic and Black students are more likely to take the course in ninth grade or later (National Center for Education Statistics 2019). Earlier completion of Algebra I can help students advance to higher-level math courses, such as Algebra II, Geometry, and Pre-calculus, earlier in high school (Cohen and Hill 2000). For example, “Algebra for All” policies aim to increase access to advanced mathematics by mandating Algebra I for all students by a specific grade level (Silver 1995). However, universal eighth-grade Algebra I enrolment has sparked debates, as some argue that it can help to close racial and socioeconomic achievement gaps (Stein et al. 2011) while it also presents challenges related to student readiness, equity, and long-term outcomes (Chazan et al. 2016; Clotfelter et al. 2015; Loveless 2008).
Instead of mandating universal eighth-grade Algebra I enrollment, a more flexible and student-centered approach has been recommended in recent years. For most students, taking Algebra I in ninth grade is appropriate, as it aligns with traditional college-preparatory math sequences. However, school districts could offer accelerated tracks for students who demonstrate readiness before ninth grade, ensuring they progress at a pace suited to their abilities (Domina et al. 2015). As an example, our study considers Algebra I enrollment by ninth grade (i.e., taking Algebra I by ninth grade based on a student’s readiness) as a key factor in reducing educational inequalities. Our intervention strategy focuses on students who have not taken Algebra I before ninth grade while allowing those who took it earlier to remain unchanged. By applying causal decomposition analysis, we assess the impact of this intervention on achievement disparities, offering insights into the impact of such enrollment policies.
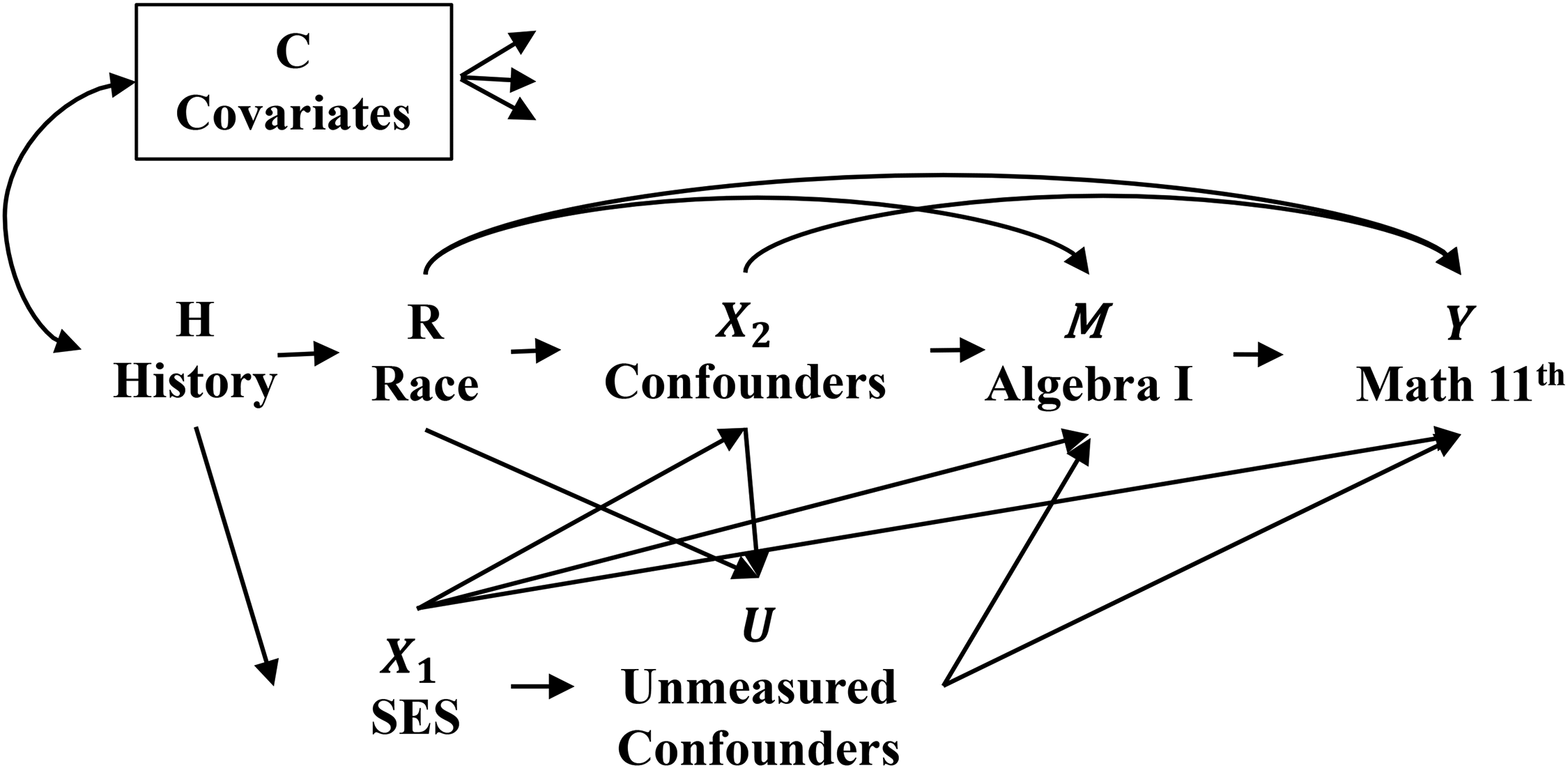
Directed acyclic graph (DAG). We consider social groups represented by two categories: Blacks () and Whites (). Our outcome of interest is the math score in 11th grade (). The risk factor is whether students took Algebra I () in ninth grade. As taking Algebra I in ninth grade is not a random process, its relationship with math score is confounded by multiple factors. Therefore, based on literature (Byun et al. 2015; Kelly 2009; Long et al. 2012; Riegle-Crumb and Grodsky 2010), we identified confounders, such as gender (), childhood socioeconomic status (SES, ), and student, parental, and school characteristics that are related to math readiness (), such as students’ grades, math interest, parental expectations and aspirations regarding their children. We also recognize the presence of unmeasured variables () that may confound the relationship.
To illustrate these relationships, we draw a DAG as shown in Figure 1. We assume that the Black-White math disparity arises through these three paths : (P1) the path from race to math score through taking Algebra I by ninth grade (e.g., ), (P2) the backdoor path from race to math score through historical processes (e.g., ), and (P3) the remaining path from race to math score not through taking Algebra I by ninth grade. The path (P1) represents when Black students are more likely to be assigned to a less rigorous curriculum track as a result of discrimination and unequal access to educational resources and opportunities (Kelly 2009), thereby contributing to Black-White math disparities. The path (P2) depicts the situation where Black students are more likely to be born into families with lower SES as a result of historical processes that involve racism, such as slavery and segregation (Jackson and VanderWeele 2018; Kaufman 2008). In all paths, the effect of taking Algebra I by ninth grade on math achievement in 11th grade will be biased if unmeasured confounders exist.
DAG showing the pathways to the racial disparity in math achievement in 11th grade. Note: (1) Baseline covariates () include gender, and placing a box around indicates conditioning on this variable. (2) The three arrows emanating from indicate that they are confounders of all bivariate relations, as visualized by the box around . (3) Childhood SES () includes the individual’s birth region, and father’s and mother’s years of education. (4) Confounders () include student, parental, and school characteristics that are related to math readines. DAG = directed acyclic graph; SES = socioeconomic status.
Sample and measures. We restricted our sample to students who had not taken Algebra I before ninth grade. This restriction ensures that intermediate confounders () measured in ninth grade were assessed before the target factor (). However, this limitation may lead to an underestimation of the initial disparity. After applying this limitation, the sample size was reduced from 14,530 to 11,050, comprising 8,920 White students and 2,130 Black students. Within the restricted data, we used predictive mean matching (Rubin 1986) to impute missing data, and our estimates are based on a single imputed dataset. Math achievement in 11th grade () was measured using the item response theory theta scores. Algebra I () was defined as students taking Algebra I in ninth grade. For baseline covariates (), we included gender.
Previous literature suggests that performance in earlier courses is the main factor influencing students’ course enrollment decisions (Kalogrides and Loeb 2013). Therefore, we selected students’ grades in their most advanced eighth grade math course as an intermediate confounder. Students’ enrollment decisions can be influences by parental factors (Byun et al. 2015). Therefore, we also included childhood SES, parents’ expectations, and their aspirations regarding their children as intermediate confounders. At the class level, we controlled for the academic disposition of the closest friend. Finally, at the school level, we controlled for school’s region, school climate, and the percentage of students in math course that are unprepared, the science and math course requirement, whether the school offers STEM extracurricular activities. We denote intermediate confounders as .
