
Abstract
According to state-of-the-art research, mobile network simulation is preferred over real testbeds, especially to evaluate communication protocols used in Opportunistic Networks (OppNet) or Mobile Ad hoc NETworks (MANET). The main reason behind it is the difficulty of performing experiments in real scenarios. However, in a simulation, a mobility model is required to define users’ mobility patterns. Trace-based models can be used for this purpose, but they are difficult to obtain, and they are not flexible or scalable. Another option is TRAce-based ProbabILiStic (TRAILS). TRAILS mimics the spatial dependency, geographic restrictions, and temporal dependency from real scenarios. In addition, with TRAILS, it is possible to scale the number of mobile users and simulation time. In this paper, we dive into the algorithms used by TRAILS to generate mobility graphs from real scenarios and simulate human mobility. In addition, we compare mobility metrics of TRAILS simulations, real traces, and another synthetic mobility model such as Small Worlds in Motion (SWIM). Finally, we analyze the performance of an implementation of the TRAILS model in computation time and memory consumption. We observed that TRAILS simulations represent the interaction among users of real scenarios with higher accuracy than SWIM simulations. Furthermore, we found that a simulation with TRAILS requires less computation time than a simulation with real traces and that a TRAILS graph consumes less memory than traces.
Keywords
1. Introduction
There is an increasing interest in the development of mobile network protocols, 1 and there are two possible methodologies to evaluate the performance of new protocols. The first methodology is real testbeds, and the second is through simulation. Testbeds can mirror real scenarios closer than simulations, but simulations are easier to scale and repeat. 2 In consequence, simulators are preferred in the evaluation of Opportunistic Networks (OppNet) and Mobile Ad hoc NETworks (MANET) protocols. 3
Mobility models have a major effect on the protocol performance of wireless networks. Therefore, a mobility model should mimic the users’ movements of the targeted real scenario. Otherwise, the observations made from the simulation may be incorrect. 4 In addition, there are recent efforts to increase the accuracy of Wireless Sensor Networks (WSN) in combination with cloud computing, such as SensorCloudSim. 5 In consequence, it is important to also improve the accuracy in scenarios where sensors are attached to humans or other mobile entities using a scalable mobility model capable of representing the movement of real users.
Mobile network protocols have an extensive range of applications. For example, they are used in WSNs to monitor sea birds 6 and opportunistic networks for workers in disaster recovery scenes. 7 In the mentioned applications and many others, mobility plays a significant role in the efficiency of the protocol. 8
Mobility models can be trace-based models or synthetic models. Trace-based models represent real users’ movement on specific scenarios, but they are difficult to obtain, and recorded scenarios available in public databases are limited. However, synthetic models are flexible and scalable, but their statistical results may differ from real scenarios depending on the model. 9
Usually, mobility models are employed to represent human mobility, which is characterized by different aspects. People usually are more attracted to visit the same places every day, but they also take irregular trips. 10 People behave as a social network with a high level of clustering. 11 Consequently, to represent a human social network, we need a model that can capture three characteristics from traces. 12 Those characteristics are spatial dependency, temporal dependency, and geographic restrictions. 13 Pure-random synthetic models such as Random WayPoint (RWP) do not capture any of these characteristics. 14 However, there are mobility models that capture one or more of the mentioned characteristics. For example, SWIM captures spatial and temporal dependency by exploiting human tendency to gather in popular locations. 15 Another example is TRAce-based ProbabILiStic (TRAILS), which captures all three characteristics by extracting information from real traces. The TRAILS model presented in this paper builds upon the paper “TRAILS-A Trace-Based Probabilistic Mobility Model.” 16 Our work enhances the previous algorithms by considering the changes of human routines over time, as explained in section 3.1.
In this paper, we explain in section 2 the concepts behind mobile networks and mobility models. Then, in section 3, we describe the TRAILS model and its algorithms. In section 4.1, we present three different scenarios that represent the mobility of pedestrians and vehicles. In sections 4.2 and 4.3, we portray the properties of users’ contacts of TRAILS, SWIM, and traces. In section 4.4, we analyze the performance of TRAILS algorithms, and we describe the effects of varying the simulation time and the number of users in TRAILS simulations. In section 4.5, we present the effects of TRAILS, SWIM, and traces of real scenarios in the performance of OppNet protocols. Finally, in section 5, we summarize our findings.
2. Related work
Mobility models are widely used in the research of mobile networks, 17 and TRAILS is a mobility model that mimics users’ statistical behavior in real scenarios. That is why, in this section, we present an overview of mobile networks and we review the key factors of synthetic and trace-based mobility models.
2.1. Mobile networks
There are two large categories of decentralized mobile networks. The first category is MANET, and the second one is OppNet. In the past decade, many researchers have studied the effects of mobility models in both categories. 18 MANET is a set of mobile users forming a network without a predefined infrastructure where a user defines a communication path before sending a message. 19 However, OppNet is a delay-tolerant mobile network where users forward messaged without an established end-to-end communication path. 20
Mobile network protocols have a different performance under different scenarios. Therefore, we should evaluate those protocols under realistic conditions, such as a mobility model capable of representing human behavior in a reasonable way. 4
To measure the performance of mobile network protocols, we can use the following metrics: end-to-end delay, that describes the mean time of a message since its creation until it reaches its destination 21 and packet delivery ratio, that represents the relation of the number of packets transmitted versus the number of packets successfully received. 22
In a wireless network protocol, the data transmission is more sensitive to failures due to deterioration of the connection in established links. 6 In addition, in OppNet protocols such as RAPID 23 or Epidemic, 24 a mobile node uses the contact history with other nodes to deliver messages. For that reason, the metrics used to evaluate mobile network protocols are very sensitive to the characteristics of the mobility model.
To evaluate OppNet protocols, we can use simulators such as ONE, that is an integrated solution that can simulate delay-tolerant wireless protocols with synthetic and trace-based mobility models; 25 Adyton, that simulates OppNets only with trace-based mobility models; 26 and Opportunistic protocol simulator (OPS), 27 that is an extension of the discrete event simulator OMNeT++. 28 OPS can simulate OppNet’s protocols with synthetic and trace-based mobility models. 27
2.2. Mobility models
There are two types of mobility: weak mobility and strong mobility. Weak mobility is characterized by unusual joins of new nodes in a network or existing nodes experimenting with a failure in their hardware. However, strong mobility is described by concurrent user’s joins and physical displacement of nodes. We use mobility models to describe strong mobility. 29
A mobility model is defined as a set of rules to generate trajectories for users. 30 The input of a mobility model is a mobility graph, and the graph contains the information that a user needs to move according to a specific model.
Mobility models are divided into two categories: synthetic models and trace-based models. Trace-based models are a set of trajectories from a real scenario, and synthetic models seek to mimic human mobility by defining rules and parameters. 9
2.2.1. Trace-based mobility models
Trace-based mobility models are a collection of information regarding the trajectories of several users from real scenarios. 9
Trace-based models are expensive and difficult to obtain because they require real people with devices to record their trajectories. We can use a combination of technologies such as global navigation satellite system (GNSS), radio frequency identification (RFID), received signal strength indicator (RSSI), and accelerometers to record real traces.31–33
There are databases of public access with trace-sets of real scenarios such as CRAWDAD, 34 Wikiloc, 35 and MobiLib. 36 However, the scenarios in those databases are limited, and each trace-set has its own format. 6
2.2.2. Synthetic mobility models
A synthetic mobility model is a collection of rules to control users’ movement in a simulation. 9
To avoid misleading results in the evaluation of mobile network protocols, a synthetic model should mimic the temporal dependency, spatial dependency, and geographic restrictions of real scenarios. Temporal dependency is related to the velocity of each user. Spatial dependency is the social relation between users. Geographic restrictions are predefined trajectories and obstacles to limit the users’ displacement. 37
There are several synthetic mobility models such as RWP, SWIM, “An area-scalable human-based mobility model,” and TRAILS. In RWP, users travel through a surface with random directions, random velocities, and without restrictions.
14
In SWIM, users’ homes and popular places are assigned at random locations. In addition, a user chooses to go to its home or a popular place based on a parameter called
RWP is a purely random mobility model that does not capture any characteristic from real scenarios. 14 However, SWIM can mimic spatial and temporal dependency if we find the right set of parameters, as explained in section 4.2.1. The model proposed by Gharib et al. restricts the users’ mobility through predefined paths. However, those paths are straight lines between hotspots that do not represent the paths of a real scenario. TRAILS captures geographic restrictions and temporal dependency using real paths from traces, and it mimics spatial dependency by automatically extracting information about common locations from real scenarios. 16 Table 1 summarizes the characteristics of different synthetic mobility models.
Mobility models characteristics captured from real scenarios.
RWP: Random WayPoint; SWIM: Small Worlds in Motion; TRAILS: TRAce-based ProbabILiStic.
3. Model description
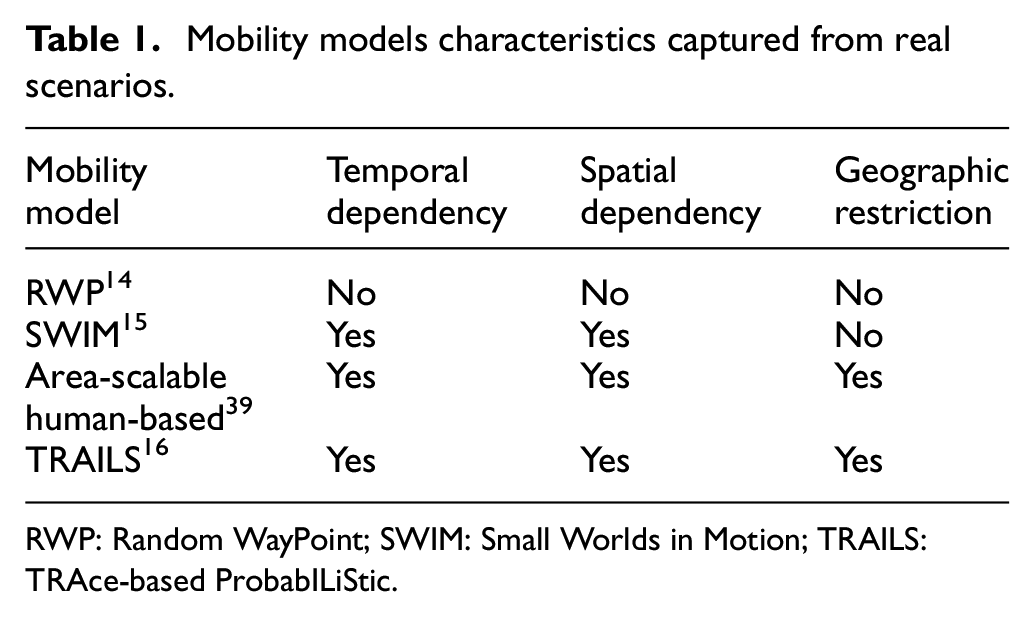
TRAILS is a mobility model in which a user travels to popular places extracted from real scenarios using real paths, as explained in section 3.1. In addition, a user selects a popular place or POI as its destination based on the POI’s popularity, as described in section 3.2. In TRAILS, a graph generator creates a mobility graph with points of interest (POIs) and paths extracted from traces and a simulator imports the graph to controls the users. Figure 1 portrays a didactic representation of a trace-set and its corresponding TRAILS graph. 16
Comparison between a trace-set and a TRAILS graph.
The paper entitled “TRAILS-A Trace-Based Probabilistic Mobility Model” does not take into account that humans have different routines at distinct moments of the day and that POIs are not equally crowded. This research takes into account both facts by introducing popularity indicators in POIs. A popularity indicator is a time-dependent property that represents the popularity of a POI at different time slots. Section 3.1.1 defines how popularity indicators are estimated, and in section 3.2, we describe how TRAILS uses those indicators in a simulator. 16
In this section, we describe the components of a TRAILS graph. Next, we specify the process used to build graphs from real traces. Finally, we explain the users’ behavior in a TRAILS simulation.
3.1. TRAILS graph
The TRAILS graph is composed by a list of POIs and a list of links. We define a POI as a place where one or more users spend a significant amount of time, for example, a supermarket, an office, or a house. In addition, we define a link as a path connecting two POIs. In TRAILS, paths are extracted from real traces. 16
In a TRAILS graph, a link is a list of coordinates with timestamps between a pair of POIs. In addition, a POI is described with a geographical position, a list of stay times, and a list of popularity indicators. Each stay time represents the amount of time a user can stay in the POI, and each popularity indicator is an element that indicates how congested a POI is at a specific time slot.
This section describes the algorithms used to extract POIs and links from a real scenario.
3.1.1. Extraction of POIs
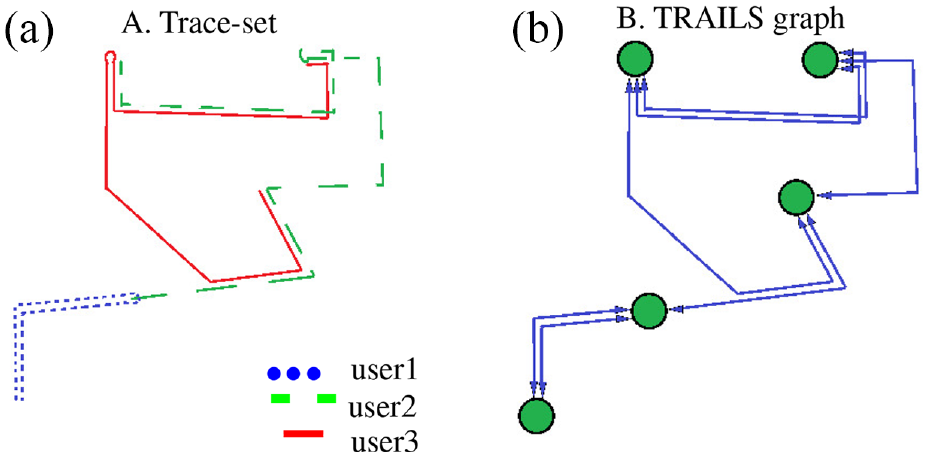
In a real scenario, if a user spends a period longer than a time threshold T in an area limited by a diameter smaller than a constant D. Then, that area represents a POI.
