
Abstract
This article presents a computational approach to examining immigrant incorporation through shifts in the social “mainstream.” Analyzing a historical corpus of American etiquette books, texts from 1922–2017 describing social norms, we identify mainstream shifts related to long-standing groups which once were and may currently still be seen as immigrant outsiders in the United States: Catholic, Chinese, Irish, Italian, Jewish, Mexican, and Muslim groups. The analysis takes a computational grounded theory approach, combining qualitative readings and computational text analyses. Using word embeddings, we operationalize the chosen groups as focal group concepts. We extract sections of text that are salient to the focal group concepts to create group-specific text corpora. Two computational approaches make it possible to examine mainstream shifts in these corpora. First, we use sentiment analysis to observe the positive sentiment in each corpus and its change over time. Second, we observe changes in each corpus's position on a semantic dimension represented by the poles of “strange” and “normal.” The results indicate mainstream shifts through increases in positive sentiment and movement from strange to normal over time for most of the group-specific corpora. These research techniques can be adapted to other studies of social sentiment and symbolic inclusion.
Introduction
Developments in computational social science provide new angles for studying old questions. The study of immigrant incorporation has a long history in the social sciences. However, research has generally focused on the adaptation of immigrant minorities to the societies where they settle. Even though many influential theories of immigrant incorporation posit the importance of the non-immigrant “mainstream” to immigration (see Alba 2005; Alba and Nee 2003; Massey and Sánchez 2010; Portes and Rumbaut 2001; Portes and Zhou 1993), “established” (Jiménez 2017) individuals rarely take center stage in studies of immigrant incorporation. When they do, they tend to be seen as part of the context of immigrant reception or as gatekeepers in the incorporation process.
There is research showing how established individuals change as a result of immigration – including developing comfort in multicultural spaces, rethinking aspects of how they live their everyday lives and conduct social relationships, relativizing their own social and cultural norms, and adopting a more expansive sense of what it means to be a neighbor and a citizen (Jiménez 2017; Voyer 2013b). These social impacts of immigration reshape group boundaries and collective practices, as well as shared meanings and sentiments associated with the “mainstream” (Voyer 2013a). Methodological innovations from computational social science provide new ways to observe immigrant incorporation through such shifts.
This article presents a computational sociological approach to examining immigrant incorporation through mainstream adaptations and adjustments. We draw on different research techniques in a computational grounded theory approach, leveraging qualitative insights and quantitative power (Nelson 2020). The analytical work begins by selecting a theoretically-indicated corpus consisting of 20 editions of Emily Post's Etiquette, which we take as a text-based representation of the American mainstream. We use human reading and machine techniques such as topic modeling and keyword-based approaches in exploratory analyses aimed at determining how immigrants and immigrant incorporation are represented in the corpus.
Based on the exploratory work, we conduct two analyses of text changes occurring in light of immigration and in relationship to long-standing groups who once were and may currently still be seen as immigrants and outsiders in the United States: Catholic, Chinese, Irish, Italian, Jewish, Mexican, and Muslim (Dumenil 1991; Portes and Bach 1985; Takaki 1993). We use Concept Mover's Distance, an approach rooted in word embeddings, to operationalize the selected groups as focal group concepts and to identify paragraph-length chunks of text that are salient to each concept within each edition (Stoltz and Taylor 2019). We then aggregate these chunks to create “pseudoeditions.” We conduct sentiment analyses, examining changes in positive sentiment across editions. We then create a semantic dimension anchored by the poles of “strange” and “normal” and establish the position of each pseudoedition on that dimension. The computational results are interpreted through triangulation with qualitative analysis of the texts.
The results provide evidence of the incorporation of immigrant groups through mainstream shifts. We find a trend toward more positive sentiment for most focal group concepts. We also find that the texts linked to most focal group concepts move from an association with “strange” toward associations with “normal” over time. However, there is group-by-group variation in the timing and trajectory of these shifts. Shared trends toward both normal-ness and positive sentiment across these different focal group concepts suggest broader social shifts in mainstream diversity and inclusion, and group-by-group differences may reflect particular social and historical circumstances. These findings also demonstrate that positive sentiment and “normal”-ness are independent aspects of incorporation into the mainstream.
Literature and Theory: Mainstream Shifts
Many influential theories of incorporation posit the importance of the mainstream to immigration (c.f. Alba 2005; Alba and Nee 2003; Massey and Sánchez 2010). For example, in segmented assimilation theory (Portes and Rumbaut 2001; Portes and Zhou 1993), immigrant incorporation hinges upon different aspects of the migration experience, including the context of immigrant reception, which consists of attitudes towards immigrants and public practices and policies shaping immigrants’ opportunities in the new country. Past work has also identified the symbolic processes underlying immigrant incorporation. Alba’s (2005) bright and blurred boundaries suggest that, in some contexts, the boundary between ethnic minorities and the mainstream majority is blurred, allowing some immigrant groups to enter the social mainstream, and, in other contexts, the boundary is bright, maintaining the exclusion of other immigrant groups. Wimmer extended this insight and developed a comprehensive typology of the boundaries between ethnic groups, including various approaches to modifying ethnic group boundaries such as the development of overarching global, civil, and local identities (Kroneberg and Wimmer 2012; Wimmer 2008; Wimmer 2009).
The literature tends to be optimistic regarding the possibilities for immigrant incorporation, which is typically seen as a multigenerational process (Drouhot and Nee 2019). We can point to immigrant “success” stories, such as how Irish, Italian, and Jewish immigrants, who all initially faced hostility and racialized exclusion, over generations came to be seen as white American ethnic groups (Brodkin 1998; Ignatiev 2009; Roediger 2005). Of course, other immigrant groups did not “become white” – including Chinese, Japanese, and Mexican immigrants (Lee 2003; Massey, Durand, and Malone 2002; Takaki 1993). As Roediger (2005) notes, these non-white immigrants and their descendants, even in cases where they achieved economic and educational success, are not always symbolically included in the American mainstream. Instead, their inclusion shifts with the ebb and flow of political and economic tides – from inclusion as racialized Americans to exclusion as potential outsiders who could be exhorted to “go back to their own country.” This in-betweenness is reflected in and reinforced by systematic racism, for example, in federal red-lining policies and the development of post-war housing that moved Irish, Jewish, and Italian immigrants into the white suburbs, while leaving Mexican and Asian immigrants in the cities (Roediger 2005). Recent research shows the continuing importance of race to immigration. Contemporary white Americans do not mind having immigrant neighbors, especially if they are white, speak English fluently, and volunteer in the community. However, they see non-white immigrants as less preferable neighbors and less similar to themselves (Schachter 2016).
We recognize the concept of the American “mainstream” is closely related to the white, middle-class Anglo-Saxon Protestant majority established through colonization, conquest, and the subjugation of native and enslaved peoples (Brown 1970; Takaki 1993). Symbolic boundaries, including racial boundaries, of the mainstream are crucial to the trajectory of immigrant incorporation. There is growing literature extending our knowledge of mainstream shifts in light of immigration. The fundamental insight of such work is that immigrant incorporation is a relational process involving the adjustments and adaptations of immigrants and the established people and practices in the societies where they settle. For example, Voyer (2013b) finds that rapid and substantial Somali immigration into a historical white town prompts a redefinition of community membership that could include black, Muslim immigrant newcomers, a revision of belonging that blurs racial boundaries. Meanwhile, in research among established individuals in Silicon Valley, Jiménez and Horowitz (2013) find that mainstream conceptions of success devalue whiteness compared to Asian-ness. Jiménez (2017) observes that established individuals in at least the third generation in the United States revise their notions of what it means to be an American as they become comfortable and familiar with the languages, foods, and cultural and religious practices of immigrant newcomers. The existing work on mainstream shifts consists mainly of ethnographies and interview studies. Computational methods for text analysis provide an opportunity to extend this research by focusing on the construction of the American mainstream over time and in relation to immigrant groups.
Data
To uncover mainstream shifts, we analyze a corpus of etiquette books. The purpose of etiquette writing is to bring mundane practices and meanings from the cultural background to the foreground, and we use this practical and symbolic background to represent the social mainstream. Sociologists have long recognized etiquette as a valuable source of data on the social world (Arditi 1999; Bourdieu 1984; Elias 2000; Goffman 1963; Mennell 2007; Wouters 2007). Recent research has used computational analysis of etiquette books to study general social changes (Abrutyn and Carter 2015). To our knowledge, this is the first research to use etiquette literature to study immigrant incorporation.
We constructed an etiquette corpus from 20 editions of the best-selling American etiquette manual, Emily Post's Etiquette, which was first published in 1922 and most recently published in 2017. 1 Etiquette is considered a “pre-eminent example of American advice literature” (Lees-Maffei 2012: 217). Etiquette's popularity is enduring, with sales at least in the 10s of millions (McHugh 2021:13). Only the bible has been purchased more by schools and libraries (Claridge 2009; Jacobs 2001). In 1995, Etiquette was featured in the New York Public Library's “Books of the Century” exhibit, and it was commemorated with a postage stamp in 1998 (Lees-Maffei 2012).
Table 1 displays the Etiquette editions and authors. Emily Post wrote Etiquette until her death in 1960. Her granddaughter-in-law, Elizabeth Post, then took over authorship. In 1997, Elizabeth was succeeded by her daughter-in-law, Peggy Post. Beginning 2011, three Post-cousins, the great-great grandchildren of Emily Post, joined Peggy in authorship. Two of those cousins, Peter Post Senning and Lizzie Post are currently the main authors of Etiquette.
Etiquette Editions Included in Corpus.
