
Abstract
Large language models (LLMs) such as ChatGPT are entering clinical practice, yet how their clinical reasoning compares with speech-language therapists (SLTs) is not well understood. This comparative multi-case qualitative study used 3 hypothetical vignettes. Ten experienced SLTs (≥10 years) participated in semi-structured interviews, providing assessment, diagnosis and therapy plans for each vignette. ChatGPT-4o was presented with identical, standardized Turkish prompts over five consecutive days to evaluate the model’s temporal consistency in clinical reasoning. All outputs were analyzed with content analysis, and day-to-day consistency of ChatGPT themes was examined. ChatGPT-4o and SLTs showed substantial overlap in core practices such as case history, spontaneous speech analysis, key diagnostic labels, and emphasis on generalization and caregiver involvement. However, SLTs utilized broader, locally normed assessment tools and offered more flexible, individualized and context-sensitive therapy approaches. ChatGPT-4o’s responses were more standardized and showed stable thematic patterns across days, yet they did not reflect the clinical nuance or contextual adaptation observed in SLTs’ reasoning. ChatGPT-4o can approximate expert-like reasoning in structured scenarios and may serve as a clinical decision support aid. Nonetheless, it does not replace experienced SLTs, particularly for culturally grounded, person-specific assessment and intervention planning.
Keywords
Introduction
Just as the invention of writing, the development of the printing press, the rise of the steam engine, and the introduction of smartphones into everyday life have created profound transformations throughout human history, the rise of artificial intelligence (AI) is regarded as a similarly pivotal turning point in the 21st century. 1 Artificial intelligence is a broad field that includes computational methods such as machine learning, which in turn support a range of application domains, including natural language processing, speech and language technologies, robotics, and AI-assisted systems. 2 Moreover, due to its ability to analyze large volumes of data, it can support evidence-based clinical decision-making processes and is therefore rapidly advancing and becoming increasingly important across a wide range of domains, particularly in medical and health services.3 -7 Recently, it has been reported that AI’s success in medical applications has increased markedly. 3 Accordingly, understanding how healthcare professionals can employ AI technologies is of great importance for improving and enhancing healthcare services. 2
The rapid expansion of AI in healthcare also extends to language-based generative models. In recent years, Generative Artificial Intelligence (GAI) tools powered by Large Language Models (LLMs) have demonstrated significant utility in healthcare. These systems assist practitioners by automating clinical documentation, simplifying complex medical information for patient education, refining the linguistic structure of scientific writing, and providing interactive scenarios for professional development.1 -8
ChatGPT and Its Use in Healthcare
The integration of LLMs enables these GAI systems to provide easy accessibility and the capacity to generate contextually relevant, human-like responses suitable for clinical dialogs. 8 With a level of convenience similar to instant access through smartphones, the widespread availability of Generative AI models-exemplified by ChatGPT, which offers both free and subscription-based professional versions-has significantly impacted modern technology. Its ability to generate human-like responses across a broad range of topics, combined with its capacity to process multimodal inputs such as text, visual, and auditory data, has established it as a prominent tool in the field. 9 ChatGPT has attracted unprecedented public attention; reports indicate that it reached around 100 million active users by January 2023, making it one of the fastest-growing consumer applications to date.10,11
While several LLMs offer rapid processing and documentation support, ChatGPT is particularly noteworthy as a primary, highly accessible interface that has set a benchmark for public and professional AI interaction in healthcare.12,13 Beyond its functional utility in facilitating documentation and preliminary patient explanations, its widespread adoption has catalyzed global discussions on the integration of Generative AI into clinical workflows. As newer versions continue to evolve, diverse medical use cases-such as clinical documentation, patient education/communication, and diagnostic decision support in emergency departments-have rapidly appeared in the literature.14 -16
However, the risk of generating inaccurate information, the need for external verification of its responses, and its occasional misinterpretation of inputs make its current use in healthcare limited yet valuable in terms of potential. 16 Recent reviews emphasize that ChatGPT performs at only a moderate level across many clinical tasks; that it can produce “hallucinated,” information presented in a highly confident tone, which may lead users to perceive the output as factual even when it contains inaccuracies. 17 Additionally, the lack of transparency in LLM decision-making processes, ambiguity regarding responsibility for erroneous recommendations, and the risk of reproducing biases present in training data-thereby disadvantaging certain patient groups-are identified as key ethical limitations. 18
ChatGPT and Its Use in the Field of Speech and Language Therapy
In recent years, AI has also begun to be used in assessment and therapy processes within the field of speech and language therapy. 19 Multimodal models such as ChatGPT-4o, with their capacity to analyze complex linguistic inputs, have been shown in several studies to offer new possibilities for clinical practice.20 -22
One such study examined the applicability of AI-based visual generation (DALL-E 2) to develop materials for aphasia assessment and intervention and found that 94.5% of 200 target stimuli accurately represented their core concepts. 23 Similarly, recent studies support the usability of AI-generated images in language assessment processes. For example, images generated using Bing Image Creator (DALL·E 3) for Turkish nouns and verbs produced naming accuracy and response time patterns consistent with classical psycholinguistic findings in neurotypical adults; moreover, they largely met criteria for imageability and clinical usability. 24 Taken together, these findings suggest that AI-based visual generation offers significant potential for developing low-cost, rapid, and culturally adaptable materials for speech and language disorders, while also underscoring the need for careful evaluation of model outputs in terms of accuracy and cultural appropriateness.
