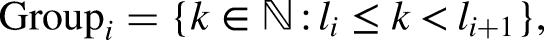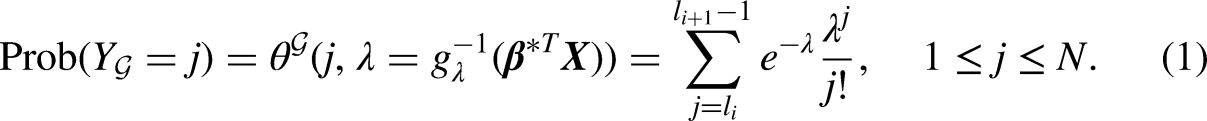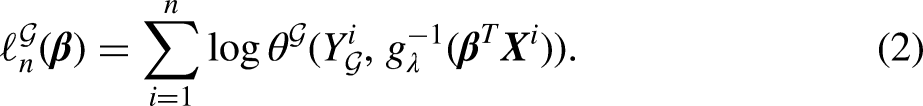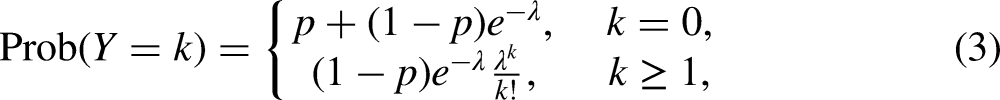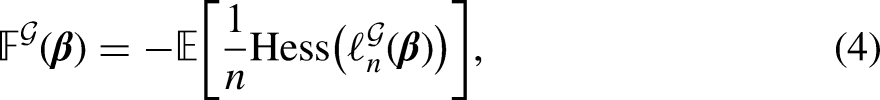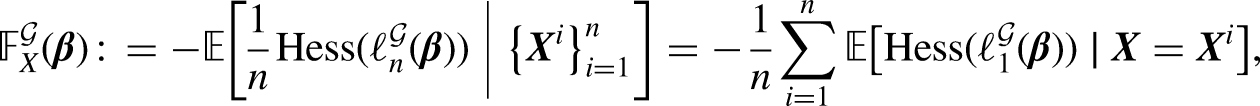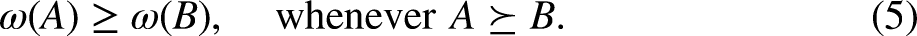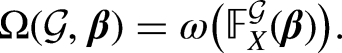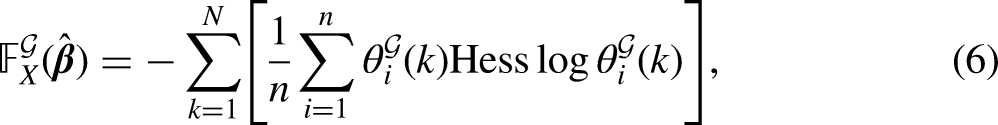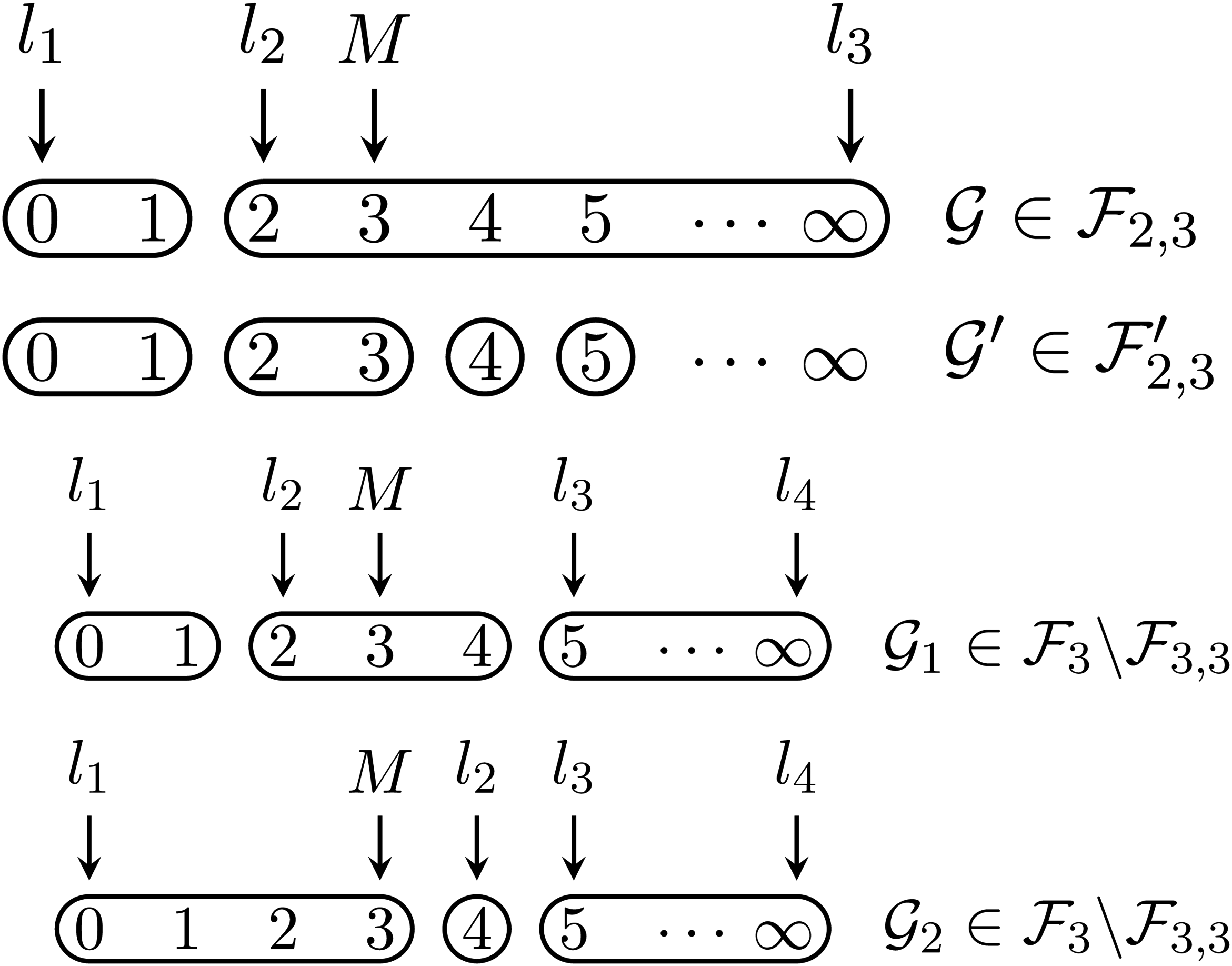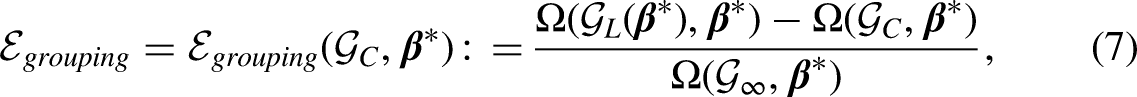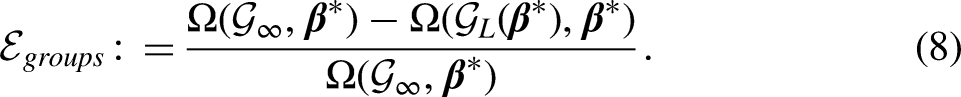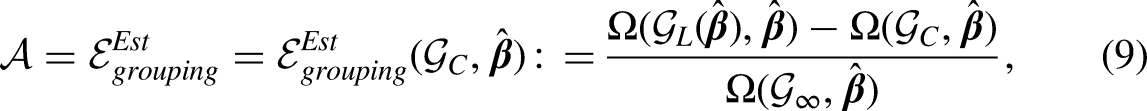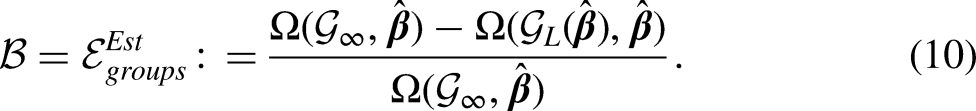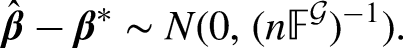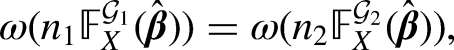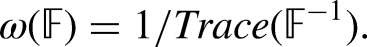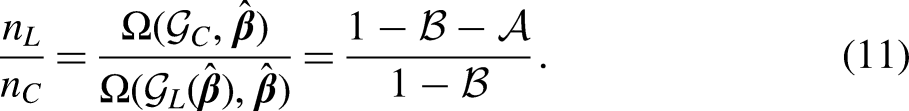Grouped and right-censored (GRC) counts have been used in a wide range of attitudinal and behavioural surveys yet they cannot be readily analyzed or assessed by conventional statistical models. This study develops a unified regression framework for the design and optimality of GRC counts in surveys. To process infinitely many grouping schemes for the optimum design, we propose a new two-stage algorithm, the Fisher Information Maximizer (FIM), which utilizes estimates from generalized linear models to find a global optimal grouping scheme among all possible -group schemes. After we define, decompose, and calculate different types of regressor-specific design errors, our analyses from both simulation and empirical examples suggest that: 1) the optimum design of GRC counts is able to reduce the grouping error to zero, 2) the performance of modified Poisson estimators using GRC counts can be comparable to that of Poisson regression, and 3) the optimum design is usually able to achieve the same estimation efficiency with a smaller sample size.
Grouped and right-censored (GRC) counts in survey research refer to response categories of discrete-value survey questions consisting of both grouped (e.g., “3–5 times” rather than precise counts of “3 times”, “4 times”, or “5 times”) and right-censored counts (e.g., an open-ended category as “6 or more times”) (Coughlin 1990; Fu et al. 2020; Guo et al. 2020; Schaeffer and Dykema 2020, 2011; Willis 2004). The advantage of GRC counts is that they do not require exact enumerations of behavioural frequencies and thus reduce cognitive burdens in data collection. Especially when respondents seek to adopt a series of answering strategies to alleviate their cognitive burdens and provide good enough answers (Schaeffer and Dykema 2011; Gehlbach and Barge 2012; Conrad et al. 1998), the use of GRC counts is a convenient and inexpensive way of coping with cross-subject heterogeneity in understanding, interpreting, recalling, and estimating target events and behaviours.1 GRC counts have been recommended by survey methodologists over other alternative formats of response categories for studying event frequencies, especially when sensitive topics (e.g., drug use, juvenile delinquency, suicide attempts) or vulnerable populations (e.g., children, youth, the elderly) are being studied (Schaeffer and Dykema 2020; Schwarz et al. 1985; Toepoel et al. 2009). For example, two nationally-representative surveys on adolescent risky behaviours in America, the Monitoring the Future project and the Youth Risk Behavior Survey, use GRC counts to track temporal patterns of substance use and juvenile delinquency (Johnston et al. 2017; Kann et al. 2018). The National Longitudinal Study of Adolescent to Adult Health (Add Health), which is the largest longitudinal survey of adolescents in America, also relies on GRC counts to collect information on various health-related outcomes (Bahr and Hoffmann 2008; Conway et al. 2013).
