
Abstract
Randomized response techniques (RRTs) are useful survey tools for estimating the prevalence of sensitive issues, such as the prevalence of doping in elite sports. One type of RRT, the unrelated question model (UQM), has become widely used because of its psychological acceptability for study participants and its favorable statistical properties. One drawback of this model, however, is that it does not allow for detecting cheaters—individuals who disobey the survey instructions and instead give self-protecting responses. In this article, we present refined versions of the UQM designed to detect the prevalence of cheating responses. We provide explicit formulas to calculate the parameters of these refined UQM versions and show how the empirical adequacy of these versions can be tested. The Appendices contain R-code for all necessary calculations.
Keywords
Throughout the social sciences, many findings are based on surveys of various groups of individuals. Most such surveys rely on the assumption that respondents will provide honest answers to survey questions. However, this assumption falters when asking respondents sensitive questions (see Tourangeau and Yan 2007)—questions that are perceived as intrusive, stigmatizing, socially undesirable, or even legally incriminating (Tourangeau, Rips, and Rasinski 2000). Faced with sensitive questions, respondents may refuse to participate in the survey or may simply answer dishonestly (Tourangeau et al. 2000), especially if they are carriers of the sensitive attribute being assessed. Thus, direct questioning has frequently been found to underestimate the true prevalence of sensitive attributes, such as having received an abortion (Fu et al. 1998), having been convicted of driving while intoxicated, having engaged in doping in athletics, and many other issues.
To address this problem, several indirect questioning techniques have been developed throughout the last half-century (see Chaudhuri and Christofides 2013). One of these methods, the Randomized Response Technique (RRT), developed by Warner (1965), introduced the idea of creating anonymity by employing random encryption of the respondents’ answers. In Warner’s model, the respondent receives one of two questions about a sensitive issue. For example, the survey instrument might be designed so that respondents will receive the question S: Have you ever used illicit drugs? with probability p (where
Several revisions and modifications of Warner’s (1965) model have been proposed over the years (e.g., Kuk 1990; Mangat 1994). One of these is the well-established unrelated question model (UQM; Greenberg et al. 1969; see Figure 1). In the UQM, as in the original Warner model, a randomization procedure determines whether the respondent is instructed to answer the sensitive question S. The alternative question, however, is not the reversed sensitive question
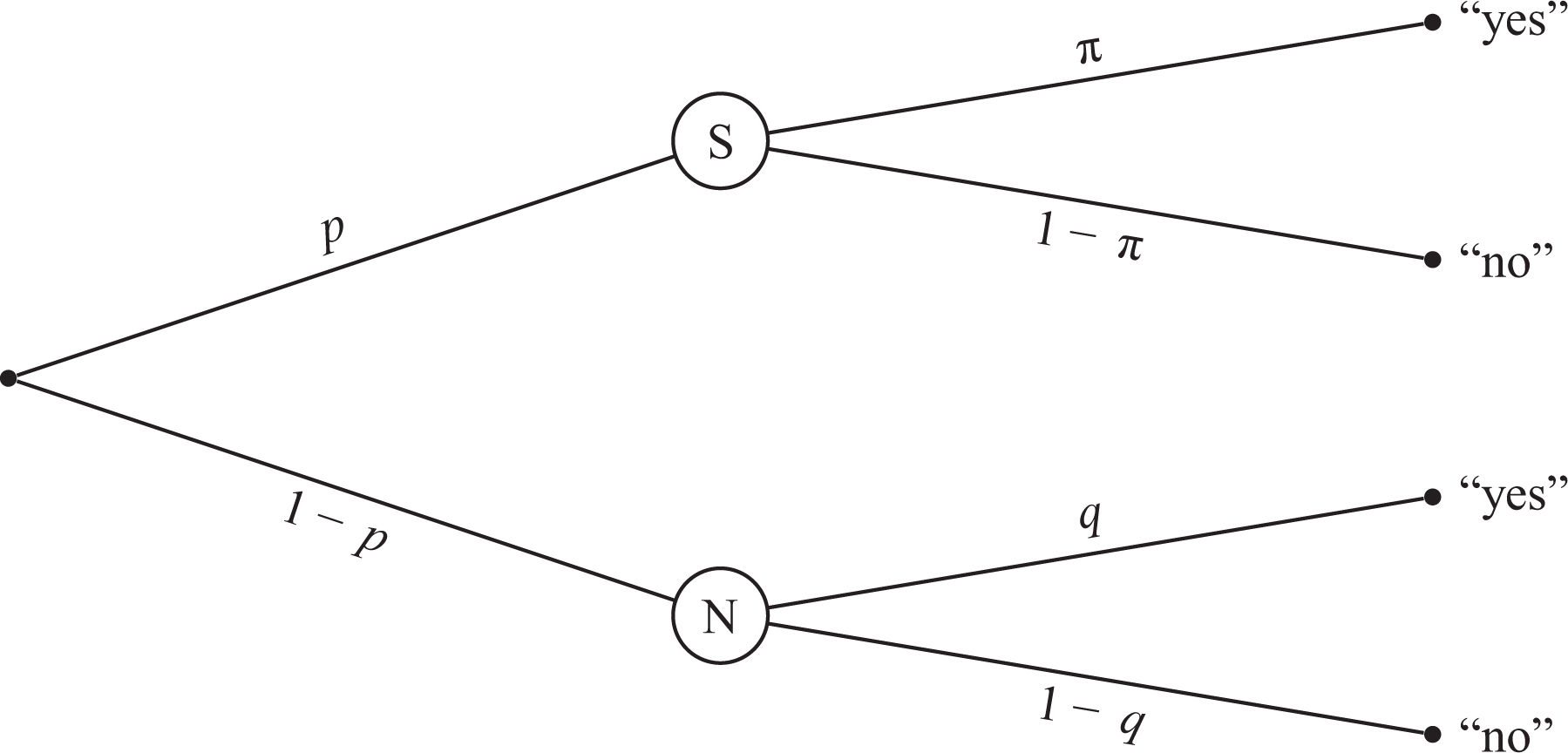
Probability tree of the unrelated question model. The sensitive question S and the neutral question N are randomly received by respondents with probability p and
With the UQM, as with Warner’s original method, the investigator cannot determine any individual respondent’s status on the sensitive attribute. However, given a large sample of respondents, the investigator can still estimate the prevalence

In several studies, the UQM has elicited prevalence estimates substantially exceeding estimates derived from direct questioning (see Lensvelt-Mulders et al. 2005), such as the prevalence of induced abortion (Abernathy, Greenberg, and Horvitz 1970) and doping in elite athletics (e.g., Ulrich et al. 2018).
