
Abstract
This article provides a meta-analysis of studies using the crosswise model (CM) in estimating the prevalence of sensitive characteristics in different samples and populations. On a data set of 141 items published in 33 either articles or books, we compare the difference (Δ) between estimates based on the CM and a direct question (DQ). The overall effect size of Δ is 4.88; 95% CI [4.56, 5.21]. The results of a meta-regression indicate that Δ is smaller when general populations and nonprobability samples are considered. The population effect suggests an education effect: Differences between the CM and DQ estimates are more likely to occur when highly educated populations, such as students, are studied. Our findings raise concerns to what extent the CM is able to improve estimates of sensitive behavior in general population samples.
Introduction
Reporting sensitive attitudes or behavior in surveys is prone to social desirability bias, that is, respondents’ tendency to overreport socially desirable and to underreport socially undesirable behavior, attitudes, or characteristics (Bradburn, Sudman, and Wansink 2004; Phillips and Clancy 1972; Thomas et al. 2017; Tourangeau, Rips, and Rasinski 2000). Different indirect question formats have been developed to protect survey respondents’ responses when they are asked about sensitive items. Randomized response techniques (RRTs) are one popular approach (Krumpal et al. 2015; Warner 1965). RRTs traditionally rely on randomization devices, such as coins or dice, to obscure respondents’ answers in a way that it is impossible to identify their true status of the sensitive characteristics. However, researchers are able to estimate the prevalence of the sensitive item relying on elementary probability theory because the randomization device has known probabilities (Boruch 1971; Greenberg et al. 1969; Horvitz, Simmons, and Shah 1968; Kuk 1990; Warner 1965). Yet, one major drawback of most RRTs is that respondents may refuse to answer a particular question, break off the survey interview, or give dishonest or self-protective answers because they are suspicious of the unusual question format and complex instructions (Krumpal et al. 2015; Ulrich et al. 2012).
The crosswise model (CM) has been developed to overcome the issues of using a randomization device (Yu, Tian, and Tang 2008). More specifically, survey respondents are asked to answer two questions—an unobtrusive one with known probabilities and a sensitive one—but to provide only one joint answer to the combination of both of these questions (Höglinger, Jann, and Diekmann 2016; Korndörfer, Krumpal, and Schmukle 2014; Ulrich et al. 2012). As the CM includes a question with known probabilities, it is possible to estimate the prevalence of the sensitive characteristic but without imposing an additional task on the survey respondents. The technique has been implemented in a variety of different social science research studies since its development. While some criticism has been raised about the method (Höglinger et al. 2016; Höglinger and Jann 2018; Jerke et al. 2019), a systematic review of the CM is still outstanding.
We begin by presenting the logic and derivation of the CM, followed by a discussion of the potential effects that this question format may introduce with regard to the quality of the final survey estimate. Next, we conduct a systematic review of the difference (
Estimating Sensitive Characteristics Using the CM
The CM asks two simple yes/no-questions: An unobtrusive question with known probabilities (Y) and a sensitive one with unknown probabilities (X) (Tan, Tian, and Tang 2009; Yu et al. 2008). Respondents are instructed to give a joint answer to the two questions instead of answering each question individually. The available response options only indicate that the answer to both questions is the same (A) or that the answer to both questions is different (B) (see Table 1).
Response Options in the Crosswise Model.

If (1) both answers are captured by dichotomous response codes, (2) the unobtrusive behavior has a known probability p, and is (3) unrelated to the sensitive one, it is possible to estimate the prevalence of the sensitive item (Yu et al. 2008). For example, the unobtrusive question could ask whether a particular person was born in October, November, or December. The probability of being born in these months is approximately
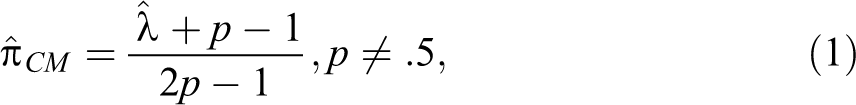
where p is the known population prevalence of the unobtrusive item (in the birthday example approximately
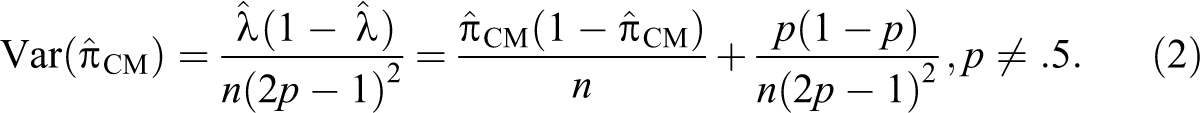
Respondents should experience more confidentiality in their responses by the question design because survey interviewers and data users are unable to identify the responses to the individual questions. The CM could thus be an attractive method for interviewer-administered but also for self-administered modes of data collection, as the technique does not require any additional randomization devices (Krumpal 2013; Yu et al. 2008). While the CM seems to have benefits in eliciting sensitive characteristics, its estimates are associated with larger standard errors and wider confidence intervals. To achieve similar precision as a direct question (DQ) format, the CM thus requires larger sample sizes (Ulrich et al. 2012).
Previous studies suggest that the CM effectively reduces misreporting of sensitive behaviors (inter alia Coutts et al. 2011; Enzmann et al. 2018; Hoffmann and Musch 2016; Höglinger and Jann 2018; Jann, Jerke, and Krumpal 2012; Korndörfer et al. 2014; Krumpal 2012; Kundt 2014). However, it is noteworthy that many of these CM results seem to rely on homogeneous, nonprobability samples that include respondents with high cognitive abilities, such as students. Krosnick (1991) suggested that bias in survey responses may vary across respondents with different cognitive abilities. This will be especially relevant for questions that impose a higher cognitive burden on respondents by design, such as RRTs and the CM (Jerke et al. 2019; Schnell, Hill, and Esser 1988, Schnell, Thomas, and Noack 2019). Thus, we hypothesize that the effectiveness of the CM may depend on respondents’ abilities and should thus depend on the target population and the sample quality of a survey.
