
Abstract
Public culture is a powerful source of cognitive socialization; for example, media language is full of meanings about body weight. Yet it remains unclear how individuals process meanings in public culture. We suggest that schema learning is a core mechanism by which public culture becomes personal culture. We propose that a burgeoning approach in computational text analysis – neural word embeddings – can be interpreted as a formal model for cultural learning. Embeddings allow us to empirically model schema learning and activation from natural language data. We illustrate our approach by extracting four lower-order schemas from news articles: the gender, moral, health, and class meanings of body weight. Using these lower-order schemas we quantify how words about body weight “fill in the blanks” about gender, morality, health, and class. Our findings reinforce ongoing concerns that machine-learning models (e.g., of natural language) can encode and reproduce harmful human biases.
As we navigate our cultural environment, we learn to ascribe pejorative meanings to seemingly arbitrary differences. Consider the case of body weight. Media descriptions and portrayals of fat and thin bodies may drive widespread idealization of thinness—and fear of fat—in the U.S (Ata and Thompson 2010; Grabe, Ward, and Hyde 2008; López-Guimerà et al. 2010; Ravary, Baldwin, and Bartz 2019). While there is little doubt that public culture (like media language) is a powerful channel of cognitive socialization, it remains unclear exactly how an individual decodes meanings in the cultural environment (Bail 2014). Nor is it obvious how cultural meanings are encoded and reconstructed as they travel from public life to personal thoughts (Foster 2018; Lizardo 2017).
Our paper begins to tackle this theoretical gap between public and personal culture. We motivate our theoretical arguments using the prominent case of internalizing public constructions of body weight. We turn our theoretical arguments into formal models using a popular method in computational text analysis: word embeddings. First, we provide a theoretical account of schemas and argue that schema learning is one of the core mechanisms by which public culture becomes personal culture. 1 Second, we suggest that neural word embeddings (those learned using artificial neural networks) provide a parsimonious and explicit formal model for this cultural learning, consistent with our theoretical account. An abundance of empirical work has already demonstrated that the substantive meanings learned by word embeddings correspond to personal meaning in human subjects (e.g., Bolukbasi et al. 2016; Caliskan, Bryson, and Narayanan 2017; Kozlowski, Taddy, and Evans 2019). Other authors use word embedding methods for empirical analyses of cultural texts (e.g., Jones et al. 2020). Nevertheless, these methods remain surprisingly undertheorized in sociology: they are largely treated as tools rather than objects of theoretical interest. In this paper, we theorize that neural word embeddings are also formal models of the learning and activation of schemas from the cultural environment. Thus our paper's contributions are both theoretical and methodological: we clarify schema theory and theorize that neural word embeddings operationalize schematic processing, thereby allowing us to reinterpret empirical analyses using word embeddings as another approach to schema measurement. Our account of schemas also draws a direct link between the connectionist tradition in cognitive and cultural sociology and contemporary machine learning with neural networks.
Schematic processing is a key mechanism for cognitive socialization. We use the term schema to denote the basic computational “building blocks” of human knowledge and information processing (DiMaggio 1997; Rumelhart 1980). Although Rumelhart (1980) describes a schema as “a data structure for representing the generic concepts stored in memory,” he emphasizes that schemas are very much processes rather than static objects. Schemas are used to do things: to make sense of a scene, fill in missing information, or interpret a story. On this account, any individual meaning-making necessarily involves creating, activating, reinforcing, or tuning schemas.
Schemas around body weight provide a salient example in which to ground our theoretical arguments and highlight their implications for the interpretation of word embeddings. Overweight individuals are commonly stereotyped as lazy, immoral, unintelligent, and unsuccessful (Puhl and Heuer 2010; Schwartz et al. 2006). News and media constructions of body weight are considered key influences for pervasive anti-fat prejudice and body weight stereotypes in the U.S. (e.g., Saguy and Almeling 2008; Grabe et al. 2008; López-Guimerà et al. 2010; Ravary et al. 2019; Lin and Reid, 2009; Ata and Thompson 2010; Latner et al., 2007; Campos et al. 2006). Here, we focus on four high-level schemas previously documented in ethnographic and survey work: the gender, moral, health, and class meanings of body weight.
After reviewing the rich literature on the social construction of meanings around body weight in the U.S., we provide a theoretical account of how schemas and frames enable the construction of meanings – such as meanings attached to body weight. We then explain word2vec (a core and parsimonious neural word embedding approach) (Mikolov, Sutskever, et al. 2013), highlighting the ways in which it instantiates our theoretical account of schemas. Finally, we expose word2vec models to news reporting about body weight and health and probe the models for the schemas they learn around body weight. This empirical work allows us to concretely demonstrate how specific analytic approaches commonly used with word embedding can be interpreted through a cognitive lens. Just as topic modeling can be used to detect frames in text (DiMaggio, Nag, and Blei 2013), we suggest that neural word embeddings may be useful to capture the schemas activated and reinforced by language.
The Social Construction of Body Weight in the U.S.
Fatness is frequently and negatively portrayed in public culture, such as in media and news reporting (e.g., Ata and Thompson 2010; Greenberg et al. 2003; Herbozo et al. 2004; Ravary et al. 2019; Saguy and Almeling 2008). Public culture is considered a key source of influence for how individuals make sense of their own and others' body weight and shape (e.g., Grabe et al. 2008; López-Guimerà et al. 2010; Ravary et al. 2019). Indeed, a vast body of work demonstrates that Americans hold a range of pejorative and stigmatizing meanings around fatness (e.g., Azevedo et al. 2014; Carels et al. 2013; Charlesworth and Banaji 2019; Hinman et al. 2015; Lieberman, Tybur, and Latner 2012; Nosek et al. 2007; Ravary et al. 2019; Schupp and Renner 2011; Schwartz et al. 2006; Teachman et al. 2003; Teachman and Brownell 2001). Thus, the social construction of obesity is an important and well-documented case to consider how public culture becomes personal culture. Here, we describe four specific meanings attached to obesity: those around gender, morality, health, and social class.
Fat is gendered in its cultural connotations and social implications. For women, the esthetically ideal weight is harder to achieve and more narrowly defined than it is for men (Fikkan and Rothblum 2012). Because female bodies are also more closely scrutinized than male bodies (Fredrickson and Roberts 1997), fat women are also disproportionately stigmatized for their weight compared to fat men (Fikkan and Rothblum 2012). Further, fat men are perceived as more effeminate than leaner, muscular men (Stearns 2002) – epitomized by colloquialisms like “man breasts,” “moobs,” and “bitch tits” (Bell and McNaughton 2007).
Shared meanings around weight also include moral judgement. While lean bodies signal restraint and self-discipline (Stearns 2002), fatness connotes gluttony and sloth (Saguy and Gruys 2010; Schwartz et al. 2006). In turn, attributing body weight to self-control constructs fat as an external signal of an internal character flaw. The gravity of this judgment is exaggerated by the value placed on agency and free-will in the U.S. (Crandall et al. 2001; Crandall and Martinez 1996).
The moral undertones of body weight are reinforced by the medicalization of body weight. Although once considered an esthetic problem, by the mid-century fatness became seen a medical condition to be “treated” by medical professionals. 2 Medical conditions are often stigmatized, and garner even more stigma when viewed as controllable (Crandall and Moriarty 1995). Thus, the moral undertones of body weight are further reinforced by the medical profession's emphasis on behavioral causes and behavioral solutions for weight control (e.g., caloric restraint) (Stearns 2002). Ultimately, America's weight “problem” was reinterpreted as a public health crisis; weight management was perceived as a civic duty and moral imperative (Saguy and Riley 2005).
Shared understandings of weight are also intertwined with socioeconomic status (SES). Historically, fatness signaled prosperity while thinness signaled starvation, poverty and illness (Ernsberger 2009). In contemporary America and other affluent societies, however, these meanings are inverted. Thinness is now a source of status distinction (Ernsberger 2009). Fatness, by contrast is construed as a problem of poor people, racial and ethnic minorities, and immigrants (Herndon 2005). Because low social class already connotes laziness under prevailing stereotypes, moralistic understandings of obesity as a “poor person's problem” are mutually reinforcing (Campos et al. 2006; Herndon 2005). Thus, public health campaigns against fat Americans implicitly blame low SES individuals (Campos et al. 2006; Herndon 2005).
News reporting presents a critical site for meaning-making around obesity. It conveys scientific and governmental understandings of obesity to a mass audience (Boero 2007; Saguy and Almeling 2008; Saguy, Frederick, and Gruys 2014). In news reporting, information is framed in ways that suggest specific interpretations and transform the original meaning (e.g., Saguy et al. 2014). For example, headlines in 1994 focused on a scientific study that documented the rising prevalence of overweight and obesity. Press coverage of that study popularized the metaphor “obesity epidemic” (Saguy and Riley 2005)— a metaphor that is now taken literally (Mitchell and McTigue 2007). However, it remains unclear exactly how public constructions of body weight become encoded by individuals. In fact, meanings of body weight present a salient and well-documented instance of a more generic theoretical puzzle: how do individuals learn personal culture from public culture? After taking up this theoretical puzzle, we turn to its methodological sequel: How can we formally model and measure the meanings that are learned from, or reinforced by, public culture?
Culture, Cognition, and Computational Models
Cognitive Socialization Through Schemas and Frames
Previous literature has identified the ways in which obesity is framed in cultural objects such as news and cites these objects as key influences on peoples’ understandings of body weight. We aim to close the theoretical circle implicit in this scholarship, by theorizing how an individual's meanings are learned from and invoked by the frames in news reporting. We begin by teasing apart schemas from the related concept of frames, and clarify the role that each plays in cognitive socialization (Wood et al. 2018).
