
Abstract
The prevention of severe injuries during crashes has become one of the leading issues in traffic management and transportation safety. Identifying the impact factors that affect traffic injury severity is critical for reducing the occurrence of severe injuries. In this study, the Fatality Analysis Reporting System data are selected as the dataset for the analysis. An algorithm named improved Markov Blanket was proposed to extract the significant and common factors that affect crash injury severity from 29 variables related to driver characteristics, vehicle characteristics, accidents types, road condition, and environment characteristics. The Pearson correlation coefficient test is applied to verify the significant correlation between the selected factors and traffic injury severity. Two widely used classification algorithms (Bayesian networks and C4.5 decision tree) were employed to evaluate the performance of the proposed feature selection algorithm. The calculation result of the correlation coefficient, accuracy of classification, and classification error rate indicated that the improved Markov Blanket not only could extract the significant impact factors but could also improve the accuracy of classification. Meanwhile, the relationship between five selected factors (atmospheric condition, time of crash, alcohol test result, crash type, and driver’s distraction) and traffic injury severity was also analyzed in this study. The results indicated that crashes occurred in bad weather condition (e.g. fog or worse), in night time, in drunk driving, in crash type of single driver, and in distracted driving, which are associated with more severe injuries.
Keywords
Introduction
Road traffic accidents have become the key cause of death of population in the current years. The occurrence of crash, especially fatality crashes, not only caused an immense damage to the humans and the economy but also hindered the development of the society. The statistical analysis results from the Fatality Analysis Reporting System (FARS) in the United States (see Figure 1) presented that the number of crashes was still at high levels (average 50,000 records were collected from 2010 to 2014 in FARS). To be more precise, due to the specificity of the FARS data, a crash was recorded if a person died within 30 days of road traffic accidents, 1 for last 5 years. It has been observed that the records of fatality injury possessed nearly 50% of the total number of records in FARS, and the highest number appeared in 2012, which reached 29,867. Although it seems that the numbers of fatality injury records have decreased in recent years (approximately 17% reduction from 2011 to 2014), considering the damage of the fatality crashes, more efforts are needed to prevent the occurrence of crashes, especially fatality crashes.

