
Abstract
Does X affect Y? Answering this question is particularly difficult if reverse causality is looming. Many social scientists turn to panel data to address such questions of causal ordering. Yet even in longitudinal analyses, reverse causality threatens causal inference based on conventional panel models. Whereas the methodological literature has suggested various alternative solutions, these approaches face many criticisms, chief among them to be sensitive to the correct specification of temporal lags. Applied researchers are thus left with little guidance. Seeking to provide such guidance, we compare how different panel models perform under a range of different conditions. Our Monte Carlo simulations reveal that unlike conventional panel models, a cross-lagged panel model with fixed effects not only offers protection against bias arising from reverse causality under a wide range of conditions but also helps to circumvent the problem of misspecified temporal lags.
Introduction
Many studies in the social sciences try to answer questions about causal relationships such as: Does bad pay cause occupations to feminize (England, Allison, and Wu 2007)? Is the risk of divorce increased by limited financial resources (Killewald 2016)? What is the effect of social contacts on labor market success (Mouw 2006)? Most methodologists consider controlled randomized experiments as the “gold” standard for causal inference (Imbens and Rubin 2015; Rosenbaum 2017). Useful as they are, however, experiments are hardly a silver bullet for social science research. Many interesting variables related to human behavior and its consequences—such as working conditions, family life, or social contacts—are difficult to manipulate, with ethical, political, and practical restrictions forcing researchers to deviate from the experimental ideal (Shadish, Cook, and Campbell 2002). More often than not, social scientists therefore have to rely on observational data for causal inference (e.g., Morgan and Winship 2015).
Panel data have become particularly prominent for causal inference based on observational data (Bell and Jones 2015; Brüderl and Ludwig 2015; Imai and Kim 2019). A key reason for the popularity of panel models is that they allow to exploit change within units over time (e.g., individual change) to eliminate unobserved time-invariant heterogeneity, which considerably reduces the risk of confounding (Allison 2009; Halaby 2004; Wooldridge 2010). Moreover, researchers frequently turn to panel data since they expect them to determine causal order (Vaisey and Miles 2017). Reconsidering the abovementioned research questions, one might ask: Does feminization of occupations reduce pay? Do spouses adjust their work behavior in anticipation of marital problems? Do successful people associate with one another? As these examples illustrate, the causal arrow often might run in both directions or even only in the other direction. Establishing causal order by accounting for reverse causality therefore is a key challenge in many social scientific areas of research. 1
In stark contrast to the well-known issue of unobserved heterogeneity, however, it is much less clear for researchers how to deal with reverse causality. Even with panel data, it is far from trivial to identify the causal effect of X on Y if reverse causality is present. Having long recognized this problem, the econometric and statistical literature has developed various models to disentangle the dynamic interplay of X and Y with observational data. This includes first-difference (FD) models with lagged independent variables (Allison 2009), dynamic panel models relying on instrumental variables (Arellano and Bond 1991), cross-lagged structural equation models (Finkel 1995), and, more recently, cross-lagged panel models with fixed effects (FE; Allison, Williams, and Moral-Benito 2017). Yet the number of suggestions seems to equal the number of critics (e.g., Bellemare, Pepinsky and Masaki 2017; Reed 2015), some of which even conclude that none of the abovementioned models solves the problem of reverse causality under general conditions (Brüderl and Ludwig 2015). 2
Further complicating the matter for applied researchers, Vaisey and Miles (2017) recently showed that panel models are sensitive to the correct specification of temporal lags. Specifically, they demonstrated that lagged first-difference (LFD) models provide highly misleading estimates if the effect of X on Y is not fully lagged as captured by the observed data. However, it is an open question whether this problem also applies to other panel models. Even more importantly, applied researchers currently find little guidance other than the warning not to “rely on the ordering of the data to establish causal priority unless the lags between panels match the real-world causal lags in the processes under study” (Vaisey and Miles 2017:64). While this advice is well justified, it does not address the question what researchers can do if they face reverse causality and/or are uncertain about the precise temporal nature of the “real-world causal lags.”
In sum, the absence of clear modeling standards leaves researchers uncertain how to deal with reverse causality in panel models and what to do if the timing of causal effects is unknown. Aiming to provide such guidance, we first give a short overview of existing approaches by discussing respective models and their key assumptions regarding reverse causality. We then simulate panel data in order to assess how different panel models perform under varying conditions. Specifically, we vary the degree of time-invariant unobserved heterogeneity, the presence of reverse causality, and the temporal lags of the causal effect of X on Y. Based on the results, we identify different scenarios for which certain panel models are adequate. We conclude with recommendations for researchers on how to deal with reverse causality in practice.
Panel Models in Face of Reverse Causality
In the following three subsections, we review different panel models, focusing on their exogeneity assumptions. These assumptions are not only crucial for understanding why reverse causality threatens conclusions derived from models that assume strict exogeneity but also offer a potential solution to the problem by relaxing this assumption. 3 For the sake of simplicity, we assume a balanced panel with n = 1,…, N, units of analysis, t = 1,…, T, panel waves, and NT observations, but the core assumptions about reverse causality also extend to unbalanced panels. We further focus on identifying the effect of X on Y, thus considering reverse causality—the effect of Y on X—as a nuisance that threatens causal inference rather than a substantive phenomenon one is interested in. 4
Panel Models Assuming Strict Exogeneity
Consider we want to estimate the effect of a set of variables X on an outcome variable Y using panel data. A good starting point for introducing models for microlevel panels with large N and small T is the pooled OLS (POLS) model,
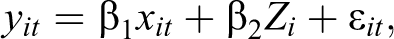
which maps the outcome variable
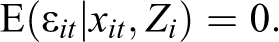
While generally allowing for the possibility of reverse causality, within POLS, causal inference for the effect of a variable X on Y is valid only if the model adequately captures all variables that simultaneously affect X and Y. Unfortunately, this strong assumption is rarely met in empirical applications, as many confounders either might not have been measured adequately or were not observed in the first place (see Brüderl and Ludwig 2015; Halaby 2004). POLS estimates therefore face an inherent risk of bias due to unmeasured unit-specific confounders that violate the key assumption of contemporaneous exogeneity.
