
Abstract
Experiments are frequently used in the travel and hospitality literature to provide stronger evidence of causal relationships between various constructs. Recently, despite the use of online platforms for experimental studies, such studies have often failed to find significant results, as expected. To increase the probability of obtaining significant results for experiments using online panels, this paper suggests six practical recommendations across three categories: (i) handling less homogenous online participants; (ii) understanding and managing different motivations and abilities in online participants; and (iii) using effective and transparent experimental designs and procedures. This paper provides the results of three empirical investigations to support these recommendations.
Introduction
Due to the popularity of online platforms such as Amazon MTurk and Prolific (Buhrmester et al., 2016; Lu et al., 2022), conducting experiments with online participants is now very popular. For instance, we analyzed journal articles published in 2022, using experimental methods, in the Journal of Travel Research. In total 33 papers used experimental methods for empirical investigation. Of these, 71% (=24/33) used an online panel such as Amazon MTurk (14 articles), a Qualtrics panel, Clickworker, Prolific, or other regional online panels (e.g., wjx.cn). This paper mainly addresses online experiments, which are operationally defined as experiments conducted using participants from online panels. Online experiments are typically conducted as controlled experiments or experiments with fully random assignment, but quasi-experiments or experiments with non-fully random assignment are also possible. Our main focus in this paper will be on controlled experiments.
Even though experimental methods are a powerful way to provide evidence of causal relationships between constructs or variables (Rosenthal & Rosnow, 2008), it is not easy for researchers to obtain successful outcomes using online experiments (e.g., Arechar & Rand, 2021; Peyton et al., 2022). Online experiments cannot be successful or cannot yield significant results as expected, for a variety of reasons, as described below.
First, the theoretical framework may be wrong, meaning that the empirical investigation will fail. However, especially in social sciences, it is very difficult to interpret the failure of experimental studies as the only and direct evidence for the failure of a suggested theoretical framework. In most cases, researchers with failed empirical evidence do not know whether such failure is attributable to faulty theory or poor empirical investigation (Van de Ven, 2007). In practice, researchers tend to relinquish a theory after the consistent failure of empirical studies. Therefore, it is possible that a potentially good theory could be rejected because of the failure to obtain successful experimental results.
Second, even if a theory is right, online experiments may fail due to the relatively small effect size of the theoretical model and the empirical setting (Rosenthal & Rosnow, 2008). When the conceptual effect size is small, online experiments may fail even with sufficient sample sizes. Similarly to previous cases, it is challenging for researchers to accurately attribute a small effect size to either theoretical failure or poor execution of an online experiment.
Finally, even strong theoretical models with high conceptual effect sizes can fail simply due to poor execution of online experiments (Van de Ven, 2007). Depending on the levels of noise and errors, variations in the empirical data can become uncontrollable error variance, resulting in failure to find significant results. This paper focuses on practical suggestions for how to conduct more effective and efficient experimental design in the online setting, with acknowledgment of the common mistakes. We will cover three categories for conducting successful online experiments: (i) handling less homogenous online participants; (ii) understanding and managing different motivations and abilities for online participants; and (iii) using effective and transparent experimental designs and procedures.
Non-Homogenous Participants
In this section, we will address the non-homogeneity of participants, mainly driven by the online environment. Compared to other samples, such as students or face-to-face interview participants, an online panel naturally consists of diverse individuals with various individual characteristics, including different cultural, social, economic, or demographic statuses (Aguinis et al., 2021), as well as different task situations, such as varying time, places, or surrounding environments (Lu et al., 2022). This uncontrolled heterogeneity can increase error variance, potentially resulting in insignificant experimental results. We provide two main recommendations to control non-homogeneity in online panels.
Heavy Exposure to Other Projects Across Different Time of Day of Experiments
The time of day can significantly influence heterogeneity, since participants may, at different times of day, have a different physiological (e.g., Page et al., 2011), cognitive, or psychological (e.g., Oakhill & Davies, 1989) status. For instance, if the study is about food choice or preference, the timing of answers could influence the preference for the food itself.
A more serious problem is that survey participants are often exposed to multiple survey projects depending on the time at which the survey is posted on the platform. For most research topics, it is better to avoid the influence of other projects. The simple solution is to post the experimental project when there are relatively small numbers of other projects available.
To check how many other projects had online samples in progress, we collected data from Amazon MTurkers through CloudResearch qualified samples (Survey #1). The survey was posted at 6:00AM (EST) on 1 June and ended at 5:59AM on 2 June 2022. In total 1,032 participants (average age = 40.85, 597 females) were asked to state how many minutes they had worked at that time of day. They were also asked to rate their tiredness (1 = not at all, 7 = very much) and mood (1 = very bad, 7 = very good) along a 7-point scale. The results are shown in Figure 1 (2 am–5 am data were ignored since there were fewer than 10 cases per hour, excluded sample n = 21). The average working times increased with the time of day (Linear trend analysis, F(1, 991) = 38.86, p < .001). Participants’ tiredness also increased throughout the day (Linear trend analysis, F(1, 991) = 22.13, p < .001). However, participants’ mood did not change with time of day (Linear trend analysis, F(1, 991) = 0.88 p = .349).