The statistical analysis for crashes.
Previous study has demonstrated a fatality crash is caused by five types of factors: driver characteristics, vehicle characteristics, accidents types, road condition, and environment characteristics. 2 Many factors such as the length of entire ramps, DeLength (length of deceleration lanes), and others had already been considered as feature variables to analyze the crashes or fatality crashes. 3 However, there are 180 variables related to the occurrence of crashes in FARS. Therefore, it is necessary to summarize the features which can provide a comprehensive evaluation of the occurrence of fatality crashes. Feature selection is a useful approach to reduce the dimensionality of feature space. With the development of data collection and machine learning techniques, feature selection plays a critical role in data mining and machine learning. It thus often provides a comprehensive overview to conduct the FARS data.
The scope of this study is to propose an algorithm for extracting impact factors that are significantly related to the occurrence of crash according to their injury severity. Moreover, the quantitative relationship between the injury severity and the selected features was also in-depth analyzed in this study. The purpose of this article is to explore the main causes that result in the severe injury in the United States. These achievements can be associated to improve the time of emergency response and drivers’ training pattern.
Literature review
This review focuses on the research developments of risk factors associated with traffic injury severity, feature selection methods in the field of traffic safety, and classification algorithm for the prediction of traffic injury severity. The constructions are stated in the following sections.
Risk factors associated with traffic injury severity
The risk factors for human, vehicle, road condition, and environment are associated with crashes and injuries/fatalities. Human factors play a critical role in road traffic accidents. As an example, driver fatigue is regarded as one of the most serious reasons which leads to fatal accident and injuries, causing 15%–20% of all traffic accidents in developed countries. 4 Meanwhile, Ma et al. 5 found that alcohol usage and drivers having a license or not significantly affect injury severity. Moreover, the relationship between the injury severity and other human characteristics, such as driver’s sex, 6 age, 7 and emotion, 8 also had been discussed in previous studies.
Meanwhile, Michalaki et al. 9 found that the number of vehicles involved in an accident, low visibility, and the hour of traffic accident had positively affected the injury severity. Abu-Zidan and Eid 10 focused on exploring the risk factors that affect injury severity of vehicle occupants. According to their research, the mechanism of injury, age of the vehicle occupant, and vehicle speed significantly affect the occurrence of injuries/fatalities. In addition, the geometric design variables (curvature, lane width, vertical grade, and so on), 11 traffic conditions (speed limit, average speed, traffic flow, and congestion), 12 weather condition (wind, rain, and fog), 13 and vehicle (vehicle type, wind dynamic, and shape) 14 also had already been confirmed as impact factors that cause traffic injuries/fatalities.
Feature selection and classification algorithm for the prediction of traffic injury severity
Feature selection not only can extract the impact factors that significantly affect traffic injury severity but also can improve the accuracy of traffic accident prediction. Two typical feature selection methods, feature ranking and feature subset selection, are widely used to conduct the big data. The feature ranking methods take features as the evaluation units and rank them according to their discrimination power. 15 The feature subset selection methods try to find the best feature subset according to the best discrimination power. 16 As an example, Yang 17 investigated the feature problem for traffic congestion prediction. According to their research, a feature ranking selection method was employed to extract traffic congestion–related features from the multi-sensors signals. In another example, Zhang et al. 18 proposed a hybrid feature selection algorithm named SRSF to overcome the impacts of traffic flows. In addition, other feature selection methods such as rough set, 19 genetic algorithm, 20 correlation-based and causal feature selection, 21 and fast correlation based filter (FCBF) 22 are also employed in the area of traffic safety. However, few feature subset selection methods are used to overcome the impacts of traffic injury severity.
The traffic injury severity classification algorithms can predict the occurrence of traffic accident with high accuracy; moreover, it can also be used to analyze the relationship between impacts and injury severity. Bayesian Networks (BN) is a commonly used algorithm to predict traffic injury severity. Huang et al. 23 proposed a hierarchical Bayesian binomial logistic model to identify the severity level of injury at signalized intersections. Yu and Abdel-Aty 24 developed a hierarchical Bayesian BP model to analyze the level of crash injury severity with real-time traffic data. Meanwhile, the application of classification and regression tree (CART) has been reported to be a powerful tool to analyze traffic safety problems. Chang and Wang 25 established a traffic severity classification model based on CART, and the results indicate that the vehicle type, motorcycle and bicycle riders, and pedestrians are the most important variables for injury severity. Kashani and Mohaymany 26 applied CART model to predict the crash severity on two-lane, two-way rural roads in Iran. In addition, other algorithms, such as artificial network, 27 fault tree analysis (FTA), 28 logistic regression, 29 and Naïve Bayes (NB), 30 have also been adopted to identify traffic crashes and traffic injury severity.
Methodologies
Feature selection algorithm (Markov Blanket)
Markov Blanket is a typical feature subset selection algorithm, and this is the first time that the algorithm has been used to select attributes in the domain which was put forward by Koller and Sahami. 31 The Markov Blanket has the advantage of being able to extract attributes from data with multi-dimensional high sample size and select attributes by eliminating redundant variables. It has been proved suitable for traffic data mining in previous studies. 32 Thus, we try to introduce the Markov Blanket theory into the area of feature selection with respect to traffic injury severity, and the definition of this algorithm is described as follows.
The Markov Blanket of the dependent variable T, denoted as MB(T), is a minimal set of variables (or factors, features; hereafter, we use these terms interchangeably) conditioned on which all other variables are probabilistically independent of T (Definition 1). Thus, knowing the values of MB(T) is sufficient to determine the probability distribution of T, and the values of all other attributes become superfluous. 33 Obviously, we can only use attributes in MB(T) instead of all the attributes for optimal prediction. Moreover, under certain conditions (faithfulness to a BN), MB(T) is the subset that contains parents, children, and parents of children of the target T in the BN. 34
Definition 1 (Markov Blanket)
The Markov Blanket of a target attribute T ∈ V, denoted as MB(T), is a minimal subset of attributes for which 35
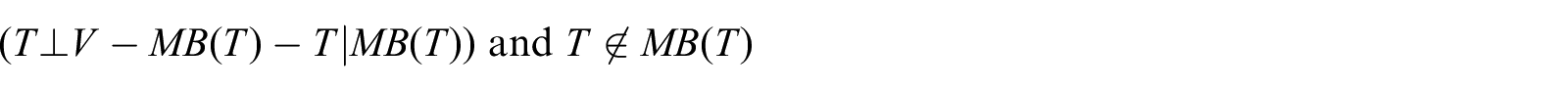
where V is the set of all attributes in the domain, and symbol “⊥” denotes independence. The specific process of the MB algorithm is as follows.

