
Abstract
Our original 2021 SMR article “Non-Invariance? An Overstated Problem with Misconceived Causes” disputes the conclusiveness of non-invariance diagnostics in diverse cross-cultural settings. Our critique targets the increasingly fashionable use of Multi-Group Confirmatory Factor Analysis (MGCFA), especially in its mainstream version. We document—both by mathematical proof and an empirical illustration—that non-invariance is an arithmetic artifact of group mean disparity on closed-ended scales. Precisely this arti-factualness renders standard non-invariance markers inconclusive of measurement inequivalence under group-mean diversity. Using the Emancipative Values Index (EVI), OA-Section 3 of our original article demonstrates that such artifactual non-invariance is inconsequential for multi-item constructs’ cross-cultural performance in nomological terms, that is, explanatory power and predictive quality. Given these limitations of standard non-invariance diagnostics, we challenge the unquestioned authority of invariance tests as a tool of measurement validation. Our critique provoked two teams of authors to launch counter-critiques. We are grateful to the two comments because they give us a welcome opportunity to restate our position in greater clarity. Before addressing the comments one by one, we reformulate our key propositions more succinctly.
Keywords
Introduction
Our original 2021 SMR article “Non-Invariance? An Overstated Problem with Misconceived Causes” disputes the conclusiveness of non-invariance diagnostics in diverse cross-cultural settings. The critique targets the increasing use of Multi-Group Confirmatory Factor Analysis (MGCFA), especially in its mainstream version. We document—both by mathematical proof and an empirical illustration—that non-invariance is an arithmetic artifact of group mean disparity on closed-ended scales. This arti-factualness renders standard non-invariance markers inconclusive of measurement inequivalence in scenarios with large group mean disparity. Using the Emancipative Values Index (EVI), OA-Section 3 of our original article demonstrates that arithmetically induced non-invariance is inconsequential for multi-item constructs’ cross-cultural performance in nomological terms, that is, explanatory power and predictive quality. Given these limitations of standard non-invariance diagnostics, we challenge the unquestioned authority of invariance tests as a tool of measurement validation.
We recognize the ongoing innovations in invariance testing and their tendency to soften the strictness of invariance requirements, which are unrealistic in settings with many and culturally diverse comparison groups (Meuleman, Davidov & Seddig 2018: 4). As Oberski (2014: 57) concludes: “when the invariance model does not fit the data, this need not necessarily invalidate the comparison of interest.” However, in spite of novelties such as alignment optimization or Bayesian approximate invariance, standard MGCFA applications continue to dominate the field of non-invariance testing (Boer, Hanke & He 2018). Consequently, our response focuses on standard MGCFA applications, although our criticism pinpoints some principled limitations in the logic of non-invariance testing.
Our critique provoked two teams of authors to launch counter-critiques. We appreciate the opportunity to respond to these two comments herewith. Before addressing the comments one by one, we reformulate our key propositions more succinctly.
Restatement
Our point of departure is the baffling ease with which MGCFA can be used to invalidate even the most established multi-item constructs, no matter how well these constructs perform in nomological terms, that is, explanatory and predictive qualities. The facility by which nomologically well-functioning constructs fail invariance tests should not be taken lightly. On the contrary, any scholar agreeing that explanation and prediction belong to the most important purposes of science should be disturbed by the apparent disconnect between invariance test results and nomological construct performance. Indeed, this disconnect raises the question of whether there could be something wrong with a testing logic that demolishes constructs effortlessly, irrespective of their performance in predictive/explanatory terms. Among other constructs, this observation includes the EVI—a multi-item measure whose nomological high-performance is as well documented (Welzel 2013; Welzel & Inglehart 2016) as its apparent non-invariance (Alemán & Woods 2015; Sokolov 2018).
Addressing this “index performance paradox,” our original article points out some manifest limitations of the MGCFA-logic writ large. First, MGCFA assumes that a construct's equivalence across groups can be inferred from the degree of similarity of its inter-item connection strength within groups (which in most cases of application are countries). This presumption takes it for granted that group-centered markers of inter-item connection strength are always perfectly comparable across groups. However, this very premise—which is the pivotal axiom of the entire MGCFA industry—is wrong on all three accounts: espistemologically, mathematically and empirically.
It is a matter of fact that group-centric metrics of inter-item connection strength are caught in an arithmetic dependence on the moderateness-vs-extremity of the group means on closed-ended item scales (Zhirkov & Welzel 2022). Indeed, inter-item connections drop in strength in exponential proportion to the extremity of group means. The reason lies in the calculation rules of covariance and correlation matrices, which allow for strong inter-item connections only in the presence of rather moderate group means. To be precise, the group-mean deviations used to calculate item variances are large enough to allow for sizeable covariances and correlations only under group means in the middle ranges of closed-ended item scales. By the same token, inter-item connections drop inescapably and steeply in strength as group means approach either extreme end on a closed scale. Kirill Zhirkov formulated the mathematical proof of this fact in OA-Section 2 of our original article. Figures 1 and 2 here provide an empirical illustration, using the EVI as a prominent target of non-invariance verdicts. From all of this, a key conclusion follows suit: the strengths of inter-item connections are incomparable across groups with a mixture of moderate and extreme means.