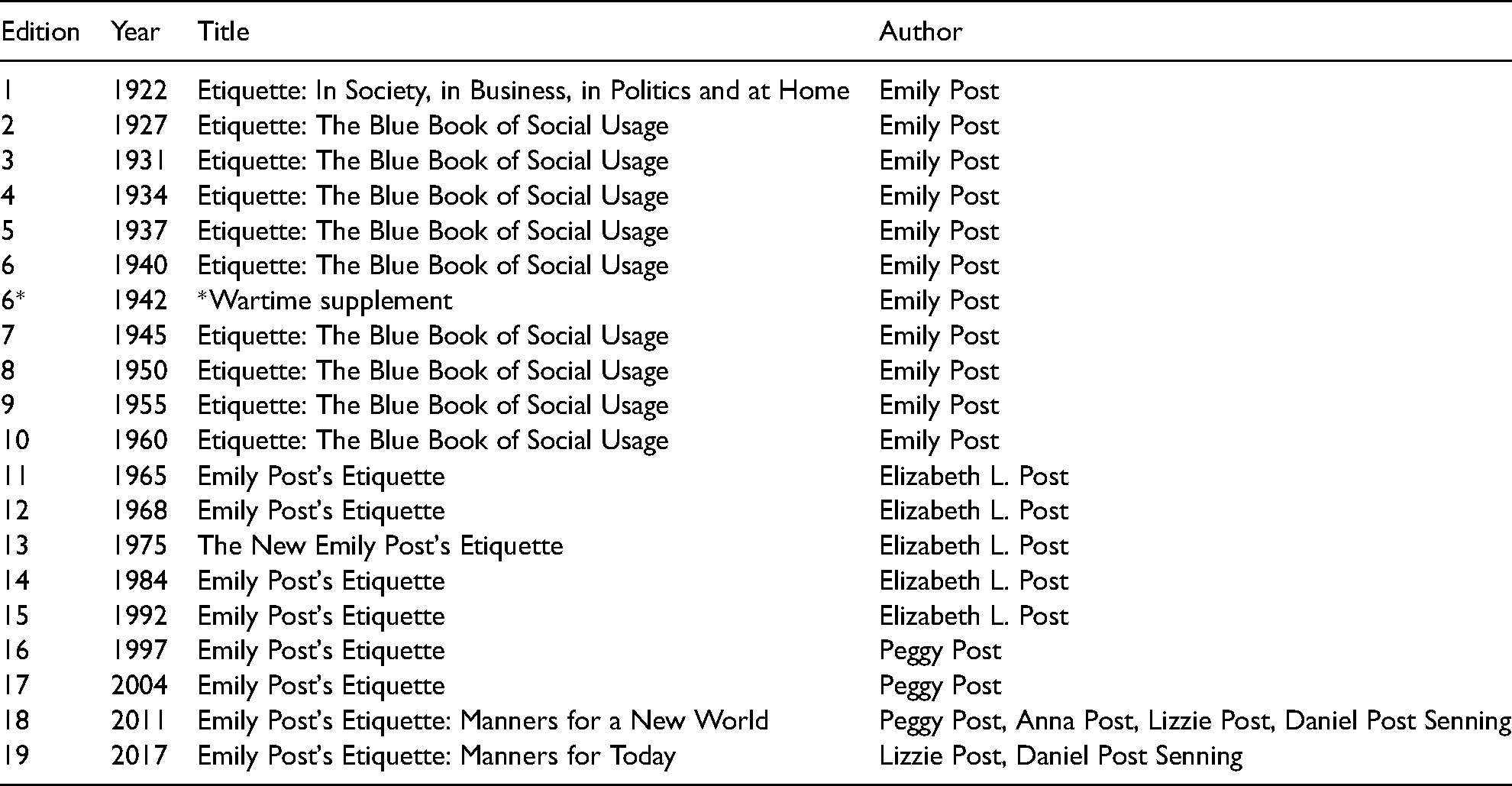
We attach no more social influence or causal power to Etiquette and its authors than we would to any other successful authors or widely read books. Etiquette provides insight into the American mainstream because presenting the mainstream is the purpose of such texts. Etiquette books are tasked with representing social organization at the time of their publication by keeping pace with the changing social norms of their intended audience. Just as Emily Post revised Etiquette in light of social changes large (e.g., the Prohibition and World War II) and mundane (e.g., the rise of the telephone and traveling by plane), so have subsequent authors adjusted to the frontiers of social life in terms of changing gender roles, family structures, and waves of rising racial and ethnic inclusivity and exclusivity, etc. But there is also consistency in form and substance across editions (see discussion of text changes in Exploratory Analyses). Research shows that Etiquette remains thematically and structurally consistent with its contemporary etiquette manuals (Arditi 1999; Wouters 2007). Our analyses of Etiquette suggest that the text has historically been written in reference to the white, middle-class, Protestant-American mainstream (Voyer, Kline, and Danton 2022).
Each edition is 500–1100 pages long and includes photographs, figures, and charts. The first edition is in the public domain. All other editions remain under copyright and are used under fair-use doctrine. A physical copy of each edition was scanned into a text document using optical character recognition (OCR) software. Errors arising during the OCR process are managed and corrected within the version control manager GitHub, and HTML mark-up assists with the retention of text features like images, tables, and sidebars. Prior to analysis, the text is tokenized and stop words are removed. Analyses are conducted using text analysis tools based in R and Python programming languages.
Method
This research followed a computational grounded theory approach. Computational grounded theory, which allows for back-and-forth movement between qualitative readings and computational analyses of text, makes it possible to answer theoretical and qualitative sociological questions by developing large-scale and reproducible analyses of the social meanings present in texts (Nelson 2020; Nelson 2021). Ongoing verification and confirmation are central to computational text analysis (Nelson 2020). We employ many different approaches to confirmation and verification. Description of confirmatory analyses is incorporated into the discussion of each aspect of the research and further described in the online appendices. An overview of the research process is depicted in Figure 1.
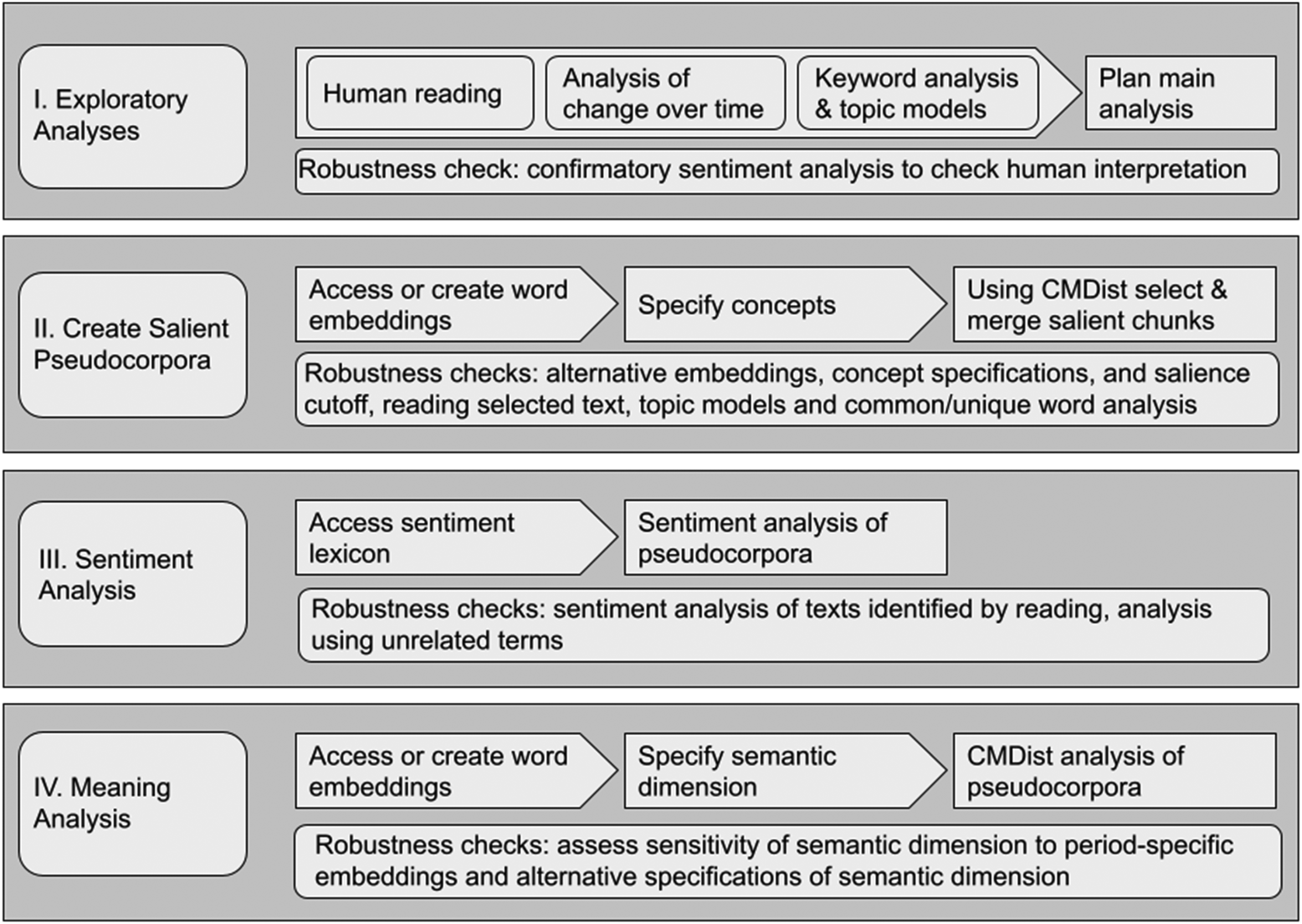
Process overview. Elements of research organized by phase of the analysis (I–IV). Arrow-shaped boxes indicate elements that occur sequentially, leading to outcome of research phase, represented by boxes with sharp corners. Ongoing robustness checks listed in rounded boxes below. Note: elements of exploratory analysis can occur simultaneously.
Exploratory Analysis
Exploratory analysis uncovers patterns that may be investigated through subsequent analysis while also providing a general sense of the corpus. By combining human reading and computational analyses, we observe that mainstream shifts associated with immigrant incorporation are often implicit in the texts. This exploratory work was crucial in determining the direction of the main analysis.