Prior work describes a frame as a “structure” (Goffman 1974) that filters how a cultural object is interpreted, such as the collection of euphemisms, stereotypes, and anecdotes in a news article. The term “frame” is typically applied to structures of meaning that are external to individuals, such as in news articles (DiMaggio et al. 2013). Frames parallel the concept of “schemas,” which are mental structures that organize individuals’ mental life (DiMaggio 1997). Thus, while frames describe ensembles of meaning external to the individual, schemas describe internal cognitive structures used in meaning-making (Lizardo 2017). 3
Broadly, schema theory provides an account of how knowledge is represented and how these representations are deployed (Boutyline and Soter 2021). Schemas are theorized as patterned ways of processing stimuli. They are representations in that they contain interpretable information about the world (unlike, for example, mere associations which refer exclusively to the connection between two elements) (Boutyline and Soter 2021; Foster 2018). Schemas are also thought to simplify cognition (DiMaggio 1997). They allow us to fill in the blanks about the world, and offer a “source of predictions about unobserved events” (Rumelhart 1980). Finally, schema-driven information processing is thought to “occur without our conscious awareness, and underlie the way we attach meaning to things” (Shepherd 2011). Hence it thought to be an implicit form of memory; it is invoked automatically (Schacter 1987).
In this paper, we aim to capture two types of schemas that may be learned from or evoked by our text data: First, schemas for individual words related to obesity; second, lower-order 4 schemas for four dichotomous concepts related to the construction of obesity (gender, morality, health, and social class). These schemas are forms of semantic memory: “memory for word meanings, facts, concepts, and general world knowledge” (Jones et al. 2015).
Both schemas and frames refer to structures and processes that allow people to generate and interpret their cultural environment. We suggest that interpreting a cultural object requires an interaction between frames and schemas: people are guided externally – by the features of the object – and internally, by their preexisting schemas. Therefore, by our account, when referring to the interpretation of a frame, we are really talking about schematic processing activated by the frame. In the special case where there are no preexisting schemas to guide learning (i.e., learning from a blank slate), the schemas learned from a cultural object may closely match the frames in that object. In other cases, features of the object activate preexisting schemas, while our preexisting schemas simultaneously tune us to certain features of the object.
Sociological work often theorizes the existence and functions of schemas (Hunzaker and Valentino 2019; Leschziner and Brett 2021; Shepherd 2011; Taylor and Stoltz 2020; Vaisey 2009; Wood et al. 2018). It also documents empirical evidence for their existence and impact, often in the form of stereotypes, implicit associations, patterned responses on surveys and interviews, and biases in information transmission (e.g., Boutyline 2017; Goldberg 2011; Hunzaker 2014, 2016; Hunzaker and Valentino 2019; Jacobs and Quinn 2022; Vaisey 2009). But there is less consensus on the specific structure and processes involved in schematic processing. We offer a theoretical account of these next, drawing on the connectionist tradition in cognitive science (Rumelhart et al. 1986) and its influence on the descriptions of schemas in cognitive anthropology (D'Andrade 1995; Strauss and Quinn 1997) and sociology (e.g., Boutyline and Soter 2021; Cerulo 2010; Hunzaker and Valentino 2019; Shepherd 2011; Vaisey 2009).
A Connectionist Account of Schemas
Connectionism (Rumelhart et al. 1986) theorizes knowledge and cognitive processes as networks of associations. This theory suggests, for example, that viewing the word “obese” triggers a pattern of activation in a limited number of units (e.g., neurons) organized in networks. That pattern of activation, then, is our mental representation of obesity, and is likely similar to patterns triggered by related words such as “overweight.” Semantic information (which includes schemas) is encoded not only in the patterns of activation but in the relationships between these patterns of activation: for example, the differences in the patterns between “unhealthy” and “healthy.”
In connectionism, 5 a pattern of activation is more formally referred to as a “distributed representation” (Hinton 1986). In distributed representations, semantic information is defined not by the activation of a single unit (e.g., a single neuron), but rather by a distribution of activations across a set of units (e.g., neurons or groups of neurons). Each unit is involved in representing many concepts. 6 To better understand a distributed representation, consider the pixels in a phone screen as an analogy (Smith 2009). When an image is flashed on the screen, the color of a single pixel is uninformative. However, a limited set of pixels can represent an enormous range of possible images, each as a distinct overall pattern of color. Following a connectionist perspective, we suggest that schemas come in the form of distributed representations (Rumelhart et al. 1986).
Connectionism also provides an account for learning and processing schemas, not only representing them. In a connectionist framework, distributed representations are learned from experiences with data, and they are learned gradually rather than from any one instance (Munakata and McClelland 2003). Distributed representations are both used to process any incoming data and are also tuned by incoming data. Hence, connectionist accounts of schemas also describe them as learned, used, and modified across exposure to cultural information (D'Andrade; Hunzaker and Valentino 2019; Shepherd 2011).
Rumelhart (1980) suggests two broad ways in which schematic processing might occur in a connectionist framework. First, from the top down, where the activation of higher-order schema then (partially) activates other sub-constructs. For example, once we envision a schema for a “body,” many aspects of the distributed representations for “waist,” “face,” etc. are also likely activated (or partially reconstructed), since our schema for “obese persons” is comprised of these sub-concepts. In other words, given a big picture, we add in additional details. Second, schematic processing may occur bottom-up, enabling us to complete partial stimuli to gain a larger picture. For instance, even from an abstract sketch of stick figure, we might infer the sketch portrays a body, because we use our schema of a body to fill in missing details. Here, we are also filling in missing information to gain a more complete picture. Filling in information with details is a heuristic, enabling speedy processing at the risk of decreased accuracy.
Both top-down and bottom-up processing also highlight that schemas are theorized to be compositional (Rumelhart 1980), such that a higher-order schema (e.g., one for a body) is comprised of lower order schemas (e.g., face and waist). While we are not aware of empirical work explicitly testing for the compositionality of schemas, there is an abundance of empirical evidence for the compositionality of language and concepts (for a review, see Frankland and Greene 2020). In particular, recent empirical work illustrates that human representations of word meanings (measured using fMRI patterns produced after exposing participants to a specific word) are compositional (Wu et al. 2022).
A variety of theoretical and empirical work in cognitive science has led cognitive scientists to reach broad consensus that semantic memory (which includes schemas) takes the form of distributed representations (for reviews see Kiefer and Pulvermüller 2012; Rissman and Wagner 2012; Rogers and McClelland 2014). Such work points out that distributing semantic information across many units explains how human knowledge is fuzzily defined, flexible, and robust (Goodfellow, Bengio, and Courville 2016; Smith 1996; Strauss and Quinn 1997:66). These properties explain a variety of observed cognitive phenomena. Even if one connection or unit is severed or not activated, a concept can still be reconstructed by the many remaining units. Empirically, connectionism with distributed representations can be used to accurately model how human brains process and represent information after impairment to semantic memory, such as due to Alzheimer's disease, semantic dementia, stroke, and/or brain injury (e.g., Hodges, Graham, and Patterson 1995; Rogers et al. 2004). Further, various semantic categories of images and words accurately predict distinct spatial patterns of neural activation (McClelland and Rogers 2003; Mitchell et al. 2008).
More generally, the connectionist cognitive architecture is supported by a vast body of theoretical and empirical work (e.g., Cree and McRae 2003; Huth et al. 2012; McClelland and Rogers 2003; Mitchell et al. 2008; Munakata and McClelland 2003; Thagard 2012). While a full review is not possible here, we pull out one branch of this prior work. As detailed by Munakata and McClelland's review of connectionism and cognitive development, connectionist models offer empirical (and theoretical) consistencies with a variety of patterns in how humans learn information. For instance, both learn information at non-linear rates, rapidly accumulating information in bursts, followed by lulls, and then again rapid bursts (2003).
In sum, distributed representation offers a cognitively plausible strategy to represent schemas, and connectionism suggests how schematic processing may occur. Connectionist learning can be computationally modeled with artificial neural networks (ANNs). We briefly introduce ANNs next and then illustrate how a specific ANN architecture (word2vec) can be used to empirically model schemas learned from text, in a way that instantiates our theoretical account.
Artificial Neural Networks
An artificial neural network (ANN) is a computational model used to detect patterns in data for some task like classification. An ANN makes predictions from data through a series of linear and non-linear transformations of the inputted data. The basic building block of ANNs is an artificial neuron. Just as biological neuron receives and weights incoming data and has a synapse which “fires” according to some activation function, an artificial neuron receives, weights, transforms and outputs data. This outputted data may be passed as input to subsequent neurons (i.e., to a “hidden” layer of neurons), or it may be a final prediction (i.e., the “output” layer). While each neuron performs a simple task, an ANN is an ensemble of neurons – each of which may receive, weight, transform, and output data. Like “ants building an anthill,” this ensemble can perform complex tasks (Geron 2017).
An ANN is trained on data; the goal of this training is to learn to weigh the incoming information to accomplish a given task with minimal errors. This may be thought of as learning to weigh the evidence for predicting an outcome. Weights may be initially random and then updated across many iterations of two steps. In the first step, data is inputted (“fed forward”) into the ANN to predict an output, and the prediction error is calculated. Second, each of the weights in the ANN are updated to minimize this prediction error. The core algorithm used to update weights is backpropagation with stochastic gradient descent. Conceptually, at a given combination of weights, backpropagation calculates how the error increases or decreases if we slightly increase or decrease each weight. We can then update each of the weights by a small amount (i.e., learning rate) in the direction that reduces their error. 7 Together, ANNs and backpropagation offer a powerful and flexible learning architecture.
Neural Word Embeddings
The ANN Architecture of Word2vec
Neural word embeddings, like word2vec, use an ANN to learn vectors that represent the meanings of words from text data. In broad strokes, the ANN is tasked with predicting words that will appear as it “reads” a corpus. To perform this task well, it learns to weigh incoming words along N latent dimensions (i.e., weights to N artificial neurons). After training, these weights to the neurons are our N-dimensional “word-vectors.” Obtaining these word-vectors is the main goal of using word2vec. In a well-trained model, words that appear in more similar contexts (and presumably, have more similar meaning) tend to have more similar word-vectors (by cosine similarity).
