
Abstract
Linkages between surveys and administrative data provide an important opportunity for social and health research, but such linkages often require the informed consent of respondents. We use experimental data collection across five different samples to study how consent decisions are made. More reflective decision processes are associated with higher rates of consent, greater comprehension of the proposed data linkage, and greater confidence in the decision, but only about a third of respondents report using a reflective decision process. This suggests that the provision of additional information is unlikely to lead to significant improvements in informed consent.
Introduction
The complementary strengths of survey and naturally occurring data (administrative data or transaction data) mean that “integrated” data that combines the two provides a particularly valuable basis for future empirical work in the social and human sciences (Benzeval et al. 2020; Davis-Kean et al. 2017; Groves 2011; Meyer et al. 2015). For legal and ethical reasons, linking administrative or other data with survey responses often requires respondent consent to data linkage. Failure to obtain consent leads to reduced rates of linkage and so to reduced sample sizes for linked data and potential representation errors (selection biases). Survey researchers therefore wish to maximize consent rates, but the same legal and ethical considerations imply that the appropriate objective is to maximize informed consent.
The existing empirical evidence on survey respondents’ consent to data linkage contains a number of puzzling findings. Empirical correlates of consent are inconsistent (e.g., Peycheva et al. 2021; Sala et al. 2012). Individual survey respondents appear to have a latent “willingness to consent” in multiple consent requests asked within one interview (Jenkins et al. 2006; Mostafa 2016; Walzenbach et al. 2022) but evidence of a latent willingness to consent over time is weaker (Mostafa and Wiggins 2018) and many respondents who decline to consent give the opposite answer if asked again at a later date (Jäckle et al. 2021a; Weir et al. 2014). Efforts to increase consent rates through experimental manipulation of the requests have produced mixed results (Kreuter et al. 2016; Sakshaug et al. 2013; Sala et al. 2014). Perhaps more worrying, comprehension of linkage requests appears to be poor (Das and Couper 2014; Edwards and Biddle 2021; but see Sakshaug et al. 2021). Overall, the process by which a particular survey respondent in a particular context does or does not provide consent is poorly understood.
Our goal in this paper is to examine how individuals make consent decisions and how informed consent happens. More specifically, our aim is to quantify the prevalence of different decision-making strategies. The implicit assumption when designing survey consent questions is that respondents make rational cost-benefit decisions: they read the information provided about what will be linked, why, and how, and weigh up the reasons for consenting against potential risks. However, there is evidence that relatively few respondents make this decision in a fully rational, systematic, or effortful way. Experiments with the wording of consent requests tend to have little effect on consent rates, even when the benefits of consenting are highlighted (Beuthner et al. 2023; Pascale 2011). Prior qualitative research suggests that respondents vary in how they process consent questions, with some using more reflective processes and others using less reflective processes (Beninger et al. 2017). Knowing the prevalence of different decision-making strategies is a necessary step towards improving informed consent: if most respondents make reflective decisions, then providing better information about the linkage (including, for example, visual representations and video animations) might improve informed consent. However, if many respondents make decisions without considering much of the information provided, then other methods need to be developed to improve informed consent.
In line with Gigerenzer and Gaissmaier (2011), we assume that many decisions are made using heuristics (i.e., strategies that ignore some of the information relevant to the decision in order to make decisions more quickly and easily) and that heuristics do not necessarily lead to less accurate decisions than more complex strategies. In fact, the consent decision is necessarily made within a limited time frame (a survey or interview) and with incomplete information. Based on prior qualitative work, we hypothesize that the heuristic decision processes used by respondents to make consent decisions are heterogeneous across individuals and contexts. Heuristic decision processes differ in the amount and nature of the information that is used in making the decision; we refer to more information-intensive heuristics as “reflective”. We also hypothesize that more reflective decision processes are associated with higher consent propensities and greater comprehension.
To quantitatively assess the prevalence of more versus less reflective processing, we use a multi-method approach as advocated by Schulte-Mecklenbeck, Kühberger, and Ranyard (2011). Since explicit measurement of decision-making processes through verbal self-reports may be limited by a lack of awareness and ability to report, we use a combination of different self-reports and survey paradata (referred to by Fific, Houpt, and Rieskamp (2019) as “covert process tracing methods”). We implemented experimental data collection across five different survey samples with different characteristics: face-to-face and online, population and convenience, cross-section, and panel. Respondents were presented with a consent request, and additional information was then collected both from survey paradata and follow-up questions, including structured post-decision verbal self-reports (Ranyard and Svenson 2019) on how the consent decision was made. All data collection was conducted in the United Kingdom, and the consent request was to link survey responses to records held by HM Revenue & Customs (HRMC; the UK's tax authority).
Using these data, we first document the extent to which self-reports indicate heterogeneity in the consent decision-making process and we validate these self-reports with more objective measures, including paradata such as time taken to respond to the consent request. Next, we document how the decision process employed to respond to a consent request is affected by the background characteristics of the respondent and by features of the survey context. Three of the latter (the placement of the consent request, the readability of the consent request, and whether respondents were “primed” to reflect on their trust in the survey organization) were experimentally manipulated (for previous research reported elsewhere) in at least one of our samples. Finally, we examine the associations between self-reports on the decision process and consent outcomes: the decision itself, measures of comprehension of the linkage process, and a measure of subjective confidence in the decision. Two of our samples are linked longitudinally, allowing us to examine the longitudinal association between decision process and consent as well.
While the present research focuses on linking survey data to government administrative records, the issues we study also apply to other linkages, such as social media (e.g., Mneimneh 2022) and digital trace data (e.g., Silber et al. 2022).
Conceptual Framework and Research Questions
Our conceptual thinking and the research design for this paper were informed by qualitative in-depth interviews, in which respondents were asked how they came up with their decision to consent or not to consent to administrative record linkage. That work is described in detail by Beninger et al. (2017) and further discussed by Jӓckle et al. (2021b). In interpreting the findings from those qualitative interviews, we drew on several strands of literature on decision making. In this section, we review that literature and present our conceptual framework and research questions.
Our view is that the decision to consent to data linkage is not an overly consequential one for the individual and is based on relatively limited information presented in a constrained time frame. Given this, the decision is likely to be made on the spot, with participants making a relatively quick decision based on the limited amount of information presented, and using information external to the request itself, such as knowledge of or trust in the organizations involved. The decision process is therefore heuristic but may involve varying degrees of information and reflection.
There is a large literature on dual-process theory or two-system processing, covering a wide range of research areas from medical decision making to behavioral economics. A common view is that the process by which people make decisions can be of two broad types, variously called systematic versus heuristic processing (Chaiken 1980), central versus peripheral processing (Petty and Cacioppo 1986), reflective versus impulsive processing (Strack and Deutsch 2004), or system 2 versus system 1 processing, respectively (Kahneman 2011). The first path or process is viewed as rational, deliberate, effortful, conscious, and often reliable. The second path is viewed as unconscious, automatic, or “fast and frugal” (Gigerenzer and Goldstein 1996; see also Gigerenzer 2000).
A key notion is that people are “cognitive misers” (see Corcoran and Mussweiler 2010), striving to process information efficiently and to make decisions without consuming too many cognitive resources, even if doing so may potentially compromise the accuracy of the results. That is, people often rely on heuristics to reduce complex cognitive tasks to more simple operations. A common view, popularized by the work of Tversky and Kahneman (1974; see also Kahneman 2011), is that heuristic decisions are error-prone. In contrast, Gigerenzer and Gaissmaier (2011) take the view that heuristics can be more accurate than more complex strategies even though they process less information. Gigerenzer and Gaissmaier (2011:454) define a heuristic as “a strategy that ignores part of the information, with the goal of making decisions more quickly, frugally, and/or accurately than more complex methods.” Similarly, Galotti (2007) found that non-experts making important real-life decisions “consistently constrained the amount of information they considered,” consistent with the notion of bounded rationality (see Simon 1957, 1959) and suggesting adaptive strategies even for complex and consequential decisions.
Where does the request for consent to data linkage fit into this literature? It has more significant consequences for participants than the hypothetical choice experiments often used to test heuristic strategies. But the stakes are lower than, say, in the field of medical or financial decision-making. The decision is made with limited information (e.g., the risks of disclosure are largely unknown; much of the information provided in surveys is about the process of linkage, rather than the consequences). Consent materials are often written to provide as much information as possible about the request, apparently assuming respondents make a careful evaluation of the pros and cons of consent. However, consent decisions seem to be made relatively quickly (Desch et al. 2011; Ghandour, Yasmine, and El-Kak 2013; Jӓckle et al. 2024; McNutt et al. 2007) and change over time (Jäckle et al. 2021a; Weir et al. 2014). Further, the decision is an unbalanced yes/no choice. A “yes” decision brings potential risks but few tangible benefits for the respondent, while there are few, if any, negative consequences of a “no” decision for the individual. Contrast this, for example, with a choice between surgery and medication in the medical decision-making literature.
The decision to consent (or not) to record linkage is also made in the context of a survey. For most survey questions, where the stakes are relatively low and the consequences of an “incorrect” answer are negligible, respondents may engage in “satisficing” (Krosnick 1991; Krosnick and Alwin 1987; Simon 1957) or taking cognitive shortcuts. Switching to a more deliberative approach to consider the pros and cons of consenting to record linkage may run counter to the default mode of responding in surveys, where respondents are sometimes encouraged to give the first answer that comes to mind.
Thus, given the constraints of time and information, and the low stakes, we hypothesize that respondents use a variety of heuristic strategies to deal with the consent request. However, we also hypothesize that the decision process varies across individuals and contexts, differing in the amount and nature of the information that is considered. Some individuals will attempt to consider some of the costs and benefits of consent, or their trust in the survey organization or data holder. We will refer to such decisions as “more reflective” (though this should not be taken to imply fully rational decision making). Others may be based on habit or gut feeling. We refer to these as “less reflective.” That is, there is variation in how information intensive the decision process is, and the extent to which central arguments (pros and cons of consent) versus peripheral cues are used in the process of making a decision.
