
Abstract
Over the past decade there has been a striking increase in the number of quantitative studies examining the effects of social mobility, with almost all based on the diagonal reference model (DRM). We make four main contributions to this rapidly expanding literature. First, we show that under plausible values of mobility effects, the DRM will, in many cases, implicitly force the underlying mobility linear effect toward zero. In addition, we show both mathematically and through simulations that the mobility effects estimated by the DRM are sensitive to the size and sign of the origin and destination linear effects, often in ways that are unlikely to be intuitive to applied researchers. This finding clarifies why, contrary to expectations, applied researchers have generally found mixed evidence of mobility effects. Second, we generalize the identification problem of conventional mobility effect models by showing that the DRM and related methods can be viewed as special cases of a bounding analysis, where identification is achieved by invoking extremely strong assumptions. Finally, and importantly, we present a new framework for the analysis of mobility tables based on the identification and estimation of joint parameter sets, introducing what we call the structural and dynamic inequality model. We show that this model is fully identified, relies on much weaker assumptions than conventional models of mobility effects, and can be treated both as a descriptive model and, if additional assumptions are invoked, as a causal model. We conclude with an agenda for further research on the consequences of socioeconomic mobility.
Introduction
Interest in the consequences of social mobility (SM) is longstanding (for reviews see Hendrickx et al. 1993; Hope 1971, 1975). From its earliest days, the scientific literature on SM, or the experience of moving up or down the class hierarchy of a given society, has debated its individual-level effects. For example, the sociologist Pitirim Sorokin (1927) hypothesized negative effects of not just downward but also upward SM on individual wellbeing, as those who reach a status different from that of their parents may suffer from the cultural gap between their attained position and their family origins (see also Friedman 2016). Nearly a century later, there is a large body of quantitative sociological research that has sought to estimate the direct effects of the experience of SM on a wide range of individual outcomes, including well-being (e.g., life satisfaction, stress, allostatic load, and substance abuse), attitudes (e.g., trust, political ideology, and redistribution preferences), and behaviors (e.g., voting, fertility, and health behaviors) (see also Appendix A, supplemental materials). The inconsistent (and often small) mobility effects that this literature has estimated appear to refute longstanding sociological theory and present a general challenge to much of the work on SM undertaken by sociologists. Since the influential work of Lipset and Bendix (1959), researchers have carried out a number of important and widely cited studies exploring differences in rates of SM across and within countries (e.g., Bloome 2015; Chetty et al. 2014; Erikson and Goldthorpe 1992; Grusky and Hauser 1984). To the extent that a high degree of social fluidity is considered a normatively desirable aim (for a critical perspective see Swift 2004), these studies provide important descriptive evidence on the degree of openness of a given society or place. However, as Lipset and Zetterberg (1959) pointed out, “unless variations in mobility rates and in the subjective experience of mobility make a difference for society or for the behavior pattern of an individual, knowledge concerning rates of mobility will be of purely academic interest” (p. 6). Based on today’s quantitative evidence, it would seem that generations of sociologists and demographers have been trying to explain an outcome that is, on the whole, of little consequence to the individual.
Progress in empirically identifying the effects of SM on individuals has been hampered by a fundamental methodological challenge. Observed SM (M) is simply the difference between an individual’s social destination (D), such as their own social class, and their social origin (O), such as their parents’ social class, so that
To estimate such effects, a variety of techniques have been proposed, but the most popular approaches are those developed by the sociologists Otis Dudley Duncan (1966) and Michael Sobel (1981, 1985). A first wave of research, influenced by Duncan's (1966) square additive model (SAM), a basic two-factor origin-destination model with residual interaction terms, found no effect of SM on a number of outcomes (see also Hope 1971, 1975). This is partly explained by the fact that Duncan’s proposed model assumes that the linear effect of mobility is zero, as was recognized by at least some social scientists at the time (Blalock 1967:794-795). Another wave of research resulted from Sobel’s (1981, 1985) diagonal reference model (DRM), 1 which is seen as the “gold standard” for mobility effects research (Houle and Martin 2011:197; Präg and Richards 2018:5; Sieben 2017). The statistician Sir David Cox (1990), for example, has lauded the DRM as an exemplar of “directly substantive” models in statistical analysis (p. 170). In recent years, sociologists have used Sobel’s model to explain a wide range of outcomes, including subjective well-being, political extremism, obesity, and so on (the list is too long to include here but see Appendix A, supplemental materials). However, as we show, like Duncan’s model, the DRM relies on very strong assumptions about the effects of SM.
This article is organized as follows. First, we outline the identification challenge, clarifying what can be known about the data from a mobility table with as few assumptions as possible. We make explicit how, under a general model of mobility effects, the nonlinear effects are identified and the linear effects are not. Second, we discuss the mathematical properties of the DRM, revealing that the DRM generates different mobility linear effects depending on both the size and sign of the linear and nonlinear effects of origin and destination. In doing so, we revisit Sobel’s (1981) findings on fertility and show that his data are consistent with a wide range of very large negative as well as positive linear mobility effects, none of which are recovered by the DRM. Third, we generalize models of mobility effects, showing how any existing mobility model that attempts to identify unique “effects” can be viewed as a special case of a bounding approach, except with extremely narrow bounds and thus extremely strong assumptions. Finally, we outline a new framework for analyzing mobility data using what we call the structural and dynamic inequality (SDI) model. Using this model, we demonstrate how one can describe both dynamic (or mobility-based) inequalities as well as those that are purely structural (reflecting an absence of SM). As we discuss, these estimates can also be interpreted as joint causal effects, and, therefore, involve much weaker assumptions than estimates from conventional models of mobility effects. We conclude with a programmatic statement outlining guidelines for further research on the individual-level consequences of SM.
The DRM
As noted in the introduction, by far the most common approach to model mobility effects is the DRM developed by the sociologist Michael Sobel (1981, 1985). This popularity is indicated by the spike in recent works using the DRM to estimate mobility effects, as shown in Figure 1. It is also demonstrated by the widespread agreement in the literature on the importance and utility of the DRM for understanding the consequences of SM. For instance, Houle and Martin (2011:197) note, the DRM is “the only method used in modern mobility effects research.” Likewise, Sieben (2017) writes that DRMs “are thought to be the best solution to [the identification] problem.” Präg and Richards (2018:5) echo this claim, correctly stating: “A consensus is emerging in the literature that the diagonal reference model is superior to other modeling approaches and results based on other approaches are questionable at best.”
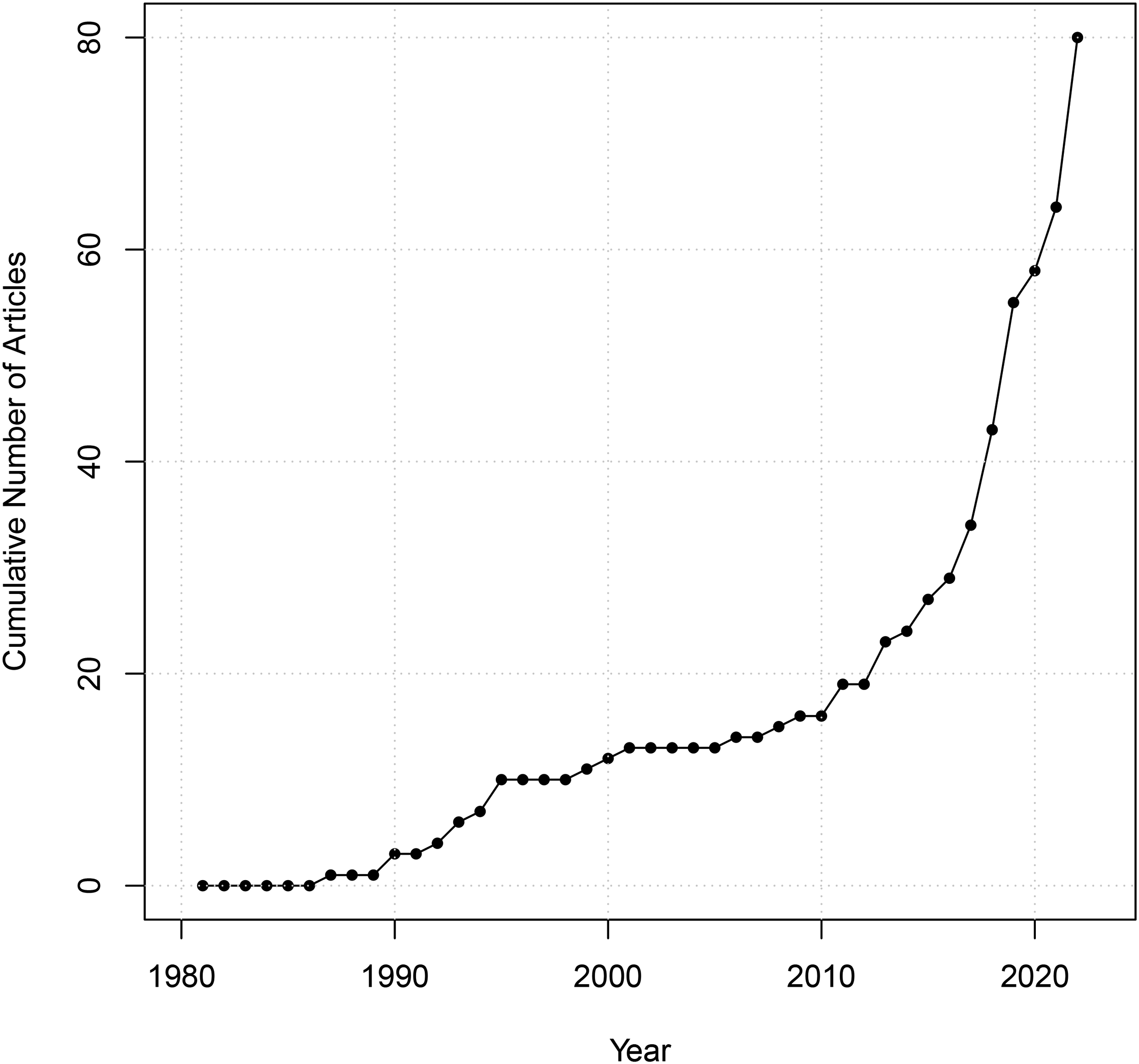
The rise of the diagonal reference model (DRM). Note: This line plot shows, by year, the cumulative number of articles using the DRM since Sobel’s (1981) publication. Appendix A, supplemental materials, contains the full list of publications that make up the data for this graph.
There is similarly widespread agreement that the DRM is effective in separating out the effects of mobility from those of origin and destination. For example, Schuck and Steiber (2018:1249) write that the DRM “tests for the net effects of intergenerational mobility over and above the effects of educational origin and destination, finally allowing mobility effects to be separated from mere level effects [emphasis in original].” Unfortunately, however, the DRM relies on extremely strong assumptions and, absent additional information external to the data, there is no reason to think that the model will actually recover the “true” underlying effect of mobility.
In this section, we first outline the basic mathematical properties of the DRM. As we illustrate, the DRM assumes that the origin and destination effects are proportional to each other, and thus we will refer to this assumption as the “proportionality constraint” (see also Weakliem 1992:157). Failure to satisfy this constraint may lead to erroneous estimates of the overall effects of origin, destination, and mobility. This is true of the linear effects, but also of the nonlinear effects, which, as noted above, are identified. 2 Second, we revisit Sobel’s (1981) fertility data and show, mathematically and with simulations, that the DRM will fix the mobility linear effect at a very specific value even when the underlying mobility linear effect is extremely positive or negative. This is another way of stating that the proportionality constraint may hold for the nonlinear effects, but still not hold for the linear effects. Unfortunately, the data are not themselves informative about whether or not this constraint is satisfied. Finally, we develop a simple formula that, when the proportionality constraint is satisfied, clarifies the nature of the bias of the estimated mobility linear effect. As we show, the mobility linear effect generated by DRM is a function of the size, sign, and shape of the origin and destination effects. It is only under very specific conditions, namely when the ratio of the origin and destination weights equals the ratio of the underlying origin and destination linear effects, that the DRM will recover the true underlying mobility linear effect.
To orient the discussion that follows, suppose we have a set of categorical variables for
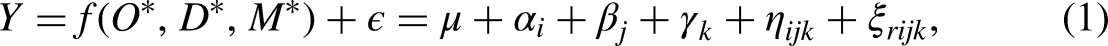
where
An alternative formulation of the C-ODM model (see equation (1)) helps clarify the nature of the identification problem. By orthogonalizing the linear from the nonlinear terms, we can specify what we call the linearized origin–destination–mobility (L-ODM) model:
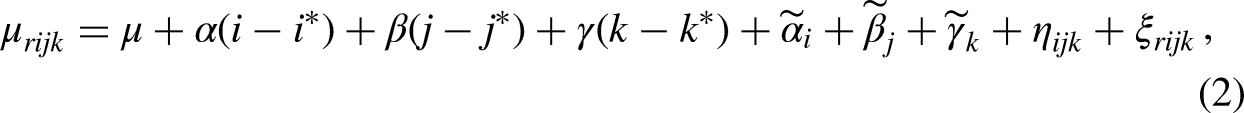
The L-ODM highlights that the core identification challenge resides in the linear effects (

Suppose we have a data set based on aggregated data from a mobility table with rows indexed by
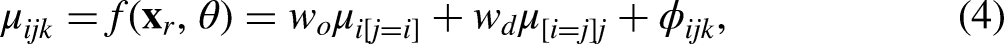
with
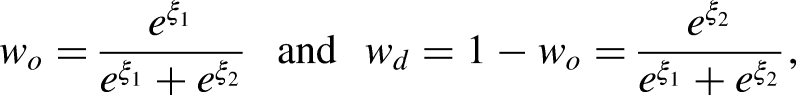
Above the baseline model, mobility effects can be parameterized as a set of categorical variables:
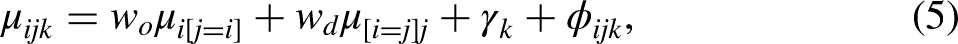
The DRM as outlined in equation (5) and applied to a three-by-three mobility table is shown in Table 1. The joint origin and destination effects for the cells on the main diagonal, representing non-mobile groups, are given by the estimates of
Diagonal Reference Model on a

Note: Number of origin and destination groups is set at I = 3 and J = 3. The diagonal reference model (DRM) is given generically by
To understand the underlying mathematical properties of the DRM, it is useful to describe the weights needed to recover the underlying origin, destination, and mobility effects.