However, by introducing an unrelated question N, the UQM opens the possibility that some respondents (“cheaters”) will be tempted to answer a self-protective “no” to either of the two alternative questions on the survey regardless of the true answer to the question. Even though a “yes” response does not necessarily imply having the sensitive attribute, a “no” response greatly reduces the possibility of that conclusion. Specifically, under the standard version of the UQM, the conditional probability
Another modification of the RRT, the cheater detection model (CDM; Clark and Desharnais 1998), addresses this drawback by dividing respondents into three mutually exclusive categories: (a) honest respondents who are carriers of the sensitive attribute, who will respond “yes” if they receive the sensitive question, (b) honest respondents who are noncarriers of the sensitive attribute, who will respond “no” if they receive the sensitive question, and (c) cheaters who choose the safe option by always responding “no” to any question regardless of whether they are carriers or noncarriers. For illustration, let A be a carrier and
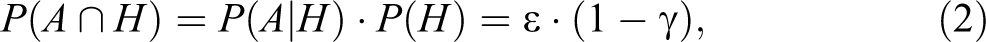
for subgroup (b)
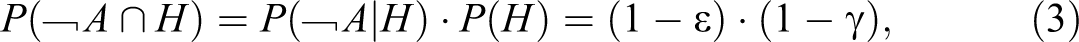
and for subgroup (c)

Note that these three probabilities add to one.
The CDM is based on another RRT variant, the forced response model (Boruch 1971). This model modifies Warner’s model by replacing the inverted question
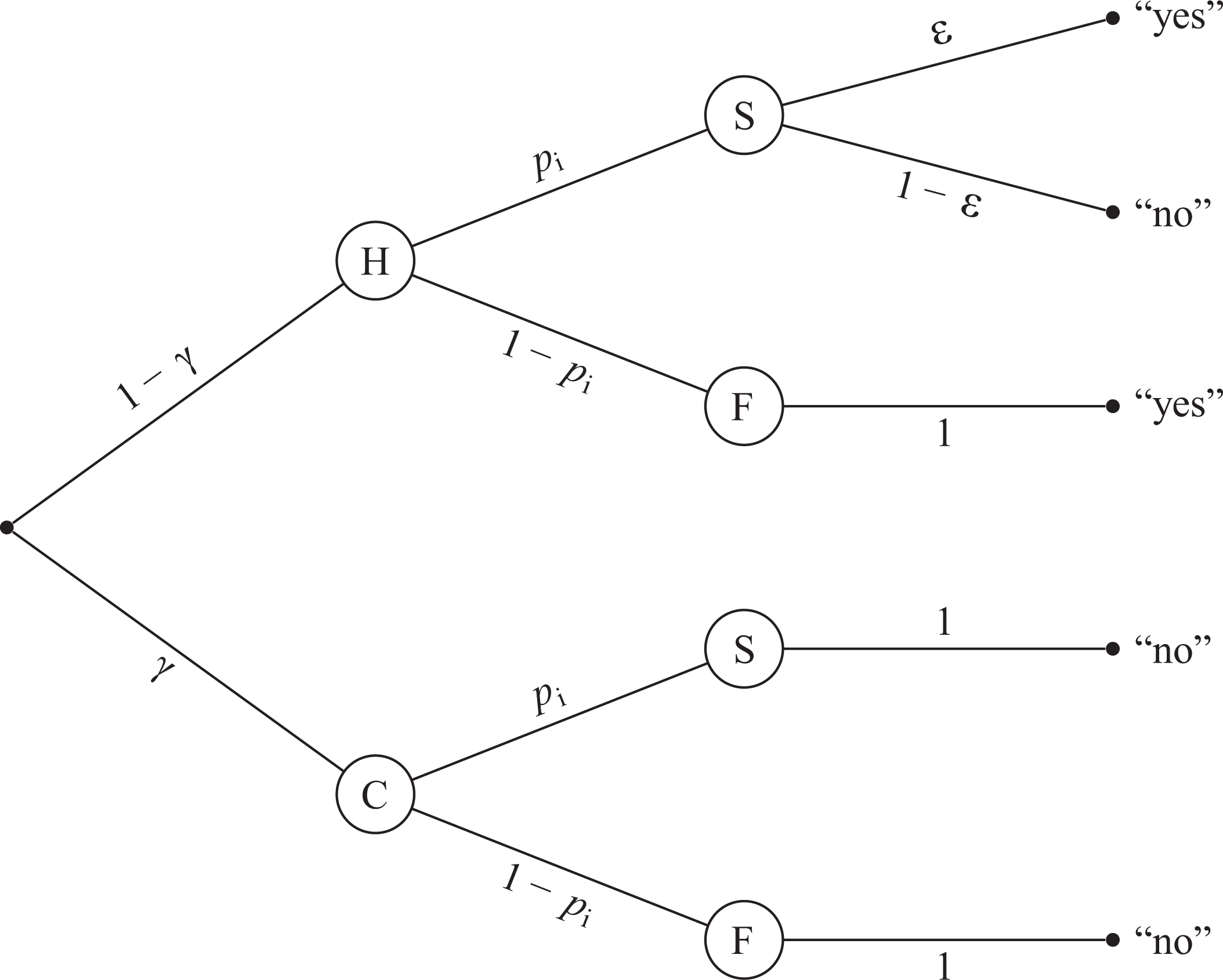
Probability tree of the cheater detection model. Respondents are either cheaters C with probability
However, note that the temptation to cheat may be especially pronounced in the forced response model because the respondent can completely eliminate any suggestion of being a carrier of the sensitive attribute by simply answering “no.” Expressed more formally, in the forced response model, the conditional probability