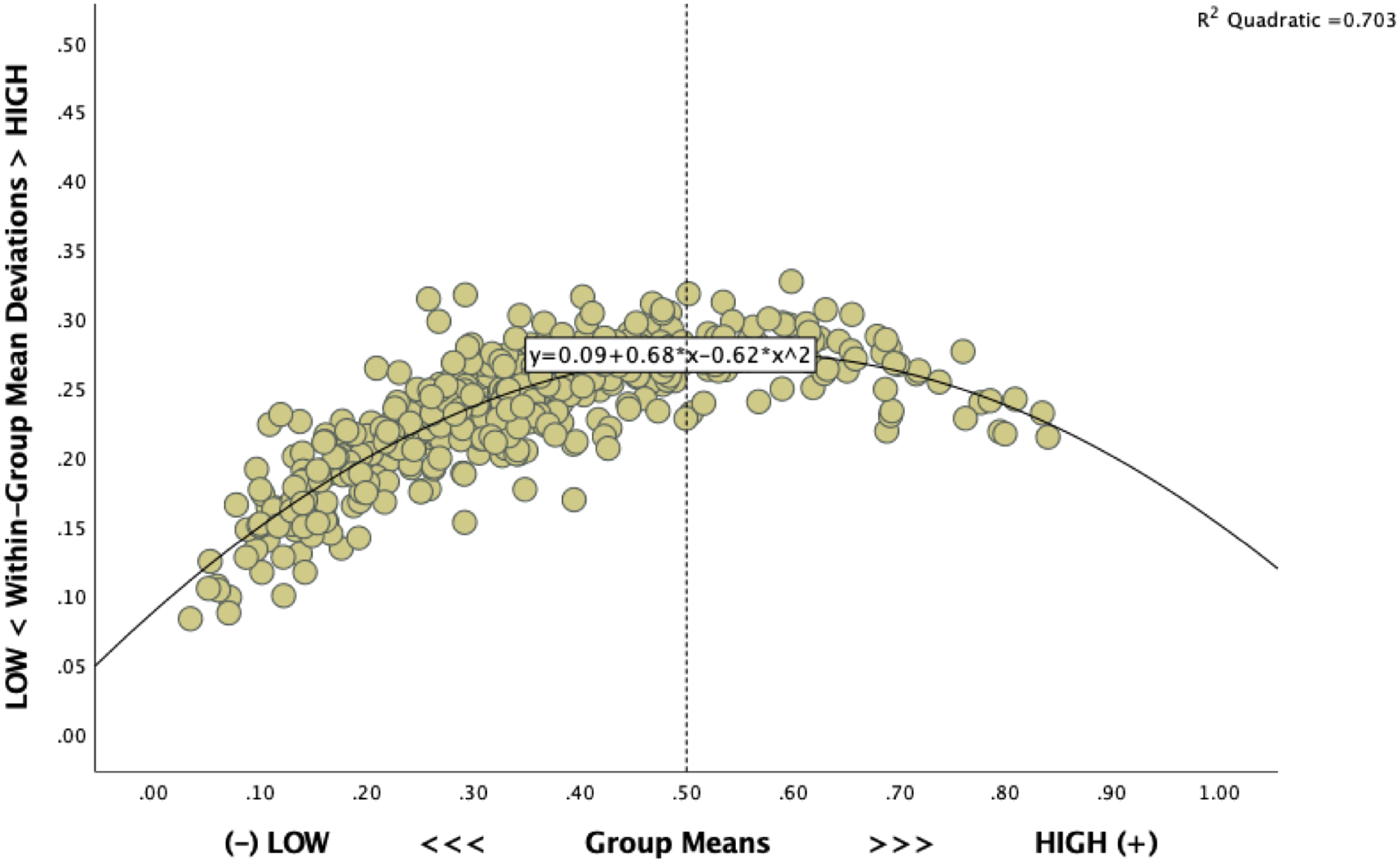
Shrinking within-group variance as a function of growing group-mean extremeties.
