
Abstract
Analyzing relationships of necessity is important for both scholarly and applied research questions in the social sciences. An often-used technique for identifying such relationships—fuzzy set Qualitative Comparative Analysis (fsQCA)—has limited ability to make the most out of the data used. The set-theoretical technique fsQCA makes statements in kind (e.g., “a condition or configuration is necessary or not for an outcome”), thereby ignoring the variation in degree. We propose to apply a recently developed technique for identifying relationships of necessity that can make both statements in kind and in degree, thus making full use of variation in the data: Necessary Condition Analysis (NCA). With its ability to also make statements in degree (“a specific level of a condition is necessary or not for a specific level of the outcome”), NCA can complement the in kind analysis of necessity with fsQCA.
Introduction
Identifying relationships of necessity is of key interest in the social sciences and beyond. Examples of work focusing on relationships of necessity include studies in policy science (Rihoux and Grimm 2006) and organizational sciences (Dul 2016a). But “for any research area one can find important necessary condition hypotheses,” as the 150 examples from a large variety of areas in Goertz (2003:65-66) testify. A condition, or variable, is necessary when the outcome does not exist without it (i.e., if Y = 1 then X = 1) and the condition does not automatically produce the outcome (i.e., when X = 1, Y can be either 1 or 0). A necessary condition is a bottleneck, a constraint, for the outcome to exist. 1 Identifying such conditions is thereby useful for both applied and fundamental research questions, because many questions concern the prerequisites for a particular outcome of interest (e.g., democracy, peace, economic growth, successful business performance, and sales performance). Necessary conditions that are relevant 2 provide actionable knowledge that can “have very powerful policy implications” (Ragin 2000:203).
The technique that is nowadays often used for the analysis of necessary conditions that are beyond dichotomous, that is, conditions that can have other levels than just 0 (absent) or 1 (present), is fuzzy set qualitative comparative analysis (fsQCA; Ragin 2000, 2008a; Schneider and Wagemann 2012). 3 FsQCA is a set-theoretical technique based on fuzzy set theory and formal logic that can identify conditions or combinations of conditions (configurations) that are minimally sufficient and/or necessary for an outcome. 4 The analysis of necessity in fsQCA focuses on identifying what we label necessary conditions in kind. These are statements of the form: “X (either the presence or absence of a condition or configuration) is necessary for the presence or absence of Y.” Even though a fuzzy set itself has more levels, this results in “qualitative” statements about necessity.
In this article, we argue that great strides can be made by not only analyzing such necessary relationships in kind, but also what we label necessary relationships in degree. The latter make full use of the existing variation in fuzzy-set membership scores, allowing researchers to identify what specific level of the condition [Xc ] is needed for a specific level of the outcome [Yc ]. The latter results in quantitative statements about necessity. Such statements enable researchers to answer both applied research questions (such as what level of intelligence is required for a specific level of job performance?) and more fundamental ones (such as the research question of Lipset’s [1959] seminal study: which level of economic development is necessary for a high level of democracy?). Necessary Condition Analysis [NCA] (Dul 2016a), a recently developed technique for analyzing relationships of necessity that is also applicable to set-theoretical thinking, can answer precisely these kinds of questions. Complementing fsQCA with NCA yields results that are more precise or complete and can thereby contribute to theory development, theory testing, and/or offer policy advice or actionable knowledge. Complementing fsQCA with NCA is especially useful when the researcher uses fuzzy sets (as opposed to crisp sets) because the variation that is relevant goes beyond the distinction between “in” and “out” of a set. In those instances, largely ignoring the existing variation in degree is a missed opportunity. NCA takes this opportunity.
Especially in fields in which fsQCA has a longer history (such as political science and sociology), many fsQCA applications follow so-called good practice by performing an analysis of necessity prior to a sufficiency analysis (Schneider and Wagemann 2010:405). Still, the results of the sufficiency analysis typically form the study’s core. Also the methodological discussion on (fs)QCA concentrates on the sufficiency analysis, as for instance the Spring 2014 symposium on set-theoretical comparative methods (especially [fs]QCA) in the American Political Science Association Qualitative and Multimethod Research newsletter testifies, or the 2014 symposium on QCA in Sociological Methodology on Lucas and Szatrowski (2014).
There are a few exceptions to this focus on sufficiency in the QCA literature. Mello (2013) pays explicit attention to necessary conditions in his analysis of 24 journal publications using fsQCA in the fields of comparative politics, international relations, and sociology published between 2010 and 2013. Mello finds that 14 of the 18 studies testing for necessary conditions identified one or several of such conditions. Moreover, Bol and Luppi (2013) pleaded for making the best of QCA possibilities when it comes to analyzing relationship of necessity. To this end, they introduced a new operation called systematic necessity assessment that enables the identification of what we label necessary OR-configurations (see below). In such configurations, either X 1 or X 2 is necessary for the outcome. For example, green apple (e.g., Granny Smith) OR red apple (e.g., Pink Lady) is necessary for making an apple pie. Bol and Luppi’s approach is a welcome contribution to the literature because of its multivariate nature (i.e., focusing on configurations of conditions). A final exception is Rohlfing and Schneider’s (2013) work on identifying so-called typical, deviant, and irrelevant cases after performing a QCA analysis of necessity. They propose to use the variation in set membership across cases to differentiate between these types of cases (e.g., Rohlfing and Schneider 2013:222). Our article adds to this body of research, taking up the call of Mello (2013:18) to place “(…) more emphasis [on] necessary conditions,” focusing especially on how to identify and evaluate them.
This article is structured as follows. First, we briefly introduce how fsQCA analyzes relationships of necessity, whereby we also present a necessary condition typology (the second section). We then discuss how NCA analyzes relationships of necessity (the third section). Next, we present a reanalysis of data from a published article that theorizes—among other things—relationships of necessity (Schneider, Schulze-Bentrop, and Paunescu 2010), using both fsQCA and NCA (the fourth section). Subsequently, we compare the findings of the two analyses (the fifth section). The final section draws conclusions (the sixth section).
Analyzing Relationships of Necessity with fsQCA
Before we proceed, we first want to stress that we employ fsQCA as a data analysis technique that identifies empirical patterns in the data. In addition to being a technique, QCA—in all its variants—is also a research approach (Berg-Schlosser et al. 2009). QCA as an approach includes an iterative process of data collection, from ideas to evidence and back; model specification; a holistic view of cases; case selection, and so on (see Wagemann and Schneider 2010:378). Employing fsQCA as a technique means that we focus only on the so-called analytical moment (Ragin 2000) when cases have been selected and all conditions and the outcome have been calibrated (Wagemann and Schneider 2010:379). We do so because NCA is mainly a data analysis technique, that is, focuses on this analytical moment, and presumes that meaningful data are available after proper case selection and measurement, and perhaps data transformation. Of course, this does not preclude scholars from employing (fs)QCA as an approach in their study as a whole, while using NCA for the analytical moment.
Let us first address some issues regarding the type of and variation in the data that are used in both techniques. For both NCA and fsQCA, the data need to be reliable, valid, and—especially, but not exclusively, in the case of fsQCA—calibrated. Calibration (as used in QCA) is the transformation of what is typically called raw data (we prefer original data) into crisp sets or fuzzy sets. A fuzzy set is a “(…) a fine-grained, [pseudo] continuous measure that has been carefully calibrated using substantive and theoretical knowledge relevant to set membership” (Ragin 2000:7). In fsQCA, three qualitative thresholds (fully in the set, fully out of the set, and neither in nor out of a set) are defined and quantified as 1, 0, and 0.5, respectively. Using these qualitative anchors, each case is scored quantitatively according to the degree of set membership (e.g., one case has 0.2 membership, another case has 0.4 membership). Hence, fsQCA captures variation across cases in degree. It also captures variation in kind by considering a case out of the set when scoring <0.5 and in the set when scoring >0.5. Fuzzy sets’ ability to also capture variation in set membership in degree is considered an important advantage over crisp set QCA, which can capture only variation in kind (fully out of the set [0] or fully in the set [1]; Ragin 2000).
We propose to make full use of the variation in the degree of fuzzy-set membership scores in the analysis of necessity. NCA can do precisely this. Using fuzzy-set data in NCA allows for a more precise, or complete, interpretation of the necessary condition(s). For example, when using the verbal labels that can be attached to a fuzzy set membership score (almost fully in the set, more out than in of the set, etc.), the results of an NCA analysis can be interpreted for example as “being almost fully in the set (membership score of condition =0.8) is necessary for the outcome (membership score of the outcome ≥0.5),” or “being more out than in the set (membership score of condition =0.4) is necessary for an outcome that is almost fully in the set (membership score of the outcome =0.8).” 5 This is particularly useful for research questions about what level of a condition is necessary for what level of the outcome (such as in the Lipset example above).
