
Abstract
Age-period-cohort analysis is often done in the context of two samples. This could be samples for women and men or for two countries. It is of interest to ask if some time effects could be common across samples. We clarify how the well-known age-period-cohort problem for one sample carries over to the two sample situation. This is done through a reparametrization in terms of parameters that are invariant to the identification issues. The new parametrization shows which hypotheses can be tested and their degrees of freedom. Testable hypotheses can be formulated for non-linear effects, but not for the linear parts of the individual time effects. This conclusion remains when imposing cross-sample restrictions. The analysis is extended to the mixed frequency situation where age and period are measured at different scales. As an empirical illustration a study of Swiss suicide rates is revisited.
Keywords
Introduction
It is common to have data in the form of two age-period tables, for instance for women and for men. Investigators often fit age-period-cohort models to each table and then compare the time affects across samples. For instance a common period effect could be attributable to societal effects. It is unclear from the literature, how the usual age-period-cohort problem for a single sample carries over to the two-sample case. The purpose of this paper is to clarify this.
Some other two-sample examples are the following. Riebler and Held (2010) compared female mortality in Danmark and Norway. Dinas and Stoker (2014) compared male and female participation rates in US presidential elections after the introduction of universal suffrage. Cairns et al. (2011) investigated selection effects in life insurance. Fannon et al. (2021) analyzed obesity for English women and men using repeated cross sections. In all these examples it is of interest to formulate and investigate hypotheses about common age, period or cohort effects.
What constitutes the individual linear parts of a model can be confusing. This point was made by Clayton and Schifflers (1987), see Fannon and Nielsen (2019) for a recent review and the comment of Keiding and Andersen (2016) on an empirical analysis linking maternal age with offspring outcomes. To appreciate this point, consider the extreme restriction where the age-period-cohort effects combine to zero for all ages and periods. While this model has no parameters and no statistical tools are needed, the age-period-cohort problem remains. The restriction stipulates that the individual effects add up to zero. It may be true that each of the age, period and cohort effects is zero. Equally, we can add a linear trend to each of the age and cohort effects if we also subtract it from the period effect. But, there are no degrees of freedom left to learn about this.
The age-period-cohort problem comprises two problems. The primary problem is of invariance. We must avoid getting confused by pernicious manipulations of the linear parts of the individual effects. We do that by focussing on the non-linear parts and the linear plane, which are unaffected by the manipulations. Mathematically, we say that these parts are ‘invariant’ to the age-period-cohort problem. The secondary problem is of identification or collinearity.
There is a lively debate about what to do about the age-period-cohort problem. This arises because we can solve the identification problem without addressing the invariance problem. Broadly speaking, there appears to be three approaches. First, one can impose constraints on the time effects to achieve identification without getting invariance. One can set a subset of the time effect parameters to zero as discussed by Fienberg and Mason (1979). More elaborate suggestions are given by Fosse and Winship (2019), Fu (2018), O’Brien (2022), Yang and Land (2013) for one-sample models, by Riebler and Held (2010) for two-sample models, and by Fu (2018), Gascoigne and Smith (2023), Riebler and Held (2010), Yang and Land (2006) for mixed frequency models. Some of these choices have attracted considerable discussion, see for instance Bell and Jones (2015), Luo (2013), Luo and Hodges (2016), Nielsen and Nielsen (2014), O’Brien (2011), Reither et al. (2015). Second, as suggested by Chauvel and Schröder (2014), Clayton and Schifflers (1987), Fienberg and Mason (1979), Holford (1983), McKenzie (2006), Rosenberg (2019), one can apply the first approach for estimation and then extract estimates for invariant functions. Third, one can reparametrize the predictor exclusively in terms of invariant parameters. This requires a mathematical representation of the predictor in terms of the invariant parameters. As a result, the age-period-cohort model can be approached as any other regression problem. This approach was proposed in (Kuang et al. 2008). See also (Smith and Wakefield 2016) for a Bayesian implementation, (Fannon and Nielsen 2019) for reviews and (Billari and Graziani 2023) for a recent fertility application. We will extend the invariance approach to the two-sample model.
When the data also have a mixed-frequency structure, the age-period-cohort problem is more involved. For instance, suppose age is grouped in five year intervals while the period is annual as in the Swiss data. Then the cohort effects related to the age-group 25–29, say, will be different in two consecutive periods due to a one-year shift. Rather, the cohort effects for the 25–29 age-group are only repeated for the 30–34 age group five periods later. Thus, the non-linear effects and linear planes have to be formed with some care to include ‘macro’ 5-year steps and ‘micro’ 1-year shifts. Key references are Holford (2006) and Riebler and Held (2010), who describe macro and micro effects. Recently, Nielsen (2022) has used the invariance approach to give a complete characterization of the mixed frequency identification problem for one sample with an arbitrary mixed-frequency structure. We extend that analysis to the two-sample situation.
The analysis of the parametrization is applicable in a broad range of statistical models. This includes generalized linear models whether they are based on the normal, the Poisson or the binomial distributions. It is applicable to aggregate tables and to repeated cross-sectional data. It will be applicable to panel data with some modification. In a particular application, the user will have to decide how to conduct inference. This problem will be addressed in the context of the empirical illustration.
Motivation: the Swiss Suicide Data
We consider the Swiss suicide data presented and analyzed by Riebler et al. (2012). The data consists of suicide mortality counts and mid-year population data organized as two mixed-frequency age-period arrays for women and men. Age is grouped in five year intervals 15–19,…,75–79 while period is annual for 1950–2007. Thus, there are 13 age groups covering a 65 year range and 58 annual periods. In the present data, the counts range from 5 to 54 for women with a median of 27. For men, the range is 18–133 with a median of 66.
Figure 1 shows crude suicide rates by age and period for women and men. The crude rates are found as the sum of all mortality counts for a given age or period divided by the sum of the population data and standardized as rates per 100,000 people. The rates increase with age while female rates are about a third of the male rates. The rates per period fall through the 1950s and 1960s, then increase through the 1970s, after which they fall back again. The peak could match socio-economic trends.
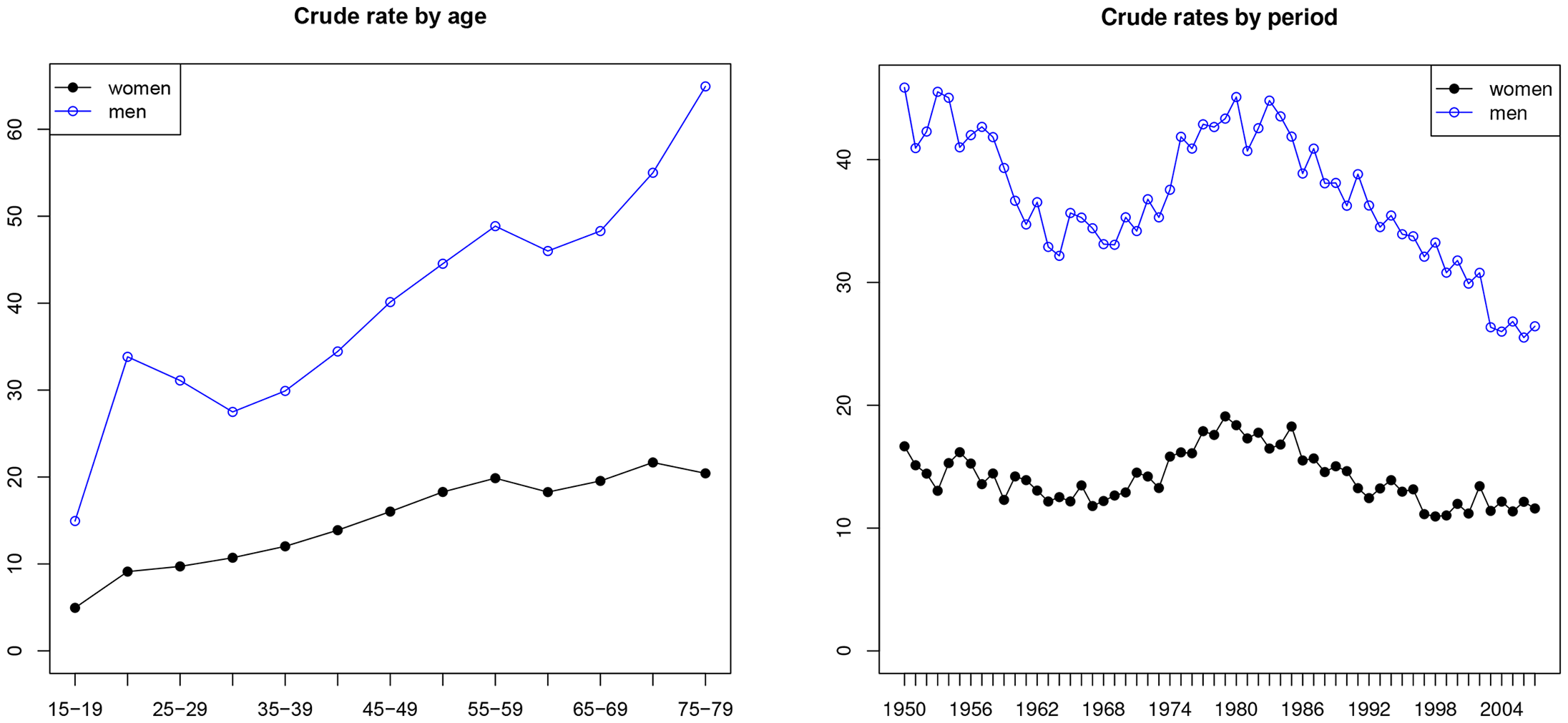
Crude rates per 100,000.
Following Riebler et al. (2012), we will replace the period effect with a family integration index composed from marriage and divorce rates as shown in Section ‘Empirical illustration’. This choice is motivated by Durkheim’s theory from the late 1800s and numerous subsequent work considering the relationship between marital status and suicide.