To effectively increase the efficiency and accuracy of feature extraction, an improved Markov Blanket (IAMB) algorithm was developed and is described as follows.
In Algorithm 2, The IAMB algorithm consists of two phases: lines 2–9 denote the growing phase and lines 10-–14 denote the shrinking phase. The main work of the growing phase is to find a Markov boundary of the target T, and all of the related factors will be redundant to T in this boundary. The shrinking phase of IAMB tries to further eliminate the redundancy in the Markov boundary discovered in the prior phase. Note that the conditional independence test in IAMB is controlled by the preselected threshold ∈, which will be nominally set to 0.01, as suggested in Aliferis et al.
36
Note that

The evaluation method
Two commonly used traffic injury severity classification algorithms named BN 24 and CART 4.5(C4.5) 26 were employed to generate classification error rates (CERs), and the characteristics of each algorithm are described as follows:
BN. This is an annotated directed cyclic graph; the basic network is connected by a node and the node of the arrow or the directed edge. The node represents the random variable that would be affected by the events. The arrow or directed edge is equal to the relationship between the factors and events. The directed edge from the parent to children nodes and the contingent probability express the degree of influence between the parent and children nodes. The K2 search algorithm was employed to perform the BN structure in this study.
C4.5. The C4.5 analysis is an effective algorithm to conduct prediction problems. The development of C4.5 model consists of four steps. The first step is data preprocessing; the data are always divided into two subsets (training set and testing set) and the target variable should be discrete. The second step is the calculation of Information Gain of each attribute—the calculation method is similar to the algorithm ID3. The next step is tree growing; according to step 2, the decision tree generation is carried out while the observed values of each attribute are equal to the division subsets. The last step is the new dataset classified based on the classification rules.
The calculation process is carried out in WEKA, and all of two classification algorithms had already been integrated in this platform. The data analysis experiment is conducted using a 64-bit Windows computer with 2.4 GHz CPU, 8 GB RAM. The CER and accuracy are computed as follows


where FP represents the number of events incorrectly classified as belonging to class A, and TN represents the number of events correctly classified as not belonging to class A. CER could represent the percentage of members of class A incorrectly classified as belonging to class A.TP represents the number of events correctly classified as belonging to class A.
The data
Description of FARS data
The FARS is a comprehensive database that became operational by NHTSA in 1975, and a majority of fatal traffic crashes are covered in this system in the United States. 38 The source of FARS data is from police crash reports (PARS), and about 100 data elements for a crash that includes information from the driver, vehicle condition, and crash level are collected. 39
In order to identify the common features associated with the occurrence of injury fatality, the data of fatal crashes for 5 years in 50 US states were used in this study. Feature selection methods and machine learning algorithms were employed to conduct the datasets. However, data quality is a quite important issue, while the result of machine learning is determined by these issues. Therefore, the technology of data mining and preprocessing is essential to analyze the cause of traffic injury fatality.
Data preprocessing
Considering the accuracy of analysis findings between traffic injury fatality and impact factors, the FARS data need to be cleaned before use. The proposed data preprocessing method for analyzing FARS data consists of six filtering rules:
The injury severity level was divided into three levels (0 = no injury, 1 = injury, and 2 = fatality) according to the worst-injured occupant. As an example, the possible injury and suspected minor injury in FARS are classified as an injury crash. The unknown values (such as 5 = uninjured; severity unknown) are deleted;
Remove the variables while all the values of the variable are 0 or otherwise;
Remove the records while the value is no-numeric or missing;
Remove the records with negative values (such as the value is −1; blank in driver-related factor);
Remove outlying or low values;
Remove or replace the variable that it had already confirmed with no-correlation with injury severity in previous study or expert evaluation.
After these filters, the number of selected crashes records was 45,490, 39,953, 40,095, 40,095, 37,427, respectively, from 2010 to 2014, and the detailed description of the datasets is presented in Figure 2. Moreover, 29 variables (e.g. atmospheric condition, day of crash, and so on) and one target variable were coded based on six above filtering rules, and the general information of the selected variables is shown in Table 1.