Both techniques assume—in line with most data analysis techniques, including regression—that the condition or configuration (X) potentially causes the outcome (Y), in that X precedes Y and could be related to Y and that the scores of X and Y are reliable, valid (and calibrated—see above). 6 Note that while fsQCA can only be conducted on fuzzy-set data, NCA can be conducted on any type of data (including fuzzy sets) as long as the data are meaningful. To reveal better the differences and similarities between the analysis of necessity with fsQCA and NCA, we propose the following typology of relationships of necessity. The analysis of type 1 is a bivariate analysis (one condition and one outcome); the analysis of types 2 and 3 is a multivariate analysis (more than one condition and one outcome). In type 1, a condition is individually necessary for the outcome. Type 1 has two subtypes. Type 1A is the dichotomous necessary condition, that is, the condition is either absent (0) or present (1). Type 1B is the beyond-dichotomous necessary condition (discrete, i.e., with a finite number of levels, or continuous, i.e., an infinite number of levels). Type 2 is what we label the necessary AND-configuration. In this configuration, X 1 and X 2 are each necessary, as is their AND-combination. For instance, apple AND flour each are individually necessary for an apple pie, making apple and flour a necessary AND-configuration (as are the other necessary ingredients for making an apple pie). Finally, type 3 is the necessary OR-configuration, in which either X 1 or X 2 (green apple or red apple) is necessary for the outcome (apple pie). In the existing set-theoretical literature, the conditions constituting necessary OR-configurations are often labeled SUIN conditions: Sufficient but Unnecessary part of an Insufficient but Necessary configuration (Mahoney, Kimball, and Koivu 2009:126). Here, we use the more general term necessary OR-configuration instead. There are three categories of necessary OR-configurations: (3A) configurations including redundant conditions (since every minimally necessary condition or configuration to which a condition is added will still be necessary), (3B) configurations of which the different components are direct logical equivalents (red or green apple), that is, can be captured by a higher-order construct (apple; Schneider and Wagemann 2012), and (3C) configurations of which the components are indirect logical equivalents (e.g., green apple or pentyl pentanoate—a chemical with apple scent—both of which may give a sensation of apple in an apple pie). A necessary OR-configuration that includes redundant conditions (3A) is not minimal and should therefore be avoided (see note 4). Necessary OR-configurations (3B) and (3C) could be useful for theory development or testing and for policy advice and are therefore worth identifying. Still, we consider single necessary conditions (type 1) and their AND-configurations (type 2) as more meaningful theoretically than the necessary-OR configurations (type 3), because types 1 and 2 refer to single ingredients that are true prerequisites—and thus truly necessary—for a particular outcome. Because NCA is geared toward exactly this—the truly single necessary condition(s)—currently NCA does not focus on necessary OR-configurations. FsQCA can identify all three types of necessary relationships to make in kind statements. An individual condition is either necessary for the presence or absence an outcome or not (type 1B); a necessary AND-configuration is necessary for an outcome or not (type 2); and a necessary OR-configuration is necessary for an outcome or not (type 3). Set-theoretically, a relationship of necessity exists if the fuzzy-set membership scores of X are at least as large as the membership scores of Y. The following relationship should thus hold: Y ≤ X. In an XY plane or plot, which Figure 1 displays, this is the case if all cases are on or below the diagonal.
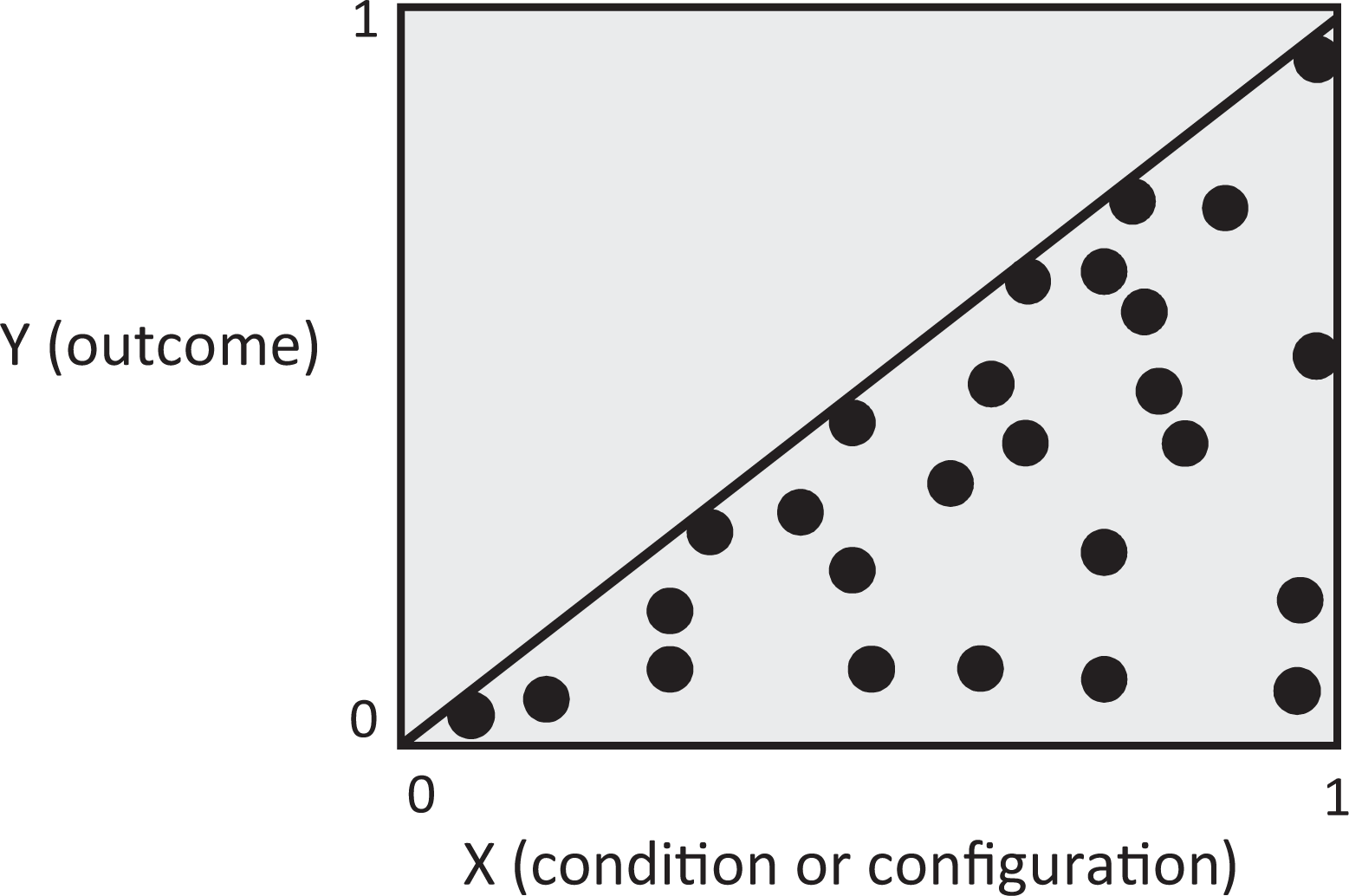
Relationship of necessity between X and Y according to fuzzy set Qualitative Comparative Analysis.
If researchers follow best practice, (fs)QCA starts with the bivariate analysis to identify any individually necessary conditions (type 1). When there are such conditions, it continues to identify if there are also necessary AND-configurations (type 2). When there are no individually necessary conditions (and thus also no necessary AND-configurations since these consist of individually necessary conditions), it identifies necessary OR-configurations (type 3). 7
In Figure 1, the subset relationship of necessity is perfect, indicated by all cases being below or on the diagonal. For a relationship to be considered as in kind necessary, fsQCA can allow that some cases are above the diagonal. Necessity consistency is the measure that captures how well a perfect relationship of necessity is approached, ranging from 0 to 1. If it is high enough (researchers typically use ≥0.90 as a standard), it is considered that a relationship of necessity exists. 8 Note that the variation across cases in the fuzzy-set membership scores of X and Y is not ignored in fsQCA; these membership scores are used to assess whether a subset relationship exists. But this judgment is dichotomous (in kind).
Analyzing Relationships of Necessity with NCA
NCA has recently been developed to analyze single necessary conditions (type 1) and necessary AND-configurations (type 2; Dul 2016a). NCA builds on earlier work and ideas on analyzing dichotomous necessary conditions (e.g., Braumoeller and Goertz 2000; Dul et al. 2010), discrete necessary conditions (e.g., Dul et al. 2010), and continuous necessary conditions (e.g., Goertz, Hak, and Dul 2013). NCA is rooted in calculus; it is thus not a set-theoretical technique as fsQCA is.
In NCA, a specific level of a condition is necessary or not for a specific level of the outcome. 9 It might be that only a medium level of the condition is necessary for a high level of the outcome. NCA extends the qualitative in kind statement “X is necessary for Y” with a quantitative in degree statement: “a specific level of X is necessary for a specific level of Y.” With more than two levels of X and Y, the necessary condition in NCA reads: “X = Xc is necessary for Y = Yc ,” where Xc is the necessary level of the condition to allow an outcome level of Yc . In Figure 2, this is visualized in the XY plane of theoretically or empirically possible XY values, the so-called theoretical or empirical scope (Dul 2016a). The point [Xc , Yc ] in Figure 2 is a point on the ceiling line. The ceiling line Y = f(X) divides the XY plane in an upper part and a lower part with only feasible points in the lower part. This line represents the constraint that a single X poses on Y, for different levels of X and Y. The higher is the constraint, the lower is the line and the more necessary is the condition. For a relationship of necessity, all XY points should be in the lower part (i.e., on or below the ceiling line). In that case, the necessary (but not sufficient) condition is mathematically described by the function Y ≤ f(X), with for the linear case: Y ≤ aX + b, where Y is the level of the outcome, a is the slope, X is the level of the necessary condition, and b is the intercept. Hence, the NCA ceiling line indicates what level of Xc is necessary for what level of Yc . When the ceiling line is continuously increasing, as in Figure 2, a level of X ≥ Xc is necessary for a level of Yc . Similarly, a level X < Xc will result in a level of Y < Yc . NCA thus adds to the in kind formulation “X is necessary for Y” the in degree formulation “Xc is necessary for Yc”, as the ceiling line represents.
