
Abstract
This paper explores the combination of agent-based social simulation (ABSS) models. Model combination facilitates the efficient development of more complex models through reuse, enabling a more comprehensive understanding of phenomena and outcomes that individual models cannot provide on their own. Through a narrative literature review of model combination in other simulation paradigms, six different approaches were identified: ensemble techniques, meta-analysis, model merging, models as modules, model integration and model chains. For each approach, examples and relevant literature are presented, and current challenges are identified. To illustrate the different approaches, a number of models of disease spread are then implemented and combined according to each approach. Through this, the paper aims to both provide inspiration to modelers and to identify paths for future research for the combination of ABSS models and model results.
1. Introduction
The combination of implemented simulation models has been identified as one of the current largest challenges in the field of modeling and simulation.1,2 Although the purpose of combining models might vary between studies, one common aim is the reuse of existing models, thus utilizing what knowledge has already been generated by other studies rather than having to start with nothing. In that sense, the combination of models is the combination of the knowledge and efforts of many different researchers, potentially enabling more efficient development of more complex and accurate models. If the combination process takes too much effort for modelers to consider it, for example, due to poor documentation, lack of standardization or misalignment of the model’s assumptions and objectives, many valuable published models that could have been reused risk going to waste.
Agent-based social simulation (ABSS) is the application of agent-based modeling (ABM) to simulate social systems. ABSS models take a bottom-up approach to describing these systems, by defining the behavior of agents (representing individuals or groups of individuals) and simulating their interactions with each other and their environment. Common applications include epidemiology, 3 land use modeling 4 and transportation. 5
Methods and advancements in model combination are highly relevant for the ABSS community. Just as in the wider simulation community, the combination of models and model results has been highlighted as an important research direction.3,6 A highly relevant example of this is the modeling of crises, such as the COVID-19 pandemic, where models need to be developed quickly while still maintaining high quality to be useful in policy-making. 7 However, both general literature on the combination of ABSS models and concrete examples of this are still rare. Reasons for this could include the short-term nature of many ABSS projects, 8 but also the existence of unique challenges regarding model combination compared with other simulation paradigms. These include how to combine agents or agent behavior, and how to manage the high uncertainty that ABSS models often deal with.
This paper is an extension of a previous study on the combination of ABSS models, 9 providing an experimental evaluation of six previously identified approaches of model combination. For this extension, a set of disease spread models is combined according to each approach, and simulation results, insights gained and the combined models themselves are presented. The overall aim of the paper is to
Provide an overview of approaches to the combination of models and simulation results currently being used, both within ABSS and in the wider simulation literature;
Identify challenges and open research questions with regard to model combination for the ABSS community;
Experimentally evaluate the identified approaches.
2. Narrative literature review
To gain an overview of both what combination methods are being used and what challenges they come with, we performed a narrative review10,11 of existing literature covering the topic. Although narrative reviews are sometimes criticized for allowing researchers to be selective with included articles and risk introducing bias, these pitfalls can be avoided if the study is performed in a structured and rigorous manner. 10 Here, we structure the method description after the five foundational elements of narrative reviews proposed by Sukhera. 11
2.1. Rationale for a narrative review
The aim of this paper is in line with the purpose of a narrative review: to examine existing literature using a wide scope to highlight current methods, challenges and paths ahead. The reason a wider scope was chosen is twofold: First, because an important part of the aim was to identify paths forward for research into the combination of ABSS models and what inspiration can be drawn from the wider simulation literature, an overview rather than a deep dive was considered a more useful first step. Fully examining all literature that relates to combining several implemented models would be impossible given the magnitude of papers, yet an analysis of a representative subset of these papers can still provide inspiration for future research within the ABSS field. Future research into one of the identified approaches could then perform a more exhaustive review of said approach. Second, a larger set of search strings was deemed necessary to understand the approaches used. The study found that there was no consensus in the terminology of describing model combinations; the same term could be used to describe different concepts or approaches in different studies and vice versa. Because this lack of a consistent terminology demanded a large set of search strings to counteract, it came naturally that the study received a wider scope.
2.2. Boundaries, scope and definitions
The word model refers in this paper to implemented, executable simulation models. By model combination, we refer to the process of using several implemented models to form a single model. A combination of purely conceptual models is thus not considered, although most if not all challenges that arise here also apply to implemented models. Similarly, model result combination refers to the aggregation of results, whether quantitative or qualitative, from several implemented models that were executed separately. Focus lay on receiving a high-level picture of how the combination was achieved, rather than differentiating based on modeling paradigms, model scopes or what systems were modeled. The combination of simulation models from any modeling paradigm was considered during the review, though that of analytical models was not. Papers describing a specific model combination, reviews and discussion papers were all included.
2.3. Inclusion and exclusion
Google Scholar was used as a search engine, which has been shown to have the largest coverage of well-established scientific search engines and databases. 12 Critique against the use of Google Scholar over other resources largely concerns its not excluding predatory journals and non-scientific or non-peer-reviewed material; this issue was deemed to have minimal impact on this study because the review did not seek to quantify results, and material deemed as non-scientific or published in questionable outlets was excluded from the study during screening. An initial set of broad search terms, such as “model combination,”“ensemble modeling” and “multimodel,” was selected. This set was then expanded when new, more specific terms were encountered in the literature. The full set of search terms used were as follows: “Ensemble (modeling OR modelling)”; “(Model OR simulation) combination”; “Model merging”; “(Model OR simulation) aggregation”; “Multimodel” OR “Multi-model”; “Multi-method (modeling OR modelling OR simulation)”; “Multi-scale (modeling OR modelling OR simulation)”; “Co-simulation”; “Model coupling”; “Hybrid (modeling OR modelling OR simulation)”; “Modular (model OR models)”; “Model (chain OR chaining)”; “Model composability”; “Model composition” AND “simulation”; “Model comparison”; “Model integration.” Each search term was used both with and without the additional term “AND ‘Agent-Based.”’ Results were ordered by relevance according to the engine, and then, the first 30 papers were screened. This translated a total of 32 search strings, and thus, 960 total articles screened (not accounting for articles showing up in more than one search). Additional relevant papers were added via snowballing. For assessing their relevance, all papers were screened by title, then abstract, then their method and/or discussion sections.