Although we controlled for an extensive set of confounders, there may still be omitted variables that could confound the relationship between taking Algebra I in ninth grade and math achievement in 11th grade. For example, childhood environment and health conditions can influence cognitive development and academic performance, potentially affecting students’ course enrollment decisions and their subsequent math achievement in high school. Therefore, omitted confounders may include variables related to childhood factors, which we denote as in Figure 1. Given this limitation, conducting a sensitivity analysis is essential to account for potential violations of the no omitted confounding assumption.
Reducing Disparities With Individualized Interventions: Review
In this section, we review OTRs and the effects of individualized interventions at aiming to reduce disparities. To identify OTRs and evaluate the effects of these interventions on reducing disparities using observational data, we assume the following:
A1. Conditional independence of : This assumption is denoted by for all and , where is a potential outcome under . It states that there are no omitted confounders influencing the risk factor-outcome relationship, given the group status, intermediate confounders, and baseline covariates.
A2. Positivity: This assumption is represented as for all and . It asserts that individuals of every group have a non-zero probability of experiencing any level of the risk factor (Algebra I) given the group status, intermediate confounders, and baseline covariates.
A3. Consistency: This assumption is represented as for all and . It indicates that the observed outcome (math score in 11th grade) of an individual with a certain level of the risk factor (Algebra I) is identical to the potential outcome after intervening to set the risk factor to that level.
These three assumptions are quite strong and the plausibility of the assumptions depends on the research context. In our example, consistency could potentially be violated, as the intervention all students to take Algebra I by ninth grade might alter the effect of Algebra I on math achievement. For example, some schools may dilute the curriculum or adjust the level of their instructional rigor (Rosenbaum 1999), which could differently impact outcomes for students across various schools. Additionally, positivity could be nearly violated if very few students with certain combinations of covariates take Algebra I by ninth grade. However, the impact of violating positivity can be mitigated through methods such as truncation or trimming (Robins et al. 2000). For the purpose of this study, we assume that these assumptions hold. Our primary concern is the conditional independence of risk factor , which is empirically unverifiable and may not hold even after accounting for existing covariates. In the Simulation-Based Sensitivity Analysis for Causal Decomposition and the Enhancing the Interpretability of Simulation-Based Sensitivity Analysis sections, we introduce a sensitivity analysis that enhance the robustness of findings against potential violations of this conditional independence assumption.
Optimal Treatment Regimes
In our example, treatment regimes refer to decision rules that describe how Algebra I should be assigned as a function of individual characteristics. Among various decision rules, we are interested in identifying OTRs that maximize the expected achievement score in 11th grade, by leveraging the heterogeneous effects resulting from individual characteristics. Specifically, we use the heterogeneous effects of Algebra I based on prior math achievement and math interest levels to identify those who would benefit from taking Algebra I in ninth grade.
To formalize, suppose that we have a decision point , where there are two options as . Let denote history variables available on an individual at decision point . Given our DAG in Figure 1, history variables are . Consider a decision rule for based on history variables, which is denoted as , where is all possible decision rules. For example, indicates that the Algebra I course will be recommended to those whose previous math score is and whose interest level is >0.3. Of these decision rules, our primary interest is to identify optimal decision rules . Assuming that larger outcomes are preferred, is the decision rules that maximize the value function , which is an potential outcome under the optimal decision. Formally, OTRs are expressed as (Tsiatis et al. 2019):
Although there are many estimation methods to obtain these optimal rules, we will briefly review the two basic estimators that we used in our analysis: Q-learning and weighting.
Q-learning
One intuitive method to obtain optimal decision rules is Q-learning (Qian and Murphy 2011). This approach involves fitting a model for the Q-function, which represents the conditional expectation of the outcome given the risk factor and history variables as . However, the true Q-function is unknown, and hence must be estimated from the data. Therefore, we assume that the Q-function follows a linear parametric model as:
where . Here, contain history variables, while represents the variables that have heterogeneous (interaction) effects on the outcome based on the risk factor . Identifying a subset of variables with heterogeneous effects () is crucial and should be grounded in substantive understanding. For example, in the case of high school math courses, students lacking interest or prior knowledge may not experience the same benefits. In this scenario, interest or prior knowledge can serve as elements of . By leveraging these heterogeneous effects, we can construct an optimal decision for as . If optimal decision rules are followed, the expected outcome will be maximized. Q-learning is intuitive and easy to understand. However, the quality of Q-learning depends on the correct specification of the outcome model, which is often violated.
Weighting
To mitigate the risk of the outcome misspecification, a weighting method was proposed by Zhang et al. (2012). The weighting method requires specifying a model for the risk factor without the need to fully specify the outcome model, making it more robust to potential misspecification of the outcome model. However, it relies on the correct specification of the model for the risk factor. To maximize the value function, it first requires constructing the following contrast function:
where represents the regression coefficient estimates in the propensity model. For example, this contrast function estimates the difference in potential math score in 11th grade between those who take Algebra I in ninth grade and those who do not. Then, we can define , so that indicates subjects who will benefit from than .
The next step is to find estimated OTRs using classification techniques. Based on the estimated contrast function, the optimal rule is obtained by minimizing a weighted classification error as follows:
The optimal decision rules are obtained by minimizing the difference between and the decision rules expressed as a function of . This optimization problem can be solved by existing classification techniques, such as classification and regression trees (CART; Breiman 2017). CART avoids making a specific functional form assumption and is relatively robust to model misspecification (Setoguchi et al. 2008). This approach is also flexible, as it separates maximizing the value function and estimation of the contrast function. In the weighting estimator, is either explicitly specified as or learned through CART during the optimization process. A comprehensive overview of both Q-learning and weighting methods can be found in Chapter 3 of Tsiatis et al. (2019).
An application to HSLS:09
To identify optimal decision rules for whether students should take Algebra I in ninth grade (), we considered students’ math efficacy, students’ interest in math courses, and their grades in the most advanced eighth-grade math course (). While it is possible that the effect of taking Algebra I may vary by school context, we believe it is inappropriate to recommend that students delay Algebra I due to poor school quality. Doing so could inadvertently reinforce inequities. Therefore, we did not consider school context for . Confounders , and were used as main effects in the Q-learning approach and for calculating propensity score in the weighting approach. We fitted separate models for Black and White students to ensure that optimal decisions were not disproportionately influenced by the majority student group. However, this approach results in applying different criteria in recommending Algebra I by ninth grade, which may prompt discussions about equal opportunity. While this topic is important, it lies beyond the scope of this article. For further discussion, refer to Hardt et al. (2016) and Kamiran and Calders (2012).
Table 1 presents the percentage of students who will be recommended to take Algebra I in ninth grade and the percentage of students whose decisions aligned with the optimal decision rules (i.e., compliance) in the observed data. According to optimal rules, more than 95% of students would be recommended to enroll in Algebra I in ninth grade, with Q-learning suggesting 95.6% and the weighting method indicating 98.1%.
Recommendation and Compliance Rates by Race.
Recommendation (%)
Compliance (%)
Black
White
Total
Black
White
Total
Q-learn
94.8
95.9
95.6
76.4
80.4
79.6
Weighting
90.9
100
98.1
74.0
83.0
81.3
Note: Recommendation: Percentage of students who would be recommended to take Algebra I in ninth grade. Compliance: Percentage of students whose course taking pattern aligns with the optimal rule.
Source: U.S. Department of Education, Institute of Education Sciences, National Center for Education Statistics. High School Longitudinal Study of 2009 (HSLS:09) Base-Year Restricted-Use File (NCES 2011-333).
Specifically, the Q-learning method recommends Algebra I for Black students who satisfy this condition: . Similarly, it recommends Algebra I for White students who satisfy this condition: . According to this rule, similar proportions of students within each race would be recommended to take Algebra I (Black: 94.8% vs. White: 95.9%), maximizing the average scores at 0.054 for Black students and 0.460 for White students.
Meanwhile, the weighting method recommends Algebra I for 100% of White students but only for 90.0% of Black students who have either a math interest score of at least 1 SD or a grade of A, maximizing the average scores at 0.069 for Black students and 0.459 for White students. Although fewer Black students were recommended based on the weighting method, the expected score is higher than that of Q-learning (0.069 with the weighting method vs. 0.054 with Q-learning). This disproportionate recommendation across racial groups is likely due, in part, to Black students facing greater barriers in achieving the necessary level of prior math achievement and interest to benefit from taking Algebra I by ninth grade.