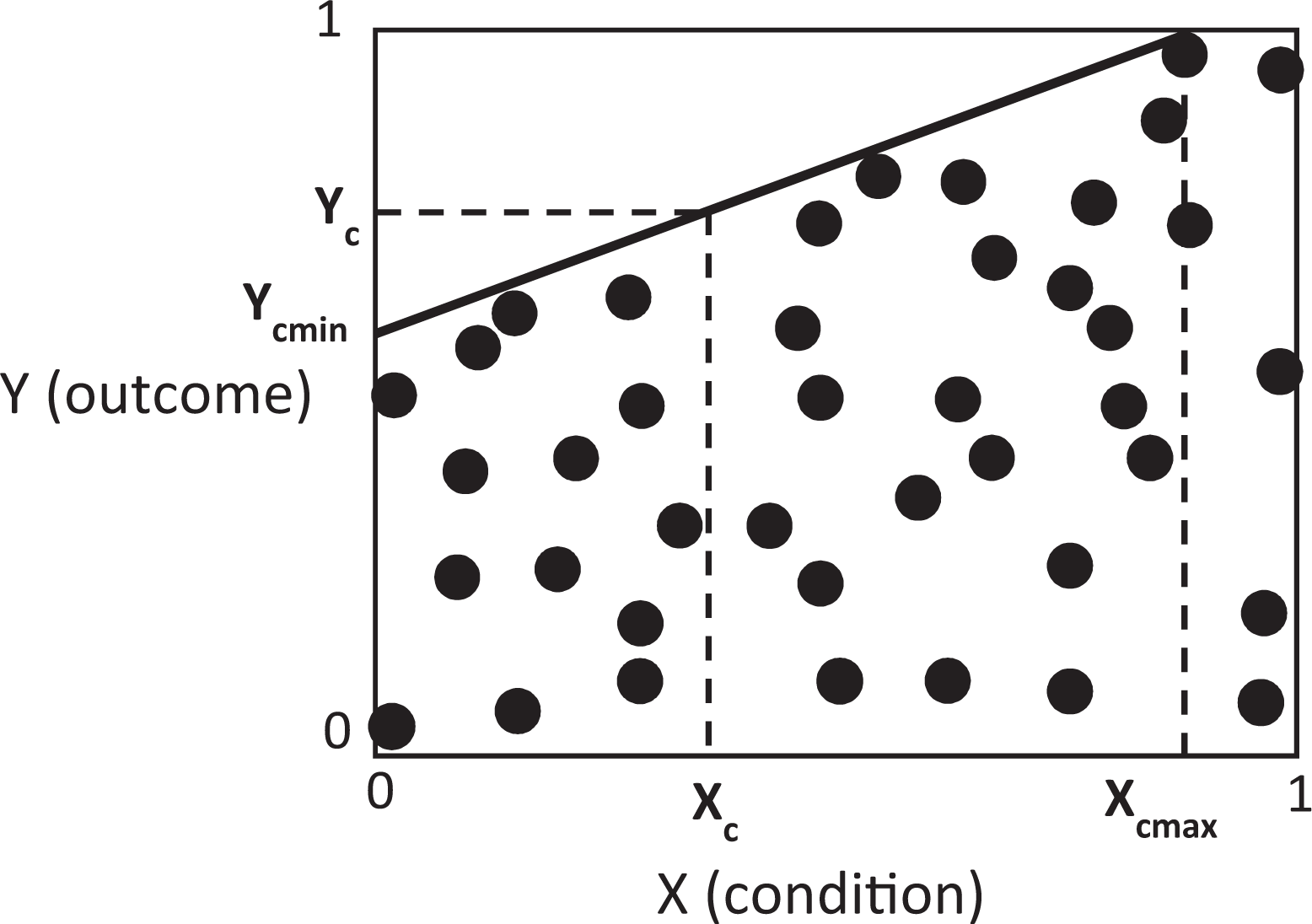
Relationship of necessity between X and Y (ceiling line) according to Necessary Condition Analysis.
In the XY plane of possible XY observations, the ceiling line may not cover the entire range of possible X and Y levels. Normally, the ceiling line intersects the Y = 1 line at the point Xc max < 1. This means that if X ≤ Xc max, X is necessary for Y (i.e., X constrains Y), but that if X > Xc max, X is not necessary for Y (i.e., X does not constrain Y). Similarly, the ceiling line normally intersects the X = 0 line at a point Yc min > 0. This means that if Y ≥ Yc min, X is necessary for Y (i.e., Y is constrained by X), but that if Y < Yc min, X is not necessary Y (i.e., Y is not constrained by X). These so-called necessity inefficiencies (Dul 2016a) indicate that X is necessary for Y for only a part of the entire range of possible X and Y levels (here between 0 and 1). Comparing Figures 1 and 2 also reveals that fsQCA’s diagonal can be seen as a special case of NCA’s ceiling line. If the ceiling line coincides with the diagonal, X constrains Y for all levels of X, and Y is constrained by X for all levels of Y. Only then, X is necessary for Y for all levels of X and Y.
To clarify the difference between NCA’s ceiling line and fsQCA’s reference line, both are graphed in the XY plane in Figure 3 of Stock (STOCK in fsQCA) and High (HIGH in fsQCA) of Schneider et al.’s (2010) data (discussed in more detail below). The upper-left line in Figure 3 is NCA’s ceiling line, and the diagonal is fsQCA’s reference line. In NCA, the ceiling line is drawn such that all, or nearly all, cases are on or below it (Dul 2016a). Several ceiling lines can be drawn to distinguish the upper-left zone without cases (the so-called ceiling zone) and the zone with cases. In this article, we use a technique called Ceiling Regression - Free Disposal Hull (CR-FDH). This technique maximizes the size of the ceiling zone by drawing a trend line through the most upper-left cases in the upper-left corner of the XY plot (for a discussion on ceiling techniques, see Dul 2016a). The technique results in a straight ceiling line. Because this line is a trend line, some cases are above it, introducing inaccuracy. This accuracy in NCA is defined as the number of cases that are on or below the ceiling line divided by the total number of cases, times 100 percent. NCA does not provide a recommended minimum level of accuracy, but Dul et al. (2010) suggest that 5 percent of the cases can be counterexamples of the necessary condition (corresponding to an accuracy of 95 percent). In the example from Figure 3, 4 (out of 76) cases are above the ceiling line, resulting in an accuracy of 94.7 percent.
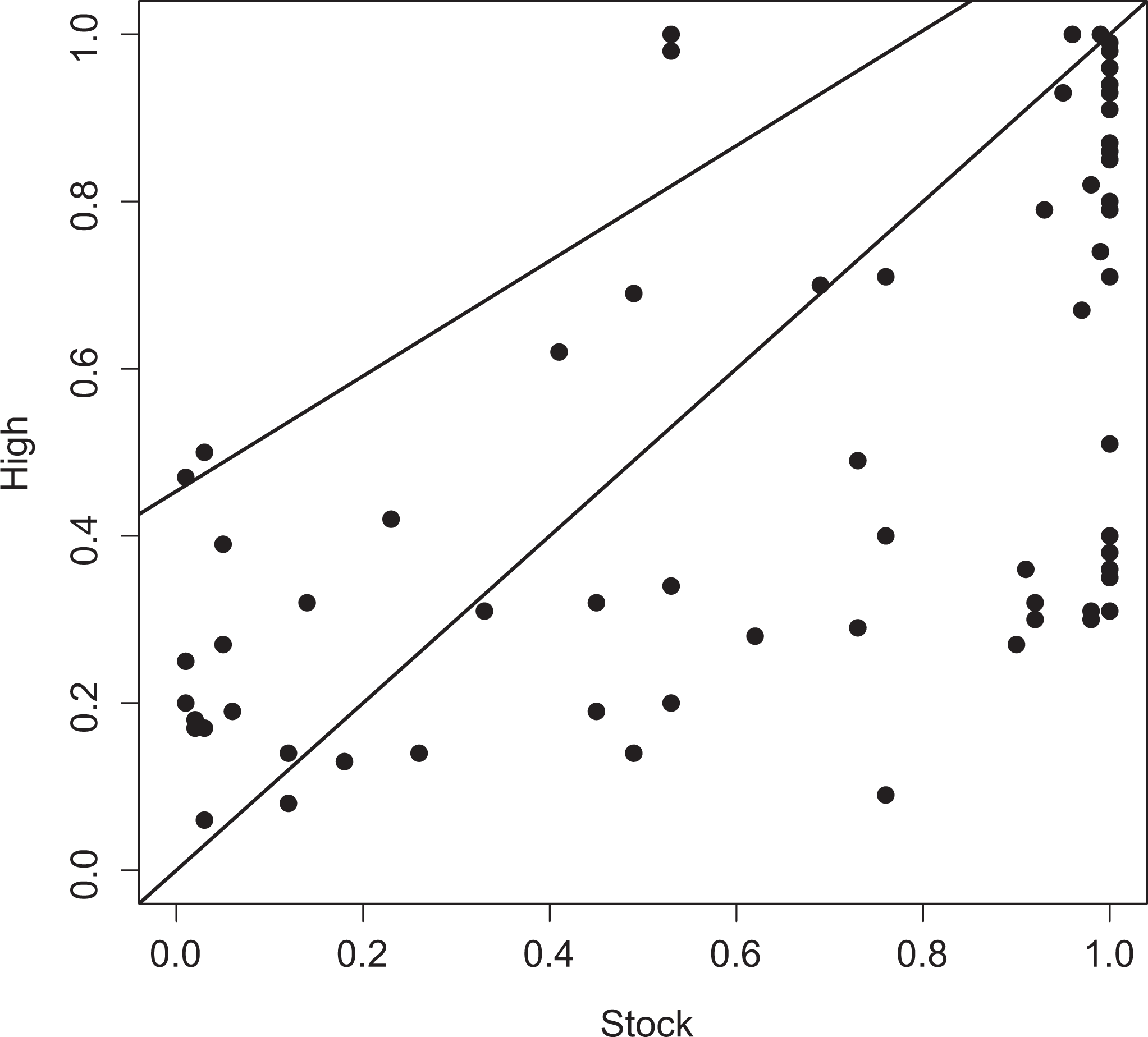
Relationship of necessity between Stock and High (Schneider et al. [2010] data). The upper-left line is necessary condition analysis’ ceiling line, and the diagonal is fuzzy set Qualitative Comparative Analysis’s reference line.
