
Abstract
Machine learning techniques have gained increasing prominence in tourism and hospitality research for data analysis and business strategy formulation. This study systematically reviews 406 peer-reviewed articles published between 2007 and 2023, highlighting the growth of machine learning studies, the expansion of academic journal coverage, and the adoption of diverse data modalities employed in this field. More importantly, it discusses emerging research topics and associated machine learning approaches across different data modalities (i.e., numerical, textual, and image data). This study further addresses key issues and challenges in current applications and outlines future research directions in this domain. Overall, it offers an in-depth understanding and assessment of the current machine learning techniques within the tourism and hospitality literature.
Introduction
Machine learning (ML) techniques, a branch of Artificial Intelligence, have emerged as an essential tool for addressing research questions across various disciplines and industries. Alpaydin (2020) defined machine learning as a process of programing computers to enhance performance by utilizing example data or previous experiences. ML can be classified into supervised learning, unsupervised learning, and reinforcement learning (Jackson, 2019). Supervised learning models train on labeled datasets, while unsupervised algorithms analyze unlabeled data to uncover hidden patterns. Reinforcement learning, in contrast, involves learning the best actions through trial and error to optimize decision-making (Alpaydin, 2020). The rapid development of ML techniques has been driven by the proliferation of both structured and unstructured data (Qiu et al., 2016). Compared to traditional data analysis methods, ML demonstrates advantages in handling informative and complex data structures, increasing accuracy, and improving result comprehensibility (Khalid et al., 2014).
In tourism and hospitality, advances in digital technology have facilitated the generation and availability of large-volume datasets. From the supply side, business entities such as destinations, hotels, restaurants, and airlines possess extensive Internet-based and transactional data. On the demand side, travelers increasingly share their experiences online through ratings, texts, pictures, and videos, producing a vast amount of user-generated content. This exponential growth of data offers innovative opportunities to uncover patterns of consumer behavior and decision-making (Balaji et al., 2021), calling for advanced analytical tools and critical insights into the data.
Employing ML techniques to gage big data in tourism and hospitality research has gained increasing popularity (K. He et al., 2021; Law et al., 2019). A diverse array of topics has been examined, including, but not limited to, tourism demand forecasting (Bi et al., 2022; Rice et al., 2019; Y. Zhang et al., 2021), destination image (Arabadzhyan et al., 2021; Lin et al., 2021), review helpfulness (C. Li et al., 2023; Ma et al., 2018), social media engagement (Tamaki, 2021; Yu & Egger, 2021); and customer experience (Guo et al., 2017; Le et al., 2021). ML techniques have been applied to predict visitor numbers using historical data (X. Li et al., 2017), assess customer satisfaction from reviews and feedback (Guo et al., 2017), detect emerging travel trends (Savaiano & Drago, 2021), and optimize real-time pricing to balance profitability with traveler value (Leoni & Nilsson, 2021).
Despite the significant surge of ML research in recent years and some preliminary attempts to synthesize existing literature, several research gaps remain. Firstly, limited systematic literature reviews have been conducted on ML applications in tourism and hospitality. Among the few published works, one reviewed ML research in the general marketing discipline (Ngai & Wu, 2022), while another focused on big data applications in a specific stream of sustainable tourism research (Rahmadian et al., 2022). Both also only considered studies published up to 2021, thereby overlooking the substantial advances and insights emerging from 2022 to 2023, which witnessed a sharp increase in ML-related publications in tourism and hospitality. Secondly, existing review papers have been limited in summarizing topics and presenting future trends (Knani et al., 2022; Ngai & Wu, 2022), with few addressing the methodological challenges and issues in ML research.
To bridge the aforementioned research gaps, this study conducts a systematic analysis of peer-reviewed articles employing ML techniques in tourism and hospitality literature. Specifically, this study has the following objectives: (1) to profile the volume of ML-related articles in tourism and hospitality and identify the main academic journals contributing to this domain; (2) to categorize the data types and sources employed in existing ML research in tourism and hospitality; (3) to analyze the research topic and ML techniques applied across different data types, including numerical, textual, and image data; (4) to critically evaluate the current ML technique applied in each data type; and (5) to propose future directions for ML research in tourism and hospitality. The rationale behind structuring the critical review based on data modalities is that ML, rooted in data science, typically employs different techniques to learn patterns and optimize performance depending on data characteristics. By synthesizing existing literature, this study advances understanding of how different types of data are analyzed through ML techniques. More importantly, it addresses the challenges and limitations in ML applications in existing tourism and hospitality research and further provides a detailed trajectory for future research agendas in the field.
Methodology
To guarantee comprehensive inclusion of relevant literature, an extensive array of search terms was deployed (C. Li et al., 2023). This study utilized the PRISMA model adapted from Moher et al. (2010) to systematically document the selection procedure and records for each step.
As ML research on tourism and hospitality may not only be published in tourism and hospitality journals, we included the following research contexts, such as “Tourism,” “Hospitality,” “Restaurant,” or “Hotel”; different types of data such as “Image,” “Text,” “Photo,” “Picture,” and variation terms of “Visual Content,” or “Visual Information”; and ML techniques, such as “Machine Learning,” “Deep Learning,” “Text Mining,” “Image Detection,” “Support Vector Machine,” “decision tree,” “Random Forest,” “Naive Bayes,” “Neural Networks,” “Natural Language Processing,” “k-Nearest Neighbors,” “Artificial Neural Networks,” “Long Short-Term Memory,” or “K-Means.” The literature search was conducted across the databases of eight platforms and publishers, including Google Scholar, ScienceDirect, Web of Science, and online journal sources from SAGE, Emerald, Springer, Wiley, and Taylor & Francis, to ensure an inclusive list of relevant ML research in tourism and hospitality. In addition, the top 24 hospitality and tourism journals, based on the SCImago Journal Rank (SJR) Q1 ranking and Observatory of International Research (OOIR) ranking, were manually checked to identify any further ML research not included in the above database search.
A total of 8,798 articles were initially retrieved, after which a rigorous exclusion process was implemented to filter the literature. First, only English-language, full-text publications were retained, and duplicate records as well as literature review papers were removed. Second, articles outside the scope of ML in tourism and hospitality, such as technical publications in computer science, were excluded to ensure the focus remained on studies directly associated with ML applications within the tourism and hospitality context. Third, the remaining 494 articles were manually assessed for eligibility by checking their titles, abstracts, and full text. Consequently, 406 records met the inclusion criteria and were utilized for the final analysis. Figure 1 presents the detailed workflow of the literature review process.
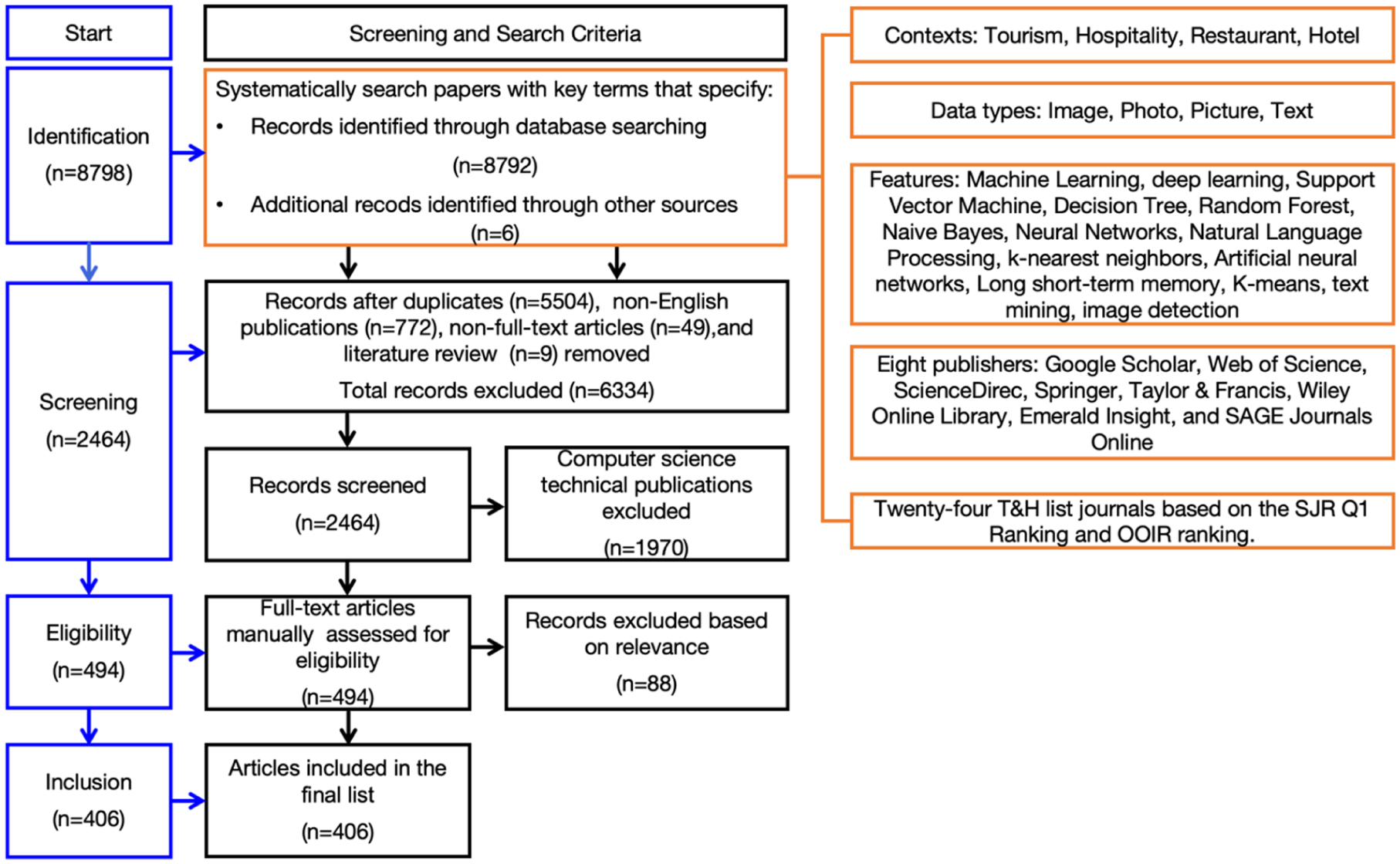
Adapted PRISMA flowchart for the literature selection process.