7
The true means on the main diagonal after adjusting for the mobility effects can be written as (cf. equation (2)):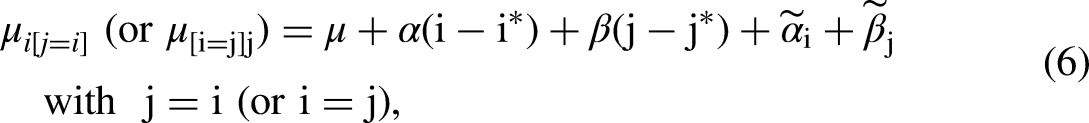
The weight required to recover the true contribution of the ith origin effect is as follows: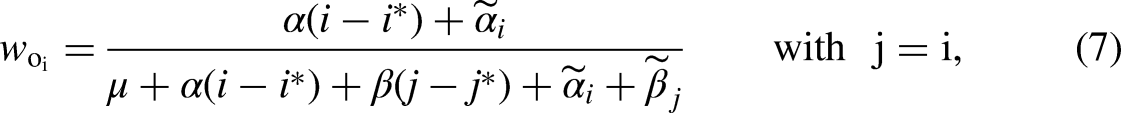
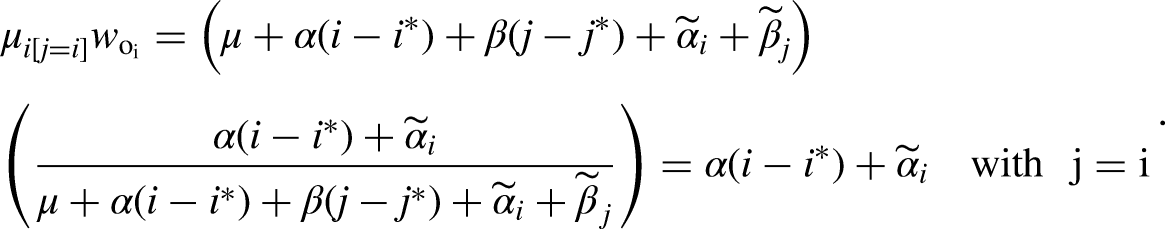
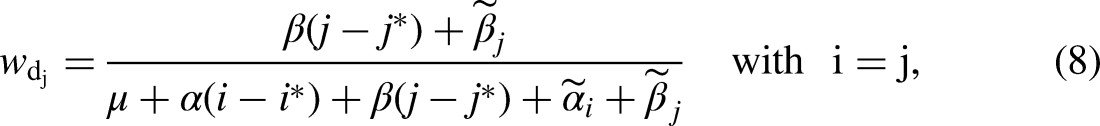
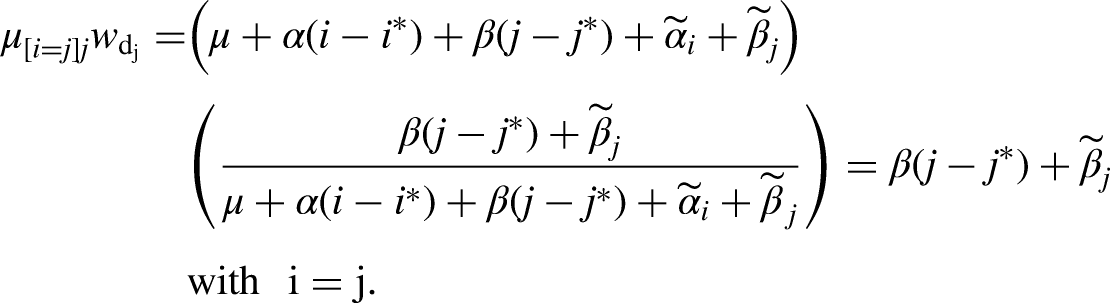
Crucially, the weights in equations (7) and (8) are unknown, because they require knowledge of the unidentified origin and destination linear effects. Note further that the weights are allowed to vary across class and destination origins, respectively, and there is no restriction that the weights sum to one (or some other value).
By contrast, the DRM’s proportionality constraint means that we assume that the origin and destination effects can be characterized by a single origin weight (or, equivalently, destination weight). In essence, the DRM attempts to recover the true origin and destination effects (and, accordingly, the true mobility effects) by splitting the main diagonal cells of a mobility table into origin and destination components. More specifically, the proportionality constraint assumes that the relative contributions of the linear and nonlinear origin effects with 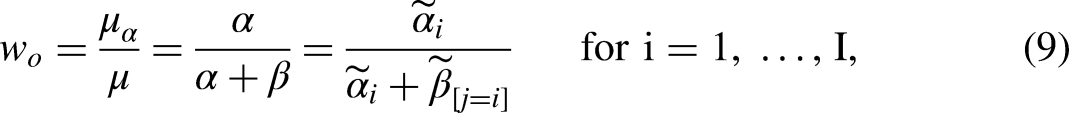
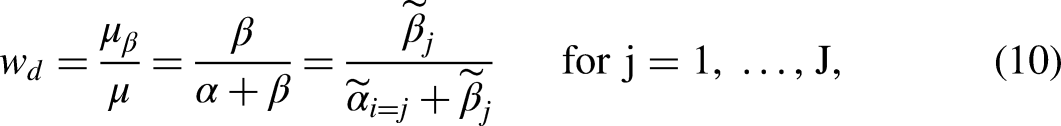
Assuming the proportionality constraint defined in equations (9)–(10) holds, multiplying the main digaonal cells in equation (6) by the origin weight w
o
yields the following set of origin effects: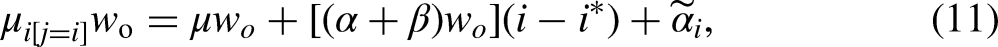
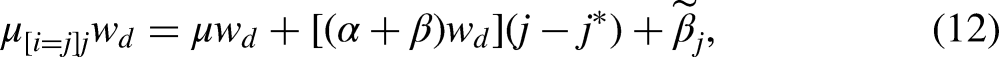
Under the proportionality constraint outlined in equations (9)–(10), simple formulas for calculating the origin, destination, and mobility linear effects can be derived. Specifically, the origin linear effect generated by the DRM is
With actual data, the origin and destination weights estimated by the DRM (i.e.,
The above suggests a procedure for at least partially testing the plausibility of the proportionality constraint against the data. By fitting the L-ODM under a constraint, such as a zero destination linear effect, we can obtain a set of estimates of the underlying overall nonlinear effects of origin, destination, and mobility. We can then compare these nonlinear effects with those estimated by the DRM. If these are discrepant, then this suggests that the DRM is inappropriate, inasmuch it fails to recover the actual nonlinear effects. Alternatively, we can test whether or not the relative ratios of the origin and destination nonlinear effects are the same, as required by the DRM’s proportionality constraint (see equations (9) and (10)). For example, we can examine whether or not the ratio of the first origin nonlinear effect to the sum of the first origin and destination nonlinear effects is the same as the ratio of the second origin nonlinear effect to the sum of the second origin and destination nonlinear effects. If these ratios are the same, then this lends indirect support for the plausibility of the proportionality constraint. However, as we show below, even when the proportionality constraint holds with respect to the nonlinear effects, there is no guarantee that the DRM will recover the underlying mobility linear effect.
In this section, we re-examine Sobel’s (1981) findings on fertility using the DRM. We show that, even though the DRM assumes that there are virtually no mobility linear effects, the data are consistent with very large negative and positive linear effects. Sobel’s original data on fertility is shown in Table 2. The outcome is the average number of children ever born by father’s occupation (origin) and husband’s 1962 occupation (destination) among wives aged 42–61 years in March 1962 who were currently living with their husband in the Occupational Changes in a Generation (OCG) sample. The total sample size is
Sobel (1981) Fertility Data.
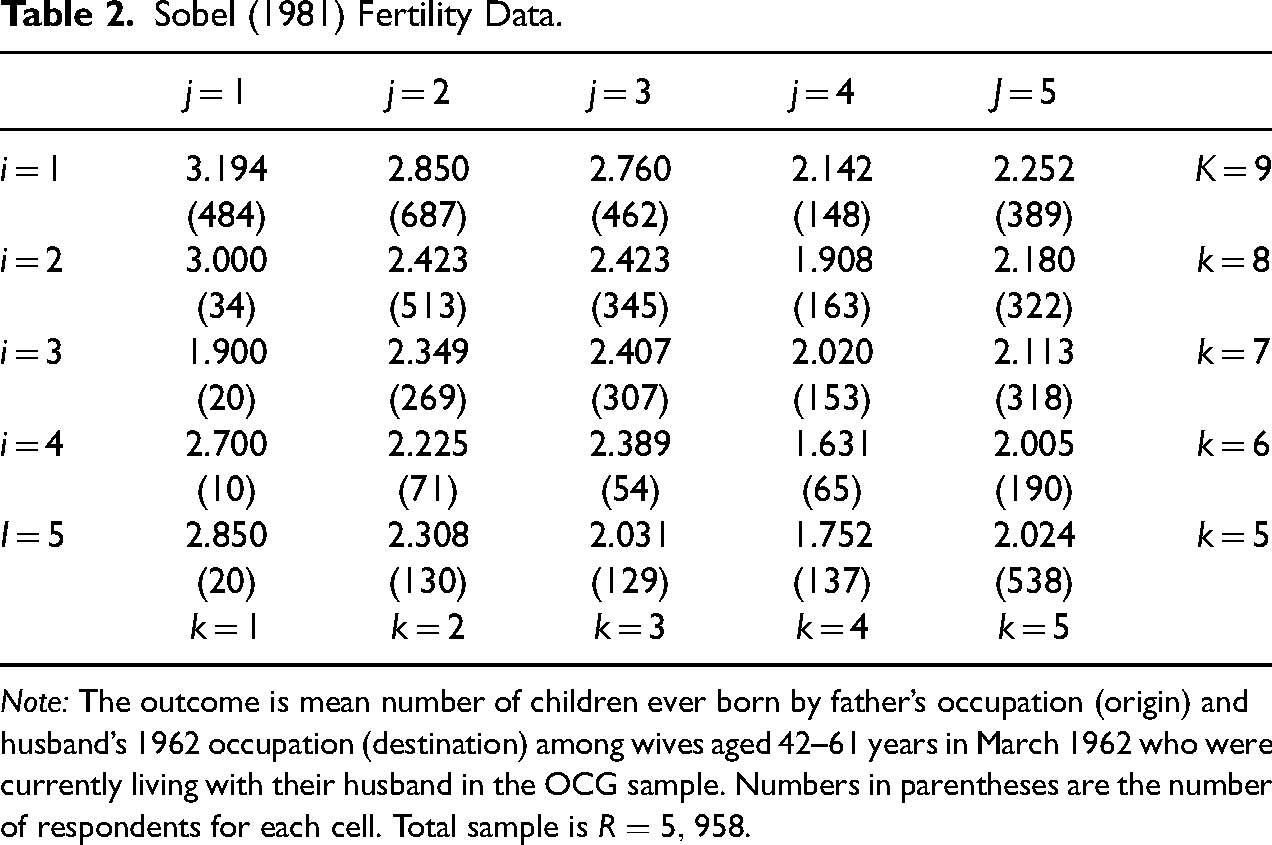
Sobel (1981) Fertility Data.
Note: The outcome is mean number of children ever born by father’s occupation (origin) and husband’s 1962 occupation (destination) among wives aged 42–61 years in March 1962 who were currently living with their husband in the OCG sample. Numbers in parentheses are the number of respondents for each cell. Total sample is
We first examine the plausibility of the proportionality constraint assumed by the DRM in the case of Sobel’s fertility data. As noted in the previous section, this can be partially tested against the data because the nonlinear effects are identified. We first fit the L-ODM model by fixing the destination slope to zero, which allows us to estimate the nonlinear effects. These estimates, which are expressed as coefficients for orthogonal polynomials,
12
are then converted to deviations from the grand (or overall) mean. We next fit the DRM and converted the estimated origin and destination effects into deviations orthogonal to their respective overall levels and linear components.