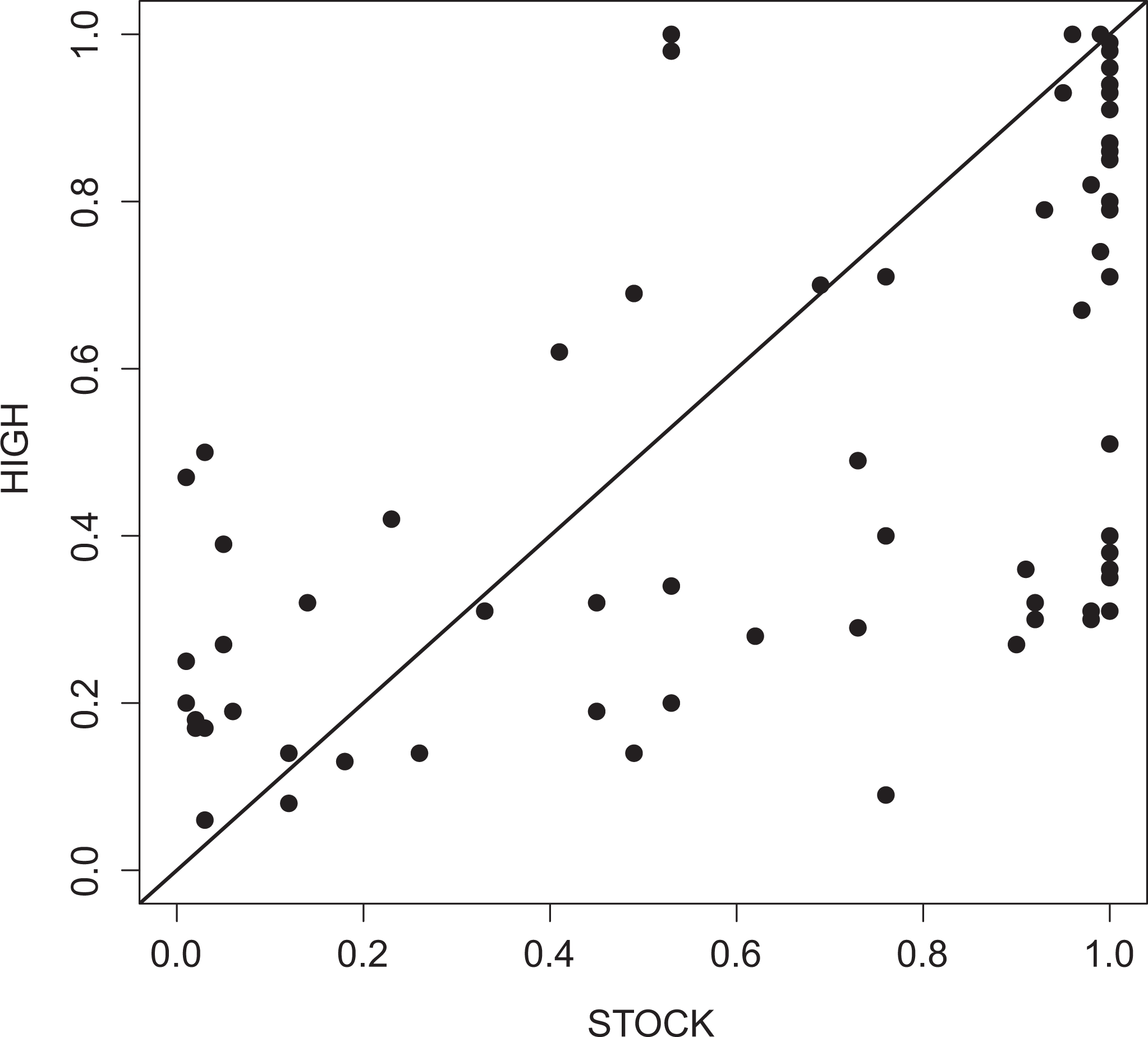
Almost necessary relationship between STOCK and HIGH according to fuzzy set Qualitative Comparative Analysis.
NCA defines the effect size of an in kind necessary condition as the size of the constraint that the necessary condition puts on the outcome. It answers the question: to what extent is the condition a bottleneck for achieving the outcome? For establishing the total constraint of X on Y, NCA considers the entire range of X values and Y values. Specifically, a necessary condition’s effect size (d) is defined as the size of the ceiling zone (the upper-left zone of the XY plane that is [almost] without observations) as a fraction of the total size of the area where cases can be expected, given the X values and Y values that are empirically observed (the empirical scope) or theoretically assumed (the theoretical scope). In the example we present in this article, the empirical scope and the theoretical scope are nearly identical (with X and Y having possible values between 0 and 1). NCA considers effect sizes above 0 as potentially meaningful depending on the context. If a researcher wishes to have a general benchmark, Dul (2016a) proposes 0 < d < 0.1 as a small effect, 0.1 ≤ d < 0.3 as a medium effect, 0.3 ≤ d < 0.5 as a large effect, and d ≥ 0.5 as a very large effect. In the case of the linear ceiling lines that we use here, the maximum effect size is 0.5. In Figure 3, there is a zone without cases in the upper-left corner, indicating the presence of a necessary condition. Specifically, the effect size of condition Stock is 0.23. Hence, using the general benchmark, Stock is considered a necessary condition with a medium effect. In addition to this in kind analysis, NCA’s ceiling line precisely identifies what level of X is necessary for what level of Y. Let us give an example. In the data set we use here, for a high level of High (0.9–1.0, i.e., being mostly or fully in the set), the level of Stock needs to be at least 0.8 (mostly in the set). However, for lower levels of High, Stock is still necessary, but at a lower level. For example, for High at 0.8 (mostly in the set), the level of Stock needs to be about 0.5 (neither in nor out of the set).
Comparing NCA’s “parameters of fit” or evaluation criteria for in kind necessity (effect size and the ceiling line’s accuracy) to one of fsQCA’s parameters of fit (consistency), the maximum level of consistency (i.e., 1.0) is achieved when there are no cases above the diagonal. Consistency reduces when the total distance of cases above the diagonal increases. If NCA’s ceiling line coincides with fsQCA’s reference line (the diagonal), that is, when fsQCA’s consistency = 1, NCA’s effect size is 0.5. As mentioned above, if the consistency is below 0.9, fsQCA considers a condition typically as not necessary. NCA, conversely, considers it necessary in a smaller range of X and Y values. In the above example, Stock is not considered as a necessary condition in fsQCA, while it is in NCA (see also below). Within the scope of XY values, NCA identifies a specific zone where X is necessary for Y (and where an in degree statement of necessity can be made) and a remaining zone where X is not necessary for Y. FsQCA, conversely, combines these zones to make a general in kind statement if consistency is large enough.
Bivariate NCA focuses on detecting individual necessary conditions for Y (i.e., type 1). When several single necessary conditions for the outcome are identified, a multivariate NCA can be performed, aimed at necessary AND-configurations (type 2). Multivariate NCA “identifies which determinants, from a set of [individually] necessary determinants, successively become the weakest links (bottlenecks, constraints) if the […] outcome increases. In other words, for a specific level of the […] outcome, multivariate NCA identifies the necessary (but not sufficient) minimum values of the determinants to make the […] outcome possible’ (Dul 2016a:25). Multivariate NCA combines several single necessary conditions into necessary AND-configurations using the so-called bottleneck table (Dul 2016a). Mathematically, the XY plane is extended toward the general Euclidean space (X 1, X 2, X 3, …, Y), and the ceiling Y = f(X 1, X 2, X 3, …) divides the space into an upper part and a lower part, with only feasible points in the lower part. For example, if there are two single necessary conditions (type 1) with linear ceiling lines, the combined ceiling surface divides the three-dimensional space into an upper part without observations and a lower part with observations (for an example, see Figure 6 below). By definition, a necessary AND-configuration consists of single necessary conditions. Table 3 (below) is an example of a bottleneck table that shows which AND-combinations are necessary for which level of the outcome. Usually, at a low level of the outcome, no or only few single conditions are part of the necessary AND-configuration, and when the level of the outcome increases more conditions become part of the AND-configuration.
Analysis of Relationships of Necessity With fsQCA and NCA
Before introducing the data set that we use for our reanalyses and presenting the analyses first a remark about notation. In the fsQCA analysis, we use the traditional QCA notation by displaying conditions and the outcome that are absent (i.e., a fuzzy-set membership score <.50) in lower cases, and conditions and the outcome that are present (i.e., a fuzzy-set membership score >.50) in capitals (e.g., “stock” and “STOCK,” respectively). Since the absent/present distinction is too crude for NCA, because NCA considers many different levels of the condition and the outcome, we display the names of the conditions and the outcome in the NCA analysis with one capital for the first letter and lower cases thereafter (e.g., Stock).
