
Abstract
Self-efficacy has emerged as a popular construct in second language research, especially in the frontline and practitioner-researcher spaces. A troubling trend in the relevant literature is that self-efficacy is often measured in a general or global manner. Such research ignores the fact that self-efficacy is a smaller context-driven construct that should be measured within a specific task or activity where time, place, and purpose domains are considered in the creation of the measurement. Task-based language teaching researchers have also largely neglected the affective factors that may influence task participation, including self-efficacy, despite its potential application to understanding task performance. In this report, we present an instrument specifically developed to measure English as a foreign language students’ self-efficacy beliefs when performing a dialogic, synchronous, quasi-formal group discussion task. The instrument's underlying psychometric properties were assessed (N = 130; multisite sample from Japanese universities) and evidence suggested that it could measure a unidimensional construct with high reliability. The aggregate scale constructed from the instrument's items also displayed a central tendency and normal unimodal distribution. This was a positive finding and suggested that the instrument could be useful in producing a self-efficacy measurement for use in the testing designs preferred by second language researchers. The potential applications of this instrument are discussed while highlighting how this report acts as an illustration for investigators to use when researching self-efficacy.
Keywords
Introduction
For many teachers in compulsory educational contexts around the world, perhaps one of the greatest challenges is fostering students’ engagement with classroom tasks (Hiver et al., 2021a), and harnessing their attention until the tasks are completed (Leeming, 2019). In order for students to be engaged with tasks, they need to be engaged in the task from beginning to end, even when faced with difficulties. This may be one reason for the increase in research investigating self-efficacy as an individual difference variable (see e.g. Teng et al., 2021; Wang et al., 2021; Xu et al., 2022). As part of Bandura's (1997: 3) social-cognitive theory, he defines self-efficacy as ‘beliefs in one's capabilities to organize and execute the courses of action required to produce given attainments’. Self-efficacy's importance lies in its capability to predict the likelihood of a student beginning a given task, how much effort they will expend on that task and the chances that they will continue when it becomes challenging (Bandura, 1997): their engagement with a task. For this reason, self-efficacy has garnered considerable interest in the field of language learning (Mills, 2014; Wyatt, 2022). Although some researchers have argued for more general measures of self-efficacy (Chen et al., 2001), Bandura is highly critical of this approach and argues that the strength of self-efficacy as an individual difference variable lies in its specificity and ability to predict task behavior. He claims that ‘the convenience of general-purpose tests of personal determinants is gained at the cost of explanatory and predictive power’ (1997: 41). Therefore, measures of self-efficacy should relate to specific tasks.
In this report, we present the development of a self-efficacy instrument designed for a specific English as a Foreign Language (EFL)/second language (L2) group discussion (spoken) task, created for high immediate speakers in the Japanese university context (see section 2.1 for further consideration of proficiency). Self-efficacy is typically low in this context (Harris, 2022), and therefore of particular interest to researchers. Group discussions are also commonly used in university courses both to foster communicative competence and to assess students (Leeming, 2019; Yashima et al., 2016). The popularity of group discussions in particular and speaking activities and tasks in general in Japanese English language teaching (ELT) settings comes into focus considering recent reviews of Japanese learner performance on standardized English assessments. As reviewed by Koizumi et al. (2022: 15, Table 8), speaking has often lagged behind the other skills such as reading and listening in these exams. Japanese ELT settings tend to use these discussion tasks and associated activities to address this ‘gap’ in their learners’ proficiency profiles.
The group discussion task instrument developed in the present study was designed to be used in a larger project with different participants from those whose data drives this current undertaking. As highlighted by Al-Hoorie and Vitta (2019), the process of collecting initial validity evidence for new instruments in the second and foreign language research context requires several measurements and various considerations over time. Instrument validation is an ongoing and iterative process requiring several rounds of data collection and analysis, as suggested by the American Educational Research Association, the American Psychological Association and the National Council on Measurement in Education (2014). No single study or incidence of reporting, in other words, can prove an instrument and its measurements(s) trustworthy or not for their intended purpose(s). Because of the nature of self-efficacy which requires task- and activity-specific instruments, the processes reported and detailed here can be of use to future researchers, especially practitioner-researchers, investigating self-efficacy in their contexts.
