
Abstract
Data assimilation (DA) is a methodology widely used by different disciplines of science and engineering. It is typically applied to continuous systems with numerical models. The application of DA to discrete-event and discrete-time systems including agent-based models is relatively new. Because of its non-linearity and non-Gaussianity, the particle filter (PF) method is often a good option for stochastic simulation models of discrete systems. The probability distributions of model runs, however, make it computationally intensive. The experimental conditions therein are understudied. This paper studied three critical conditions of PF-based DA in a discrete event model: (1) the time interval between two consecutive DA iterations, (2) the number of particles, and (3) the actual level and perceived level of measurement errors (or noises). The study conducted identical-twin experiments of an M/M/1 single server queuing system. The ground truth is imitated in a stand-alone simulation model. The measurement errors are superimposed so that the effect of the three conditions can be quantitatively evaluated in a controlled manner. The results show that the estimation accuracy of such a system using PF is more constrained by the choice of time intervals than the number of particles. An under estimation of measurement errors produces worse state estimates than an over estimation of errors. A correct perception of the measurement errors does not guarantee better state estimates. Moreover, a slight over estimation of errors results in better state estimates, and it is more responsive to abrupt system changes than an accurate perception of measurement errors.
Keywords
1. Introduction
Data assimilation (DA) is a methodology that combines observational data and the underlying dynamical principles that govern a system to produce the best estimate (according to some criteria) of the evolving state of that system.1–3 It is widely used by different disciplines of science and engineering (e.g., hydrology, meteorology, geophysics, and petroleum engineering) for state estimation and optimal control. 1 DA in its various forms has typically been applied to continuous systems with numerical models.4–7 The application of DA to discrete event systems (DESs) and discrete time systems (DTSs) including agent-based models (ABMs) is a recent development.
For example, Lloyd et al. 8 used an urban crime ABM to generate ground truth data which was then assimilated into a discretized partial differential equation (PDE) model. The PDE was converted from the original ABM 8 to overcome the computational demand of ABM. One of the first publications that explains how to use ensemble Kalman filter (EnKF) to calibrate simple ABM for social simulation is by Ward et al. 9 They aim to present the method to ABM practitioners who are unfamiliar with DA. They also illustrate to DA experts the value of using DA (particularly sequential DA) in ABMs of complex social systems, and the new challenges these types of models present. Similarly, a DA framework for DES was published by Hu and Wu 10 who applied particle filters (PFs) to a roadway modeled as a one-dimensional cellular space.
Different DA methods have been reported extensively. For example, Kalman filter (KF), 11 extended KF (EKF), 12 and EnKF 13 are known for their efficiency. But they often are not applicable to DES, DTS, and ABM because of the requirement for linearity of model state and Gaussian errors. 14 In addition, DES and ABM of real-world applications are typically stochastic and high dimensional. For these reasons, the PF method,11,15 which approximates the posterior distribution by Monte Carlo samples (also called particles), is a good alternative (in place of classical DA methods) for non-linearity and non-Gaussianity. However, the probability distributions of the runs (also called replications) of the DES and ABM models make the PF-based sequential DA computationally highly expensive. 8
1.1. Background
The performance of sequential DA is strongly influenced by conditions such as the time interval between two consecutive iterations (hereafter simply time interval), sample sizes, and measurement errors. Surprisingly, not many publications studied and quantified the effect of such important conditions so far.
In a survey of DA in surface water quality modeling, Cho et al. 16 stated that their domain utilized mainly three DA methods: the variational DA, EKF, and EnKF. With EKF-based DA for algal bloom prediction, 17 longer update time intervals resulted in lower accuracy. Contradictory results also exist. For example, the frequency of EnKF-based water content DA is investigated for soil hydraulic models. 18 The results show that DA with high update frequencies does not provide better results than those obtained using low frequencies. An EnKF-based DA procedure for water quality forecasting is developed by Kim et al. 19 The authors suggested that the time interval (they called it window size) should be chosen carefully: if the window size is too small, the procedure works largely as a filter rather than a smoother, which reduces performance; if the window size is too large, some of the observations being assimilated may be too old and/or redundant to be informative.
Adaptive DA methods are also reported. For example, a (frequency) adaptive EnKF-based method is developed for hydrodynamic simulation 20 which reduced computation and increased error reduction. Besides works that used KF and its variations, PF is also coupled with a hydro-biogeochemical model using high-frequency data. 21 However, how the change of the intervals and the number of particles can affect the results are not studied. 21
In general, the literature on sensitivity analysis of DA conditions is not as rich as the literature on various DA methods and their applications. When such results are reported, as those mentioned above, they are often in the context of continuous systems (and numerical models). It is unknown whether such results are also applicable to PF-based DA for discrete systems.