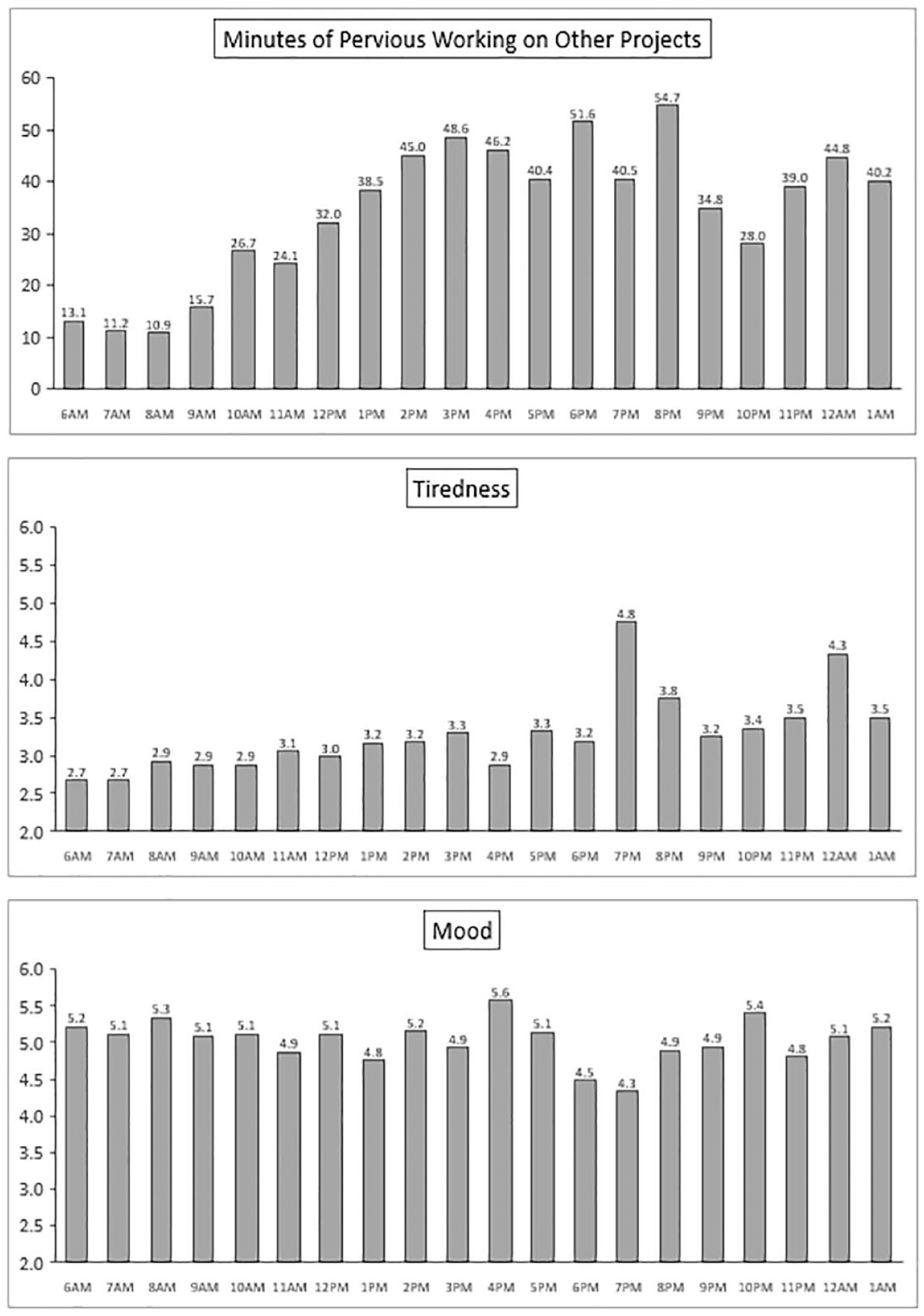
Results of Survey #1.
Therefore, it is crucial for researchers to understand how participants in an online experiment approach their study in relation to other tasks they had prior to it. When individuals are fatigued, they are less likely to process information deeply and accurately, potentially leading to a weakened manipulation of the independent variable or lower-quality measurements. So, all else being equal, it is generally better to post online experimental tasks in the morning rather than in the afternoon or evening. When researchers need a relatively large sample size, the survey will be available to potential participants at different times. If it is critically important, researchers might collect data over multiple days, but during a limited time period each day (e.g., 9 am–5 pm).