More specifically, an ANN is given one of two possible semantic prediction tasks: Continuous Bag of Words (CBOW) or Skip-Gram. In CBOW, the ANN is given a context window from the data and then predicts the missing word that was actually used in the data. Skip-Gram inverts this task, predicting context words given a focal word. We focus on CBOW, although our arguments generalize to Skip-Gram. Figure 1 illustrates the ANN architecture of word2vec with CBOW. See appendix A for a more detailed account of CBOW.
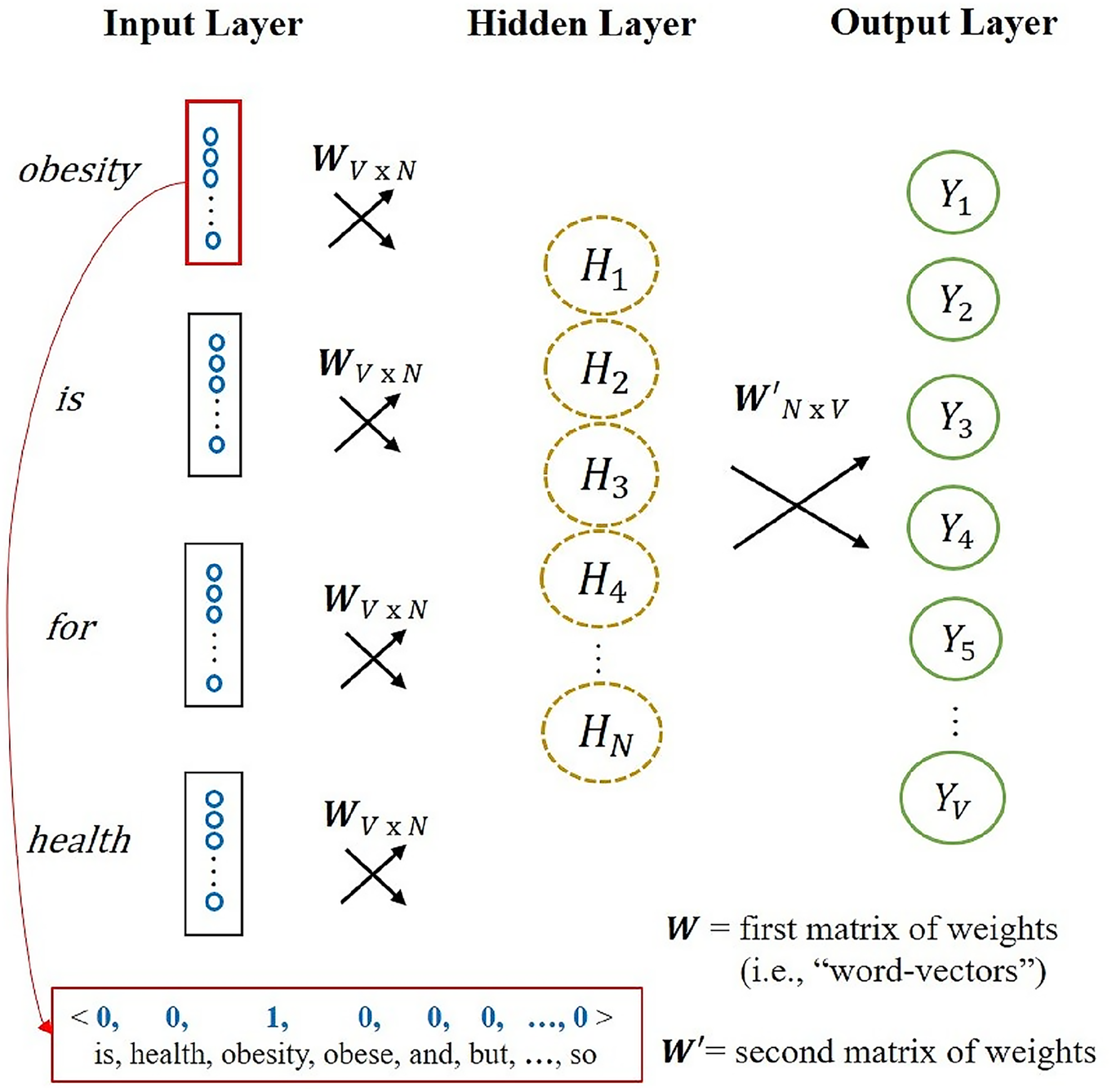
Artificial neural network for Word2vec with continuous bag of words (CBOW). Design inspired by (Rong 2014).
Although the word-vector for a particular word is derived from the ANN weights, in practice we abstract word-vectors from their neural network origins and treat them as vectors in an N-dimensional vector space. The number of dimensions is often set between 100–1000, and thus is far less than the vocabulary size of the dataset itself. What is striking about word2vec is that, despite its simplicity, it can abstract from text data to learn rich and nuanced semantic meanings that match human intuitions, as we show next.
Neural Word Embeddings as Models for Cognitive Socialization via Schemas
We have described how neural word embeddings (specifically, word2vec) learn semantic representations by “reading” text and making predictions. Now, we evaluate the cognitive plausibility of neural word embeddings as operationalizing how human “internalize” public culture through schematic processing. We focus on word2vec given its relative simplicity and ubiquity, but many of our arguments generalize to neural embedding methods more broadly.
To organize this section, we draw inspiration from how cognitive scientists structure their accounts of information processing systems in minds and machines (Marr 1982; for sociological applications see Boutyline and Soter 2021; Foster 2018; Leschziner and Brett 2021). Cognitive scientists aim to be explicit about the level of granularity at which they describe (and/or computationally model) a cognitive phenomenon. Doing so offers analytic clarity and precision when describing a system or comparing two systems (Mitchell 2006). Most commonly, cognitive scientists distinguish levels according to “Marr levels” (1982) which range from abstract and functional (e.g., what problem is the system solving?) to concrete (e.g., how is the system physically realized in the brain or in computer hardware?). We translate Marr's levels into guiding questions, beginning at the most abstract level.
Do neural word embeddings learn and reinforce schemas from public culture?
We begin with questions at the most abstract level: what problem is being solved and why? What is the input and output? In this paper, we theorized how humans internalize public culture by learning new schemas and reinforcing existing ones from experiences with public culture. More specifically, we focus on learning schemas related to word meanings. As noted earlier, these schemas are a form of semantic memory (Jones et al. 2015). We also argue that schemas for words are often cultural, to the extent that they are both shared and gain their content through participation in social life (Foster 2018).
Like schemas, neural word embeddings learn semantic information (e.g., word-vectors) and reinforce existing semantic information from experiences with public discourse. In fact, it is no coincidence that neural word embeddings solve this problem. While contemporary word embeddings were developed as tools to work with natural language data at scale, language modeling in computer science emerges from efforts in cognitive science to explain how humans learn, process and represent semantic information (i.e., semantic memory) from words’ distributional patterns in natural language (Günther, Rinaldi, and Marelli 2019; Jones et al. 2015; Kumar 2021; Mandera, Keuleers, and Brysbaert 2017). Such language models are thus called distributional models.
We also argue that neural word embeddings (e.g., word2vec) more closely model the problem of learning schemas from public culture, compared to other distributional models (Günther et al. 2019; Mandera et al. 2017). The input to many distributional models (e.g., standard topic modeling, Latent Semantic Analysis, and GloVe) is a term-by-document frequency matrix of a corpus, and this matrix is then compressed using a dimensionality reduction algorithm. Such a matrix is not cognitively plausible input (Günther et al. 2019): it would require us to build (and store) a large co-occurrence matrix, before reducing it to arrive at condensed, more efficient representations. Upon experiencing new co-occurrences of words, it would require us to completely re-do this dimensionality reduction.
In contrast, the input to neural word embeddings is a vast number of experiences with text, where semantic information is learned (and used) incrementally. This parallels theoretical work suggesting that schemas are gradually built up across cultural experiences (e.g., D'Andrade 1995; Goldberg 2011; Hunzaker and Valentino 2019; Shepherd 2011). More specifically, neural word embeddings learn distributed representations from the statistical experiences of stimuli (i.e., words) in their cultural environment in order to efficiently represent these experiences and efficiently process new experiences. Put another way, word-vectors are learned while trying to do things with incoming data and are abstractions of previously encountered data. As noted earlier, schemas are also described as heuristics used to do things, such as to “process sensory input” (Goldberg 2011). Schemas are specifically described as abstractions of experience rather than representations of a single experience (e.g., a single instance of a word) (Cerulo 2010; Ghosh and Gilboa 2014). 8 Thus, neural word embeddings closely operationalize the theoretical problem of learning and using schemas from experiences with public culture.
Abundant empirical evidence demonstrates that semantic information learned by neural word embeddings (and other distributional models) corresponds to humans’ own semantic information (for a review, see Lenci 2018). For instance, distributional models can perform linguistic tasks that require deep semantic understanding, such as analogy completion (Landauer 2011; Mandera et al. 2017; Mikolov, Chen, et al. 2013; Mikolov, Sutskever, et al. 2013; Pennington, Socher, and Manning 2014). Further, numerous studies illustrate that the substantive content captured by word-vectors from embeddings correlates to human participants’ meanings of words, based on implicit association tests and surveys (e.g., Bolukbasi et al. 2016; Caliskan et al. 2017; Garg et al. 2018; Grand et al. 2022; Joseph and Morgan 2020; Kozlowski et al. 2019; Lewis and Lupyan 2020). While schemas are challenging to directly observe, implicit association tests and surveys are commonly used to measure traces of schemas (e.g., Goldberg 2011; Hunzaker and Valentino 2019; Shepherd 2011). 9 The strong correspondence is convincing, especially given that that we would not expect a perfect relationship between word embedding and these metrics. For instance, these studies compare the content learned by a word embedding (from a specific text) with the aggregated content of meanings in groups of participants (accumulated across their lifetimes).
