
Abstract
Merino lambs’ wool fiber has a unique chemical structure that gives the wool many unique properties and technical benefits. For example, the small fiber diameters mean that Merino wool is soft, countering the scratchiness commonly associated with wool. It is also biodegradable, organic, and environmentally friendly, making it a popular choice of sustainable fabric material. Unfortunately, some fiber sellers unduly sell coarse wool tops to wool yarn factories as Merino wool tops. It is, therefore, an important task to identify the actual wool type for quality assurance in the textile manufacturing process.
This paper describes applying the spectral-domain optical coherence tomography (OCT) imaging and automatic machine learning (AutoML) techniques for distinguishing Merino wool from coarse wool. We present the results of wool measurements that were performed by the OCT scans and AutoML algorithms. We conclude that OCT imaging and AutoML algorithms can be applied to distinguish Merino wool from coarse wool in a simple, non-destructive, and contactless manner.
Keywords
Merino wool consists of fine fiber structures, giving it unique properties and benefits. The protein structure makes the fibers interlock, making the Merino wool strong and elastic. Air pockets trapped among the fiber structures increase resistance against cold weather, rendering Merino wool an excellent insulator. 1 Because the fibers are finer than any other sheep fibers, the wool has a soft and pleasant nature. 2 Merino wool does not have the itchiness associated with traditional wool and therefore does not irritate the skin. Moreover, recent studies have shown that wearing superfine Merino wool next to the skin benefits patients who suffer from a chronic skin conditions such as eczema and dermatitis.3,4 The wool also possesses anti-odor and antibacterial properties thanks to the natural lanolin in the sheep's wool that repels bacteria. 5 The cuticle of the Merino wool fiber has hydrophobic water-repelling proneness, whereas the fiber’s interior is hydrophilic. This enables the wool to absorb and evaporate moisture, giving Merino wool excellent breathability and making it an ideal and comfortable base layer for outdoor activities. 6 Merino wool has anti-static traits thanks to its neutral charge and ability to absorb up to 35% of its weight in water vapor, preventing static charge from building up. 7 Merino wool attracts, therefore, much less dust and lint.
Compared to cotton wool, Merino wool has a much higher ignition temperature thanks to the high moisture and nitrogen content, making it an excellent flame-retardant material. Wool's inherent chemical structure makes it naturally flame resistant. Merino wool does not ignite until the temperature reaches 580–600°C, making it an ideal choice of material for fire hazards and risks. 8 Due to such traits, NASA uses Merino wool widely and even uses it for making sweaters for its astronauts. 9
The vast application areas arise from the next-to-skin softness, strength, innate versatility, and technical benefits of Merino wool. This has made Merino wool a luxurious and popular choice of fiber and has driven demand worldwide, increasing the price of Merino wool compared to other wool types. 10 Also, because the Merino sheep breed produces a new fleece every year, Merino wool becomes a renewable fiber source, which is attractive for the sustainable textile industry. 11
Unfortunately, some fiber sellers unduly sell coarse wool tops to wool yarn factories as Merino wool tops for financial gain. It is, therefore, crucial to distinguish genuine Merino wool within the textile manufacturing industry. Moreover, it is essential to determine the wool content when dying fabrics, as most dyes are specific to certain fiber types. 12
The traditional burning test performed to distinguish genuine wool fails with Merino wool since all wools, cashmere, Merino, and silk have a similar smell and chemical decomposition. In the test, they all smell like burning feathers, with a sharp hint of burning sulfur. The disadvantage of this method is that it cannot be automated.
In order to solve this conundrum, recently a variety of different studies have been performed by researchers all around the world to determine a method to detect counterfeit Merino wool efficiently and effectively.
There are different approaches reported by scientists that enable distinguishing Merino wool. These methods' main objective is to examine fiber strands individually and microscopically to distinguish Merino wool from coarse wool. 13
For example, Molloy and Naftaly 14 utilized terahertz spectroscopy performed between 0.2 and 3 THz to test various woven and knitted fabrics containing yarns of different animal origins. The received signal that lay within the terahertz spectrum carried information on the wool's animal origin, giving a possibility to distinguish wool type.
Similarly, near-infrared spectroscopy was another alternative method reported in identifying textiles. 15 Yan and Siesler 16 measured the diffuse reflection spectra of various textile samples of synthetic and natural origin. The research project concluded that test samples could readily be authenticated for uncomplicated cases by solely near-infrared spectra visual inspection; for more comprehensive identification of unknown samples, principal component analysis combined with soft independent modeling of class analogies was applied. Very recently, Notayi et al. 17 reported on the analysis of wool fiber bundles using a Fourier transform (FT) Raman system, equipped with an Nd:YAG excitation laser (1064 nm), to determine whether such a system can be used to distinguish Merino wool. They showed that even in cases where the Raman spectra are similar, the heights of the spectra contain information about certain chemical bands, which can facilitate wool-type identification. Some of these microscopic-based systems were also integrated into the automatic identification of wool fiber types by using network models. 18 Sharma et al. 19 introduced a mechanism that utilized tailored machine learning (ML) algorithms on microscopic images of physical objects to distinguish between genuine and counterfeit versions of the same textile product.