To find a POI, we search for a trace segment that has a duration longer than T and that we can enclose in a circle with a diameter equal to D. To calculate the smallest enclosing circle around a trace segment, we used the “Smallest enclosing circle” algorithm proposed by Emo Welzl and implemented by Project Nayuki.40,41 Once we find a POI, we search inside the POI additional trace segments that have a duration longer than T. Then, we save the duration of all the trace segments as the POI’s list of stay times. Finally, we build the POI’s list of popularity indicators. Figure 2 shows a graphical illustration of a POI.
Representation of a POI formed with two trace segments.
In TRAILS, a popularity indicator is equal to the number of users from real traces inside a POI. In a real scenario, the number of users in a POI changes over time. That is why, a POI requires a list of popularity indicators to represent its congestion at different time slots. In addition, we define a time slot as the interval in which the number of users in the POI does not change. TRAILS simulations use the popularity indicators to estimate the probability of a user traveling to a POI.
In a TRAILS simulation, popularity indicators make POIs more or less appealing to users depending on the time slot. Therefore, a simulated user can mimic the routines of users in a real scenario. In addition, the time slots of POIs’ popularity indicators can reduce errors caused by sporadic crowdedness over areas that do not represent an actual place of interest. For example, in a TRAILS simulation, a traffic jam in a roundabout would behave as a POI only during rush hours.
3.1.2. Extraction of links
After we identify the POIs, we extract the links by identifying trace segments connecting a pair of POIs. Once we identify all links, we remove links that we consider unrealistic, and we add new links to guaranty that the TRAILS graph is strongly connected.
We consider a link unrealistic when the link has two consecutive coordinates at a distance longer than a threshold Maximum link gap. For example, if a taxi stops recording its GNSS position for a considerable time while moving around a lake. Then, the taxi’s recorded trace may lead to the false conclusion that it moved through the middle of the lake. Therefore, TRAILS identifies and removes these links from the mobility graph.
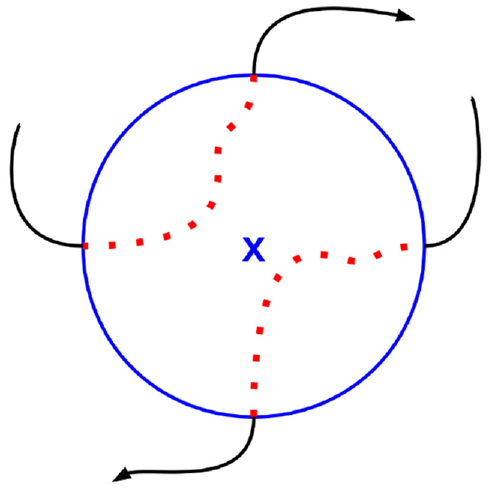
As shown in Figure 3, we search for any pair of POIs connected with links only in one direction. Then, we duplicate those links, and finally, we invert the orientation of the duplicated links. In consequence, if the simulation time is long enough, a user should reach any POI from any other POI.
Example of the generation of links for a TRAILS graph.
If we do not add the duplicated links in the TRAILS graph, users that arrive to certain POIs would not be able to travel back to POIs they visited before. In other words, the constraints of the users’ mobility would increase over time. Therefore, to guaranty that TRAILS can scale in time, we need to have a strongly connected graph.
3.2. Simulation algorithm
In Figure 4, we present a diagram describing the TRAILS simulation algorithm. The algorithm requires a mobility graph with POIs and links as input parameters, as explained in section 3.1. At the beginning of the simulation, each user starts at a random POI. Then, the user chooses a stay time randomly from the POI’s list. After the stay time is over, the user chooses a random link for each possible destination. Then, the user assigns a weight to each destination POI. The weight is equal to the POI’s popularity indicator estimated at the expected arrival time (AT). After estimating the popularity indicators, the user selects a POI based on a weighted random method. Finally, the user travels to the chosen POI.
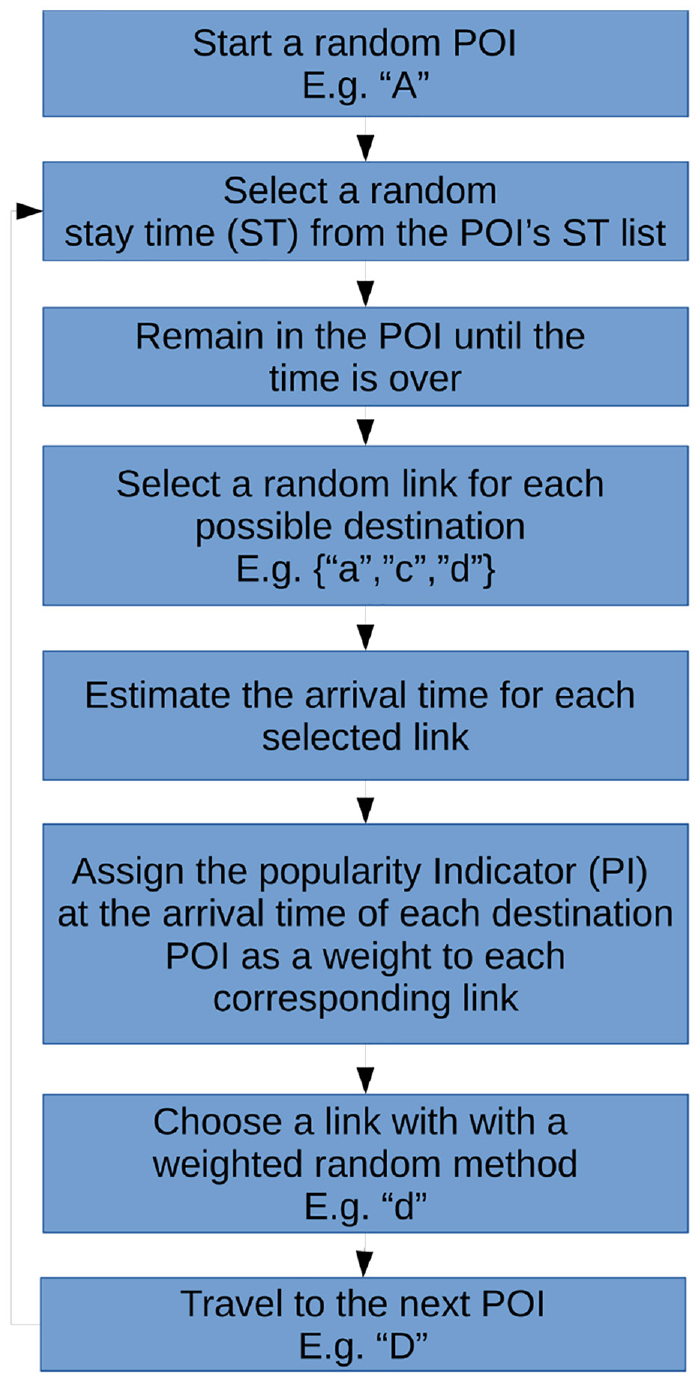
Flowchart of TRAILS algorithm.
As described in Equation (1), when TRAILS estimates the expected AT, it calculates the residue of the AT extracted from traces modulus the total recorded time (RT) of the real scenario. TRAILS simulations have several advantages over trace-based models. For example, due to Equation (1), it is possible to simulate TRAILS without a time limit. In addition, all users in a TRAILS simulation follow the same logic described in Figures 4 and 5. Therefore, we can simulate the same TRAILS graph with different amounts of users. Furthermore, the TRAILS model reduces the number of events produced in a discrete simulator because a user does not generate new events while it stays in a POI. Accordingly, TRAILS presents an increase in time performance compared to trace-based models, as shown in section 4.4:
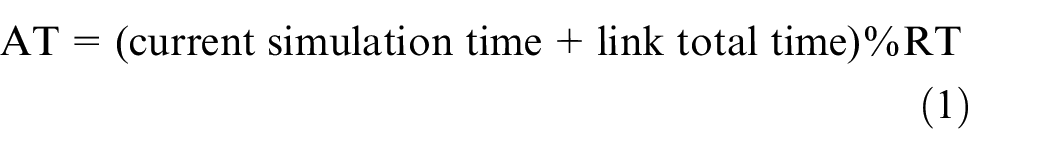
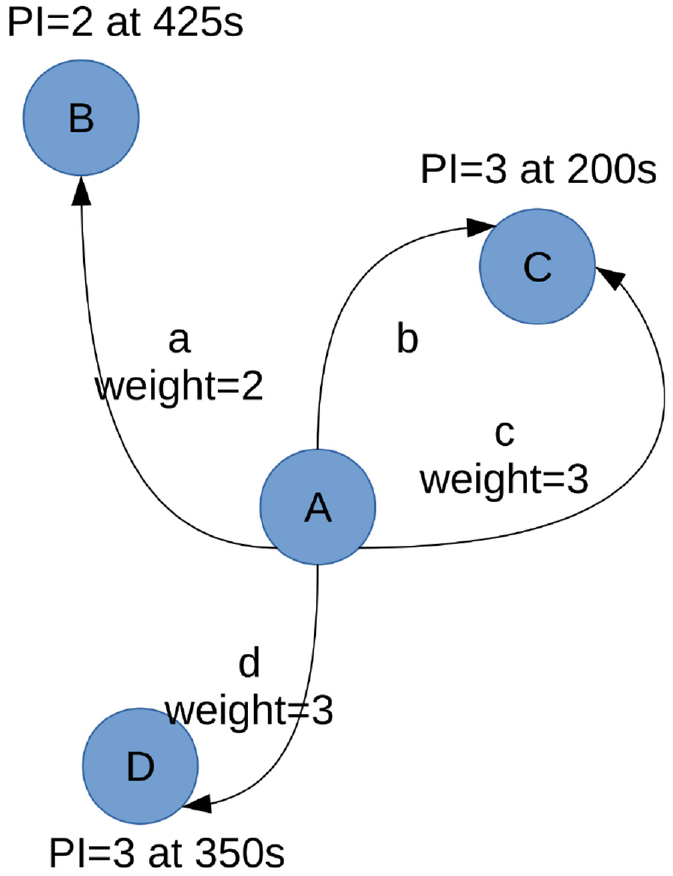
User behavior in a TRAILS simulation.
4. Results
TRAILS goal is to mimic human social contacts in a real scenario. Therefore, we compare different mobility metrics of TRAILS, real traces, and another fully flexible mobility model such as SWIM.
We chose SWIM as a reference model in the analysis of TRAILS because of its well-defined algorithm and implementation. 38 There are more recent models than SWIM such as “An area-scalable human-based mobility model” by Gharib et al. However, Gharib et al. uses the Dijkstra algorithm to search a path between a two hotspot zones, and the Dijkstra algorithm adds a significant computation time overhead for relatively large scenarios. In addition, Gharib et al. 39 do not describe a method to extract hotspot zones from real scenarios.
To avoid biased results, we perform our experiments with three different scenarios. We simulate each scenario with its original traces, a TRAILS graph, and two SWIM models with different parameters chosen empirically to approximate the user’s contacts of SWIM simulations to traces.
For each experiment, we compute the TRAILS graphs with a script implemented in the programming language Python 3. 42 Then, we simulate each mobility model with the discrete simulator OMNeT++ 5.4 28 and the framework INET 4.1. 43 In addition, we used the model implementation described in the paper “Implementation of the SWIM mobility model in OMNeT++” to perform SWIM simulations. The SWIM implementation requires configuring a set of parameters manually. To analyze the effect of SWIM parameters in our experiments, we execute two SWIM simulations with different sets of parameters for each scenario. 38
To find the best set of SWIM parameters, we perform various simulations. Then, we compare the box-plots of the mobility metrics between each SWIM simulation and the original traces. Finally, we select the sets of parameters of the two simulations that presented the fewest differences compared to traces. As shown in Tables 3–5.
We used our own TRAILS model implementation stored in a GIT repository. 44 In addition, we used the tool MobilityModelCheck to extract the user’s contacts of each simulation. 45
In this section, we analyze the users’ contacts by observing three mobility metrics: contact duration, inter-contact time, and repeated contacts. In addition, we describe the repeatability of TRAILS by comparing the variability of mobility metrics between simulations with different random seeds. Furthermore, we discuss the performance of TRAILS in comparison with traces and SWIM simulations by observing the computation time and memory consumption. Finally, we discuss the performance of an OppNet protocol such as Epidemic with different mobility models by comparing the end-to-end delay and the packet delivery ratio in simulations with TRAILS, SWIM, and traces. 24
4.1. Scenarios
To study TRAILS and its performance in comparison to traces and SWIM, we used three scenarios: Orlando, New York, and San Francisco. For each scenario, we compute the TRAILS graphs with position trace-sets and the parameters from Table 2.
Parameters to generate TRAILS graphs.

POI: point of interest.