13
Finally, for both models we calculated the estimated relative contributions of the origin and destination nonlinear effects. Specifically, for each model and for each of the origin nonlinear effects we calculated
Table 3 highlights the main findings with respect to our evaluation of the validity of the proportionality constraint. First, the nonlinear effects for origin and destination differ between the DRM and L-ODM model, in some cases substantially. On balance, however, in all cases but one the direction of the nonlinear effects is correctly captured by the DRM. Second, as shown in the second row of Table 3, with the DRM all of the ratios are the same for the origin and destination nonlinear effects. This reflects the fact that the estimated origin and destination weights for the DRM are
Comparing Nonlinear Effects Using Data From Sobel (1981).
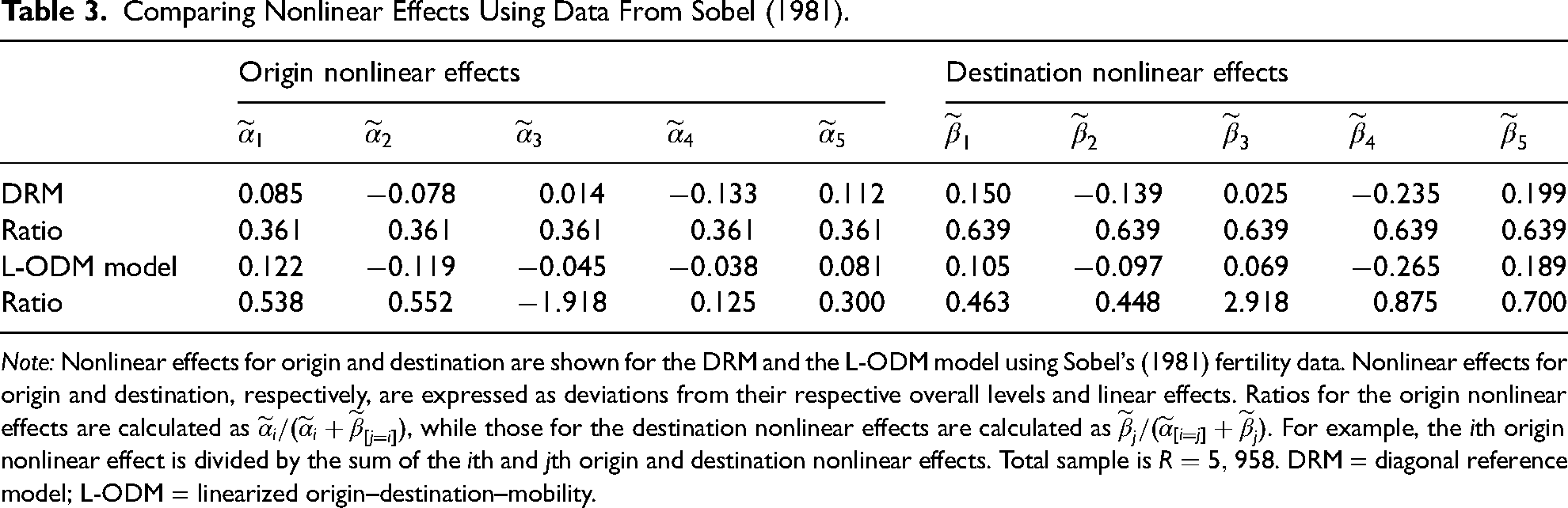
Note: Nonlinear effects for origin and destination are shown for the DRM and the L-ODM model using Sobel’s (1981) fertility data. Nonlinear effects for origin and destination, respectively, are expressed as deviations from their respective overall levels and linear effects. Ratios for the origin nonlinear effects are calculated as
An additional issue is that even when the proportionality constraint of the nonlinear effects is valid, the DRM can generate highly biased estimates of the underlying mobility linear effect. This is the case even if the underlying mobility linear effect is extremely large. To show this, we conduct simulations based on the DRM and fertility data. Specifically, we fit the DRM and calculate the underlying estimated coefficients as linear and nonlinear effects, similar to the L-ODM. Then we use these to set up the data generating parameters (DGPs) in the simulations. Specifically, we first fix the origin, destination, and mobility linear effects to the values assumed by the DRM, which are
The results from the simulations based on Sobel’s data are shown in Table 4. The table reveals that the DRM fixes the mobility linear effect to a particular value,
Biased Mobility Linear Effects Using the DRM.
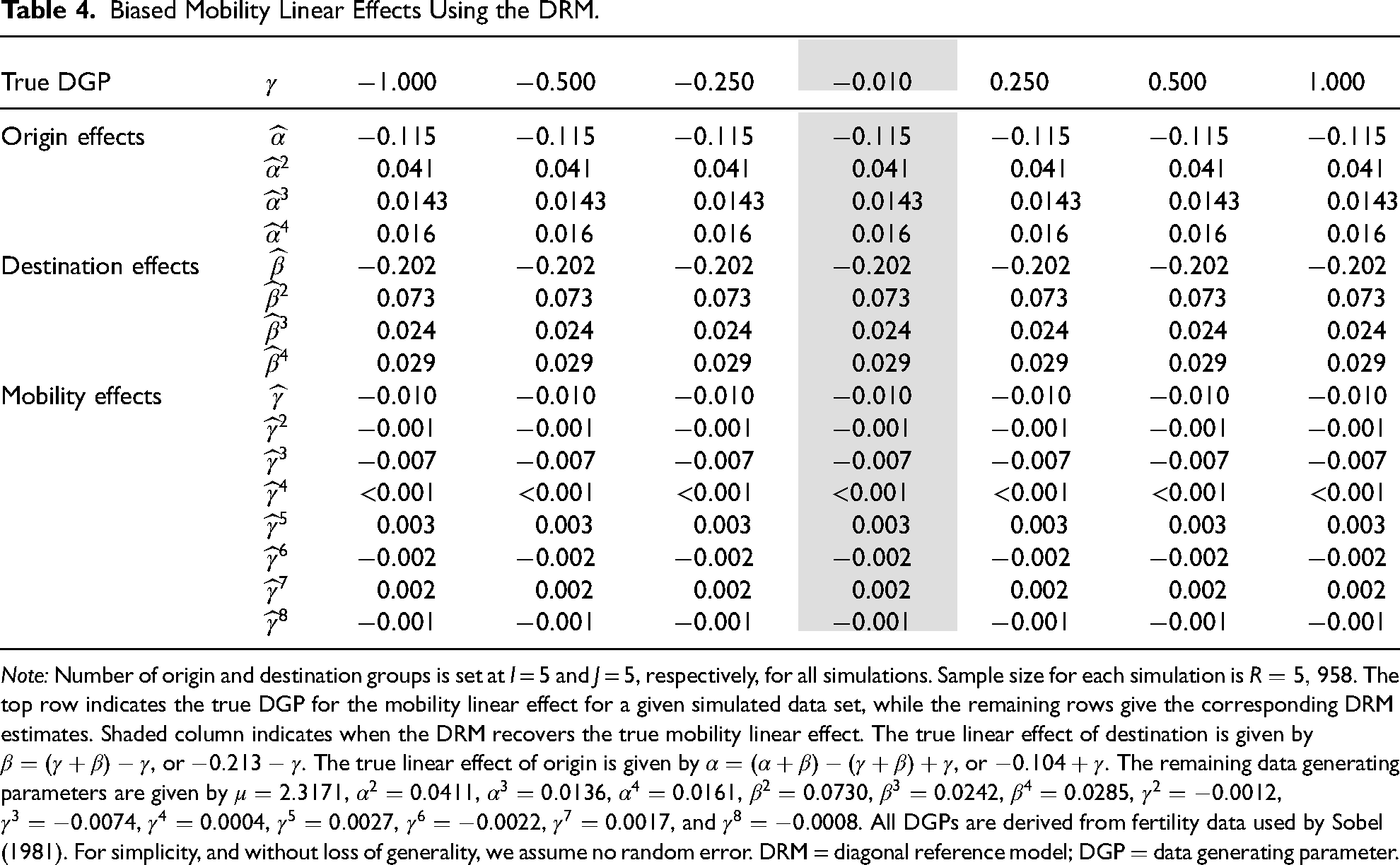
Note: Number of origin and destination groups is set at I = 5 and J = 5, respectively, for all simulations. Sample size for each simulation is
In the previous example, why does the DRM fix the mobility slope to nearly zero even when the mobility linear effect is quite large? When the underlying nonlinear effects obey the proportionality constraint, the nature of the bias from the DRM can be expressed as a mathematical function of the estimated weights. Specifically, assuming the true nonlinear effects conform to the proportionality constraint (see equations (9) and (10)), the bias in the DRM’s estimated mobility linear effect can be written as follows
15
: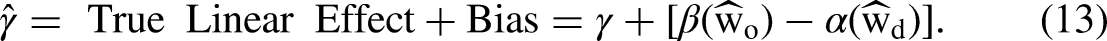
To illustrate the sensitivity of the DRM, we show the bias in the mobility linear effect across different values of the true origin and destination linear effects. In these simulations, we set the nonlinear effects to zero, so the DRM’s underlying origin and destination weights are
Sensitivity of Estimated Mobility Linear Effect to Values of True Origin and Destination Linear Effects.
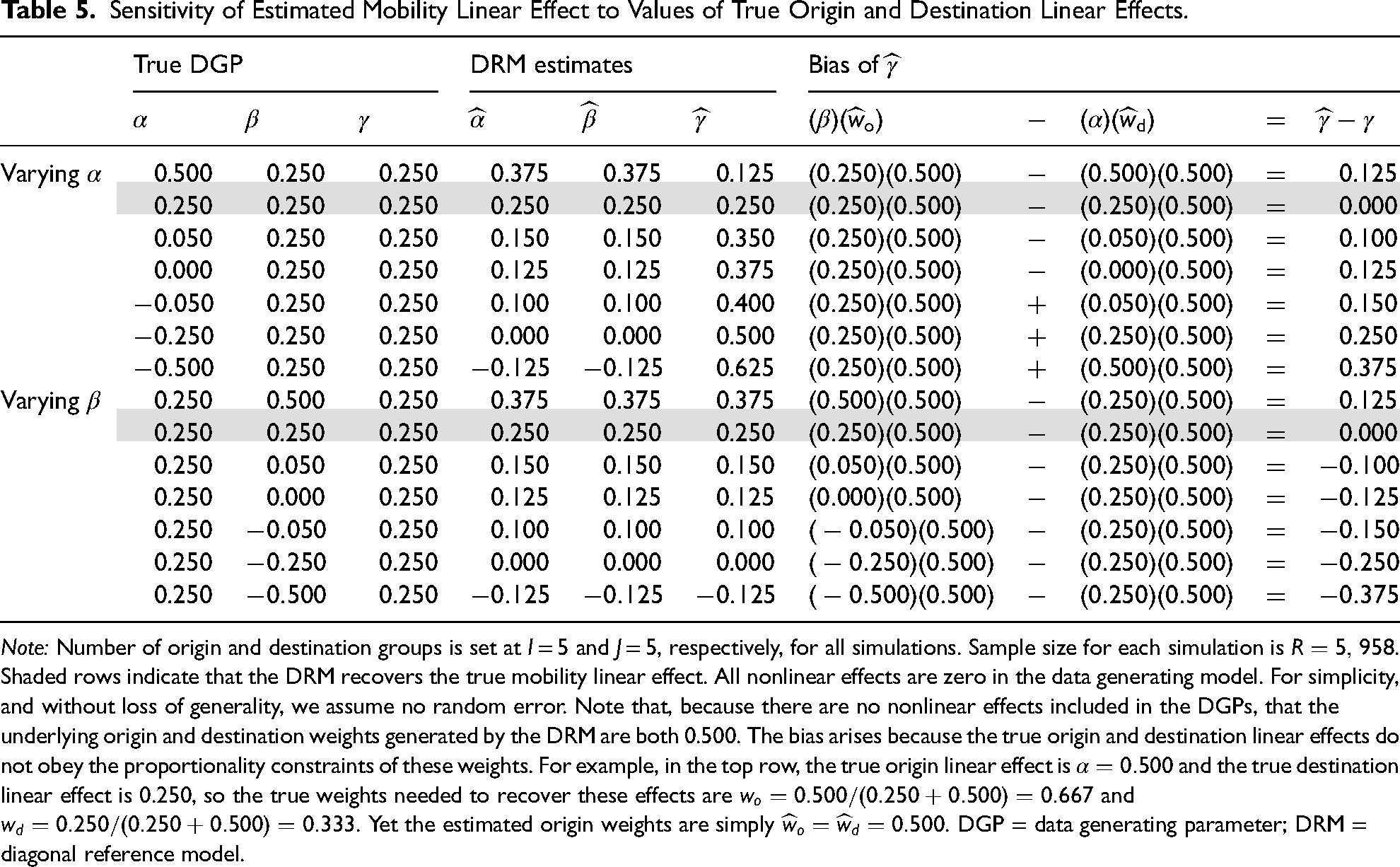
Note: Number of origin and destination groups is set at I = 5 and J = 5, respectively, for all simulations. Sample size for each simulation is
The bias of the DRM’s estimated mobility linear effect depends not only on the true origin and destination and linear effects, but also the underlying nonlinear effects. That is, because the bias formula depends on the DRM’s estimated weights, the estimated mobility linear effect from a DRM is in turn a function of the underlying nonlinear origin and destination effects. 17 In Appendix Table C.1, supplemental materials, we present results from simulations with various values of the nonlinear effects for origin and destination. Together, these simulations reveal that the estimated mobility effects are quite sensitive to the true values of the nonlinear origin and destination effects.