During exploration, we examined the nature of changes in Etiquette over time. Many factors contribute to edition-by-edition change in texts (Giuliani et al. 2006). Because each edition of Etiquette is written in explicit reference to the previous edition(s), the decision to add or delete topics might reflect social change. At the same time, simple shifts in vocabulary, editorial practices, developments in publishing and printing, and authors’ stylistic quirks also shape Etiquette's development. Authorship changes provide a compelling alternative explanation, as opposed to mainstream shifts associated with immigrant incorporation, that could be driving relevant changes. For this reason, we assessed the impact of author changes on text changes. Table 2 shows changes in the corpus over time by plotting the cosine similarity between all editions. Editions generally display a high degree of similarity, with edition-by-edition changes rarely exceeding .3. The pace of change is largely independent of author, outside an increase in the rate of change following the death of Emily Post. These results suggest that changes in Etiquette do not merely reflect changes in authorship. Given etiquette books’ purpose, it is reasonable to assume that at least some of the changes in the texts represent mainstream shifts.
We continued exploratory work by looking at the presence and depiction of immigrants in Etiquette. We first constructed a list of immigrant keywords by drawing words from contemporary and historical dictionaries, thesauri, and keyword generation tools. These exploratory analyses yielded few explicit mentions and no clear trends. Likewise, exploratory topic modeling and reading explicit mentions uncovered just a few topics, such as foreign travel, hosting foreign guests, choosing between continental or American manners (e.g., the style of holding one's fork and knife), and the correct use of foreign expressions while speaking English. These early analyses led us to conclude that it was difficult to locate explicit evidence of immigrants and immigrant integration in Etiquette through keyword-based analyses.
Exploratory analyses also included independent human reading and analysis of Etiquette. While the computational exploration turned up few patterns, we determined through human reading that mainstream shifts indicating incorporation are, in fact, present. These mainstream shifts are visible in the inclusion of new religions, foods, cultural practices, and non-Anglo-Protestant names in the texts, among other things. For example, in 1937 Post first instructed readers on how to address and introduce both priests and rabbis, and in 1997 readers were first counseled how to behave at a religious service in a mosque and informed about what to expect at a quinceañera. Bar and bat mitzvahs, appropriate attire for Catholic church services, and what to expect at 100-day parties for babies were added and developed as topics as Etiquette was revised in light of its role as an encyclopedic guide to navigating social situations its readers might encounter. So, although preliminary computational exploration focused on immigrant keywords was ineffective at identifying mainstream shifts associated with immigrant integration, immigrant incorporation is visible through changes in the texts that are implicitly or explicitly associated with particular non-Anglo-Protestant immigrants and their descendants.
Based on qualitative and computational exploration, we determined that we could uncover mainstream shifts by examining focal group concepts consisting of the bundles of people, practices, identifications, and objects associated with current or former immigrant groups. We do this by analyzing the semantic contexts in which the focal group concepts appear in Etiquette and considering how those contexts change across editions.
We approached the main analysis with two expectations derived from the exploratory work. First, we expect incorporation to be reflected in increased “normal”-ness in the semantic contexts of the focal group concepts. For example, let's return to the addition of quinceañeras in the 1997 edition. At that time, and again in the 2004 edition, the discussion of quinceañeras presumed that the reader would likely encounter the event as a guest and not as a host (see Table 3). This is clearly visible in comparison with the discussion of the sweet-sixteen celebration, which describes how one should arrange the invitations and the meal. Meanwhile, the discussion of quinceañeras focuses on what a guest who is less familiar with such events needs to know, including appropriate attire and whether or not gifts are expected. In this case, we see the representation of “foreign” practices in Etiquette, but not the inclusion of people who would hold a quinceañera in Etiquette's readership.
Discussion of Quinceñara and Sweet-Sixteen Tradition, 1997.

Quinceñaras are described for someone who is unfamiliar with the event and attending as a guest. Sweet-sixteen parties are described for those who will be hosting such an event.
Table 4 shows a shift in Etiquette's mainstream readership. The 2011 edition of Etiquette presumes it has readers who need advice on hosting a quinceañera. An altered description of the event says a “quince” originates in Latin America, instead of being something that “Latin American girls” do. Furthermore, the text offers advice related to hosting the event. The book also includes a sample quinceañera invitation in the appended resources. In the case of the quinceañera, we observe mainstream shifts reflecting increased “normal”-ness attached to cultural practices associated with immigration.
Discussion of Quinceñara, 2011.

Discussion assumes the reader may be hosting the event.
We also expect increased positive sentiment to coincide with mainstream shifts indicating incorporation. Sentiment may be accessible through human reading. For example, there is an underlying negative view of immigrants in this quotation from the 1937 and 1942 editions: “[A child] must never be allowed to hold his fork immigrant fashion, perpendicularly clutched in the clenched fist, and to saw across the food at its base with his knife” (Post 1937:745). Computational tools can follow qualitative insights by exploring latent sentiment in texts (Prabowo and Thelwall 2009). During exploratory research, we conducted a basic sentiment analysis of the excerpts presented in Tables 3 and 4. 2 These results confirm our qualitative interpretations: there is more positive sentiment in the texts around quinceañeras in 2011 than in 1997. However, the positive sentiment in the 1997 excerpt about Sweet 16 celebrations is higher than in either quinceañera excerpt. 3
Document Similarity Matrix, by Edition.
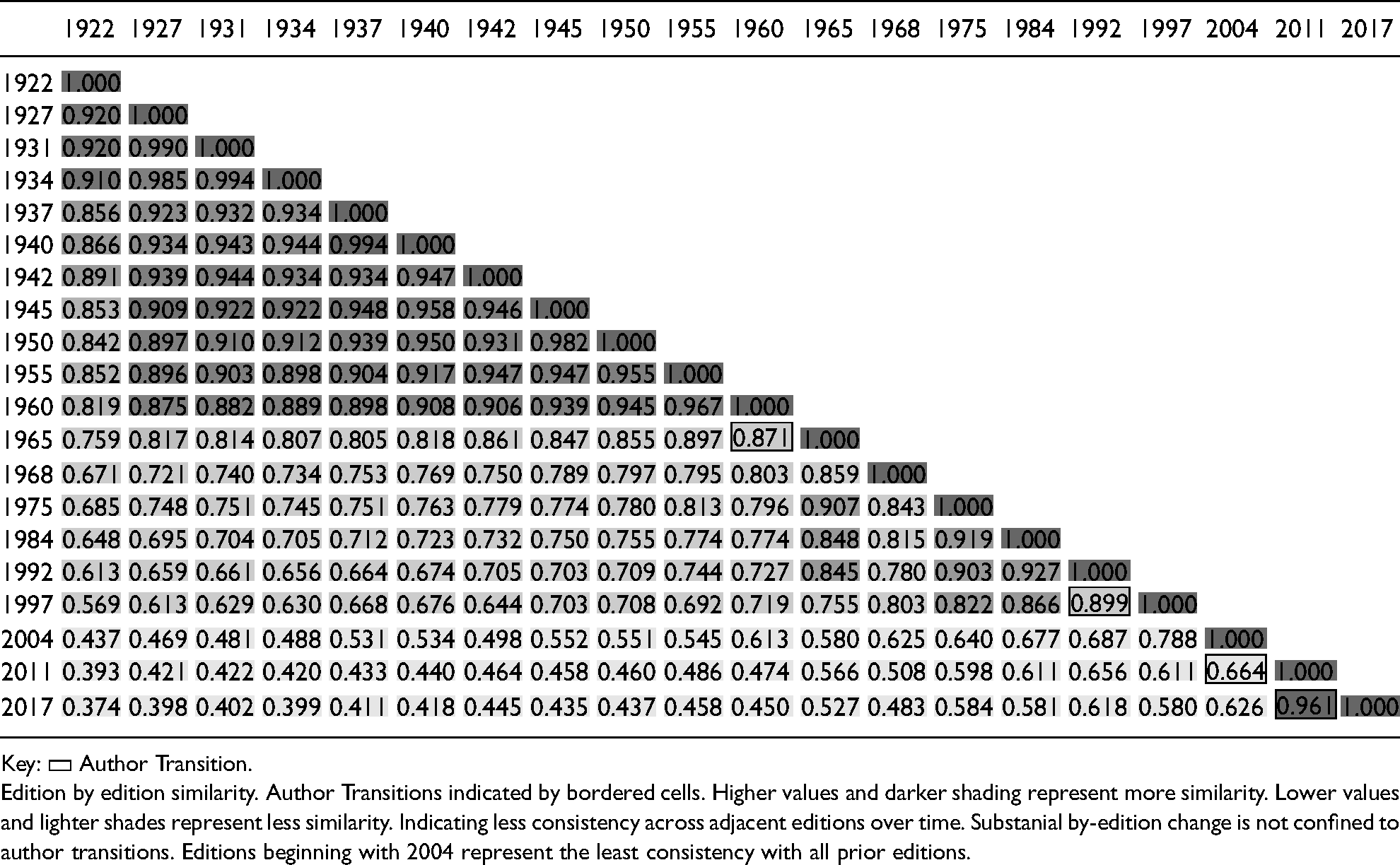
Key: ▭ Author Transition.
Edition by edition similarity. Author Transitions indicated by bordered cells. Higher values and darker shading represent more similarity. Lower values and lighter shades represent less similarity. Indicating less consistency across adjacent editions over time. Substanial by-edition change is not confined to author transitions. Editions beginning with 2004 represent the least consistency with all prior editions.
In planning the main analysis, we determined that we would consider mainstream shifts related to long-standing group categories that were and may still be seen as immigrant outsider categories in the United States: Catholic, Chinese, Irish, Italian, Jewish, Mexican, and Muslim. We selected these particular focal groups because we had a sense from reading that they were present in the texts. Moreover, they are associated with different historical waves of migration from both European and non-European contexts, and, as discussed in the theory section, they have different trajectories when it comes to incorporation through “becoming white”.