Therefore, the CDM includes a parameter to assess the extent of cheating. This is depicted in the lower part of Figure 2 starting at node C and representing cheaters. In this diagram of the CDM, the proportion of cheaters is
Several empirical implementations of the CDM (e.g., Elbe and Pitsch 2018; Moshagen et al. 2010; Ostapczuk 2011; Ostapczuk et al. 2009; Pitsch, Emrich, and Klein 2007; Schröter et al. 2016) have provided evidence of cheating behavior—showing the importance of including a cheating parameter in RRTs. However, studies utilizing the forced response model (e.g., Höglinger, Jann, and Diekmann 2016; Kirchner 2015; Wolter and Preisendörfer 2013) have raised doubts about the validity of this particular method. Specifically, it has been shown (Coutts and Jann 2011; Höglinger et al. 2016) to elicit lower estimates than other indirect questioning techniques, and respondents have reported greater difficulties in understanding this technique. Respondents also seem to express less trust that the technique guarantees anonymity. For example, Lensvelt-Mulders and Boeije (2007) reported that respondents perceived being forced to give a “yes” response as being “forced to be dishonest” (p. 600), which seemingly triggered reluctance.
Ostapczuk et al. (2009) proposed a method to reduce this problem by adding a forced “no” response to the forced “yes” response. In this symmetric design, none of the response options is conclusive of the respondents’ status. Specifically, it is not only possible to be forced to respond “yes” even though one is a noncarrier but also to be forced to respond “no” even though one is in fact a carrier. This should increase compliance with the instructions, and indeed, the authors found cheating to be reduced in an empirical comparison to the original design. Still, it is plausible that a forced response can feel like an implicit response to the sensitive question, something that even this approach does not address.
