
Abstract
This project explored perceptions of ChatGPT in higher education among students and faculty to assess teaching and learning implications of this Generative Artificial Intelligence (Generative AI)–based novel tool. Two theoretical frameworks inspired the project, including Diffusion of Innovation theory (Rogers, 1962) and Technology Acceptance Model (Davis, 1989). An online survey was completed by 380 participants (N = 380). Participants indicated that they would not use ChatGPT to plagiarize but believed others would. When asked to rate the accuracy of ChatGPT's output, more than half took the incorrect output as correct/somewhat correct or could not tell whether it was correct or incorrect. Results varied based on participant demographics, including age, gender, and occupation. These findings support the need for data literacy. If Generative AI is to be used in higher education to aid in the learning process, it is imperative to continue teaching critical thinking.
Introduction
In early 2023, news outlets were extensively reporting on a powerful artificial intelligence (AI) tool called ChatGPT (Dotan, 2023; Jolly, 2023; O’Brien, 2023; Reuters, 2023). Developed by OpenAI, ChatGPT acquired one million users in five days and reached 100 million users two months after it was made public in November 2022; setting the record for the fastest-growing consumer application (Hu, 2023). This Generative AI chatbot was built on top of OpenAI's foundation large language models (LLMs) (Murphy Kelly, 2023). ChatGPT is a technology that leverages deep learning, transformer-based, neural network models generating human-like content (e.g., images, words) in response to various prompts (e.g., languages, instructions, questions) (Lim et al., 2023).
Generative AI is not just an extractive question-answering system, providing a response elicited from a document to a question formulated by the user: It also generates content in that response, going beyond human-like interactions in conversational AI (Lim et al., 2023; Lim et al., 2022). For example, ChatGPT made headlines in early 2023 for passing law exams in four courses at the University of Minnesota and another exam at University of Pennsylvania's Wharton School of Business (Murphy Kelly, 2023).
As a result, Generative AI has forced educators and institutions to reconsider how students learn (McMurtrie, 2023). Although Generative AI can be used for crafting intelligent tutoring systems that provide personalized assistance to students (Marr, 2023) and can provide a proactive pathway (Dowling & Lucey, 2023), it can also be viewed as a threat that needs to be regulated (Nature, 2023).
Therefore, it is important to examine the perceptions in higher education about Generative AI. The paper's primary goal is to provide a quantitative assessment of the early perceptions of tools like ChatGPT among faculty and students in a higher-education setting. In satisfying the above objective, the paper makes two important contributions: (1) It measures how instructors and students in a college setting felt early on about this Generative AI tool. The opinions among faculty and students may certainly vary, and for this reason, it is critical to identify public perceptions as an important first step in determining how best to proceed; (2) It measures perceptions by faculty and students of how Generative AI tools like ChatGPT will affect teaching and learning over time. These tools will continue to develop and improve, making it imperative that higher education institutions critically consider how to navigate the uncharted waters of Generative AI.
The paper frames this goal and contributions in the spirit of two well-known theoretical frameworks: (1) Technology Acceptance Model (TAM; Davis, 1989) grounded in information systems research, that studies how users accept, adopt, and use new technology; and (2) DOI—Diffusion of Innovation theory (Rogers, 1962) grounded in social science and the field of communication that describes how an idea or product acquires significance and spreads through a social system over time. Technology Acceptance Model posits that the adoption of a new technology—that is, the decision of how and when users will use it—is influenced by two critical factors: (1) perceived usefulness; (2) perceived ease-of-use. Diffusion of innovation, in turn, organizes potential adopters into categories according to the time it takes to adopt a new idea or technology and qualifies this new technology in terms of how it is perceived by society, using metrics such as relative advantage, user compatibility, simplicity of use, and visibility.
Through a survey study, a broad number of metrics with close ties to both TAM and DOI were collected, constructed, and analyzed, including awareness and overall opinion of ChatGPT; benefits, implications, and limitations of this new Generative AI tool; work productivity in the context of ChatGPT; plagiarism induced by Generative AI; usage and reliability of ChatGPT; and perceptions of the future of learning in the context of Generative AI tools like ChatGPT.
The paper starts with a literature review of the technology breakthroughs in natural language processing (NLP) that have given way to the current state of Generative AI, as well as its most common use cases and limitations. Next, the paper tackles the details of the study, including the research questions, a description of the survey data, data collection procedure, derived measures and constructs, subsequent data analysis, in the form of analysis of variance (ANOVA) and ordinal logistic regression, and the results of the data analysis. The paper follows with a discussion of the findings, along with implications for theory and practice that can help shape how educators can approach teaching and student learning and in a broader framework how educational institutions can adopt these disruptive technologies. The paper concludes by addressing the limitations of the study and makes some final remarks on the need to continue to explore these matters in depth.
Literature Review
Generative AI Background
The last decade has seen a dramatic paradigm shift in NLP, particularly with the rise of deep neural networks, and in the last five years with the development of transformer-based LLMs and Generative AI. These models have revolutionized the way in which text can be processed and generated, with applications in sentiment analysis, machine translation, question-answering, and language generation among others. The paradigm shift is also manifested in the explosion of research related to LLM development and the skyrocketing rate of adoption of recently released technologies such as ChatGPT.
An early breakthrough in the development of this new-generation NLP was the introduction of word embedding models that encode words as dense vector representations embedded in a high-dimensional semantic space, followed by pretrained word-embedding models such as Word2Vec (Mikolov et al., 2013), and GloVe (Pennington et al., 2014) trained over large amounts of data to learn word embedding representations. A special consideration in the evolution of NLP has been the design and implementation of deep neural network architectures. The first milestone in the development of neural NLP was recurrent neural networks architectures; in particular, Long Short-Term Memory (Hochreiter & Schmidhuber, 1997; Jozefowicz et al., 2015) and Gated Recurrent Units (Cho et al., 2014).
But perhaps the single most important breakthrough was the introduction of the self-attention mechanism and the transformer architecture in Google's 2017 seminal paper (Vaswani et al., 2017). In very simple terms, self-attention is an algorithm that allows sequence data (e.g., a phrase or sentence) to focus on its different components (words), and with it captures the relationships and dependencies between those words. Self-attention is an inherently parallel algorithm, as opposed to recurrent neural net architectures that are sequential by definition. This allows for much more efficient computation through massively (GPU-based) parallel architectures.
A transformer model is an encoder–decoder deep neural net architecture that uses the self-attention algorithm to process sequences. Trained over massive amounts of data, transformers can achieve state-of-the-art performance across a wide range of NLP tasks.
Transformer models have since paved the way for the development of the current cutting-edge LLMs. Transformers can implement full encoder–decoder architectures, encoder-only components (e.g., BERT) (Devlin et al., 2018), and decoder-only components.
Decoder models, the brightest star in the constellation of transformer architectures, are trained using an autoregressive approach, where the model learns to predict the next word (Note: The term word is used here in a broad sense, but it is technically less precise; transformer models handle tokens, which are encoded representations of words or fractions of words).
Decoder-only models are some of the most popular architectures used today. Initially developed for language generation, decoder models have continuously scaled, and their capabilities keep growing, with applications in a wide variety of tasks, and sometimes exhibiting emerging abilities that were not originally designed by developers. The quintessential example of decoder-only models is the GPT series; a language model architecture developed by OpenAI (Radford et al., 2018, 2019). GPT stands for “Generative Pre-trained Transformer.” Its current versions (GPT3.x and GPT4) power the popular application ChatGPT.
These large pretrained language models (encoder, decoder, or encoder–decoder architectures) can be fine-tuned using task specific data, and with it adjusting the model weights adjusted to enhance its performance on the given task. But lately, the scale and power of these models—in particular decoder-only models, which are currently the most commonly used architecture—makes it difficult (and in many cases unnecessary) to fine-tune the models for specific tasks and domains. To give an idea of the scale of these models, let us consider the GPT family: GPT-2 was released in 2019 and had 1.5B parameters. GPT-3, released in 2021, has 175B parameters. And although OpenAI has not released its numbers, the current speculation is that GPT-4 has 1.76 trillion parameters (Schreiner, 2023). These are unfathomable numbers. The human brain has 86B neurons and 100 trillion synapses. And although a brain cell is a much more complicated structure than a neural net node, and neural net weights are only oversimplified versions of brain cell synapses (neuroscientists would probably cringe at the comparison), it is worth considering the exponential growth in complexity and power of these models.
Use Cases for Generative AI
These models that have been released to the public have driven many people into a frenzy. As detailed previously, the models can produce very accurate output based on the input given due to the training methods that have been put into practice. The use cases that come from Generative AI are lacking scarcity. More generally, these models have a range of applications from generating text such as a professional email, an argumentative essay, or a poem, to generating art for all different types of uses such as graphic design and content creation (Hiter, 2023).
Using the knowledge base of these Generative models, users can perfect their output through prompt engineering, or when a user selects specific words or phrases to input to the model to get a specific type of output that they are looking for (Acar, 2023). In software such as DALL-E or Stable Diffusion, user text input allows for the quick generation of art that is very accurate to what the user was looking for with simple prompt engineering. This allows for users to generate very impressive looking images simply with the help of the Generative model for use in wherever someone would like to apply it (Kerner, 2023). There has also been the application of Generative models in art for the use of analyzing artwork. There are various types of applications within this field of growing research such as classification, object recognition (including human face recognition), and multimodal tasks, which involves itself in areas such as multimodal retrieval systems for art or visual question/answering (Cetinic & She, 2022).