Potential Effects of the CM on the Final Survey Estimates
The total survey error (TSE; Andersen, Kasper, and Frankel 1979; Groves and Lyberg 2010; Weissberg 2009) posits that a survey estimate is influenced by potential representation and measurement error. While the former includes sampling and nonsampling errors, the latter refers to all influences that may affect the accuracy of the measured concept.
Representation error depends on the sample type, with probability samples resulting in more accurate estimates as coverage, sampling, and nonresponse errors are minimized (Cornesse et al. 2020). By contrast, nonprobability samples lack the probability mechanism, and it has been recommended to report the results based on nonprobability samples as “indications” rather than estimates (Baker et al. 2013; Matthews 2008). For example, especially web surveys recruited on the basis of self-recruitment into access panels, such as Amazon Mechanical Turk, have been found to be biased by well-educated and (politically) more interested, professional survey respondents. 1 Moreover, we expect that the specific sample composition of nonprobability samples may affect the performance of special question techniques (Schnell et al. 1988). Little research has explored how well survey respondents understand the CM, some evidence indicates that it is harder to cognitively process the CM’s question wording (Jerke et al. 2019).
Similarly, it can be difficult to disentangle the effects of education and motivation in nonprobability samples or samples recruiting special populations, such as students. With regard to the latter, educational effects are obvious and inevitable. For the former, we should observe a similar effect, given self-recruited individuals have been found to be more interested and have higher cognitive abilities in comparison to samples that include the general population. These samples have been described by Henrich and coauthors as Western, Educated, Industrialized, Rich, and Democratic (WEIRD; Henrich, Heine, and Norenzayan 2010a, 2010b) populations. Due to an increasing educational heterogeneity, we expect the difference (
The objective of the CM is to reduce the risk of social desirability bias. For socially undesirable items, higher proportions in the CM condition are considered to be better estimates because they arguably reflect the unknown “true” status more accurately than the DQ according to the “more-is-better” assumption (Cannell, Oksenberg, and Converse 1977; Cannell, Miller, and Oksenberg 1981; Lensvelt-Mulders et al. 2005; Umesh and Peterson 1991). By contrast, respondents are believed to overreport socially desirable characteristics, which should result in a lower prevalence estimate in the CM condition compared to the DQ.
Previous research suggested the “more-is-better” assumption might be undermined by a respondent’s interpretation of what is desirable or undesirable, resulting in subgroups differences (Smith 1992). For example, in a study of imprisonment by Maxfield, Weiler, and Widom (2000), 21 percent falsely reported that they have been imprisoned but have never been arrested. Thus, overreporting might be the result of respondents not comprehending or following the instructions of the question correctly, thus giving an inaccurate answer or deliberately providing an inaccurate answer. These mechanisms may result in false-positives answers (Höglinger and Diekmann 2017; Höglinger and Jann 2018; Jerke et al. 2019). Although we acknowledge the possibility of different subgroup interpretations of social desirability resulting in false-positives and a violation of the “more-is-better” assumption, the discussion of these problems is beyond the scope of this article. As a large body of the literature still relies on this assumption when using RRT, in general, or the CM, in particular, it is yet important to investigate the difference in estimates based on the CM and the DQ.
Empirical Studies Using the CM
Following the guidelines on Preferred Reporting of Items for Systematic Reviews and Meta-Analyses (Moher et al. 2009), we reviewed all empirical studies on the CM published by February 2020. Our search was conducted using four large and commonly used databases for academic publications in survey methodology (Web of Science, Google Scholar, PubMed, and ScienceOpen). The number of publications included in the systematic review is 33 (np
= 33), including 141 items (ni
= 141)
2
estimating proportions of sensitive characteristics using the CM and comparing them to DQ. If the authors reported the difference in the prevalence estimates of the CM and DQ, we include the reported estimates in our analysis.
3
Four publications with 27 items include results that have already been published elsewhere, at least partially.
4
Six publications, including 10 items, did not report the necessary information to calculate
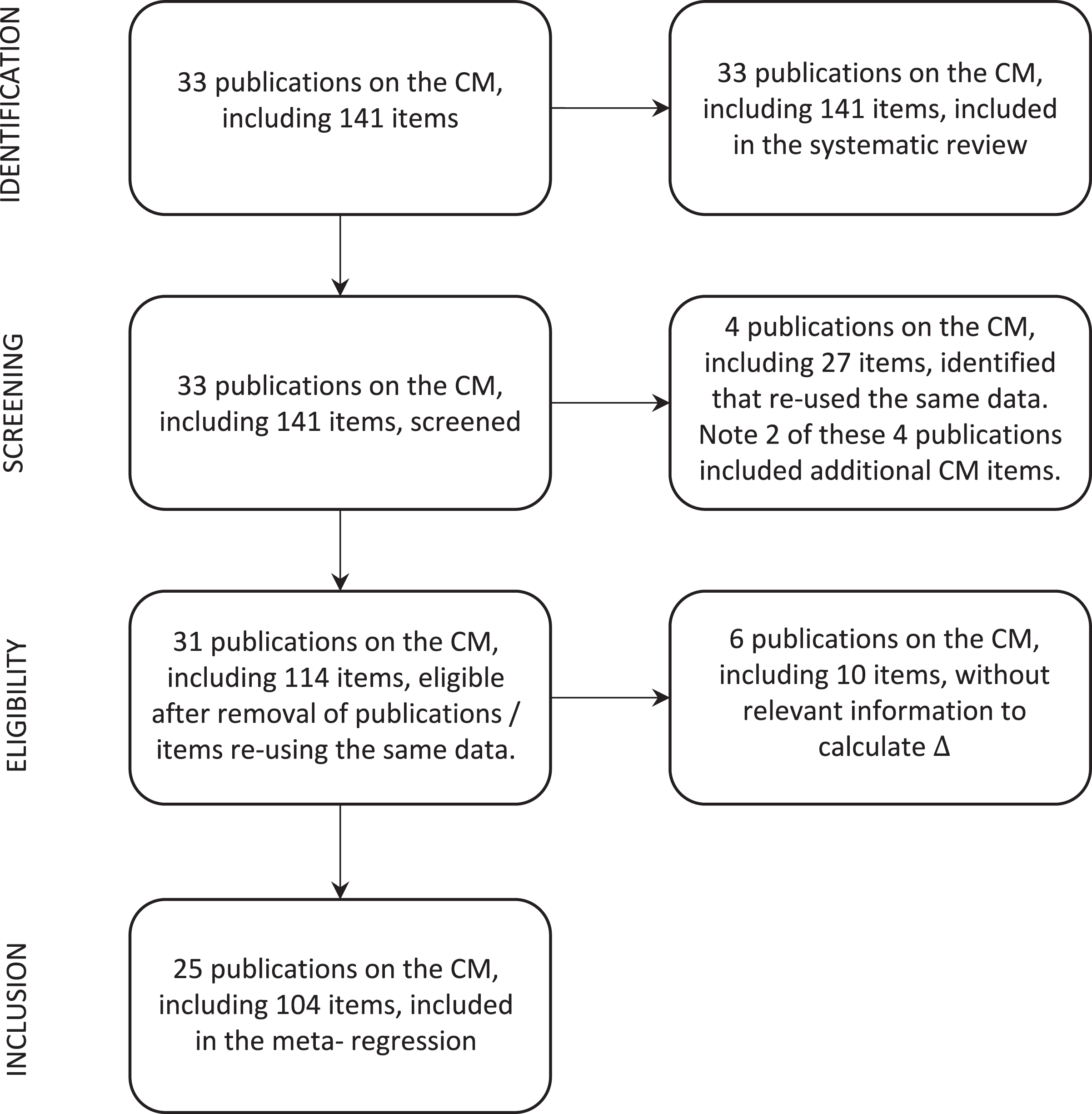
Selection process of crosswise model studies for inclusion in the systematic review and meta-analysis.
