
Abstract
The present study investigated whether work-related subjective well-being (SWB) can be assessed using employee responses to interview questions. Our objective was to provide proof-of-principle evidence that unstructured language can be used to simultaneously predict multiple SWB components. To achieve this goal, we asked 386 employees (52% women) from various industries to complete self-reported measures of SWB, and then we conducted individual interviews. The responses collected during structured interviews were analyzed using transformer-based models to extract semantic characteristics. Next, the semantic characteristics were used to predict multiple SWB indicators. Results showed that descriptions of typical work activities offered fair predictive accuracy of SWB scales, performing better than narratives focused on positive or on negative experiences. Furthermore, simpler machine learning algorithms such as Naïve Bayes achieved higher accuracy than more complex models, demonstrating the effectiveness of transformers-based approaches. Although the study has limitations, the results provide a foundation for using NLP in assessments of SWB, opening the way for tools that are customizable and text-sensitive.
Well-being is a multidimensional concept that reflects how a person evaluates own quality of life (Diener et al., 2018; Ryan & Deci, 2001). Because of the subjective nature of the concept, psychologists rely on one’s subjective perspective and use self-reported questionnaires to assess the quality of life (Diener et al., 2018). Traditionally, assessment of well-being involves questionnaires for hedonic well-being (i.e., subjective reports of one’s satisfaction or positive affect), and other questionnaires for assessing various forms of eudaimonic well-being (i.e., subjective reports regarding self-actualization and experiencing positive psychological functioning) (Ryan & Deci, 2001). Because researchers must use different measures for each of these components, participants must answer a large number of items. This can be problematic, as a larger number of items is associated with larger dropout rates (Hoerger, 2010).
An alternative to assessing subjective well-being (SWB) can be through the computerized analysis of people’s narratives regarding their life. Unlike structured questionnaires, responses to open-ended questions are a rich source of information and can be used for assessing multiple variables simultaneously. However, researchers are generally reserved when they must infer psychological variables from unstructured language (van Roekel et al., 2023), and they usually rely on self-reported measures or on other behavioral measures (e.g., quantity or quality of the products resulted from one’s activities, time spent in various contexts, etc.). Recent developments in computational linguistics and computer sciences suggested that language can also be used to assess psychological variables (for a review, see Kjell et al., 2019), but the technology readiness level of this approach is still low (see Lavin et al., 2022 - for an overview of technology readiness levels for machine learning systems). Most existing evidence on this research venue can be classified as specific to level-1 technological readiness: it involves small sample studies that provide evidence for various approaches aimed at investigating the conditions in which computerized text analysis is potentially useful. At best, limited research provided evidence for the proof of principle development, by analyzing the utility of computerized analysis on data that matched data from real scenarios (i.e., corresponding to the second level of technological readiness, as described by Lavin et al., 2022).
In the present study, we investigated whether unstructured language can be used to assess multiple variables relevant for work-related SWB. Unlike previous studies that focused on predicting a single criterion, we attempted to predict multiple criteria simultaneously from a single narrative. If successful, the estimation of multiple criteria from a single corpus of textual data could represent a significant improvement in developing psychological indices derived from unstructured language. Furthermore, in the present study we focused on a specific form of SWB, and there are at least three arguments for focusing on a domain-specific form of SWB. Firstly, when asking people to talk in general about their life, they tend to focus on specific life domains (e.g., work, family, friends etc.). Secondly, psychologists developed theoretical models for SWB that described domain-specific variables. By focusing on work-related SWB, we assessed the variables described by a popular model (i.e., the Job Demands and Resources Model - JD-R, Bakker et al., 2022), and we used interviews focused on participants’ work experiences to predict these variables. We selected the JD-R model because it provides a comprehensive framework that connects workplace characteristics to various aspects of well-being that can be expressed in language, such as work engagement, job satisfaction, and burnout. Unlike more general well-being models (e.g., well-being models developed by Diener et al., 2018; or by Ryan & Deci, 2001), the JD-R model offers a robust framework for understanding the impact of workplace characteristics on employee well-being. For example, the Self-Determination Theory (Ryan & Deci, 2001) emphasizes motivational dynamics (e.g., autonomy, competence, and relatedness) that one can interpret as resulting from personal work experiences, but the theory is not focused on the relationships between work experiences and motivational components. Because we used work-contextualized narratives, the JD-R framework also provided theoretical reasons for using employees’ descriptions of work experiences to predict work-related well-being. As employees are naturally describing their workplace experiences, they are talking about work demands and work resources that are highly relevant (i.e., from the JR-R perspective) for predicting their work-related well-being. Thirdly, technologies based on natural language processing are now contributing to advances in various fields of management sciences (for a review, see Kang et al., 2021) but their use in personnel management is still underdeveloped. By integrating methods aligned with the Technology Readiness Level framework (Lavin et al., 2022), we aimed to address this knowledge gap. Specifically, our study contributes to the proof-of-principle step of technology readiness by illustrating the applicability of natural language processing (NLP) technologies in assessing multiple components of SWB simultaneously. Providing support for assessment of multiple components should encourage future studies in focusing on more than one criterion and should open new possibilities regarding the use of NLP technologies in psychological assessment.
The structure of the manuscript is as follows: first, we described work-related SWB according to the JD-R model (Bakker et al., 2022), and we discussed previous research studies that attempted to predict these variables using NLP techniques. Next, we presented the two main approaches in natural language processing, and we discussed their advantages and limitations. Finally, based on the information presented in the previous sections, we described the objectives of the present research study.