More specifically, there has been a very big use case in the computer science world when it comes to code generation, documentation, and quality assurance (Hiter, 2023). Generative AI that is trained on data based off GitHub repositories or Stack Overflow forum questions have shown to be immensely helpful in completing code statements, testing code, and identifying bugs. One of these tools, GitHub's Copilot, has come into the computer science world proving to be a big help to developers. In an internal research study conducted with less than 2,000 users using Copilot, Github found that 88% of users feel more productive using Copilot, with 88% noticing faster completion and 77% feeling that they spend less time searching for answers or context. Github put together a focus group of 95 developers and randomly split them into two groups. They asked both groups to write a web server using the Javascript language with only one group having access to Copilot. A total of 78% of the group that was able to use Copilot finished with an average of 1 h and 11 min, while 70% of the group who did not use Copilot finished with an average of 2 h and 41 min. That is 55% less time than the group that did not have Copilot to use (Kalliamvakou, 2023).
The easily accessible nature of these Generative models has completely upended how schools are operating, giving both students and faculty alike access to an incredibly powerful tool in a space such as academia. Regarding models like ChatGPT specifically, they are heavily capable of carrying out complex tasks given by a user in a very sophisticated manner (Baidoo-Anu & Ansah, 2023). For example, ChatGPT can very effectively write argumentative papers, clearly stating arguments that are evidence-based and also includes analysis (McMurtrie, 2023). In the words of psychology professor Serge Onyper, “It's sort of frustrating how good it is at those basic tenets of argumentative writing” (McMurtrie, 2023).
One of the most apparent use cases that comes from these types of Generative models would be the increase in productivity and efficiency a user gets when using a model like ChatGPT for a specific task that would otherwise take a lot more time and brainpower. One of the reasons why these models can be so effective though is due to the model's need to provide the most accurate output it thinks it can provide. This allows for the model to adapt to a user's learning style since it is taking direct input from the user and providing back output that is supposed to be as accurate as can be in reference to the input. This allows for a lot of different options for both students and faculty. For students, there are opportunities for personalized tutoring, interactive/adaptive learning, and language translation for material, allowing for more effective and accessible learning. From the educator's standpoint, these models have shown to be effective in automating grading for instructors as well as generating assignments, test questions, or grading rubrics for lesson material (Baidoo-Anu & Ansah, 2023).
General Limitations and Bias
Although the use cases and benefits that come from Generative AI are abundant, there are numerous drawbacks to the modern technology that is causing a rift in opinions. Overall, there are some general known limitations that come with Generative AI. For one, LLMs are known to regurgitate inaccurate information presented as factual information, or “hallucinations.” This inaccurate information can include anything from citations to incorrect biographical information (USC Libraries, 2023). The dangerous thing to note with this limitation is that because of the autoregressive nature of decoder-only models that are trained to predict the next token in lieu of being factual, often the incorrect information that is being outputted is displayed in an authoritative manner that can very well pass as a correct statement.
The nature of how output is produced is also a limitation within itself. Although these LLMs are utilizing a vast amount of data to produce responses, these models are not retrieving information directly. The models being trained on the data means that the models are using the information known to attempt to synthesize and reproduce a response that is accurate with respect to what they know and what was inputted. This makes it difficult to discern how the model came to a specific conclusion when providing a response (USC Libraries, 2023). The model synthesizing responses instead of retrieving the response also entails a lack of contextual understanding (Baidoo-Anu & Ansah, 2023).
To reiterate, the system is not using logic to make output, resulting in responses that may lack logic. The data in which the model is trained upon also has its set of limitations as well. In reference to publicly accessible Generative AI, a lot of those models have cutoff dates for the training data, meaning that the models sometimes only have information up to a certain point in time. This results in an inability to provide a response or even give an incorrect response due to the system trying to improvise an answer with what it has to work with in terms of data (USC Libraries, 2023).
In the case of the GPT 3.5 model, the system does not know anything after 2021 and in most cases appropriately lets the user know if the input is out of the realm of possibility to answer. Bias is also a concern when it comes to the data that the model is trained on. Artificial Intelligence bias is a phenomenon that occurs with AI systems “when an AI algorithm produces results that are systemically prejudiced due to erroneous assumptions in the machine learning process” (Shashkina, 2023). For example, in 2018 the American Civil Liberties Union discovered that Amazon's Rekognition, face surveillance software used by the police across the United States, showed AI bias by incorrectly matching 28 members of Congress with mugshots of people who have been convicted of a crime, 40% having been people of color (Snow, 2023). Although the Generative nature of AI tends to make reproducibility hard, ChatGPT has shown to have a political bias: Having a “pro-environmental, left-libertarian orientation” (Hartmann et al., 2023). The causes of bias stem from a lot of different things, but, overall, a big contributor to AI bias is human prejudice, whether it be conscious or unconscious (Shashkina, 2023). This can include algorithmic bias, or when prejudiced hypotheses make their way into a model upon designing AI models, or poor data quality as a result of not being cleaned or sourced properly (Shashkina, 2023). This becomes a major issue with Generative AI models as a whole since there are certain predispositioned biases that can be imposed on a given output and therefore translated into the real world. This can be very harmful, especially now with the development of Generative AI being publicly accessible.
Current Study
ChatGPT is currently a new technology in the public eye, so it is important to explore perceptions of this tool and its future uses. The purpose of this project is to examine perceptions in higher education of ChatGPT among students and faculty; specifically, age, gender, and occupation are measured using a number of metrics including, among them, awareness and overall opinion; benefits, implications, and limitations; work productivity; plagiarism; usage and reliability of ChatGPT; and future outlook. The study presents the following research questions:
Data and Methods
Survey
Data were collected from faculty and college students aged 18 and older at a private, medium-sized liberal arts college in the northeast. A total of 380 participants were found to have completed more than half of the survey (N = 380). See Table 1 for details.
Survey Data.
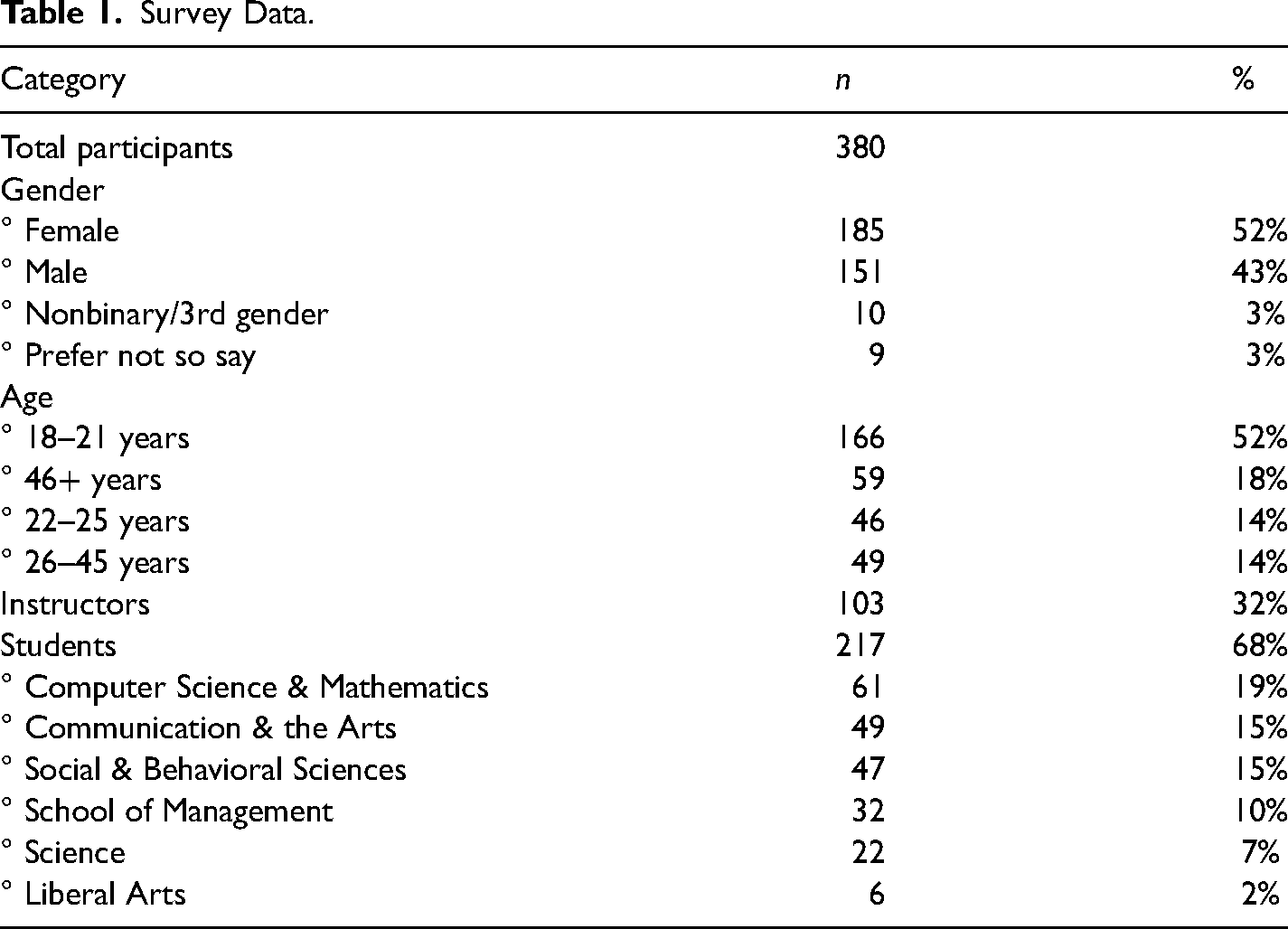
In terms of participant sex, 52% (N = 185) identified as female and 43% (N = 151) identified as male, 3% identified as nonbinary/3rd gender (n = 10), and 3% preferred not to say (n = 10). Regarding age, the majority of participants were aged 18–21, with this group taking about 52% of the distribution (N = 166). The next biggest group was the 46 years and older group, making up 18% of the distribution (N = 59). A total of 14% consisted of 22–25 year-olds (N = 46) and the rest of the sample resulted in 14%, consisting of 26–45 year-olds (N = 49). Finally, for occupation/academic major, 32% of the distribution was made up of faculty members (N = 103). A total of 19% of the students came from the School of Computer Science & Mathematics (N = 61), 15% came from the School of Communication & the Arts (N = 49), about another 15% came from the School of Social & Behavioral Sciences (N = 47), 10% came from the School of Management (N = 32), and the School of Science and the School of Liberal Arts made up about 9% together (N = 22 & N = 6, respectively).