The next question is: What percentage of students’ enrollment decisions aligned with the recommendations obtained from the optimal decision rule? Interestingly, both Q-learning and weighting methods reveal that enrollment decision patterns of White students align more closely with the optimal decision rules compared to those of Black students. Specifically, 80.4% of White students’ decisions are consistent with the Q-learning recommendations, compared to 76.4% for Black students. Similarly, 83.0% of White students’ decisions are consistent with the recommendations derived from the weighting method, whereas 74.0% of Black students’ decisions align with these recommendations. This suggests that White students’ enrollment decision patterns are more aligned with the rules that maximize their achievement in 11th grade compared to Black students, even when OTRs were determined separately for each group. This finding potentially indicates that fewer Black students are in circumstances that allow them to enroll in Algebra I by ninth grade, despite the potential benefits of taking the course at that time.
Hereafter, we use the term “compliance” to refer to whether a student’s decision aligns with the recommendation. Formally, , where is an indicator function. This compliance is determined by the observed consistency between the student’s decision and the recommendation.
Causal Decomposition Analysis With Individualized Interventions
Causal decomposition analysis begins by estimating the initial disparity, defined as the average difference in an outcome between groups within the same levels of outcome-allowable covariates. Formally,
where is the comparison group (Black students) and is the reference group (White students). For simplicity, we focus on two groups in this manuscript; however, all the subsequent definitions can be generalized to accommodate multiple comparison groups. Causal decomposition does not aim to estimate the causal effect of socially ascribed characteristics such as race/ethnicity or gender, as these are non-modifiable. Instead, it focuses on estimating the causal effect of malleable risk factors (VanderWeele and Robinson 2014).
In the example, the initial disparity represents the average difference in math achievement in the 11th grade between Black and White students, within the same gender group. We controlled for gender since males are slightly overrepresented in each racial group (51.3% for Whites and 53.1% for Blacks), and adjusting for these differences help address potential biases due to restricting data to students who did not take Algebra I before 9th grade. Additionally, gender is a factor contributing to outcome differences that we consider “allowable” to remove when defining racial disparities. Although we refer to them as allowable covariates, they can include a subset of both baseline covariates () and intermediate confounders (). For a detailed discussion on allowability, refer to Jackson (2021).
Individualized controlled direct effects (ICDEs)
Park et al. (2024) proposed an intervention in which all students followed optimal decision rules based on their prior achievement and interest levels. The recommendation obtained from OTRs serve as a reference for each student, and we can examine whether this hypothetical intervention reduces disparities in an outcome. Formally, disparity remaining at is defined as follows:
where is an optimal value for risk factor . This definition of disparity remaining states the difference in an outcome between the comparison (e.g., Black students) and reference groups (e.g., White students) after setting their risk factor (Algebra I) to the optimal value obtained from OTRs. Park et al. (2024) referred to this quantity as individualized controlled direct effects (ICDE) given that the risk factor is fixed to a pre-specified value—that is, optimal values obtained in response to individual characteristics.
Given Assumptions A1–A3, the ICDE can be estimated by fitting a marginal structural model with baseline covariates centered at as follows:
given the weight of . The disparity remaining is then estimated as . If significant, the interaction effects between and can be specified. In this case, the disparity remaining is still given by .
Individualized interventional effects (IIEs)
However, requiring all students to adhere strictly to optimal decision rules is neither realistic nor necessarily beneficial. Some students may have valid reasons to take Algebra I in ninth grade, even if it was not recommended for them. A more feasible approach is to ensure that Black students comply with recommendations at the same rate as White students among individuals who share the same levels of target-factor-allowable covariates (denoted as ). Equalizing compliance with recommendations within the same levels of allowable covariates requires an equity-based judgment—determining which variables should be considered fair or appropriate for assigning interventions at the same level. For instance, it may not be fair to equalize compliance within the same levels of student SES, as student SES is a source of structural inequality. In our example, we did not specify any covariates as target-factor-allowable covariates for the fairness of the intervention.
To precisely define, let . Then, disparity reduction and disparity remaining due to equalizing compliance rates across groups can be expressed as follows:
where is an optimal value for risk factor , and is a random draw from the compliance distribution for of the reference group given target-factor-allowable covariates . The notation indicates a potential outcome under the value of that is determined by a random draw from the compliance distribution of the reference group among individuals with the same levels of target-factor-allowable covariates. For example, if a random draw indicates that a reference group individual complied with the optimal value, the corresponding individual in the comparison group will likewise adopt the optimal value. Disparity reduction () represents the disparity in outcomes among a comparison group (e.g., Black students) after intervening to setting the compliance rate equal to that of a reference group (e.g., White students) within the same target-factor-allowable covariate levels. Disparity remaining () quantifies the outcome difference that persists between a comparison and reference group even after the intervention.
Under Assumptions A1–A3, the calculation of disparity reduction and disparity remaining using a regression estimator follows these steps. First, fit a compliance model as follows:
where is an indicator function. Next, fit a marginal structural model using centered baseline covariates , formulated as follows:
given the weight of . Then, can be obtained as . In cases where an interaction exists between race and compliance , can be expressed as , where represents the coefficient for the interaction effect, and can be obtained as .
Alternatively, a weighting estimator can be used to estimate disparity reduction and disparity remaining through the following steps. First, compute the compliance rate among the reference group given , denoted as . For each value of , weights can be formulated as . Finally, the disparity reduction is estimated as and disparity remaining is estimated as . To address multiple-stage estimation, we used bootstrapping to estimate the standard errors of disparity remaining and disparity reduction.
An application to HSLS:09
For subsequent analyses, we use the optimal decision rule obtained from the weighting method, which is relatively robust to misspecification of the outcome model. We estimate initial disparity, disparity remaining, and disparity reduction with ICDE and IIE as described in the Causal Decomposition Analysis With Individualized Interventions section. Table 2 presents estimates of quantities of interest. The initial disparity in 11th grade math achievement between Black and White students is 0.413 SD and significant at the level, indicating that Black students achieve significantly lower scores than White students, controlling for gender.
Estimates of the Initial Disparity, Disparity Reduction, and Disparity Remaining.
Estimate (SE)
ICDE
IIE
Initial disparity
(0.010)
(0.010)
Disparity remaining
(0.059)
(0.035)
Disparity reduction
% Reduction
%
4.36%
Note:ICDE = Individualized controlled direct effect; IIE = Individualized interventional effect. The asterisk followed by estimates indicates the level of statistical significance (*: significant at .05, **: at .01, ***: at .001). Gender and native language are centered at the mean. The regression estimator was used for the IIE estimates.
Source: U.S. Department of Education, Institute of Education Sciences, National Center for Education Statistics. High School Longitudinal Study of 2009 (HSLS:09) Base-Year Restricted-Use File (NCES 2011-333).
We then estimate the remaining disparity using ICDE. Forcing every students to follow the optimal rule obtained from the weighting method results in a remaining disparity of SD, representing a 15.5% increase from the initial disparity (a widening gap between racial groups). This larger disparity indicates that while both White and Black students benefit from following optimal rules in terms of maximizing their scores, White students experience a greater improvement than Black students.
Equalizing the proportion of students whose decisions align with the recommendations between groups results in a remaining disparity of SD, which represents a 4.4% reduction from the initial disparity. In the analyses, we have incorporated the interaction between race and compliance. Our findings support minorities’ diminished return hypothesis (Assari 2020), showing that the effect of compliance was greater for White students than for Black students. Consequently, after incorporating the interaction effect, the disparity reduction due to equalizing compliance rates across groups is minimal (4.36%) and not statistically significant.
These results suggest that while following optimal rules as well as equalizing the compliance rate with the optimal rule between the groups may maximize the average math achievement at 11th grade, it does not effectively reduce the disparity in math achievement. These findings can only be interpreted causally if Assumptions A1–A3 are met. Therefore, in the next section, we develop a sensitivity analysis to evaluate the robustness of the findings to potential violations of the no omitted confounding Assumption A1.
Simulation-Based Sensitivity Analysis for Causal Decomposition
The goal of sensitivity analysis is to understand what the effect estimates would be if we measured and conditioned on omitted confounder . Carnegie et al. (2016) proposed a simulation-based approach to sensitivity analysis to account for the absence of omitted confounding for continuous outcomes. Qin and Yang (2022) subsequently extended this approach to the context of mediation analysis and addressed different types of outcomes and unmeasured confounders. In this section, we extend this simulation-based sensitivity analysis to estimate OTRs as well as disparity reduction and disparity remaining using ICDE and IIE.
Framework
Following Carnegie et al. (2016), we proceed with three steps: (1) specify a model to compute a complete-data likelihood, (2) use this model to derive conditional distribution of unmeasured confounder on observed variables, and (3) compute disparity reduction or disparity remaining using generated unmeasured confounder and sensitivity parameters.