Work-Related Subjective Well-Being as Expressed by Employees’ Narratives regarding Work
To measure work-related subjective well-being, we used the popular JD-R model (Bakker et al., 2022), who described three specific types of work-related SWB: work engagement (i.e., a highly energetic, positive state of mind related to work); (2) job satisfaction (i.e., experiencing satisfaction with own work), and finally (3) burnout (i.e., experiencing low energy, mental distancing, and cognitive and emotional impairment when involved in work activities). Within the framework of SWB, understanding the nuances of lexical variation among employees’ responses could hold significant relevance. Although employees may speak about similar workplace situations, they may use different words, and these differences in language can be related to internal psychological processes. Certain words have a meaning regardless of the context in which they are used (e.g. love, enjoyment). However, other words can change the meaning based on the context. For example, the word challenging carries a connotation when paired with words such as engaging or satisfying, but it can have a negative meaning when combined with words such as stressful or overwhelming (Wijngaards et al., 2020).
In the following sections, we will present existing evidence regarding the linguistic patterns of employees with different levels of engagement, satisfaction and stress.
Linguistic Patterns of Engaged Employees
Previous findings showed that work engagement is related to linguistic patterns (e.g., van Roekel et al., 2023; Tanaka et al., 2024). Studies concluded that engaged employees are describing their fatigue as transitory due to the sense of achievement it brings (Bakker et al., 2012). When talking about their jobs, engaged employees often use rewards-related terms like benefit, bonus and promotion (van Roekel et al., 2023). Also, engaged employees focused more on power dynamics using terms like manager, attack, and dependent often, and expressed concerns about their work environment by using words such as job, and burden frequently (van Roekel et al., 2023). Similar to van Roekel et al. (2023), Tanaka et al. (2024) also reported that language-based measures can be used for predicting work engagement. In their work, Tanaka et al. (2024) successfully used internal communications between employees to predict work engagement scores. These results highlighted different language patterns based on employees’ levels of engagement, thus supporting the idea that different linguistic patterns are indicative of different levels of work engagement.
Linguistic Patterns of Satisfied Employees
Recent research has highlighted the potential of NLP to uncover complex psychological constructs such as life satisfaction. Kjell et al. (2019), showed that semantic measures obtained from natural language can perform better than traditional rating scales in assessing life satisfaction. This approach provides deeper insight into context-specific meanings, in addition to quantifying linguistic patterns. Following on from his 2019 study, Kjell et al. (2021) found that computational language assessments could better differentiate between constructs such as life harmony and life satisfaction. They found that computational-based measures captured subtleties that rating scales missed. For example, life satisfaction was often associated with self-focused constructs such as achievements and goals. These distinctions highlight the importance of context in interpreting linguistic patterns and demonstrates how NLP can bring out latent psychological constructs (i.e., job satisfaction, work engagement), that are essential to understanding subjective well-being.
In a similar vein, Wijngaards et al. (2020) showed that the answers to a semi-open question regarding job satisfaction can be used to refine sentiment analysis dictionaries and uncover factors influencing job satisfaction. More specifically, some words can have both positive and negative connotations depending on their context. For example, words such as stressful and busy often do not imply stressors that are harmful for the SWB. In contrast, words such as underpaid and overwhelming, always will have negative connotations. Finally, these findings suggest that based on the context, the presence of stressful job demands, such as job complexity and work pressure, does not inevitably lead to diminished SWB.
Linguistic Patterns of Stressed Employees
The study of linguistic indicators of stress has seen significant progress. Pennebaker et al. (2003) demonstrated that an increased use of first-person singular pronouns and negative emotion words, alongside a decrease in cognitive processing terms (e.g., think, because), consistently indicates psychological distress. Tausczik and Pennebaker (2009) synthesized this area of research, concluding that narratives associated with high stress typically contain fewer social or achievement-oriented expressions and more self-focused or physiological language.
Unlike work engagement and job satisfaction, there are few studies that investigated the linguistic patterns used by burned-out employees to describe their workplace. Some initial work conducted by Reid et al. (2017) analyzed press conferences of college football head coaches and developed text analytic dictionaries for each burnout dimension. However, this work focused on a very specific type of employees and it is unclear how their findings can be extrapolated. More recently Omranian et al. (2025) applied transformer-based natural language processing (NLP) models to a large corpus of nurses’ narrative (i.e., about 2000 open-ended comments) and demonstrated that burnout levels, as measured by the Maslach Burnout Inventory, could be inferred from linguistic embeddings. Similar findings were reported by Kurpicz-Briki et al. (2024), who used a different burnout measure and showed that burnout detection can extend from online corpora to real-world organizational texts. Similarly, Belz et al. (2022) analyzed open-ended survey comments from healthcare workers and found that the frequency of negative emotion words, references to power, and overall word count predicted increases in emotional exhaustion over time.
Using a different approach, Šćepanović et al. (2023) focused on how workplace stress manifests within employees’ online reviews. These authors reported that reviews of low-stress employers typically included terms related to workplace flexibility, competitive compensation, and bonuses, while reviews of stressful employers included dissatisfaction with both working conditions and high-pressure levels. To determine whether the content of the reviews had unique characteristics depending on stress level, Šćepanović et al. (2023), identified the most relevant words by running a topic model algorithm (i.e., BERTopic - Grootendorst, 2022). There were three workplace themes identified in these employee reviews: career drivers, benefits, and emotional aspects of the job. Based on the words used by employees, high-stress companies were associated with words such as overtime, mandatory, horrible, while low-stress companies were associated with words such as flexibility, autonomy, friendly, or good (Šćepanović et al., 2023).
A systematic review by Bieri et al. (2024) mapped emerging methodologies for automatically detecting work-related stress, emphasizing emotional, syntactic, and semantic indicators. Further evidence from Hasan et al. (2025) shows that large language models can detect occupational stress with high accuracy. Taken together, these findings suggest that language associated with stress differs systematically from that of engaged or satisfied employees. This provides strong justification for including burnout dimensions in our predictive framework.