4.1.1. Orlando
The first scenario, Orlando, represents the movement of 41 pedestrians for 14 h. As shown in Table 3, this section describes the Orlando scenario with its traces, a TRAILS graph, and two sets of SWIM parameters.
Specification of models that represent pedestrians in Orlando.
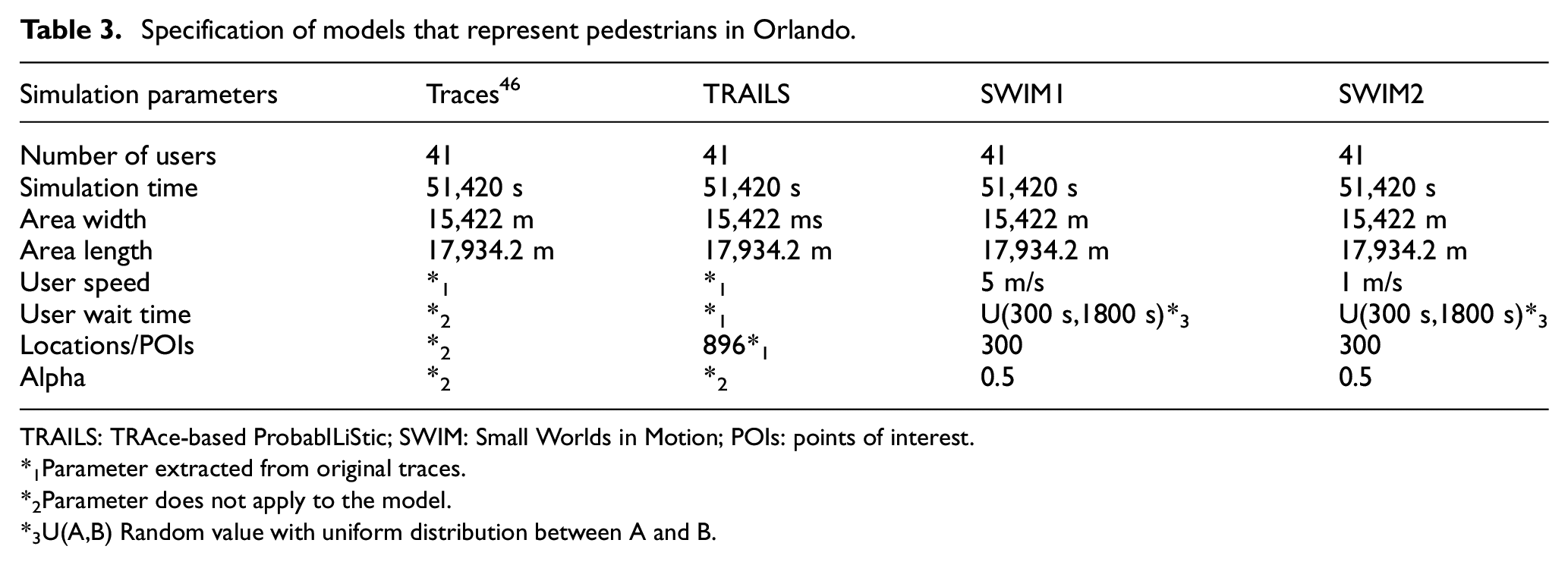
TRAILS: TRAce-based ProbabILiStic; SWIM: Small Worlds in Motion; POIs: points of interest.
*1Parameter extracted from original traces.
*2Parameter does not apply to the model.
*3U(A,B) Random value with uniform distribution between A and B.
The traces of the Orlando scenario portrayed in Figure 6 are available in the Crawdad database. 46 The TRAILS graph presented in Figure 6 (right) has 896 POIs and 1433 links. The SWIM simulations described in Figure 7 have the same parameters except for the user speed, as shown in Table 3.
Traces and TRAILS graph of the Orlando scenario.
Coordinates of users in SWIM simulations of the Orlando scenario.
4.1.2. New York
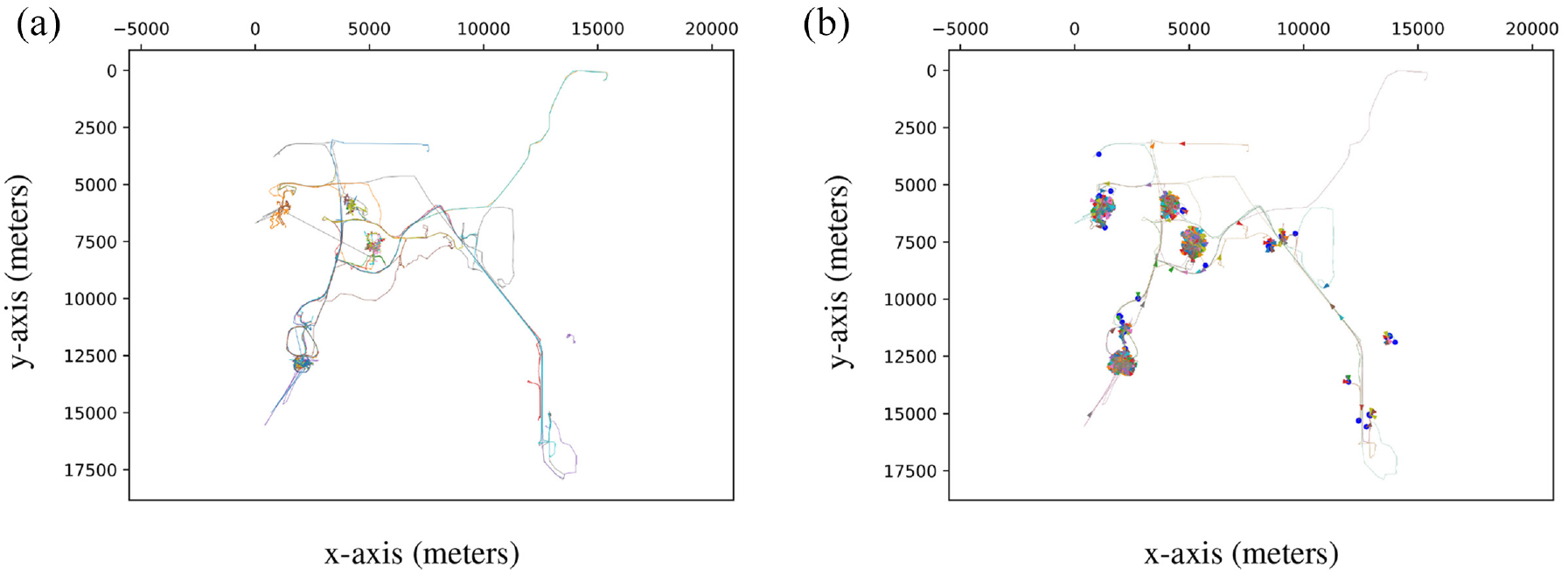
The second scenario, summarized in Table 4, represents the movement of 39 pedestrians for 22 h in the city of New York.
46
Figure 8 (left) presents the GNSS trace-sets. The TRAILS graph shown in Figure 8 (right) describes 195 POIs and 293 links between them. Table 4 shows that the SWIM simulations described in Figure 9 share the same parameters except for the
Specification of models that represent pedestrians in New York.
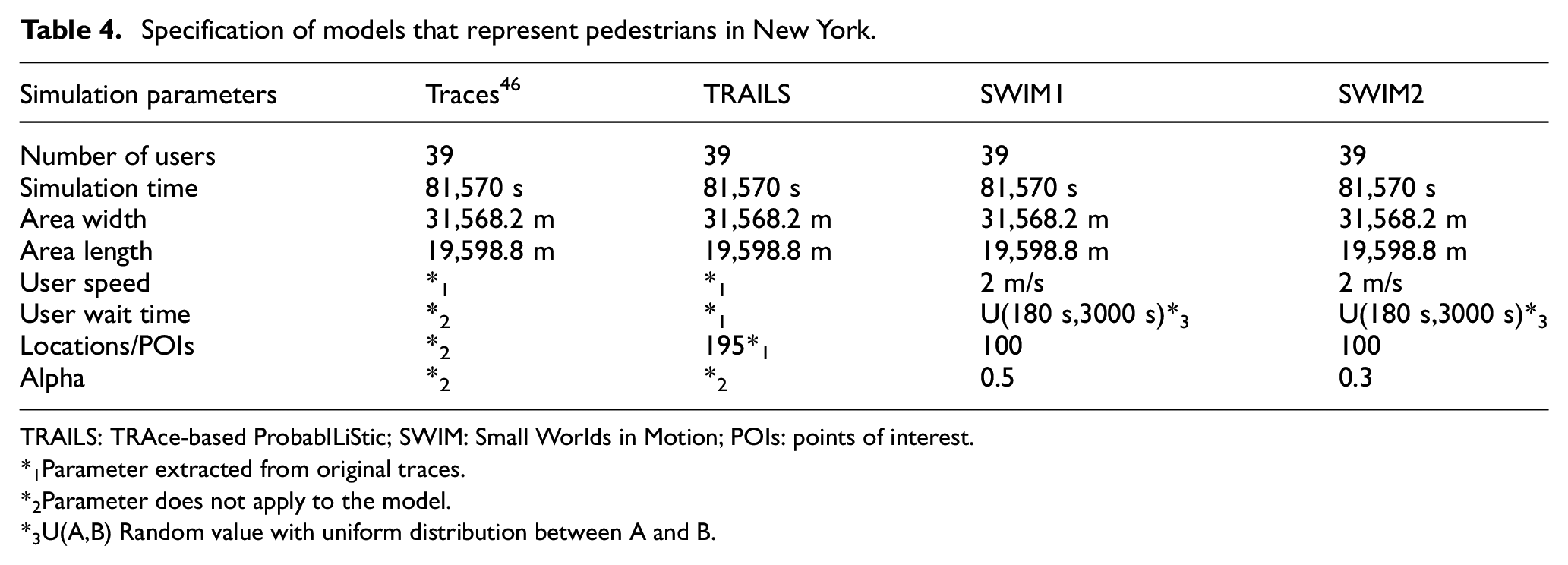
TRAILS: TRAce-based ProbabILiStic; SWIM: Small Worlds in Motion; POIs: points of interest.
*1Parameter extracted from original traces.
*2Parameter does not apply to the model.
*3U(A,B) Random value with uniform distribution between A and B.
Traces and TRAILS graph of the New York scenario.
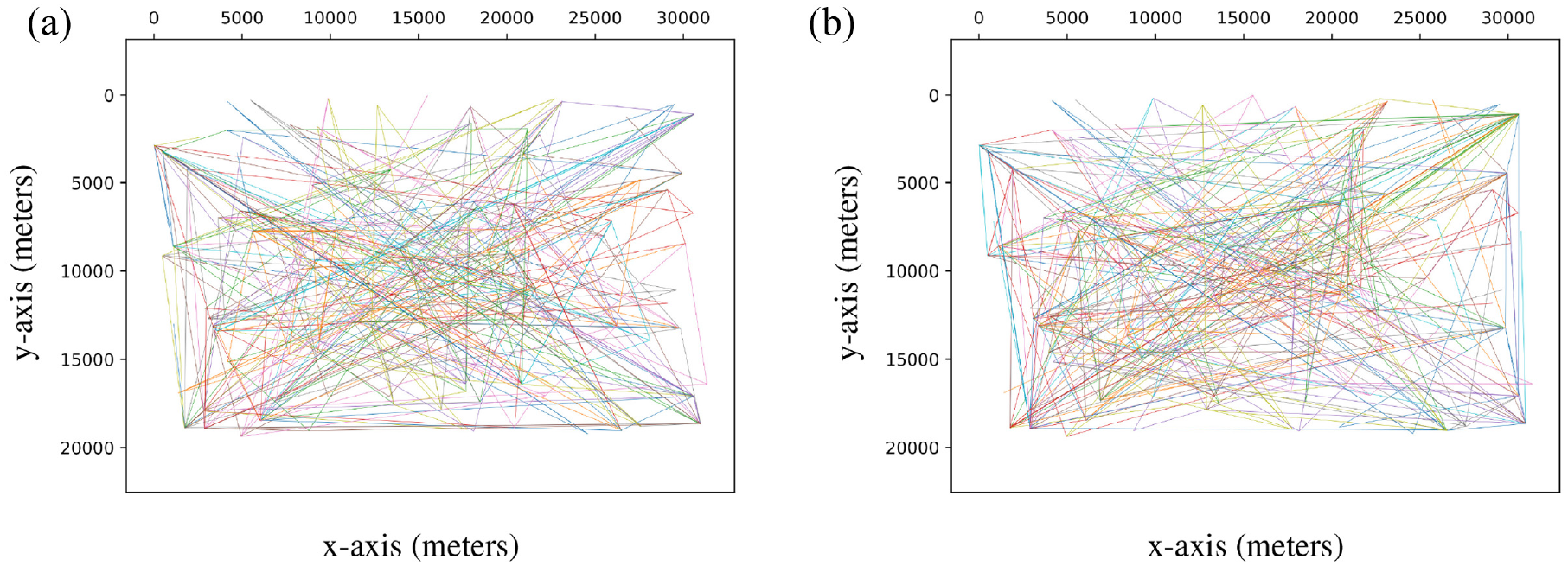
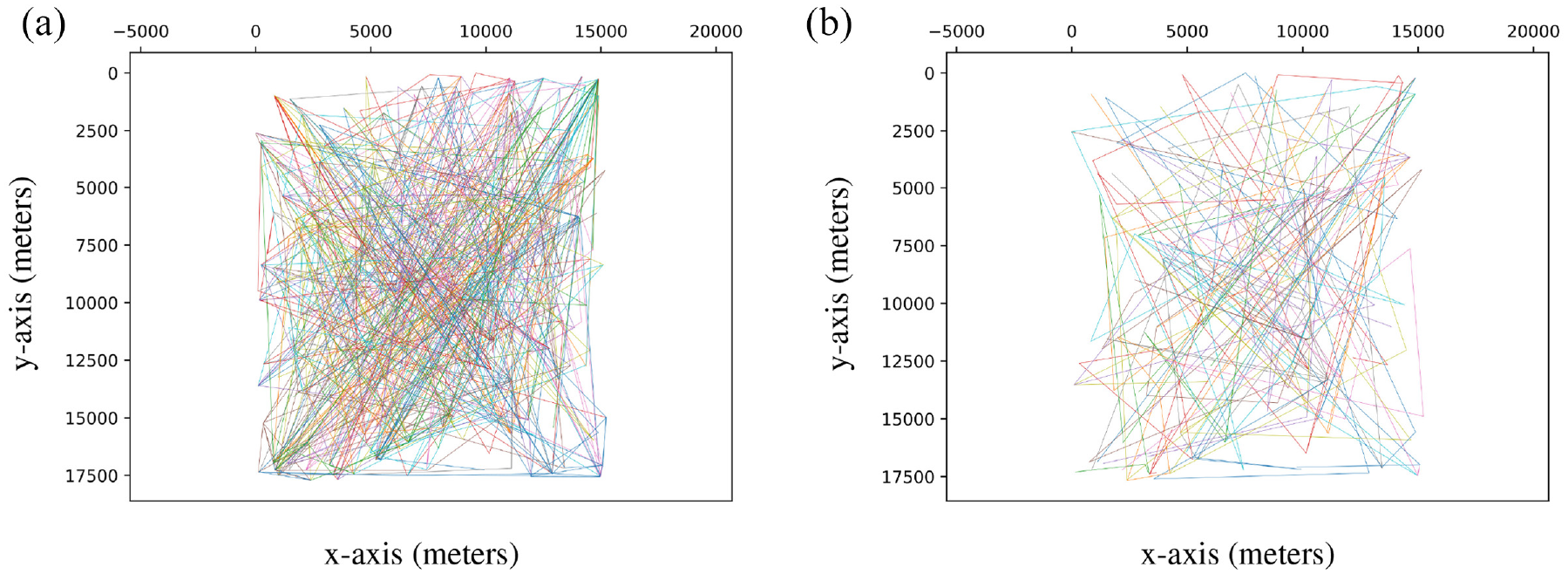
Coordinates of users in SWIM simulations of the New York scenario.