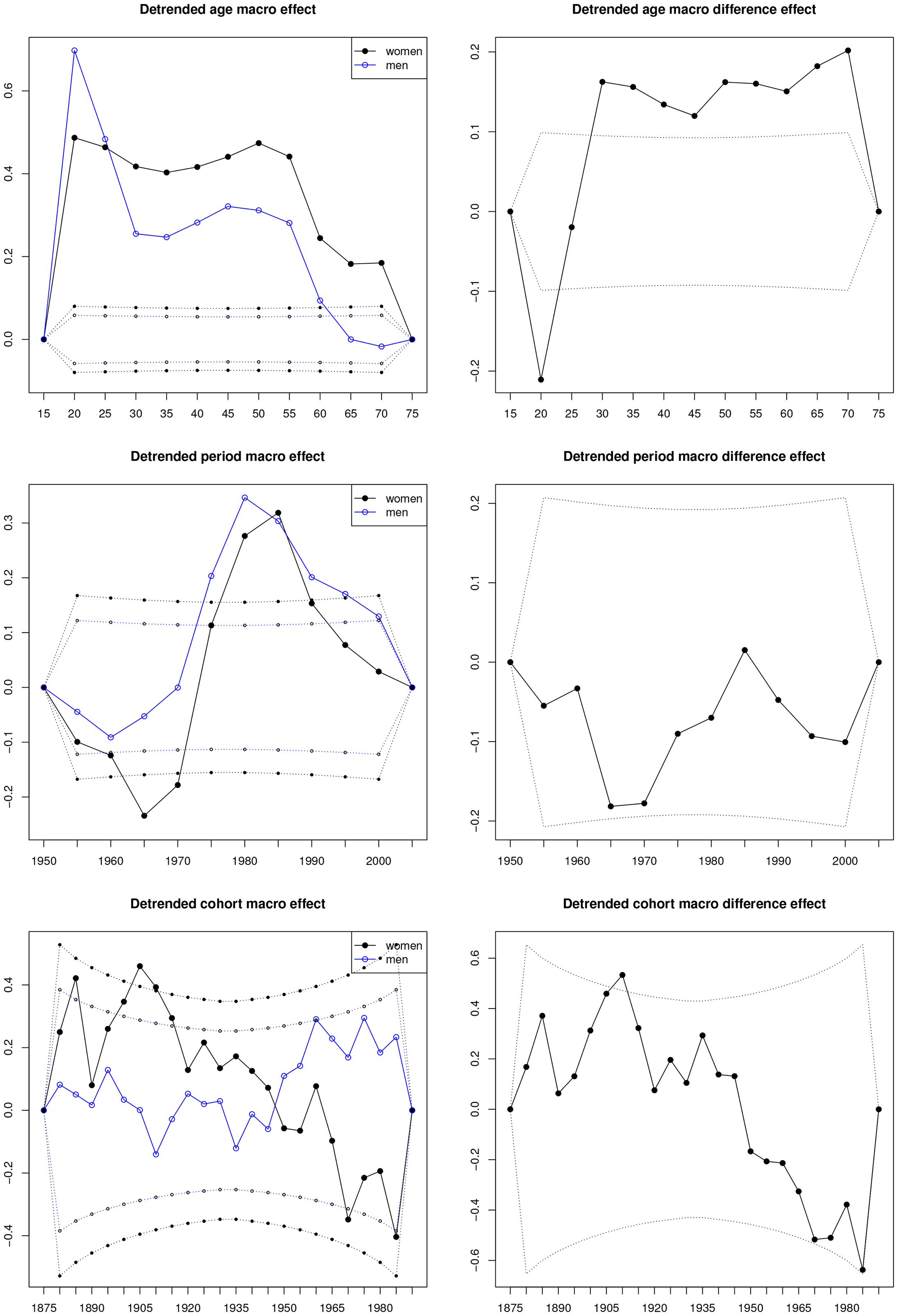
Detrended macro effects. Solid lines are estimates and dotted lines are
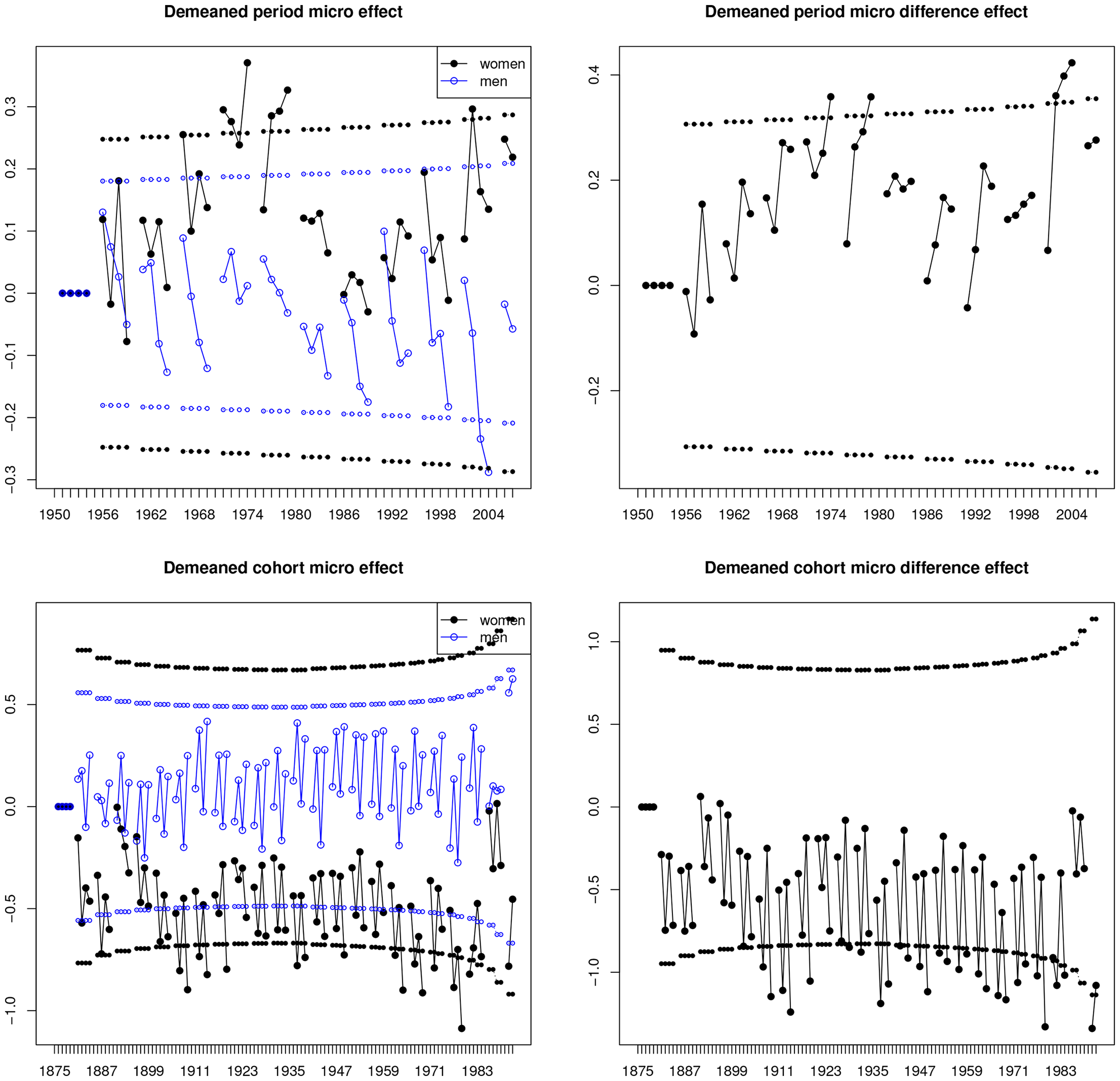
Demeaned micro effects. Solid lines are estimates and small plot symbols are
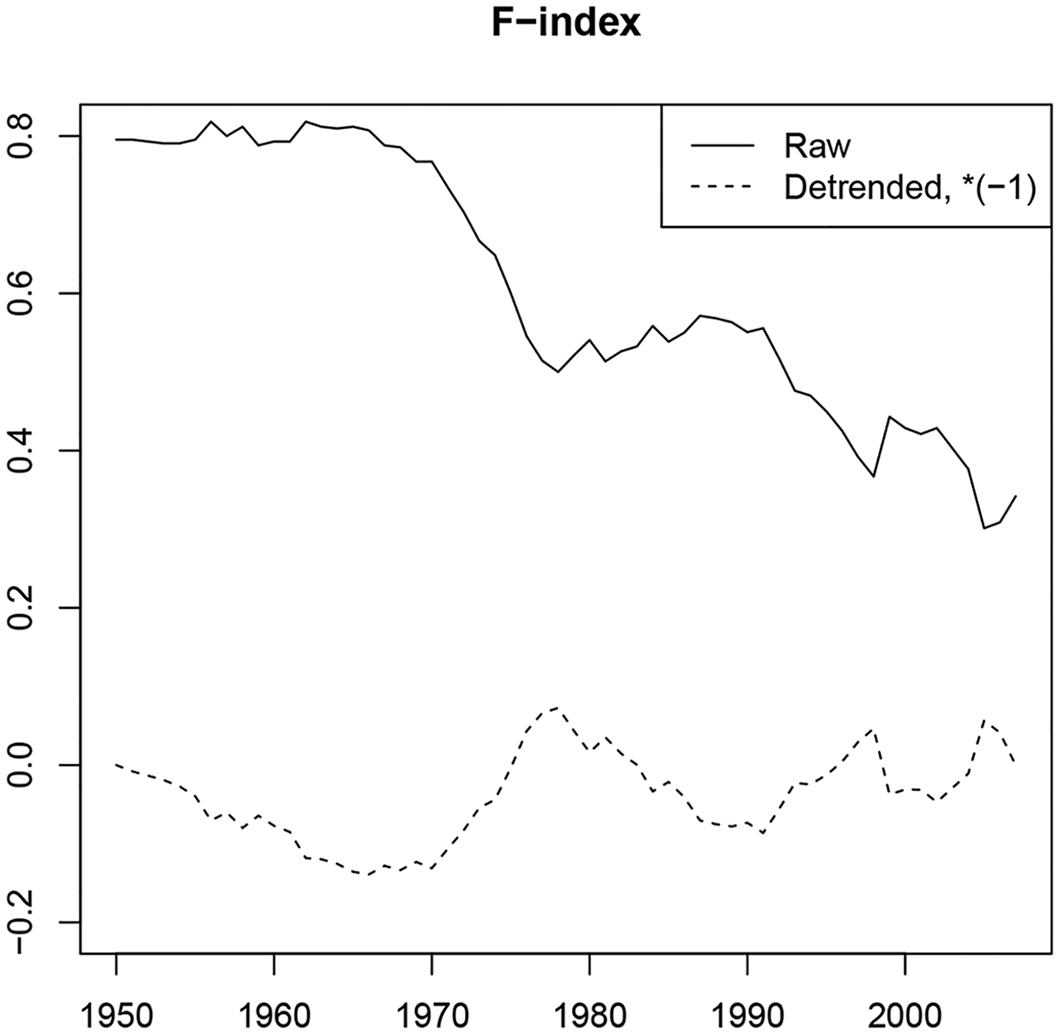
F-index. The solid line shows the raw F-index. The dashed line, the F-index is detrended to start and end in zero. It is also multiplied by -1 to facilitate comparison with the detrended cross-sample difference of the macro period effect in Figure 2.