Country Selection and VPN Problems
People can vary due to environmental factors, and location is an important consideration for online experiments. In such cases, the solution is straightforward: it is preferable to limit data collection to specific countries unless researchers intentionally aim to collect data from various countries. However, even if researchers limit the research participants’ countries of residence, many surveys may still include participants from a different country, where the social background is dramatically different from the focus country. This is possible because survey takers can use Virtual Private Network (VPN) services, enabling them to participate in a survey that is linked to a different country. Practically, researchers can easily detect potential problems with VPN users by analyzing the location of the survey takers using latitude and longitude data, which are available to researchers as additional data for all participants. Researchers can simply analyze the frequency of this latitude and longitude data. If more than 3 to 5 participants are from the same geographic location from a moderate sample size (e.g., total 200 participants) in a single study, it is highly likely that they are using a VPN service from another country. For example, when we re-analyzed the data collected from an Amazon MTurk panel, restricted to US participants only, on September 10, 2020 (n = 351), we found that 24 participants’ latitude and longitude records were exactly the same (i.e., 37.7510, −97.8219). We suspect that these participants came from different countries and were using a VPN.
The issue of VPN usage can be significantly mitigated through technological measures (see Ghosh et al., 2019), such as technically prohibiting participants who employ VPN software. Alternatively, researchers can opt to use selective high-quality or pre-qualified panels, such as those provided by CloudResearch (Ghosh et al. 2019), to reduce the number of survey takers using VPN services. These pre-qualified panels help researchers minimize the uncontrolled variance introduced by VPN users.
Different Motivations and Abilities in Participants
Online panel members’ motivations and abilities for the given tasks will differ across time and between people. The motivation for participating in online surveys has also changed dramatically in recent years. In 2011, Buhrmester and his colleagues examined five reasons why people participated in Amazon MTurk online surveys. The motivation of “enjoy doing interesting tasks” was rated as the highest. Participants in Buhrmester et al. (2011)’s study selected “making money” as the second to last motivation and scored it below 4 on a 7-point scale (1 = strongly disagree, 7 = strongly agree). We replicated this study with 400 US MTurkers (Survey #2, average age = 42.56 years, 213 females) in July 2022. The results are provided in Figure 2. There was no difference with regard to “enjoy doing interesting tasks” (p = .715) in the results of Buhrmester et al. (2011) and our recent empirical investigation. The motivations of “killing time” and “having fun” dropped significantly (ps <0.01). However, the motivations of “making money” and “gaining self-knowledge” had increased significantly (ps <0.01). The most important change was in the “making money” motivation, which scored very highly (M = 6.32, SD = 0.98) in the 2022 survey.
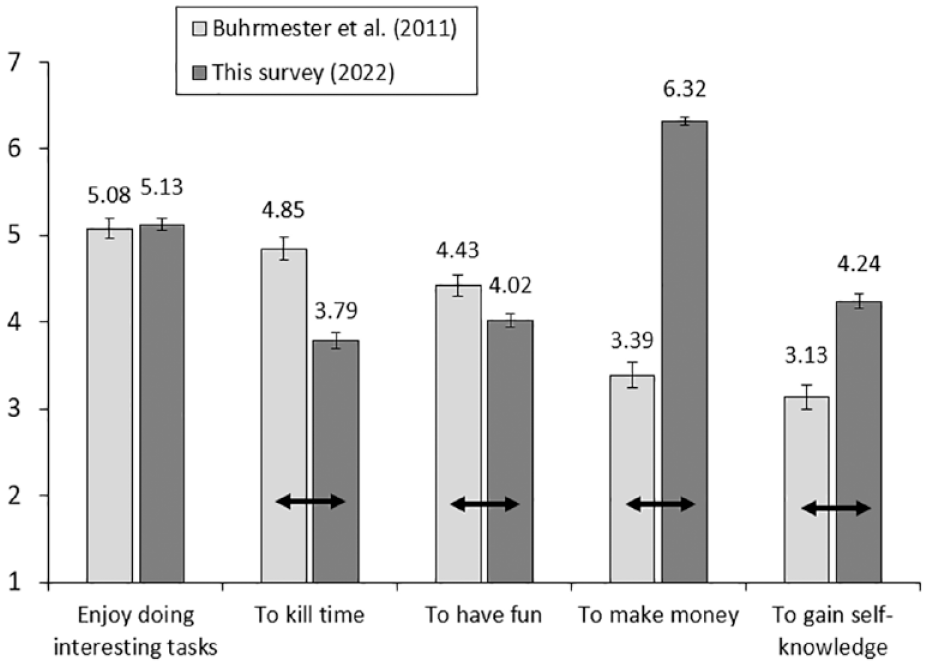
Results of Survey #2. * Error
Even though the key motivations for online participants have changed, these motivation factors can be managed effectively to obtain meaningful results by ensuring detailed execution of experiments. In this section, we focus on handling experimental elements to maintain the right levels of motivation and ability in an online panel.