Analysis and Results
Computational social scientific analysis of text data extends the possibilities for research on mainstream shifts. A computational approach can include a larger volume of text than is feasible for hand-reading, subjects qualitative interpretations of texts to additional scrutiny through the application of quantitative methods designed with interpretation in mind, and leads to the development of research techniques that can be applied to other empirical questions and text data (Nelson 2020). We came to the final results through theory-based interpretation, examination of the texts in their historical moments, and robustness checks. This interpretive and confirmatory work is presented along with the presentation of results.
Two points must be emphasized concerning the analysis. First, our study examines immigrant incorporation in an interpretive and symbolic sense. It does not include measures or estimates of immigrant incorporation in a material sense (e.g., rates of intermarriage or citizenship acquisition). Second, immigrant incorporation is mainly implicit in Etiquette. Politics and public policy, including the topics of immigration and citizenship, are rarely addressed. Instead, etiquette books describe everyday manners and offer counsel for behavior during key moments. However, as Jiménez’s (2017) investigation of established individuals shows, mainstream adaptations in light of immigration occur precisely within the mundane world of everyday life: workplace relationships, food and fashion, norms of communication, familiarity with different religions, and the rituals that punctuate the life course from birth to death. The Etiquette corpus is well-suited to revealing the scope of immigrant incorporation in relation to these elements of the mainstream.
Identifying Focal Group Concepts Through the Creation of Pseudocorpora
For the analysis, we created a pseudocorpus for each focal immigrant group by sampling texts from Etiquette that were more related to the group. To do this, we used the word embedding method Concept Movers Distance (CMDist; Stoltz and Taylor 2019). Word embeddings leverage the connection between particular words and their linguistic contexts (Ellis 2019; Firth 1957; Garvin 1962; Lenci 2018; Stoltz and Taylor 2019). The underlying premise is that language can be conceptualized as a multidimensional map of words that reflects all the contexts in which words are used. Word embeddings are trained over very large text corpora. Through that training, they develop a detailed account of the interrelationships of words. Words used in similar contexts are presumed to have a similar meaning, which is quantified as cosine similarity. Even when words do not appear together but are used in similar ways, they are assumed to have similar meanings. CMDist uses cosine similarity scores from word embeddings to estimate the salience of a focal concept. CMDist does this by calculating the distance between all words in a document and the word or words denoting that focal concept (Stoltz and Taylor 2019). CMDist makes it possible to estimate the salience of implicit concepts that do not appear directly in the texts, making it particularly useful to this research since the exploratory analyses turned up few explicit references to immigration and immigrant groups but many examples of implicit immigrant integration through mainstream shifts.
To select parts of Etiquette in which various immigrant focal groups are most salient, we first parsed every edition into paragraph-length 150-word chunks. We then specified each focal immigrant group as a concept. For clarity, we will use italics when referring to the focal groups (Catholic, Chinese, Irish, Italian, Jewish, Mexican, and Muslim) when they are operationalized as focal group concepts in CMDist. CMDist assigns each chunk a standardized score for each focal group concept. These CMDist scores estimate how salient the focal group concept is to the text in the chunk (Stoltz and Taylor 2019). Scores generally range between −3 and 3. Chunks with scores exceeding 1.65 – corresponding to roughly 5 percent of the text – were then aggregated into concept-specific pseudoeditions to be used in subsequent analyses. Table 5 presents the count of salient chunks for each immigrant group. The proportion of salient chunks in the corresponding edition is shown in parentheses.
Count and Proportion of Chunks Selected from Full Corpus That Compose Pseudo Corpus for Each Immigrant Group.

Embedding selection, including considerations of historical period and the style and genre of the texts used to train the embedding, is important (Stoltz and Taylor 2021). Since CMDist takes embeddings as its foundational building block, CMDist results are only as strong as the embeddings used to create the model. The researcher is responsible for justifying the applicability of their embeddings in their particular context (Stoltz and Taylor 2019; Stoltz and Taylor 2021). We use a combination of historical word embeddings from Google N-Grams and FastText to select the chunks for the pseudocorpora. For editions published prior to 2000, we use decade-specific Google N-Gram embeddings (Timm 2019). Google N-Gram embeddings are trained using books that Google has digitized. While limited by a variety of selection factors (Hamilton, Leskovec, and Jurafsky 2016), historical embeddings may better reflect implicit meanings in texts from their particular period, increasing accuracy when selecting chunks that are salient to each focal group concept. For twenty-first century editions, pseudoeditions are created using FastText embeddings. FastText embeddings are pretrained on a larger set of sources than Google N-Grams, including Wikipedia and common crawls of the web (Bojanowski et al. 2017; Joulin et al. 2016). Prepared by Facebook's AI research team, FastText is among the most reliable and widely-used of embeddings. 4
Selecting a salience cutoff requires researchers to balance the tradeoff between concept specificity and robustness. To our knowledge, there is no standardized best-practice for assessing this potentially-important tradeoff in the context of varying text types and theoretical goals. The general premise is that a higher cutoff level will select chunks that more closely relate to the focal group concepts in question, at the expense of smaller corpora. Recent research using CMDist to select “salient” texts have considered scores of “1” as “high,” (Carbone and Mijs 2022). We use a salient cutoff of 1.65, representing roughly 5 percent of the sample on one side of a normal distribution, and employ various robustness checks to assess that decision. See online Appendix A for details regarding how we selected the appropriate cutoff.
We also examined the validity of the selected chunks. Since we know of no way to quantitatively establish the validity of chunks selected based on concept salience, we relied upon a variety of qualitative and interpretive checks. It is important to note that validity in this case does not mean that a salient chunk needs to be about Irishness, Mexican-ness and etc. Focal group concepts are in “the background” in some salient chunks. The value of our method is precisely in leveraging word embeddings’ ability to access background meanings. Analyzing meaning through semantic contexts is the unique contribution of embedding approaches over human analysis or dictionary/keyword-based approaches. If salience were synonymous with explicit mentions, there would be no value added relative to keyword searches. If the association between the focal group concepts and the texts was always apparent to a reader, the only benefit of using word embeddings to select the text would be the ability to manage larger amounts of text.
To check validity, we sought to establish 1. that the pseudocorpora were plausibly connected to the focal groups, and 2. that they were somewhat unique to the focal groups. In terms of plausible connection, we confirmed that parts of Etiquette we previously identified through reading (e.g., the sections on quinceañeras) were also selected into the pseudocorpora. We also examined the salient texts. Using the word tokens in a selection of salient chunks, we located the text excerpts and considered the connection to the focal groups. Some connections were implicit. Take, for example, the following implicit reference to Catholic (through the mention of rosaries) in a discussion of appropriate gifts from the 2004 edition (Post 2004, Chunk 3315, page 508): perfume; or a scarf, belt, or other fashion accessory.
For quinceanera parties
For quinceanera—a girl's fifteenth-birthday celebration in Latin cultures—religious items such as rosaries or crosses are appropriate. Monetary gifts and personal items for teenage girls are also popular gifts. (See also Chapter 16. page 214: “Quinceanera.”)
Explicit mentions referred to the focal group concepts directly. Take, for example the explicit reference to Italian immigrants and food from the 1975 edition (Post 1975, Chunk 254, page 33): There are many foreign words that have become an accepted part of our language, and we should be familiar with their meaning and pronunciation. We cross paths so often with the many foreigners living in the United States that it is easy to increase one's knowledge of their languages. We have Italian grocers, German bakers, French and Spanish waiters—to name only a few—all of whom are delighted if you show an interest in their language, how it sounds, and what it means. In fact, if you ask the waiter how to pronounce “parmigiana”, he very well may tell you not only how to say it, but how to cook it. Everyone loves to be an expert, and foreigners as well as Americans like to have you express interest in their language and their customs.
However, the connection to the focal group concept is not always clear to a human reader, as in the case of this salient chunk for Jewish from the 1965 edition (Chunk 1887, page 311): On occasion, divorced parents may remain good friends and their daughter's time may be divided equally between them. If this is true, they may both wish to announce the engagement.
Mr. Gordon Smythe of Philadelphia, and Mrs. Howard Zabriskie of 12 East 72nd Street, New York City, announce the engagement of their daughter, Miss Carla Farr Smythe…
Since the word embeddings were generally effective in identifying clearly related chunks, we retained chunks like this one where the connection was not immediately apparent (see previous discussion of the unique value of word embeddings and online Appendix B for examples of salient chunks for all focal groups). 5
As these excerpts show, salient chunks can be selected by multiple focal group concepts. The text about rosaries, and the text about foreigners living in the United States were salient for Mexican as well as Catholic and Italian – and for good reason since rosaries are discussed as a quinceañera gift, and Italian grocers are discussed alongside Spanish (a term often used in Etiquette to refer to Latin America) waiters. To some extent, this is an artifact of our corpus, which is relatively small and takes up a set number of topics relevant to everyday manners. Overlaps are also in tune with our theory, which posits that the intermingling of focal group concepts is to be expected with immigrant incorporation – for example, including quinceañera gifts on a list of presents for high moments one is likely to encounter.
However, in terms of validity, it is important to establish the differences in how different focal group concepts are implicitly and explicitly present in Etiquette. As a robustness check, we examined the uniqueness of each focal group concept's pseudocorpus. Table 6 presents the 60 most common tokens (words), ranked by frequency in each pseudocorpus within 25-year periods (1920–1945; 1945–70; 1970–1995; 1995–2020). To visualize these distinctions, we split the list into three tiers per period, the 20 most frequent words, and terms ranked 21–40 and 41–60 in frequency. The highlighted words in the table are unique to the focal group concept's respective pseudocorpus in that period and within that tier. For example, “wedding” is only present in the top 20 words of the Catholic pseudocorpus in period 1, so it is highlighted. By period 4, “wedding” ranks top 20 in all pseudocorpora, so it is not highlighted. These descriptive measures demonstrate the pseudocorpora are, to some degree, distinct, although some concepts are less uniquely represented. 6 These analyses also demonstrate stability and change in the generalized contexts present in pseudocorpora. Although there is overlap in frequent words, there are clear differences in the actual frequency of those words. These focal-group-concept-specific differences in word frequency are reflected in the sentiment analyses and salience scores in CMDist.