The dataset of crashes records after filtering.
Variable description.

Results and discussion
The result of feature selection
In order to excavate the main factors associated with traffic injury severity, six datasets in FARS from 2010 to 2014 are applied in our study, and all of the datasets had already completed data preprocessing before our experiments. General information of six datasets is presented in Table 2, and the minimum descriptive length (MDL) method is adopted to discrete continuous features while the continuous and mixed datasets existed.
Description of datasets.

To evaluate the performance of IAMB in training speed in processing large sample datasets, three widely used feature selection algorithms—FCBF (fast correlation–based feature selection), ReliefF, and Wrapper-SVM (support vector machine)—are employed as comparisons (see Figure 3). The brief introduction about three contrast algorithms is as follows.
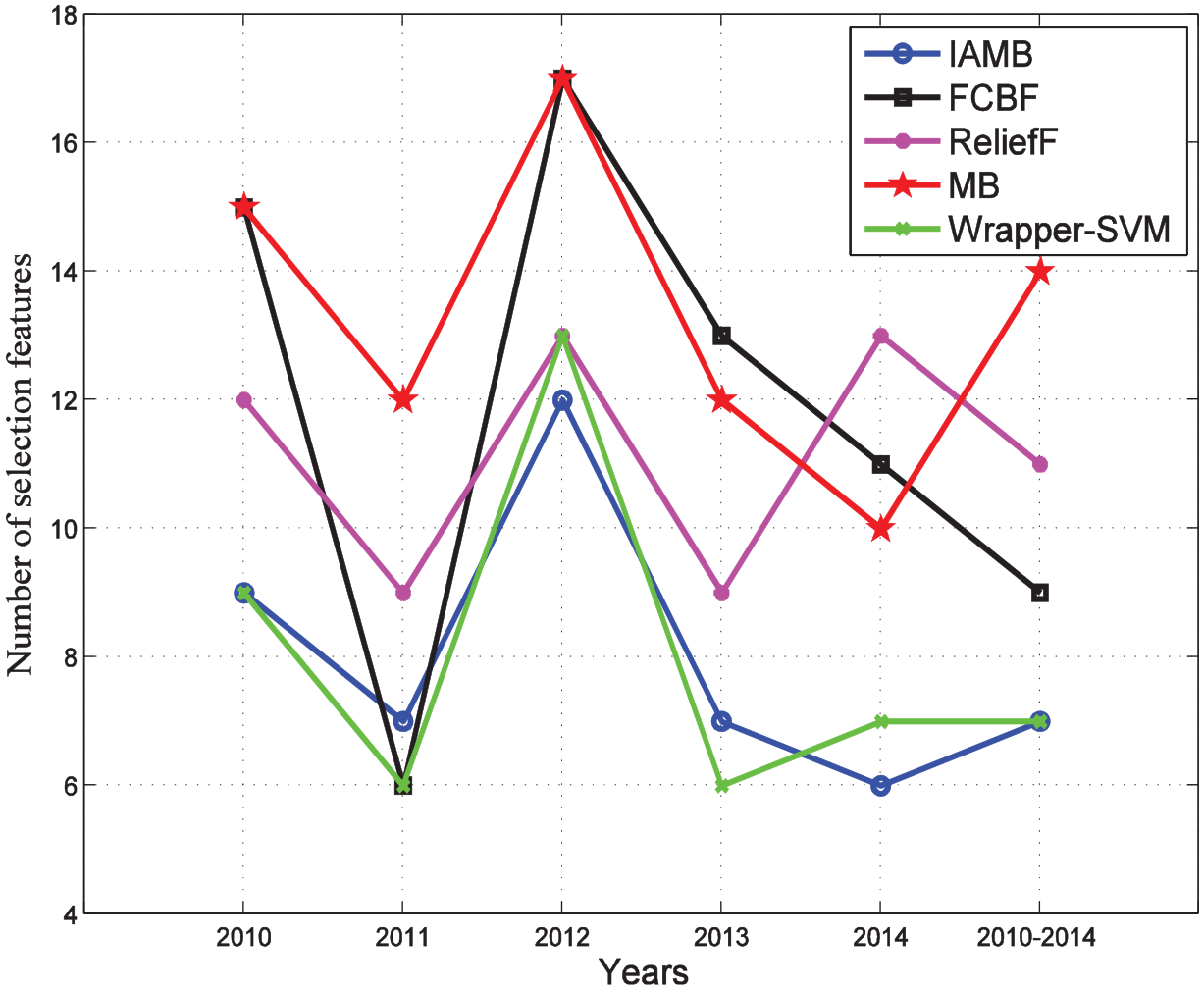
Comparison with different feature selection algorithms.
FCBF (fast correlation–based feature selection).
40
The measurement criterion is symmetrical uncertainty (SU) in this algorithm. First, all the features are ranked based on the correlation test, then the redundant features are eliminated using approximate Markov Blankets, and the judgment criteria are as follows: if
ReliefF. 41 It is a well-known feature sorting method based on distance. The feature selection criterion of this method is to select the feature with the maximum distinguishing distance of different class tags and the minimum distinguishing distance of the same class tags. The algorithm needs to set the nearest neighbor number k and the number of participating samples m before training, and k = 5, m = 30 in this study.