Different Incentives and Low Motivations
Even though key motivations are diverse, such as killing time or enjoy engaging in interesting tasks, financial motivation is important for online panel participants (Buhrmester et al., 2011). A critical factor influencing financial motivation is the amount of money offered to participants. It is not a good idea to give monetary payments that are too small for the time and effort participants need to put in. In such circumstances, study participants tend to read instructions carelessly and answer the questions without serious engagement with the experimental procedure, resulting in poor responses, such as scores that are all 4 or all 7. In this case, a reliability index such as Cronbach’s alpha can be high even if survey takers answer very carelessly. For example, Buhrmester et al. (2011) found that the Cronbach’s alpha of a scale was consistently high regardless of differences in incentives (e.g., 2 vs. 10vs. 50 cents) for the same length task.
There are also problems if excessive monetary compensation is offered to participants. The study participants may focus on the monetary compensation rather than participating in the study seriously. Solely prioritizing financial gain does not foster a profound engagement with the assigned task. In addition, highly paid research projects may increase the numbers of non-qualified participants (e.g., VPN users), resulting in higher random deviation and failure of the experiments. Therefore, it is important to give adequate incentives, possibly based on the minimum wage. Using expected survey lengths, researchers can calculate an adequate amount of payment based on the time required to sensibly complete the survey. For example, as of October 2023, we recommend paying $0.13–0.15 per min. Thus, if you want to run a 3-min survey, around $0.40~$0.45 would be an adequate payment.
In addition, participants in online panels are exposed to many other studies and their motivation for any specific survey is expected to be low (Chandler et al., 2019; Lu et al., 2022). If researchers run complex studies involving multiple tasks (e.g., priming task + other main task) or have lengthy instructions or measurements, participants may not pay adequate attention to the task, resulting in a higher failure rate of the experiment. It is better to use an experimental design with a single task rather than multiple tasks, if possible. If researchers have to use relatively long experimental instructions, it is better to expose the instructions sequentially by displaying a limited amount of information on each page.
Finally, the problem of low motivation can be mitigated by employing consequential choice with real non-monetary incentives as the dependent variable, where participants receive the chosen option after making a decision (e.g., Klein & Hilbig, 2019; List, 2021). Even in online experiments, researchers can employ consequential choice as a crucial dependent variable. For instance, online participants have the opportunity to select an actual monetary bonus for compensation or tangible products like restaurant or travel vouchers (Y. G. Cui et al., 2021). By incorporating consequential choice into online experiments, researchers can enhance participants’ motivation, thereby increasing the likelihood of achieving successful outcomes.
Low Attention or Failure of Reading the Instruction
Participants’ attention to the given tasks can be quite different. A common remedy for low attention is an attention check or instructional manipulation check (IMC; Oppenheimer et al., 2009). This method is commonly used and is recommended for increasing the probability of finding a significant result when the alternative hypothesis is true, by eliminating careless participants’ responses regardless of the experimental conditions (e.g., Lu et al., 2022; Paas et al., 2018).
However, successfully finding and removing participants displaying low attention by applying an IMC depends on several factors. One is that the pass rate for the attention check is totally different from the quality of the panel. For instance, for Amazon MTurk panels, CloudResearch provides additional tools and features for quality control and data validation by implementing stricter criteria for participant selection or filtering out low-quality participants (Litman et al., 2017). We conducted two studies on 14 June 2022 and 15 June 2022. One study used only Amazon MTurk participants who had been pre-qualified by the CloudResearch platform (study #3A: n = 766, average age = 40.54, 420 females), while the other used Amazon MTurk participants who had not been pre-qualified through CloudResearch (Study 3B: n = 897, average age = 38.26, 438 females). All participants were invited to complete a relatively short survey (2–3 min). In the last stage of the survey, we used the attention check for color preference (based on Savary et al., 2015), as shown in Figure 3. Even though the study sub-title was “color preference,” the detailed instructions told participants to skip answering the question, which they would do if they had read and retained the instruction. If participants answered the question, we categorized this as a failure in the attention check. The failure rate was dramatically different in the two samples. For the CloudResearch qualified sample it was very low; less than 1% of participants failed this task (0.9% [=7/766]), whereas the Amazon MTurk sample’s failure rate was relatively high (13.7% [=123/897], χ2(1), p < .001, ϕ = 0.238). Therefore, we strongly recommend using Amazon MTurk participants who have been pre-selected by CloudResearch. When researchers directly use Amazon MTurk participants without filtering using CloudResearch, it is advisable to use IMC to exclude participants who have paid poor attention to the study. To summarize, the use of IMC should be managed according to the characteristics of online panels.