Self-Efficacy as an Activity- and Task-Specific Construct
Recent L2 research supports Bandura's (1997) calls for detailed measures of self-efficacy. Despite a substantial body of research supporting the strength of self-efficacy as a predictor variable (see Bandura, 1997 for an overview), a number of second language acquisition (SLA) studies have found weak relationships between self-efficacy and behavioral outcomes. Xu et al. (2022), for instance, investigated English proficiency in the context of Chinese EFL learners studying abroad and observed minuscule predictive power for prior self-efficacy (less than 1% of the explained variance). The study involved holistic performance on the English component of college entrance exams as the dependent variable, where the self-efficacy measure lacked the constraints to a specific task in terms of function and use (e.g. writing a business letter). Questions measuring self-efficacy concerned general proficiency (skills), with items such as Can you introduce yourself in English?, while English speaking proficiency was assessed by performance on read-aloud and presentation tasks. Wang et al. (2021) used the same questionnaire and measures of proficiency in a similar design and also found small effects. Their low-medium-high grouping variable could only account for 4% and 2% of the participants’ L2 English listening and reading proficiency variance, respectively. As stated previously, the weak relationships observed in these studies run contrary to findings in psychology (Bandura, 1997), and suggest that measures of self-efficacy should be specific, detailed and relate directly to the task being performed.
Task-based language teaching (TBLT) is an increasingly popular approach, with a large body of research showing the benefits that tasks provide for language learning (see Ellis et al., 2020 for a comprehensive review). Although the psycholinguistic benefits of tasks have been investigated (Leeming and Harris, 2022), the motivational side has been neglected, with a dearth of research investigating factors that may influence student engagement and interest in tasks and learning (Aubrey and Philpott, 2019; Dörnyei, 2019; Ellis et al., 2020). Self-efficacy has potential in this area, and measures can be designed to predict performance on highly specific tasks. SLA researchers have developed measures of self-efficacy for speaking, but, as stated previously, items tend to be of a general nature and are therefore unlikely to have the predictive power that comprise self-efficacy's strength as a latent variable. For example, Leeming (2017) developed a measure of speaking self-efficacy for an oral English course in the Japanese university EFL context that followed a task-based approach. However, the items tended to be of a general nature, relating to the class and course, rather than specific tasks, for instance, I can understand what is taught in English Communication Class. While this may measure general self-efficacy towards the course, it is unlikely to predict specific task behavior.
Despite the general focus of such instruments, research has been conducted with more task-specific self-efficacy instruments. The items developed by Harris (2022) were more specific than those of Leeming (2017) (for example, I can talk about my daily life in English). Although Harris’ self-efficacy measure had single items specifically relating to different tasks, the scores for items were combined with the apparent assumption that they could constitute an overall general measure of speaking self-efficacy. This resulted in a measure that was unlikely to provide predictive power for a specific task. Harris (2022) used Test of English for International Communication (TOEIC) Speaking and Writing scores as behavioral outcomes and examined the correlation between those scores and his speaking self-efficacy measure. Although the small sample size (n = 32) makes interpretation of the results difficult (see Nicklin and Vitta, 2021 for the challenges that unpowered samples present regarding trustworthy generalizations), Harris found a moderate correlation of .490. This demonstrated a link between general speaking proficiency and self-efficacy but did not provide information regarding specific speaking tasks.
Present Study
In this study, we present the design process and initial validation evidence (see Norris et al., 2015) relating to a self-efficacy instrument designed for quasi-academic L2 discussion tasks. The quasi-academic (or quasi-formal) label reflected an aspect of our task design where the topics and discussion prompts were created to allow the majority of the students, who were B1 or B2 on the Common European Framework of Reference for Languages To what extent did the survey items avoid collinearity and unrelatedness? To what extent did the survey items enable a unidimensional and reliable measurement of speaking discussion task self-efficacy? What were the descriptive characteristics of the survey items’ aggregated scale?