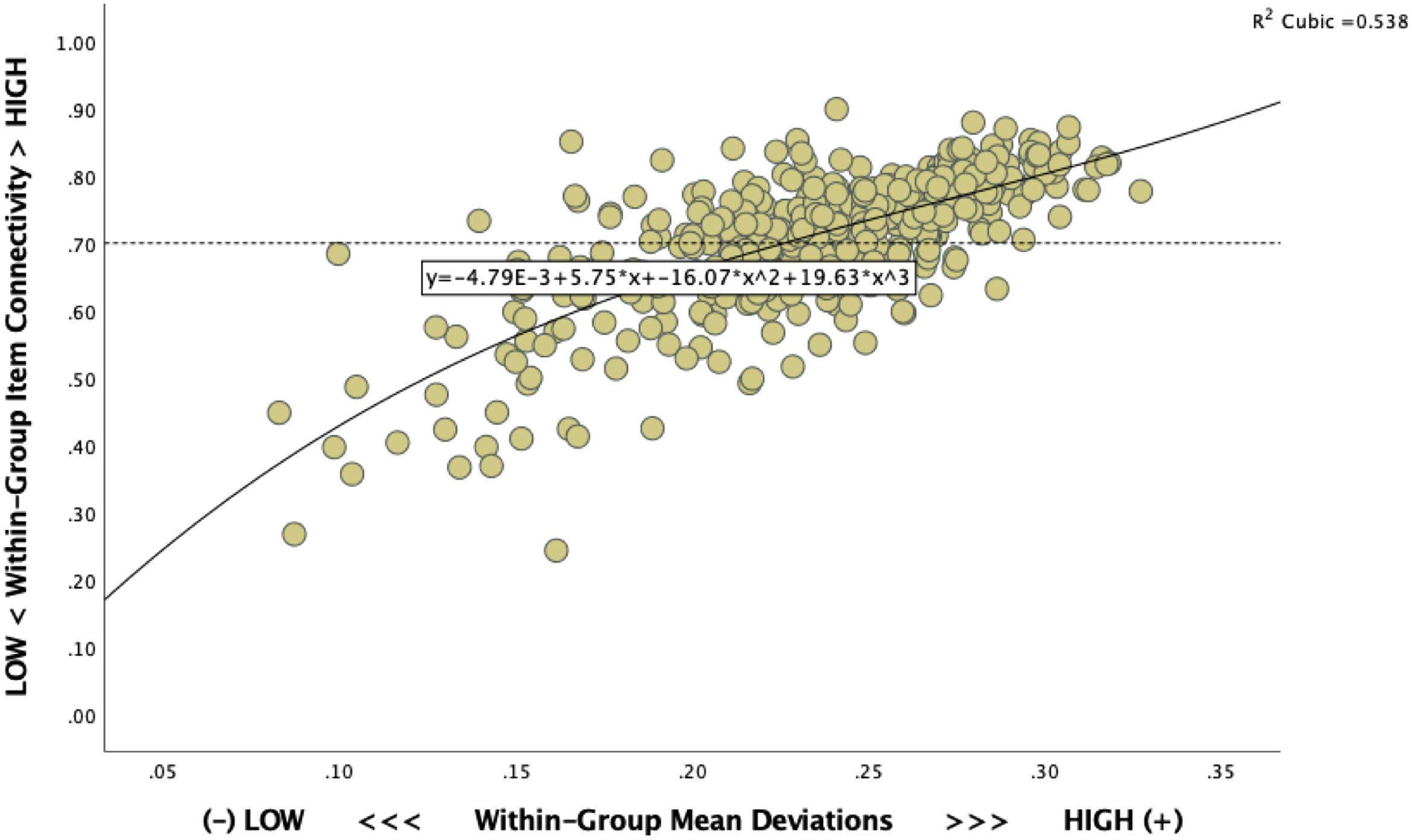
Shrinking group-wise item connectivites as a function of small mean deviations within groups.
Comparing group-centered item connections in ignorance of this limitation is a computationally consuming but elusive exploration into inconclusive territories. Indeed, since arithmetic principles force non-invariance markers to turn on automatically in the face of group-mean disparity, non-invariance is partly a mathematical artifact, void of substantive meaning. The very artifactuality of non-invariance diagnostics increases in direct proportion to the extent of group mean disparity. Accordingly, the inconclusiveness of non-invariance as a marker of measurement inequivalence grows on the same gradient.
Logically, non-invariance markers that are largely void of substantive meaning prove empirically inconsequential for nomological construct performance. As OA-Section 3 of our original article illustrates, the EVI's well-documented non-invariance does in no way disturb the construct's nomological performance at either the individual level or the group level. More precisely, modelling non-invariance by statistical markers of between-group variability in within-group item connections and introducing these markers into regressions does nothing to diminish the effect of the overall EVI-scores on their supposed outcomes. Neither as a suppressor, nor as a moderator does non-invariance affect the explanatory-predictive performance of the EVI. In brief, non-invariance turns out to be irrelevant in terms of nomological construct performance. Figure 3 summarizes our sequence of conclusions in a 7-step causal cascade.