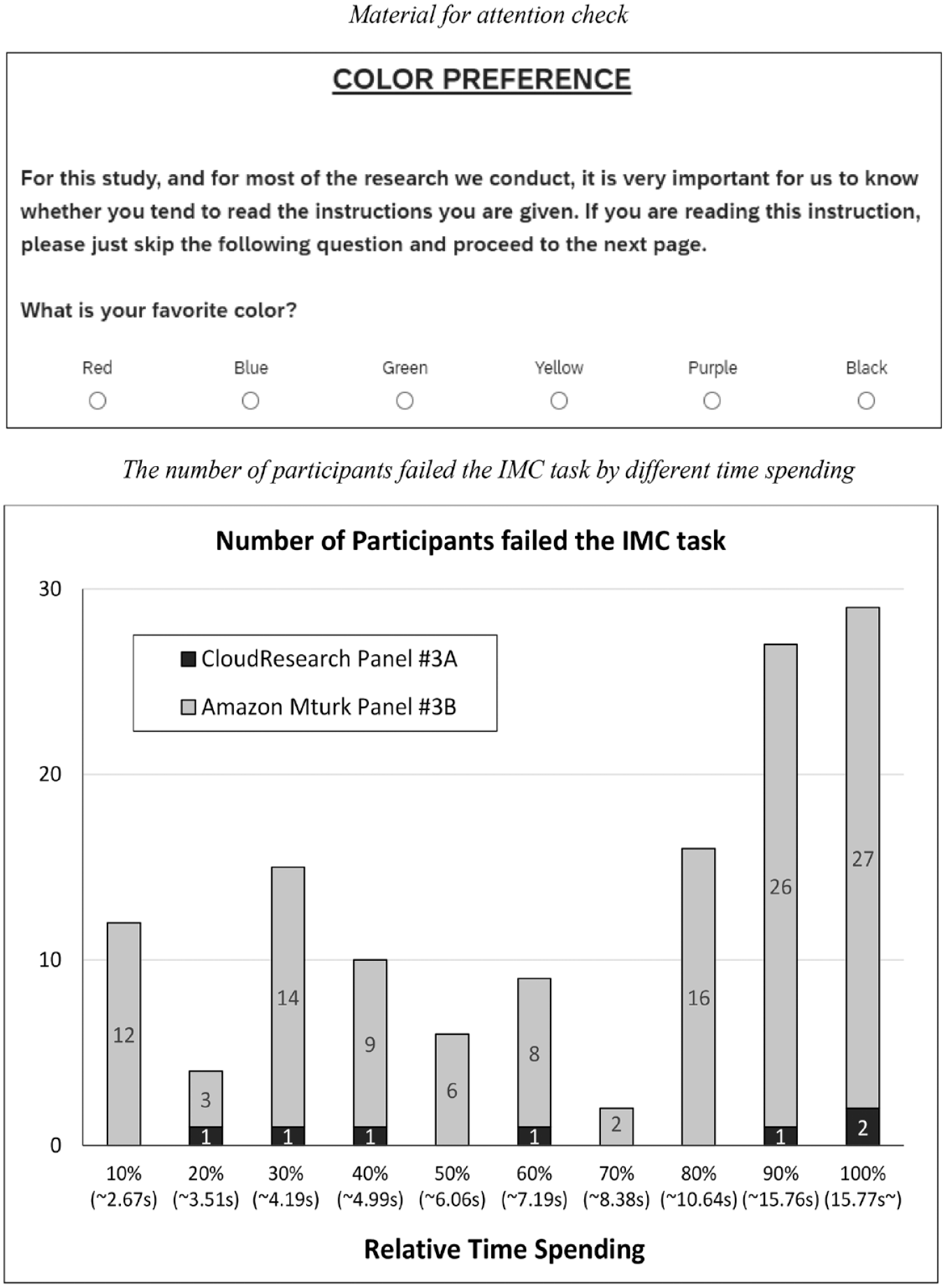
Survey #3.
One reason for a relatively high pass rate for an IMC is the repeated exposure of participants to similar IMC tasks. If researchers use an IMC frequently, survey participants may know this question and respond to the answer to pass the attention check. To check this possibility, we further analyzed the time spent by participants on the IMC task above. First, the timing for the IMC task was different across two panels. Very interestingly, the total time spent on this task was actually shorter for panel #3A, which had a high success rate in passing the attention check (M = 6.96 s, SD = 6.81, than for panel #3B, which had a low success rate (M = 9.47 s, SD = 9.77, F(1, 1661) = 35.71, p < .001, η2 = 0.021). We also checked the success rate for 10 different categories of time spent. As Figure 3 shows, the failure rate did not decrease as time spent increased. This analysis also supported our assumption that participants had the ability to detect the IMC task quickly and could avoid failing it.