2.4. Sufficiency and saturation
The literature search was concluded when all search strings had been exhausted, and no new search terms or clusters were generated. It should be acknowledged that because of the nature of narrative reviews it cannot be concluded that all possible methods of model combination were identified in the review; this was also not the aim of this study.
2.5. Analysis and interpretation
A clustering of the different types of approaches was generated during the review. We grouped similar approaches and sought to identify suitable umbrella terms describing the approaches within a cluster. New clusters were created when approaches did not fit into the existing ones. Again, the focus of the clustering lay on how models were combined, not on the paradigm, scale or topic of the models. This means that concepts such as hybrid modeling 13 and multi-scale modeling 14 did not receive their own cluster, but were grouped based on the linking of the models themselves. For each identified article, the introduction, methods, discussion and conclusion sections were screened for mentions of challenges regarding the discussed approach.
3. Model result combination
This section describes approaches to how the results or conclusions from multiple models can be combined or synthesized. Two approaches were identified: ensemble techniques and meta-analysis.
3.1. Ensemble techniques
Ensemble techniques (Figure 1(a)) here denote methods for the quantitative combination of simulation results from different models. In the literature, ensembles can also refer to the combination of results from different parameterizations of the same model; this is not considered here. Common ensemble methods include averaging and weighted averaging of results, but there exist many others. 15

Combination of models (M) or results (R) to draw conclusions (C) using the approaches identified in the paper: (a) Ensemble techniques, (b) meta-analysis, (c) model merging, (d) models as modules, (e) model integration and (f) model chaining.
Ensemble forecasts have, on many occasions, been shown to have higher accuracy than single-model forecasts.16,17 One explanation for this could be that the inclusions of several structurally different models mean that the structural uncertainty of the modeled system is compensated for. 18 There are more advantages to the ensemble approach than increased prediction accuracy, however. Using more than one model means the full range of potential outcomes can be more thoroughly explored, 19 and more comprehensive uncertainty estimations can be made. 18
Ensemble methods are widely used in simulation-based forecasting. Examples include weather forecasting, 20 epidemiology, 16 clinical prediction, 21 land use 17 and biochemistry, 22 just to name a few. As a concrete example, the COVID-19 Forecast Hub 23 collects and combines forecasts of COVID-19 transmission in the United States from more than 50 different research groups. Model ensembles consisting of, or including, agent-based models appear to be much rarer, though; in the review, only one such ensemble was found. 24
3.1.1. Challenges
Some challenges concern technical aspects, such as model selection, selecting the best ensemble method and calculating ensemble weights.18,21 There is also the challenge of how to best communicate and visualize ensemble results to policymakers. 25 Furthermore, there exist challenges with regard to understanding the ensemble itself. For instance, while ensemble models are often claimed to be more generalizable than singular models, it is unclear how one would measure or prove this. 18
Using ensemble approaches for ABSS models appears to be very rare, as only a single ensemble model, including an agent-based model, was identified in the review. One explanation for this could be that ensemble methods are commonly associated with forecasting. This is rarely attempted within ABSS, and there are several reasons as to why predictions often fail. 26 It is possible that ensembles of such predictions could improve their accuracy, although this would need to be tested, as no research proving this appears to exist.
Conversely, there exist plenty of purposes of using ABSS models beyond forecasting26,27 where it is not as obvious how ensembles should be constructed. Simply creating averages of results risks the loss of relevant information in the individual models. Ensemble methods could still be of help, but effort would have to go into understanding what outcomes can be beneficially combined and how.
Finally, the combination of models requires the availability of models to combine. Here, the low reusability of many ABSS models 28 and the necessary context-specificness of many models are obstacles. Resources such as the Comses model library 29 and the Overview, Design concepts and Details (ODD) protocol for documenting agent-based models 30 are valuable here and could lead to more models being available to create ensembles in the future.
3.2. Meta-analysis
Meta-analysis (Figure 1(b)) here denotes the process of combining the insights and conclusions drawn from different models. Rather than quantitatively combining multiple results into one, meta-analysis aims to qualitatively analyze and compare models to gain a broader understanding of the simulated system than any single analyzed model could have led to. The purpose of this is similar to that of ensemble techniques: to get a wider picture of the simulated system, as well as to understand the uncertainty and spread of results. Two of the added benefit of meta-analysis is that differences and uncertainties can be not only measured, but explained, and that joint conclusions can be drawn from models even if their outputs vary greatly.
One of the more straightforward ways of drawing conclusions from several models is to look for similarities in results. This approach is sometimes referred to as Model Consensus. The idea is that conclusions supported by all (or most) models will be more robust than those drawn from singular ones. Gårdmark et al. 19 illustrate this approach using models of cod population, while Bosetti et al. 31 compare technology cost models. In their systematic review of ABM of malaria transmission, Smith et al. 32 identified three different studies performing consensus modeling.
Conversely, much can be learned by comparing differences in model outcomes and investigating what assumptions or parameterizations lead to these. While this is sometimes part of the model selection step rather than the combination step,33,34 the explanatory power of model comparisons should not be underestimated. Thorve et al. 35 present a framework for performing this kind of model comparison of agent-based models, although they mention comparing models with other types of output data than those over a numerical domain as future studies.
A different approach is suggested by Radosavljevic et al. 36 They propose a procedure for iteratively learning from agent-based and Dynamical System models. The insights generated from one model are used to create experiments from the other model. By doing this, the benefits of both using a more complex agent-based model and a simpler dynamical system model can be reaped.
3.2.1. Challenges
Although the review found several examples of papers performing meta-analyses of models, the literature here appears to be much more scarce than that covering ensemble techniques. One explanation for this could be that the purpose of models in many fields is to generate as-accurate-as-possible forecasts; in this case, ensemble methods have more to offer than a more “qualitative” analysis of the simulation output. Another explanation could be that the large diversity in models means these types of combinations often have to be made ad hoc. Even still, the shortage of papers discussing the synthesis of simulation results beyond creating forecasting examples could be considered surprising, and points toward a research gap to be filled.
Not much literature was found combining the results of ABSS models in this manner. Creating a general blueprint for the meta-analysis of models might not be possible; 36 still, the exploration of different means of performing this combination, for instance, through case studies, could bring generalizable methodological insights. Similar to how uncertainty and sensitivity analysis are used to understand how differences in parameter values affect a model, the systematic comparison of models would illuminate how different assumptions and conceptual models affect the modeling of the system. This, however, requires that the models were created with the same purpose and are suitable for studying the same scenarios.