There are many factors that could affect the processes survey respondents use when making a decision about consent. These are illustrated in Figure 1. Some of these are individual characteristics, experiences, and attitudes that may predispose respondents to a certain decision process or even outcome. These may include such factors as cognitive capacity, prior knowledge or experience of administrative data and risks of linkage, motivation, general attitudes towards data sharing and privacy, and so on. A second set of factors that may influence the decision process adopted relate to attributes of the organizations involved, including both the survey organization and the data holder. Participants’ knowledge of, experience with, and trust in, those organizations may influence how they process the request. Finally, the design of the consent request and the survey context in which it is posed may affect the decision process. Both the content (what information is conveyed) and the format (how the information is presented) of the request are important here. The survey mode in which the request is delivered and the role of the agent (interviewer) in delivering the request also play a role (see Jäckle et al. 2022b for a detailed examination of differences in the decision process between face-to-face and web respondents). Much of the experimental research on consent has focused on manipulating the content and format of the request (e.g., gain vs. loss framing, longer vs. shorter descriptions of the linkage process, etc.). This literature, which is reviewed by Jäckle et al. (2021b), has found small and often contradictory effects on consent.
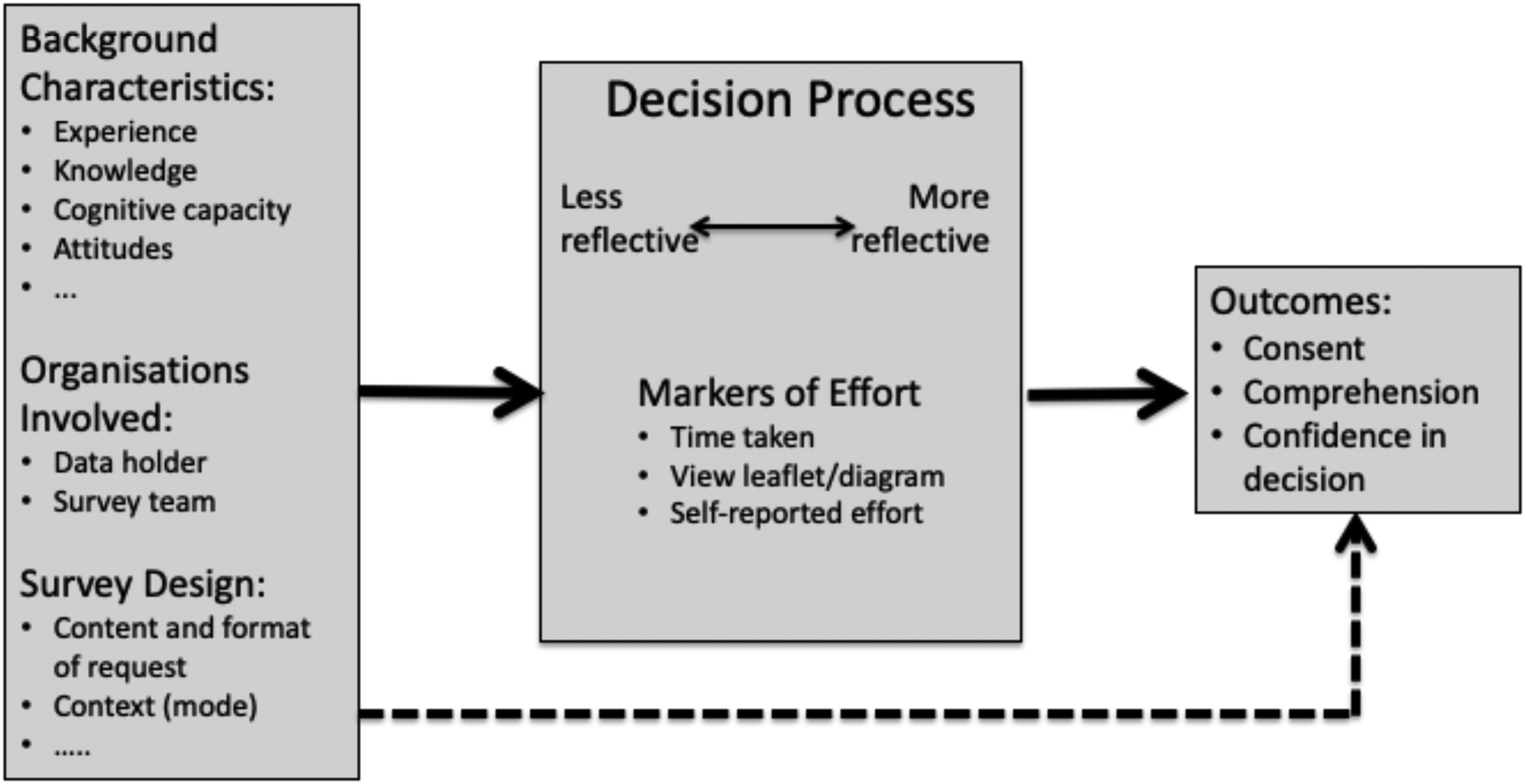
Conceptual framework.
In the conceptual framework described in Figure 1, the decision process mediates the effect of these background variables on outcomes, including the decision itself and comprehension of the request. At the same time, we do not rule out that characteristics of the individual, survey organization, consent request, and survey context may have direct effects on these outcomes (as indicated by the dotted arrow in Figure 1). An important implication of this is that it is very challenging to estimate the causal effect of the decision process on outcomes. To do so requires a source of variation (e.g., an instrumental variable) that affects outcomes only through the decision process, or a strong sequential ignorability assumption (Imai et al. 2011; Keele et al. 2015). It is not clear how either requirement could be met. Nevertheless, associations between decision processes and consent outcomes are suggestive, and to our knowledge, have not previously been documented. We can however plausibly estimate the (full) causal effects of pre-determined characteristics of individuals on decision processes, as well as the causal effects of experimentally-manipulated survey design features.
To summarize, our research questions are as follows:
With respect to RQ1, we hypothesize that most consent decision processes are heuristic, but that they vary across individuals and contexts, particularly in the degree to which they are reflective (i.e., in the nature and amount of information that is considered). RQ2 is exploratory, given a lack of a prior evidence on consent decision processes. However, the linkage consent literature documents weak, and often inconsistent, associations between respondent and survey characteristics and consent outcomes, and so one might expect similar findings for the consent decision processes. Finally, with respect to RQ3, we hypothesize that more reflective decision processes are associated with higher rates of consent and more informed consent. We also expect those associations to hold longitudinally. Changes in the decision process may help explain the individual changes in consent response over time that have been observed in the literature (Jäckle et al. 2021a; Weir et al. 2014). We now turn to describing our data.
Data, Measures, and Experimental Design
Samples and Research Stages
We use data collected from five samples in three stages. In the first stage, we collected data in Wave 11 of the Understanding Society Innovation Panel (University of Essex 2024). The Innovation Panel is a probability sample of households in Great Britain that is used for methodological testing and experimentation and its design mirrors the main panel. The Innovation Panel was first fielded in 2008 with an achieved sample of 1,500 households. Interviews are sought with all household members aged 16 + once a year. To maintain the sample size, refreshment samples are added every few years. The 2018 wave was fielded from May to October 2018. In the text below we refer to this survey as IP11. For more information on the design and implementation of the Innovation Panel, see the User Guide (Institute for Social and Economic Research 2024). Where we present results separately for face-to-face and web respondents, we refer to IP11-A and IP11-B, respectively, but our focus is on the replication of findings across samples with different characteristics. For further details of the mode experiment, see Jäckle et al. (2022b). In the current article, we define samples by mode of response, rather than assigned mode.
Since the sample size constrained the number of experimental treatment groups we could implement, additional surveys were fielded using an access panel (Jäckle et al. 2022a). The PopulusLive access panel (AP) is a non-probability online panel in the United Kingdom with around 130,000 active sample members at that time, who were recruited through web advertising, word of mouth, and database partners. To enable some comparison with the Innovation Panel, the sample was restricted to Great Britain, and quotas based on age, gender, and education were set to match the characteristics of the IP11 sample.
Two samples were selected in this way. The first was surveyed in May 2018 and a sub-set was surveyed again in May 2019. We refer to the surveys from this two-wave panel as AP1.1 and AP1.2, respectively. The second sample was selected independently in December 2019 and surveyed only once. We refer to this survey as AP2. The implementation of these surveys was led by NatCen Social Research, in collaboration with the PopulusLive panel. The AP samples included other experiments not reported on here (Jäckle et al. 2022b, 2024; Walzenbach et al. 2022). Table 1 presents a summary of the key features of the five samples used in our analyses. Additional information on response and participation rates is presented in Appendix 1, Supplemental Material.
Overview of Samples and Experiments.

Note. Prob = probability sample; non-prob = non-probability sample; FTF = face-to-face survey; Web = online survey.
Measures
Outcomes: Consent, Understanding, and Confidence
The key outcome we examine is consent to link to income, employment, and tax records held by the UK tax authority, HM Revenue and Customs (HMRC). All respondents were asked this question and shown an information leaflet and a flowchart visualizing the data linkage process. They were not told about the data linkage request in the invitation to the survey. The full wording of the question is reproduced in Appendix 2, Supplemental Material. A subset of the AP samples was in addition asked to link data on health, education, benefits and state pensions, energy usage, and education. The randomized subset of the AP samples that were asked multiple consents were excluded from the analysis in this article, and so that treatment will not have affected the consent question studied in this article. We report on the decision process for multiple consent questions in a separate paper (Walzenbach et al. 2022).
At the end of the AP surveys, respondents were told that their data would not actually be linked as the purpose of the survey was to collect information about the attitudes and concerns of the general public about data sharing. The Innovation Panel data will however be linked.
Item nonresponse rates for the consent request were low, ranging from 0 in the AP1 sample to 3.2 percent in the IP11-A sample. In practice, failure to answer a consent question means that consent has not been granted, so for this question, we code item nonresponse as non-consent.