First, a complete-data likelihood can be expressed as follows:
This factoring allows the sensitivity parameters to be coefficients of unmeasured confounder on the risk factor and the outcome , which is straightforward to interpret for applied researchers. Previous studies assume the independence of the unmeasured confounder with the remaining confounders , and () to reduce the number of sensitivity parameters. In disparities research, unmeasured confounders are likely affected by the group status and demographic variables . Therefore, we conceptualize unmeasured confounder as the remaining portion after accounting for , and .
To calculate the complete-data likelihood, we specify the following models for the outcome and the intervening factor. We assume a normal distribution for the outcome, and a Bernoulli distribution for the binary risk factor, consistent with our example.
where denotes the normal distribution, denotes the Bernoulli distribution, and is a subset of history variables that modify the effect of the risk factor (e.g., prior math achievement and math interest). Here, we only included interaction terms between and for the outcome model, as specified in equation (2). While additional nonlinear terms can be specified as needed, caution is advised when interaction terms involving are included. Refer to the Simulation Study section for performance results of this simulation-based sensitivity analysis in the presence of such interaction terms.
For unmeasured confounder , we assume a normal distribution when is continuous and a Bernoulli distribution when is binary as follows:
where is the variance of , and is the proportion of . We assume that the continuous is centered at zero and for , we use an existing covariate as a benchmark, which will be explained in the Benchmarking With Observed Covariates section.
The sensitivity parameters for the outcome and the risk factor are denoted as and , respectively. The sensitivity parameters represent the effect of the unmeasured confounder on the outcome and the risk factor. The purpose of sensitivity analysis is to identify plausible combinations of these sensitivity parameters that could potentially alter the study’s conclusions or affect the significance level.
Second, the conditional probability of , , can be derived using the formula below. For a binary , we have
where . When is continuous, the denominator should be integrated over the values of . When , and are all continuous, a closed-form expression of the distribution of conditional on observed variables can be obtained. For the derivation and its result, refer to Carnegie et al. (2016) and Qin and Yang (2022). For a binary , the stochastic EM algorithm (Feodor Nielsen 2000) was used to estimate the unknown parameters , which consists of two steps: (1) E-step: simulate unmeasured confounder from its conditional distribution, given the parameters obtained in the previous iteration and the specified sensitivity parameters, and (2) M-step: maximizing an expected complete data log-likelihood with respect to parameters. Then, these two steps are iterated until convergence.
Finally, once the EM algorithm converges, we first obtain OTRs and then estimate the disparity reduction and disparity remaining conditional on the generated and specified sensitivity parameters. Note that a certain degree of uncertainty is involved when generating the unmeasured confounder from its conditional distribution. To address this uncertainty, previous studies suggest running the EM algorithm multiple times (e.g., 30 times) and repeatedly estimating the effects of interest given the multiple values of . The estimates are then combined by averaging over the number of simulations, and standard errors are computed based on Rubin’s rule (Rubin 2004).
While this approach effectively addresses the uncertainty related to generating , it is computationally intensive especially when is continuous where integrate() R function is used. Therefore, we made a minor adjustment to the existing algorithm to simulate multiple values of based on its conditional distribution without repeating the integrate() R function.
Simulation Study
The purpose of this simulation study is to evaluate the performance of simulation-based sensitivity analysis in identifying OTRs and in estimating disparity reduction and disparity remaining with individualized interventions in the presence of unmeasured confounder . Specifically, we evaluate the accuracy in obtaining OTRs and the performance in terms of bias and variance of estimating the effects of interest, comparing with and without adjustment for unmeasured confounder . The evaluation is conducted under two scenarios: when exerts constant effects, and when exhibits heterogeneous effects with the risk factor. Additionally, we vary the sample sizes (500, 1,000, and 2,000) and the magnitude of sensitivity parameters (0.5, 1, and 1.5).
Data generation and simulation setting
To generate the population-level simulation data, we create the baseline covariate , the social group , intermediate confounders , , , the unmeasured confounder , and the outcome variable as follows with a population size of . Here, , , , and are generated as continuous variables, while the remaining variables are binary, taking values of 0 or 1. Specifically, we generate a binary covariate with a probability of 0.4 for and a binary social group status with the probability for . We generate an unmeasured confounder with a probability of 0.5 for , as we conceptualize as the remaining part after accounting for , and . The variables are generated as follows:
where the error terms , , and are drawn from a standard normal distribution. When has constant effects, the optimal decision rule dictates that should take 1 for subjects with and . When has heterogeneous effects, the optimal decision rule dictates that should take 1 for subjects with and . However, subjects determine the value of according to the following logit function: , where is a pre-set true value of the sensitivity parameter. Although it is challenging to generate the exact form that maximizes the outcome under the OTR, it can be approximated. Following Zhang (2019), the outcome is generated as follows:
where is drawn from a standard normal distribution, and is a pre-set true value of the sensitivity parameter.
In this study, the population-level simulation data is generated using varying magnitudes of sensitivity parameters . After generating the data, we randomly selected subsets with sample sizes of . The proposed simulation-based sensitivity analysis described in the Framework section was then conducted. For the homogeneous effect of , the outcome model specified in Equation (12) included interaction terms between and as well as and . For the heterogeneous effect of , the outcome model included interaction terms between and as well as and . The simulation results are based on 500 iterations.
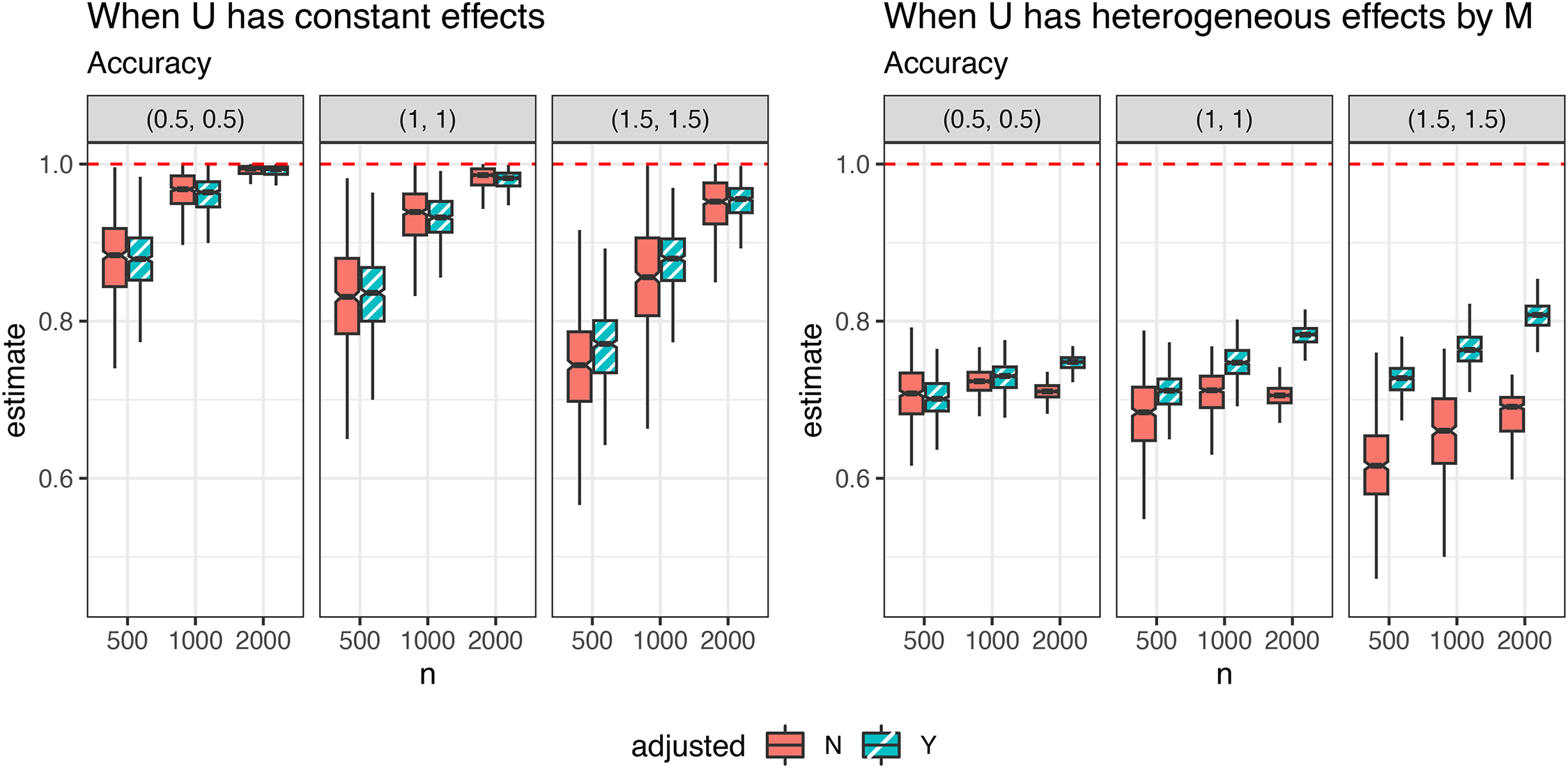
Simulation results.Figure 2 presents the accuracy of predicting OTRs, with the maximum possible accuracy of 1 indicated by red dashed lines. When exerts constant effects, OTR predictions are relatively robust to omitted variable bias. With sensitivity parameters of 0.5 and 1, the accuracy exceeds 0.95 with a sample size of 2,000, both with adjusting for (green boxplots in Figure 2) and without adjusting for (red boxplots). However, when the sensitivity parameter is 1.5, accuracy generally improves after adjusting . For example, the median accuracy increases from 0.74 before adjustment to 0.78 after adjustment for a sample size of 500.
