
Abstract
Many studies have compared individual measures of health expectancy across older populations by time-invariant characteristics. However, very few have included time-varying variables when calculating health expectancy. Even among older adults, socioeconomic and demographic characteristics are likely to change over the life course, and these changes may have substantial implications for health outcomes. This paper proposes a multiple multistate method (MMM) that situates the multistate model within the broader family of vector autoregressive models. Our approach allows the incorporation of the coevolution of multiple life course factors and provides a flexible yet simple way to model two or more time-varying variables with the multistate model. We demonstrate the MMM in two empirical applications, showing the flexibility of the approach to explore health expectancies with complex state spaces.
Introduction
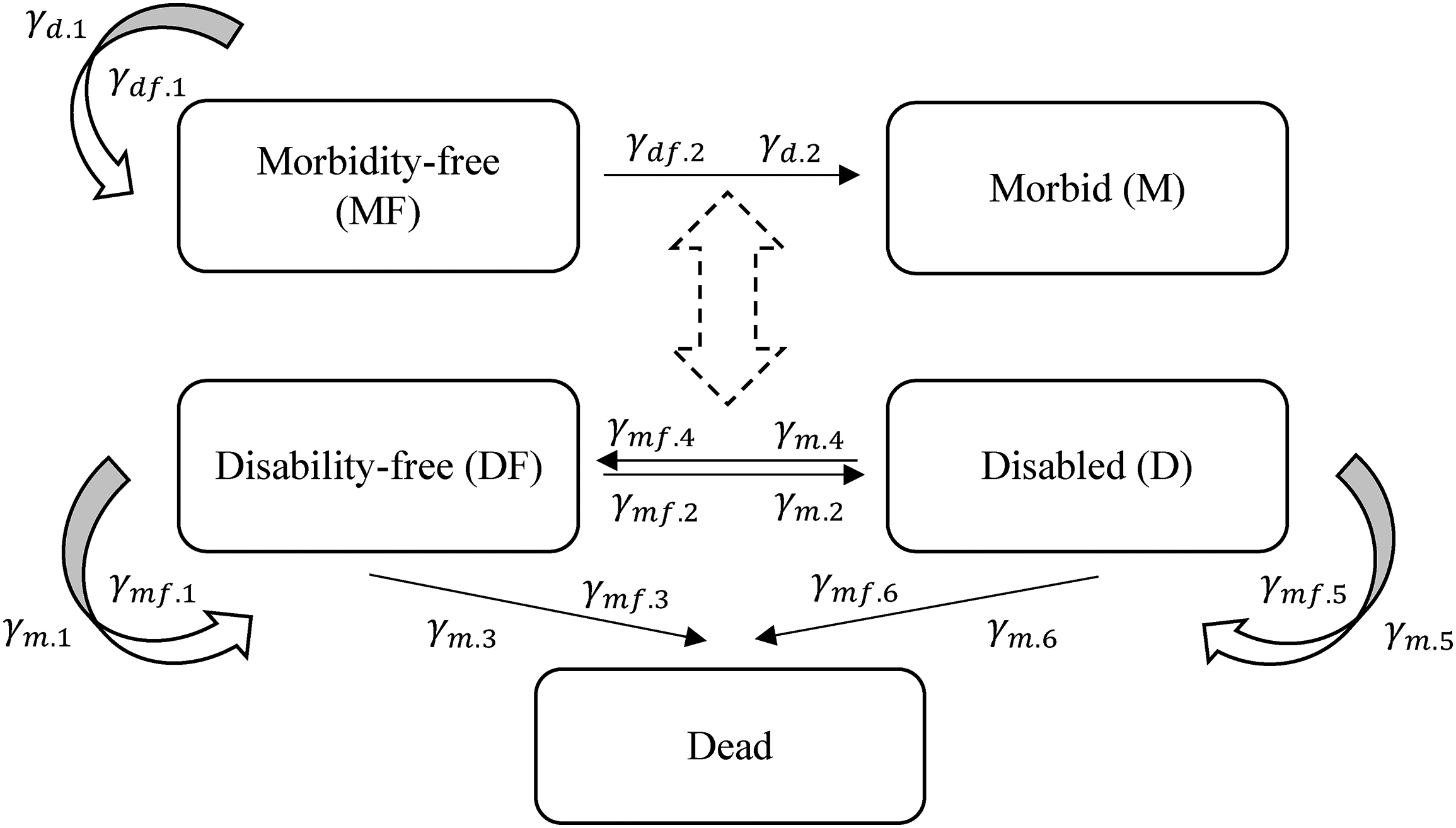
In recent years, a considerable body of research has developed multistate models to explore health expectancies based on data from longitudinal sample surveys. Several main analytical approaches have been developed to estimate multistate life table quantities from longitudinal data, including the Stochastic Population Analysis for Complex Events program (Cai et al. 2010), the Interpolated Markov Chain Method (Lièvre et al. 2003), and the Gibbs Sampler for Multistate Life Tables Software (Lynch and Brown 2005). However, a shared challenge that these models face is the difficulty of handling large, complex state spaces—a shortcoming that is mostly due to the relatively small sample sizes available from longitudinal sample survey data. With some transitions represented by only a few individuals, models used to estimate transition probabilities (often logistic regression) are prone to convergence issues or may produce unreliable estimates (Allison 2008). In multistate models, including a more refined categorization of health or having more than one time-varying variable leads to a rapid growth in the size of the state space to be estimated. As this state space increases, “the number of transition schedules to be estimated increases multiplicatively” (Saito, Robine and Crimmins 2014: 216). This scaling issue leads to issues of sparsity, as observed transitions become rare and age-patterns difficult to estimate.
Due to these methodological challenges, existing studies have mostly computed health expectancy or other multistate life expectancies assuming that individual's sociodemographic characteristics remain constant over time. The literature focuses heavily on differences across time-invariant factors such as sex, race/ethnicity, and education. A few studies have explored time-varying variables such as urban/rural residence (Liu et al. 2019) and marital status (Martikainen et al. 2014) by assuming these variables remain unchanged in later life. A small body of recent studies has attempted to include time-varying variables by including them in the state space, an approach that we hereafter call the “complex multistate model (CMM).” Jia and Lubetkin (2020) combined marital and disability status into a CMM with two disability states and five different states of marital status. The resulting state space is extremely large, with many transition probabilities needing estimation. Estimating accurate transition probabilities for such a large, complex state space requires a massive amount of data, and Jia and Lubetkin (2020) used data from Medicare Health Outcomes Survey comprising over 160,000 respondents. Huang et al. (2021) computed the health expectancy of older Chinese adults combining physically active and cognitive impairment-free life in a CMM. Yet, their state space omitted some of the possible states without further explanation. Another paper by Shen and Payne (2023) developed a multidimensional extension to prior work on health expectancy by simultaneously modeling changes in morbidity and disability across a set of cohorts in the U.S. Health and Retirement Survey (HRS). However, they used a simple state space of five states (using binary measures of any vs. no morbidities and any vs. no disability) to estimate these quantities, even with the substantial sample size of the HRS.
An active strain of research on multistate methods has sought to overcome some of the limitations associated with estimating health expectancies in complex state spaces. A recent paper by Lynch and Zang (2022) used a Bayesian approach to account for issues of data sparsity when estimating quantities in CMMs. This, to some extent, could be helpful when transition events between some states are rare. However, they still experienced convergence issues due to sparsity in the transition matrix in their 10-state example. Other studies have also sought to incorporate time-varying variables using methods other than the traditional multistate model. Chiu (2019) computed the disability-free life expectancy by living arrangements in the U.S.A., claiming that living arrangement is treated as a time-varying covariate in the model. However, the description of the method is unclear about how this time-variant covariate was operationalized. Only one method—the simultaneous equation system used by Yang and Hall (2008)—appears to address this issue. This method estimates health expectancy with several time-variant covariates (i.e., body mass index, medical events, and chronic diseases) within a system of equations. Yet, little existing research has applied this method, partly due to its statistical complexity. Thus, the aim of this paper was to develop a simple and generalizable method to allow increased complexity of coevolution in multistate models, such as multiple dimensions of health, or interactions between health and socioeconomic variables, when estimating health expectancies or other multistate life expectancies.
Conceptually speaking, in multistate models, when an individual moves to a different state that individual assumes a new set of transition probabilities. A similar idea can be found in CMMs, where a change in one of the time-varying variables impacts both its own transition probabilities and the transition probabilities of the other time-varying variables. For example, an individual becoming obese shifts not only the probability of whether they will be obese in the future but also their probability of developing diabetes.
In this paper, we introduce a formulation of a CMM with more than one time-varying variable (e.g., Jia and Lubetkin 2020; Shen and Payne 2023) as a recursive vector autoregressive (VAR) model. We call this new representation of the CMM the multiple multistate method (MMM). The concept of this modeling framework shares many similarities with the VAR model popular in econometric time-series studies, which is used to capture the relationship between multiple variables as they change over time. VAR models have not been used in the context of modeling health expectancy before, although they have been applied in actuarial studies to forecast mortality (e.g., Chang and Shi 2021; Guibert, Lopez and Piette 2019; Li and Lu 2017; Li and Shi 2021). In the Method section, we describe how the MMM can exactly replicate a CMM and discuss how the flexibility of the MMM approach can reduce estimation difficulties by removing less important interactions when estimating complex state spaces.
To better illustrate our method, we apply it to two examples. The first example replicates the results in a recent paper (Shen and Payne 2023) which uses a five-state multistate model to estimate health expectancies in morbidity and disability among four successive birth cohorts in the U.S. born from 1914–1923 to 1944–1953. To demonstrate the method, we adopt the same data and compare results between the CMM and the MMM. In the second example, we explore a similar research question to Jia and Lubetkin (2020). Instead of looking at marital status and activities of daily living (ADL) disability, we select another commonly used health indicator—self-rated health (e.g., Crimmins 2004; Payne 2022). Kananen et al. (2021) suggest that self-rated health is a valid indicator of individual's overall health assessment including biological conditions. For decades, many studies have discussed the association between marital status and health. Most of them suggest a positive or protective effect of marriage on health and survival (Goldman, Korenman and Weinstein 1995; Rendall et al. 2011; Verbrugge 1979). Others also found negative effects of widowhood or divorce (Korinek et al. 2011; Verbrugge 1979). Yet, only very few studies examined the impact through the lens of multistate life expectancy until Jia and Lubetkin’s (2020) study. Thus, this example may provide dynamic insight into how marital status and health status interact as individuals’ age. At the end, we discuss that the MMM could be even more useful when modeling more than two variables with more refined categories.