Objective understanding was measured using a series of eight true/false questions about the data linkage process (see Appendix 4, Supplemental Material). These are based on a similar test of understanding by Das and Couper (2014). Across samples < 4 percent of respondents answered some but not all eight test questions. We assume that question-specific nonresponse indicates an inability to answer that question, and so don’t know and refusal answers are coded as incorrect answers. In contrast, the test score is set to missing for respondents who did not answer any of the eight test questions. This was below 1.5 percent in all samples except for IP11-B, where it was 11 percent of the sample. We have not been able to pinpoint the cause of the significantly higher item nonresponse for this item in this sample, despite extensive investigation. Sensitivity analyses making different assumptions about these missing cases do not alter the key findings.
Subjective understanding was measured with a single item asking “How well do you think you understand what would happen with your data…,” with a four-point response scale ranging from “I do not understand at all” to “I understand completely.” Confidence was similarly measured with a four-point response scale ranging from “Very confident in my decision” to “Not confident in my decision.” Full details of these questions are presented in Appendix 4, Supplemental Material. For both measures, item nonresponse was below 2 percent in all samples.
Decision Processes
Measuring and identifying cognitive processes is difficult (Nisbett and DeCamp Wilson 1977). We, therefore, use a multi-method approach (Schulte-Mecklenbeck, Kühberger, and Ranyard 2011) and validate self-reports with survey paradata that are indicative of the cognitive effort respondents made in answering the consent question.
The first self-report is a structured post-decision question. The wording of this question is based on prior qualitative research that examined which factors influence the decision to consent to data linkage (Beninger et al. 2017). In that qualitative work, the projective technique of construction (Mesías and Escribano 2018) was used and participants were asked to take a third-party perspective (see Appendix C Section 3 of Beninger et al. (2017) for the prompts used). This was intended to enable participants to access thinking or beliefs that are less conscious or may be difficult to speak about and to elicit truthful rather than socially acceptable answers. The findings revealed sub-conscious, rational, social, and environmental factors and variations between participants in which of these they take into account when making the consent decision. The findings also hint at differences between participants in the decision process they use when answering consent questions. Some responses are indicative of reflective processing, for example, “I would say yes because there is nothing I would say that could be used against me. If I was doing something dodgy, working and claiming and avoiding tax and stuff like that I would say ‘no, I don't want to do it’.”; some responses are indicative of habit-based processing, for example, “I think I was just so in the habit, and I still am, of if a site asks you for information you don't give it, unless you trust the source”; and some responses are indicative of instinctive processing, for example, “It isn’t in my nature; I don’t tend to [worry about those kinds of things]” (Beninger et al. 2017:10).
As our aim in this article is to quantify the prevalence of broad decision-making strategies, in our surveys we used structured post-decision self-reports, which can be implemented in large-scale quantitative surveys and are “efficient and informative” if they are used to test specific predictions (Ranyard and Svenson 2019). Respondents were asked “How did you decide whether to say ‘yes’ or ‘no’ in response to the question about data linkage? Please select all of the answers that apply to you.
I thought about what would happen if I said ‘yes’ or ‘no’
Instinct or gut feeling
I said what I usually say when I’m asked for information that is very personal
I thought about how much I trust the organizations involved (AP1.1. and AP1.2 only)
Something else (please specify)”
The response options are deliberately broad, and each is likely to include different specific decision-making processes. Respondents might not be aware of specific heuristics they used, but the qualitative findings suggested that they might be aware in broad terms whether they gave the question some thought, made an instinctive decision, or did what they usually do in response to this type of request. In their review of the accuracy of self-reported cognitive processes, Nisbett and DeCamp Wilson (1977) suggested that there are situations where a self-report will be more accurate than a “judgement of plausibility.” These are situations where the cognitive process is influenced by knowledge that is personal to the respondent, including knowledge of prior idiosyncratic reactions to a class of stimulus (this corresponds to response category 3), and knowledge of whether they paid attention to a particular stimulus or whether they pursued a particular intention (this would correspond to options 1 and 2—whether they thought the question through or made an instinctive decision).
This question was pretested in a pilot for the AP surveys. After reviewing and coding the open text responses in the “something else” category from the AP pilot survey, we decided to add the fourth response option about trust in the organizations involved to the AP1.1 and AP1.2 surveys; however, it was too late to add this response option to the Innovational Panel.
Nonresponse to this question—defined as not selecting any option, not even “something else”—was completely absent in the AP samples, and 1.3 percent and 3.6 percent in the IP11-A and IP11-B samples, respectively. The “something else” response option was selected by 3.7 percent of respondents in AP1.1, 3.2 percent in AP1.2, 5.1 percent in AP2, 9.1 percent in IP11-A, and 7.0 percent in IP11-B.
Note that respondents could select more than one option. For the analyses below, we employ two coding schemes for the responses to this question. For descriptive statistics and testing for differences between groups defined by the response to this question, we adopt an “exclusive” coding system, where we examine the five most common combinations of one or more response options. These patterns define mutually exclusive groups of respondents, and they cover the majority of respondents (between 72 percent and 87 percent, depending on the sample). However, when we estimate models in which the self-reported decision process is either the dependent or independent variable, we employ an “inclusive” coding. For example, we code “trust” as one if the respondent selected that option, either alone or in conjunction with other options (and zero otherwise). This allows the full sample to be employed in model estimation and means that the contrast is between all those who report trust, and all those who do not.
Markers of Cognitive Effort
We use a combination of survey paradata and additional self-reports to validate the self-reported decision processes.
The time taken to answer the consent question (in seconds) is derived from the keystroke paradata. This measure is right-skewed, so we perform a logistic transformation for analysis.
For web respondents, we also use paradata to identify whether they clicked on the links to access additional information (leaflet and diagram) about the data linkage. For face-to-face respondents in IP11-A, we use an interviewer observation asking whether the respondent read the leaflet or whether the interviewer explained the diagram to the respondent.
In samples AP1.2 and AP2, we added a self-reported measure of effort, asking respondents “On a scale of 0 to10, where 0 is no effort at all and 10 is a great deal of effort, how much effort did you put into coming up with your answer about data linkage?” There was no item nonresponse on this question in either sample.
Further, in the AP2 sample, we also asked people what role various factors played in making their decision. The full list of possible factors is given in Table 3 and in Appendix 4, Supplemental Material. The order of these response options was randomized to reduce primacy effects. Each option was rated on a five-point scale with 1 being “played no role” and 5 being “played a very big role.” There was no complete nonresponse for this item battery, but 0.5 percent of respondents had missing values on some of the factors.
Markers of Decision Effort by Reported Decision Process.
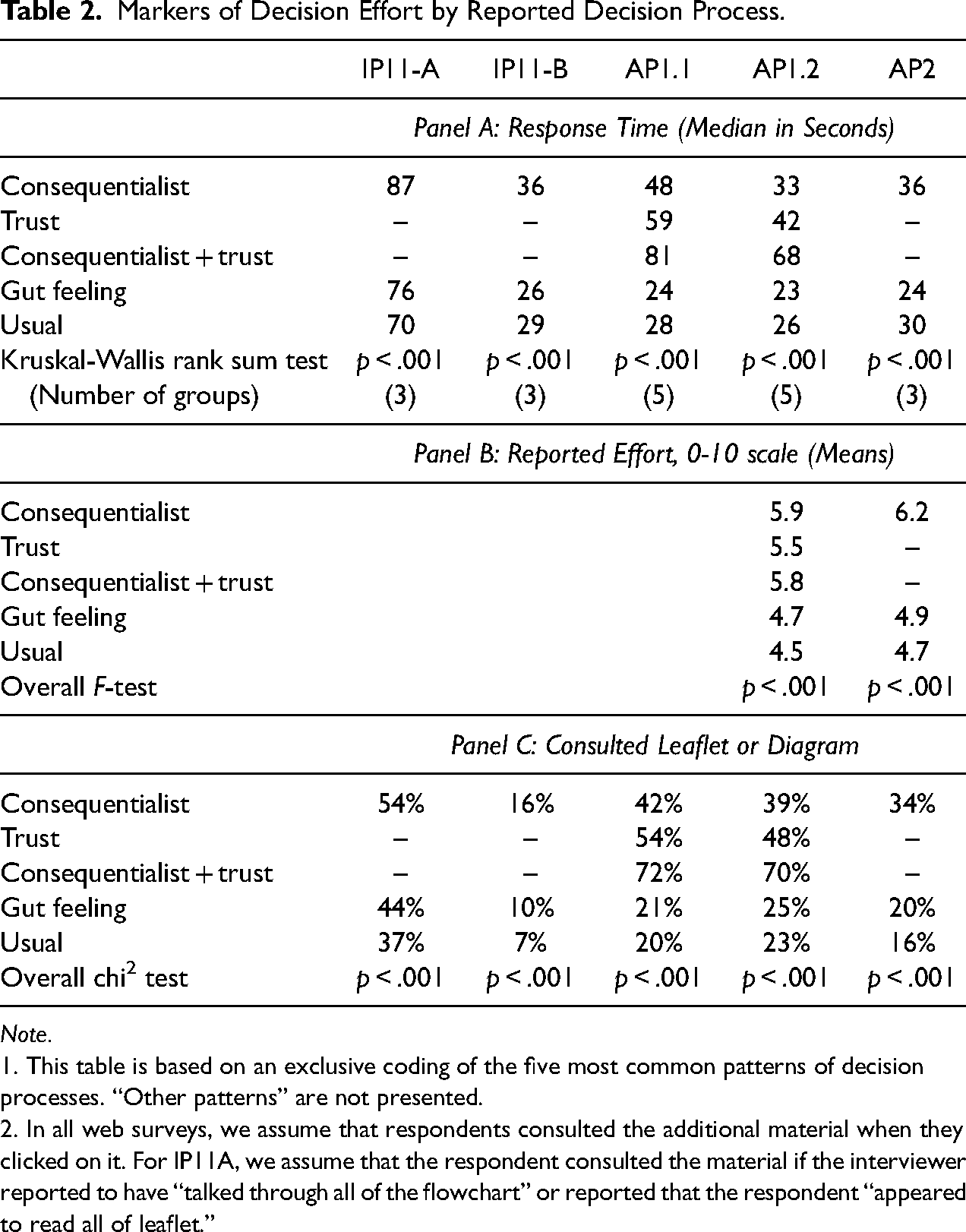
Note.