1.2. DA for discrete systems
The sequential simulation of a DES, DTS or ABM can be denoted as a discrete time process, given by:
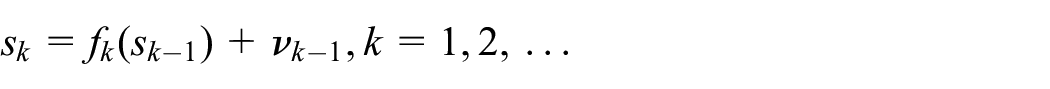
where

where
The objective of sequential DA is to estimate the conditional distribution of all states up to time
For DES, sensitivity analysis of PF-based DA conditions and related issues are particularly important since applying PF to DES can be very beneficial but also computationally intensive. More research is needed to understand better how to use PF for applications such as social simulation and socio-technical systems simulation. For example, people’s location estimation in smart buildings,23,24 household energy consumption behavior,25,26 vehicle trajectory reconstruction, 27 and traffic density estimation. 28
Those simulation models often provide detailed information about system states. But they are not typically data driven in the sense that the models are generally developed and calibrated (by human modelers) using historical data before simulation.9,29 The data availability of such systems had been poor but is becoming greater with the advance of cheaper sensing technologies and pervasive use of smart devices such as smart meters and smartphones. This gave rise to the so-called dynamic data-driven simulation in DES, DTS, and ABM communities. The more available data offer new opportunities to complement and empower traditional simulation modeling approaches which have limitations in situational awareness and adaptation in a highly evolving socio-technical environment.9,10,30,31
In this context, dynamic data-driven simulation can be explored in several directions, e.g., to automatically generate model structure aggregating predefined model components;32,33 to discover simulation models and their generative behaviors in an automated or semi automated way; 34 to assimilate real-time data into (online) simulation to support real-time decision-making.10,35 There is a rich body of knowledge with which experts from different domains using diverse simulation modeling paradigms and methods can collaborate and learn from one another. However, reported cases and synergies are rare in the literature. 9
Some examples can be found with regard to the use of PF for discrete systems.9,10,36,37 The effect of conditions in PF such as modeling errors, measurement errors, and number of particles are studied with DES transportation models.27,38 The results show that the estimation accuracy of PF is robust to error assumptions of both the model and measurement data in the application. The accuracy increases as the error magnitude decreases, but it is far from being proportional. The estimation accuracy also improves as the number of particles increases due to increased state-space coverage. Similar findings are reported in a few other studies.24,28,35
In this paper, we aim to further study the experimental conditions of PF applied to DES. The focus is on three common and critical conditions: the time interval, the number of particles, and the measurement errors. We study their influences on estimation accuracy with respect to computational demand. Sensitivity analysis of the time interval and number of particles in the PF method commonly used a one-factor-at-a-time approach.27,38 With this approach as a starting point, we explore the mutual influence of the two conditions. In addition, we experiment with the actual level and perceived level of measurement errors. The actual level of measurement errors refers to the level of noises added to the “ground truth” in order to imitate noisy measurement data. Because the actual measurement noises are often unknown in real-world situations, we distinguish the concept of perceived level of measurement errors in our experiments. It is the (assumed) level of measurement noises used for posterior computation in the DA sampling step.
The main contribution of this paper can be summarized as follows. First, we quantitatively analyze the effect of time intervals and the number of particles in different experimental settings of PF-based sequential DA for DES. Second, the joint influence of the time interval and the number of particles is experimented and analyzed. These two conditions are often mutually restrictive because of limited computational time between two consecutive DA iterations. Third, the actual level of measurement errors is imitated such that it allows an investigation of the differences between the actual and perceived measurement errors. We analyze their effects on the estimation accuracy, discuss the implications, and give recommendations on future research directions. This paper is an extended version of Cho et al. 39
2. Methodology
This study conducted identical-twin experiments of a discrete event
2.1. Scenario description
In the
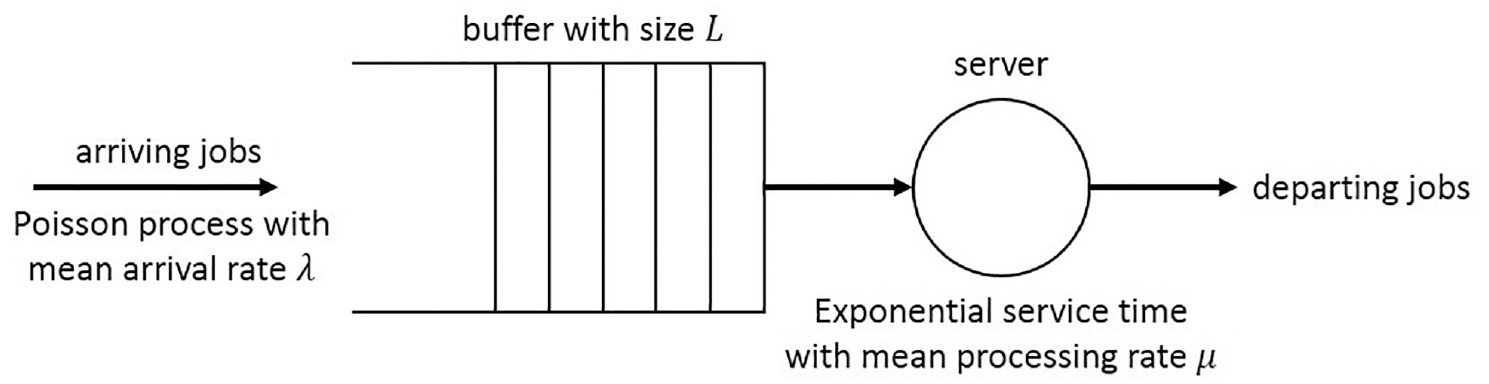
2.2. Modeling the scenario with Discrete Event System Specification formalism
The scenario described is a typical DES, which can be modeled using the Discrete Event System Specification (DEVS).