Consistent with these clinical applications, Birol et al 21 further demonstrated how ChatGPT-4o could be effectively integrated into assessment, diagnosis, and therapy processes within the SLT context. In this study, ChatGPT’s responses related to language, speech, and swallowing disorders were evaluated by 15 experts in terms of accuracy, comprehensiveness, and appropriateness. ChatGPT was found to provide innovative support in functions such as preparing clinical documents and generating materials; however, improvements were recommended regarding its effectiveness in therapeutic processes. Another study presented the most frequently asked questions related to stuttering to the ChatGPT-4o mini model and had SLTs evaluate the responses in terms of content quality and readability. 25 The findings indicated that ChatGPT has promising potential in providing appropriate responses to common stuttering-related questions. However, the study emphasized that generative AI tools are intended solely for educational purposes and should not replace diagnosis or treatment provided by qualified SLTs. 25
Nevertheless, reviews summarizing the current literature highlight that research on ChatGPT remains largely in its early stages; that most studies examine the model descriptively or exploratorily within limited contexts such as academic writing, education, or patient communication; and that significant limitations persist due to issues such as information accuracy, reliability of responses, and hallucinatory outputs.26 -28 Existing studies typically evaluate ChatGPT’s responses through qualitative or quantitative expert ratings, thereby offering valuable insights into content quality. Yet, to understand how ChatGPT might be positioned within clinical decision-making processes, it is necessary to examine not only expert evaluations but also the extent to which the model’s clinical reasoning across the assessment, diagnosis, and therapy planning chain aligns with the decision patterns of experienced clinicians.
This study aims to systematically compare ChatGPT-4o’s assessment, diagnosis, and therapy planning responses to case histories involving speech and language disorders with the responses of speech and language therapists who have at least 10 years of clinical experience. This 10-year threshold was specifically chosen to ensure that the human comparison group represents “expert” clinical reasoning, as a decade of experience is a widely recognized benchmark for achieving professional mastery in healthcare. In doing so, the study examines the stages of the clinical reasoning chain in which ChatGPT-4o converges with expert decisions, the stages in which it diverges, and the degree of internal consistency within its own responses to the same cases. The findings are expected to clarify the validity and safe use boundaries of AI-supported clinical decision-making systems within the SLT field. By directly comparing ChatGPT-4o’s responses to structured hypothetical case scenarios with the decisions of these highly experienced therapists, this study also evaluates the reliability and clinical nuance of AI-generated assessment and therapy planning across identical cases.
Materials and Methods
This study is a comparative, multi-case qualitative study conducted using 3 hypothetical clinical cases: adult stuttering, developmental language disorder (DLD), and speech sound disorder (SSD). The study’s design and reporting follow the Consolidated Criteria for Reporting Qualitative Research (COREQ) guidelines to ensure methodological rigor and transparency. 29 The aim of this qualitative, multi-case design is to enable an in-depth and detailed examination of ChatGPT-4o’s clinical reasoning by systematically comparing its outputs with responses from licensed Speech and Language Therapists (SLTs). Each participant was required to have at least 10 years of clinical experience in the assessment, diagnosis, and therapy of the specified disorders. Furthermore, the study evaluates the temporal consistency and variations of ChatGPT-4o’s responses by examining outputs generated across five consecutive days using identical standardized prompts.
Participants
A purposeful sampling strategy was used to recruit licensed Speech and Language Therapists (SLTs) with at least 10 years of clinical experience in the field. Recruitment occurred via professional networks and clinical associations across Türkiye, utilizing a snowball sampling approach to identify and contact highly experienced clinicians with diverse specialization profiles. Ten SLTs (9 females, 1 male) working in diverse clinical and academic contexts participated in the study.
The inclusion criteria required participants to: (a) hold at least a master’s degree in speech and language therapy, (b) be registered and actively practicing, (c) have a minimum of 10 years of professional experience, and (d) provide informed consent to participate. To ensure the specificity and quality of the clinical insights, the following exclusion criteria were applied: (1) having less than 10 years of professional experience, (2) a lack of active clinical practice within the last 2 years, and (3) failure to complete the full interview process for all 3 clinical vignettes. No potential participants or data points were excluded based on these criteria in the final analysis.
Participants represented a variety of professional backgrounds, including university-affiliated clinics, hospitals, private practices, and rehabilitation centers. This diversity in professional settings was intended to capture a broad range of clinical perspectives. While these settings do not represent the entire heterogeneity of the field, they provide a multifaceted view of clinical reasoning across frequent disorder areas with distinct diagnostic and intervention frameworks.
Participants represented 3 primary clinical settings, including university-affiliated clinics, private practices, and rehabilitation centers. Recruitment occurred via professional networks and snowball sampling to identify experienced clinicians across these professional contexts. Each participant completed a brief demographic questionnaire capturing age, gender, years of experience, highest degree, and primary workplace. They were also asked to list the most frequent disorder areas they encounter in their daily clinical practice. The characteristics of the participating SLTs are summarized in Table 1.
Demographic and clinical characteristics of the participants.

DLD: Developmental Language Disorder; SSD: Speech Sound Disorder; ASD: Autism Spectrum Disorder.
Development of Interview Questions and Case Scenarios
Three hypothetical clinical case vignettes-adult stuttering, developmental language disorder (DLD), and speech sound disorder (SSD)-were developed by the researchers, along with a semi-structured interview guide, to elicit and compare responses from both experienced speech-language therapists and ChatGPT-4o regarding assessment, diagnosis, and therapy. These instruments were designed based on current evidence-based clinical guidelines in speech-language pathology. While the vignettes and interview guide were not previously validated as standardized scales, they underwent a pilot-testing phase with 2 independent senior SLTs (not included in the final study sample) to ensure content validity, clinical realism, and linguistic clarity. Minor refinements were made to the phrasing of the prompts and questions based on the pilot feedback. The complete set of vignettes and the semi-structured interview guide are provided as a separate “Supplemental File” for transparency.