Finally, a body of empirical work additionally shows that word-vectors trained with word embedding methods correspond to human participants’ subconscious, neural activations upon reading and hearing language (e.g., Abnar et al. 2017; Dehghani et al. 2017; Hollenstein et al. 2019; Ruan, Ling, and Hu 2016; Vodrahalli et al. 2018). In fact, word-vectors from word embeddings are now commonly used to “translate” (i.e., decode) fMRI patterns into language, rendering fMRI patterns more interpretable to researchers (e.g., Sun et al. 2019; Wang et al. 2020). This illustrates that the semantic information in word-vectors also corresponds to the content activated in individuals’ minds, by cultural stimuli.
Does word2vec use cognitively plausible representations of schemas?
Recall that schemas are defined as representational (e.g., Boutyline and Soter 2021), and our account of schemas suggested that humans represent and process schemas as distributed representations. In fact, word-vectors found by word embeddings are also distributed representations: each word is defined by where it lies on N latent dimensions, and each dimension is shared across words. In our cognitive interpretation of word2vec, each word-vector may also be thought of as the pattern of activation of the hidden layer (with N artificial neurons), triggered by a particular word (Günther et al. 2019). Each element in a word-vector corresponds to a weight to an artificial neuron in the hidden layer. Therefore word embeddings use distributed representations to represent and reconstruct learned knowledge, matching our theoretical account of human schemas.
We noted earlier that human schemas are thought to be decomposable into lower order schemas or composable into higher order schemas (Rumelhart 1980). Similarly, the representations in word embeddings are compositional, to an extent (e.g., Arora et al. 2018; Arora, Liang, and Ma 2017; Mikolov, Sutskever, et al. 2013). This was famously demonstrated by the fact that word2vec word-vectors encode analogical relationships between words (Mikolov, Sutskever, et al. 2013). A query for analogy (such as king:man as ?:woman) can be answered by selecting the word-vector with the maximum cosine similarity to the vector resulting from
Does word2vec use cognitively plausible algorithms to learn and process these representations?
Theoretical accounts of schema suggest that one of their core tasks is to predict or “fill in missing information” (Boutyline and Soter 2021; Cerulo 2010; DiMaggio 1997; Hunzaker 2016; Rumelhart 1980). Prediction is at the crux of how neural word embedding algorithms not only use, but also learn and modify distributed representations. Word2vec with CBOW uses, learns, and tunes distributed representations while it predicts target words in contexts, while with word2vec with Skip-Gram does so by predicting contexts given target words.
In fact, a body of theoretical and empirical work in cognitive science and neuroscience suggests that human learning and perception, too, hinges on prediction (for a review, see Millidge, Seth, and Buckley 2022). A large subset of this work even suggests that prediction, and the minimization of prediction errors, is the core goal of the brain. Such work argues that humans constantly engage in “predictive coding” as we try filling in missing information in our environment, based on our prior and contextual knowledge (Clark 2013). Further, empirical and theoretical scholarship specifically reveals the important role of prediction in human processing of linguistic data (DeLong, Urbach, and Kutas 2005; Lupyan and Clark 2015; Pickering and Garrod 2007). As detailed by such work, predictive coding works as a heuristic, enabling us to process incoming information more efficiently (and sometimes, more accurately).
To perform and learn from prediction, word2vec adjusts word vectors (i.e., the weights to artificial neurons in the hidden layer) to minimize errors of predicted target words (or contexts). Word2vec specifically uses backpropagation to learn from prediction errors.
In fact, brains engaged in predictive coding are also thought adjust processes and structures such as synapse firing in response to errors, to minimize the error of future predictions (DeLong et al. 2005; Lupyan and Clark 2015; Mandera et al. 2017; Rumelhart et al. 1986). Further, backpropagation is a special case of a classic model in psychology for how human brains learn from error (i.e., the Rescorla-Wagner model) (Mandera et al. 2017; Miller, Barnet, and Grahame 1995). Note that this account of schematic processing blurs the line between perception and learning. It illustrates how schemas, when implemented in this way, are dynamic and adaptable (as often described in sociological work on schemas (e.g., Boutyline and Soter 2021)).
Is word2vec a cognitively plausible account of how schemas might be physically implemented in the brain?
Here, we touch on the cognitive plausibility of word2vec at the most granular possible level: Does word2vec have any correspondences with how schemas might be physically instantiated in the brain? While ANNs were initially dismissed as mere metaphors for biological neural networks, ANN-based models of the brain are not as unrealistic as once thought and appear to explain a variety of neurobiological phenomena (Richards et al. 2019). For example, biological neural networks, like ANNs, are thought to operate by minimizing some costs (i.e., errors from predictions) (Marblestone, Wayne, and Kording 2016). Further, while learning via backpropagation was also once dismissed as biologically implausible, scholars have more recently suggested that biological neural networks may indeed approximate backpropagation (e.g., Marblestone et al. 2016; Sacramento et al. 2018; Whittington and Bogacz 2019).
Of course, the cognitive plausibility of word2vec should not be overstated, particularly at the hardware level. For example, the scale of ANNs is often much smaller than that of biological neural networks; while we use a hidden layer with 500 artificial neurons in our models, a human brain has around 86 billion biological neurons (Herculano-Houzel 2012). Further, while the most complex ANN-based language model to date boasts more neurons (175 billion) than do humans (Brown et al. 2020), it still struggles on various basic natural language tasks (Zellers et al. 2020). Such supersized ANNs are also unrealistic in that they require far more experiences with language than do humans.
Despite their limitations, neural word embeddings offer mathematical sociologists a crucial step towards a formal model of schema extraction and schematic processing of text data. These models highlight specific, and cognitively plausible ways in which abstract, structured information may be internalized across experiences with public culture. ANNs and distributional models have pushed neuroscientists and cognitive scientists to formalize and even question theoretical concepts about knowledge and learning. These models offer similar promise to sociologists seeking to understand how culture may be “internalized” and how public and personal culture interact. Further, neural word embeddings may be used to empirically identify the schemas activated and reinforced by public cultural data, as we do next.
Interpreting Word Embeddings as Schemas: The Case of Obesity
Approach and Data
Thus far we have (1) provided a theoretical account of schemas as a mechanism for learning public culture, and (2) theorized that neural word embeddings operationalize our account. Now, we revisit our empirical case: learning the meanings of obesity from news reporting. We use word2vec to empirically capture several schemas we expect to be learned from New York Times (NYT) articles on the body and health. Our primary goal here is to illustrate how practical applications of neural word embeddings may be (re)interpreted as schemas. As we show, empirical results from word embeddings also reveal implicit assumptions and gaps in our theoretical account.
Our empirical work includes four steps, which we describe in detail in the following sections.
Collecting and pre-processing a corpus (in our case, NYT news articles on the body and health). Training word2vec word embeddings on this corpus. Probing two specific types of schemas: schemas for specific words, and lower-order schemas for dimensions of gender, morality, health, and socioeconomic status. We then examine how schemas for words relate to each dimension. Validation to assess the robustness of our methods and findings.
Our data includes NYT articles which were published between 1980 and 2016. We chose the NYT for several reasons. First, using the NYT enables us to compare our empirical conclusions to core prior work on obesity news discourse which also use the NYT (Boero 2007; Lawrence 2004; Saguy and Gruys 2010). Second, like these previous studies, we selected the NYT because it is an important news source; it is a leading national newspaper with wide readership in the American public (Kohut et al. 2012). To limit our embeddings’ cultural diet to news on health and obesity, we only included articles with at least one of the words: overweight, obesity, obese, diet, fitness, fat, fatty, fattier, or fatter. We collected NYT articles from Lexis Nexis, and this process yielded 103,581 articles. We also replicated our study using word embeddings trained on Google News (a corpus that aggregates across various news sources), suggesting that the NYT is not a unique site for learning these schemas around fat.
As part of cleaning the NYT text data, we removed vocabulary words occurring less than 40 times in the data to prevent word2vec from learning poor-quality word-vectors. We also detected commonly occurring phrases based on collocation counts (Řehůřek and Sojka 2010), to enable word2vec to learn word-vectors for these phrases. This process yielded a vocabulary size of 81,250 words, and total of 92,785,779 tokens.
Training Word2vec Models and Benchmarking Model Quality
Training a word2vec model requires several hyperparameter choices (Řehůřek and Sojka 2010). We chose the hyperparameters that maximized performance on the Google Analogy Test, a common benchmark for the quality of word embedding models which tests how well the model completes analogies (Mikolov, Chen, et al. 2013; Mikolov, Sutskever, et al. 2013). The Google Analogy Test includes a series of approximately 20,000 analogies divided up into 14 subsections.
Analogy tests are useful to efficiently (if imperfectly) assess word embedding quality and select hyperparameters. With our theoretical framework, we can also give them a substantive interpretation. First, analogy tests may be thought of as testing the extent to which a word embedding learns schemas (i.e., word-vectors) as compositional, as noted earlier. Second, analogy tests may be thought of as asking the model to “fill in” missing information (by using its word-level schemas and the relationships between them, to do this decomposition). As also noted earlier, key features of schemas include compositionality and using schematic information to fill in the blanks. Further, the specific schemas learned depend on the cultural diet; analogously, we would not expect an embedding trained on U.S. news reporting about bodies to learn how to decompose schemas about, say, currency or countries’ capitals. The Google Analogy Test was developed using a general news domain in mind (Mikolov, Chen, et al. 2013; Mikolov, Sutskever, et al. 2013). For these reasons, we prioritized model performance on Google Analogy Test sections about family and syntax which are most relevant to our corpus.