State-of-the-Art Results of ML Research in Tourism and Hospitality
Descriptive Statistical Analysis
The application of ML techniques in tourism and hospitality can be traced back to 2007. Of the studies reviewed, 86% (350 articles) were published within the past 5 years, reflecting the rapid acceleration of scholarly interest. Notably, by November, the publications in 2023 had already reached 105. The trajectory highlights the growing prominence of ML in tourism and hospitality research and suggests the trend of new peaks in future years.
Regarding the journals, the 406 reviewed articles were published in 98 journals spanning tourism, hospitality, business, marketing, and computer science disciplines, including outlets such as Journal of Business Research, Global Business Review, and Neurocomputing. This distribution highlights growing interest from diverse journals in applying ML in the tourism and hospitality context. The top 10 journals based on the number of articles jointly published 234 articles, representing 60% of the total sample. The five leading journals are Tourism Management (58), International Journal of Hospitality Management (32), Current Issues in Tourism (31), International Journal of Contemporary Hospitality Management (23), and Tourism Management Perspectives (21).
Regarding the data types and sources, three major categories were identified: numerical data (e.g., tourist flows and search indices), textual data (e.g., online reviews), and visual data (e.g., photos). As shown in Figure 2, data sources fall into five primary categories, with user-generated content (UGC) representing the largest share (58.8%), followed by government/organizational databases (25.4%), surveys (7.4%), search engines (6.7%), and mobile devices (1.7%). Each source category encompasses different data types. For example, within UGC, most data are textual (71%), followed by image-based (13%) and numerical (5%) data, while the hybrid format, which combines multiple data types, accounts for 11%.
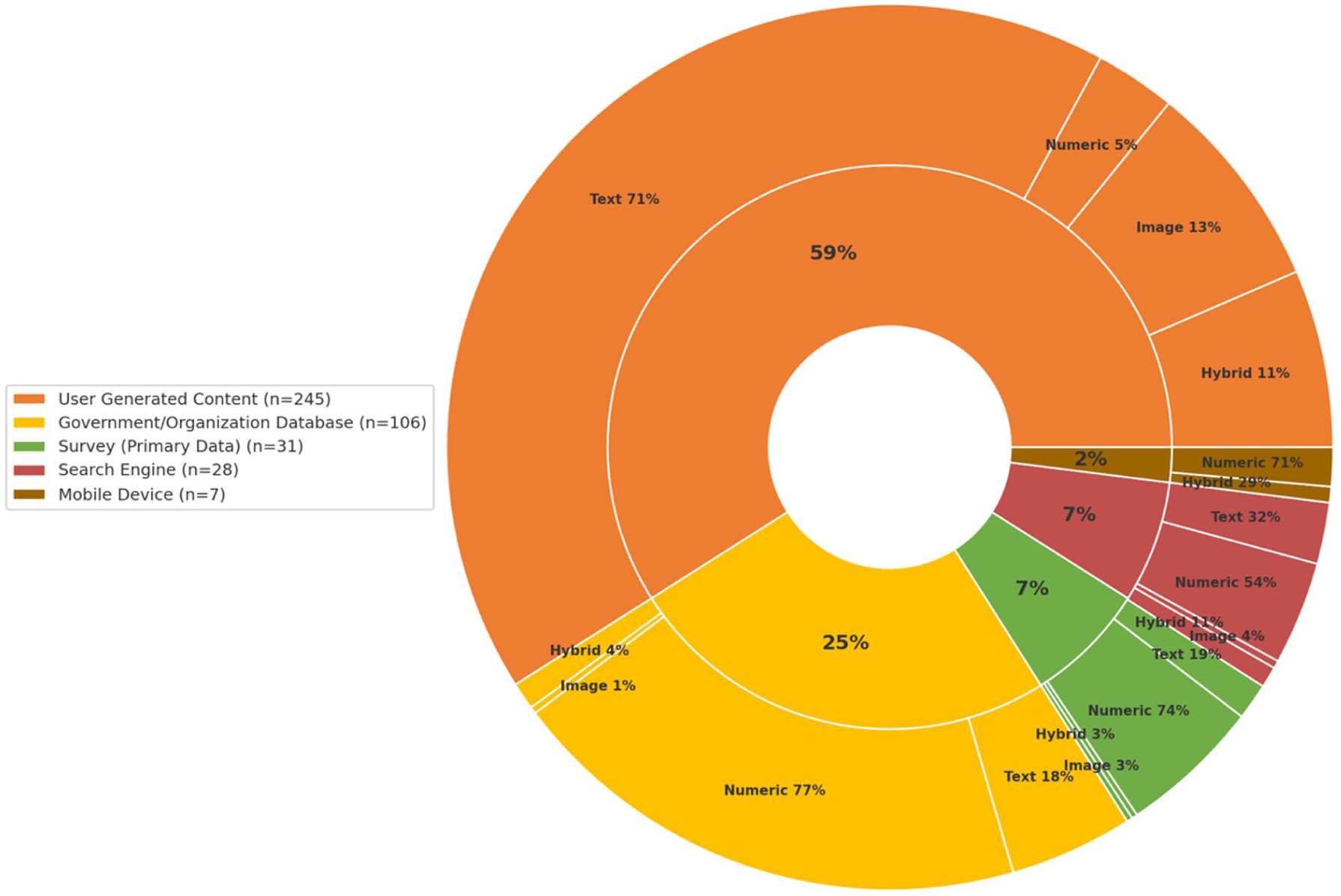
Distribution of data source and data type.
Machine Learning Techniques on Numerical Data in Tourism and Hospitality
Based on the keywords co-occurrence analysis, the dominant topics that use numerical data as the direct data source include tourism demand forecasting (Akın, 2015; Höpken et al., 2021; Law et al., 2019; X. Li et al., 2021; A. Liu et al., 2021; Xie et al., 2021; T. Zheng et al., 2021), hotel/peer-to-peer accommodation booking or demand forecasting (Antonio et al., 2019; Assaf & Tsionas, 2019; Sánchez-Medina & C-Sánchez, 2020; M. Zhu et al., 2021), and hotel revenue management (Al Shehhi & Karathanasopoulos, 2020; Chattopadhyay & Mitra, 2019). The data are derived mainly from surveys (primary data) and online sources (secondary data).
Forecasting represents the dominant research stream in numeric mining research. With the development of big data and computer algorithms, the method has evolved from traditional econometric models, such as the Autoregressive Moving Average Model (ARMA), Autoregressive Integrated Moving Average (ARIMA), Autoregressive Distributed Lag (ADL), and Gravity Model (GM), to ML algorithms. Compared with the traditional approaches, ML algorithms, especially deep learning techniques, offer distinctive advantages: they can automatically extract features from data, handle dynamic and non-linear relationships, operate without prior distribution assumptions, and, more importantly, improve forecasting accuracy (Bi et al., 2022; X. Li et al., 2021).