In summary, researchers, in addition to carefully using attention checks or instructional manipulation checks, are recommended to use selective high-quality or pre-qualified panels in order to reduce the problem of low attention from online participants.
Effective and Transparent Experimental Design and Execution
This section focuses on the issues relating to experimental design and execution in online experiments, such as replication of previous experimental procedures or materials, and the advantages of pre-registration.
Use of Previous Experimental Materials
Researchers frequently replicate previous empirical studies, conducted based on existing theory and published articles. During replication in online settings, researchers use the same material for their main study. Especially if the previous study was conducted some years previously, it is important to modify the stimuli based on the specific online situation, or on environmental changes that have occurred since the previous study was conducted. We present two examples.
First, the psychological effect of physical cleaning (e.g., activating the moral purity concept) has been demonstrated in various areas such as psychology (Zhong & Liljenquist, 2006), food choice (Kim, Kim, & Park, 2018) and travel choice (Y. Cui et al., 2020). One manipulation of physical cleaning is to engage in actual handwashing or to watch a video of another person’s handwashing (e.g., Y. Cui et al., 2020). However, the effect and meaning of this physical cleaning manipulation changed dramatically due to the COVID-19 pandemic. Because of the pandemic, people have been strongly advised to wash their hands frequently, so the physical or hygienic effect of hand-washing is much more salient than the psychological effect. Therefore, if researchers replicate previous studies with the purpose of investigating the psychological effect of hand-washing during the pandemic, the experiment is likely to fail.
The second example relates to the attraction effect or decoy effect (Huber et al., 1982; Kim et al., 2019), which is the tendency to choose an asymmetrically dominating option. Kivetz et al. (2004) tested subscription option selections for the Economist magazine using the decoy effect (n = 59 MBA students). The share of “print & online subscription for $125 [target option]” for the magazine compared with “online subscription for $59 [competitor option]” was increased (i.e., 43% → 72%; decoy effect = +29%) when a decoy option was introduced in the choice set (e.g., ‘print subscription for $125 [decoy option]’). The decoy option an asymmetrically dominated option since the target option is obviously superior to the decoy option, whereas there is still a trade-off between the competitor and decoy options. However, this study was unable to be replicated by Frederick et al. (2014) 10 years later (i.e., 25% → 21%; decoy effect = −4%), even though they used a large online sample (n = 2,003 as determined by Google surveys). This dramatic result may be attributed to the environmental changes regarding online versus print magazine subscriptions. The overall attractiveness of print options had decreased by 2014. This is important, since one requirement condition for a decoy option is that the decoy option should be at least somewhat attractive and should not detract from the consideration set during decision-making (Huber et al., 2014; Kim et al., 2019). To test this explanation, we conducted an experiment comparing the decoy option with “print option [as original version]” and with “online option [as modified version].” We found an insignificant decoy effect with the original version, but a significant decoy effect using the modified version. The detailed study and results are available from the corresponding author.
To summarize, it is better to use a conceptual replication (Crandall & Sherman, 2016) rather than exact replication, by modifying the original stimuli or experimental procedure when replicating previous studies, while maintaining the basic elements of the experiment, such as the independent and dependent variables, as in the previous examples. Therefore, researchers need to continuously question the existing manipulation of the independent variable and moderators, the experimental setting, and the measurement of mediators and the dependent variable (Kim, Hwang et al., 2018). It is important to ensure that these aspects directly relate to online participants. (Kim, Kim et al., 2023). Any alterations to the original stimuli or procedures should be carefully considered and closely monitored, particularly when the environmental circumstances have changed. This recommendation requires closer attention when researchers attempt to replicate a previous study using non-online setting.
Participants Exclusion and Pre-registration
As mentioned previously, the general attention level of participants in online panels is lower compared to the attention levels in face-to-face settings (Chandler et al., 2019; Lu et al., 2022). This problem could be caused by the fact that the given task is not physically observed by the experimenter in online experiments. Therefore, researchers frequently exclude some participants from online experiments. For 24 articles published in the 2022 JTR issues using online experiments, 18 articles (75.2%) used exclusion, with various criteria such as excluding participants who failed an attention check or manipulation check, failed to perform adequately in a comprehension task, submitted an incomplete survey, or took too little time to complete their responses.
There are several existing methods of handing the exclusion of some participants. First, researchers can set up exclusion criteria by using attention checks either in the main task (i.e., attention check) or outside of the main task (i.e., IMC). For example, an attention check in the main task could be introduced when participants are exposed to IV manipulation (e.g., after reading newspaper articles, participants were asked to remember the topic of the article, Study 5 by Kim et al., 2022). Alternatively, an attention check could be conducted in a separate task using IMC (Lu et al., 2022; Paas et al., 2018). Second, experiments with online panels can allow researchers to measure the response time for the whole task, and for each page, very precisely. Researchers can therefore establish exclusion criteria based on the response time. For example, researchers could exclude some participants based on a specific rule such as failing to stay on a given page for a specific minimum time, or by analyzing the time taken for the overall task (Berger & Kiefer, 2021). Finally, researchers can use response patterns for the exclusion of some participants. For instance, researchers could set up an exclusion rule to detect extremes, such as values exceeding ±3 standard deviations from the mean.