Of the included CM items, a majority have been implemented to capture socially undesirable behavior or attitudes (ni = 135 items). For example, the CM has been applied to estimate plagiarism (Coutts et al. 2011; Hoffmann et al. 2015; Höglinger et al. 2016; Hopp and Speil 2018; Jann et al. 2012), substance abuse (Banayejeddi et al. 2019; Höglinger and Diekmann 2017; Höglinger et al. 2016; Nakhaee et al. 2013; Shamsipour et al. 2014), risky sexual behavior (Klimas et al. 2019; Nasirian et al. 2018; Safiri et al. 2018; Vakilian et al. 2019; Vakilian et al. 2014, 2016), carrying rare diseases (Höglinger and Diekmann 2017; Schnapp 2019), tax/fee evasion and corruption (Corbacho et al. 2016; Gingerich et al. 2016; Höglinger and Jann 2018; Hopp and Speil 2018; Korndörfer et al. 2014; Kundt 2014; Kundt, Misch, and Nerré 2016; Oliveros and Gingerich 2019), nonvoting (Höglinger and Jann 2018), radical right voting (Gschwend, Juhl, and Lehrer 2018; Lehrer, Juhl, and Gschwend 2019), antisocial behavior (Enzmann 2017; Enzmann et al. 2018; Höglinger and Jann 2018), as well as prejudice, Xenophobia, and Islamophobia (Hoffmann and Musch 2016, 2019; Johann and Thomas 2017). However, little research has applied the CM to estimate socially desirable behavior, such as self-reported blood and organ donations (Höglinger and Diekmann 2017; Walzenbach and Hinz 2019). 6
We also coded the sample type, referring to probability versus nonprobability samples. A majority of the CM items (ni = 89; 63 percent) has been implemented on nonprobability samples (Coutts et al. 2011; Gschwend et al. 2018; Hoffmann et al. 2015; Hoffmann et al. 2017; Hoffmann and Musch 2016; Höglinger et al. 2016; Höglinger and Jann 2018; Hopp and Speil 2018; Jann et al. 2012; Johann and Thomas 2017; Korndörfer et al. 2014; Kundt 2014; Kundt et al. 2016; Nakhaee et al. 2013; Shamsipour et al. 2014; Vakilian et al. 2014, 2016; Waubert de Puiseau, Hoffmann, and Musch 2017), only 52 items in 8 publications are based on samples drawn on the basis of probability methods (Corbacho et al. 2016; Enzmann et al. 2018; Enzmann 2017; Gingerich et al. 2016; Gschwend et al. 2018; Lehrer et al. 2019; Oliveros and Gingerich 2019; Schnell et al. 2019). 7
A majority of items were drawn from studies involving WEIRD samples (ni = 119, 84 percent). This includes ni = 105 (74 percent) students samples and ni = 14 (10 percent) other WEIRD subjects. Only 22 items in 10 different publications (16 percent) rely on general populations. 8
Systematic Review of CM Studies
A forest plot (Palmer and Sterne 2009) of all items, for which
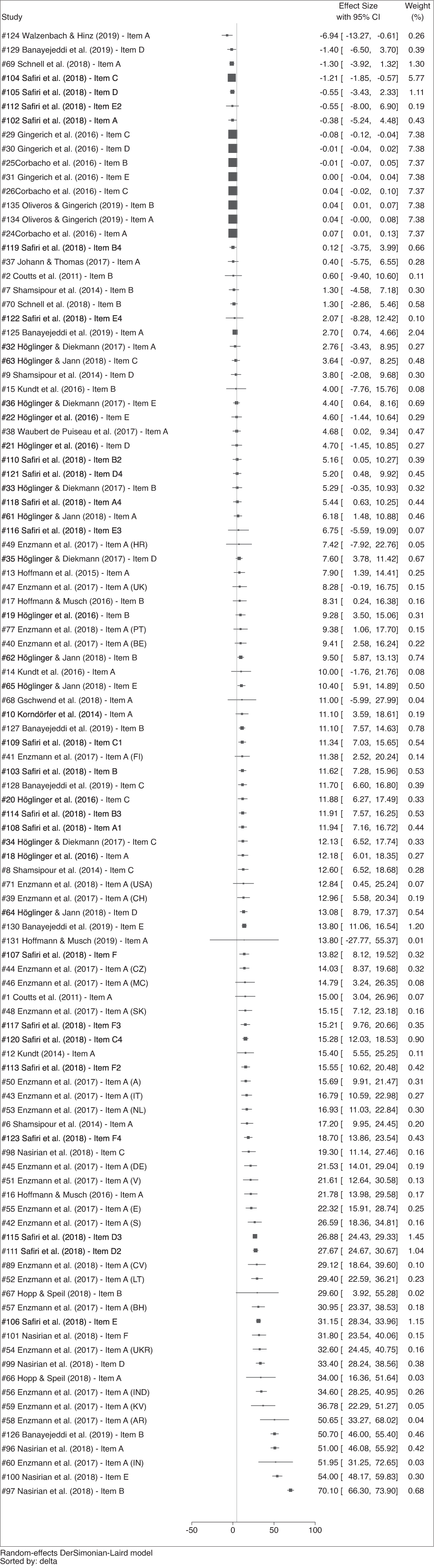
Forest plot organized by effect size, restricted sample (ni = 104).