Riebler et al. (2012) applied a Bayesian, two-sample, age-period-cohort, over-dispersed Poisson model. They found a common period effect for the two samples and investigated the extent to which the period effects could be replaced by socio-economic time series.
A theory for two-sample age-period-cohort analysis follows. Subsequently, we reanalyze the data in Section ‘Empirical illustration’ by implementing this theory in a generalized linear model. Comments on Bayesian analysis are given in Appendix A.4 in the online Supplemental Material.
The Two-sample Model for Regular Data
Suppose we have two samples of data in the form of rates, counts, or doses and responses. The samples are organized in terms of common regular age-period arrays. We first review the organization of the data. Then, we introduce the unrestricted age-period-cohort model and the age-period-cohort problem, which we address through a reparametrization in terms of invariant parameters. Finally, we turn to a discussion of relevant hypotheses. A generalization to mixed-frequency age-period arrays follows in Section ‘The Two-sample Model for Mixed Data’.
Data Structure
We consider two data arrays with the same regular structure with
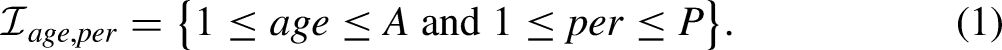


The Two-sample Age-period-cohort Model
The two-sample age-period-cohort model has the well-known age-period-cohort problem, which we present. We circumvent this problem by finding invariant parameters and reparametrizing the model in terms of those invariant parameters. One could say that the initial formulation of the model is a wish list of effects we may want to include, while the reparametrized model describes the consequences of these wishes in a way that is better suited for statistical analysis.
Age-period-cohort model formulated with level effects
We set up age-period-cohort models for each of the two samples. This is a model for the predictor, which could be the expected outcome in a linear model or the log expected outcome in a log-linear model. It has the form
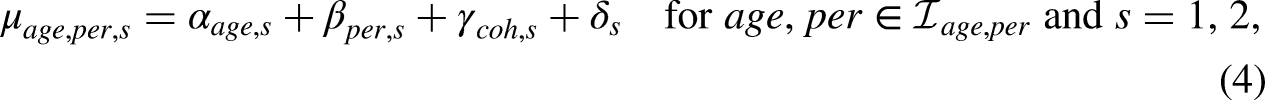
The time effects on the right hand side of the model equation (4) have dimension
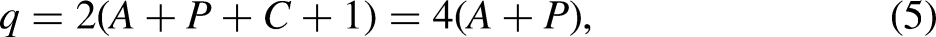
The age-period-cohort problem
We describe the classicial age-period-cohort problem and how this effects the two-sample model. In short, the problem is that the time effects on the right hand side of (4) are not identified from the possible variation of the left hand side of (4).
It is well-understood that the age-period-cohort problem arises, since the cohort identity (2) implies the identity
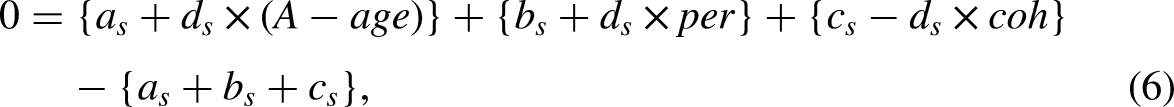
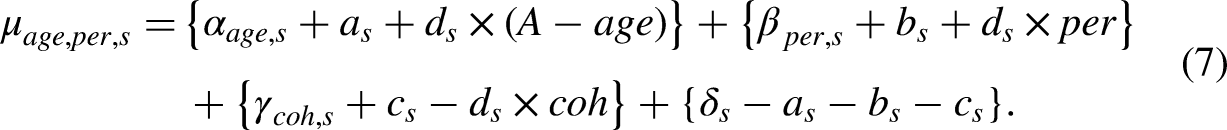
There are
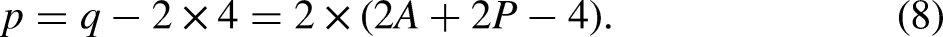
We will proceed by finding a
Invariant parameters
We address the age-period-cohort problem by working with invariant parameters. These are parameters that do not change with the transformations in (7). The idea of the approach is to generalize the notion of contrasts in two-way analysis. Contrasts eliminate unidentified common levels by taking differences. In the age-period-cohort context, we eliminate unidentified common slopes by taking double differences. In accordance with statistical theory, the resulting parameters are said to be invariant to the transformations (7) (Cox and Hinkley 1974).
We decompose the period effects
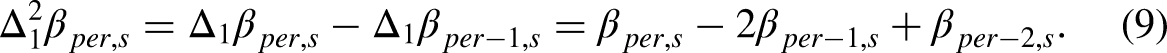
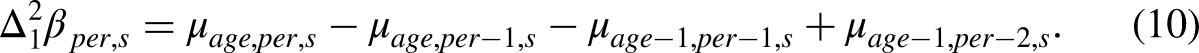
The consequence of the invariance is that we can learn about the double differences without any worry about the age-period-cohort problem. Moreover, if two researchers choose different ad hoc identification schemes, such as setting different choices of four time effect values to zero, but otherwise use the same estimation method, then these researchers will get the same fit and their estimates of the second diffences
In a similar fashion, the age and cohort double differences
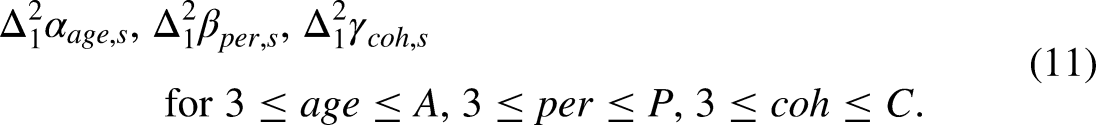
The points sofar have been made in the literature at least as far back as (Fienberg and Mason 1979). Now, we will deviate from the classic literature. The aim is to express the predictor in terms of invariant parameters. This will allow us to conduct the entire analysis in terms of invariant parameters without worrying about the original time effect parametrization (4) and its identification problem. This requires further 3 invariant parameters for each sample as proposed by Kuang et al. (2008).
Linear planes can be defined from a level and two slopes. The level is chosen from
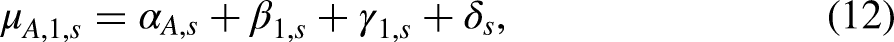
The slopes are chosen as an age-cohort slope and a period-cohort slope given by
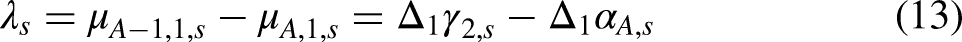
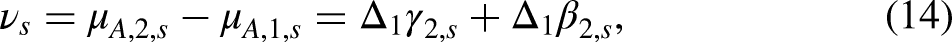
The slopes in (13)–(14) cannot be separated into individual slopes for age, period, cohort. By imposing additional constraints such as
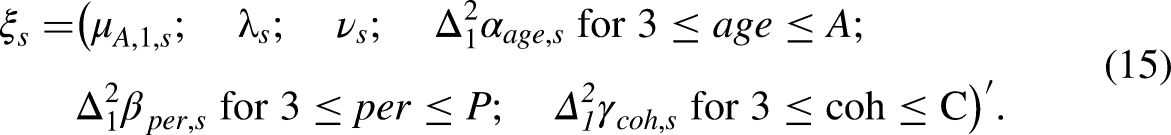
Writing the predictor in terms of invariant parameters
We write the predictor as a function of the invariant parameter in order to reparametrize the model. The main purpose of this step is to facilitate computer code. That is, we can sidestep the initial formulation of the model in (4) and the age-period-cohort problem (7), and just think of age-period-cohort modeling in terms of a standard regression model. For the practitioner, who relies on the code of someone else, the main consequence of the following argument is that hypotheses can be thought of in terms of the invariant parameter (15).