The evidence presented above suggested that different components of SWB can be predicted using processed employee narratives. However, all studies mentioned previously focused on a single form of SWB, although it is theoretically possible to use different prediction rules from the same narrative to predict different forms of SWB. Consequently, we formulated our first research question as follows: RQ1: Can we predict multiple components of SWB using the same narrative?
Approaches in Coding the Natural Language
When it comes to coding unstructured narratives (or natural language), there are two main approaches that must be mentioned: word counting approaches and transformer-based approaches. Initial techniques for processing natural (or unstructured) language simply counted how many times people used various target-words that are relevant for a particular psychological construct (e.g., valence of the tone). This approach was used by popular tools such as the Linguistic Inquiry and Word Count (LIWC - Pennebaker et al., 2007). Word counting breaks down the text into individual units of words, and each word will be treated separately, often overlooking the context or the relationships between words. Despite its popularity, the word count approach was criticized because it does not take into account the complexity of human language, which is contextual (Zhao & Mao, 2018). For example, the word count approach cannot distinguish between I appreciate only your latest project and Only I appreciate your latest project because both sentences used exactly the same words. Recent literature reviews (i.e., Koutsoumpis et al., 2022) suggested that word counting algorithms (i.e., in this case, LIWC) can generate indices that are significantly associated with self-reported personality traits, but the effect sizes are generally small (i.e., up to 5% shared variance).
More recent developments in computational linguistics and large language models allowed researchers to provide promising results regarding the assessment of psychological states using unstructured language (Kjell et al., 2019). Unlike the prediction algorithms based on word counting, the new approach uses transformers technology (Vaswani et al., 2017) for coding unstructured language. Transformers represent significant advancements in NLP by addressing the limitations of traditional methods (Vaswani et al., 2017). They are a form of deep learning model that enable machines to understand, interpret, and generate human language with the highest level of accuracy so far (Kjell et al., 2022). Unlike algorithms based on word counting, transformers process entire sentences or paragraphs, capturing linguistic patterns and semantic meaning. (Kjell et al., 2022). Text is converted to numerical representations called tokens, and each token is converted into a vector via looking up from a word embedding table (Vaswani et al., 2017). Through vectorization, each word is connected to its more general category (e.g., the word appreciate is linked to a more general category such as positive appraisal). These transformers act as a tool to organize the raw input data into a structured format typically like a matrix, which can be processed by the model (Vaswani et al., 2017). This process involves operations such as normalizing the data, filling in missing values and encoding variables. The approaches based on transformers are taking into account the entire sequence of words, contextual nuances and dependencies through mechanisms such as self-attention (Jurafsky & Martin, 2000). This enables transformers to code the meaning and relationship in text more effectively, thus providing significant advancements in tasks such as sentiment analysis (Kokab et al., 2022). Results reported by Kjell et al. (2021), suggested that language-based indices computed with the transformers technology can predict psychological well-being, can distinguish between forms of well-being (Kjell et al., 2022), and these predictions seem superior to results summarized by Koutsoumpis et al. (2022).
Can We Use Any Type of Narrative to Predict One’s SWB?
As computer-aided techniques for text analyses evolved, researchers used various types of unstructured texts. However, the use of different types of narratives can lead to different results regarding the correlations between text-derived indices and self-reported data. For example, Yarkoni (2010) demonstrated that longer texts tend to produce stronger correlations, while shorter texts may not provide sufficient linguistic data for accurate analysis. This conclusion was also confirmed by Kjell et al. (2022) who concluded that longer narratives are more useful for predicting one’s level of life satisfaction.
Furthermore, text length is not the only characteristic that has an impact on prediction accuracy. In a comprehensive review of the literature, Chen et al. (2020) analyzed whether the type of text had an impact on the correlation between the LIWC score and self-reported extraversion. They reported that LIWC scores were more strongly correlated with extraversion when the narrative was public (i.e, as compared with private narratives), from a real-life setting (i.e., as compared with narratives from lab settings), and when individuals had the opportunity to present themselves in a positive manner. Although the effect sizes reported by Chen et al. (2020) were generally very small (i.e., the averaged correlation value was .08), the type of text seems to have an influence on the convergent validity of the computer-aided techniques for text analysis.
Last but not least, van Roekel et al. (2023) also hypothesized that different types of narratives play different roles in predicting high or low levels of work engagement. In their view, low levels of engagement can be predicted by narratives in which employees are describing situations with negative emotions at work or are describing workplace crises. On the other hand, high levels of engagement can be predicted using neutral narratives or narratives in which employees described positive emotions at work. Although van Roekel et al. (2023) concluded that their expectations were met only in the case of high work engagement, the idea that the type of narrative has an influence on its predictive capability is important and requires further investigations.
In conclusion, based on the evidence presented above we were wondering whether the ability to predict one’s well-being is influenced by the type of narrative content that is being analyzed. Consequently, we formulated our second research question as follows: RQ2: Are there any differences in the prediction accuracy between various types of narratives?
The Present Study
In the present study, we aimed to investigate whether an employee narrative can be used to predict multiple indicators of workplace SWB. To achieve this goal, we conducted one-to-one interviews with employees that previously completed self-reported questionnaires relevant to SWB. We assessed positive indicators of SWB such as work engagement, and job satisfaction, together with negative indicators such as burnout (Bakker et al., 2022).