4. Model combination
This section describes approaches to how different models can be combined into one. Four approaches were identified: model merging, models as modules, model integration and model chains.
4.1. Model merging
Model merging (or model fusion) (Figure 1(c)) is the process of fully and irreversibly combining two or more models. 37 This can be done automatically by using markup language or formalism, manually through cutting and pasting parts of the models, or through complete reimplementation. Generally, the aim is to unify the overlap between the models, while including each model’s unique features. 38
The main purpose of model merging is the reuse of existing models.37,39 If this is done automatically, it can be the most efficient approach of the combination approaches presented here. The merging process also removes any redundancies in used models, 37 potentially improving its performance.
The model merging approach appears to be relatively uncommon in the simulation literature compared with the approaches discussed below, although some examples exist. In system biology modeling, the System Biology Markup Language (SBML) is being used to semi-automatically compose models.39,40 The theoretical side of merging is also explored by, for instance, Sabetzadeh 41 and Nejati et al., 42 although models here refer to software models and not necessarily simulation models.
4.1.1. Challenges
The full merging of models appears to be rare in the simulation literature. It has been argued that the approach is most suitable for smaller models, as larger merged models will be difficult to manage. 37 Challenges include how to best deal with overlaps and conflicts in the models. 38 Generally, automatic or semi-automatic merging requires the use of markup languages or formalisms, which in turn requires that models are sufficiently similar, as well as conceptually aligned. Manual merging, on the contrary, takes a great deal of effort, and apart from the elimination of redundancy in the models, it is not clear what advantages it holds over the other approaches discussed here.
There exists no well-established framework or markup language specifically for ABSS that would enable model merging. Moreover, the diversity of ABSS models means that such merging likely would not be possible without placing large constraints on modelers regarding how models should be constructed, which could hamper their intended purposes. If model merging is to be useful in agent-based models, it would likely require more narrow tools for specific applications.
Merging of ABSS models could come in different forms. A merged model could add new types of agents or environmental entities, or it could modify existing ones, such as adding agent attributes or options for deliberation. While some steps of this process could likely be automated, modelers would most likely have to define how the deliberation process and interaction of agents are to be updated, thus removing some of the efficiency benefit of the merging approach.
4.2. Models as modules
The models as modules approach (Figure 1(d)) views models included in the combination as black boxes. The modeler should never (or rarely) have to look at or modify the source code of models, but instead feed them the correct inputs and process their outputs. This means that the included models need to have been built with composability in mind. Co-simulation 43 typically would fall under this approach.
The idea behind this approach is that it will take less effort for the creator of the original models to make them composable than it would take for the modelers reusing the models to interpret and integrate them otherwise. Lowering the bar for reuse and composition benefits both the model’s creator (in seeing their model get more use) and its (re)user.
There exist plenty of tools, interfaces and the like arguing to facilitate the models as modules approach. Examples include the Functional Mockup Interface (FMI), 44 the Base Object Model (BOM), 45 the Model Coupling Toolkit 46 and OpenMI 47 for linking models, although there are many others. 48 While not all of these may enable models to be completely treated as black boxes, they all raise the reuse and composition of models as important applications.
ABM has received attention here. This includes applying existing ontologies and formalisms to ABM,49,50 tools for simulation software to make ABMs composable with other types of models51,52 and architectures aimed to increase composability. 53 Some attention has been given to human behavior; for instance, Bae et al. 49 discuss formalisms such as the Belief-Desire-Intention (BDI) architecture, Markov Decision Processes (MDPs) and game theory approaches, which are common within ABSS. Meanwhile, Zhang and Verbraeck 54 present a cognitive agent based on the Discrete Event System Specification (DEVS) framework, intended to be used as a component in other simulations.
4.2.1. Challenges
The literature has identified several challenges tied to the models as modules approach. Several of these apply to all types of model combinations identified here (they will be listed here only, to avoid redundancy). Many of these challenges can be classified into concerns about either syntactic or semantic composability. 55 Syntactic composability refers to technical challenges in combining models, such as different programming languages being used in the models. Semantic composability, on the contrary, concerns maintaining model validity and avoiding issues such as conflicting assumptions. Tolk 56 identifies five additional levels of conceptual interoperability, including dynamic interoperability and pragmatic interoperability. Some identified challenges include the following:
Different incompatible ontologies, formalisms or abstractions. 57 These need to be well-established and commonly used to be of any help.
Aligning model assumptions. This is hard even in simulations of physical systems, 58 and the difficulty increases further in applications where context plays a large part. A model that works well for its intended use could cause issues if it were packaged as a module and used outside of that scope. 59
Differences in scales and resolutions, and how time and space are represented.57,60 Exchanging information “each time step” is not straightforward if time is represented in completely different manners in the models. This might mean even models intended to be reused might require modifications to be compatible at all. 61
Single points of failure. 62 Bugs or errors in one included model could cause faults in the larger model.
Uncertainty and noise propagation. 57 As each module comes with some level of uncertainty, the uncertainty of the entire model might become difficult to estimate or too large for any results to be useful.
The learning curve and extra effort required to build reusable models. 63 Modelers need to consider it worth the effort to build reusable modules over ad hoc models, fulfilling the specific needs of this study.
Communicating models. 57 While modular models might be easier to describe than some of the other approaches discussed here, large models can still easily become daunting to stakeholders or intended users.
All these challenges grow in size if included models are proprietary, not open-source or poorly documented.
While proposals have been made for a formalism for ABSS models (e.g. by Bae and Moon 64 ), none is currently well-established within the modeling community. One could imagine modules describing different types of agents, agent behavior architectures, environments or environmental elements. However, for such modules not to have to go through the more effort-consuming model integration approach (see below), there would need to exist some sort of standards for how they should be coupled. Because of the diversity between ABSS models, even ones describing similar systems, the probability is quite low for models to readily fit with one another, semantically as well as syntactically.
Arguably, semantic composability is an even larger issue in ABSS than in other simulations. While a “semantically invalid” model in theory could still generate accurate forecasts (thanks to the equifinality principle), it could lead to faulty conclusions if used for other purposes. If the model, for instance, is meant to describe or visualize a complex system, or if it is used to explore the system’s underlying mechanisms, contradicting assumptions and misunderstandings of the meanings of variables becomes detrimental. The more context-specific models are, the more likely it is for clashes in assumptions to arise. Efforts to analyze, describe or visualize systems could also be hampered if models grow too large; while higher complexity in theory could lead to greater explanatory power, it is countered by the model becoming harder to understand.