In summary, although it appears important to account for possible cheating when using RRTs, a technique based on the forced response model may not be ideal. By contrast, the UQM is conceptually and mathematically similar without potentially triggering reluctance by forcing responses. Here, responses to the neutral question are clearly not responses to the sensitive question because the neutral question has content of its own. Thus, in the next section, we propose a model combining the greater psychological acceptability of the UQM’s design with the CDM’s concept of cheating.
Unrelated Question Model—Cheating Extension (UQMC)
Below, we introduce the UQMC, a model combining the basic idea of the CDM (Clark and Desharnais 1998) with the standard version of the UQM (Greenberg et al. 1969). The setup of the UQMC resembles that of the UQM, in that respondents receive the sensitive question S with probability p and the neutral question N with probability
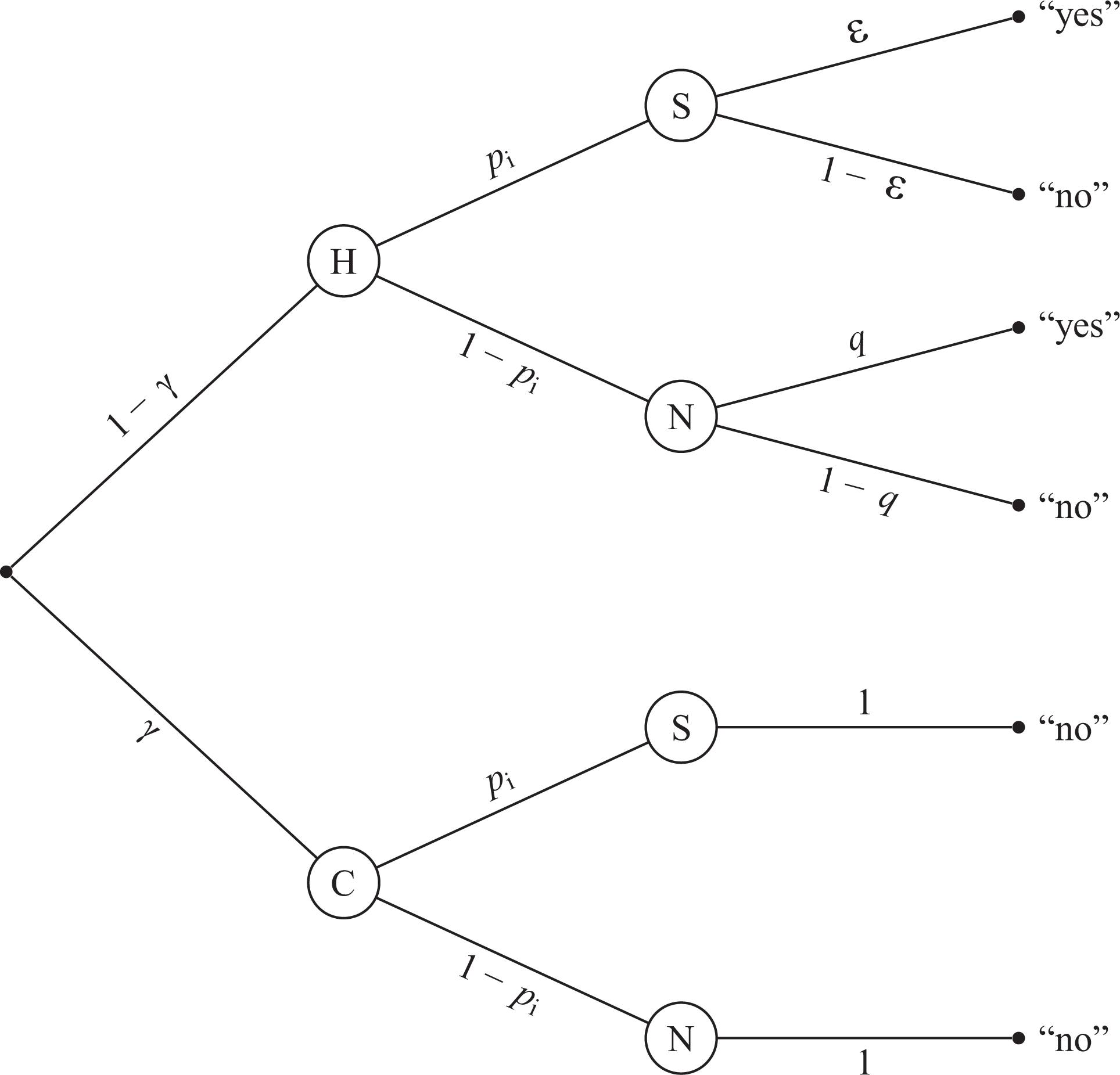
Probability tree of the unrelated question model—cheating extension. The prevalence of cheaters C is
As in the CDM, two independent samples of respondents are required to estimate
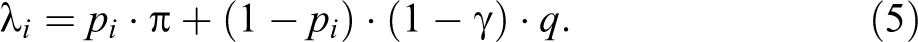
As
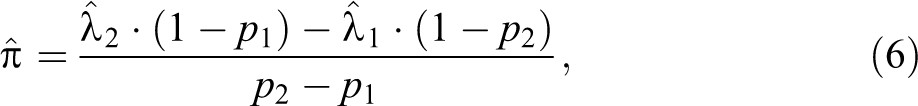
and
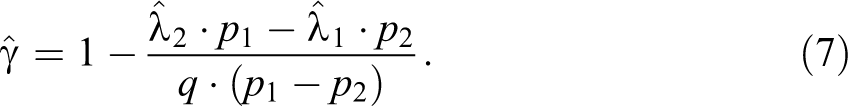
The corresponding sampling variances of the two estimates are
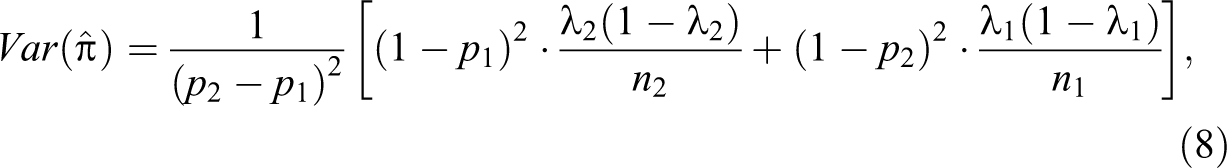
and
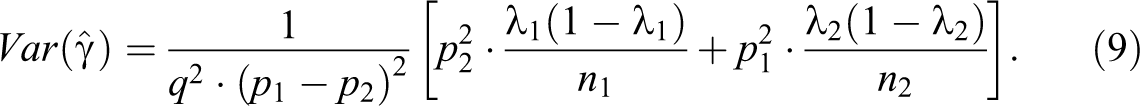
The covariance of these estimators is
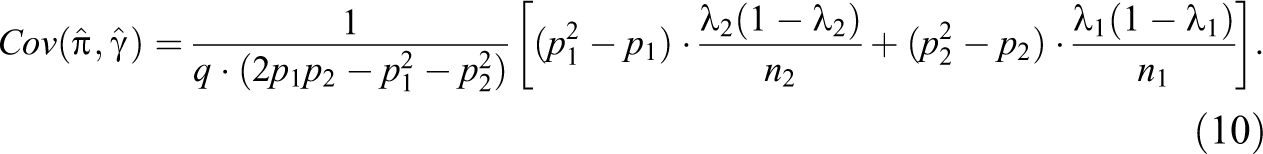
Table 1 provides a numerical example to illustrate the UQMC. This example assumes that the estimates
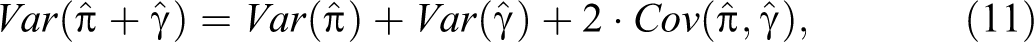
Numerical Example Illustrating the Unrelated Question Model—Cheating Extension.