41
As shown in Figure 2, our DEVS model of the
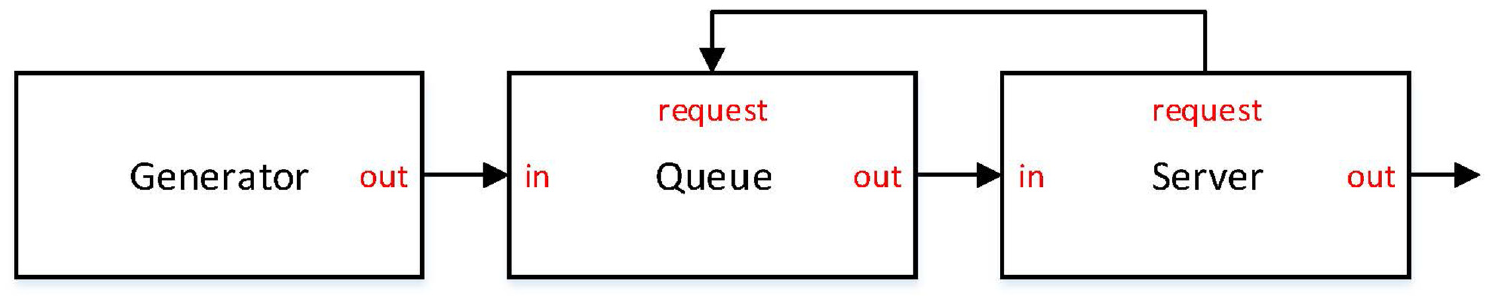
DEVS model of
To imitate the second-order dynamics
30
in the queuing system, at each time step during the simulation, the values of
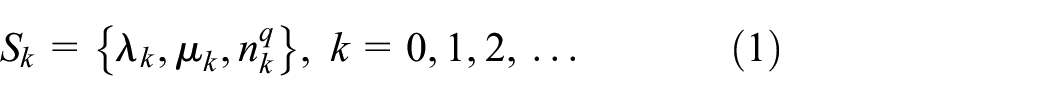
where
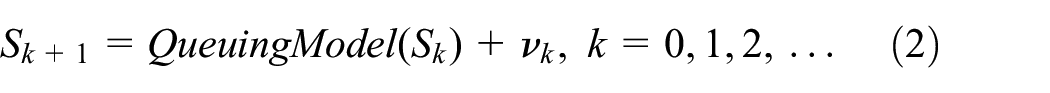
where QueuingModel is the (discrete event) simulation model of the
The QueuingModel is used as the base model for the simulation of ground truth, where
The QueuingModel is also used for DA (assimilating the noisy
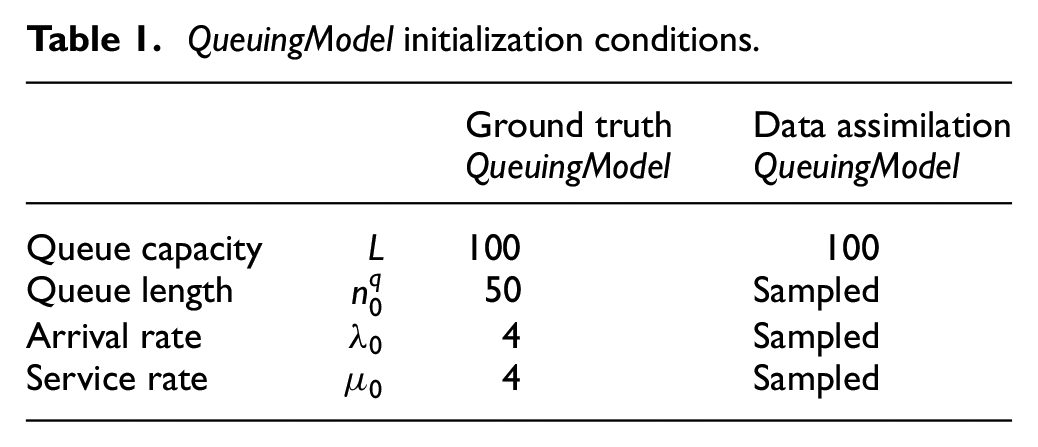
QueuingModel initialization conditions.