4.3. Model integration
Model integration (Figure 1(e)) here denotes the combination of models that were not built to be readily combined with each other; that is, models that need to be modified or complemented to fit together.55,65 While this approach requires substantially more effort from the modeler than the models as modules approach discussed above, it might thus be necessary for gaining the same benefits. Even if a framework existed that would allow models to combine seamlessly, model integration approaches would still most likely be needed, both for legacy models and for models from fields that do not use said framework.
The line between this approach and the previous one is not always clear-cut. As pointed out above, it is very common that models need some tweaking to be able to work together. Thus, the models as modules approach could be considered an ideal case for the “reuser,” while in practice, it is model integration that is being performed. There is, however, a spectrum of model reusability, causing more or less work to be required for modelers. Since modelers who gauge that the effort required to integrate a model is too large are likely to instead implement that model or functionality from scratch, it should always be in the interest of the original model to make the model as easily integrable as possible.
There exist plenty of examples of model integration in the literature. In ABM alone, example cases exist of integrated models of climate modeling, 66 construction, 67 land use 68 and energy markets. 69 Wu et al. 70 present a framework for model integration, providing an example of an integrated airport model that includes an agent-based model of individual passengers.
Model integration can be divided into deep integration and functional integration. 71 Deep integration means the code of models is modified. Functional integration, on the contrary, refers to the use of wrappers or other software to bridge the gap between models, handling the exchange of information between them. Although this means the models themselves are not modified, it still requires access to and understanding of the model code to be possible. Such wrappers sometimes appear in the models as modules approach as well, but can here be used to reduce the required amount of code to be rewritten. 63 Boyd and Sarjoughian 72 present an example of such a wrapper for agent-based and cellular automata models.
4.3.1. Challenges
Generally, all the challenges listed in the models as modules section apply here as well. The difference is that rather than it being up to the framework or formalism to mitigate these challenges, it now falls on the “re-users” to solve them themselves. Particularly, syntactic composability becomes more difficult (as this is often the simpler type of composability for models as modules approaches to solve). 73 Understanding the model that is to be reused also becomes more challenging if it was never communicated with reusability in mind.
While the ODD protocol 30 is far from sufficiently detailed to allow the automatic combination of models, it is a large aid in the integration process. Although the matter of how to best integrate ABSS models is far from solved, the prevalence of examples in the literature proves that this is a matter actively being tackled.
4.4. Model chaining
A model chain (Figure 1(f)) is a combination of models such that the output from one (or several) models becomes the input of the next. Instead of models continuously exchanging information, input models can here be run independently of the following model, providing data for it once its execution is finished. Examples could include a weather model generating a forecast that is used for an agricultural model, an epidemiological model that uses an estimate of disease infectiousness that another model has predicted, or a model generating movement patterns for citizens in a city that is then used to estimate their exposure to pollution.
This approach solves several of the technical challenges of the other model combination approaches. The output of a model can simply be treated the same way as data from any other source in the modeling process; it does not matter what programming languages the models were implemented in or if they follow the same formalism. Model chains can be seen as a means of sequentially describing a system, or models can be used as a substitute for missing empirical data for a “main” model.
The review did encounter a few examples of model chains being used. Mayer and Yang 74 discuss model chains for photovoltaic power forecasting, while Postacchini et al. 75 present a model chain of coastal inundation. The model chain presented by Lefebvre et al. 76 describes traffic and pollution levels and includes an agent-based model controlling travel behavior.
4.4.1. Challenges
Literature discussing the challenges of chaining models was not found in the review. Some of the identified challenges for the approaches above still apply to model chains, however, such as the issue of uncertainty propagation. When each model in a chain brings uncertainty, both parametric and structural, it is difficult to gauge the uncertainty of the chain’s output and whether it is too uncertain to be useful.
Generally speaking, model chaining is the presented approach that is the most method-agnostic. Assuming the previous model in the chain is able to generate relevant data for the next, which modeling paradigm each model follows is not as relevant as for other approaches. Thus, the challenges for chaining ABSS models are effectively the same as for the chaining of other types of models.
4.5. Experimental comparison: combinations of epidemic models in NetLogo
In this section, we perform experiments to illustrate and compare the six discussed combination approaches using a number of simple epidemiological ABSS models implemented in the NetLogo language. 77 These models do not aim to represent any real-world epidemic, but to serve as simple examples of the different approaches. The models, which are also available at https://github.com/emjolund/ABSS-combination-models, are as follows:
The network-based models were built using the virus on a network model 78 from the NetLogo Model Library as a starting point. For the experiments below, each model contained a population of 800 agents, and testing (when enabled) was performed every second day. Parameter values used in the experiments presented in the paper can be found in the Supplemental Materials of this paper.
4.6. Ensemble techniques
We begin by looking at the combination of quantitative model results. Using the models Network, AgeGroups and WorkHome (see Figure 2(f)), let us assume that we are interested in determining the following for the epidemic at hand: the total number of agents infected; the maximum number of infected (or exposed) agents at any given time; and after how many days this peak occurs. We want to estimate these metrics with and without the intervention of population-wide testing and isolation of positive cases.