The initial case drafts were developed and edited by a primary research team consisting of 2 PhD students and 1 PhD-level researcher, all of whom are licensed Speech and Language Therapists (SLTs). Each vignette was written to reflect typical clinical decision points relevant to its disorder domain (for instance, fluency features and avoidance behaviors in stuttering; receptive–expressive balance and contextual language use in DLD; and phonological processes and auditory discrimination in SSD). Phrases that could directly imply a diagnosis or bias responses toward specific interpretations were intentionally avoided. To maintain neutrality, diagnostic labels such as “severe stuttering” or “phonological delay” were replaced with descriptive clinical data; for example, instead of stating a diagnosis, the vignettes provided objective observations such as “the speaker exhibits involuntary repetitions of initial syllables in 12% of words” or “the child consistently replaces velar stops with alveolar stops.” This approach required both ChatGPT-4o and the expert SLTs to independently synthesize the raw information to reach their clinical conclusions.
To ensure objective validation, these drafts were subsequently reviewed by an independent expert panel comprising 1 Associate Professor, 1 PhD-level SLT, and 3 PhD students who were not involved in the initial development of the vignettes. This panel, also consisting entirely of licensed SLTs, assessed the cases for content coverage, linguistic clarity, and neutrality. The clinical background of both the research team and the independent panel ensured that the vignettes were technically accurate and representative of real-world SLT scenarios. While this domain expertise was essential for creating high-fidelity research materials, potential for subjective bias was minimized by using these vignettes to elicit independent, blind-coded responses from 10 external expert participants, rather than relying on the internal panel’s clinical judgments for the final AI comparison. Following the panel’s feedback, necessary revisions were made and the final versions were constructed for use in data collection.
Finally, a concise, semi-structured interview guide paralleled the vignette design and was organized into 3 neutral prompts per case:
Assessment: planned procedures and rationale;
Diagnosis: most likely diagnosis, differentials, and justification;
Therapy: initial targets, hierarchy/procedures, and generalization strategies.
Procedure
Interview with SLTs
The 3 finalized vignettes were presented in the same fixed order for every participant. Each vignette was standardized in length, ranging between 150 and 200 words, to ensure a comparable level of clinical detail across the different disorder domains. The semi-structured guide from the development phase was used verbatim (Assessment → Diagnosis → Therapy).
Individual interviews were conducted online (MS Teams) by the first author, typically lasting 30 to 45 min. During the sessions, the vignettes were presented visually via the “screen sharing” feature, allowing participants to read the text at their own pace. Simultaneously, the interviewer read the vignettes aloud to ensure full comprehension. Participants provided their professional clinical reasoning orally, which was captured in real-time. The interviewer used minimal, non-leading follow-ups only when clarification was needed (eg, “Could you elaborate?”), as specified in the guide.
All interviews were audio- and video-recorded with participants’ consent and transcribed verbatim. Transcripts were checked for accuracy and anonymized by removing any identifying information.
ChatGPT-4o’s Responses
Model responses were collected under 2 independent laptop-based environments running Windows and macOS. To prevent any prior conversational context or personalization effects, 2 new OpenAI accounts were created specifically for this study, 1 for each operating system environment.
For each vignette, the model was instructed to assume the role of a speech-language pathologist with at least 10 years of clinical experience and to provide detailed responses addressing assessment, diagnosis, and therapy components. The prompts were entered in Turkish to match the linguistic context of the participating clinicians and were identical in wording across all sessions to ensure consistency. The standardized prompt presented to
ChatGPT-4o stated: “Imagine that you are a speech and language therapist with at least ten years of clinical experience. Based on the case vignettes I will share, provide detailed explanations under the following three headings:
1. Assessment: Which assessment tools or procedures would you use in this case? Explain why you would select each and what information you aim to obtain.
2. Diagnosis: What is the most likely diagnosis for this client? Describe the findings or observations that led you to this conclusion.
3. Therapy: What therapy goals and methods would you plan for this client? Explain the process in detail (e.g., specific techniques, session structure, and generalization strategies).
Please respond with the level of detail expected from a clinician with at least ten years of professional experience.
If anything is unclear, please indicate. When you are ready, I will share the first case vignette.”
Each vignette was queried on five consecutive days within each account and environment. Every run began in a fresh session with no retained chat history or contextual memory. Outputs were exported verbatim and systematically labeled with the corresponding case ID, environment (Windows/macOS), date, and run number to facilitate alignment across days and between sources.
Data Analysis
The qualitative data analysis process was carried out systematically and transparently. First, the audio recordings of interviews with 10 Speech and Language Pathologist (SLTs) were transcribed verbatim by the first and second authors, who are licensed SLTs and PhD candidates with expertise in both clinical terminology and qualitative methodology. To ensure the high fidelity and accuracy of the textual data, a cross-check procedure was implemented where each transcript was reviewed against the original audio recordings by a third member of the research team, a senior PhD-level SLT. This resulted in 1438 lines and 38 pages of textual data. Similarly, the responses generated by ChatGPT-macOS and ChatGPT-Windows for the 3 clinical vignettes were converted into text format (641 lines, 26 pages) and incorporated into the analysis.