We trained candidate word2vec models with varied learning architectures (CBOW or Skip-Gram, described earlier) and two possible algorithms that speed up learning by approximating the softmax function (hierarchical softmax or negative sampling). We also trained models with various dimensionality of word-vectors (between 50- and 500-dimensional word-vectors), and two possible context window sizes (5 or 10 words on either side of the target word). Our final candidate model using CBOW, negative sampling, 500-dimensional word-vectors, and 10 context words performed the best among the candidate models. Trained on all data, this model correctly answered 90% of analogies in the family sections, 60% of analogies in the syntactic sections, and 57% of analogies across all sections. This performance is comparable to other published word2vec models (Mikolov, Chen, et al. 2013; Mikolov, Sutskever, et al. 2013).
We also performed another common quality check for word embeddings, which is to compare word similarities in the model with a data set of human-rated similarities of words. Conceptually, this may be thought of as assessing the association between schemas for two different words. If a word embedding's training data reflects the cultural environment of raters, we might expect a correlation between human-rated and embedding-rated similarities between words. We use the WordSim 353 data, a common benchmark which includes 353 human-rated similarities between word pairs (similarity of two words can range 0–10), rated by at least 13 individuals (Finkelstein et al. 2002). The human-rated similarities from the WordSim 353 test significantly and strongly correlated to similarities produced by our model (Spearman correlation of 0.61, p < .001). This correlation offers another potential indicator for the quality of our models. Like with the analogy test, word similarity tests offer efficient but imperfect approaches to assess word embedding quality. 10 For a critical review on word embedding evaluation, we refer to Wang et al. (2019).
Word-Level Schemas
We first describe word-level schemas for 36 obesity-related words. Our 36 terms include those about fat and thin body shapes/weights, and terms reflecting related concepts in our literature review, such as weight management, physical fitness, health, and muscularity. We also include terms for eating disorders; prior work often discusses social constructions of fat in context of their implications for eating disorders (e.g., Thompson and Stice 2001). All terms are listed in Figures 2–5. Although word-vectors are just points in a semantic space, we argue that they are schemas. Word-vectors take the form of distributed representations, and they are learned as word2vec aims to predict incoming words and complete patterns. In our theoretical framework, we consider these word-vectors as activations of lower-level units (i.e., artificial neurons). Therefore, cosine similarity between two word-vectors may also be thought of as measuring the extent to which they share similar patterns of activation, or their connotations.
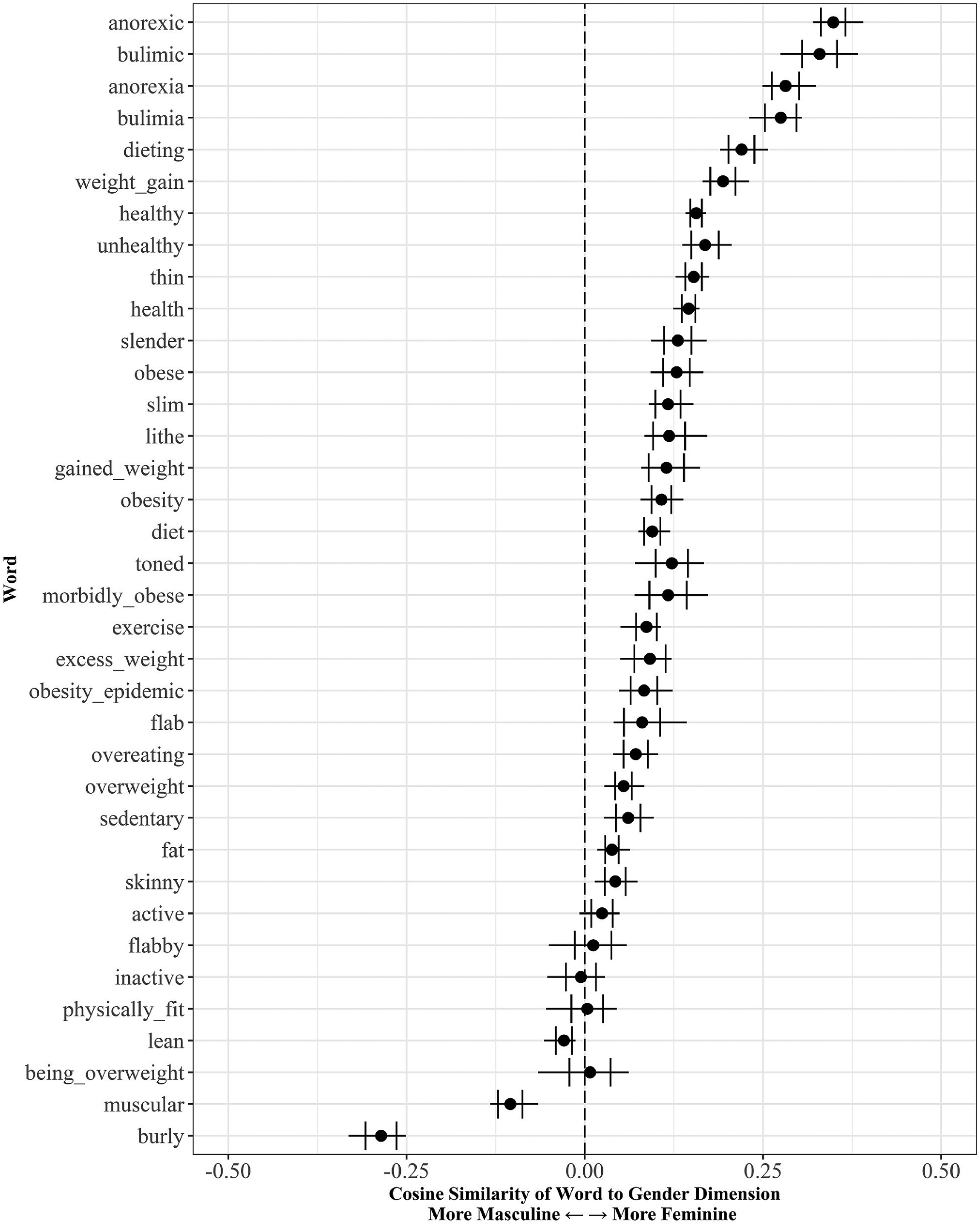
Gendering of obesity-related words.
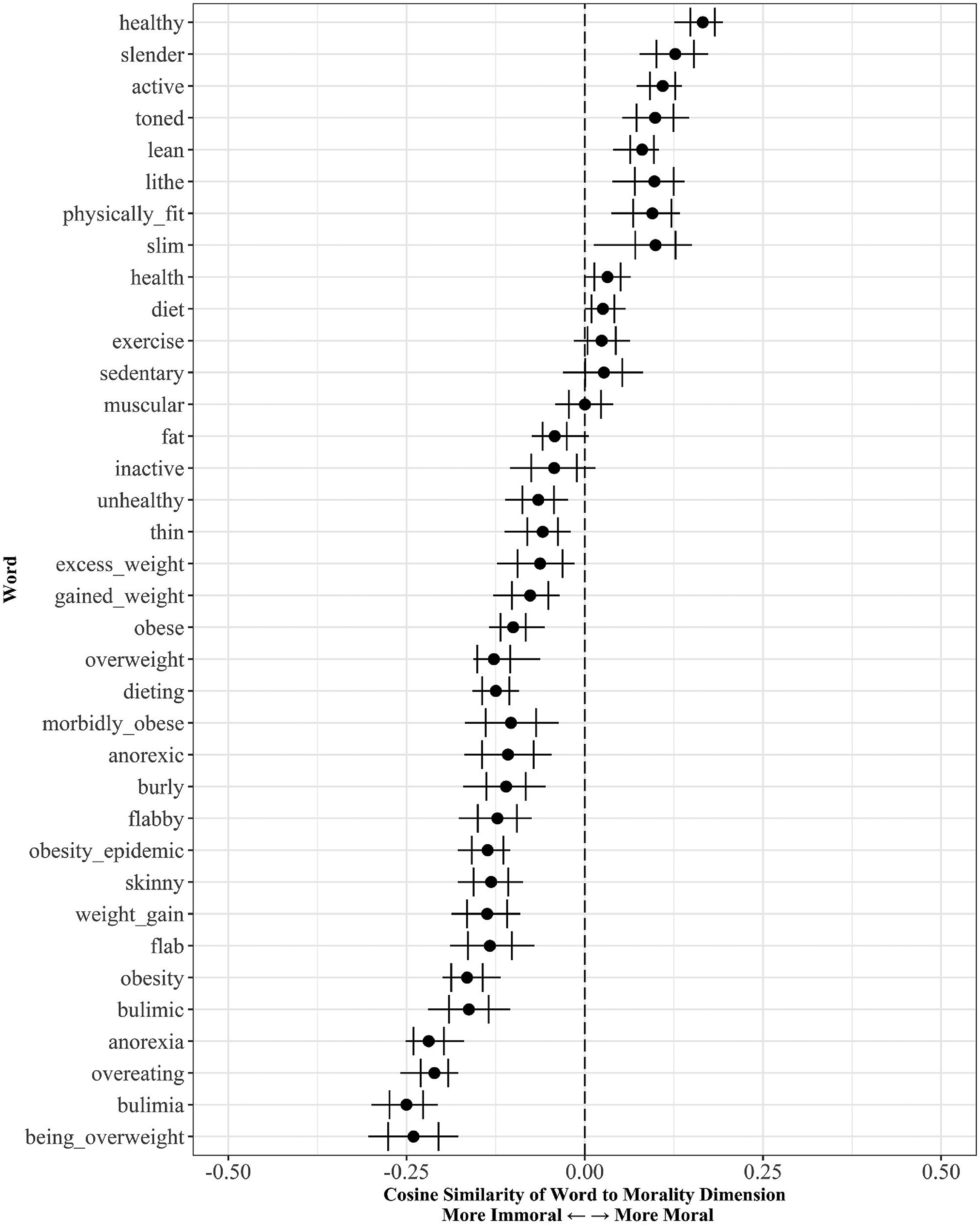
Morality of obesity-related words.