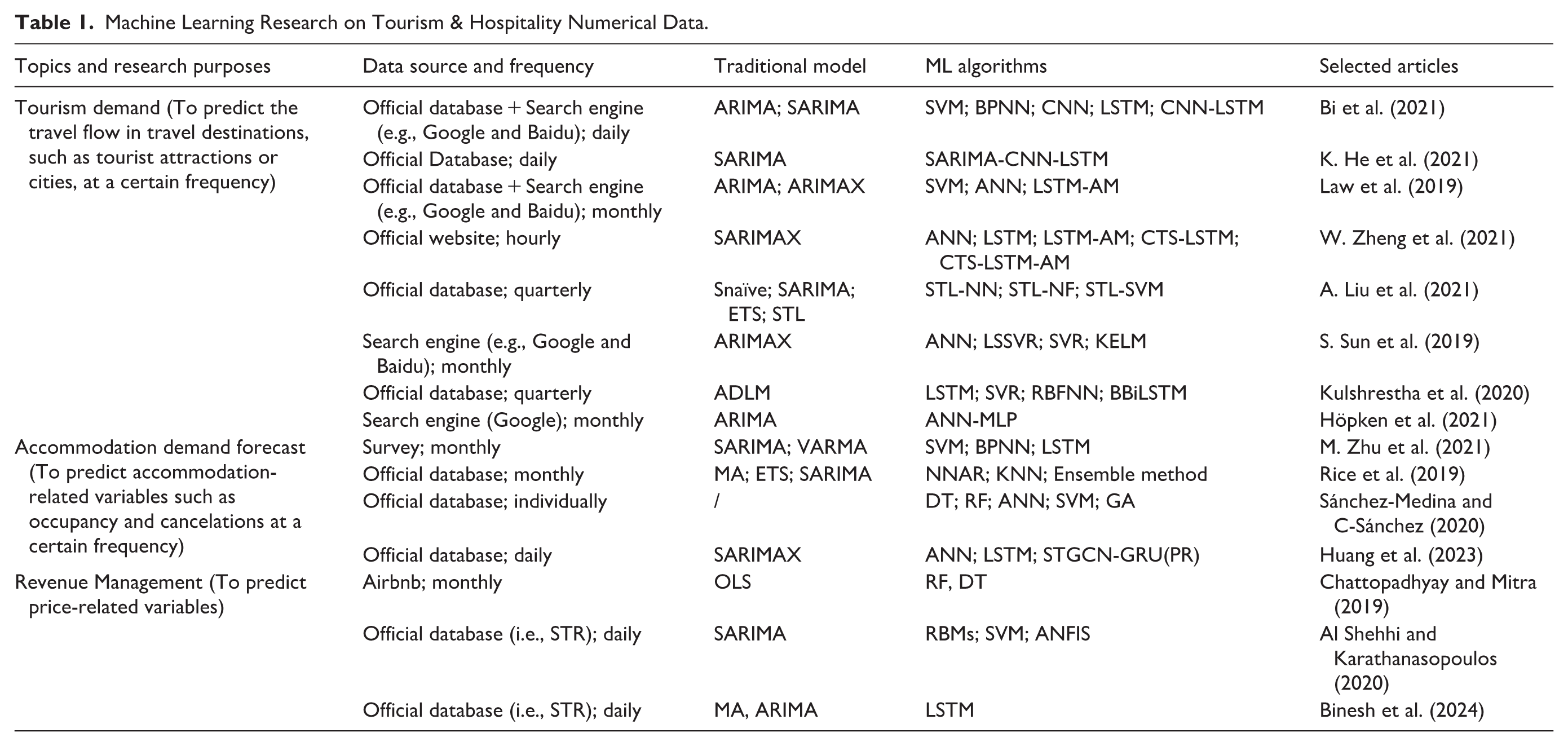
Table 1 summarizes the major ML techniques adopted using numerical data and data sources, along with selected article examples. The time horizon covers hourly (T. Zheng et al., 2021), daily (Bi et al., 2022; K. He et al., 2021), weekly (X. Li et al., 2021), monthly (Law et al., 2019), and quarterly data (A. Liu et al., 2021). Common ML algorithms, such as Multilayer Perceptron (MLP), Support Vector Machines (SVM), Random Forests (RF), and Neural Network (NN), have been used in various studies. Notably, Deep Learning algorithms, especially Recursive Neural Networks (RNNs), served as the most popular tool for demand forecasting. Nearly all Deep Learning models employed in the tourism and hospitality forecasting studies were based on RNNs, with Long Short-Term Memory (LSTM) networks being the most frequently used (Kulshrestha et al., 2020), as LSTM can automatically learn the lag order of data (Bi et al., 2020).
Machine Learning Research on Tourism & Hospitality Numerical Data.
Specifically, the secondary data used in ML forecasting research in tourism and hospitality can be summarized into four categories based on data sources: search engine data, government/organization database (e.g., web traffic), user-generated content, and multi-source data. Forecasting based on search engine data typically involves identifying highly pertinent keywords from large-scale search queries on platforms such as Google and Baidu. These keywords denote users’ interests, and this approach has been demonstrated to improve forecasting accuracy while reducing overfitting (X. Li et al., 2021). For example, Law et al. (2019) constructed 250 keywords and used LSTM with an attention mechanism to estimate monthly tourist arrivals in Macau, while S. Sun et al. (2019) extracted 24 keywords from Baidu Index and 16 keywords from Google Trends to predict monthly tourist arrivals in Beijing.
Web traffic data-based forecasting pertains to using webpage visit volumes in a given period as predicting variables (X. Li et al., 2021). For instance, W. Zheng et al. (2021) extracted real-time visitor flow data to estimate arrivals at specific attractions, demonstrating that Correlated Time Series Oriented Long Short-Term Memory with Attention Mechanism (CTS-LSTM-AM) outperformed all five other baseline models examined in the study (see Table 1).
Recent forecasting studies in tourism and hospitality also utilized UGC, which integrates both textual and image information from social media. For instance, these textual and pictorial data were used as indicators in predicting restaurant survival on Yelp (M. Zhang & Luo, 2023). Increasing studies have also adopted multi-source data to include more holistic features. For example, beyond numerical data on hotel PMS systems, sentiment analysis on review data from Twitter can be integrated to increase the precision of demand forecasting (Ampountolas & Legg, 2021).
Machine Learning Techniques on Textual Data in Tourism and Hospitality
Textual data in tourism and hospitality has increased notably in recent years, in which researchers primarily use UGC (i.e., online review data and social media posts), along with media news (Hao et al., 2020) and journal articles (Ali et al., 2019; Arici et al., 2021). Major topics include online review helpfulness (Bigne et al., 2021), destination brand (Seyyedamiri et al., 2022), destination image (Y. Chen et al., 2024; Lin et al., 2021), customer experience (Garner et al., 2022; Le et al., 2021; Neidhardt et al., 2017; Xu, 2018); fake reviews (X. Zhang et al., 2020; T. Zheng et al., 2021); demand forecasting (Ampountolas & Legg, 2021; S. X. Chen et al., 2021); and electronic word-of-mouth (Neidhardt et al., 2017).
Text mining, as the primary method in generating and analyzing textual data, lies at the crossroads of linguistics, natural language processing, ML, and data mining (Zhai & Massung, 2016). Textual data collection, as the initial stage, involves data crawling from user-generated channels such as TripAdvisor, Booking.com, and Yelp. Data pre-processing follows, mainly including word segmentation, part-of-speech tagging, stemming, lemmatization, and stop word removal (Alaei et al., 2019). Text mining analysis techniques in tourism and hospitality mainly focus on sentiment analysis and attribute extraction/classification (C. Zhang et al., 2021).
Sentiment Analysis
Sentiment analysis mines opinion-oriented texts/words and identifies polar opinions (Ma et al., 2018). It classifies the text-based content into binary (positive/negative; Hao et al., 2020), trinary (positive/neutral/negative; Seyyedamiri et al., 2022; T. Yang et al., 2024), and multiple categories (C. Zhang et al., 2021). Existing tourism and hospitality literature on sentiment analysis falls into three categories: lexicon-based approach, ML approach, and hybrid method (Ravi & Ravi, 2015; C. Zhang et al., 2021).
The lexicon-based approach is based on a sentiment lexicon containing a list of words with polarity values and depends on predetermined terms (Alaei et al., 2019). This approach consists of dictionary-based (pre-defined lexicons to improve sentiment coverage) and corpus-based (clustering algorithm) sentiment analysis (Singh & Gupta, 2019). It enables researchers to calculate a sentiment score of each word based on predefined dictionaries such as Leximancer, Linguistic Inquiry and Word Count (LIWC; Hwang et al., 2020), WordNet, SentiWordNet (Neidhardt et al., 2017), and AFINN (Ampountolas & Legg, 2021). Traditional lexicon-based approaches provide great resources and tools for researchers to identify the polarity in text, but with high domain dependence, they are not highly effective in dealing with contextual and sequential information (Wankhade et al., 2022).
ML approaches, using typical ML algorithms with linguistic features, have gained popularity in recent years due to their competence in handling contextual information, reducing human intervention, and training complex models on substantial datasets with higher accuracy (C. Zhang et al., 2021). Among the supervised ML techniques used for sentiment analysis in tourism and hospitality, SVM is one of the frequently used algorithms to conduct the polar classification (Kwok et al., 2020; Ramos-Henríquez et al., 2021), and it has been applied to detect residents’ attitude based on the textual content of news articles (Hao et al., 2020) or destination brand love based on tourist review data on TripAdvisor (Seyyedamiri et al., 2022). Besides, Decision Tree (Hwang et al., 2020), Naïve Bayes (Hwang et al., 2020; Ramos-Henríquez et al., 2021), Random Forest, K Nearest Neighbors, Artificial Neural Network (ANN; Le et al., 2021), LSTM (T. Yang et al., 2024), and Recursive Neural Tensor Network (RNTN; C. Zhang et al., 2021) have been applied in recent tourism and hospitality research.
Unlike supervised ML, the unsupervised ML approach used for text analysis mainly involves clustering a set of data into groups based on similarity, with K-means and Naïve Bayes as the main techniques (Alaei et al., 2019). Notably, the word-embedding technique has recently attracted scholarly interest because of its dependable accuracy and rapid processing capabilities (Kwon et al., 2020). Word embedding converts vocabulary words into vectors of continuous, precise numerical values to support language modeling and feature extraction, with all the vectors used as input features. Word2vec (Mikolov et al., 2013), as a deep learning algorithm, has been applied to create a word-embedding model to convert the sentences into dense vectors of continuous numeric values (Bigne et al., 2021; Le et al., 2021). It is an unsupervised learning process and can reflect semantic relationships/patterns of words that emerged in vectors and retrieve semantically similar words. Nie et al. (2020) built a hotel word2vec model to calculate the semantic similarity degree for each online review aspect. Additionally, GloVe and FastText, two widely recognized word embedding algorithms, are increasingly employed as modern text mining methods in social science research (Bigne et al., 2021; Vargas-Calderón et al., 2021).