In the one-to-one interviews, we asked participants to talk about their work routines and their workplace. Because we were interested in studying whether the type of narrative makes a difference regarding the predictive capabilities, we asked our participants to describe (i) their typical workday, (ii) positive and (iii) negative work experiences. To investigate whether we could use the participants’ answers to predict their scores on the self-reported questionnaires, we used a computational linguistics approach based on transformers derived from large language models. We predicted each self-reported measure using transformers computed from the interview narratives. This approach is consistent with recent advances in machine learning research (e.g., Lavin et al., 2022). Through the present study, we aimed to provide evidence for the 2nd level of technological readiness (i.e., proof of principle).
Our study exemplifies a TRL-inspired approach by integrating high-quality narrative data with validated self-report scales, and by applying principled-based modelling steps that prioritize predictive reliability and generalizability. We used the methodological approach described by van Roekel et al. (2023), who predicted whether the employee had high or low levels of work engagement. Consequently, we split our sample on each criterion variable and we conducted separate analyses in which we attempted to predict whether the respondent had a high or low level of each criterion.
Method
Participants
The sample included 386 employees (52% women, mean age of 32 years, SD = 12.45 years). They were employed in various areas of activity: Technology/IT (25%), Commerce (16%), Education (9%), HORECA (8%), or Marketing (6%). 72% of the participants were full-time employees, and 77% worked for a private company.
Measures
To assess SWB, participants completed a series of questionnaires upon registration for the study, and the narratives were collected using a structured, face to face interview.
Work engagement was assessed using the 9-item short version of Utrecht Work Engagement Scale, (UWES-9 - Schaufeli et al., 2006). All items are rated on a 7-point scale from 1 = never to 5 = always (e.g., At my work, I feel bursting with energy). Following the recommendations formulated by Schaufeli et al. (2006), we computed the overall score of the UWES-9, and its Cronbach’s α value was .91.
Job satisfaction was assessed using the 3-item Job Satisfaction - Subscale from Michigan Organizational Assessment Questionnaire, (Tepper, 2000). All items are rated on a 7-point scale, from 1 = Strongly disagree to 7 = Strongly agree (e.g., All in all, I am satisfied with my job). Cronbach’s α value is .78.
Burnout was assessed with the 12-item short version of Burnout Assessment Tool (BAT - Schaufeli et al., 2020). The BAT includes four subscales: Emotional Exhaustion (Cronbach’s α = .76), Mental Distance (Cronbach’s α = .58), Cognitive Impairment (Cronbach’s α = .64), Emotional Impairment (Cronbach’s α = .68). All items are related on a 5-point scale, from 1 = never to 5 = always (e.g., Everything I do at work requires a great deal of effort).
After the online registration which included the completion of the self-reported scales, participants booked an appointment for the online interview, which was conducted via Google Meet platform. Participants were informed regarding the necessity for recording the interview when they registered for the study, and at the beginning of the online meeting. All participants agreed with the audio recording. In the structured interview, we asked 4 different questions to collect different types of narratives. Firstly, we asked a neutral question in which we collected information regarding the typical day at work and most frequent tasks: I suggest we start by learning a bit about your workplace. Please describe to me what was the main activity that took the most of your time today or on your last workday. Next, we asked the participants to describe a negative work experience: Please describe a situation in the last month when you felt that what you had to do was too much and you felt that you could not cope. In the third question, we asked about a positive work experience: Please describe a situation in the last month in which you felt excited or proud of your work or results. Finally, we asked the participants whether they are satisfied with their work (In general, can you say that you feel satisfied at work?) and we asked them to justify their answer. All questions were addressed in the same order to all participants, and the average interview length was 11,5 minutes.
All interviews were conducted individually in quiet, private settings via the Google Meet platform. Because participants were instructed to ensure stable internet connections and minimal background noise, we did not experience any interruptions or sound interferences from the background in any of the recordings. The use of the standardized setup and interviewer protocol minimized environmental variability and maintained consistency across sessions. The study was conducted in accordance with the World Medical Association Helsinki declaration (World Medical Association, 2000). No ethical board approval was required because of the minimal risk nature of the study. Participants gave their informed consent before the interview, and all recordings and transcripts were stored securely and anonymized prior to analysis.
Processing of Interview Recordings
First, we analyzed the interview responses separately, as each question provided a different type of narrative: neutral narratives (i.e., the description of the main activity), negative work experiences, positive work experiences, and argumentation of one’s job satisfaction. We transcribed the audio recordings into text using the speech-to-text platform SONIX (Sonix, n.d), and we checked each transcript for errors and for misspelled words. Because the tools for analyzing Romanian narratives were less developed as compared with the options for the English narratives, we translated all responses from Romanian to English, using the GoogleTranslate service (Google Translate, n.d). After translation, each transcript was manually reviewed to correct obvious mistranslations, grammatical inconsistencies, or missing words. Although a formal back-translation procedure was not implemented, this manual verification process minimized semantic drift and ensured the English transcripts accurately conveyed the original meaning of the Romanian narratives. We acknowledge that minor idiomatic differences resulting from automated translation workflows could have occurred.
The translated transcripts were then processed using the text package in R (Kjell et al., 2023) using the Bidirectional Encoder Representations from Transformers (BERT), which is a state-of-the-art NLP model developed by Google (Devlin et al., 2018). Using BERT-based transformers, we analyzed our narratives using algorithms that were previously trained on large corpus of online texts. The BERT encoding algorithm considers the relationship between words, which provides better feature extraction for predictive models, and performs more and more in-depth analyses on up to 12 layers. Following the computation of BERT-based transformers, we computed word embeddings for the 10th and the 11th layers or BERT-based transformers, as recommended by Kjell et al. (2023). These layers were selected because the deeper layers of BERT-based transformers are known to encode high-level semantic representations of text which are particularly useful for extracting relevant features. This process resulted in a database that contained 1536 columns (i.e., corresponding to the embeddings of the 10th and 11th BERT layers). The values on these columns can be seen as parts of more general topics that are present in the narratives, and were used for the prediction of the self-reported scores. Because we conducted separate analyses with each question type (i.e., neutral, positive, negative or satisfaction-related), we estimated different word embeddings for different question types.