The first two questions touched on the main focus of this report in presenting initial psychometric validation evidence for a task-specific scale to be used in the larger project. The third question was a prospective one, in that the larger project and others like it would use the survey to create an aggregate scale for inferential modeling. Reporting descriptive data is worthwhile for this purpose. L2 researchers in general (see Plonsky and Gass, 2011) and psychology in language learning (PLL) researchers in particular (see e.g. Al-Hoorie et al., 2022; Hiver et al., 2021b) tend to favor linear modeling. Therefore, the distributional characteristics of the data collected via the instrument were also assessed, since normal distributions tend to result in satisfying the residual assumptions of the general linear model (Field, 2018; Glass et al., 1972). In line with practices of operationalizing self-efficacy as described above, we designed the self-efficacy instrument specifically for a dialogic, synchronous, quasi-formal group discussion task, which are common activities in Japanese university ELT (see e.g. Aoyama, 2020; Nakatani, 2006).
Method
Setting and Participants
In the larger project, two Japanese universities, both in western Japan, were selected based on the criteria that their EFL programs allowed discussion tasks to be implemented. The universities in question were well regarded and the classes where the research was conducted had relatively high English proficiency for the Japanese context (see Koizumi et al., 2022). Because we intended to construct a survey enabling a unidimensional construct with 10 indicators, a 100-participant sample was determined a priori as the minimum number required for the analysis (for sample size thresholds in factor analysis, see Wolf et al., 2013). Unrelatedness, which was part of RQ1’s focus, was assessed with a threshold of r = .300. Accordingly, this effect size was incorporated in an a priori power analysis with G*Power (Faul et al., 2007), which indicated that 122 participants were necessary, assuming ɑ = .010, which was corrected from ɑ = .05 to somewhat account for multiple comparisons in the correlation matrix addressing RQ1, and β = .200.
In addition to the training and testing samples recruited for the larger project, a convenience sample of 130 students (i.e. the participants; nsite1 = 66; nsite2 = 64) was recruited from the two universities to conduct the initial self-efficacy instrument piloting presented here. Only one student refused to provide informed consent and thus bias was not a concern in that regard. The students were first language (L1) Japanese freshmen aged between 18 and 19, who had been studying English in school settings since at least junior high school as per Japanese government guidelines. In relation to their English proficiency, the students sampled from both universities had a similar holistic English proficiency profile as measured by Educational Testing Service (ETS) tests (i.e. Test of English for International Communication [TOEIC] and Test of English as a Foreign Language [TOEFL]), where 65% were B1 or higher and 35% were A2 or lower on the CEFR (Council of Europe, 2023). As per Japanese universities’ restrictive data culture (Ross, 2019), such cursory claims are all that can be reported here. This limitation notwithstanding, the participants from both universities did not significantly differ in relation to the task output dependent variable (i.e. the amount of words spoken during the task) in the larger study, t(228) = 1.340, p = .206, ds = 0.177 [−0.083, 0.437]. 1 When multisite samples feature such nonsignificant differences, they enable stronger generalizations to meaningful contexts vis-à-vis single-site samples, especially in instructed second language acquisition (ISLA) (see Vitta et al., 2022; Moranski and Ziegler, 2021). Although this null finding was not from the sample presented here, the 130 students comprising this current study's sample were drawn from the same sites. It is thus reasonable to assume that the invariance that the null finding suggests might also apply to this data set thereby tacitly supporting generalizations from the current study's findings.
Task-Aligned Instrumentation
The survey was designed for a specific discussion task involving students discussing quasi-academic topics in groups of three. It was used in the larger project to elicit a task behavioral engagement variable (L2 spoken task production) along with linguistic complexity data. The group size is relevant because talking in groups of three (or more) involves the added discourse competencies of turn taking, inviting opinions and joining a discussion (see Leeming, 2019; Nakatani, 2006). The ‘quasi-academic’ label, as highlighted in the preceding text, implies that topics and corresponding tasks were selected and designed to allow A2 (CEFR speaking descriptors; see Council of Europe, 2023) speakers to engage with personal stories, opinions and simple descriptions, but also give high B1 and B2 speakers the opportunity to discuss somewhat more abstract and impersonal ideas and concepts. When students engaged in the Japanese and Foreign Customs task and pre-task activities, for instance, there were A2-aligned prompts (What is your favorite Japanese holiday? Why?) juxtaposed with upper B1/B2 prompts (Which are the most important Japanese customs that foreigners living in Japan must follow? Explain why.) to invite task engagement from as many students as possible irrespective of their individual speaking proficiency.