1. This table is based on an exclusive coding of the five most common patterns of decision processes. “Other patterns” are not presented.
2. In all web surveys, we assume that respondents consulted the additional material when they clicked on it. For IP11A, we assume that the respondent consulted the material if the interviewer reported to have “talked through all of the flowchart” or reported that the respondent “appeared to read all of leaflet.”
Model Covariates
We include two kinds of covariates in models to explore the determinants of the consent decision process. The first are survey characteristics. Three of these were experimentally manipulated in our data for the previously reported research (Jӓckle et al. 2024). These are a wording experiment, an experiment varying the placement of the consent question within the survey instrument, and a trust-priming experiment. These experiments were not designed with the decision process in mind, but they do provide some experimental variation in survey characteristics. More details on these experiments are given in Appendices 2 and 3 Supplemental Material.
Second, we also include selected socio-demographic background covariates in our multivariable models: sex, age, education, and employment status. One might expect more reflective decision making among those with more education, for example. In general socio-demographic variables were included because they have been used in analyses of consent outcomes. For these covariates, item missingness is very low: below 1 percent for all variables in all samples except education, which reaches 1.9 percent in IP11-B and 3.1 percent in IP11-A. We considered a number of additional predictors including household size, home ownership, measures of mood, and, in the Innovation Panel samples, time in the panel (a measure of commitment to the panel). As these did not have statistically significant effects in any sample, they are dropped from the final models reported below.
Given the very low rates of item nonresponse throughout, we code nonresponse as described in this section and conduct complete-case analyses below.
Results
RQ1. Does the Consent Decision Process Vary Across Individuals and Survey Contexts?
When asked after the fact how they made their decision to grant or deny consent to data linkage, the majority of respondents chose a single response option (e.g., consequentialist thinking or gut feeling). Multiple answers were allowed, but were relatively infrequent; each combination was reported by < 3 percent of respondents, with one exception: In the AP1.1 and AP1.2 samples, where, as noted earlier, we additionally offered “trust” as a response option, a substantial fraction of respondents (9.3 percent and 7.8 percent, respectively) selected both consequentialist and trust response options.
In light of this, Figure 2 uses an exclusive coding of the decision process and shows the five most common patterns, subsuming all other combinations of answers (as well as all those who selected “something else”) in “other patterns.” For example, the label “consequentialist” refers to respondents who exclusively selected the option “I thought about what would happen if I said ‘yes’ or ‘no’.” Across samples, this option was chosen (alone) by 12.5 percent to 35.7 percent of respondents. We consider both “consequentialist” and “trust” to be more reflective decision processes. They are often reported together, and indicate reflection, either on the consequences of consent, or on the organizations involved.
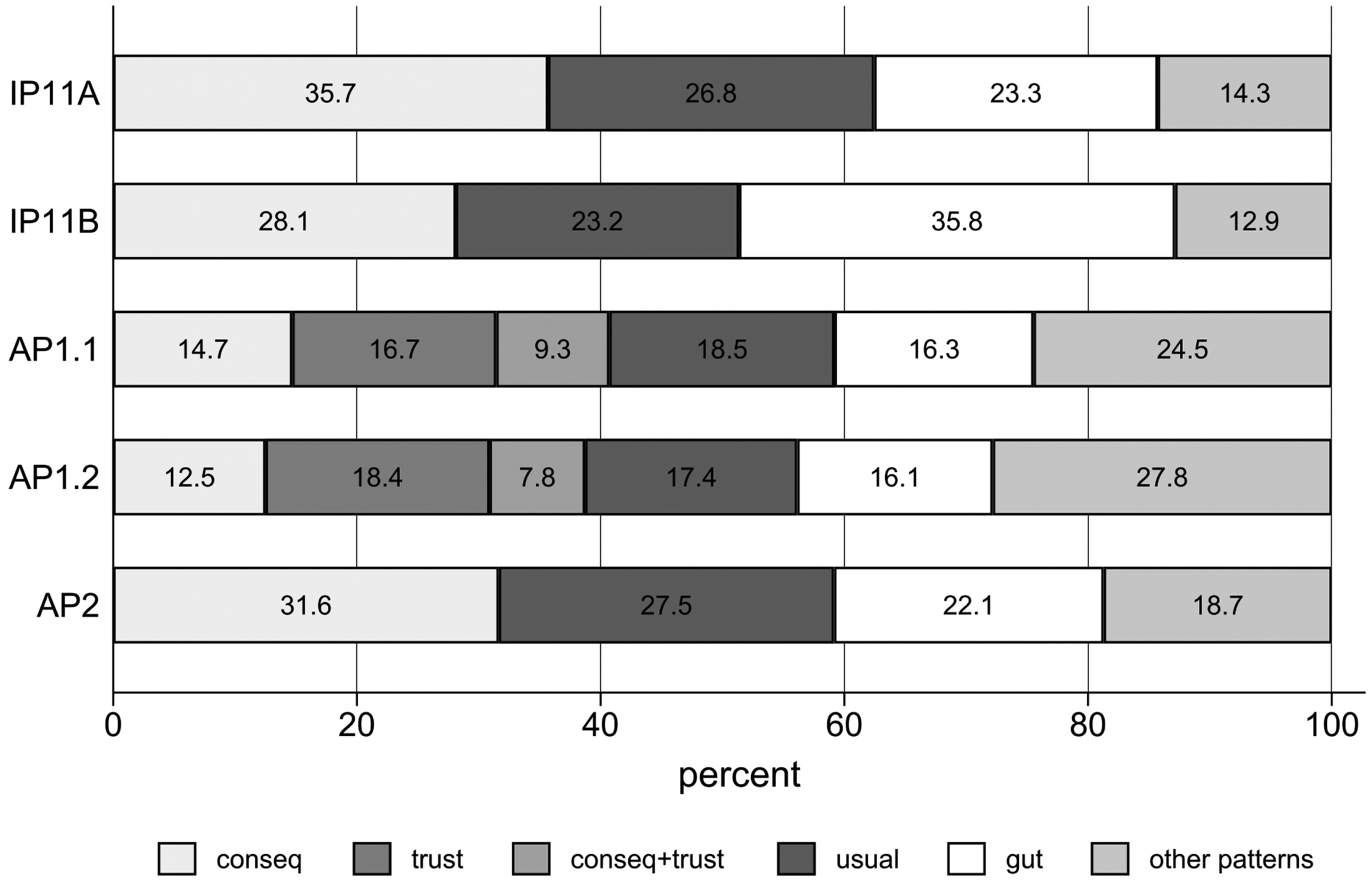
Frequencies of self-reported decision processes.
Other respondents reported decision processes that were less reflective or more instinctive. For example, across all samples, 17 percent to 28 percent of respondents selected only the option “I said what I usually say” (labeled “usual” in Figure 2) and 16 percent to 34 percent reported only “instinct or gut feeling” (labeled “gut” in Figure 2).
It is clear that respondents make decisions in heterogeneous ways. A significant fraction of respondents report thinking about the consequences of consent, but another group instead consider their trust in the survey organization and data holder, and further groups make less reflective decisions, relying on a gut feeling or instinct, or on habit or usual practice.
In AP1.2, respondents who chose several decision processes were asked to specify the most important one in a follow-up question. Of these, 36.8 percent reported trust to be their prime motivation behind their consent decision, followed by 24.7 percent who picked a consequentialist approach, 18.9 percent who did the usual, 16.7 percent who relied on their gut feeling, and 3 percent who picked “something else.” If we only consider one most important decision process per respondent, trust remains the single most important decision process in the AP1.2 sample. Trust was either the only or main decision process reported by 30 percent of all AP1.2 respondents.
Importantly, we find that the fraction of respondents reporting an exclusively reflective decision process (consequentialist and/or trust) is 40 percent or less in all samples (ranging from 27 percent in IP11-A to 40 percent in AP1.1). In contrast, the fraction of respondents who exclusively report unreflective decision processes (“gut” or “usual”) range from 37 percent in the AP1 samples to 60 percent in IP11-A. Taken on their face, these self-reports are an important challenge to the usual strategy of increasing consent through the provision of additional information.
Are these self-reports of the decision process meaningful? To assess this question, we looked at markers of decision effort. These are reported in Table 2 and they are consistent with the self-reports.
Decision Processes and Information Considered for the Consent Decision (AP2).