In short, DRM relies on a specific proportionality constraint to identify unique origin, destination, and mobility effects in a mobility table. Unfortunately, because the linear effects are not identified, the validity of this assumption can only be tested indirectly using the nonlinear effects. Even more problematic, regardless of the size of the underlying linear mobility effect, the DRM will set the linear effect to a very specific value. For example, as illustrated using Sobel’s (1981) fertility data, even if the mobility linear effect is extremely positive or negative, the DRM still fixes the mobility linear effect close to zero. Finally, we have provided a simple bias formula for the mobility linear effect, showing that the estimates from the DRM are sensitive to both the size and sign of the underlying origin and destination linear effects, as well as to the nonlinear effects. Taken together, these results suggest that the DRM should not be used to identify the effects of SM unless its very specific assumptions are strongly supported by sociological theory or background knowledge.
While the conventional DRM assumes fixed origin and destination weights, alternative specifications have been proposed that allow these weights to vary across the mobility table. Sobel (1985) extended the model to permit weights to differ by either origin or destination class, while Weakliem (1992) further allowed weights to vary simultaneously by both origin and destination. These extensions can accommodate more complex patterns of nonlinear effects in the data. Nevertheless, a fundamental limitation persists: due to the inherent identification problem, these extended DRM variants still impose specific constraints to identify unique linear effects of origin, destination, and mobility. In essence, all DRM formulations, regardless of their flexibility in handling nonlinearities, ultimately rely on point identification, requiring researchers to make highly specific and, as a consequence, strong assumptions about the magnitude and direction of the linear effects. Crucially, as we demonstrate in subsequent sections, the core assumptions of mobility effects models cannot be directly tested against the empirical data, making any results contingent in a nontrivial way on untestable modeling choices.
In this section, we show how previous generations of mobility effects models, such as the SAM and the DRM, can be understood as special cases of a bounding analysis. We first present a visualization of the identification problem at the core of mobility effects models, showing how the DRM and SAM achieve point identification by imposing extremely strong assumptions on the magnitude and direction of the linear effects. We then show how one can construct bounds on the linear effects using a variety of other constraints that generally involve much weaker assumptions. It is important to emphasize, however, that the results of any analysis of mobility effects are only as valid as the social theory or substantive knowledge used to justify the bounds.
Point Identification and the Canonical Solution Line
To understand how the DRM, SAM, and related models can be viewed as special cases of a bounding approach, it is crucial to recognize the geometric interpretation of the non-identifiability of the linear effects. Because mobility effects models are not fully identified, we cannot obtain point estimates for each of the origin, destination, and mobility linear effects (or effects that are partially a function of the linear effects). A convenient way to express the identification problem is to note that for any particular mobility effects model we can specify the slope as follows
18
: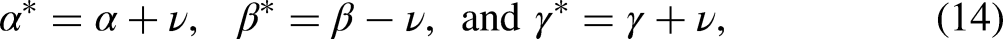
By varying values of
Figure 2 shows the canonical solution line based on the Sobel (1981) fertility data.
20
Several crucial points are worth emphasizing regarding this figure. First, in the absence of data from a mobility table and a corresponding mobility effects model, the origin, destination, and mobility slopes may take on any combination of values in a three-dimensional parameter space. With a mobility effects model, vast areas of the parameter space can be ruled as inconsistent with the data. However, as we discuss later, this does not mean that quite strong assumptions are unnecessary for identifying unique mobility effects. Second, depending on the data, the location of the canonical solution line relative to the origin will differ, leading to different trade-offs from setting various constraints. Specifically, the location of the canonical solution line is a function of the parameters
Three-dimensional (3D) canonical solution line. Note: This graph shows the canonical solution line based on Sobel’s (1981) fertility data. All possible combinations of origin, destination, and mobility slopes, denoted by
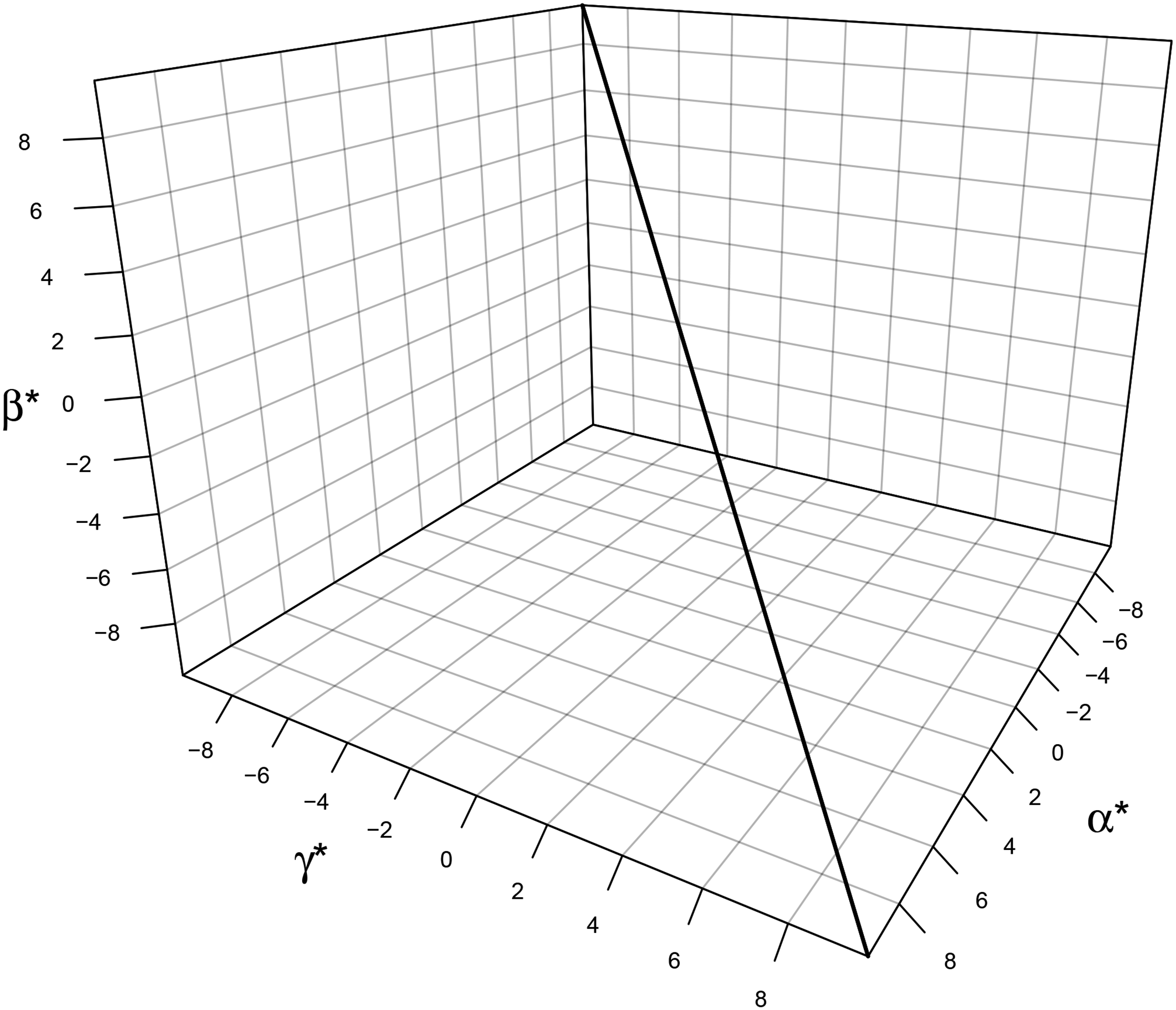
Point identification of mobility effects models: 2D canonical solution line. Note: This graph shows the 2D canonical solution line based on Sobel’s (1981) fertility data. Solution line is identical to that shown in Figure 2, but flattened to two dimensions. Points indicate estimated linear effects for the SAM, DRM, and under the assumption that origin and destination have the same slope (same-slopes). 2D = two-dimensional; SAM = square additive model; DRM = diagonal reference model.
Figure 3 shows a two-dimensional representation of the canonical solution line shown in Figure 2, again using Sobel (1981) fertility data. As in Figure 2, this line is based on values of
Three estimates are displayed in Figure 3. First, as shown by the triangle in Figure 3, there is the set of estimates corresponding to Duncan’s SAM. As noted previously, the SAM’s estimates are equivalent to assuming that the mobility linear effect is zero (i.e.,
The DRM and the SAM have traditionally been the most popular ways of point identifying mobility effects, but these are not the only options. Making any assumption about the sign and size of one of the three linear effects is sufficient to point identify the remaining two linear effects. Thus, for example, one might assume that the origin linear effect is zero, or that the destination linear effect is some specific negative value. One particularly attractive approach is to use what we call the same-slopes assumption. Presumably, origin and destination effects reflect similar, if not identical, underlying causal processes. Accordingly, in some contexts it might be reasonable, at least as a first pass, to assume that the origin and destination linear effects are the same, such that they have the same direction and magnitude. In other words, we might assume that origin and destination linear effects are the same such that
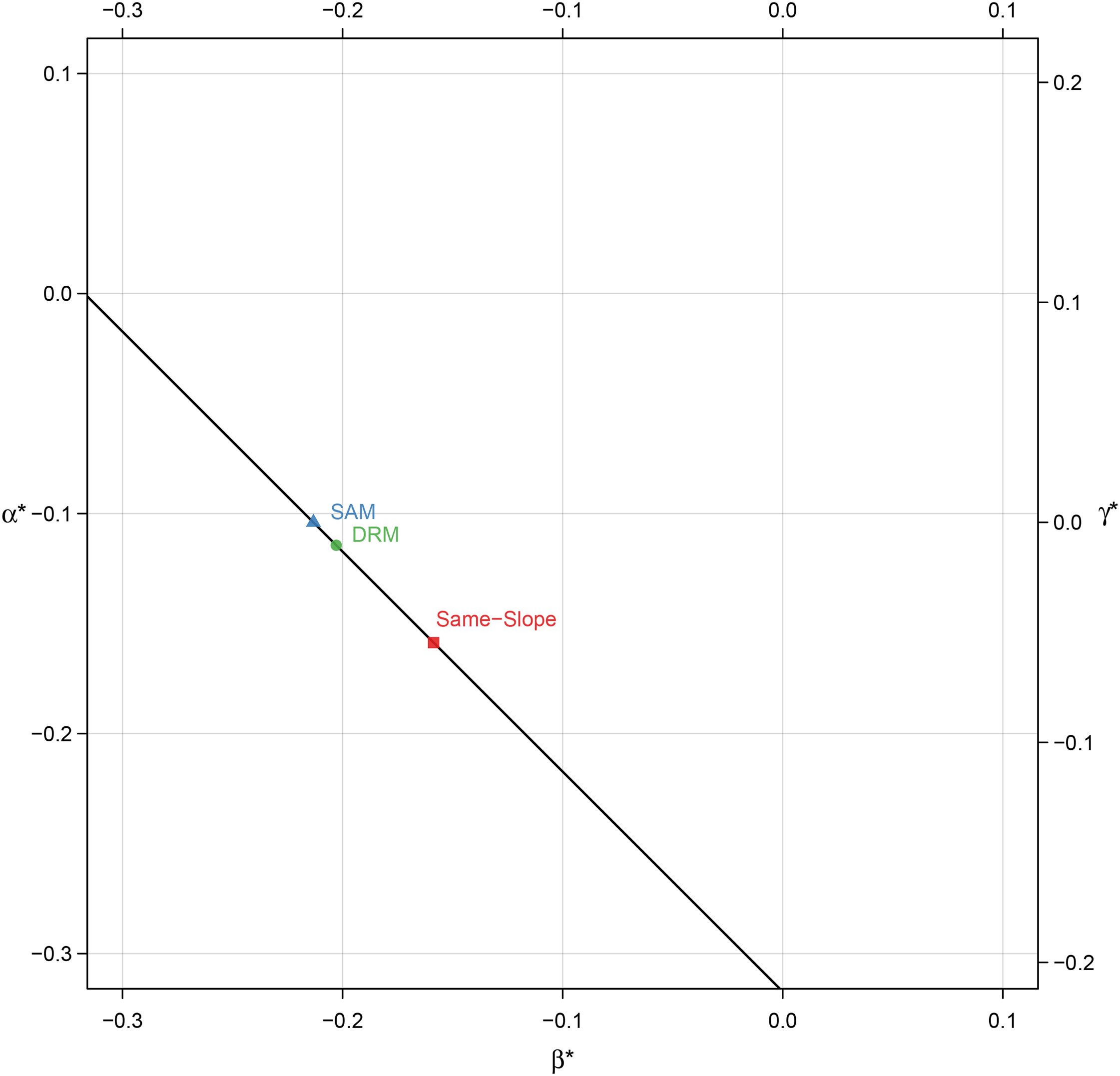
Each of these three estimates of the mobility linear effects correspond to different patterns of overall mobility effects, which incorporate the nonlinearities. Figure 4 shows the estimated mobility effects using the three identification strategies discussed above. The main conclusion is that both the DRM and the SAM, as indicated by the appropriate lines in Figure 4, are broadly consistent with no meaningful pattern of mobility effects, apart from the up-and-down pattern of the nonlinear effects. By contrast, the assumption of equal origin and destination slopes yields an overall negative effect of SM on fertility, as indicated by the appropriate line in Figure 4. That is, upward (or downward) SM causes households to have fewer (or more) children.