A next natural step is to decompose the error term into a unit-specific part
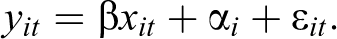
The second approach is the random effects (RE) model. The RE model also includes a unit-specific error term
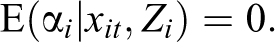
Despite these differences of the FE and the RE models in handling unobserved heterogeneity, they share the core assumption of strict exogeneity:
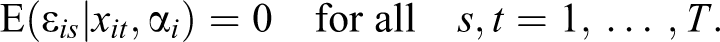
The key point is that this assumption is necessarily violated in case of reverse causality. Strict exogeneity forbids current values of
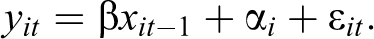
The idea behind this approach is that while
Panel Models Relaxing the Strict Exogeneity Assumption
The key takeaway message from the previous section is that relaxing the assumption of strict exogeneity is needed for dealing with reverse causality. One such approach is offered by a close relative of the FE model, the FD model. Instead of controlling for time-invariant unobserved heterogeneity by demeaning the data, the FD model eliminates
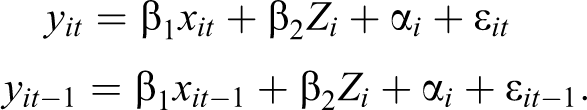
Taking the difference of these equations removes both the unit-specific error
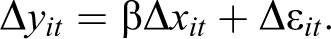
Since the unit-specific error term
In particular, a LFD model has been suggested in order to tackle reverse causality (Allison 2009; for empirical applications, see England et al. 2007; Leszczensky 2013; Levanon, England and Allison 2009; Martin, Van Gunten, and Zablocki 2012). The model is specified as follows:
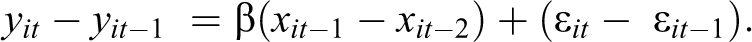
Compared to FE or RE models, the LFD model promises to offer protection not only against bias arising from unobserved time-invariant heterogeneity but also from reverse causality. The former is achieved by eliminating the unit-specific error term
Unfortunately, though, as Vaisey and Miles (2017) recently showed, estimates from the LFD model suffer from severe bias if the model does not adequately depict the true timing of causal effects. This is because the LFD model rests on the crucial assumption that the change of Y between two points in time is indeed a function of the specified difference of X between two preceding points in time. Yet as Vaisey and Miles (2017) demonstrate in simulations with three panel waves, if the true causal effect of X on Y is contemporaneous rather than lagged, the LFD model substantially underestimates the true effect size and provides estimates that go in the opposite direction. Whether or not the application of the LFD model is appropriate thus crucially depends on whether or not the lags in the panel data match the real-world causal lags in the process under study. This risk of specification error highlights the need for precise theorizing regarding the actual lag structure of the causal process under investigation. The LFD model accordingly is hardly a panacea for dealing with reverse causality; in fact, it can do more harm than good if it is applied without precise theoretical knowledge about the underlying data generating process or if the temporal lags in the available data simply do not match the actual causal process.
Dynamic Panel Models Allowing for Both Strict and Sequential Exogeneity
In addition to the LFD model, dynamic panel models have been suggested to address the endogeneity problem caused by reverse causality. Dynamic panel models try to map the interplay between X and Y over time by including lagged values of the dependent variable on the right-hand side of the equation:
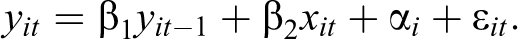
However, as Nickell (1981) has shown, including a lagged-dependent variable (LDV) in FE or RE models necessarily induces a correlation of the idiosyncratic error
One prominent econometric model to resolve this issue has been suggested by Anderson and Hsiao (1981, 1982) and extended and popularized by Arellano and Bond (1991). Since the LDV from the first lag is correlated with
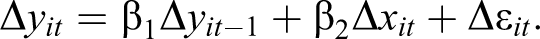
Then
The important point is that both types of GMM estimators allow distinguishing between strictly exogenous variables on the one hand and sequentially exogenous, so-called predetermined, variables on the other. As in case of FE or RE models, strictly exogenous variables are not allowed to be correlated with past, present, and future values of the error term. By contrast, predetermined variables are assumed to be sequentially exogenous. Like strict exogeneity, sequential exogeneity forbids the current idiosyncratic error
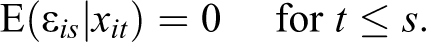
Independent variables that are assumed to be predetermined are treated in a similar way as Y is in the Arellano-Bond (AB) model, that is, they are instrumented using lagged values of the same independent variable. Compared to RE and FE models, AB-type panel estimators thus weaken the exogeneity assumption for a subset of regressors, thereby providing consistent estimates even if reverse causality is present. 5
In principle, the AB estimator and related dynamic panel models offer a powerful toolbox to tackle endogeneity problems caused by both reverse causality and unobserved heterogeneity. However, despite its wide application in econometrics, the approach is known to suffer from downward bias in face of a large number of moment conditions (Hsiao 2007:90) and weak instruments problems (Bun and Windmeijer 2010), both of which can undermine causal inference. In addition, AB estimators show poor finite-sample performance (Newey and Windmeijer 2009) and require a large number of sampled units (Moral-Benito, Allison, and Williams 2018).