Although GRC counts have been widely used in survey research (Ackard et al. 2002; Akers et al. 1989; Bachman et al. 1990; Baiden et al. 2019; Fu et al. 2013; Hagan et al. 2005; Kumar et al. 2008; Marsden 2003), their design and analysis create methodological challenges. Due to the lack of conventional tools to capture the data generating process of GRC counts, they are often treated as categories instead of counts, and accordingly analyzed by (ordinal/multinomial) logistic regression models instead of Poisson-based models (Connor et al. 2013; John et al. 2006). While some recent studies have attempted to implement regression models and derive asymptotic properties of estimators to analyze GRC counts (Fu et al. 2021; Guo et al. 2020; Wang 2022), the optimum survey design of GRC counts in a regression setting remains a critical yet challenging issue faced by survey methodologists and social scientists in general.
More specifically, the optimum survey design of GRC counts in a regression setting needs to take three key issues into account (Fu et al. 2020; Biemer 2010). First, to achieve the optimum design, a search algorithm should be designed to incorporate available information on regression covariates, process infinitely many grouping schemes for GRC counts, and identify an optimal grouping scheme that maximizes (a score function of) the Fisher information matrix of the population parameters to achieve maximum estimation efficiency. Second, for a specific (and usually suboptimal) scheme chosen by researchers, its difference from the identified optimal grouping scheme and the impact of such difference on statistical inference need to be assessed. Third, to establish optimality criteria for assessing grouping schemes, design errors associated with grouping schemes also need to be defined, decomposed, and calculated. By critically synthesizing and greatly extending a series of recent advances in the design and analysis of GRC counts (Davillas and Pudney 2020; Fu et al. 2020; Guo et al. 2020; Schaeffer and Dykema 2020), the current study addresses these three issues. While the optimum design of GRC counts is the primary focus of this study, it should be noted that the unified framework to be described here also solves a more general question of optimality and design of counts when they are either grouped, right-censored, or both, in surveys.
Methods
Generalized Linear Models for Grouped and Right-Censored Counts
To characterize the data-generating distribution of GRC counts, we let denote the total number of GRC response categories used in a survey question, and divide all non-negative integers into these groups. The ’th group () consists of one or a successive sequence of integer(s),
where is the totality of all the non-negative integers, and are used to define boundaries separating these groups of an -group scheme.
We first illustrate how generalized linear models (GLMs) are used to analyze GRC counts. The choice of GLMs permits a more flexible parameterization of GRC counts, such as a zero-inflated model, a negative binomial model, a hurdle model, or a mixture of these models (Hilbe 2011; Land et al. 1996). We begin with the following GLM model, Poisson regression, which is well studied and widely used to model count data (Agresti 2003; Lawless 1987; Rhodes et al. 1996). Let be a random variable that has a Poisson distribution with mean , namely, , for in . In Poisson regression, the expected frequency is specified by a linear combination of regressors through a link function , where is the vector of unknown coefficients.
Instead of using exact enumeration in the original Poisson model, counts are now measured in a grouped and right-censored form given by . Here, refers to a GRC grouping scheme and is a random variable obtained by categorizing with respect to . Specifically, if and only if is in the ’th group. So has a categorical distribution on , with
Based on (1), the modified log-likelihood function for a sample is
The Poisson distribution requires that the variance be the same as the mean. However, this equi-dispersion assumption is often violated due to the existence of excessive zeros (Fu et al. 2013; Tucker et al. 2021). The zero-inflated Poisson (ZIP) distribution incorporates a binomial process to take into account excessive zeros (Hall 2000; Lambert 1992; Land et al. 1996). Take binge drinking, for example: the ZIP distribution considers two potential sources of zeros. Those who are exposed to the risk of binge drinking but do not report any episode of binge drinking, and those who are not exposed to the risk of binge drinking due to various religious, health, or socio-relational factors (Jun et al. 2016; Luczak et al. 2002; Tucker et al. 2021). The probability mass function for the ZIP distribution is:
where and . The ratio is the population’s proportion subject to . Here also has a categorical distribution obtained by categorizing (3) according to . The modified log-likelihood function is obtained by replacing the summand in (2) with , where represents the vector of regressors, the vector denotes corresponding coefficients, and is the generalized linear model for with the corresponding link function . The proof (available upon request) of existence, consistency, and asymptotic normality of these modified Poisson estimators readily follows (Fahrmeir and Kaufmann 1985; Fu et al. 2018; Serfling 1980).
Define and Decompose Design Errors of GRC Counts
To define and decompose errors in the optimum design of GRC counts, or more broadly, survey counts, we next investigate possible sources of errors. First, the total number of count response categories is restricted to be finite. As compared to the scenario of exact enumeration, the finite number of count response categories entails a loss of information in measurement and further leads to less efficient estimation. In other words, although corresponds to a measure of counts (of human behaviours) that are infinite in nature, the finiteness of originates from the total number of response categories fixed by survey investigators. The first design error is essentially a product of survey designs, rather than the finiteness of . We hereafter refer to this design error caused by the restriction in as the groups error. Second, with a finite , a suboptimal grouping scheme chosen by survey investigators from all possible -group schemes leads to less efficient estimation and produces the grouping error. Without the optimum design of survey counts, a grouping scheme specified by researchers is likely to be suboptimal. For example, the grouping error occurs when the most observed counts (e.g., 3 times and 4 times) are arbitrarily categorized in a wide group (e.g., 3 to 10 times). The sum of the groups and grouping errors gives the total error in the design of survey counts. The optimum design of survey counts, as we will show next, is able to reduce the grouping error to zero.
The asymptotic normality of modified Poisson estimators suggests that a suboptimal grouping scheme has less Fisher information. Based on the literature on optimum experimental designs (Atkinson et al. 2007; Goos et al. 2016), one may employ a score function (e.g., A-, D-, E-, or I-optimality) to compare Fisher information matrices of different grouping schemes and then decompose the total error into the groups and grouping errors. In particular, if is a real strictly positive definite matrix, A-optimality maximizes , D-optimality maximizes the determinant of , and E-optimality maximizes the minimum eigenvalue of .
When and each group only contains one integer, exact enumeration clearly provides the universal optimal grouping scheme that maximizes a score function. When is finite for survey counts, the search for a global optimal grouping scheme that eliminates the grouping error plays a key role in the optimum design. For a specific score function of Fisher information (matrix), the difference between a global optimal grouping scheme and the universal optimal scheme corresponds to the groups error, while the difference between the global optimal scheme and an actual scheme chosen by survey investigators corresponds to the grouping error.
The Optimum Design of GRC Counts: Fisher Information Maximizer
We develop and describe a two-stage search algorithm, the Fisher Information Maximizer (FIM), to achieve the optimum design of survey counts with generalized linear models (GLMs). The FIM specifically addresses two related methodological issues. First, how to process and assess infinitely many grouping schemes based on an optimality criterion. Second, how to utilize information provided by data so that the search algorithm is informed by generalized linear models (described in Section 2.1) of survey counts.
We focus on the modified Poisson model in (2) and the discussion can be readily extended to the ZIP case. The Fisher information matrix of Model (2) could be defined via the Hessian matrix of (2):
where the mean is taken with respect to the sample . In particular, we have . We omit the measure-theoretic discussion and assume that (4) is well defined and finite for all . Since we usually have no knowledge of the marginal distribution on the input space , is replaced by a statistic
where the conditional expectations are finite sums and easy to calculate.
Let and be two grouping schemes. We say that is finer than if . For example, the grouping scheme [never, 1–2 times, 3–5 times, 6–9 times, 10+ times] is finer than [never, 1–2 times, 3–9 times, 10+ times]. When , one has and for Poisson-based models (proof available upon request). Here, for two symmetric matrices and , one writes or , if is positive semi-definite. This agrees with the intuition that, for both Poisson and ZIP models, a finer grouping scheme always leads to a more efficient estimation. This monotonicity condition has two implications. First, the estimation based on schemes without grouping or right censoring achieves maximum efficiency. Second, with the restriction of no more than groups in any grouping scheme, a global optimal grouping scheme can always be found among the schemes with exactly groups.
Drawing on ideas from optimum experimental design (Atkinson et al. 2007; Goos et al. 2016), we develop the FIM to find a global optimal design among all the -group schemes with generalized linear models. Let be a function defined on the space of strictly positive definite matrices such that
The requirement in (5) makes the scores and monotonic functions of the grouping schemes, where may take the form of the A-, D-, E-, or I-optimality scores (Atkinson et al. 2007).
For any grouping scheme and a coefficient vector , we define as follows to apply the search algorithm:
We use , , and to denote a sufficiently large integer, the family of all -group schemes, and the subset of with contained in the last group, respectively. For positive semi-definite matrices , , and , does not necessarily lead to so that the dynamic programming approach (Bai and Perron 2003) cannot be applied. The maximization of over (where is an estimate of obtained, for example, from a pilot study) is then thwarted by two problems: the computation of is time consuming, and one has a large set of grouping schemes to assess.