Method
Complex Multistate Model
To explore the interaction between two time-varying variables with, for example, two categories each, the traditional complex multistate method would combine the two variables to form five distinct states with one absorbing state for death; the first time-varying variable G has two categories,
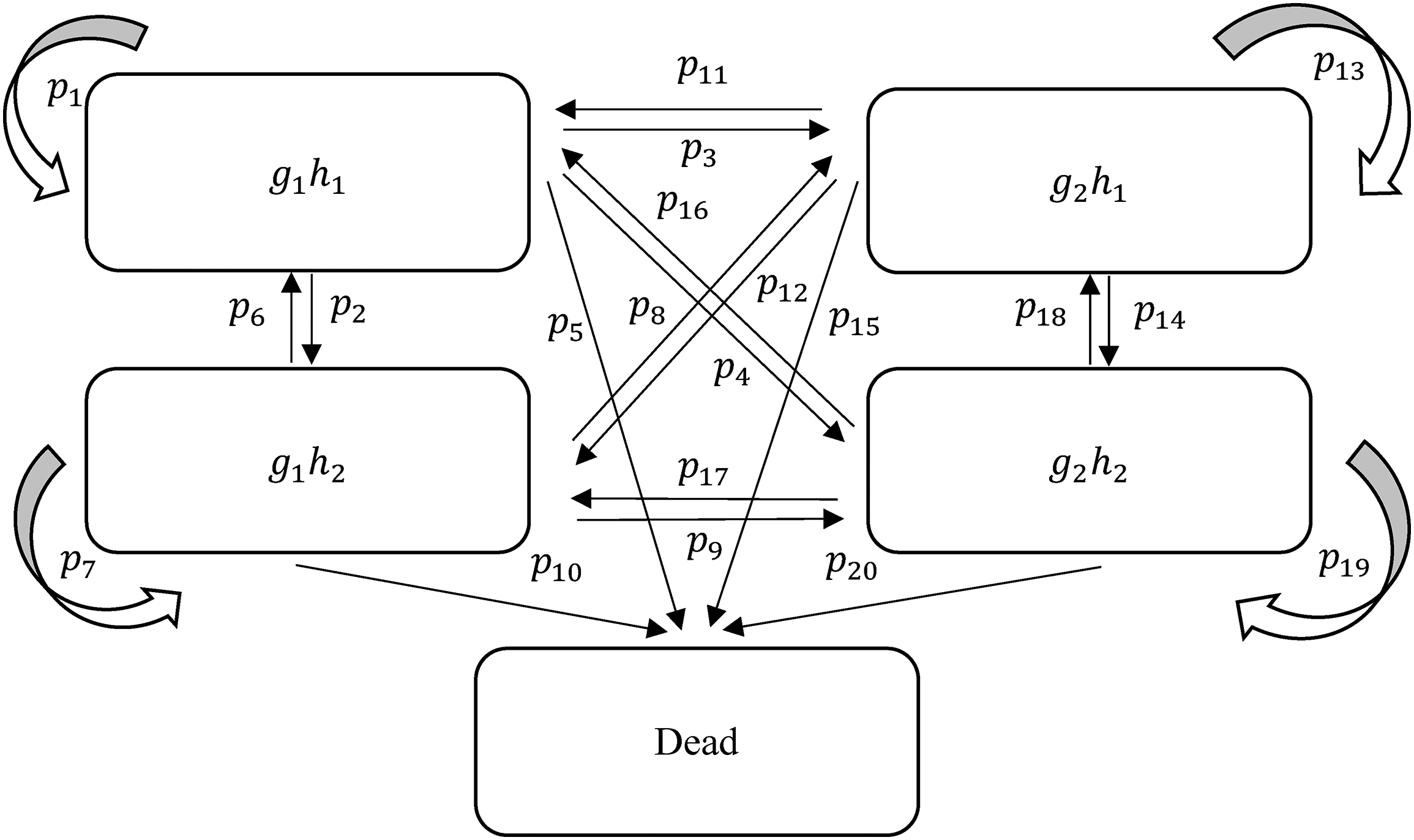
Complex multistate model.
Transition Probabilities of the CMM in Figure 1.

Note: Probabilities in each row sum to one.
Using multinomial regression, we can estimate the transition probabilities as shown below: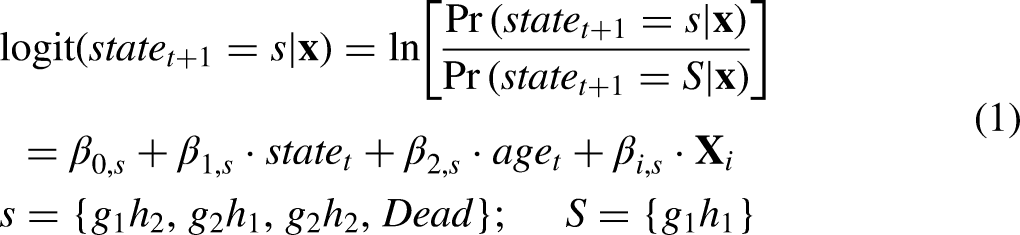
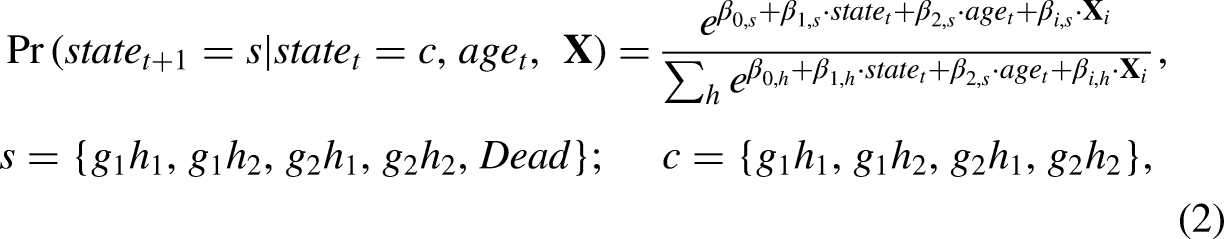
Apart from the transition probabilities, we also need to obtain the baseline (radix) characteristics at the starting age. One of the common methods is to use the information directly from the longitudinal survey. In cases where single age groups are small, one could combine 5–10 years around the starting age to construct a synthetic cohort (e.g., Crimmins, Hayward, and Saito 1994; Laditka et al. 2021; Payne 2022; Shen and Payne 2023). Alternatively, one could source external data such as a census or a large-scale cross-sectional dataset around the same period as the longitudinal survey to construct the baseline at the starting age (e.g., Moretti et al. 2023).
After obtaining the transition matrix and baseline, we can use microsimulation to calculate the life and health expectancies. To do this, we would generate 100,000 individuals, with their characteristics set to match the baseline population. The probabilities in each row of Table 1 are mapped into subsets in the interval of 0–1 based on the size of each probability. For example, the first row would be turned into five subsets:
With the basis of the traditional multistate model explained, we can introduce the MMM and highlight its distinct features. As mentioned in the Introduction, one of the challenges of the traditional multistate model lies in handling sparse transitions in a large state space. In the case of two categories within each dimension of health and five states in total, the traditional multistate model is still manageable. However, when the number of categories within variables or the number of time-varying variables increases, the observed events could become too sparse to reliably estimate transition probabilities in a regression. Additionally, building coevolving variables from very different domains of the life course into one state space may not be theoretically reasonable. The relationship between the coevolving variables cannot be easily modified according to the theory or hypothesis because it is built into the state space. To better compute life expectancy with coevolving relationships, the MMM instead models different time-varying variables separately in multiple logistic regressions.
Multiple Multistate Method
The concept of MMM shares many similarities with the VAR model, which is commonly used in macroeconomic and financial modeling to capture the relationship between multiple coevolving variables within the system as they change over time. VAR models allow for several endogenous (i.e., coevolving) variables to be estimated via a series of ordinary least squares regressions where each regression has identical covariates (Enders 2014; Greene 2000). Standard VAR models are therefore simple to estimate, and if required, the error correlation matrix can subsequently be estimated with average sums of squares or cross products of the least squares residuals (Greene 2000). In our context, this means that a VAR model can estimate a system of equations where, for example, disability can be modeled as a function of morbidity, and morbidity can be modeled as a function of disability. A VAR model usually takes one of the three forms: reduced-form VAR, recursive VAR, and structural VAR (Stock and Watson 2001). In a reduced-form VAR, each variable is modeled as a function of its own past and the past values of the other variables (i.e., the lags of the variables), but the model does not capture the contemporaneous effects (Enders 2004). On the other hand, recursive and structural VAR models include the lags of the variables similar to a reduced-form VAR, but in addition, they also allow the outcome variables in each equation to depend on the contemporaneous values of the other variables (Stock and Watson 2020).
The CMM is analogous to a structural VAR model, as the coevolving variables are estimated within one equation system. However, both reduced-form and recursive VAR models can be estimated by separate equations for each of the coevolving variables (Enders 2014; Pfaff 2008; Stock and Watson 2001). One can use recursive VAR to reverse-engineer the parameters in the structural VAR (Enders 2014). This is the basis of why our recursive MMM can replicate a CMM. On the other hand, the advantage of a reduced-form VAR compared to a recursive VAR is in its simplicity, as we can reduce the insignificant parameters in the model. However, by doing so, a reduced-form VAR cannot recover the structural VAR because of the under-identification of parameters (Enders 2014). Put it another way, a reduced-form VAR does not include the contemporaneous variables, and the short-run concurrent relationship would be ignored. Thus, a reduced-form VAR is a suitable model that the variables not directly influence each other contemporaneously, but rather any influence occurs with a time lag between the variables.