All transcripts were imported into MAXQDA software and analyzed through conventional content analysis.30,31 Each transcript was examined line by line, and coding was conducted according to the study’s analytical framework. During the process, the responses of the human participants and the ChatGPT models were coded separately, and 3 overarching themes were defined for each vignette: Assessment, Diagnosis, and Therapy.
In alignment with these themes, the data were organized into detailed thematic categories, enabling a systematic and comparative examination of how clinical reasoning patterns emerged across human and AI-generated responses.
Trustworthiness and Rigor
To ensure analytic rigor and transparency, multiple strategies were applied throughout the data analysis process. First, the content validity of the research instruments (vignettes and interview guide) was established through a pilot-testing phase and expert review by 2 independent senior SLTs. Two researchers independently coded all transcripts, followed by consensus meetings to refine category definitions and resolve discrepancies. Inter-coder agreement was established on a random 20% subset of the data, yielding satisfactory reliability (κ ≥ 0.87).
Furthermore, data saturation was rigorously monitored; recruitment and analysis continued until no new clinical themes emerged, confirming that the sample size (n = 10) was sufficient to capture the depth of the clinical reasoning patterns. All transcripts were anonymized prior to analysis, and a detailed audit trail was maintained to document coding decisions, thematic refinements, and interpretive shifts. Additionally, researcher reflexivity was carefully considered throughout the analysis to minimize interpretive bias.
A multi-level comparative analysis was conducted across primary data sources (human vs. ChatGPT-4o responses) and clinical vignettes (stuttering, DLD, SSD). Additionally, data collection for ChatGPT-4o was performed across 2 distinct technical environments (Windows/Chrome and macOS/Safari) to verify the stability and replicability of the AI’s responses. While the operating system and browser were included in the initial procedural design to rule out any session-specific technical artifacts, our analysis confirmed that these factors had no discernible impact on the content or clinical accuracy of the model’s outputs. Therefore, findings reflected consistent systematic patterns rather than isolated instances or environment-specific variations.
Ethical Approvement
Inclusion criteria required participants to: (a) hold at least a master’s degree in speech and language therapy, (b) be registered and actively practicing, (c) have a minimum of 10 years of professional experience, and (d) provide written informed consent prior to the commencement of the study. The written consent form, approved by the Bahçeşehir University Scientific Research and Publication Ethics Committee, outlined the study’s purpose, the voluntary nature of participation, and the confidentiality of the data. This study was reviewed at the meeting of the Bahçeşehir University Scientific Research and Publication Ethics Committee dated November 6, 2025 (Meeting No: 2025/09; Document No: E-85646034-604.01-115398) and was approved, indicating that it complies with the principles of scientific research and publication ethics.
Results
The findings obtained from the analysis of the data are presented in this section, in which the diagnostic, therapeutic, and assessment processes for each case are compared between the SLT and ChatGPT and supported with direct quotations. To provide a holistic overview before detailing each disorder domain, Table 2 summarizes the primary similarities and differences across the assessment, diagnosis, and therapy themes for Stuttering, DLD, and SSD. This summary serves as a roadmap for the more granular comparisons presented in Figures 1 to 9.
Summary of Clinical Reasoning Patterns Across SLTs and ChatGPT-4o.

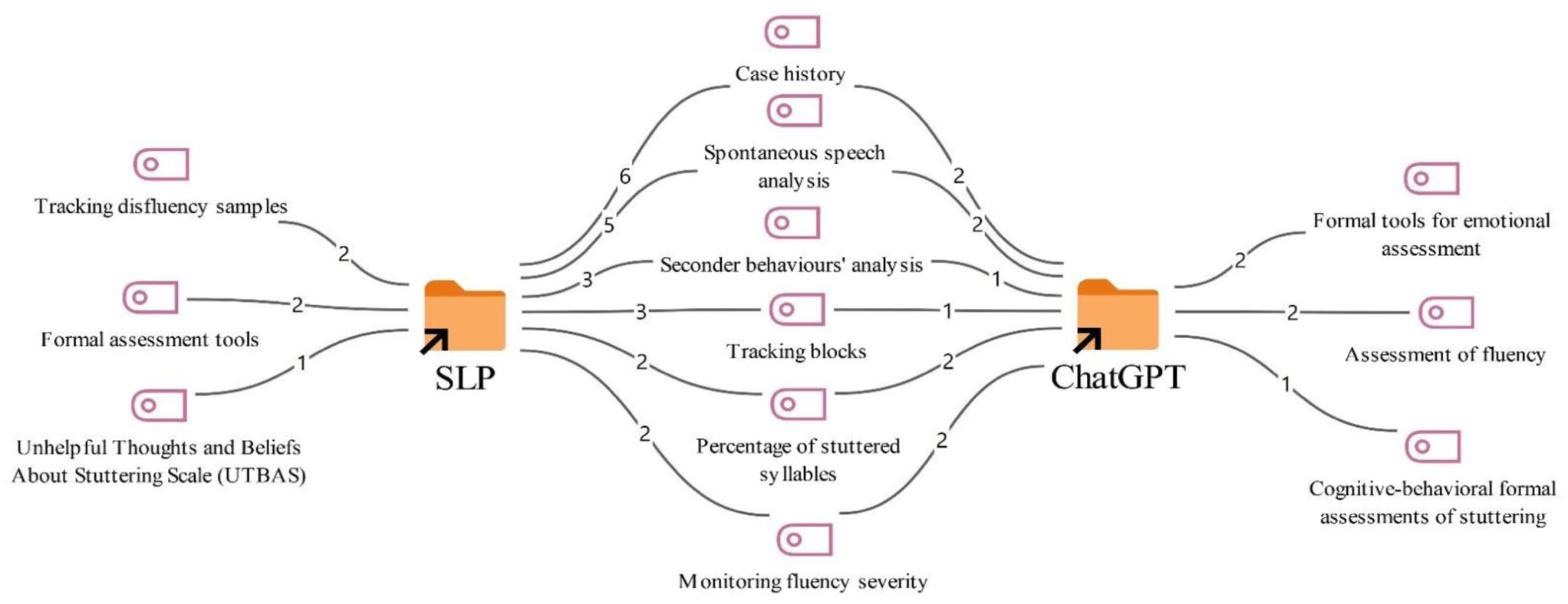
Case I-assessment.