Survey Procedure
An online survey was used to collect data from participants. The participants were informed about the study and given the online survey link via email. The participants were told to set aside no more than 15 min to complete the survey. The instructions explained that the survey did not seek any personal information and that all responses would remain confidential and would be used for research purposes only, and that the data would be anonymous and would not contain any identifying information. Before participants could begin the survey, they read an information sheet and agreed to the terms of the study via an electronic consent form. All survey items and procedures were approved by the college's Institutional Review Board.
Survey Recruitment
A convenience sample was used, whereas undergraduate students and faculty were contacted via internal email list through the academic institution during the spring 2023 academic semester. The researchers sent emails out to all faculty employed at the institution. Incomplete surveys were recorded as partial data.
Survey Language
This study looks at Generative AI and its effects as a whole, however, with ChatGPT being one of the most recognizable AI tools at this point in time, the survey specifically focuses on that technology.
Survey Questions and Composite Scores of Underlying Concepts
The survey was composed of questions regarding perceptions by respondents of ChatGPT and well as respondent demographics. Measures were not designed to be assessed individually but rather to gather an overall understanding of higher education individuals’ perceptions of the concepts used in the study. To ensure that all survey items were measuring unique concepts, similar items were grouped together and composite scores were created prior to inferential testing (for details see the Data Pre-Processing section). The resulting composite scores are discussed below (see Table 2 for a summary).
Constructs and Composite Scores.
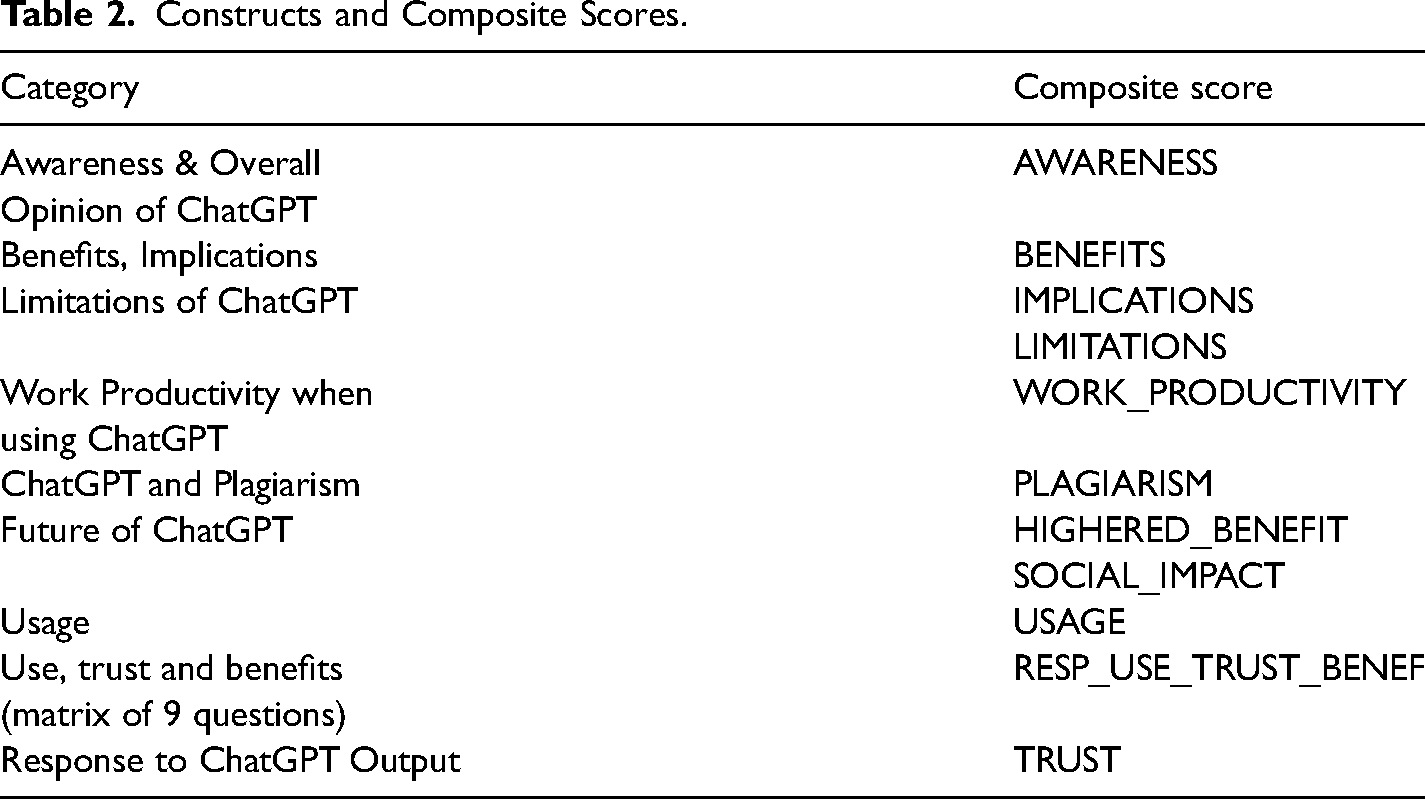
Awareness and Overall Opinion of ChatGPT
The first section of the survey assessed participants’ familiarity with ChatGPT. The initial question stated: “ChatGPT is an example of an AI computer program. How much have you heard about ChatGPT?” The responses included: “A great deal,” “A good amount,” “A little,” and “Nothing at all.”
Next, a definition of ChatGPT was provided. Then, the following question was asked: “From what source(s) have you heard about ChatGPT? Select all that apply.” The responses included: “From the news,” “From a family member,” “From a friend,” “From a colleague,” “None,” “Other; please specify,” and “From this questionnaire.”
General opinions were then gauged with two questions. First, “In your opinion, identify the primary reason why a student would use ChatGPT.” Secondly, “In your opinion, identify the primary reason why a professional would use ChatGPT.” The responses for both questions included: “Curiosity,” “To get started with a project,” “To aid in completion of a project,” “To obtain significant help with a project,” and “Other; please specify.” The first question was kept as the AWARENESS score.
Benefits, Implications, and Limitations of ChatGPT
Three statements were used to evaluate this section: “There are benefits to using ChatGPT,” “There are technological limitations when using ChatGPT,” and “There are implications when using ChatGPT.” Answers were collected using a Likert scale, ranging from 1 (Strongly Agree) to 5 (Strongly Disagree). The statements were used to extract the BENEFITS, IMPLICATIONS, and LIMITATIONS scores.
Work Productivity When Using ChatGPT
Four statements were used to evaluate this section: “A person can be productive when using ChatGPT,” “A student is likely to use ChatGPT in a productive manner,” “A professional is likely to use ChatGPT in a productive manner,” and “A person in everyday life is likely to use ChatGPT in a productive manner.” These statements used a Likert scale, ranging from 1 (Strongly Agree) to 5 (Strongly Disagree). Answers to these statements with Cronbach's α = 0.72 were assembled into the WORK_PRODUCTIVITY composite score.
ChatGPT and Plagiarism
Four items were used to evaluate opinions of plagiarism related to ChatGPT. The statements included: “A student is likely to use ChatGPT in a manner for plagiarism,” “A professional is likely to use ChatGPT in a manner for plagiarism,” “A person in everyday life is likely to use ChatGPT in a manner for plagiarism,” and “Someone who plagiarized using ChatGPT is likely to get caught.” Responses were measured using a 5-point Likert-type response scale, ranging from 1 (Strongly Agree) to 5 (Strongly Disagree). Answers to the first three questions with Cronbach's α = 0.72 were composed into the PLAGIARISM composite score.
Future of ChatGPT
Two questions were used to determine perceptions of how ChatGPT will evolve. First, “How much do you think ChatGPT will impact society going forward?” Secondly, “Do you think colleges and universities could benefit from accepting AI & ChatGPT into its curriculum/work culture? (i.e., giving workshops for students/faculty, providing resources, using it for school affairs, etc.)?” Both questions were assessed with the following measures: “Very much so,” “Somewhat,” and “Not at all.” Out of them, HIGHERED_BENEFIT and SOCIAL_IMPACT scores were extracted.
Usage
A series of questions were then included to assess the participant's first-hand experience with ChatGPT. The first question: “How much have you used ChatGPT?” included the responses: “Quite a lot,” “A good amount,” “A little,” and “Not at all.”
Secondly, “Please indicate the number of times you have used ChatGPT,” with the responses: “0,” “1 to 5,” “6 to 10,” and “11 or more times.”
Next, “What is the primary reason why you have used ChatGPT?” with the responses: “Curiosity,” “To get started with a project,” “To aid in completion of a project,” “To obtain significant help with a project,” and “I have not used ChatGPT.”
Answers to these questions with Cronbach's α = 0.89 were assembled into the USAGE score.