Note. ni
= size of sample i; pi
= probability of being assigned to the sensitive question in sample i; q = prevalence of the neutral attribute;
Numerical Example Illustrating the Unrelated Question Model—Cheating Extension (Continued).
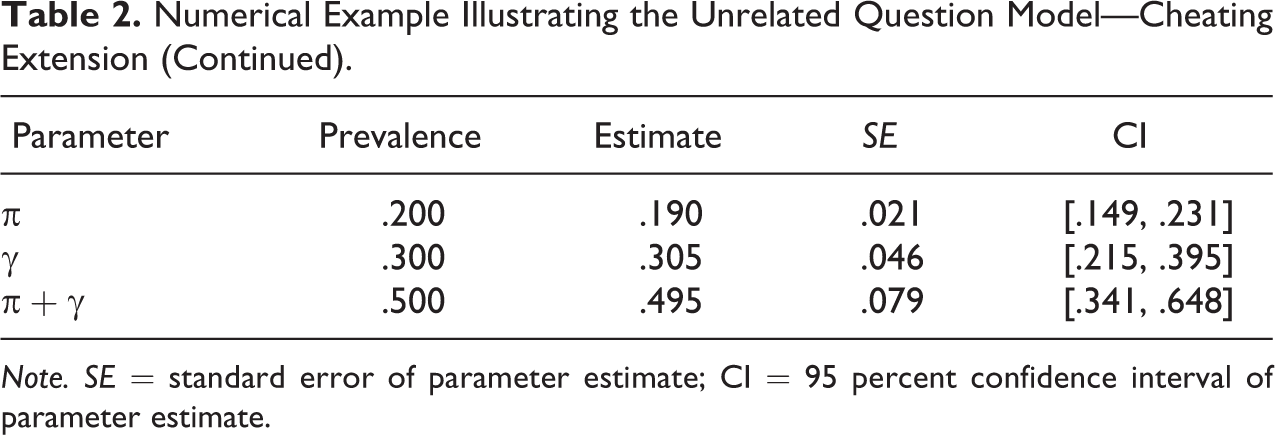
Note. SE = standard error of parameter estimate; CI = 95 percent confidence interval of parameter estimate.
using equations (8
–10). Therefore, the 95 percent confidence interval of the upper bound ranges from
It is important to note that the size of this range is in large part due to the true cheating proportion, which is 0.3 in this example, and not merely due to random sampling error. A model that does not take cheating into account, such as the original UQM, would therefore yield an estimate with a smaller confidence interval. On first sight, this may look preferable. However, this estimate would be biased, as it disregards the true prevalence of cheating. As such, there is uncertainty in both cases, but only the UQMC makes the degree of this uncertainty explicit by taking cheating into account. If on the other hand, there is in fact no cheating, the UQMC can capture this as well (with
In addition to estimating the above parameters, the UQMC can test whether a substantial amount of cheating is present. Indeed, Clark and Desharnais (1998) introduced a likelihood ratio test for this purpose in their initial presentation of the CDM. This test utilizes the ratio of the maximum likelihood of a model setting cheating to
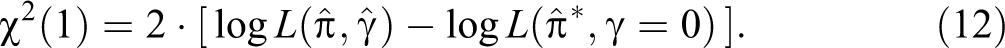
In the above example, this likelihood ratio test supports the hypothesis that cheating is present, with
As is true for all indirect questioning techniques, the sampling variance of the estimates is quite high. Due to the additional estimation of the cheating parameter, this variance becomes even higher than in one-parameter RRMs, such as the original UQM. An optimized choice of pi and q, and an optimized division of the sample into the two subsamples can minimize this drawback. Appendix B (which can be found at http://smr.sagepub.com/supplemental/) illustrates the influence each of these parameters has on the sum of standard errors and power of the model estimates. In short, more extreme values of pi and larger values of q make the sum of standard errors smaller and the relative size of the two subsamples within the overall sample has only a small impact, as long as the difference is not too extreme. Thus, a division of the sample into two equal subsamples is desirable. However, minimizing the standard error cannot be the only consideration when choosing the values for pi and q because in case of values for pi and q close to 0 or 1, the responses become more indicative of the respondents’ status and thus anonymity protection decreases. Therefore, the applied values must be chosen to represent a compromise between efficiency and anonymity protection. Recommended values would therefore be 0.75 and 0.70 for p 1 and q, respectively.
Different parameter combinations might be advantageous if the focus of the study is mainly on prevalence estimation or mainly on cheater estimation. In the former case pi should be more extreme, q should be smaller, and the larger part of the sample should be allocated to the subsample with higher pi . In the latter case, pi should be closer to 0.5, q should be higher, and the larger part of the sample should be allocated to the subsample with lower pi .
The above recommendations are based on the influence that the design parameters have on the standard error and statistical power, together with an intuitive evaluation of the influence that these parameters have on perceived privacy protection. In specific applications, the parameters should be informed by the specific sensitive question at hand and the implementation of the questioning design. In doing so, one can refer to theoretical as well as empirical work on the optimal choice of design parameters in RRMs with respect to efficiency and perceived privacy protection (e.g., Greenberg et al. 1977; Lanke 1975; Leysieffer and Warner 1976; Ljungqvist 1993; Soeken and Macready 1982). An overview on this topic is given by Fox (2016).