In economics, the lag length for the variables in each equation is typically estimated via F-tests or information criteria (such as the Akaike information criterion or the Bayesian information criterion). Using one lag is consistent with the common multistate assumption of a first-order Markov chain, and annual or biannual survey data collection. With the Markov assumption, the current state depends only on the previous state, which can be regarded as a univariate autoregression with lag one, VAR(1). When the state spaces are the combinations of two variables (a complex multistate), it is possible to turn this into bivariate autoregressions with lag one maintaining the Markov assumption. As aforementioned, there are various types of VAR models, and the CMM model is close to a structural VAR and the structural VAR can be estimated with a recursive VAR.
VAR models are usually estimated with continuous time-series variables such as macroeconomic and financial data, where each equation in the VAR system is estimated via ordinary least squares regressions. However, in our context, the variables are binary, and we therefore estimate the equations via logit regressions. Such “logistic VAR models” have previously been applied in empirical work (e.g., Epskam 2013; Huang et al. 2020). In the following paragraphs, we will first explain how the estimation is done and demonstrate the comparability between the CMM and the bivariate recursive MMM. Then, we will discuss the potential alternative model—the reduced-form MMM—in the Applications section.
For an MMM with a recursive term, the idea is to separately model variables H and G in sequence. One of the variables is a function of the lag of this variable (or time t), and the second variable is a function of value of time 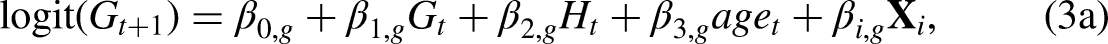
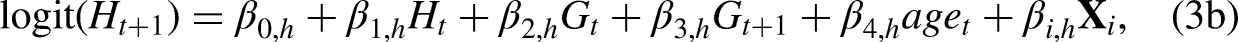
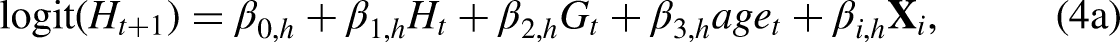
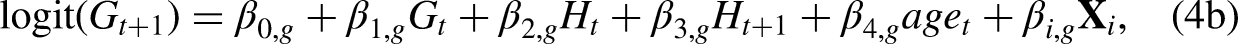
Another related issue is how to model the transition to mortality with two regressions. In the following paragraphs, we explain that mortality only needs to be modeled in one of the regressions and that both sets of equations produce the same results after joining probabilities for these variables together. A person can possess multiple time-varying characteristics at the same time, but there is only one dead state in Figure 1. If we look at these time-varying characteristics in separate models, the transition probabilities to death for the same group of individuals should be equivalent because the number of transitions to death are the same from any time-varying characteristic. Since the probabilities of death are theoretically equivalent, death can be modeled alongside any of the time-varying variables when the contemporaneous term in equation (3b) (i.e.,
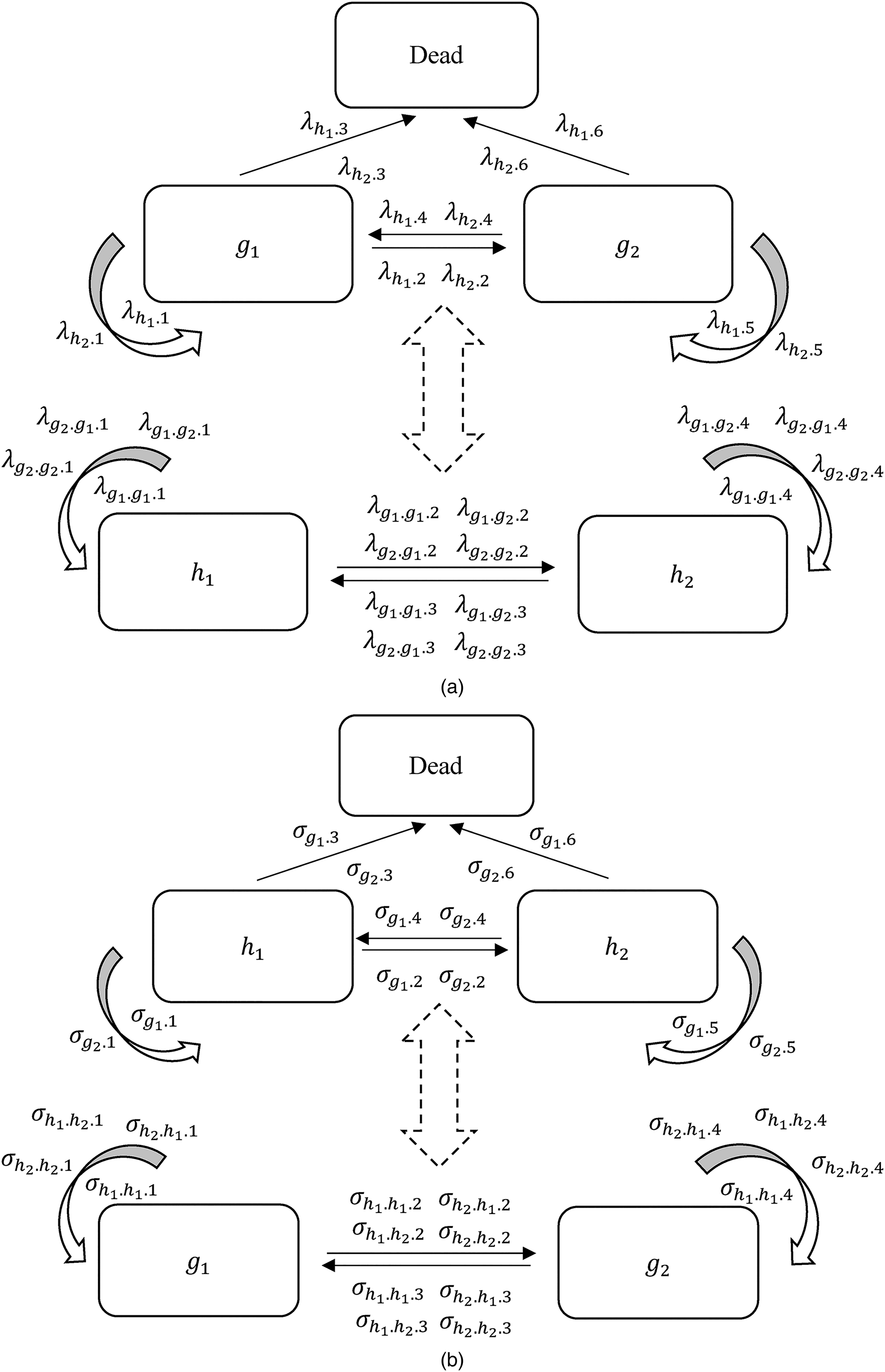
Tables 2a and 2b show the corresponding transition matrices for each option of the model. Both tables have two panels. Panel i represents the transitions in the upper model (i.e., equation (3a) or (4a)) and panel ii the lower one (i.e., equation (3b) or (4b)). Each row should also sum to one. The row names in Tables 2a and 2b represent the current state of the time-varying variable that is modeled, and the state at time t (and
Transition Probabilities of the MMM in Figure 2(a).

ii. Transition Matrix for Variable H
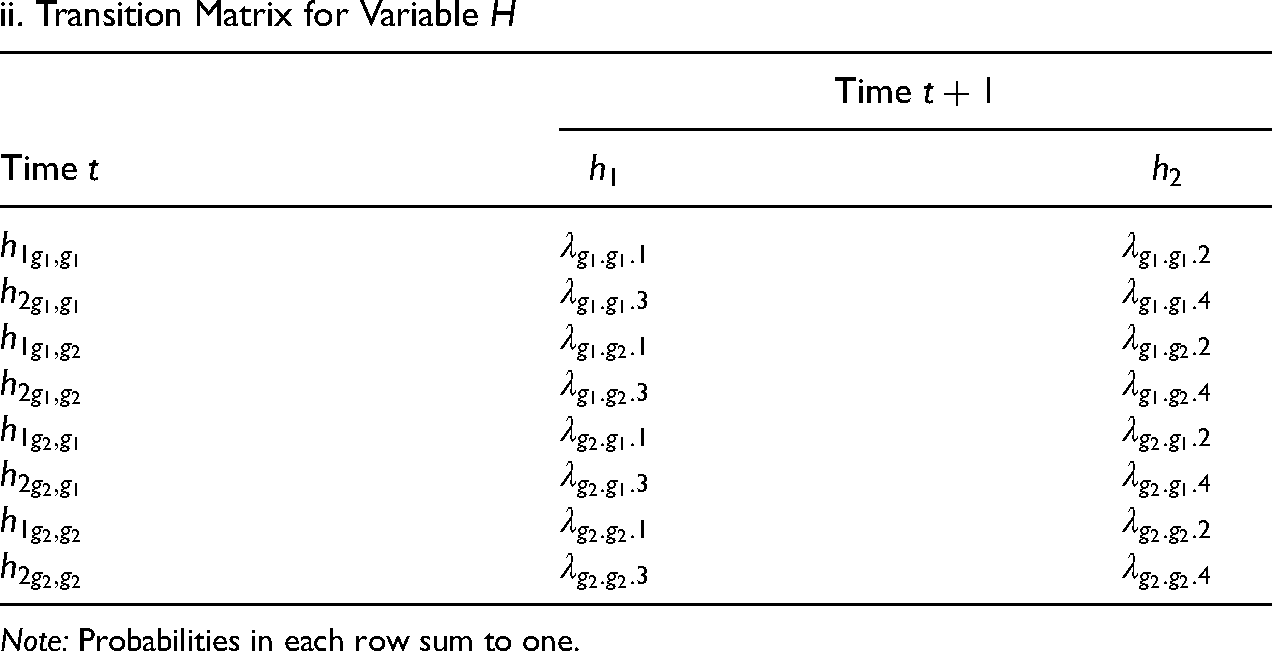
Note: Probabilities in each row sum to one.
Transition Probabilities of the MMM in Figure 2(b).