Analysis of Self-Reported Data
The measurement quality of our criterions was assessed through confirmatory factor analyses for each scale. For the Burnout Assessment Tool (Schaufeli et al., 2020) we estimated a model with 4 separate factors, while for work engagement and for job satisfaction we estimated models with single factors. We obtained excellent fit indices for all scales, and the results of these analyses are presented in the Supplemental material.
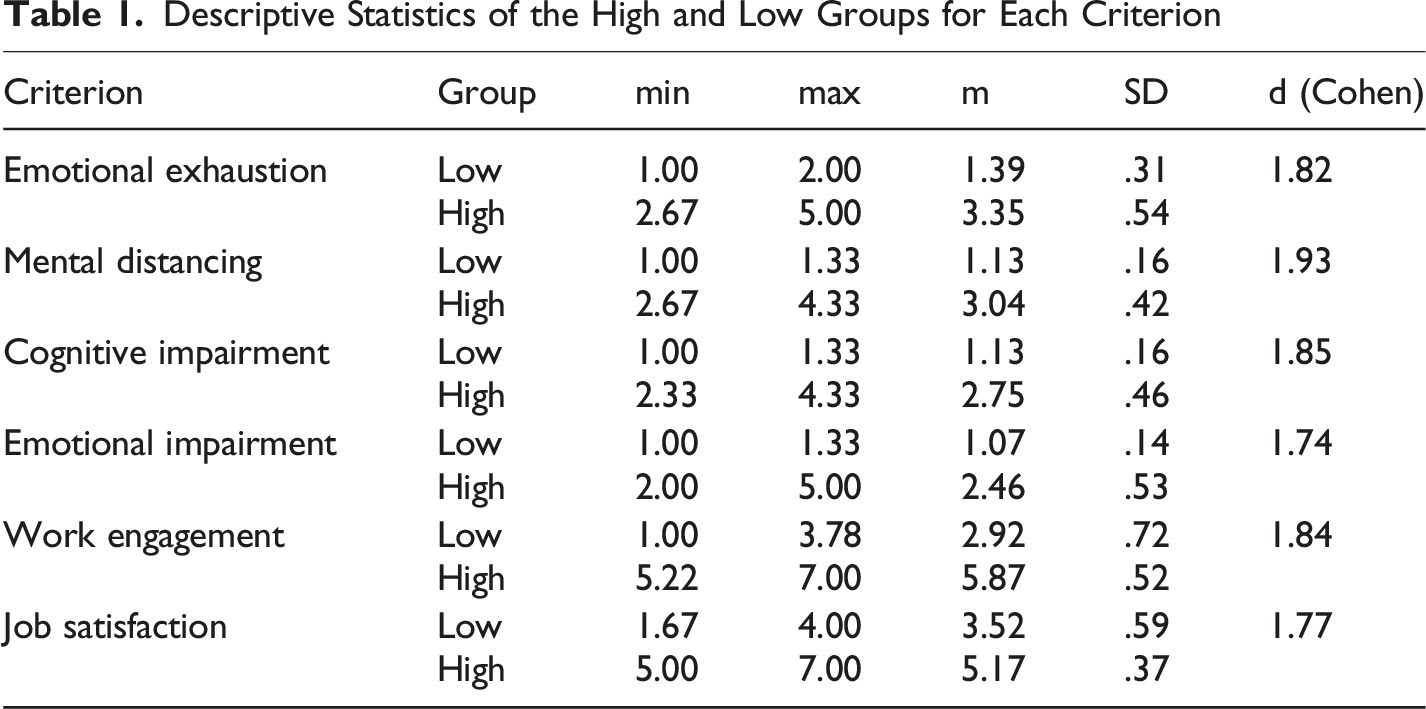
To create the criterion variables for our analyses we imputed all factor scores. Following a procedure similar to that used by van Roekel et al. (2023), for each variable, we selected 30% of the participants with the lowest factor scores and 30% of the participants with the highest factor scores. Van Roekel et al. used Forman’s (2004) recommendation of selecting extreme values when building predictive models, pointing out that focusing on the lowest and highest values of a criterion variable increases accuracy of machine learning models. Although dichotomizing continuous self-report scores reduces the variance of our criteria variables, this approach was adopted to maximize class separability in smaller samples, in line with the methods of Forman (2004) and van Roekel et al. (2023). By using on groups with high and low values, we increased the likelihood of identifying meaningful linguistic patterns when developing proof-of-principle predictive models. This is because participants that have scores close to the average values of the scales could have included mixed content in their responses (i.e., content that is relevant to high levels of the criterion together with content that is relevant to low levels of the criterion). Therefore, for developing and testing each predictive model we used 252 out of the 386 participants.
Descriptive Statistics of the High and Low Groups for Each Criterion
Development of Prediction Algorithms
We conducted separate analyses for each self-reported variable, and we used different algorithms to predict it using the word embeddings. In line with the current practices in machine learning (Hu, 2024), for each prediction model we split each dataset into a training dataset that contained 70% of all participants, and a testing dataset. We used stratified random sampling to ensure balanced distributions of high and low criterion values in the training (70%) and testing (30%) datasets. To minimize overfitting, we used the training dataset to estimate each algorithm, and we cross-validated this algorithm using the testing dataset, to have an estimation of the generalizability of the algorithms. Consequently, we reported the classification performance of each prediction only on the testing dataset (i.e., the results of the cross-validation analysis). Although more approaches complex approaches (e.g., 10-fold cross-validation analyses) provide more robust results, we used only simple cross-validation due to sample limitations.