Accuracy of the optimal value when has constant (left) and heterogeneous (right) effects by . In each panel, the red dashed line represents an accuracy of 1. “N” refers to not adjusted for , and “Y” refers to adjusted for .
When exerts heterogeneous effects, the accuracy of predicting OTRs substantially improves after adjusting for across all sample sizes and sensitivity parameters. However, the accuracy does not reach the same level as when exerts constant effects. This improvement is most pronounced with a sample size of 2,000 and sensitivity parameters of 1.5, where the median accuracy increases from 0.69 before adjustment to 0.81 afterward.
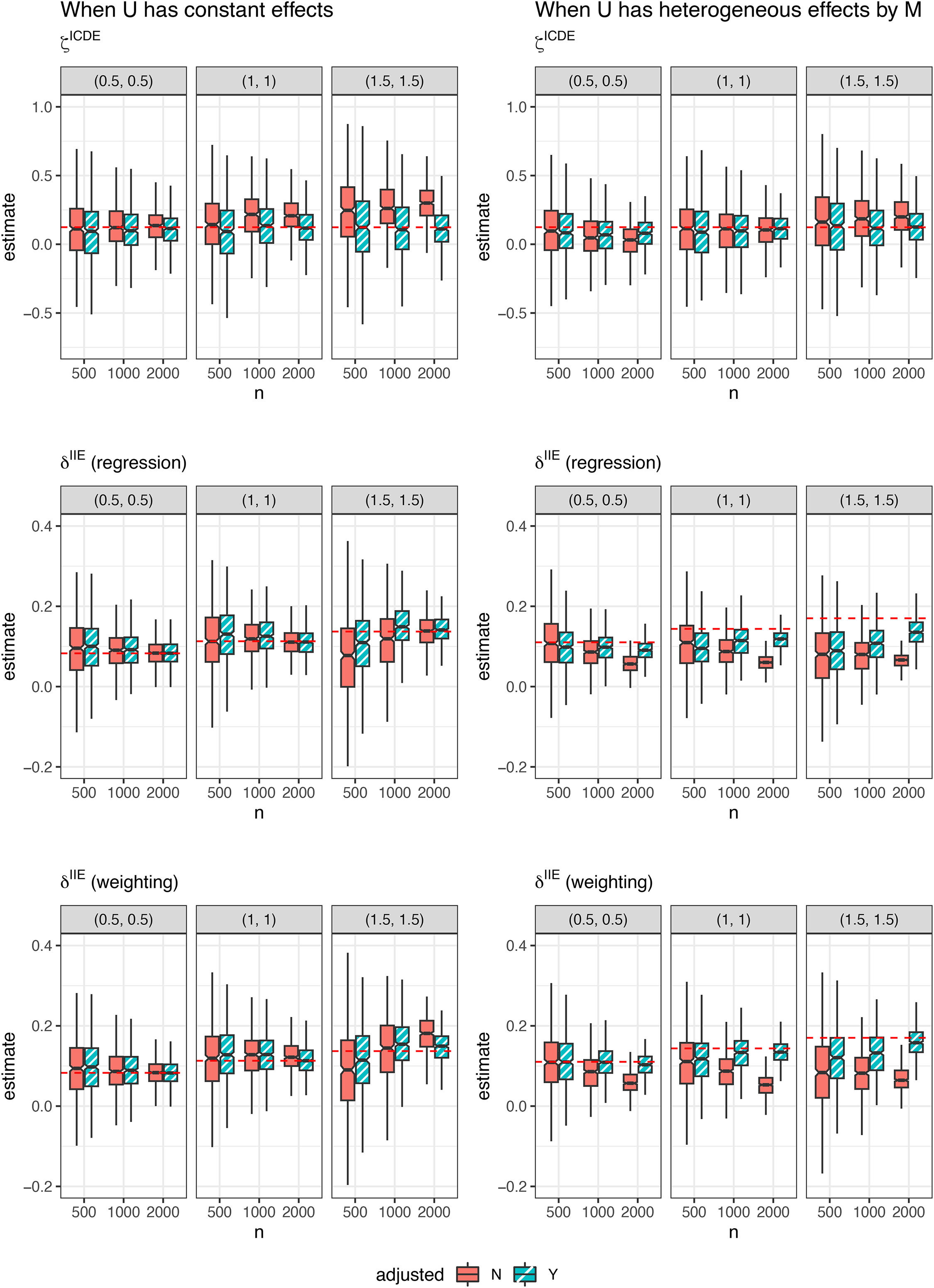
In Figure 3, we present boxplots of the estimated values of , using the regression estimator, and using the weighting estimator, with their true values represented by red dashed lines. The results for using both the regression and weighting estimators are provided in Appendix A, Supplemental Material, and show little difference compared to using the respective regression and weighting estimators.
Estimates of using the regression estimator and using the weighting estimator, when has constant (left) and heterogeneous (right) effects by . In each panel, the red dashed line represents the true value of the estimates. “N” refers to not adjusted for , and “Y” refers to adjusted for . IIE = individualized interventional effect.
When exerts constant effects, the unadjusted estimates (green boxplots in Figure 3) remain relatively robust with a sensitivity parameter of 0.5. However, as the magnitude of the sensitivity parameters increases, the unadjusted estimates become increasingly biased. In contrast, the adjusted estimates remain accurately centered around the true value, regardless of the sensitivity parameters, particularly as the sample size increases. For , the regression estimator performs slightly better in terms of bias compared to the weighting estimator.
When exerts heterogeneous effects, the adjusted estimates show substantial improvement in terms of bias compared to the unadjusted estimates. However, despite this improvement, using the regression estimator remain biased, even with a sample size of 2,000. In contrast, and using the weighting estimator are centered around the true value as the sample size increases.
Overall, our simulation study results indicate that the proposed sensitivity analysis is effective when has constant effects, addressing two sources of biases arising from obtaining OTRs and from estimating disparity reduction and disparity remaining. However, When exhibits heterogeneous effects across levels of the risk factor , the accuracy of predicting OTRs decreases to about 0.8, even with a sample size of 2,000, and the regression-based estimator for IIEs become biased. This decline in accuracy of predicting OTRs is due to the misspecification of the outcome model used to simulate the unmeasured confounder (see Equation (12)). The regression-based estimator of IIEs is particularly susceptible to this outcome misspecification, as it relies on the specified outcome model shown in Equation (10). The implications of this reduced performance is further discussed in the Discussion section.
As a sensitivity analysis, we also examined the performance when the distribution of is skewed. Appendix B, Supplemental Material provides results using left- and right-skewed distributions of , showing that overall performance trends remain similar to those in the symmetric case. While the bias was slightly larger in some cases for skewed distributions of , the increased bias does not affect inference significantly. The 95% confidence interval coverage rates indicate that adjusting for maintains coverage near or above the nominal level (0.95). In contrast, failing to adjust for leads to lower coverage, highlighting biases introduced by unaccounted confounding.
It is noteworthy that the 95% confidence interval coverage rates for ICDE are approximately at the nominal level. However, the coverage rates for IIEs, whether estimated using regression-based and weighting-based methods, exceed the nominal level, indicating that the standard errors are larger, leading to conservative inference. The implications of these larger standard errors for IIE estimates are discussed in the Discussion section.
Enhancing the Interpretability of Simulation-Based Sensitivity Analysis
Sensitivity analysis is an essential component of causal inference. However, it has been underutilized in the social sciences, perhaps due to its complex nature and difficulty of interpretation (Cinelli and Hazlett 2020). A crucial question, therefore, is “How can we enhance the interpretability of results obtained from simulation-based sensitivity analysis?” The literature frequently offers graphical tools to illustrate how the estimates and their statistical significance change based on different combinations of sensitivity parameters. However, validating results against potential omitted confounding using graphical tools can be challenging, as estimates can vary from positive to negative and from significant to non-significant, depending on the range of sensitivity parameters.