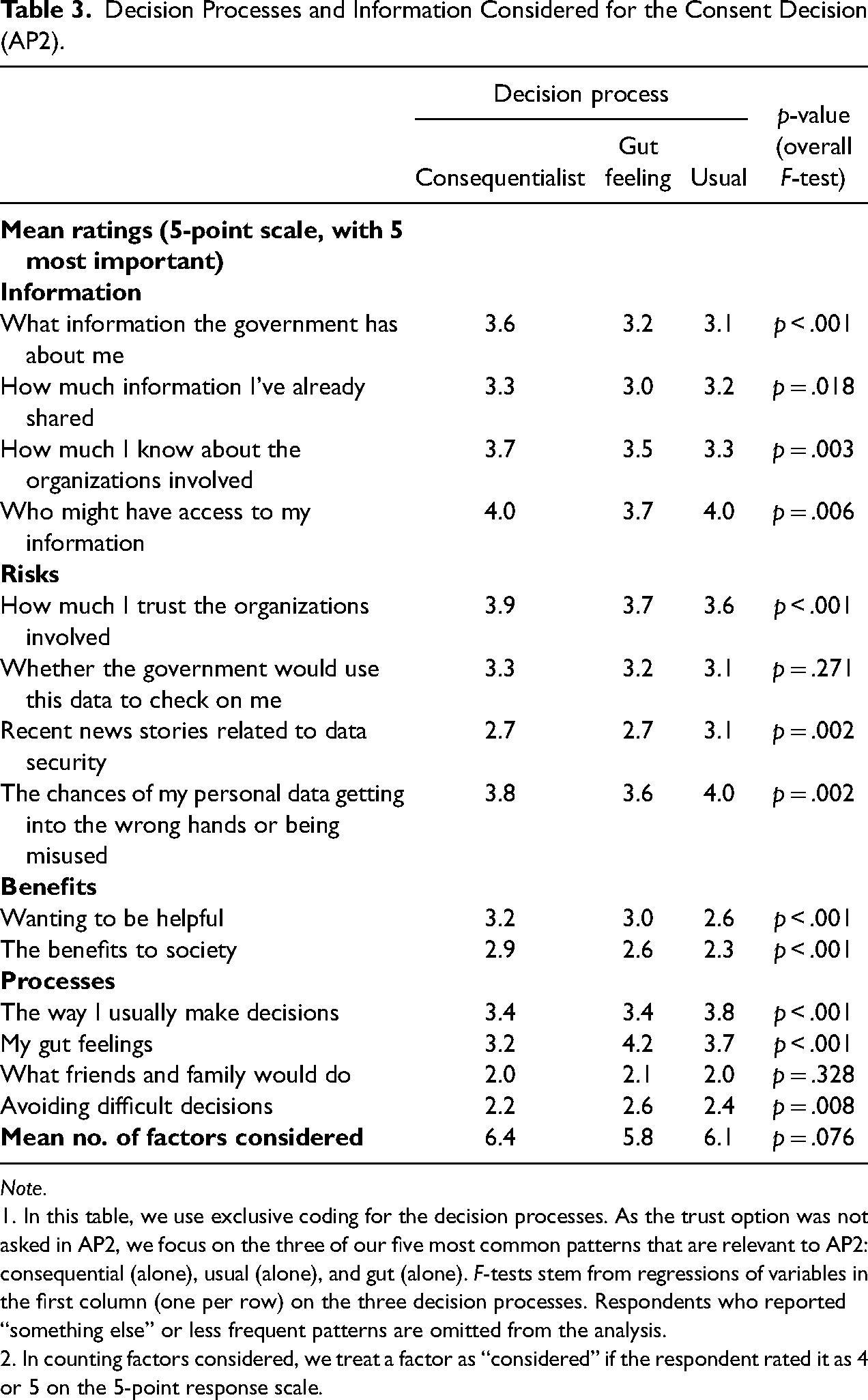
Note.
1. In this table, we use exclusive coding for the decision processes. As the trust option was not asked in AP2, we focus on the three of our five most common patterns that are relevant to AP2: consequential (alone), usual (alone), and gut (alone). F-tests stem from regressions of variables in the first column (one per row) on the three decision processes. Respondents who reported “something else” or less frequent patterns are omitted from the analysis.
2. In counting factors considered, we treat a factor as “considered” if the respondent rated it as 4 or 5 on the 5-point response scale.
Starting with response time, in AP1.1 respondents who reported “consequentialist”- or “trust”-based decision processes had median response times for the consent question of 48 and 59 s respectively (see Panel A of Table 2). Particularly the combination of “consequentialist” and “trust” was associated with longer response times and presumably more thorough processing. In contrast, those respondents who reported “gut feeling” or “usual” decision processes had much shorter response times, with medians of 24 and 28 s, respectively. Qualitatively similar results for response time were obtained in all samples. Differences in mean response times across decision processes are statistically significant in all samples.
A similar pattern can be observed in the respondent self-reports of the effort required for the decision (see Panel B of Table 2). Effort was reported using an 11-point scale ranging from 0 to 10, with higher values indicating higher effort. These data are only available in AP1.2 and AP2. As with response times, the responses align with the chosen descriptions of the decision process, with those reporting “consequentialist” or “trust” reporting greater effort than those reporting “gut feeling” or “usual,” and again differences across decision processes are statistically significant.
Our third marker of effort is whether respondents consulted the additional materials on the data linkage process while deciding whether to consent. In the online surveys, this required clicking hyperlinks to access the leaflet or diagram. In the face-to-face survey (IP11-A), the interviewer provided these materials and noted whether the respondent looked at them or not. These results are presented in Panel C of Table 2 and show similar patterns to the other markers of effort. Respondents who based their consent decision on consequentialist thinking or trust made more use of additional materials than respondents who reported gut feeling or their usual behavior as their decision process. This is even more so if respondents used a combination of both consequentialist and trust-based decision processes. Although the absolute levels of consultation vary quite substantially between the samples, the relative pattern across self-reported decision processes is the same for all samples, and the differences across decision processes are statistically significant in all samples.
Finally, recall that as a further check in the AP2 sample, we also asked people what role various factors played in making their decision. Each item was rated on a five-point scale with 1 being “played no role” and 5 being “played a very big role.” Items such as “what information the government has about me,” “how much I know about the organisations involved,” and “the benefits to society” played a larger role for those respondents who reported a consequentialist decision process.
Table 3 shows the results of the reported decision process. As the trust option was not asked in AP2, we focus on consequential, usual, and gut responses. The answers to this question also show that respondents who reported a consequentialist decision took a broader range of factors into account in making their decision. We treat a factor as ‘considered’ if the respondent rated it as 4 or 5 on the scale. Respondents who reported a consequentialist decision considered on average 6.4 factors, while respondents who reported a gut- or habit-based decision considered on average 5.8 and 6.1 factors, respectively, an overall F-test yields F(2) = 2.59 and p = .076. These results suggest that the decision process varied both in which type of information respondents based their decision on, and in the amount of information they considered.
In summary, these multi-method findings give us confidence that self-reported decision processes measure genuine differences in how respondents arrived at their answers to the consent question. Relative to those who report less-reflective processes (instinct or gut feeling, habit or usual practice), those who report using more-reflective processes (consequentialist and/or trust) took longer to answer the consent question, reported investing more effort in the decision, consulted the additional materials at a higher rate, and these patterns replicate across all samples. In addition, the nature and quantity of reported factors that play a role in their decision are consistent with the decision process respondents reported.