Point identification of mobility effects models. Note: This graph shows the mobility effects for the SAM, DRM, and under the same-slopes assumption for origin and destination (same-slopes). Data are based on Sobel (1981). SAM = square additive model; DRM = diagonal reference model.
The results in Figure 4 are compelling, but great caution is warranted. Only the nonlinear effects in Figure 4 are identified, while the linear effects are a function of the particular model employed, which encodes very specific assumptions about the size and sign of the linear effects. Because there is an infinite number of possible linear effects that are consistent with the data, there is also an infinite number of possible results that could be derived by applying any of a variety of mobility effects models (including those that have not yet been devised). For example, constructing a model that assumes that the origin linear effect is very negative will result in a very negative mobility linear effect, and thus a steep downward pattern in Figure 4. Conversely, using a model that assumes the origin linear effect is positive will result in a very positive mobility linear effect and, accordingly, a steep upward pattern in Figure 4. The extreme sensitivity of mobility effects models to the underlying identifying constraints used has not been generally appreciated in the literature. It should also be emphasized that the conventional mobility effects models rely on point identification, which requires invoking very specific and extremely strong assumptions that are not directly testable against the data. In the next section, we outline a number of identification strategies that involve weaker assumptions, albeit at the potential expense of the precision of the estimates.
Conventional models of mobility effects, as outlined above, are based on point identification, where the true parameter is uniquely estimated from the data given the specification of a particular model. Unfortunately, in the case of mobility effects, point identification depends crucially on the model (or, equivalently, on assumptions about the linear effects). As we have shown, different models (or different assumptions) lead to different estimates of mobility effects. A more principled approach is to abandon point identification in favor of partial identification. Rather than trying to extract a single estimate of a linear mobility effect, one uses (potentially weaker) assumptions to generate a range of estimates, thus partially identifying (or bounding) the mobility effect.
In the case of point identification, fixing the values of one of the slopes determines the values of the other two. For example, assuming that the mobility linear effect is zero, as is the case with the SAM, will fix the values of the origin and destination linear effects. In a similar way, setting upper and lower bounds on the magnitude and direction of any one of the linear effects will automatically set bounds on the size and sign of the remaining two linear effects. Likewise, setting the sign of any two linear effects will establish bounds on the size and sign of the remaining linear effect. 25 These strategies for specifying bounds are based only on assumptions about the magnitude and direction of the underlying linear effects. However, a third strategy, which may entail even weaker assumptions, is to use the nonlinear effects to make assumptions about the shape of one or more of the effects over a particular range of the data. For example, one might assume that the pattern of destination effects is monotonically decreasing, increasing, or neither decreasing nor increasing for some (possibly restricted) set of destination categories. These assumptions will, in turn, place constraints on the underlying linear effects. 26 Crucially, as Manski (1990, 2003) pointed out in his seminal work on partial identification, there is a direct trade-off between the strength of one’s assumptions and the width of the bounds on the parameters. While, in some applications, analysts may bemoan the width of the bounds to be too large to be analytically useful, wide bounds merely demonstrate that much stronger theoretical assumptions are required if the analyst seeks to usefully interpret a given estimate.
To illustrate how one might proceed with a bounding analysis of mobility effects, we outline three main partial identification strategies. First, there is what we call the same-sign assumption. Rather than assuming that the origin and destination linear effects have the same magnitude and direction, as with the same-slopes assumption, in some settings it might be appealing to assume that the origin and destination linear effects have the same sign but not necessarily the same magnitude. The justification for this assumption is again that the causal processes proxied by class origin and destination are similar, if not identical.
The constraints implied by the same-sign assumption are easily calculated from the data. Because
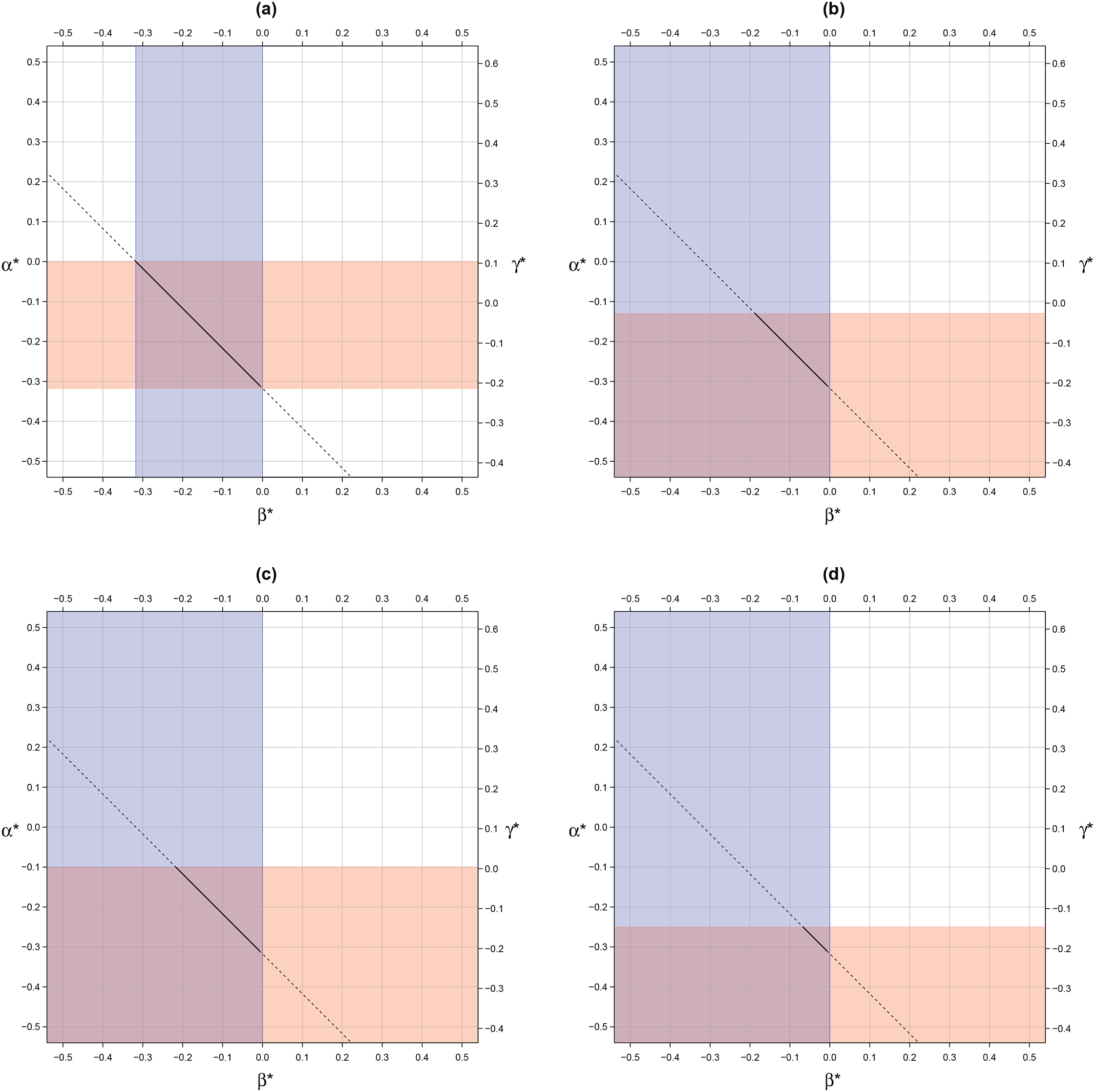
Partial identification of mobility effects models: two-dimensional (2D) canonical solution line. Note: Panel (a) shows bounds on the canonical solution line using the same-sign assumption for class origin and destination. Panel (b) shows bounds on the canonical solution line under the assumption of a monotonically downward effect for class origin (with respect to the quadratic component of the origin nonlinear effects) as well as a same-sign assumption for class destination. Panel (c) shows bounds on the canonical solution line under the assumption of a monotonically decreasing origin effect for lower-class groups (1, 2, and 3) in addition to a same-sign assumption for class destination. Lastly, Panel (d) shows bounds on the canonical solution line under the assumption of a monotonically decreasing origin effect for upper-class origin groups (3, 4, and 5) as well as a same-sign assumption for class destination. Horizontal rectangle indicates bounds on class origin while vertical rectangle denotes bounds on class destination. Bold line indicates that part of the canonical solution line consistent with the data given the particular assumptions invoked. Data are based on Sobel (1981).
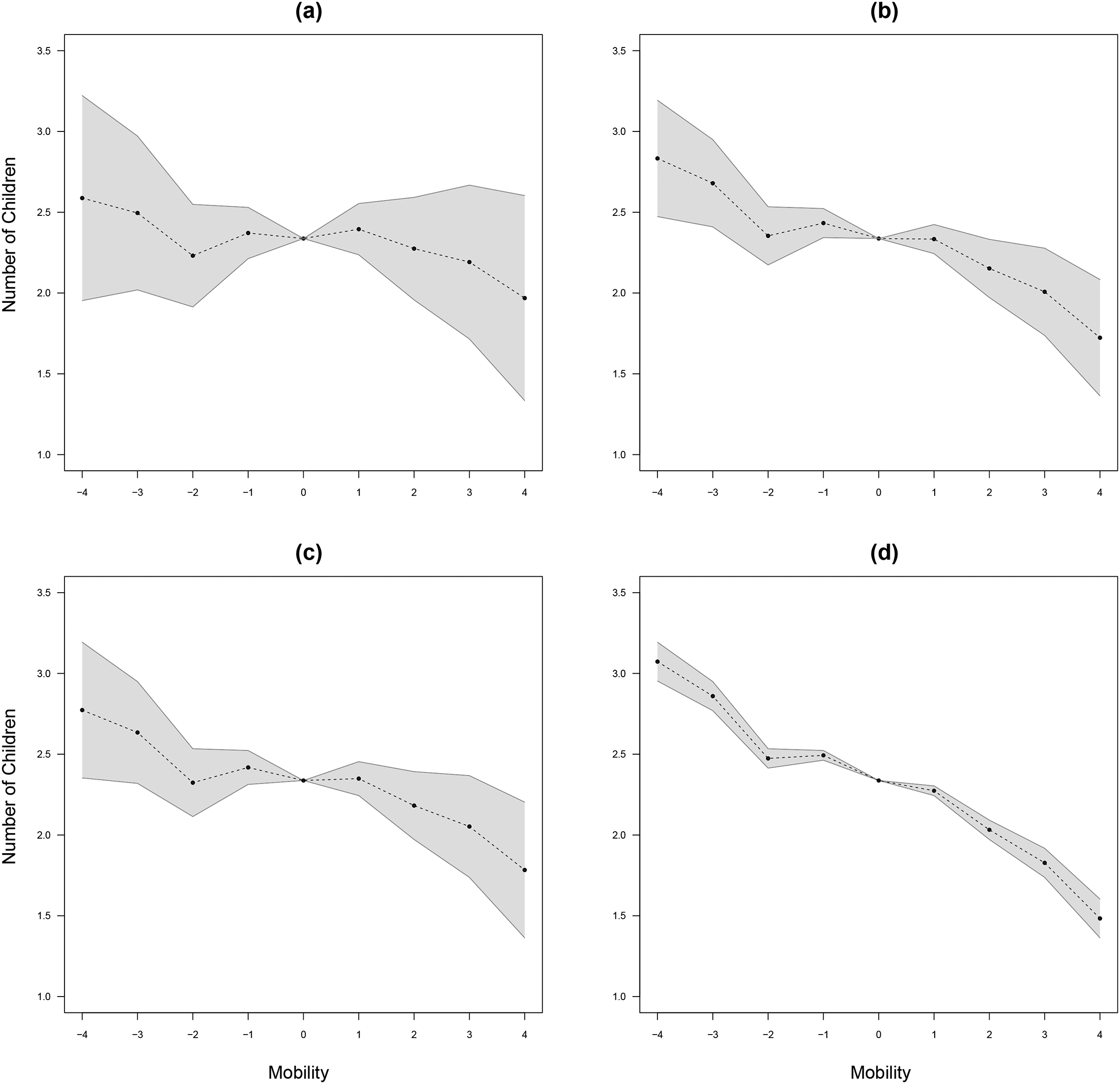
Partial identification of mobility effects models. Note: Panel (a) shows the mobility effects using the same-sign assumption for class origin and destination. Panel (b) shows bounds on the mobility effects under the assumption of a monotonically downward effect for class origin (with respect to the quadratic component of the origin nonlinear effects) as well as a same-sign assumption for class destination. Panel (c) shows bounds on the mobility effects under the assumption of a monotonically decreasing origin effect for lower-class groups (1, 2, and 3) in addition to a same-sign assumption for class destination. Lastly, Panel (d) shows bounds on the mobility effects under the assumption of a monotonically decreasing origin effect for upper-class origin groups (3, 4, and 5) as well as a same-sign assumption for class destination. Dotted line indicates the midpoint of the bounds. Data are based on Sobel (1981).