On the testing dataset, we computed three types of indices to assess classification quality: overall accuracy, Cohen’s kappa index, and the AUC index. Cohen’s kappa, introduced by Cohen (1960), measures the level of agreement between predictions and actual classifications. To interpret kappa values, we followed the guidelines proposed by Landis and Koch (1977), which define values of .21 and .40 as fair agreement, and values above .30 were considered suitable for meaningful practical implications. Consistent with the criteria established by Hosmer et al. (2013), AUC values above .70 were interpreted as indicating fair classification performance. We integrated these metrics to provide a comprehensive evaluation of each algorithm’s predictive performance.
In our predictive models we used algorithms that are popular in the machine learning research domain (Hu, 2024): simple prediction algorithms (i.e., Naïve bayes predictions, linear regression, ridge regression) and complex algorithms (i.e., random forests, and gradient boosting machines). Random forests algorithms combine multiple decision trees to produce a more robust and accurate model (i.e., each tree is trained on a random subset of the data and features, and the final prediction is made by averaging the prediction of all trees) (Natekin & Knoll, 2013). One of the advantages of this method is reducing the risk of overfitting and improves generalization. Gradient boosting machines (GBM) build models sequentially, with each new model attempting to correct errors made by the previous models, therefore are known for their high accuracy in predictive tasks (Khan, 2023).
Consequently, each self-reported variable was predicted in 16 different prediction models, as we used 4 types of algorithms on each of the 4 types of narratives.
Results
Accuracy of Prediction Algorithms as a Function of Question Type and Algorithm Type
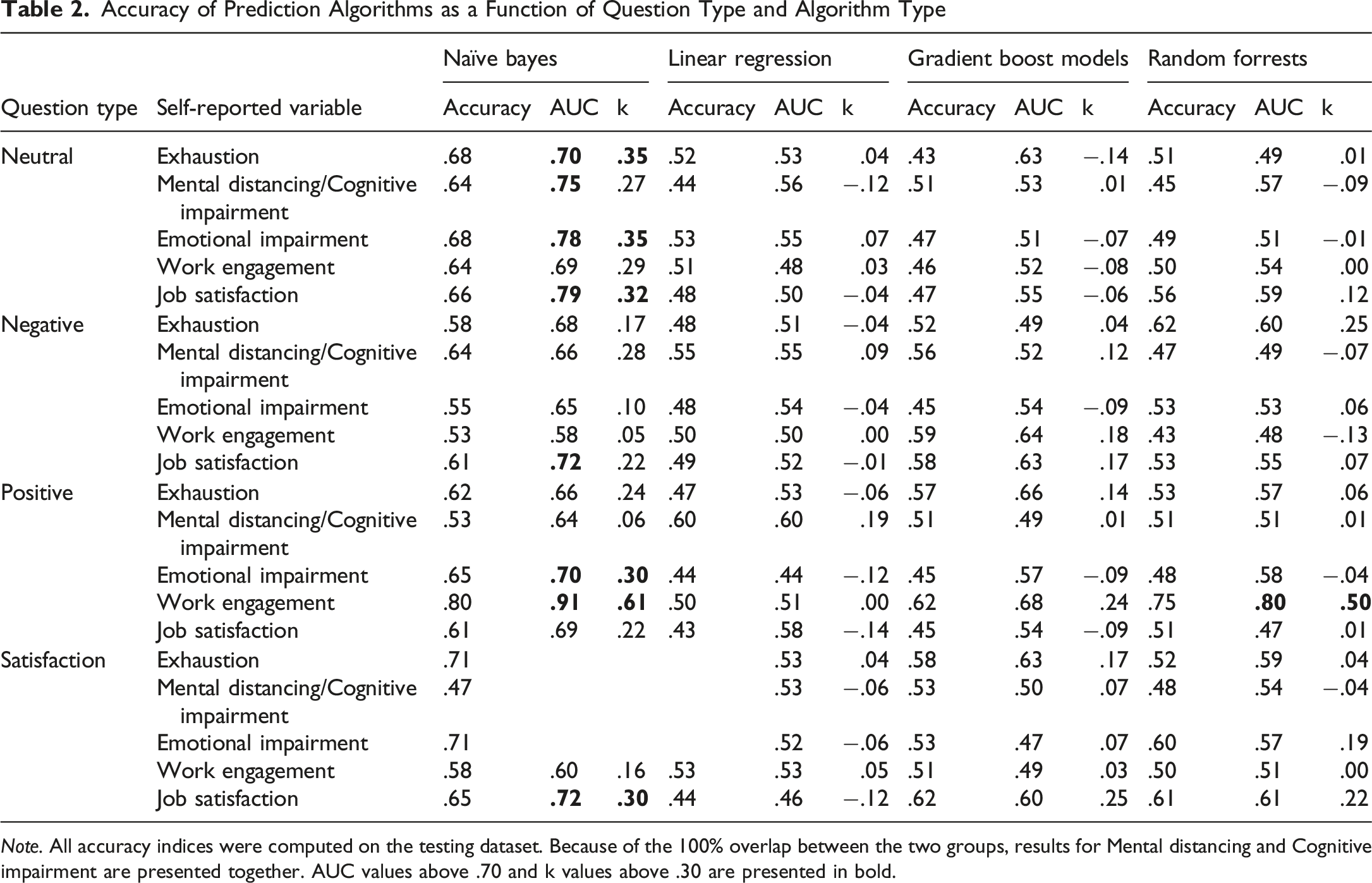
Note. All accuracy indices were computed on the testing dataset. Because of the 100% overlap between the two groups, results for Mental distancing and Cognitive impairment are presented together. AUC values above .70 and k values above .30 are presented in bold.