Attribute Extraction/Classification
By extracting or classifying commonly discussed topics and their associated keywords within the text-based dataset, attribute extraction/classification supports the sentence-level sentiment analysis and aspect-based review mining (Bigorra et al., 2019; S. X. Chen et al., 2021). Attributes/topics classification on textual data mainly includes topic modeling methods such as Latent Dirichlet Allocation (LDA), Structural Topic Modeling (N. Hu et al., 2019; Kwon et al., 2020), and Correlated Topic Models (CTM; Garner et al., 2022). As one of the most common methods in topic modeling, LDA uses an unsupervised Bayesian learning algorithm to effectively capture the contextually related dimensions (Guo et al., 2017) and discover underlying topics and word distribution of each topic, such as hotel service quality (Vargas-Calderón et al., 2021). Extensive studies in the tourism and hospitality domain have applied LDA to extract topics in textual data. Notably, sentiment analysis and feature extraction have been utilized in combination, such as using LDA to extract the service attributes in the online review and then applying RNTN to analyze the sentiment tendencies of each service attribute (C. Zhang et al., 2021).
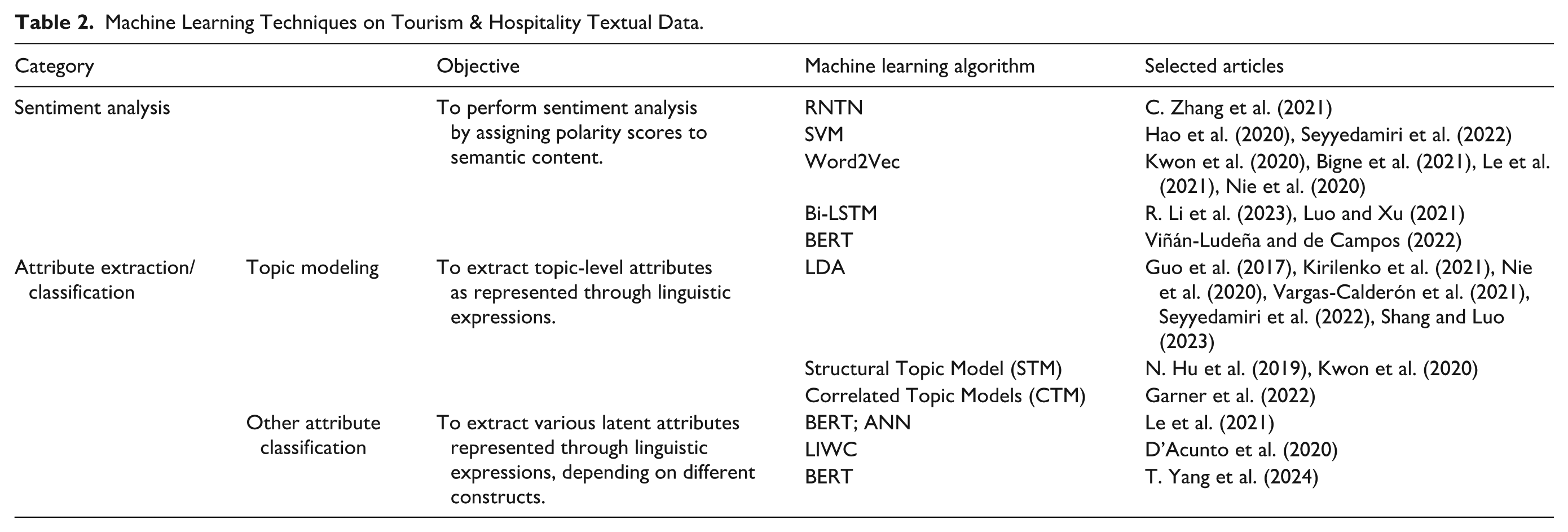
Besides topic modeling methods, the use of CNN-related algorithms to identify various dimensions from textual data has gained increasing attention. For example, Le et al. (2021) adopted a combination of the BERT model and artificial neural networks to explore multi-dimensions of authenticity; T. Yang et al. (2024) utilized the BERT model to measure customer satisfaction. Table 2 demonstrates the ML techniques applied in textual data analysis in tourism and hospitality research.
Machine Learning Techniques on Tourism & Hospitality Textual Data.
Machine Learning Techniques on Image Data in Tourism and Hospitality
Over the past decade, there has been notable progress in employing ML methods to examine image data. Major themes are across destination image (Arefieva et al., 2021; Deng & Li, 2018; Z. He et al., 2022; Qian et al., 2023), hotel brand marketing (Giglio et al., 2020; Ren et al., 2021), review helpfulness (Ma et al., 2018), satisfaction (X. Liu et al., 2022), and social media engagement (Hou & Pan, 2023; Tamaki, 2021; Yu & Egger, 2021). Minor research topics also include restaurant survival (M. Zhang & Luo, 2023), Airbnb property demand (S. Zhang et al., 2017), online identity of the travel agency (Luo et al., 2021), and tourist movement patterns (Payntar et al., 2021).
Initially, the metadata of geotagged photos were collected to examine tourists’ movement (Y. Sun et al., 2015), tourist flow (W. Chen et al., 2019), and destination perception (Deng & Li, 2018). These studies are essentially text mining-related research due to the textual tag information. With the development of ML algorithms, researchers have started to focus on pictures per se, to discover the underlying patterns. We categorized three types of studies in terms of the primary purposes and technical approaches.
The first category involves identifying low-level attributes. Specifically, image features are the focus of this category of research. For example, Trpkovski et al. (2018) extracted five features, including brightness, colorfulness, contrast, sharpness, and noisiness, to assess hotel photo quality. Yu and Egger (2021) used the Google API to detect travel pictures’ dominant colors and examine how lightness, chroma, and hue may impact Instagram posts’ popularity.
The second category is object detection, aiming to identify and locate instances of objects in image data. For instance, Giglio et al. (2020) employed Wolfram Mathematica software to identify the objects in 7,395 UGC hotel photos on TripAdvisor to investigate consumers’ perception toward luxury hotel brands. C. Li et al. (2023) crawled 464,316 photos from a Chinese OTA site, Qunar, to study the effect of visual content on hotel reviews’ helpfulness. Furthermore, Deng and Liu (2021) employed Amazon Rekognition to perform facial and content recognition in tourist photos on Instagram.
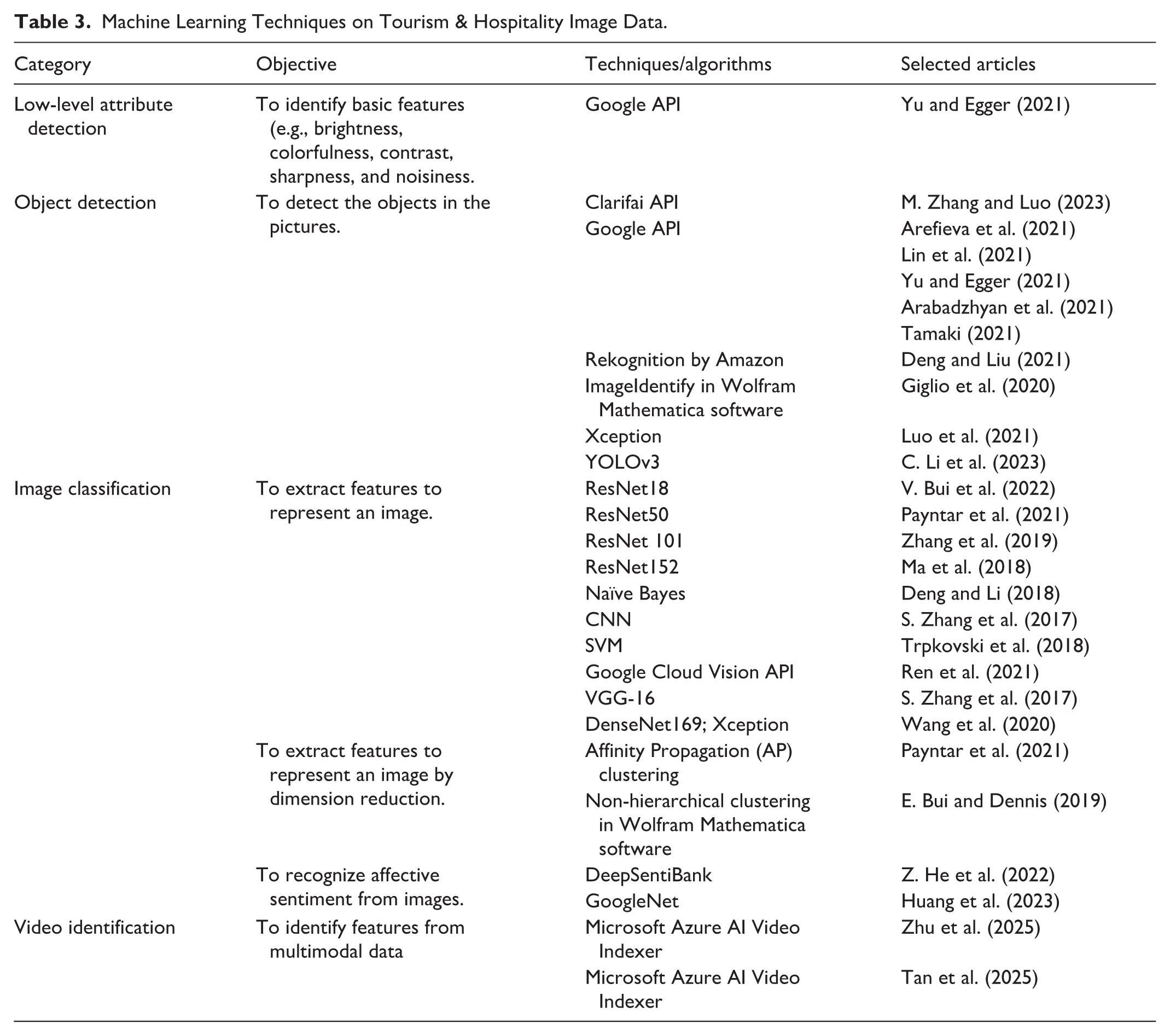
The third category is characterized as image classification, which means extracting features to represent the images. For example, S. Zhang et al. (2017) extracted 12 image attributes under three dimensions (color, composition, figure-ground relationship) and adopted a pre-trained ML algorithm (i.e., VGG-16) to classify them, to estimate the economic impact of image factors on property demand in Airbnb. In Zhang et al. (2019)’s research, 60 scenes were classified using ResNet 101 to uncover tourists’ perceptions of Beijing. By contrast, Wang et al. (2020) identified 25 image categories covering all the tourism scenes using transfer learning of DenseNet169 and Xception. Particularly, revealing sentiment or affective information from photos has become increasingly popular in recent tourism and hospitality research. For example, via DeepSentiBank, Z. He et al. (2022) extracted cognitive elements (object) and affective elements (emotion) in both user-generated and officially produced photos to explore how tourists perceive a destination’s image and help destinations select the “right” photo to project the destination image. Additionally, Huang et al. (2023) investigated the impact of photo sentiment on review helpfulness and enjoyment by using GoogleNet to train and test the model established through a dataset labeled and voted on MTurk. Table 3 summarizes the ML techniques applied in image data analysis in tourism and hospitality research.