A second strategy that one might employ with mobility data is what we call the monotonic origin-destination effects assumption. The idea here is that, again to the extent that origin and destination can be understood as having similar underlying causal processes, we might assume not only that both of their linear effects have the same sign, but that one or both of the effects are monotonically increasing (if
Some care is warranted, however, in calculating underlying linear effects based on monotonicity constraints. In many if not all cases, one might believe that the origin and destination nonlinear effects capture, at least in part, some amount of random error. Applying monotonicity constraints in such circumstances may thus be misleading. An alternative, which we use here, is to calculate the monotonicity constraints based only on some restricted set of higher-order terms, such as only the quadratic component or only the quadratic and cubic components. In other words, the effect is assumed to be monotonic only with respect to a specific subset of higher-order terms, such that the remaining nonlinear effects may themselves be monotonically decreasing, randomly fluctuating, or monotonically increasing. 27 For Sobel’s fertility data, we calculate the monotonicity constraints using only the quadratic component, but substantively similar findings were obtained using higher-order terms. 28
Based on the quadratic component, the maximum possible slope for a monotonically decreasing origin effect is
So far we have employed two approaches to partially identifying mobility effects, one based on the same-sign assumption and another based on monotonically decreasing origin and/or destination effects. A third approach is to invoke the assumption of monotonically decreasing effects, but to do so for some restricted range of class categories. For example, suppose we assume that fertility rates across class origin categories are monotonically decreasing, but only among those classes lower in the hierarchy (1, 2, and 3). This assumption aligns with the claim that fertility may decline consistently across individuals from lower class origins, as even modest differences in resources, education, health care, and family planning may significantly shape reproductive strategies. However, for individuals from middle class origins or higher, the primary determinants of lower fertility might be largely satisfied, resulting in stabilized fertility levels across these class groups, or at least fertility levels that are not monotonically decreasing.
The assumption that fertility is monotonically decreasing, but only across class origin categories lower in the hierarchy, results in a maximum possible origin slope of
Alternatively, suppose we assume that fertility rates across class origin categories are monotonically decreasing, but only among those classes higher in the hierarchy (3, 4, and 5). This assumption is consistent with the claim that fertility differences are most pronounced among individuals from higher class origins, as distinctions in economic resources, aspirations, and family formation norms become increasingly influential at higher class origin positions. By contrast, among lower class origins, fertility rates may already reflect uniformly constrained resources and limited opportunities, resulting in less variation in fertility across these categories. The assumption that fertility is monotonically decreasing, but only across class origin categories higher in the hierarchy, yields a maximum possible origin slope of
The above approaches to identifying mobility effects employ much weaker assumptions than conventional models, such as the DRM and SAM, which rely on point identification. This is not to imply that these assumptions are not very strong, however. 30 In many applications, theories or additional information about the underlying causal processes may be quite ambiguous, precluding any practical guidance on how to set bounds on the effects. Moreover, even when one believes that theory or background information provides useful guidance on how to set the bounds, it is absolutely critical to understand that the results are by definition extremely sensitive to the assumptions invoked. This means that any analysis that attempts to identify unique effects of mobility is inherently provisional, and thus should always be presented transparently, clearly specifying the assumptions invoked and explicitly discussing the tentative nature of the conclusions. As we have shown, this is facilitated by parameterizing the model so that the unidentified part is separate from the unidentified part, as we have done with the L-ODM model.
Finally, it is worth underscoring that even if one believes that the true effects have been identified, there are additional and serious complications with treating such effects as “causal” in any meaningful sense. As Zang, Sobel, and Luo (2023) have recently emphasized, it is important to recognize that the DRM and related models were developed in a historical context that largely predated modern frameworks for causal inference. While these techniques represented innovative solutions to the methodological challenges of their time, they now face significant limitations when evaluated against contemporary standards for causal identification. In Appendix D, supplemental materials, we outline in detail these issues regarding parallel-world counterfactuals, the consistency assumption, the assumption of no confounding (given composite exposures), and complications that arise due to the fact that mobility is likely an exposure-induced confounder. These difficulties mean that even if the underlying bundles of mechanisms for origin, destination, and mobility could somehow be observed, there remain substantial barriers to interpreting estimated parameters as causal effects. These problems apply not only to the DRM and SAM but also to methods using bounds to partially identify effects. 31
The prior sections have critically assessed the DRM and the general challenges for the identification of independent origin, destination, and mobility effects. Taken together, we believe that the problems identified call for a fundamentally new direction in the analysis of the consequences of SM. We now begin to outline what we consider a particularly promising way forward. To be clear, this entails a re-framing of the analytic question. But, in words typically ascribed to Charles Kettering, “a problem well stated is a problem half-solved.”
The alternative framework for analyzing SM that we propose in this section is based on the concept of positional sociology (Fosse and Pfeffer 2025). This approach differentiates between two distinct forms of inequality: (1) structural inequalities, associated with stable positions within the social hierarchy, and (2) dynamic inequalities, arising from movements between social positions. Building on this distinction, we introduce the SDI model, which extends the L-ODM model by explicitly re-indexing parameters according to social origin and mobility status. The result is a fully identified model with clearly interpretable parameters that effectively capture both types of inequality. As we go on to show, this method enables a decomposition of population-level variation within mobility tables, leading to highly informative sets of parametric expressions and visualizations.
Our approach broadly aligns with recent contributions by Zang, Sobel, and Luo (2023) and Breen and Ermisch (2024). Like us, these authors emphasize challenges in isolating unique mobility effects and suggest alternative conceptualizations of SM. Specifically, they conceptualize class destinations as “treatments” whose effects vary across origin categories. However, we adopt a model that, while fully identified, nonetheless leverages the distinct, identifiable components of origin, destination, and mobility. Furthermore, and more importantly, our framework diverges from their approach by explicitly emphasizing mobility as a positional dimension rather than as a variation in destination treatment effects. Consequently, our primary objective is to use the SDI model to systematically dissect mobility tables into their constituent structural and dynamic inequalities, thereby highlighting the inequalities experienced by distinct social groups. 32
Mobility as a Metric of Positionality
In contrast to conventional models of mobility effects, what we term “positional sociology” takes a distinctly different approach to the deterministic relationship between origin, destination, and mobility (Fosse and Pfeffer 2025). Whereas conventional models regard this relationship as an obstacle to be overcome, positional sociology embraces it as a natural observational fact, recognizing that origin, destination, and mobility are interrelated dimensions that locate positions in an observed social space, rather than as proxies for distinct bundles of causal mechanisms that must be separated. Positional variables are not themselves causal, but are axes along which variation is observed. Treating them as causal in and of themselves is a fundamental “category mistake” (e.g., see Ryle 1959).
Suppose, for example, that an individual from a given class origin group moves up the social hierarchy and reaches a new class destination. Reaching this new position in the social structure (ST) is observed conjointly with the degree of SM. From this perspective, SM as a dimension of positionality can never be completely separated from class destination, nor should it be, because SM is experienced in the context of class destination rather than independently of it. 33 However, treating origin, destination, and mobility as dimensions of social position rather than as surrogates for underlying causal factors does not mean that positional sociology does not involve the study of causal processes; far from it. Rather, the causal factors are distinct and separate from the dimensions of social position, which describe the observed locations of individuals and other groups in an observed multidimensional social space. 34
Given this epistemology, a key question is: how exactly should we describe population-level variability using information from a mobility table? There are six logically possible ways, as shown in Table 6. Let
Typology of Models for a Mobility Table.
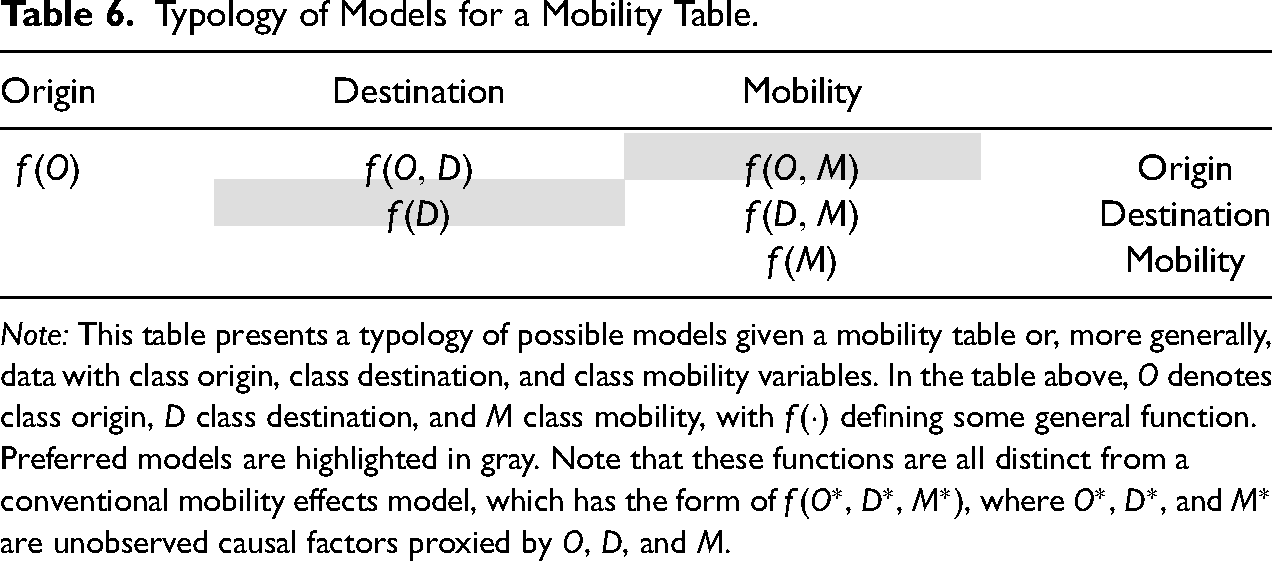
Typology of Models for a Mobility Table.
Note: This table presents a typology of possible models given a mobility table or, more generally, data with class origin, class destination, and class mobility variables. In the table above, O denotes class origin, D class destination, and M class mobility, with
Among these various generic models for summarizing population-level variability in a mobility table, we have a strong preference for models of the form
Consider first a model of the form
It is crucial to understand that SM analysis is distinct from any analysis using models of the form
Likewise, suppose we attempt to specify a model based on a function
Our approach is also distinct from one-factor models of the form
The injunction to use functions of the form
To examine differences with respect to ST and SM, we introduce what we call the structural and dynamic inequality model, or, for short, the SDI model. This model is derived by taking the L-ODM model, substituting destination with origin and mobility, and rearranging the terms. The result is a fully identified model, expressed in terms of the origin, destination, and mobility parameters, with the following general form: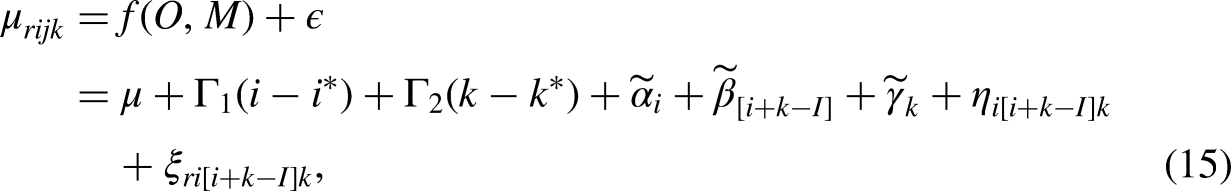
Somewhat remarkably, equation (15) encompasses a great deal of information about the underlying structural and dynamic inequalities in a mobility table. Accordingly, a large number of parametric expressions can be derived from the model. Among the most useful for describing the main patterns in a mobility table are those discussed and visualized in the remaining sections: the social structure matrix and social mobility matrix, the social structure slope and the social mobility slope, social structure and social mobility curves, and comparative mobility curves. In Appendix F, supplemental materials, we include a full list of expressions that can be derived from the SDI model (Appendix Table F.1, supplemental materials) and illustrate the analytic use of one additional expression (marginal class destination curve).
The SDI model allows us to decompose the overall pattern observed in a mobility table into two distinct underlying matrix-based components. This decomposition helps separate inequalities associated with social positions from those associated with movement between these positions. First, we can extract the social structure matrix. This matrix reflects the joint origin-destination parameters from the SDI model and is calculated as
Figure 7 provides a visualization of these components of a mobility table using Sobel’s (1981) fertility data. Panels (a) and (b) display the overall predicted fertility values from the main parameters of the SDI model in 2D and 3D, respectively, showing the combined influence of ST and SM. Panel (c) presents the social structure matrix, illustrating how predicted fertility varies according to the joint combination of origin and destination positions, thereby highlighting structural inequalities. Panel (d) displays the social mobility matrix, showing how predicted fertility varies based on the joint combination of mobility experience and class destination, highlighting dynamic inequalities. Comparing Panels (c) and (d) visually separates the relative contributions of structural and dynamic inequalities to the overall fertility patterns. The ST matrix (Panel (c)) exhibits marked gradients, especially the trend towards lower fertility with higher origin-destination status, suggesting a prominent role for structural position. Similarly, the SM matrix (Panel (d)) illustrates significant fertility differences across various origin–mobility combinations, indicating that the dynamic component also accounts for a considerable part of the overall observed variation.