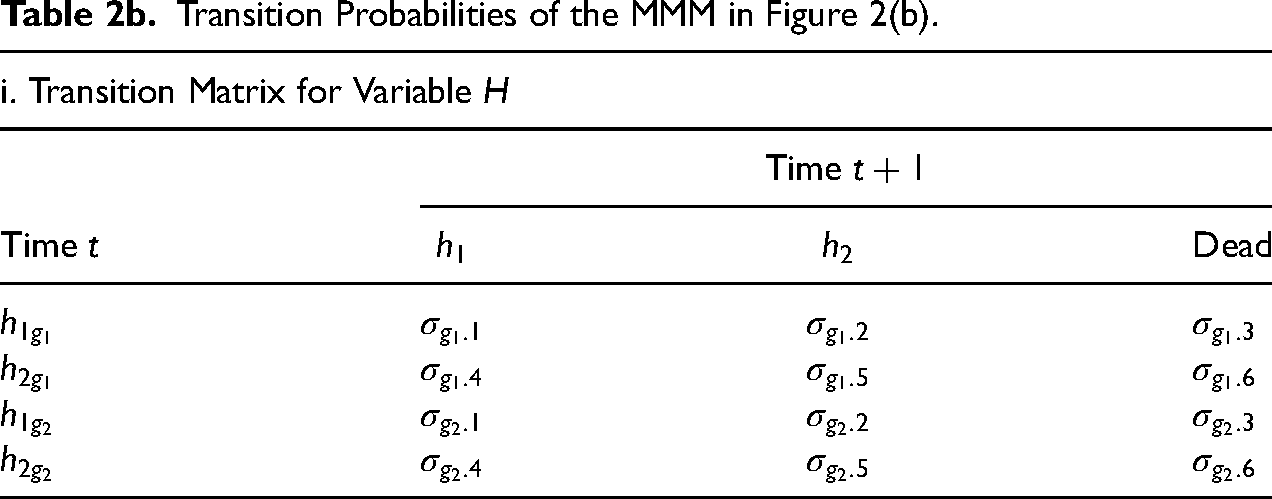
ii. Transition Matrix for Variable G
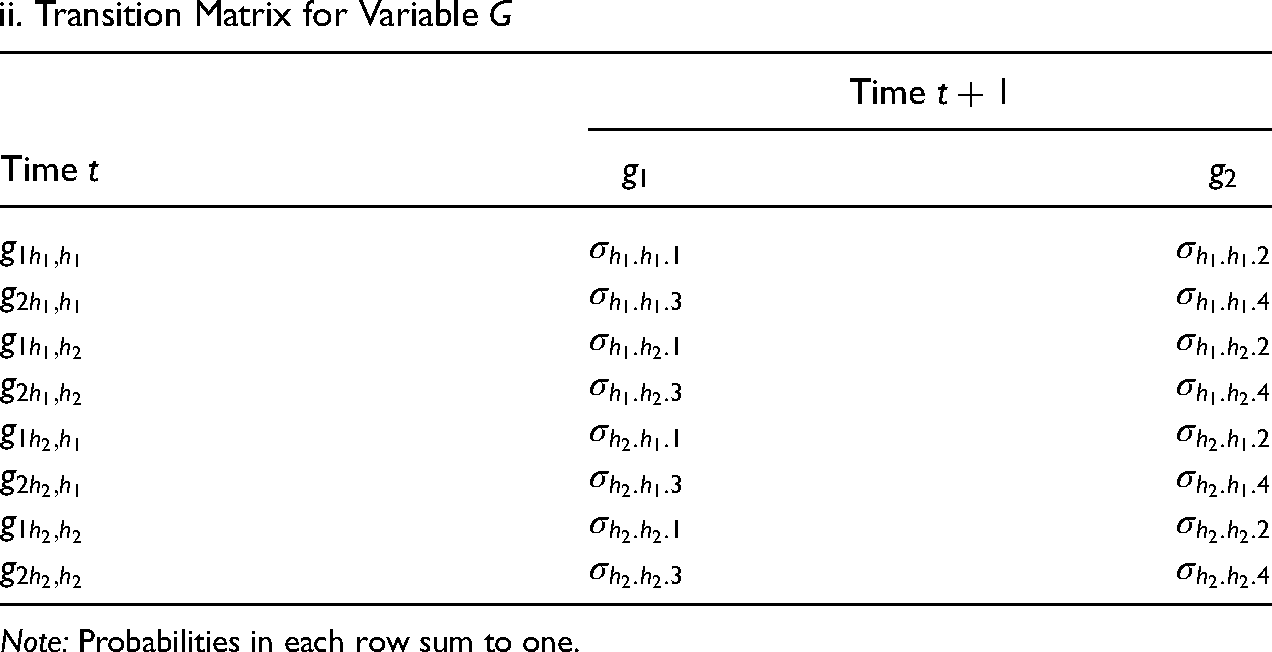
Note: Probabilities in each row sum to one.
Therefore, transition probabilities in Table 2, panel i have an equivalent relation with those in Table 1. The probability of transitioning to state
Highly similar equivalencies can be found for Tables 2b and 1. For instance, the transition probability for individuals in states

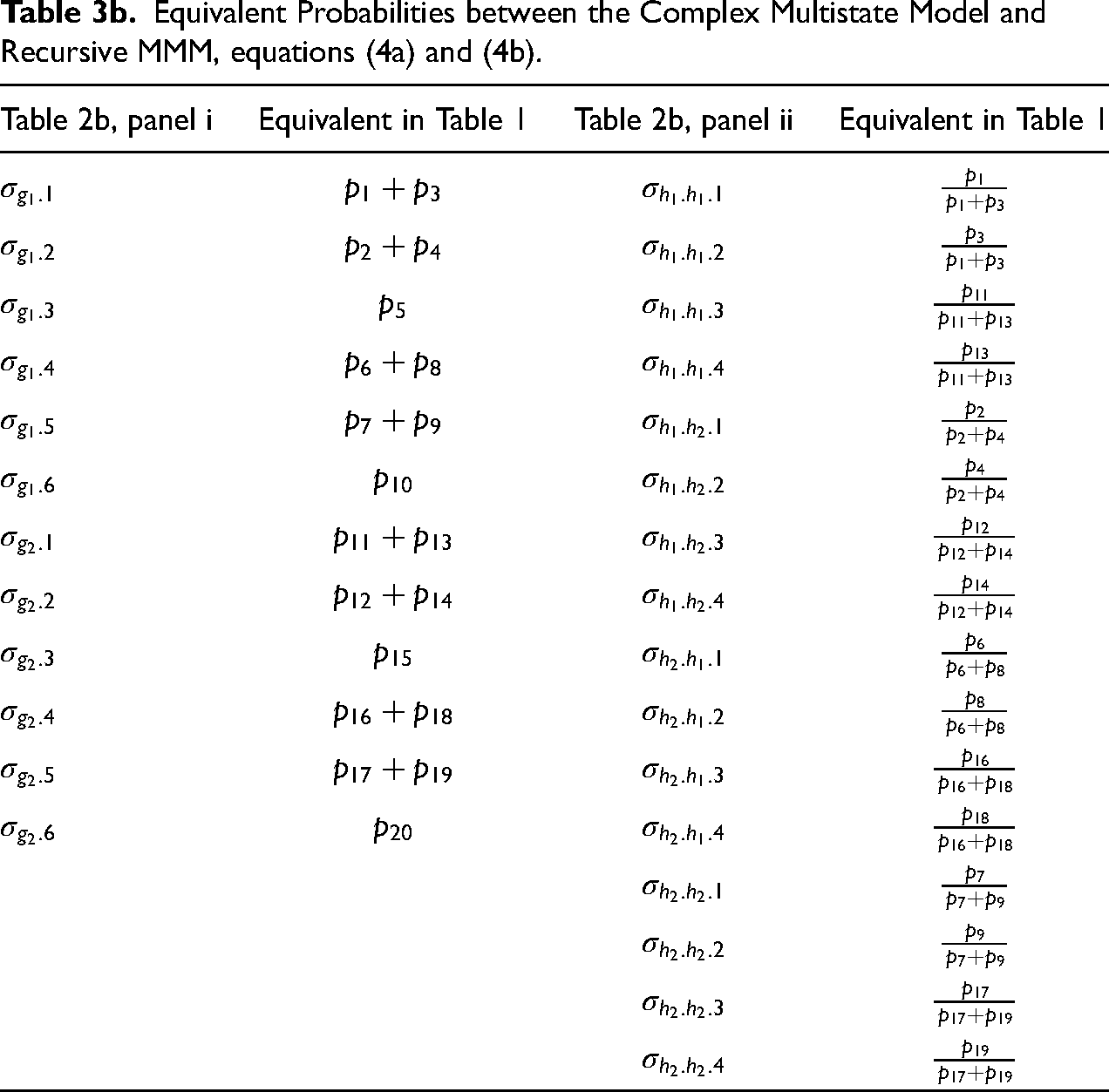
The dashed arrow that connects the two models can also be estimated in two ways as in the CMM: the life table method or through microsimulation. In the life table, the transition probability from time t to
In this paper, we apply the microsimulation method, but the underlying calculation is the same for the life table method. To get the life/health expectancies, we need the baseline characteristics and transition probabilities. In most cases, the distribution of baseline characteristics can be constructed directly from the longitudinal survey. However, when a large number of baseline characteristics needs to be controlled, the sample size for each group could become very small. In this case, it may be helpful to borrow information from external data sources to construct the baseline. With the baseline, we can proceed to the microsimulation process. As there are more than one set of transition probabilities, we run multiple independent microsimulations for each regression. Taking probabilities from Table 2a as an example, for an individual starting from
So far, we have shown that the recursive MMM can exactly replicate the CMM. By disentangling one regression into multiple regressions, our approach facilitates more flexibility in model design. Modeling each coevolving variable with its own regression means that it is possible to modify or optimize the regressions for these variables separately. To be more specific, borrowing the idea from the reduced-form VAR concept, the MMM could incorporate time-varying variables with complex models by allowing researchers to reduce insignificant interactions and manipulate the relationship between coevolving variables according to their research questions and theoretical framework. We further demonstrate the flexibility of modeling with the MMM framework by walking through real-life examples of different MMM models in the Applications section.
Applications
In this section, we first compare results from two MMM models with recursive and reduced-form VAR against the results from a five-state multistate model focusing on two dimensions of health as in Shen and Payne (2023). By this comparison, we demonstrate how the reduced-form VAR model can be used to estimate multistate life table quantities in complex state spaces, reducing estimation difficulties through removing less important interactions. For a second example, we further present how the MMM can be applied to incorporate other time-varying variables. This example uses the MMM to explore healthy life expectancy while accounting for changes in marital status.