The data set for reanalyzing necessary relationships with fsQCA and NCA is from Schneider et al. (2010). 10,11 They examine both necessary and sufficient configurations for the outcome strong export performance in high-tech industries (HIGH in QCA; High in NCA). Schneider et al. use six conditions from the existing literature: strict employment protection (EMP in QCA; Emp in NCA), strong collective bargaining (BARGAIN in QCA; Bargain in NCA), high share of university graduates in the population (UNI in QCA; Uni in NCA), high share of nonuniversity occupational training schemes in the population (OCCUP in QCA; Occup in NCA), high degree of stock market capitalization (STOCK in QCA; Stock in NCA), and high level of institutional arbitrage captured by high market value of mergers and acquisitions (MA in QCA; Ma in NCA). Schneider et al.’s necessary condition hypothesis is that “international knowledge flows (as measured by cross-border mergers and acquisitions) act as a functional equivalent to university training and to a large stock market in providing the knowledge base required for strong export performance in high-tech” (p. 251). Thus, the OR-configuration MA OR UNI and the OR-configuration MA OR STOCK are hypothesized to be necessary for the presence of strong export performance in high-tech industries (HIGH). While sufficiency relationships are generally considered the core of (fs)QCA (see introduction), and Schneider et al. (2010) also formulate one sufficiency hypothesis, in this article we concentrate on relationships of necessity only, and hence do not discuss nor reanalyze the sufficiency analysis.
Table 1 displays the results of the reanalysis of Schneider et al.’s data with fsQCA. The bivariate analysis with fsQCA found none of the conditions individually necessary for the presence of strong export performance in high-tech industries (HIGH; configurations 13 through 18 in Table 1). This means that no type 1 relationships of necessity were identified. By definition, this also means that there were no type 2 relationships, that is, necessary AND-configurations, because these derive from single necessary conditions. While no single condition passed the cutoff point for consistency (≥0.90), the presence of a high degree of stock market capitalization (STOCK) came very close (consistency 0.891). This is also visible in Figure 4, which plots STOCK against HIGH. Most of the cases fall below the reference line (diagonal), in line with a relationship of necessity in fsQCA, and the cases that do not are—with a few exceptions—relatively close to the reference line.
Analysis of Relationships of Necessity of Schneider et al. (2010) With fsQCA.
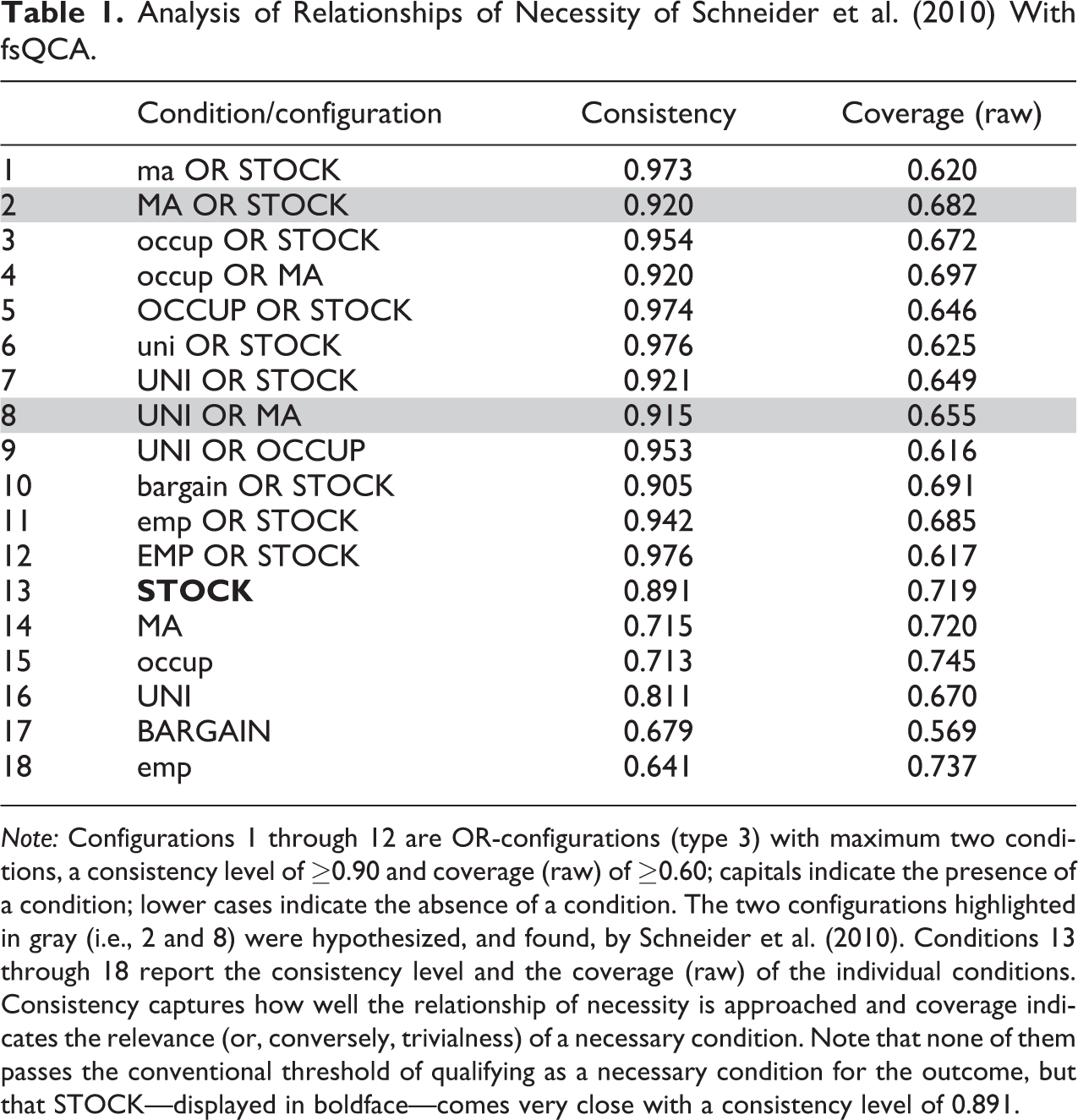
Note: Configurations 1 through 12 are OR-configurations (type 3) with maximum two conditions, a consistency level of ≥0.90 and coverage (raw) of ≥0.60; capitals indicate the presence of a condition; lower cases indicate the absence of a condition. The two configurations highlighted in gray (i.e., 2 and 8) were hypothesized, and found, by Schneider et al. (2010). Conditions 13 through 18 report the consistency level and the coverage (raw) of the individual conditions. Consistency captures how well the relationship of necessity is approached and coverage indicates the relevance (or, conversely, trivialness) of a necessary condition. Note that none of them passes the conventional threshold of qualifying as a necessary condition for the outcome, but that STOCK—displayed in boldface—comes very close with a consistency level of 0.891.
The multivariate fsQCA focusing on necessary OR-configurations (type 3 relationships) identified 12 such configurations (1 through 12 in Table 1). Configuration 2 indicates that, in line with Schneider et al.’s hypothesis and findings (pp. 251, 255), the OR-configuration MA OR STOCK is necessary for the presence of strong export performance in high-tech industries (HIGH). Either a high level of cross-borders mergers and acquisitions (MA), and/or a high degree of stock market capitalization (STOCK) is thus necessary for strong export performance in high-tech industries (HIGH). Configuration 8 indicates that—again in line with Schneider et al.’s hypothesis and findings (pp. 251, 255), also the OR-configuration UNI OR MA is necessary for strong export performance in high-tech industries (HIGH). The presence of international knowledge flows (MA) is thus also a functional equivalent (OR) to the presence of a high share of university-graduates in the population (UNI) for the presence of strong export performance in high-tech industries (HIGH).
However, in addition to these two theorized necessary OR-configurations, another 10 OR-configurations were identified as necessary for the outcome (the other configurations at the top of Table 1). In only three of these, STOCK is not part of the configuration. Given that STOCK came very close to being necessary by itself, this is not surprising—since a combination of a single necessary condition with any another condition is a necessary OR-combination of type 3A (see above). The problem of such necessary OR-configurations is that they include redundant conditions. In this case, STOCK may already be necessary by itself while the other condition in the OR-configuration is redundant.
Interestingly, and problematic for Schneider et al.’s (2010) hypothesis, also the configuration ma OR STOCK was identified as necessary for the outcome (configuration 1 in Table 1). This means that a high level of stock market capitalization (STOCK) that is combined with either a high level of cross-borders mergers and acquisitions (configuration 2) or the absence of a high level of cross-borders mergers and acquisitions (configuration 1) is a necessary OR-configuration. As the XY planes in Figure 5 reveal, and as the level of consistency signifies, the necessity relation for configuration 1 (bottom panel, 0.973) is even stronger than that for configuration 2 (top panel, 0.920). These results are driven primarily by STOCK being almost a single necessary condition.