2.3. Available data and measurement model
The ground truth QueuingModel is run for a certain length during which the state evolution of the model is recorded and regarded as the ground truth system state. In addition, the number of job arrivals (after balking)
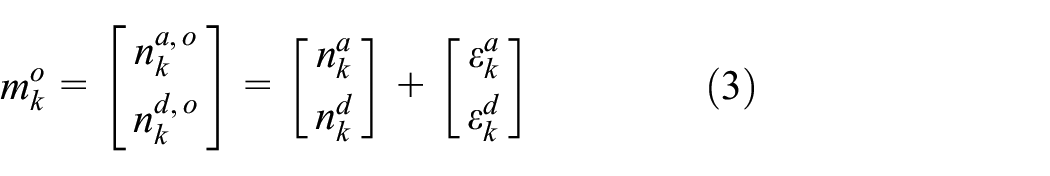
where
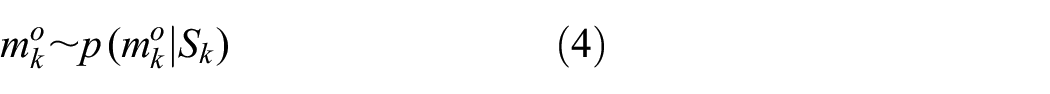
Note that in our experiments, the DA process uses the perceived level of measurement errors, denoted as
2.4. DA process
In our experiments, PF (Algorithm 1) are employed to assimilate the noisy measurements
Initialization: in the initialization step (lines 2–5 in Algorithm 1),
Sampling: after initialization,

Note that the actual error level of the noisy measurement
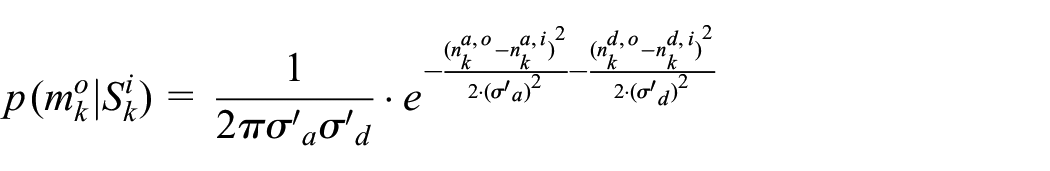
where
Resampling: to solve the degeneracy problem,11,15,22 we resample the particles using the standard resampling scheme (line 15 in Algorithm 1), which samples particles in proportion to their weights. Thereafter, all resampled particles are equally weighted, i.e.,
Estimation: we estimate the system state at time step
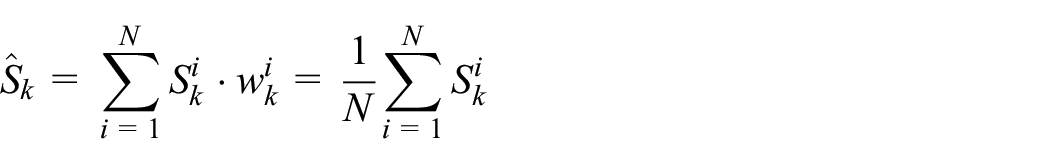
The data assimilation procedure based on particle filters.

2.5. Evaluation criteria
In the experiments discussed in the next section, three conditions in DA were investigated to study their effects on the estimation accuracy, i.e., the time interval
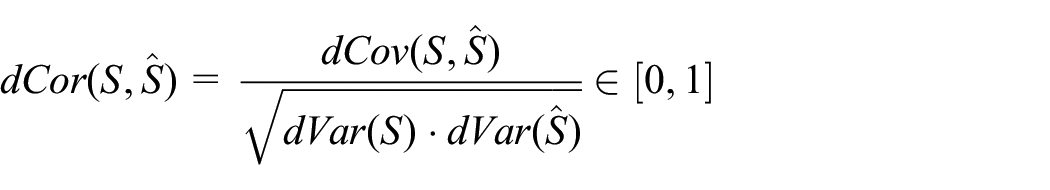
where
3. Scenarios, sensitivity analysis, and discussions
The
In the following, the results regarding
3.1. Time interval and number of particles
In this set of experiments, the time interval
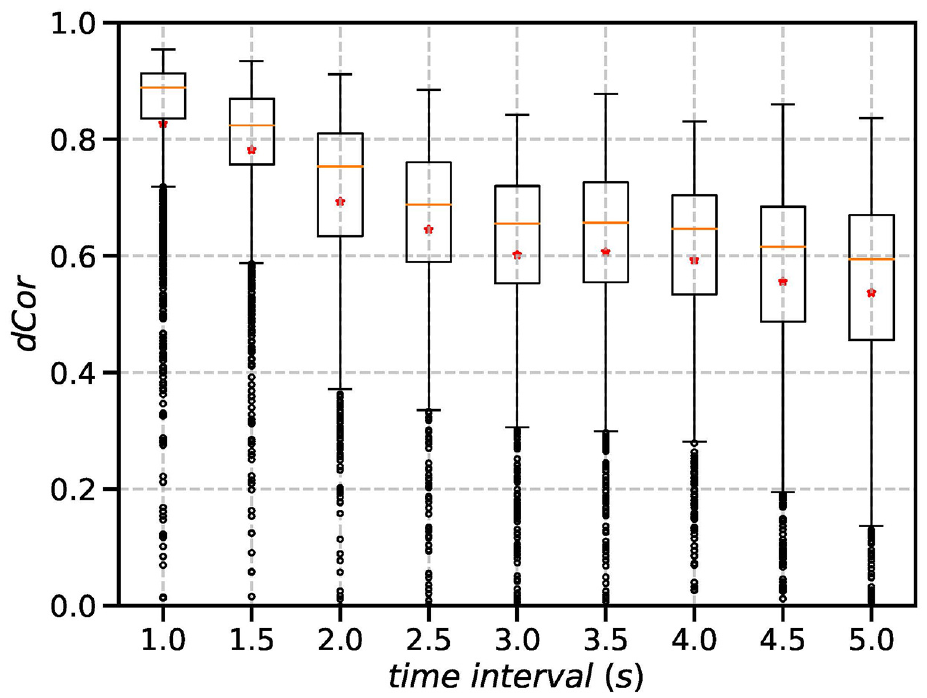
The effect of time interval
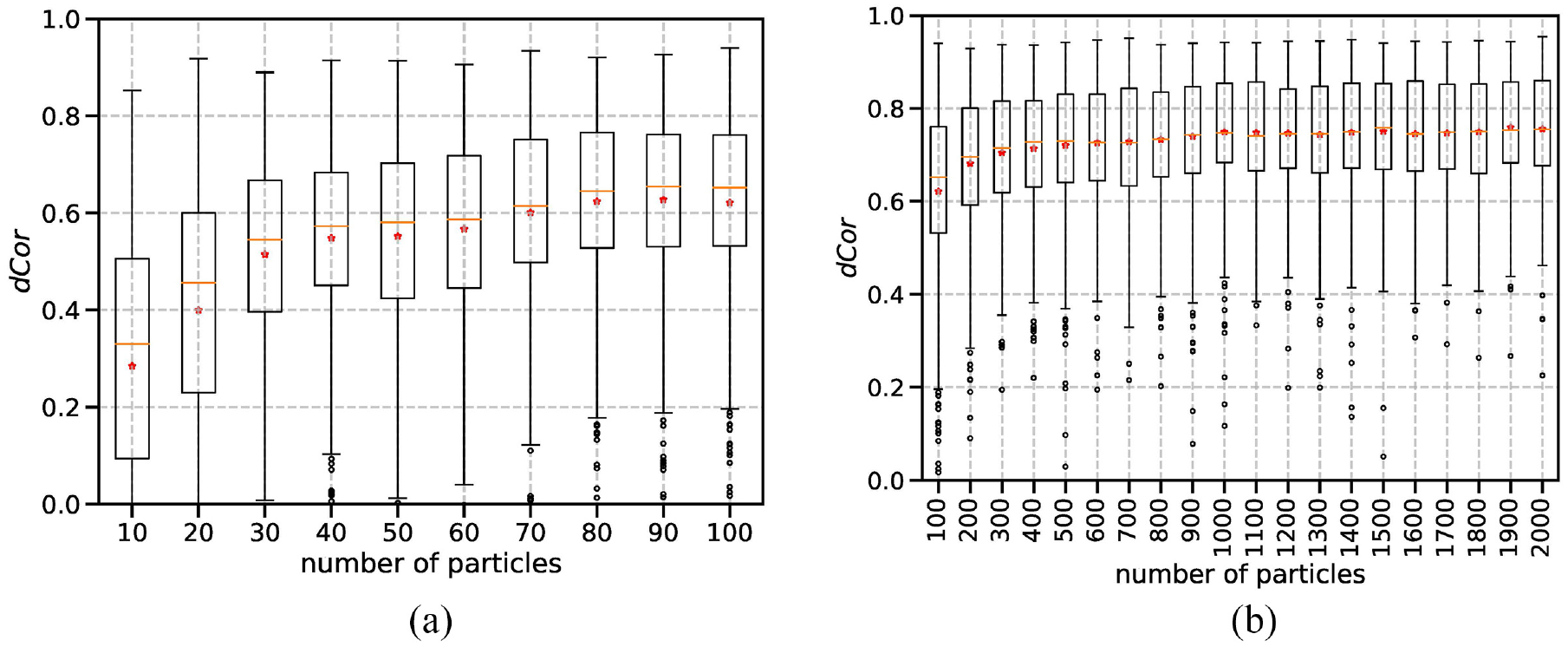
The effect of number of particles
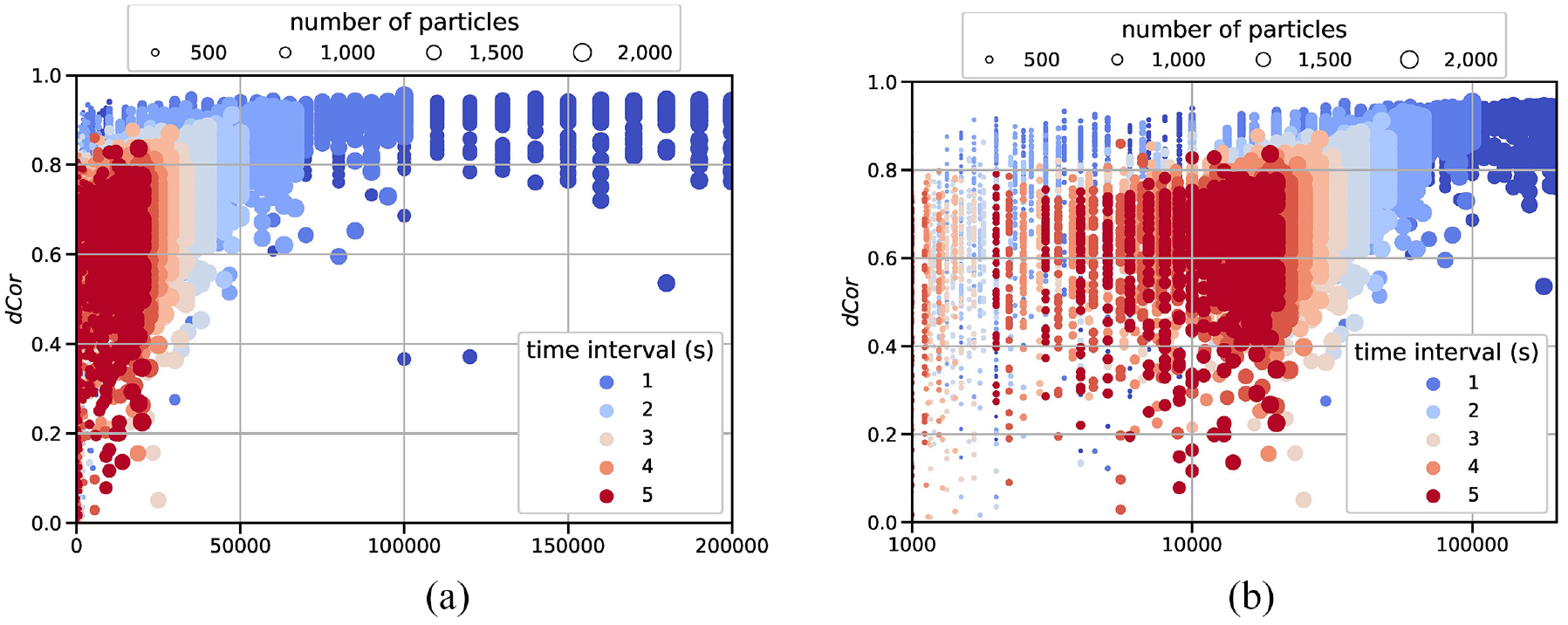
The effect of time interval
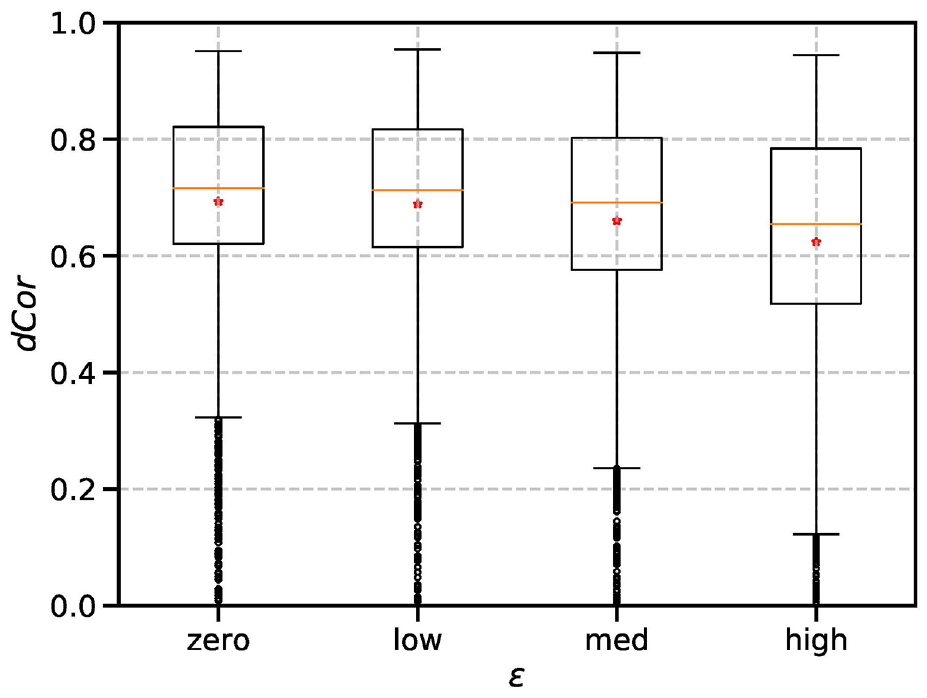
The effect of the actual level of measurement errors
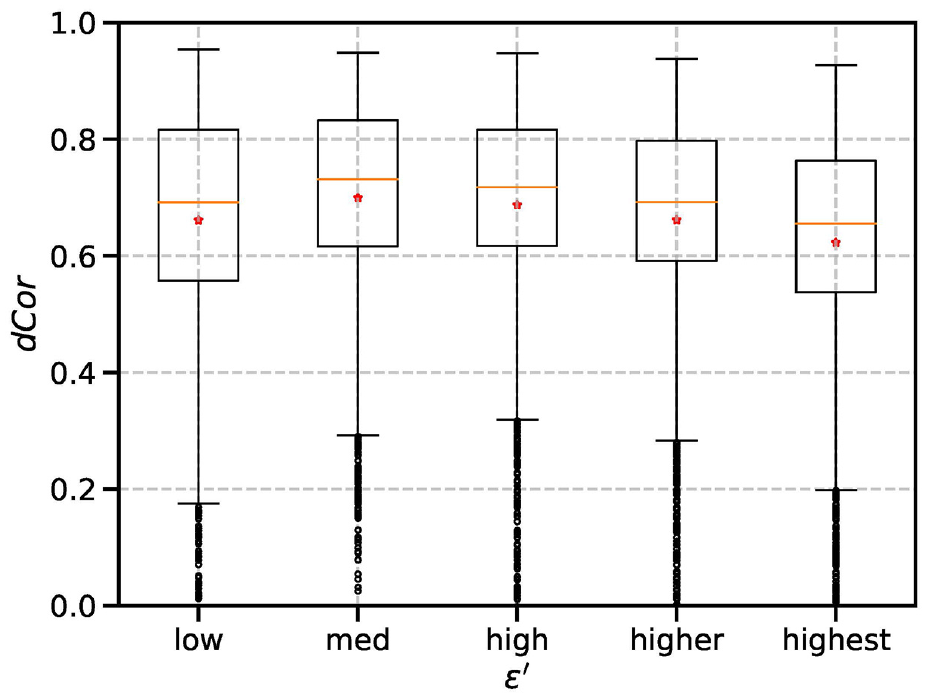