Optical coherence tomography (OCT), on the other hand, as a relatively contemporary imaging technique, takes advantage of the short coherence length of broadband light sources to perform a micrometer-scale, cross-sectional scan of the material sample.20,21 OCT can penetrate into tissues with a highly light-scattering soft texture since it uses optical sources at longer wavelengths. 22 Moreover, OCT has numerous other advantages that make it sought by researchers. OCT has demonstrated the ability to produce high-quality images within the range of 1–10 µm axial resolution usually and even sub-micrometer (0.5 µm) resolution too. 23 The scanning speed of the OCT system can allow it reach temporal resolutions up to milliseconds. 24 OCT does not require injecting any contrast agents into the material, making it a label-free imaging method.25,26 OCT is a low-cost alternative to most other imaging techniques, making it an attractive choice for researchers and the industry in developing countries. OCT possesses extra functionality enabling it to take depth-resolved structural images of the target. 23 Moreover, since OCT is a nonionizing imaging method, it is becoming used more frequently in sensitive areas such as medical and dental applications.27–29 Compared to other high-resolution optical imaging methods, such as confocal microscopy, OCT has the advantage of decoupling axial and lateral resolutions. This allows the imaging optics to be located away from the sample without being detrimental to the axial resolution. 30 Due to these traits, OCT has become an essential method in non-destructive testing and evaluation and is being applied in many different industries. 31 OCT has been analyzed thoroughly and compared to other methods, and it has been concluded that OCT is now considered an affordable, reliable, and versatile non-destructive testing system. 32
In this article, OCT images of different wool types were fed into an automated machine learning (AutoML) algorithm to investigate whether the Merino wool type could be distinguished or not. We emphasize that AutoML is suitable to apply to real-world problems because it automates the many separate tasks involved in ML. AutoML starts with the raw OCT image dataset to generate a machine learning model ready for potential deployment. AutoML was first proposed as an artificial intelligence-based solution to the increasing challenge of applying ML. In a standard ML application, specialists have a dedicated set of input data that is allocated for training. Of course, the raw data may not be in the desired condition that all algorithms can be applied to. In this situation, the expert may have to apply appropriate data pre-processing, feature engineering, feature extraction, and feature selection methods to make the data suitable for ML execution. Then comes the crucial step, where algorithm selection and hyperparameter optimization are performed to maximize the model's predictive performance. Each of these steps may be challenging, resulting in significant obstacles to using ML. AutoML is an application that smooths all of these steps and increases the efficiency of ML.33,34 In summary, AutoML tools get rid of the need to manually search for neural architectures and optimize hyperparameters, which can significantly reduce development effort and allow developers to focus on harder-to-automate tasks, such as data curation. 35
Today, AutoML algorithms enable researchers to find the right neural network automatically without requiring manual experimentation. In order to achieve this goal, techniques such as the neural architecture search (NAS), use algorithms such as reinforcement learning (RL), evolutionary algorithms, and the combinatorial search are used to build a neural network out of a given search space. The automated techniques have, in many demonstrations, outperformed their manually designed counterparts. 35 These algorithms demand much computational power, requiring thousands of models to train before converging. In addition, they explore domain-specific search spaces and include considerable previous human knowledge that does not transfer well across domains. Model Search is an open-source platform that helps researchers develop the best ML models efficiently and automatically allowing them to extend access to AutoML solutions to the broader scientific community. Built on TensorFlow (TF), Model Search discovers the appropriate architecture that best matches a given dataset and problem while diminishing coding time, effort, and compute resources. It is computationally flexible and can run either on a single machine or in a distributed setting. 36
The main limitations of AutoML arise from its trial-and-error nature. Since the AutoML system tries nearly every model available to come up with the optimal algorithm, it can require tremendous computational power. In some cases, the precision of the output may need to be improved. The most traditional criticism of AutoML has been the lack of model explainability, making AutoML known as a “black box.” The AutoML algorithm was applied in a computer vision task in our case. To address model explainability and transparency, we applied an AutoML platform from which the final created TF model can be downloaded and implemented by anyone. The trend in the usage of AutoML algorithms is on the rise, which indicates that the advantages outweigh the limitations. 37
AutoML is being used in engineering and scientific research and has followed a growing commercial and academic trend. Analyzing the development timeline, one can observe that Google Cloud AutoML was introduced exactly when the rising trend in AutoML became clear. Also, from recent research, it has been found that some tasks are more suitable for implementation in AutoML. Since image classification is the most mature field in image-based deep learning, all AutoML platforms support this task. Many investigations show that AutoML algorithms provide comparable results to state-of-the-art ML algorithms. Recently, an AutoML model was utilized in a medical application for characterizing benign or malignant breast lesions. 38 The study found that AutoML Vision showed high accuracy comparable to the current commonly used state-of-the-art classifiers. The conclusion of such research works indicates that AutoML will find more future applications in clinical practice. Moreover, since image classification tasks can be applied to various fields, we utilize it in textiles.
In this study, we use the advantages mentioned above of both OCT and AutoML and report a new method to identify wool type non-destructively. We apply spectral-domain OCT and AutoML to identify wool types and distinguish Merino wool from coarse wool. OCT imaging employs a low-coherence infrared light source that facilitates high-resolution photonic tomographic scans of the tested wool samples, making the fine fiber structures visible. The technique functions in a noncontact and non-destructive aspect. OCT imaging traits have enabled it to be successfully applied to various applications encountered in various research projects. OCT is highly suitable for non-destructive inspection systems since it allows for taking sensitive and high-resolution scans and can be integrated into inline-online streaming. The OCT imaging resolution is high enough to detect individual Merino wool fibers that typically lie between 11.5 and 24 µm.
Initially introduced in the medical profession for use in ophthalmology, OCT has quickly expanded its application areas.39,40 OCT has, for example, also been applied in textiles for examining the internal and (near-) surface structure of different types of polymers and composites subjected to different treatments and effects.41–46 The high image scanning rate of OCT enables it to be integrated in automated online streaming systems. Later, the recognition of weave patterns of fabrics automatically in the textile industry was reported.47–49 Very recently, OCT was used successfully to classify different material types automatically. 50
Because of the micrometer resolution images they provide, OCT scans can be used to precisely measure distances and fabric thicknesses and estimate gap widths.51,52
On the other hand, ML and AutoML algorithms have also been used in the textile industry: Wan et al. 53 introduced an automated identification system for fiber cross-sectional shapes using a nonlinear support vision machine, a typical ML method. Ribeiro et al. 54 compared three input feature representation strategies related to fabric design and finishing processes. For this purpose, they used data from a textile company to execute two CRoss-Industry Standard Process for Data Mining (CRISP-DM) iterations. They used an AutoML procedure to select the best regression model during the modeling stage of CRISP-DM. In another study, Ribeiro et al. 55 used data mining (DM) technology and the CRISP-DM methodology to model the textile testing process. They adopted AutoML during the modeling stage of CRISP-DM.
Therefore, in this project, we combined the unique traits of both OCT and AutoML and applied them to the textile industry. We use micrometer resolution OCT, which employs an infrared light beam to obtain photonic depth scans and AutoML in generating image classifiers that facilitate the task of distinguishing Merino wool.