Wrapper-SVM. 42 The characteristics of this algorithm are that the SVM algorithm is embedded into the Wrapper class attribute sorting algorithm, and the optimal or locally optimal attribute sets are obtained based on the classification accuracy.
A comparison between IAMB and four other feature selection algorithms with respect to the number of selected features is shown in Figure 3.
The results shown in Figure 3 clearly present that the dimension of features is decreased after using five feature selection algorithms, and the IAMB algorithm is superior to other four algorithms in different four datasets (the number of selected features are 9, 12, 7, and 7, respectively). It ranked second in the other two datasets (the number of selected features is 7 and 7, respectively). Meanwhile, training time is also considered as an essential indicator to evaluate the performance of a feature selection algorithm; thus, the training time is also recorded and can be seen in Table 3.
The training time of different feature selection algorithms.

MB: Markov Blanket; FCBF: fast correlation–based filter; IAMB: improved Markov Blanket; SVM: support vector machine.
Bold values represent the highlighted number results of IAMB approach in this research, the details of significance have been analyzed in paper.
As shown in Table 3, the training time in six datasets shows that IAMB (1.85, 1.37, 1.44, 1.32, 1.00, and 4.21 s, respectively) outperforms the other algorithms. Although the Wrapper-SVM extracted less number of selected features in 2011 and 2013 (the number of selected features is 6 and 6, respectively) in Figure 3, the training time of Wrapper-SVM is more than 600 s. Meanwhile, the results in Figure 4(a) and (b) show that the IAMB algorithm presented the best performance irrespective of the number of selected features and the training speed in most of the datasets, which indicated that the IAMB selected fewer features using the shortest training time.