RQ2. What Respondent and Survey Characteristics Influence the Consent Decision Process?
We next consider the extent to which the decision process is predicted by socio-demographic background characteristics (sex, age, education, and employment status) and by survey design. As described above, we experimentally manipulated the difficulty of the question wording (for the AP1 and IP11 samples), the location of the consent question in the questionnaire (for the IP11-A sample), and whether the respondents were shown a trust-priming statement (for AP2).
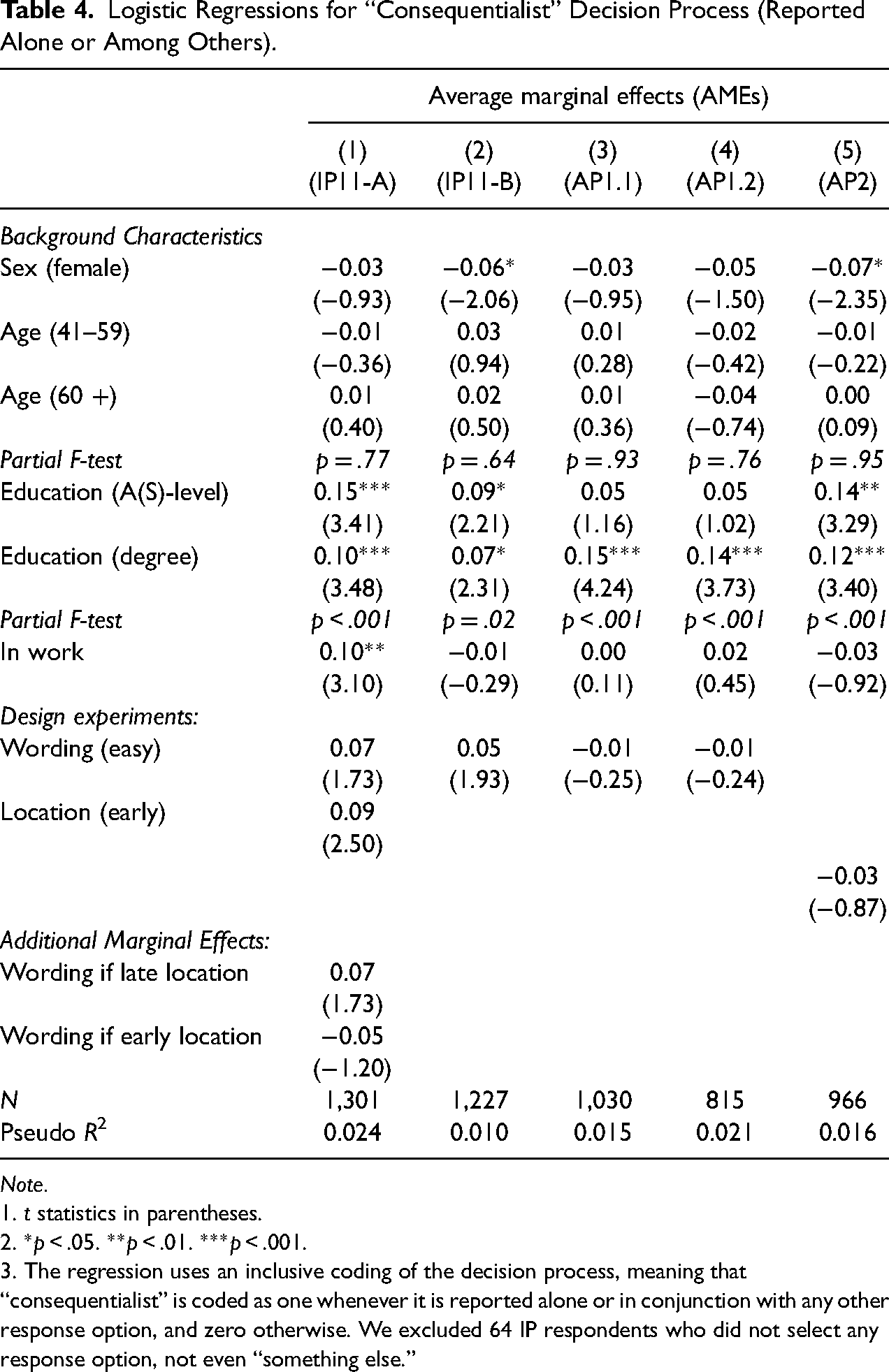
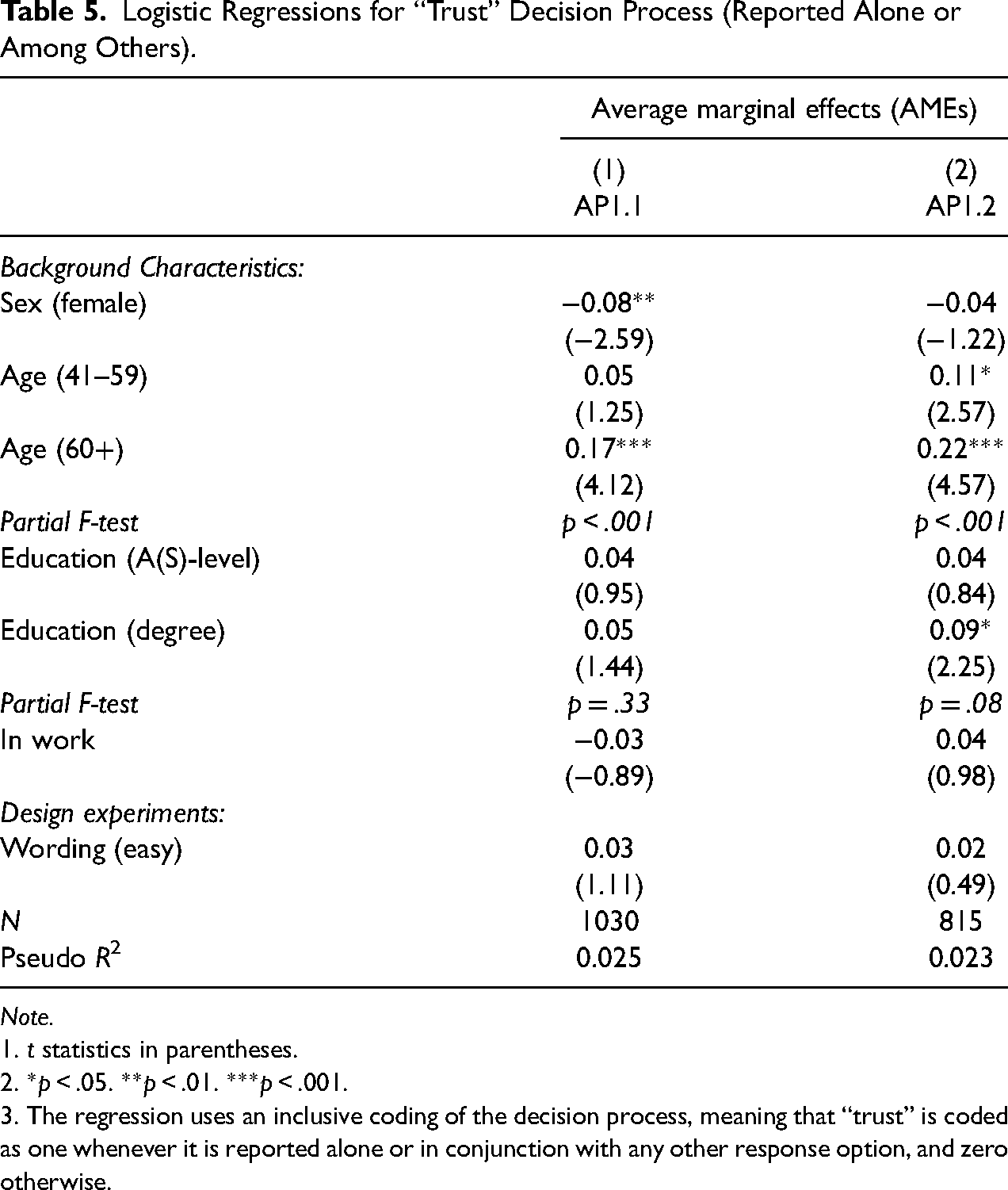
Table 4 reports average marginal effects (AMEs) estimated from logit models of the probability that the consent decision was processed in a consequentialist way. Table 5 similarly reports AMEs of the probability that the self-reported decision process involved trust. Overall, Tables 4 and 5 indicate that the decision process is not strongly predicted by socio-demographic variables or the survey design elements that we experimentally manipulated. All models have limited explanatory power with McFadden pseudo-R2 values ranging between 0.01 and 0.024.
Logistic Regressions for “Consequentialist” Decision Process (Reported Alone or Among Others).
Note.
1. t statistics in parentheses.
2. *p < .05. **p < .01. ***p < .001.
3. The regression uses an inclusive coding of the decision process, meaning that “consequentialist” is coded as one whenever it is reported alone or in conjunction with any other response option, and zero otherwise. We excluded 64 IP respondents who did not select any response option, not even “something else.”
Logistic Regressions for “Trust” Decision Process (Reported Alone or Among Others).
Note.
1. t statistics in parentheses.
2. *p < .05. **p < .01. ***p < .001.
3. The regression uses an inclusive coding of the decision process, meaning that “trust” is coded as one whenever it is reported alone or in conjunction with any other response option, and zero otherwise.
The F-tests reported in Table 4 indicate that higher levels of education are associated with more consequentialist processing in all samples. Those with a university degree are seven to fifteen percentage points more likely to report a consequentialist process than the lowest education group. Effects for A-levels (an academic-track high school qualification) are of similar magnitudes, albeit less consistently statistically significant at conventional levels. Table 5 indicates that older respondents (aged 60 and above) are more likely to report a trust-based decision process, by 17 to 22 percentage points relative to those aged 40 and below, and these effects are statistically significant (p < .001).
Turning to survey design, easier wording does not induce more consequentialist or trust-based processing in any sample. Both the wording difficulty and question placement experiments were implemented in IP11-A and the logistic regression model in column 1 of Table 4 allows for both main effects of these experiments and an interaction. We found no significant interaction between wording and placement in the decision process used.
RQ3. Is the Consent Decision Process Associated With Consent Outcomes?
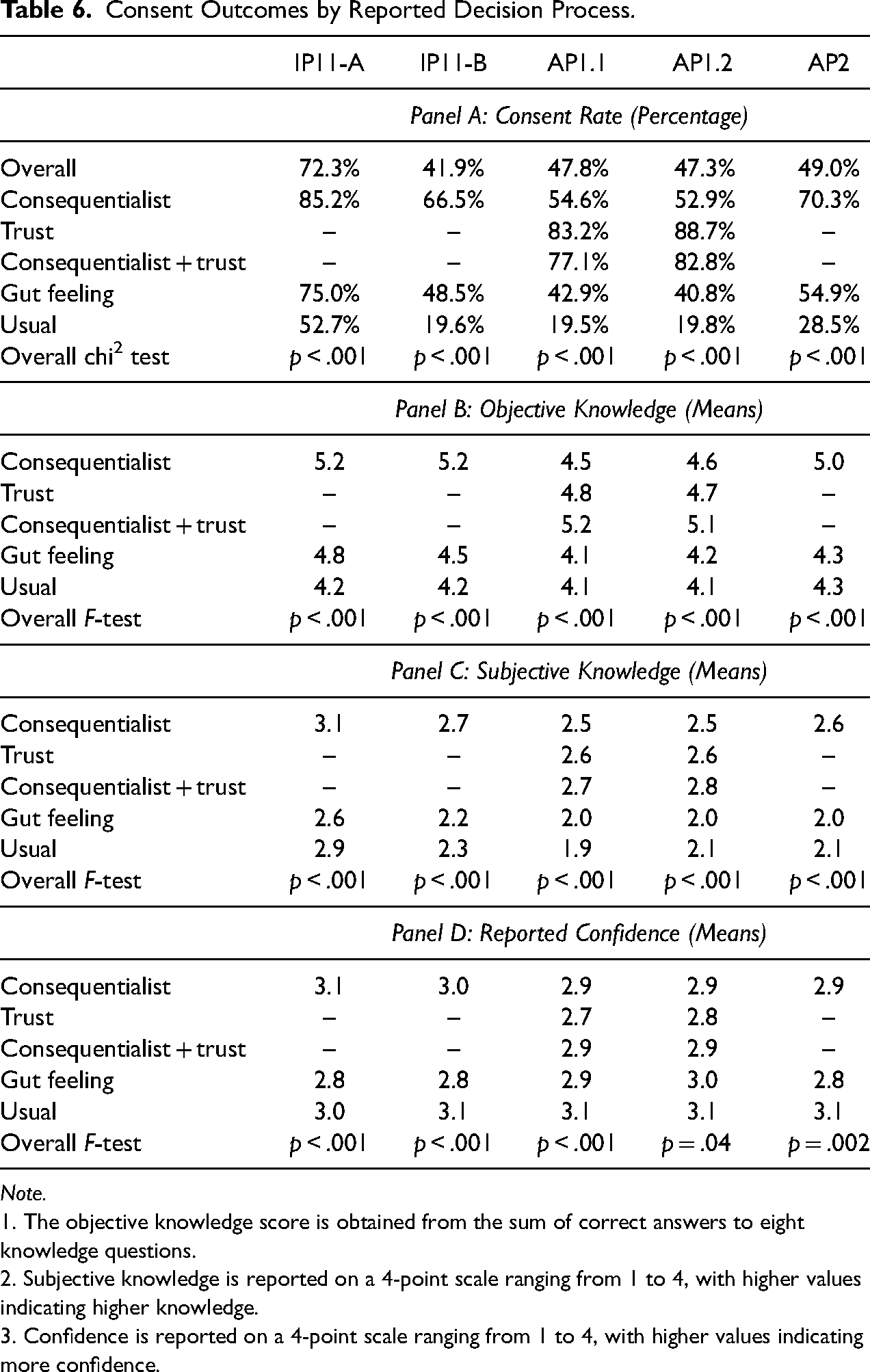
Table 6 reports how our four consent outcomes (consent rate, objective knowledge, subjective knowledge, and confidence) vary by self-reported decision process. We again contrast the five most common response options for the decision process. Panel A shows that respondents who reported more reflective processes (“consequentialist” and/or “trust”) had higher consent rates than those who reported less reflective processes (“gut feeling” or “usual”). This replicates across all five samples and the differences are large, with the consent rate in the “consequentialist” or “trust” groups often double or more than the consent rates in the “gut feeling” or “usual” groups. The differences are also statistically significant at conventional levels. In those samples where we offered “trust” as a response option, it is associated with the highest consent rates. Those who report “usual” have very low consent rates. For example, in AP1.1, 83.2 percent of those who reported “trust” alone and 77.1 percent of those who reported “trust” together with “consequentialist” consented to record linkage, compared with only 19.5 percent of those who reported doing what they usually do.