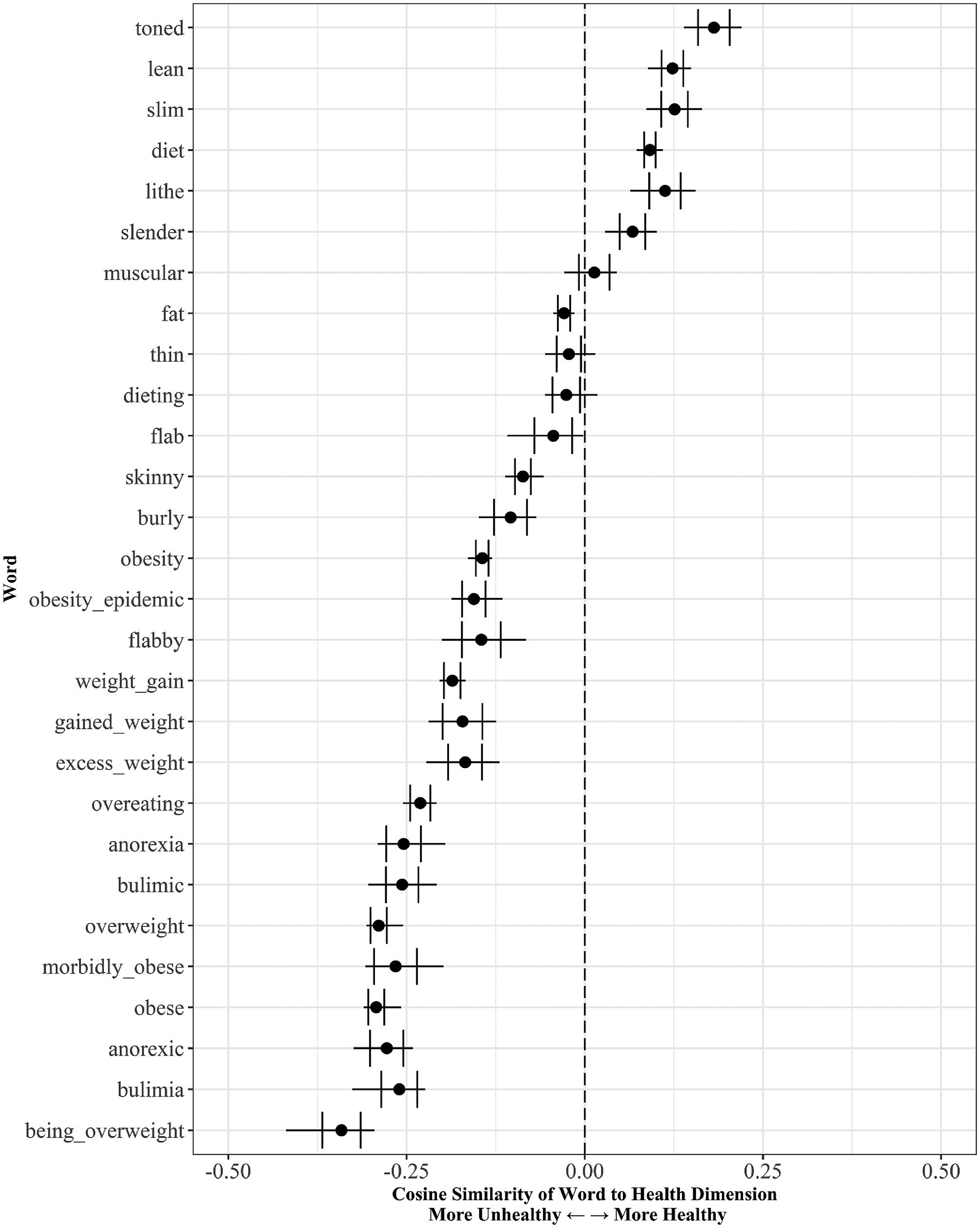
Health of obesity-related words.
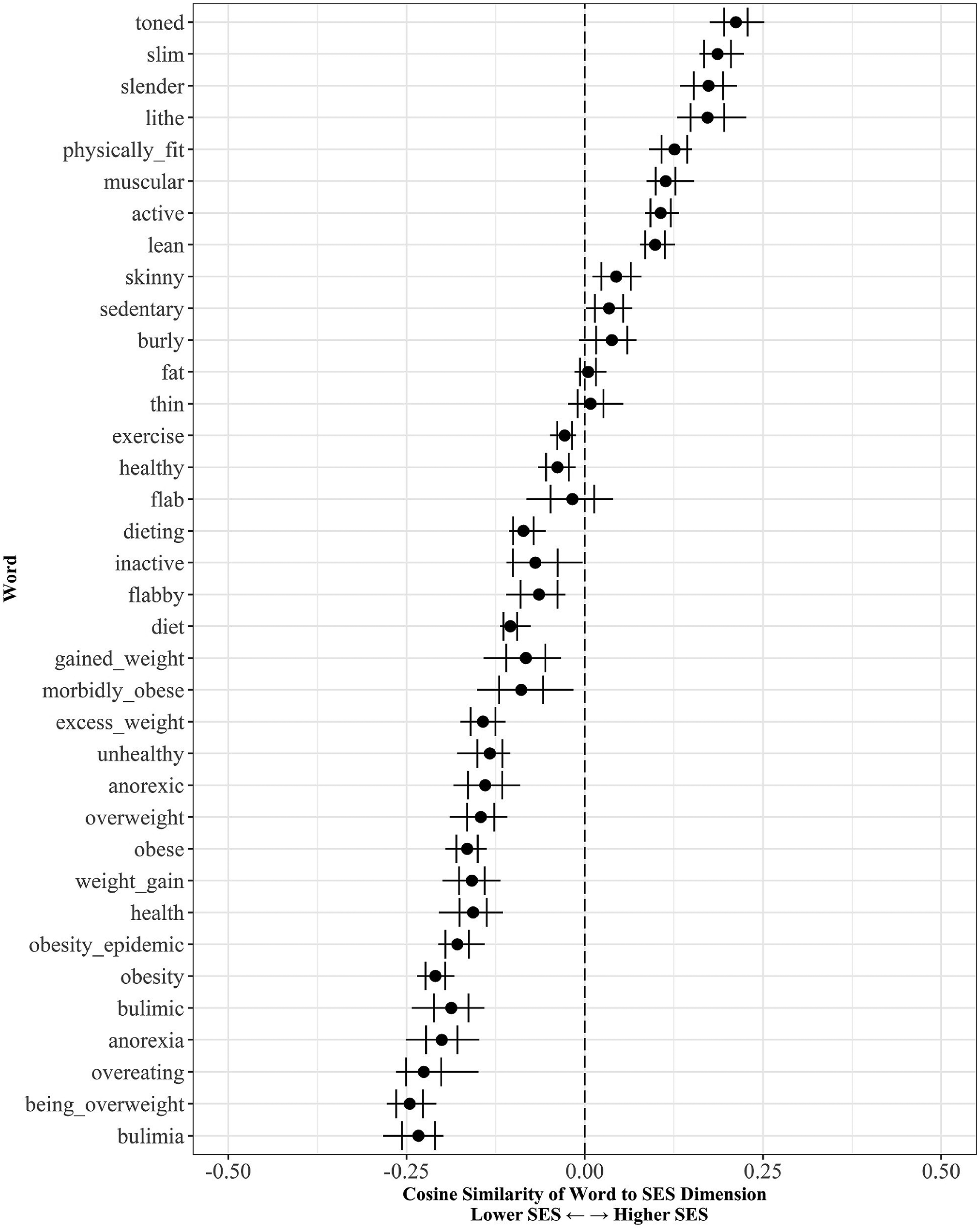
Socioeconomic Status (SES) of Obesity-Related Words.
Dimensional Schemas and Their Relationship to Word-Level Schemas
Second, we extract four lower-order schemas (dimensions of gender, morality, health, and social class), and then describe the relationship between our obesity-related terms and these four schemas. Our approach builds on and extends established word embedding methodology (Bolukbasi et al. 2016; Kozlowski et al. 2019; Larsen et al. 2015), described next. Our interpretation of the results illustrates how these methods may be re-interpreted from a cognitive lens.
We show how to extract these four dimensions using the case of gender. We begin by choosing a set of “anchor” (i.e., training) words denoting femininity and masculinity. Consider first a simplified approach to extract a schema for gender: we pick a single anchor word for each end of the dimension (e.g., “woman” and “man” for gender). We then subtract the word-vector representing masculinity from its feminine word-vector counterpart. Conceptually, if we assume that the meanings of woman and man are largely equivalent except for their opposing gender, then subtraction (largely) cancels out all but the gender differences across each component. The remainder is our gender direction:
To extract a less noisy gender difference
We interpret these dimensions, too, as schemas. Each takes the form of distributed representations and may be thought of as containing semantic information about the differences in schemas for one set of anchor words and another set (e.g., in the case of gender, the difference between patterns activated by “woman” and “man”). Like word-vectors, these schemas are also independently learned by word2vec models tasked with predictively coding words in an incoming stream of news data. Unlike word-vectors, these types of schemas are hierarchical: composed of the difference between schemas for the word-vectors about women and men.
Upon extracting a dimension, we compute how this dimension relates to each word-level schema – such as how the meaning of “overweight” is gendered. This is encapsulated by the cosine similarity between the dimension and the word, which produces a scalar. This scalar ranges from −1 to 1, and tells us both direction of meaning (e.g., whether “overweight” connotes men or women), and magnitude (e.g., strength of the connotation with men or women). From a cognitive lens, cosine similarity tells us how a dimension “fills in the blank” or completes information in a given word-level schema. For instance, how is our schema of “overweight” structured in terms of our schema for gender?
From our literature review on obesity, we expect that our model will learn schemas for these four dimensions from news reporting, and will learn to connote obesity with women, immorality, illness, and low class. We additionally report the extent to which several of our dimensional schemas are mutually reinforcing (encapsulated by cosine similarities between dimensions), as suggested by our literature review.