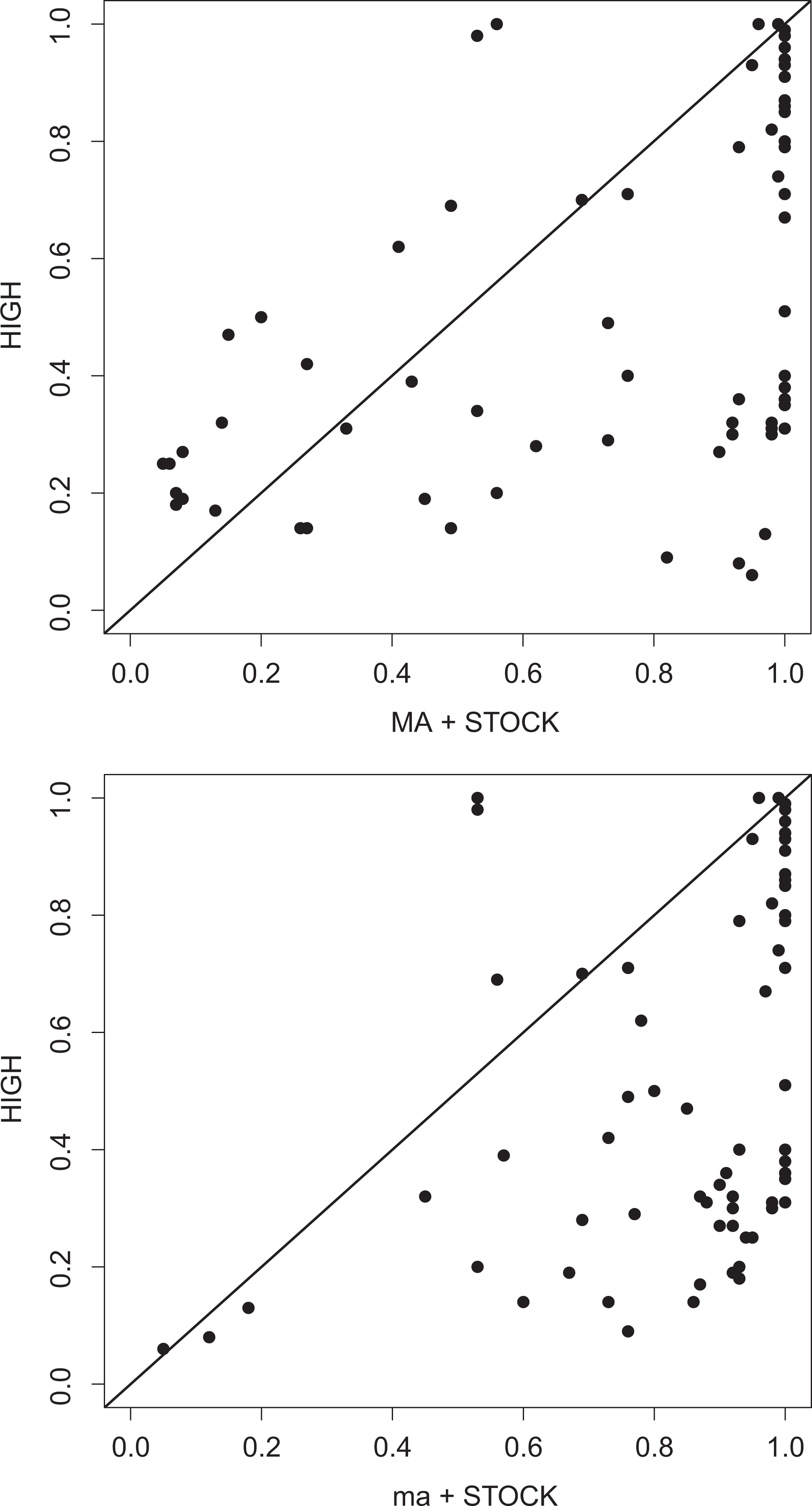
Necessary relationship between MA OR STOCK and HIGH (top panel) and ma OR STOCK and HIGH (bottom panel) according to fuzzy set Qualitative Comparative Analysis.
Summing up, in its bivariate analysis, fsQCA can identify conditions that are individually necessary for the outcome (type 1 relationships), but in the reanalysis of an existing data set, none were found (although STOCK came close). Given that a condition can be either necessary or not in fsQCA, and given that the cutoff point for being necessary is high (≥0.90 consistency), this may not be surprising. FsQCA can in principle also identify type 2 necessary conditions, that is, necessary AND-configurations. However, we did not find those here. FsQCA is also capable of identifying type 3 necessary conditions, that is, necessary OR-configurations. We found many (12) of those, most of which had not been theorized by the authors. In general, prudency is needed when OR-configurations are found in fsQCA without prior theoretical justification, because such configurations may not have a theoretical meaning. From the perspective of removing confounding conditions, necessary OR-configurations can be interesting though. If a necessary OR-configuration consists of conditions that are logical equivalents (category 3B identified above), it may make sense to collapse these conditions into one “super condition” (higher-order equivalent), since their effect is the same.
What can an NCA analysis of necessity of the same data add to these findings? The results of the bivariate NCA analysis are shown in Table 2. NCA finds that Occup was not individually necessary for High but that the other conditions (Emp, Bargain, Uni, Ma, Stock) were individually necessary (type 1). However, these latter conditions’ effect sizes differ. Emp, Bargain, and Ma have small effect sizes (0 < d < 0.1), and Uni and Stock have medium effect sizes (0.1 ≤ d < 0.3). The accuracies are 92.1 percent, 98.7 percent, 97.4 percent, 96.1 percent, and 94.7 percent, respectively. The last column of Table 2 displays the formulae of these necessary conditions’ ceiling lines using the ceiling technique CR-FDH. The ceiling line for Stock is depicted in Figure 3 above. Recall that the ceiling line represents the minimum level of X that is necessary for a specific level of Y.
Analysis of Relationships of Necessity of Schneider et al. (2010) With NCA (Bivariate: Single Necessary Conditions).

Note: Conditions 1 through 6 are single conditions (type 1B). The extent to which a condition is necessary is expressed with the effect size d (general benchmark 0 < d < 0.1 “small effect,” 0.1 ≤ d < 0.3 “medium effect,” 0.3 ≤ d < 0.5 “large effect,” and d ≥ 0.5 “very large effect.”) Accuracy is defined as the number of cases that is on or below the ceiling line divided by the total number of cases, times 100 percent. Ceiling lines are drawn using the CR-FDH ceiling technique, where the ceiling line is the linear trend line through “upper-left” border points obtained by mathematical optimization (Dul 2016a). N = 76.
* d ≥ 0.1.
In the multivariate NCA analysis, the individual necessary conditions are combined into necessary AND-configurations (type 2). A configuration of two necessary conditions can be represented by a ceiling surface. Figure 6 shows the ceiling surface of the configuration Uni AND Stock. The ceiling surface is the three-dimensional extension of the ceiling line; above the ceiling zone, there are virtually no cases: the cases can be found under the ceiling. This surface is obtained by combining the ceiling lines of the two conditions by taking the minimum ceiling value Yc (Yc is the ceiling value of High) for a specific X 3(Uni) − X 6(Stock) combination; thus, the ceiling point Yc for point X 3, X 6 is min[(Yc = 0.457X 3 + 0.654), (Yc = 0.689X 6 + 0.453)]. For X 3 = Uni = 1 (when Uni cannot constrain High), the ceiling line of Stock for High is shown on the left back wall. Similarly, for X 6 = Stock = 1, the ceiling line of Uni for High is shown on the right back wall.
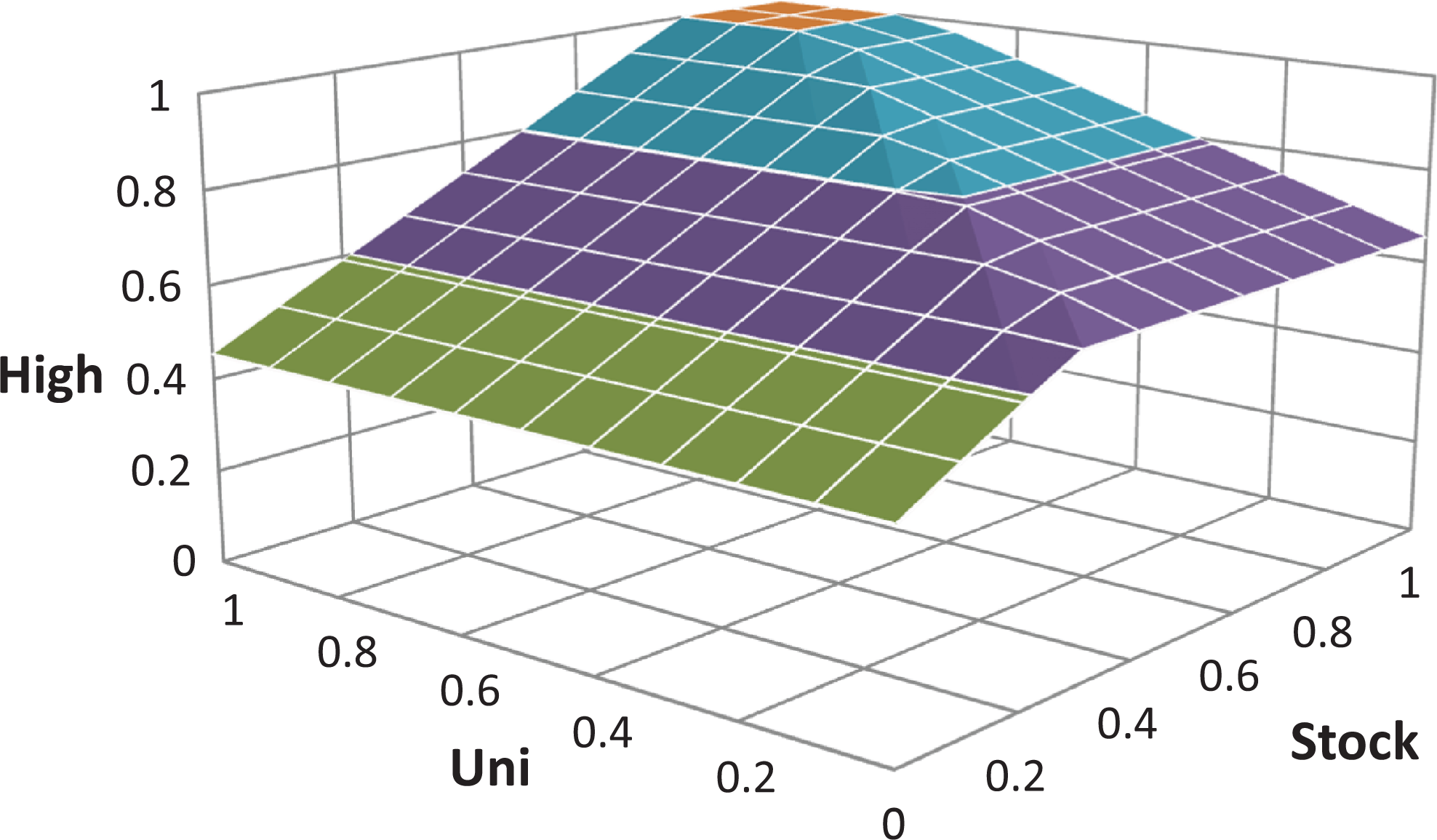
Ceiling surface of the necessary configuration Uni AND Stock according to Necessary Condition Analysis.