To make sensitivity analysis more useful, it is important to reduce the range of sensitivity parameters. Previous literature has often employed informal benchmarking strategies using observed covariates, assuming that the strength of unmeasured confounders (represented by sensitivity parameters) would be comparable to the associations between an observed covariate and the outcome, after accounting for all other antecedent variables, except for that observed covariate. However, Cinelli and Hazlett (2020) cautioned that this informal benchmarking strategy could lead to erroneous conclusions due to collider bias (see the Discussion section for further discussion). In response, they proposed a formal bounding method to benchmark the strength of unmeasured confounders using observed covariates through . However, this approach is not applicable to simulation-based sensitivity analysis when the risk factor is binary.
To address this limitation, we propose a formal benchmarking strategy specifically designed for simulation-based sensitivity analysis when the risk factor is binary. Our covariate benchmark is based on original data scales rather than , allowing for more interpretable results with a binary risk factor. It is important to note that the scope of this formal benchmarking strategy is limited to cases with a normally distributed outcome and a binary risk factor. Additionally, this strategy assumes that the unmeasured confounder is continuous. While binary offers advantages in terms of computation time, it is more reasonable to assume that represents a linear combination of several omitted factors, given that researchers usually do not have precise knowledge of unmeasured confounders. In our example, includes a linear combination of neighborhood factors that are related to the decisions to take Algebra I in ninth grade and math achievement in 11th grade.
Benchmarking With Observed Covariates
In this section, we propose a method to use existing covariates to benchmark the strength of unmeasured confounders using original data scales. We employ an approach that compares the coefficient of the omitted confounder with that of an observed covariate , preferably a significant one, after controlling for the remaining observed covariates and . Although we compare the coefficients, we are essentially comparing the strength of the omitted confounder with that of an observed covariate by assuming equal residual variance between them (i.e., ). In our example, we use childhood SES () for this comparison, as few factors exhibit greater predictive power than childhood SES on both math achievement and the likelihood of taking Algebra I in ninth grade.
To formally compare coefficients of with that of , we define parameters and as follows:
where represents the vector of intermediate confounders excluding significant variable . Here, and are the regression coefficient of and , respectively, on after conditioning on in the logit scale; and are the regression coefficients of and , respectively, on after conditioning on in the original scale. To enhance interpretability and comparability, we use odds ratio scales for binary and the original scales for continuous . Specifically, indicates the extent to which is associated with a one unit increase in relative to how much it is associated with a one unit change in , after controlling for and . Likewise, indicates the extent to which the odds of are explained by unmeasured confounder relative to how much they are explained by , after controlling for and . These parameters ( and ) should be specified by researchers based on the assumed strength of relative to that of the given observed covariate (e.g., childhood SES).
To proceed further, we make the following assumptions: (B1) the unmeasured confounder is independent of the remaining covariates , and (i.e., ) and (B2) the effect of on the outcome as well as the logit scale of the risk factor is constant across the strata of and . The first assumption is implied by the fact that is a remaining part after controlling for , and . The second assumption is strong but could be reasonably met in some research contexts.
Under Assumptions B1 and B2, we can rewrite our sensitivity parameters given and as below. We use the notation and to differentiate them with and , respectively.
where is an expected difference in probability of when increases by one unit, after controlling for , and ; is a function of , , and the conditional variances of () and (). See Appendix C, Supplemental Material for details and a proof.
For , our sensitivity parameter is equal to the logit coefficients of the significant observed covariate on the intervening factor , after controlling for the remaining covariates (). This implies that the informal benchmarking approach—replacing the sensitivity parameter with the coefficient of one observed covariate after removing that covariate from the same controlling set—is valid for under the Assumptions B1 and B2. In contrast, for , our sensitivity parameter is not equal to the coefficient of the significant observed covariate on the outcome , after controlling for and (). Following the informal benchmarking approach, one may wonder whether is comparable to the coefficient of the significant observed covariate on the outcome , after removing that covariate from the same controlling set (i.e., ). However, this approach also leads to biased result due to collider bias. Refer to the Discussion section for a detailed explanation. Overall, this implies that the informal benchmarking approach does not work for and requires further calculation.
An Application to HSLS:09
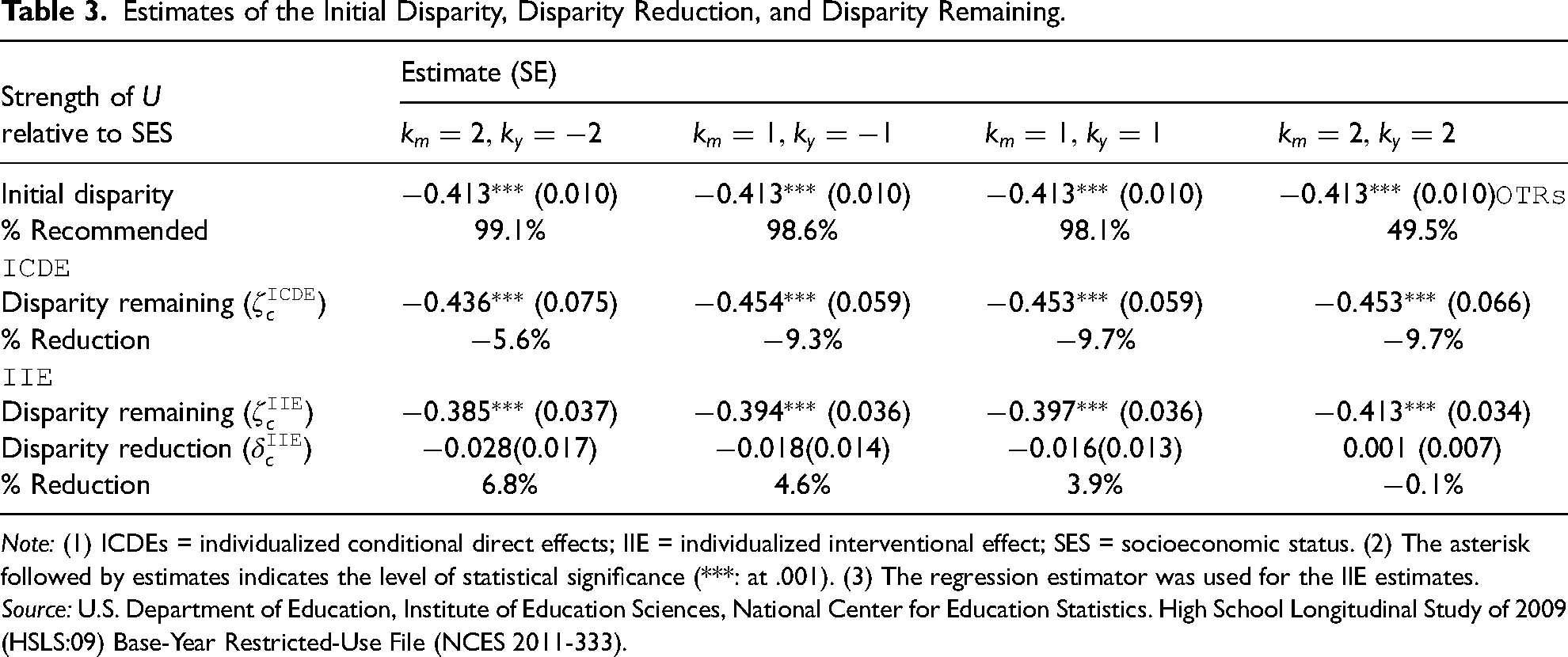
We illustrate the newly developed method of benchmarking the strength of unmeasured confounders using our example where the risk factor is binary. Table 3 illustrates the extent to which the disparity reduction and disparity remaining estimates vary if a linear combination of unmeasured confounders was as influential as childhood SES, or twice as influential as, childhood SES. Positive values of indicate that the unmeasured variables affect the intervening factor and the outcome in the same direction as childhood SES. Conversely, negative values of indicate that the unmeasured variables affect the outcome in a direction opposite to that of childhood SES. In contrast, we consider only positive values of , as positive values of indicate that the odds of explained by the unmeasured confounder are equal to or greater than the odds explained by childhood SES after controlling the remaining variables.
Estimates of the Initial Disparity, Disparity Reduction, and Disparity Remaining.
Strength of U
Estimate (SE)
relative to SES
Initial disparity
(0.010)
(0.010)
(0.010)
(0.010)OTRs
% Recommended
99.1%
98.6%
98.1%
49.5%
ICDE
Disparity remaining ()
(0.075)
(0.059)
(0.059)
(0.066)
% Reduction
%
%
%
%
IIE
Disparity remaining ()
(0.037)
(0.036)
(0.036)
(0.034)
Disparity reduction ()
0.001 (0.007)
% Reduction
6.8%
4.6%
3.9%
%
Note: (1) ICDEs = individualized conditional direct effects; IIE = individualized interventional effect; SES = socioeconomic status. (2) The asterisk followed by estimates indicates the level of statistical significance (***: at .001). (3) The regression estimator was used for the IIE estimates.