We present a plot of the overall effects size and the prediction interval in Figure 3. The overall effect size is 4.88; 95% CI [4.56, 5.21]. It was calculated employing the DerSimonion–Laird random effects estimator (DerSimonian and Laird 1986) and is represented in Figure 3 by the narrow grey diamond and whiskers. Although the effect is statistically significant at conventional levels, the overall effect size is small. 11 The 95% prediction interval (Borenstein et al. 2009) [95% PI: 3.616, 6.153] is represented by the hollow diamond in the Figure 3 and indicates the plausible range for the effect size in a future study.
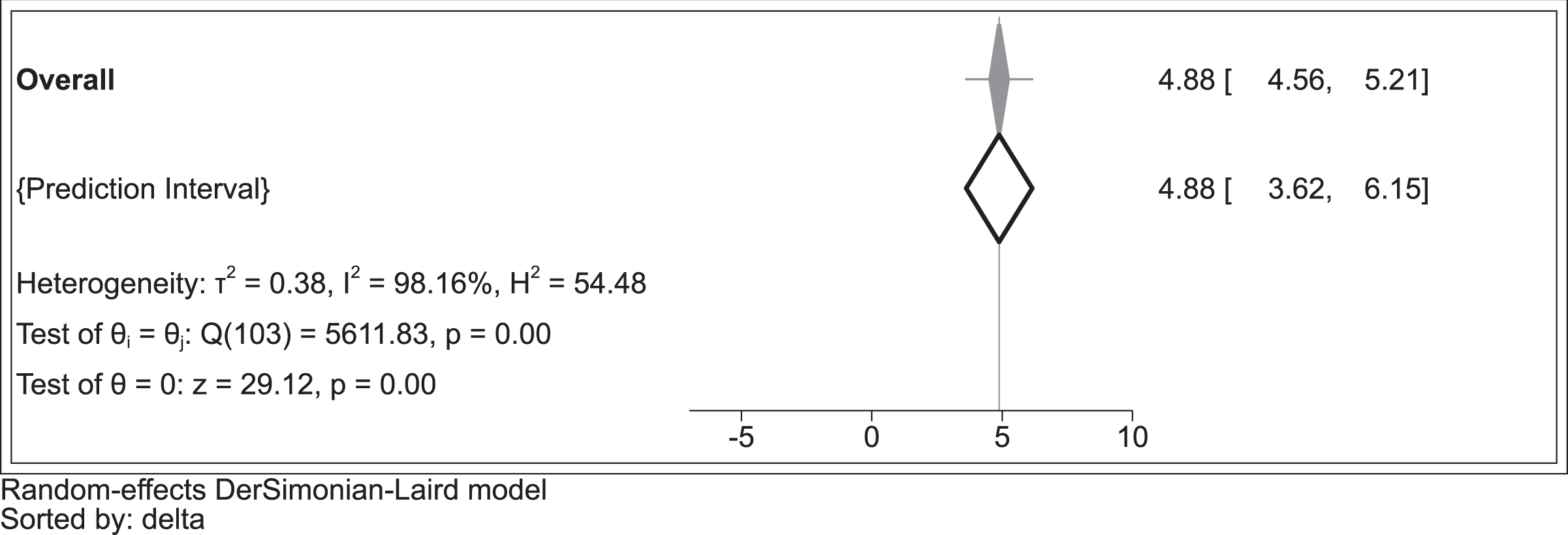
Overall effect size (4.88 [4.56, 5.21]) and prediction interval [3.616; 6.153], restricted sample (ni = 104).
Previous research suggest that between-study variation could cause bias (Borenstein 2019). To control for this factor, we estimated three indicators of study heterogeneity: Cochran’s Q, I
2, and
Heterogeneity Tests. Restricted Sample.
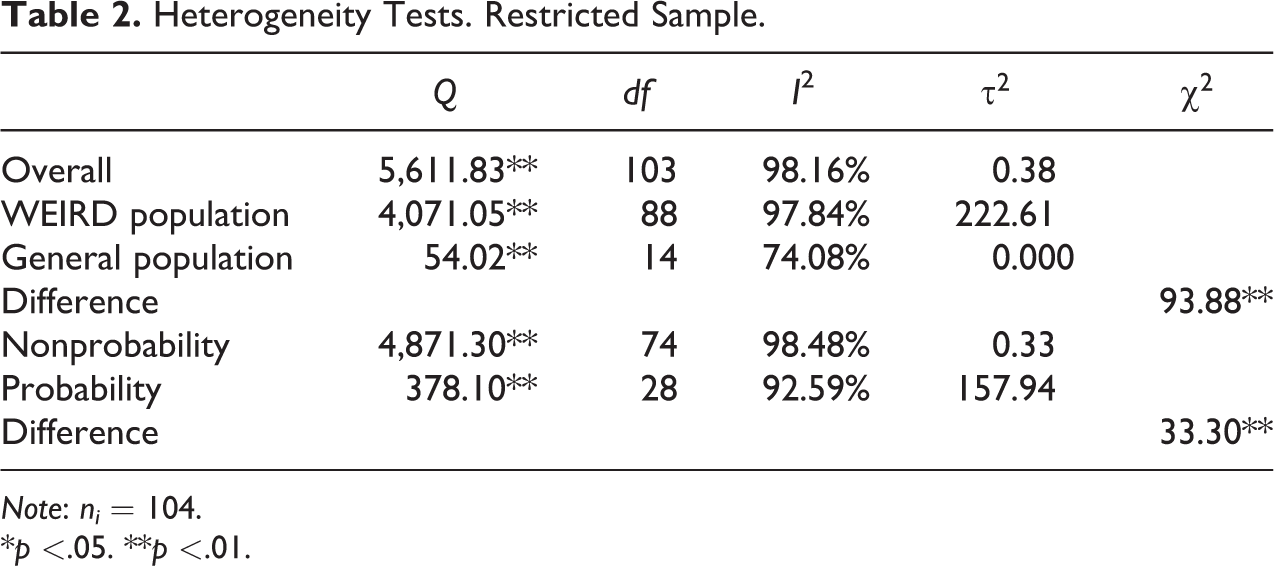
Note: ni = 104.