Validation
After extracting our dimensions, we checked the robustness of our methods and findings in four ways. Here, we summarize our validation steps, and provide details in appendix C and in our code (https://github.com/arsena-k/Word2Vec-bias-extraction). First, we evaluated the accuracy of the dimensions at classifying words expected to lie at one end of the dimension or the other. For each dimension, we examined accuracy on anchor words used to extract the dimension (i.e., training words), and on a fresh set of words that had not been used to find the dimension (i.e., testing words). Second, we examined the robustness of our accuracy rates and empirical findings to the sampling of news articles, by training 25 word2vec models on our data (we refer to these as validation models). We describe results across these validation models and interpret results that are consistent across every model. This second validation step may also be interpreted as focusing on schemas that are consistently learned (i.e., shared, or cultural) from the training data. Third, we evaluated how sensitive our methods are to the selection of anchor words. Fourth, we evaluate the sensitivity of our findings to the particular method used to extract the dimension. We find that our results are robust across all these four facets of uncertainty. As mentioned earlier, we also replicated our work using a word2vec model which was trained on Google News.
Obesity Schemas Evoked by News Reporting
Word-Level Schemas
Here, we describe schemas for our keywords related to obesity and body weight management (i.e., word-level schemas) which are learned by word2vec. In Table 1, we list the ten words with highest cosine similarity to vectors for selected keywords. Word2vec appears to capture our own intuitive understanding of these keywords. For example, the word-vector with the highest cosine similarity to “obese” was “overweight” and vice versa (cosine similarity of 0.80), suggesting that these two words activate very similar patterns of information.
Top 10 Most Semantically Similar Words and Phrases to Selected Obesity-Related Keywords.

Note: Words and phrases are ordered most to least similar (by cosine similarity) to each keyword on the left, based on a word2vec model trained on New York Times articles from 1980–2016.
It may surprise some readers to see that, for both “obese” and “overweight,” the next most similar word-vector was “underweight.” This counterintuitive result highlights important but nuanced differences between cosine similarity and the folk concept of “similarity.” When applied to word vectors, cosine similarity should be interpreted as operationalizing shared activations, or associations, between words, rather than colloquial notions of similarity (i.e., synonymy). Like shared activations, cosine similarity weighs all features of a distributed representation equally (Chen, Peterson, and Griffiths 2017). Antonyms, like underweight and overweight, are viewed as semantic opposites precisely because they share most of their meaning (and are often used in similar contexts), except for a single distinguishing component (i.e., quantity of body weight). 11 Thus, antonyms should display similar patterns of activation, and be associated, despite these focal dissimilarities. Comparing words by their positions along specific cultural dimensions, rather than by their raw cosine similarities (as we do next), offers analysts a way to disentangle the ways in which they may be similar or different. 12
We also observe that the words closest to “fat” include words about nutritional meaning of fat such as “carb,” “content,” and “trans fat.” Other closest words were about body fat, such as “flabby” and “flab.” This observation highlights another specification of the model: it smooths over all the different ways in which a term, like “fat” is used in the corpus, and only learns one schema per term. While we do not focus on ambiguity in this paper, this observation raises several important questions. How can a single symbol activate multiple distinct schemas? More generally, how do human schemas handle context and ambiguity (e.g., when a context could activate two distinct possible schemas)?
Schemas for Dimensions of Gender, Morality, Health, and Socio-Economic Status
As described in our methods, we identified lines in semantic space corresponding to dimensions of gender, morality, health, and SES. These dimensions are schemas in that (1) they are distributed representations and (2) they are used as part of processing incoming cultural data. Now, we describe how obesity-keywords map onto each dimension in space. The cosine similarity between an obesity keyword and a dimension captures how the dimension “fills in the blank” or completes information about the keyword. This may be thought of as “probing” our obesity keywords for their schematic properties. For example, when processing the description of a person as “overweight”, how likely are we to fill-in that person's gender as a man or a woman?
Gender and obesity
First, we focus on gender. Our gender dimension operationalizes one specific gender schema we expect to be learned from popular culture – a gender binary whereby men and women are constructed as categorically distinct (Ridgeway and Correll 2004). To be clear, this does not capture “femininity vs masculinity” in the sociological sense of hegemonic gender ideals. Instead, it captures the difference between being “about women” versus “about men.”
Although our models began as “blank slates,” with randomly initialized word-vectors, after reading and predicting news reporting on body weight and health they learned to connote nearly all words about fatness with women (rather than men). Indeed, the word “obese” is connotes women almost as strongly as do the words “slender” and “slim.” These results are consistent with literature on the framing of obesity, and literature on individuals’ meanings of obesity (measured in human participants directly), reviewed earlier. Using a limited set of cognitively plausible mechanisms (e.g., prediction and distributed representations), our results illustrate the gendered meanings of obesity that may indeed be learned from news.
Strikingly, we also found our models learned to connote most of our keywords with women (e.g., “healthy,” “exercise,” “sedentary,” and “unhealthy”) – suggesting that our models not only learned to connote body weight, but also health, fitness, and weight management more generally with women more so than with men. This finding resonates with the claim that female bodies are more closely surveilled and scrutinized than are male bodies (Fredrickson and Roberts 1997).
In addition, we also observe that terms about eating disorders, and especially “anorexic,” had the strongest connotations with women among our keywords. This result is consistent with prior work finding that news articles about overweight tend to discuss women more often than men, and that this gendered pattern is exaggerated among articles about eating disorders (Saguy and Gruys 2010).
Morality and obesity
Our second dimension captures one pervasive schema for morality: the opposition between purity and impurity (Haidt and Craig 2007). Words about obesity all connote immorality. While some words about slenderness connote morality (e.g., “slender,” “slim,” “lithe”), “skinny,” and “thin,” do not. While theoretical work on the moralization of body weight often dichotomizes the concept of body weight as fat versus slender (but see Oswald, Champion, and Pedersen 2022), our results suggest that the lexical (i.e., word-based) meanings of body weight are not so easily lumped into two categories; for example, there are moral and immoral ways to be slender.
Previous literature contrasts obesity/overweight with eating disorders, given that both are labeled as “deviant” categories related to body weight (e.g., Saguy 2013; Saguy and Gruys 2010). Saguy and Gruys find that while overweight individuals are portrayed as culpable for their weight in news, individuals with eating disorders are portrayed as victims (2010). In contrast, we find that not only do our models learn overweight and obesity as immoral, but also they also learn eating disorders as immoral – especially, “bulimia.” Examining the terms with similar activation patterns to eating disorders (Table 1) sheds light on these immoral undertones. For example, “bulimic” is similar to “sexually active,” while “anorexic” is similar to “addict” and “alcoholic,” suggesting that both eating disorders evoke very similar information about moral purity as other “deviant” behaviors.
Health and obesity
Our third dimension captures a schema for health: the contrast between health and illness. Our models learn to connote all terms about heavy body weight with illness (rather than health), consistent with literature reviewed earlier. In fact, “obese,” “overweight,” and “morbidly obese” connote unhealthiness almost as strongly as do terms about eating disorders. While many terms about slenderness connote health, we find that “thin” and “skinny” are again outliers, similar to our findings for morality. These two terms denote the lack of fatness, but perhaps they also connote a lack of fatness due to underlying disease or malnourishment (Ernsberger 2009).
Socioeconomic status and obesity
Our fourth and final dimension captures a schema for Socioeconomic Status (SES): the dichotomy between low and high SES. Like literature reviewed earlier, we find that nearly all terms about fatness connote low class, and most terms about slenderness connote high class, although “thin” is again inconsistently categorized. 13
Previous literature also suggests that while obesity is framed as a low-class condition, anorexia is framed as problem associated high class (e.g., Saguy and Gruys 2010). However, we find that our models learn to connote both obesity and eating disorders with low class. “Bulimia” evokes some of the strongest meanings of low class out of all our terms. More generally, we find that many terms related to weight management and health concerns evoke meanings of low class. As health issues are tightly intertwined with finance and social class, it is plausible that discussions of health concerns at large often occur in the context of financial burden, and so our models learn to connote health issues with low class.
Relationships Between Schemas for Morality, Health, and SES
As described in our literature review, theoretical work on the construction of body weight highlights the relationships between meanings of body weight. In particular, our review covered how morality, health, and social class are thought to be mutually reinforcing. In earlier results, we already saw some evidence of this. Many of our obesity keywords about healthiness and weight management connoted morality. Keywords related to the lack of health tended to connote immorality. Here, we test the relationships between these three schemas more directly, by computing their cosine similarities. This may be interpreted as measuring the extent to which these schemas share semantic information, or patterns of activation.
We find that schemas for morality and health have a cosine similarity ranging between 0.52 and 0.56 across all validation models. Schemas for social class and health have a cosine similarity ranging 0.25 to 0.30 across our validation models, and schemas for morality and social class have a cosine similarity of 0.25 to 0.33 across our models. For comparison, the cosine similarity between two randomly selected dimensions (i.e., using randomly selected anchor words) ranges from −0.02 to 0.02 across various possible random samples of anchor words and across models. 14 This suggest that our three dimensions (morality, health, and class) are indeed far more mutually reinforcing than we might expect from chance. These results match what we might anticipate from theoretical prior work on health and the body; they additionally illustrate that schemas for morality and health are the most strongly reinforcing among these schemas.
Discussion
This paper provides a computational account of the process of learning schemas from public culture. It suggests that neural word embeddings offer computational models to instantiate this account using natural language data. While neural embedding methods are pervasively used as tools for text analysis, we additionally propose that they offer formal models for schematic processing. Drawing on the empirical case of obesity, we then illustrate how empirical applications of word embedding may be reinterpreted from a cognitive perspective. Specifically, we illustrate two types of schemas learned by word2vec: schemas of words (focusing on those related to obesity) and schemas of lower-order constructs (dimensions of gender, morality, health, and social class). In addition to replicating many prior empirical findings on the pejorative meanings of obesity, we illustrate that the descriptions of body weight are more nuanced than a simple dichotomy of “fatness” versus “slenderness.” For example, while the words “slender” vs “skinny” both denote the lack of fat, they evoke different connotations along certain dimensions of meaning (but not others). We also empirically show that dimensions of meaning which scaffold our understandings of body weight, such as morality and health, are mutually reinforcing.