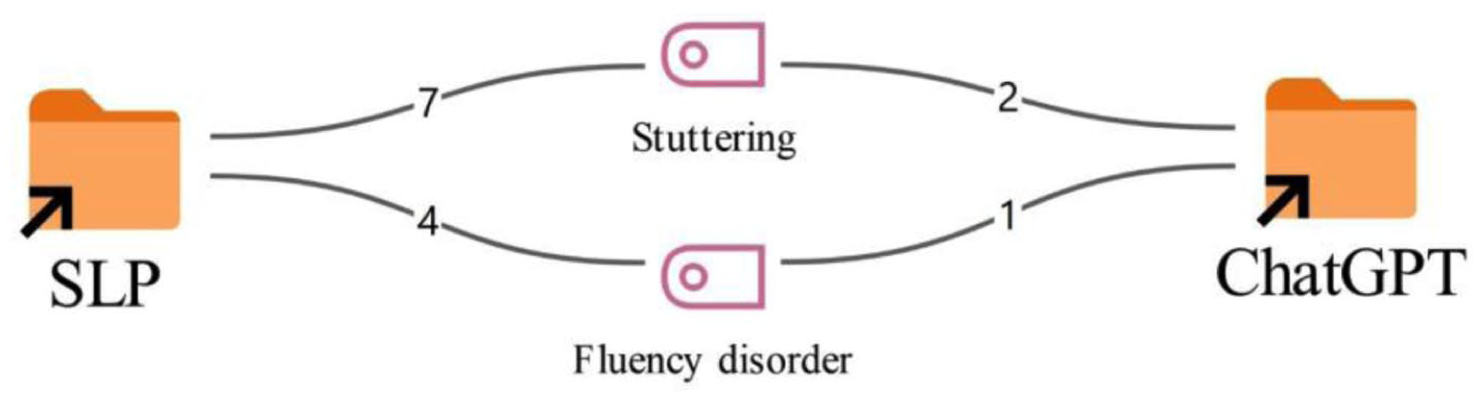
Case I-diagnosis (Please refer to Figure 1 for the visual interpretation key and coding legend).

Case I-therapy (Please refer to Figure 1 for the visual interpretation key and coding legend).

Case II-assessment (Please refer to Figure 1 for the visual interpretation key and coding legend).

Case II-diagnosis (Please refer to Figure 1 for the visual interpretation key and coding legend).

Case II-therapy (Please refer to Figure 1 for the visual interpretation key and coding legend).

Case III-assessment (Please refer to Figure 1 for the visual interpretation key and coding legend).

Case III-diagnosis (Please refer to Figure 1 for the visual interpretation key and coding legend).

Case III-therapy (Please refer to Figure 1 for the visual interpretation key and coding legend).
Analysis of the Thematic Consistency of ChatGPT Responses Across Days
When the ChatGPT outputs obtained on five different days were coded in a binary present/absent manner with respect to the pre-specified core themes for the 3 cases (diagnostic formulation, core assessment components, and main intervention approaches), theme-level consistency for the core themes was 97.5% in Case 1 and 100% in Cases 2 and 3. When auxiliary themes (eg, technology-supported approaches, group/family involvement, and the structuring of goals) were also included in the analysis, overall theme-level consistency was calculated as 88% for Case 1, 92% for Case 2, and 100% for Case 3.
Case I (Stuttering)
The responses of the SLT and ChatGPT regarding the diagnostic, therapeutic, and assessment processes for the first case are presented comparatively in Figures 1 to 3.
According to Figure 1, in the assessment process for the first case, both overlapping and distinct assessment methods were used by the SLTs and ChatGPT. Common assessment methods proposed by both SLTs and ChatGPT include taking a case history (8), spontaneous speech analysis (7), analysis of secondary behaviors (4), monitoring blocks (4), calculating the percentage of stuttered syllables (4), and tracking overall fluency severity (4).
However, among the assessment methods suggested only by the SLTs were monitoring disfluency samples (2), the use of formal assessment tools (2), and the use of UTBAS (Unhelpful Thoughts and Beliefs About Stuttering) (1).
On the other hand, among the assessment approaches suggested by ChatGPT were the use of formal tools for emotional assessment (2), the assessment of fluency (2), and formal cognitive-behavioral assessments of stuttering (1).
Cognitive-Behavioral Assessment:
Attitude Scales Related to Stuttering:
KiddyCAT (for children), CAT (for adults): Measure emotional and cognitive attitudes toward stuttering. Murat’s cognitive distortions such as ‘I must always speak fluently’ should be identified.”