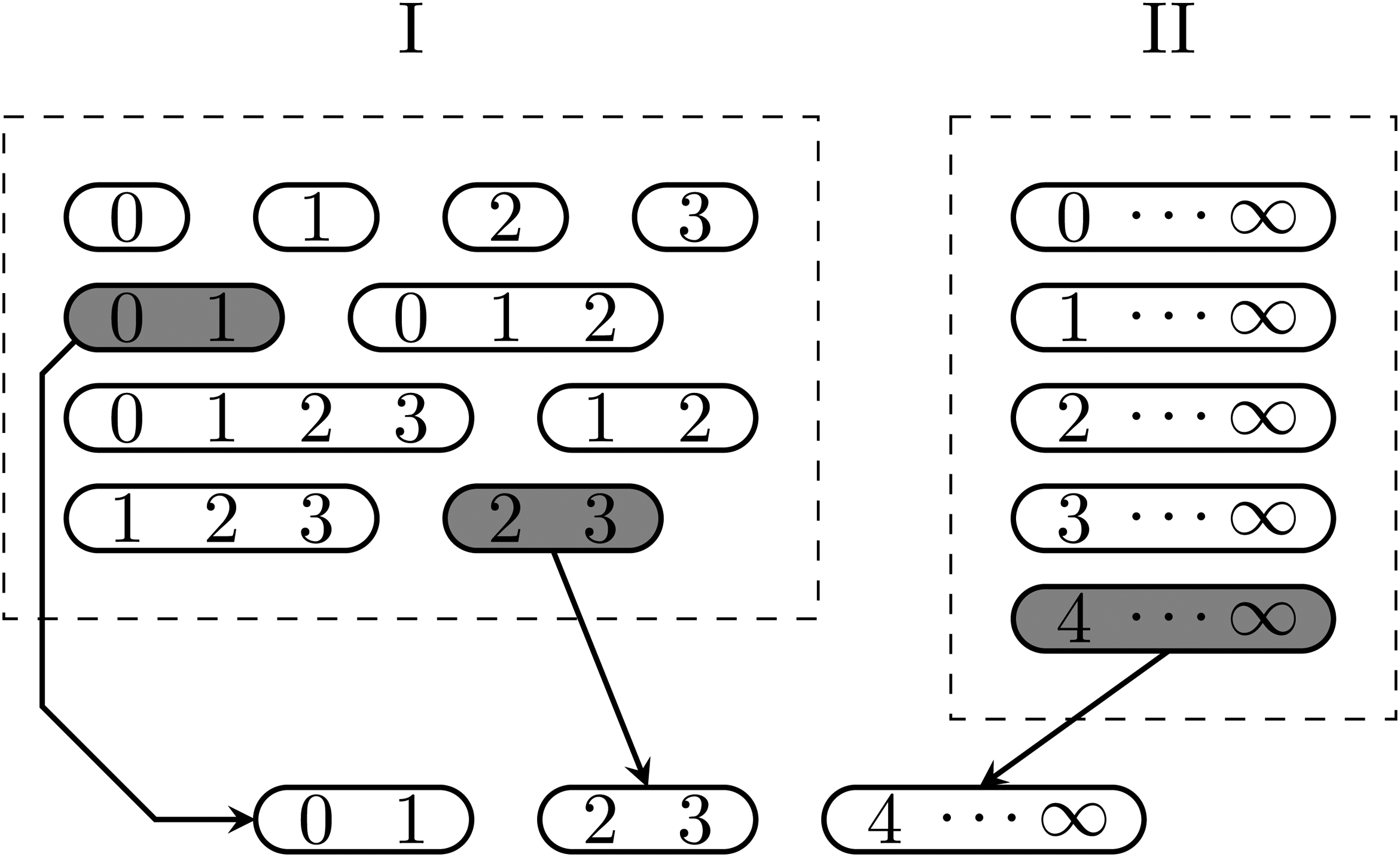
To solve these problems, the synthesis stage of the FIM computes the “building blocks” of , and then synthesizes the Fisher information matrices by adding up the corresponding blocks. More specifically, for , we have
where , , and the Hessian is taken with respect to the vector at . In (6), the expression in the square bracket can be calculated before the choice of a grouping scheme because the calculation only needs to specify the pair defining the boundaries of a group to be included in . The FIM’s synthesis stage is illustrated with the example in Figure 1. Instead of assessing infinitely many grouping schemes, the FIM considers two finite sets of groups for building a grouping scheme through the introduction of : the first set (dashed box I) consists of all possible groups not containing any integer , while the second set (dashed box II) consists of all possible groups containing all the integers . A building block (i.e., the Fisher information matrix of a group in the dashed boxes) is computed, stored, and later retrieved to synthesize of a specific grouping scheme.
An illustration of the synthesis stage of the FIM: synthesizing with .
We use to denote the maximizer of on . In the next validation stage of the FIM, the FIM proceeds differently depending on whether is validated as the maximizer of on . We define as the totality of all the schemes , which are obtained from some by dividing every integer larger than into a separate group. For every scheme in , there is some in that is finer than ; the size of cannot be larger than that of . We then compare with . If the latter is not smaller, is guaranteed to be the maximizer of on . Otherwise one may choose a larger and start over. The specified integer controls the sizes of and so that a larger is associated with a longer search time. Yet, should be large enough to pass the aforementioned validation criterion, namely, is not smaller than . The FIM’s validation stage is illustrated with the example in Figure 2, where is clearly finer than both and in .
An illustration of the validation stage of the FIM: validating maximizers with .
Calculate Design Errors and Assess Grouping Schemes
We now use to denote the current -group scheme chosen by survey investigators. Given a coefficient vector and a data matrix , we use to denote the global maximizer of among all possible -group schemes. In other words, is the maximizer of on , which can be obtained by the FIM. We next define as the grouping scheme that each group only contains one non-negative integer, which corresponds to the scenario of exact enumeration of counts in conventional Poisson regression. As we discussed above, is the universal maximizer of . The groups and grouping errors, both of which are non-negative by definition, are given below:
For empirical applications, the true coefficient vector is unknown, so neither of the errors is computable. We define and in the same way as in (7) and (8), respectively, substitute with its estimate from generalized linear models, and have:
In general, to compute and assess design errors, we treat these estimates inferred using modified Poisson models as prior information, identify a global optimal scheme that maximizes the score function via the FIM, and then use the diagonal elements of the inverse Fisher information matrix2 to calculate regressor-specific design errors.
To take into account the design effect and calculate the effective sample size, we note that the estimator with grouping scheme and sample size has approximately a normal distribution centred on the true coefficient vector ,
Here, the covariance matrix considers the influence of the sampling error: a “smaller” covariance matrix indicates a smaller error, whereas the “larger” Fisher information matrix provides more efficient parameter estimation.
An optimal grouping scheme can usually achieve the same estimation efficiency with a smaller sample size. The FIM also allows us to assess relative estimation efficiencies based on different grouping schemes. We let and be the corresponding sample sizes of two different grouping schemes and , respectively, and use the following equation:
to calculate the ratio , which suggests the relative efficiency. The estimation efficiency based on is more efficient relative to that based on if is larger than 1. Here, we adopt the -optimality score function to make a comparison between Fisher information matrices:
For any number , we have .
We use and to denote sample sizes associated with the grouping scheme and , respectively. Based on calculated design errors in (9) and (10), we have
Using generalized linear models, the calculation of both design errors and the assessment of grouping schemes is regressor-specific.
Simulation and Empirical Results
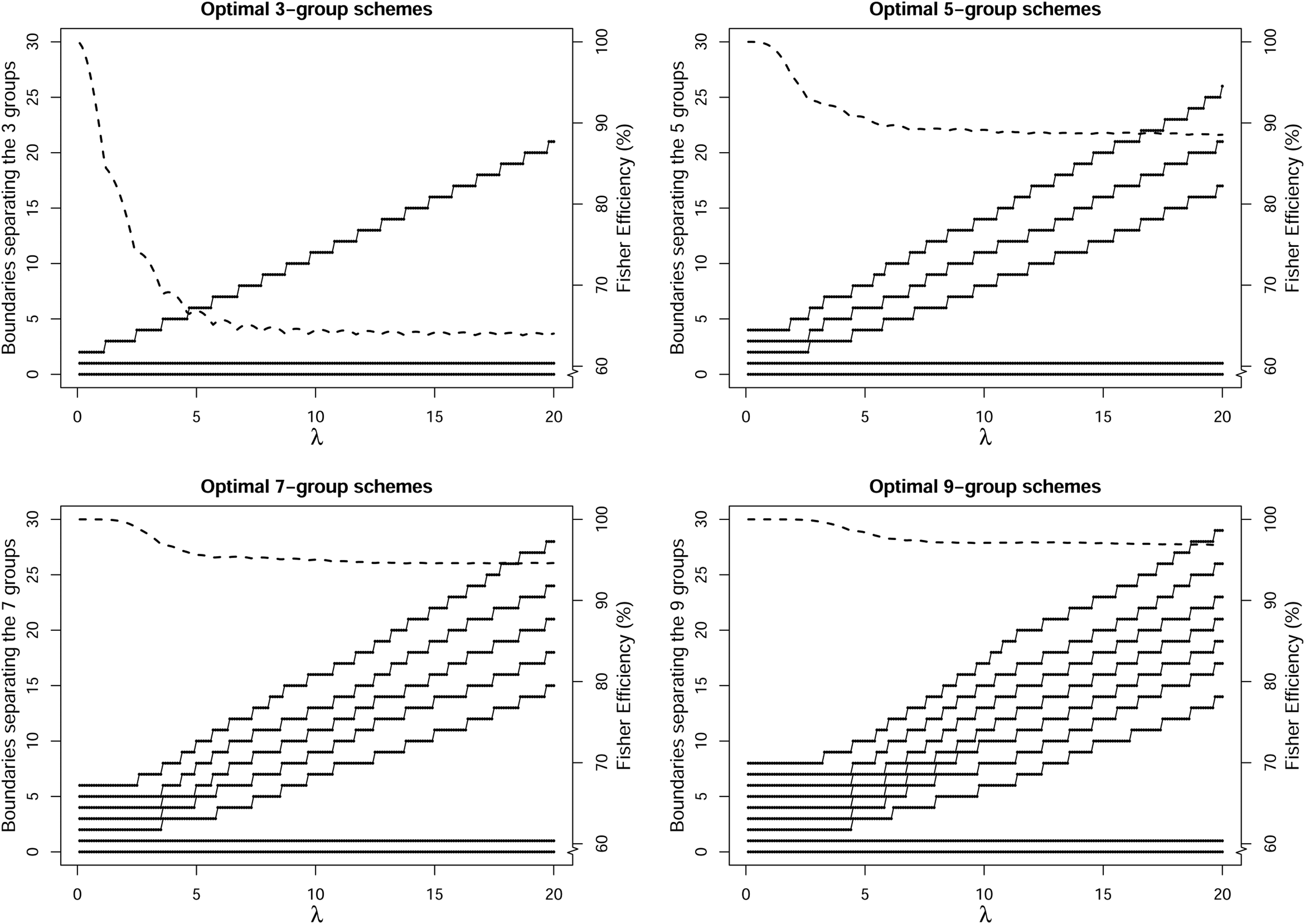
Based on different combinations of (200 values evenly spaced from to ) and (3, 5, 7, and 9), we apply the FIM to empty models (models without covariates), identify an optimal grouping scheme with respect to each combination, and plot the boundaries of these optimal grouping schemes in Figure 3. For a specific , the boundaries separating the groups of an optimal -group scheme are plotted in dots, and then linked by solid lines across different values of . With a specific combination of and , a point in the dashed line denotes the efficiency of a modified Poisson estimator with an optimal -group scheme relative to the conventional Poisson-regression estimator. The denominator of the relative efficiency is Fisher information of the conventional Poisson-regression estimator . Following a general practice in survey research (Coughlin 1990; Johnston et al. 2017; Kann et al. 2018), zero is designed to be contained in a separate group.