Our paper makes several theoretical contributions to the field of culture and cognition. While the distinction between personal and public culture has garnered much attention (Cerulo, Leschziner, and Shepherd 2021; Lizardo 2017; Sperber 1996; Strauss and Quinn 1997), we provide new theoretical insights into how information travels between these two levels of culture (Foster 2018). By describing how word embeddings instantiate our account, we concretely and more precisely show how our theoretical description might work with actual cultural data. The representations produced in this way can encode more complex semantic structures, like the gender, morality, health, and SES dimensions which we empirically focused on in this paper.
Our paper also makes several contributions to computational sociology. Word embedding methods are increasingly being used in sociology for empirical analyses of cultural texts (Jones et al. 2015; Kozlowski et al. 2019; Stoltz and Taylor 2019, 2021). Our paper theoretically motivates these methods by drawing parallels to cognitive sociology. We illustrate how methods commonly used with word embeddings (e.g., the Google Analogy Test or extracting dimensions) may be reinterpreted from a cognitive lens. We offer a range of robustness checks for empirical work using word embeddings, including cross-validation of word-choices for dimensions, and three distinct strategies to capture dimensions.
We also contribute to the body of work on the measurement of schemas. Schemas are challenging to measure directly, and no single approach is thought to measure all aspects of schemas (Boutyline and Soter 2021; Leschziner and Brett 2021). One key tactic is to aggregate individuals’ responses on surveys and interviews, and then identify patterned ways of responding in this aggregate data (Boutyline 2017; Goldberg 2011; but see Martin 2000). Another tactic is to measure participants’ implicit associations with an implicit association test (or some variant of it) (Hunzaker and Valentino 2019; Shepherd 2011). Patterns identified with these approaches are thought to reflect external traces of internalized schemas shared among participants. We offer a distinct and complementary vantage point: neural word embeddings as approaches to capture the schemas learned from and activated by real cultural stimuli. Crucially, neural word embeddings operationalize the content of schemas, as well as the processes of learning, modifying, and deploying schemas. Neural word embeddings are especially useful to study the dynamic relationship between public and personal culture – and do so with exquisite control and efficiency. We offer specific future directions in more detail next.
Limitations and Future Research
Our work has several limitations; these offer direction for future sociological research. For instance, while we replicate meanings of obesity which are extensively documented in prior work, validate our empirical findings in numerous ways, and illustrate that our model can solve linguistic tasks (e.g., the Google Analogy Test), we do not compare word-level schemas around obesity learned by our model with extrinsic cognitive data around obesity terms. However, as described earlier, it is already well-established that humans’ personal meanings substantively correspond to semantic information in embeddings and distributional models more broadly. Our paper builds on this established empirical finding, to theorize that neural embeddings also learn and represent these meanings in ways that are consistent with how humans are thought to do so based on connectionist theory and empirical work in cognitive science.
For future research, we offer a call to integrate cultural and cognitive sociology with connectionist models for processing language. First, word embeddings offer powerful approaches to study the “cultural context of cognition” (Shepherd 2011). They can model the meanings that are activated in a single cultural encounter (e.g., a specific article or specific word) or learned across cumulative exposure to a set of cultural objects (e.g., a corpus). Unlike humans, who accumulate schemas across a lifetime of diverse experiences, neural embeddings can begin at a randomized state before learning from a given dataset. This naivete is useful because it enables us to identify schemas learned from or activated by a specific field or discourse by restricting training data (as we do, with discourse on body weight and health).
Furthermore, neural word embeddings are useful to model the relationships between variation in cultural environments and variation in personal culture. For instance, to model heterogeneity, future work could expose neural embeddings to varying cultural diets or to the same cultural diet in different ways. This might include pre-training to establish a learner's prior schemas, manipulating the learning rate to model a learner's flexibility or brittleness, or adjusting the order in which a learner encounters cultural data (Bengio et al., 2009). Simulated results could be compared to data on human interactions with text to test and refine our argument that neural word embeddings can be empirically used to model schematic processing. Doing so may offer additional opportunities to refine theories of schematic processing and refine neural word embedding methods for text analysis.
Second, word embeddings may be used to study how “individual meaning-making aggregates into larger scale cultural dynamics” (Shaw 2015). For example, in an agent-based model, each agent's “meaning-making” may be operationalized as a neural word embedding trained on some cultural diet. Or, for example, embeddings may be used to model agents’ schemas in transmission chains, to identify meanings that may be more or less resistant to change across interaction (Boutyline, Cornell, and Arseniev-Koehler 2021).
Third, a variety of connectionist architectures and distributed representations are ubiquitously used to process text (e.g., Goldberg 2016; Young et al. 2018). While we focus on word2vec in this paper given its parsimony and popularity, our theoretical arguments generalize to more elaborate approaches to neural word embeddings (Günther et al. 2019). These models offer sociologists opportunities to study a range of phenomena in culture and cognition. Most notably, contextualized word embeddings model each instance of a word as a vector, rather than modeling all instances of that word in a corpus with a single vector like word2vec (Devlin et al. 2019; Peters et al. 2018). This offers an ideal framework to investigate the role of ambiguity in schematic processing and account for both stability and context sensitivity (Smith 2009).
We also note that neural embedding may be used to model a range of modalities beyond text, such as images (e.g., Kriegeskorte 2015) and sound (Liu et al. 2017). Practically this means that future work can study the interaction of personal and public culture in a wide range of media and cultural contexts. But it also suggests that many theoretical arguments made in this paper could generalize beyond language (Günther et al. 2019). We drew on computational meta-theory (Marr's levels of analysis) to guide our comparison between human schemas and neural word embeddings, translating Marr's levels into concrete questions. We suggest that a similar strategy may be useful to compare a range of cognitive phenomena and embedding models.
Implications
This paper responds to calls to integrate computational methods and cultural sociological theory (Edelmann et al. 2020; Foster 2018; Mohr and Bogdanov 2013; Wagner-Pacifici, Mohr, and Breiger 2013). We not only use a new text analysis method (word embeddings) as a tool to empirically investigate cultural meanings, but also theorize that this tool operationalizes learning schemas from public culture. As illustrated in this paper, computational modeling offers a powerful tool for theory-building in cognitive and cultural sociology. It forces us to be more precise and explicit. In the process, it reveals assumptions and gaps in theory itself (Guest and Martin 2021).
Our empirical results also have practical implications. They validate concerns that machine-learned models encode pejorative frames in public culture (e.g., Bolukbasi et al. 2016; Caliskan et al. 2017). Scholarship on machine-learned bias often focuses on legally protected attributes (e.g., Zhang, Lemoine, and Mitchell 2018). However, our results highlight that this phenomenon generalizes to other deeply stigmatizing attributes like obesity. Furthermore, machine-learned language models are not only methods and potential theoretical models, but they are also pervasively used to structure our cultural environment, such as through recommendation systems, machine translation, and search engines. Thus, machine-learned models not only internalize but also deploy schemas (Mehrabi et al. 2021) such as those around body weight.
Schemas are not inherently harmful; they are merely mental structures that enable us to efficiently interpret social life. However, they become harmful when they systematically and unduly constrain groups of people's well-being and life chances. Then, schemas (e.g., that obese individuals are lazy or immoral) reinforce stigma, discrimination, and, ultimately, inequality. Our words are loaded with negative meaning about body weight in a pervasive and systematic fashion. Therefore, it is unsurprising that Americans hold, and act on, deeply internalized negative beliefs about body weight, in the forms of body dissatisfaction, eating disorders, fat prejudice, and discrimination on the basis of body weight. Similarly, our words may be vehicles to transmit and reinforce many other stigmatizing schemas, such as those around mental illness, sexual orientation, and race.
We view our paper as an early encounter in a broader agenda of engagement between cultural and cognitive sociology and artificial intelligence. We hope our paper can serve as a template that other researchers can follow in their use of cutting-edge models from artificial intelligence. Rather than using such models only as tools for empirical analysis, researchers can use them to advance and clarify sociological theories of culture and cognition.
Footnotes
Acknowledgments
We are grateful to Abigail Saguy, Andrei Boutyline, Omar Lizardo, Hongjing Lu, Eleni Skaperdas, Bernard Koch, and the students in the graduate course on “Cognitive Sociology of Culture” at the University of Michigan for their invaluable feedback on this work. We also thank audiences at our presentations at the American Sociological Association Annual Meeting, the Text Analysis Across Domains (TextXD) Conference, the Networks & Culture workshop at Stanford GSB, the Networks & Time Workshop at Columbia, and the UCLA Computational Sociology Working Group for their feedback. This paper was awarded the 2020 Outstanding Graduate Student Paper Award from the American Sociological Association, Section on Mathematical Sociology.
Author's Note
We provide Jupyter Notebooks with code and documentation to accompany this paper on GitHub: https://github.com/arsena-k/Word2Vec-bias-extraction. We cannot redistribute the raw news data, which we accessed through the University of California, Los Angeles subscription to Lexis Nexis. However, we provide word embedding models trained on our data through the Open Science Framework: ![]() . Our Jupyter Notebooks also illustrate how to perform analyses using a public, pre-trained word embedding model trained on Google News.
. Our Jupyter Notebooks also illustrate how to perform analyses using a public, pre-trained word embedding model trained on Google News.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Alina Arseniev-Koehler was supported by a National Library of Medicine Training Grant (NIH grant T15LM011271) and the National Science Foundation Graduate Research Fellowship (grant number DGE-1650604). Jacob G. Foster was supported by an Infosys Membership at the Institute for Advanced Study. Any opinion, findings, and conclusions or recommendations expressed in this material are those of the authors(s) and do not necessarily reflect the views of our funders.