Top 60 Most Frequent Terms, by Group and Period, with Groups' Unique Terms in First, Second and Third 20 Highlighted.
Most frequent terms in the pseudocorpus for each edition for 4 25-year periods (p1: 1920-1945; p2: 1945-70; p3: 1970-1995; p4: 1995-2020). List is divided into three tiers. Terms that are unique to a group within that tier and period are highlighted.
That meaning is relational is a core principle of the word embedding method. We see this as a strength of embeddings. However, there are trade-offs in comparison with more direct methods. For example, in the case of the selection and analysis of only texts that explicitly mention the focal group concepts, we would be able to establish that all selected texts engaged the focal groups explicitly, and we could leave out texts that also include other focal groups to isolate that one group for the purposes of analysis. With the embedding method, even with robustness checks, we cannot completely rule out that some changes in sentiment and strange-to-normal associations could be unrelated to our focal group concepts.
We use the pseudocorpora to assess mainstream shifts in the texts that are salient to the focal group concepts. We first look at how the sentiment in these pseudocorpora changes over time. We then look at how these pseudocorpora have moved along a single dimension represented by the binary poles of “strange” and “normal”. We present results in two ways: combined and concept-specific. Combined results demonstrate the overall change across all the pseudocorpora. Concept-specific results demonstrate the overall change within each focal group concept's pseudocorpus. It is important to note that there is no shared absolute middle position between strange and normal or negative and positive sentiment across focal-group-specific pseudocorpora. This means that we cannot compare CMDist scores across pseudocorpora, as the point of reference against which scores are standardized is unclarified. It is nonetheless possible to compare general trends within and across groups.
Sentiment
As evident in the differences between how sweet sixteen parties and quinceañeras are covered in Etiquette, it is not enough to establish the presence of focal group concepts in Etiquette. We expect increased positive sentiment to be an element of incorporation through mainstream shifts. Sentiment analysis uses pre-existing measures of the sentiment of words to establish the general emotive characteristics of the pseudocorpus (Prabowo and Thelwall 2009). Sentiment analysis on the pseudocorpus of salient chunks was conducted using the SocialSent package in R (Hamilton et al. 2016). SocialSent contains a collection of code and data for performing domain-specific sentiment analysis and includes historical sentiment lexicons. These lexicons include sentiment scores for the top 5000 words (excluding stop words) for all decades ranging from 1850–2000. Period-dependent sentiment lexicons are crucial since the sentiment of words is influenced by both domain and sociohistorical context (Hamilton et al. 2016). Analyses that span many decades without considering changes in sentiment can be misled by modern-day understandings (Hamilton et al. 2016).
Sentiment analyses produce a sentiment score for each edition in the pseudocorpus. Since baseline sentiment varies across Etiquette editions, we present scores for the pseudoedition relative to the average sentiment of the pseudocorpora. Sentiment scores from the SocialSent package are obtained from an algorithm that propagates sentiment polarities from small seed sets that consider the context of use (for example, soft may have a negative connotation when speaking about intelligence but a positive connotation when speaking about bath towels). These propagated scores were then bootstrapped using B = 50 and 7 words per random subset to lessen the influence of corpus artifacts that might be present in a seed set (see Hamilton et al. 2016 for more information). Sentiment scores are finally represented as the average inferred sentiment across these bootstrap samples.
The sentiment analysis results are presented in Figures 2, 3, and 4. Results from simple regressions yielded significant coefficients across all 7 groups for the effect of year on sentiment scores (p < .05). Interestingly, the effect of year on Muslim and Italian sentiment is only significant when considered as a polynomial, suggesting, as depicted in Figure 4, that the century can be characterized first by decreasing, and then increasing positive sentiment (p < .05). We revisit this finding in the discussion.
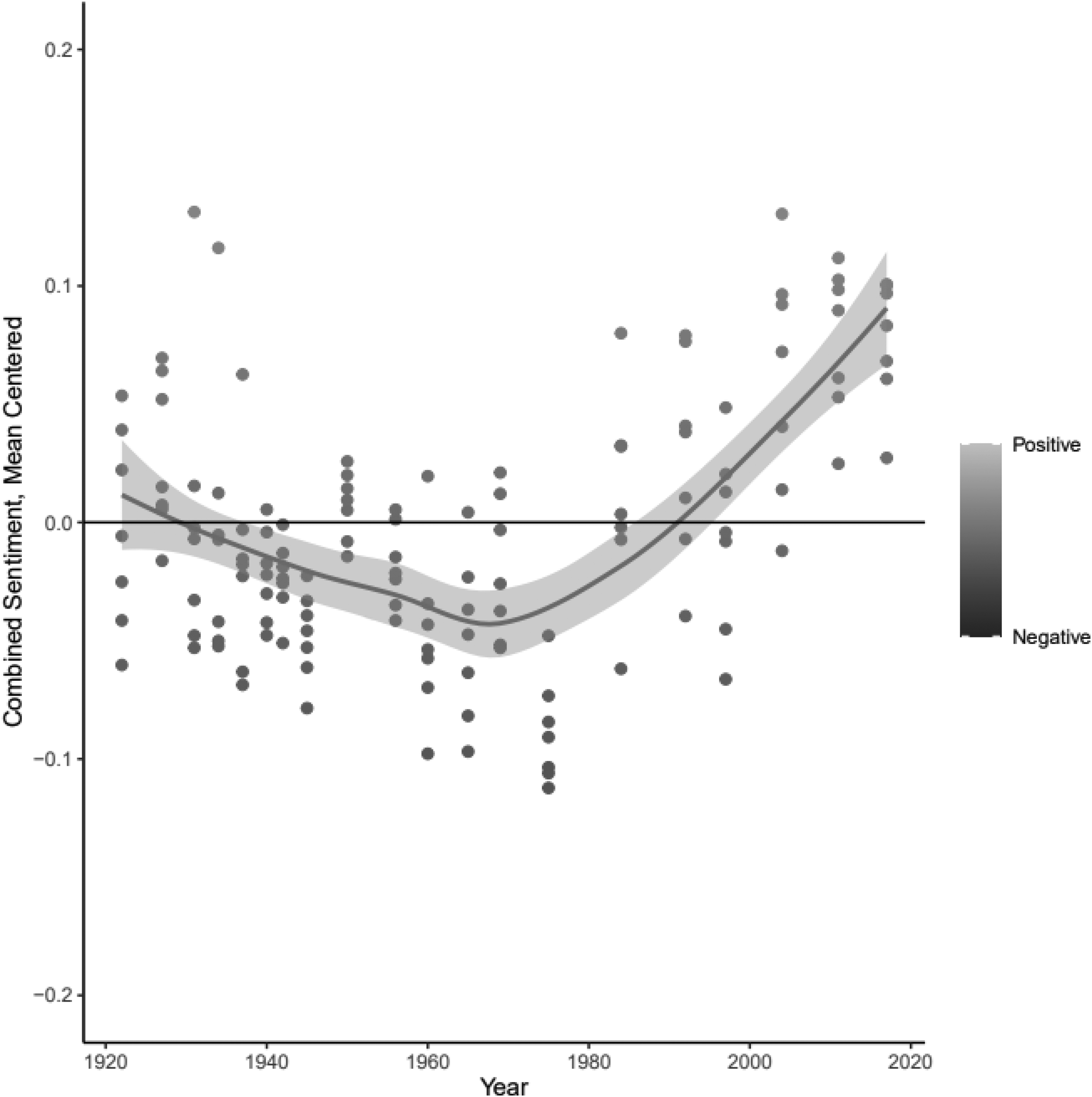
Sentiment: more or less positive relative to the edition for all focal groups, by edition year. Higher scores are more positive. Figure includes a LOWESS plot of median scores and a bar representing a 95 percent confidence interval.
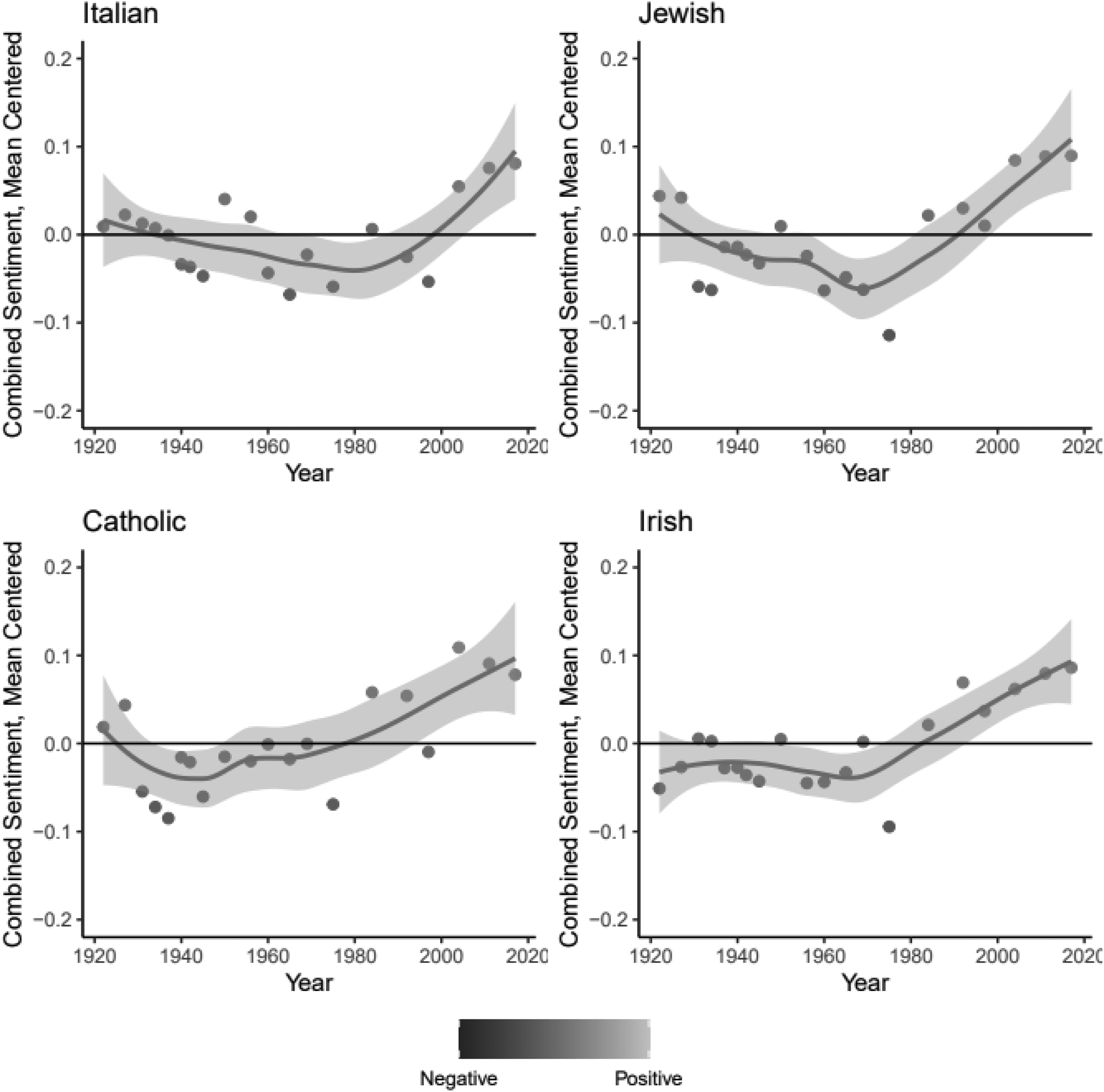
Sentiment: more or less positive relative to the edition for focal group set 1, by edition year. Higher scores are more positive. Figure includes a LOWESS plot of median scores and a bar representing a 95 percent confidence interval.