Finally, a matrix question with nine statements was included. The items were: “I am likely to use ChatGPT going forward,” “ChatGPT could be beneficial for me,” “I could be productive as a result of using ChatGPT,” “I feel that I would be plagiarizing by using ChatGPT,” “I think I could trust the output given to me by ChatGPT,” “I would use the output from ChatGPT to make a decision,” “I would plagiarize with ChatGPT,” “I could be more productive by using ChatGPT,” and “ChatGPT could directly impact me/my field of study/work.” Responses were measured using a 5-point Likert-type response scale, ranging from 1 (Strongly Agree) to 5 (Strongly Disagree). Answers to these questions with Cronbach's α = .84 were assembled into the RESP_USE_TRUST_BENEF composite score.
Response to ChatGPT Output
In the next section of the survey, three examples of ChatGPT output with varying accuracy were shared and participants were asked to rate the degree to which they agreed that the output was accurate, how likely they were to trust it, and how likely they were to use it. Specifically, three output questions were shared. The first prompt asked ChatGPT to respond to an upset customer about a recent order. The second prompt asked ChatGPT to create a poem analysis on “A Coat” by W.B Yeats, which prompted ChatGPT to hallucinate a response about a fabricated poem. The third prompt asked ChatGPT what the largest country in South America was besides Mexico. ChatGPT responded with Guatemala, which contradicts Statista's answer of Nicaragua (Alves, 2023). Responses were measured using a 5-point Likert-type response scale, ranging from 1 (Strongly Agree) to 5 (Strongly Disagree). Answers to these questions with Cronbach's α = .77 were assembled into the TRUST composite score.
Demographics
The last section of the survey asked for demographic information, including gender (female, male, nonbinary/third gender, “prefer not to say”); age, a numerical value discretized into ranges in the data preprocessing stage (18–21, 22–29, 30–41, 42–45, 46+); and occupation (students, instructor).
Data Preprocessing
Analysis was conducted in Python and its data science stack, in particular the statsmodels library. It consisted of exploratory analysis of the data, and explanatory analysis using inferential statistics to look at different trends. The data were initially preprocessed; this involved dropping rows with missing data and reformatting information for analysis purposes (e.g., recoding age into age ranges). The final clean dataset was made up of 302 respondents (N = 302). Figure 1 depicts the distribution of clean data by demographic features (gender, age range, and occupation).
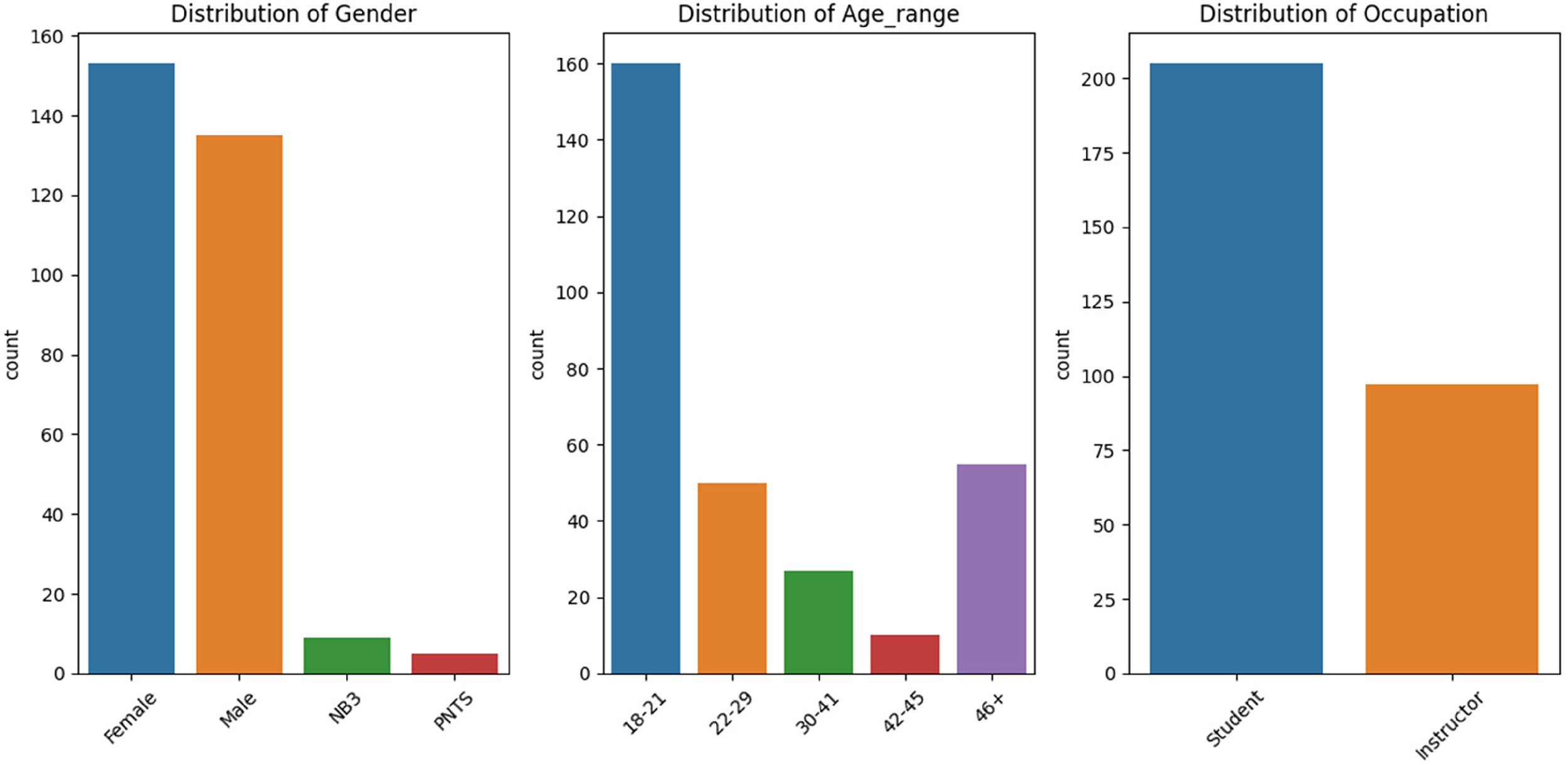
Distribution of clean data by gender, age range, and occupation.
For age, the 18–21 range represented roughly 53% of the sample, the 22–29 range carried 16.5% of the sample; the 30–41 range had 8.9% of the sample, 42–45 had 3.3% of the sample; and finally 46+ represented 18.2% of the sample.
For gender, data were mostly evenly distributed between male and female: Female represented 50.6% of the sample, male carried 44.7%; nonbinary/third gender represented roughly 3% of the sample; and those who preferred not to say carried 1.65%.
In the case of occupation, there were 97 instructors (32.1%) and 205 students (67.89%).
After the data were cleaned, exploratory analysis was conducted. This consisted of looking at each question to get a better idea of how people responded to each question, which also served to get a better idea about which questions to look at alongside one another.
Composite scores of survey questions identifying underlying concepts (e.g., awareness, benefits, limitations) were created using the following two-step approach: (1) groups of similar survey items were tested for reliability, (2) those groups with Cronbach's alpha value above 0.7 were subsequently subjected to Principal Component Analysis (PCA) using the first component to extract the communality across the chosen survey items. The PCA loadings were used as weights to calculate a weighted average of the survey items, and with it compute each composite score for each group of survey items identifying a concept. We found that this approach yielded better results than computing a simple average of the survey items to calculate each composite score. For more details on this approach, see De Pauw et al. (2009).
The next step tackled inferential analysis, namely ANOVA and ordinal logistic regression, which helped identify trends in the data with other variables.
Data Analysis and Results
Descriptive Statistics and Correlations
Descriptive statistics and correlations were computed for all composite scores. Descriptive statistics for all composite scores are listed in Table 3. Composite scores were derived using a PCA approach so they are therefore normalized (mean = 0, stdev = 1). Figure 2 includes a boxplot of each composite score to visually depict the distribution and skewness of the data.