Consent Outcomes by Reported Decision Process.
Note.
1. The objective knowledge score is obtained from the sum of correct answers to eight knowledge questions.
2. Subjective knowledge is reported on a 4-point scale ranging from 1 to 4, with higher values indicating higher knowledge.
3. Confidence is reported on a 4-point scale ranging from 1 to 4, with higher values indicating more confidence.
Objective knowledge of the consent request (Panel B) follows a similar pattern. Recall that this measure is the sum of correct answers to eight knowledge questions about the information provided about the data linkage for which consent was sought. Respondents who reported “consequentialist”- or “trust”-based decision processes had higher levels of knowledge than those who reported less reflective processes (“gut feeling” or “usual”). The magnitude of the differences are 0.5–1.0 correct items (in means), and the differences are again statistically significant at conventional levels. The same pattern is seen for subjective knowledge (Panel C). Respondents who reported “consequentialist”- or “trust”-based decisions have a higher mean self-rated understanding of between 0.2 and 0.6 points on a four-point scale, and again the differences are significant at conventional significance levels. Together these results suggest that those employing consequentialist and trust-based decision processes have more informed consent.
Interestingly, reported confidence in the consent decision (Panel D) is less correlated with the decision process than comprehension. Respondents who report basing their decision on what they “usually do” report high levels of confidence in that decision. The same respondents also show the lowest consent rates by far. Thus, this is a group of respondents that confidently refuses consent and is likely to be difficult to persuade otherwise.
Those surveyed in both AP1.1 and AP1.2 form a panel of respondents observed at two points in time a year apart (May 2018 and May 2019). In the second wave, respondents were asked exactly the same consent and follow-up questions as in the first wave, without any mention of the answers they had given previously. This also allows us to examine how stable decision processes are across consent decisions for a single individual, and to test for a longitudinal association between decision processes and consent outcomes. The literature has shown that consent decisions are not stable over time. A longitudinal analysis allows us to explore whether changes in the decision process might explain this instability. A longitudinal analysis is also a natural first step in thinking about whether the associations documented in Table 6 are causal. A “fixed-effects” or “within-individual” estimator can eliminate time-invariant unobservables as potential confounders.
Between AP1.1 and AP1.2, 75 percent of respondents made some change in their reported decision process, and 24 percent of respondents changed their response to the request for consent to data linkage (13 percent changed from “yes” to “no” and 11 percent changed from “no” to “yes”). In Table 7, we document these transitions in more detail. Here for ease of exposition we group responses about the decision process into three categories: those who only report one or more reflective decision processes (“consequentialist” or “trust”-based, or both); those who only report one or more instinctive decision processes (“gut,” “usual,” or both); and finally a residual category that includes those who responded with “something else,” alone or in conjunction with other responses, and the small number of respondents who reported some mix of more and less reflective decision processes (e.g., “trust” and “usual”). The rows of Table 7 correspond to decision process responses in AP1.1, while the columns correspond to responses in AP1.2.
Stability of Decision Process and Consent.
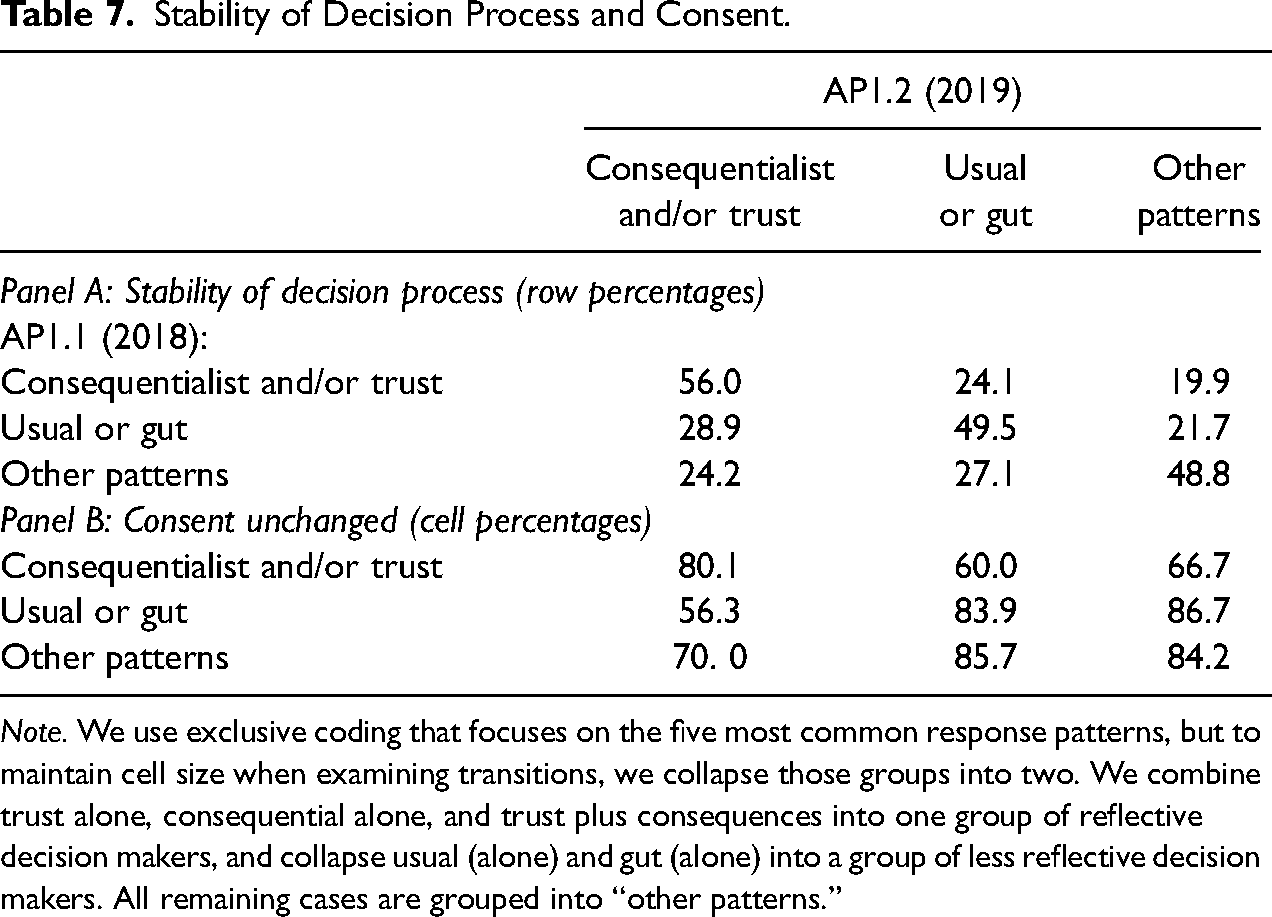
Note. We use exclusive coding that focuses on the five most common response patterns, but to maintain cell size when examining transitions, we collapse those groups into two. We combine trust alone, consequential alone, and trust plus consequences into one group of reflective decision makers, and collapse usual (alone) and gut (alone) into a group of less reflective decision makers. All remaining cases are grouped into “other patterns.”
Panel A of Table 7 indicates that decision processes are persistent, but not unchanging. The number in each cell is the row percentage. So, for example, of those who said: “consequentialist” or “trust” (or both) in AP1.1, 56.0 percent reported a more reflective decision process in AP1.2 as well, while 24.1 percent switched to a less reflective or more instinctive decision process (“gut” or “usual”) and 19.9 percent moved to the other patterns. Respondents who reported a reflective decision process in 2018 were more likely than not to do the same in 2019, and similarly, those who reported a more instinctive decision process in 2018 were more likely than not to do the same in 2019. But there is significant mobility, with almost a quarter (24.1 percent) of respondents who reported a reflective decision process in 2018 reporting an instinctive decision process in 2019, and more than a quarter (28.9 percent) of those who reported an instinctive decision process in 2018 reporting a reflective decision process one year later.
Panel B of Table 7 further indicates that changes in the decision process are associated with changes in consent decisions. In this panel, each number is a cell percentage. For example, the top left corner of Panel B indicates that of those who reported a reflective decision process in both 2018 (AP1.1) and 2019 (AP1.2), 80.1 percent gave the same consent decision (and hence 19.9 percent changed their consent decision, from “yes” to “no,” or “no” to “yes’). Similarly, of those who reported an instinctive decision process in both 2018 and 2019, 83.9 percent gave the same consent decision. Those who switched from a reflective decision process to an instinctive process, or from an instinctive process to a reflective process had much less stable consent decisions (60.0 percent and 56.3 percent, respectively). Together these results suggest that some of the instability in consent decisions is due to changes in the reported decision process.
Table 8 reports estimates of linear “fixed-effects” models which document the longitudinal (or within-person) association between decision process and consent outcomes (columns 2 through 4), as well as between decision process and the logarithm of response time (column 1). These estimates use a “within” transformation to eliminate additive, time-invariant unobservables that might confound associations estimated in the cross-sectional data. The independent variables are two binary indicators: one for whether the respondent reported a consequentialist decision and one for whether they reported a trust-based process. The two indicators are each coded as 1 if mentioned and 0 otherwise and are not mutually exclusive. Objective and subjective knowledge are, respectively, 9- and 4-point scales, and log response time is a continuous variable. Nevertheless, we report a linear model in all cases. Using a conditional logistic regression (allowing for individual fixed effects) for the binary consent variable does not change our conclusions.