Using I can statements (see Leeming, 2017 for this design feature in self-efficacy), the 10 Likert-scale items presented in Table 1 were designed to focus upon the different skills and competencies that the discussion task involved. These items were written, via researcher collaboration, and were qualified for a discussion of three or more people, which was a feature of the task design. Participants reacted to these items using a 6-point Likert scale with descriptive labels (for description on labeled scales enhancing psychometric quality see Saris and Gallhofer, 2007): 1 = I can definitely not do it; 2 = I cannot do it; 3 = Maybe I cannot do it; 4 = Maybe I can do it; 5 = I can do it; 6 = I can definitely do it. The instrument was translated into Japanese by two bilinguals (for Japanese translations, see Open Science Framework (OSF) link at the end of the study).
Task-driven speaking self-efficacy instrument items.

Note: The framing dependent clause ‘When … in English’ was included in each item when presented to the participants (see materials shared on www.osf.com).
In an effort to capture the taught skills and competencies that the student participants would use in the discussion task, items were written along several different lines. Some items focused on sharing information in the task (items 1, 2, 4, 7 and 9). Others focused on asking for such information in the task (items 3, 6 and 10). Some of these items were written to reflect the overt teaching of discourse competencies (for emphasis in Japanese-speaking ELT, see Nakatani, 2006) that occurred, such as supporting opinions with reasons (item 4) or asking follow-up questions to learn more (item 3). Where appropriate, items were written to reflect the contrast between simpler (items 1, 9 and 10) and more complex topics and ideas (items 2 and 7). Two additional items (5 and 8) were included to reflect the teaching of strategic competencies (Nakatani, 2006). These competencies were taught to ensure meaning did not break down (or could be repaired) during the discussion and to facilitate the successful completion of the task.
While the instrument's items were primarily designed with an inward approach referencing the task design to be employed in the larger project, they were also written to connect to published research on discussion tasks in the Japanese ELT context. Schaefer et al. (2022), for instance, found that discourse competencies (‘cognitive discourse functions’ in their terms) helped learners comfortably engage in discussions. Aoyama (2020), to cite another example, stressed how group dynamics influenced the amount of L2 engagement students had with the task. The larger project's task had a teaching design where overt consideration was given to maintaining good dynamics and encourage English output. Items in our survey reflected this (e.g. item 8).
Although the items touched on different areas, we still hypothesized a unidimensional construct for three reasons. First, the teaching points they reflected were presented to students in a singular and unified manner. Second, it was doubtful that the students would have the linguistic meta-awareness to be cognizant of these distinctions. Finally, the tasks emphasized behavioral or spoken engagement as opposed to the skills and competencies supporting such behavior (see proposed research plan in Vitta, 2021). The analyses addressing RQ2 would test this assumption of unidimensionality.
Data Collection and Data Analysis
Data was collected using Google Forms and the items and instructions were presented in the students’ L1 (i.e. Japanese). Google Forms allowed randomized item presentation, thus order of exposure was not a concern. In addition to collecting responses to the 10 survey items, we collected informed consent, and all but one of 131 students complied (N = 130). There were no missing data, so bias was not a concern in this regard. Students took approximately 10 minutes to complete the form, but there was no time restriction.
Data was analyzed according to the three research questions presented above. RQ1 was addressed via a Pearson's r correlation matrix of the 10 survey items, where values were deemed satisfactory if .300 ≤ r ≥ .900. The thresholds were chosen a priori referencing the relevant literature for collinearity (r > .900; upper threshold; see Dormann et al., 2013) and unrelatedness (r < .300; practical significance threshold for L2 research; see Plonsky and Oswald, 2014). Thresholds were employed because unrelated items might not converge on the theoretically proposed single construct. Additionally, collinear items might not be discriminant enough and thus the assumption of parsimony would be violated. Unsatisfactory correlation coefficients resulted in excluding items until these two checks were ‘passed’. Pearson's r was employed for this analysis, given the arguments of the robustness of the general linear model in handling Likert scales, especially as clearly labeled categories increase (Carifio and Perla, 2007; Norman, 2010), and the power advantage Pearson has relative to other correlation tests (Pagano, 2012).