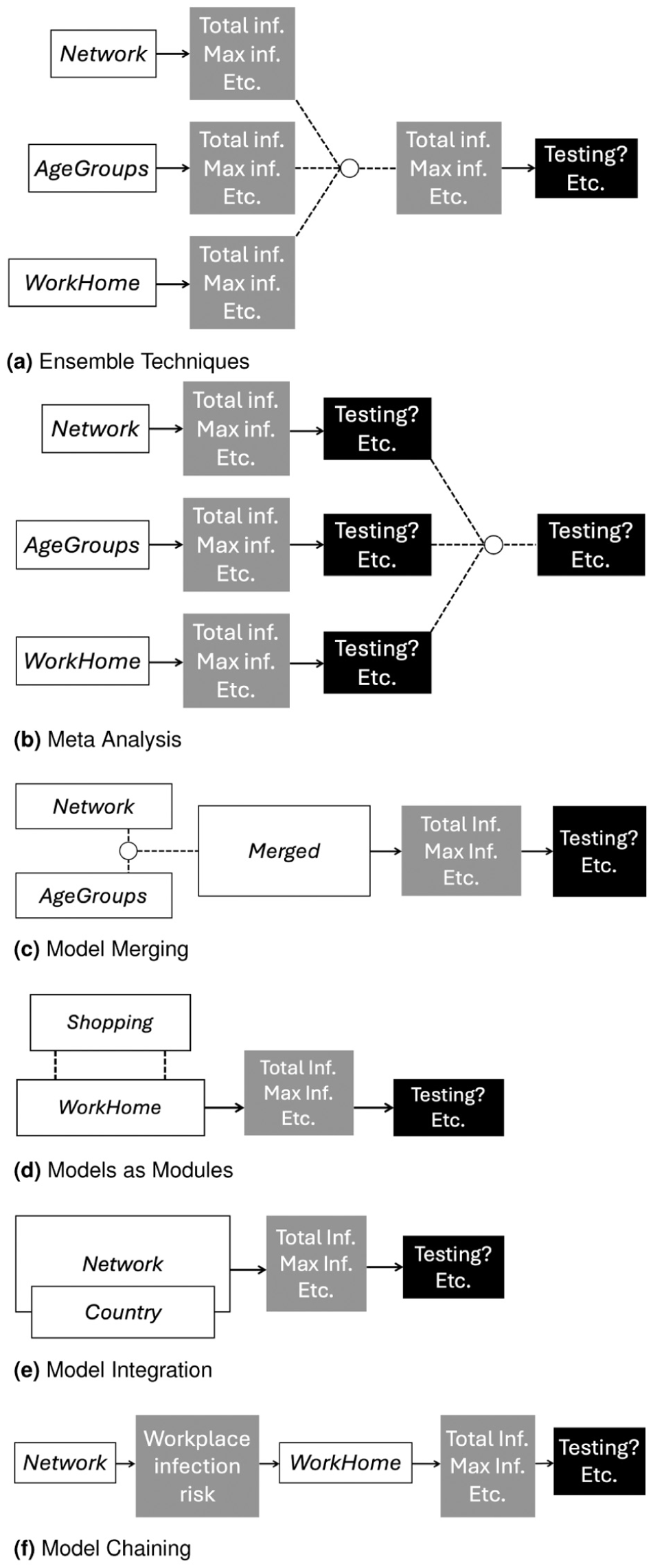
An illustration of how the models Network, AgeGroups, WorkHome, Country and Shopping were combined to illustrate the different model combination and model result combination approaches: (a) Ensemble techniques, (b) meta-analysis, (c) model merging, (d) models as modules, (e) model integration and (f) model chaining.
A simple form of model ensemble is illustrated in Table 1, which shows the average and standard deviation of the numbers requested above from 1000 runs of each of the models, and the average for each metric over the three models. While it cannot be determined whether such an ensemble would provide better estimations than the “best” of the individual models (such studies are left for future works), it is clear that only focusing on the means and standard deviation of the metrics at hand would result in a loss of information, which could potentially be more useful than the estimates themselves. Perhaps most striking is the difference in the estimates of the total number of infected agents when testing is performed. It could be argued that this discrepancy points to differences in the understanding of the simulated system so fundamental that a quantitative combination of their results would be of little use on its own. A meta-analysis of the model would instead be necessary.
The total number of infected individuals, the peak number of infections and the day at which this peak occurs from Network, AgeGroups and WorkHome, with and without population-wide testing, and the average of these estimates across models.
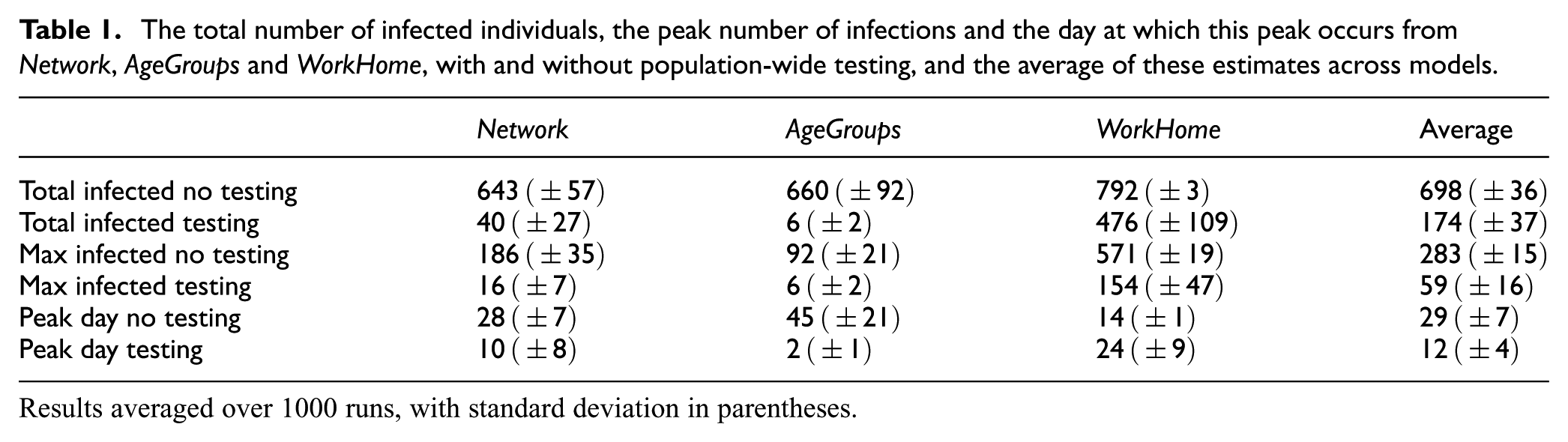
Results averaged over 1000 runs, with standard deviation in parentheses.
4.7. Meta-analysis
Using the same three models as in the previous section, we move on to perform a meta-analysis of the model outputs (see Figure 2(b)). Since the review found no systematic methods for this sort of analysis, we focus here on identifying and explaining similarities and differences between the outcomes of the different models, and leave the design of a more structured approach for future studies. For differences in model outputs, we differentiate between those that can be explained by different parameterizations of the models and those stemming from different modeling assumptions and which typically would not disappear from a recalibration of the models.
Beginning with similarities, all models suggest that testing individuals for infection helps reduce both the total number of individuals infected and the highest number of infections at a point in time (although the effectiveness varies between the models). Further experiments also show a consensus between the models that a higher infectiousness risk and a higher number of contacts for individuals both increase the spread of the disease, and that testing is more effective the higher the testing frequency.