The cross-lagged panel model with FE addresses some of these concerns. It is based on work by Moral-Benito (2013) who showed that a dynamic panel model with lagged independent variables and FE can be estimated by maximum likelihood without taking FDs and without any assumptions about initial observations of X and Y. Allison, Williams, and Moral-Benito (2017) further showed that the maximum likelihood (ML) method suggested by Moral-Benito (2013) can be implemented in a structural equation modeling (SEM) framework, hence calling it the ML-SEM method (also see Bollen and Brand 2010 for a general structural equations approach to panel models). 6 Consider the following equation:
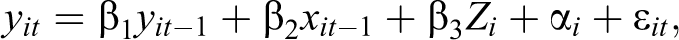
which includes lagged values of the dependent variable
The equation above can then be reproduced within the SEM framework. Following Allison et al. (2017), Figure 1 illustrates the model for T = 4. For the ease of model presentation, covariates Zi
are not displayed. Like the LFD model and AB-type estimators, the ML-SEM method allows for reverse causality by assuming sequential exogeneity for
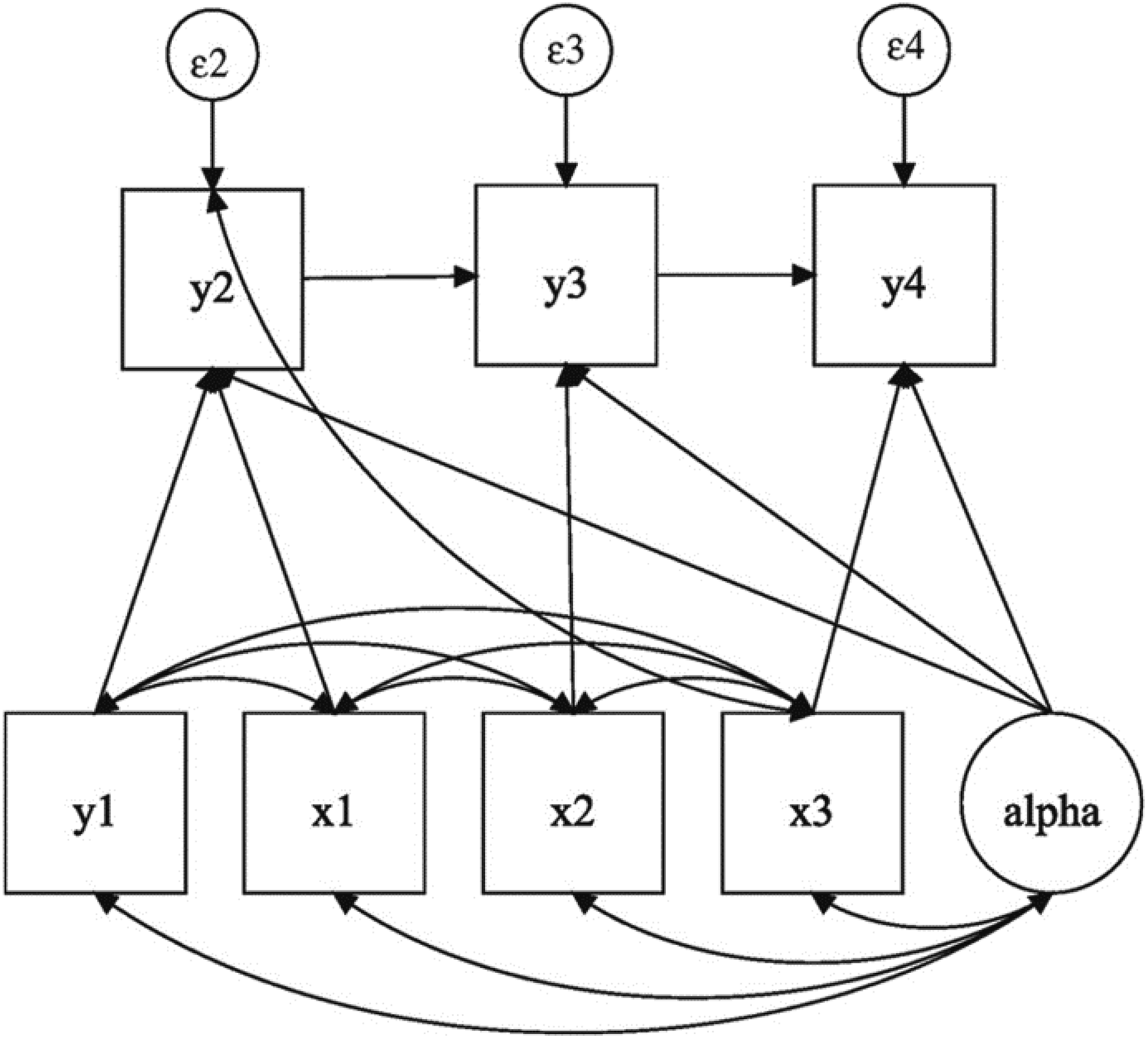
Path diagram for four-period ML-SEM. Source: Allison et al. (2017:6).