Boundaries of optimal grouping schemes (solid lines) and relative efficiencies of modified Poisson estimators (the axis of dashed lines starts from 60%) with combinations of (evenly spaced from to ) and (3, 5, 7, and 9).
Except for the first group (containing zeros), integers separating groups demonstrate an increase with a larger in all scenarios. When the total number of groups is small (), the relative efficiency decreases substantially (to around 60%) with a larger but the decrease levels off around . While a similar pattern holds for the other three scenarios (i.e., is 5, 7, and 9), it appears that such loss in the relative efficiency is greatly attenuated with a larger . As approaches 20, the relative efficiency is still around 95% and 97% with and , respectively. These results suggest that, with a reasonably large and the optimal design of survey counts, the performance of modified Poisson estimators with grouped and/or right-censored counts is comparable to that of the conventional Poisson-regression estimator.
The second simulation study uses generalized linear models with covariates to investigate the finite-sample performance of different types of regressor-specific design errors. Based on the logarithm link function , we have the Poisson parameter and set , , and . Besides the logarithm link function, the ZIP case also uses the logit link to consider the binomial parameter , where we set and . The initial values of all the parameters are set to zero for maximum likelihood estimation and design errors are calculated based on 1000 replications with different sample sizes (, , , and ).
For each parameter estimated with a specific sample size , their corresponding design errors , , and (see Section 2.2) are reported. Because and are obtained by substituting with its estimate , these two design errors are expected to be close to and , respectively, if the estimation is accurate. Likewise, by replacing with in (7), the grouping error is expected to converge to zero as . The value of associated with the universal maximizer , or , is also reported for readers’ reference. After 1000 replications, standard deviations of these estimated design errors are reported in parentheses. The grouping scheme of [never, 1–2 times, 3–5 times, 6–9 times, 10+ times] is used for all simulation scenarios.
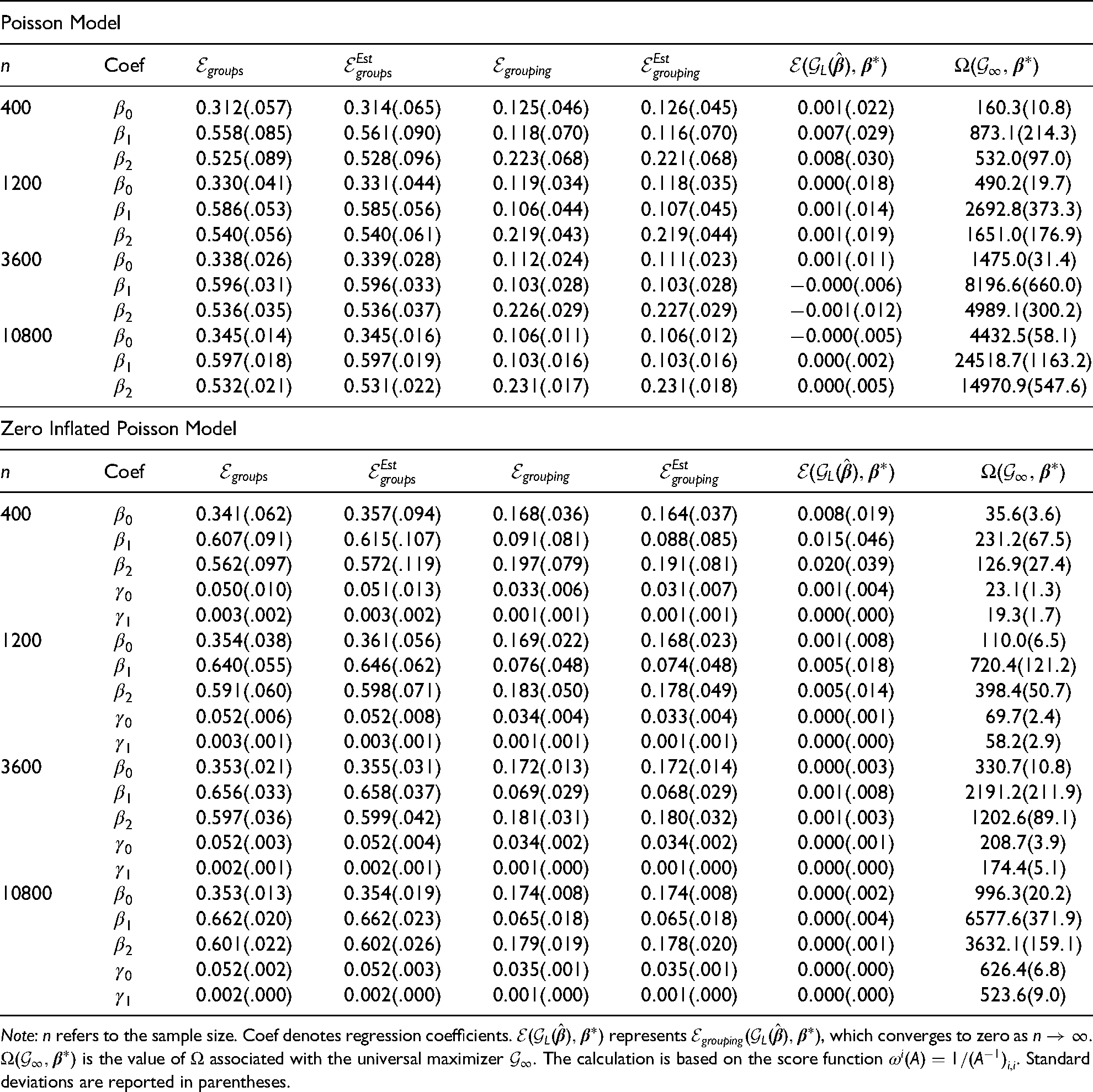
Results from Table 1 clearly suggest the validity of the FIM. When actual parameters are replaced by sample estimates for both Poisson and ZIP cases, both and are very close to their counterparts and , respectively, even when the sample size is relatively small (). When the sample size becomes moderate or large, sample estimates are almost identical to actual parameters and their differences become negligible. Grouping errors are small and converge to zero as . As expected, increases with sample size. Design errors associated with the binomial part of ZIP models appear to be trivial as compared with those of Poisson models: the choice of grouping schemes has little impact on the estimation of the binomial parameters as long as the zero count (i.e., never) is contained in a separate group. In Table 1, groups errors appear to be higher than grouping errors for both Poisson and ZIP cases, but this conclusion is specific to the choice of simulation parameters and may not hold in other simulation or empirical scenarios.
Modified Poisson and ZIP models with GRC counts: regressor-specific design errors based on 1000 replications.
Poisson Model
Coef
400
3600
10800
Zero Inflated Poisson Model
Coef
400
1200
3600
10800
Note: refers to the sample size. Coef denotes regression coefficients. represents , which converges to zero as . is the value of associated with the universal maximizer . The calculation is based on the score function . Standard deviations are reported in parentheses.
We next present results from an empirical example of adolescent alcohol abuse, which is an important determinant of adverse health and psychosocial outcomes, including unintentional injuries, suicide, mental disorders, domestic violence, traffic accidents, and impaired productivity (Courtney and Polich 2009; Stewart 1996). Alcohol abuse during adolescence can be especially hazardous given its long-term impacts on lifetime alcoholism, educational attainment, cognitive impairments, social isolation, and mental illness (Courtney and Polich 2009; Crum et al. 1998; Stewart 1996).
The dataset is from the Monitoring the Future project. As the largest repeated cross-sectional survey on adolescent risky behaviours (e.g., drug use and juvenile delinquency) in the United States, the Monitoring the Future project annually interviews students from hundreds of American middle and high schools (Johnston et al. 2017). Our empirical analysis was based on 12 graders (=2,748) included in the 2018 wave of the Monitoring the Future project. One’s frequency of alcohol abuse is measured by the same question [i.e., “on how many occasions (if any) have you been drunk or very high from drinking alcoholic beverages”] and the same 7-group GRC scheme as the response category: [0 occasions, 1–2 occasions, 3–5 occasions, 6–9 occasions, 10–19 occasions, 20–39 occasions, 40+ occasions]. Yet, three reference periods (during the last 30 days, during the last 12 months, and in one’s lifetime) are used to explore frequencies of adolescent alcohol abuse, and we separately analyzed outcome variables with different reference periods to assess the performance of the FIM.
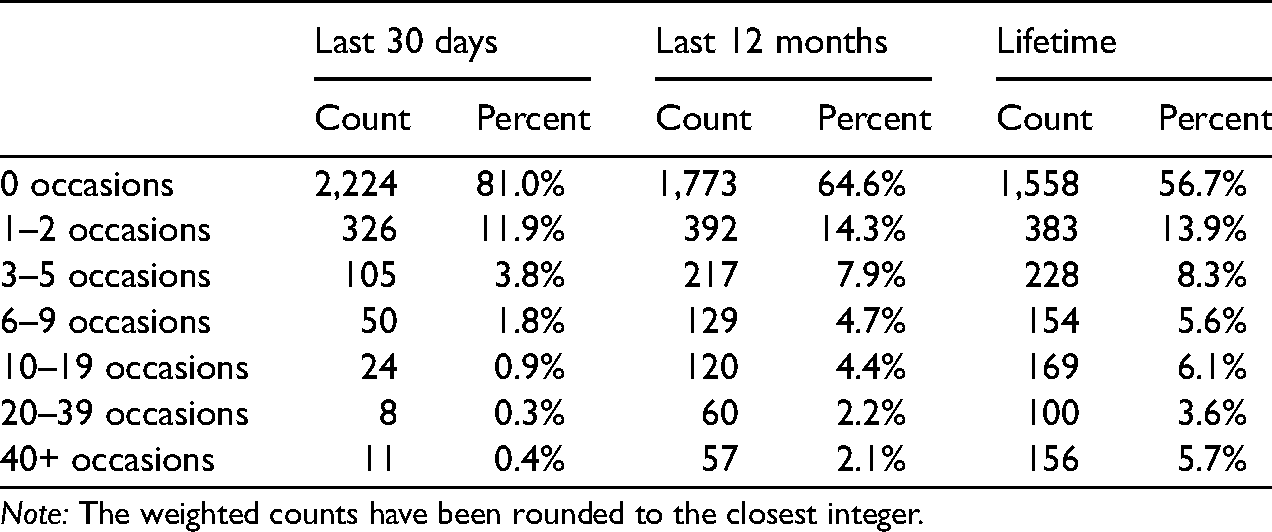
The descriptive statistics of outcome variables are shown in Table 2. As expected, respondents reported more occasions of alcohol abuse with longer reference periods. For those who were asked to report their lifetime frequencies of alcohol abuse, the specific 7-group scheme does not appear to be a preferred way to capture the full spectrum of counts because its 7 groups tend to concentrate on the lower end of the observed distribution (e.g., 0 occasions, 1–2 occasions, 3–5 occasions). Therefore, we may expect larger design errors when the frequencies of adolescent alcohol abuse have longer reference periods.