*p
The results in Table 2 indicate study heterogeneity for the overall sample. This is shown by the statistically significant coefficient of Cochran’s Q and the high ratio of I
2 in the top row. Moreover,
To investigate this issue further, we check for potential publication bias looking at the funnel plots in Figure 4. The top graph is for the restricted sample (ni = 104). The asymmetrical distribution of studies around the estimated effect size suggests that publication bias may be present. However, funnel plot asymmetry should not be interpreted as proof of publication bias (Egger et al. 1997; Sterne and Egger 2001; Sterne, Egger, and Smith 2001; Sterne et al. 2011). Other possible causes for asymmetric funnel plots are selection bias, heterogeneity, data irregularities, artefacts, or chance (Sterne et al. 2001). Moreover, if a larger treatment effect can be identified in smaller studies—that is, there is heterogeneity of treatment effects—the funnel plot is likely to be asymmetric (Sterne and Egger 2001).
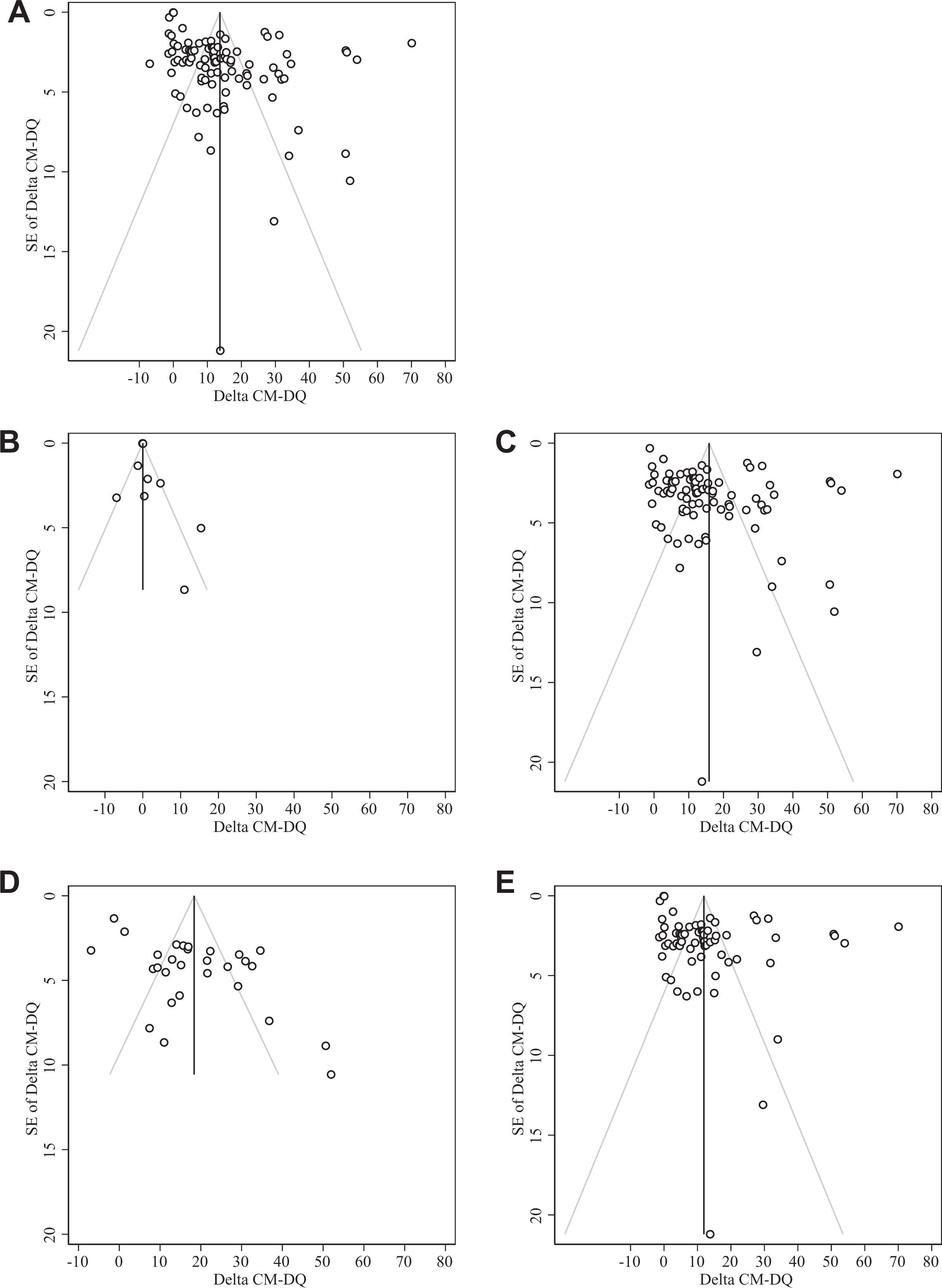
Funnel plots of crosswise model studies with 95% pseudo confidence intervals, effect size estimated by a random effects model. For ease of comparison, the scale of all plots has been fixed. Restricted sample (ni = 104). (A) Full sample. (B) General populations. (C) WEIRD populations. (D) Probability samples. (E) Nonprobability samples.