In Monte Carlo simulations, Moral-Benito (2013), Allison et al. (2017), and Moral-Benito et al. (2018) show that applying the ML-SEM method to the cross-lagged panel model with FE seems to keep the promise of offering protection against both time-invariant unobserved heterogeneity and reverse causality. Comparing ML-SEM and AB estimators, all three simulation studies highlight advantages of ML-SEM regarding unbiasedness efficiency, and finite sample performance.
However, these earlier simulations do not consider the problem raised by Vaisey and Miles (2017), that is, that inference based on FD models is prone to bias due to misspecification of temporal lags. 7 Hence, like for RE, FE, and AB models, it remains open whether the ML-SEM method for cross-lagged panel models with FE is sensitive to the correct specification of temporal lags.
Summary
Let us briefly summarize our discussion of different panel models and their exogeneity assumptions, which are crucial for addressing reverse causality. As is well known, the POLS and the RE model will provide biased estimates if reverse causality and/or time-invariant unobserved heterogeneity are present because both of them introduce endogeneity and therefore violate the key exogeneity assumptions. While the FE and the FD model provide protection against endogeneity arising from unobserved heterogeneity, they also yield biased estimates in case of reverse causality because reverse causality violates the assumption of strict exogeneity. In contrast, the LFD model accounts for both time-invariant unobserved heterogeneity and reverse causality by relaxing the strict exogeneity assumption and only requiring sequential exogeneity. As shown by Vaisey and Miles (2017), however, the LFD model only provides unbiased estimates if the effect of X on Y is indeed fully lagged, thus being prone to specification error. Finally, the AB and ML-SEM models also promise to perform well in case of time-invariant unobserved heterogeneity and/or reverse causality, the latter of which is achieved by assuming sequential rather than strict exogeneity. However, it is an open question whether these models are also sensitive to the specification of temporal lags.
Simulation Study
In order to assess how different panel models perform under different conditions regarding reverse causality, we simulate panel data varying the degree of unobserved heterogeneity, the extent of reverse causality, and the temporal nature of the causal effect of X on Y.
Consider two random variables, Y and X, which might have a reciprocal causal relationship, as well as a vector of time-invariant variables Zi
that have time-invariant effects on both Y and X. To determine the starting values
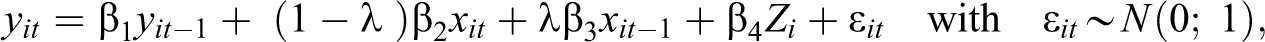
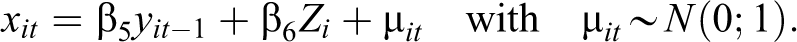
The parameter
The parameters
Reverse causality is captured by the parameter
Table 1 summarizes the different parameters of the simulation and their possible values. In total, our simulation covers 3 × 3 × 2 × 2 = 36 scenarios. For each scenario, we simulated 500 data sets with N = 500 observations and T = 5 panel waves. 11
Components of the Simulation and Parameter Values.
Based on these simulated data, we estimated the different panel models discussed above in order to assess their performance. To explore how the different models respond to the problem of wrong temporal lags, we used three different specifications for each model: one including only the contemporaneous effect of X, one including only the lagged effect of X, and one including both the contemporaneous and the lagged effect of X. The model that includes both a contemporaneous and a lagged effect is justified on two grounds. On the one hand, both contemporaneous and lagged values of X might affect Y; for example, marital problems can be caused both by past and by current financial problems. On the other hand, such a model corresponds to a situation in which substantive knowledge and theory are not precise enough to determine the correct temporal lag for the effect of X on Y. A model with both a contemporaneous and a lagged effect allows researchers to address this uncertainty by estimating both effects (for an approach to handle atheoretical lags, see also Cranmer, Rice, and Siverson 2017).
We estimated all models using Stata version 14.1. For the AB-estimators, we used the user-written command xtabond2 (Roodman 2012), which is more flexible than the standard Stata command. We rely on the approach advocated by Arellano and Bond (1991) taking FDs in a first step to remove unobserved heterogeneity and then using second- and higher order lags of the dependent variables as instruments in a standard GMM framework to deal with reverse causality. 12 For the ML-SEM method, we used the user-written command xtdpdml, which serves as a shortcut for Stata’s sem command (Williams, Allison, and Moral-Benito 2018). In the ML-SEM, coefficients for the effects of X on Y, and vice versa, are constrained to be equal across all points in time. Our Stata code is publicly and permanently available at the Harvard Dataverse (Leszczensky and Wolbring 2019).