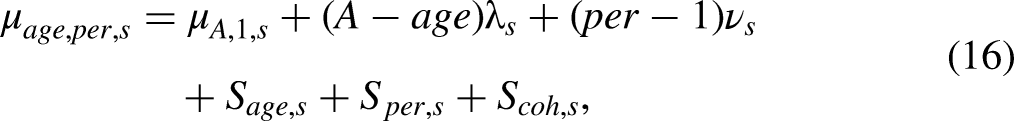
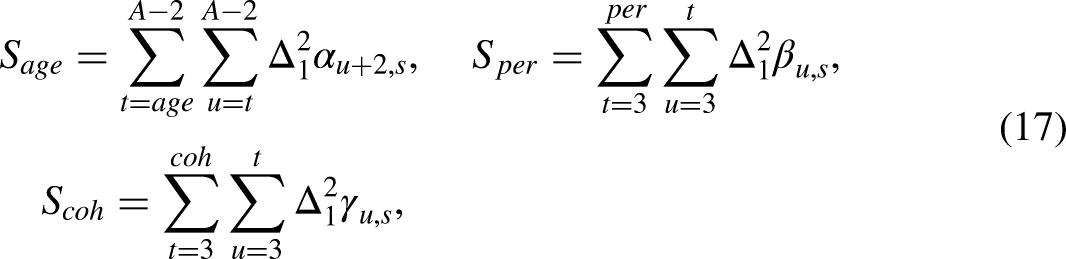
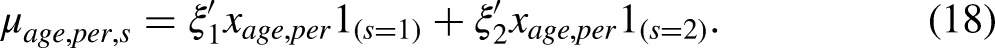
The exact expression of the design vector
In other words, in the original model (4), the time effects generate a certain variation in the predictor, which we will match with the variation in the data. The age-period-cohort problem means that different time effects can generate the same predictor. This redundancy is eliminated when parametrizing the predictor in terms of the canonical parameter. Since
The property that the predictor
We must check that
Restrictions on the Age-period-cohort Parameters
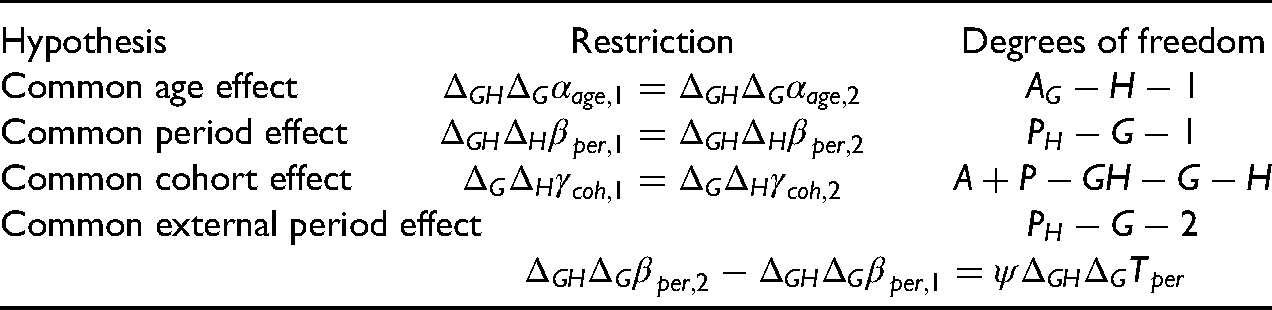
In the context of the two-sample model it is natural to ask if any of the age, period or cohort effects are common? Initially, we consider the hypotheses of common period effects and whether period effects could be driven by some external developments in the wider society. Finally, we consider a wider range of age, period, cohort hypotheses.
The hypothesis of common period double differences
In a two-sample analysis, it will often be relevant to ask if the period effects could be common across the two samples. We need to be careful when posing this question. The non-linear parts of the period are identified whereas the linear parts are not. Thus, restrictions on the restrictions on the non-linear parts will be binding, whereas restrictions on the linear parts are not binding.
The hypothesis that the non-linear parts of the period effects are common is that
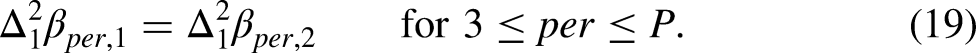
For estimation under the hypothesis it is convenient to rewrite the design vector expression for the predictor in (18). By adding and subtracting
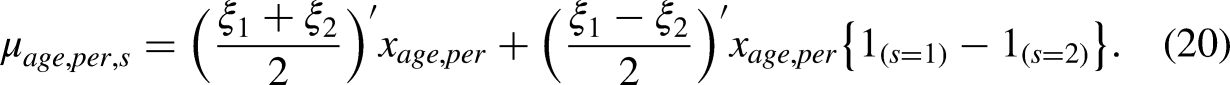
The hypothesis of common period effects
A hypothesis formulated directly on the common period effects may appear attractive. Yet, it turns out to be observationally equivalent to the hypothesis of common period double differences in (19). The hypothesis of common period effects is
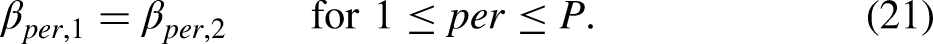
If it were true that the linear, cross-sample differenced, period effects were zero, then one would be able to identify the cross-sample age and cohort slopes as argued by Riebler and Held (2010). However, this truism remains untestable, as the linear parts of an age-cohort model and of an age-period-cohort model remain observationally equivalent. For further details, see Appendix A.2 in the online Supplemental Material.
The point that the linear parts of age-period-cohort models are observationally equivalent to the linear parts of age-cohort models has been made in various places in the literature. An early reference is Clayton and Schifflers (1987). Nielsen and Nielsen (2014) described this in terms of linear algebra. Keiding and Andersen (2016) raised the point in a comment on a paper concerned with the question whether delaying childbearing to older ages might be associated with more positive educational and health outcomes for the children. Fannon and Nielsen (2019) give a detailed analysis of the model where only linear planes are present.
To conclude, from a statistical viewpoint, the hypothesis (19) of common double-differenced period effects,
Replacing period effect with time series
Could it be that socio-economic effects explain the period movements that we see in the data? In other words, does the period effect follow some external time series? Hypotheses of this kind can be tested, but we need to take the age-period-cohort problem into account. The period effect is only determined up to arbitrary linear trends, see (6). Thus, the testable hypothesis is that the non-linear part of the period effect follows the non-linear part of the external time-series.
The hypothesis can be implemented by replacing the double differenced period parameter
In a two-sample age-period-cohort model the external time series restriction can be done in various ways. It can be imposed on the cross-sample differenced parameter
Further sub-models
Other sub-models may be relevant. We give an overview, but see also Fannon and Nielsen 2019. We will be particularly interested in restrictions on the cross-sample differenced predictor
A period-cohort model for the cross-sample differenced predictors arises when the non-linear parts of the age effects are common, that is
An age-period model for the cross-sample differenced predictors arises with the restriction
An age-drift model arises when both the period and cohort cross-sample double differences are restricted to be zero. That is
A pure age model occurs when restricting the age-drift model further by requiring a zero cross-sample period-cohort slope through
A constant model occurs when only the cross-sample level
The zero model has
The Two-sample Model for Mixed Data
The two-sample age-period-cohort model is generalized to general mixed-frequency arrays building on Nielsen (2022), henceforth N22. We proceed as before by reviewing the organization of the data, introducing the unrestricted age-period-cohort model, analyzing the identification problem and giving an invariant, identified reparametrization.
Data Structure
Mixed frequency age-period data arise by a fairly easy generalization of the regular data we have seen before. However, it is now more complicated to describe which cohort values are possible.
The general mixed-frequency setup has
Cohort indices for
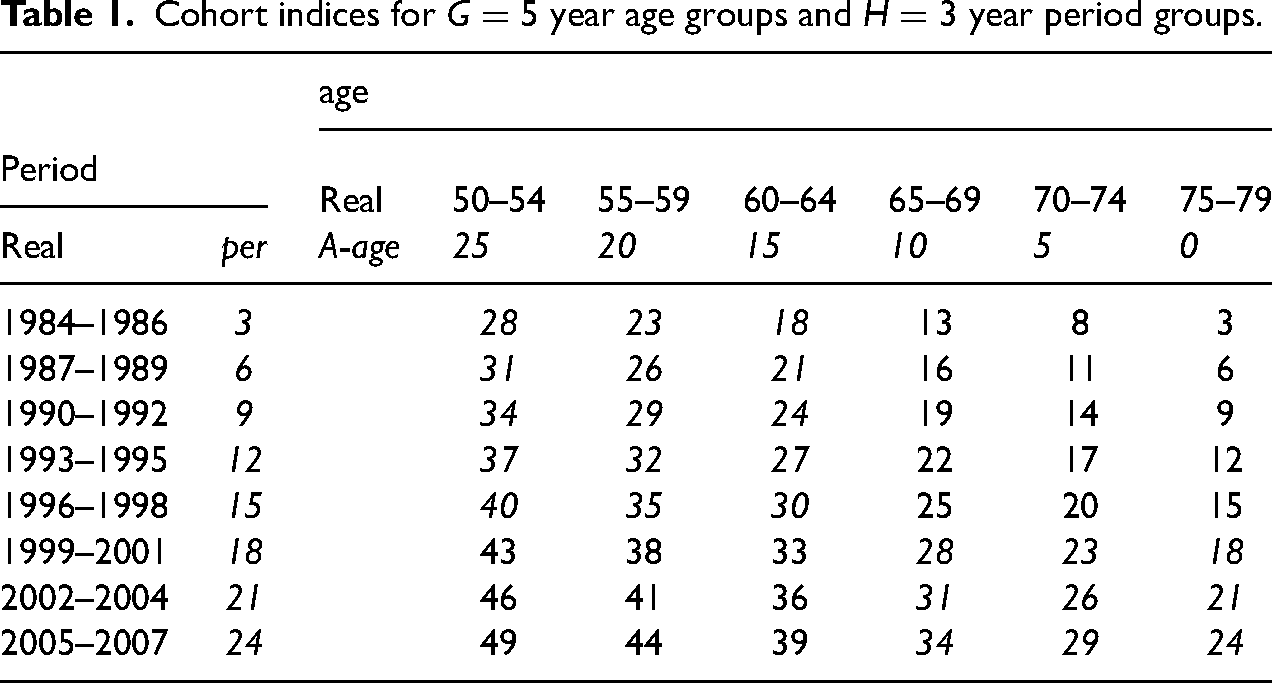
An age-period data array has index set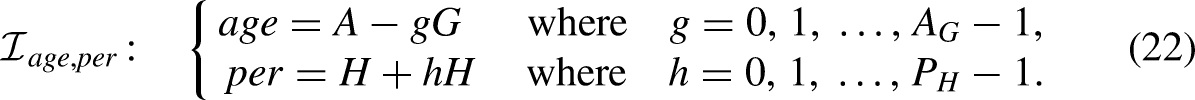
Regular data arise when
The Swiss data has
Mixed frequency data with
The fact that some cohort values are skipped will be rather important for understanding how many parameters the an age-period-cohort model has. In turn this will feed into the calculation of degrees of freedom. It turns out that there is theory for the skipping (N22). The possible cohorts over the set 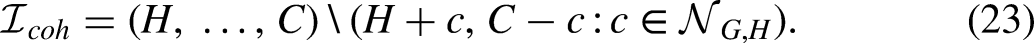
The skipping is akin to the coin problem in algebra : If we have groups (coins) of denomination
In the example with
The Two-sample Age-period-cohort Model
We now present the two-sample age-period-cohort model for mixed frequency data. The approach is the same as for the regular case. We will need to discuss how the age-period-cohort problem changes. Based on that, invariant parameters can be found and the predictor will have to represented in terms of those.