As an additional investigation of the issue, we apply Egger’s test for small-study bias using random effects. A statistically significant Egger test indicates that the null hypothesis of no publication bias has to be rejected. The test statistic for the overall sample indicates a small study bias (Egger’s test = 4.76; z = 40.18; p
It is important to note, to account for between-study variation of publication bias, Egger’s test can be extended to incorporate moderators (Sterne and Egger 2005). To investigate this issue, we also reestimated the funnel plots along with the Egger tests including these subgroups as moderators. The second row of Figure 3 displays funnel plots controlling for the population type. The left plot in the second row is for general populations, the right plot for WEIRD populations. The graph for general populations is asymmetric and indicates small effects in general population samples.
13
Egger’s test produces a statistically significant result for publication bias (Egger’s test = 3.01; z = 17.21; p
Funnel plots by sample type are presented at the bottom of Figure 3: The left plot is for probability samples; the right plot for nonprobability samples. The graph for probability samples is largely symmetric but has a few large and small study outliers. The Egger test for probability samples indicates publication bias (Egger’s test = 3.29; z = 3.93; p
We performed Duval and Tweedie’s trim and fill (Duval and Tweedie 2000) to estimate how many studies are required to achieve funnel plot symmetry and therefore no publication bias. The results suggest that 50 additional items would have to be included. We present the estimated funnel plot in Figure 5. The observed items are displayed as circles; the imputed items as triangles. This high number of potentially missing studies can be interpreted as clear evidence of publication bias.
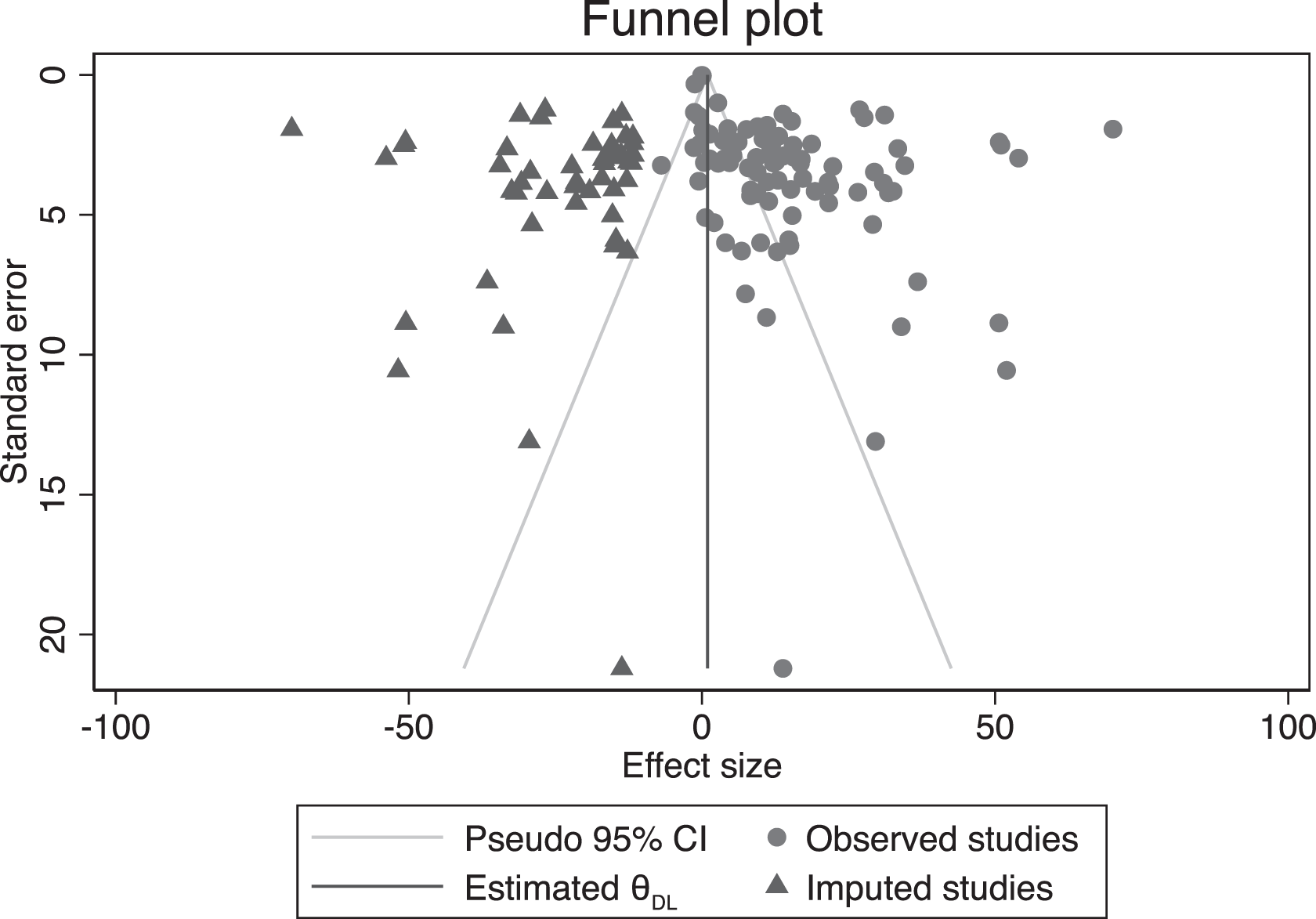
Trimmed funnel plot with 95% pseudo confidence intervals, full sample.