Results
We present results obtained from three different specifications of the six models discussed in Panel Models in Face of Reverse Causality section: the POLS model, the RE model, the FE model, the FD model, the AB estimator, and the cross-lagged model with fixed effects (ML-SEM). Following Vaisey and Miles (2017), we distinguish between three worlds that differ with respect to the timing of causal effects. In the contemporaneous world, xt
has an effect on yt
. In the lagged world,
Contemporaneous World
We start by considering a world in which Y is only affected by the contemporaneous value of X, that is, in which
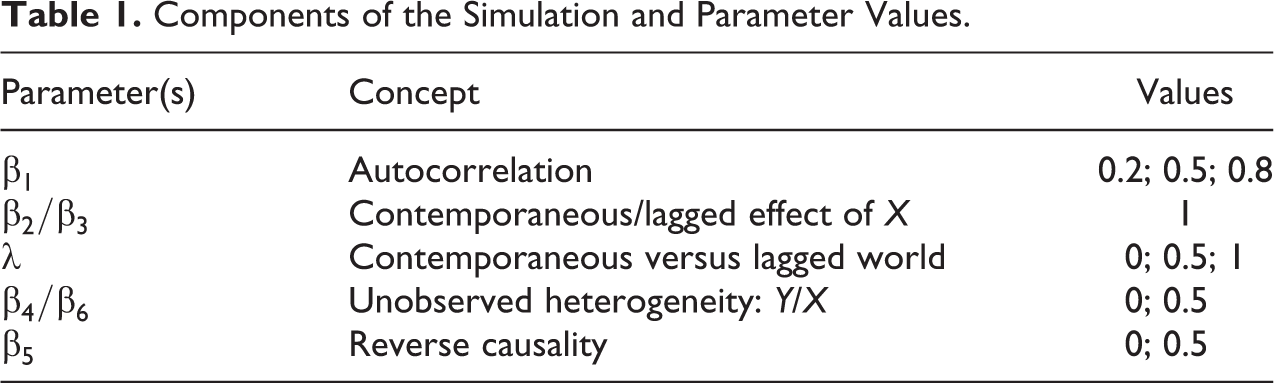
Figure 2 shows how the different panel models perform in four different scenarios. The tabulated results of all models in Figure 2 are found in Section B in the Online Supplementary, as are all other models on which the following figures are based. The two horizontal lines in Figure 2 represent the true causal effects of
Simulation results for the contemporaneous world (n = 500, t = 5, 500 iterations; 95% confidence intervals). Unbiased estimates are colored in black, biased estimates in gray. The solid horizontal lines represent the true estimates.
Panel A in Figure 2 depicts the simplest possible scenario in which neither time-invariant unobserved heterogeneity nor reverse causality contributed to the data generating process. Although empirical applications rarely face the luxury of such an idealized scenario, it serves as a useful benchmark for comparison.
Starting with the models that only include the contemporaneous effect of X on Y (squares in Figure 2), from POLS to ML-SEM, all of them correctly identify the true effect of xt . This is hardly surprising, of course, since the assumption of strict exogeneity as well as the weaker assumptions of contemporaneous and sequential exogeneity hold if neither time-invariant unobserved heterogeneity nor reverse causality are present.
Turning to the models that include only the lagged effect of X on Y (circles in Figure 2); however, most models fail to identify the lagged nil effect. The coefficient of the FD model (−0.5) replicates the finding by Vaisey and Miles (2017), that is, a LFD model produces biased estimates in the opposite direction of the true effect if the specification does not accurately map the actual causal process. Extending their finding, Figure 2 indicates that this problem of misspecified lags similarly applies to the RE, the FE, and the ML-SEM model, all of which yield significant negative coefficients even though no lagged effect contributed to the data generating process. In fact, only the POLS and the AB model correctly identify the lagged nil effect.
Finally, if both the contemporaneous and the lagged effect of X on Y are included in the estimation equation, all models correctly identify both effects (triangles in Figure 2). This finding suggests that it may be a promising approach to include both contemporaneous and lagged effects for addressing the problem of misspecified temporal lags. The question, however, is whether this approach also works in the other scenarios and worlds.
In the next scenario, we therefore added time-invariant unobserved heterogeneity to the data generating process. The results in panel B of Figure 2 show precisely the pattern one would expect for this scenario. Estimates from the POLS and the RE model are biased, as both of them assume the absence of time-invariant unobserved factors. In contrast, the other four models account for such unobserved heterogeneity; accordingly, the results of the FE, the FD, the AB, and the ML-SEM model are not biased by time-invariant unobserved heterogeneity.
In the third scenario, we switched time-invariant unobserved heterogeneity back off, the well-known consequences of which we just saw. Instead, we added reverse causality, that is, a causal feedback loop from
In the final scenario, we switched time-invariant unobserved heterogeneity back on, thus considering the most likely case for applied researchers in which causal inference is threatened both by time-invariant unobserved heterogeneity and by reverse causality. Minor variations aside, panel D in Figure 2 shows that reentering time-invariant unobserved heterogeneity does not change the main conclusions derived from panel C. While results of POLS, RE, FE, and FD models are biased in presence of time-invariant unobserved heterogeneity and reverse causality, AB and ML-SEM yield unbiased estimates of the effects of X on Y even in this most delicate scenario.
Comparing the AB and ML-SEM models that successfully identify the effects of X on Y, two results stand out. First, whereas AB always correctly identifies the lagged nil effect of X, ML-SEM only does so if it additionally includes the contemporaneous effect of X. Adding to the results by Vaisey and Miles (2017), ML-SEM therefore falls prey to precisely the same problem as the FD or FE model; AB, by contrast, is not affected by this particular specification problem. Second, however, ML-SEM produces smaller standard errors than AB, thus being more efficient. This advantage in efficiency is consistent with simulations by Allison et al. (2017) and Moral-Benito (2013).