Data
Data for both application examples are from the U.S. HRS (Health and Retirement Study 2021), a bi-annual national longitudinal survey (Sonnega et al. 2014). In example 1, our analyses use data from 1998 to 2018 of the HRS to estimate cohort partial health expectancy with disability and morbidity across birth cohorts. Disability and morbidity are defined the same way as in Shen and Payne (2023). Disability is classified into two categories: “Disability-free” (DF) and “Activities of Daily Living (ADL) disabled” (D). Individuals are classified as “Morbid” (M) if they have ever been diagnosed with any of the five chronic diseases including cancer, diabetes, heart disease, lung disease, and stroke, and “Morbidity-free” (MF) otherwise.
In the second example, we use data from the 2008 to 2018 waves of the HRS to estimate remaining healthy life expectancy by sex and marital status for those aged 55 plus. Marital status is divided into three categories: “married/partnered,” “divorced/separated,” and “widowed/widower.” Individuals who never married are excluded from the analyses as they are a very small population and are unlikely to change marital status over time in older cohorts. Health is defined by self-rated health, where individuals who responded “Excellent” or “Very good” are reclassified as “very good,” “Good” as “fair,” and “Fair” or “Poor” as “poor.”
Example 1: Two Dimensions of Health
Figure 3 describes the CMM and state space in Shen and Payne (2023), replacing the variables G and H in the Method section to Morbidity and Disability. Note that the state space is slightly constrained as compared to Figure 1, as transitions from morbid to morbidity-free are not allowed under the definition of morbidity as ever diagnosed. In this CMM, the transition probabilities are estimated using a single multinomial logistic regression as shown below: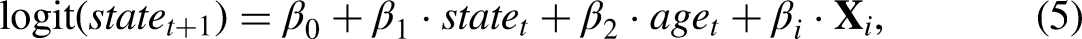
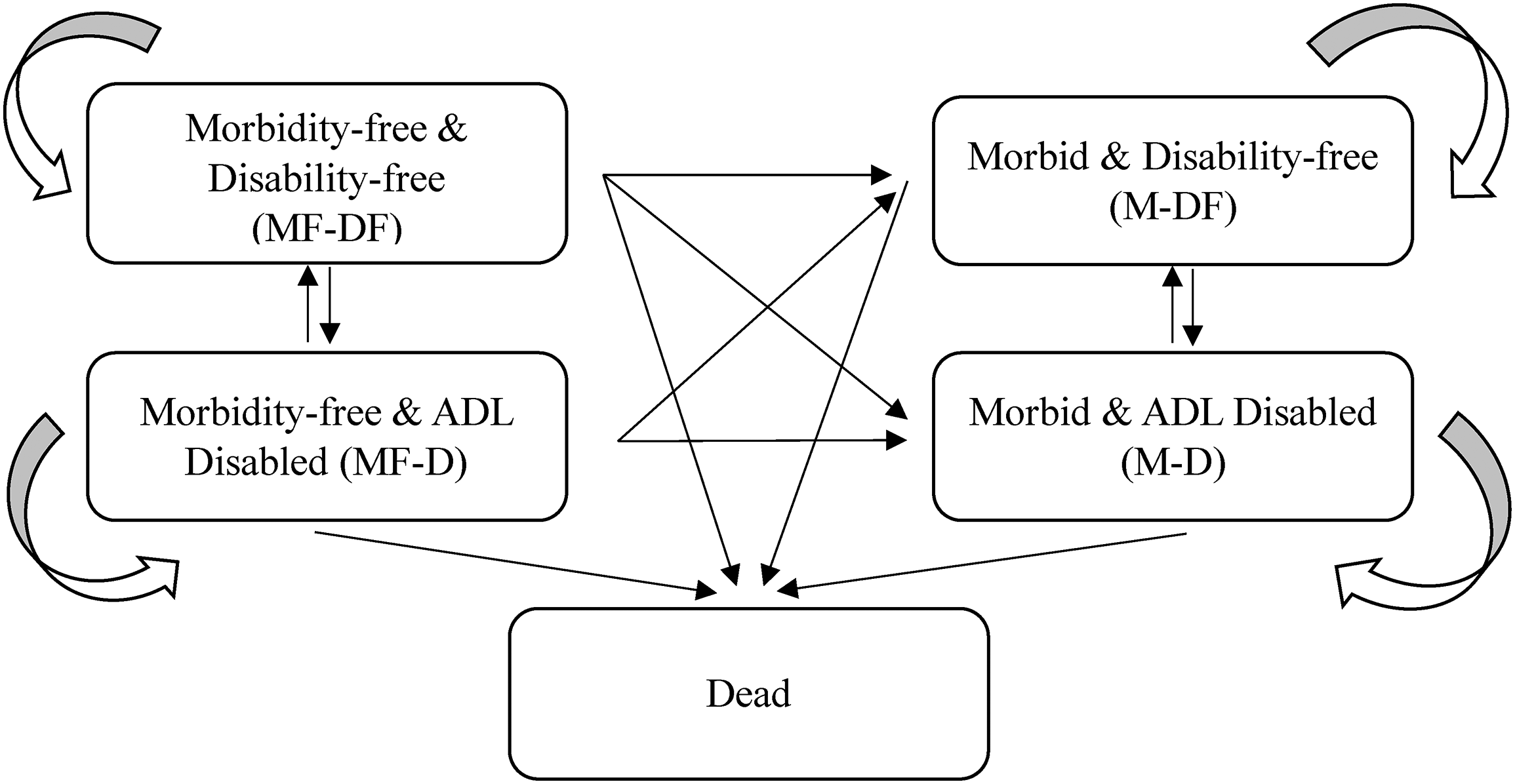
Complex multistate model with disability and morbidity.
Here, we estimate this same five-state model with the MMM framework. First, we demonstrate the MMM with recursive VAR(1), which has highly similar procedures as what is described in the Method section. Variable G is replaced by morbidity and variable H by disability as follows: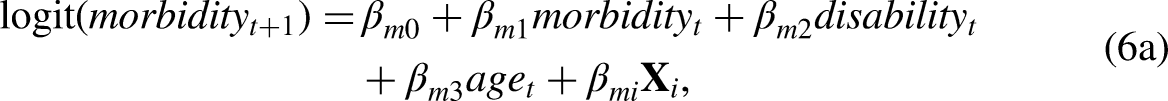
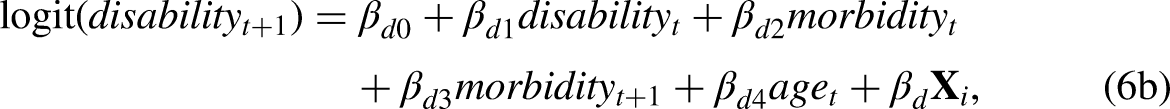
In this section, we focus on describing and comparing one of the potential alternatives that utilizes features of the reduced-form MMM to reduce complexity in the state space. This MMM would be estimated by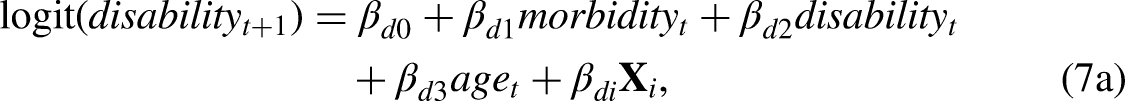
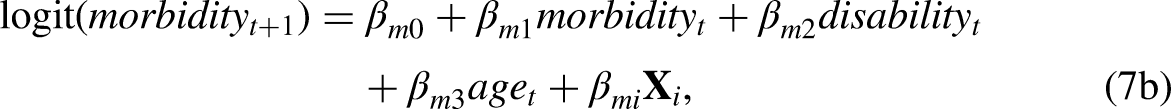
Multiple multistate method with reduced-form VAR(1).
Transition Probabilities of the MMM in Figure 4.

ii. Transition Matrix for Disability
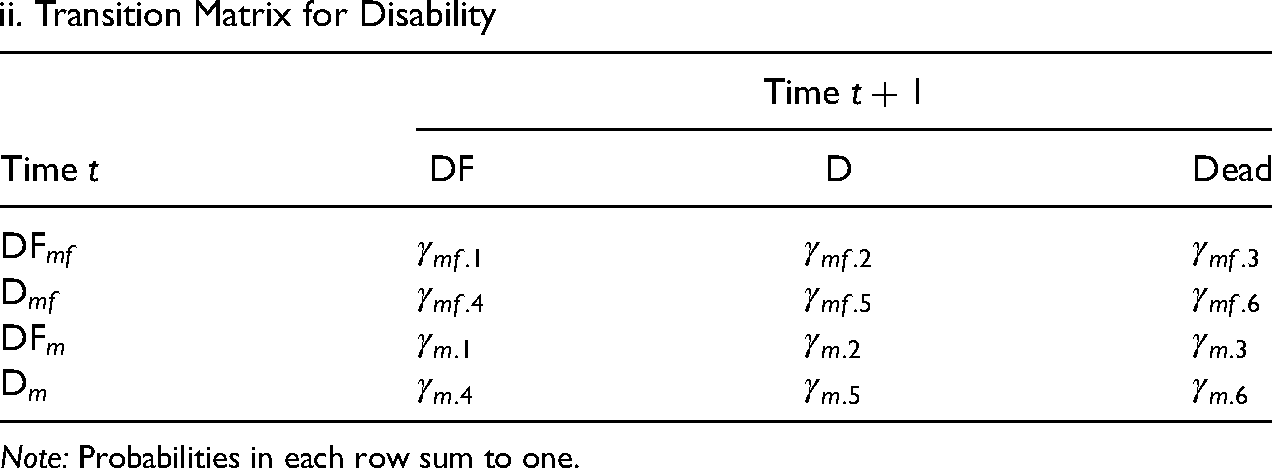
Note: Probabilities in each row sum to one.