Our research project involved creating an image dataset by scanning an invisible infrared light beam over the surfaces of wool samples to classify their type.
Experimental details
In this study, we present an automated Merino wool inspection system designed to enhance the efficiency and accuracy of wool quality assessment. Figure 1 illustrates a flowchart comparing the traditional manual inspection process with the proposed automated system. The latter employs OCT technology for acquiring high-resolution images of wool samples, which subsequently undergo analysis by the AutoML algorithms.
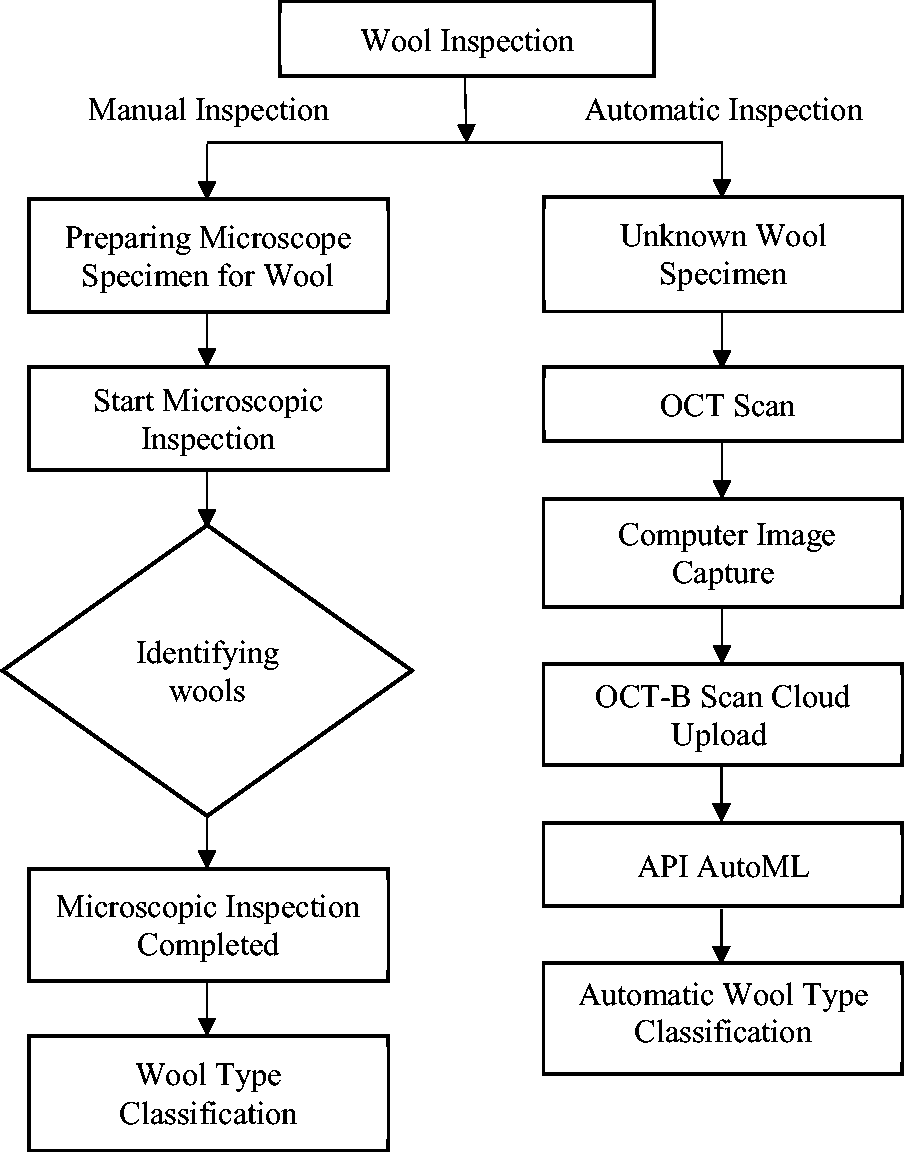
Comparative flowchart depicting the processes involved in manual and automatic fabric inspection methods for wool-type recognition. OCT: optical coherence tomography; API: application programming interface; AutoML: automatic machine learning.
Optical coherence tomography of various wool types
We investigate four different samples of scoured wool types by OCT: Merino top, mixed (blended) coarse wool, card slivers from coarse wool, and medium thickness scoured slivers. A low-coherence infrared light source centered at 0.93 µm is used to perform the OCT scans of the wool samples. The spectral width of the light source reduces the speckle noise in the setup, enabling a high-resolution tomographic image.56,57 The measurement setup is shown in Figure 2. The wool samples to be measured are placed in the sample arm consecutively.