Lagged World
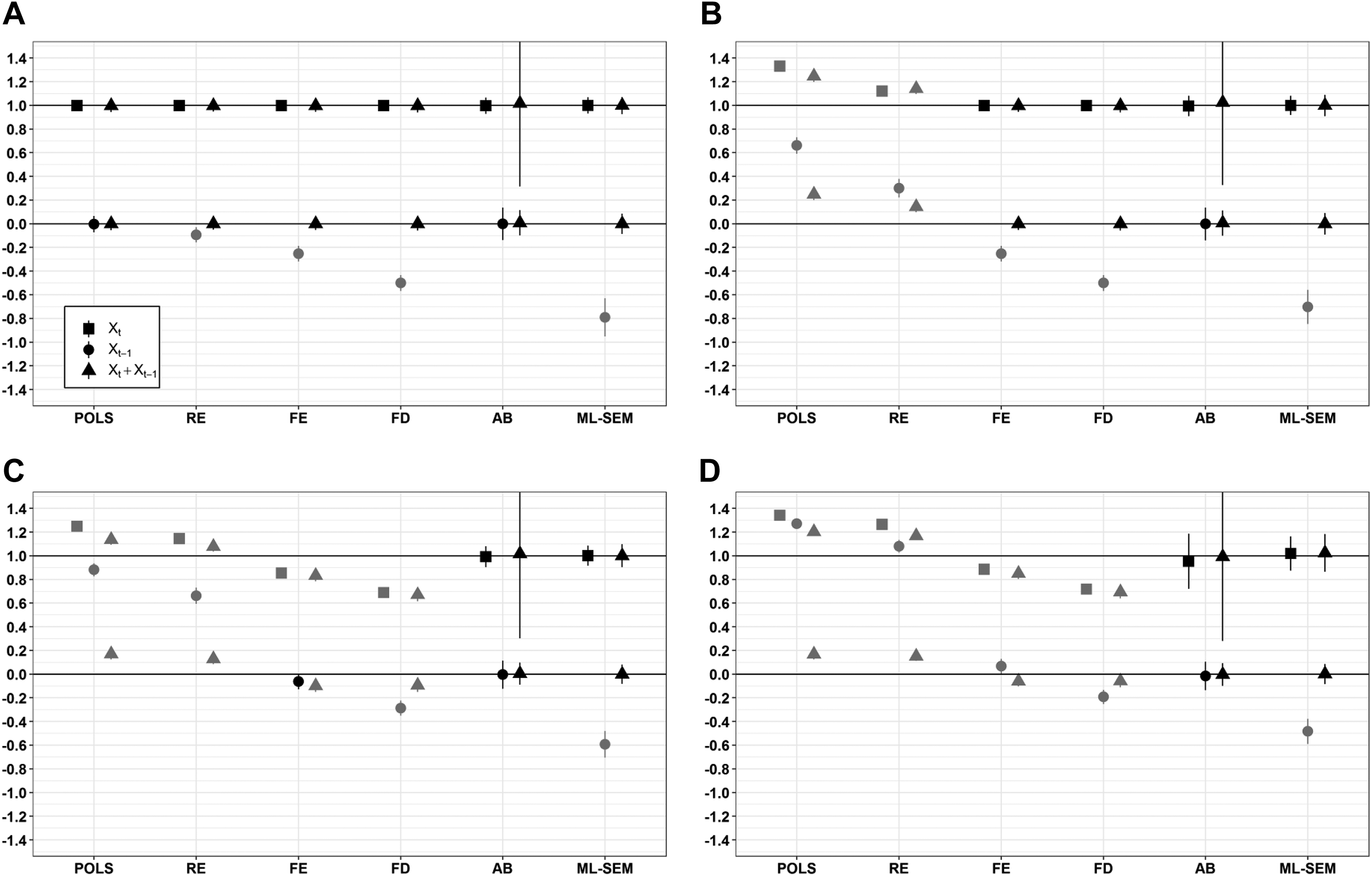
We continue with a world in which Y is solely a function of the lagged value of X, that is, in which
Simulation results for the lagged world (n = 500, t = 5, 500 iterations; 95% confidence intervals). Unbiased estimates are colored in black and biased estimates in gray. The solid horizontal lines represent the true estimates.
In sum, the results confirm that only the AB and ML-SEM model are able to identify the true causal effects of both the lagged and the contemporaneous value of X in all scenarios. Complementing the finding by Vaisey and Miles (2017), the results caution against including (only) a contemporaneous effect in panel models as a default. If the actual causal effect is lagged, only modeling a contemporaneous effect leads to the underestimation of the actual causal effects with coefficients potentially even switching signs.