4.1.3. San Francisco
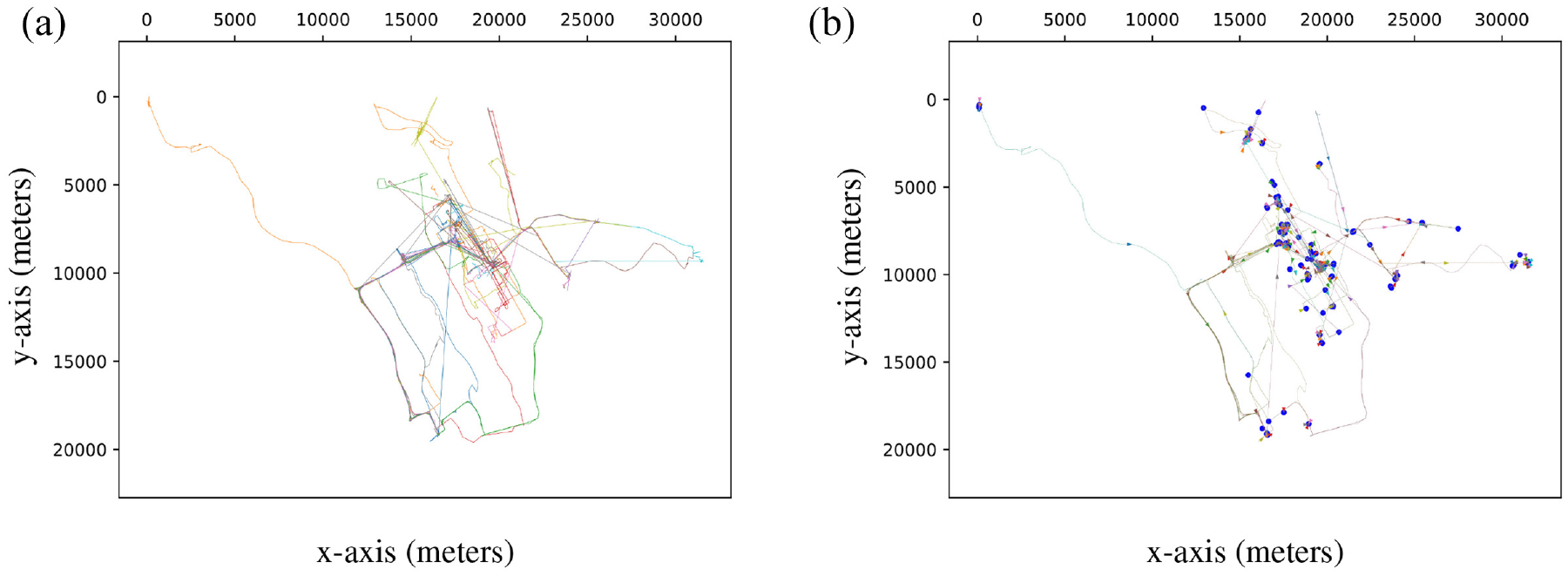
The third scenario portrays in Figure 10 (left) the traces of 536 taxis for 24 days in San Francisco. 47 As shown in Table 5, the parameters used for the SWIM simulations presented in Figure 11 are the same except for the number of locations. The TRAILS graph shown in Figure 10 (right) describes 40,701 POIs and 189,765 links. In addition, we observe in Figure 10 (right) that TRAILS filters discontinuous traces, as explained in section 3.1.2.
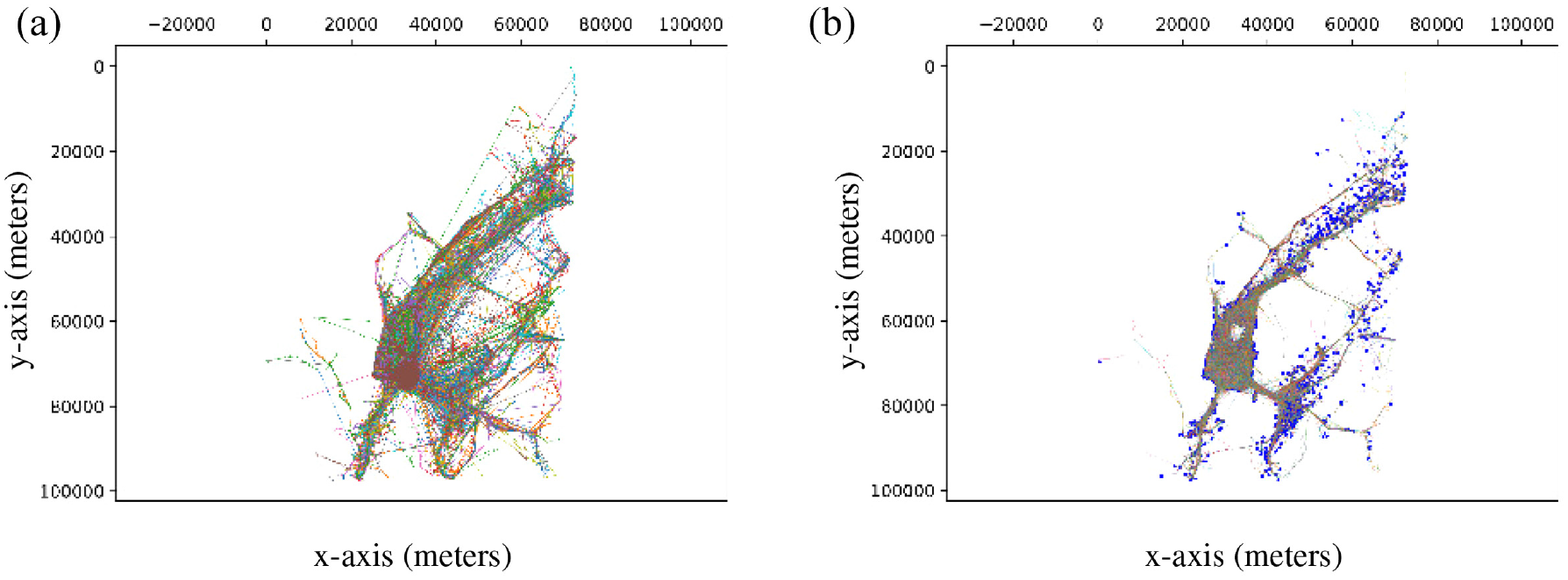
Traces and TRAILS graph of the San Francisco scenario.
Specification of models that represent taxis in San Francisco.
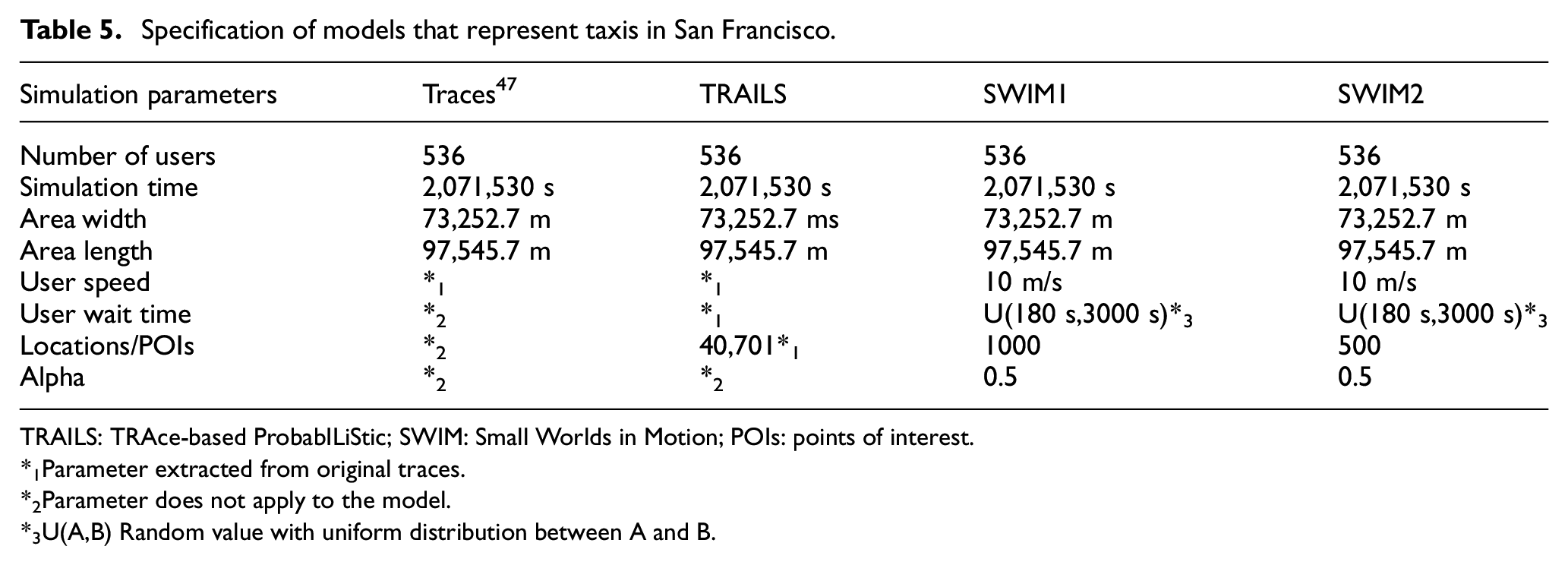
TRAILS: TRAce-based ProbabILiStic; SWIM: Small Worlds in Motion; POIs: points of interest.
*1Parameter extracted from original traces.
*2Parameter does not apply to the model.
*3U(A,B) Random value with uniform distribution between A and B.