Looking at differences between model outputs, WorkHome suggests a much higher number of infected individuals than Network and AgeGroups, both with and without testing. There exist several explanations for this, some of which could be explained by the calibration of the models. Agents have a larger number of average contacts in the WorkHome model (although some of these contacts have a lower infection risk than others), and the risk of infection is calculated differently in the models, meaning the parameters controlling this have different meanings.
Another difference between the models is how agents who have tested positive are handled. In WorkHome, these agents no longer go to work but can still infect their household members, who in turn can pass on the disease. In AgeGroups, on the contrary, agents who have tested positive cannot infect others at all, which likely contributes to why the disease appears to die out immediately in this scenario. This difference in output is thus not due to any differences in parameter configuration, but the effect of different underlying assumptions in the models.
Depending on the purpose of the modeling study, the next step of comparing the models could, therefore, be to recalibrate the models to return similar outputs in one of the studied scenarios (e.g. the no-testing scenario) and then compare the results for the other scenario. Alternatively, the meta-analysis could aid in model selection, either to find a single most suited model or a subset of models to be used in a model ensemble.
4.8. Model merging
We next set out to merge the Network and AgeGroups models (see Figure 2(c)). Specifically, we want a new model with the Susceptible - Exposed - Infected - Recovered compartmental structure and chance of infection between random agents of Network, and the different age groups of AgeGroups. Since this results in a model which is fundamentally different from either of the original models on their own, the other combination approaches in this paper would be difficult to apply.
The resulting model Merged is available in the GitHub repository. The combination process was, in this case, simple, thanks to both models being small, similar in implementation, developed in the same language and by the same team. Thus, the new model could be created simply by cutting and pasting code between the models. Had not all of the above factors been true, the process would have been much less straightforward.
Table 2 shows a comparison of the results from running the Merged model 1000 times to those from the original Network and AgeGroups models. Interestingly, Merged indicates a lower number of infections than both of the models it was created from; given the nonlinearity of the models in question, however, it is not very surprising that the results of a merged model would deviate from the original models.
The total number of infected individuals, the peak number of infections and the day at which this peak occurs from Network, AgeGroups and Merged, with and without population-wide testing.
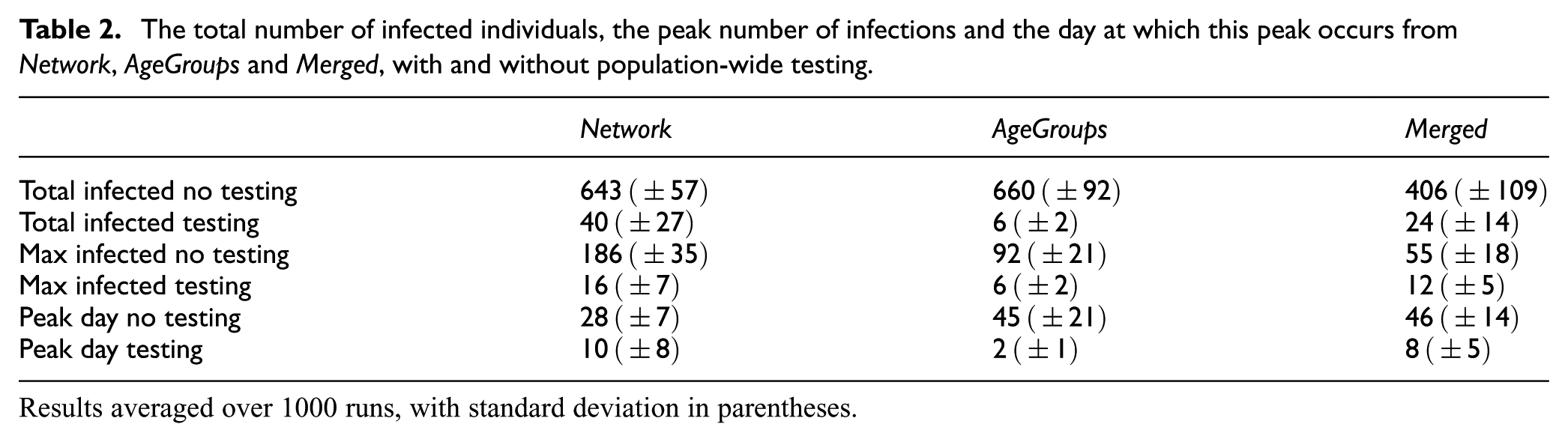
Results averaged over 1000 runs, with standard deviation in parentheses.
4.9. Models as modules
Now, we want to simulate how changing the opening and closing hours of stores in a city would affect the spread of the studied epidemic. For this, we use the Network model, but replace the random infections of non-contacts with runs of the Shopping model (see Figure 2(d)). This model is run in full each time step of the Network model, using the current number of susceptible, exposed, infected and recovered agents for each run.
To link the models together, we use NetLogo LevelSpace. 79 The combination is an example of models as modules, since no modification of the Shopping models was necessary, and it could be treated almost entirely as a black box for the sake of the simulation. The resulting model Modules is available in the GitHub repository.
Table 3 shows the means and standard deviations from 1000 runs of Modules in three scenarios: no infections at the grocery store, long (24 h) store opening hours and short (8 h) store opening hours. The results from the original Network model are included for reference. From the simulations, we can conclude that infections at the simulated store can have a large impact on the spread of the disease, and that shorter opening hours lead to an increased number of infections. These types of conclusions were not possible to draw from the original Network model.
The total number of infected individuals, the peak number of infections and the day at which this peak occurs from Modules in three scenarios: zero infection risk at the store, long (24 h) opening hours or short (8 h) opening hours.