One critical problem with exclusion is that it can be arbitrary, and there is the potential for researchers to selectively and post hoc use exclusion rules to obtain statistically significant results from their experiment. For instance, among the 18 articles using exclusion mentioned above, 14 articles used multiple experiments. Nine of these 14 articles (64.2%) used different methods of exclusion for each of the empirical studies, suggesting potential problems of arbitrary exclusion and inflation of the effect size.
This problem can be easily solved using pre-registration (e.g., P. Simmons et al., 2021), which involves registering the key elements of an empirical study before data collection. Researchers can use either the Open Science Framework (cos.io) or As Predicted (aspredicted.org). This includes determining the criteria for exclusion of data in advance and outlining the experimental procedure explicitly. Researchers can also use the same exclusion criteria for multiple online experiments in a single paper (Kim, Kim et al., 2023), to increase the transparency of the experiment.
In summary, we strongly recommend researchers use pre-registration of exclusion criteria to increase the statistical probability of finding results from theoretical predictions and to increase the transparency of the empirical investigation.
General Discussion and Conclusion
This paper has suggested six practical guidelines for successful online experiments, based on analysis of the reasons for experimental failure and three empirical investigations. The additional detailed and actionable suggestions are summarized in Table 1.
Summary of Recommendations.
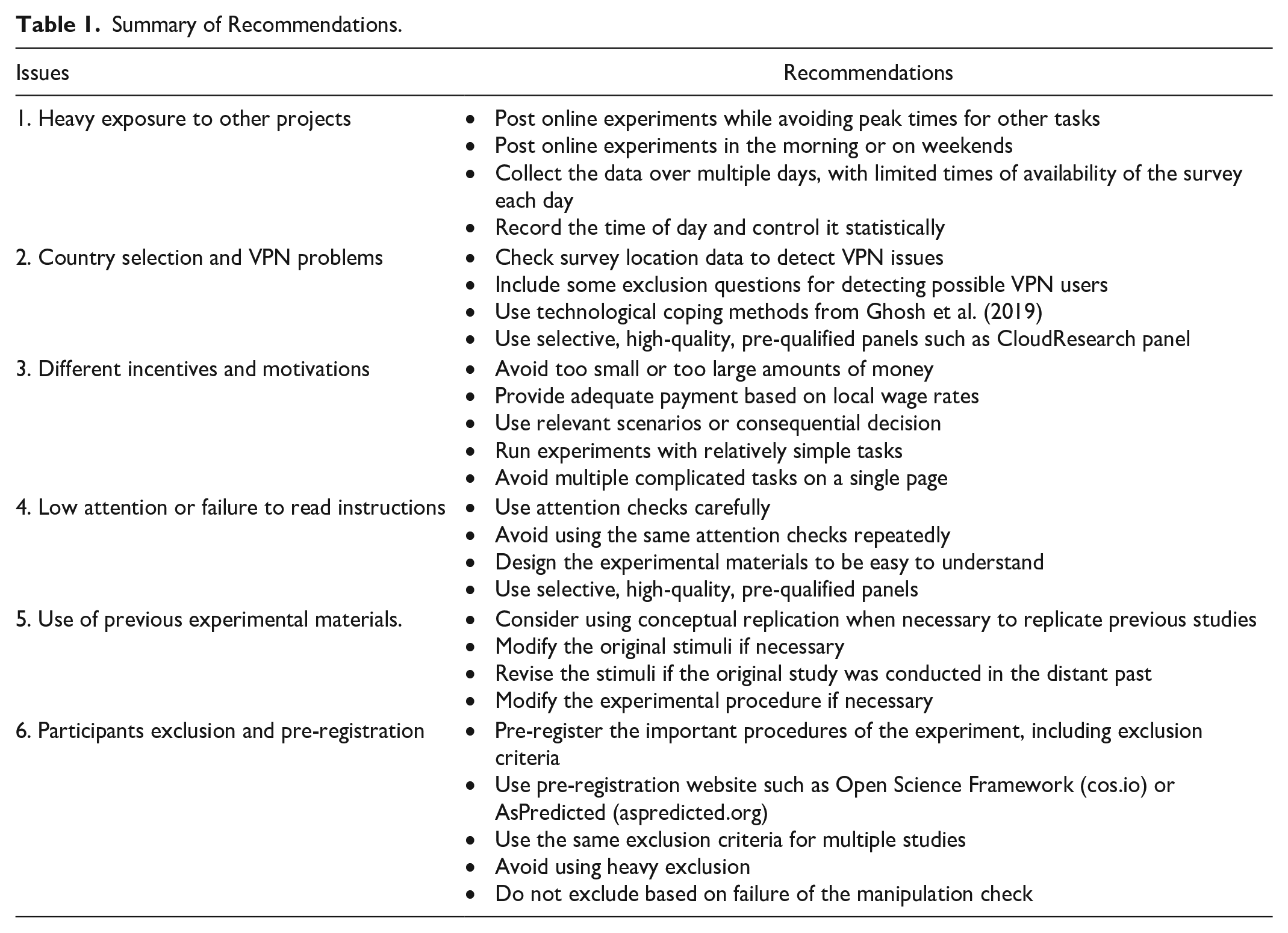
Our recommendation makes a unique contribution compared to various suggestions, particularly from other fields (Aguinis et al., 2023; Eckerd et al., 2021; Lonati et al., 2018). For example, while Aguinis et al. (2023) focus on the conceptual categorization of four different experimental approaches, our recommendation primarily focuses on the practical implications for successful online experiments. Our set of six recommendations for online experiments differs significantly from the “Ten Commandments” of experimental research (Lonati et al., 2018), as well as the five recommendations proposed by Eckerd et al. (2021) in the field of operational management, except for the common utilization of field experiments or the recommendation of more realistic experimental settings.