The weighted frequencies of being drunk or very high by different reference periods (N=2748).
Last 30 days
Last 12 months
Lifetime
Count
Percent
Count
Percent
Count
Percent
0 occasions
2,224
81.0%
1,773
64.6%
1,558
56.7%
1–2 occasions
326
11.9%
392
14.3%
383
13.9%
3–5 occasions
105
3.8%
217
7.9%
228
8.3%
6–9 occasions
50
1.8%
129
4.7%
154
5.6%
10–19 occasions
24
0.9%
120
4.4%
169
6.1%
20–39 occasions
8
0.3%
60
2.2%
100
3.6%
40+ occasions
11
0.4%
57
2.1%
156
5.7%
Note: The weighted counts have been rounded to the closest integer.
To compare regressor-specific design errors, we use the same set of eleven regressors (including the intercept) in both modified Poisson and ZIP models. The demographic background of respondents is indicated by female (versus male), Hispanic (versus non-Hispanic), and Black (versus non-Black). Mother’s education is an ordinal variable with the following values and categories: (1) completed grade school or less, (2) some high school, (3) completed high school, (4) some college, (5) completed college, (6) graduate or professional school after college. Here, we treat mother’s education as an ordinal variable for the sake of model parsimony (Adida et al. 2010; Martin and Shehan 1989). Mother’s full-time job is a dummy variable indicating whether a mother had full-time employment (coded as one), or part-time or no employment (coded as zero). Single-parent family means no or only one parent was present at home (coded as one) and the variable is coded as zero for intact families. GPA refers to a respondent’s grade point average in school. North-eastern, north-central, and western indicate if a school was located in the north-eastern, north-central, or western states, respectively (southern states as reference).
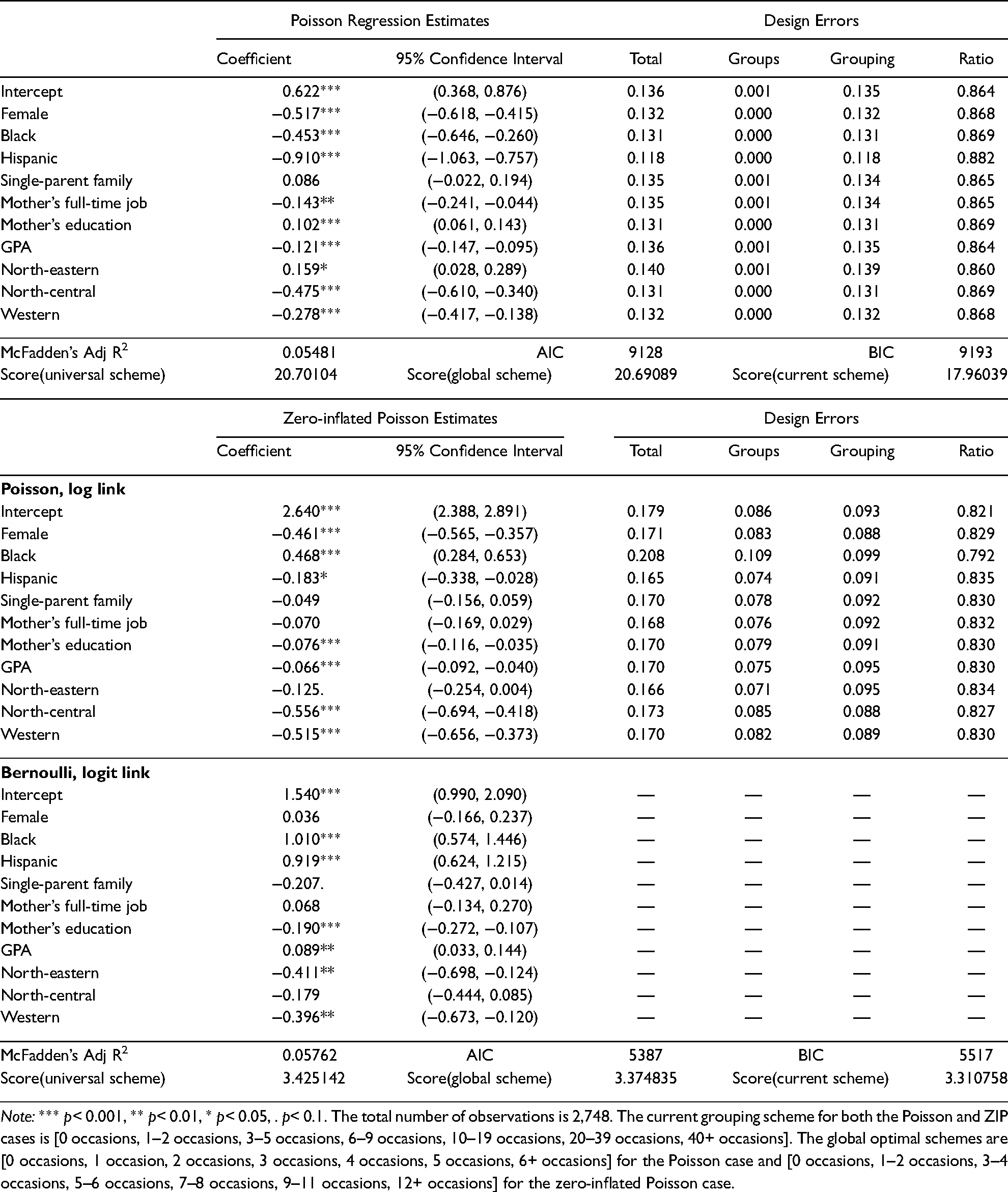
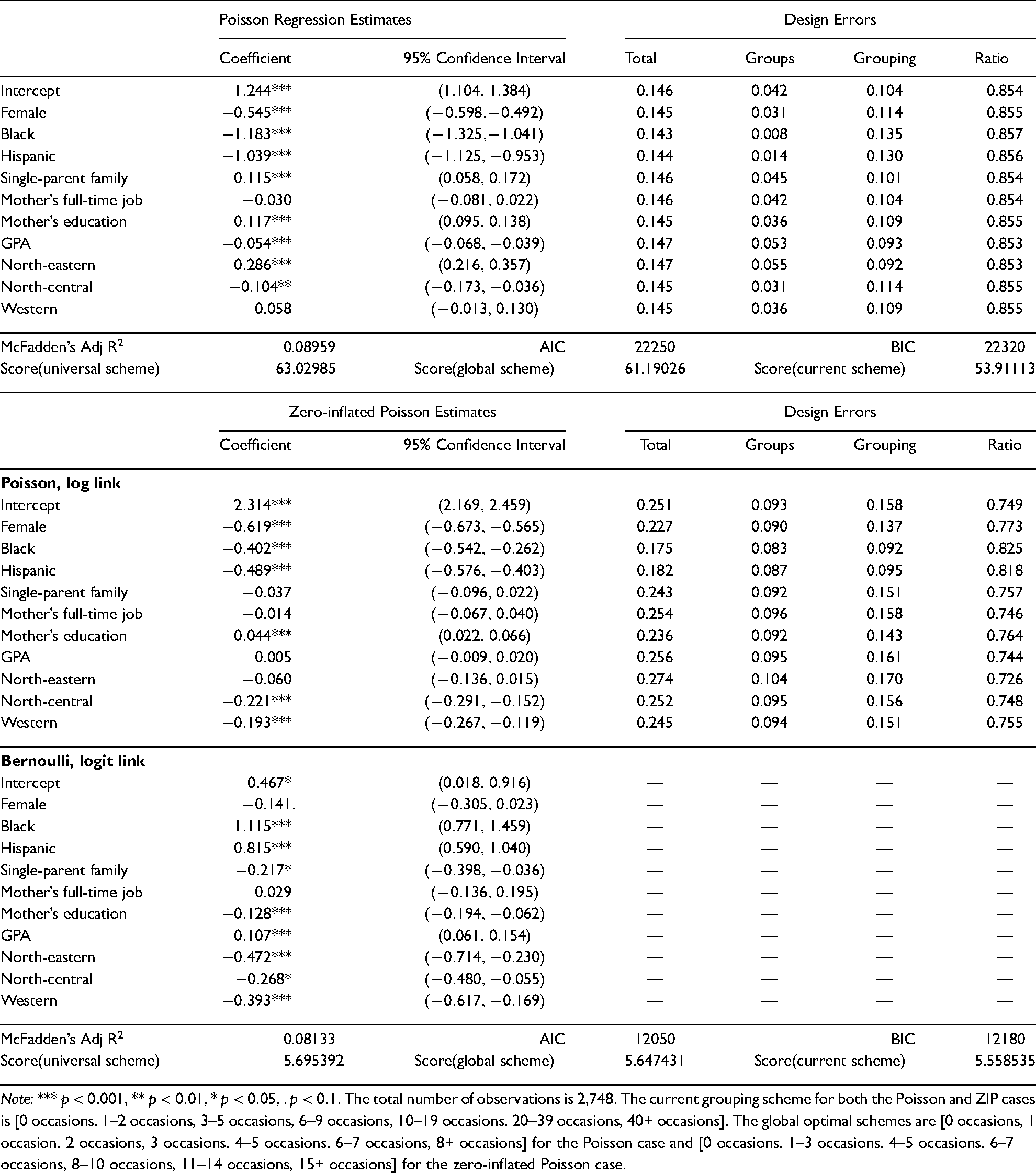
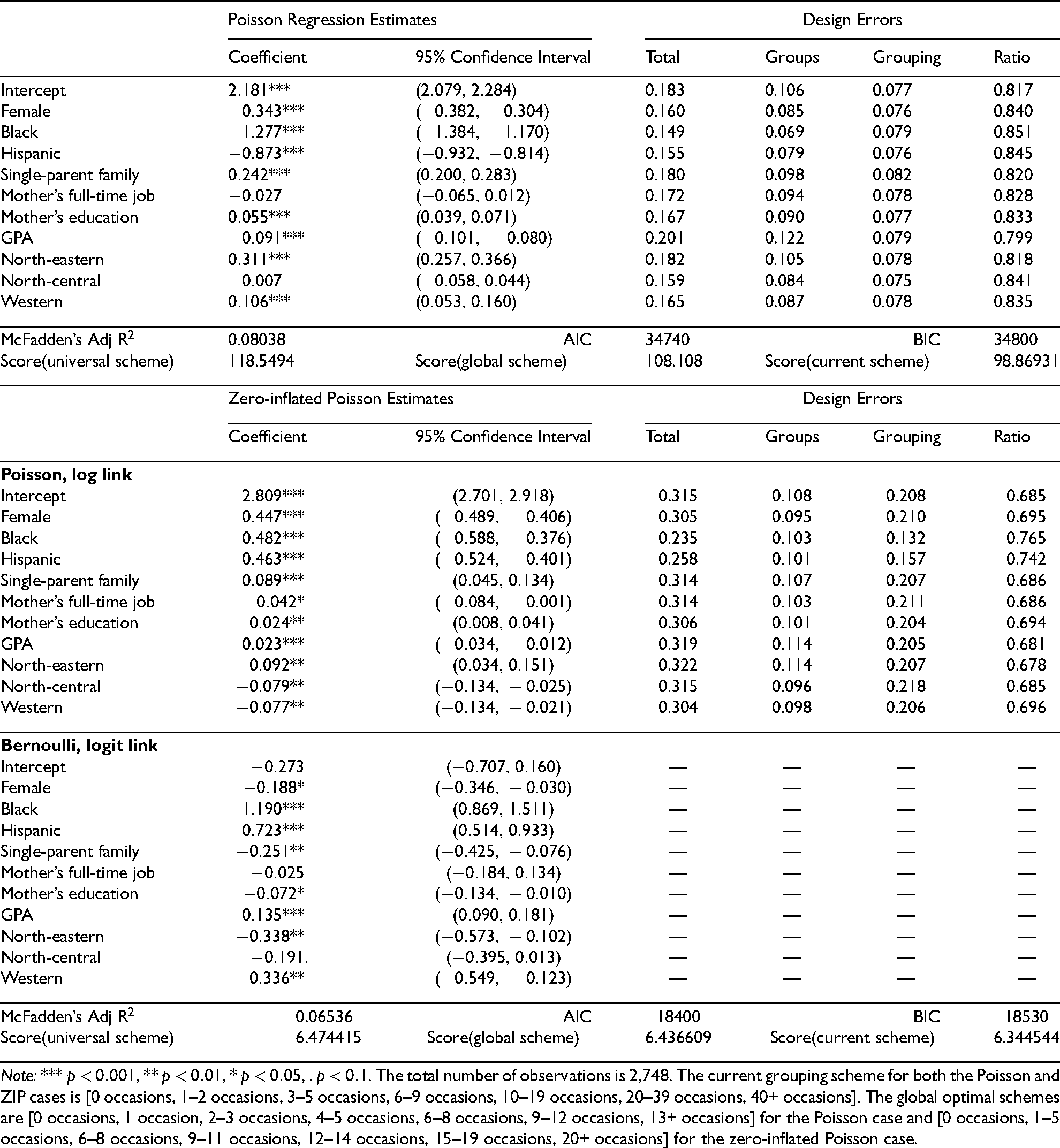
Regression estimates and regressor-specific design errors are presented in Table 3 (adolescent alcohol abuse over the last 30 days), Table 4 (adolescent alcohol abuse over the last 12 months), and Table 5 (adolescent alcohol abuse in one’s lifetime). There are several notable findings pertaining to regressor-specific design errors. First, as expected, the total design error associated with the same regressor increases when the outcome variable has a longer reference period. For example, the total design errors associated with the regressor female are 0.132, 0.145, and 0.160, when the reference periods are over the last 30 days, over the last 12 months, and in one’s lifetime, respectively. Second, based on regression estimates from generalized linear models, the FIM identifies a global 7-group optimal scheme that maximizes (a score function of) the Fisher information matrix. This global optimal grouping scheme (reported in the note below each corresponding table) allows us to decompose the total design error into the groups and grouping errors, and further assess their changes with different empirical distributions. When 7 groups are adequate to measure alcohol abuse with a shorter reference period (i.e., over the last 30 days), the groups error is negligible and the total design error is mainly attributable to the grouping error. The optimality of GRC counts can be largely achieved by replacing the current grouping scheme with a global optimal scheme, which substantially reduces, if not eliminates, the grouping error. With a longer reference period, any 7-group scheme may not provide a precise measure of observed counts despite an optimization of grouping schemes. As a result, the groups error of the same regressor increases and becomes a major source of the total error. For example, the groups error associated with GPA increases from 0.001 in Table 3 (reference period: over the last 30 days) to 0.053 in Table 4 (reference period: over the last 12 months) to 0.122 in Table 5 (reference period: in one’s life time), which contribute to 0.7%, 36.1%, and 60.7% of their corresponding total errors. Third, we calculate the (regressor-specific) ratio of to to assess the relative efficiency between the use of GRC counts and exact enumeration of counts. As suggested by these ratios in the last column of each table, the values of score functions estimated with the current 7-group GRC grouping scheme are comparable to those obtained from conventional Poisson-regression settings (all are at or above 0.8), which lend further support to the validity of the FIM and the use of GRC counts in survey research. In accordance with our discussion above, the relative efficiency associated with the same regressor tends to decrease with a longer reference period.