Figure 4 is similar to the recursive MMM in Figure 2(a). In panel i of Table 4, the transition matrix for morbidity is almost the same as panel i in Table 2a. Transitions between morbidity states rely on morbidity and disability at time t. The major difference is in panel ii of Table 4 (the transition matrix for disability), where disability at time
Since the reduced-form VAR estimated fewer parameters in exchange for a more parsimonious model, unlike the recursive MMM, the reduced-form MMM cannot derive the exact probabilities in the CMM. More specifically, the relationship between contemporaneous changes in the two dimensions of health (or time-varying variables) is not controlled. For example, an individual with
A comparison of results from the complex multistate method and two types of MMM (recursive and reduced-form) is presented in Table 5 and in Figures A1–A3. Table 5 presents health expectancies calculated through three models: complex five-state model (CMM), MMM with recursive VAR(1), and MMM with reduced-form VAR(1); inside the parentheses are 95 percent confidence intervals from bootstrapping. For brevity, we only show the results at age 70 from cohort 1934–1943 (the full comparison for all age groups can be found in Figures A1 and A2 in the Appendix). The three models have very close point estimates for all expectancies, with differences under 0.1 for all expectancies. Based on the confidence intervals, none of them are significantly different from one another. Note that the source of uncertainty in the MMM is somewhat different from that in the CMM, as in MMM the uncertainties are combined from separate equations through microsimulation. Nonetheless, the bootstrapping technique (Kulesa et al. 2015) still captures the individual variation in the data and the confidence intervals are very similar. In Figures A1 and A2, the MMM model is compared to the CMM. The figures are superimposed on each other so that it is easier to examine the difference. Figure A3 further disaggregates results in Figure A2 by initial morbidity status, which is a type of status-base life expectancy. Similar to Table 5, none of the age and gender groups are significantly different.
Partial Health Expectancies of Various Health States (Age 70–79 for Cohort 1934–1943): Comparison of Three Models.
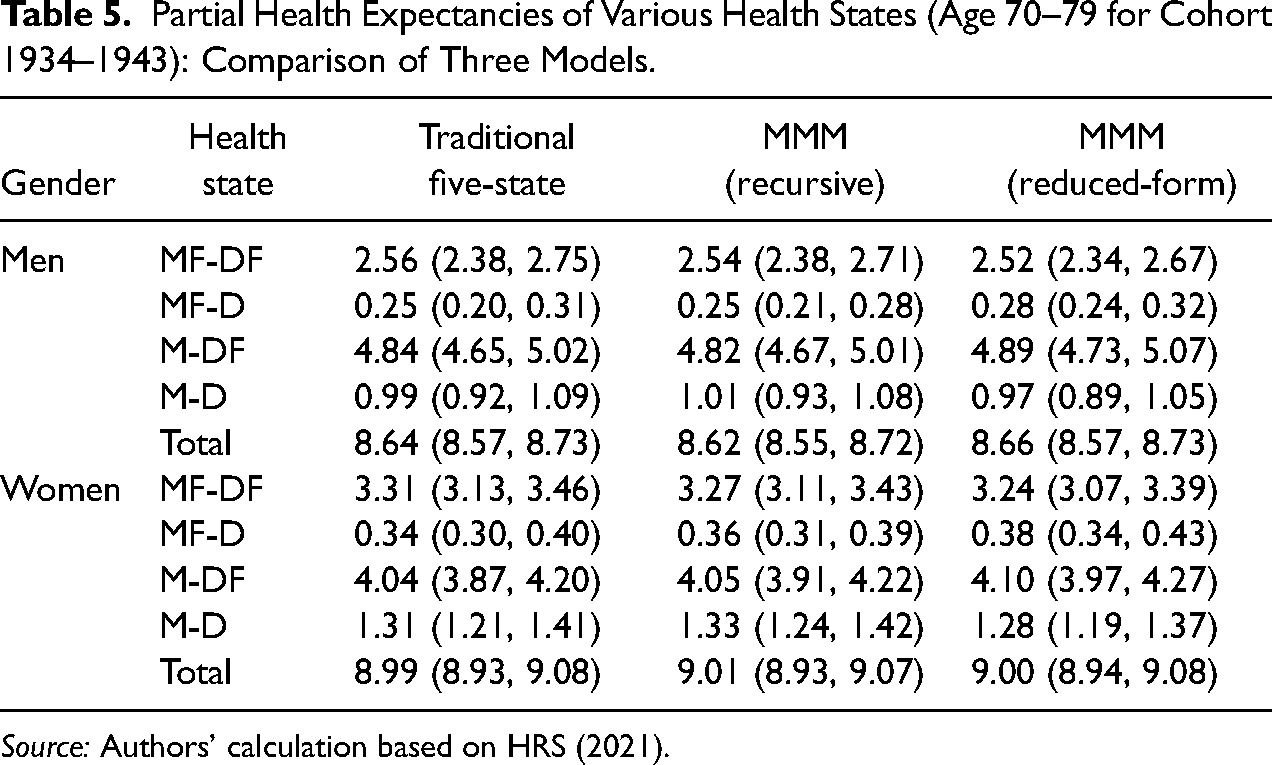
Source: Authors’ calculation based on HRS (2021).
To produce these similar results, the reduced-form MMM is simpler, with fewer interaction terms. The benefit of reduced-form MMM is apparent by looking at the number of transitions between health states in Table 6. We show the transitions modeled in CMM in panel a, and in reduced-form MMM in panel b. The dependent variables (i.e., health status at time
Transitions between Various Health States in Example 1 (Cohort 1934–1943 Age 70–79).
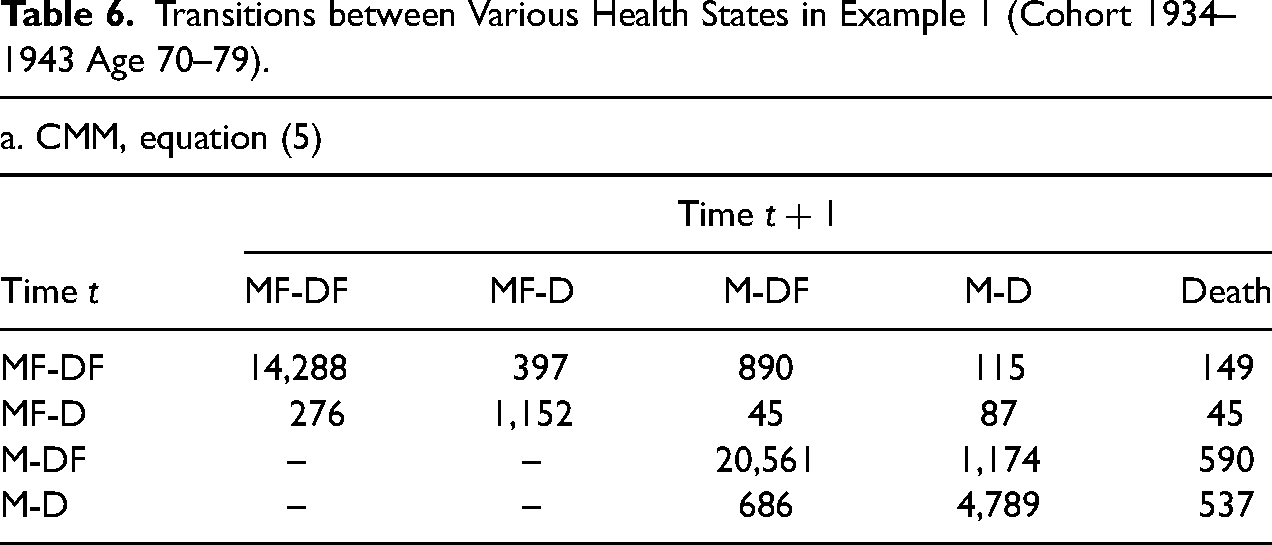

Note: “–” represents that no event is modeled.
Source: Authors’ calculation based on HRS (2021).
Death is not estimated in equation (7b) and it has the same amount of transitions as the left-hand side of panel b.
Example 2: Marital Status and Healthy Life Expectancy
As a second example to demonstrate the flexibility of the MMM, we apply the MMM to model self-rated health and marital status. Each outcome has three categories, leading to a state space of 10 states which is quite large to estimate using the CMM. Furthermore, marital status and health could coevolve over time but are very different domains of the life course. Even though there are papers (Goldman et al. 1995; Jia and Lubetkin 2020; Rendall et al. 2011) about the association between marital status and health/survival, the mechanism is likely to be indirect through behavior change (Wilson and Oswald 2005), social support (Becker et al. 2019; Berkman 1984), and other long-term accumulated processes (Verbrugge 1979). Thus, it is a good case to demonstrate the advantages of the MMM when the contemporaneous relationship between outcomes is theorized to be weak.