Machine Learning Techniques on Tourism & Hospitality Image Data.
Beyond static images, videos, which consist of continuous image frames, have increasingly attract scholarly attention in recent years. Moving beyond traditional videography studies that primarily relied on content analysis, ethnography, or video typology (Masset et al., 2024; Zaim et al., 2024), recent advances in machine learning, particularly deep learning, have enabled the analysis of multimodal data embedded in videos (e.g., visual, textual, and audio components) to generate richer insights. For example, J. Zhu et al. (2025) employed video mining to extract information across three modalities and identified an inverted U-shaped relationship between video informativeness/visual variation and engagement. Similarly, Tan et al. (2025) decomposed video data into visual, textual, and auditory modalities, revealing that natural scenery combined with a moderate energy level and textual emphasis on Maori culture generated a higher user engagement, measured by the number of likes.
Discussions on Common Issues and Mitigation Strategies
By leveraging multilayered structures and large-scale datasets, ML models can extract complex patterns and reach high levels of abstraction, resulting in accurate outcomes (Kulshrestha et al., 2020; X. Zhang et al., 2020). Consequently, a range of machine learning algorithms (as illustrated in Figure 3) have gained prominence in tourism and hospitality research, where data-driven insights span a variety of topics (Deng & Liu, 2021). Nevertheless, the intricate nature of ML models and the diverse formats of data in this field present distinct challenges and complications.
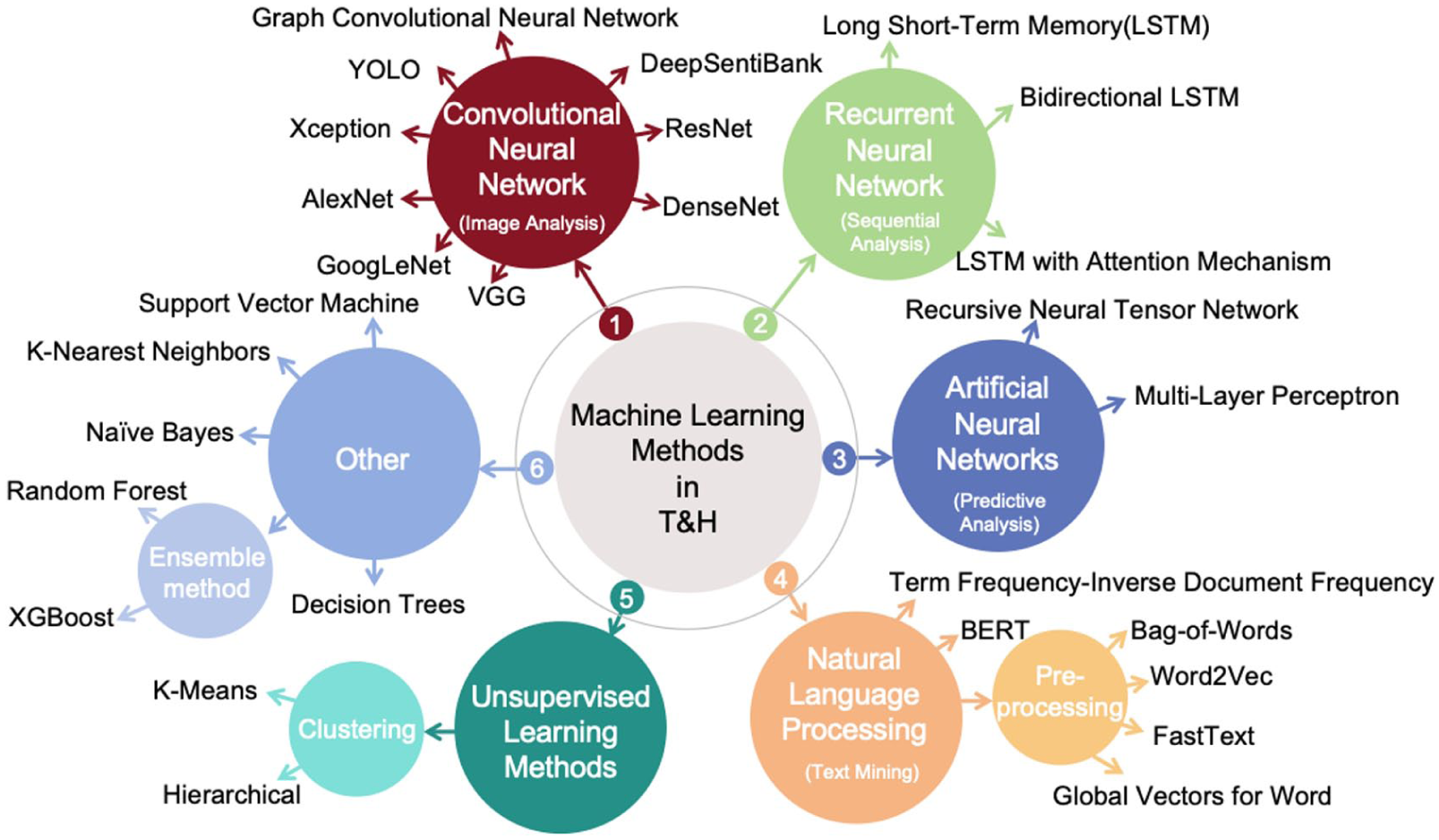
ML methods employed in tourism and hospitality research.
Issues and Challenges on Different Data Types in Machine Learning Research
In ML-related research applied to tourism and hospitality, different data types, including numerical, textual, and image data, present distinct issues and challenges (Rajkomar et al., 2019). These issues are not only inherent in the data itself, such as the data quality, but also arise during analysis and processing stages (Guo et al., 2017; Le et al., 2021).
Issues in ML Research Based on Numerical Data
Tourism and hospitality research topics that frequently adopt ML techniques, such as demand forecasting, strategic planning, and operational efficiency (García et al., 2016), tend to depend heavily on numerical and historical datasets. However, this reliance introduces several critical issues, particularly associated with data accuracy, consistency, and predictive analysis. These challenges are especially significant in tourism and hospitality, where datasets are highly susceptible to external disruptions such as pandemics, natural disasters, and political instability. As a result, numerical data often exhibit non-stationarity and volatility, creating unique obstacles that necessitate the development of more robust and adaptive ML models. Addressing these issues can generate insights with implications for other dynamic and event-driven domains.
Data Accuracy and Consistency
Ensuring the accuracy and consistency of historical data, such as daily travel volume, monthly accommodation demand, or booking cancelations, requires particular attention. Such datasets often contain ambiguous values, missing entries, outliers, and irrelevant records (Akter et al., 2022). Consequently, data cleaning and preprocessing are both complex and resource-intensive tasks. It is essential to refine existing pre-processing methods or develop new algorithms for optimizing ML applications and ensuring the utilization of diverse data sources.
Predictive Analysis Challenges
In demand forecasting research, which increasingly contains unstructured data in the social media era, the presence of heterogeneous data types and databases with varying formats poses obstacles due to the absence of standardization protocols and a unified public database that integrates all relevant data (Alpaydin, 2020). These issues not only complicate the integration of different data types but also underscore the potential value of developing a universal database. At the same time, not all data utilized in tourism forecasting research are publicly available, which raises certain legal and ethical concerns regarding user privacy and the types of data that can be shared.