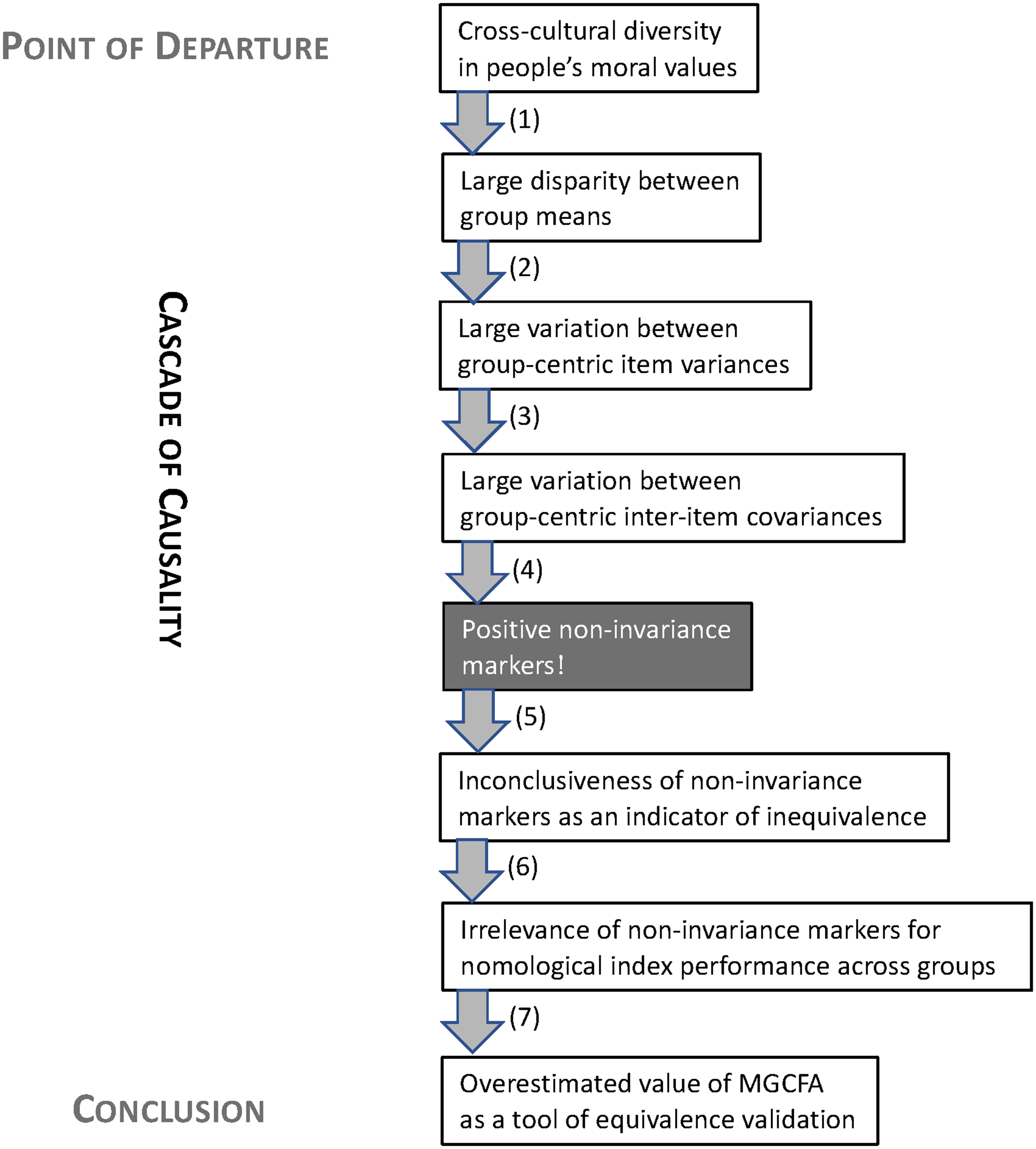
The 7-step causal chain to MGCFA's irrelevance as an equivalence validation tool.
In light of MGCFA's inner limitations, its inferential value as a tool of construct validation is overestimated even within the “reflective” logic of construct design. For the alternative and equally legitimate logic—“formative” construct formation, that is—MGCFA has no inferential value at all, simply because formative constructs escape the dimensionality assumptions to which MGCFA is tailored. Subjecting formative constructs the testing arsenal of MGCFA needs therefore to be considered as a malpractice.