Marriage selection theory suggests that healthier individuals are more likely to get married (Goldman 1993; Murray 2000). In our analyses below, we exclude the never-married group. We also hypothesize that, conditional on being ever married, the current health of the respondent is likely not a strong predictor of marital status but not the other way around. We deploy this hypothesis partly because it is conceptually plausible and partly because we want to demonstrate the flexibility of the MMM. Therefore, this hypothesis can be removed depending on the research question. The regression models are constructed as follows: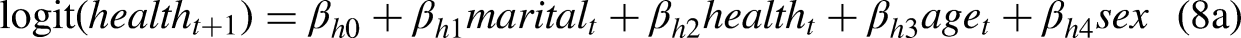
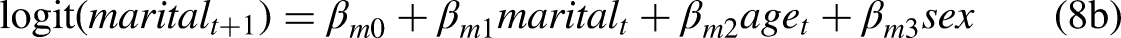
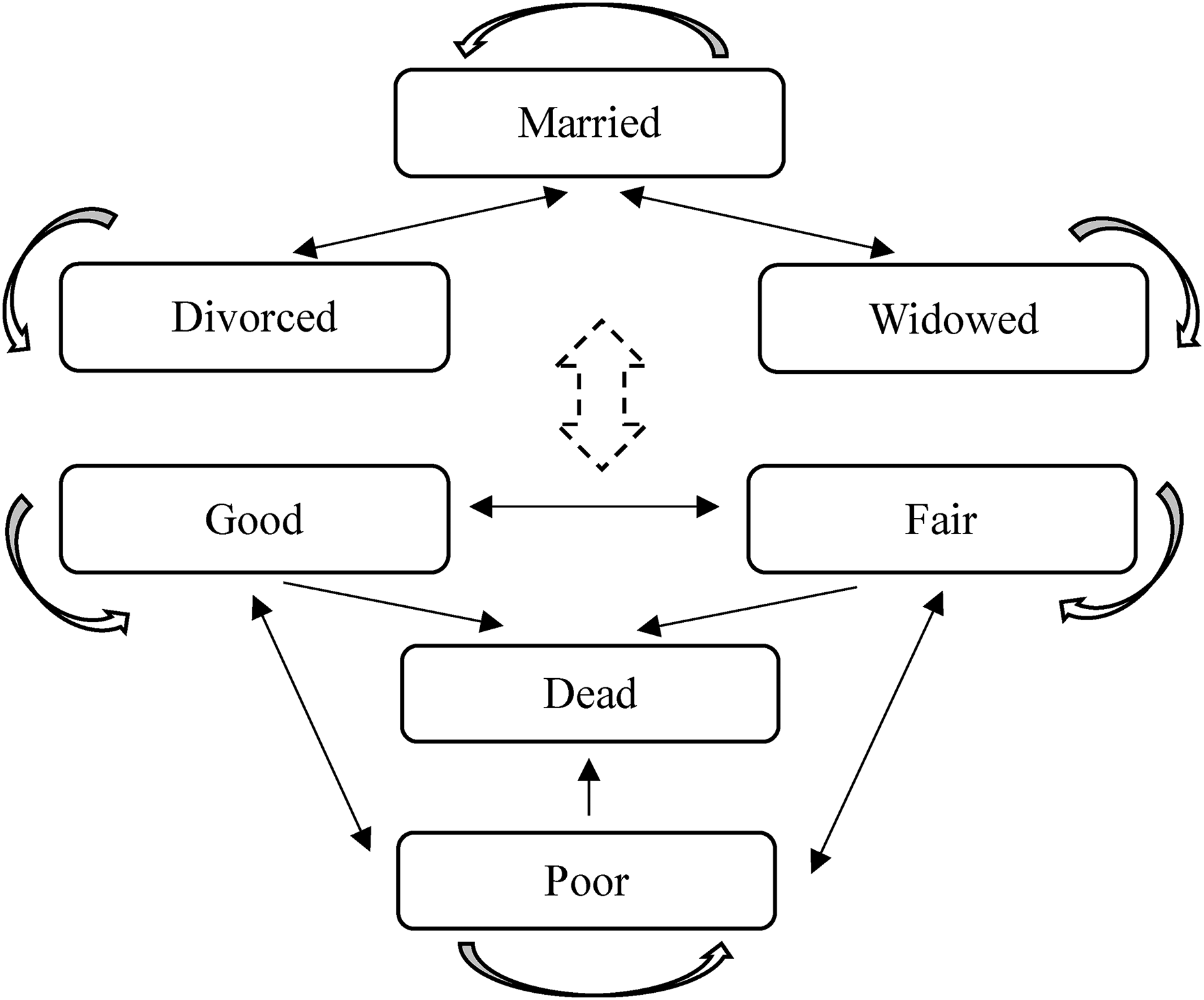
Marital status and health with MMM.
Transitions between Self-Rated Health and Marital Status Example 2.
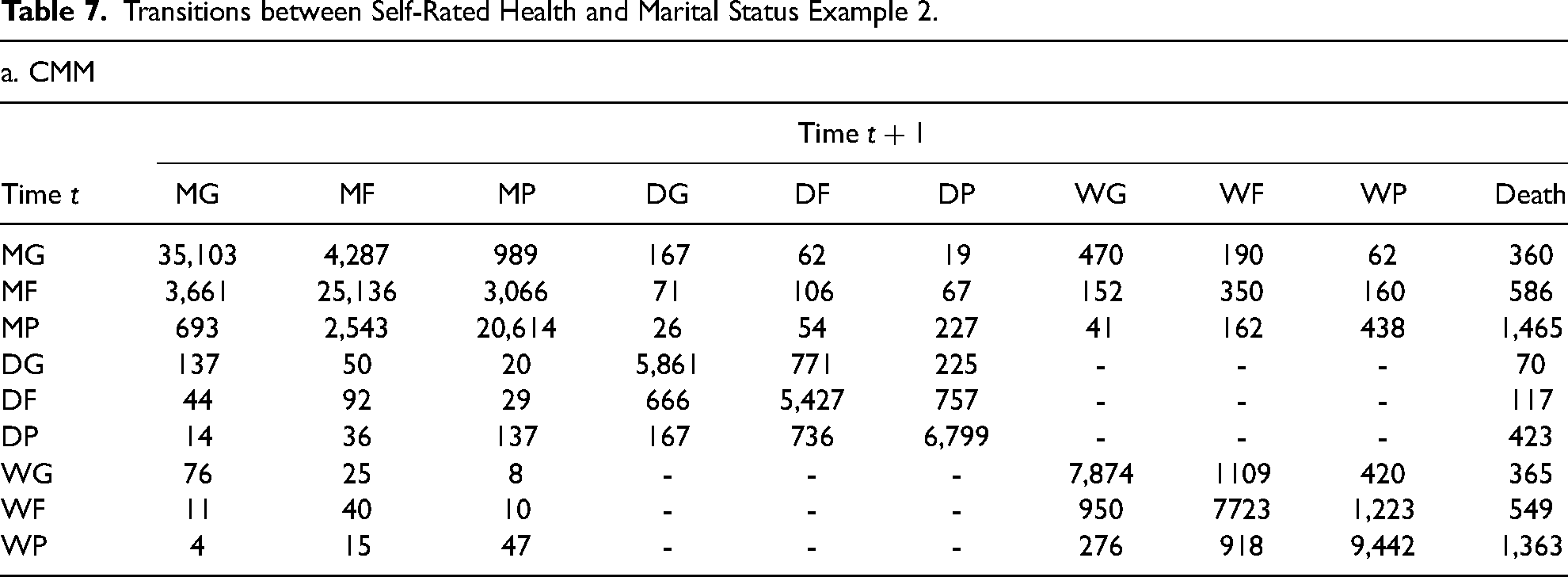
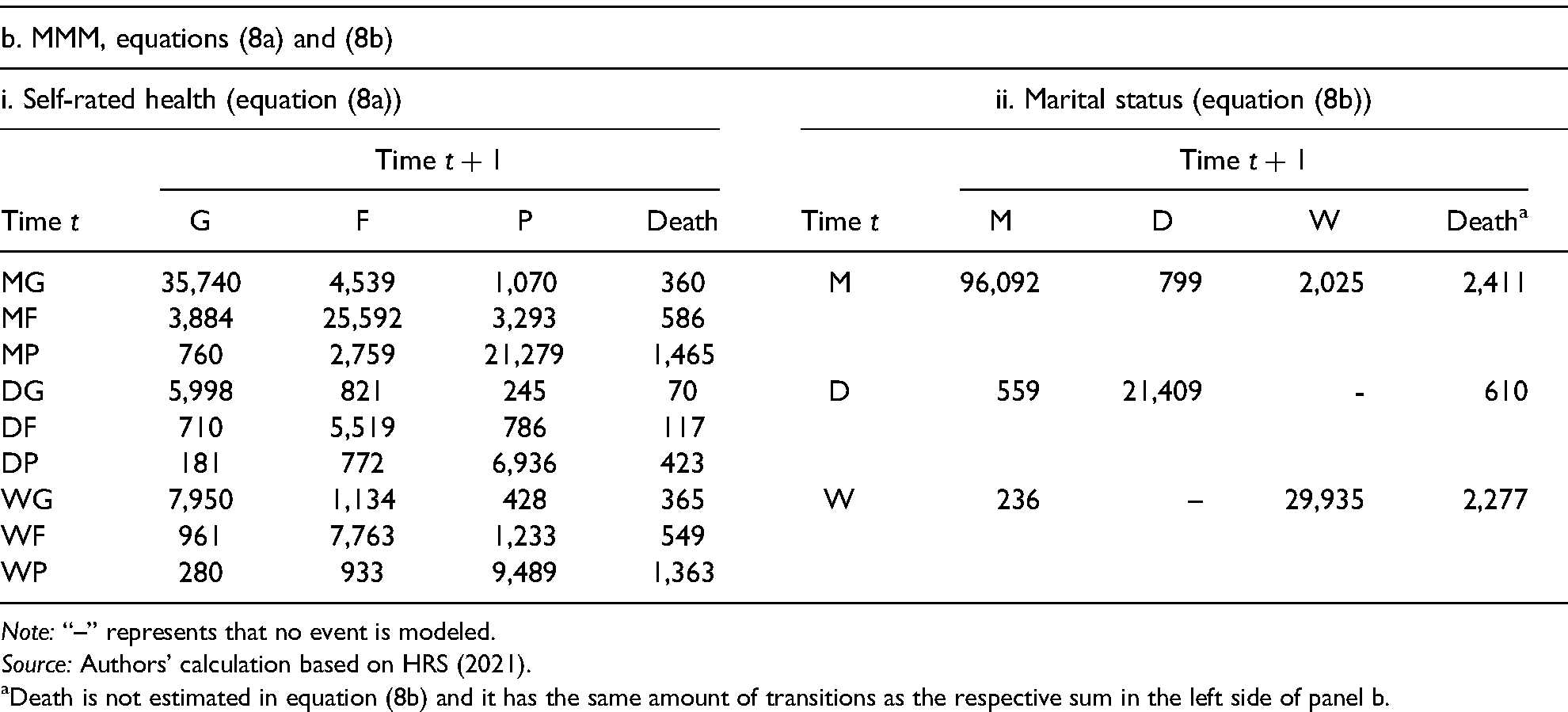
Note: “–” represents that no event is modeled.
Source: Authors’ calculation based on HRS (2021).
Death is not estimated in equation (8b) and it has the same amount of transitions as the respective sum in the left side of panel b.
Since marital status varies over time, the population-averaged expectancies at any age are rather difficult to interpret and understand. Instead, we group individuals based on the period in the life-course that a marital status change occurs to explore the potential health impacts of a marital dissolution (i.e., becoming divorced or widowed) on remaining healthy life expectancy, and how these may change over age. Table 8 presents the results of the remaining healthy life expectancy by gender and age according to the timing of a change in marital status. The first group of people remains married from age 55 to the starting age of remaining life expectancy and the other group experience at least once marital dissolution within a certain age range (also including people who change back to married within that age range). For example, a married man at age 55 who remained married at 64 could expect 7.40 years healthy life expectancy and a total of 19.09 years of total remaining life expectancy remaining at age 65. In contrast, a married man at age 55 who experienced a marital dissolution between 55 and 64 could expect to live only 6.08 years of healthy life and 17.63 years of total remaining life at age 65.