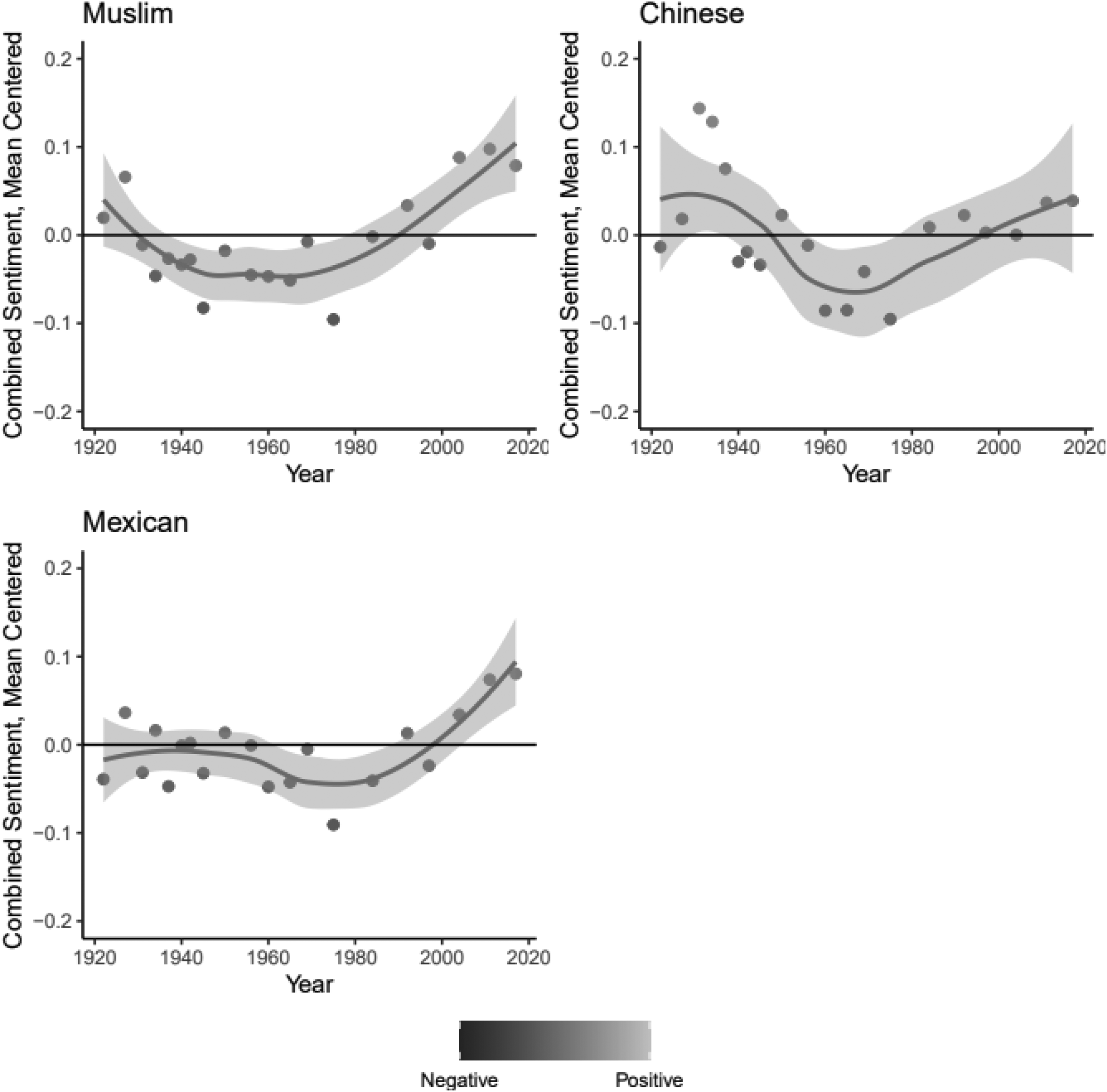
Sentiment: more or less positive relative to the edition for focal group set 3, by edition year. Higher scores are more positive. Figure includes a LOWESS plot of median scores and a bar representing a 95 percent confidence interval.
Figure 2 shows trends in positive sentiment across all pseudoeditions. Though there is variation, sentiment is generally less positive from around the 1930s to the 1970s before becoming more positive. Positive sentiment increases at a greater rate after 2000.
Figure 3 presents within-concept sentiment plots for texts most salient to the focal group concepts Italian, Jewish, Catholic, and Irish. Based on the previous literature, we expect this set of focal concepts to show a clear trajectory of integration through mainstream shifts (Brodkin 1998; Ignatiev 2009; Roediger 2005; Takaki 1993). Note that concept-specific plots show trends in sentiment across editions for an individual focal group concept, making it possible to view how sentiment in texts salient to the focal group concept in question have changed irrespective of trends in the other focal group concepts. While the general pattern of increasing positive sentiment in more recent editions after declining or stagnating positive sentiment is evident for all focal group concepts, there is variation across focal group concepts. For example, the sentiment around Italian and Jewish crosses into positive territory later than Catholic and Irish.
Figure 4 plots the sentiment scores for texts most salient to the focal group concepts Muslim, Chinese, and Mexican. Based on the literature, we expect these focal concepts to show less evidence of integration through mainstream shifts (Lee 2003; Maghbouleh 2017; Massey, Durand, and Malone 2002; Takaki 1993). In this case, our observations were not consistent with our expectations. In the texts most salient to these focal group concepts there are also trends toward increased positivity after the 1970s. This is especially evident for texts salient to Muslim and, to a lesser extent, Mexican, focal group concepts. The shift into above-average positive sentiment does not fall outside the confidence interval for Chinese.
Trends in sentiment are fairly consistent across the focal group concepts – both those that are often considered to be successfully incorporated into the mainstream and those that are not. This suggests a broader transformation in sentiment toward difference as an element of the mainstream over and above group-specific processes. However, there are limitations to consider in interpreting the results of the sentiment analyses. Although we have selected texts with high salience to the focal group concepts, we cannot be certain that these concepts drive the observed sentiment changes. As a robustness check, we conducted the same analyses for pseudocorpora built around various concepts that are neutral to the focal groups. These analyses demonstrated various sentiment trajectories (see online Appendix D) and lend credibility to the conclusion that increased positive sentiment is not an artifact of the method.
Position Between “Strange” and “Normal”
A trend toward more positive sentiment in texts associated with the focal group concepts may suggest a decrease in the sense that the focal group is a “problem” for the mainstream. However, with mainstream shifts, we would expect that Catholic, Chinese, Irish, Italian, Jewish, Mexican, and Muslim would not just have positive sentiment, they would also be seen as normal and ordinary – characteristics associated with the kind of Americans looking for advice on hosting their daughter's quinceañera, for example. Our final analyses explore whether Etiquette shows these expansions of the boundary of the mainstream (see also Schachter 2016).
Our assumption is that incorporation into the mainstream would lead texts associated with the focal group concepts to be more “normal” over time. To test this assumption, we specify a semantic dimension anchored by a conceptual antonym pair: strange and normal. We then analyze the same salient pseudocorpora as in the sentiment analyses by establishing the position of each edition of the pseudocorpus within the semantic dimension. We continue with the convention of using italics when referring to strange and normal as concepts operationalized in CMDist. The premise of these analyses is that incorporation through mainstream shifts can be measured based on a focal group concept's relative position, a proxy for meaningful association, between strange and normal. By assuming a continuum between this antonym pair (Fellbaum 1998), we can assess how the semantic association of texts that are salient to the focal group concepts move along that conceptual continuum over time (see also Kozlowski, Taddy, and Evans 2019).
Analyses are conducted using the CMDist antonym pair function (Taylor and Stoltz 2020). FastText embeddings are used to prepare a semantic continuum between strange and normal. CMDist calculates the focal groups’ pseudoeditions’ position between strange and normal, giving each pseudoedition a standardized score. These scores are used to show how the texts that are salient to each focal group concept changed in relation to being “normal” from the perspective of Etiquette's depiction of the mainstream.