To what extent group mean disparity in psychological constructs reflects “true” mental responses to societal conditions remains a question of how tightly these group means map on other group-level characteristics of an existential nature, such as economic poverty-vs-prosperity, cultural tightness-vs-looseness or institutional autocracy-vs-democracy. Hence, the validation of constructs remains primarily a question of their external linkages to other phenomena of substantive meaning. In a nutshell, construct validity hinges on external linkage strength—the field of nomological networks. Looking instead at the internal linkage strength inside a construct's item set is strictly speaking not about validity but about reliability. The distinction between internal linkage strength (i.e., reliability) and external linkage strength (i.e., validity) is fundamental because internal reliability and external validity are in a partial trade-off relation, as Clifton (2020) demonstrates in all clarity.
OA-Section 3 of our original article provides another example, juxtaposing two constructs capturing how people understand democracy: a three-item index of authoritarian notions (ANDs) of democracy and another three-item index taping liberal notions of democracy (LNDs). Significantly, while the LND-index outperforms the AND-index in internal linkage strength (i.e., reliability), the AND-index greatly outperforms the LND-index in external linkage strength (i.e., validity), at both the individual level and group level. In a nutshell, the partial trade-off between validity and reliability is real. Since MGCFA's testing arsenal focuses solely on a construct's internal linkage strength, this tool kit addresses the validity-reliability tension one-sidedly in reliability's favor. Such an inherent imbalance in favoring competing measurement qualities is a serious issue for anyone recognizing that—as a measurement quality—validity is at least as important as reliability.
MGCFA's inbuilt imbalance is aggravated by the fact that a construct's internal reliability is more easily inflated by systematic measurement bias than is true for the same construct's external validity. Indeed, as Clifton also points out, internal reliability is particularly susceptible to systematic measurement error that infuses a consistent bias in interviewees’ response behavior. That is, a systematic response bias easily increases covariances and correlations among the affected items, thus inflating a construct's internal reliability. External validity, by contrast, is less likely inflated by systematic measurement bias. The reason is that systematic measurement bias can inflate the correlation among sets of variables only if the involved variables embody the same measurement bias. Validity, however, focuses on a construct's linkages to external variables, which usually derive from different sources and, hence, undergo a different data generation process. It is unlikely, for this reason, that the same systematic measurement bias inflates external linkages.
Response
Contradicting the point just outlined, Fischer, Karl, Fontaine and Poortinga (forthcoming) (henceforth FK et al.) report a simulation study to demonstrate that systematic measurement bias infuses data with “nomological noise,” thus falsely inflating the strength of nomological connections. To prove their claim, FK et al. create a methods factor that introduces a systematic measurement bias into a set of related items and run a large number of repetitions by gradually increasing the methods bias. As this happens, the internal linkages of the overall construct's items grow systematically in strength and this growth in linkage strength at the individual level spills over to the group level where inter-item linkages also grow much tighter as a function of the measurement bias's size. Due to this simulation, nomological linkages can be infused with noise that erroneously bloat the linkage strength. FK et al. conclude that nomological validity tests are no reliable substitute for non-invariance tests to establish measurement equivalence.
We agree that nomological linkages can be affected by measurement error, as much as any other type of linkage can be compromised by measurement error. Therefore, researchers are always well advised to perform data quality checks. But this requirement is no particularity of nomological linkages but holds true for the examination of any kind of linkage.
Against this backdrop, FK et al.'s simulation does actually not demonstrate “nomological noise.” If anything, the simulation demonstrates “dimensional noise”: systematic response bias inflates a construct's dimensional inter-item coherence beyond its true strength. The point is that the simulation fails to model the respective construct's nomological linkages to external variables but models instead the construct's internal inter-item linkages. Therefore, this simulation demonstrates how vulnerable a construct's internal linkages are to inflation by measurement bias, thus confirming Clifton's emphasis that internal construct reliability is particularly susceptible to systematic bias. This vulnerability affects above all non-invariance tests because they focus exclusively on constructs’ internal linkage strengths. Given the partial trade-off between internal reliability and external validity, external validity would rather be underestimated in the presence of measurement bias that overestimates internal reliability. Again, external validity is less likely to fall victim to systematic measurement bias because the variables that a nomological network comprises usually derive from different sources and different data generation processes, which makes them unlikely to be similarly biased by the same source of error. Examples include the correlations of the EVI group means with levels of economic development and degrees of liberal democracy—two indicator groups generated by completely different data collection processes, which forecloses with certainty an inflation of the EVI's correlations with these external variables.
FK et al.'s remarks about measurement bias in IQ tests are illuminating in this context. The authors cite findings showing that individuals’ performance in IQ-tests correlates strongly with how familiar the respondents are with the types of tasks used in standard IQ-tests. They conclude from this evidence that differences in respondents’ task familiarity is a source of measurement bias that renders IQ-scores incomparable across individuals with different levels of test familiarity.