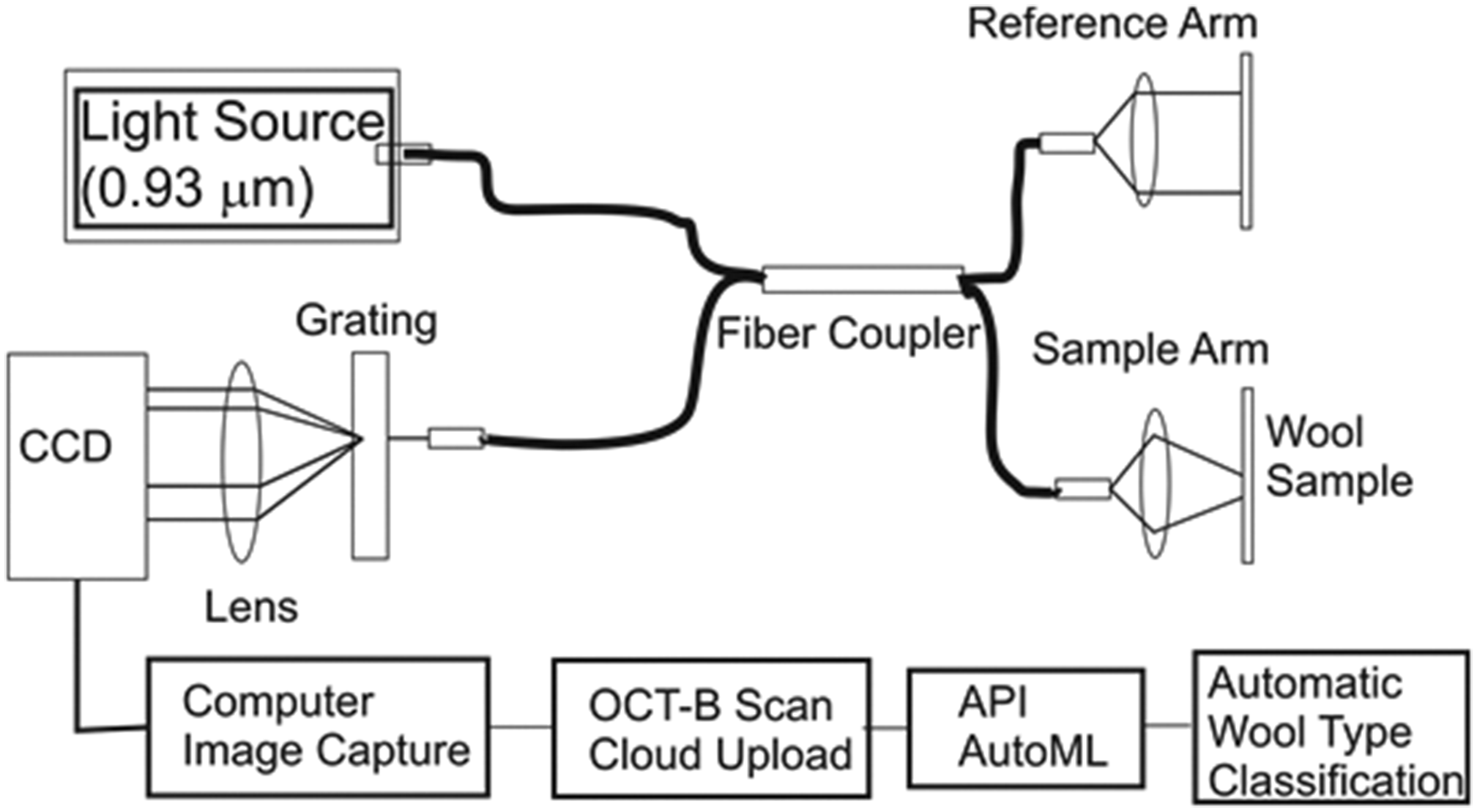
The experimental setup corresponding to wool identification via optical coherence tomography (OCT). CCD: charge-coupled device; API: application programming interface; AutoML: automatic machine learning.
The individual wool fiber structures reflect the arriving photons off their air–fiber interface. This reflected optical signal then interferes with the beam from the fiber coupler's reference arm. The optical grating immediately splits the various frequency components to allow spectral-domain OCT. The one-dimensional OCT-A scan of the sample wool bundle is retrieved by performing a mathematical Fourier transformation onto the signal collected with a charge-coupled device (CCD) camera by a lens. These OCT-A scans are combined in succession, resulting in the two-dimensional OCT-B images. Every OCT image corresponds to the OCT-B scans of the wool fiber samples. Before the OCT scanning procedure begins, the different samples are separated and stored in their respective categories. Each wool sample was placed onto the sample arm and scanned by the OCT system separately. An OCT-B scan for each wool sample category is included in Figure 2.
For a successful classification, the automated separation algorithm requires at least a certain number of images per category. If the model is advanced, at least 50 images are needed per label. In order to have a more accurate model, we took at least 125 OCT images per sample. These images were taken with the same settings in the same environment to facilitate a standard categorization task, as demonstrated very recently. Every OCT-B image had an equal scan length of exactly 2 mm, and each image was recorded in portable network graphics (PNG) format to have consistent data across the wool samples.50,58 The OCT image of the wool sample in PNG format is saved using a commercial image capture software program since the PNG format is supported when requesting a prediction from the online model. Before the online upload, no further image processing or filtering was performed on the image files. The spectral-domain OCT images corresponding to Merino top, mixed (blended) coarse wool, a card sliver from coarse wool, and a medium thickness scoured sliver are given in Figure 3.
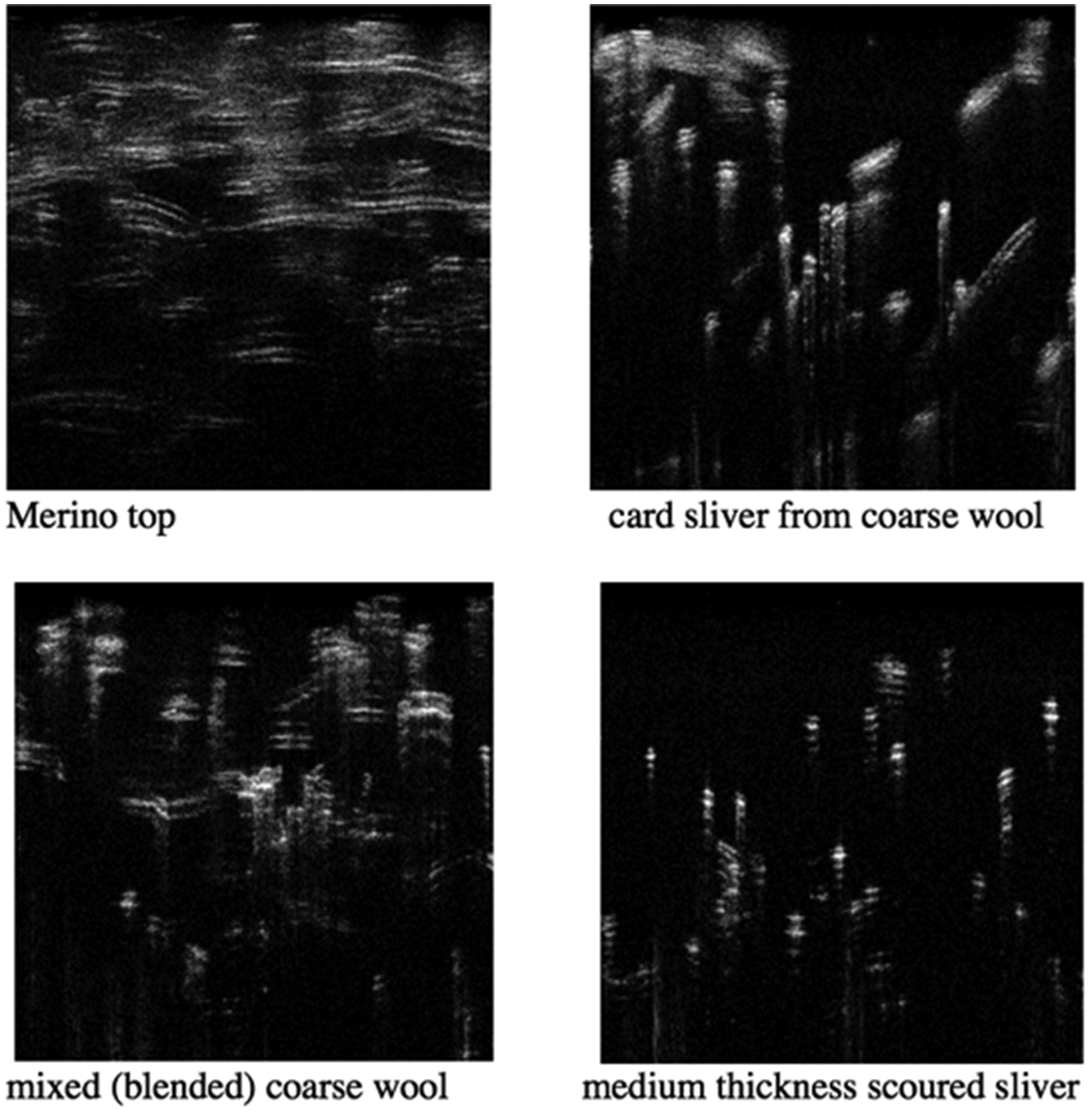
Optical coherence tomography scans of the different wool types.
Machine learning methodology
The methodology for machine vision and ML consists of a systematic approach to designing, implementing, and evaluating algorithms and systems capable of autonomously extracting meaningful information from visual data. This process typically encompasses the following steps.
59
Data acquisition: acquiring relevant data for training and testing the ML model, such as the OCT wool image data in this study. Data pre-processing: cleaning and preparing the collected data for analysis, which includes tasks such as noise removal, image resolution adjustment, and data normalization. Feature extraction: identifying relevant characteristics or patterns in the visual data that can distinguish between different classes of objects or scenes. This may involve using hand-crafted features, such as edge detection or texture analysis, or automatically learning features via deep learning algorithms. ML model selection: choosing an appropriate ML model capable of accurately classifying or detecting the objects or scenes of interest. This may entail selecting between supervised or unsupervised learning algorithms, specific model architectures, and optimizing model