There are several implications from our recommendations. The first relates to the effect of external validity issues on experimental findings (i.e., the degree to which the empirical findings of the experiment can be generalized to real settings, or different participants, places or times). Establishing external validity is also important for causal research (Lynch, 1983; Winer, 1999). Since we argue for the reduction in heterogeneity of participants to increase the possibility of finding a significant experimental results or enhance the internal validity, the external validity of the findings could be naturally reduced. Since it is very difficult to conduct a single experiment achieving high levels of both external and internal validity, one solution can be to conduct multiple experiments, including studies focusing primarily on external validity. For example, Kim, Jhang et al. (2023) investigated the impact of price preciseness (e.g., a rounded price − $39.00 vs. a precise one − $40.09) of original and discounted prices on consumers’ purchase intentions. After demonstrating the effect of price format on purchase intention using hypothetical scenarios, they conducted a consequential study, where participants could actually provide an option based on their own choice from real brands (i.e., Canway travel bag vs. Wohlbege travel bag). The results of this additional study could reduce weaknesses in other aspects of the study in terms of external validity. Alternatively, research can use multiple methods such as secondary data analysis or field experiments (e.g., Kim et al., 2022; Winer, 1999). For example, after demonstrating the impact of the threat of Covid-19 on extremeness aversion in hypothetical travel scenarios, Kim et al. (2022) provided actual behavioral data using Google Trend search data and the room occupancy rates of Hong Kong hotels before and during the pandemic. Researchers could also consider other recommended methods, such as using the experimental vignette methodology hypothetical, but highly relevant scenarios to measure participants’ reactions to them. In sum, the empirical package with multiple studies could enhance both internal and external validity.
The second issue concerns recommendations for non-experimental methods using online samples. Lu et al. (2022) and Aguinis et al. (2021) suggested practical guidelines for collecting data from online panels, including MTurk. Compared to existing recommendations, this paper provides additional and more detailed guidelines for online experimental research. This research emphasizes the unique role of considering potential problems with VPN users or exposure to other tasks, and suggests using pre-qualified online panels and attention checks to control the quality of empirical studies. It also recommends the pre-registration of exclusion criteria for online participants across multiple empirical studies.
The third issue is about exclusion through IMC or attention checks. Even though previous literature recommends applying IMC in data collection (e.g., Lu et al., 2022) in general, our research suggested that IMC is not necessary, especially when researchers use a qualified online panel. In addition, in multiple experimental settings, we emphasize the need to apply consistent rules for exclusion based on IMC or attention checks to increase the accuracy and transparency of the empirical findings.
Finally, we emphasize that the characteristics of online panels can change dramatically over time, as shown in Figure 2. For example, the key motivation for online panel tasks has changed significantly. In addition, participants’ availability in online panels may vary depending on the time of the task requested (e.g., weekday vs. weekend for MTurkers who have another full-time job). Therefore, it is the researchers’ responsibility to continuously monitor the changes in online panels and to conduct online experiments with modifications and considerations based on those changes and different participant availability statuses.
To summarize, despite the limitations of online panels, online experiments are expected to be popular in travel and hospitality settings in future (Kim, Kim et al., 2023). We hope that these practical guidelines will be helpful for researchers, enabling them to support interesting and impactful theory with experimental studies.
Footnotes
Acknowledgements
The author thanks Jooyoung Park, Jihoon Jhang, and Daniel C. Lee for helpful comments on earlier versions of this article and Judy McDonald for editing assistance.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.