Age-period-cohort model formulated with level effects
We consider exactly the same two-sample age-period-cohort model as before for the mixed frequency data. This gives the same model equation as in (4), that is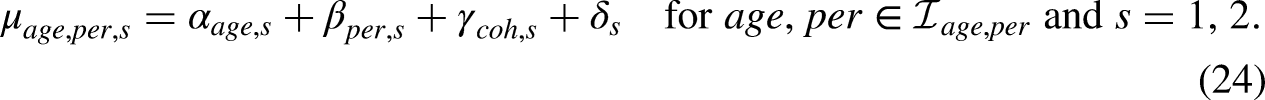
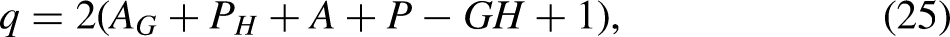
The age-period-cohort problem
We are now faced with new identification issues. First, we have the standard age-period-cohort problem that only one level and two linear slopes are identifiable. Second, the mixed-frequency indexation results in additional constraints as noted by Fienberg and Mason (1979). N22 describes the full set of constraints for one mixed-frequency sample. This carries immediately over to the two-sample model.
The mixed-frequency structure results in macro steps of length
In addition, we get a micro effect in age by adding
Combining the possible macro and micro transformations gives the following mixed-frequency, one-sample identity, which generalizes (6),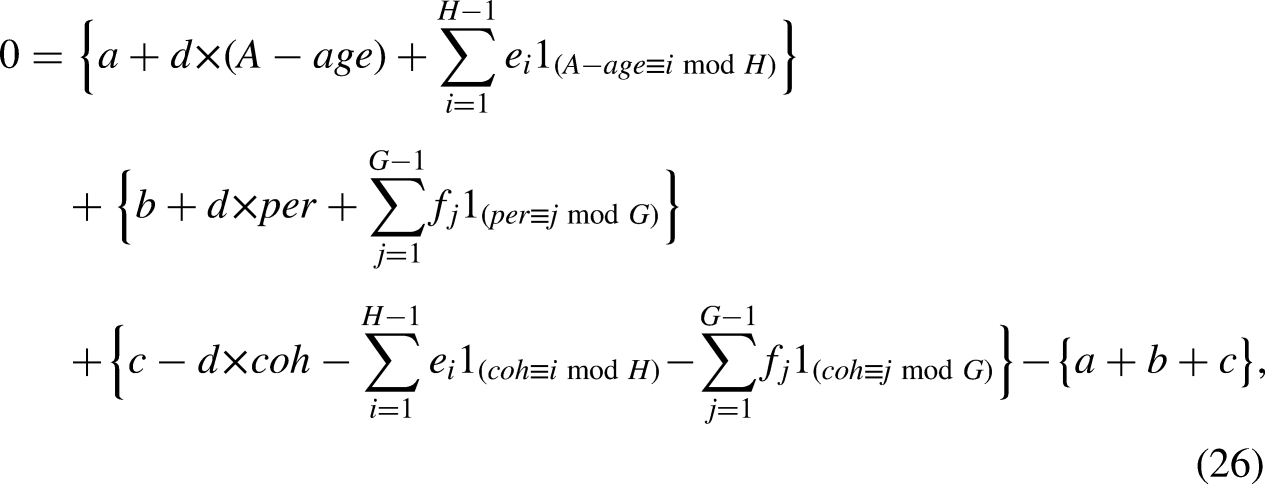
The transformations in (26) have dimension
When it comes to the mixed-frequency two-sample case, we will want to characterize the transformations of the time effects that leave the predictor 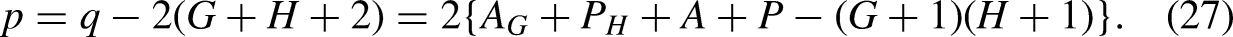
Invariant reparameter
The next step is to find invariant parameters. Holford (2006) discusses this in terms of macro effects and micro effects and argues that standard double differences will not be invariant, but explicit formulas are not given. Instead we build on N22. Following the approach for the regular case, we will describe the relevant double differences at first and then the relevant linear planes.
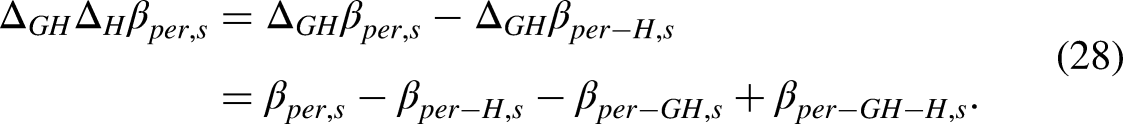
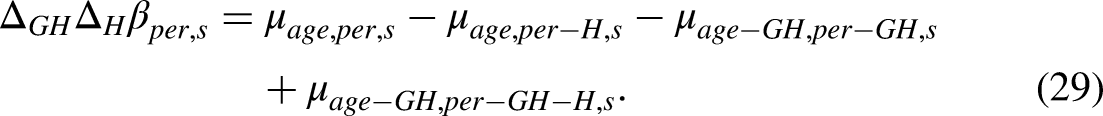
The double differences
The simpler one-period double differences
For the age effect, we will by a similar argument use double differences 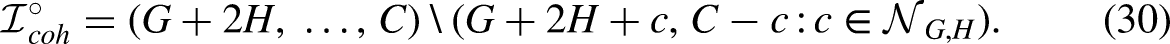
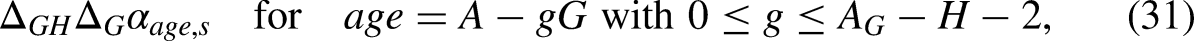
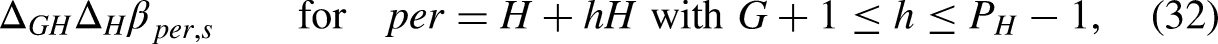
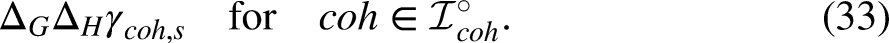
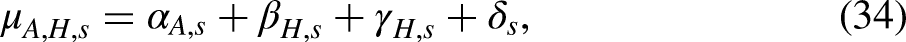
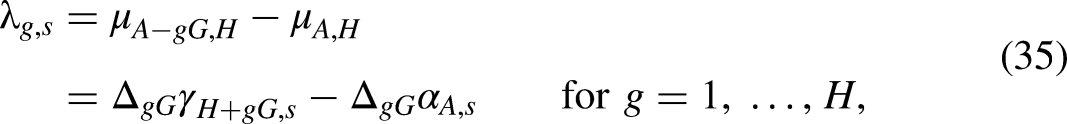
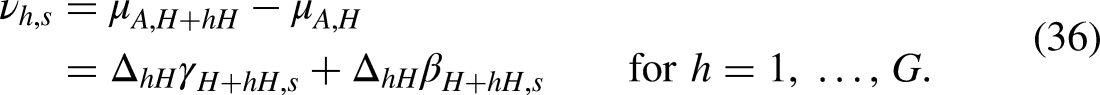
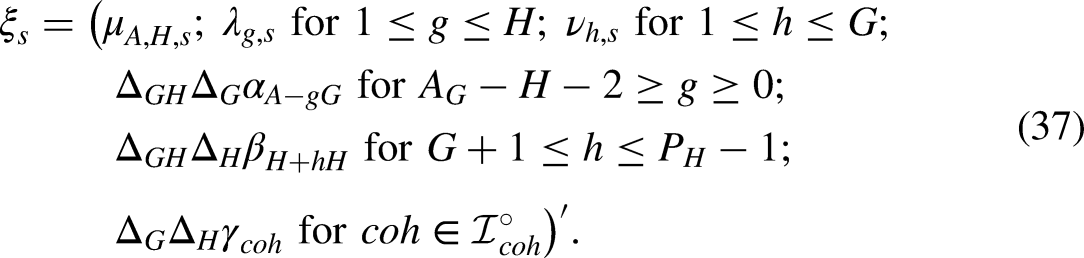
Writing the predictor in terms of invariant parameters
The next step is to write the predictor in terms of the invariant parameters. This serves two purposes: To given an interpretation of the model and to derive a design matrix. The added difficulty is to deal with the mixed frequency. Here we rely on N22. We start by defining macro and micro steps in the time scales.