RQ2 was addressed via exploratory factor analysis (EFA) with a maximum likelihood (ML) estimation method and a subsequent reliability assessment. Loewen and Gonulal (2015) have suggested that principal components analysis reduces noise when the items are theoretically hypothesized to represent a single construct, but EFA was used to be conservative (i.e. give the greatest chance of a null finding). In a similar vein, ML was chosen as opposed to other estimations, such as minimum residual, that reduce ‘noise’ and redundancy (Comrey and Lee, 1992).
Finally, the items were aggregated and their descriptive statistics were reported to address RQ3. Normality was assessed via skewness and kurtosis z-scores, where ±3.29 was the maximum threshold (see Kim, 2013). Although arguments have been made in SLA for normality only being consequential at the residual level (see e.g. Vitta et al., 2023), this current study did not involve inferential testing where such residuals would be available. Field (2018), moreover, highlights that when variables are normally distributed, the residuals from models involving them will also meet this assumption. In the spirit of Open Science, we have shared our materials and data on the OSF (see link at the end of this study) with the hope that future researchers exploit the work that is presented here.
Results
RQ1. Assessment of Items’ Collinearity and Unrelatedness
As highlighted in Table 2, the observed correlation values among the 45 pairs of items ranged from r = .497 (items 7 and 10) to r = .817 (items 3 and 4) and thus the items passed the checks for collinearity (i.e. no r value above .900) and unrelatedness (i.e. no r value below .300). This assessment supported the inclusion of all 10 items in the next analysis addressing RQ2.
Correlation matrix of self-efficacy survey items.
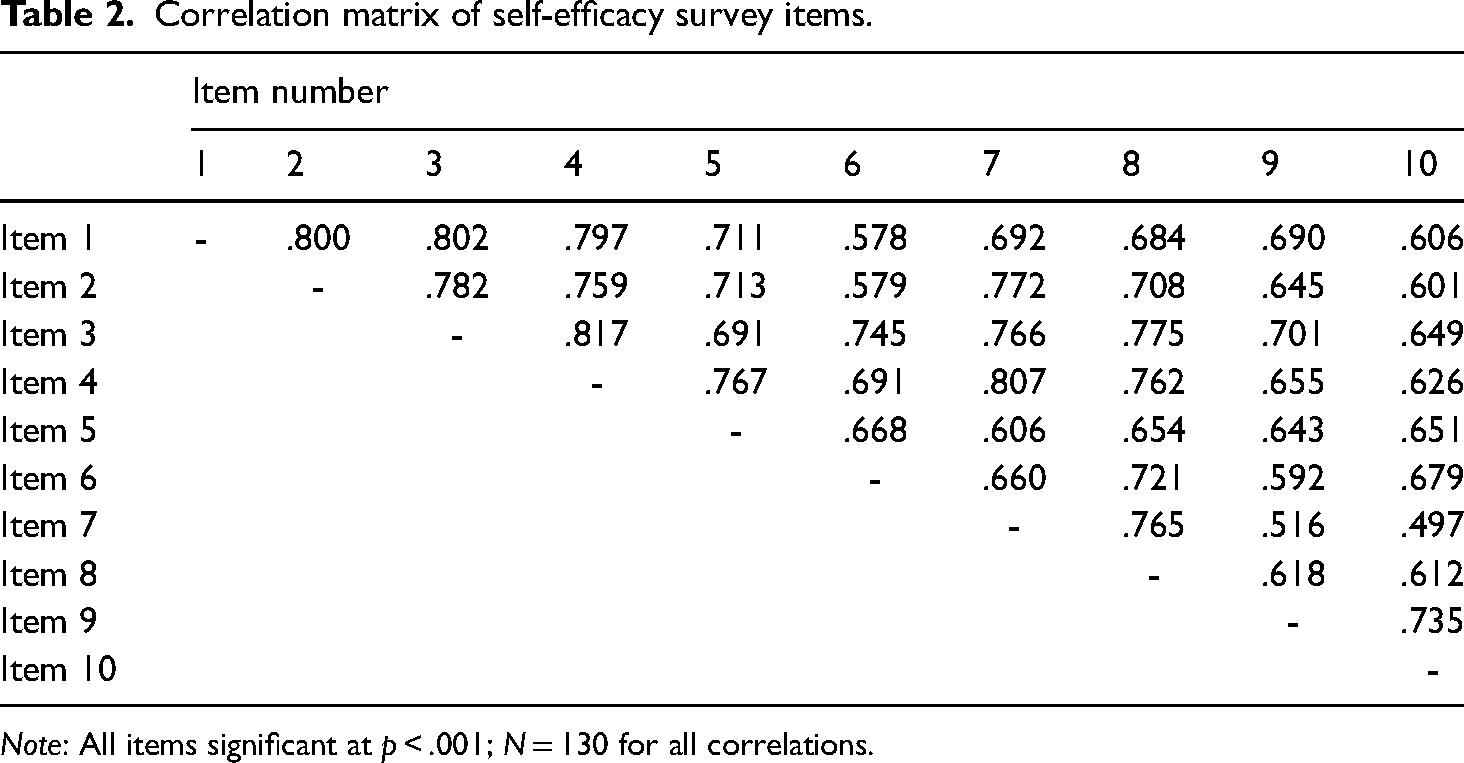
Note: All items significant at p < .001; N = 130 for all correlations.
RQ2. Assessing the Instrument Items’ Homogeneity and Reliability
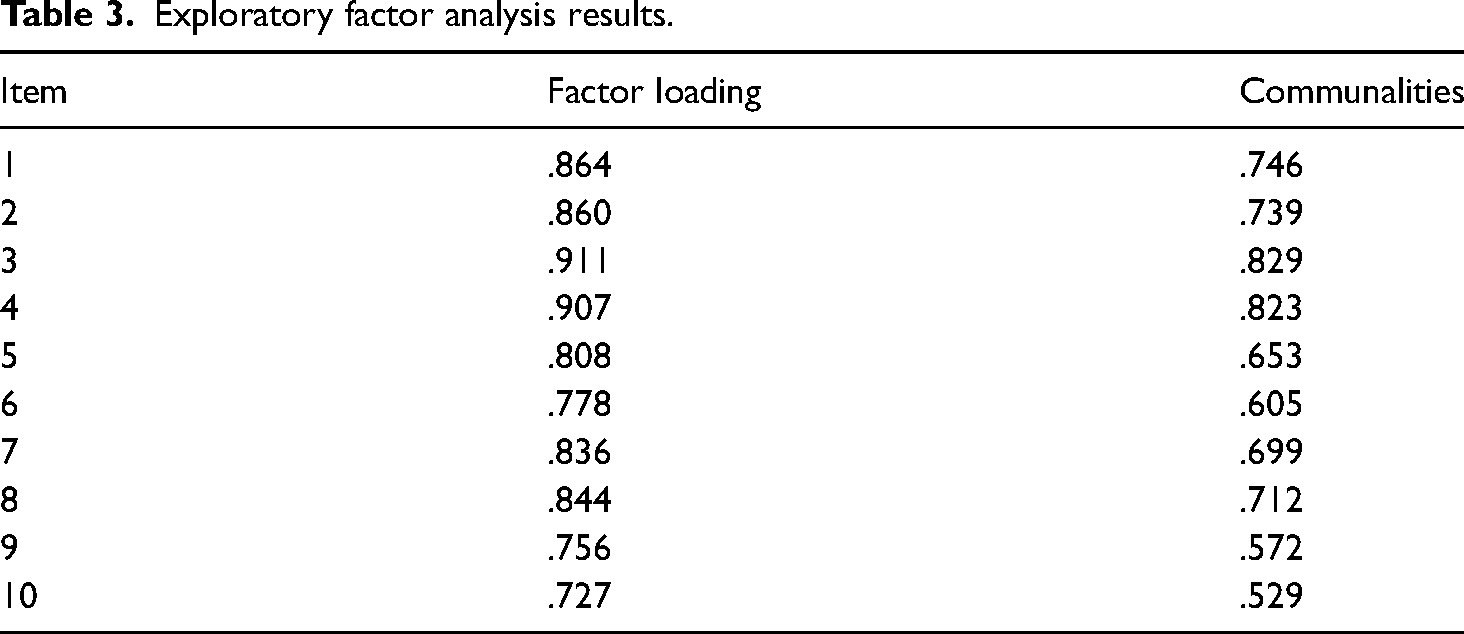