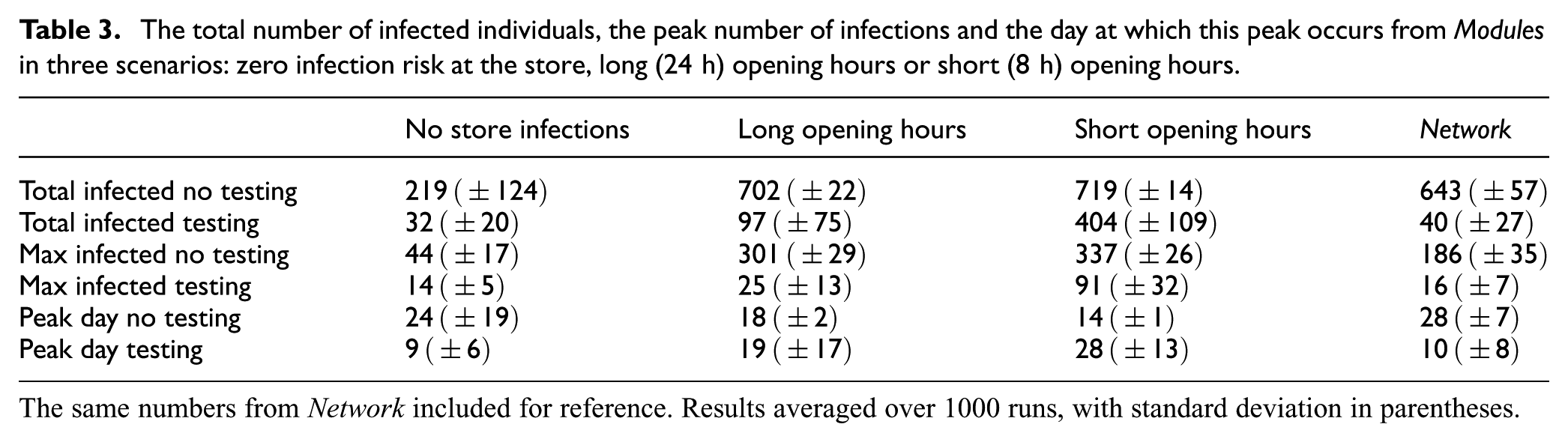
The same numbers from Network included for reference. Results averaged over 1000 runs, with standard deviation in parentheses.
4.10. Model integration
On its own, the WorkHome model only simulates a single town and assumes no agents arrive in or leave the simulation. To simulate how mobility between towns affects the epidemic’s progression, the WorkHome and Country models are integrated (see Figure 2(e)). Both models need to inform each other: the town modeled in WorkHome corresponds to a specific agent in Country, and at each timestep of each model (being run alternatingly), the number of agents with each disease state needs to be updated based on the other model.
Unlike in the models as modules case above, this combination was not possible to perform without several modifications in both models. This included the updating of the number of agents with each disease state, as well as dealing with agents being added or removed in the town model. Challenges also arose with regard to the models using different compartmental structures (Susceptible - Infected - Recovered vs Susceptible - Exposed - Infected - Recovered) and defining days since infection for newly arrived agents in the WorkHome model. The resulting model integration is available in the GitHub repository.
Table 4 shows the means and standard deviations from 1000 runs of the Integration model, as well as the original WorkHome model. Note that because of agents appearing and disappearing in the city simulated by Integration, the number of infections in the town is able to exceed 800. Since the integration of Shopping has fundamentally changed Integration, it is now difficult to directly compare the results to those of WorkHome, since the total and maximum number of infected agents in the models refer to slightly different things. It does, however, appear that the introduction of agent mobility between towns increases the number of infections in the studied town.
The total number of infected individuals, the peak number of infections and the day at which this peak occurs from WorkHome and Integration, with and without population-wide testing.
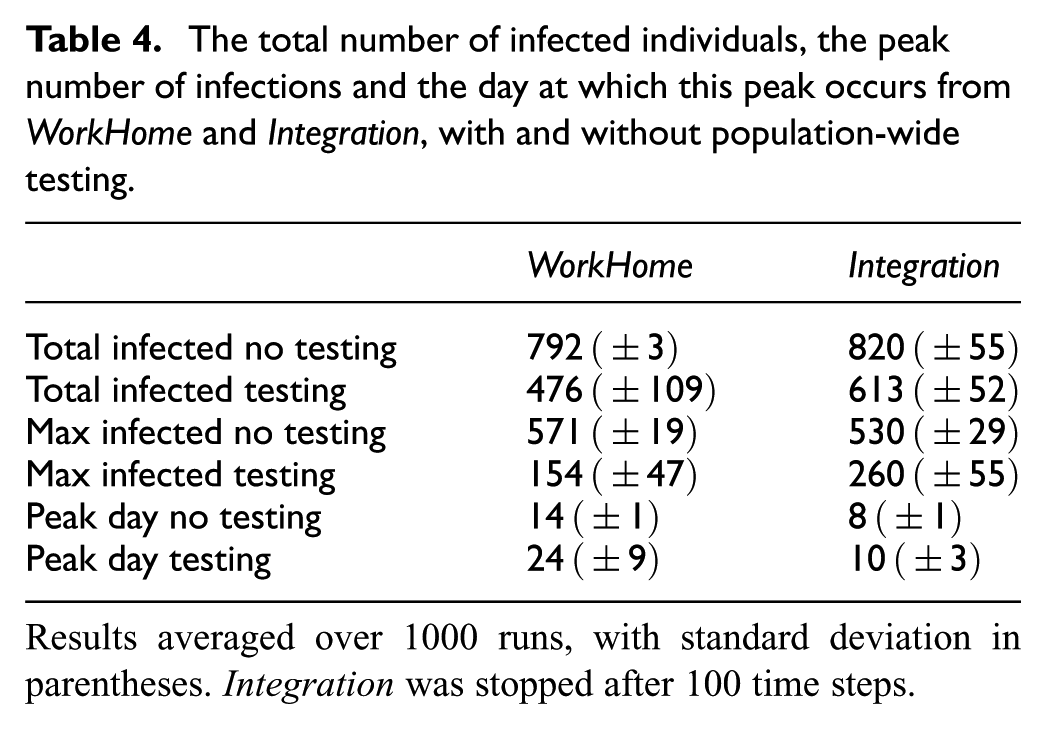
Results averaged over 1000 runs, with standard deviation in parentheses. Integration was stopped after 100 time steps.
4.11. Model chaining
Finally, to illustrate model chaining, we note that the WorkHome model requires the risk of transmission at workplaces as an input. This parameter would be difficult to estimate empirically, especially in the early stages of the epidemic. Instead, we modify the Network model to represent a single office and use this model to estimate the infection risk, calculated as the percentage of individuals in the office that are infected in a single time step per infectious individual at that office. The modified models, ChainOffice and ChainTown, are available in the GitHub repository. These two models now form a model chain (see Figure 2(f)), where the infection risk at workplaces estimated by ChainOffice is used as an input parameter in ChainTown. Note that, unlike for the other types of model combination, the models can be run completely separately, as no information needs to be passed from ChainTown to ChainOffice. It should be noted that, as the predicted infection risk is highly uncertain, this uncertainty will propagate into the ChainTown model, affecting its accuracy; still, it is not necessarily true that an estimate from any other source would be less uncertain.