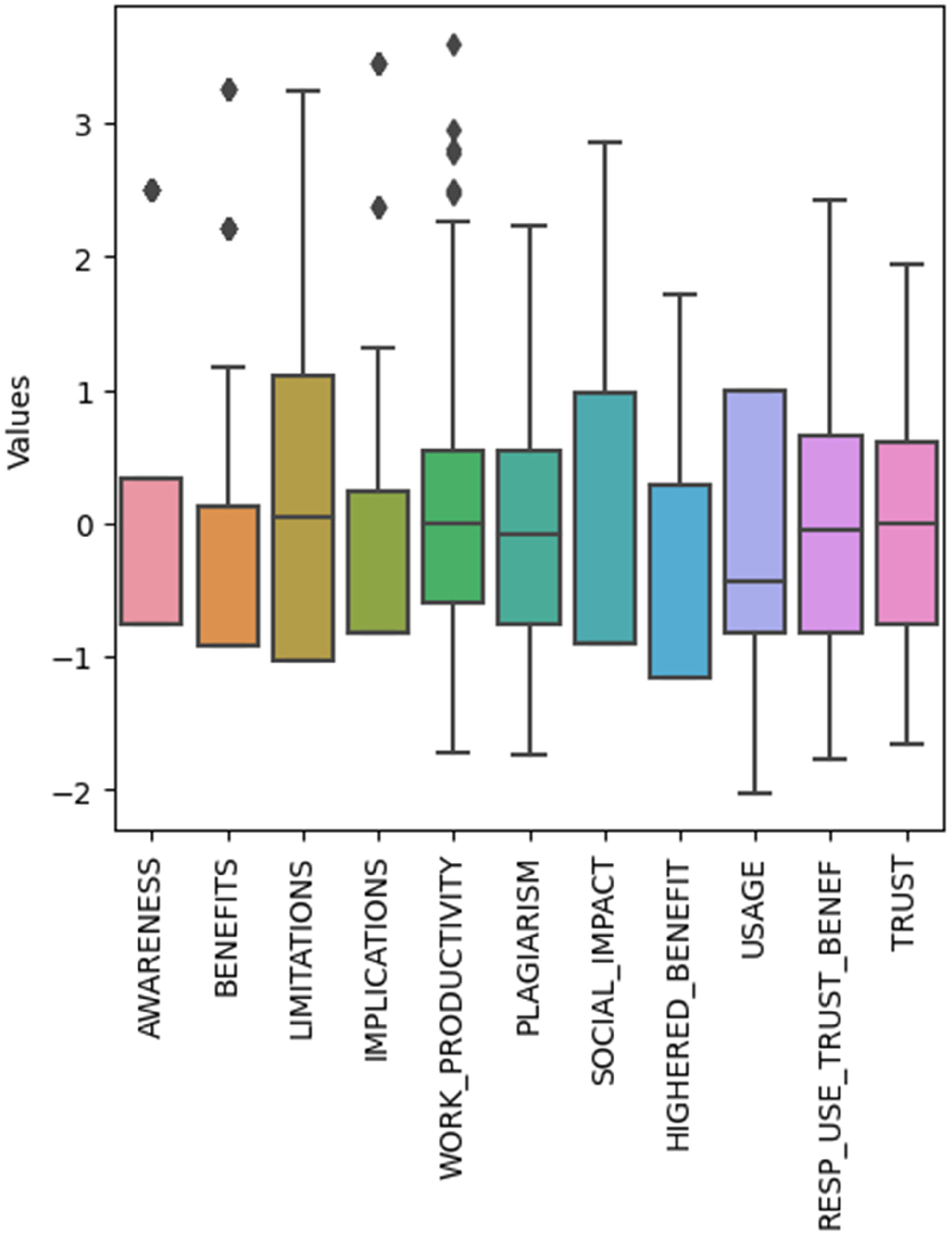
Boxplot of the composite measures depicting their distribution.
Descriptive Statistics for All Composite Scores.
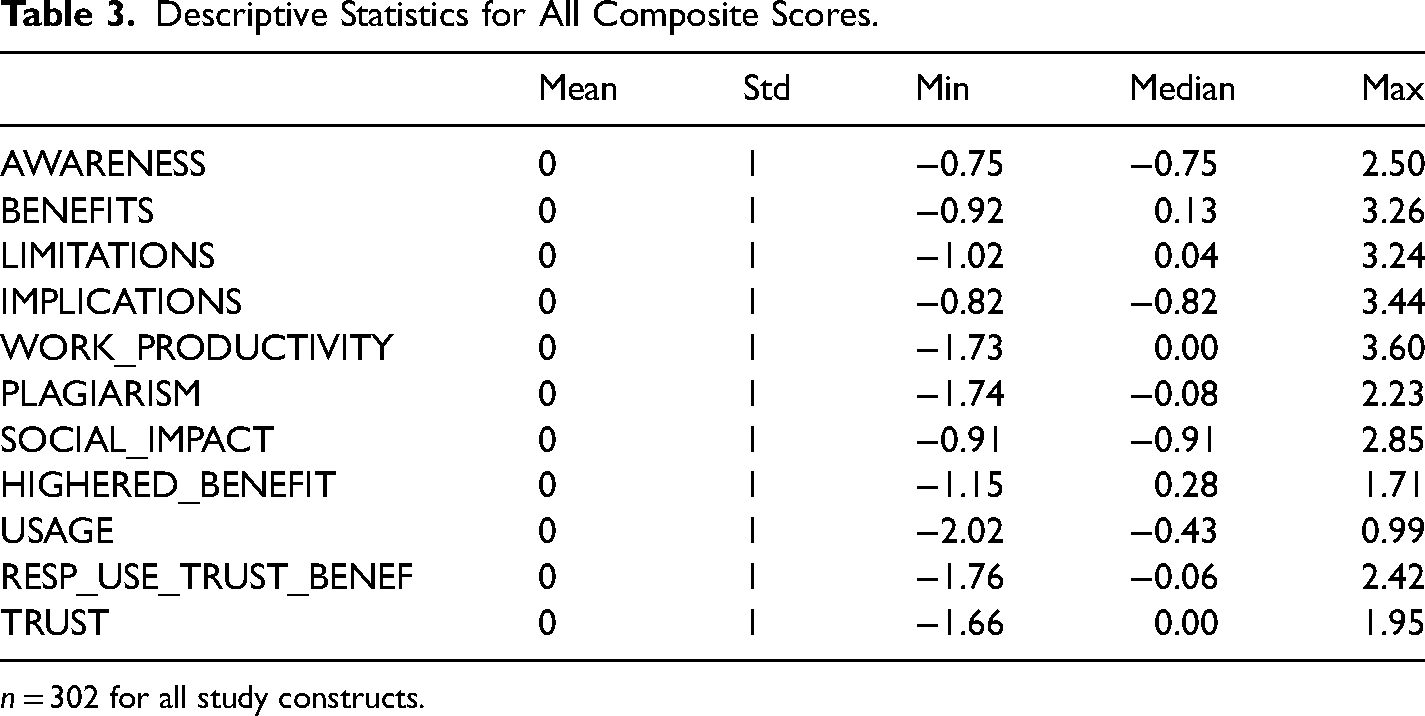
n = 302 for all study constructs.
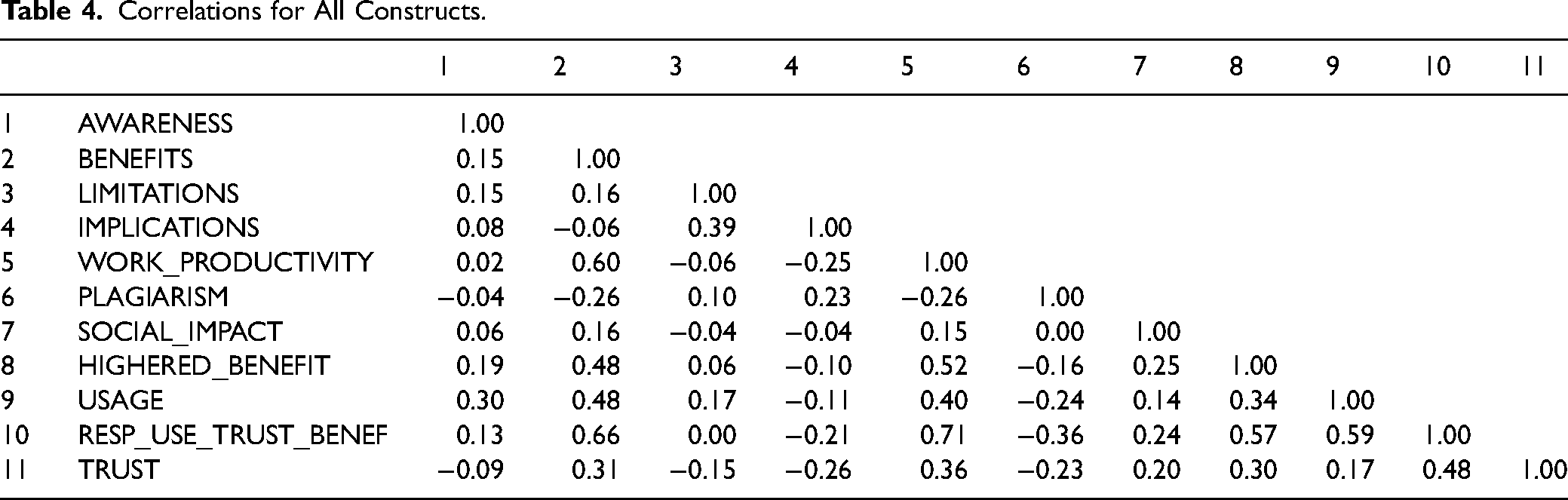
Correlations between composite scores are shown in Table 4. Several correlations are of interest. BENEFITS is positively correlated with WORK_PRODUCTIVITY (r = 0.60), HIGHERED_BENEFIT (r = 0.48), USAGE (r = 0.48), and RESP_USE_TRUST_BENEF (r = 0.66). IMPLICATIONS and LIMITATIONS are positively and moderately correlated (r = 0.39). WORK_PRODUCTIVITY is positively correlated with HIGHERED_BENEFIT (r = 0.52) and USAGE (r = 0.40). RESP_USE_TRUST_BENEF is positively correlated with HIGHERED_BENEFIT (r = 0.57), USAGE (r = 0.59), and TRUST (r = 0.48). There are several constructs with low negative correlations, among them PLAGIARISM and BENEFITS (r = −0.26), TRUST and IMPLICATIONS (r = −0.26), WORK_PRODUCTIVITY and IMPLICATIONS (r = −0.25), and RESP_USE_TRUST_BENEF and PLAGIARISM (r = −0.36).
Correlations for All Constructs.
Analysis of Variance on the Full Dataset
Multiway ANOVA was performed on each of the composite measures using the three demographic features (gender, age range, and occupation) to measure the effects of demographics on each composite measure. The analysis was made only on main effects—considering only the independent effect of each demographic factor on the composite scores. The analysis addressed the two research questions by considering specific composite measures specifically related to each of the research questions.