We find this conclusion shaky because it redefines a meaningful piece of causality into a source of measurement bias. Therefore, our conclusion from the same evidence is different. Specifically, if differences in the individuals’ familiarity with particular cognitive tasks partly explain their IQ-results, then it is clear that IQ-scores do not only indicate cognitive ability but also cognitive training. But this insight into the causality of IQ-scores does not make them meaningless and incomparable: they still measure cognitive performance, which has demonstrable effects on people's economic success and social standing. And when low IQ-scores incur the same negative consequences, regardless of whether low cognitive ability or low cognitive training is the source, low IQ-scores remain real in their consequences and retain comparability for precisely this reason.
Another attempt of the FK et al. to demonstrate the fallibility of nomological linkages is their analysis of the “pro-choice” sub-index of the EVI, in particular the item referring to the respondents’ toleration of homosexuality. The authors note a strong correlation between, on one hand, how strongly criminalized homosexuality is in given countries and the share of the respective public who expresses a homophobic position. This correlation is highly plausible and from a nomological perspective one would consider it a piece of construct validation because it sheds light on a constitutive element of homophobic realities: the symbiosis between the enactment of homophobic laws, on one hand, and the enculturation of homophobic attitudes, on the other.
This reply, however, again redefines a potential causal mechanism into a source of measurement bias. Indeed, they argue that when people in countries with legal sanctions on homosexuality report a strong rejection of homosexuality, then they do this out of social desirability or out of fear of repression and not because they really think what they say. Accordingly, individual responses are an artifact of a country's laws and cannot be compared across countries with different laws. To further corroborate this conclusion, FK et al. present a multi-level model in which the restrictiveness of countries’ sexual laws inflates the individuals’ homophobic response.
However, the idea that countries with sexually discriminatory laws make people giving fake answers to hide more liberal sexual orientations is pure speculation and does not eliminate an equally plausible interpretation that would produce the exact same evidence: countries with restrictive sexual laws socialize their people successfully into homophobia. If so, the documented evidence provides no proof of measurement bias but is part of a substantive causal explanation.
For instance, one of the best predictors of patriarchal family, fertility and sex norms (including homophobia) is the percentage of devout Muslims at the country level and the degree of religiosity at the individual level (Inglehart & Norris 2003; Alexander & Welzel 2011; Alexander, Inglehart and Welzel 2015). Anyone with sufficient traveling experience has a sense of how massively cultures differ in tabooing homosexuality and that survey responses represent this reality, which is the reason why toleration of homosexuality is one of the survey items most strongly correlated with other key aspects of social reality. Thus, homophobia is real and survey data convey in rough accuracy how deeply entrenched it is in a given culture, even more so as state repression shows an only minor impact on response behavior in surveys under control of cultural factors (Welzel 2013; Kirsch & Welzel 2018). Hence, homophobic responses in surveys are the valid expression of a culture's homophobic normative pressure into which every individual is socialized since birth. In fact, governments might actually enact homophobic laws precisely because such laws are highly popular under their subjects’ homophobic socialization. If so, FK et al.'s multi-level model mis-specifies the causal arrow when defining individual-level survey responses as a function of the countries’ laws. Indeed, longitudinal studies of the interplay between public opinion change and public policy change show consistently that countries have liberalized their gender, family and sex laws in response to a prior emancipatory shift in their populations’ values, rather than the other way around (Alexander & Welzel 2015; Ruck et al. 2020).
In the end, we won’t be able to figure out whether opponents of homosexuality really think as they say or whether they only say so under social expectations fueled by normative group pressures. As long as we cannot look right into people's brains and read their minds, no one can tell the truth. But plausibility considerations suggest a conclusion. As beings with a highly evolved social sense, humans are highly susceptible to normative group pressure and likely to internalize as their own the values that dominate in the reference groups with which they identify. And if people truly believe in something, they are eager to express their belief in order to signal to like-minded others their moral standing, in return for social recognition in their reference group. Against this backdrop, the assumption that people in sexually repressive cultures give mostly fake responses to hide a sexually more liberal position seems implausible. Since people have a natural urge to express their deeply held moral convictions, feeling forced to say something else in an interview situation would be a classic case of “cognitive dissonance,” which is something people try to avoid. The obvious avoidance behavior in an interview would be response refusal. Therefore, if it is right that many respondents in sexually repressive societies feel forced to mask a liberal sexual position in interviews, response refusal in the related questions should be systematically higher in societies with homophobic laws. Evidence for such a pattern is unavailable, however. Kirsch and Welzel (2018), for example, test whether state repression increases response refusal to questions about which liberal-minded interviewees might feel uneasy. Yet, they found no evidence to confirm this suspicion. To close this point, there are reasons to believe that the relationship between homophobic state laws and homophobic survey responses exists because the homophobic responses are a true reflection of predominantly homophobic cultures to which correspondingly repressive laws give a legal expression.