Beyond data challenges, forecasting in tourism and hospitality is also constrained by the availability of appropriate algorithms and tools. The performance of commonly applied ML models, such as LSTM (W. Zheng et al., 2021), Bi-LSTM (Kulshrestha et al., 2020), and ANN (Höpken et al., 2021), is heavily dependent on the selection and tuning of hyperparameters (Rajkomar et al., 2019). In existing tourism and hospitality research, hyperparameter tuning has largely been conducted manually, with key parameters such as learning rate, number of hidden layers, kernel size, and dropout ratio typically adjusted by hand. This approach is labor-intensive and requires considerable domain expertise. Techniques such as Grid Search (Young et al., 2015) and Random Search (Bergstra & Bengio, 2012) have been applied in some tourism and hospitality studies, particularly for optimizing models like SVM, RF, and LSTM.
Bayesian Optimization (Bertrand et al., 2017) has seen limited use, mainly in recent deep learning applications, offering greater efficiency compared to exhaustive search methods. Similarly, the Adam optimizer (Kingma & Ba, 2014), although originally designed for adaptive learning rate adjustment rather than explicit hyperparameter search, has been widely employed in deep learning training. More advanced techniques, such as Hyperband (H. Li et al., 2022), Optuna (Akiba et al., 2019), evolutionary algorithms, and Neural Architecture Search (NAS; Elsken et al., 2019), remain largely unexplored in tourism and hospitality research. Furthermore, while Transformer-based architectures (Vaswani et al., 2017) have demonstrated superior performance and training efficiency in sequential data processing, their adoption within tourism and hospitality research has been minimal. Additionally, many forecasting models developed to date have seen limited deployment in industry settings, representing a promising avenue for future scholars to strengthen industry collaboration and empirical validation.
Issues in ML Research Primarily Based on Textual Data
Textual data in the tourism and hospitality domain exhibit several unique linguistic and contextual characteristics, including highly emotional, experience-driven content, a wide variance in writing quality, and rapid shifts in language trends, which make such data particularly complex and difficult to model. These domain-specific challenges offer valuable opportunities to extend natural language processing (NLP) techniques beyond general-purpose benchmarks. Despite notable progress, persistent issues remain regarding data quality and complexity, nuanced language use, and multilingual analysis.
Quality and Complexity of Data
The performance of ML methods is closely tied to data quality, as unreliable, biased, or missing information may result in flawed analyses or misleading predictions (Hao et al., 2020; T. Zheng et al., 2021). Textual analysis in tourism and hospitality frequently relies on online review data provided by tourists or guests (T. Hu & Zhang, 2025). However, such reviews are often subject to credibility issues due to the existing fake reviews (Mohawesh et al., 2021; Singhal & Kashef, 2024), which can distort assessments of customer sentiment and market trends. Although various detection tools have been proposed, relatively limited research has applied NLP specifically to fake review detection (Martin-Fuentes et al., 2018; Shang & Luo, 2023).
ML systems typically convert text to numerical vectors through word vectorization or word embedding, often relying on lexicon-based methods. However, the domain-specific nature of corpora and lexicons restricts their applicability across contexts (Nandwani & Verma, 2021). To address these challenges, transfer learning models like XLNet and BERT have been applied to large-scale datasets (e.g., Yelp wine reviews) for sentiment analysis (Tao & Fang, 2020). These models, initially trained on large-scale text corpora, can be fine-tuned for domain-specific tasks, offering efficiency gains and improved performance (Nandwani & Verma, 2021; Tao & Fang, 2020). Hybrid methods that integrate deep learning with conventional ML techniques have also shown superior performance by mitigating the individual limitations of each model type (Al Amrani et al., 2018). For instance, rule-based methods integrated with domain-specific lexicons have achieved superior results in aspect-level sentiment analysis, outperforming standard lexicon-based baselines by 5% (Alqaryouti et al., 2020). In addition, newer architectures such as Conv-char-Emb have been introduced to handle noisy textual inputs while maintaining low memory usage for embedding (Arora & Kansal, 2019).
Nuances of Human Language Context
Human language itself poses challenges to ML tools, leading to misinterpretation of sentiment, especially in informal or context-heavy reviews (Puh & Bagić Babac, 2023). Sarcasm and irony, for instance, remain difficult for models to detect (Ghanbari-Adivi & Mosleh, 2019). For example, a statement such as “The nightlife around the hotel was vibrant – I didn’t even need to go outside to enjoy the party until 4 a.m.” seems to signify a positive sentiment, but it is negative in nature. Similarly, opinion-rich sentences may express multiple emotions simultaneously, for example, “The view at this site is so serene and calm, but this place stinks” (Shelke et al., 2014). Further challenges include ambiguous expression of emotions (Nandwani & Verma, 2021) and the rapid evolution of internet slang. To address these issues, multiple modalities that integrate textual and visual data have been increasingly used to improve the robustness of sentiment analysis (Gandhi et al., 2023).
Multilingual Data
While most textual datasets are in English, the global nature of tourism demands effective analysis across multiple languages. Advanced multilingual NLP models such as Multilingual BERT (mBERT; Devlin et al., 2018), XLM-R (Cross-lingual Language Model for English and 100+ Languages; Conneau et al., 2019), mT5 (Multilingual T5; Xue et al., 2020) provide valuable tools for cross-lingual applications. Nevertheless, tourism-related textual data often involves informal local expressions, code-switching, and culturally embedded meanings, which pose significant challenges for current cross-lingual NLP models. Addressing these complexities not only enhances the applicability of ML in tourism but also contributes to the development of more inclusive, culturally adaptive, and semantically robust multilingual NLP systems.
Issues in ML Research Primarily Based on Image Data
The application of ML techniques presents unique challenges when dealing with visual data, including the highly subjective nature of images, the emotional variability in user-generated visuals, and the esthetic diversity across cultural contexts. These domain-specific complexities position tourism and hospitality as a valuable testbed for advancing computer vision techniques in areas such as emotion recognition, cross-cultural visual semantics, and image captioning. Recent advancements in image-text matching analysis and zero-shot learning are pioneering changes, enabling sophisticated image understanding without the prerequisite of labeled datasets (Egger, 2024). Despite these technological strides, academic research in tourism and hospitality still faces persistent challenges, such as constrained sentiment categorizations and a lack of domain-adapted pre-trained models.
Constrained Sentiment Categorizations
Many current ML models operate with restricted sentiment classes, typically positive, neutral, and negative (Onyenwe et al., 2020), which oversimplify the rich tapestry of human emotional expression. This reductionism often results in a loss of granularity in understanding customer preferences, satisfaction, and overall experiences (Arefieva et al., 2021; F. X. Yang et al., 2022; D. Zhang & Wu, 2023). Such simplifications are especially problematic in tourism and hospitality, where consumer experiences conveyed through images often reflect multidimensional sentiments that extend beyond conventional binary or nominal classifications.
Advancements in ML techniques have led to new approaches to deploying deep learning for automatic feature generation in emotion detection. For instance, tools such as MediaPipe provide face detection capability with 468 facial landmarks, which have been used for keypoint-based emotion detection (Siam et al., 2022). These models encode complex features into distinguishable patterns, enabling the detection of a wide array of emotions, such as happiness, sadness, surprise, fear, anger, disgust, and contempt.
Lack of Pre-trained Models
A central challenge in applying ML to visual data is the resource-intensive process of data labeling. Emotion recognition and sentiment analysis rely on large, annotated datasets, but manual labeling is time-consuming, costly, and prone to inconsistencies (Balahur & Turchi, 2014). Consequently, most studies in tourism and hospitality have employed pre-trained ML models to analyze their own datasets, often assuming these models can transfer effectively across domains (H. Li et al., 2023; M. Zhang & Luo, 2023). However, models originally trained on limited, task-specific datasets in computer science frequently demonstrate reduced effectiveness when applied to domain-specific tourism and hospitality data (X. Li et al., 2021).
These difficulties highlight the necessity for developing more generalizable and adaptive vision models capable of learning from sparse, heterogeneous, and culturally nuanced visual data. Tourism and hospitality research is well-positioned to contribute insights to the broader ML community, especially in the realm of few-shot learning, domain adaptation, and cross-modal alignment. Large-scale pre-trained models, such as CLIP, trained on 1.28 million labeled examples (Radford et al., 2021), offer promising directions for enhancing image analysis in tourism applications.
Similar issues extend to video analytics. Current studies often lack pre-trained models tailored to tourism-related content, which limits the extraction of higher-dimensional, theoretically informed features. Moreover, much of the existing research merely focuses on scene-level information within the image modality, whereas richer, higher-level insights could be gained by analyzing video data that capture temporal dynamics and multimodal interactions.
Other General Challenges in Machine Learning Research
Drawing from an in-depth analysis of current ML studies in tourism and hospitality, we classify the primary challenges into four key categories: (1) data distribution, concerning the volume and representativeness of input datasets; (2) model quality, including model selection, validation processes, and interpretability of outputs; (3) explainable AI (XAI); and (4) ethical considerations.
Data Distribution
Processing large volumes of data through ML introduces challenges not only related to data quality but also to data distribution. Three primary issues are particularly salient: overfitting, class imbalance or bias, and data leakage.
Overfitting arises when an ML model is excessively complex relative to the available training data, often due to a disproportionately large number of parameters (W. Zheng et al., 2021). Consequently, the model becomes overly attuned to the training data, capturing noise and subtle variations that hinder its ability to generalize to unseen inputs. Strategies such as cross-validation, regularization, pruning, and increasing the size of training datasets are commonly applied to reduce overfitting and enhance model robustness (Goodfellow et al., 2016).