The comparison between IAMB and other algorithms: (a) the number of selected features and (b) the training speed.
In addition, the results of using IAMB presented in Table 4 indicate that atmospheric condition, hour of crash, alcohol test result, crash type, and the driver’s distraction are critical factors that influenced traffic injury severity among different years from 2010 to 2014. There also exist many features that are not common in different datasets, such as work zone, month of crash, and so on.
The general information of selected features using IAMB.

IAMB: improved Markov Blanket.
Calibration and validation of feature selection
In order to check the quality of the selected features by IAMB, the Pearson correlation coefficient test and the CER test were employed. The relationship between the selected features and injury severity was also analyzed, and the different classification algorithms were employed to classify different injury severity levels based on the selected features.
The result of Pearson correlation coefficient test
As shown in Figure 5, the results present that the vast majority of selected features are significantly correlated with the traffic injury severity (p < 0.01) in different datasets, where p value <0.01 indicates the statistical significance of the correlation between the two selected variables. Only driver’s distraction (ID: 24) in 2010 and 2011, driver alcohol involvement (ID: 20) in 2010, month of crash (ID: 4) in 2010–2014, and license state (ID: 22) are not significantly correlated with injury severity. Thus, the result of correlation test indicates that the feature selection by IAMB is effective.

Correlation test between injury severity and selected features in different years: (a) in 2010, (b) in 2011, (c) in 2012, (d) in 2013, (e) in 2014, and (f) in 2010–2014.
In addition, Figure 5 also records the calculation results of the correlation coefficient between selected features and injury severity. The absolute value of correlation coefficient of alcohol test result (0.325 in 2010, 0.447 in 2011, 0.398 in 2012, 0.441 in 2013, 0.482 in 2014, and 0.268 in 2010–2014) is greatest in different datasets, which indicates that the alcohol test result is a critical impact factor that caused the occurrence of traffic injury. Meanwhile, the features of 1, 3, 23, and 24 are also associated with traffic injury severity.
The result of CER test
Two famous and most frequently used classifiers, BN and C4.5, in traffic accident analysis are adopted to generate the accuracy of classification and CER on six datasets with selected features by different feature selection algorithms. Three types of selected features extracted by genetic search, rank search, and un-selected were adopted as a comparison. Ten-fold cross-validation method was applied to evaluate the accuracy of different algorithms.
The results of Figures 6 and 7 show that the accuracy of classification with IAMB in BN and C4.5 is better than the results with compared algorithms and un-selected in most of the datasets. Although the improvement of accuracy of classification is not significantly greater, the huge losses to humans and the society due to fatality injury are worthy of consideration. In addition, the result of Figure 6 also indicated that a better classification results could be achieved by C4.5 in FARS data analysis, and the best accuracy of classification appeared in 2014 by C4.5 reached 68.71%.

The accuracy of BN.