Finally, we agree with the FK et al. that “it is theoretically meaningful to analyze the size and sources of non-invariance.” In fact, this is exactly what we did. Indeed, the analyses in OA-Section 3 of our original article quantify the cross-cultural non-invariance of the EVI and use the non-invariance markers as predictors to figure out whether they affect—as suppressors or moderators—the nomological performance of the EVI. The result is negative: the EVI's existing non-invariance has no effect on the EVI's nomological functioning, neither at the individual level nor the group level. Moreover, our analyses actually reveal the sources of non-invariance to establish that disparity in group means is a powerful such source. Further illuminating this issue, Zhirkov and Welzel (2022) use the EVI's “pro-choice” sub-index to demonstrate that—in predicting non-invariance—group mean disparity greatly outperforms and actually renders insignificant various substantive indicators of cross-cultural differences, including ethno-linguistic differences, religious traditions, economic development, and political regimes. Accordingly, the authors conclude that, in diverse cross-cultural settings, non-invariance is largely a mathematical artifact of group mean disparity, in which case non-invariance is void of substantive meaning. This is the result of an examination of the sources of non-invariance, as called for by FK et al.
The second comment—authored by Meuleman, Zoltak, Pokropek, Davidov, Muthen, Oberski, Billiet and Schmidt (forthcoming) (henceforth MZ et al.)—stresses that our critique of MGCFA only addresses approaches using covariance matrices as the basis of their invariance estimations. Accordingly, we ignore long-known solutions of the problems of closed-ended scales using tetrachoric (and polychoric) correlations.
It is indeed true that our contribution does not pay special attention to tetrachoric approaches, which are based on contingency tables and cell frequencies. But there is a good reason for this neglect: tetrachoric approaches represent a negligible niche in invariance testing, while the overwhelming majority of practical applications are still covariance-based. Hence, the bulk of invariance tests does not escape our criticism. Whether the suggested tetrachoric approaches resist our critique still remains to be seen. We rather doubt it, however, because the equivalent to extreme group means in tetrachoric terms are extreme cell distributions in groups, which—by all rules of arithmetic—should diminish also tetrachoric item correlations in the affected groups, thus turning on non-invariance markers across groups merely because of the arithmetic of distributional extremity and not because of substantive reasons.
Contrary to the MZ et al.'s claims, tetrachoric correlations as well might be vulnerable to distributional extremity. Two experts on this issue, Lorenzo-Seva and Ferrando (2021) underline this point: “So, the tetrachoric estimate based only on two categories is the one that has maximal sampling error (e.g. Guilford & Lyons, 1942, Olsson, 1979). And, as for (d), the sampling error of a polychoric estimate varies widely as a function of item locations or thresholds, so it increases
MZ et al. are accurate in noting that the genealogy from “self-expression values” to “emancipative values” leads from the “reflective” to the “formative” summarization logic. We frankly admit that this transition most likely produces confusion. Yet, we do not wave our flag with the wind. Instead, our transition is the result of a learning process, triggered not the least by our critics. Through this learning process, we became increasingly aware of the inherent limitations of MGCFA invariance tests. These limitations do not disqualify the reflective logic as such, yet certainly those approaches ignoring that group-centered item covariances turn increasingly incomparable alongside group mean disparity. Within the reflective realm, we continue to see great value in approaches modelling within-group and between-group item covariances simultaneously, using a holistic factor model in multilevel design.
As the exemplification by Duelmer, Inglehart and Welzel (2015) demonstrates, the holistic between-within modeling strategy in a multilevel framework is able to establish inter-item uni-dimensionality where MGCFA fails: namely, in settings covering many groups with largely disparate means. The reason for the greater elasticity of the holistic approach is straightforward: unlike the group-centered data handling in MGCFA, the holistic multilevel treatment avoids the trap of “de-meaning” item covariances and, instead, explicitly models the between-group partition of inter-item covariances. Often, the between-group partition of inter-item covariances is sufficiently large to establish uni-dimensionality, especially in the context of large cross-cultural diversity in group means.
Then, a second learning process made us increasingly concerned about the reflective logic's strict insistence on one-dimensional constructs. This insistence is leading indicator research into a situation in which scholars rely too slavishly on “mindless” factor loading statistics in their decisions about construct design. The alternative is to follow theoretical intuition in building multi-item constructs and then to see how they perform in nomological terms. This thought process shaped our idea that (a) constructs do not have to be uni-dimensional to be meaningful, (b) that constructs do not have to be uni-dimensional to be real in their consequences and (c) that even variation in a construct's seeming dimensionality from group to group might be irrelevant for the construct's nomological performance across groups. From here, we began to think of the EVI increasingly as a formative rather than a reflective construct.