Meta-Regression of CM Studies With Moderators
To test the impact of the population and sample type on the difference (
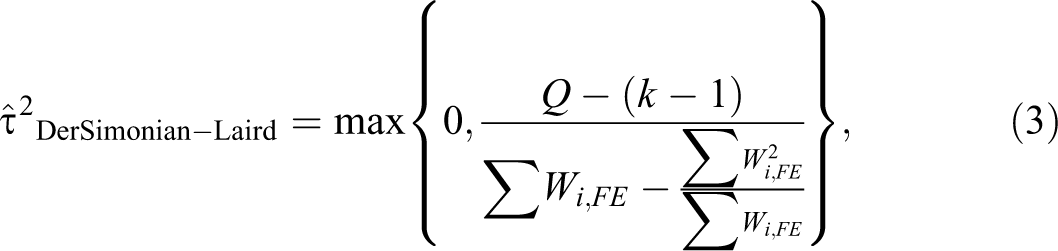
where Q is calculated based on an estimate from a fixed effect (FE) analysis:
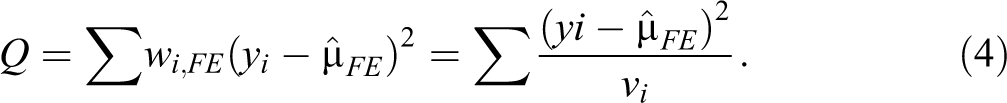
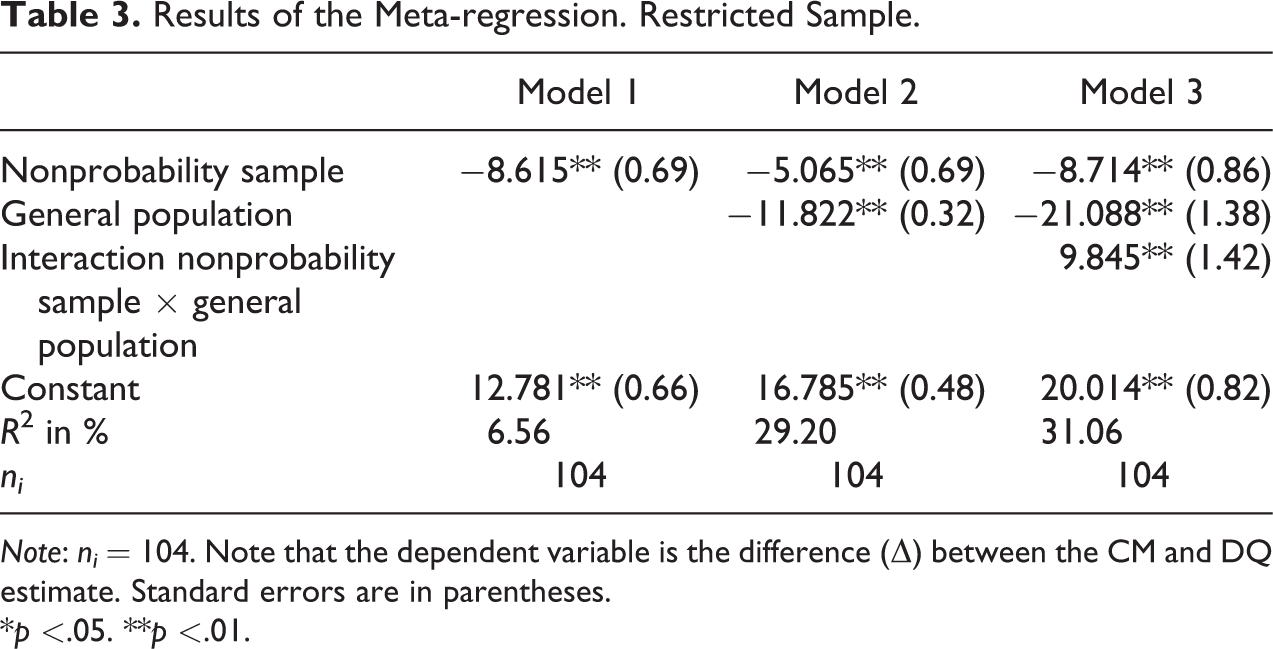
The results of the meta-regression are presented in Table 3. Model 1 includes the sample type. The population type is added in model 2. Next, an interaction term between the population and sample type is included in model 3.
Results of the Meta-regression. Restricted Sample.
Note: ni
= 104. Note that the dependent variable is the difference (
*p
The results of the meta-regression suggest that the sample and population type matter: Nonprobability samples are more likely to produce a smaller difference (
The positive interaction effect of the sample and population type suggests a larger
To investigate these issues, we also reestimated the models using robumeta in Stata for robust variance estimates (Hedges, Tipton, and Johnson 2010; Tanner-Smith and Tipton 2017). However, the Stata macro only allows to either estimate robust estimates for correlated or for hierarchical clustering effects. Thus, separate models controlling for each kind of clustering were estimated.
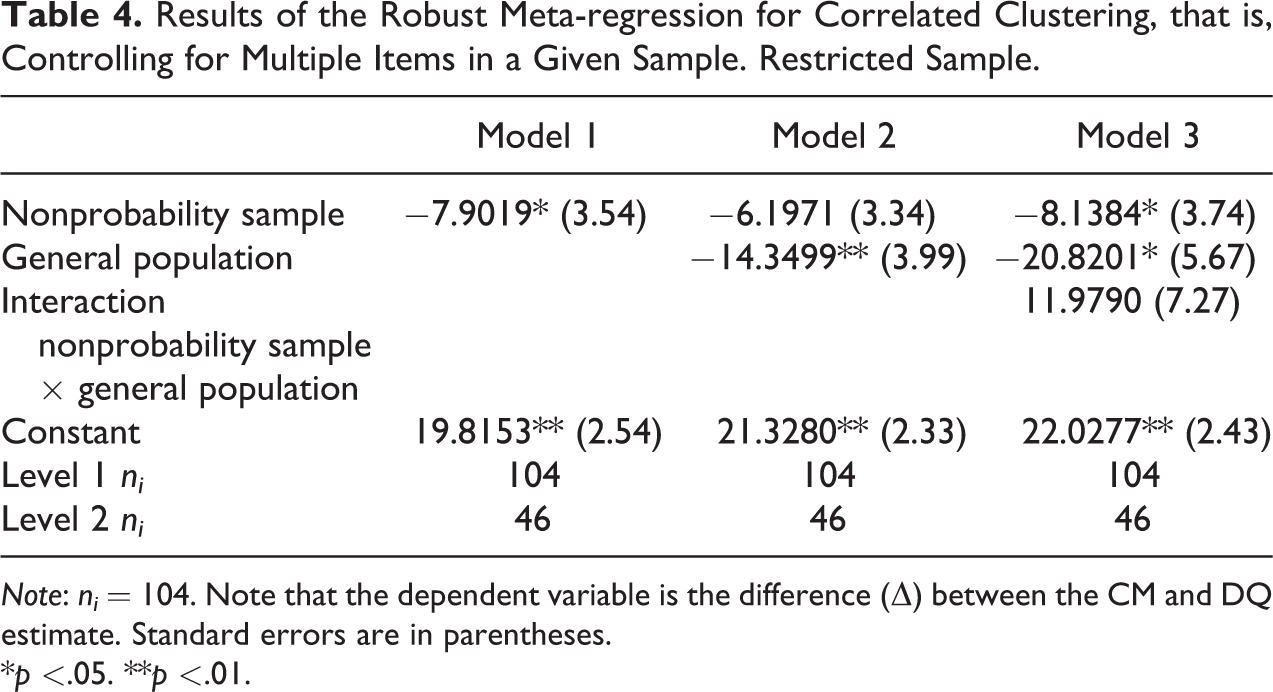
The results of the robust variance models for correlated clustering, that is, controlling for multiple items in a given sample, with
Results of the Robust Meta-regression for Correlated Clustering, that is, Controlling for Multiple Items in a Given Sample. Restricted Sample.