Mixed World
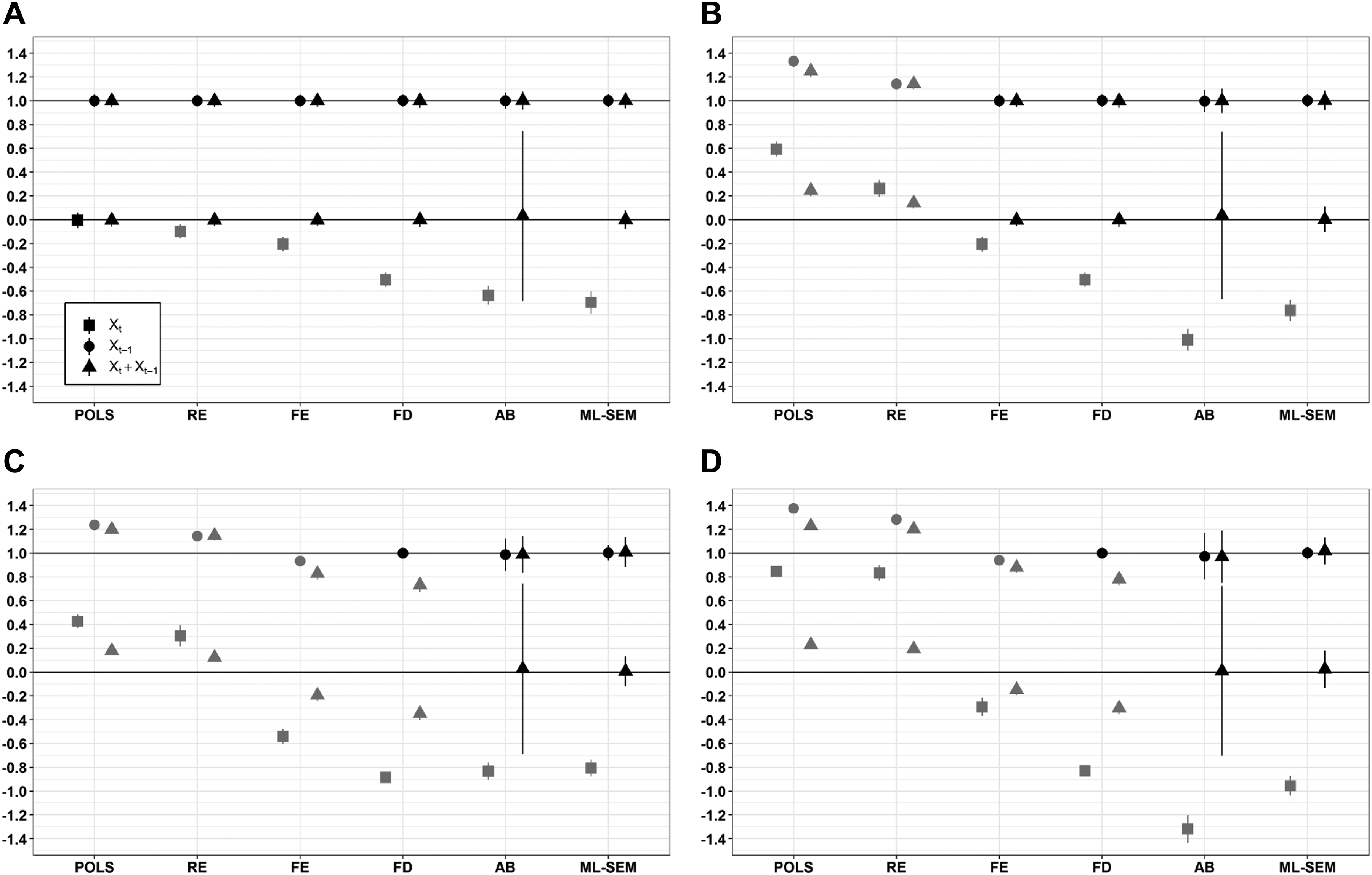
In the final step, we consider a world in which Y is affected both by the contemporaneous and by the lagged value of X, that is, in which
Figure 4 shows the results for such a mixed world. In contrast to the previous figures, the graphs include only one horizontal line, at which both effects of 0.5 should be located in case of unbiased estimation. We again address the four different scenarios, in turn, beginning with the simplest one in which neither time-invariant unobserved heterogeneity nor reverse causality are present.
Simulation results for the mixed world (n = 500, t = 5, 500 iterations; 95% confidence intervals). Unbiased estimates are colored in black and biased estimates in gray. The solid horizontal lines represent the true estimates.
Panel A in Figure 4 shows that all six models correctly identify both the contemporaneous and the lagged effect of X, but only if both of them are included in the model. The exception from this pattern is the POLS model, which always correctly identifies the respective effect because of its weaker requirement of contemporaneous exogeneity. In contrast, due to their more demanding assumptions of strict or sequential exogeneity, most other models underestimate the respective effect if only either one of the two effects is included.
Panel B in Figure 4 shows once again that entering time-invariant unobserved heterogeneity induces bias in estimates from POLS and RE models. The pattern mirrors the one of the scenario with a fully contemporaneous effect that we described above, so we do not reiterate it here. Likewise, panels C and D in Figure 4 show that, irrespective of whether or not time-invariant unobserved heterogeneity is present, reverse causality again biases the results not only of the POLS and RE model but also of the FD and FE model. In contrast, both AB and ML-SEM yield unbiased estimates. However, as before, the former model is much less efficient than the latter one.
Robustness Checks
To examine whether our findings are sensitive to sample size, we ran all simulations with n = 100. As the results in Section C of the Online Supplementary show, reduced sample size has little implications for our findings; all results described above hold. Reflecting the loss of statistical power, the only notable yet entirely expectable differences are increased standard errors. This holds true for all models, but especially for ML-SEM.
As a further robustness check, returning to a sample size of n = 500, we varied the length of the panel, considering both less (t = 3) and more (t = 10) points in time. Section D in the Online Supplementary shows that with t = 10—besides more precise estimates—the results are again very similar to those obtained for t = 5.
Section E in the Online Supplementary shows that with t = 3, the results also are very similar to those obtained for t = 5. Again, only the AB model with one effect and the ML-SEM that include both the contemporaneous and the lagged effect of X on Y identify the actual effects in all different scenarios. However, in the most complex scenario that entails both time-invariant unobserved heterogeneity and reverse causality, losses in efficiency are so huge that point estimates are neither significantly different from zero nor from one in most cases. This serves as a note of caution that dynamic panel models might be the right choice in face of reverse causality but are pretty demanding regarding the data. As these robustness checks illustrate, the length of the panel appears to be more important than the number of observations in this regard.