The accuracy of C4.5.
For further analysis, the CER is calculated to visualize the difference of IAMB compared with the other selected feature selection algorithms under two classifiers on six datasets. Figure 8(a) and (b) presents that the value of CER of IAMB under BN and C4.5 is lower when compared with that in most of the datasets, respectively. The lowest CER of IAMB appeared in 2014 under BN and reached 16.04%. The result of CER indicates that IAMB achieves better performance in most of the datasets, and it is useful to extract the critical factors that influenced traffic injury severity in FARS.
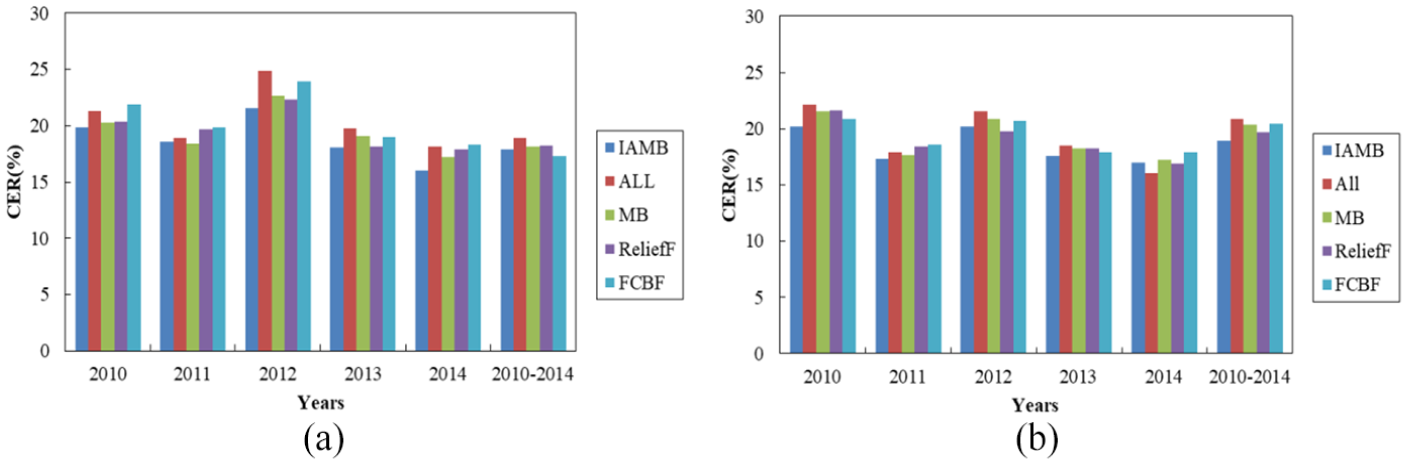
The CER of (a) BN and (b) C4.5 in different feature selection algorithms.
Discussions on common and significant impact factors
As shown in Table 4, when using the IAMB algorithm, five variables were identified as significant and common factors that contribute to traffic injury severity. They are as follows: (1) atmospheric condition, (2) time of crash, (3) alcohol test result, (4) crash type, and (5) driver’s distraction. The values of different factors were defined by combining requirements from the manual of FARS and engineering experiences in previous studies. As an example, the alcohol test result was divided into three states: it was defined as drunk driving while the alcohol test result is greater than 0.08% blood alcohol concentration (BAC) and the state is defined as others while the value of alcohol test is greater than 0.94% BAC. Moreover, in order to deeply analyze the relationship between the common features and traffic injury severity, the crash rate (CR) was defined and was calculated as follows

where i is the mean level of traffic injury severity, and CN is the the number of crash.
The description of the selected variables, together with their CN and CR, is presented in Table 5. The statistical analysis indicates that the value of CN and CR of different levels of traffic injury severity in different states of selected features is different. Therefore, the detailed interpretation for these five features is needed and is provided in Table 5.
Variables, values, and actual classification by severity.