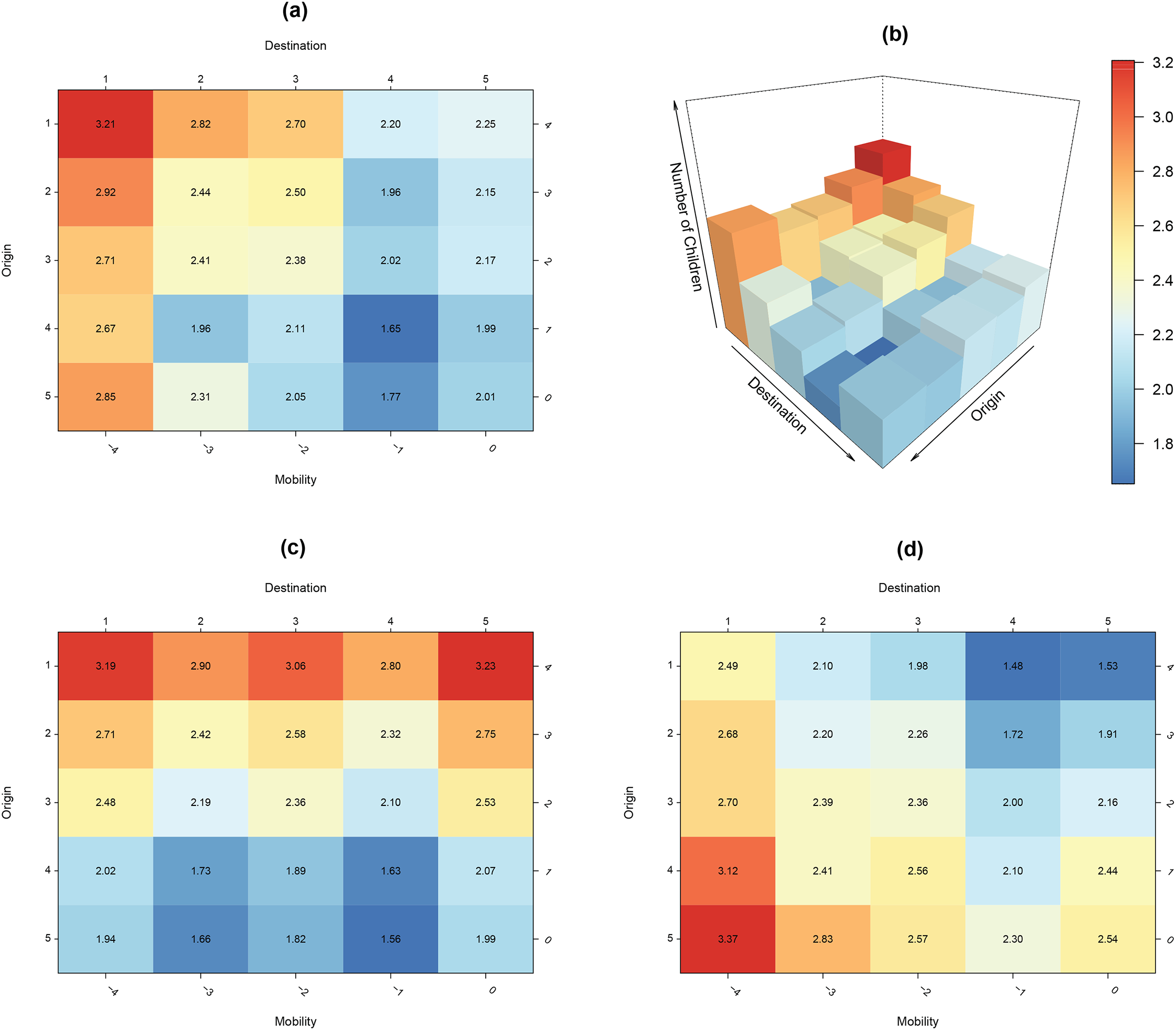
Social mobility matrices. Note: Panels (a) and (b) present 2D and 3D visualizations, respectively, of the predicted mean fertility based on the SDI model’s main parameters. That is, each cell is given by
At a more fundamental level, the two linear parameters of interest in equation (15) are
The ST and SM slopes can take on different values, with different implications for the patterns observed in a mobility table (see Appendix Table G.3, supplemental materials). In a world with no SM (i.e., where the SM slope is zero), linear differences within different class destinations are the same as linear differences within different mobility groups (i.e., both will reflect the ST slope). Visually, this will appear as a set of linear differences that vary only by class origin, or across the rows of an origin–destination mobility table. Conversely, in a world with no structural inequality (i.e., the ST slope is zero), the linear differences within class origin groups will be the same as those within class destination groups (i.e., both will reflect the SM slope). Visually, this will appear as a set of linear differences that vary across mobility groups, or across the diagonals of an origin–destination mobility table. 43 To our knowledge, these features of mobility tables have not been recognized before.
Social Structure and Social Mobility Curves
The ST and SM slopes provide basic overall information on the overall structural and dynamic inequalities observed in the data. However, more informative summaries incorporate the origin and mobility nonlinearities, respectively. Specifically, adding the origin nonlinearities along with the ST slope results in the social structure curve, or ST curve, defined by
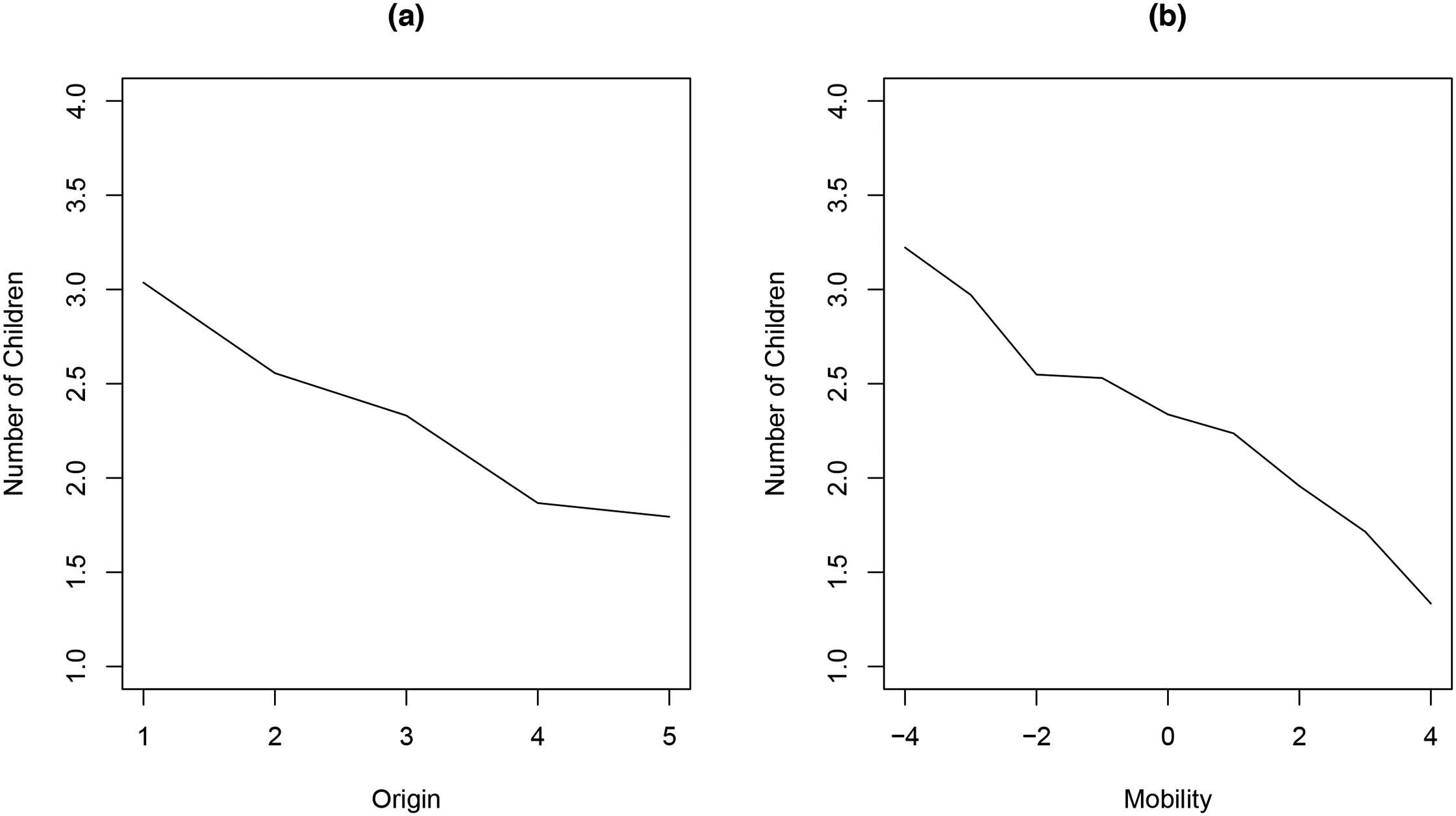
Social structure and social mobility curves. Note: Panel (a) shows the social structure (ST) curve, given by
The ST and SM curves (as well as the slopes) are highly informative, compact summaries of the variability on a mobility table. However, in practice it is often useful to supplement these measures with mobility curves specific to each class origin group, or what we call comparative mobility curves. Two particularly useful versions of these curves are shown in Figure 9, again using the fertility data. First, there are what we call overall comparative mobility curves, which are defined as follows: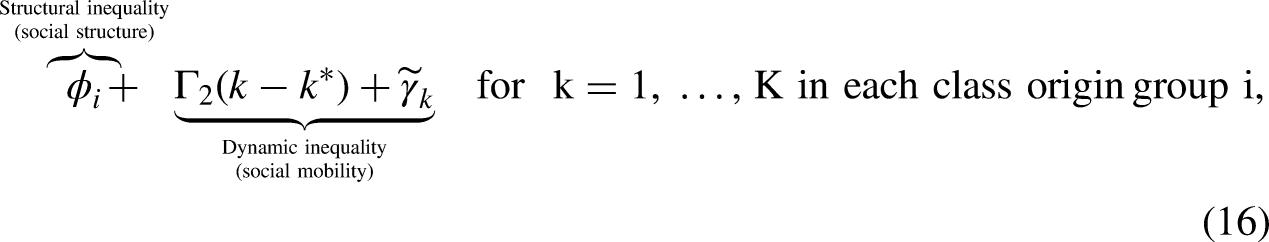
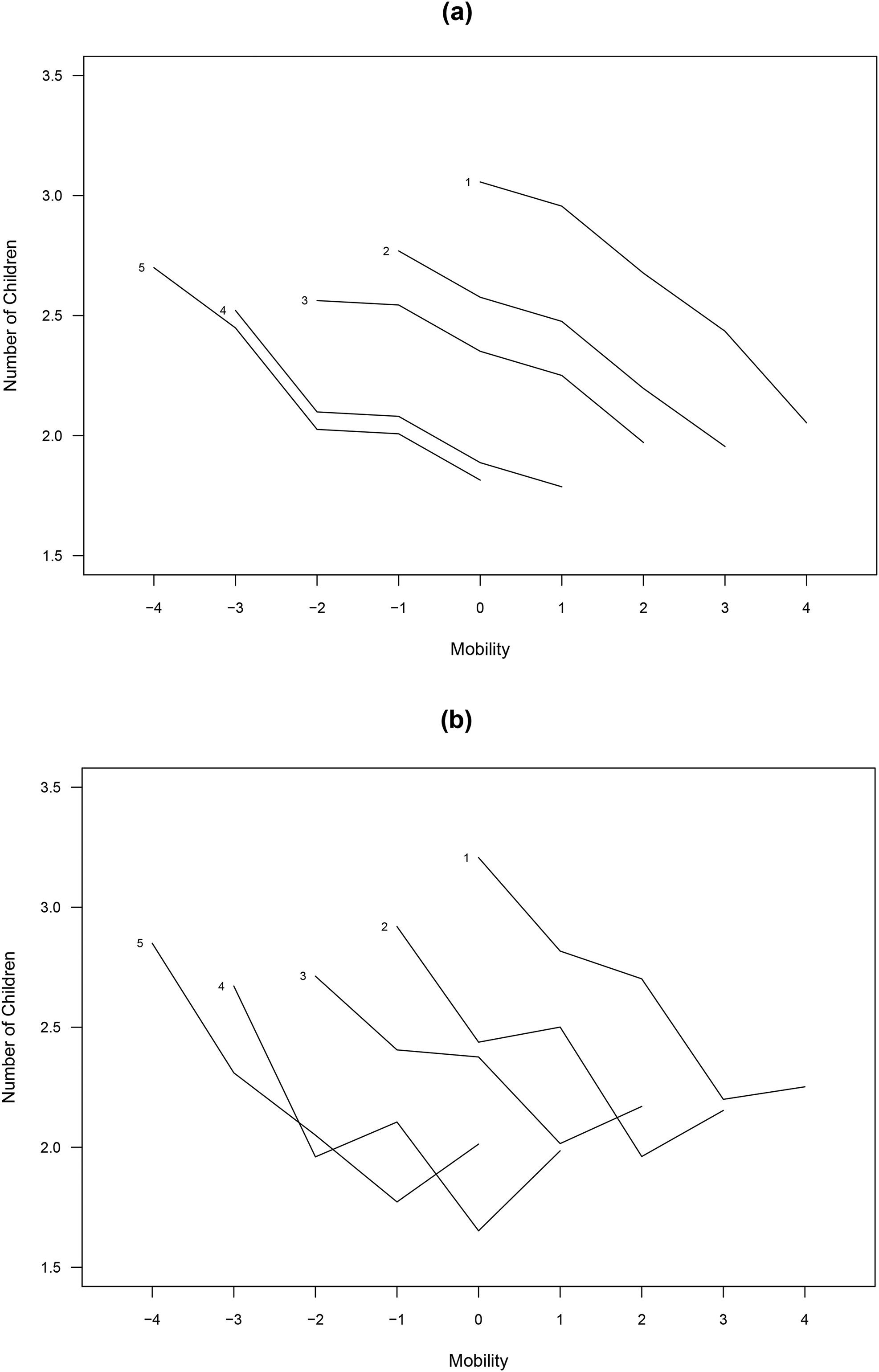
Comparative mobility curves. Note: Panel (a) illustrates the overall comparative mobility curve. Each curve represents a function of
A slightly more complex representation is identical to equation (16) but includes the nonlinearities attributable to class destination. This results in what we call adjusted comparative mobility curves:
45
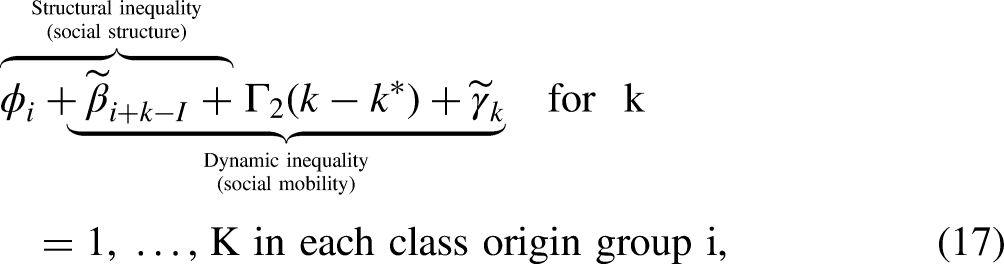
Figure 9 shows overall and adjusted comparative mobility curves using Sobel’s (1981) fertility data. Panel (a) of Figure 9 displays the collection of overall comparative mobility curves (equation (16)). Each of the class origin groups are labeled from 1 to 5. The vertical axis is the number of children, while the x-axis is the mobility dimension. Note that each class origin group is entitled to only a specific pattern of SM. For example, those at the top of the class hierarchy (Class 5) can either be immobile or move downward, while those at the bottom of the class hierarchy (Class 1) can either be immobile or move upward.