hyperparameters. In our work, we employed an automated approach using the AutoML Vision platform. Training and validation: training the selected model using pre-processed data, while allocating a portion of the data for validation to avoid overfitting and ensure generalization to new data. Evaluation: assessing the trained model's performance in classifying wool types using metrics such as accuracy, precision, recall, and F1 score. Deployment: implementing the model in real-world applications, which may include integration into larger software systems, performance optimization for specific hardware platforms, and performance monitoring over time to ensure continued accuracy.
In summary, the methodology for machine vision and ML comprises data acquisition, pre-processing, feature extraction, ML model selection, training, and validation, evaluation, and deployment. The aim is to develop accurate and reliable systems for extracting information from visual data. Steps 2–7 were performed automatically using the AutoML Vision platform. 60
Processing of OCT images of wool with AutoML
The collected OCT image data is split into a training dataset, a validation dataset, and a test dataset to build the AutoML model. In our work, we utilized AutoML Vision, which recently was proven capable of generating image classifiers whose performance is on par with the literature results.
AutoML Vision uses techniques such as Bayesian optimization and the NAS to automatically optimize hyperparameters and architectures. Bayesian optimization is a probabilistic method that uses a model to predict the performance of different hyperparameters and selects the best-performing ones for further evaluation. It iteratively updates the model based on the results of previous evaluations and selects hyperparameters to evaluate based on their expected performance. Google AutoML Vision uses the NAS to automatically discover the best neural network architecture for a given computer vision task. The NAS process in Google AutoML Vision involves the following steps.
Search space definition: the first step is to define the search space of possible neural network architectures. The search space in Google AutoML Vision includes a wide range of convolutional neural network (CNN) architectures, including variants of ResNet, MobileNet, and EfficientNet. Search algorithm: Google AutoML Vision uses a combination of RL and evolutionary algorithms to efficiently explore the search space and identify promising neural architectures. The search algorithm generates a set of child models by mutating or combining existing models, evaluates their performance on a validation set, and uses the results to update its policy for generating new models. Performance estimation: the search algorithm estimates the performance of each child model using a metric such as accuracy or F1 score. The models are trained and evaluated on a subset of the training data, to avoid overfitting. Architecture selection: the search algorithm selects the most promising child models based on their performance estimates, and generates new child models by mutating or combining the selected ones. Repeat steps 3 and 4: the process of architecture selection and evaluation is repeated for a fixed number of iterations or until a satisfactory architecture is found. Once the best architecture is found, Google AutoML Vision automatically trains and optimizes the selected model, and provides a representational state transfer (REST) application programming interface (API) for users to deploy the model for inference.