According to Figure 2, for the diagnosis of the first case, the labels stuttering (7) and fluency disorder (4) stand out among the speech and language therapists. A similar pattern is observed in the ChatGPT responses as well; of the 3 outputs produced, 2 use the diagnosis stuttering (2), while 1 uses fluency disorder (1).
According to Figure 3, in the therapeutic approaches proposed for the first case, there are strategies that substantially overlap as well as diverge between the SLTs and the ChatGPT responses. Common therapy approaches suggested by both SLTs and ChatGPT include the accompaniment of psychotherapy (8), desensitization (7), fluency-shaping techniques (6), a modification approach (5), and cognitive-behavioral therapy (3).
However, among the therapy methods suggested only by the SLTs were an additional component of cognitive-behavioral therapy (1), components of ACT (Acceptance and Commitment Therapy) (1), and work on strengthening communication skills (1).
On the other hand, among the therapy approaches suggested only by the ChatGPT responses were transfer and generalization work (2), technology-supported therapy with DAF (Delayed Auditory Feedback) (1), and techniques to reduce avoidance behaviors (1).
Case II (Developmental Language Disorders)
The responses of the SLTs and ChatGPT regarding the diagnosis, therapy, and assessment processes for the second case are presented comparatively in Figures 4 to 6.
As shown in Figure 4, both similarities and differences were observed between SLTs and ChatGPT in the assessment of the second case. The assessment tools commonly used by both SLTs and ChatGPT included the Turkish Early Language Development Test (TELD 3-TR), case history, natural language sample analysis, analysis of pragmatic language skills (2), APT (Turkish Articulation and Phonology Test) (1), AS (Articulation Subtest-APT) (1), ADS (Auditory Discrimination Subtest-APT) (1), CLT-TR (Crosslinguistic Lexical Task-Turkish version) (1), and the TİFALDİ (Turkish Inventory for Expressive and Receptive Language Development) (1).
The assessment methods suggested only by ChatGPT were more focused on international, standardized language tests, connected speech analysis, and vocabulary assessment. Codes appearing exclusively on the ChatGPT side include connected speech analysis (2), PLS-5 (Preschool Language Scale- Fifth Edition) (2), Turkish Communicative Development Inventory (TİGE) (2), vocabulary analysis (1), vocabulary tests (1), and EOWPVT (Expressive One-Word Picture Vocabulary Test) (1).
According to Figure 5, broadly similar patterns were observed between SLTs and ChatGPT in the diagnosis of the second case. The majority of SLTs described the case as a developmental/specific language disorder (8), while 2 therapists (2) indicated an expressive language disorder. ChatGPT showed a comparable distribution: 2 responses (2) classified the case as a developmental/specific language disorder, whereas 1 response (1) proposed a diagnosis of expressive language disorder.
According to Figure 6, the common therapy approaches proposed for the second case by both SLTs and ChatGPT include collaboration with the family and teacher (9), play-based therapy (8), interactive book reading (6), expanding the child’s vocabulary (5), generalization work (4), engaging in structured activities (4), planning an interaction-focused therapy process (4), and supporting peer interaction (2).
However, among the therapy methods suggested only by SLTs were a phonological approach (4), psychologist support (4), a DIR/Floortime-based therapy process (3), the use of natural language techniques (3), and continuing with traditional articulation therapy (1).
Among the therapy approaches suggested only by ChatGPT were the use of words in meaningful contexts (2), modeling (2), and creating opportunities for expressive language (1).
Case III (Speech Sound Disorders)
According to Figure 7, there are substantially overlapping as well as diverging approaches between SLTs and ChatGPT in the assessment processes for the third case. The assessment methods commonly used by both SLTs and ChatGPT include taking a case history (6), administering auditory discrimination tests (5), analyzing spontaneous speech (4), conducting phonological process analysis (3), oral–motor examination (3), analyzing error types and consistency (3), phoneme recognition tests (2), analysis of speech in context (2), and the Ankara Articulation Test (AAT) (2).
Among the assessment methods suggested only by SLTs were the SST (7) and the Turkish Early Language Development Test (TELD 3-TR) (1).
By contrast, among the assessment approaches suggested only by ChatGPT were the Minimal Pairs Test (1), target–actual production comparison (1), GFTA-3 (Goldman-Fristoe Test of Articulation) (1), Turkish phonological process tests (1), and articulation and phonology tests (1).
The responses of the SLTs and ChatGPT regarding the assessment, diagnosis and therapy, processes for the third case are presented comparatively in Figures 8 and 9.
According to Figure 8, there is a high degree of consistency between SLTs and ChatGPT in the diagnostic evaluations for the third case. The vast majority of SLTs classified the case as a phonological disorder (8), and ChatGPT likewise proposed a diagnosis of phonological disorder (2).
According to Figure 9, the therapy methods commonly recommended by both groups for the third case include auditory discrimination training (10), the minimal pairs method (7), generalization work (7), collaboration with the family (7), reducing stopping processes (7), reducing gliding processes (7), reducing fronting processes (6), articulation therapy (3), developing phonological awareness skills (3), and motor exercises (2).
However, among the therapy methods suggested only by SLTs were the maximal oppositions approach (1), the minimal oppositions approach (1), and collaboration with the teacher (1).
On the other hand, among the therapy approaches suggested only by ChatGPT were sound manipulation activities (1), therapy targeting the reduction of phonological processes (1), and auditory listening activities (1). These findings suggest that ChatGPT places greater emphasis on technically focused and structured approaches within the therapy process.