These curves encapsulate a great deal of information about the relationships between the ST and SM with respect to fertility. Vertical differences between the class origin groups are a function of the structural component, or
Panel (b) of Figure 9 shows the adjusted comparative mobility curves, which are identical to the overall curves in Panel (a) except that the class destination nonlinearities are included. Vertical and horizontal differences in the graph still represent structural and dynamic inequalities, respectively, but they are now represented in a more complex way. Specifically, vertical differences between the class origin groups are now a function of
Two fundamental conclusions are apparent from the mobility curves shown in Figure 9. First, conditional on SM, differences in the ST are systematically related to lower levels of fertility, particularly between Classes 1 and 2 as well as Classes 3 and 4. Second, conditional on the ST, upward (or downward) SM is systematically related to lower (or higher) levels of fertility for all class origin groups. Note that these conclusions hold even for the adjusted mobility curves shown in Panel (b), which inject additional heterogeneity into the patterns.
The results in this section underscore that there is much to be learned from a purely descriptive analysis of a simple mobility table. Rather than focusing on using information external to the data to extract unique “effects” for origin, destination, and mobility, as is common in the existing literature on mobility effects, our focus has been on estimating quantities that represent various aspects of structural and dynamic inequality. This has the great advantage of facilitating the accumulation of knowledge, as the underlying models are fully identified.
Conclusion
Despite decades of research, quantitative evidence on the consequences of social mobility has been inconclusive as it has been hampered by longstanding methodological challenges. In this article, we make a number of important contributions to the literature on social mobility effects, which has been dominated in recent years by the DRM.
We demonstrate that the DRM should not, in general, be used to identify mobility effects. Under plausible conditions, the mobility effects it estimates are biased towards zero and highly sensitive to non-intuitive and untestable assumptions, clarifying why empirical studies frequently find weak or null mobility effects. We also show that the DRM and related methods can be understood as special cases of a bounding analysis where extremely strong assumptions are invoked to achieve point identification. In this context, we provide alternative bounding strategies that not only make the assumptions more transparent but also reveal the inherently provision nature of the findings from such approaches. To address the fundamental limitations in existing methods, we conclude by introducing the structural and dynamic inequality (SDI) model, a fully identified model that relies on much weaker assumptions. As we show, the SDI model yields a large number of novel parametric expressions, and we introduce a range of graphical representations of these expressions that capture and distinguish between structural and dynamic inequalities.
An important and perhaps controversial conclusion from this article is that researchers should avoid using models that attempt to extract unique omnibus “effects” for origin, destination, and mobility. The assumptions behind these models are not only very strong but also not directly testable against the data. Of course, assumptions are fundamental to all statistical modeling, including standard approaches like ordinary least squares regression. However, we have sought to show that the necessary assumptions to identify mobility effects are much stronger than generally recognized. As a result, we consider the evidentiary basis for the individual-level effects of social mobility highly debatable. Not because this rapidly expanding literature, which overwhelmingly uses the DRM, has produced mixed and often null findings. But because using a model that is unidentified carries with it very strong, untestable assumptions, with parameters that are compatible with an infinite number of solutions. If researchers still wish to identify omnibus factors for origin, destination, and mobility, we would recommend using bounding analyses that make explicit assumptions about the size, sign, and/or shape of the effects. Ideally, these assumptions should be driven by social theory or background knowledge, and the conclusions should be stated as inherently tentative.
More importantly, however, we call for a fundamental shift in the analytic focus of mobility research. This shift rests on the basic insights that it is not meaningful to divorce social class destination from social mobility. We consider the most appropriate goal of social mobility analysis the identification of joint sets of parameters, such as the joint influence of social class destination and social mobility. We hope that this shift in focus will move the literature to more meaningful answers that can be falsified against the data. Our new approach, consistent with what we term “positional sociology,” is to treat origin, destination, and mobility as dimensions along which variability is observed, rather than as proxies for unobserved causal factors (Fosse and Pfeffer 2025). Interpreting origin, destination, and mobility as dimensions of variability, and working with functions of the form
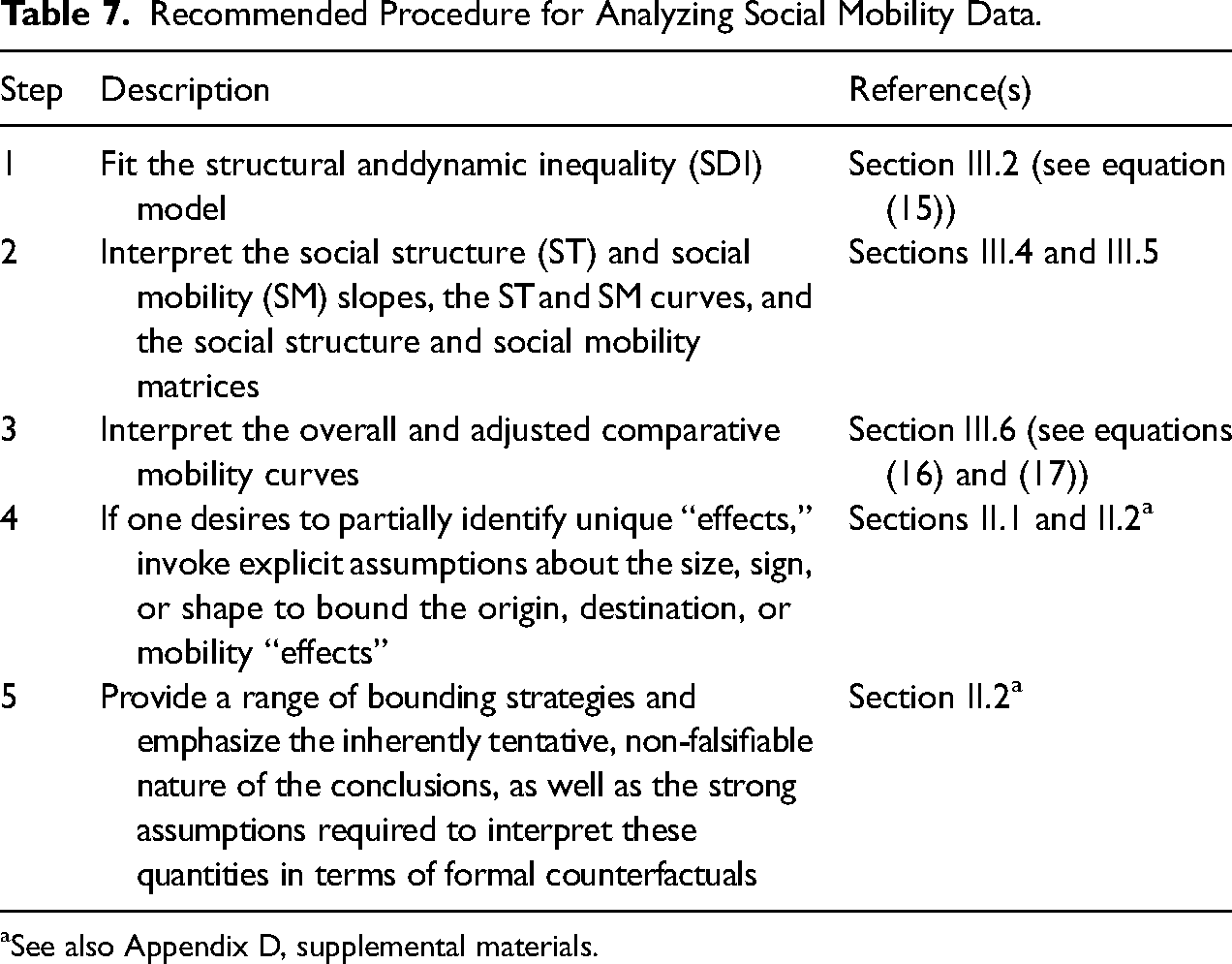
At the same time, we acknowledge that, despite the aforementioned discussion, some analysts will persist in attempting to isolate distinct “effects” for origin, destination, and mobility. To help guide applied researchers, we outline a sequence of steps for analyzing data from a social mobility table, whether one’s aim is to describe structural and dynamic inequalities based on identifiable, joint parameter sets or to extract unique effects for origin, destination, and mobility. Table 7 summarizes these steps and calls out the sections or equations in the article that match each step.
Recommended Procedure for Analyzing Social Mobility Data.
See also Appendix D, supplemental materials.
First, researchers should fit the SDI model, as detailed in Section III.2 and equation (15). This model serves as the foundation for understanding the distinct components of inequality. Second, the interpretation phase involves examining the social structure and social mobility slopes, the social structure and social mobility curves, as well as the social structure and social mobility matrices. These elements, discussed in Sections III.4 and III.5, provide fundamental insights into the structural and dynamic aspects of inequality. Third, a more detailed examination involves interpreting the overall and adjusted comparative mobility curves, as explained in Section III.6 and outlined in equations (16) and (17). These curves illustrate specific mobility patterns for different origin groups. Fourth, if the goal is to identify the unique “effects” of origin, destination, and mobility, then we recommend that researchers adopt a partial identification approach in which the parameters are bounded based on explicit assumptions about the size, sign, or shape of the effects. This method is covered in Sections II.1 and II.2. Finally, when employing bounding strategies, it is crucial to provide a range of these strategies and to emphasize the inherently tentative, non-falsifiable nature of the conclusions. Moreover, the strong assumptions required to interpret these quantities in terms of formal counterfactuals should be clearly articulated, as discussed in Section II.2 and Appendix D, supplemental materials.
We end by outlining a few options for future research that could extend the SDI model in a variety of different directions: first, the SDI model can be extended by interacting the components with time, allowing one to examine how the roles of social structure and social mobility change over time. Note, however, that this requires a large sample due to the sparseness at the extremes of the mobility table, as well as appropriate restrictions to deal with overfitting noise. Second, another extension is to include covariates in the model and examine potential interactions. Third, researchers should consider extending the SDI model to continuous data. This will require models that use more flexible functional forms, such as cubic regression splines or generalized additive models (GAMs), to deal with complex nonlinearities in the data. Fourth, the SDI model can be extended to address directional mobility, i.e., to distinguish the distinct patterns associated with downward and upward mobility. As currently formulated, the model captures the average linear component representing mobility-related differences (via the social mobility slope,
Supplemental Material
sj-pdf-1-smr-10.1177_00491241251358895 - Supplemental material for Beyond the Diagonal Reference Model: Critiques and New Directions in the Analysis of Mobility Effects
Supplemental material, sj-pdf-1-smr-10.1177_00491241251358895 for Beyond the Diagonal Reference Model: Critiques and New Directions in the Analysis of Mobility Effects by Ethan Fosse and Fabian T. Pfeffer in Sociological Methods & Research
Supplemental Material
sj-docx-2-smr-10.1177_00491241251358895 - Supplemental material for Beyond the Diagonal Reference Model: Critiques and New Directions in the Analysis of Mobility Effects
Supplemental material, sj-docx-2-smr-10.1177_00491241251358895 for Beyond the Diagonal Reference Model: Critiques and New Directions in the Analysis of Mobility Effects by Ethan Fosse and Fabian T. Pfeffer in Sociological Methods & Research
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors received financial support for this project from a grant from the National Science Foundation (SES-1948310).
Data and Code Availability Statement
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.