A three-way ANOVA was performed to study the effect of OCCUPATION GENDER, and AGE_RANGE on respondents’ awareness to ChatGPT (AWARENESS), ChatGPT perceived benefits (BENEFITS), ChatGPT's perceived limitations and implications (LIMITATIONS, IMPLICATIONS, and perception of enhanced work productivity WORK_PRODUCTIVITY). The results are displayed in Table 5.
Results of 3-Way Analysis of Variance—RQ1.
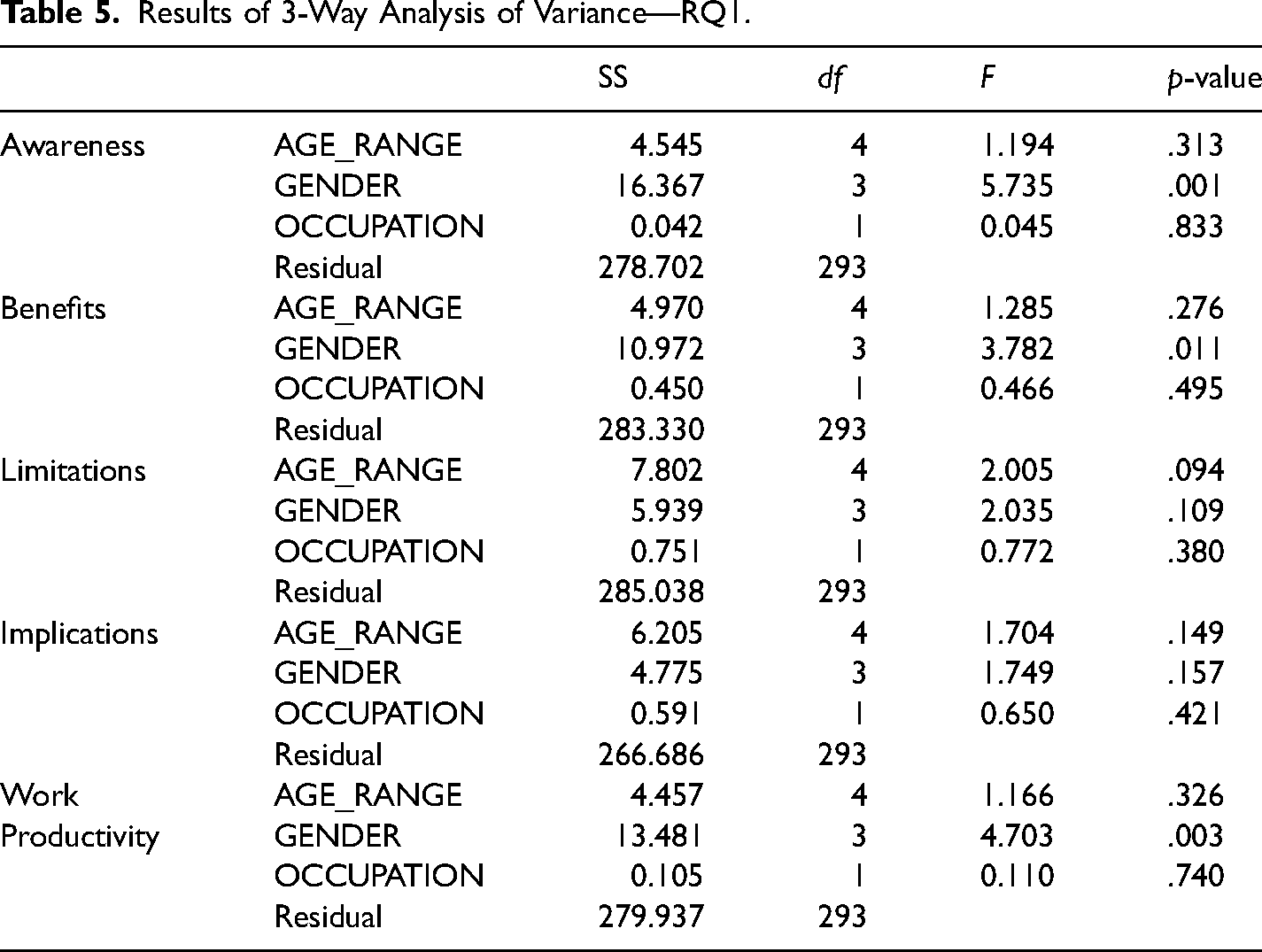
In the case of AWARENESS, GENDER had a significant influence (F = 5.735, df = 3, p = .001), while AGE_RANGE (p = .313) and OCCUPATION (p = .833) were not statistically significant. These findings suggest that GENDER is associated with variations in awareness levels.
GENDER had statistically significant influence over BENEFITS (F = 3.782, df = 3, p = .011), while AGE_RANGE (p = .276) and OCCUPATION (p = .495) were not statistically significant. GENDER appears to be associated with variations in perception of benefits.
In the case of LIMITATIONS, none of the three factors were statistically significant: AGE_RANGE (p = .094); OCCUPATION (p = .380); GENDER (p = .109).
Similarly, for IMPLICATIONS, none of the three factors were statistically significant: AGE_RANGE (p = .149); OCCUPATION (p = .421); and GENDER (p = .157).
GENDER had statistically significant influence on WORK_PRODUCTIVITY (F = 4.703, df = 3, p = .003), suggesting that GENDER could be associated with variations in perceptions of increased work productivity. AGE_RANGE (p = .326) and OCCUPATION (p = .740) lacked significance statistical significance.
In summary, GENDER seems to significantly affect awareness, perceived benefits and work productivity, while AGE_RANGE and OCCUPATION had no significant effect on any of these dimensions.
A three-way ANOVA was performed to study the effect of OCCUPATION, GENDER, and AGE_RANGE on respondents’ perception of increased plagiarism (PLAGIARISM), perception of SOCIAL_IMPACT, perceived benefits to higher education (HIGHERED_BENEFIT), USAGE, TRUST and respondents’ perception of use, trust, and benefits (RESP_USE_TRUST_BENEF). Results are displayed in Table 6.
Results of 3-Way Analysis of Variance—RQ2.
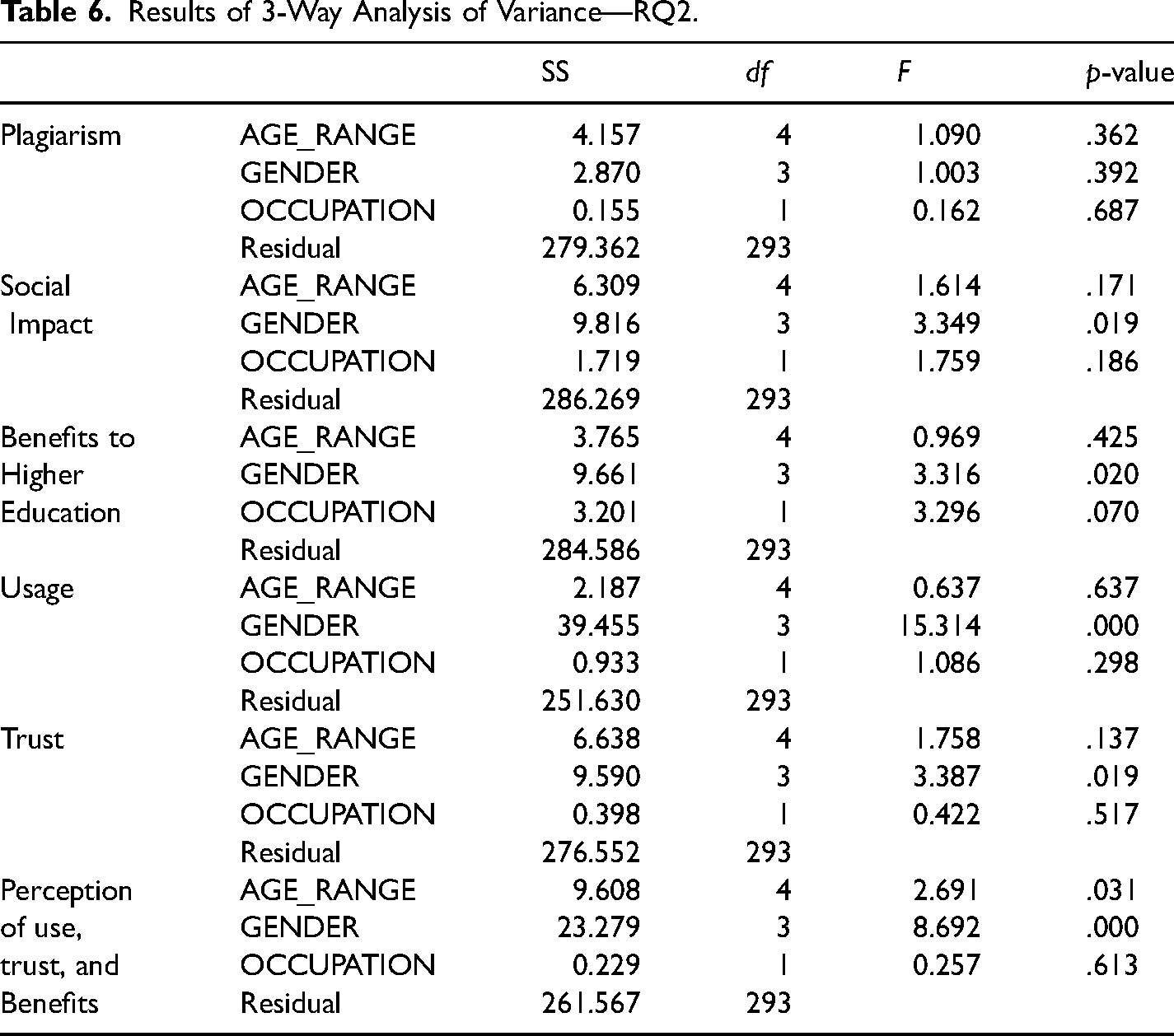
In the case of PLAGIARISM perception, none of the variables AGE_RANGE (p = .362), OCCUPATION (p = .687), and GENDER (p = .392) showed significant influence.