Discussion
In this study, the consistency of responses provided by ChatGPT-4o regarding assessment, diagnosis, and therapy processes based on specific case histories with the responses given by SLTs working in the field are compared. The findings obtained from the study indicate that ChatGPT displays approaches similar to therapists in providing standardized information, decision-making and managing structured processes. However, the results also show that ChatGPT falls behind human experts in areas requiring clinical experience, individualized (case-specific) and multi-faceted diagnostic assessment. This supports the prevailing view in the literature that AI is a complementary and supportive technology designed to lighten the therapist’s workload and support decision-making mechanisms, rather than a tool that can replace the therapist. This is reflected in our data, where ChatGPT primarily generated structured, literature-based and standardized recommendations, while SLTs incorporated individualized, context-dependent, and experience-driven clinical reasoning. These findings suggest that AI contributes to organizing clinical processes and offering preliminary guidance, whereas final clinical judgments remain grounded in human expertise.
With respect to the consistency of ChatGPT responses across days, these findings indicate that, at least at the level of broad clinical themes, ChatGPT-4o behaves in a highly reproducible way across days for the same case vignettes. In other words, while the exact wording or the specific examples suggested by the model may vary, the core diagnostic formulation, key assessment components and main intervention approaches are largely preserved. This pattern is partly in line with previous work showing moderate to high repeatability of ChatGPT when the same clinical or examination questions are posed multiple times, even though item-by-item agreement is not always perfect. Importantly, this consistency was observed across both system environments (Windows and macOS), suggesting that the operating system did not have a discernible impact on the model’s clinical reasoning outputs. 32
According to the findings of the current study, both ChatGPT-4o and SLTs use common fundamental assessment tools-such as taking case histories, analyzing spontaneous speech, and auditory discrimination-when evaluating speech and language disorders. This finding aligns with the work of Birol et al, 21 which noted that ChatGPT-4.0 demonstrates high accuracy and appropriateness in report writing, clinical decision support, and creating assessment materials. It can be stated that ChatGPT versions and SLTs generally use similar diagnostic categories in the current study. Similarly, as noted in a review by Balo et al, 20 AI algorithms show promise for diagnostic classification across many areas, from swallowing disorders to voice disorders. The results of another study also provide a foundation for advancing AI supported diagnostic tools adapted to varied linguistic environments, thereby strengthening early intervention approaches within pediatric speech pathology. 33
On the other hand, in this study it is observed that SLTs adopt a broader perspective when making a diagnosis, considering multiple diagnostic possibilities based on clinical experience, whereas AI tends to adhere more strictly to standard tests found in the literature. This tendency may be related to the nature of large language models, which are trained predominantly on large-scale, publicly available datasets, including a substantial proportion of English-language scientific literature. As a result, AI systems may prioritize widely established, standardized assessment frameworks over context-specific, culturally embedded clinical reasoning. This may also help explain why, despite the Turkish context of the cases, the model occasionally suggested non-Turkish assessment tools. This situation is consistent with the results of a systematic mapping study in which it is emphasized that while AI is successful in the screening, it cannot fully replace speech and language therapists in the diagnosis, where data must be interpreted to reach a final decision. 34 Correspondingly, the findings of another study showed that ChatGPT is an additional source to support patients to find suitable clinical services and make informed decisions. 35
Another study drew attention to a similar distinction, stating that while AI is successful in analyzing measurable data such as acoustic features, it remains more limited in multi-dimensional clinical assessment. 36 Consequently, the finding that SLTs in this study viewed cases from a wider perspective supports the conclusion that AI lacks the human flexibility required to interpret potentially complex clinical pictures. As in Dronkers et al 37 study, ChatGPT and Llama show restrictions in accurately suggesting the proper treatments for a complex disorder like bilateral vocal fold paralysis (BVFP).
The finding that both AI and SLTs place common importance on generalization studies in therapy and collaboration with the client’s caregiver is thought to stem from AI’s capacity to scan evidence-based information in the literature. However, the most distinct difference revealed in the current study is that while SLTs prefer individualized techniques, AI focuses more on technology-supported and structured techniques.38 -40
In another recent study it is noted that SLTs tend to use AI to reduce administrative burdens and produce materials such as personalized stories and visuals. 40 Nevertheless, the structured suggestions offered by AI cannot always meet cultural and individual needs. A recent study on this subject reported that ChatGPT experiences limitations in creating therapy materials (particularly those specific to culture and language) and can make erroneous suggestions involving phonological impossibilities in languages like Turkish. 21 In another study regarding stuttering, Saeedi and Bakhtiar 25 stated that even when AI responses are correct, they are sometimes overly complex and do not always fully align with clinical observation. The fact that SLTs in this study used a wider range of flexible, appropriate, and individualized (person-specific) techniques while AI lagged in this regard may be attributed to AI’s limited contextual adaptation. This is reflected in the data, where SLTs incorporated context-sensitive practices such as collaboration with teachers and caregivers and tailoring therapy based on individual needs, whereas ChatGPT predominantly suggested more structured and technique-driven activities, such as sound manipulation and auditory listening tasks. These differences highlight the model’s tendency to rely on standardized approaches rather than adapting to the specific clinical and environmental context of the client.
The finding in this study that SLTs adopt individual assessment methods based on clinical observation and experience, while AI suggests standard tests, supports the warning by Green 19 that computer algorithms should not be confused with clinical observation. While AI is quite successful at processing big data to reveal patterns, it faces challenges regarding transparency and clinical trust. 22 Furthermore, as stated in the study by Azevedo et al 3 on aphasia rehabilitation, AI currently provides support mostly in classification and diagnosis. Rather than acting as a tool to replace therapeutic interaction, it assumes the role of an assistant that saves time for the therapist. Despite a positive outlook and belief that AI tools are supportive for clinical practice, Austin et al 41 indicate that ChatGPT and other AI tools are rarely used by SLTs and students for clinical goals, generally limited to administrative activities.