In specifying the strange to normal semantic dimension, we determine that mainstream inclusion should be seen as conceptually and definitionally independent of immigrant-ness (e.g., American/Foreign; Immigrant/Citizen). It is possible, and even likely, that a focal group concept becomes more or less associated with immigrant-ness over time, for example, as part of the process of immigrant incorporation or as a result of new waves of immigration from the same location. In theory, the relationship between these shifts in the immigrant-ness of the focal group concepts are independent of whether or not a focal group concept becomes more or less normal. Likewise, a focal group concept could maintain a similar level of association with immigrant-ness and become more normal through mainstream shifts that normalize immigration. We conducted multiple sensitivity analyses to buttress this claim, which can be found in online Appendix E. Analyses include reproduction of the results using alternative embeddings and alternative concept specifications. Other specifications may be relevant with other data (e.g., news articles, see Stoltz and Taylor 2021).
Simple regressions with the CMDist strange-to-normal scores yielded significant coefficients across all seven groups (p < .05). Figure 5 presents results from an analysis that included all pseudocorpora. Results depict clear movement towards normal. The scores are standardized and mean-centered at 0 across all focal group concepts, reflecting overall trends.
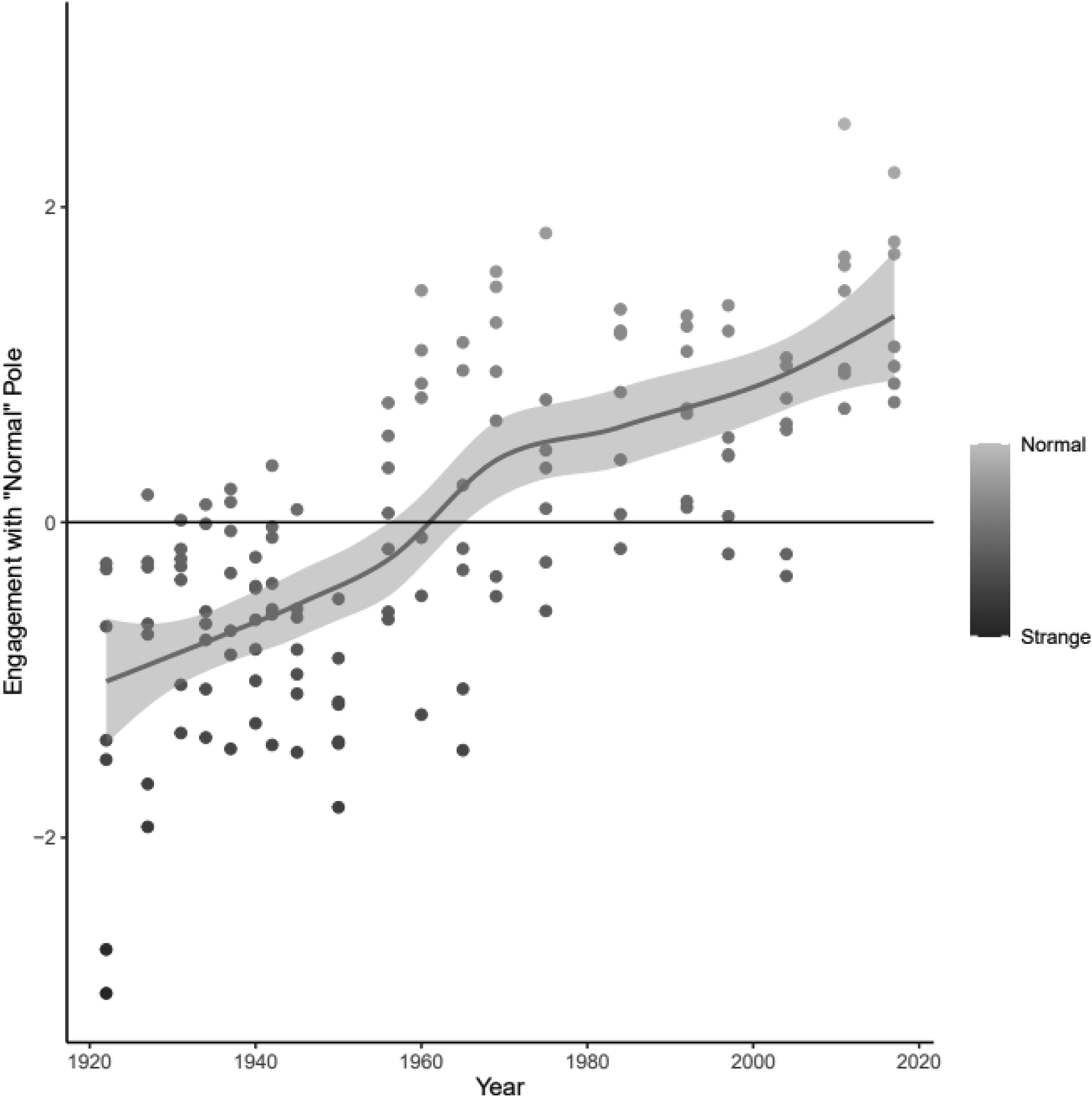
Meaning: normal versus strange over time for all focal group pseudocorpora, by edition year. Lower scores are closer to strange and higher scores are closer to normal. Figure includes a LOWESS plot of median scores and a bar representing a 95 percent confidence interval.
Figure 6 plots the strange-to-normal CMDist scores for the first set of focal group concepts: Italian, Jewish, Catholic, and Irish. These scores are mean-centered within the pseudocorpus for the individual focal group concept, with a score of 0 representing the average for the pseudoeditions salient to that focal group. As such, scores should not be compared between focal group concepts, but trajectories can be compared. A positive trend doesn't suggest incorporation so much as relative incorporation. Similarly, no positive trend doesn't suggest a lack of incorporation so much as a lack of change in incorporation. Figure 6 shows texts salient to Catholic, Irish, and Italian trend towards normal. Texts salient to Jewish, are less normal, beginning in the 1970s. This is the same period in which there was more positive sentiment associated with the texts for Jewish and many other focal group concepts. This finding is taken up in the discussion.
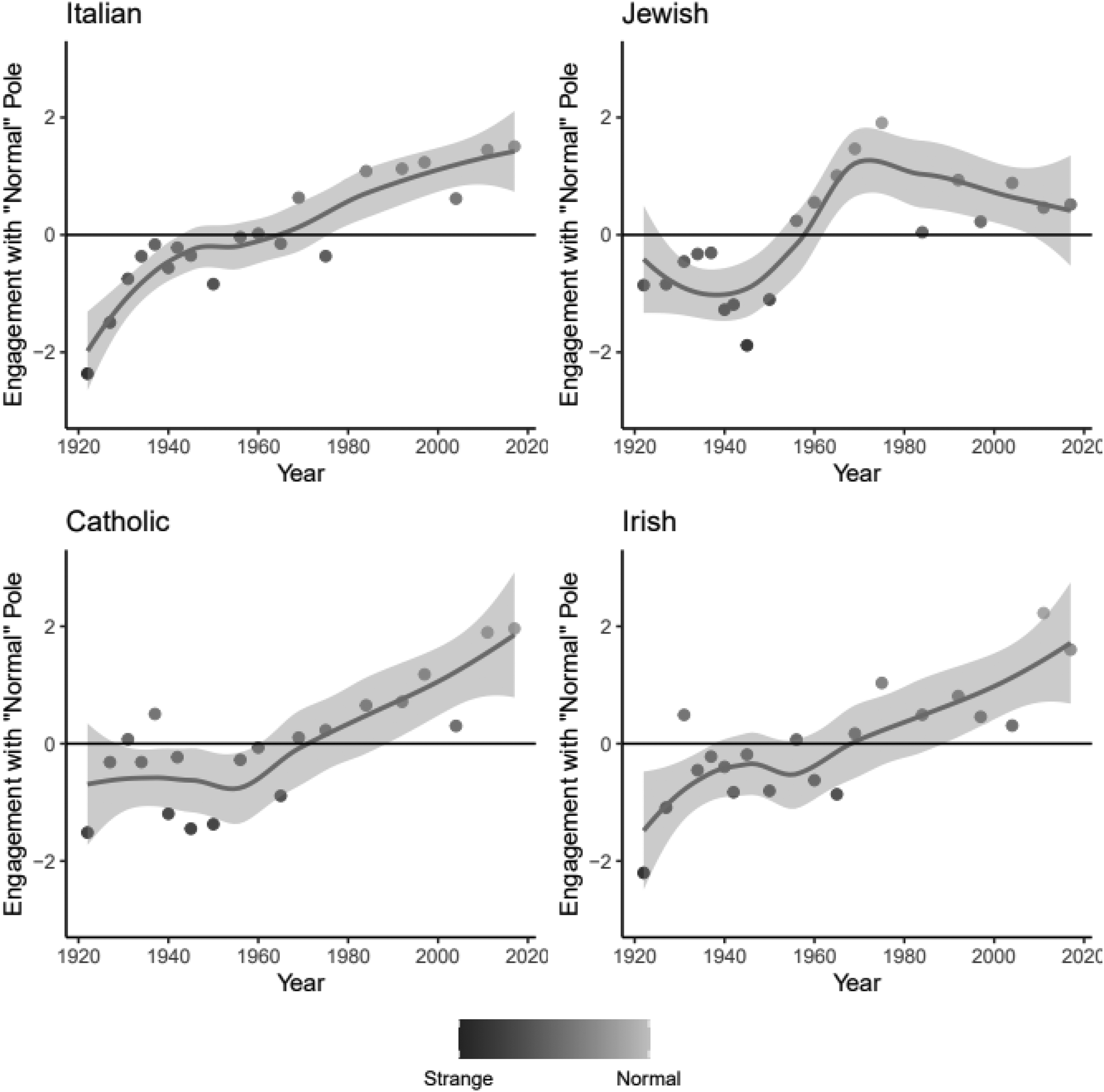
Meaning: normal versus strange over time for set 1 focal group pseudocorpora, by edition year. Lower scores are closer to strange and higher scores are closer to normal. Figure includes a LOWESS plot of median scores and a bar representing a 95 percent confidence interval.