Partial Cheating
As explained above, the UQMC utilizes the cheating concept as initially defined in the CDM, where “cheaters” are assumed to always choose the safe option of a “no” response, regardless of the question presented. However, this may be an unduly restrictive assumption, as there might be respondents who would cheat when confronted with the sensitive question but would answer the neutral question truthfully, since they do not feel threatened by this latter question. Allowing for cheating in this broader and probably more realistic sense implies that the original categories (completely honest respondents and complete cheaters) should be extended by the category “partial cheaters” (i.e., cheating only if presented with the sensitive question). In the following, we refer to the original group of cheaters, who always respond “no,” as “complete cheaters.”
Figure 4 depicts how partial cheating affects the probabilities for “yes” and “no” responses. Honest respondents still answer honestly to whichever question they are assigned. Complete cheaters, as before, respond “no” to whichever question they are assigned. In this figure, we add partial cheaters, who answer honestly if assigned to the neutral question, but always respond “no” to the sensitive question, regardless of whether they are carriers of the sensitive attribute. Thus, there is a new branch of the probability tree leading to a “yes” response, Probability tree of the unrelated question model—cheating extension including partial cheating. Participants are (a) honest H with probability 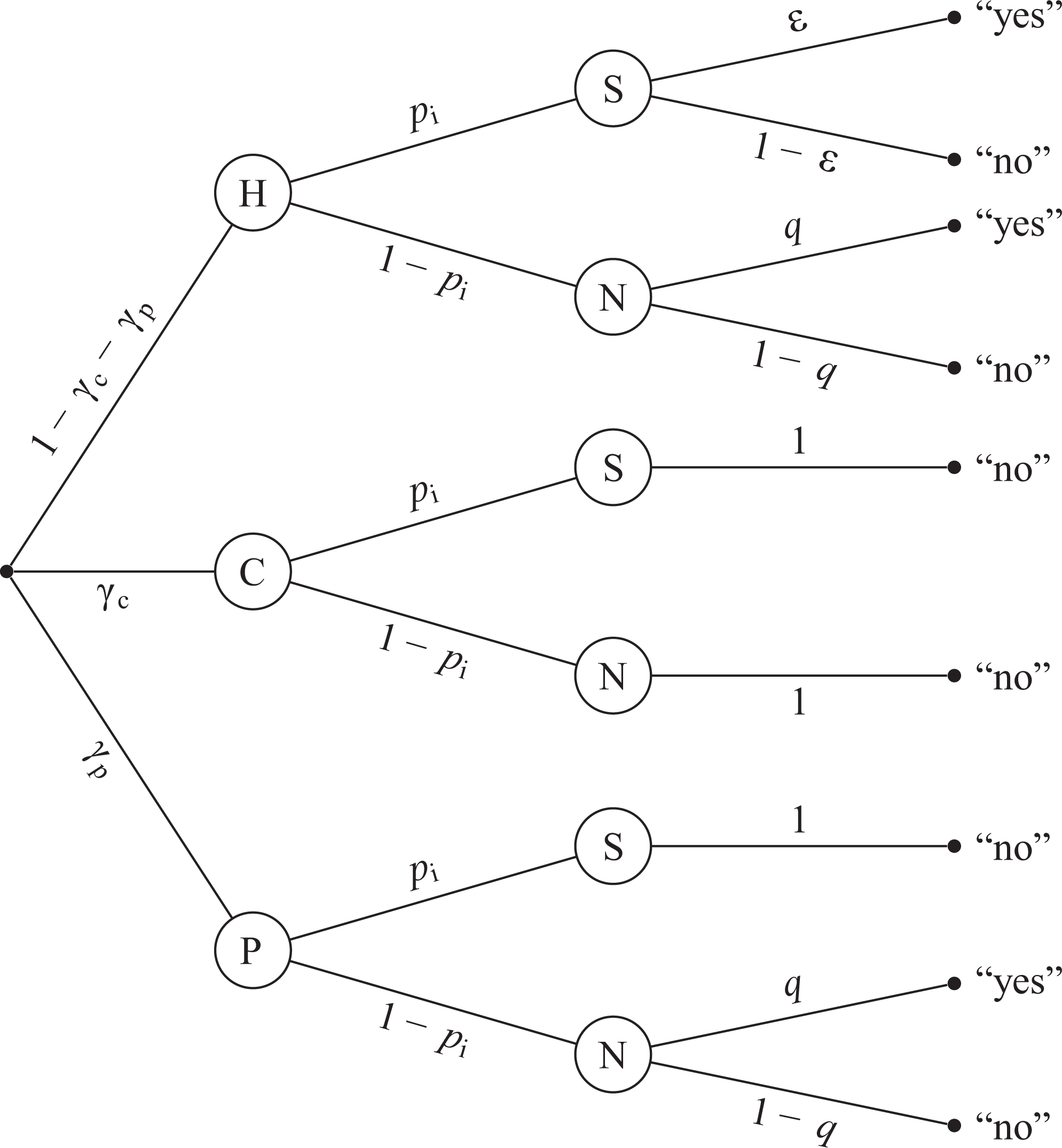
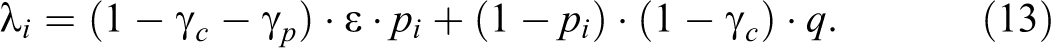
It should be stressed that not all three parameters
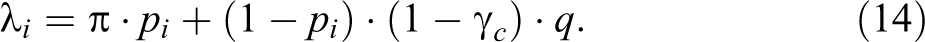
It is clear that equation (14) is equivalent to equation (5), except that
For the above numerical example, this would mean that the estimate for the lower bound of the prevalence range would remain at
It is worth mentioning that the same line of reasoning would apply to the CDM. That is, the possibility of partial cheating would involve a reinterpretation of the parameters estimated by the CDM. Specifically, as before, in the presence of partial cheating, the lower bound of the prevalence would remain at
A Survey Design for Testing the UQMC