The advantage of using the NAS in Google AutoML Vision is that it can automatically discover novel and efficient neural network architectures that may not have been discovered by human experts. By automating the architecture design process, Google AutoML Vision can save time and resources, and enable faster development and deployment of accurate computer vision models. 60
Within the given framework, the previously introduced Model Search system consists of multiple trainers, a search algorithm, a transfer learning algorithm, and a database to store the various evaluated models. Once the data is fed into the automated cloud-based system, it runs both training and evaluation experiments for various ML models (different architectures and training techniques) in an adaptive yet asynchronous manner. Even though each trainer conducts experiments independently, the knowledge gained from their experiments is shared among all trainers. Before every cycle, the search algorithm looks up all the completed trials and uses a beam search to decide what to try next. The next step is to invoke a mutation over one of the best architectures found thus far and assign the resulting model back to a trainer. Figure 4 depicts the distributed search and ensembling functions in Model Search, where S is the set of training, and validation examples and A represents all the candidates used during training and searching. 36
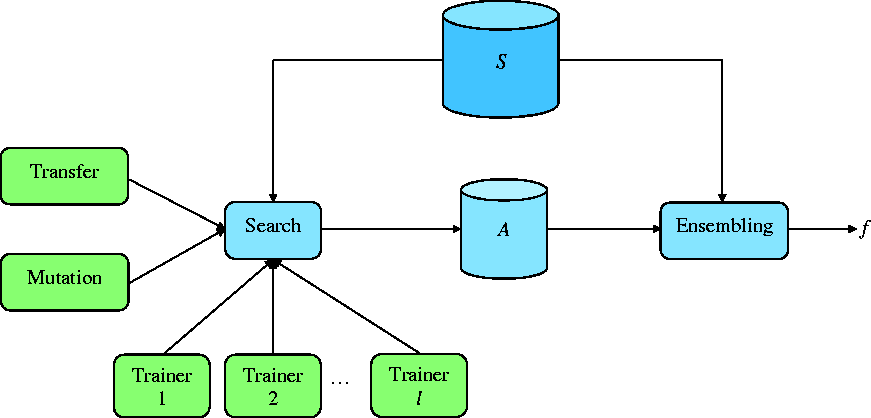
Model search schematic. 36
Model design and model convergences are time- and resource-intensive problems. AutoML’s model search system uses a two-phased approach similar to the “exploration versus exploitation” tradeoff in RL. In the exploration phase, a broad range of possibilities is tested through the search algorithm to find an optimal DotNetNuke (DNN) architecture. This algorithm produces several candidate architectures and then creates arbitrary tweaks on them by adding blocks or setting parameters to random values. Using the parameter-sharing technique, the system then transfers knowledge to these new candidates from the previously trained candidates. Finally, the candidate models will be trained and evaluated, and then the top-scoring models will be the seed for the next exploration phase. In the exploitation phase, the model search technique uses an ensemble strategy. The candidate model will be copied several times, and each copy is trained at the beginning with a random shuffling of the training data and a different set of initial parameters. The weighted average of the outputs of these copies is used to create a final result during inference. This method results in higher model accuracy with fewer parameters. In addition, the training of the models becomes faster. 61
The AutoML model is created in TF. TF is a specialized, open-source numerical computation library for deep learning. Many researchers, engineers, and industry practitioners use TF to develop their deep learning algorithms. The TF platform is suitable for converting deep learning models into products. Keras, for example, facilitates through programming languages a high-level specification for developing deep neural network models and architectures. The Keras platform is an API and was previously separate from TF and only provided an interface or model building with TF as one of the frameworks running at the backend. 60
The AutoML we utilized in our Merino wool identification task was also accessed through an API. Moreover, the created deep learning model can be downloaded as a TF model. Any scientist can access this file, modify it, analyze, and use it for their classification tasks. Within this framework, a system called the Estimator API with high-level TF functionality is used, reducing the complexity involved in building ML models by exposing methods that abstract common models and processes. The Estimator class exposes four major methods, namely, the fit(), evaluate(), predict(), and export-saved model() methods. The fit() method is called to train the data by running a loop of training operations. The evaluate() method is called to evaluate the model performance by looping through a set of evaluation operations. The predict() method uses the trained model to make predictions, while the export-saved model() method exports the trained model to a specified directory. More detailed information regarding the theory is given in the literature. 60
Google Cloud AutoML system
The AutoML framework used in this manuscript is Google Cloud AutoML which was introduced in 2018. Google Cloud AutoML provides a unified API, client library, and user interface all in one place and has quickly become a leading ML cloud provider. Many computing languages, such as Go, Java, Node.js, and Python, form the API libraries and are chosen with respect to the desired AutoML services. The complete ML pipeline, from the initial phase of importing data to the final stage of evaluating the model’s performances through the metrics and exporting the deployment model, is accomplished by a graphical user interface (GUI). 37
Regarding computational units, parallel/distributed central processing unit (CPU), graphics processing unit (GPU), and tensor processing unit (TPU) computations are all supported, and more computational units are available upon request. Depending on the data analysis, multiple AutoML services are available in Google Cloud AutoML, such as AutoML Tables, AutoML Video Intelligence AutoML Vision, and AutoMl Natural Language. Since our task involved OCT images taken from various wool samples, we utilized AutoML Vision. Available tasks include classification, regression, object detection, object tracking, and action recognition. The costs of services are calculated by taking into account several criteria—for example, machine type, computational unit(s), usage time (per node hour), data type (image, video, text, or tabular), task (classification, object detection, action recognition, etc.), usage mode (training or prediction), etc. An extra fee is also added if the model is further optimized into a suitable format for deployment on an edge device. 37
AutoML Vision
For the modeling in AutoML Vision, the steps are straightforward, as Google provides instructions and a user-friendly interface. The OCT images corresponding to various wool samples were zipped together and uploaded to a Google Cloud Platform. AutoML Vision can recognize the label for each image. The OCT images were separated into training, validation, and test datasets (80%, 10%, and 10%, respectively) automatically by Google Cloud.
60
The training computation for this model is set to 16 node hours. The model type was set to “Cloud.” AutoML Vision provides an accessible and versatile tool when dealing with image classification tasks; hence, we choose it as an AutoML algorithm. There are many other platforms, such as Google AutoML Vision, IBM Watson AutoAL, Microsoft Azure Automated ML, and Amazon SageMaker, all of which are cloud-based ML platforms that provide AutoML services. Here is a comparison of the four platforms.