The effect of the perceived level of measurement errors
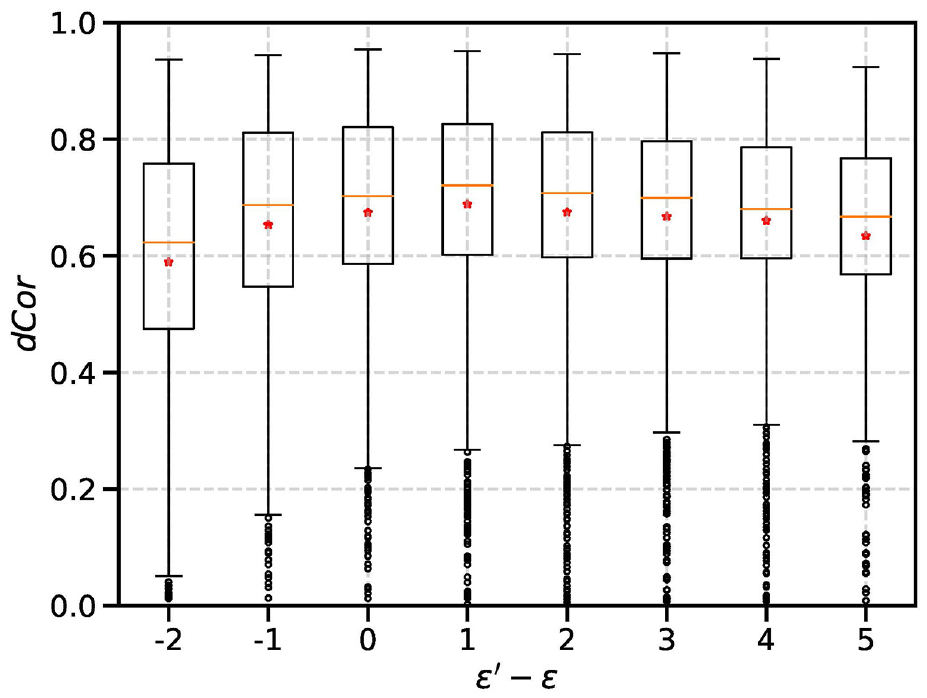
The effect of the difference between perceived level
The three horizontal bars (from bottom to top) of each box represent the first, second and third quartiles of a data set (The second bar indicates the median.). The dot indicates the mean. The whiskers (i.e., the two vertical lines outside the box) extend to 1.5 times the inter quartile range (IQR). The upper whisker stops at the largest value smaller than 1.5 IQR above the third quartile; the lower whisker at the smallest value greater than 1.5 IQR below the first quartile. The data points beyond the whiskers are considered outliers and are plotted as individual circles (This applies to all boxplots in this paper.).
Figure 3 shows a convex decreasing trend between
In the next set of experiments, the number of particles
To understand the relation between
Note that, in our experiments, when the number of simulation runs (
In Figure 5(a), different shades of large blue dots span a large horizontal area. Those are the experiments with short intervals and high numbers of particles as these conditions resulted in high numbers of runs. Consequently, they have high
To make the small dots more visible, Figure 5(b) shows the x-axis on a log scale such that the part below
The results show that the estimation accuracy improves (
To summarize, while the number of particles is positively correlated and the time interval is negatively correlated to the estimation accuracy in DA, the accuracy is more constrained by the choice of time interval than by the number of particles. This implies that given limited computational resources in DA applications, once the number of particles is sufficiently large, more computational resources can be allocated to shorten the time interval to improve the estimation accuracy.
3.2. Actual level and perceived level of measurement errors