Results presented in Table 2 suggested that best predictions were made by the Naïve Bayes algorithms. As compared with Naïve Bayes algorithms, predictions that used multiple linear regression or gradient boost machines did not yield fair accuracy on any predictive models, while random forests algorithms had fair accuracy only when word embeddings from positive narratives were used to predict work engagement (Accuracy = .75, AUC = .80, k = .50). These results highlight the effectiveness of simpler algorithms, particularly when paired with transformer-coded linguistic features, demonstrating their ability to better perform against traditionally more robust models like gradient boosting machines and random forest.
Regarding the type of narrative used for computing the BERT-based transformers, results suggested that the best predictions used the transformers computed from employees’ responses to the neutral question (i.e., Please describe what was the main activity that took the most of your time today or on your last workday). Using the BERT encodings from responses to the neutral questions, the Naïve Bayes algorithm provided fair predictions of most criterions: AUC indices were larger than .70 for all criterion variables except work engagement (AUC = .69), while Cohen’s k values were all larger than .27. The poorest prediction performance was obtained when we used BERT-based transformers from the question that asked our participants to describe a negative work experience (i.e., Please describe a situation in the last month when you felt that what you had to do was too much and you felt that you could not cope). When using these BERT encodings from the descriptions of negative work experiences, none of the algorithms reached fair classification accuracy.
Discussion
In the present study, we investigated whether a single narrative can be used to predict multiple components of work-related subjective well-being. We used advanced natural language processing to see if responses to a question could be used to predict psychological constructs such as work engagement, job satisfaction, and burnout. This approach is completing previous work done by van Roekel et al. (2023) or by Kjell et al. (2021). By combining traditional psychometric techniques with the advanced features of machine learning, we provided evidence that supported the use of unstructured language data for assessing work-related well-being, thus providing a proof-of-principle for future technological advances in this direction.
Our findings suggested that the description of one’s workplace activities can be used to predict more than one component of work-related SWB. The word embeddings computed from descriptions of a typical day predicted all forms of work-related SWB with fair classification rates, thus supporting the idea that a single narrative can be used to make multiple predictions. Previous studies (e.g., van Roekel et al., 2023; Šćepanović et al., 2023) showed that descriptions of daily workplace activities could include positive or negative cues that are convergent with one’s psychological states. As these cues are detected by NLP algorithms, they are also effective at predicting more than one psychological variable. In general, our classification rates were similar (albeit a little higher) with the ones reported by van Roekel et al. (2023), who used a much larger sample to reach 60% classification accuracy. However, there are three notable differences between our study and the van Roekel et al. (2023) work: (i) we used a more advanced NLP approach, and (ii) we used less restrictive criteria to create our contrasting groups. Because we reached similar classification rates using less data and less discrepant groups, we can conclude that we compensated for these limitations using more advanced text processing (i.e., the BERT-based transformers).
Other results suggested that responses to questions that asked respondents to describe positive or negative work experiences showed a weaker predictive ability for the SWB scales. This result was surprising, as previous studies also expected that superior predictions can be achieved by narratives that are convergent with the content they are predicting (i.e., positive stories used for predicting positive attitudes) (van Roekel et al., 2023). In the case of the present study, it is possible that the words or topics used by respondents are more related to their explicit task (i.e., to describe a positive or a negative workplace event), and were less convergent with their inner psychological states. One possible explanation for this finding is that responses to neutral questions (i.e., Please describe a typical day at work) capture spontaneous language reflecting everyday thought patterns rather than emotionally charged or self-presentational speech. When describing their everyday work activities, participants spontaneously included positive and negative affective information that is relevant for assessing their well-being. Also, participants were likely less influenced by social desirability or impression management motives when asked to describe their typical workday, which tend to appear in explicitly positive or negative accounts. Consequently, these neutral narratives may offer a clearer representation of the cognitive and emotional processes associated with well-being. Conversely, positive or negative prompts may induce rehearsed or emotionally charged responses that hide the subtle linguistic markers linked to psychological states. However, more research is needed to gain a more thorough understanding of this result.
Our analyses showed that these promising results were obtained using the Naïve Bayes algorithm, a simpler classification method traditionally considered less robust than other complex models such as Random Forest or Gradient Boosting Machines. The superior performance of the Naïve Bayes classifier may be due to the fact that transformer-derived embeddings reduce inter-feature correlations, making the model’s assumption of conditional independence less detrimental in practice. In these representations, each embedding vector captures context-specific meaning, which reduces inter-feature redundancy and allows for models that rely on independent predictors. Furthermore, given the moderate sample size, simpler algorithms were inherently less likely to overfit than complex ensemble methods. These results suggested that when semantic information is richly encoded, greater algorithmic complexity does not necessarily provide superior predictive accuracy. This result is similar to the findings reported by Kjell et al. (2021), who also reported that simple algorithms are effective in predicting SWB using transformers computed from participants’ narratives. Taken together, these findings highlighted the potential of transformer-based NLP approaches, where operationalization by BERT-based transformers appears to reduce the need for complex predictive models. As BERT embeddings scores already reflect the semantic topics (i.e., combinations of words) that occur in the narratives, these scores do not require complex algorithms that are developed for exploring intricate combinations of predictors (e.g., random forests or gradient boost machines). On the other hand, it is possible that the limited sample used in the present study did not allow for complex algorithms to develop to their full potential. Therefore, future studies should use larger datasets to explore whether complex prediction algorithms can provide superior classification accuracy, which is needed in the next steps of technological development.