Class imbalance or data bias occurs when certain output categories generated by a classification process are unevenly represented in the dataset (Höpken et al., 2021; Kulshrestha et al., 2020; X. Zhang et al., 2020). Accurate data labeling is essential, as misrepresentation of subgroups can compromise interpretability and reliability across populations (Akter et al., 2022; Davenport et al., 2020; Lesko & Atkinson, 2001; Paulus & Kent, 2020).
Data leakage occurs when training data overlaps with validation sets, which inflates performance metrics and produces models that underperform in real-world applications. Preventing data leakage requires careful separation of datasets and dedicated validation procedures, including cross-validation and independent test sets (Kaufman et al., 2012).
Model Quality
The multi-layered architecture of ML models enables the extraction of high-level features from data but also introduces challenges in model quality (Rajkomar et al., 2019). Reliability can be compromised when models generate biased outputs due to misalignment with task requirements (Shahriar & Hayawi, 2023). As ML algorithms rely on statistical associations within datasets (Paulus & Kent, 2020), overlooking critical relationships between input features and target variables can result in systematic prediction bias affecting both protected and unprotected groups (Tsamados et al., 2021). Strategies to reduce avoidable bias include modifying input features based on error analysis, enlarging the model by adding more layers, and exploring alternative model architectures.
Selecting the most appropriate model is not always straightforward, even when data characteristics appear to favor a particular modeling approach (Bi et al., 2020; Bi et al., 2021; Rezapouraghdam et al., 2023). For example, in feature extraction from tourism and hospitality images, CNNs are widely used for this task, Auto Encoders are preferred for very noisy images, and GANs excel in extracting information by generating new images from input data (Goodfellow et al., 2014).
Enhancing ML model accuracy for analyzing tourism and hospitality images typically requires considerable computational and storage resources, which increase both time and space complexity (Maxwell et al., 2018). Researchers have addressed these challenges through advanced hardware solutions (e.g., GPUs) and streamlined methods for lower-dimensional inputs or smaller datasets (Guo et al., 2017; N. Hu et al., 2019; Song et al., 2021).
Additionally, model selection should consider research objectives, such as identifying correlations versus uncovering causal relationships. Although machine learning has predominantly been employed for prediction, approaches such as causal forests extend its application to the estimation of heterogeneous treatment effects (Athey & Wager, 2019). Nevertheless, the capacity of ML to support causal inference remains limited, and the interpretation of results within a causal framework requires careful consideration.
Explainable AI
Explainable AI (XAI) encompasses ML approaches aimed at clarifying how predictive models generate outputs, thereby enhancing transparency in decision-making processes (Gunning, 2017). The opaque nature of ML models, especially convolutional and recurrent neural networks, has driven the development of diverse XAI methods designed to improve model interpretability (Arrieta et al., 2020). However, the complexity of both ML architectures and data presents ongoing challenges in applying XAI in tourism and hospitality research. Notably, efforts in improving interpretability can sometimes come at the expense of model accuracy and predictive performance, potentially compromising the overall quality of the results.
Ethical Considerations
Ethical and privacy concerns surrounding the use of online big data, such as social media content, remain significant and often lack clear guidelines for researchers. Key considerations include ethical acquisition of data, access rights, and secure storage (Essien & Chukwukelu, 2022). Ethical considerations in this area are part of an ongoing discourse, and greater effort is needed to develop standardized practices. While no universally accepted guidelines currently exist, researchers should ensure compliance with platform Terms of Use, anonymize data, restrict usage to non-commercial academic purposes, and obtain platform consent when necessary. Future research should prioritize establishing a systematic, ethics-oriented framework for ML applications in tourism and hospitality. This includes, but is not limited to, clearly specifying protocols and agreements for responsible data use across various sources.
Based on these identified challenges and feasible actions, Figure 4 presents a visual framework that summarizes key issues and recommended actions aligned with the phases of the ML research process. This framework offers practical guidance for scholars conducting ML-based research in tourism and hospitality.
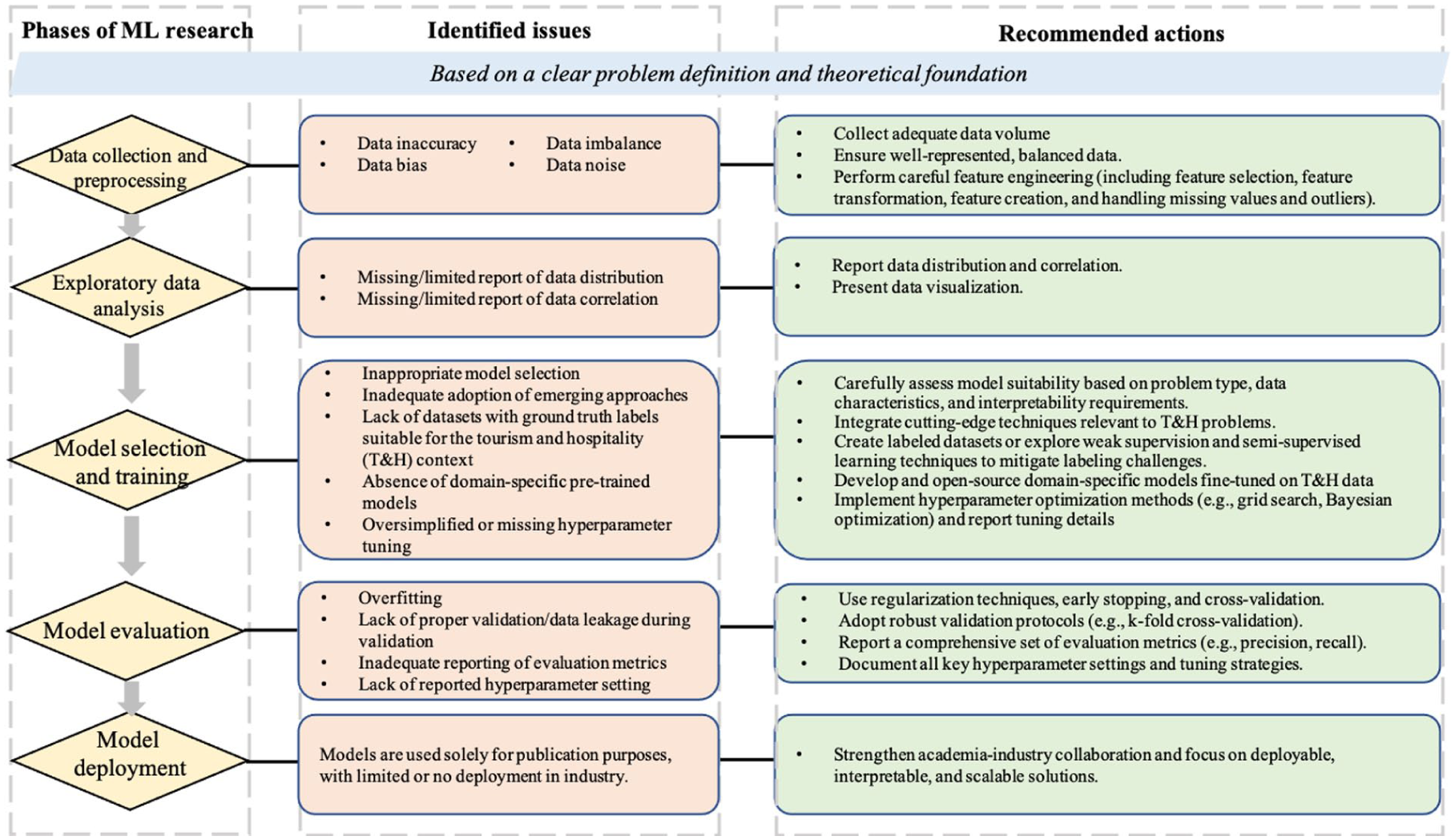
Machine learning phases, identified issues, and recommended actions in tourism and hospitality.
Conclusion and Propositions for Future Machine Learning Research in Tourism and Hospitality
This study provides a comprehensive overview of tourism and hospitality research that uses ML techniques by critically reviewing the existing literature and offering insights for the future. Through a systematic review of 409 scholarly articles published over the past two decades, several conclusions can be drawn.
Firstly, the number of publications has escalated markedly since 2019, with the leading role of journals such as Tourism Management, International Journal of Hospitality Management, and Current Issues in Tourism in developing ML research in tourism and hospitality academia. Among all the data sources, UGC has been the dominant source for researchers. Secondly, this study summarized research topics and methods based on the nature of data modalities: numerical, textual, and image data, thus providing a clearer framework for understanding the scope of existing work. Lastly, current issues and challenges in applying ML techniques to tourism and hospitality were discussed, with particular attention to data quality, data distribution, and model quality.
In contrast to existing ML literature reviews, which primarily focus on broad bibliographic-related outcomes and future research agendas (Doborjeh et al., 2022; Knani et al., 2022; Lv et al., 2022), this study offers several distinct contributions. Specifically, it categorizes research topics and methods based on different data types, providing a clearer blueprint for researchers who work with diverse datasets. By covering a longer time span, the study helps identify which topics and methods have been applied to various types of data. In doing so, it delineates practical data analysis processes, highlights common pitfalls, and suggests strategies to mitigate these challenges for each data type. Furthermore, it provides comprehensive and insightful propositions for future research directions in ML applications within the tourism and hospitality fields.