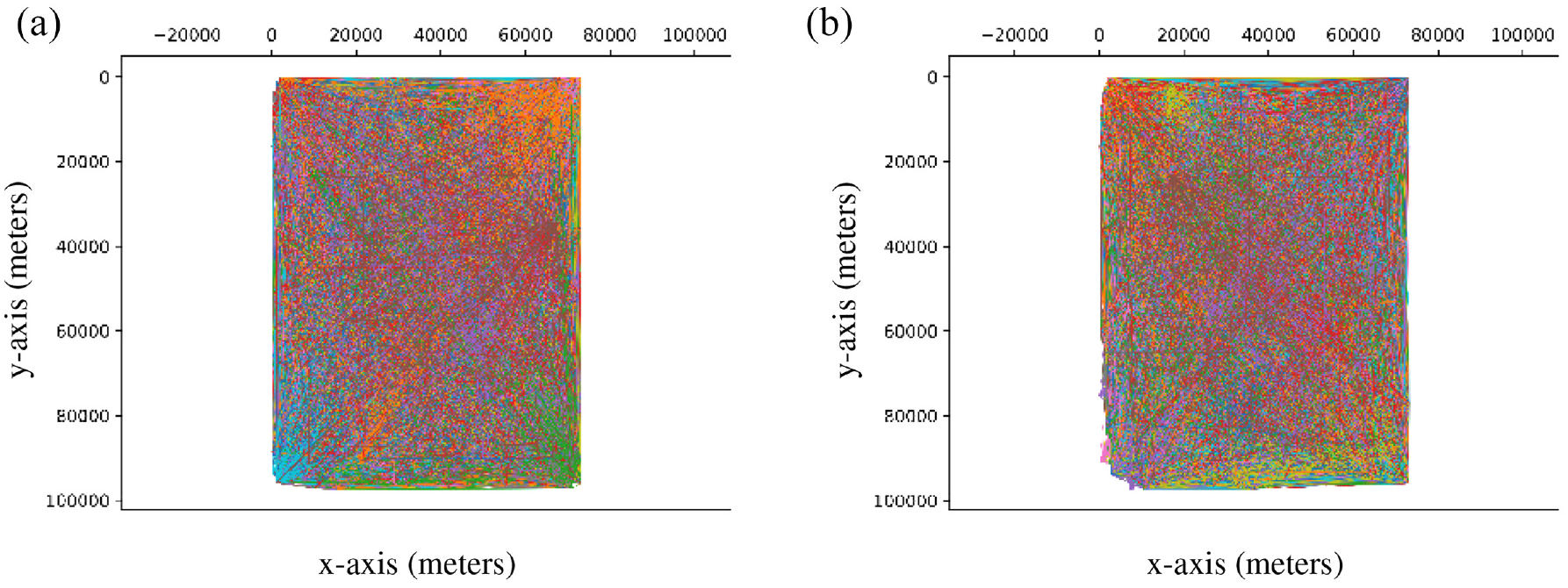
Coordinates of users in SWIM simulations of the San Francisco scenario.
4.1.4. Visual inspection
We observe in Figures 7, 9, and 11 that in the three scenarios, users in SWIM simulations move differently than users in traces. However, Figures 6, 8, and 10 reveal that users in TRAILS follow the same paths described by traces. That is because TRAILS mimics the geographic restrictions of real scenarios, as explained in sections 3.1 and 3.2.
4.2. Analysis of user’s contacts
SWIM requires a manual adaptation of simulation parameters, as shown in Tables 3–5. However, TRAILS extracts features such as POIs and links directly from the traces, as explained in section 3.1. In this section, we present the difficulties of finding the right set of parameters to approximate the mobility metrics such as contact duration, inter-contact time, and repeated contacts of SWIM and real scenarios. We also describe how TRAILS overcomes those difficulties. In addition, we summarize our findings by comparing the cumulative distribution function (CDF) of the mobility metrics of simulations with SWIM, TRAILS, and traces.
In this research, we define contact duration as the period of two users in contact, inter-contact time as the time between two successive contacts of the same pair of users, and repeated contacts as the number of times the same users were in contact during a simulation.48,49 In this section, we consider that two users are in contact when they are at a distance shorter than 30 m. Other researchers used the same metrics to describe users’ contacts. For example, the paper “Age Matters: Efficient Route Discovery in Mobile AdHoc Networks Using Encounter Ages” uses the inter-contact time to define users’ link strength. 50 In addition, the paper “BUBBLE Rap: Social-based forwarding in delay-tolerant networks” uses the contact duration and contact frequency (repeated contacts over time) to measure users’ connectivity. 51
We present each mobility metric with different statistical parameters, such as the median and interquartile range (IQR). We use the median because it is a better indicator of the probability density function (PDF) center than the arithmetic mean when the distribution of the metric is asymmetric. 52 In addition, we use the IQR to describe the dispersion of the data around the median. 53 We also represent the metrics graphically with box-plots and the CDF. Box-plots depict the mobility metrics with their median and their quartiles, 54 while the CDF portrays the metrics’ distribution. 55
4.2.1. Contact duration and inter-contact time
In Figures 12–14, we use box-plots to portray the contact duration and inter-contact time of user’s contacts of the three scenarios. Each figure shows the results of real traces, a TRAILS simulation, and two SWIM simulations. We describe the simulation parameters for each scenario in section 4.1.
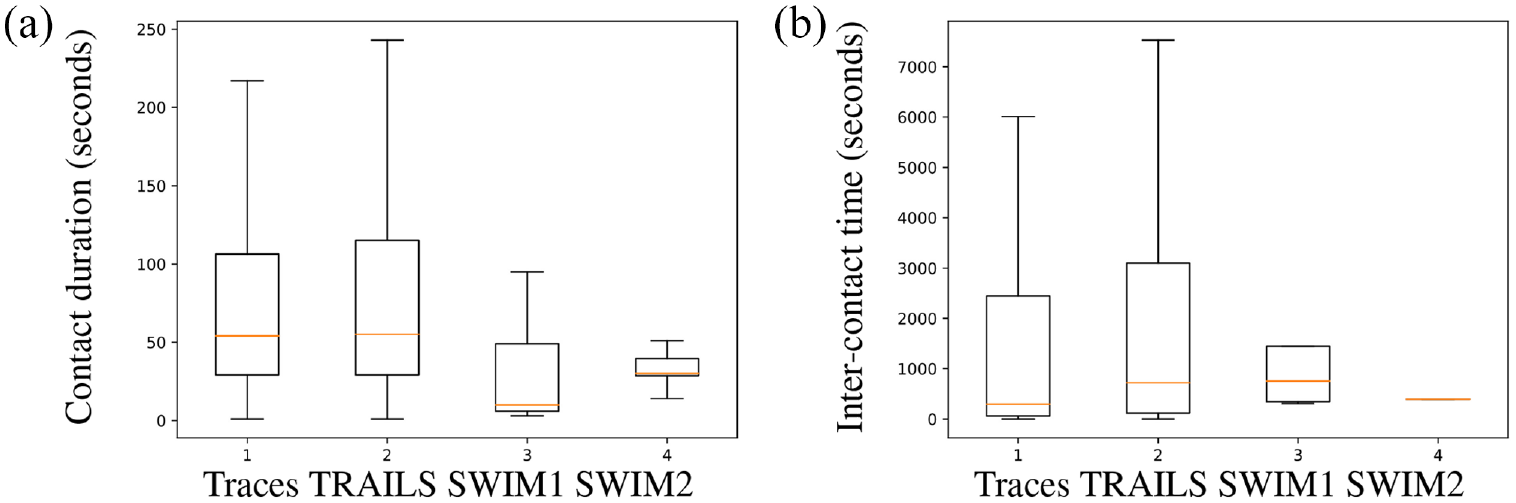
Box-plots of simulations of the Orlando scenario.
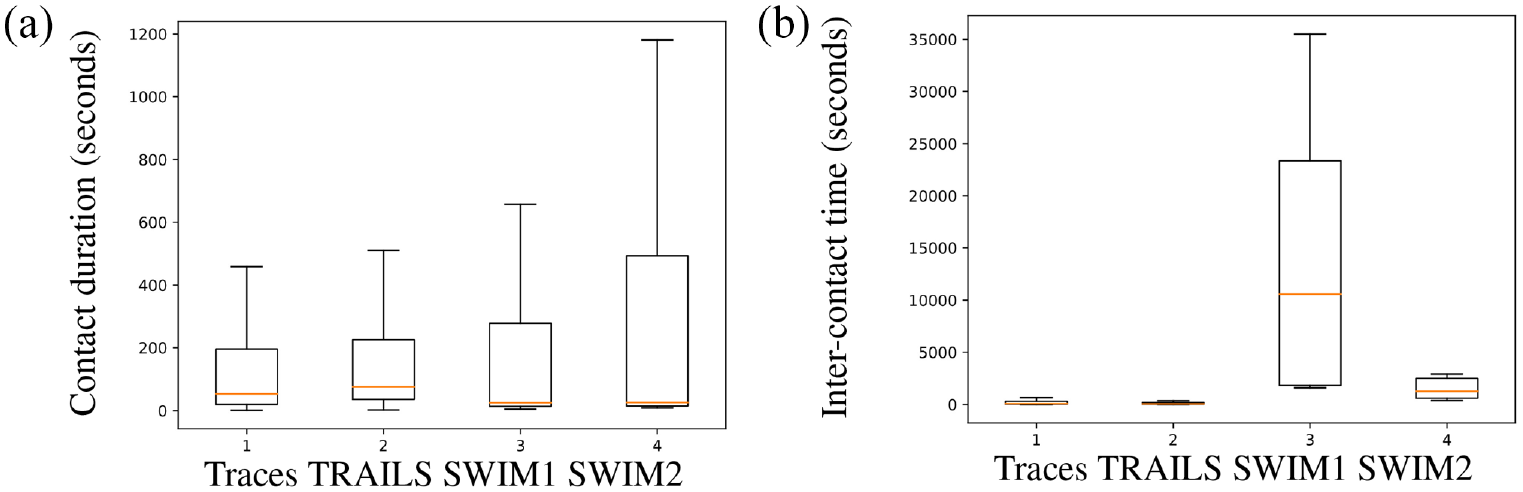
Box-plots of simulations of the New York scenario.
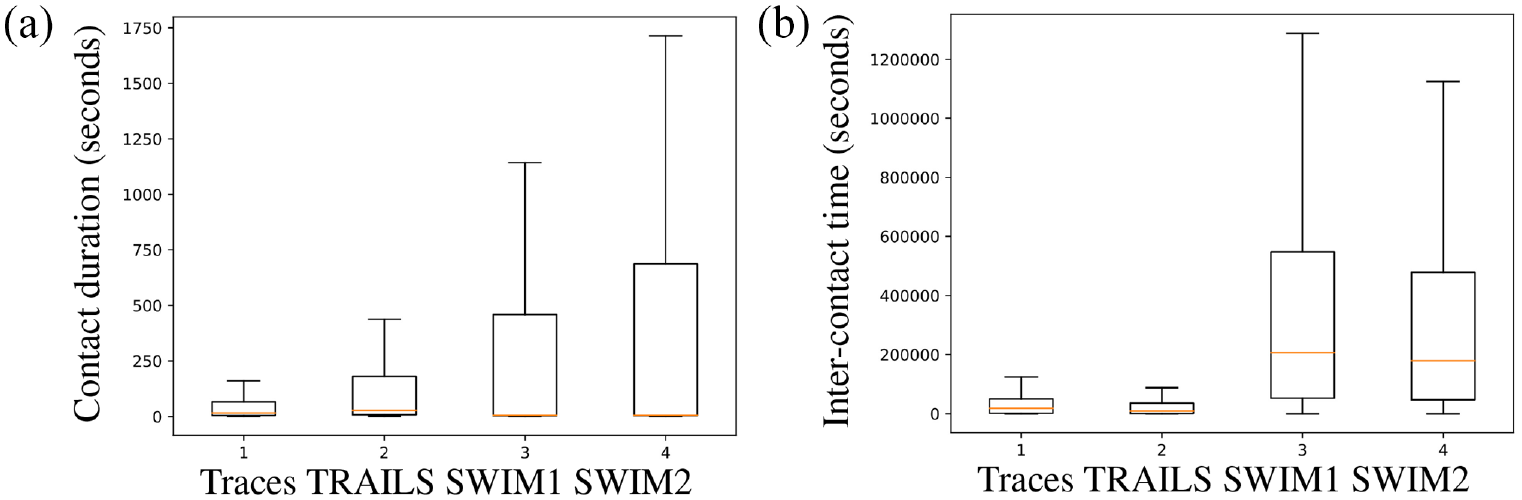
Box-plots of simulations of the San Francisco scenario.
In Figure 12, we observe that in the Orlando scenario, the median of contact duration of the original trace-set is more similar to the second SWIM simulation (SWIM2) than to the first SWIM simulation (SWIM1). However, the contact duration IQR of the same trace-set is more similar to SWIM1 than to SWIM2. In addition, in Figures 13 and 14, we see that for the New York and San Francisco scenarios, the contact duration IQR of traces is closer to SWIM1 than that is to SWIM2. Meanwhile, the inter-contact time IQR of New York’s and San Francisco’s traces is closer to SWIM2 than that is to SWIM1. In conclusion, if we want to approximate the properties of users’ contacts of SWIM simulations to real traces, we may need to spend considerable effort performing several SWIM simulations until we find an adequate set of SWIM parameters.
Figures 12–14 also reveal that contrary to SWIM, the medians and IQR of contact duration and inter-contact time are similar between TRAILS simulations and traces in the three scenarios. For example, in Figure 13, the mean absolute percentage error (MAPE) of the median contact duration between TRAILS and traces is 0.4, and the MAPE of the median contact duration between SWIM1 and traces is 0.53. However, the MAPE of the median inter-contact time between TRAILS and traces is 0.32, and the MAPE of the median inter-contact time between SWIM1 and traces is 125. In conclusion, we do not need to spend several iterations trying out different parameters to improve the results of TRAILS simulations.
4.2.2. Repeated contacts
As shown in Figure 15, for the three scenarios, the number of repeated contacts of SWIM simulations is considerably lower than the number of repeated contacts of traces. However, the box-plots of repeated contacts of TRAILS are more approximate to traces than SWIM simulations. The reason behind it is that a user in SWIM has a lower probability of making contact with other users because it can move to any position in a square area, as revealed in Figures 7, 9, and 11. However, Figures 6, 8, and 10 show that a user in a real scenario has more geographical restrictions such as buildings or lakes. In addition, TRAILS replicates those geographical restrictions by allowing a user to move only through predefined links extracted from traces. Therefore, in TRAILS simulations as in real scenarios, users have a higher probability to get in contact with each other.