Age moves in micro steps of length 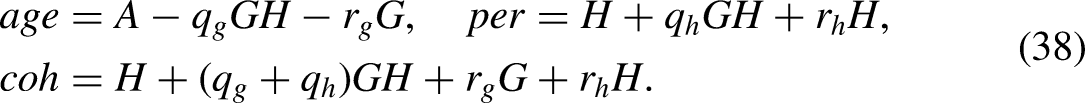
The Euclidean representations is vizualized by Table 1 where
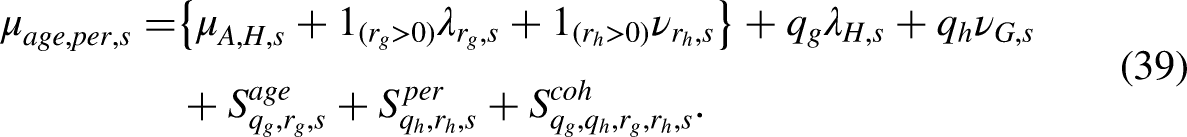
The mixed-frequency representation (39) has a more complicated appearance than that for the regular case in (16). This is because of the micro steps associated with the different values of
A closer inspection of the mixed-frequency representation (39) reveals that certain components are common across different values of
Turning to the level term in curly brackets in (39), we see different levels for different
The non-linear age term
The non-linear period term
The non-linear cohort term
The age, period and cohort double differences in (A.13), (A.15), (A.16) measure curvature in the predictor. In general, we would expect the predictor to be smooth, so that double differences are non-zero but small. Thus, we would only expect slightly different period-cohort slopes for different values of
In practice, parameters are estimated. Data will typically not be entirely smooth due to random noise or model error. Because of the large number of parameters, the fit will track the data quite well, but with quite volatile double differences. If the underlying double difference parameter is small corresponding to a smooth predictor, its signal will be dominated by the double difference estimation error. In particular, if the double difference parameters are zero, as in a linear plane model, their estimates can be quite volatile. When cumulated, such estimation errors can generate an impression of seasonality as observed. The seasonal patterns may be constant over time or varying over time. There is a considerable literature on seasonality in time series econometrics, with a distinction between deterministic and stochastic seasonality (Ghysels and Osborn 2001; Hylleberg et al. 1990). Such distinctions are of interest if the seasonality is part of the signal. But the seasonality is perhaps of less interest when it is driven mainly by estimation error. This seems to be the case in the present situation. We will return to these points in the data example.
Hypotheses on Common Time Effects
Hypotheses on common time effects can be formulated for the mixed case in a similar fashion as for the regular case.
In the unrestricted model the predictors are expressed in terms of the canonical parameters through the representation in (39). From this we can extract a design vector
Further submodels can be formulated as for the regular case, see also N22.
Empirical Illustration
We now consider the Swiss suicide data reviewed earlier. A two-sample age-period-cohort predictor will be applied in the context of a log-normal model using least squares for the log rates. We will first analyze the two samples separately using one-sample age-period-cohort analyses. All time effects will appear significant. The scale parameters are found to be different across samples. Correction for this difference will be done through generalized least squares regression combined with a small-dispersion asymptotic theory. We will then find that we cannot reject the hypothesis of a common period effect. We will also explore the use of a marriage-divorce index as period effect.
The data analysis was done in R (R Core Team 2022) using code building on the apc package (Nielsen 2015).
Initial One-sample Analyses
At first, we model the two samples separately using 1-sample mixed-frequency age-period-cohort analyses. We assume that the log rate is normal, where the expectation has a linear age-period-cohort structure as in (24) and constant variance. The models are estimated using least squares. For inference we can, at this point, rely on the exact distribution theory for the normal model.
Tables 2 and 3 show separate standard 1-sample analyses of variance for women and for men. Each table consider 1-sample APC models and reductions to 1-sample sub-models AP, AC and PC where, respectively, the cohort, the period and the age effects are omitted. Thus, in Table 2, APC refers to a standard 1-sample age-period-cohort model for women while AP refers to a standard 1-sample age-period submodel for women. All restrictions are strongly rejected. We note that the residual standard deviation,
Analysis of variance, women.
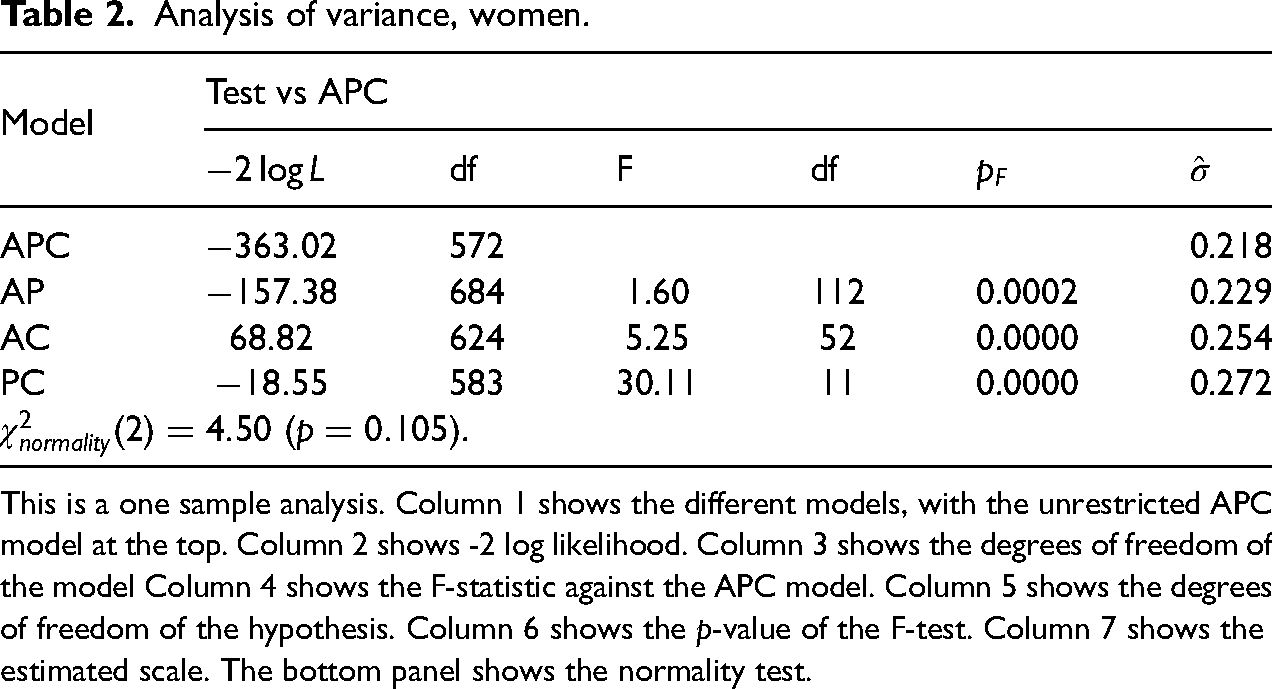
This is a one sample analysis. Column 1 shows the different models, with the unrestricted APC model at the top. Column 2 shows -2 log likelihood. Column 3 shows the degrees of freedom of the model Column 4 shows the F-statistic against the APC model. Column 5 shows the degrees of freedom of the hypothesis. Column 6 shows the
Analysis of variance, men. The table is structured as Table 2.
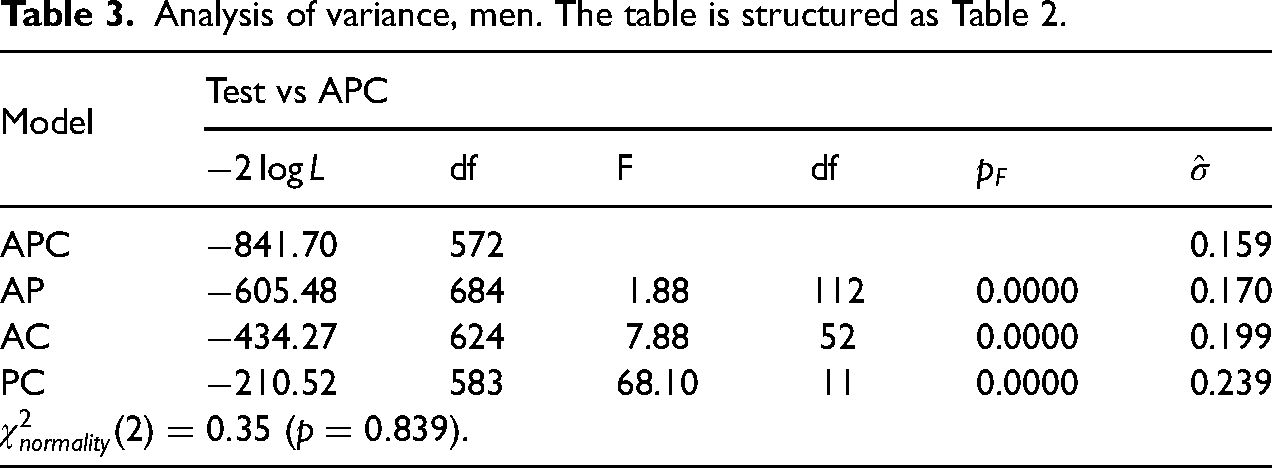
Tables 2 and 3 also show tests for the normality assumption. The tests are standard skewness and kurtosis based tests, see for instance Hendry and Nielsen (2007). In both cases, the
Two-sample Analysis by Least Squares
We apply the proposed two-sample age-period-cohort analysis, where the common predictor is unrestricted while the cross-sample differenced predictor is restricted in various ways. The log normal specification is maintained. We consider both the case with common scale parameter so that least squares estimation can be used and the case of different scale parameters in the two samples so that generalized least squares estimation is needed. Table 4 summarizes the results. Thus, APC refers to the unrestricted two-sample age-period-cohort model. Further, AP refers to the sub-model where the common predictor is an unrestricted APC model where the cross-sample difference is an AP model, so that the non-linear cohort effect is restricted to be common for women and men, while all other effects are unrestricted.