Linear Fixed Effects Models of the Effect of Decision Mode on Consent Outcomes and Response Time.
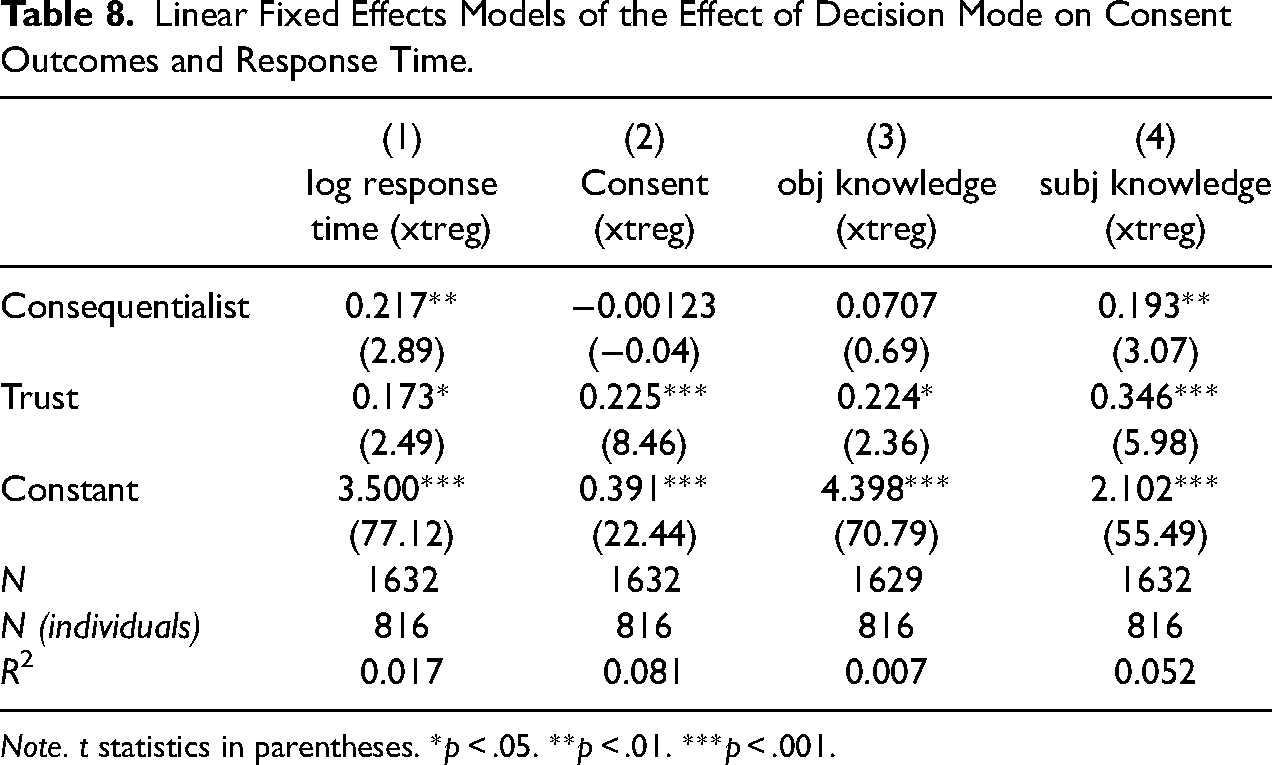
Note. t statistics in parentheses. *p < .05. **p < .01. ***p < .001.
Table 8 indicates that, within individuals over time, more reflective decision processes (consequentialist and trust-based) are associated with longer response times. This further strengthens the case that self-reported decision processes are capturing real differences in decision making. Turning to consent outcomes, Table 8 indicates that the strong association of trust-based processing with consent, previously documented in the cross-sectional data, is also found longitudinally, within respondents (and even with this relatively modest sample size). The same is not true however of the association between consequentialist processing and consent. Subjective knowledge is strongly associated with both trust-based and consequentialist processing within respondents over time. Longitudinal associations with objective knowledge are weaker, though for trust-based processing the effect size is substantively meaningful, and marginally statistically significant.
Discussion and Conclusions
Our analyses indicate that survey respondents use different decision processes, some of which are more “reflective” (e.g., considering the consequences of consent or their trust in the organizations involved) while others suggest the use of less or different information (e.g., based on “gut-feeling”). Across all samples, fewer than 40 percent of our respondents report using a reflective decision process exclusively. These self-reported processes are validated by markers of cognitive effort: those who report more reflective processing of the request take longer to respond, are more likely to read additional information about the linkage, and are more likely to self-report higher levels of effort in answering the question. Reported decision processes align with the nature and quantity of information respondents report drawing on in making the decision. The self-reported process is weakly predicted by background characteristics and not affected by our survey design manipulations.
Nevertheless, different decision processes are associated with very different levels of consent and comprehension, with the more reflective decision processes associated with better outcomes on both measures. It is notable that we find these associations consistently across different samples and interview modes. Respondents in the IP11 samples (which are part of a longitudinal study) have an existing relationship with the survey organization and have been asked for consent to data linkage before, and so bring a history to the request. In contrast, AP participants are not used to requests like this. Despite this, the samples give very similar results.
Many attempts to achieve higher consent rates and more informed consent involve the provision of additional information and, as our review of the literature indicates, these have had limited success. Our analyses point to an explanation: if many of those who withhold consent are using a very rapid and less reflective decision process, additional information is unlikely to be incorporated into their decision, and hence unlikely to change that decision. Instead, our results suggest that a fruitful strategy for promoting informed consent may be to try to shift respondents towards more reflective decision processes, whether that be a “consequential” decision process, or one based on trust in the relevant organizations. Our results indicate that if it were possible to shift respondents to more reflective decision processes, this could have a double benefit: in our data, those employing the more reflective decision processes are both more likely to consent and have greater understanding of the request. That is, they are more likely to give informed consent.
Our analysis has several limitations, which in turn suggest important directions for future research. First, while we found that respondents were able to answer a question about their decision process, and those answers were validated by paradata and follow-up questions, our multi-method approach to broadly classifying the consent decision was the first attempt to elicit such information. A useful next step would be to refine the measurement of decision processes.
Second, while we replicated our analysis on samples with different characteristics (face-to-face vs. online; probability vs. non-probability; and cross-section vs. panel), all of the data were collected in the United Kingdom. Moreover, we study one consent request (for linkage to tax authority records). It would clearly be useful to explore whether our findings generalize to other populations and geographies, and to linkage to other types of records.
Third, we do not claim a causal interpretation for the associations we find between reflective decision processes and consent, and reflective decision processes and understanding. The longitudinal associations we document in the AP eliminate the selection of time-invariant unobservables as an alternative explanation, but we remain cautious. Alternative designs to establish causality should be a priority for future research.
Related to this, more work is needed to investigate if and how more reflective decision processes can be encouraged. The experimental manipulations in the data we analyzed were not effective in altering respondents’ choice of decision process. However, those manipulations were not designed with the decision process in mind. “High hurdle” techniques are sometimes used in the medical world to push individuals to more reflective decision making by, for example, requiring the individual to satisfy a comprehension test before giving consent. A related idea is to ask participants to list pros and cons of granting consent before responding to the consent question. Future work could study the efficacy of such approaches in time-constrained and low-risk contexts such as surveys. Because consent rates are higher in face-to-face interviews than in web surveys, another direction to explore is to mimic the presence of an interviewer by, for example, using a short, recorded video to deliver the consent request in web surveys.
In sum, there is a need for further work on understanding how respondents select a decision process, on how that choice can be influenced whether the decision process has a causal effect on consent outcomes, and on whether such results generalize to different populations, different geographies, and different linkages.
Supplemental Material
sj-pdf-1-smr-10.1177_00491241251344289 - Supplemental material for How Do Survey Respondents Decide Whether to Consent to Data Linkage?
Supplemental material, sj-pdf-1-smr-10.1177_00491241251344289 for How Do Survey Respondents Decide Whether to Consent to Data Linkage? by Jonathan Burton, Mick P. Couper, Thomas F. Crossley, Annette Jäckle and Sandra Walzenbach in Sociological Methods & Research
Footnotes
Acknowledgments
This research was funded by the Nuffield Foundation (![]() ) with co-funding from the Economic and Social Research Council (OSP/43279). Data collection on the Innovation Panel was funded by the ESRC grant for Understanding Society: The UK Household Longitudinal Study, Waves 9-11 (ES/N00812X/1). The views expressed here are those of the authors and not necessarily of the Nuffield Foundation or the ESRC. For the purpose of Open Access, the authors have applied a CC BY public copyright license to any Author Accepted Manuscript (AAM) version arising from this submission. We thank Brendan Read for excellent research assistance and are grateful for the feedback and suggestions received from the project advisory board.
) with co-funding from the Economic and Social Research Council (OSP/43279). Data collection on the Innovation Panel was funded by the ESRC grant for Understanding Society: The UK Household Longitudinal Study, Waves 9-11 (ES/N00812X/1). The views expressed here are those of the authors and not necessarily of the Nuffield Foundation or the ESRC. For the purpose of Open Access, the authors have applied a CC BY public copyright license to any Author Accepted Manuscript (AAM) version arising from this submission. We thank Brendan Read for excellent research assistance and are grateful for the feedback and suggestions received from the project advisory board.
Authors’ Contributions
All authors contributed to all aspects of the present research, including conceptualization, experimental design and implementation, analysis and writing. The order of co-authors is alphabetical.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical Approval
Ethics approval for the relevant wave of the Innovation Panel was received on 22/09/2017. Ethics approval for the project on which this article is based was received on 07/02/2018 with an amendment on 17/04/2018.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Nuffield Foundation, Economic and Social Research Council (grant numbers OSP/43279 and ES/N00812X/1).
Data Availability Statement
The replication code for this article, as well as links to the data, are available through OSF at https://osf.io/x6jgv/ (![]() ).
).
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.