A limitation of RRTs in general is that their empirical adequacy cannot be tested because the number of unknown parameters usually equals the number of independent samples, and therefore, there are no degrees of freedom left for testing empirical adequacy. Thus, empirical adequacy must simply be assumed. Fortunately, this drawback can be resolved in the UQMC by varying the prevalence of the neutral attribute q. In the basic UQMC, p
1 and p
2 are applied to two independent samples in order to generate two independent equations for
Table 3 illustrates what the setup of the UQMC with four samples could look like, including exemplary estimates
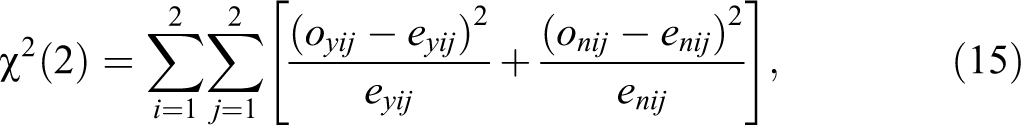
Numerical Example Illustrating the Unrelated Question Model—Cheating Extension with Four Samples.
Note.
Numerical Example Illustrating the Unrelated Question Model—Cheating Extension with Four Samples (Continued).
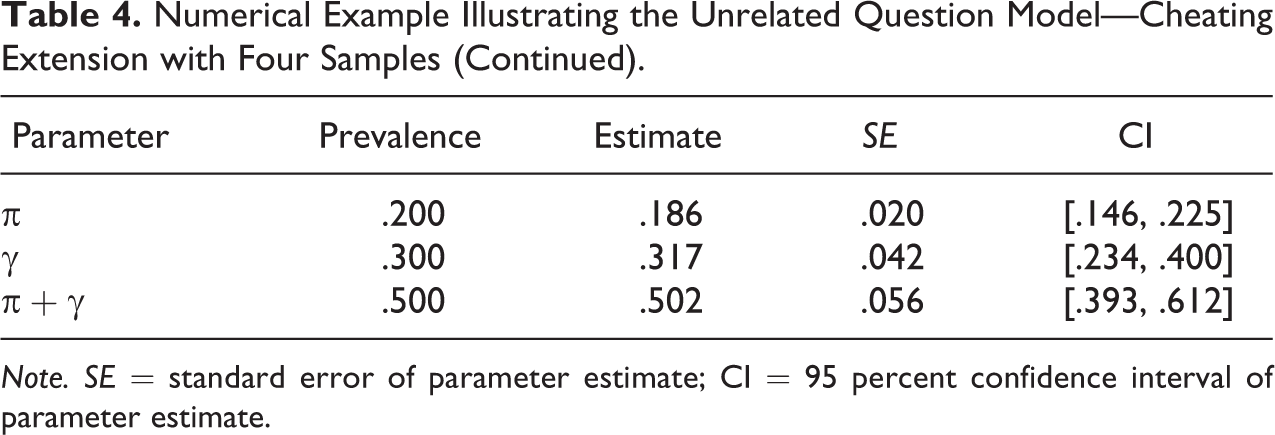
Note. SE = standard error of parameter estimate; CI = 95 percent confidence interval of parameter estimate.
where
Discussion
The present article extends the UQM to allow it to assess cheating while still ensuring respondents’ anonymity. This extension incorporates the basic idea of the CDM (Clark and Desharnais 1998) while preserving the more psychologically acceptable design of the UQM. Such an extension seems appropriate because there is ample evidence that many respondents cheat by always answering “no” in randomized response surveys (e.g., Elbe and Pitsch 2018; Moshagen et al. 2010; Ostapczuk 2011; Ostapczuk et al. 2009; Pitsch et al. 2007; Schröter et al. 2016), probably because a “no” response reduces the fear of embarrassment or other negative consequences. In particular, when a respondent is administered the UQM, such cheating would greatly diminish the conditional probability of being deemed a carrier of the sensitive attribute. For example, as noted earlier, Bayesian analysis reveals that for the design parameters
In the present article, we have first introduced an extension of the UQM utilizing the standard assumptions of the CDM—namely the assumption that cheaters will always respond “no” regardless of whether they are directed to the sensitive or to the neutral question. For this extension of the UQM, which we have termed the UQMC, we provide explicit formulae to compute the lower and upper bound of the prevalence estimate range, together with a likelihood ratio test to statistically assess the presence of cheating.