The experiments presented in this section set the actual level of measurement errors
The first set of experiments varied the actual level of measurement errors
The second set of experiments changed the perceived level of measurement errors
The difference between
To further illustrate the effect caused by misalignment of the perceived measurement errors with the actual level of errors, we present and discuss another experiment that compares two cases: (a) perfect knowledge about measurement errors (
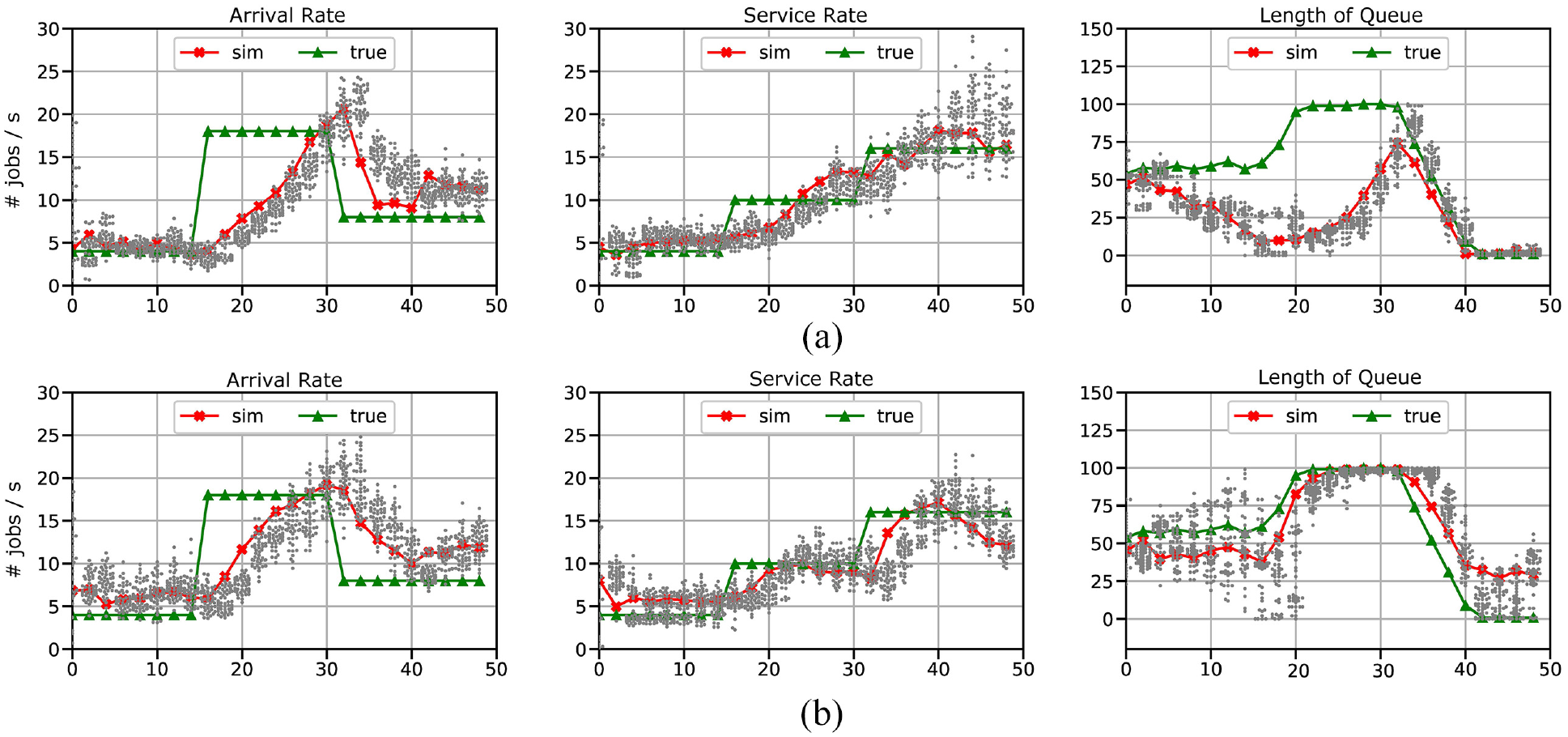
The effect of the different perceived levels of measurement errors on the estimation accuracy (
The difference in response time in the two cases can be explained by the spread of particles, which are depicted as gray dots in Figure 9. Note that the vertical spread of particles in case (a) is narrower than that in case (b). In case (a), only a few particles having a small deviation from the measurement can “survive” throughout the experiment, while the particles located apart are discarded. Consequently, abrupt changes in the system are not detected rapidly because of the restricted spread of particles. In case (b), as the particles spread wider, the aggregated result can quickly converge to the true value after sudden changes. Thus, more widespread particles are more tolerant and show more a responsive estimation in detecting capricious system changes.
Given these observations in the experiments, we conclude that a pessimistic view on measurement errors brings advantages over an optimistic view on measurement errors with respect to the accuracy of DA results. In addition, a slight pessimistic view on measurement errors leads to better estimation accuracy than an accurate view on measurement errors in the experiments. This is rarely an intuitive choice in DA experimental setups.
4. Conclusion and future work