Regression estimates and design errors: alcohol abuse during last 30 days.
Poisson Regression Estimates
Design Errors
Coefficient
95% Confidence Interval
Total
Groups
Grouping
Ratio
Intercept
0.622***
(0.368, 0.876)
0.136
0.001
0.135
0.864
Female
−0.517***
(−0.618, −0.415)
0.132
0.000
0.132
0.868
Black
−0.453***
(−0.646, −0.260)
0.131
0.000
0.131
0.869
Hispanic
−0.910***
(−1.063, −0.757)
0.118
0.000
0.118
0.882
Single-parent family
0.086
(−0.022, 0.194)
0.135
0.001
0.134
0.865
Mother’s full-time job
−0.143**
(−0.241, −0.044)
0.135
0.001
0.134
0.865
Mother’s education
0.102***
(0.061, 0.143)
0.131
0.000
0.131
0.869
GPA
−0.121***
(−0.147, −0.095)
0.136
0.001
0.135
0.864
North-eastern
0.159*
(0.028, 0.289)
0.140
0.001
0.139
0.860
North-central
−0.475***
(−0.610, −0.340)
0.131
0.000
0.131
0.869
Western
−0.278***
(−0.417, −0.138)
0.132
0.000
0.132
0.868
McFadden’s Adj R2
0.05481
AIC
9128
BIC
9193
Score(universal scheme)
20.70104
Score(global scheme)
20.69089
Score(current scheme)
17.96039
Zero-inflated Poisson Estimates
Design Errors
Coefficient
95% Confidence Interval
Total
Groups
Grouping
Ratio
Poisson, log link
Intercept
2.640***
(2.388, 2.891)
0.179
0.086
0.093
0.821
Female
−0.461***
(−0.565, −0.357)
0.171
0.083
0.088
0.829
Black
0.468***
(0.284, 0.653)
0.208
0.109
0.099
0.792
Hispanic
−0.183*
(−0.338, −0.028)
0.165
0.074
0.091
0.835
Single-parent family
−0.049
(−0.156, 0.059)
0.170
0.078
0.092
0.830
Mother’s full-time job
−0.070
(−0.169, 0.029)
0.168
0.076
0.092
0.832
Mother’s education
−0.076***
(−0.116, −0.035)
0.170
0.079
0.091
0.830
GPA
−0.066***
(−0.092, −0.040)
0.170
0.075
0.095
0.830
North-eastern
−0.125.
(−0.254, 0.004)
0.166
0.071
0.095
0.834
North-central
−0.556***
(−0.694, −0.418)
0.173
0.085
0.088
0.827
Western
−0.515***
(−0.656, −0.373)
0.170
0.082
0.089
0.830
Bernoulli, logit link
Intercept
1.540***
(0.990, 2.090)
—
—
—
—
Female
0.036
(−0.166, 0.237)
—
—
—
—
Black
1.010***
(0.574, 1.446)
—
—
—
—
Hispanic
0.919***
(0.624, 1.215)
—
—
—
—
Single-parent family
−0.207.
(−0.427, 0.014)
—
—
—
—
Mother’s full-time job
0.068
(−0.134, 0.270)
—
—
—
—
Mother’s education
−0.190***
(−0.272, −0.107)
—
—
—
—
GPA
0.089**
(0.033, 0.144)
—
—
—
—
North-eastern
−0.411**
(−0.698, −0.124)
—
—
—
—
North-central
−0.179
(−0.444, 0.085)
—
—
—
—
Western
−0.396**
(−0.673, −0.120)
—
—
—
—
McFadden’s Adj R2
0.05762
AIC
5387
BIC
5517
Score(universal scheme)
3.425142
Score(global scheme)
3.374835
Score(current scheme)
3.310758
Note: *** p< 0.001, ** p< 0.01, * p< 0.05, . p< 0.1. The total number of observations is 2,748. The current grouping scheme for both the Poisson and ZIP cases is [0 occasions, 1–2 occasions, 3–5 occasions, 6–9 occasions, 10–19 occasions, 20–39 occasions, 40+ occasions]. The global optimal schemes are [0 occasions, 1 occasion, 2 occasions, 3 occasions, 4 occasions, 5 occasions, 6+ occasions] for the Poisson case and [0 occasions, 1–2 occasions, 3–4 occasions, 5–6 occasions, 7–8 occasions, 9–11 occasions, 12+ occasions] for the zero-inflated Poisson case.
Regression estimates and design errors: alcohol abuse during last 12 months.
Poisson Regression Estimates
Design Errors
Coefficient
95% Confidence Interval
Total
Groups
Grouping
Ratio
Intercept
***
0.146
0.042
0.104
0.854
Female
***
0.145
0.031
0.114
0.855
Black
***
0.143
0.008
0.135
0.857
Hispanic
***
0.144
0.014
0.130
0.856
Single-parent family
***
0.146
0.045
0.101
0.854
Mother’s full-time job
0.146
0.042
0.104
0.854
Mother’s education
***
0.145
0.036
0.109
0.855
GPA
***
0.147
0.053
0.093
0.853
North-eastern
***
0.147
0.055
0.092
0.853
North-central
**
0.145
0.031
0.114
0.855
Western
0.145
0.036
0.109
0.855
McFadden’s Adj R
0.08959
AIC
22250
BIC
22320
Score(universal scheme)
63.02985
Score(global scheme)
61.19026
Score(current scheme)
53.91113
Zero-inflated Poisson Estimates
Design Errors
Coefficient
95% Confidence Interval
Total
Groups
Grouping
Ratio
Poisson, log link
Intercept
***
0.251
0.093
0.158
0.749
Female
***
0.227
0.090
0.137
0.773
Black
***
0.175
0.083
0.092
0.825
Hispanic
***
0.182
0.087
0.095
0.818
Single-parent family
0.243
0.092
0.151
0.757
Mother’s full-time job
0.254
0.096
0.158
0.746
Mother’s education
***
0.236
0.092
0.143
0.764
GPA
0.256
0.095
0.161
0.744
North-eastern
0.274
0.104
0.170
0.726
North-central
***
0.252
0.095
0.156
0.748
Western
***
0.245
0.094
0.151
0.755
Bernoulli, logit link
Intercept
*
—
—
—
—
Female
.