Second, we have discussed in this article the possibility of partial cheating in addition to complete cheating—a perhaps more realistic assumption. Partial cheaters answer honestly if directed to the neutral question but always respond “no” if directed to the sensitive question, even if they are in fact carriers of the sensitive attribute. The parameters of a model including partial cheating are only partially identifiable. Currently, we are not aware of a mathematical or experimental solution for this limitation. However, we have shown that even if partial cheating is disregarded, as in the UQMC, the lower prevalence limit is not affected if partial cheaters are present, although the upper limit may be higher than that estimated by the UQMC if partial cheaters are present. Importantly, such a lower bound provides relevant information like, for example, in a study on the prevalence of doping in elite athletics using the UQM (Ulrich et al. 2018). The UQM estimates of more than 30 percent were clearly much higher than the prevalence estimates from physical doping tests, which indicated a prevalence of about 2 percent at the time (World Anti-Doping Agency 2012). Consequently, even if this only represents a lower bound to the prevalence, the implications are considerable. In addition, the UQMC can account for a very likely type of nonadherence, namely complete cheating. Thus, even if one wants to avoid overconfident conclusions and regards partial cheating, UQMC estimates can have important implications.
Third, we have also shown how the adequacy of the UQMC can be empirically tested. Finally, we have performed power analyses to show that reliable parameter estimates can be obtained even with modest total sample sizes.
The described RRT cheating models assume the presence of “no” cheating for self-protective reasons. Nevertheless, it is at least conceivable that some respondents could cheat with a false “yes” response. For example, a clean athlete might be tempted to cheat with “yes” in order to inflate the prevalence estimate of doping in the hope that this would lead to stricter anti-doping policies (Elbe and Pitsch 2018). In light of this possibility, Feth et al. (2017) extended the CDM to address not only “no” cheating but also “yes” cheating. These authors regard the idea of the CDM in the context of a more general variant of the forced response method, in which there is a forced “no” response in addition to the forced “yes” response. The authors provide an in-depth discussion of the estimation of “yes” and “no” cheating within this framework and also mention the possibility of transferring this idea to the UQM. This CDM extension was recently applied to estimate the prevalence of doping among elite Danish athletes (Elbe and Pitsch 2018). Although the model revealed a high proportion of “no” cheaters, the proportion of “yes” cheaters was virtually nil. A similar conclusion was reached in a recent experimental individual-level validation study (Höglinger and Jann 2018), which examined whether cheating in a dice game could be accurately assessed by several indirect questioning techniques—and, if not, in which direction respondents misreport on their actual behavior. In case of the UQM, these investigators found a substantial prevalence of false-negative responses (i.e., “no” cheating), but not of false-positive responses (i.e., “yes” cheating). These findings are consistent with several lines of evidence indicating that misreporting usually occurs in the socially desirable direction (see Tourangeau and Yan 2007). In the present article, we have extended the standard UQM only for “no” cheating, but future extensions of the UQM could include the possibility of “yes” cheating (including, at least in theory, the possibilities of both complete and partial “yes” cheating). However, assessing for “yes” cheating would likely be useful only in rare situations where social desirability plays a subordinate role, or where there might be a plausible motivation for “yes” cheating.
In the UQMC, the estimation of two parameters requires independent subsamples. A possible limitation of this approach is that it relies on the assumption that these subsamples do not differ with respect to the true parameter values. In case of the cheating parameter, this assumption could be violated because different probabilities of receiving the sensitive question might induce different levels of trust and hence different levels of cheating. There are alternative approaches to estimate nonadherence parameters that do not rely on independent subsamples (e.g., Böckenholt and van der Heijden 2007; Böckenholt, Barlas, and van der Heijden 2009; Cruyff, Böckenholt, and van der Heijden 2016). However, these approaches usually involve the assessment of multiple RRM questions instead of using independent subsamples. Thus, these alternative approaches are not equally suited to the same research questions as approaches using subsamples. When applying the UQMC, this risk of violating the above-mentioned assumption can be minimized by defining the design parameters such that the motivation to cheat would not be expected to strongly differ between subsamples. Additionally, and most crucially, the model test proposed in this article allows one to assess the adequacy of these assumptions.
In this article, we have focused on the UQM and CDM. The Crosswise Model (Yu, Tian, and Tang 2008) provides an alternative to these two models. An advantage of this model is that it does not necessitate a randomization device, nor does it require a “yes”/“no” response. Thus, a response cannot be interpreted as a direct response to the sensitive question, which seems to increase perceived anonymity (Hoffmann et al. 2017). Despite these advantages, this model also has drawbacks. First, the sampling variance of this model’s prevalence estimate is relatively high and thus samples much larger than those typically used in the original UQM are required (Ulrich et al. 2012). Second, the Crosswise Model has been shown to be susceptible to other types of instruction nonadherence, which may distort the prevalence estimate (e.g., Höglinger and Diekmann 2017; Höglinger and Jann 2018).
In summary, the present article attempts to enrich the RRT toolbox by extending one of the most common RRT models, the UQM, to allow for the estimation of cheaters. This extended model is relatively easy to implement in surveys. Therefore, we recommend that cheating and model adequacy should be routinely taken into account in future RRT surveys that will employ the UQM.
Supplemental Material
Supplemental Material, Appendix - Cheater Detection Using the Unrelated Question Model
Supplemental Material, Appendix for Cheater Detection Using the Unrelated Question Model by Fabiola Reiber, Harrison Pope and Rolf Ulrich in Sociological Methods & Research
Supplemental Material
Supplemental Material, onlineSupp - Cheater Detection Using the Unrelated Question Model
Supplemental Material, onlineSupp for Cheater Detection Using the Unrelated Question Model by Fabiola Reiber, Harrison Pope and Rolf Ulrich in Sociological Methods & Research
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the Deutsche Forschungsgemeinschaft (DFG), grant 2277, Research Training Group “Statistical Modeling in Psychology” (SMiP).
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.