Remaining Healthy Life Expectancy by Marital Status and Age.
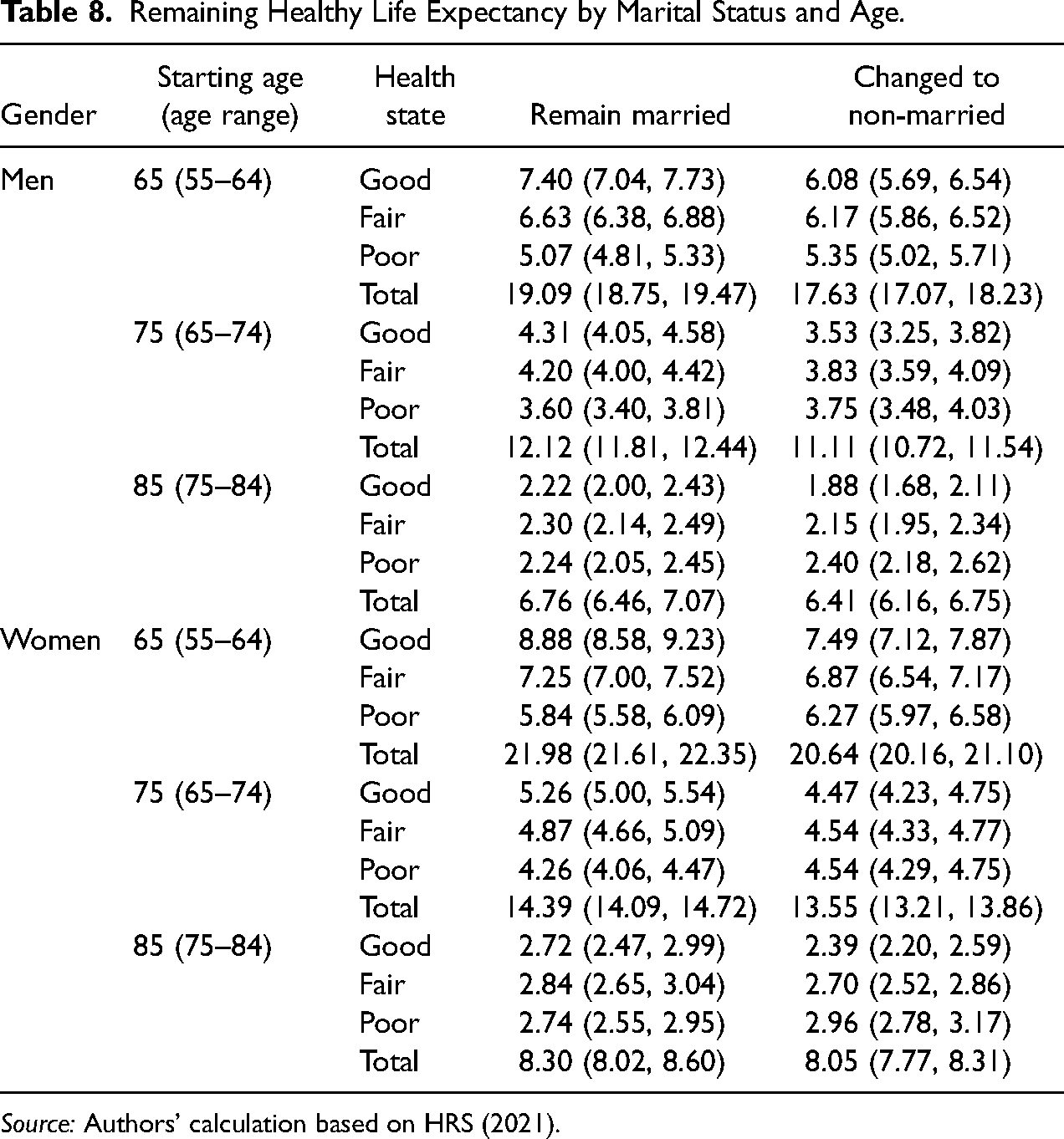
Source: Authors’ calculation based on HRS (2021).
In general, individuals who stay married over the period have higher remaining life expectancy. The two groups are also significantly different in their remaining healthy life expectancy at ages 65 and 75, and in the percentage of remaining life lived in good health. However, this beneficial effect on health and survival diminishes with increasing age. Though insignificant, individuals who remain married at age 85 have a slightly higher healthy life expectancy compared to those who experience a marital dissolution between 75 and 84. As expected, women's healthy life expectancy and total life expectancy are always higher than men's at the same age. This is only one of the research questions we can answer by these simulated individual trajectories. It is possible to explore a number of more specific questions, e.g., the number of transitions between self-rated health states in the 5 years after a married woman becomes a widow.
Discussion and Conclusion
This paper introduces and develops a flexible method, MMM, to estimate health expectancy in models with more than one coevolving variable. Previously, time-varying variables other than the main health indicator would either be assumed static in the health expectancy estimation or be incorporated into the state space. Neither of these methods has been widely used, as they both come with substantial drawbacks: the static assumption may not be realistic in many cases, and the sample size required to estimate the complex state space is larger than available in most longitudinal data sources. In addition, the multistate model is used in modeling transitions and durational expectancies in research on labor force status (Hayward and Lichter 1998; Studer, Struffolino and Fasang 2018), marital status (Schoen and Canudas-Romo 2006; Willekens et al. 1982; Zeng et al. 2012), and migration (Land and Rogers 1982; Raymer, Willekens and Rogers 2019). Thus, the method is not confined to health expectancy, and it could be used to explore other durational expectancies based on the multistate model. Our approach opens new research directions using detailed state spaces that are unfeasible to explore using the standard CMM.
The MMM can fully reproduce the CMM, but the advantage of the MMM lies in its flexibility to trade off reductions in interaction terms for greater complexity in the modeled state space. As shown in the first example, the MMM with reduced interactions produces very similar results as compared to the CMM. Furthermore, the second example also presents coherent findings with other related studies. Our results provide similar evidence on the protective effect of marriage on survival and health that is suggested in Rendall et al. (2011) and Jia and Lubetkin (2020). The protection effect also fades over age as found in other studies. Robards et al. (2012) suggest that when it comes to the elderly, other time-varying variables may also be important, such as living arrangements, which are highly correlated with marital status.
With the MMM, it is feasible to generalize our framework and apply it to estimate more than two time-varying variables at a time. Although our example only presents two coevolving variables, the advantage of the MMM is that it makes estimation of even larger state spaces possible, and can estimate models with multiple coevolving variables and large numbers of outcome categories. Furthermore, the MMM approach could also be combined with Bayesian multistate life table methods (Lynch and Zang 2022) to address very complicated research questions with many coevolving variables and a relatively large state space in each of these variables.
As is common in statistical modeling, the reduced complexity of the MMM approach does come with a stronger set of assumptions than the CMM. By providing a toolkit to flexibly reduce interaction terms, the MMM approach substantially expands the complexity of multistate models that can be estimated using longitudinal sample survey data. Reducing these interaction terms can most clearly have an impact in cases where the two time-varying variables of interest have a strong contemporaneous relationship—that is, where a change in one variable has a strong, immediate impact on the likelihood of a change in the other variable(s). However, what interactions to include, and what to drop, is a question that must be largely guided by theory and previous evidence.
There are other limitations (or assumptions) related to a multistate method. The multistate life table is essentially a discrete-time Markov process. One of the Markov properties is that it is a memoryless system, where the immediate next state only depends on the current state. This is a common limitation of studies using multistate life table with left-censored survey data. Cai, Schenker, and Lubitz (2006) combined the semi-Markov model with a backward simulation algorithm to impute the starting point and avoid the left-censored issue. This is a promising method to relax the Markov assumption by incorporating the duration dependence but has not been widely used due to the small sample size and the short follow-up period of most social surveys. Another limitation lies in the discrete-time approach and the assumption of no unobserved transitions between time points. The main reason for this approach is that HRS (and many other health surveys) are conducted about every 2 years. Our paper presents the MMM using an event-history approach in line with Crimmins, Hayward and Saito (1994) and Cai et al. (2010). A possible extension to the MMM is to adopt the embedded Markov model (EMC) approach by Laditka and Wolf (1998). Wolf and Gill (2009) suggest that compared to the event-history model, EMC may perform better in certain contexts, although it is not fully unbiased. EMC assumes multiple unobserved transitions between observed intervals. It is possible to apply a similar estimation procedure as the EMC model to estimate the multiple multinomial logistic regressions in the MMM framework. With the foundation laid in this paper, further research could explore this possibility and potential caveats. A recent study by Dudel and Schneider (2023) also presents a way to quantify the potential bias from this assumption. Thus, it is important to bear these biases in mind when using the MMM and interpreting the results.
In conclusion, MMM provides researchers with a powerful tool to estimate health expectancy with more than one time-varying variable and in complex state spaces. Although expectancy-based models are most common in estimating health expectancies, our approach could be used to explore a number of other durational expectancies such as time in employment, homelessness, and marriage. Overall, MMM represents a flexible approach to estimating durational expectancies in complex models based on longitudinal sample survey data, and one that makes a wider array of social research questions possible in the multistate framework.
Supplemental Material
sj-pdf-1-smr-10.1177_00491241241268775 - Supplemental material for Dynamics of Health Expectancy: An Introduction to the Multiple Multistate Method (MMM)
Supplemental material, sj-pdf-1-smr-10.1177_00491241241268775 for Dynamics of Health Expectancy: An Introduction to the Multiple Multistate Method (MMM) by Tianyu Shen, Collin F. Payne and Maria Jahromi in Sociological Methods & Research
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Australian Research Council (grant number DE210100087) and also by an ANU Futures Scheme Award funded by the Australian National University.
Data Availability Statement
The data used in this study are available in HRS website, https://hrsdata.isr.umich.edu/data-products/rand-hrs-longitudinal-file-2018. Our analysis is conducted in R software (R Core Team 2023). The R scripts to produce the results are available at ![]() .
.
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.