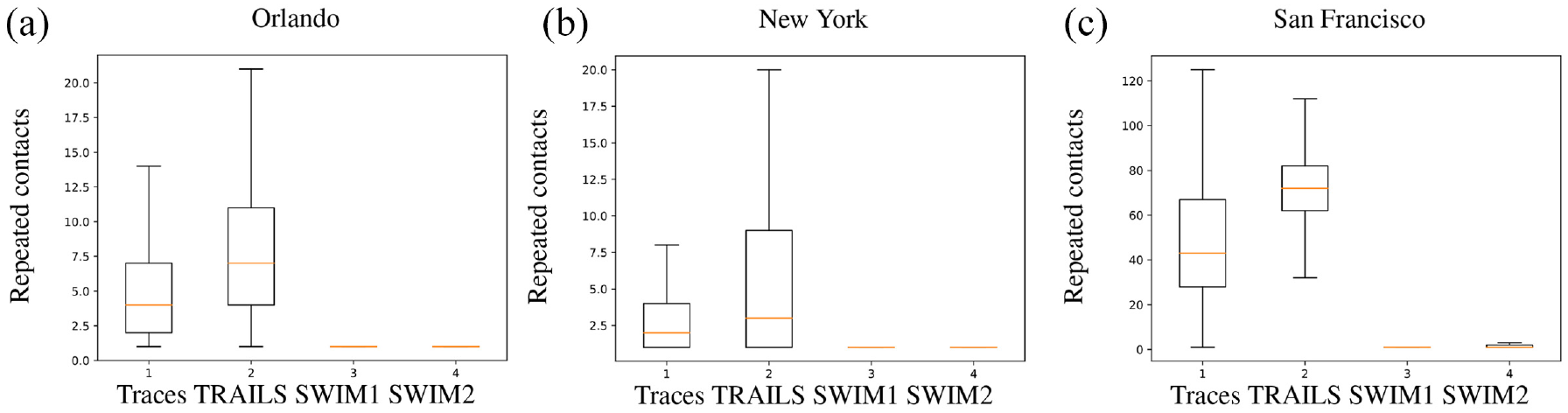
Box-plots of simulations of repeated contacts.
4.2.3. CDF of contact’s metrics
We observe in Figures 16 and 17 that the CDF of TRAILS and traces is smooth compared to SWIM simulations. The underlying reason is that the smoothness of the CDF depends on the number of contacts between users. As explained in section 4.2.2, SWIM simulations reproduced a relatively low number of contacts. Furthermore, we observe in Figures 16–18 that without the need for parameter tuning, TRAILS’ CDFs present a lower difference between real traces than SWIM simulations.
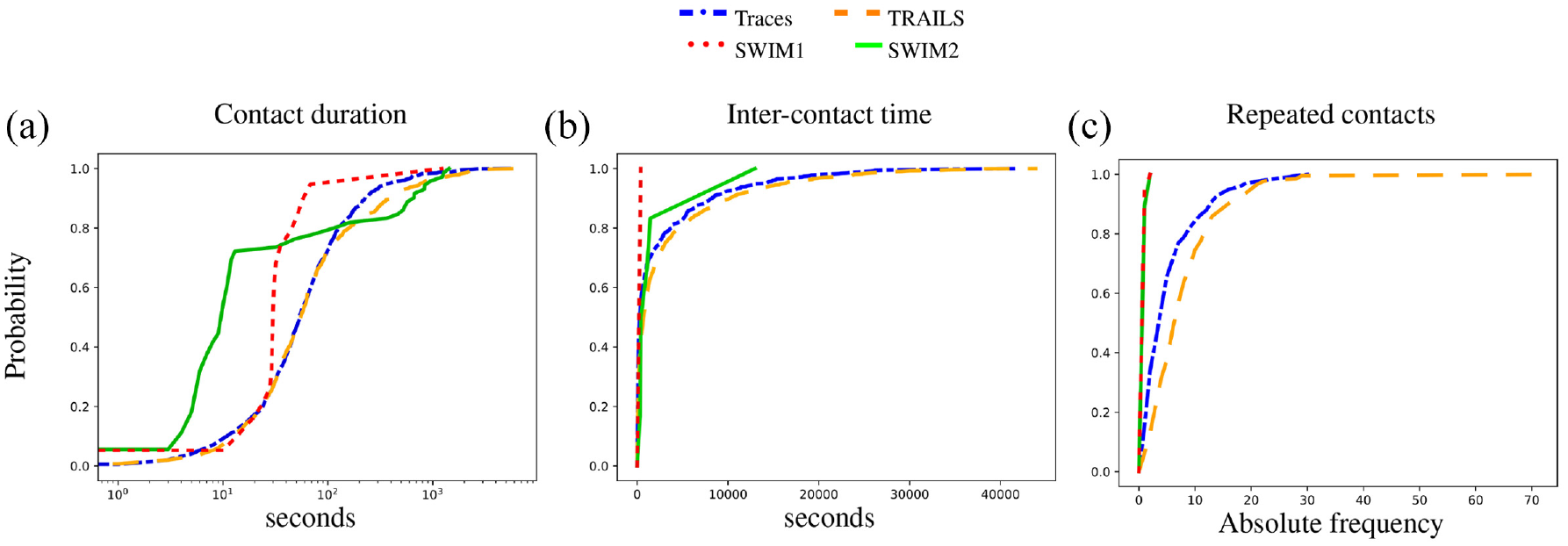
CDF of the Orlando scenario.
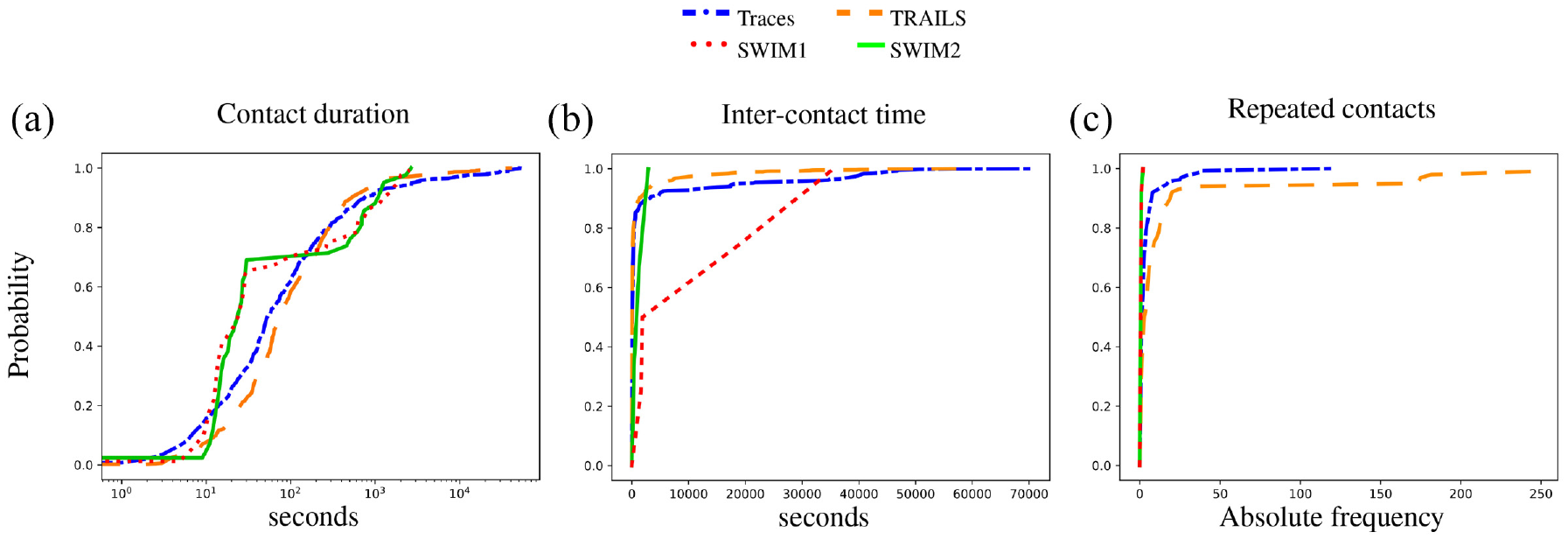
CDF of the New York scenario.
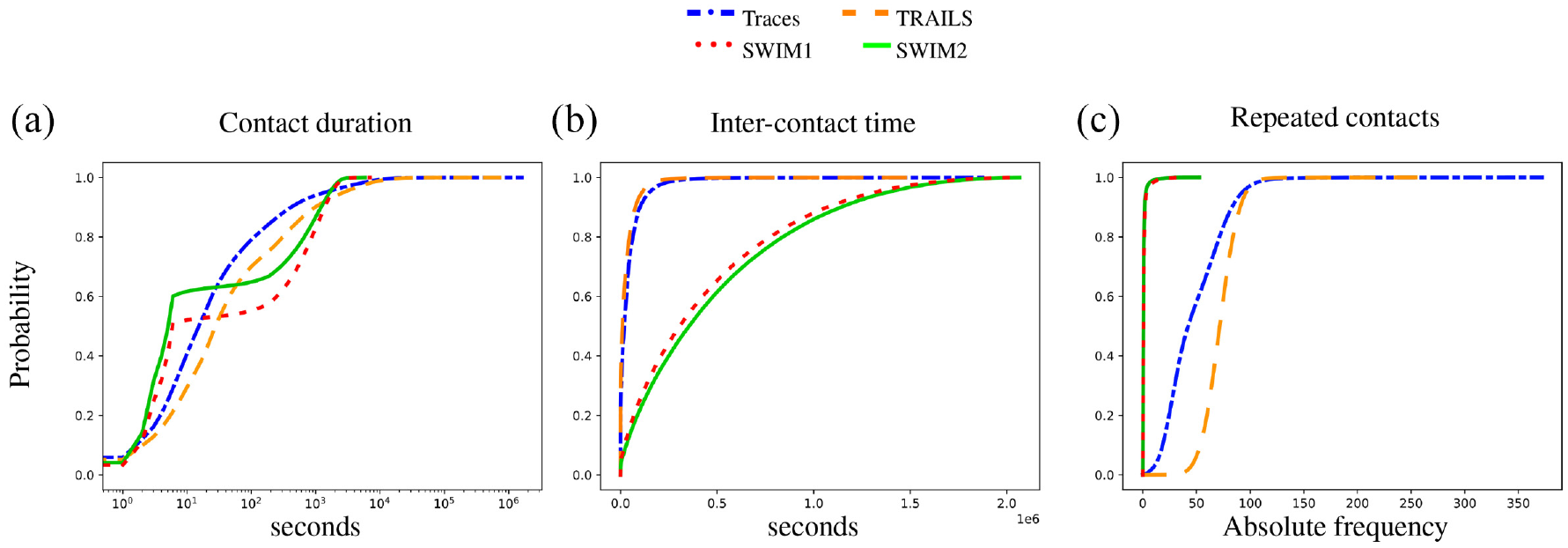
CDF of the San Francisco scenario.
4.3. Results’ variability between simulations
If two simulations of the same scenario are very different, each simulation will lead to a different conclusion. That is why, it is vital to use a mobility model where the variability in the results between simulations is not high. In this section, we analyze the reliability of the TRAILS model compared to SWIM by performing several simulations with the same scenario and then observing the medians of mobility metrics of each simulation.
In Figures 19–21, we describe the spread of medians of mobility metrics of TRAILS simulations, SWIM simulations, and the real traces of the scenarios described in section 4.1. To avoid misleading results caused by outliers, for each scenario, we computed five TRAILS simulations and five SWIM simulations for each set of parameters (SWIM1 and SWIM2).
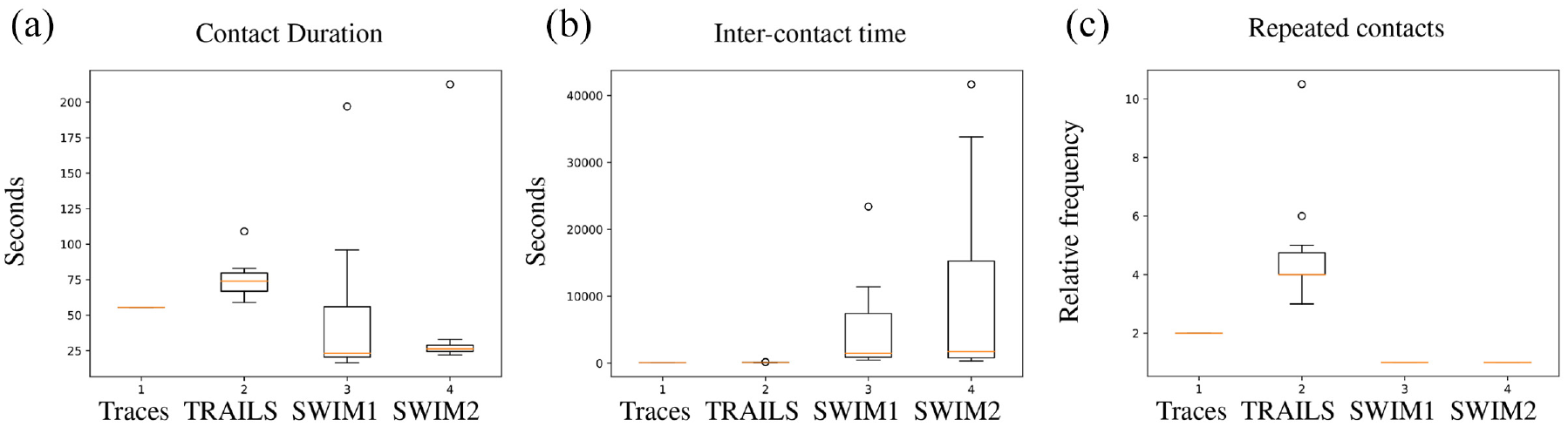
Box-plots of medians of mobility metrics of the simulations of the New York scenario.