Source: U.S. Department of Education, Institute of Education Sciences, National Center for Education Statistics. High School Longitudinal Study of 2009 (HSLS:09) Base-Year Restricted-Use File (NCES 2011-333).
In the context of our example, we assume that unmeasured confounders are as strong as childhood SES or, conservatively, even twice strong as childhood SES. Furthermore, we assume that the unmeasured confounders do not interact with race, intermediate confounders, risk factor, or covariates. Under this condition, we examined how the percentage of students recommended and the effect estimates vary with the level of unmeasured confounding.
First, when the unmeasured confounders are as strong as childhood SES, the percentage of students recommended to take Algebra I in ninth grade remains relatively stable (98.1% when unadjusted vs. 98.1%–98.6% when ). However, when the unmeasured confounders are twice as strong as childhood SES, the percentage changes significantly, dropping to 49.5% () or increasing to 99.1% ().
Second, despite this change in the percentage of students recommended, the disparity remaining after following OTRs remains robust. The disparity remaining estimates () are all significantly negative, ranging from () to (). The percentage of disparity reduction ranges from % to %, meaning that following OTRs (under the consideration of the unmeasured confounders) would increase the initial disparity.
Third, disparity reduction due to equalizing the compliance rate with optimal rules across groups () is statistically insignificant and remains stable in the presence of potential omitted confounders. With the omitted confounding as influential as childhood SES (), the disparity reduction estimates () remain negative and are not significant, with the estimates ranging from 0.018 to 0.016.
This result was derived under the assumptions of a constant effect of unmeasured confounders, but there could be cases where the effects of unmeasured confounders are heterogeneous. If the unmeasured confounder is school quality and the effect of taking Algebra I is weaker in schools with poor quality, then the sensitivity results obtained would be invalid.
Discussion
This study presents a sensitivity analysis for OTRs and individualized effects. We summarize our contributions to the literature and highlight opportunities for future research as follows:
Extending a simulation-based sensitivity analysis to causal decomposition analysis
The bias in estimating the individualized effects due to unmeasured confounding arises from two sources: (1) identifying OTRs and (2) estimating disparity reduction and disparity remaining due to following OTRs. This bias is not easily addressed through a formula-based sensitivity analysis. Typically, formula-based sensitivity analysis calculates bias as the difference between the estimate and the true effect. While this approach can provide numerical solutions for points where the estimates become zero or lose significance due to confounding, the bias formula must be recomputed for each new estimand. In the case of individualized effects, bias is influenced by a combination of sensitivity parameters and the optimal values, making it challenging to compute.
To address these two sources of bias, we extended a simulation-based sensitivity analysis to assess the robustness of individualized effects. Our simulation study demonstrates that this approach performs well when the unmeasured confounder exerts a constant effect across the strata of remaining variables. However, the accuracy of optimal recommendations declines, and the regression-based estimator for IIEs is biased when the unmeasured confounder interacts with the risk factor. This reduced performance arises from the misspecification of the outcome model when simulating the unmeasured confounder (see Equation (12)). While this issue could be mitigated to some extent if the data-generating model aligns with the specified outcome model, our simulation results indicate that the validity of the simulation-based sensitivity analysis for the regression estimator of IIEs is sensitive to outcome model misspecification. As a result, the weighting estimator is recommended, as it does not rely on outcome modeling. Future research could explore the incorporation of machine learning techniques, which are generally more robust to model misspecification, to enhance the effectiveness of simulation-based sensitivity analyses.
In our case study, we assume a constant effect of unmeasured confounding across the strata of remaining variables. Although this is a strong assumption, applying a sensitivity analysis that accounts for heterogeneous effects of unmeasured confounding may not be practical, particularly for individualized effects. Such an analysis would require more sensitivity parameters than the two currently needed, making it difficult to validate results. Additionally, optimal decision rules determined by the unmeasured confounder (due to heterogeneous effects of ) would complicate meaningful interpretation. For example, recommending Algebra I to students whose unmeasured confounding exceeds 1.5 SD would be meaningless in practice.
Another issue is the larger standard errors for IIEs obtained from the proposed sensitivity analysis. In the simulation study, the proposed method of estimating standard errors tends to be larger across a wide range of generative models, leading to conservative findings. While the literature on optimal treatment regimes recommends the m-out-of-n bootstrap (Shao 1996; Tsiatis et al. 2019), in our case, this approach resulted in even larger standard errors. Determining the correct standard errors for IIE estimates remain an important area for future research. However, we argue that overcoverage is a less severe issue than undercoverage. Therefore, we recommend using the proposed method despite of its conservative nature until a more refined approach is developed.
Bounding strategy for binary intervening factors
Previous literature on sensitivity analysis has often used the association between an observed covariate and the outcome, after accounting for the remaining covariates to benchmark the strength of unmeasured confounding (i.e., ). However, Cinelli and Hazlett (2020) highlighted that this informal benchmark approach may lead to invalid conclusions and demonstrated the potential bias of this approach through a simulation study.
This bias also can be explained by collider bias (Pearl 2009). A collider is a variable that is influenced by other variables (referred to as “ancestors”) and conditioning on a collider can induce an association between the ancestor variables, even if they are independent to each other. For example, suppose that students with high SES () and those attending high quality school () are more likely to take Algebra I by ninth grade (). If we know that a student took Algebra I by the ninth grade (i.e., conditioning on ) and that the student is not from high SES (), we can infer that this student is from a high-quality school (). This creates an induced association between and due to conditioning on . Such collider bias occurs when we use informal benchmarking strategies. When we benchmark the strength of unmeasured confounding against student SES (), we use the association between student SES () and the outcome () after conditioning on race (), remaining covariates ( and ), and Algebra I (). We expected that this association captures the direct path between and , but also inadvertently captures the indirect path between them via , induced by conditioning on .
To avoid this collider bias, the formal covariate benchmark strategy should be used, as suggested by Cinelli and Hazlett (2020). Their method, which is based on , can be applied to continuous risk factors and outcomes. However, since OTRs and individualized effects are primarily based on binary risk factors, we developed a formal benchmark method that applies to binary intervening factors using original data scales. While this method was developed in the context of OTRs and individualized effects, it can also be used to estimate any causal effects involving a binary treatment variable.
The newly developed benchmark method relies on the logistic approximation to the cumulative normal distribution. The deviation between the two distributions is <0.01 for all values of (Bowling et al. 2009; Ulrich and Wirtz 2004), making this approximation suitable for practical purposes. Developing a benchmark method for binary treatments without relying on this approximation is a task for future research.
Finally, in extending the simulation-based sensitivity analysis and developing the bounding strategy, we did not account for the multilevel structure where students are nested within schools or neighborhoods. While an alternative approach, such as including school fixed effects in the propensity model and/or the outcome model, could be considered as a quick remedy, this was not feasible in our case study. This is because the outcome (11th-grade math achievement) was measured in high school, while the risk factor (taking Algebra I by ninth grade) was measured in middle school. Addressing the multilevel structure is crucial, and we left this as a direction for future research.
Supplemental Material
sj-pdf-1-smr-10.1177_00491241251377741 - Supplemental material for Simulation-Based Sensitivity Analysis in Optimal Treatment Regimes and Causal Decomposition With Individualized Interventions
Supplemental material, sj-pdf-1-smr-10.1177_00491241251377741 for Simulation-Based Sensitivity Analysis in Optimal Treatment Regimes and Causal Decomposition With Individualized Interventions by Soojin Park, Suyeon Kang and Chioun Lee in Sociological Methods & Research
Footnotes
Author’s Note
The authors thank the Editor and two anonymous reviewers for their constructive feedback, which greatly improved the manuscript.
Data Availability Section for Data,Code,and Materials
Data
For our case study, we used data from the Midlife Development in the U.S. (MIDUS) study. However, as the MIDUS data is restricted from circulation, and the original data can be downloaded from the MIDUS portal at .
Code
The code used during this study and documentation for the code are available in the Github repository, and have been permanently archived on Zenodo (DOI: 10.5281/zenodo.17038437).
Declaration of Conflicting Interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
Research reported in this publication was supported by the National Science Foundation (NSF, 2243119) and the National Institutue on Aging of the National Institues of Health (NIH, R24AG077433).
ORCID iDs
Soojin Park
Suyeon Kang
Chioun Lee
Preregistraction Statement
This study was not preregistered.
Supplemental Material
Supplemental material and Appendix for this article are available online.
Author Biography
Soojin Park is an associate professor in the School of Education at the University of California, Riverside. Her research focuses on causal inference, sensitivity analysis, and the application of machine learning.