The multivariate analysis with NCA also demonstrates that the five conditions identified as individually necessary were not always necessary. Whether they were, depended on their level and on the level of the outcome. NCA’s bottleneck table, displayed in Table 3, indicates what levels of the condition(s) were necessary for different levels of the outcome. In line with the bivariate analysis discussed above, Table 3 indicates that for any level of High, Occup was not necessary (NN). When High is maximum (1; i.e., fully in the set), the other five conditions were all necessary but do not need to be at their maximum level (i.e., the fuzzy-set membership can be lower than 1). For maximum High (fully in the set), the necessary levels of Emp, Bargain, Uni, Ma, and Stock were, respectively, 0.08 (mostly out of the set), 0.30 (more or less out), 0.75 (more or less in), 0.47 (more or less out), and 0.79 (mostly in). Hence, all these five conditions were necessary for a maximum level of High, but their level need not be maximum (and the required level of Emp is very low or, stated differently, being mostly out of the set of Emp is—in combination with the levels of Bargain, Uni, Ma, and Stock—already enough for being fully in the set of High). For a level of High just below maximum (0.9; i.e., mostly in the set), only Emp, Uni, and Stock were necessary; for High at levels of 0.7 (more or less in) and 0.8 (mostly in) only Uni and Stock were necessary, and for High at a level of 0.5 (neither in nor out) and 0.6 (more or less in) only Stock was necessary. For High being below 0.5 (variants of being out of the set), no ingredient was necessary for the outcome. Hence, Table 3 shows three necessary AND-combinations, depending on the level of the outcome (Uni, Stock; Emp, Uni, and Stock; Emp, Bargain, Uni, Ma, and Stock).
Analysis of Relationships of Necessity of Schneider et al. (2010) With Necessary Condition Analysis (Multivariate: Bottleneck Table).
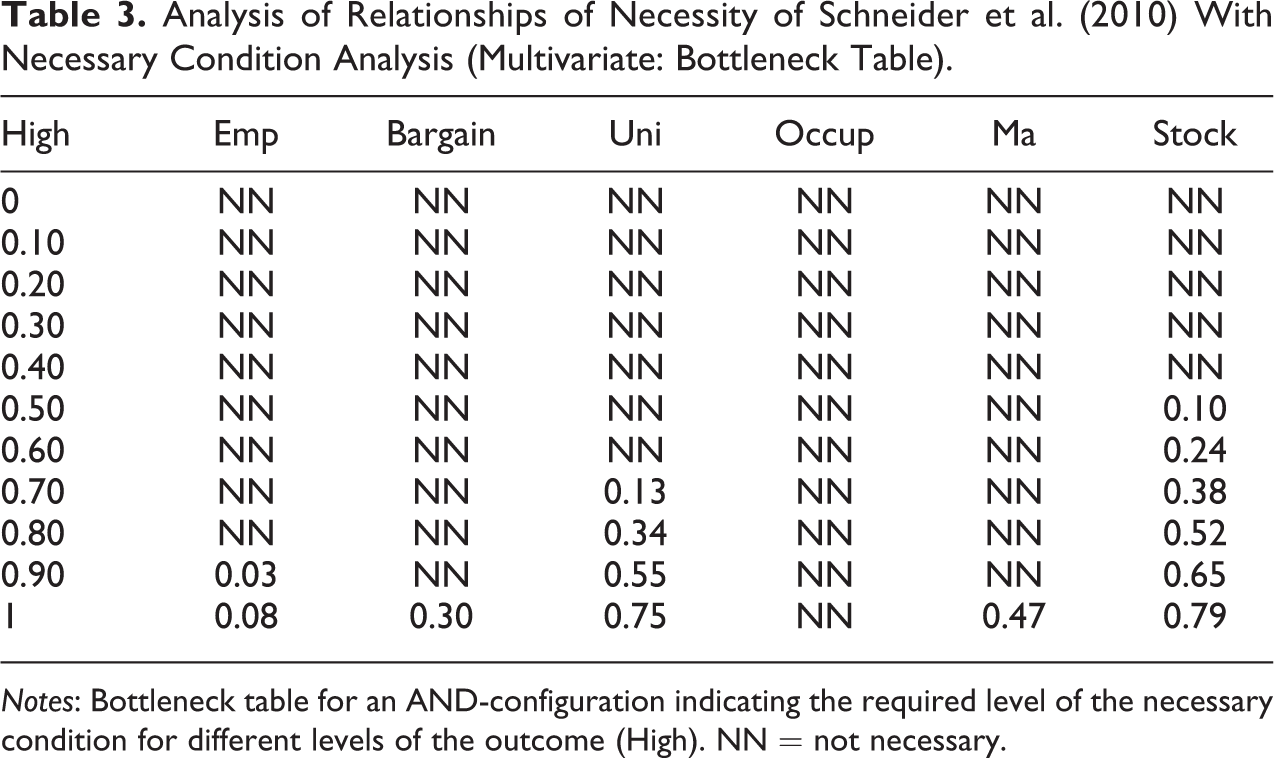
Notes: Bottleneck table for an AND-configuration indicating the required level of the necessary condition for different levels of the outcome (High). NN = not necessary.
Comparison of the fsQCA and NCA Findings
In the previous section, we demonstrated that the results of the analyses of different types of relationships of necessity with fsQCA and NCA of the Schneider et al. (2010) data differ. Starting with the bivariate analyses, fsQCA identified no condition to be individually necessary (though STOCK came close), while NCA identified five (of the six) conditions as individually necessary. The level at which these conditions were necessary according to NCA varied across the different levels of the outcome. The higher was the level of the outcome, the higher was the number of required conditions. Interestingly, and making full use of the existing variation in membership scores, to obtain a maximum level of the outcome (fully in the set), the required level of three of the five necessary conditions (Emp, Bargain, and Ma) was below 0.5 (0.08, 0.30, and 0.47; mostly out of the set and more or less out), whereas the required level of two necessary conditions (Uni and Stock) was above 0.5 (0.75 and 0.79; more or less in and mostly in).
Also in the multivariate analyses, fsQCA and NCA’s results differed. We identified no necessary AND-configurations in the fsQCA analysis and three in the NCA analysis. Necessary OR-configurations are not the focus of NCA, since this technique is geared to identifying single conditions and their AND-configurations because only these are truly necessary for an outcome to occur. Still, the bottleneck table (Table 3) provides some useful information regarding the conditions making up the Schneider et al.’s hypothesized necessary configurations: Ma, Uni, and Stock. For one, the presence of Ma (i.e., a fuzzy-set membership score >0.50) is hypothesized to be part of both necessary OR-configurations. NCA’s bottleneck table, however, reveals that for no level of High, Ma needed to be higher than 0.50. In fact, Ma was only part of the necessary AND-configuration for High = 1 (fully in the set), but with a required level of only 0.47 (more or less out of the set). Uni, conversely, was required for levels High = 0.70 onward. For High ≥ 0.90, Uni needed to be >0.50. Based on the bottleneck table, and in line with the fsQCA analysis, Stock could be argued to be the condition that is most important in terms of necessity. Stock was required for High ≥ 0.50 (at least neither in nor out of the set), and for High ≥ 0.80 Stock needed to be >0.50. These findings from NCA thus allow us to examine the necessity of different specific levels of the condition for different specific levels of the outcome, thereby making full use of the variation in set membership scores. This makes clear that NCA adds precision to fsQCA.
Note that while thus far this rarely, if ever, happens in the analysis of necessity, also fsQCA results can be made more precise, namely by examining the fuzzy-set membership scores of the identified necessary condition or configuration and outcome across all cases. The researcher examines which level of the necessary condition or configuration corresponds to which level of the outcome. She might find that, for some cases, to be more or less in the condition or configuration (e.g., 0.55) is necessary for being mostly in the outcome (e.g., 0.83). For other cases, the pattern may be different. Such knowledge of specific (groups of) cases can especially be useful if the researcher works in a case-oriented tradition. But the extra information on the case level differs from the more precise statements that NCA can make about the relationships between the conditions (X) and the outcome (Y).
Earlier, we already indicated that NCA is especially useful for answering research questions of the type: Which condition(s) needs to be in place at what level to obtain a particular level of the outcome? Applied research questions are often of this type. For example, how ambitious and sociable does a sales person need to be to allow a particular level (the target) of sales performance (Dul 2016a)? How much training is necessary for high-quality just-in-time manufacturing (McLachlin 1997)? Which level of trust between partner organizations is necessary for the highest level of innovation performance (Van der Valk et al. 2015)? We can also formulate Schneider et al.’s (2010) study in such terms, even though they do not do this so themselves: Which levels of stock market size and university training are necessary for a high level of export performance in high-tech industries?
Table 4 summarizes the similarities and differences between fsQCA and NCA. In this article, we considered both techniques as data analysis techniques. They are identical with respect to the definition of a necessary condition and configuration, the assumption that the necessary condition is a necessary cause of the outcome and the assumption that the data are precise and meaningful. Then, both techniques are able to identify necessity relations in kind formulated as “X is necessary for Y.”