Limitations
Although our results seem promising, there are some limitations that should be mentioned. Firstly, while the sample size was adequate for the proof-of-principle objectives of a TRL-2 investigation, its number of respondents limited the statistical power to detect small effects in our cross-validation models. Since we did not conduct formal power or sensitivity analyses, the present findings should be interpreted as preliminary estimates of effect sizes and classification performance. Future studies aiming for higher TRL stages should use larger, independent samples to strengthen external validity and to provide more generalizable estimates of model stability. As Lavin et al. (2022) explained, development of proof of principle evidence involves conducting analyses on limited data from simulated environments (i.e., interviews with employees, in our case), aimed at identifying the conditions that can increase prediction accuracy (i.e., using neutral questions, according to our data). A second limitation derived from our small sample size is the use of dichotomized criterions instead of normally distributed scale scores. While we acknowledge that scale scores have higher practical utility as compared to dichotomized criterions, we needed a much larger sample size to predict the normally distributed scores. Thirdly, our sample included employees from multiple industries, but Technology/IT professionals were overrepresented (i.e., 25% of our participants worked in this domain). This distribution reflects the composition of the online recruitment pool, which limits the generalizability of our findings. To validate the robustness of NLP-based assessments of work-related well-being, future studies should adopt stratified sampling across industries and cultural contexts.
Thirdly, although we conducted interviews that included questions from real-life situations (i.e., questions that can be used in an employment interview), the present study is still a simulated environment study. While other studies used real-life data such as employee feedback collected by the company (van Roekel et al., 2023) or employee discussions within the company (Tanaka et al., 2024), these studies also had limited access to self-reported data and included only work engagement as self-reported criterion. Because we needed to collect data on all components of work-related SWB, we opted for a simulated environment approach.
While we acknowledge that the kappa and AUC values we used for our conclusions are only fair, we argue that these values serve the purpose of the present study, which was to provide evidence regarding the possibility of using computerized text analysis to predict psychological well-being. Obviously, such values are not acceptable for studies aimed at testing superior levels of technology readiness such as developing prototypes of real-life systems, or technologies to be used in real-life scenarios.
Implications for Future Research
Based on our findings, there are some implications for future research that should be mentioned. Firstly, future studies should continue to explore how we can predict multiple self-reported variables using transformers computed from a single set of narratives. In this vein, future studies could either have an intensive approach (i.e., by predicting other components of SWB, together with the variables included in the present study), or an extensive approach (i.e., by predicting variables that are different from SWB). When it comes to descriptions of their workplace, employee narratives can also contain information about their job (e.g., job characteristics such as job demands and job resources), together with information relevant for assessing SWB. For example, recent research conducted by Koenig et al. (2023) used candidates’ responses to behavioral interviews to extract job specifications (i.e., employee characteristics that are needed for the job), thus demonstrating the large applicability of unstructured narratives in personnel and organizational studies.
The second implication for future research concerns the use of transformers technologies in analyzing narratives. Future studies should use more advanced transformer architectures that use more than 12 layers. For example, the large BERT model has 24 layers (Devlin et al., 2018) that should provide enhanced predictive capabilities, as compared with the base BERT used in the present study which only has 12 layers.
Thirdly, based on the current TRL-2 results, the next stage of development should focus on validating these predictive models in larger, independent samples and in real organizational settings. The focus should shift toward predicting continuous subjective well-being (SWB) scores instead of dichotomized groups. Full cross-validation procedures should be implemented, and the models’ generalizability should be tested across languages and job sectors. Additionally, developing automated, text-based well-being monitoring technology would demonstrate the feasibility of practical implementation. These efforts would mark a transition from proof of principle to applied technological readiness.
Finally, future studies that aim for reaching superior levels of technology readiness should focus on predicting continuous variables, not high vs. low categories. In order to test prototypes in real-life settings, researchers should predict continuous scores because the output of such models should be similar with the output of self-reported measures (i.e., continuous estimations of the criterion variables that have a normal distribution). As these prediction algorithms prove more generalizable in future investigations, researchers and practitioners could rely on NLP indices based on employee narratives to assess SWB when employees do not have enough time to answer lengthy questionnaires, or when repeated completion of the self-reported questionnaires might become problematic (e.g., when one needs frequent monitoring of SWB).
Conclusions
In conclusion, the present research provided evidence for the feasibility of using descriptive narratives to predict multiple components of work-related SWB. This highlights the potential of computational linguistics in assessing psychological variables in general, and in organizational research in particular. Despite the limitations discussed above, the present study suggested that NLP-driven approaches can be useful for predicting multiple variables from the same narrative, thus suggesting that the responses to open questions have good potential be used for assessing employees’ SWB.
Supplemental Material
Supplemental Material - Assessment of Work-Related Subjective Well-Being Using Natural Language Processing of Employee Interviews. A Proof of Principle Investigation
Supplemental Material for Assessment of Work-Related Subjective Well-Being Using Natural Language Processing of Employee Interviews. A Proof of Principle Investigation by Eusebiu Stefancu, Laurentiu P. Maricutoiu in Psychological Reports
Footnotes
Acknowledgements
The authors are grateful for the support received during the development and implementation of the present study.
Ethical Consideration
The study was conducted in accordance with the World Medical Association Helsinki declaration. No ethical board approval was required because of the minimal risk nature of the study.
Consent to Participate
Each participant granted own informed consent to participate.
Author Contributions
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a Horia Pitariu scholarship no 1/2023 grant of the Romanian Association of Industrial and Organizational Psychology.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data supporting this study is available upon request from the corresponding author.
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.