Two-sample analysis of variance.
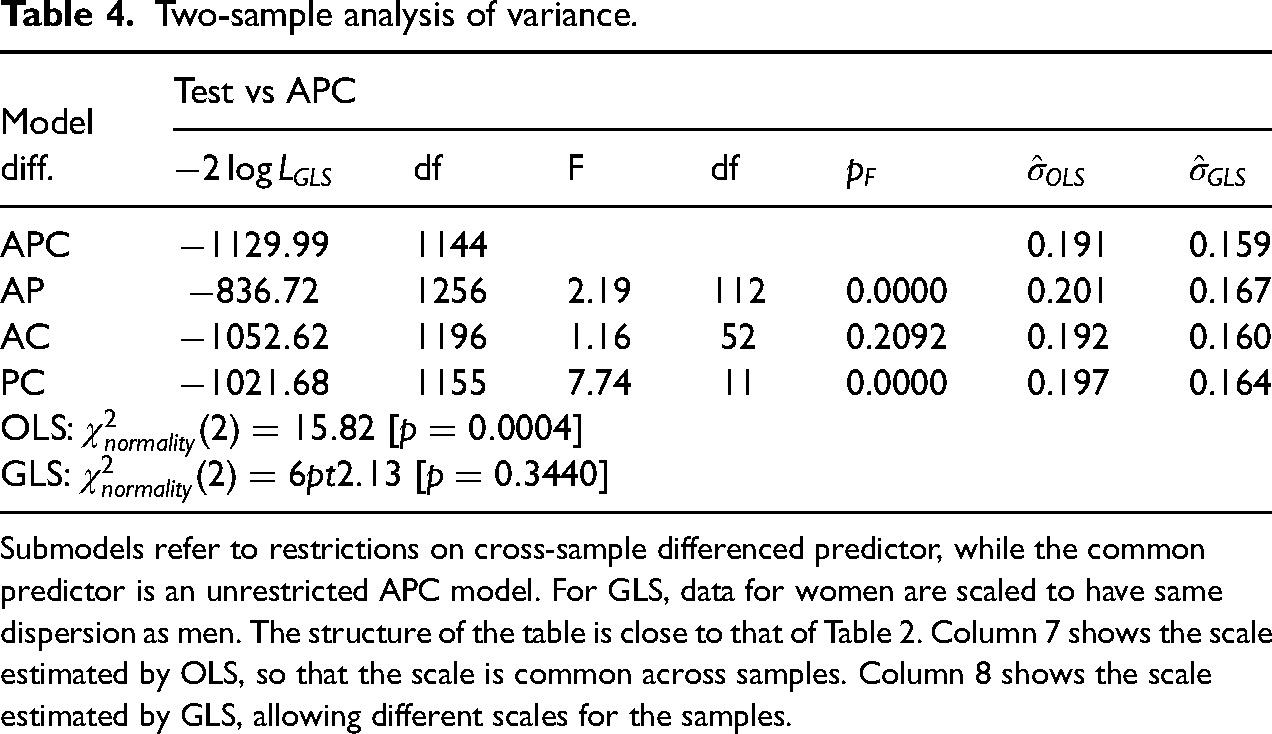
Submodels refer to restrictions on cross-sample differenced predictor, while the common predictor is an unrestricted APC model. For GLS, data for women are scaled to have same dispersion as men. The structure of the table is close to that of Table 2. Column 7 shows the scale estimated by OLS, so that the scale is common across samples. Column 8 shows the scale estimated by GLS, allowing different scales for the samples.
Inference relies on asymptotic arguments. We must specify the assumptions underlying the asymptotics. One approach is to let the size of the data array and therefore the size of the parameter vector increase as in Fu (2016). Another approach is to use small-dispersion asymptotics, where the size of the data array is kept fixed while the scale, or dispersion, parameters are shrinking in the asymptotic experiment. The second approach seems particular useful here as the dose, or exposure, is large. The dose is the entire Swiss population of the relevant age and gender. It is in the order of 100,000 for each cell. With the second approach it is possible to justify use of F distributions as limiting distributions. Formal analysis is given by Jørgensen (1987) in the context of exponential dispersion models whereas Harnau and Nielsen (2018) develop a Central Limit Theorem for this situation. Both setups allow log normal distribution, but the latter has some flexibility in allowing approximate log normal distributions and some types of over-dispersed Poisson models. The implementation in Kuang and Nielsen (2020) is suited for the present situation. Thus, the idea of the asymptotic experiment is that log suicide rates converge to constant parameters for large values of the dose appearing as denominator of the rates. Convergence of the rates to constant parameters corresponds to a shrinking dispersion. More specifically, we apply a log normal model where we hold fixed the dimension of the index array, the canonical age-period-cohort parameter, and the ratio of the scales in the samples, while the scale parameters shrink in the asymptotic experiment.
The common variance assumption can be tested by comparing the least squares log likelihoods for the APC model in Table 4 and in Tables 2 and 3 to get the Bartlett test statistic (Harnau 2018; Kuang and Nielsen 2020). The test statistic is
We now consider the restrictions on the age-period-cohort structure for the differenced predictor. The F-statistics for the three sub-models considered in Table 4, turn out to be exactly identical when estimating by ordinary least squares and by generalized least squares. This is a consequence of the particular block structure of the design and covariance matrices and can be checked through a somewhat detailed derivation. However, given the difference in dispersion for women and men, we must apply the F-statistics under the generalized least squares setup. In that case the F-statistics are asymptotically F-distributed under the small-dispersion setup. Thus, from Table 4 we learn that we can reduced the model for the cross-sample differenced predictor to an age-cohort model, whereas the age-period and period-cohort models are strongly rejected. The interpretation of the age-cohort model is that the period effect is common across samples. This matches conclusions by Riebler et al. (2012).
Plots of Macro Time Effects
Plots of the time effects will give us more insight in the age-period-cohort variation in suicide rates. In the present mixed frequency situation, we start with the macro effects, where interpretations are strongest. The macro effects are affected by arbitrary linear trends in the same ways as for regular data. Thus, the graphs will be detrended to minimize the confusion over the arbitrary linear trends.
Figure 2 shows macro time effects deduced from the initial one-sample age-period-cohort models, discussed in §5.1. The reason for showing the one-sample plots as opposed to the plots in models with cross-sample restrictions imposed is as follow. In the empirical analysis one will start by looking at the one-sample plots to gain insight into the data and the model. This then motivates the choice of testable cross-sample restrictions. By using the invariant parametrization, estimates of the remaining parameters should not change very much as long as the restrictions are statistically valid. Above, it has been discussed whether to replace the cross-sample period effect with an external time series or to remove it entirely. Each will give a slight variation in the plots. This variation seems less interesting than the formal tests that were carried out above.
On the left, effects are shown for each sample. On the right, the cross-sample differences are shown. Solid lines are estimates, dotted lines are
The plots are constructed as follows. We start by computing the non-linear effects
The actual computation of the effects
Detrending serves three purposes. First, to emphasize non-linearity, which is the only part of the time effects that is invariant to the identification problem. Second, to disentangle the plots, so that they can be viewed separately. Indeed, with fewer constraints the plots are linked inextricably and must be viewed jointly (Carstensen 2007). Third, to ensure that the degrees of freedom shown in the plot matches the degrees of freedom associated with the time effects. Detrending can be done in various ways. Here, time effects are restricted to be zero at the beginning and at the end. There is no estimation uncertainty at those two points and the degrees of fredom can be appreciated. One can then focus on the shapes in the pictures, such as skew concave shapes for age and S-shape for period. Chauvel and Schröder (2014) suggest to set the averaged time effect to zero and then eliminate the time trend. This achieves the first two objectives above.
Figure 2, first row, shows the two detrended age effects. We will look for global and local peaks and the general shape of the age effects. Peaks indicate ages at which there is a relative acceleration in the prevalence of suicide. With the two-sample analysis we can get an insight into how these peaks differ for women and men. The non-linear age effects should come more clearly out in Figure 2 than in the raw data plots in Figure 1, where age effects are contaminated by period-cohort effects. With aggregate data one will of course only be able to conclude that one should seek to understand why these peaks arise using other sources of information.
The one-sample detrended age effects first rise considerably. This corresponds to a relatively large increase in suicide rates for people in their twenties. The curves then decline gradually corresponding to relative declines in rates. There are small local peaks around the age of 50 and for men also at age 75. The age-effects are significant for both men and women in line with the individual tests for the period-cohort models in Tables 2 and 3. The plot on the right shows the (women-men) difference of the age trends. This is also significantly different from zero in line with the rejection of the PC model in Table 4.
Figure 2, second row, shows detrended macro period effects, detrended to start and end in zero. Once again, we see that the period effects are individually significant, although somewhat less than for ages, in line with the tests for the age-cohort models reported in Tables 2 and 3. The difference plot indicates that the period-trends follow each other in line with the non-rejectance of the AC model in Table 4.
Figure 2, third row, shows detrended cohort macro effects. Again, restricted to start and end in zero. Overall, the individual cohort effects are less significant than age and period effects – compare with the age-period tests in Tables 2 and 3. The cohort effects are somewhat different across samples in line with Table 4.
The plots of the detrended age and cohort macro effects resemble the plots in Figure 5 of Riebler et al. (2012). Two features of the original plots are worth pointing out. First, macro detrending and micro demeaning was not applied in the age plots, so the reader will have to do an occular adjustment to interpret the plots correctly. Second, the cohorts were smoothed over macro and micro effects, which are subject to the transformations in (26).