For SOCIAL_IMPACT, AGE_RANGE (p = .171), and OCCUPATION (p = .186) exhibited no significant influence. GENDER, instead, was statistically significant (F = 3.349, df = 3, p = .019), implying that social impact perception is influenced by gender.
For HIGHERED_BENEFIT, GENDER (F = 3.316, df = 3, p = .020) was statistically significant, implying that perception of higher education benefits is influenced by gender. Instead, AGE_RANGE (p = .425) and OCCUPATION (p = .070) did not demonstrate significance.
Analyzing USAGE, GENDER exhibited statistical significance (F = 15.314, df = 3, p = 2.78-09), indicating that perceptions of usage is also impacted by gender, whereas AGE_RANGE (p = .637) and OCCUPATION (p = .298) were not statistically significant.
FOR TRUST, neither OCCUPATION (p = .517) nor AGE_RANGE (p = .137) were statistically significant. Instead, GENDER (F = 8.692, df = 3, p = .000015) showed statistical significance, which means that trust may be influenced by gender.
Finally, for RESP_USE_TRUST_BENEF, OCCUPATION (p = .613) yielded nonsignificant results. In comparison, GENDER (F = 8.692, df = 3, p = .000015) and AGE_RANGE (F = 2.691, df = 4, p = .031) were both significant, which means that variations in perception of use, trust, and benefits may be related to both gender and age.
Summarizing, GENDER seems to have significant influence on perceptions of benefits to use, trust, and benefits in general, as well as benefits to higher education in particular, whereas AGE_RANGE significantly influenced use, trust, and benefits. OCCUPATION had no significant effect on any of these dimensions.
Analysis of Variance for Student and Instructor Populations
A one-way ANOVA test and a subsequent Tukey HSD post hoc test was conducted using just student data points to gain insight on the impact of age and gender on awareness. For age range, all groups were not statistically significant (F = 2.23), all with p-values over .05. The opposite is true with gender, showing a high f-score (F = 6.55) and a very low p-value for the female/male group (p = .0001). The same type of test was conducted using only instructor data points. The same pattern follows for age here with low f-scores and high p-values across groups (F = 0.73). Gender in terms of instructors was also insignificant, with low f-scores and low p-values across groups (F = 0.59).
For one-way ANOVA tests, age had no significant impact on benefits, limitations, implications, work productivity, plagiarism, social impact, higher education benefit, usage, (RESP_USE_TRUST_BENEF), and trust, with very low f-scores and p-values across the board for both instructors and students.
Again, for one-way ANOVA tests, gender had low effect on benefits, limitations, implications, work productivity, plagiarism, social impact, higher education benefit, and trust for students. Similarly, for instructors, (RESP_USE_TRUST_BENEF) along with the previously mentioned factors, all had low impact when viewed with gender.
When gender's impact is viewed with usage, impact rates vary highly with both students and instructors, further indicating a correlation with gender and one's views of usage of ChatGPT (F = 9.32, 7.30, respectively). It is also worth noting the p-values were very low, rating .0 and .0002, respectively, for the female/male groups of students and instructors.
When gender's impact is viewed with statements of trust and benefits, gender rates vary highly with students with F = 6.41, further indicating a correlation between gender and how much someone trusts and believes in the benefits of ChatGPT (p-male/female = .0008).
In terms of the two-way ANOVA tests and subsequent Tukey HSD post hoc tests conducted, age and gender had no impact on awareness (should be noted that the male/female group for students rated well in the Tukey HSD test, showing a p-value of p = .0001), benefits, limitations, implications, work productivity, plagiarism, social impact, higher education benefit, usage (should be noted gender, specifically male/female group, rated well with both students and instructors; p = .0, .0002, respectively), statements of trust and benefits (should be noted that the male/female group for gender rated well with students with p = .0008), and trust (female/PNTS rated well for students with a p-value of p = .03) all rated poorly overall for both students and instructors with low f-scores and high p-values across the board.
Overall, the two groups of age and gender don’t provide much impact across variables. When there is impact, gender is the factor that comes through on top, specifically with awareness (just students), usage, and (RESP_USE_TRUST_BENEF), potentially indicating a relation between gender and outlook on Generative AI software such as ChatGPT. It is also worth noting that the student data points seem a bit more susceptible to gender influence on opinions (albeit, not by much more than the instructors).
Ordinal Logistic Regression
Given that AGE_RANGE is an ordinal variable (although treated before as categorical for the sake of the ANOVA study), it was useful to treat it as such and therefore perform an ordinal logistic regression using AGE_RANGE, as the response variable and the composite scores as covariates. A collinearity analysis was performed on the composite scores (see Table 7), computing the Variance Inflation Factor (VIF) to detect the presence of multicollinearity among the composite scores predictor variables in a regression model.
Multicollinearity Analysis Using Variance Inflation Factor (VIF).

VIF = 1: Not correlated to any other variables.
1 < VIF < 5: Moderately correlated, but within acceptable boundaries.
VIF ≥ 5: Indicates potential problematic multicollinearity.
None of the composite scores had a VIF factor above 5, which is typically the cutoff for identifying multicollinearity issues. The highest VIF was approximately 3.63 for RESP_USE_TRUST_BENEF, which suggests that this variable has some moderate correlation with other variables. The variable also exhibited a rather large correlation with other composite scores (see Table 4) and is based on questions that have some redundancy with question that gave way to other composite scores, so it was decided to remove the variable from the analysis. All the other variables have VIF values well below the threshold of 5, indicating that multicollinearity is unlikely to be a concern for those variables. This means that the regression coefficients for these variables are likely to be reliable and that the standard errors are not unduly inflated due to multicollinearity (we previously trained the model with the full set of scores and verified that it yielded more nonsignificant composite scores, presumably due to multicollinearity).
GENDER was included after transforming the categorical feature into binary indicators and excluding GENDER_female, which acts as a reference. Also excluded was OCCUPATION, as OCCUPATION = instructor is highly associated with the top AGE_RANGE category and is therefore not informative in this analysis. Ordinal logistic regression outcomes are displayed in Table 8. Model fit is good (Wald χ2 = 46.11, p < .01). Together, the predictors in the model explain 60.01% of the variation in the dependent variable.
Results of Ordered Logistic Regression—Target AGE_RANGE.
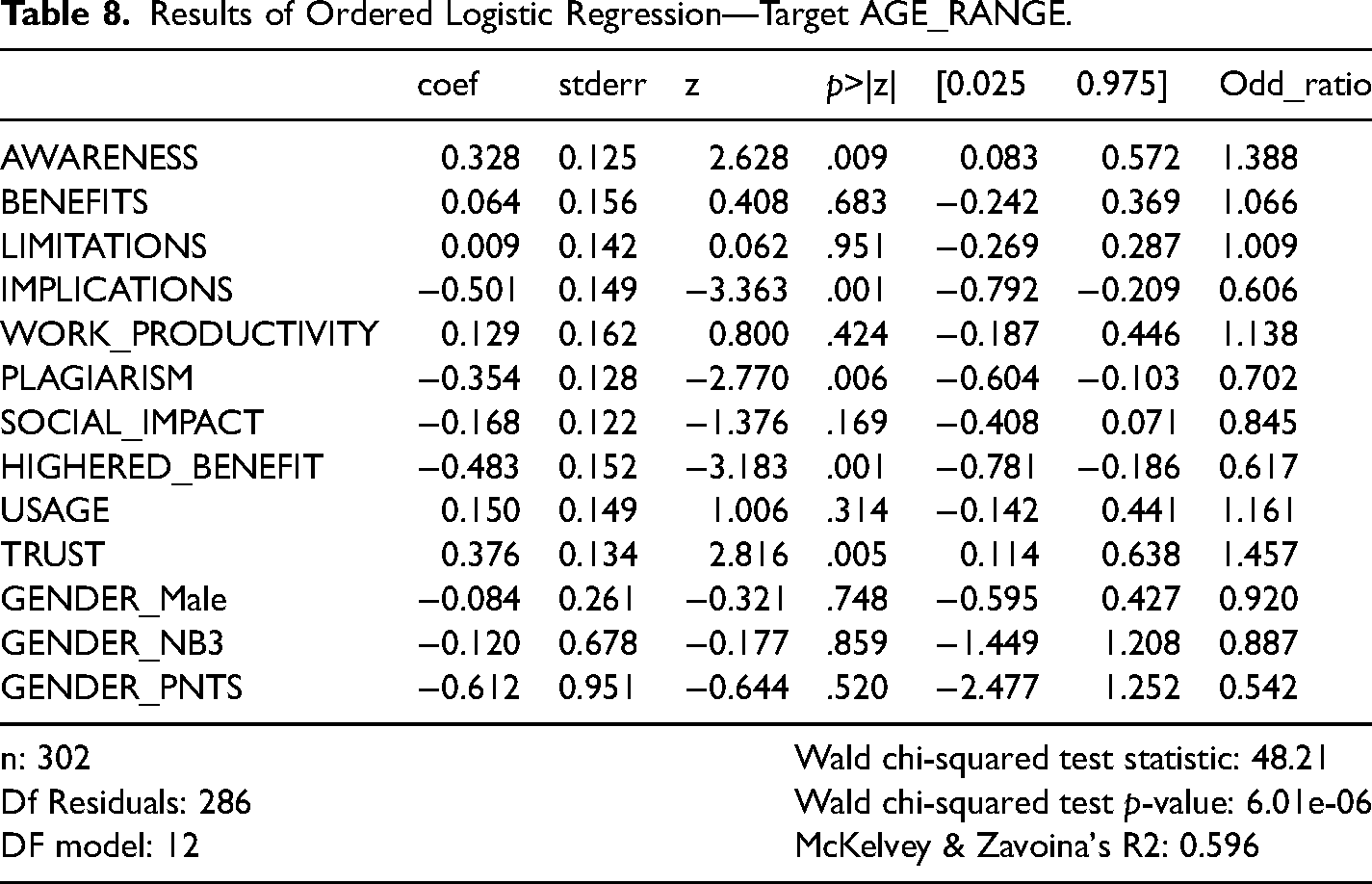
Several covariates were found to be statistically significant, namely:
AWARENESS: The regression coefficient is 0.328, with a p-value = .009. This implies that higher awareness of Generative AI is significantly related to a higher age range. Older age groups tend to have higher levels of awareness. The odds are about 1.388 times higher for each unit increase in AWARENESS.