The next stage involved analyzing the 10 items via EFA. The observed Kaiser-Meyer-Olkin value of .926 and the significant result in Bartlett's sphericity test, Χ2 = 1257.285, p < .001, suggested that the sample and the 10 items were, respectively, suitable for factor analysis (Comrey and Lee, 1992). The EFA results demonstrated that there was only one significant extracted factor, eigenvalue = 6.907, accounting for 69.068% of the observed variance. The observed ranges of items’ communalities displayed in Table 3, h2 ≥ .529, and factor loadings, .727 ≤ λs ≤ .911 were acceptable (Loewen and Gonulal, 2015), and the internal reliability was high, Cronbach's α = .956. Overall, the EFA results supported the homogeneity assumption of the reliability check being met.
Exploratory factor analysis results.
RQ3. Considering the Aggregated Scale's Descriptive Properties
The aggregated scale, M(SD) = 3.919(.915) displayed a clear central tendency and approximate unimodality. The z-score results for skewness, z = .765, and kurtosis, z = .839, were under the threshold of 3.29 (Kim, 2013), thus there was empirical evidence to infer that distribution was normal. These results support the use of this instrument with the linear inferential testing approaches that L2 researchers, as well as PLL academics, tend to prefer (see Al-Hoorie et al., 2022; Hiver et al., 2021b; Plonsky and Gass, 2011).
Discussion and Potential Applications
Results as Initial Validation Evidence
The rationale for undertaking this research was to gather initial validation evidence for the larger study proposed by Vitta (2021). As argued in the literature, optimal self-efficacy instruments are time and place specific and within a TBLT framework should relate directly to the task (Bandura, 1997). It is therefore reasonable to argue that a unique task requires its own self-efficacy instrument, which in turn necessitates an initial assessment of psychometric suitability. The positive results of this study suggest that the instrument presented here can be used with some confidence in the larger study.