Proposition 1. Expanding Future Research to Encompass Broader Topics
Existing studies have commonly investigated topics including demand/revenue forecasting, destination image, review helpfulness, and social media engagement. Multiple underexplored or emerging areas warrant particular attention, including robotics, sensory marketing, pricing models, and food image analysis, especially in domains that have traditionally relied on conventional survey-based approaches. For example, constructs such as perceived sustainability in business sectors, traditionally measured through surveys, can now be investigated using ML techniques by extracting latent variables from user-generated social media content. This approach allows researchers to capture consumer perceptions in a more dynamic and data-driven manner. Similarly, traditional pricing models in tourism and hospitality, which typically rely on historical and property-level data, can be extended through multimodal ML approaches that leverage multi-source information to produce more adaptive and dynamic pricing strategies. Furthermore, image-related research can progress beyond object recognition toward more sophisticated tasks enabled by ML techniques, such as emotion and sensory detection, to capture multidimensional affective responses conveyed through visual content. Figure 5 synthesizes current and emerging ML research topics in tourism and hospitality, together with related research questions aligned with these emerging areas, offering a structured roadmap for future scholars seeking to advance ML applications within the field.
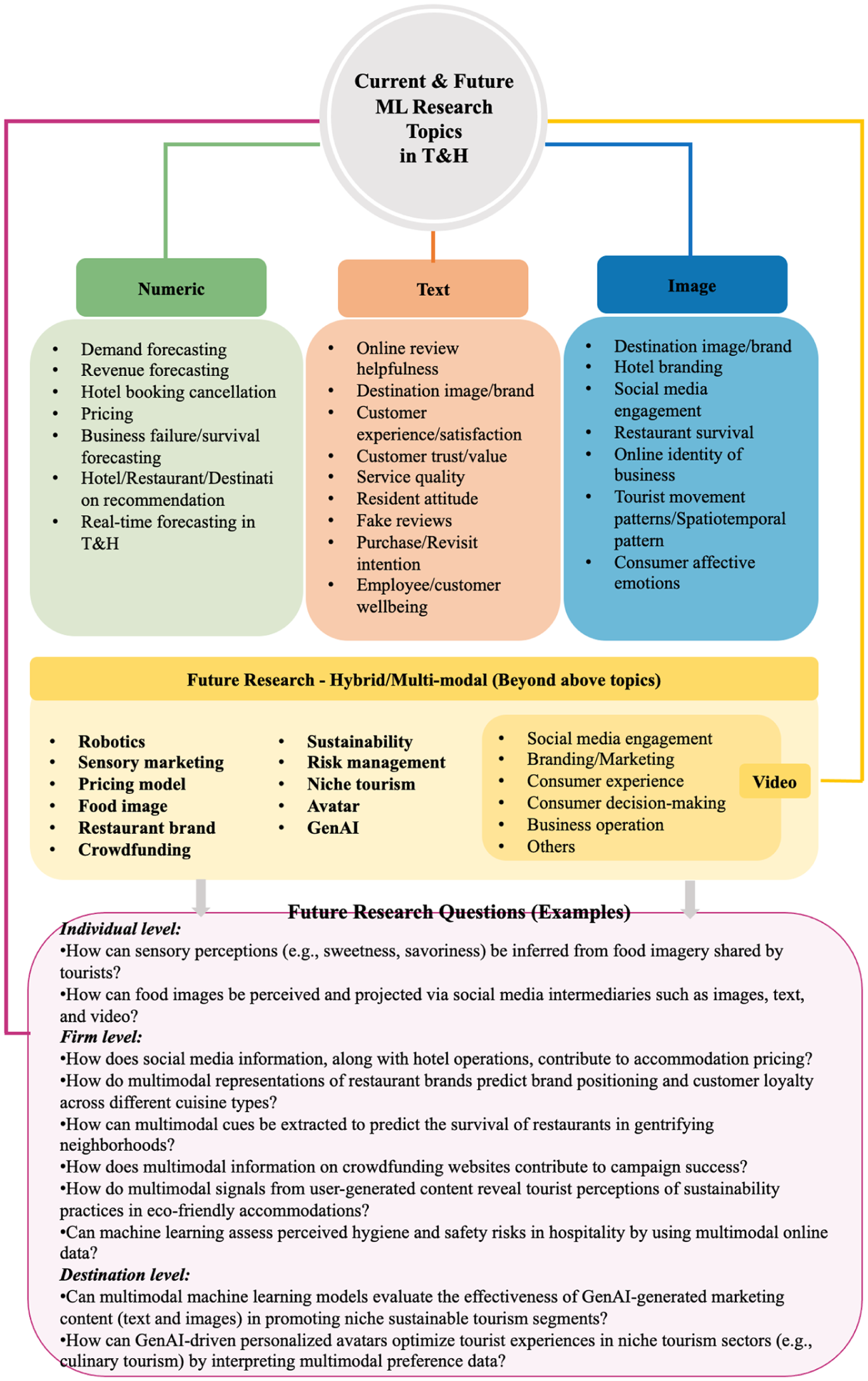
Current and future machine learning research topics in tourism and hospitality.
Proposition 2. Advancing Theory Development Through ML Techniques
While ML has been increasingly employed across a wide range of research topics, many studies lack a strong theoretical foundation or provide limited theoretical justification for research questions. The potential of ML to advance theory development remains relatively unexplored. ML techniques can be leveraged to test relationships between constructs across different scenarios. When large-scale datasets are available, ML can validate relationships that were previously examined through small-scale surveys or experimental data. Additionally, in areas where little prior theory exists, techniques such as topic modeling or clustering can be used in exploratory studies to identify emerging constructs.
Notably, qualitative studies can first be employed to discover novel themes, after which ML techniques can be used to train models that detect and validate these themes within large-scale datasets, ultimately enabling the testing of consequential relationships. For such research, scholars should move beyond reliance on pre-trained models and algorithms by generating training datasets with ground truth labels specifically aligned with their research questions. Historically, time, budget, and methodological constraints have led many studies to heavily rely on pre-trained models developed in domains unrelated to tourism and hospitality. However, limitations of using “off-the-shelf” algorithms have drawn increasing critical attention among researchers (Mariani & Baggio, 2022). There is a growing emphasis on establishing domain-specific datasets, labels, and models tailored to the distinctive research needs of tourism and hospitality.
Proposition 3. Leveraging Multimodal Data to Capture a Broader and More Nuanced Spectrum of Features
As noted earlier, a growing trend has emerged toward embracing a combination of multiple data modalities as model inputs. ML techniques are well-suited to converting various forms of data into numerical features, enabling the model to learn patterns and perform forecasting tasks. For example, natural language processing models such as BERT can extract features from textual online reviews, while CNNs can process images, with all extracted features combined for joint prediction.
This multimodal approach offers several advantages. First, it provides a more comprehensive overview by leveraging richer data sources and mitigating potential confounding effects that could challenge single-modality models. Second, different data modalities can complement one another, particularly in cases of data imbalance or missing values. Third, multimodal feature integration enhances prediction accuracy by creating more complete and compensatory feature representations. Although recent studies have increasingly recognized the advantages of multimodal approaches (Y. Chen et al., 2024; H. Li et al., 2023, 2024), ample opportunities remain for applying multimodal data in tourism and hospitality research. Such approaches can be highly beneficial for topics related to social media analytics, such as demand forecasting, online review helpfulness, and customer engagement.
Proposition 4. Addressing Validity Challenges, Particularly in the Context of Generative Artificial Intelligence (GenAI) and Large Language Models (LLMs)
Future research should place greater emphasis on the validity issue in both model employment and result interpretation. Many existing ML studies within tourism and hospitality have prioritized computational applications while dedicating limited effort to validating findings through human raters, mixed-method designs, or triangulation. Scarcer research has critically examined data quality and distribution, model robustness, feature selection, or the appropriateness of “borrowing” certain approaches from other fields into the tourism and hospitality domain. These oversights may raise important validation issues.
Recent breakthroughs in artificial intelligence, particularly in GenAI and LLMs, have further amplified the need to reassess validity. While such technologies present powerful tools for analyzing complex data, concerns remain regarding the accuracy, consistency, and interpretability of the results they generate. Given that these models are typically trained on massive, general-purpose datasets, their alignment with domain-specific phenomena in tourism and hospitality is uncertain. Validating AI-generated results, including model explanations and predictive insights, therefore represents a novel yet critical area of inquiry. In addition to technical performance metrics, researchers must also evaluate the epistemological and contextual soundness of ML applications in this domain.
Limitations and Future Research Directions
This study has certain limitations. Although it includes journals beyond the tourism and hospitality field, it focuses exclusively on peer-reviewed articles, thereby excluding book chapters, conference papers, and other types of publications. Moreover, only English-language articles were considered. While recognizing video research as an emerging field, this study does not incorporate video as a data type for review, given its nascent stage in tourism and hospitality academia. Future research would benefit from incorporating more insights on video data and assessing its potential contributions, along with continuing to monitor the development of other underexplored modalities in ML research in tourism and hospitality.
Footnotes
Author Note
The first two authors contribute equally to the manuscript. The authors are listed in alphabetical order.
Author Contributions
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the National Natural Science Foundation of China [No. 72372164].
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.