Google Auto ML Vision: this service allows users to create custom ML models for image recognition tasks. It uses transfer learning to create models based on pre-trained models. Users can upload their own labeled images to train models, and AutoML Vision will automatically perform tasks such as feature engineering, hyperparameter tuning, and model selection. IBM Watson Auto ML: this service provides automated model building for a range of tasks, including text classification, object detection, and time-series forecasting. It uses an ensemble of algorithms to create models and provides explanations for the models it produces. Microsoft Azure Automated ML: this service automates the selection of the best algorithm and hyperparameters for a given ML task. Users can select from a range of ML algorithms and tune them using a variety of hyperparameters. It supports both supervised and unsupervised learning. Amazon Sage Maker: this service provides a range of automated ML capabilities, including model training, tuning, and deployment. It also supports automatic model creation using built-in algorithms or custom algorithms. It also supports popular frameworks like TF, PyTorch, and MXNet.
In summary, all of these platforms offer AutoML capabilities, but they differ in terms of the specific ML tasks they support, the algorithms and frameworks they use, and the level of customization they offer. Users should choose a platform based on their specific needs and the type of ML task they want to automate. 60
We uploaded the OCT scan data onto the cloud server of the AutoML Vision system. In the AutoML algorithm, concurrently, the validation and a test dataset are created. During the validation stage, optimal model parameters are used, resulting in wrong metrics. This insures the model is impartial. The training dataset builds and optimizes the online automated Merino wool identification model. The model uses a trial-and-error approach by testing multiple algorithms and parameters while searching for patterns in the training data. Once the model picks out patterns, it then uses the validation dataset to test the algorithms and patterns. The best-performing algorithms and patterns are selected from those recognized during the training stage. In order to quantify the performance, the optimized algorithms and patterns are then tested for error rate, quality, and accuracy using the test dataset.
Results and discussion
The high-resolution capability of OCT enables the imaging of individual wool fibers. The automatic Merino wool-type identification process is given in Figure 1 and starts with the OCT image capture. The raw OCT scans corresponding to various wool fiber samples are included in Figure 2. Note that Merino wool collected from Merino sheep's coats is of high caliber and consists of extra-fine wool between 11.5 and 24 µm in diameter.
An online API is then used to upload the data. This program is linked to an online AutoML algorithm that uses transfer learning to train and create a network model that automatically classifies the wool type. A similar strategy employed recently successfully automatically recognized various material types. 50
Wan et al. 38 compared the performance of different ML algorithms for the classification of breast lesions in ultrasound images. The study evaluated the performance of three different approaches: traditional ML algorithms, CNNs, and AutoML Vision, which is a tool that automates the selection and optimization of ML algorithms. The researchers used a dataset of ultrasound images of breast lesions and evaluated the performance of each approach in terms of accuracy, precision, recall, and F1 score. The results showed that the CNN approach achieved the highest accuracy, precision, and F1 score, followed by the AutoML Vision approach. Traditional ML algorithms achieved the lowest performance. The study highlights the potential of deep learning approaches, such as CNNs, for the classification of breast lesions in ultrasound images. It also suggests that tools like AutoML Vision can help automate the process of selecting and optimizing ML algorithms, potentially saving time and improving performance.
More information on the details of the operation principles of the AutoML algorithm can be found in the recent scientific literature. In order to achieve the detection of Merino wool and classify it into the respective category, the online program automatically matches the generic neural network architecture to a given imaging dataset. The algorithm is optimized by finely adjusting specific parameters, which results in optimized network performance. The system saves a number of the labelled OCT-B scans for the separate tasks of training and validating the deep learning architecture. The whole process runs entirely on the cloud server and operates by RL and a recurrent neural network (RNN) that defines the hyperparameters for a model. Firstly, the RNN establishes a random set of hyperparameter specifications, such as the layer count, receptive fields, and nodes per layer. 62 The optimization of the specifications is achieved by a feedback loop, closely monitoring the model accuracy and feeding this signal into the RL algorithm as either reward or punishment to update the necessary RNN parameters. This procedure, which consecutively rewards models with high accuracy and punishes those with less accuracy, enables the AutoML algorithm to mitigate towards higher accuracy in its classification task. Google AutoML Vision provides built-in hyperparameter tuning functionality that uses a technique called AutoML to automatically optimize hyperparameters. AutoML is a ML technique that uses algorithms to search the hyperparameter space and find the best combination of hyperparameters for a given ML model. AutoML Vision's hyperparameter tuning functionality uses a combination of random search and Bayesian optimization to efficiently search the hyperparameter space. Random search involves randomly selecting hyperparameters within a given range, while Bayesian optimization uses a probabilistic model to intelligently search the hyperparameter space based on past results. The user specifies the hyperparameters to tune, along with their range of values, and AutoML Vision automatically runs multiple training jobs with different hyperparameter configurations. It then evaluates the resulting models and selects the best hyperparameters based on a chosen evaluation metric, such as accuracy or mean squared error. AutoML Vision also provides a feature called “early stopping,” which stops the training process early if the model's performance on the validation set does not improve after a certain number of iterations. This helps to avoid wasting computation resources on hyperparameters that are unlikely to improve the model's performance. Overall, AutoML Vision's built-in hyperparameter tuning functionality helps to simplify the process of optimizing hyperparameters, allowing users to more efficiently build high-performing ML models. More detail on the theoretical details of automated online algorithms works can be found in Bisong. 60
The main objective is to quantify the wool-type detection by the algorithm objectively. We fed additional OCT-B images from wool fibers into the AutoML algorithm and analyzed the outcome comparatively. This experiment is performed with dedicated OCT-B test scans. In the actual experiment, there were 589 OCT-B scans, out of which 59 images were separated by the algorithm randomly and used for the test runs, from which the recall, precision, and confusion matrixes are calculated. The computation was performed in 16 node hours via the Vision AutoML API program, from which the trained models and the analysis results can all be accessed on the cloud server.
The final AutoML algorithm provides an aggregate set of the evaluation metrics for wool categorization. This is a direct indicator of the overall performance of the model. The generated model’s main task was to categorize wool fiber types from the corresponding OCT scans. The separation labels correspond to Merino top, mixed (blended) coarse wool, card slivers from coarse wool, and medium thickness scoured slivers, as described earlier in the Experimental details section. The model and the results can be viewed on the cloud server; for this, one has to select the project file corresponding to the wool-type recognition task from the drop-down list in the upper right of the title bar.