Similarities and Differences of Fuzzy Set Qualitative Comparative Analysis (fsQCA) and Necessary Condition Analysis (NCA) as a Technique to Analyze Continuous Empirical Data for Identifying Necessary Conditions.
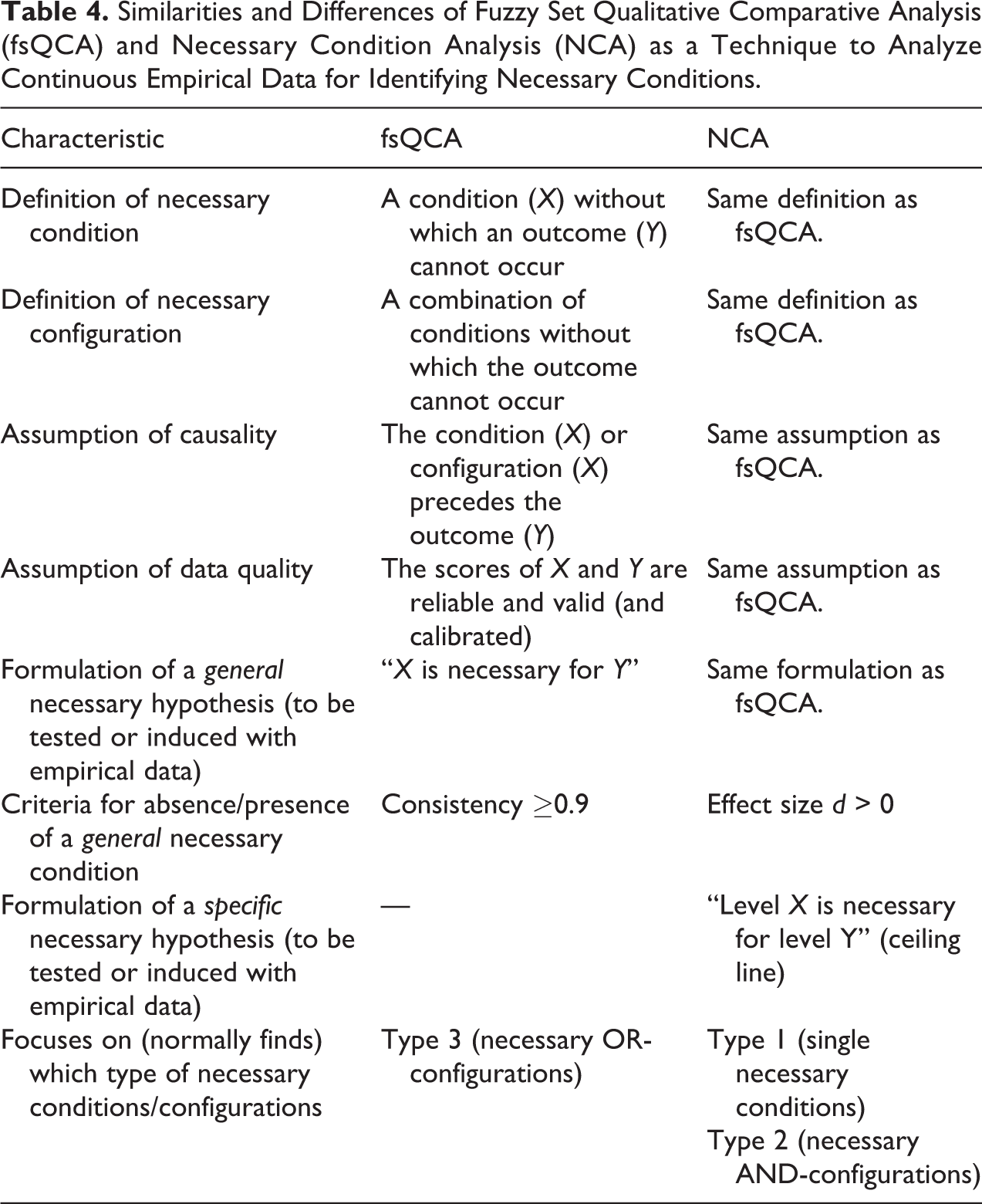
Still, fsQCA and NCA differ in their approach to necessity. In fsQCA is based on fuzzy-set logic and set theory while NCA is based on calculus. The former means that a necessary condition or configuration (X) is considered to be a superset of the outcome (Y). This means that in an XY plane, almost all cases are on or below the reference line, which in fsQCA is the diagonal (Y ≤ X). NCA focuses on the ceiling line, which is the border line between the zone with cases and the zone without cases, with most cases on or below the ceiling line (Y ≤ aX + b). Another difference is that fsQCA decides whether a necessary condition is present or not depending on the extent to which the cases are on or below the reference line, that is, the level of consistency. NCA evaluates how much a necessary condition is present depending on the effect size, that is, the size of the ceiling zone in comparison to the entire XY zone, where cases could be possible. If the effect size d > 0, then there is a ceiling line and “X is necessary for Y.” Hence, while both fsQCA and NCA can formulate in general terms that “X is necessary for Y,” they arrive at such a conclusion differently. Additionally, NCA formulates necessary conditions in degree by using the ceiling line, which indicates that a specific level Yc of the outcome is only possible if the level of the condition Xc ≥ (Yc − b)/a.
Furthermore, both fsQCA and NCA can identify single necessary conditions (type 1) and necessary AND-configurations (type 2). Because NCA uses a different line than the diagonal, this technique normally finds many more single necessary conditions, and therefore necessary AND-configurations, than does fsQCA. If there is an empty space in the upper-left corner of an XY plane (see Figure 3)—even if it is relatively small—, this means that a condition at a particular level is necessary for a particular level of the outcome. NCA can identify those conditions, as the analysis above demonstrated. If the threshold for consistency in fsQCA would be lowered, fsQCA would identify more necessary conditions and would thus be less likely to make type II errors (false negatives, not identifying a necessary condition where it actually exists, see Dul 2016b for a discussion). However, lowering this threshold will increase the number of type I errors (false positives, identifying a condition as in kind necessary whereas actually it is not), so should never be done mechanistically. Still, depending on the exact location of the cases in an XY plane, a level of consistency of say 0.89 may be high enough for a relationship of necessity to exist.
NCA would be the preferred technique for the analysis of necessity if a researcher is interested in which level of a condition (for instance, economic development or intelligence) is necessary for a particular level of the outcome (like democracy or job performance). Complementing fsQCA with NCA is thus particularly useful—and perhaps even needed—when the researcher has turned to fuzzy sets (as opposed to crisp sets) because the relevant variation goes beyond the qualitative in and out of a set distinction.
However, if a researcher is interested in necessary OR-configurations, fsQCA would be the preferred technique, since currently NCA does not identify such relationships. FsQCA may also suffice for analyzing relationships of necessity when the researcher is interested only in necessity in kind. An example of a recent research question for which this applies is what is the necessary condition for multiparty wars (Vasquez and Rundlett 2015)? For such a research question, an NCA analysis would add a level of precision, or completeness, to the results that may not be needed for the research problem at hand.
Conclusion
In this article, we discussed two techniques for identifying relationships of necessity: fsQCA and NCA. Both are able to make in kind statements about necessity (“a condition or configuration is necessary or not for an outcome”). In NCA, whether a condition is considered as necessary in kind depends on the researcher’s choice of the threshold for effect size (e.g., 0.1). In fsQCA, this depends on the researcher’s choice of the consistency threshold (e.g., 0.9). NCA’s additional contribution is that it can make in degree statements about necessity (“a specific level of a condition is necessary or not for a specific level of the outcome”). In this article, we demonstrated that in degree statements can add important detail and precision to an analysis of necessity. Not seldom this results in the identification of additional necessary conditions compared to fsQCA, as we also showed in the example here.
The logic of necessity implies that all necessary conditions should be part of all sufficient configurations, otherwise the configuration will not produce the outcome (and not be sufficient). Although—in contrast to NCA—fsQCA can also identify sufficient configurations, fsQCA has no generally accepted procedure yet on how to ensure that all necessary conditions are part of them. Future work is needed to establish a procedure how necessary conditions (either identified by NCA or by fsQCA) can be integrated in sufficient configurations identified by fsQCA.
NCA’s additional focus on variation in degree allows for making full use of the existing variation in fuzzy-set membership scores. NCA is attuned to identifying which level of set membership of which condition (individual or necessary AND-configuration) is required for which level of the outcome. This brings an entire range of new applied and fundamental research questions within reach of (fs)QCA scholars. Like Dul (2016b), we also therefore see much merit in using a variety of techniques to understand the complex relationships in social science research. Researchers could use traditional, quantitative techniques for identifying single sufficient but not necessary conditions that can increase the outcome; employ fsQCA for identifying sufficient but not necessary configurations and—if desired—for identifying necessary OR-configurations; and NCA for identifying single necessary but not sufficient conditions and necessary AND-configurations. Researchers wishing to apply NCA to their data set can use the freely available R package NCA (Dul 2015) for drawing ceiling lines, calculating NCA parameters such as effect size and accuracy, and for creating bottleneck tables.
Footnotes
Acknowledgment
An earlier version of this article has been presented at the 2nd International QCA Expert Workshop, Zurich, Switzerland in November 2014. We thank all participants at the 2nd International QCA Expert Workshop, for their useful comments and suggestions. Additionally, we thank Michael Baumgartner, Tony Hak, Patrick Mello and Zsofia Toth and the anonymous reviewers of Sociological Methods and Research for their helpful comments and suggestions.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Barbara Vis’ research is supported by a VIDI grant from the Netherlands Organization for Scientific Research (NWO, grant nr. 452-11-005).