Plots of Micro Time Effects
We now consider plots of the micro effects. The micro effects are affected by arbitrary levels, but not not by linear trends.
Figure 3 shows demeaned micro effects. Micro effects only occur for the period and cohort effects as
We construct the micro effects along the principles for constructing the macro effects. For period micro effects for
We observe seasonal patterns as discussed in §4.2.1 and by previous authors including Holford (2006), Riebler and Held (2010). We note that the seasonal pattern is nearly constant over time for the cohort effects, but changing somewhat over time for the period effects and in particular for women. It is possible that seasonal patters mainly generated by estimation error or model error, see §4.2.1. Indeed, the vertical variation within each macro block is modest relative to the shown confidence bands.
Replacing the Period Effect with an External Time Series
We now investigate if the period effect can be replaced by an external time series. Following Riebler et al. (2012), we consider a family integration index computed as
The hypothesis that the period effect follows the F-index only concerns the non-linear parts, see Section ‘Replacing period effect with time series’. Thus, we implement the restriction by substituting the double differences of the period effect with those of the F-index. Table 5 gives an analysis of variance. Here, the common predictor and the cross-sample differenced predictor are restricted either individually or jointly. The first model has an age-period-cohort structure for both predictors. The third model has an age-cohort structure for the cross-sample differenced predictor. The second model sits in between the two models and allows a period effect following the F-index for the cross-sample differenced predictor.
Two-sample analysis of variance.
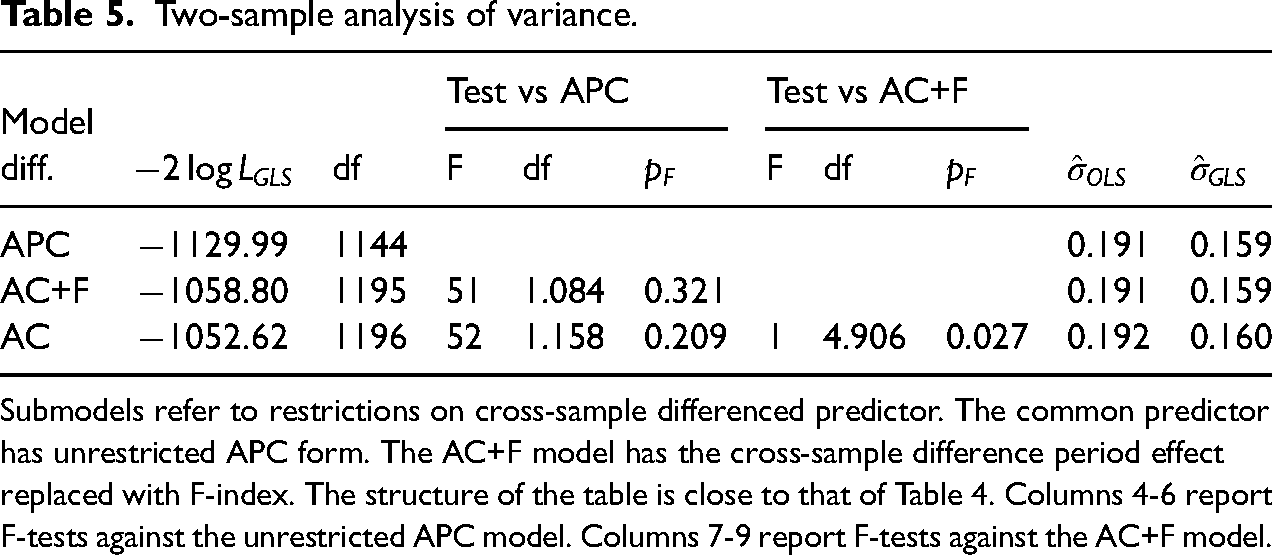
Submodels refer to restrictions on cross-sample differenced predictor. The common predictor has unrestricted APC form. The AC+F model has the cross-sample difference period effect replaced with F-index. The structure of the table is close to that of Table 4. Columns 4-6 report F-tests against the unrestricted APC model. Columns 7-9 report F-tests against the AC+F model.
The conclusion from the table is that we cannot reject replacing the period effect of the cross-sample differenced parameter with the F-index. Eliminating the F-index from that model to get an age-cohort structure adds another degree of freedom. The relevant F-statistic is 4.906 with p-value 2.7%, which gives a marginal decision. Thus, there is slight evidence that it is better to replace the period effect in the difference parameter with the F-index than eliminating it all together. The coefficient
Conclusions
We considered the linear two-sample age-period-cohort model. The main contribution is the analysis of the two-sample age-period-cohort problem for regular and for mixed frequency data. The age-period-cohort predictors are linear combinations of different time effects as in (4). The age, period and cohort time scales are linked through the identity (2) which leads to the age-period-cohort problem that the linear parts of the age, period and cohort effects can be altered by moving arbitrary linear trends between age, period and cohort effects. For regular data, this is described by the transformation identity (6). There are two aspects to the age-period-cohort problem: identification and invariance.
The identification problem is essentially a collinearity problem, where parameters cannot be estimated uniquely. A common approach is to remove the collinearity by imposing sufficiently many restrictions on the design matrix. However, this will in general not solve the invariance problem.
The invariance problem relates to interpretation. Two investigators may solve the identification problem by imposing different restrictions on the design matrix. They will then find different linear parts of the estimated age, period and cohort effects. The solution is to focus on parameters that are invariant to the pernicuous linear trend manipulations. This argument goes back to Fienberg and Mason (1979). The contribution of this paper is to extend this to a characterization of all invariant parameters and reparametrize the model exclusively in terms of the invariant parameter (15). This removes the age-period-cohort problem as in the one-sample analyses by Kuang et al. (2008) and Martínez Miranda et al. (2015).
The consequence of the analysis is that all interpretation and inference should be based on the non-linear parts of the age, period and cohort effects or the combination of their linear parts. In contrast, one cannot learn about the individual linear effects from the data. As an example, in the context of two samples for women and for men, the non-linear period effects are interpretable for each sample, whereas the linear period effects are not. One can compare the period effects across samples and one may impose a restriction of common period effects across samples. Even so, all individual linear effects remain sensitive to transformations by arbitrary linear terms. In the extreme case where the predictor is restricted to zero across age, period and sample, the linear age, period and cohort effects remain illusive due to the transformation identity (6).
Graphical representation of the age, period and cohort effects brings the age-period-cohort problem back. It is important to remember that such graphs can be altered arbitrarily due to the transformations in (6). Thus one should focus on deviation from linearity rather than linear trends. This can be done by detrending the age, period and cohort effects separately. Here, we detrended by ensuring that each of the (macro) graphs start and end in zero, so that one can focus on shapes instead of slopes.
The two-sample model could be appealing in many sociological studies. In the suicide example, the initial analysis was to apply standard one-sample age-period-cohort analysis to each of the two sample for women and for men. By graphical inspection one got the impression that the period effects are similar. This was tested formally using a two-sample analysis. These ideas will be relevant in many sociological contexts, where investigators have hitherto conducted separate one-sample analyses without being able to test cross sample restrictions. The outcomes could be crime rates, attitudes, social mobility, obesity, fertility or mortality. The stratification could be done by sex, racial group, parental social class or country.
Some studies use more than two samples. Jacobsen et al. (2004) compared female mortality in Danmark, Norway and Sweden. Held and Riebler (2012) analyzed chronic obstructive pulmonary disease mortality for England and Wales stratified by sex and by three regions. Rosenberg and Miranda-Filho (2024) considered cancer surveillance for many US samples. The transformation identity (6) and the invariant parameter (15) generalize to situations where the sample index
A feature of the presented analysis is that it focuses on the parametrization. The results can therefore be transferred to a wide range of statistical models. In the suicide example, the chosen model was a log-normal model combined with the small-dispersion inference (Harnau and Nielsen 2018). For other types of data the invariant parametrization could be embedded in a Poisson regression, where over-dispersion may be handled by the small-dispersion idea, or perhaps a Binomial regression. If the data consists of repeated cross-sections, one could make a two-sample version of the model in Fannon et al. (2021). Some comments on Bayesian implementation are given in Appendix A.4 in the online Supplemental Material.
The presented analysis of the two-sample age-period-cohort problem was extended to mixed frequency data. The transformation identity (26) is then more complicated and results in macro and micro effects as described by Holford (2006) and the invariant parameter has the more complicated expression (15). A hypothesis of common non-linear effects across samples is tested by a linear restriction on the parameters. Graphs of the macro effects are interpretable in a similar fashion as for regular data. In the suicide example, the interpretation of the micro effects was less clear. Future analysis of other data may bring some light on the interpretation of micro effects.
To conclude all interpretation and inference should rest exclusively on the non-linear age, period and cohort effects and on the combined linear plane(s). With the invariant parametrization, the practitioner can focus on just this with the benefit of only have to use standard regression techniques.
Supplemental Material
sj-pdf-1-smr-10.1177_00491241251376509 - Supplemental material for Two-sample Age-period-cohort Models
Supplemental material, sj-pdf-1-smr-10.1177_00491241251376509 for Two-sample Age-period-cohort Models by Bent Nielsen in Sociological Methods & Research
Supplemental Material
sj-pdf-2-smr-10.1177_00491241251376509 - Supplemental material for Two-sample Age-period-cohort Models
Supplemental material, sj-pdf-2-smr-10.1177_00491241251376509 for Two-sample Age-period-cohort Models by Bent Nielsen in Sociological Methods & Research
Footnotes
Declaration of Conflicting Interest
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by ERC grant DisCont 694262.
Preregistration Statement
The data were publically available prior to the study and not preregistered.
Data and Code Availability Statement
The analysis used the R package apc version 3.0.0 from https://CRAN.R-project.org/package=apc, see (Nielsen 2015). The package includes the Swiss data. A vignette with details of the code is available as supplementary material.
Author Biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.