Suyeon Kang is an assistant professor in the Department of Statistics and Data Science at the University of Central Florida. Her research interests include multivariate analysis, causal inference, and mixture models.
Chioun Lee is an associate professor in the Department of Sociology at the University of California, Riverside. Her research focuses on the life course, aging, and the social determinants of health.
References
1.
AssariS.2020. “Blacks’ Diminished Health Returns of Educational Attainment: Health and Retirement Study.” Journal of Medical Research and Innovation4(2): e000212–e000212.
2.
BowlingS. R.KhasawnehM. T.KaewkuekoolS.ChoB. R.. 2009. “A Logistic Approximation to the Cumulative Normal Distribution.” Journal of Industrial Engineering and Management2(1): 114–127.
3.
BreimanL.2017. Classification and Regression Trees. Routledge.
4.
ByunS. Y.IrvinM. J.BellB. A.. 2015. “Advanced Math Course Taking: Effects on Math Achievement and College Enrollment.” The Journal of Experimental Education83(4): 439–468.
5.
CarnegieN. B.HaradaM.HillJ. L.. 2016. “Assessing Sensitivity to Unmeasured Confounding Using a Simulated Potential Confounder.” Journal of Research on Educational Effectiveness9(3): 395–420.
6.
ChazanD.SelaH.HerbstP.. 2016. “Is the Role of Algebra in Secondary School Changing?.” Journal of Curriculum Studies48(4): 506–528. doi:10.1080/00220272.2015.1122091.
7.
CinelliC.HazlettC.. 2020. “Making Sense of Sensitivity: Extending Omitted Variable Bias.” Journal of the Royal Statistical Society: Series B (Statistical Methodology)82(1): 39–67.
8.
ClotfelterC. T.LaddH. F.VigdorJ. L.. 2015. “The Aftermath of Accelerating Algebra: Evidence From a District Policy Initiative.” Journal of Human Resources50(1): 159–188. doi:10.3368/jhr.50.1.159.
9.
CohenD. K.HillH. C.. 2000. “Instructional Policy and Classroom Performance: The Mathematics Reform in California.” Teachers College Record102(2): 294–343.
10.
CuiY.Tchetgen TchetgenE.. 2021. “A Semiparametric Instrumental Variable Approach to Optimal Treatment Regimes Under Endogeneity.” Journal of the American Statistical Association116(533): 162–173.
11.
DominaT.McEachinA.PennerA.WimberlyL.. 2015. “Universal Algebra and Math Achievement: Evidence From the District of Columbia.” Educational Evaluation and Policy Analysis37(1): 70–92. 10.3102/0162373714527783.
12.
Feodor NielsenS.2000. “The Stochastic EM Algorithm: Estimation and Asymptotic Results.”
13.
HardtM.PriceE.SrebroN.. 2016. “Equality of Opportunity in Supervised Learning.” Advances in Neural Information Processing Systems29.
14.
JacksonJ. W.2021. “Meaningful Causal Decompositions in Health Equity Research: Definition, Identification, and Estimation Through a Weighting Framework.” Epidemiology (Cambridge, Mass.)32(2): 282–290.
15.
JacksonJ. W.VanderWeeleT.. 2018. “Decomposition Analysis to Identify Intervention Targets for Reducing Disparities.” Epidemiology (Cambridge, Mass.)29(6): 825–835.
16.
KalogridesD.LoebS.. 2013. “Different Teachers, Different Peers: The Magnitude of Student Sorting Within Schools.” Educational Researcher42(6): 304–316.
17.
KamiranF.CaldersT.. 2012. “Data Preprocessing Techniques for Classification Without Discrimination.” Knowledge and Information Systems33(1): 1–33.
18.
KaufmanJ. S.2008. “Epidemiologic Analysis of Racial/Ethnic Disparities: Some Fundamental Issues and a Cautionary Example.” Social Science & Medicine66(8): 1659–1669.
19.
KellyS.2009. “The Black-White Gap in Mathematics Course Taking.” Sociology of Education82(1): 47–69.
20.
LongM. C.CongerD.IatarolaP.. 2012. “Effects of High School Course-Taking on Secondary and Postsecondary Success.” American Educational Research Journal49(2): 285–322.
21.
LovelessT.2008. The Misplaced Math Student: Lost in Eighth-Grade Algebra. Washington, DC: Brookings Institution.
22.
LundbergI.2020. “The Gap-closing Estimand: A Causal Approach to Study Interventions That Close Disparities Across Social Categories.” Sociological Methods & Research53(2): 507–570.
23.
MurphyS. A.2003. “Optimal Dynamic Treatment Regimes.” Journal of the Royal Statistical Society: Series B (Statistical Methodology)65(2): 331–355.
ParkS.KangS.LeeC.MaS.. 2023. “Sensitivity Analysis for Causal Decomposition Analysis: Assessing Robustness Toward Omitted Variable Bias.” Journal of Causal Inference11(1): 20220031.
26.
ParkS.LeeN.QuintanaR.. 2024. “Causal Decomposition Analysis With Time-Varying Mediators: Designing Individualized Interventions to Reduce Social Disparities.” Sociological Methods & Research00491241241264562.
27.
ParkS.QinX.LeeC.. 2022. “Estimation and Sensitivity Analysis for Causal Decomposition in Health Disparity Research.” Sociological Methods & Research53(2): 571–602.
28.
PearlJ.2009. Causality: Models, Reasoning, and Inference. 2nd ed. Cambridge: Cambridge University Press.
29.
QianM.MurphyS. A.. 2011. “Performance Guarantees for Individualized Treatment Rules.” Annals of Statistics39(2): 1180.
QiuH.CaroneM.SadikovaE.PetukhovaM.KesslerR. C.LuedtkeA.. 2021. “Optimal Individualized Decision Rules Using Instrumental Variable Methods.” Journal of the American Statistical Association116(533): 174–191.
32.
Riegle-CrumbC.GrodskyE.. 2010. “Racial-Ethnic Differences At the Intersection of Math Course-Taking and Achievement.” Sociology of Education83(3): 248–270.
33.
RobinsJ. M.HernanM. A.BrumbackB.. 2000. “Marginal Structural Models and Causal Inference in Epidemiology.” Epidemiology (Cambridge, Mass.)550–560.
34.
RosenbaumJ. E.1999. “If Tracking Is Bad, Is Detracking Better?” American Educator23(4): 24.
35.
RubinD. B.1986. “Statistical Matching Using File Concatenation With Adjusted Weights and Multiple Imputations.” Journal of Business & Economic Statistics4(1): 87–94.
36.
RubinD. B.2004. Multiple Imputation for Nonresponse in Surveys. Vol. 81. John Wiley & Sons.
37.
RubinsteinM.BransonZ.KennedyE. H.. 2023. “Heterogeneous Interventional Effects With Multiple Mediators: Semiparametric and Nonparametric Approaches.” Journal of Causal Inference11(1): 20220070.
38.
SetoguchiS.SchneeweissS.BrookhartM. A.GlynnR. J.CookE. F.. 2008. “Evaluating Uses of Data Mining Techniques in Propensity Score Estimation: A Simulation Study.” Pharmacoepidemiology and Drug Safety17(6): 546–555.
39.
ShaoJ.1996. “Bootstrap Model Selection.” Journal of the American Statistical Association91(434): 655–665.
40.
SilverE. A.1995. “Rethinking Algebra for All.” Educational Leadership52(6): 30–33.
41.
SteinM. K.KaufmanJ. H.ShermanM.HillenA. F.. 2011. “Algebra: A Challenge at the Crossroads of Policy and Practice.” Review of Educational Research81(4): 453–492.
42.
TsiatisA. A.DavidianM.HollowayS. T.LaberE. B.. 2019. Dynamic Treatment Regimes: Statistical Methods for Precision Medicine. Chapman and Hall/CRC Press.
43.
UlrichR.WirtzM.. 2004. “On the Correlation of a Naturally and an Artificially Dichotomized Variable.” British Journal of Mathematical and Statistical Psychology57(2): 235–251.
44.
VanderWeeleT.RobinsonW. R.. 2014. “On Causal Interpretation of Race in Regressions Adjusting for Confounding and Mediating Variables.” Epidemiology (Cambridge, Mass.)25(4): 473–483.
45.
ZhangB.TsiatisA. A.DavidianM.ZhangM.LaberE.. 2012. “Estimating Optimal Treatment Regimes From a Classification Perspective.” Stat1(1): 103–114.
46.
ZhangZ.2019. “Reinforcement Learning in Clinical Medicine: A Method to Optimize Dynamic Treatment Regime Over Time.” Annals of Translational Medicine 7(14): 345.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.