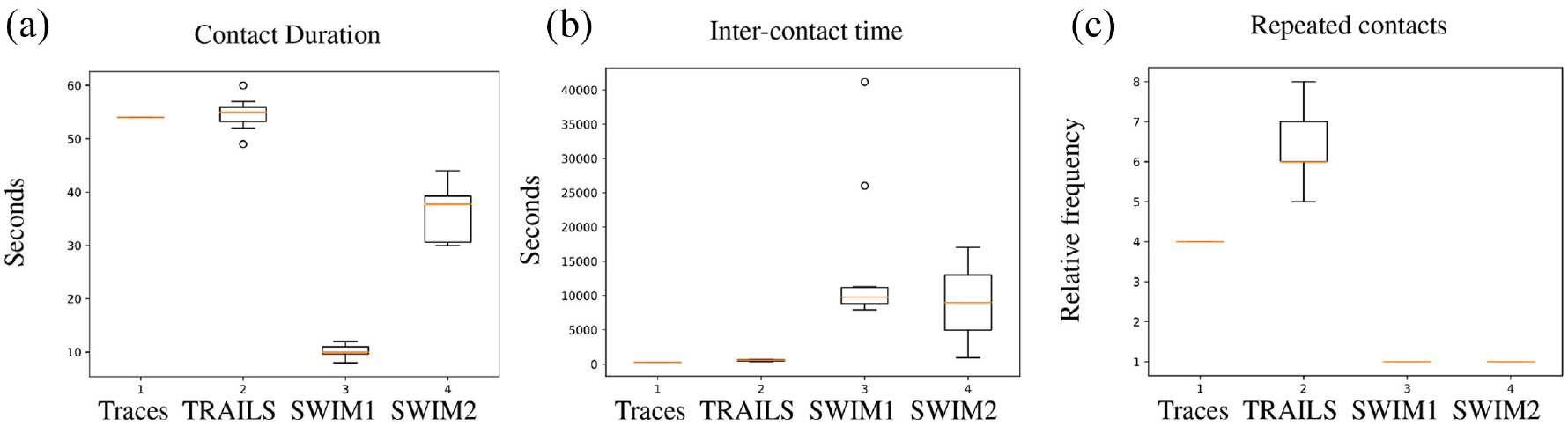
Box-plots of medians of mobility metrics of the simulations of the Orlando scenario.
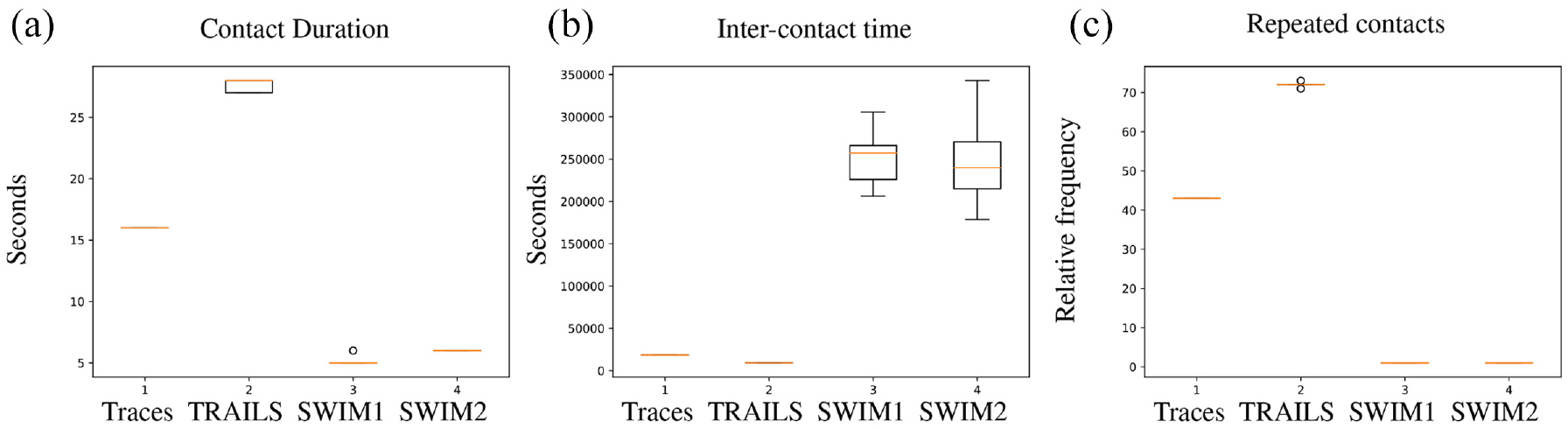
Box-plots of medians of mobility metrics of the simulations of the San Francisco scenario.
In each scenario portrayed in Figures 19–21, we observe that the medians of inter-contact time of TRAILS simulations present a lower dispersion than SWIM. In the case of the contact duration, the spread of the medians of TRAILS and SWIM is similar. However, the medians of the contact duration of TRAILS simulations are more similar to traces than the SWIM simulations. In case of repeated contacts, the medians of SWIM simulations are always around one contact per simulation. The low number of repeated contacts for SWIM simulations is related to their low contact probability, as explained in section 4.2.2.
In conclusion, the repeatability of results in TRAILS simulations is higher than SWIM, especially for the inter-contact time. The reason behind it is that in TRAILS, a node can travel only to a POI that has a direct link with the user’s current POI. However, a user in SWIM can travel from a given location to any other location. Consequently, the probability that a node would choose the same destination is higher in TRAILS simulations than it is in SWIM.
4.4. Performance analysis of TRAILS
This section describes the computation time of TRAILS, traces, and SWIM. Then, it discusses the disk memory used by real traces versus TRAILS graphs. After, this section discusses the memory required (log memory) to record simulation results for each model. Finally, it presents how the computation time and log memory are affected when TRAILS simulations are scaled by simulation time and by the number of users.
In order to present a performance analysis, we performed the TRAILS graph generation and the model simulation in a computer with a processor Intel i7 2.60 GHz and a memory RAM of 16 GB under a 64-bit Linux operating system.
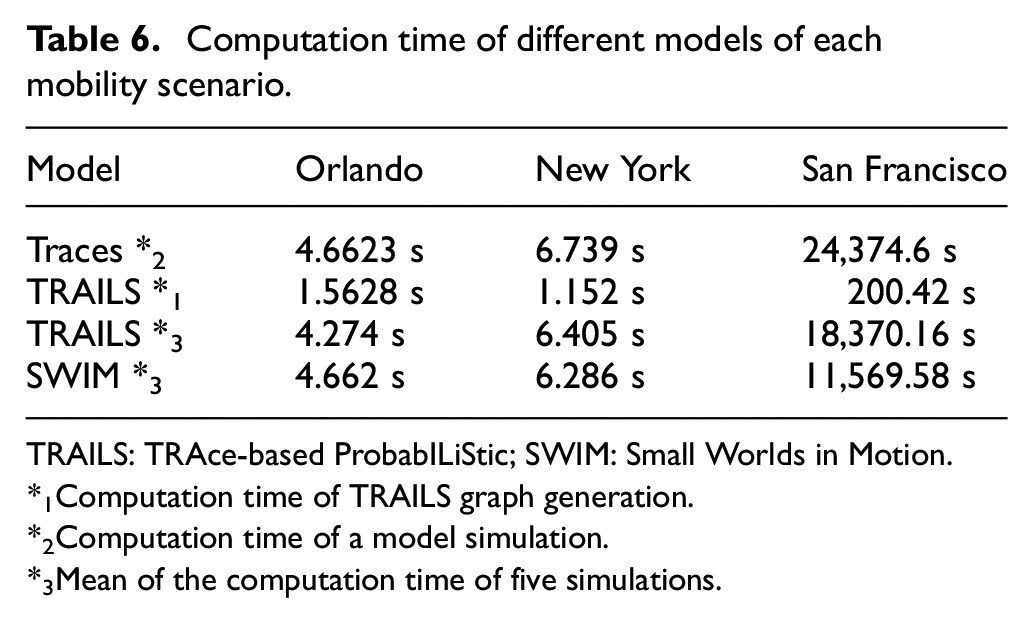
As we observe in Tables 6 and 7, the computation time and memory usage of the San Francisco scenario is considerably higher than the scenarios Orlando and New York. The reason is mostly the difference in the number of users, San Francisco has more than 500 users while Orlando and New York have less than 50 users. In section 4.4.3, and Figure 23, we show that the computation time and memory consumption have a logarithmic relation to the number of users.
Computation time of different models of each mobility scenario.
TRAILS: TRAce-based ProbabILiStic; SWIM: Small Worlds in Motion.
*1Computation time of TRAILS graph generation.
*2Computation time of a model simulation.
*3Mean of the computation time of five simulations.
Memory size of mobility graphs.

TRAILS: TRAce-based ProbabILiStic.
4.4.1. Computation time
As described in Table 6, TRAILS simulations require less computation time than real traces because TRAILS reduces the number of events in a discrete simulator, as explained in section 3.2. However, SWIM simulations require less computation time than TRAILS. However, we may require several SWIM simulations to adapt SWIM parameters to a specific scenario, as demonstrated in section 4.2. In addition, the generation of TRAILS graphs requires an additional computation time. Still, for large scenarios such as San Francisco, this time is significantly lower than the time difference between the computation time of TRAILS simulations and traces.
4.4.2. Memory performance
According to graph sizes described in Table 7, TRAILS graphs require less memory than traces. The reason behind it is that TRAILS transforms several user coordinates into a single POI, as explained in section 3.1.
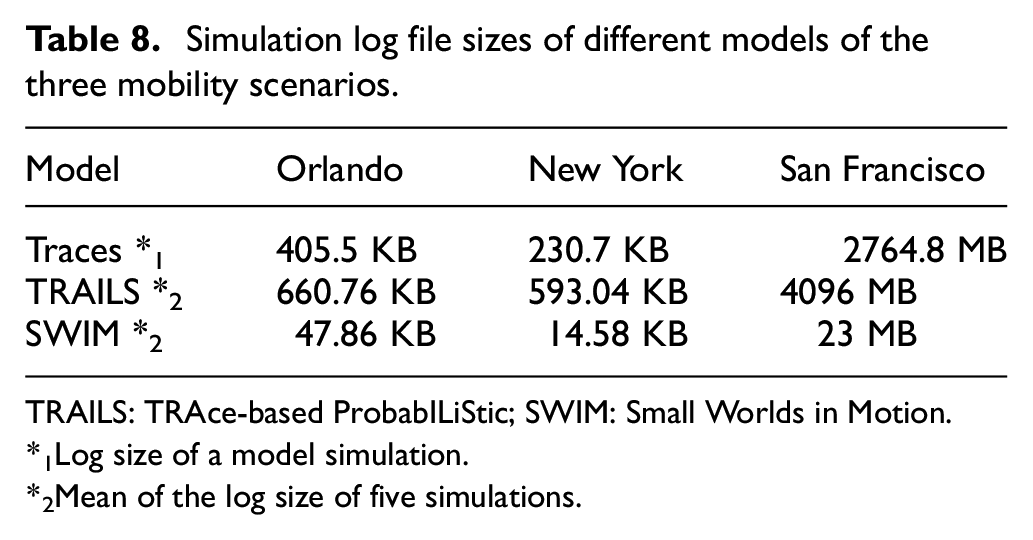
Table 8 shows that the log files generated by SWIM simulations are shorter than log files generated by traces. However, the log files generated by TRAILS simulations are larger than traces’ log files. According to the implementation of the algorithm to record simulation data, 45 the size of the log file is related with the total number of contacts. In addition, we can see in Figures 19–21 that the number of repeated contacts in SWIM is lower than it is in TRAILS.
Simulation log file sizes of different models of the three mobility scenarios.
TRAILS: TRAce-based ProbabILiStic; SWIM: Small Worlds in Motion.
*1Log size of a model simulation.
*2Mean of the log size of five simulations.
4.4.3. Scalability effect in TRAILS performance
As explained in section 3.2, with TRAILS, we can simulate a scenario with a higher number of users or a longer simulation time than the original traces. For example, the trace-set of the New York scenario has 39 users and an RT of 81,570 s. However, in Figure 23, we show the performance of TRAILS simulations with a simulation time of 81,570 s and up to 312 users. Figure 22 describes the performance of TRAILS simulations with 39 users and with simulation time up to 652,560 s.