—
—
—
—
Black
***
—
—
—
—
Hispanic
***
—
—
—
—
Single-parent family
*
—
—
—
—
Mother’s full-time job
—
—
—
—
Mother’s education
***
—
—
—
—
GPA
***
—
—
—
—
North-eastern
***
—
—
—
—
North-central
*
—
—
—
—
Western
***
—
—
—
—
McFadden’s Adj R
0.08133
AIC
12050
BIC
12180
Score(universal scheme)
5.695392
Score(global scheme)
5.647431
Score(current scheme)
5.558535
Note: *** , ** , * , . . The total number of observations is 2,748. The current grouping scheme for both the Poisson and ZIP cases is [0 occasions, 1–2 occasions, 3–5 occasions, 6–9 occasions, 10–19 occasions, 20–39 occasions, 40+ occasions]. The global optimal schemes are [0 occasions, 1 occasion, 2 occasions, 3 occasions, 4–5 occasions, 6–7 occasions, 8+ occasions] for the Poisson case and [0 occasions, 1–3 occasions, 4–5 occasions, 6–7 occasions, 8–10 occasions, 11–14 occasions, 15+ occasions] for the zero-inflated Poisson case.
Regression estimates and design errors: alcohol abuse in one’s lifetime.
Poisson Regression Estimates
Design Errors
Coefficient
95% Confidence Interval
Total
Groups
Grouping
Ratio
Intercept
***
0.183
0.106
0.077
0.817
Female
***
0.160
0.085
0.076
0.840
Black
***
0.149
0.069
0.079
0.851
Hispanic
***
0.155
0.079
0.076
0.845
Single-parent family
***
0.180
0.098
0.082
0.820
Mother’s full-time job
0.172
0.094
0.078
0.828
Mother’s education
***
0.167
0.090
0.077
0.833
GPA
***
0.201
0.122
0.079
0.799
North-eastern
***
0.182
0.105
0.078
0.818
North-central
0.159
0.084
0.075
0.841
Western
***
0.165
0.087
0.078
0.835
McFadden’s Adj R
0.08038
AIC
34740
BIC
34800
Score(universal scheme)
118.5494
Score(global scheme)
108.108
Score(current scheme)
98.86931
Zero-inflated Poisson Estimates
Design Errors
Coefficient
95% Confidence Interval
Total
Groups
Grouping
Ratio
Poisson, log link
Intercept
***
0.315
0.108
0.208
0.685
Female
***
0.305
0.095
0.210
0.695
Black
***
0.235
0.103
0.132
0.765
Hispanic
***
0.258
0.101
0.157
0.742
Single-parent family
***
0.314
0.107
0.207
0.686
Mother’s full-time job
*
0.314
0.103
0.211
0.686
Mother’s education
**
0.306
0.101
0.204
0.694
GPA
***
0.319
0.114
0.205
0.681
North-eastern
**
0.322
0.114
0.207
0.678
North-central
**
0.315
0.096
0.218
0.685
Western
**
0.304
0.098
0.206
0.696
Bernoulli, logit link
Intercept
—
—
—
—
Female
*
—
—
—
—
Black
***
—
—
—
—
Hispanic
***
—
—
—
—
Single-parent family
**
—
—
—
—
Mother’s full-time job
—
—
—
—
Mother’s education
*
—
—
—
—
GPA
***
—
—
—
—
North-eastern
**
—
—
—
—
North-central
.
—
—
—
—
Western
**
—
—
—
—
McFadden’s Adj R
0.06536
AIC
18400
BIC
18530
Score(universal scheme)
6.474415
Score(global scheme)
6.436609
Score(current scheme)
6.344544
Note: *** , ** , * , . . The total number of observations is 2,748. The current grouping scheme for both the Poisson and ZIP cases is [0 occasions, 1–2 occasions, 3–5 occasions, 6–9 occasions, 10–19 occasions, 20–39 occasions, 40+ occasions]. The global optimal schemes are [0 occasions, 1 occasion, 2–3 occasions, 4–5 occasions, 6–8 occasions, 9–12 occasions, 13+ occasions] for the Poisson case and [0 occasions, 1–5 occasions, 6–8 occasions, 9–11 occasions, 12–14 occasions, 15–19 occasions, 20+ occasions] for the zero-inflated Poisson case.
As noted in our discussion of Table 1, design errors associated with the binomial part of a modified ZIP model are trivial so we focus on design errors associated with the Poisson part. Given that only a proportion of respondents are exposed to the risk of alcohol abuse under a ZIP model, its estimated average frequency is expected to be higher than that estimated from a Poisson regression model. Consequently, with a larger estimated from the modified ZIP model, the 7-group GRC scheme does not provide an adequate measure of observed counts. For the same regressor, we observe larger design errors and lower relative efficiencies (as indicated by ratios of to ) in the Poisson part of a modified ZIP model than their counterparts in a modified Poisson regression model. These regressor-specific design errors also allow us to compute effective sample sizes associated with different variables in this empirical setting. For example, the calculated groups and grouping errors associated with the intercept of the Poisson part in Table 4 are 0.042 and 0.104, respectively. According to (11), we have as 0.891. In other words, if the optimum design of survey counts were considered by survey investigators, it can save about 11% of the sample size to reach the same efficiency for the estimation of the intercept.
According to regression estimates, females, Hispanics, and students with higher GPAs reported lower frequencies of alcohol abuse than their counterparts did. Adolescents from single-parent families or north-eastern states (versus those in southern states) had higher frequencies of alcohol abuse. Yet, the impacts of race and mother’s socioeconomic status on adolescent alcohol abuse are mixed. Results from the binomial part of the modified ZIP models suggest that African Americans, Hispanics, students with better school performance, and students from intact families have significantly less exposure to alcohol abuse. As expected, measures of goodness of fit, such as Akaike information criterion (AIC) and Bayesian information criterion (BIC), favor a modified ZIP model over a corresponding modified Poisson model.
Discussion
Counts are often grouped and/or right-censored in survey instruments to study a wide range of behavioural, attitudinal, and event frequencies, especially when concerning sensitive research topics, vulnerable populations, or respondents with less cognitive capacities. Yet, grouping and right-censoring also pose major difficulties in survey methodology and statistical analysis. The optimum design of survey counts and its impacts on statistical analysis have not been systematically investigated by researchers. Despite the recent advances in designing and modeling GRC counts, existing studies fail to address the intrinsic link between the design and analysis of survey counts in a regression setting. As a result, after survey investigators decide to choose GRC response categories, their grouping and right-censoring decisions are often subjective due to the absence of a yardstick against which the performance of a GRC grouping scheme in statistical analysis can be assessed.
To develop a unified framework for assessing and analyzing GRC counts in a regression setting, we begin with modified Poisson models to conceptualize GRC counts and then describe in detail the definition, decomposition, and optimization of their regressor-specific design errors. We further demonstrate how the optimum design of survey counts can be informed by generalized linear models. In particular, we develop a novel search algorithm, the FIM, to process infinitely many grouping schemes and identify a global optimal grouping scheme maximizing the Fisher information matrices of the modified Poisson estimates. By doing so, the global optimal grouping scheme reduces the grouping error to zero. The unified framework makes the calculation of regressor-specific design errors possible, which clearly provides a powerful tool for assessing the performance of a specific GRC grouping scheme in empirical research. The validity of this unified framework is corroborated by results from both simulation and empirical studies. This study suggests that, with the optimum design of survey counts, the performance of modified Poisson estimators based on GRC counts is comparable to that of conventional Poisson estimators based on the exact enumeration of counts. The optimum design is able to achieve the same estimation efficiency with a smaller sample size.
Survey design is an iterative and interactive multi-purpose optimization process (Biemer 2010; Groves et al. 2009; Schaeffer and Dykema 2011). The minimization of design errors is not the sole principle for designing response categories; rather, survey investigators need to consider various factors such as the consistency of response categories over years, the comparability of survey estimates across studies and survey questions, and answering strategies adopted by respondents (Gehlbach and Barge 2012; Schaeffer and Dykema 2020, 2011). Since design errors are an essential component of this multi-purpose optimization process, it is not the presence of design errors but the absence of a tool for assessing design errors that scholars should be concerned about and continue to work on. Without such a tool, it is difficult if not impossible for survey investigators to tell how good (or bad) their design is, adjust their survey design, or allocate resources or budgets to where they are most needed (Biemer 2010). This study not only provides a powerful tool for assessing the design errors of survey counts, but also offers an integrated perspective from which to unify survey design and statistical analysis before, during, and after data collection.
Footnotes
Acknowledgements
Qiang Fu gratefully acknowledges the financial support from an Insight Grant from the Social Sciences and Humanities Research Council of Canada (435-2021-0720). Part of the present work was done when Xin Guo worked at The Hong Kong Polytechnic University, supported by the Research Grants Council of Hong Kong [Project No. PolyU 15334616]. We are indebted to Professor Kenneth C. Land for enlightening discussions and generous support during our study at Duke University.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Authors’ Note
The 2018 wave of the Monitoring the Future data is available from the National Addiction & HIV Data Archive Program (). Our software package GRCdata for designing and optimizing survey counts is available at the Comprehensive R Archive Network (CRAN).
ORCID iDs
Xin Guo
Qiang Fu
Notes
Author Biographies
Xin Guo is a Senior Lecturer in Mathematical Data Science at School of Mathematics and Physics, The University of Queensland. His research interests include statistical learning theory (kernel methods, support vector machine, error analysis, deep learning, and the implementation of algorithms), and computational social science.