Figure 7 plots the scores for Muslim, Chinese, and Mexican. This figure also demonstrates varied patterns. Mexican and Muslim have flatter trajectories toward normal relative to Chinese and most other focal groups. Chinese has a fairly clear trajectory toward normal. The confidence interval around Muslim is quite wide and remains close enough to 0, suggesting that Muslim may not have achieved a significant move towards normal.
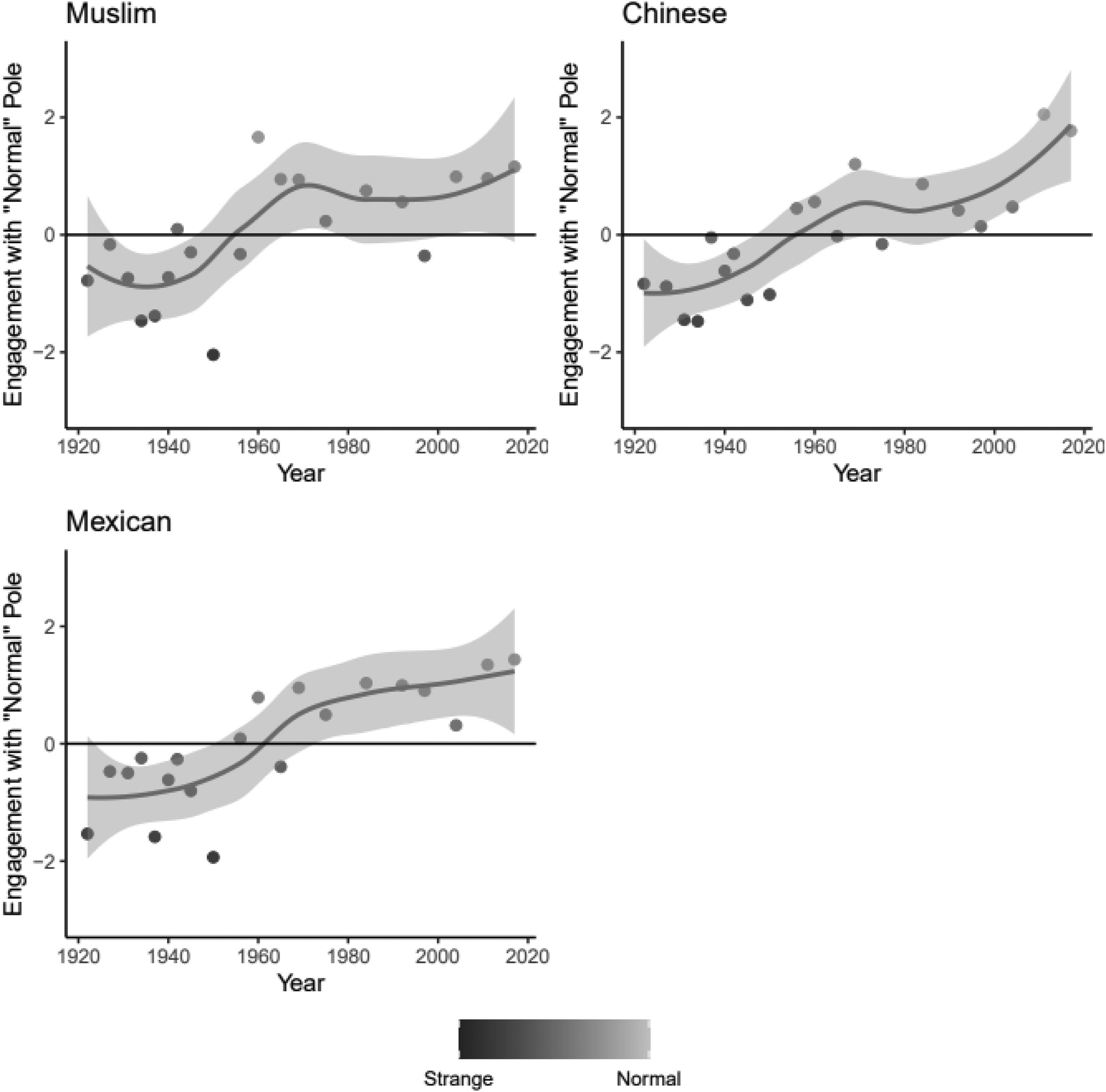
Meaning: normal versus strange over time for set 2 focal group pseudocorpora, by edition year. Lower scores are closer to strange and higher scores are closer to normal. Figure includes a LOWESS plot of median scores and a bar representing a 95 percent confidence interval.
The results from these analyses of the position of Catholic, Chinese, Irish, Italian, Jewish, Mexican, and Muslim between strange and normal show a general trend toward immigrant incorporation through shifts in the mainstream. However, particular focal group concepts follow different trajectories. Despite trends toward more positive sentiment, Jewish, Mexican, and Muslim are particularly noteworthy in their divergence from a solid upward trajectory from strange to normal. Although they remain closer to normal than in pre-1960, the texts associated with Jewish group concepts were less normal after the 1960s. Although there is not a clear decline for Muslim, there is a noticeable leveling of the trajectory. There is no similar situation observed for Catholics, which suggests this does not reflect mainstream shifts around religion. These findings are potential evidence of mainstream disaffiliation for Jewish and Muslim.
Discussion and Conclusions
The “remaking of the American mainstream” (Alba and Nee 2003) is crucial to the trajectory of immigrant incorporation. Past research on individuals’ attitudes, preferences, and practices has determined that established, non-immigrant, Americans become comfortable and familiar with the languages, foods, and cultural and religious practices that immigrant groups introduce. In some cases, established individuals develop a more expansive and less ethnocentric notion of what it means to be American. In this research, we sought to observe these mainstream shifts. Applying sociological computational text analysis methods to a unique text corpus, we examined mainstream shifts that show immigrant incorporation at the level of society's social and symbolic organization. We examined mainstream shifts related to immigrants by analyzing texts focused on practical and mundane elements of everyday life. Our data consisted of Emily Post's Etiquette – a book guiding Americans through high moments and everyday encounters for nearly a century. Taking Etiquette as a depiction of the mainstream, we examine the text for evidence of the incorporation of different groups.
Based upon exploratory analyses, we determined that our texts were best suited to observing mainstream shifts in relationship to long-standing groups who were and may still be seen as immigrants and outsiders in the United States: Catholic, Chinese, Irish, Italian, Jewish, Mexican, and Muslim. We theorized that this incorporation should be evident through positive sentiments attached to the people, practices, identifications, and objects associated with these groups. We theorized that incorporation would also include a background sense that these people, practices, identifications, and objects were not strange but normal elements of mainstream social life. To examine this, we used word embeddings to select text excerpts that were most salient to these groups. We then analyzed the sentiment and the meaning of these texts in terms of position between being strange and normal.
We uncover mainstream shifts indicating some incorporation of all of these groups. We observed more positive sentiment and a movement from more strange to more normal on the aggregate, but there is variation within and across groups. Simple regressions showed these shifts were statistically significant (p < .05). However, as depicted in the figures, it often appears that the trajectory of incorporation over time is not linear. Instead, the analyses often demonstrate curves with increasing, decreasing, and stable incorporation periods. Furthermore, some focal groups acquire consistent positivity and a view of normalness over time, but others have less consistent trajectories of incorporation. Positive sentiment and normal-ness operated independently. In this article, we have not interpreted these trends in relation to the facts of migration history for each group, and in relation to periods of pro- and anti-immigrant attitudes and politics in the United States, but such analysis is a next logical step in the research. For example, in the case of Chinese, there was lagging positive sentiment but still a clear movement toward normal. Meanwhile, increased positive sentiment for Jewish and Muslim group concepts was coupled with declining or stagnating normal-ness, suggesting the possibility of rising disaffiliation instead of incorporation. Future research could follow up on these findings and examine the possible relationship between mainstream disaffiliation and related research that has observed Muslim American experiences being reclassified outside of whiteness after the 9/11 terrorist attacks (Maghbouleh 2017) and the rise of anti-Semitism in the contemporary United States (Moshin 2018).
Beyond immigrant integration, the techniques presented here could be adapted to a variety of questions related to social sentiment and symbolic inclusion. In particular, we emphasize the value of using a theoretically-selected text corpus instead of relying on a sampling logic in corpus selection. We also demonstrate the potential of computational sociological methods by moving beyond relying on explicit occurrences and focusing on implicit and explicit meanings through word embeddings and sentiment analyses, which are much more interpretive computational tools.
Finally, we want to underscore the continued centrality of qualitative epistemology in the practice of computational social science (Nelson 2021). Both human and machine reading and text analysis were crucial to this project - a mutual give and take combining the interpretive logics of the social scientists and machine neural networks of word embeddings in a computational grounded theoretic approach (Nelson 2020). Human analysis of the text served two functions in our analyses: to confirm the validity of our embedding techniques and provide insight into how the mainstream shifts associated with immigrant integration actually played out in the texts. Computational approaches extend the interpretive toolkit, but human interpretation is crucial for correcting, confirming, and interpreting the results of the computational text analysis.
Supplemental Material
sj-docx-1-smr-10.1177_00491241221122596 - Supplemental material for From Strange to Normal: Computational Approaches to Examining Immigrant Incorporation Through Shifts in the Mainstream
Supplemental material, sj-docx-1-smr-10.1177_00491241221122596 for From Strange to Normal: Computational Approaches to Examining Immigrant Incorporation Through Shifts in the Mainstream by Andrea Voyer, Zachary D. Kline, Madison Danton and Tatiana Volkova in Sociological Methods & Research
Footnotes
Acknowledgments
The authors wish to thank Lauretta Czarnezki, Alexander Karl, Asia Letlow, Pedro Pinales, Olivia Reid, and Stuart Riepl for their research assistance.
Author's Note
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This article is based on research supported by the United States National Science Foundation Award No. 1851304, The University of Connecticut Office of the Vice President for Research, The University of Connecticut College of Liberal Arts and Sciences, and the University of Connecticut Department of Sociology.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.