Category 1: single driver; category 2: same traffic way, same direction; category 3: same traffic way, opposite direction; category 4: changing traffic way, vehicle turning; category 5: intersecting paths; category 6: miscellaneous; CN: number of crash; CR: crash rate.
Atmosphere condition
As shown in Table 5, compared with crash occurrences during fine weather condition, the rate of fatality crashes decreases 1% in rain day and increases 1.9% in fog or worse. This finding is consistent with Edwards 43 who found that accident severity in rain decreases significantly when compared with fine weather. The reason for the results may be high speed and paying less attention to driving during fine weather. Moreover, the rate of no-injury crashes in fine weather is the highest when compared with other weather conditions, which indicates that although the crash easily occurs in fine weather, the damage of an accident is lower than in other weather conditions.
Time of crash
The classification of time of crash occurrence was similar to that of Huang et al.’s 23 who defined the time of crash as day time (10:00 a.m.–5:00 p.m.), peak time (7:00 a.m.–10:00 a.m. and 5:00 p.m.–8:00 p.m.), and night time (8:00 p.m.–7:00 a.m.). In previous studies,2,23,24 it had already been confirmed that more severe injuries occur during darkness, and crashes occurring in peak time are associated with lower severity when compared with those in day time and night time. The visibility is poorer at night time, and the drivers’ attention is more easily to distract. This is the main cause of traffic accidents at night. In contrast, at peak time, the driving speed will be lower and dangerous driving behaviors such as forced lane changes will be reduced, leading to lower severity of accidents. This coincides with the results found in this study.
Alcohol test result
The alcohol test result was classified into three types: normal driving (0%–0.08% BAC), drunk driving (0.09%–0.94% BAC), and others (higher than 0.94% BAC). The results shown in Table 5 present that 62% of the occurrence of crashes are fatal accidents while drivers are convicted of drunk driving, and the rate of fatal crashes is significantly higher than in normal driving. Previous studies have observed that drunk driving impairs driving abilities and large numbers of fatal and injury crashes were related to drunk driving. 44 Stübig et al. 45 found that drunk driving increases the probability of injures and fatal injury in a crash.
Crash type
The results shown in Table 5 indicate that the crash type of single driver was found to be more involved in fatality accidents, with the fatality rate reached at 44.8%. The highest CR of no-injury appeared in category 2, which indicated that a same traffic way and same direction accident resulting in lower accident severity. De Oña et al. 46 found that the probability of killed or seriously injured accidents increased while the rollover (belong to category 1 in this study) occurred.
Driver’s distraction
It was found that the crash rate of injury and fatality (the CR reached 35.7% and 40.3%, respectively) was increased when the driver is distracted when compared with a non-distracted driver. This is consistent with Neyens and Boyle 47 who found that the passengers are easier to suffer from severe injuries when the driver is distracted than with a non-distracted driver. In addition, the results shown in Table 5 also indicate that crashes that occur always result in no-injury severity while the driver is non-distracted or attentive.
Conclusion and recommendations
A feature selection (IAMB) algorithm was proposed to extract the main factors that are associated with the injury severity while traffic accident occurred. It is useful to help the department of transportation to develop the related policy to decrease the occurrence of severe injuries. This algorithm only needed simple preprocessing about the initial data, and it is helpful to analyze the big data. The FARS data from 2010 to 2014 were preprocessed and applied as the datasets for the analysis. Two commonly used classification algorithms (BN and C4.5) and three indicators (correlation coefficient, accuracy of classification, and CER) have been employed to examine the performance and effectiveness of IAMB algorithm. The results of validation and verification indicate that IAMB is a good feature selection algorithm to analyze injury severity of FARS data, with significant correlation between the selected factors and injury severity, with the increase in the accuracy of classification, and with the decrease in the classification rate.
The IAMB algorithm selected five impact factors (including atmosphere condition, time of crash, alcohol test result, crash type, and driver’s distraction) that significantly influenced traffic injury severity from the initial 29 variables. These five factors are regarded as common features which were selected in all six dataset (the FARS data from 2010 to 2014). It was found that crashes occurred in bad weather condition (e.g. fog or worse), in night time, in drunk driving, in crash type of single driver, and in distracted driving, which are associated with more severe injuries. Specially, results indicated that crashes in peak time resulted in low severity. The result of the Pearson correlation coefficient test shown in Figure 4 indicates that the alcohol test result is the most important factor that significantly influenced traffic injury severity. All in all, the results are consistent with the previous research.
This study shows that the combined use of feature selection (IAMB) algorithm and data analysis method provides new insights and ideas on the extraction of main causes of crash severity for FARS data. It is worthwhile to do the feature selection before applying other machine learning techniques to predict traffic injury severity while a traffic accident occurred.
However, no study is without limitations. In this study, due to the incomplete and bias of FARS data, the best of accuracy of injury severity classification only reached 68.71%. A better dataset is needed to achieve a high enough traffic injury severity prediction model. Different results might have obtained if other types of data had been applied. Moreover, in order to increase the efficiency and simple data processing, the traffic injury severity was concluded into three states (no-injury, injury, and fatality) and the unknown value of all the variables was deleted. It might be influenced by the final result of crash data analysis.
Footnotes
Data availability
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is sponsored by the National Natural Science Foundation of China (51805169, 51605350, and U1764262); Wuhan Science and Technology Project (2019010702011301); and the National Engineering Laboratory for Transportation Safety & Emergency Informatics in China (YW170301-09). This work was also supported by the China Scholarship Council (CSC).