IMPLICATIONS: The coefficient is −0.501, and the p-value is .001. This indicates that higher values of implications of Generative AI are significantly associated with being in a lower age range—the odds are about 0.606 times lower for each unit increase in IMPLICATIONS. This could mean that younger age groups are more concerned about the implications of Generative AI.
PLAGIARISM: The coefficient is −0.354, and the p-value is .006. This suggests that higher values of potential plagiarism are significantly associated with being in a lower age range—the odds are about 0.702 times lower for each unit increase in PLAGIARISM. Younger age groups tend to believe that Generative AI is conducive to plagiarism.
HIGHERED_BENEFIT: The coefficient is −0.483, and the p-value is .001. This suggests that higher values of a perception of benefits to higher education are significantly associated with being in a lower age range—the odds are about 0.617 times lower for each unit increase in HIGHERED_BENEFIT. That means that younger age groups see more benefit in higher education as related to Generative AI.
TRUST: The coefficient is 0.376, and the p-value is .005. This indicates that higher trust levels are significantly related to being in a higher age range—the odds are about 1.457 times higher for each unit increase in TRUST. Older age groups tend to have higher levels of trust in Generative AI.
Discussion
The purpose of this project was to evaluate the perceptions of Generative AI among students and instructors in a higher education environment. The study has provided interesting insights into those perceptions of Generative AI technology (ChatGPT) as they relate to teaching and learning. Diffusion of Innovation theory (Rogers, 1962) and TAM (Davis, 1989) served as the theoretical inspirations for this study. While it was expected that there would be an increasing level of awareness regarding ChatGPT, it was interesting to see specific perceptions of usage, behavior, and implications of this technology in a classroom setting. The study found that a significant number of participants indicated that they would not plagiarize with ChatGPT but believed that others would. When asked to rate the accuracy of the output generated by ChatGPT in reply to a user's prompt, more than half of the respondents either took the incorrect output given by ChatGPT as correct/somewhat correct (a false negative) or did not know whether it was correct or incorrect, raising a need for emphasis on teaching data literacy outside of the data science and computer science fields in higher education.
Accessibility
Older age groups in this sample tended to have higher levels of awareness about ChatGPT. This makes sense, as news sources and popular press outlets, oftentimes utilized by an older audience, have been covering ChatGPT since it was released in November 2022. Similarly, in the higher education community, a number of academic studies have been published assessing the dangers of ChatGPT. For example, Frith (2023) has referred to ChatGPT as a “disruptive educational technology” and noted that “nurse educators are concerned about the erosion of students’ accountability to learn rather than take shortcuts.” Considering this finding and prior sentiment, it is surprising that while older age groups tend to have higher awareness about ChatGPT, they also tend to have higher levels of trust in the technology.
Younger age groups, though, saw benefits in ChatGPT within the classroom, but they were also concerned about the implications of Generative AI. This is an important finding, as it implies that students are aware of and may have even seen how Generative AI can be used with malicious intentions. This contradicts research findings by Chan and Hu (2023), who, in their study of 399 undergraduate and postgraduate students surveyed from various disciplines in Hong Kong, found that students had a generally positive attitude toward Generative AI in teaching and learning. According to the study, students recognized the potential for personalized learning support, writing, brainstorming assistance, and research and analysis capabilities. The authors pointed out, however, that concerns about accuracy, ethical issues, career prospects, and the impact on personal development, and societal values had been raised by the student sample.
Learning
There have been a number of articles, both scholarly and nonacademic, that have addressed the potential for plagiarism using ChatGPT (Keegin, 2023; Michel-Villarreal et al., 2023). This study has found that younger age groups tended to believe that Generative AI is conducive to plagiarism. This supports previous literature, which addresses the concerns students have about Generative AI (Smolansky et al., 2023).
Another finding from this study was that younger age groups agreed on the potential for benefits in higher education with the use of Generative AI. This supports previous research by Adiguzel et al. (2023) who found that there is great potential for personalized learning, language instruction, and feedback applications in education by using Generative AI technology such as ChatGPT.
This study also found that older age groups in this sample tended to have higher levels of trust in Generative AI. This is also supported by previous studies. In particular, Opara et al. (2023) looked at literature on the educational implications of AI. OpenAI's ChatGPT was evaluated for teaching, learning, and research and the results indicated that ChatGPT delivers instantaneous text-generated response to user prompts that resembles conversational dialog.
Moving Forward
It is evident that Generative AI is not leaving higher education anytime soon. As such, it is critical to have a plan in place. Rawas (2023) offers a number of critical success factors in the implementation of Generative AI technology like ChatGPT, namely (1) Integration with existing systems at the institution; (2) Training and support, including recommendations on approaches to teaching and learning; (3) Quality assurance to avoid inaccurate responses and control hallucinations, something Generative AI systems remain prone to; (4) Piloting and evaluation; and (5) Scalability and sustainability to make sure that rising demand is not an impediment of use.
Robin (2023) suggests that educators must think less about policing and more about pedagogy; in other words, it is more important to offer students meaningful experiences with Generative AI rather than monitoring them and punishing bad behavior. Similarly, Miller (2023) has looked at ways to integrate Generative AI in the classroom. In Miller's words: “(1) Experiment with AI tools from the perspective of your discipline, (2) Identify at least one genuinely helpful way to use AI in your own field, and (3) Devise at least one AI-based teaching activity suitable for your own courses.” Similarly, Mejia and Sargent (2023) found that educators must leverage technology tools to support the development of students’ critical thinking skills. Additionally, Onal and Kulavuz-Onal (2023) looked at uses of ChatGPT in generating assessment tasks and noted that ChatGPT is not designed to replace human expertise or judgment.
Chan (2023) presents a comprehensive AI policy education framework for university teaching and learning. The study proposes an AI Ecological Education Policy Framework to address the implications of AI integration in higher education 1 . The framework is organized into three dimensions: (1) Pedagogical, which focuses on the use of AI to improve teaching and learning outcomes; (2) Governance, which deals with privacy, security, and accountability matters; and (3) Operational, which addresses infrastructure and training.
Alignment
With the abundant list of pros and cons on both ends of the spectrum, it becomes difficult to pinpoint where Generative AI fits into a given community and how to mitigate unwanted outcomes. History is replete with examples of technologies that were developed without consideration of the harmful effects of their deployment, from fossil fuels to plastics, nuclear technology, and social media platforms, to mention just a few. Data-driven AI systems, the type of AI to which current LLMs belong, are trained to optimize an objective function—minimize the error of predicting the next word, in the case of Generative AI. And herein lies the challenge: How to align the optimization goal of such AI system with human needs and goals? Korinek and Balwit (2022) describe two types of alignment: direct and social. Direct alignment is when “a system pursues goals that are consistent with the goals of the user, regardless of the outcomes that affect parties who are not involved.” Social alignment is when the goals of an AI system are “consistent with the broader goals of society, which takes into account the welfare of others who may be impacted by the system.” This becomes a very arduous task in fields like higher education. It is important for Generative AI systems to socially align with the goals of institutions, to ensure that learning is maximized for students. We understand the benefits of this technology, which has the potential to make domain experts more productive. It is still not clear what effect it will have on students who are by definition subjected to the learning process.
Conclusions
The purpose of this project was to study and measure perceptions in higher education of Generative AI and ChatGPT regarding the impact on teaching and learning. Several factors were measured, including awareness, usage, behavioral intention, and trust. Given the timely nature of this topic, it was beneficial to assess perceptions early on, as people are still familiarizing themselves with Generative AI and the many use cases.
Like all studies, there are limitations to this project. First, the sample size was not as large or heterogeneous as it could be, given that it was completed on a single population of students and faculty at a private liberal arts institution in the northeast. As a result, the findings cannot be generalized to other schools with different characteristics. The paper focused on three demographic features (gender, age range, and occupation) to denote the factors extracted from the survey questions and measure their differences among the surveyed population along these demographics. A broader survey and additional analysis could take into account other demographics and dig deeper into categorizing students and faculty in terms of their majors, specializations, and schools to which they belong. The authors have considered launching a second survey to pair these early perceptions of faculty and students with those emerging from the same population after a year of exposure to Generative AI tools like ChatGPT.
We believe that this study is a valuable attempt to assess early perceptions of Generative AI in a higher education setting. Hopefully, this paper will provide additional motivation for other researchers, educators, and administrators to continue exploring the use of this potentially highly disruptive technology.
Footnotes
Availability of Data and Materials
The datasets used and/or analyzed during the current study are available from the corresponding authors on reasonable request.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Notes
Correction (March 2024):
Eitel J.M. Lauría is also added as corresponding author.