Against this backdrop, we agree with MZ et al. that one should not just stamp the label formative or reflective onto a construct but rather provide convincing theoretical reasons of why a construct is to be considered as being of the one kind and not the other. Speaking of it, the typical rationale informing formative constructs originates in what we call the “combinatory” logic and its consequentialist thinking. Like Goertz's (2006) “ontological concepts,” formative constructs start from theory, assuming a predefined thematic field, which is composed of related and yet distinct domains, each of which can be observed by a set of indicators. Given the domains’ distinctiveness, one further assumes that the constituent indicators have unique (i.e., non-redundant) variance components by which they complement each other in “forming” the overall construct. In other words, it is the very combination of these complementary components that completes the construct. From here follows the final and most important assumption: the combined presence of the constituent domains makes the construct consequential in yielding certain outcomes of interest.
The EVI may again serve as an example. In theory, the underlying idea of “emancipative values” is loosely defined as people's indiscriminate support for human freedoms. Now suppose we break down emancipative values into four domains on which individuals can endorse human freedoms, including (a) child autonomy, (b) gender equality, (c) public voice and (d) sexual self-determination, as operationalized by Welzel (2013). Then we collect data to test the idea that emancipative values in this summative sense are consequential in yielding certain outcomes of interest, such as the individuals’ engagement in progressive social movements (think of the Black Lives Matter, Me Too or Fridays for Future movements). If it then turns out that individuals’ activity in such progressive social movements associates most closely with their overall scoring across all four domains of emancipation, no matter in which particular domain the individuals support freedoms the most, the combinatory logic is confirmed. In this case, the Welzel-Inglehart principle of “compositional substitutability” applies and justifies the use of the overall EVI. 2 How strongly the four domains of the EVI are correlated in different groups of comparison and whether these correlations vary across these groups, tells us something about how frequently in a given group we find low or high scores on the four domains of the EVI in consistent combination. But it tells us nothing about how consequential the combined EVI-scores are in yielding certain outcomes. In formative logic, constructs are not real depending on the extent to which their components overlap. Instead, constructs are real to the extent to which they yield similar consequences. This is the essence of nomological thinking, which—in judging construct validity—we consider as the pivotal corrective of the established equivalence thinking.
MZ et al. criticize our assumption that culture is observable in the aggregate distribution of individual-level responses. We disagree. Culture's power is manifest in how strongly it pulls the thinking and behavior of individuals into its gravitational orbit. Exactly this gravitational force is evident in the central tendency of individual responses and their dispersion (Akaliyski, Bond, Minkov & Welzel 2021). Central tendencies accurately reflect the normative group pressure under which individuals answer survey questions. Supporting this notion, Akaliyski et al. visualize that the distribution of individuals’ values condenses exponentially as one approaches the core of the central tendency. Vice versa, the density thins out quickly as one moves away from the center of gravity towards the periphery of its orbit. This is a powerful illustration of the gravitational pull that a culture's central tendency exerts over the values of its individuals, as we measure them in surveys. Even though we calculate cultures’ central tendencies from individual survey responses, in the moment we measure these individual responses they have already been shaped by the normative group pressure that the central tendencies indicate. In that sense, aggregate constellations are ontologically prior to the data from which we calculate them.
In the same vein, we disagree with MZ et al.'s remarks about the alleged spuriousness of aggregate-level correlations, compared to those found at the individual level. To clarify this point, we recite what we write in OA-Section 1 (point 3) of our original article: “… individual-level survey data include a substantial amount of random measurement error. Alwin (2007), for instance, reports that fifty percent and more of the individual-level variation found in standardized surveys is just random noise that is inexplicable by other variables of interest, which is the reason why individual-level correlations are usually so small […] The fact that aggregation cleans group-level variables from random measurement error at the individual level is the reason why correlations between the same two variables are usually much stronger between their aggregated group-level version than between their disaggregated individual-level version.”
Conclusion
In closing this response, we appreciate the critical comments by FK et al. and MZ et al. for three reasons. First, they provide valuable contributions to push forward the important debate about item summarization logics and their underlying epistemological principles. Second, both comments raise a number of points that are insightful in their own right. Third, these comments gave us a lot of food for thought to reflect upon our initial position, which makes us grateful to both groups of authors for helping us to reformulate in even greater strength our reservations about the conclusiveness and relevance of invariance tests.
On the latter account, we remain unconvinced that either comment demonstrates a logical flaw in our seven-step causal chain of invariance test limitations shown in Figure 3. Specifically, the comments fail to disprove the incomparability of inter-item connection strengths across groups with disparate means. Likewise, they fail to falsify the irrelevance of variability in inter-item connection strengths for a construct's nomological performance. Consequently, we stick—with no loss of confidence—to our original takeaway: non-invariance remains an “overstated problem with misconceived causes.”
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.