Once the model training has been completed, the results are provided in specific quantification evaluation metric categories. The AutoML algorithm uses precision, recall, and the confusion matrix to quantify the success of wool categorization. The area under the precision/recall curve is calculated to be 94.6%, as shown in Figure 5. This indicates an almost ideal average precision value. The precision and recall were 88.68% and 79.66%, respectively, meaning that there were some false interpretations in the test run. The user interface lets one scrutinize specific examples of model performance that resulted in true positive (TP), false negative (FN), and false positive (FP) instances from the sub-datasets.
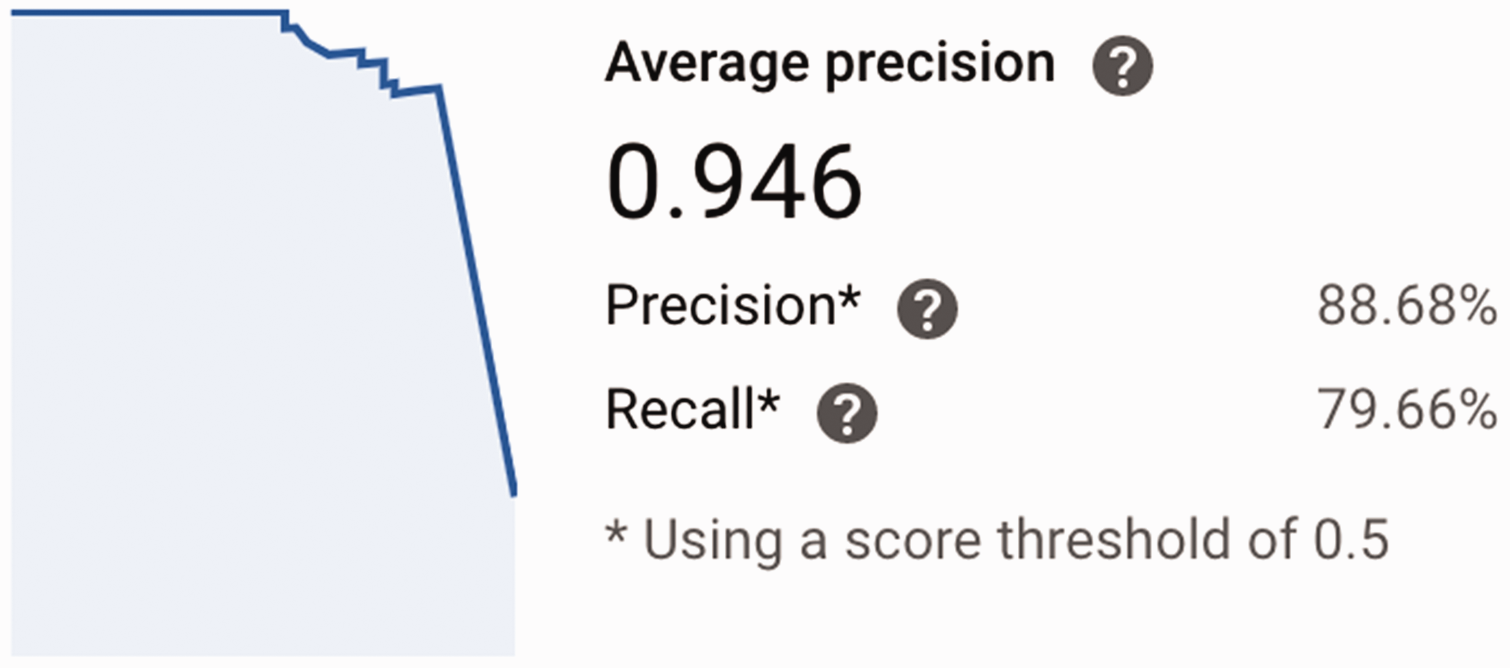
Output of the actual cloud-based model, corresponding to 589 optical coherence tomography images and 16 node hours of computation. The average precision is calculated as 0.946.
One can access these results by choosing the evaluate tab and the specific label via the user interface. Figure 5 includes a screenshot of the output of the analysis of the results. If one decides that the prediction results are lower than a certain success ratio acceptable for that desired application, the training set can be modified to improve the model performance further. Alternatively, one can also allocate more computational power by increasing the node hours. This extra procedure would increase the accuracy of the model at a given added cost. Please note that the current cost for AutoML Vision Image Classification model training is US$3.15 per node hour. We started our model with four node hours and gradually went up to 16 node hours until we were satisfied that the model could distinguish Merino wool with a certain success ratio. At 16 node hours, the average precision value approached 0.95. The generated TF model is accessible through the AutoML Vision API and can be downloaded from the server.
The confusion matrix of the model is given in Table 1. The matrix presents results for each separate label corresponding to Merino top, mixed (blended) coarse wool, card slivers from coarse wool, and medium thickness scoured slivers. The off-diagonal elements are small compared to the diagonal elements. This means that the model correctly predicts the sample category of the tested wool sample for most of the cases during the evaluation for all types. This confusion matrix indicates that the desired categories are all being identified with high success.
The confusion matrix of the model

Based on these results, we conclude that in most cases, Merino wool can be determined correctly by spectral-domain OCT.
Conclusions
Merino wool is a versatile and popular wool type thanks to the wool fiber’s unique properties and technical benefits. For example, the small fiber diameters mean that Merino wool is soft, countering the scratchiness commonly associated with wool. It is also biodegradable, organic, and environmentally friendly, making it a popular choice of sustainable fabric material. Unfortunately, some fiber sellers unduly sell coarse wool tops to wool yarn factories as Merino wool tops. It is therefore an important task to identify the actual wool type for quality assurance in the textile manufacturing process. In this manuscript, we demonstrated that OCT and AutoML can help distinguish Merino wool from coarse wool. OCT and AutoML perform this process in a noncontact and non-destructive manner.
This paper described applying the spectral-domain OCT imaging and AutoML techniques to analyze wool fiber type. We presented the results of wool measurements that were performed by OCT scans. The results indicate that the wool yarn industry could implement this technique in distinguishing wool types automatically.
We thus conclude that OCT imaging combined with AutoML can be used to distinguish Merino wool from coarse wool in a simple, non-destructive, and contactless manner.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.