In a final robustness check, we introduced serial correlation by simulating a first-order autoregressive process:
Conclusions and Recommendations for Researchers
This simulation study aimed to provide guidance on how to deal with reverse causality using panel data. After reviewing existing panel models and their key assumptions regarding reverse causality, we assessed their performance under different specifications and a wide range of conditions. Our results demonstrate that frequently used panel models, such as RE or FE models, suffer from biases due to reverse causality, thus being hardly a silver bullet if causal inference is threatened by reverse causality. As also shown, and consistent with Vaisey and Miles (2017), the LFD model is generally better suited to handle reverse causality, but only if the effect of X on Y is indeed fully lagged.
Extending the findings by Vaisey and Miles (2017), we further showed that not only the LFD model, but all considered panel models except for POLS are very sensitive to the correct specification of temporal lags. Our simulation thus reveals that the problem of misspecified lags is rather general, as it also applies to the RE model, the FE model, the AB estimator, and the cross-lagged panel model with FE (ML-SEM). If the effect of X on Y is fully contemporaneous and no lagged effect contributed to the data generating process, all of these models, except for AB, nevertheless yield a statistically significant lagged effect. On the other hand, if the actual causal effect is fully lagged, only modeling a contemporaneous effect all models, including AB, underestimated the actual causal effect with coefficients even switching signs. These findings caution against an unreflected specification of contemporaneous effects in panel models without knowledge about the actual causal process at work. The same holds for using lagged effects as a default.
Our simulation results also show that ML-SEM may help researchers to overcome the problem of misspecified temporal lags. Whereas ML-SEM falls prey to precisely the same lag specification problem as other models, our simulations show that this problem only occurs if ML-SEM includes either a contemporaneous or a lagged effect of X on Y. If both effects are specified, by contrast, ML-SEM provides correct estimates of both effects in all scenarios.
While earlier work has warned researchers what not to do in order to deal with reverse causality (e.g., Brüderl and Ludwig 2015; Vaisey and Miles 2017), our simulation study thus offers guidance on what researchers can do with (at least) three waves of panel data. In short, ML-SEM including both a contemporaneous and a lagged effect of X on Y provides correct estimates of both effects, even in case of reverse causality. If the contemporaneous effect in ML-SEM is negligible, this approach can also serve to justify the application of the LFD model or the AB estimator.
While our simulation results indicate that researchers can rely on ML-SEM to address reverse causality, the method is no panacea either. First of all, it is important to note that our simulation only generated scenarios in which the correct lags are available in the data. While applied empirical research has to make this assumption, more research is needed to explore how ML-SEM and other models perform in cases in which the timing of panel waves does not match the true causal process under investigation. In any case, addressing reverse causality imposes high requirements on the data. Like other panel models, ML-SEM requires a sufficient amount of within variation and at least three panel waves if a lagged effect is included. In addition, ML-SEM contains more parameters to estimate than standard panel models, especially if—as we recommend—both the contemporaneous and the lagged effect of X are specified. While our simulations showed that point estimates are still correct in a setting with three waves and 500 observations, standard errors become so large that it became hard to derive any meaningful substantive conclusions from the empirical results.
Using ML-SEM, further problems can arise that are not directly related to reverse causality but might still limit its usefulness in empirical applications. First, as shown in a robustness check, ML-SEM provides biased estimates in case of serial correlation. Given that serial correlation is rather common using panel data, researchers must be aware of this issue and pay special attention to serial correlation, for example, by directly modeling persistence of variables over time and controlling for variables causing it. Second, ML-SEM requires an iterative algorithm that can fail to converge or can be slow to run (Williams et al. [2018] provide tips for dealing with convergence problems). As shown in Section G in the Online Supplementary, convergence of ML-SEM is not a major issue in simulations with five waves, but it proved to be problematic in shorter panels with only three waves. Furthermore, longer panels (t >10) and unbalanced panels can cause estimation problems; sometimes, switching the software (e.g., to MPlus or R’s lavaan package) might help. Finally, given the rather favorable conditions in our simulation of a simple and systematic data generating process, complete data, and the exclusion of time-varying covariates, additional challenges may also arise in real-world data that contain missing values, nonnormally distributed variables, and interaction effects. Although Moral-Benito et al. (2018) and Williams, Allison, and Moral-Benito (2018) highlight that ML-SEM can use full information maximum likelihood to deal with missing data and also give recommendations on how to deal with nonnormality, it remains open to future research whether our simulation results also hold for such more complex scenarios.
These practical issues aside, our recommendation for researchers facing reverse causality with panel data is straightforward: use ML-SEM to estimate both the contemporaneous and the lagged effect of X on Y. Only this approach yields unbiased estimates of both effects even if reverse causality is present, and it allows solving the problem of misspecified lags that plagues other panel models.
Supplemental Material
Online_Appendix - How to Deal With Reverse Causality Using Panel Data? Recommendations for Researchers Based on a Simulation Study
Online_Appendix for How to Deal With Reverse Causality Using Panel Data? Recommendations for Researchers Based on a Simulation Study by Lars Leszczensky and Tobias Wolbring in Sociological Methods & Research
Footnotes
Authors’ Note
Both authors contributed equally.
Acknowledgments
We thank Henning Best, Josef Brüderl, Thorsten Kneip, Gerhard Krug, Volker Ludwig, Jochen Mayerl, Fabian Ochsenfeld, Robin Samuel, and the reviewers for helpful comments. We are also grateful for feedback from the participants of the Fall meeting 2017 on “Causal Inference” of the section “Model Building and Simulation” of the German Sociological Association, the 2017 research seminar “Analytical Sociology” at Venice International University, and the Sixth Interdisciplinary International Pairfam Conference 2018 on “Innovations in Panel Data Methods” at the University of Munich.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplementary material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.