Montazeri et al 16 also drew attention to AI’s lack of emotional intelligence and empathy, emphasizing that the bond established with the patient and the ability to understand the patient’s emotional state cannot be easily mimicked AI. Consistent with this perspective, our findings suggest that AI’s reliance on standard and structured methods limits its ability to integrate extra-data variables-such as the case’s immediate psychosocial state, motivation, and environmental factors-into clinical observation. This limitation may partly explain why AI systems struggle to capture the nuanced, context-dependent, and emotionally informed aspects of clinical decision-making. Even though the cases provided to both AI and SLTs were in Turkish, ChatGPT’s suggestions of non-Turkish assessment tools (eg, GFTA-3, PLS-5, EOWPVT etc.) raise concerns regarding its reliability. This may be related to the nature of its training data, which predominantly consists of large-scale, publicly available datasets with a strong representation of English-language research literature. As a result, the model may prioritize widely recognized international assessment tools over context-specific or locally validated instruments.
Limitation
This study has several limitations. First, the sample consisted of a limited number of SLTs from a single country, which may restrict the generalizability of the findings. Second, the comparison between human clinicians and AI was based on written responses to brief case vignettes involving only 3 cases; real-world, longitudinal assessment and therapy processes were not observed. Third, only a single general-purpose large language model (ChatGPT-4o, accessed in 2025) was evaluated, so the results cannot be generalized to other AI tools or future model versions. Fourth, the clinical vignettes and interview guide used for data collection were researcher-developed rather than formally validated standardized instruments. While these tools underwent a pilot-testing phase with independent experts to ensure clinical realism and content validity, this may still limit the psychometric consistency of the findings. Finally, the consistency and appropriateness of the responses were examined mainly through qualitative analysis; it is recommended that future studies complement this approach with quantitative indicators of reliability and clinical impact.
Conclusions
In conclusion, the findings of this study, consistent with current literature, reveal that ChatGPT and similar AI tools hold potential as strong clinical decision support systems in speech and language therapy. AI stands out as a time-saving tool, particularly in reporting, decision-making and standard assessment processes. However, it is evident that it cannot reach the competence of SLTs in the human, individualized, case-specific, and cultural aspects of therapy and assessment. It is believed that the most efficient clinical outcomes can be achieved when the structured and literature-based framework offered by AI is combined with the clinical experience and flexibility of SLTs. It is suggested that future studies focus on how AI can be transformed from a tool that merely suggests standard tests into a more inclusive model capable of understanding cultural and individual differences and constructing guidelines for its appropriate use. Additionally, it should be noted that current chatbots and large language models are general-purpose systems rather than tools specifically designed for speech and language therapy, which may partly explain their limitations in domain-specific clinical reasoning. Future developments in domain-adapted or specialized AI systems may help address these limitations.
Supplemental Material
sj-docx-1-inq-10.1177_00469580261445316 – Supplemental material for Artificial Intelligence in Speech and Language Therapy: A Qualitative Comparative Analysis of Clinical Applications and Outcomes
Supplemental material, sj-docx-1-inq-10.1177_00469580261445316 for Artificial Intelligence in Speech and Language Therapy: A Qualitative Comparative Analysis of Clinical Applications and Outcomes by İbrahim Can Yaşa, Muhsin Dölek, Seda Eyilikeder Tekin, Ayşe Serra Kaya, Pınar Akgün, Sakine Deniz Yılmaz and Selin Tokalak in INQUIRY: The Journal of Health Care Organization, Provision, and Financing
Supplemental Material
sj-docx-2-inq-10.1177_00469580261445316 – Supplemental material for Artificial Intelligence in Speech and Language Therapy: A Qualitative Comparative Analysis of Clinical Applications and Outcomes
Supplemental material, sj-docx-2-inq-10.1177_00469580261445316 for Artificial Intelligence in Speech and Language Therapy: A Qualitative Comparative Analysis of Clinical Applications and Outcomes by İbrahim Can Yaşa, Muhsin Dölek, Seda Eyilikeder Tekin, Ayşe Serra Kaya, Pınar Akgün, Sakine Deniz Yılmaz and Selin Tokalak in INQUIRY: The Journal of Health Care Organization, Provision, and Financing
Footnotes
Acknowledgements
We would like to thank all the therapists who agreed to participate in this study.
Ethical Considerations
The study was conducted in accordance with the Declaration of Helsinki and approved by the Bahçeşehir University Clinical Research Ethics Committee (Approval No: E-85646034-604.01-115398; Date: 06.11.2025).
Consent to Participate
Written informed consent was obtained from all participants involved in the study. The consent form, approved by the Bahçeşehir University Ethics Committee, outlined the study’s purpose, the voluntary nature of participation, and the confidentiality of data.
Author Contributions
Conceptualization I.C.Y. Methodology I.C.Y., M.D., S.E.T. Formal analysis M.D., S.E.T., A.S.K., P.A., S.D.Y., S.T. Investigation M.D., S.E.T., A.S.K., P.A., S.D.Y., S.T. Writing original draft M.D., S.E.T., A.S.K., P.A., S.D.Y., S.T. Writing review and editing I.C.Y. Supervision I.C.Y. Project administration I.C.Y. All authors approved the final version of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.