Note: ni
= 104. Note that the dependent variable is the difference (
*p
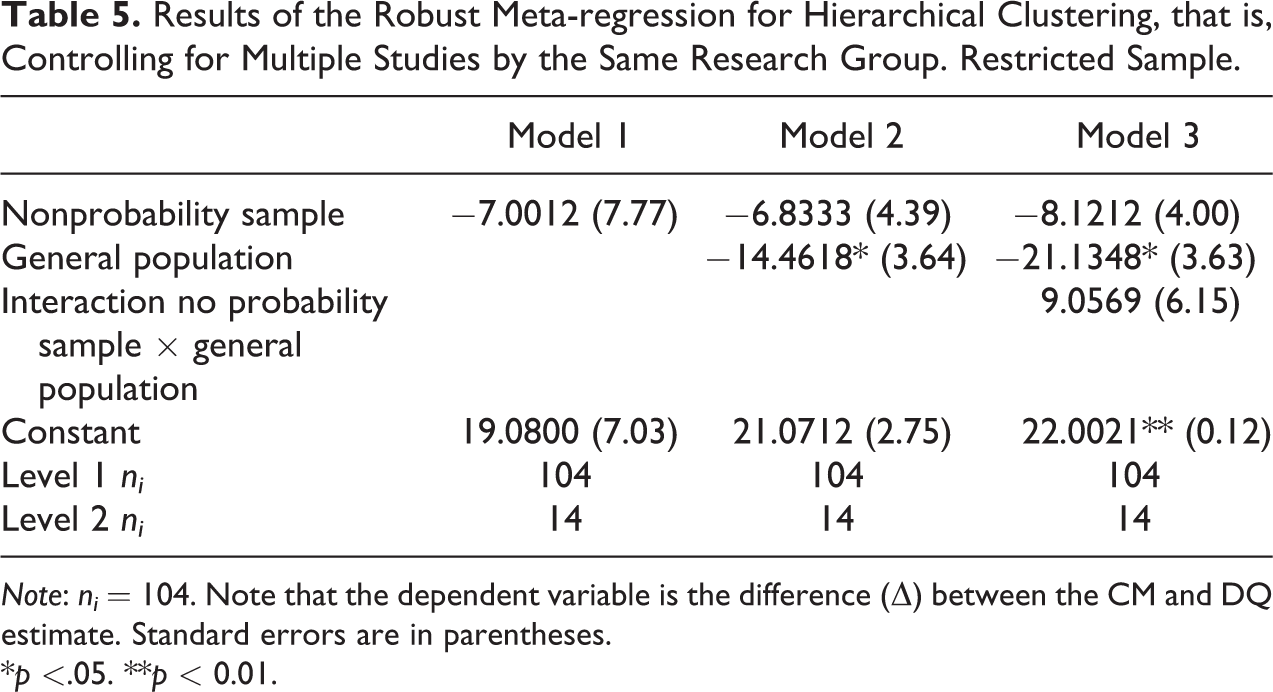
The results presented in Table 5 are for hierarchical clustering, that is, controlling for multiple studies by the same research group. The effect sizes of nonprobability samples and of general populations have a similar magnitude as in Table 3. However, only general populations reach conventional levels of statistical significance. The interaction term is statistically insignificant as in Table 4. 15
Results of the Robust Meta-regression for Hierarchical Clustering, that is, Controlling for Multiple Studies by the Same Research Group. Restricted Sample.
Note: ni
= 104. Note that the dependent variable is the difference (
*p
Regardless of the kind of dependencies considered—correlated or hierarchical clustering—the result that general population samples are more likely to produce a smaller difference between the CM and DQ remains robust and statistically significant.
Discussion
It has been suggested that the CM is a straightforward way to estimate sensitive characteristics in survey environments, as it presumably provides more confidentiality in responses for survey respondents, who should be encouraged to more honest self-reports. To date, differences in the CM and DQ estimates capturing sensitive behavior, and thus whether or not the CM actually has a substantive gain over the DQ, has not been reviewed. This article provides a systematic review and meta-analysis studying the impact of sample and population types on whether or not the CM produces a different result than the DQ.
In sum, the results presented here raise concerns about the use of the CM in estimating sensitive characteristics. While the findings suggest heterogeneity across studies, even within the same population and sample type, the meta-regression models indicate that general populations do reduce the difference between the CM and DQ estimates. We find limited evidence that this is also the case for nonprobability samples. We consider the main result—that is, a smaller difference between the CM and DQ estimate on general population samples—to be in accordance with our hypothesis that the ability to answer questions using the CM depends on the target population. Moreover, the results suggests clear evidence of publication bias, as negative or null findings seem to be less likely to be published.
Our findings suggest that the effectiveness of the CM might be restricted to better educated subgroups, for example, students or professional survey respondents. It is desirable to test the CM and other indirect methods for estimating sensitive characteristics on probability samples of general populations. As these methods require high cognitive effort and trust, it is plausible that similar effects for related RRTs could be observed, too. Should this be case, the number of methods currently available to estimate the prevalence of sensitive characteristics in social science research diminishes sub-stantively.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.