Qiang Fu is an Associate Professor of Sociology at The University of British Columbia. His research focuses on computational sociology, social capital, health, place making, demography, and Chinese societies. Some of his recent publications are: “Sleeping Lion or Sick Man? Machine Learning Approaches to Deciphering Heterogeneous Images of Chinese in North America” (Annals of the American Association of Geographers, in press), “Modified Poisson Regression Analysis of Grouped and Right-censored Counts” (J. of the Royal Statistical Society: Series A, 2021), “Mega Neighborhoods, Depression, and Actually Existing Urban Governance” (Cities, 2022), “Choosing among Eight Topic-Modeling Methods” (Big Data Research, 2021), “Adolescent Marijuana Use in the United States and Structural Breaks” (American J. of Epidemiology, 2021), and “A Manifesto for Computational Sociology: The Canadian Perspective” (The Canadian Review of Sociology, 2022).
References
1.
AckardD. M.CrollJ. K.Kearney-CookeA. 2002. “Dieting Frequency Among College Females: Association with Disordered Eating, Body Image, and Related Psychological Problems.” Journal of Psychosomatic Research52(3): 129-36.
2.
AdidaC. L.LaitinD. D.ValfortM. -A.2010. “Identifying Barriers to Muslim Integration in France.” Proceedings of the National Academy of Sciences107(52): 22384-90.
3.
Agresti, A. 2003. Categorical Data Analysis. (Vol. 482). Hoboken: John Wiley & Sons.
4.
AkersR. L.La GrecaA. J.CochranJ.SellersC. 1989. “Social Learning Theory and Alcohol Behavior Among the Elderly.” Sociological Quarterly30(4): 625-38.
5.
AtkinsonA.DonevA.TobiasR. 2007. Optimum Experimental Designs, with SAS. Oxford, UK: Oxford University Press.
6.
BachmanJ. G.JohnstonL. D.O’MalleyP. M. 1990. “Explaining the Recent Decline in Cocaine Use Among Young Adults: Further Evidence that Perceived Risks and Disapproval Lead to Reduced Drug Use.” Journal of Health and Social Behavior31(2): 173-84.
7.
BahrS. J.HoffmannJ. P. 2008. “Religiosity, Peers, and Adolescent Drug Use.” Journal of Drug Issues38(3): 743-69.
8.
BaiJ.PerronP. 2003. “Computation and Analysis of Multiple Structural Change Models.” Journal of Applied Econometrics18(1): 1-22.
9.
BaidenP.GraafG.ZaamiM.AcolatseC. K.AdekuY. 2019. “Examining the Association Between Prescription Opioid Misuse and Suicidal Behaviors Among Adolescent High School Students in the United States.” Journal of Psychiatric Research112 : 44-51.
10.
BiemerP. P. 2010. “Total Survey Error: Design, Implementation, and Evaluation.” Public Opinion Quarterly74(5): 817-48.
11.
ConnorJ.PsutkaR.CousinsK.GrayA.KypriK. 2013. “Risky Drinking, Risky Sex: A National Study of New Zealand University Students.” Alcoholism: Clinical and Experimental Research37(11): 1971-8.
12.
ConradF. G.BrownN. R.CashmanE. R. 1998. “Strategies for Estimating Behavioural Frequency in Survey Interviews.” Memory (Hove, England)6(4): 339-66.
13.
ConwayK. P.VulloG. C.NichterB.WangJ.ComptonW. M.IannottiR. J. 2013. “Prevalence and Patterns of Polysubstance Use in a Nationally Representative Sample of 10th Graders in the United States.” Journal of Adolescent Health52(6): 716-23.
14.
CoughlinS. S. 1990. “Recall Bias in Epidemiologic Studies.” Journal of Clinical Epidemiology43(1): 87-91.
15.
CourtneyK. E.PolichJ. 2009. “Binge Drinking in Young Adults: Data, Definitions, and Determinants.” Psychological Bulletin135(1): 142.
16.
CrumR. M.EnsmingerM. E.RoM. J.McCordJ. 1998. “The Association of Educational Achievement and School Dropout with Risk of Alcoholism: a Twenty-five-year Prospective Study of Inner-city Children.” Journal of Studies on Alcohol59(3): 318-26.
17.
DavillasA.PudneyS. 2020. “Using Biomarkers to Predict Healthcare Costs: Evidence From a UK Household Panel.” Journal of Health Economics73: 102356.
18.
FahrmeirL.KaufmannH. 1985. “Consistency and Asymptotic Normality of the Maximum Likelihood Estimator in Generalized Linear Models.” Annals of Statistics13(1): 342-68.
19.
FuQ.GuoX.LandK. C. 2018. “A Poisson-multinomial Mixture Approach to Grouped and Right-censored Counts.” Communications in Statistics-Theory and Methods47(2): 427-47.
20.
FuQ.GuoX.LandK. C. 2020. “Optimizing Count Responses in Surveys: a Machine-learning Approach.” Sociological Methods & Research49(3): 637-71.
21.
FuQ.LandK. C.LambV. L. 2013, Mar 01. “Bullying Victimization, Socioeconomic Status and Behavioral Characteristics of 12th Graders in the United States, 1989 to 2009: Repetitive Trends and Persistent Risk Differentials.” Child Indicators Research6(1): 1-21.
22.
FuQ.ZhouT.-Y.GuoX. 2021. “Modified Poisson Regression Analysis of Grouped and Right-censored Counts.” Journal of the Royal Statistical Society: Series A (Statistics in Society)184(4): 1347-67.
23.
GehlbachH.BargeS. 2012. “Anchoring and Adjusting in Questionnaire Responses.” Basic and Applied Social Psychology34(5): 417-33.
24.
GoosP.JonesB.SyafitriU. 2016. “I-optimal Design of Mixture Experiments.” Journal of the American Statistical Association111(514): 899-911.
25.
GrovesR. M.FowlerF. J. J.CouperM. P.LepkowskiJ. M.SingerE.TourangeauR. 2009. Survey Methodology. Hoboken, NJ: John Wiley & Sons.
26.
GuoX.FuQ.WangY.LandK. C. 2020. “A Numerical Method to Compute Fisher Information for a Special Case of Heterogeneous Negative Binomial Regression.” Communications on Pure and Applied Analysis.19(8): 4179-89.
27.
HaganJ.SheddC.PayneM. R. 2005. “Race, Ethnicity, and Youth Perceptions of Criminal Injustice.” American Sociological Review70(3): 381-407.
28.
HallD. B. 2000. “Zero-inflated Poisson and Binomial Regression with Random Effects: a Case Study.” Biometrics56(4): 1030-9.
29.
HilbeJ. M. 2011. Negative Binomial Regression. Cambridge: Cambridge University Press.
30.
JohnU.HankeM.MeyerC.VölzkeH.BaumeisterS. E.AlteD. 2006. “Tobacco Smoking in Relation to Pain in a National General Population Survey.” Preventive Medicine43(6): 477-81.
31.
JohnstonL. D.O’MalleyP. M.MiechR. A.BachmanJ. G.SchulenbergJ. E. 2017. Monitoring the Future national survey results on drug use, 1975–2016: overview, key findings on adolescent drug use. https://files.eric.ed.gov/fulltext/ED578534.pdf. (accessed July 17, 2019).
32.
JunM.AgleyJ.HuangC.GassmanR. A. 2016. “College Binge Drinking and Social Norms: Advancing Understanding Through Statistical Applications.” Journal of Child & Adolescent Substance Abuse25(2): 113-23.
33.
KannL.McManusT.HarrisW. A.ShanklinS. L.FlintK. H.QueenB.EthierK. A.2018, Jun 15. Youth risk behavior surveillance - United States, 2017. Morbidity and mortality weekly report. Surveillance summaries (Washington, D.C.: 2002), 67(8), 1–114. (29902162[pmid]).
34.
KumarR.O’MalleyP. M.JohnstonL. D. 2008. “Association Between Physical Environment of Secondary Schools and Student Problem Behavior: A National Study, 2000-2003.” Environment and Behavior40(4): 455-86.
35.
LambertD. 1992. “Zero-inflated Poisson Regression, with An Application to Defects in Manufacturing.” Technometrics34(1): 1-14.
36.
LandK. C.McCallP. L.NaginD. S. 1996. “A Comparison of Poisson, Negative Binomial, and Semiparametric Mixed Poisson Regression Models: with Empirical Applications to Criminal Careers Data.” Sociological Methods & Research24(4): 387-442.
37.
LawlessJ. F. 1987. “Regression Methods for Poisson Process Data.” Journal of the American Statistical Association82(399): 808-15.
38.
LuczakS. E.SheaS. H.CarrL. G.LiT. -K.WallT. L. 2002. “Binge Drinking in Jewish and Non-Jewish White College Students.” Alcoholism: Clinical and Experimental Research26(12): 1773-8.
39.
MarsdenP. V. 2003. “Interviewer Effects in Measuring Network Size Using a Single Name Generator.” Social Networks25(1): 1-16.
40.
MartinJ. K.ShehanC. L. 1989. “Education and Job Satisfaction: The Influences of Gender, Wage-earning Status, and Job Values.” Work and Occupations16(2): 184-99.
41.
RhodesP. H.HalloranM. E.Longini JrI. M. 1996. “Counting Process Models for Infectious Disease Data: Distinguishing Exposure to Infection From Susceptibility.” Journal of the Royal Statistical Society: Series B (Methodological)58(4): 751-62.
42.
SchaefferN. C.DykemaJ. 2011. “Questions for Surveys: Current Trends and Future Directions.” Public Opinion Quarterly75(5): 909-61.
43.
SchaefferN. C.DykemaJ. 2020. “Advances in the Science of Asking Questions.” Annual Review of Sociology46(0): 37-60.
44.
SchwarzN.HipplerH.-J.DeutschB.StrackF. 1985. “Response Scales: Effects of Category Range on Reported Behavior and Comparative Judgments.” Public Opinion Quarterly49(3): 388-95.
45.
SerflingR. J. 1980. Approximation Theorems of Mathematical Statistics. New York, USA: John Wiley & Sons, Inc. (Wiley Series in Probability and Mathematical Statistics).
46.
StewartS. H. 1996. “Alcohol Abuse in Individuals Exposed to Trauma: a Critical Review.” Psychological Bulletin120(1): 83.
47.
ToepoelV.VisC.DasM.Van SoestA. 2009. “Design of Web Questionnaires: An Information-processing Perspective for the Effect of Response Categories.” Sociological Methods & Research37(3): 371-92.
48.
TuckerJ. S.PollardM. S.Green JrH. D. 2021. “Associations of Social Capital with Binge Drinking in a National Sample of Adults: The Importance of Neighborhoods and Networks.” Health & Place69: 102545.
49.
WangC. 2022. “Modified Poisson Estimators for Grouped and Right-censored Counts.” Communications in Statistics-Theory and Methods51: 1-17.
50.
WillisG. B. 2004. Cognitive Interviewing: A Tool for Improving Questionnaire Design. Thousand Oaks, USA: Sage publications.