5. Discussion
This section has presented experiments aimed to illustrate and compare the six identified methods to combine models or model results. It should be noted that all models used in the experiments were quite simple, implemented in the same programming language by the same people, and for the same setting with the same aim (at least for the Network, AgeGroups and WorkHome models). These factors greatly simplified the combination process for all six approaches, rendering them easier to illustrate but hiding many of the challenges discussed in the previous section. If the aim is the reuse of models and modelers not having to develop every model from scratch, syntactic and semantic composability become much less straightforward.
The models did not follow any particular well-established formalism (such as DEVS). While such standards could be adapted to ABSS, they are currently not commonly used by the community. 80 As discussed above, exploring and eventually agreeing upon formalisms or frameworks for reusable ABSS models could mitigate many of the challenges tied to their combination.
The study did not touch on the matter of verification and validation of models. In any empirical study applying any of the combination approaches covered here, the models would need to be verified and validated. This goes both for the models that are being combined and the final model. It is generally not sufficient that each of the used models has been previously validated, partly since the current purpose and setting of the model may vary from those under which it was validated. However, model combination can also add new opportunities for validation, rather than only new challenges. ABSS models are commonly used not only for numerical predictions but also for describing, understanding and visualizing social systems and comparing interventions to these. These purposes require not only the numeric outputs of the model to be validated but also the entire model, its patterns and semantics. The separate validation of model components would be a very natural step in this process. Because of this, it is possible that validating a model that has been created through the combination of other models could require less effort to validate rather than more, compared with a model created from scratch.
The experimental study shows that it is not possible to choose a “superior” combination approach out of the six presented here. Model result combination aims to acquire a better picture of a system by using several models of that same system, by exploring and/or attempting to mitigate some of the structural uncertainty associated with that system. Which of the approaches to choose depends on the aim of the study and the character of the produced model outputs. Model combination, on the contrary, aims to describe a system by combining models describing parts of that system. Which of the approaches to choose depends on the nature of the models to be combined and their composability.
More specifically: Ensemble techniques are useful when there are available multiple models of the same system which generate similar quantitative results. Meta-analysis is useful when there are multiple models describing different aspects of the same system, or when the purpose of the models goes beyond forecasting. Model merging is useful when models are low in complexity and/or follow some framework or markup language that allows their automatic merging. The models as modules approach is useful when a larger, more descriptive model is desired, and there exist models that can be readily used as sub-models for it. Model integration is useful when a larger, more descriptive model is desired, but existing models need to be modified to be used. Finally, model chains are useful when there is a lack of empirical data for a model, and there exists another model that can be used as a substitute, or when one wishes to use a model to describe a longer chain of events.
Since the benefits of model combination and model result combination are slightly different, one could consider a method that uses both of these approaches at once. Looking at the models produced through model combination (in particular Merged, Modules and Integration), since the aim and type of output from these are in line with each other and the original models, they could potentially all be used as ensemble members or parts of a meta-analysis. Using a modular approach where smaller models are combined into a set of larger ones could be an alternative to creating completely new models from scratch or having to align aim and outputs of reused models. It is, however, left to future studies to explore whether such an approach would lead to useful conclusions, and whether the similarities between such models would increase or decrease their usefulness.
6. Conclusion
This paper has presented a narrative literature review of different approaches to combining models or model results. Six different approaches have been discussed: ensemble techniques, meta-analysis, model merging, models as modules, model integration and model chains. For each approach, examples of their usage were given, and challenges have been highlighted for the ABSS community if they are to be applied to these models. Furthermore, experiments were performed where a set of models of disease spread was combined according to each of the identified approaches. Through this, the paper has aimed to aid both individual modelers in providing inspiration for how models can be combined and researchers in identifying gaps in the model combination research.
Limitations of the literature review include the identification of relevant search strings. The narrative literature review method assumes that relevant strings are either known beforehand or will show up in the studied literature. This means that there could be approaches that were not captured in the review, due to a completely different terminology being used. The review’s reliance on existing literature also means that it cannot identify new methods of combination that have not yet been explored. Novel combination approaches could be investigated in future research. Finally, while the choice of Google Scholar as a search engine is motivated in the method section of this paper, future research could include the validation of this study’s findings through the use of other scientific databases and libraries.
Regarding the experimental evaluation of the different combination approaches, this study is only one step toward fully understanding the combination of ABSS models. Although the results of the evaluation generally were in line with the literature, further studies are needed, especially with regard to the combination approaches that are still rare in the ABSS community.
The paper has highlighted some promising research directions. To summarize some of these, challenges for ABSS researchers to tackle include the following:
Exploring the prediction capabilities of ensembles of ABSS models.
Exploring the systematic comparison of ABSS models and their results.
Exploring how the (potentially conflicting) outputs of different simulation models can be used to gain a wider picture of a simulated system.
Exploring and eventually agreeing upon formalisms or frameworks for reusable ABSS models.
Exploring how agent behavior can take into account new options provided by combined models, and the compatibility of agent behavior between models.
Implementing wrappers or other software to simplify the combination process.
Exploring means of measuring and potentially mitigating uncertainty propagation.
Exploring the concepts of conceptual alignment and semantic composability in ABSS models.
A first step toward tackling these challenges could be through case studies. Then, once sufficiently many examples exist to draw from, more general conclusions could be drawn, and guidelines for modelers could be agreed upon. If the obstacles of efficient combinations of models and simulation results are overcome, the rewards would include higher model reuse, more robust model results and, ultimately, better models.
Supplemental Material
sj-docx-1-sim-10.1177_00375497261453360 – Supplemental material for Combination of agent-based social simulation models: An experimental evaluation using epidemic models
Supplemental material, sj-docx-1-sim-10.1177_00375497261453360 for Combination of agent-based social simulation models: An experimental evaluation using epidemic models by Emil Johansson, Fabian Lorig and Paul Davidsson in SIMULATION
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was partially supported by the Wallenberg AI, Autonomous Systems and Software Program—Humanities and Society (WASP-HS) funded by the Marianne and Marcus Wallenberg Foundation.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.