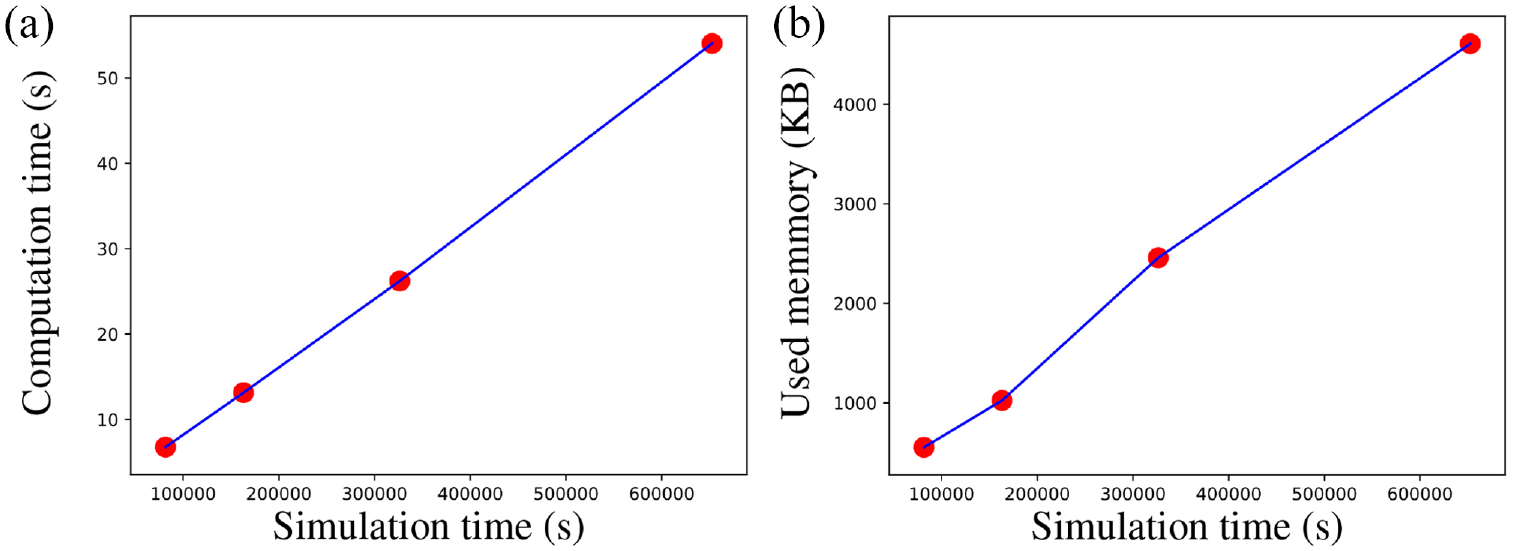
Mean of the performance metrics of the TRAILS model of the New York scenario scaled by simulation time.
Figure 22 portrays that the computation time and the log memory size have a positive linear relationship with the simulation time; however, in Figure 23, the computation time and the log memory size have a positive logarithmic relationship with the number of users. Those results respond to the hypothesis that if a scenario does not change drastically, an increase in time should produce a linear increase in users’ contacts. However, an increase in the number of users should produce an exponential increase in users’ contacts. In addition, sections 4.4.1 and 4.4.2 reveal a strong relationship between performance and the number of users’ contacts.
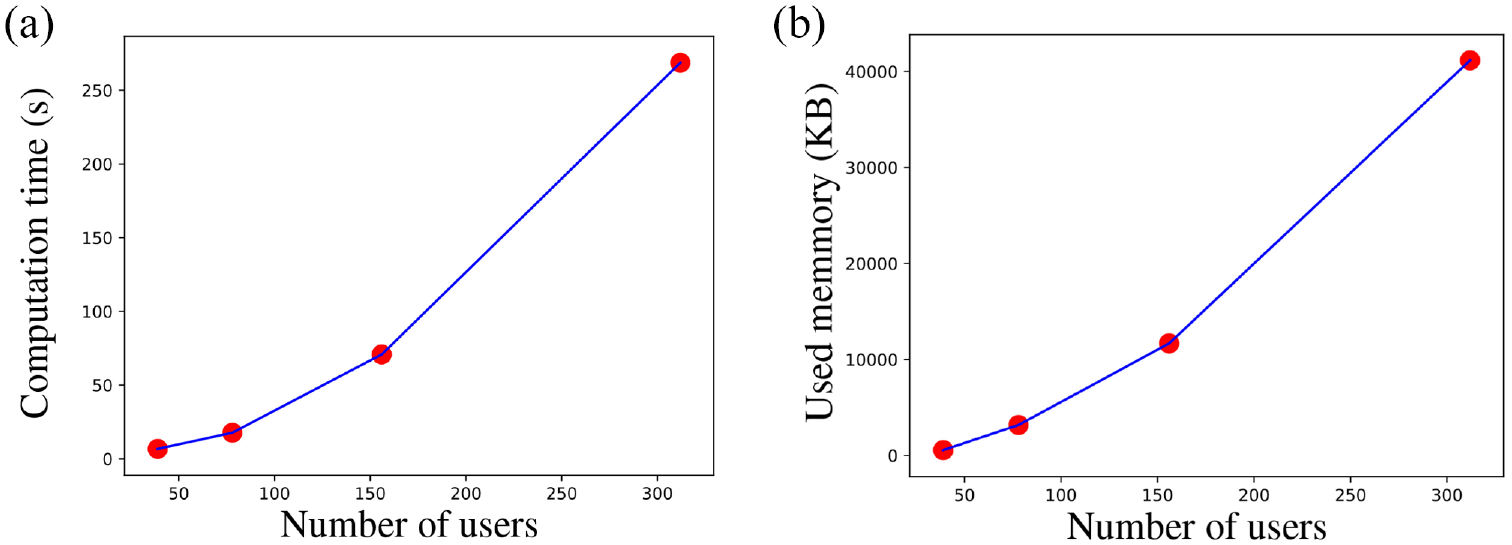
Mean of the performance metrics of the TRAILS model of the New York scenario scaled by number of users.
4.5. Network communication
One of the reasons to use mobility models is to measure the performance of OppNet protocols. However, the same protocol produces different results with different mobility models. For this purpose, we describe how communication metrics vary depending on the mobility model.
In this section, we repeat the simulations described in section 4.3, but now each user forwards data using an OppNet protocol. In our simulations, each user generates a broadcast message of 10 KB each 900 s. Later, each message is propagated using the Epidemic protocol. 24 To simulate the Epidemic protocol with TRAILS, traces, and SWIM, we used the OPS framework alongside the discrete simulator OMNeT++. 27
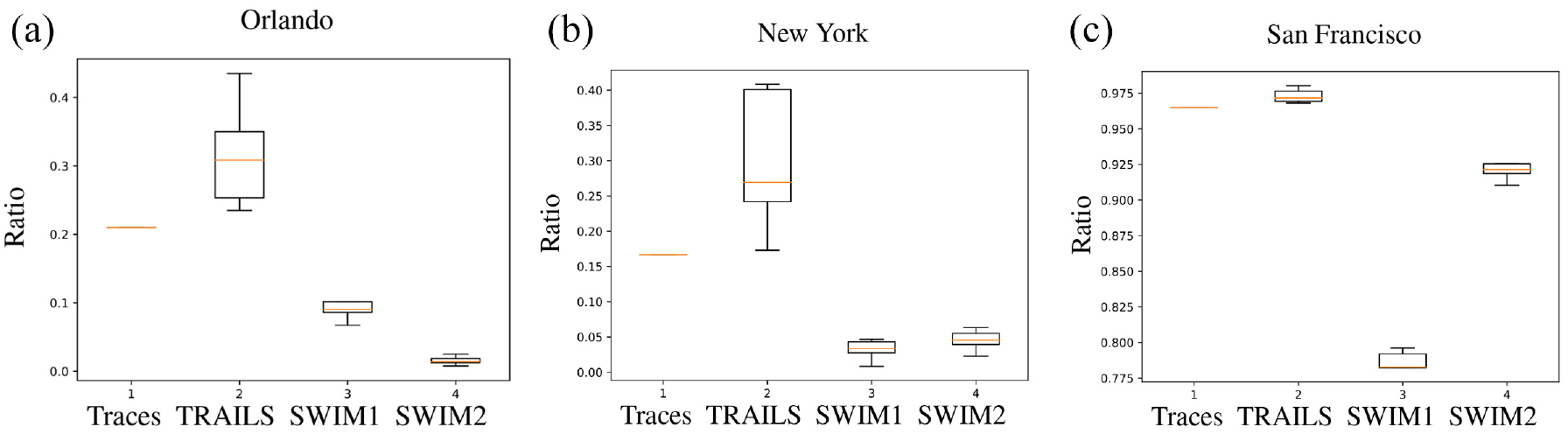
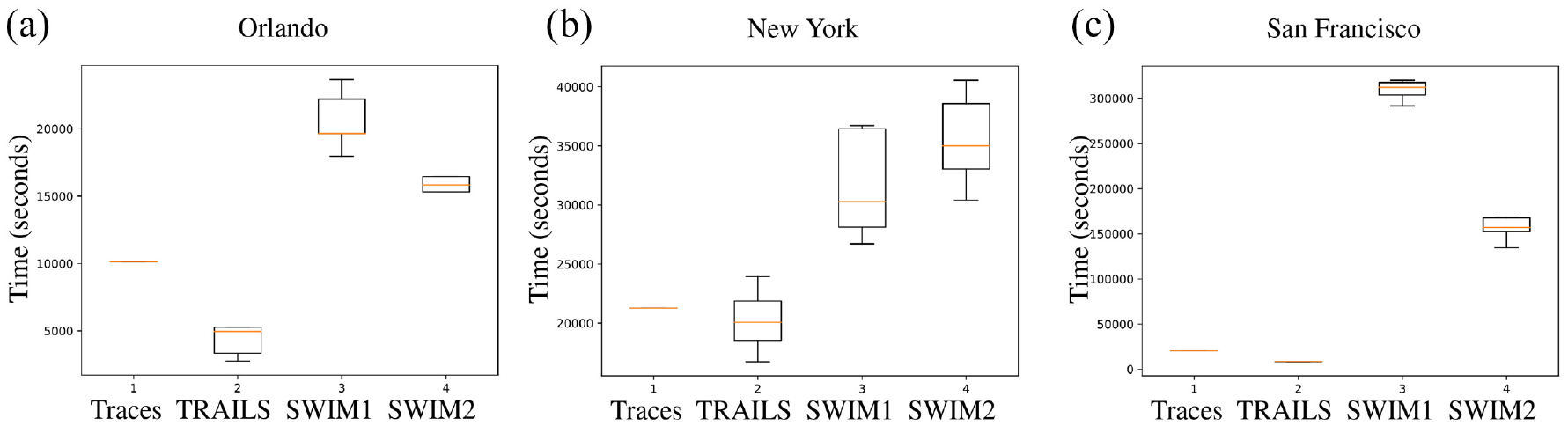
In Figure 24, we present the delivery ratio, and in Figure 25, we describe the mean end-to-end delay of each simulation. 22
Box-plots of the delivery ratio of the simulations of the New York scenario.
Box-plots of the end-to-end delay of the simulations of the New York scenario.
Figures 24 and 25 reveal that the medians of the end-to-end delay and the delivery ratio of TRAILS simulations are more similar to traces than SWIM simulations. In addition, we observe in Figure 24 that the median of the delivery ratio of TRAILS simulations is always higher than traces. Similarly, Figure 25 shows that the median of the mean end-to-end delay of TRAILS simulations is always lower than traces. The reason behind these results is that any user in a TRAILS simulation can visit any POI, as explained in section 3.1.2. However, a user in a real scenario may never visit all POIs. Consequently, in TRAILS, a user can get in contact with any other user, while in real traces, there are users that may never get in contact.
5. Conclusion
The TRAILS mobility model can capture specific mobility characteristics of realistic scenarios such as temporal dependency, spatial dependency, and geographic restrictions. A user mimics a real scenario’s temporal dependency in a TRAILS simulation by moving between POIs with the same speed as a user in traces. As shown in section 3.1.1, TRAILS reflects the spatial dependency of traces by capturing the relation between users and POIs with popularity indicators. A user in a TRAILS simulation only moves through links between POIs. In addition, links describe real paths of traces. Therefore, TRAILS represents the geographic restrictions of real scenarios.
The movement patterns of users in real scenarios vary over time because they have different routines at different hours or days. Therefore, the interaction between users also changes. TRAILS considers these changes by matching the probability of traveling to a POI with the number of users the POI had in the original traces, as described in section 3.2.
It is possible to simulate the same TRAILS graph with a different number of users and simulation time. Therefore, unlike trace-based models, TRAILS is a fully scalable and flexible mobility model, as explained in section 3.2.
TRAILS graphs are capable of summarizing several trace-coordinates in a single POI. In consequence, the data size of TRAILS graphs is smaller than traces. In addition, a TRAILS simulation produces fewer events than a simulation of traces because when a user stays in a POI, it does not generate additional events. However, in a simulation of traces, a user may produce events even if the user is not moving or it is moving inside a small area. Therefore, TRAILS simulations require less computation time than traces, as shown in section 4.4.
Although the implemented TRAILS model presents a satisfactory performance in computation time and memory consumption, we determined that TRAILS cannot mimic real traces perfectly. However, we can scale TRAILS scenarios by simulation time and the number of mobile users in a way that we cannot achieve with trace-based mobility models.
A single user in TRAILS mimics the behavior of all users of real traces, and it does not take into account the differences of the mobility patterns among real users. Therefore, section 4.5 shows that we get a higher delivery ratio and a lower end-to-end delay when we evaluate the performance of the Epidemic Network protocol with TRAILS rather than real traces. As future work, we propose to categorize users into communities, generate a TRAILS graph for each community, and simulate users assigned to different graphs. In our proposed solution, two users who belong to different communities will have different POIs but also common POIs. Therefore, we believe that our future work will capture the spatial dependency of real scenarios in a more effective way.
In summary, the TRAILS mobility model can capture mobility characteristics of realistic scenarios. TRAILS graphs take into consideration the dynamic interaction between users and POIs. In addition, we can scale TRAILS simulations by the number of users and the simulation time. Moreover, TRAILS graphs use less memory than traces, and simulating TRAILS graphs requires less computation time than trace-based models.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.