The experiments presented in this paper quantitatively studied the effect of three common and critical experimental conditions of PF-based sequential DA for DES: the time interval of assimilating measurement data, the number of particles, and the level of measurement errors (or noises). An identical-twin experimental scheme (of an
The time interval of assimilating measurement data has a negative correlation with the estimation accuracy of system states. Although this is expected, it is not always true as reported by some studies (see section 1). More frequent assimilation of measurement data is effective to improve the estimation accuracy and the responsiveness of the estimation results. Although the number of particles has in general a positive correlation with the estimation accuracy, increasing the number of particles is ineffective in improving accuracy beyond a certain level. Notably, good estimation accuracy can be achieved even though not many particles are used if the time interval is sufficiently short. Since both decreasing the time interval and increasing the number of particles require more computation, the former can be more cost effective when the number of particles is sufficiently large. With regard to measurement errors, in the experiments an over estimation of the level of measurement errors leads to more accurate estimation results than an under estimation. Under estimating the errors always produces worse state estimates. Interestingly, a correct perception of the measurement errors does not guarantee better state estimates. A slight over estimation of errors has better accuracy and more responsive model adaptation to system states than an accurate estimation of measurement errors. An exaggerated over estimation of errors, however, deteriorates the accuracy of state estimates.
Our work used a simple single server queuing model to explore conditions in PF-based DA applied to DES. The choice of a simple target system and simple scenarios has the advantage that thorough experiments can be performed with a high number of iterations and particles. The states of “real” and simulated systems can be easily compared. The work, nonetheless, demonstrates the usefulness and challenges of using PF-based DA for DES and points out a few interesting future directions.
The sensitivity quantification of the PF conditions investigated in this paper is specific to the target system and scenario setup of our experimental choices. In that regard, many uncertain (and/or stochastic) factors in DES models can be interesting to further investigate in order to understand better how to efficiently use PF for DES. For example, the level of system noises, the number of estimated state variables, and their relations to the level of measurement noises. We conjecture that the “regular” stochasticity captured by probabilistic distributions in DES models can be covered by the number of particles and their disperse in PF. The “irregular” uncertainty that falls out of the model descriptive power can be compensated by the power of sequential DA. With that in mind, it is possible to smartly balance out the number of particles (or even to calibrate the probabilistic distributions in DES models) and the time intervals to produce acceptable DA results for DES. Since the computational demand to apply PF-based DA to discrete systems will remain a challenge (in the foreseeable future), a better understanding of the interplay between the time interval and particles is key to promoting wider use of DA in social and socio-technical applications. Furthermore, an event-based DA method can be a novel approach unique for DA applications in DES. This means PF can be dynamically adjusted for, e.g., the time intervals, number of particles, and perception of measurement errors, according to certain event-triggers (which is relatively simple for a DES model to implement) tailored to the application in order to obtain more cost effective state estimation performance.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.