The first component of this evidence was the correlation matrix that addressed RQ1. The correlations in Table 1 showed that the relationship between items was acceptable. All items were related but not collinear, and thus they were potentially loading onto a unidimensional construct. If items correlate too highly then there is a risk of collinearity and redundancy in measurement. Conversely, if items have no practical correlation then it becomes doubtful that they are measuring the same construct. Although this was not a direct psychometric test, it was useful to support the decision to carry all 10 items forward into the psychometric assessments that addressed RQ2 and we offer this preceding procedure as something that can be followed by future researchers.
The results addressing RQ2 suggested that the data provided suitable initial evidence for construct validity, in relation to what the instrument measured, and also reliability. SLA researchers have expressed concern over a perceived lack of thorough instrument validation (Derrick, 2016; Sudina, 2021) and RQ2 was formulated and tested with this in mind. In the present study, the potential construct validity of the instrument's results was first assessed via factor analysis. Evidence of unidimensionality via the EFA (only one observed significant factor explaining a majority of the variance) was interpreted as initial evidence that the instrument was measuring what it was designed to. The results also suggested the instrument's results had potentially strong reliability, ɑ = .956, which is an expectation and requirement for valid measurements (Al-Hoorie and Vitta, 2019; Connolly, 2007). The ‘potential’ hedge is necessary in this case, where a new instrument has been developed and is first being assessed, as the validation process can involve different types of validity evidence and is longitudinal when a new instrument is developed (see Al-Hoorie and Vitta, 2019; Norris et al., 2015). L2 researchers often neglect issues of dimensionality and assume that the items in a questionnaire are all measuring the same construct (Al-Hoorie and Vitta, 2019). Particularly for new instruments, this assumption must be tested, and this current study provides a model that future researchers can follow to demonstrate whether their newly designed instruments are suitable in this regard.
The descriptive results and inferential testing of normality addressing RQ3 suggested that the instrument also had the potential to construct a latent variable suitable for the linear models favored by quantitative PLL researchers (Al-Hoorie et al., 2022; Hiver at al., 2021b). However, one should be mindful that there is nuance in creating aggregate scales from Likert indicators (see Shao et al., 2022) and that there are alternatives to the averaging process employed in this current study. In more complex designs, for instance, Likert indicators can first be analyzed with procedures such as confirmatory factor analysis (CFA) to measure latent variables that are then used in pathway structural equation modeling (SEM pathways) to test hypotheses (for illustration and explanation of CFA to SEM pathway(s) models and other alternatives besides averaging, see Kline, 2011; Marsh et al., 2009; Shao et al., 2022).
It should be noted that the results presented in this report offer only initial validity evidence. In the larger project, a cross-validation design was executed, where this instrument was tested with regard to measuring a distinct construct when juxtaposed with other instruments designed to measure willingness to communicate and perceived communicative competence. Any instrument validation process is an ongoing endeavor, where a one-off measurement cannot offer full resolution. This point was stressed in the jointly published set of standards for educational and psychological testing by the American Educational Research Association, the American Psychological Association and the National Council on Measurement in Education (2014). This current study models how the process of collecting initial validation evidence can begin when researchers make unique instruments with the intent of using them alongside other instruments in larger-scale projects. This model would be especially useful in frontline and practice-orientated L2 research contexts because self-efficacy is a construct of interest that has direct relevance to the language classroom (see e.g. Teng et al., 2021; Wang et al., 2021; Xu et al., 2022).
Making Task-Specific Self-Efficacy Measures in the Future: Current Study as an Illustration
As noted in the preceding text, some ISLA researchers have employed general self-efficacy measures in their research (Leeming, 2017; Harris, 2022). While it would be inappropriate to label such practices as wrong, Bandura (1997) is quite clear that the strength of self-efficacy as a predictor variable comes from its specificity. There are increasing calls from researchers to understand the affective side of tasks in the hope that this will help to show how they are carried out in more typical, low motivational contexts such as compulsory EFL classrooms (e.g. Leeming and Harris, 2022; Dörnyei, 2019; Ellis et al., 2020). Only by developing instruments that relate specifically to given tasks can researchers hope to understand how self-efficacy relates to task performance. This paper has outlined an approach to establishing the validity of a new instrument, and it is hoped that it will serve as an illustration for future research in this area.
TBLT employs a wide range of tasks, but discussion tasks are particularly prevalent in tertiary academic contexts in Japan (Aoyama, 2020; Nakatani, 2006). While we would stress that it is important for researchers to design, adapt and validate measures for their own context, we hope that the self-efficacy measure introduced in this paper can serve as a basis for others. The results suggest that it is a reliable and unidimensional measure that can be employed in similar contexts. In order to facilitate this, the instrument has been made available on the OSF (https://osf.io/f5r2n). By sharing measures through sites such as this, researchers can help each other to replicate studies and move the field of SLA forwards (Gass et al., 2021; Liu et al., 2021).
Conclusion
This report has presented positive initial validity evidence for an L2 discussion task-specific self-efficacy instrument in the Japanese context. This initial collection of validation evidence was necessary to justify the subsequent use of the instrument in a larger project where other individual difference measurements would be operationalized. The process presented in this report has broader implications for the L2 research community in that it models a process for others to use and exploit when investigating self-efficacy in their learning contexts. As a final note, the researchers have shared data and materials to conform to the latest calls for openness and methods rigor (Al-Hoorie and Vitta, 2019) while also facilitating an easier replication process by others in similar contexts.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The first author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Japan Society for the Promotion of Science (grant number 21K20214 - awarded to the first author).